Walsh-Hadamard 변환 기반 선형 벡터 기호 아키텍처
Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in are 'bound' together to produce a new vector in the same space.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 문제는 벡터 기호 아키텍처(Vector Symbolic Architectures, VSAs)라는 독특한 신경-기호 AI 개발 접근 방식에서 비롯된다. 이 학문적 계보는 Smolensky [38]로 거슬러 올라가며, 그는 텐서 곱 표현(Tensor Product Representation, TPR)으로 VSA 접근 방식을 개척했다. TPR에서 개념은 고차원 벡터로 표현되며, 이 벡터들은 외적 곱을 계산하여 새로운 복합 개념을 형성하도록 "결합(bound)"된다. 이 기초적인 연구는 연결주의 프레임워크 내에서 기호적 조작을 가능하게 하여 논리적 명제와 구조를 표현할 수 있도록 하는 방법으로 등장했다 [13].
역사적으로 대부분의 VSA는 딥러닝과 자동 미분이 널리 채택되기 전에 개발되었다. 이들의 주요 초점은 수작업으로 설계된 시스템에서의 효능에 있었으며, 종종 고전 AI 작업이나 인지 과학에서 영감을 받았다. 그러나 이러한 초기 초점은 VSA를 현대 미분 가능한 시스템에 통합하려고 할 때 몇 가지 근본적인 한계, 즉 "고충점(pain points)"을 야기했다.
- 계산 복잡성: TPR과 같은 초기 VSA 방법은 비현실적인 계산 복잡성을 겪었다. 예를 들어, TPR을 사용하여 $p$개의 항목을 결합하는 것은 벡터 차원 $d$에 대해 $O(d^p)$의 복잡성을 초래했다. 행렬 연산으로 결합을 표현하는 보다 일반적인 선형 VSA조차도 일반적으로 $O(d^2)$의 복잡성을 부담하여 실시간 또는 대규모 애플리케이션에는 너무 느렸다.
- 수치적 불안정성: 홀로그래픽 축소 표현(Holographic Reduced Representations, HRR) [32]과 같은 다른 인기 있는 VSA 방법은 푸리에 변환(FT) 및 순환 곱셈에 의존한다. 강력하지만 이러한 연산은 비합리적인 곱셈과 복소수를 포함하므로 실제 구현에서 수치적 불안정성을 초래할 수 있다. 이전 연구 [9]에서는 이를 완화하기 위해 투영 단계를 시도했지만 근본적인 문제는 남아 있었다.
- 미분 가능한 시스템에서의 최적화되지 않은 성능: 많은 기존 VSA 방법은 딥러닝 프레임워크에 원활하게 통합하는 데 필요한 속성을 갖도록 설계되지 않았다. 기울기 하강 및 자동 미분과 함께 사용할 때 유리한 계산 효율성과 수치적 안정성이 부족한 경우가 많아 현대 신경-기호 AI 작업에서 기대보다 낮은 성능을 초래했다.
본 논문은 Walsh Hadamard 변환의 속성을 활용하여 결합에 대해 $O(d)$ 복잡성을 제공하고 수치적 안정성을 개선하며 미분 가능한 딥러닝 애플리케이션에서 더 나은 성능을 목표로 하는 새로운 VSA, 즉 Hadamard-유도 선형 결합(Hadamard-derived Linear Binding, HLB)을 도출하여 이러한 한계를 해결한다.
직관적인 도메인 용어
본 논문의 개념을 쉽게 이해할 수 있도록 몇 가지 전문 용어를 일상적인 비유로 설명하겠다.
- 벡터 기호 아키텍처(Vector Symbolic Architectures, VSAs): 당신의 뇌에 고유한 "사고 벡터(thought-vectors)" 세트가 있다고 상상해보라. 각 벡터는 "고양이", "행복한", "빨간색"과 같은 기본 개념을 나타낸다. VSA는 이러한 사고 벡터를 결합하여 "행복한 고양이" 또는 "빨간색 자동차"와 같은 새롭고 더 복잡한 아이디어를 형성하고, 나중에 당신의 뇌에 그 복잡한 아이디어의 일부를 검색하도록 "질문"할 수 있게 해주는 특별한 정신 언어와 같다. 이는 컴퓨터가 단어를 사용하는 것처럼 개념을 조작하는 방법이지만 숫자를 사용한다.
- 결합(Binding): 두 개 이상의 개념 벡터를 결합하여 그 관계나 구성을 나타내는 새로운 벡터를 생성하는 과정이다. 마치 레시피에서 "밀가루"와 "물" 두 가지 재료를 섞어 "반죽"을 만드는 것과 같다. "반죽"은 원래 두 재료를 모두 포함하지만 결합된 형태인 새로운 개체이다. VSA에서 "고양이"와 "행복한"을 결합하면 "행복한 고양이"에 대한 새로운 벡터가 생성된다.
- 분리(Unbinding): 결합의 반대이다. 결합된 개념 벡터("반죽")와 원래 구성 요소 중 하나("밀가루")가 주어졌을 때, 분리는 다른 구성 요소("물")를 검색할 수 있게 한다. "행복한 고양이" 벡터와 "행복한" 벡터를 가지고 "고양이" 벡터를 검색할 수 있게 하는 것과 같다. 이 연산은 복합 표현에서 정보를 쿼리하고 추출하는 데 중요하다.
- Hadamard 변환(Hadamard Transform): 특별한 종류의 디지털 "셔플링" 또는 "인코딩" 과정을 상상해보라. 파동과 허수를 다루는 더 복잡한 푸리에 변환과 달리, Hadamard 변환은 훨씬 간단하다. 덧셈과 뺄셈만 사용하며, 출력 값은 항상 +1 또는 -1이다. 이는 매우 빠르고 수치적으로 안정적이어서, 역변환이 쉬운 매우 효율적인 노프릴(no-frills) 데이터 압축기와 같다.
- 신경-기호 AI(Neuro-symbolic AI): 이는 인공지능 분야에서 두 가지 세계의 장점을 모두 얻으려는 접근 방식이다. 즉, 신경망의 직관적인 패턴 학습 능력(사람이 얼굴을 인식하는 방식과 유사)과 전통적인 기호 AI의 논리적 규칙 기반 추론(컴퓨터가 지침을 따르는 방식과 유사)이다. 이는 구조화된 방식으로 "느끼고" "생각할" 수 있는 AI로, 단독으로 사용될 때 각 접근 방식의 한계를 극복하는 것을 목표로 한다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $B(x, y)$ | 두 개념/벡터 $x$와 $y$를 연결하여 새로운 벡터 $z$를 생성하는 결합 연산. |
| $B^*(x, y)$ | 다른 구성 요소를 주어진 결합 벡터의 한 구성 요소를 검색하는 분리 연산. |
| $x, y, z$ | VSA 공간에서 개념 또는 데이터 포인트를 나타내는 일반적인 벡터. |
| $d$ | VSA에서 벡터의 차원, 즉 $x \in \mathbb{R}^d$. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 현대 딥러닝 시스템에 적용될 때 기존 벡터 기호 아키텍처(VSA)의 한계에 있다.
시작점 (입력/현재 상태):
현재 VSA는 개념을 나타내는 두 벡터 $x, y \in R^d$를 결합 연산 $B(x, y) = z$를 사용하여 새로운 복합 벡터 $z \in R^d$로 결합하여 작동한다. 역 분리 연산 $B^*(x, y)$는 구성 요소 검색을 허용한다. 이러한 아키텍처는 자연스러운 기호 AI 스타일 조작(가환성, 결합성, 역 연산)으로 인해 신경-기호 방법에 매력적인 플랫폼을 제공하지만, 대부분 딥러닝 및 자동 미분이 널리 채택되기 전에 개발되었다. 결과적으로 많은 기존 VSA 방법은 몇 가지 심각한 단점을 보인다.
1. 높은 계산 복잡성: 많은 VSA, 특히 선형 연산 $B(a,b) = a^T G b$ 및 $B^*(a,b) = a^T F b$ (여기서 $G$와 $F$는 $d \times d$ 행렬)로 간주되는 경우 결합 단계에 대해 $O(d^2)$의 계산 복잡성을 부담한다. 이는 대각 행렬의 경우 $O(d)$로 줄일 수 있지만, 더 복잡하고 표현력이 풍부한 결합의 경우에는 그렇지 않은 경우가 많다. 예를 들어 텐서 곱 표현(TPR)은 $p$개의 항목을 결합하는 데 비현실적인 $O(d^p)$ 복잡성을 갖는다.
2. 수치적 불안정성: 푸리에 변환 및 복소수를 사용하는 홀로그래픽 축소 표현(HRR)과 같은 방법은 실수 벡터에 대해 작동할 때 "비합리적인 곱셈"으로 인한 수치적 불안정성에 취약하다.
3. 미분 가능한 시스템에서의 최적화되지 않은 성능: 기존 VSA는 기울기 기반 학습을 위해 명시적으로 설계되지 않았으므로, 추가 제약 없이 기울기 하강을 통해 기본 행렬이 학습된 경우 속성(예: 가환성)이 유지되지 않을 수 있다. 딥러닝 애플리케이션에서의 성능은 종종 기대보다 낮다.
원하는 종점 (출력/목표 상태):
본 논문은 Hadamard-유도 선형 결합(HLB)이라는 새로운 VSA를 도입하여 이러한 한계를 극복하는 것을 목표로 한다. 목표는 다음과 같은 VSA를 개발하는 것이다.
1. 계산 효율성: 결합 단계에 대해 $O(d)$ 복잡성을 달성하여 $O(d^2)$ 또는 $O(d \log d)$(일반적으로 Hadamard 변환 자체와 관련되지만 여기서의 도출은 선형 복잡성을 산출함)보다 훨씬 빠르다.
2. 수치적 안정성: 실수와 간단한 산술(덧셈, 뺄셈, $\{-1, 1\}$ 값)만 사용하여 복소수 기반 VSA의 불안정성 문제를 피한다.
3. 높은 효능: 고전 VSA 작업과 현대 딥러닝 애플리케이션 모두에서 기존 VSA와 비슷하거나 더 나은 성능을 발휘한다.
4. 미분 가능한 시스템 호환성: 미분 가능한 시스템에 원활하게 통합되고 잘 작동하도록 처음부터 설계되어 신경-기호 AI를 지원한다.
5. 대칭성: 결합 연산 $B(x,y)$는 대칭이어야 한다. 즉, $B(x,y) = B(y,x)$여야 하며, 이는 많은 VSA 애플리케이션에서 바람직한 속성이다.
누락된 연결 또는 수학적 격차:
정확한 누락된 연결은 Hadamard 변환의 유리한 속성을 활용하여 선형 계산 복잡성과 수치적 안정성을 달성하면서 핵심 기호 조작 기능을 유지하고 미분 가능한 학습에 적합한 VSA 결합 및 분리 메커니즘의 도출이다. 이전 시도는 복잡성, 불안정성으로 어려움을 겪거나 딥러닝 통합을 위한 명시적 설계를 놓쳤다. 본 논문은 푸리에 변환(HRR에서 사용됨)을 Hadamard 변환으로 대체하고 고유한 특성(예: 재귀 구조 및 자체 역 성질)을 활용하도록 결합 및 분리 연산을 신중하게 설계하여 이 격차를 해소한다.
고통스러운 절충 또는 딜레마:
이 문제를 해결하려는 이전 연구자들은 몇 가지 고통스러운 절충안에 갇혀 있었다.
* 표현력 대 계산 비용: 풍부하고 구성적인 표현(예: 여러 항목 결합)을 달성하는 것은 종종 TPR의 $O(d^p)$ 비용에서 볼 수 있듯이 기하급수적으로 증가하는 계산 복잡성으로 이어진다. 이는 매우 표현력이 풍부한 기호 구조와 실용적인 계산 사이에서 선택을 강요한다.
* 기호 충실도 대 학습 가능성: VSA는 강력한 기호 속성을 제공하지만, 이를 딥 신경망의 기울기 기반 학습에 적용하는 것은 종종 이러한 속성을 손상시킬 위험이 있다. 추가 제약 없이 기본 행렬 $G$와 $F$를 학습하는 것은 원하는 가환성 또는 결합성을 깨뜨릴 수 있다. 이는 "신경-기호 속성"을 유지하는 것과 현대 기계 학습 패러다임을 최적화하는 것 사이의 딜레마를 만든다.
* 수학적 우아함 대 수치적 견고성: 순환 곱셈(HRR의 경우)에 푸리에 변환과 같은 수학적으로 우아한 도구를 사용하는 것은 복소수와 비합리적인 곱셈을 도입하여 실제 벡터를 사용하는 실용적인 시스템에서 구현할 때 수치적 불안정성을 초래할 수 있다. 이는 이론적 순수성과 견고한 실제 성능 사이에서 선택을 강요한다.
제약 조건 및 실패 모드
이 문제는 저자들이 직면한 몇 가지 가혹하고 현실적인 벽으로 인해 매우 어렵다.
- 계산 복잡성 벽: 결합 단계에 대해 $O(d)$ 복잡성이 필요하다는 것은 엄격한 제약 조건이다. 많은 기존 VSA는 $O(d^2)$ 또는 $O(d \log d)$의 복잡성을 가지며, 이는 고차원 벡터($d$)에 대한 확장성에 상당한 장벽이다. 이는 효율성이 가장 중요한 대규모 딥러닝 모델에서의 적용 가능성을 제한한다.
- 수치적 불안정성: HRR과 같은 기존 VSA의 주요 실패 모드는 수치적 불안정성이다. 이는 복소수 및 비합리적인 곱셈을 포함하는 연산에서 발생하며, 특히 실수 벡터를 다룰 때 부동 소수점 오류와 신뢰할 수 없는 결과를 초래할 수 있다. 제안된 해결책은 본질적으로 이를 피해야 한다.
- 복합 표현에서의 노이즈 축적: 여러 개념이 단일 복합 벡터로 결합될 때(즉, $p \ge 2$개의 항목이 번들로 묶일 때) 노이즈가 필연적으로 축적된다. 이 노이즈는 분리 연산의 정확도를 저하시켜 개별 구성 요소를 안정적으로 검색하기 어렵게 만든다. 이 문제를 완화하는 메커니즘이 없으면 복잡한 기호 구조에 대한 VSA의 유용성이 심각하게 제한된다. 본 논문은 투영 단계가 없으면 노이즈 구성 요소 $\eta'$가 투영이 있는 $\eta''$보다 훨씬 높다고 보여준다.
- 벡터 초기화 문제: 결합 및 분리 연산이 올바르게 작동하려면 벡터의 기대값이 0이어야 한다. 그러나 벡터 구성 요소가 0에 가까운 값으로 초기화되면 분리 중 이러한 쿼리 벡터로의 후속 나누기가 "노이즈 구성 요소를 불안정하게 만들고 수치적 불안정성을 유발할 수 있다." 이 특정 초기화 제약 조건은 신중한 설계 선택을 요구하며, 이는 정상 분포 혼합(Mixture of Normal Distribution, MiND)의 도입으로 이어진다.
- 다중 결합에 걸친 크기 안정성: 이상적인 VSA는 복합 벡터의 안정적인 크기를 유지해야 한다. 즉, 크기가 $p$가 증가함에 따라 "폭발/소멸"하지 않아야 한다(결합된 항목 수). 이는 다른 VSA의 근사 분리 절차에서 일반적인 실패 모드로, $p$가 증가함에 따라 유사도 점수가 감소하거나 크기가 불안정해진다.
- 하드웨어 메모리 제한: 단일 NVIDIA TESLA P100 GPU와 32GB 메모리를 사용하는 실험 설정은 제안된 VSA가 이러한 일반적인 딥러닝 하드웨어 환경 내에서 작동할 만큼 메모리 효율적이어야 한다는 제약 조건을 암묵적으로 부과한다.
- 다중 레이블 분류에서의 극단적 희소성: 극단적 다중 레이블(Extreme Multi-label, XML) 분류와 같은 애플리케이션에서는 가능한 클래스 수($L \ge 100,000$)가 입력 차원($d \approx 5000$)을 훨씬 초과하며, 주어진 입력에 대해 관련성이 있는 클래스는 소수(종종 100개 미만)에 불과하다. 이러한 극단적인 희소성은 전통적인 선형 계층을 계산적으로 불가능하게 만든다($O(L)$ 복잡성). 따라서 이 방대한 희소 출력 공간을 효율적으로 표현할 수 있는 VSA가 필요하다(복잡성을 현재 클래스 수 $K$로 줄임, 여기서 $K$는 존재하는 클래스 수).
왜 이 접근 방식인가
선택의 불가피성
Hadamard-유도 선형 결합(HLB)의 채택은 단순히 선호가 아니라 현대 딥러닝 맥락에 적용될 때 기존 벡터 기호 아키텍처(VSA)의 고유한 한계에 의해 주도된 필요성이었다. 저자들은 홀로그래픽 축소 표현(HRR), 벡터-유도 변환 결합(VTB), 곱셈-덧셈-순열(MAP)과 같은 전통적인 "SOTA" VSA 방법이 특히 수치적 안정성, 계산 효율성 및 미분 가능한 시스템과의 원활한 통합과 관련하여 근본적으로 불충분하다는 것을 인식했다.
결정적인 깨달음은 VSA가 신경-기호 방법에 매력적인 플랫폼을 제공하지만, 많은 기존 접근 방식은 딥러닝 및 자동 미분이 널리 채택되기 전에 개발되었으며 대신 수작업으로 설계된 시스템에서의 효능에 초점을 맞추었다는 관찰에서 비롯되었다. 예를 들어, 푸리에 변환(FT) 및 순환 곱셈에 의존하는 HRR은 복소수 및 비합리적인 곱셈에 의존하기 때문에 수치적 불안정성을 겪는다(3페이지). 이는 특히 기울기가 관련된 시스템에서 견고한 수치 연산이 필요한 시스템에서 사용하기 어렵게 만든다.
대조적으로, Hadamard 변환은 본질적으로 이러한 문제를 피한다. 이는 순전히 실수로 작동하며 덧셈과 뺄셈만 수행하므로 비합리적인 곱셈과 복소수 산술을 제거한다(3페이지). 이 속성은 미분 가능한 시스템에서 학습을 불안정하게 만들 수 있는 작은 수치 오류가 전파될 수 있는 시스템에서 특히 중요한 수치적 안정성을 유지하는 데 독특하게 실행 가능한 솔루션이 된다. 또한 Hadamard 행렬의 자체 역 행렬이라는 속성은 분리 연산 $B^*$의 설계를 단순화하여 전체 시스템을 더 우아하고 견고하게 만든다.
비교 우위
HLB는 단순한 성능 지표를 넘어 여러 핵심 측면에서 이전의 황금 표준에 비해 질적인 우수성을 보여준다.
첫째, 계산 복잡성 측면에서 HLB는 결합 단계에 대해 인상적인 $O(d)$ 복잡성을 달성한다(1페이지). 이는 일반 선형 연산($O(d^2)$ 복잡성을 가지며 많은 VSA가 그렇게 볼 수 있음) 또는 일반적으로 고유한 고유값(eigenvalue)이 1인 행렬의 경우 $O(d)$ 복잡성을 가지는 행렬 연산의 경우 $O(d^2)$ 복잡성보다 훨씬 빠르다. 이는 Hadamard 도메인에서 결합 함수를 요소별 곱셈으로 재정의함으로써 달성된다($B'(x, y) = x \odot y$, 5페이지). 이는 고차원 벡터에 대해 매우 효율적이다.
둘째, 수치적 안정성은 핵심 장점이다. 언급했듯이 Hadamard 변환은 $\{-1, 1\}$ 값과 실수 산술만 사용하므로 복소수 및 비합리적인 곱셈을 포함하는 푸리에 변환 기반 방법(HRR과 같은)의 수치적 불안정성 문제를 완전히 피한다(2, 3페이지). 이 고유한 안정성은 특히 모델이 수치적 정밀도에 민감한 딥러닝에서 신뢰할 수 있는 작동에 매우 중요하다.
셋째, HLB는 뛰어난 노이즈 처리를 보여준다. 본 논문은 투영 단계(정의 3.2, 4페이지)를 도입하여 분리 중 축적된 노이즈를 크게 줄인다. 경험적 결과(그림 4, 15페이지)는 이 투영이 있는 노이즈 구성 요소($\eta''$)가 없는 노이즈($\eta'$)보다 훨씬 낮다는 것을 명확하게 보여주며, 검색 정확도를 향상시킨다. 이 구조적 강화는 여러 결합으로 노이즈가 축적되는 VSA의 일반적인 문제를 직접적으로 해결한다.
마지막으로 HLB는 크기 및 유사도 점수의 놀라운 일관성과 안정성을 보여준다. 그림 3(7페이지)은 HLB가 현재 항목에 대해 이상적인 유사도 점수 1을 일관되게 반환하고 결합된 벡터 수에 관계없이 일정한 크기를 유지한다는 것을 보여준다. 이는 HRR, VTB 및 MAP에서 관찰되는 "폭발/소멸" 값을 방지하며, 이는 안정적인 VSA 솔루션을 설계하고 안정적인 정보 검색을 보장하는 중요한 속성이다. 이러한 안정성은 벡터 초기화에 사용되는 정상 분포 혼합(Mixture of Normal Distribution, MiND)(속성 3.1, 5페이지)의 속성에 기인한다.
제약 조건과의 일치
선택된 HLB 방법은 현대 신경-기호 AI에 적합한 VSA 개발의 암묵적 및 명시적 제약 조건과 완벽하게 일치한다.
- 계산 효율성: VSA, 특히 딥러닝의 주요 제약 조건은 낮은 계산 오버헤드이다. HLB의 $O(d)$ 결합 복잡성은 이를 직접적으로 해결하여 고차원 데이터 및 대규모 애플리케이션에 실현 가능하게 만든다(1, 5페이지).
- 수치적 안정성: 견고한 수치 연산에 대한 요구 사항은 복소수 및 비합리적인 산술을 피하는 Hadamard 변환에 기반한 HLB에 의해 충족되어 안정성을 보장한다(2, 3페이지).
- 미분 가능한 시스템에서의 성능: 본 논문은 "미분 가능한 시스템에서 잘 작동하는" VSA라는 목표를 명시적으로 명시한다(초록, 1페이지). HLB의 선형 연산, 실수 값 특성 및 수치적 안정성은 딥러닝의 초석인 기울기 기반 최적화와 본질적으로 호환된다.
- 신경-기호 속성: VSA는 기호 조작 기능(가환성, 결합성, 역 연산)으로 높이 평가된다. Hadamard 변환은 "이미 결합성이 있고 분배적"이므로(2페이지), 추가적인 복잡한 제약 없이 이러한 필수 속성을 유지하도록 설계를 단순화한다.
- 노이즈 관리: 복합 표현에서의 노이즈 축적 문제는 중요한 과제이다. HLB의 MiND 초기화(방정식 6, 5페이지)와 명시적인 투영 단계(정의 3.2, 4페이지)는 이 노이즈를 최소화하고 관리하도록 맞춤화되어 많은 결합된 항목에서도 정확한 검색을 보장한다.
문제의 가혹한 요구 사항과 HLB의 고유한 속성 간의 이러한 "결합"은 변환 선택부터 초기화 및 투영 단계까지 설계 선택에서 분명하다.
대안의 거부
본 논문은 다른 인기 있는 VSA 접근 방식과 암묵적으로 일반 딥러닝 방법에 대한 명확한 이유를 제공한다.
- 기존 VSA (HRR, VTB, MAP):
- 수치적 불안정성: 주요 기준선인 HRR은 "복소수의 비합리적인 곱셈으로 인한 수치적 불안정성"으로 명시적으로 비판받는다(3페이지). 이는 실수 값 연산을 사용하는 HLB와 같은 대안을 찾는 직접적인 이유이다.
- 계산 복잡성: 본 논문은 많은 VSA가 일반 선형 연산으로 구현될 경우 $O(d^2)$의 복잡성을 부담할 것이라고 언급하며, 이는 너무 높다(1페이지). 텐서 곱 표현(TPR)은 여러 항목을 결합하는 데 " $O(d^p)$ 복잡성으로 인해 비현실적"이므로 기각된다(2페이지). HLB의 $O(d)$ 복잡성은 상당한 개선을 제공한다.
- 미분 가능한 시스템에서의 성능: "대부분의 VSA"에 대한 일반적인 비판은 "딥러닝 및 자동 미분이 인기를 얻기 전에 개발되었으며 대신 수작업으로 설계된 시스템에서의 효능에 초점을 맞추었다"는 것이며, "수치적 안정성, 계산 복잡성 또는 미분 가능한 시스템 맥락에서 기대보다 낮은 성능에 문제가 있었다"(1페이지). 이는 해당 응용 분야에 대한 부적합성을 강조한다.
- 노이즈 및 안정성 문제: 그림 3(7페이지)은 HRR, VTB 및 MAP-C/B가 결합된 벡터 수가 증가함에 따라 유사도 점수가 감소하고 크기가 폭발/소멸하는 문제로 어려움을 겪는다는 것을 경험적으로 보여준다. HLB가 일정한 크기와 이상적인 유사도 점수를 유지하는 능력은 대안에서 이러한 실패를 직접적으로 해결한다.
- 일반 딥러닝 (예: 표준 CNN, 기본 확산, 트랜스포머): 직접적인 비교에서 명시적으로 "거부"되지는 않았지만, "신경-기호 AI"(초록, 1페이지)에 대한 논문의 초점은 순전히 연결주의 모델이 VSA가 제공하는 내재적인 기호 조작 기능을 부족하다는 것을 암시한다. "연결주의 기호 가짜 비밀(Connectionist Symbolic Pseudo Secrets, CSPS)" 또는 "극단적 다중 레이블 분류(Xtreme Multi-Label Classification, XML)"와 같은 작업의 경우, VSA의 기호 속성이 특정 이점을 위해 활용된다.
- CSPS: 안전한 계산 오프로딩의 경우, 동형 암호화(HE)는 "신경망 자체를 실행하는 것보다 수행하는 데 더 비싸다"고 간주되어 유용성을 저해한다(8페이지). VSA는 로컬 계산을 줄이면서 입력/출력을 모호하게 하는 휴리스틱 대안을 제공한다. 순수 신경망은 이러한 "암호화/복호화" 메커니즘을 내재적으로 제공하지 않을 것이다.
- XML: VSA는 기호 조작을 활용하여 복잡성을 $O(K)$(여기서 $K$는 존재하는 클래스 수, $K \ll L$)로 줄임으로써 $O(L)$ 계산 복잡성 비용을 "회피"하는 데 사용된다(9페이지). 표준 딥러닝 아키텍처는 일반적으로 VSA가 피하도록 설계된 $O(L)$ 비용을 부담하는 대규모 출력 계층이 필요하다.
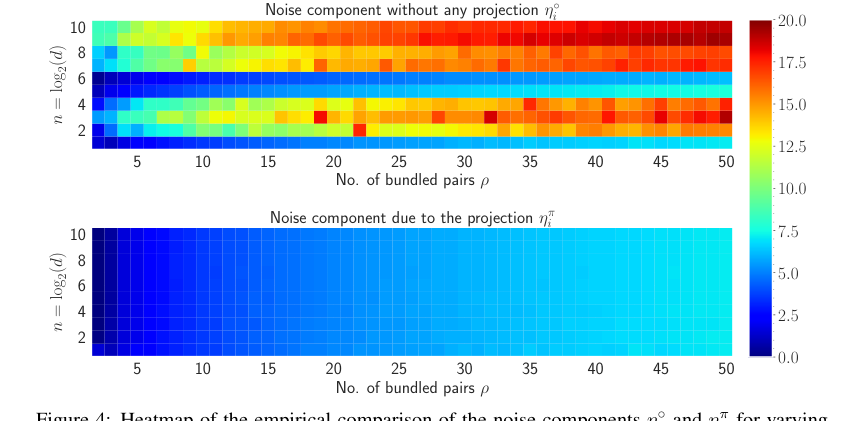 Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
수학적 및 논리적 메커니즘
마스터 방정식
Hadamard-유도 선형 결합(HLB) 메커니즘의 핵심은 Walsh-Hadamard 변환을 활용하는 결합 및 분리 연산의 정의에 있다. 이 변환 논리를 정의하는 절대적인 핵심 방정식은 결합 함수와 분리 함수이며, 특히 성능과 안정성을 향상시키기 위해 투영된 입력에 적용될 때 그러하다.
두 벡터 $x, y \in \mathbb{R}^d$에 대한 결합 연산 $B(x,y)$는 다음과 같이 정의된다.
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) \quad \text{(방정식 2)} $$
개별 투영된 결합 쌍을 합산하여 형성된 복합 표현을 다루고 입력 벡터에 투영 단계를 적용한 후, 분리 연산 $B^*(\chi_p, \pi(y_i)^\dagger)$는 중간 결과를 산출한다. 투영 함수 $\pi(v)$는 $\pi(v) = \frac{1}{d} Hv$로 정의된다. 복합 표현 $\chi_p$는 $p$개의 투영된 결합 쌍의 합으로 형성된다: $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$. 투영된 쿼리 벡터 $\pi(y_i)$를 사용하여 이 복합 표현에 적용된 분리 연산은 다음과 같이 주어진다.
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) \quad \text{(방정식 4)} $$
본 논문은 추가적인 역 투영 단계를 거친 후 이 중간 결과가 최종 검색된 출력으로 단순화됨을 보여주며, 이는 노이즈 항 $\eta''$에 원래 벡터 $x_i$( $y_i$와 관련된 원래 벡터)가 더해진 근사치이다.
항별 분석
이 마스터 방정식의 구성 요소를 분해하여 수학적 정의, 물리적/논리적 역할 및 저자의 설계 선택을 이해해 보자.
결합 방정식 (방정식 2) 분석
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) $$
- $B(x,y)$:
- 수학적 정의: 입력 벡터 $x$와 $y$ 사이의 결합 연산에서 발생하는 출력 벡터.
- 물리적/논리적 역할: 이는 벡터 $x$와 $y$로 표현되는 두 개념을 단일의 새로운 벡터로 연관시키는 핵심 함수이다. VSA에서 구성적 표현을 생성하기 위한 기본 빌딩 블록이다.
- 이 선택을 한 이유: 이 특정 형태는 홀로그래픽 축소 표현(HRR)에 사용되는 순환 곱셈에서 푸리에 변환을 Hadamard 변환으로 대체하여 더 나은 계산 효율성과 수치적 안정성을 목표로 도출되었다.
- $x, y$:
- 수학적 정의: 차원 $d$의 입력 벡터, $x, y \in \mathbb{R}^d$.
- 물리적/논리적 역할: 각 벡터는 VSA 프레임워크 내에서 개별 개념, 기호 또는 정보 조각을 나타낸다.
- 이 선택을 한 이유: VSA는 본질적으로 기호 정보를 인코딩하고 조작하기 위해 고차원 실수 벡터를 사용한다.
- $d$:
- 수학적 정의: 입력 벡터 $x$와 $y$의 차원.
- 물리적/논리적 역할: 정규화 계수 역할을 한다.
- 이 선택을 한 이유: $d$로 나누는 것은 결과 결합 벡터의 크기를 합리적인 범위 내로 유지하여 값이 폭발하는 것을 방지하고 대략적인 직교성을 보장하기 위해 VSA에서 일반적인 관행이다. 또한 두 번의 Hadamard 변환 적용($H(Hv) = dv$)으로 인한 스케일링 계수를 상쇄한다.
- $H$:
- 수학적 정의: 크기 $d \times d$의 Hadamard 행렬. 이 행렬은 $+1$과 $-1$ 항목만 포함하며 재귀적으로 정의된다(예: $H_1 = [1]$, $H_{2n} = \begin{pmatrix} H_n & H_n \\ H_n & -H_n \end{pmatrix}$).
- 물리적/논리적 역할: 벡터에 Hadamard 변환을 적용한다.
- 이 선택을 한 이유: Hadamard 변환은 계산 효율성(이 도출에서는 선형 복잡성 $O(d)$, 일반 고속 Walsh-Hadamard 변환의 경우 $O(d \log d)$), 수치적 안정성(복소수 또는 비합리적인 곱셈을 피하는 $\pm 1$ 값만 사용), 그리고 역 연산 설계에 편리한 자체 역 행렬이라는 속성 때문에 선택되었다.
- $Hx$:
- 수학적 정의: 벡터 $x$의 Hadamard 변환.
- 물리적/논리적 역할: 입력 벡터 $x$를 원래 도메인에서 Hadamard 도메인으로 변환한다.
- 이 선택을 한 이유: 이 변환은 결합 연산에 매우 중요하다. 벡터를 Hadamard 도메인으로 변환함으로써, 요소별 곱셈은 원래 도메인에서의 순환 곱셈과 유사한 결합 효과를 달성할 수 있다(이는 일반적으로 HRR의 푸리에 도메인에서의 요소별 곱셈을 통해 수행됨).
- $Hy$:
- 수학적 정의: 벡터 $y$의 Hadamard 변환.
- 물리적/논리적 역할: 입력 벡터 $y$를 Hadamard 도메인으로 변환한다.
- 이 선택을 한 이유: $Hx$와 동일한 이유.
- $\odot$:
- 수학적 정의: 요소별 곱셈(Hadamard 곱이라고도 함).
- 물리적/논리적 역할: 이 연산자는 변환된 벡터의 결합을 Hadamard 도메인에서 수행한다.
- 이 선택을 한 이유: Hadamard 도메인에서 요소별 곱셈은 푸리에 도메인에서의 순환 곱셈과 유사하게 결합 메커니즘 역할을 한다. 이 연산은 계산 효율적이며 VSA에 대한 원하는 대수적 속성을 유지한다.
- $H(\dots)$:
- 수학적 정의: 역 Hadamard 변환. $H$는 자체 역 행렬이므로(스케일링 계수 $d$까지), $H$를 다시 적용하면 이전 변환이 효과적으로 반전된다.
- 물리적/논리적 역할: 결합된 벡터 $B(x,y)$가 원래 입력과 동일한 벡터 공간에 있도록 Hadamard 도메인에서 다시 변환한다.
- 이 선택을 한 이유: 결과 결합 벡터 $B(x,y)$가 원래 입력과 동일한 벡터 공간에 있도록 하여 합과 같은 일관된 연산을 허용한다.
분리 방정식 (방정식 4) 분석
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) $$
- $B^*(\chi_p, \pi(y_i)^\dagger)$:
- 수학적 정의: 투영된 쿼리 벡터 $\pi(y_i)$의 역을 사용하여 복합 표현 $\chi_p$에 적용된 분리 연산의 출력 벡터.
- 물리적/논리적 역할: 이는 결합의 역 연산으로, 번들 표현에서 특정 개념(이상적으로는 $\pi(x_i)$)을 검색하도록 설계되었다.
- 이 선택을 한 이유: 이 연산은 VSA에서 지식 검색에 필수적이며, 시스템이 주어진 쿼리와 결합된 것을 "질문"할 수 있게 한다.
- $\chi_p$:
- 수학적 정의: 각 입력 벡터가 투영 함수 $\pi$로 사전 처리된 $p$개의 개별 결합 쌍의 합으로 형성된 복합 표현. 수학적으로 $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$.
- 물리적/논리적 역할: 여러 연관 또는 개념을 간결하게 저장하는 단일 벡터.
- 이 선택을 한 이유: VSA는 벡터 합을 사용하여 복합 구조 또는 연관 집합을 나타낼 수 있으며, 벡터 덧셈의 선형성을 활용한다.
- $\pi(x_j), \pi(y_j)$:
- 수학적 정의: 투영된 입력 벡터, 여기서 $\pi(v) = \frac{1}{d} Hv$.
- 물리적/논리적 역할: 원래 개념 벡터 $x_j, y_j$의 사전 처리된 버전.
- 이 선택을 한 이유: 투영 단계는 벡터를 정규화하고 Hadamard 도메인으로 변환한다. 이는 수치적 불안정성을 완화하고 노이즈 축적을 줄이는 데 도움이 되며, 특히 여러 항목이 함께 번들로 묶일 때 중요하다.
- $\sum_{j=1}^p (\dots)$:
- 수학적 정의: 투영된 입력 벡터의 요소별 곱셈인 $p$개의 개별 항에 대한 합.
- 물리적/논리적 역할: 개별 결합 표현(중간 형태)을 단일 복합 벡터로 집계한다.
- 이 선택을 한 이유: 덧셈의 선형성은 여러 결합 쌍을 단일 벡터로 번들로 묶을 수 있게 하며, 이는 복잡한 구조를 나타내는 VSA의 핵심 기능이다.
- $\odot$:
- 수학적 정의: 요소별 곱셈.
- 물리적/논리적 역할: 합 내에서, 이는 Hadamard 도메인에서 투영된 입력의 결합을 수행한다. 합 외부에서는 쿼리의 역과 곱하여 분리를 수행한다.
- 이 선택을 한 이유: 요소별 곱셈은 효율성과 대수적 속성으로 인해 Hadamard 도메인에서 선택된 결합/분리 메커니즘이다.
- $H(\sum \dots)$:
- 수학적 정의: 투영된 입력의 요소별 곱셈 합에 적용된 Hadamard 변환.
- 물리적/논리적 역할: 이는 복합 표현에 적용되는 중간 Hadamard 변환이다.
- 이 선택을 한 이유: 이 단계는 분리 과정의 일부로, 합을 개별 나눗셈에 적합한 도메인으로 변환한다.
- $\frac{1}{H \pi(y_i)}$:
- 수학적 정의: 투영된 쿼리 벡터 $\pi(y_i)$의 Hadamard 변환의 요소별 역.
- 물리적/논리적 역할: 이 항은 Hadamard 도메인에서 "분리 키" 역할을 한다.
- 이 선택을 한 이유: 역 연산을 수행하기 위해, 쿼리 벡터로 "나누는" 효과가 있다. Hadamard 도메인에서는 투영된 쿼리의 Hadamard 변환의 역과 요소별 곱셈으로 달성된다. 역 사용은 $Hx \cdot Hx^\dagger = 1$ 속성에서 파생된다.
- $H(\dots)$:
- 수학적 정의: 역 Hadamard 변환.
- 물리적/논리적 역할: 결과를 Hadamard 도메인에서 원래 벡터 공간으로 다시 변환한다.
- 이 선택을 한 이유: 검색된 벡터를 원래 입력 벡터와 동일한 공간에서 얻어 해석 가능하고 추가 VSA 작업에 사용할 수 있도록 한다.
- $\frac{1}{d}$:
- 수학적 정의: 스케일링 계수.
- 물리적/논리적 역할: 검색된 벡터의 크기를 정규화한다.
- 이 선택을 한 이유: 결합 연산과 유사하게, 이 스케일링은 일관된 벡터 크기를 보장하고 Hadamard 변환으로 인한 스케일링을 상쇄하여 수치적 안정성을 유지한다.
단계별 흐름
추상 데이터 포인트, 예를 들어 $x_1$이 $y_1$과 결합되어 복합 표현 $\chi_p$(다른 $p-1$개의 쌍과 함께)로 형성되고 이후 분리되는 과정을 추적해 보자.
-
개념 초기화: 우리는 $\mathbb{R}^d$에 있는 원시 개념 벡터, 예를 들어 $x_1, y_1, \dots, x_p, y_p$로 시작한다. 이러한 벡터는 일반적으로 정상 분포 혼합(MiND) $\Omega(\mu, 1/d)$에서 샘플링하여 초기화되며, 이는 기대값이 0이지만 0이 아닌 절대 평균을 갖도록 보장한다. 이 초기화는 수치적 안정성을 위한 기초 단계이다.
-
입력 투영: 결합이 발생하기 전에 각 개별 개념 벡터(예: $x_j$ 및 $y_j$)는 투영 단계를 거친다. 임의의 벡터 $v$에 대해, 이는 Hadamard 변환 및 스케일링을 적용하는 것을 포함한다: $\pi(v) = \frac{1}{d} Hv$. 이는 원시 입력 벡터를 "투영된" 형태인 $\pi(x_j)$ 및 $\pi(y_j)$로 변환하며, 이는 정규화되고 Hadamard 도메인에 있다. 이 사전 처리는 나중에 노이즈를 줄이는 데 중요하다.
-
개별 결합 (쌍별): 투영된 개념 벡터 쌍, 예를 들어 $(\pi(x_j), \pi(y_j))$에 대해 HLB 결합 연산 $B(\pi(x_j), \pi(y_j))$이 수행된다.
- Hadamard 변환 (암시적): $\pi(v)$의 정의는 $H(\pi(v)) = H(\frac{1}{d} Hv) = \frac{1}{d} H(Hv) = v$를 의미한다. 따라서 방정식 2를 사용하여 $B(\pi(x_j), \pi(y_j))$를 계산할 때, $H(\pi(x_j))$ 및 $H(\pi(y_j))$ 항은 효과적으로 $x_j$ 및 $y_j$가 된다.
- 요소별 결합: 벡터 $x_j$와 $y_j$는 요소별 곱셈 $x_j \odot y_j$을 통해 결합된다. 이것이 핵심 연관 단계로, Hadamard와 유사한 도메인에서 결합된 표현을 생성한다.
- 역 Hadamard 변환 및 스케일링: 이 요소별 곱셈 $x_j \odot y_j$은 Hadamard 행렬 $H$를 적용하고 $1/d$로 스케일링하여 다시 변환된다. 결과는 $B(\pi(x_j), \pi(y_j)) = \frac{1}{d} H(x_j \odot y_j)$이다.
-
복합 표현 형성: 이러한 개별 결합 벡터 $B(\pi(x_j), \pi(y_j))$ 각각 $p$개가 합산된다. 이 선형 합은 이제 $p$개의 연관 번들을 나타내는 단일 고차원 벡터 $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$를 생성한다.
-
쿼리 투영 (분리를 위해): 복합 표현 $\chi_p$에서 특정 개념, 예를 들어 $x_i$를 검색하려면 해당 쿼리 벡터 $y_i$를 사용한다. 이 쿼리 벡터 $y_i$도 동일한 투영 단계를 거친다: $\pi(y_i) = \frac{1}{d} Hy_i$.
-
분리 연산 (방정식 4): 분리 과정 $B^*(\chi_p, \pi(y_i)^\dagger)$가 펼쳐진다.
- 복합 변환: Hadamard 변환 $H$가 복합 표현 $\chi_p$에 적용된다. $H$의 선형성과 $\chi_p$의 구조로 인해 이는 $H(\chi_p) = \sum_{j=1}^p (x_j \odot y_j)$로 단순화된다. 이는 전체 번들을 개별 결합 쌍이 요소별 곱셈으로 명확하게 표현되는 도메인으로 가져온다.
- 쿼리 변환: Hadamard 변환 $H$가 투영된 쿼리 벡터 $\pi(y_i)$에 적용되며, 이는 $H(\pi(y_i)) = y_i$로 단순화된다.
- 역 쿼리: 이 변환된 쿼리의 요소별 역 $1/y_i$가 계산된다. 이는 Hadamard 도메인에서 "분리 키" 역할을 한다.
- 요소별 분리: 변환된 복합 표현 $\sum_{j=1}^p (x_j \odot y_j)$은 역 쿼리 $1/y_i$와 요소별로 곱셈된다. 이 단계는 $y_i$ 구성 요소를 "나누어" 이상적으로 $x_i$를 분리하려고 시도한다.
- 역 Hadamard 변환 및 스케일링: 이 요소별 곱셈의 결과는 Hadamard 행렬 $H$를 적용하고 $1/d$로 스케일링하여 다시 변환된다. 이는 중간 분리 결과 $B^*(\chi_p, \pi(y_i)^\dagger)$를 산출한다.
-
역 투영 (최종 출력): 본 논문은 이 중간 결과에서 "원래 데이터"(즉, 원래 $x_i$)를 얻기 위해 역 투영 단계가 적용된다고 명시한다. 이 최종 단계는 중간 결과를 방정식 5와 같은 형태로 효과적으로 단순화하며, 이는 단일 쌍이 결합된 경우($p=1$) $x_i$에 대한 근사치이거나, 여러 쌍이 결합된 경우($p>1$) 노이즈 항 $\eta''$에 대한 근사치이다.
최적화 역학
Hadamard-유도 선형 결합(HLB) 메커니즘은 본 논문에서 설명한 대로 학습 알고리즘 자체가 아니라, 매우 효율적이고 수치적으로 안정적이도록 설계된 고정된 수학적으로 도출된 연산 집합이다. 따라서 이의 "최적화 역학"은 내부 매개변수의 반복적인 업데이트를 기울기 하강을 통해 포함하지 않는다. 대신, 그 역학은 설계 자체와 더 큰 미분 가능한 시스템에서 학습을 촉진하는 방식에 내재되어 있다.
-
고정된 결정론적 연산: HLB의 핵심 결합 및 분리 함수는 Hadamard 행렬 및 요소별 연산을 기반으로 하는 결정론적 변환이다. HLB 연산 자체 내에는 기울기 하강 또는 다른 학습 규칙을 통해 업데이트되는 학습 가능한 가중치, 편향 또는 기타 매개변수가 없다. Hadamard 행렬은 미리 정의된 정적 구성 요소이다.
-
내재된 수치적 안정성: HLB의 핵심 역학적 속성은 내장된 수치적 안정성이다. Hadamard 변환은 설계상 $\pm 1$ 값만 포함하는 연산을 사용하므로 HRR과 같은 다른 VSA 방법에서 불안정성을 초래할 수 있는 복소수 및 비합리적인 곱셈을 피한다. 또한 벡터 초기화에 사용되는 정상 분포 혼합(MiND)(방정식 6)은 벡터의 기대값이 0이지만 0이 아닌 절대 평균을 갖도록 보장한다. 이 설계 선택은 분리 과정 중 0에 가까운 값으로 나누는 것을 방지하여 수치적 폭발을 유발할 수 있다.
-
노이즈 감소 메커니즘: 투영 단계($\pi(x) = \frac{1}{d} Hx$)는 검색 정확도를 향상시키기 위한 HLB의 내부 역학의 중요한 부분이다. 결합 전에 입력 벡터에 이 투영을 적용함으로써 메커니즘은 여러 항목이 함께 번들로 묶일 때 발생하는 축적된 노이즈($\eta''$)를 적극적으로 줄인다. 이것은 학습된 것이 아니라 미리 정의된 정적 노이즈 감소 전략이지만, 시스템의 성능과 견고성에 상당한 영향을 미친다.
-
시스템 통합을 위한 미분 가능성: HLB 자체는 학습하지 않지만, "미분 가능한 시스템"과 호환되도록 명시적으로 설계되었다. 이는 HLB를 구성하는 수학적 연산(행렬 곱셈, 요소별 곱셈, 합)이 모두 미분 가능하다는 것을 의미한다. 따라서 HLB가 더 큰 신경망 아키텍처에 통합될 때(연결주의 기호 가짜 비밀 및 극단적 다중 레이블 분류 작업에서 입증된 바와 같이), 전체 시스템은 여전히 표준 기울기 기반 최적화 알고리즘(예: 확률적 기울기 하강)을 사용하여 종단 간 학습될 수 있다. HLB 메커니즘은 이러한 학습 시스템 내에서 기호 정보를 표현하고 조작하는 안정적이고 효율적인 방법을 제공하여, 주변 네트워크 매개변수가 정의된 손실 지형(예: XML 분류를 위한 방정식 11의 코사인 유사도 손실)을 기반으로 최적화될 수 있도록 한다. HLB 연산 자체는 수정 없이 기울기를 통과시킨다.
결과, 한계 및 결론
실험 설계 및 기준선
저자들은 고전적인 벡터 기호 아키텍처(VSA) 작업과 현대 딥러닝 애플리케이션 모두에서 Hadamard-유도 선형 결합(HLB)을 검증하기 위해 세심하게 실험을 설계했으며, 이를 확립된 기준선과 가차 없이 비교했다.
고전 VSA 작업의 경우 두 가지 주요 시나리오가 구성되었다.
-
기본 결합/분리 정확도: 이 실험은 HLB가 복합 표현에서 결합된 벡터를 올바르게 검색하는 능력을 입증하는 것을 목표로 했다. 설정은 1000개의 무작위 벡터 풀을 생성하는 것을 포함했다. 이 풀에서 $p$개의 벡터 쌍(여기서 $p$는 1에서 25까지 범위)이 샘플링되어 VSA의 결합 연산 $B(x_i, y_i)$를 사용하여 결합된 다음 복합 표현 $s = \sum_{i=1}^p B(x_i, y_i)$을 형성하도록 합산되었다. "희생자" 기준선 모델에는 홀로그래픽 축소 표현(HRR) [32], 벡터-유도 변환 결합(VTB) [12], 곱셈-덧셈-순열(MAP) [10]이 포함되었다. 각 복합 $s$에 대해 실험은 원래 번들의 일부였던 모든 좌변 구성 요소 $x_q$를 반복하고 분리 연산 $B^*(s, x_q)$를 사용하여 해당 $y_q$를 검색하려고 시도했다. 검색은 점 곱 $B^*(s, x_q)^T y_q$가 다른 모든 $j \neq q$에 대해 $B^*(s, x_q)^T y_j$보다 클 때 올바른 것으로 간주되었다. 이 과정은 50번의 시도 동안 반복되었으며, 결정적인 증거는 다양한 벡터 차원 $d$(특히 VTB 제약 조건을 수용하기 위한 완전 제곱)에 걸쳐 결합된 항 수 $p$에 대한 정확도 대 곡선 아래 면적(AUC)으로 제시되었다.
-
순차 결합/분리 안정성: 이 작업은 반복적인 결합 연산 하에서 유사도 점수의 품질과 벡터의 크기 안정성을 평가했다. 두 가지 하위 시나리오가 테스트되었다.
- 무작위 결합: 초기 벡터 $b_0$는 $p$ 라운드 동안 새로운 무작위 벡터 $x_t$와 결합하여 순차적으로 수정되었으며, 결과는 $b_{t+1} = B(b_t, x_t)$였다. 목표는 각 $x_t$를 분리하고 이전 $b_t$를 복구하는 것이었다.
- 자동 결합: 단일 무작위 벡터 $x$는 진화하는 상태와 반복적으로 결합되었다: $b_{t+1} = B(b_t, x)$.
이 실험의 기준선은 HRR, VTB 및 MAP-C였다. 추구된 중요한 증거는 현재 항목에 대한 유사도 점수 $B^*(b_{t+1}, x_t)^T b_t$가 이상적으로 1로 유지되는지, 그리고 벡터의 크기 $||B^*(b_{t+1}, x_t)||_2$가 $p$가 증가함에 따라 일반적인 VSA 함정인 폭발 또는 소멸 값을 피하면서 일정하게 유지되는지 여부였다.
딥러닝 애플리케이션의 경우 HLB는 두 가지 최신 신경-기호 작업에 통합되었다.
-
연결주의 기호 가짜 비밀 (CSPS) [3]: 이 작업은 신뢰할 수 없는 제3자에게 계산을 오프로드할 때 입력과 출력을 모호하게 하기 위해 "일회용 패드"를 모방하는 휴리스틱 보안을 위해 VSA를 사용하는 것을 탐구했다. 실험에는 무작위 VSA 벡터 $s$( "비밀")를 입력 $x$에 결합하여 모호한 표현 $B(s, x)$를 생성하는 것이 포함되었다. 제3자 네트워크는 이 모호한 입력을 처리하여 출력 $y$를 반환했으며, 이는 로컬에서 비밀 $B^*(y, s)$로 분리되어 최종 답변을 얻었다. 기준선은 HRR, VTB, MAP-C 및 MAP-B였다. 실험은 단일 NVIDIA TESLA P100 GPU와 32GB 메모리에서 실행되었다.
- 정확도: 주요 지표는 5가지 표준 이미지 데이터셋(MNIST, SVHN, CIFAR-10, CIFAR-100, Mini-ImageNet)에 대한 Top@1 및 Top@5 분류 정확도였다.
- 보안: 정보 숨김 주장을 철저히 증명하기 위해 조정된 Rand 지수(ARI)가 계산되었다. 염탐하는 제3자는 다양한 클러스터링 알고리즘(K-means, Gaussian Mixture Model, Birch, HDBSCAN)을 사용하여 모호한 입력 $B(x, s)$ 및 출력 $y$를 클러스터링하려고 시도했다. 0에 가까운 ARI 점수는 성공적인 정보 숨김을 입증하는 결정적인 증거였으며, 공격자 관점에서 무작위 레이블 할당을 나타낸다.
-
극단적 다중 레이블 (XML) 분류 [9]: 이 작업은 단일 입력이 가능한 클래스의 방대한 수($C \gg d$, 여기서 $d$는 입력 차원)로 분류되어야 하는 시나리오를 다루었다. 이는 전자 상거래에서 일반적이다. VSA는 희소 출력 공간을 나타내는 데 사용되었다. 실험 설정은 [9]의 네트워크 세부 정보를 따랐으며, 원래 VSA를 HLB 및 기준선 VSA(HRR, VTB, MAP)로 대체했다. 평가는 8가지 다양한 데이터셋(BIBTEX, DELICIOUS, MEDIAMILL, EURLEX-4K, EURLEX-4.3K, WIKI10-31K, AMAZON-13K, DELICIOUS-200K)에서 수행되었다. 주요 지표는 다중 레이블 분류 성능을 평가하는 표준인 정규화된 할인 누적 이득(nDCG) 및 경향 점수 nDCG(PSnDCG)였다.
증거가 입증하는 것
경험적 증거는 이론적 주장을 강력하게 뒷받침하며 HLB의 우수하거나 경쟁력 있는 성능을 광범위한 VSA 애플리케이션에 걸쳐 입증한다.
이론적 검증:
본 논문은 HLB의 핵심 수학적 메커니즘이 의도한 대로 작동한다는 설득력 있는 증거를 제공한다. 원본 벡터 $x_i$와 검색된 버전 $\hat{x}_i$ 간의 코사인 유사도 $\phi$가 약 $1/\sqrt{p}$인 이론적 관계(정리 3.2)는 히트맵(그림 1) 및 플롯(그림 6)에 의해 경험적으로 검증된다. 이는 제안된 유사도 증강의 효과를 확인한다. 또한 복합 표현의 노름에 대한 이론적 예측 $||X_p||_2 \approx \mu^2 \sqrt{p} \cdot d$(정리 B.1)도 실험 결과(그림 5)와 밀접하게 일치하지만, 근사치로 인해 $p$가 증가함에 따라 약간의 변동이 있다. 결정적으로 HLB에 도입된 투영 단계는 축적된 노이즈를 감소시키는 것으로 명확하게 입증되었다. 투영 유무에 따른 노이즈 구성 요소를 비교하는 히트맵(그림 4)은 투영이 없을 때 최대 노이즈가 투영이 있을 때(7.18)보다 훨씬 높다는 것(19.38)을 명확하게 보여주며, 이 아키텍처 선택이 검색 정확도를 개선하는 데 효과적임을 증명한다.
고전 VSA 작업:
기본 결합/분리 정확도 작업에서 HLB는 HRR 및 VTB와 비슷하거나 심지어 능가하는 성능을 일관되게 보여주며, 다양한 차원에서 MAP를 확실히 능가한다(그림 2). AUC 점수로 제시된 이 강력한 증거는 HLB의 결합 및 분리 연산이 기본 VSA 작업에 대해 견고하고 효과적임을 증명한다. 더 인상적으로, 순차 결합/분리 안정성 작업(그림 3)에서 HLB는 현재 항목에 대해 이상적인 유사도 점수 1을 유지하고 결정적으로 결합된 벡터 수 $p$에 관계없이 일정한 벡터 크기를 유지함으로써 두드러진다. 이는 HRR, VTB 및 MAP와 같은 기준선이 유사도 점수가 감소하거나 크기가 폭발/소멸하는 문제를 보이는 것에 비해 상당한 이점이다. 이러한 안정성은 HLB가 다른 VSA에 만연한 주요 수치적 안정성 문제를 해결한다는 부인할 수 없는 증거이며, 복잡한 기호 처리를 위한 더 안정적인 기반이 된다.
딥러닝 작업:
HLB의 효능은 딥러닝 맥락으로 강력하게 확장된다. 연결주의 기호 가짜 비밀 (CSPS) 작업에서 HLB는 5가지 데이터셋(MNIST, SVHN, CIFAR-10, CIFAR-100, Mini-ImageNet) 모두에서 분류 정확도 측면에서 모든 이전 VSA 방법보다 훨씬 뛰어날 뿐만 아니라(표 2), 정보 숨김도 향상시킨다. 조정된 Rand 지수(ARI) 점수(표 3)는 HLB에 대해 SVHN, CIFARs 및 Mini-ImageNet에 대해 일관되게 0에 더 가깝게 나타나, 염탐하는 제3자가 입력 또는 출력을 클러스터링하기가 훨씬 더 어렵다는 것을 나타내어 이중 이점(정확도 향상 및 향상된 보안)을 증명한다. MNIST가 모든 방법에 대해 ARI에서 일부 퇴화를 보였지만, 이는 CSPS 보안에 대한 알려진 문제로 인정된다. 이러한 이중 개선은 HLB의 실용적인 유용성에 대한 강력한 증거이다.
극단적 다중 레이블 (XML) 분류의 경우 HLB는 새로운 최첨단(SOTA)을 설정한다. 표 4는 특징과 레이블의 관점에서 "쉬운"에서 "어려운"까지 다양한 8가지 데이터셋에 대한 nDCG 및 PSnDCG 점수를 제시한다. HLB는 두 지표 모두에 대해 모든 데이터셋에서 최고의 점수를 달성하여, 고차원 희소 출력 공간을 효율적이고 효과적으로 처리하는 능력이 우수함을 입증한다. 여러 데이터셋과 지표에 걸친 이러한 포괄적인 승리는 HLB의 핵심 메커니즘이 복잡한 실제 딥러닝 시나리오에서 실질적인 성능 향상으로 이어진다는 결정적이고 부인할 수 없는 증거를 제공한다.
한계 및 향후 방향
제안된 Hadamard-유도 선형 결합(HLB)이 인상적인 성능과 이론적 타당성을 보여주지만, 특정 한계를 인정하고 이러한 결과를 더욱 발전시키기 위한 미래 개발 방향을 고려하는 것이 중요하다.
한계:
명시적으로 언급되지는 않았지만, 한 가지 암묵적인 한계는 수학적 도출에서 비롯된다. HLB의 핵심인 Hadamard 행렬은 일반적으로 벡터 차원 $d$가 2의 거듭제곱이어야 한다. 이는 많은 계산 맥락에서 일반적이지만, 임의의 차원을 가진 애플리케이션의 경우 패딩 또는 기타 해결책이 필요할 수 있으며, 이는 비효율성이나 복잡성을 초래할 수 있다. 본 논문은 또한 정리 B.1(방정식 17에서 노이즈 항 $\xi$ 무시)에서 이루어진 근사치가 번들 쌍 수 $p$가 증가함에 따라 복합 표현의 노름에서 변동이 증가한다는 점을 지적한다(그림 5). 전반적인 추세는 유지되지만, 이는 $p$가 매우 클 경우 근사치가 덜 정확해질 수 있으며 시스템의 예측 가능성에 영향을 미치거나 더 정교한 노이즈 처리가 필요할 수 있음을 시사한다.
또한 CSPS의 보안은 휴리스틱이지 암호론적으로 보장되지 않는 것으로 설명된다. MNIST 데이터셋의 ARI 결과는 일부 퇴화를 보여주며, 이러한 보안이 절대적이지 않다는 것을 상기시킨다. 이는 엄격하고 증명 가능한 보안을 요구하는 애플리케이션의 경우 CSPS 프레임워크 내에서 HLB만으로는 충분하지 않을 수 있음을 시사한다. 마지막으로, 결합 단계 자체는 $O(d)$ 복잡성을 자랑하지만, 본 논문은 HLB가 대규모 딥러닝 시스템에 통합될 때의 전체 계산 부담(예: 메모리 사용량, 매우 큰 모델의 훈련 시간 또는 에너지 소비)에 대해 자세히 다루지 않는다. 특히 $d$ 또는 $p$가 극단적인 값으로 확장될 때.
향후 방향:
-
임의 차원 및 대체 변환으로의 일반화:
- 논의: 비효율적인 단순 패딩에 의존하지 않고 2의 거듭제곱이 아닌 벡터 차원에 대한 HLB의 이점을 어떻게 확장할 수 있는가? 실용적인 엔지니어링 솔루션의 문을 열면서 차원 유연성이 더 뛰어난 유사한 계산 이점과 바람직한 VSA 속성을 제공하는 "근사" Hadamard 변환 또는 다른 직교 변환을 탐색할 수 있는가? 이는 HLB의 적용 범위를 크게 넓힐 수 있다.
- 관점: 이론적 관점에서 이는 Hadamard 기저의 엄격한 수학적 우아함에 도전하지만 실용적인 엔지니어링 솔루션의 문을 열어준다. 응용 관점에서 이는 다양한 기존 데이터셋 및 모델과의 통합에 대한 잠재적 장벽을 제거한다.
-
신경-기호 AI에서 증명 가능한 보안으로:
- 논의: CSPS 보안이 휴리스틱이므로, 더 강력한 암호화 기본 요소와 HLB를 통합하기 위한 다음 단계는 무엇인가? HLB의 선형 속성과 효율적인 분리는 동형 암호화 체계 또는 안전한 다자간 계산 프로토콜과 결합하여 증명 가능한 보안 보장을 제공하는 신경-기호 시스템을 설계하는 데 활용될 수 있는가? 이는 휴리스틱 보안을 넘어 진정한 신뢰할 수 있는 AI로 나아갈 것이다.
- 관점: 이는 민감한 애플리케이션을 위한 중요한 영역이다. 보안에 초점을 맞춘 연구자는 형식 검증 방법을 탐색하는 반면, AI 실무자는 보안과 성능의 균형을 맞추는 실용적이고 효율적인 구현을 찾을 것이다.
-
동적 $p$ 추정 및 적응형 유사도 증강:
- 논의: 본 논문은 유사도 증강 단계에 대해 $p$(번들 쌍 수)를 알고 있거나 추정하는 것의 중요성을 강조한다. 복잡하고 동적인 신경-기호 시스템에서 $p$는 항상 명시적으로 알려지지 않을 수 있다. 복합 표현 자체에서 동적으로 $p$를 추론할 수 있는 적응형 메커니즘 또는 학습된 추정기를 어떻게 개발할 수 있으며, 실시간 컨텍스트 인식 유사도 수정을 허용하는가?
- 관점: 이는 VSA 기반 시스템의 자율성과 견고성을 향상시킬 것이다. 기계 학습 전문가는 $p$ 추정을 위한 신경망 아키텍처를 제안할 수 있으며, 인지 과학자는 구성 표현에서 불확실성을 처리하는 생물학적 시스템과의 유사점을 끌어낼 수 있다.
-
비대칭 결합 및 고급 구성성 탐색:
- 논의: HLB는 대칭이지만, 본 논문은 VTB의 비대칭 특성을 언급한다. 어떤 종류의 기호 관계 또는 인지 작업이 본질적으로 비대칭 결합(예: "행위자-행동-객체" 관계)으로부터 이익을 얻는가? Hadamard-유도 프레임워크는 계산 효율성과 수치적 안정성을 유지하면서 비대칭 결합 연산을 지원하도록 확장 또는 수정될 수 있는가? 이는 방향성 관계 및 더 복잡한 의미 구조를 나타내는 새로운 기능을 잠금 해제할 수 있다.
- 관점: 이는 VSA의 표현력으로 들어간다. 언어학자 또는 인지 AI 연구자는 비대칭 결합을 요구하는 특정 문법 또는 논리 구조를 식별하여 더 풍부한 기호 표현을 수용하도록 수학적 프레임워크를 추진할 수 있다.
-
최첨단 딥러닝 아키텍처와의 심층 통합:
- 논의: HLB는 CSPS 및 XML에서 유망한 결과를 보여주었다. 최첨단 딥러닝 아키텍처에 더 깊고 고유하게 통합될 수 있는가? HLB 기반 결합 및 분리 연산은 트랜스포머 모델(예: 주의 메커니즘 또는 위치 인코딩용), 그래프 신경망 또는 순환 신경망의 구성 요소를 대체하거나 보강하여 더 강력한 기호 추론 기능과 향상된 구성 일반화를 부여할 수 있는가?
- 관점: 이는 기호 및 연결주의 AI 간의 격차를 해소하는 것이다. 신경망 아키텍처 설계자는 새로운 계층 설계를 탐색할 수 있으며, 이론 컴퓨터 과학자는 이러한 하이브리드 시스템의 계산 그래프 및 정보 흐름을 분석할 수 있다.
-
적대적 공격 및 실제 노이즈에 대한 견고성:
- 논의: 투영 단계는 노이즈를 줄이지만, HLB는 특히 안전이 중요한 애플리케이션에서 다양한 형태의 적대적 공격 또는 실제 센서 노이즈에 얼마나 견고한가? 견고한 초기화 전략, 노이즈 인식 학습 또는 오류 수정 코드와 같은 추가 메커니즘을 HLB와 통합하여 노이즈가 많거나 적대적인 환경에서 복원력과 신뢰성을 향상시킬 수 있는가?
- 관점: 이는 배포에 중요하다. 보안 연구자는 공격 벡터와 방어에 초점을 맞출 것이며, 엔지니어는 실제 노이즈 모델과 하드웨어 수준 복원력을 고려할 것이다.
-
하드웨어 가속 및 에너지 효율적인 구현:
- 논의: HLB의 결합에 대한 $O(d)$ 복잡성과 Hadamard 변환(고속 알고리즘에 적합함)에 대한 의존성을 고려할 때, 특수 하드웨어 가속 기회는 무엇인가? HLB는 신경 형태 칩, FPGA 또는 기타 사용자 정의 하드웨어에서 효율적으로 구현되어 엣지 AI 장치 또는 대규모 기호 처리 시스템에 대해 초저전력 소비와 높은 처리량을 달성할 수 있는가?
- 관점: 이는 하드웨어-소프트웨어 공동 설계 과제이다. 컴퓨터 아키텍트는 병렬화 및 메모리 액세스 패턴을 조사할 것이며, 지속 가능성 옹호자는 에너지 효율적인 AI의 잠재력을 강조할 것이다.
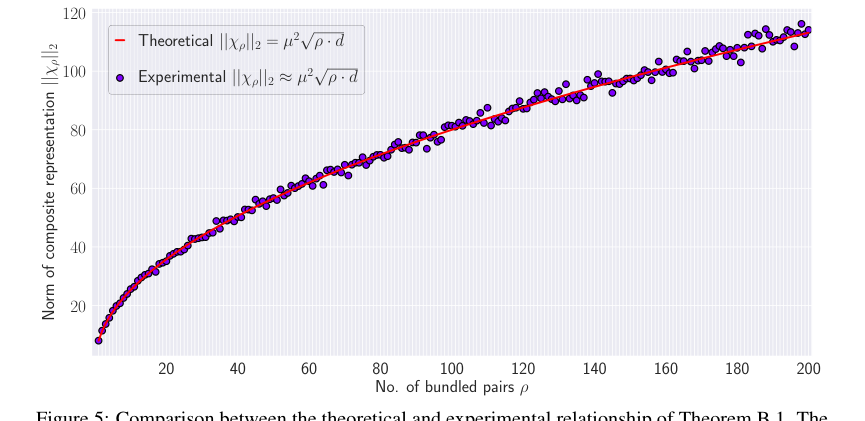 Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
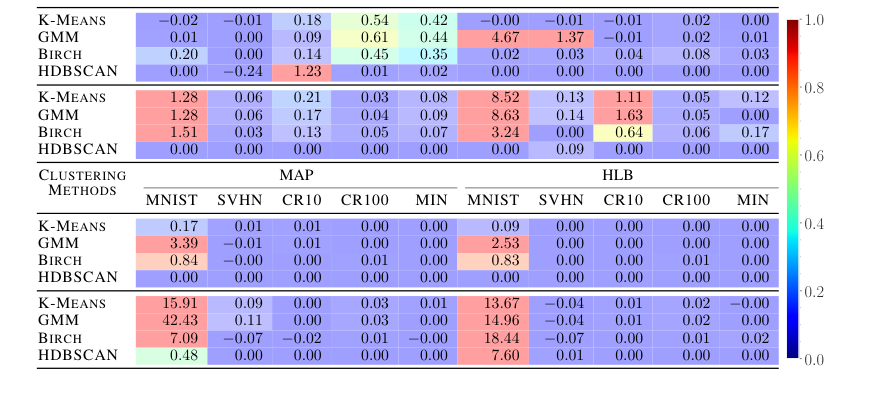 Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
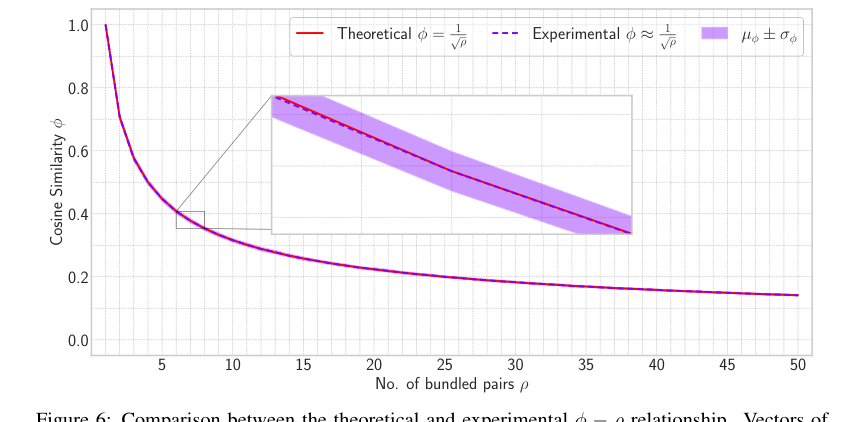 Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion
Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion