ハーダマール変換誘導線形ベクトル記号アーキテクチャ
Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in are 'bound' together to produce a new vector in the same space.
背景と学術的系譜
起源と学術的系譜
本稿で取り扱う問題は、ニューロシンボリックAIの開発における独特なアプローチであるベクトル記号アーキテクチャ(VSA)の分野に端を発する。この学術的系譜は、Smolensky [38] にまで正確に遡ることができ、彼はテンソル積表現(TPR)を用いてVSAアプローチを開始した。TPRでは、概念は高次元ベクトルとして表現され、これらのベクトルは外積を計算することによって「束縛」され、新しい複合概念を形成する。この基礎的な研究は、コネクショニストフレームワーク内でシンボリックな操作を可能にし、論理文や構造の表現を可能にする方法として登場した [13]。
歴史的に、ほとんどのVSAは、ディープラーニングと自動微分が広く普及する前に開発された。それらの主な焦点は、古典的なAIタスクや認知科学に触発された、手作業で設計されたシステムにおける有効性であった。しかし、この初期の焦点は、VSAを現代の微分可能なシステムに統合しようとする際に、いくつかの根本的な限界、すなわち「ペインポイント」につながった。
- 計算複雑性: TPRのような初期のVSA手法は、非現実的な計算複雑性に悩まされていた。例えば、TPRを用いて $p$ 個の項目を束縛すると、ベクトルの次元を $d$ とした場合、O($d^p$) の複雑性が発生した。さらに一般的な線形VSAでさえ、束縛を行列演算として表現する場合、通常はO($d^2$) の複雑性を招き、リアルタイムまたは大規模なアプリケーションには遅すぎた。
- 数値的不安定性: ホログラフィック削減表現(HRR)[32] のような他の一般的なVSA手法は、フーリエ変換(FT)と巡回畳み込みに依存している。これらは強力であるが、これらの演算は非有理数乗算と複素数を含み、実際のインプリメンテーションにおいて数値的不安定性を引き起こす可能性がある。先行研究 [9] ではこれを軽減するために射影ステップを試みたが、根本的な問題は残った。
- 微分可能なシステムにおける最適でない性能: 多くの既存のVSA手法は、ディープラーニングフレームワークへのシームレスな統合に必要な特性を持って設計されていなかった。勾配降下法と自動微分と併用した場合、それらはしばしば計算効率と数値的安定性に欠け、現代のニューロシンボリックAIタスクにおいて期待されるよりも低い性能につながった。
本稿では、これらの限界に対処するため、ハーダマール変換の特性を活用することで、束縛にO($d$) の複雑性、数値的安定性の向上、および微分可能なディープラーニングアプリケーションにおける性能向上を目指す、新しいVSAであるハーダマール誘導線形束縛(HLB)を導出する。
直感的なドメイン用語
本稿の概念を理解しやすくするために、いくつかの専門用語を日常的なアナロジーで分解してみよう。
- ベクトル記号アーキテクチャ(VSA): あなたの脳内にユニークな「思考ベクトル」のセットがあると想像してください。各ベクトルは、「猫」、「幸せ」、「赤」のような基本的な概念を表します。VSAは、これらの思考ベクトルを組み合わせて「幸せな猫」や「赤い車」のような新しい、より複雑なアイデアを形成し、その後、あなたの脳にそれらの複雑なアイデアの一部を検索するように「尋ねる」ことができる特別なメンタル言語のようなものです。これは、コンピュータが単語で私たちが行うように概念を操作する方法ですが、数値を使用します。
- 束縛(Binding): これは、2つ以上の概念ベクトルを組み合わせて、それらの関係または構成を表す新しいベクトルを作成するプロセスです。レシピで2つの材料、「小麦粉」と「水」を混ぜて「生地」を得るようなものだと考えてください。この「生地」は、元の両方の成分を含んでいますが、組み合わされた形である新しい実体です。VSAでは、「猫」と「幸せ」を束縛すると、「幸せな猫」の新しいベクトルが作成されます。
- 束縛解除(Unbinding): これは束縛の逆です。結合された概念ベクトル(「生地」など)と元の成分の1つ(「小麦粉」)が与えられた場合、束縛解除はもう一方の成分(「水」)を取得することを可能にします。これは、「幸せな猫」ベクトルと「幸せ」ベクトルを取得し、その後「猫」ベクトルを取得できるようなものです。この操作は、複合表現から情報をクエリおよび抽出するために不可欠です。
- ハーダマール変換(Hadamard Transform): 特別な種類のデジタル「シャッフル」または「エンコード」プロセスを想像してください。波と虚数数を扱うより複雑なフーリエ変換とは異なり、ハーダマール変換ははるかに単純です。加算と減算のみを使用し、その出力値は常に+1または-1です。これにより、非常に高速で数値的に安定しており、簡単に逆転できる、超効率的な、飾り気のないデータ圧縮機のようなものになります。
- ニューロシンボリックAI(Neuro-symbolic AI): これは、人工知能へのアプローチであり、両方の世界の利点を得ようとします。つまり、ニューラルネットワークの直感的でパターン学習能力(人間が顔を認識する方法など)と、従来のシンボリックAIの論理的でルールベースの推論(コンピュータが指示に従う方法など)です。これは、構造化された方法で「感じ」と「考える」ことができるAIであり、単独で使用された場合の両方のアプローチの限界を克服することを目指しています。
記法表
| 記法 | 説明 |
|---|---|
| $B(x, y)$ | 2つの概念/ベクトル $x$ と $y$ を接続して新しいベクトル $z$ を生成する束縛操作。 |
| $B^*(x, y)$ | もう一方の成分が与えられた束縛ベクトルの1つの成分を取得する束縛解除操作。 |
| $x, y, z$ | VSA空間における概念またはデータポイントを表す一般的なベクトル。 |
| $d$ | VSAにおけるベクトルの次元、すなわち $x \in \mathbb{R}^d$。 |
問題定義と制約
コア問題の定式化とジレンマ
本稿で取り扱うコア問題は、現代のディープラーニングシステムに適用された際の既存のベクトル記号アーキテクチャ(VSA)の限界にある。
出発点(入力/現在の状態):
現在のVSAは、概念を表す2つのベクトル $x, y \in R^d$ を、束縛操作 $B(x, y) = z$ を使用して新しい複合ベクトル $z \in R^d$ に束縛することによって動作する。逆の束縛解除操作 $B^*(x, y)$ は、成分の取得を可能にする。これらのアーキテクチャは、自然なシンボリックAIスタイルの操作(可換性、結合性、逆操作)により、ニューロシンボリック手法に魅力的なプラットフォームを提供するが、それらはディープラーニングと自動微分の広範な普及前に主に開発された。その結果、多くの既存のVSA手法は、いくつかの重要な欠点を示す。
1. 高い計算複雑性: 多くのVSA、特に線形操作 $B(a,b) = a^T G b$ および $B^*(a,b) = a^T F b$ (ここで $G$ と $F$ は $d \times d$ 行列)と見なされるものは、束縛ステップで $O(d^2)$ の計算複雑性を招く。これは対角行列の場合は $O(d)$ に削減できるが、より複雑で表現力のある束縛の場合はそうでないことが多い。テンソル積表現(TPR)は、例えば $p$ 個の項目を束縛するための非現実的な $O(d^p)$ の複雑性を持つ。
2. 数値的不安定性: フーリエ変換と複素数に依存するホログラフィック削減表現(HRR)のような手法は、実数値ベクトル上で動作する場合の「非有理数乗算」による数値的不安定性に陥りやすい。
3. 微分可能なシステムにおける最適でない性能: 既存のVSAは、勾配ベース学習のために明示的に設計されておらず、追加の制約なしに勾配降下法によって基底行列が学習された場合、それらの特性(可換性など)が維持されない可能性がある。ディープラーニングアプリケーションにおけるそれらの性能は、しばしば期待されるよりも低い。
目標終点(出力/目標状態):
本稿は、これらの限界を克服する、ハーダマール誘導線形束縛(HLB)と名付けられた新しいVSAを導入することを目指している。目標は、以下のVSAを開発することである。
1. 計算効率: 束縛ステップで $O(d)$ の複雑性を達成し、$O(d^2)$ または $O(d \log d)$(通常はハーダマール変換自体に関連するが、ここでは導出により線形複雑性が得られる)よりも大幅に高速であること。
2. 数値的安定性: 実数値と単純な算術演算(加算、減算、および $\{-1, 1\}$ 値)のみを操作することにより、複素数ベースのVSAの不安定性の問題を回避すること。
3. 高い有効性: 古典的なVSAタスクと現代のディープラーニングアプリケーションの両方で、既存のVSAと同等またはそれ以上の性能を発揮すること。
4. 微分可能なシステムとの互換性: 微分可能なシステムにシームレスに統合され、良好に動作するようにゼロから設計され、ニューロシンボリックAIをサポートすること。
5. 対称性: 束縛操作 $B(x,y)$ は対称であるべき、すなわち $B(x,y) = B(y,x)$ であり、これは多くのVSAアプリケーションにとって望ましい特性である。
欠落しているリンクまたは数学的ギャップ:
正確な欠落しているリンクは、線形計算複雑性と数値的安定性を達成し、コアのシンボリック操作能力を維持し、微分可能な学習に適したハーダマール変換の有利な特性を活用するVSA束縛および束縛解除メカニズムの導出である。以前の試みは、複雑性、不安定性、またはディープラーニング統合のための明示的な設計の欠如のいずれかに悩まされていた。本稿は、フーリエ変換(HRRで使用)をハーダマール変換に置き換え、そのユニークな特性(再帰構造や自己逆性など)を活用するために束縛および束縛解除操作を慎重に設計することによって、このギャップを埋める。
痛みを伴うトレードオフまたはジレンマ:
この問題を解決しようとした以前の研究者は、いくつかの痛みを伴うトレードオフに囚われていた。
* 表現力 vs. 計算コスト: 豊かな、構成的な表現(例えば、多くの項目の束縛)を達成することは、TPRの $O(d^p)$ コストに見られるように、しばしば指数関数的に増加する計算複雑性につながる。これにより、非常に表現力のあるシンボリック構造と実用的な計算との間で選択を強制される。
* シンボリック忠実性 vs. 学習可能性: VSAは強力なシンボリック特性を提供するが、それらをディープニューラルネットワークでの勾配ベース学習に適応させることは、しばしばそれらの特性を損なうリスクを伴う。追加の制約なしに基底行列 $G$ と $F$ を学習することは、望ましい可換性または結合性を破る可能性がある。これにより、「ニューロシンボリック特性」を維持することと、最新の機械学習パラダイムを最適化することとの間でジレンマが生じる。
* 数学的優雅性 vs. 数値的堅牢性: 巡回畳み込み(HRRなど)にフーリエ変換のような数学的にエレガントなツールを使用すると、複素数と非有理数乗算が導入され、実数値ベクトルを用いた実際のシステムでの実装時に数値的不安定性を引き起こす可能性がある。これにより、理論的な純粋さと堅牢な実世界でのパフォーマンスとの間で選択を強制される。
制約と失敗モード
この問題は、著者たちが直面したいくつかの厳しい現実的な壁によって非常に困難になっている。
- 計算複雑性の壁: 束縛ステップで $O(d)$ の複雑性が必要であることは、厳格な制約である。多くの既存のVSAは $O(d^2)$ または $O(d \log d)$ の複雑性を持ち、これは高次元ベクトル($d$)のスケーラビリティにとって大きな障壁である。これは、効率が最重要視される大規模なディープラーニングモデルでの適用性を制限する。
- 数値的不安定性: HRRのような既存のVSAの主要な失敗モードは数値的不安定性である。これは、複素数と非有理数乗算を伴う演算から生じ、特に実数値ベクトルを扱う場合に、浮動小数点誤差と信頼性の低い結果につながる可能性がある。提案された解決策は、本質的にこれを回避する必要がある。
- 複合表現におけるノイズ蓄積: 複数の概念が単一の複合ベクトルに束縛されると(すなわち、$p \ge 2$ 個の項目がバンドルされる)、ノイズが必然的に蓄積する。このノイズは束縛解除操作の精度を低下させ、個々の成分を確実に取得することを困難にする。この問題を軽減するメカニズムがない場合、複雑なシンボリック構造に対するVSAの有用性は著しく制限される。本稿では、射影ステップがない場合、ノイズ成分 $\eta'$ が射影付きの $\eta''$ よりも著しく高いことを示している。
- ベクトル初期化の課題: 束縛および束縛解除操作が正しく機能するためには、ベクトルはゼロの期待値を持つ必要がある。しかし、ベクトル成分がゼロに近い値に初期化されている場合、束縛解除中のこれらのクエリベクトルによる後続の除算は、「ノイズ成分を不安定にし、数値的不安定性を引き起こす」可能性がある。この特定の初期化制約は、慎重な設計上の選択を必要とし、正規分布混合(MiND)の導入につながる。
- 複数束縛における大きさの安定性: 理想的なVSAは、複合ベクトルの大きさを安定に維持する必要がある。すなわち、大きさは「$p$ が増加するにつれて爆発/消失しない」必要がある(束縛された項目の数)。これは、他のVSAにおける近似束縛解除手順の一般的な失敗モードであり、$p$ が増加すると類似性スコアが減衰したり、大きさが不安定になったりする。
- ハードウェアメモリ制限: 32GBメモリを搭載した単一のNVIDIA TESLA P100 GPUを使用した実験設定は、提案されたVSAがそのような一般的なディープラーニングハードウェア環境内で動作するのに十分なメモリ効率的でなければならないという制約を暗黙的に課している。
- 多ラベル分類における極端なスパース性: 極端な多ラベル(XML)分類のようなアプリケーションでは、可能なクラスの数($L \ge 100,000$)が入力次元($d \approx 5000$)をはるかに超え、任意の入力に対して関連するクラスはごく一部(通常は100未満)である。この極端なスパース性は、従来の線形層を計算上不可能にする($O(L)$ の複雑性)ため、この広大でスパースな出力空間を効率的に表現できるVSAを要求する(複雑性を存在するクラスの数 $K$ に削減する、ただし $K$ は $L$ よりはるかに小さい)。
なぜこのアプローチなのか
選択の必然性
ハーダマール誘導線形束縛(HLB)の採用は、単なる好みではなく、現代のディープラーニングコンテキストに適用された際の既存のベクトル記号アーキテクチャ(VSA)の固有の限界によって駆動された必然性であった。著者らは、ホログラフィック削減表現(HRR)、ベクトル誘導変換束縛(VTB)、および乗算加算置換(MAP)のような従来の「SOTA」VSA手法が、特に数値的安定性、計算効率、および微分可能なシステムとのシームレスな統合に関して、それらの目標にとって根本的に不十分であると認識した。
重要な認識は、VSAがニューロシンボリック手法に魅力的なプラットフォームを提供する一方で、多くの既存のアプローチはディープラーニングと自動微分の広範な普及前に開発され、代わりに手作業で設計されたシステムでの有効性に焦点を当てていたという観察から生じた。例えば、フーリエ変換(FT)と巡回畳み込みに依存するHRRは、複素数と非有理数乗算への依存による数値的不安定性に悩まされている(p. 3)。これは、特に勾配が関与する場合に、堅牢な数値演算を必要とするシステムでの使用を困難にする。
対照的に、ハーダマール変換は本質的にこれらの問題を回避する。それは排他的に実数上で動作し、加算と減算のみを実行するため、非有理数乗算と複素数演算を排除する(p. 3)。この特性は、学習を不安定にする可能性のある小さな数値誤差が伝播する可能性のある微分可能なシステムにおいて、最重要の懸念事項である数値的安定性を維持するためのユニークに実行可能な解決策となる。さらに、ハーダマール行列の自己逆行列であるという特性は、束縛解除操作 $B^*$ の設計を簡素化し、システム全体をよりエレガントで堅牢にする。
比較優位性
HLBは、単なる性能指標を超えて、いくつかの重要な側面で以前のゴールドスタンダードに対して定性的な優位性を示す。
まず、計算複雑性の観点から、HLBは束縛ステップで印象的な $O(d)$ の複雑性を達成する(p. 1)。これは、一般的な線形演算の $O(d^2)$ の複雑性(多くのVSAがそれと見なされる可能性がある)や、ウォルシュ・ハーダマール変換自体に通常関連付けられる $O(d \log d)$ の複雑性(p. 2)と比較して、構造的な利点である。この線形複雑性は、束縛関数をハーダマール領域での要素ごとの積として再定義することによって達成される、$B'(x, y) = x \odot y$(p. 5)であり、高次元ベクトルに対して非常に効率的である。
次に、数値的安定性が中核的な利点である。前述のように、ハーダマール変換は排他的に $\{-1, 1\}$ 値と実数演算のみを使用し、複素数と非有理数乗算を伴うフーリエ変換ベースの手法(HRRなど)に一般的な数値的不安定性の問題を完全に回避する(p. 2, 3)。この固有の安定性は、モデルが数値精度に敏感であるディープラーニングにおいて特に重要な、信頼性の高い操作のために不可欠である。
第三に、HLBは優れたノイズ処理を示す。本稿では、束縛解除中の蓄積ノイズを大幅に軽減する射影ステップ(定義 3.2, p. 4)を導入している。経験的な結果(図 4, p. 15)は、この射影付きのノイズ成分($\eta''$)がそれなしの場合($\eta'$)よりも著しく低いことを明確に示しており、検索精度の向上につながる。この構造的な強化は、複数の束縛でノイズが蓄積するVSAにおける一般的な課題に直接対処する。
最後に、HLBは大きさおよび類似性スコアの顕著な一貫性と安定性を示す。図 3(p. 7)は、HLBが常に存在する項目に対して理想的な類似性スコア1を返し、束縛されたベクトルの数に関係なく一定の大きさを維持することを示している。これは、HRR、VTB、およびMAPで観察される「爆発/消失」値を防ぎ、安定したVSAソリューションの設計と信頼性の高い情報検索の保証にとって重要な特性である。この安定性は、ベクトル初期化に使用される正規分布混合(MiND)(特性 3.1, p. 5)の特性に起因する。
制約との整合性
選択されたHLB手法は、現代のニューロシンボリックAIに適したVSAの開発という、暗黙的および明示的な制約と完全に一致している。
- 計算効率: VSA、特にディープラーニングにおける主要な制約は、低い計算オーバーヘッドである。HLBの $O(d)$ 束縛複雑性はこれを直接満たし、高次元データおよび大規模アプリケーション(p. 1, 5)での実現可能性を高める。
- 数値的安定性: 堅牢な数値演算の必要性は、複素数と非有理数演算を回避するハーダマール変換に基づくHLBの基盤によって満たされ、安定性を保証する(p. 2, 3)。
- 微分可能なシステムにおける性能: 本稿は、明確に「微分可能なシステムで良好に動作する」VSAという目標を述べている(要旨, p. 1)。HLBの線形演算、実数値性質、および数値的安定性は、ディープラーニングの基盤である勾配ベース最適化との互換性を本質的に高める。
- ニューロシンボリック特性: VSAは、シンボリック操作能力(可換性、結合性、逆操作)で評価される。ハーダマール変換は「既に結合可能であり、分配可能」である(p. 2)ため、設計を簡素化し、追加の複雑な制約なしにこれらの不可欠な特性を維持する。
- ノイズ管理: 複合表現におけるノイズ蓄積の問題は、重要な課題である。HLBのMiND初期化(式 6, p. 5)と明示的な射影ステップ(定義 3.2, p. 4)は、このノイズを最小限に抑え、管理するように調整されており、多くの束縛された項目があっても正確な検索を保証する。
この「問題の厳しい要件」と「HLBのユニークな特性」との「結婚」は、変換の選択から初期化および射影ステップに至るまで、その設計選択に明らかである。
代替案の却下
本稿は、他の一般的なVSA手法、および暗黙的に、一般的なディープラーニング手法を、特定の問題コンテキストのために却下する明確な理由を提供している。
- 既存のVSA(HRR、VTB、MAP):
- 数値的不安定性: 主要なベースラインであるHRRは、「複素数の非有理数乗算による数値的不安定性」のために明示的に批判されている(p. 3)。これは、実数値演算を使用するHLBのような代替案を求める直接的な理由である。
- 計算複雑性: 本稿では、多くのVSAが一般的な線形演算として実装された場合、$O(d^2)$ の複雑性を招き、高すぎると指摘している(p. 1)。テンソル積表現(TPR)は、「複数の項目を束縛するための $O(d^p)$ の複雑性」のために非現実的であるとして却下されている(p. 2)。HLBの $O(d)$ 複雑性は、大幅な改善を提供する。
- 微分可能なシステムにおける性能: 「ほとんどのVSA」に対する一般的な批判は、それらが「ディープラーニングと自動微分が人気になる前に開発され、代わりに手作業で設計されたシステムでの有効性に焦点を当てていた」ことであり、「数値的安定性、計算複雑性、または微分可能なシステムという文脈での期待されるよりも低い性能に問題を示している」(p. 1)。これは、本稿の主要なアプリケーションドメインへの不適合性を示している。
- ノイズと安定性の問題: 図 3(p. 7)は、HRR、VTB、およびMAP-C/Bが、束縛されたベクトルの数が増加するにつれて、類似性スコアの減衰と大きさの爆発/消失に悩まされていることを経験的に示している。HLBが一定の大きさで理想的な類似性スコアを維持する能力は、代替案におけるこれらの失敗に直接対処する。
- 一般的なディープラーニング(例:標準CNN、基本的な拡散、Transformer): 明示的に直接比較で「却下」されているわけではないが、「ニューロシンボリックAI」(要旨, p. 1)への本稿の焦点は、純粋にコネクショニストモデルがVSAが提供する固有のシンボリック操作能力を欠いていることを示唆している。例えば、「コネクショニストシンボリック疑似秘密」(CSPS)や「Xtreme Multi-Label分類」(XML)のようなタスクでは、VSAのシンボリック特性が特定の利点のために活用される。
- CSPS: 安全な計算オフロードのために、準同型暗号(HE)は「ニューラルネットワーク自体を実行するよりも高価」であると見なされ、その有用性を損なう(p. 8)。VSAは、ローカル計算を削減しながら、入力/出力を曖昧にするためのヒューリスティックな代替手段を提供する。純粋なニューラルネットワークは、この「暗号化/復号化」メカニズムを固有に提供しないだろう。
- XML: VSAは、シンボリック操作を活用して複雑性を $O(K)$ (存在するクラスの数 $K$)に削減することにより、$O(L)$ の計算複雑性(クラスの数 $L$)のコストを回避するために使用される(p. 9)。標準的なディープラーニングアーキテクチャは、通常、VSAが回避するように設計されている $O(L)$ コストを招く、大きな出力層を必要とするだろう。
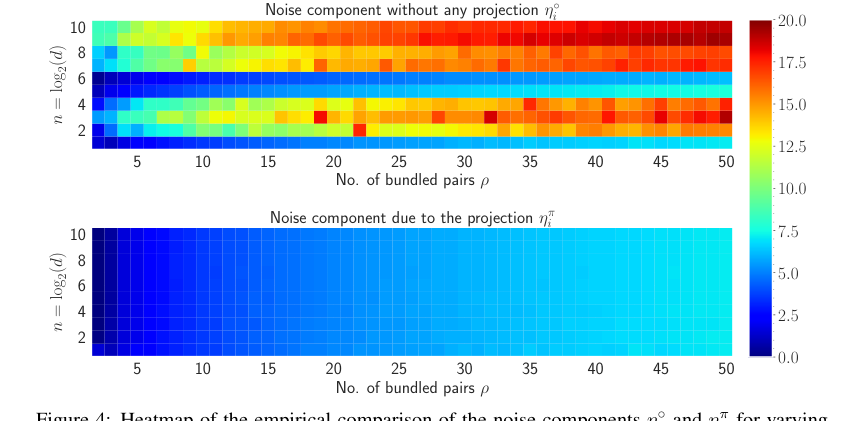 Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
数学的・論理的メカニズム
マスター方程式
ハーダマール誘導線形束縛(HLB)メカニズムの中核は、ウォルシュ・ハーダマール変換を活用する束縛および束縛解除操作の定義にある。この変換ロジックを定義する絶対的なコア方程式は、束縛関数と束縛解除関数であり、特に性能と安定性を向上させるために射影された入力に適用された場合である。
2つのベクトル $x, y \in \mathbb{R}^d$ に対する束縛操作 $B(x,y)$ は次のように定義される。
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) \quad \text{(式 2)} $$
複数の束縛ペアから形成された複合表現を扱い、入力ベクトルに射影ステップを適用した後、束縛解除操作 $B^*(\chi_p, \pi(y_i)^\dagger)$ は中間結果を生成する。射影関数 $\pi(v)$ は $\pi(v) = \frac{1}{d} Hv$ として定義される。複合表現 $\chi_p$ は、$p$ 個の射影された束縛ペアの合計として形成される:$\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$。射影されたクエリベクトル $\pi(y_i)$ を使用したこの複合表現に適用される束縛解除操作は、次のように与えられる。
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) \quad \text{(式 4)} $$
本稿では、追加の逆射影ステップの後、この中間結果が最終的な取得出力に単純化されることを示しており、これはノイズ項 $\eta''$ に加えて、おおよそ $x_i$($y_i$ に関連付けられた元のベクトル)である。
項ごとの解剖
これらのマスター方程式の各成分を詳細に分析し、それらの数学的定義、物理的/論理的役割、および著者の設計選択を理解しよう。
束縛方程式(式 2)の解剖
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) $$
- $B(x,y)$:
- 数学的定義: 入力ベクトル $x$ と $y$ の間の束縛操作から生じる出力ベクトル。
- 物理的/論理的役割: これは、ベクトル $x$ と $y$ によって表される2つの概念を、単一の新しいベクトルに結び付けるコア関数である。VSAにおける構成的表現を作成するための基本的なビルディングブロックである。
- この選択の理由: この特定の形式は、ホログラフィック削減表現(HRR)で使用される巡回畳み込みにおけるフーリエ変換をハーダマール変換に置き換えることから導出されており、より優れた計算効率と数値的安定性を持つことを目指している。
- $x, y$:
- 数学的定義: 次元 $d$ の入力ベクトル、$x, y \in \mathbb{R}^d$。
- 物理的/論理的役割: 各ベクトルは、VSAフレームワーク内での個々の概念、シンボル、または情報の断片を表す。
- この選択の理由: VSAは、シンボリック情報をエンコードおよび操作するために、本質的に高次元の実数値ベクトル上で動作する。
- $d$:
- 数学的定義: 入力ベクトル $x$ と $y$ の次元。
- 物理的/論理的役割: 正規化係数として機能する。
- この選択の理由: $d$ による除算は、結果の束縛ベクトルの大きさを妥当な範囲内に維持し、値が爆発するのを防ぎ、おおよその直交性を確保するために、VSAで一般的に行われる慣習である。また、2回ハーダマール変換を適用することによって導入されるスケーリング係数($H(Hv) = dv$)を相殺する。
- $H$:
- 数学的定義: サイズ $d \times d$ のハーダマール行列。この行列は $+1$ と $-1$ のエントリのみを含み、再帰的に定義される(例:$H_1 = [1]$、$H_{2n} = \begin{pmatrix} H_n & H_n \\ H_n & -H_n \end{pmatrix}$)。
- 物理的/論理的役割: ベクトルにハーダマール変換を適用する。
- この選択の理由: ハーダマール変換は、その計算効率(この導出では線形複雑性 $O(d)$、または一般的な高速ウォルシュ・ハーダマール変換では $O(d \log d)$)、数値的安定性(複素数や非有理数乗算を回避する $\pm 1$ 値のみ)、およびその転置がそれ自身の逆行列であるという便利な特性($H^T = H$ および $H H = dI$)により選択されており、逆操作の設計を簡素化する。
- $Hx$:
- 数学的定義: ベクトル $x$ のハーダマール変換。
- 物理的/論理的役割: 入力ベクトル $x$ を元のドメインからハーダマールドメインに変換する。
- この選択の理由: この変換は束縛操作に不可欠である。ベクトルをハーダマールドメインに変換することにより、要素ごとの乗算は、元のドメインでの巡回畳み込みに類似した束縛効果を達成できる(これは通常、HRRのフーリエドメインでの要素ごとの乗算によって行われる)。
- $Hy$:
- 数学的定義: ベクトル $y$ のハーダマール変換。
- 物理的/論理的役割: 入力ベクトル $y$ をハーダマールドメインに変換する。
- この選択の理由: $Hx$ と同じ理由。
- $\odot$:
- 数学的定義: 要素ごとの積(ハーダマール積とも呼ばれる)。
- 物理的/論理的役割: この演算子は、変換されたベクトルをハーダマールドメインで実際に束縛する。
- この選択の理由: ハーダマールドメインでは、要素ごとの乗算は、フーリエドメインでの巡回畳み込みと同様に、束縛メカニズムとして機能する。この操作は計算効率が高く、VSAの望ましい代数的特性を維持する。
- $H(\dots)$:
- 数学的定義: 逆ハーダマール変換。$H$ はそれ自身の逆行列である(スケーリング係数 $d$ を除いて)、そのため $H$ を再度適用すると、前の変換が効果的に反転される。
- 物理的/論理的役割: 束縛されたベクトルをハーダマールドメインから元のベクトル空間に変換する。
- この選択の理由: 結果の束縛ベクトル $B(x,y)$ が元の入力と同じベクトル空間に存在するようにし、他のベクトルとの一貫した操作(合計など)を可能にする。
束縛解除方程式(式 4)の解剖
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) $$
- $B^*(\chi_p, \pi(y_i)^\dagger)$:
- 数学的定義: 複合表現 $\chi_p$ に、射影されたクエリベクトル $\pi(y_i)$ の逆を適用して得られる束縛解除操作の結果である出力ベクトル。
- 物理的/論理的役割: これは束縛の逆操作であり、バンドルされた表現から特定の概念(理想的には $\pi(x_i)$)を取得するように設計されている。
- この選択の理由: この操作はVSAにおける知識検索に不可欠であり、システムが「尋ねる」ことを可能にする。
- $\chi_p$:
- 数学的定義: 各入力ベクトルが射影関数 $\pi$ によって前処理された、$p$ 個の個々の束縛ペアの合計として形成された複合表現。数学的には、$\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$。
- 物理的/論理的役割: 複数の関連付けまたは概念をコンパクトに格納する単一のベクトル。
- この選択の理由: VSAは、複合構造または関連付けのセットを表すために束縛ベクトルを合計することを可能にし、ベクトルの加算の線形性を活用する。
- $\pi(x_j), \pi(y_j)$:
- 数学的定義: 射影された入力ベクトル、ここで $\pi(v) = \frac{1}{d} Hv$。
- 物理的/論理的役割: 元の概念ベクトル $x_j, y_j$ の前処理されたバージョン。
- この選択の理由: 射影ステップはベクトルを正規化し、ハーダマールドメインに変換する。これは数値的不安定性を軽減し、ノイズ蓄積を低減するのに役立ち、特に複数の項目がバンドルされる場合に重要である。
- $\sum_{j=1}^p (\dots)$:
- 数学的定義: 射影された入力ベクトルの要素ごとの積である各項に対する $p$ 個の合計。
- 物理的/論理的役割: 中間形式で、個々の束縛表現を単一の複合ベクトルに集約する。
- この選択の理由: 加算の線形性は、複数の束縛ペアを単一のベクトルにバンドルすることを可能にし、複雑な構造を表現するためのVSAの主要な機能である。
- $\odot$:
- 数学的定義: 要素ごとの積。
- 物理的/論理的役割: 合計内では、これは射影された入力の束縛を実行する。合計外では、クエリの逆数との乗算によって束縛解除を実行する。
- この選択の理由: 要素ごとの乗算は、その効率と代数的特性により、ハーダマールドメインでの束縛/束縛解除メカニズムとして選択されている。
- $H(\sum \dots)$:
- 数学的定義: 射影された入力の要素ごとの積の合計に適用されるハーダマール変換。
- 物理的/論理的役割: これは複合表現に適用される中間ハーダマール変換である。
- この選択の理由: これは束縛解除プロセスの一部であり、合計を要素ごとの除算(クエリの逆数との乗算)に適したドメインに変換する。
- $\frac{1}{H \pi(y_i)}$:
- 数学的定義: 射影されたクエリベクトル $\pi(y_i)$ のハーダマール変換の要素ごとの逆数。
- 物理的/論理的役割: この項は、ハーダマールドメインでの「束縛解除キー」として機能する。
- この選択の理由: 逆操作を実行するために、クエリベクトルで効果的に「除算」する。ハーダマールドメインでは、これはクエリのハーダマール変換された逆数との要素ごとの乗算によって達成される。逆数の使用は、$Hx \cdot Hx^\dagger = 1$ という特性から導出される。
- $H(\dots)$:
- 数学的定義: 逆ハーダマール変換。
- 物理的/論理的役割: 結果をハーダマールドメインから元のベクトル空間に変換する。
- この選択の理由: 元の入力ベクトルと同じ空間で取得されたベクトルを得るために、解釈可能でさらなるVSA操作に使用できるようにする。
- $\frac{1}{d}$:
- 数学的定義: スケーリング係数。
- 物理的/論理的役割: 取得されたベクトルの大きさを正規化する。
- この選択の理由: 束縛操作と同様に、このスケーリングはベクトルの大きさを一貫させ、ハーダマール変換によって導入されたスケーリングを相殺し、数値的安定性を維持する。
ステップバイステップフロー
抽象的なデータポイント、例えば $x_1$ が $y_1$ と束縛され、複合表現 $\chi_p$ (他の $p-1$ 個のペアと共に)を形成し、その後、束縛解除されるライフサイクルを追ってみよう。
-
概念初期化: まず、生の概念ベクトル、例えば $x_1, y_1, \dots, x_p, y_p$ から開始する。これらはすべて $\mathbb{R}^d$ に存在する。これらのベクトルは通常、正規分布混合(MiND)$\Omega(\mu, 1/d)$ からサンプリングすることによって初期化される。これにより、期待値はゼロであるが、絶対平均はゼロではないことが保証される。この初期化は、数値的安定性のための基本的なステップである。
-
入力射影: 束縛が発生する前に、各個別の概念ベクトル(例:$x_j$ と $y_j$)は射影ステップを経る。任意のベクトル $v$ に対して、これはハーダマール変換とスケーリングを適用することを含む:$\pi(v) = \frac{1}{d} Hv$。これにより、生の入力ベクトルは「射影された」形式 $\pi(x_j)$ および $\pi(y_j)$ に変換され、正規化され、ハーダマールドメインに配置される。この前処理は、後でノイズを低減するために不可欠である。
-
個別の束縛(ペアごと): 射影された概念ベクトルの各ペア、例えば $(\pi(x_j), \pi(y_j))$ に対して、HLB束縛操作 $B(\pi(x_j), \pi(y_j))$ が実行される。
- ハーダマール変換(暗黙的): $\pi(v)$ の定義は、$H(\pi(v)) = H(\frac{1}{d} Hv) = \frac{1}{d} H(Hv) = v$ を意味する。したがって、$B(\pi(x_j), \pi(y_j))$ が式 2 を使用して計算される場合、$H(\pi(x_j))$ と $H(\pi(y_j))$ は効果的に $x_j$ と $y_j$ になる。
- 要素ごとの束縛: 次に、ベクトル $x_j$ と $y_j$ は要素ごとの積 $x_j \odot y_j$ によって結合される。これはコアの結合ステップであり、ハーダマール様ドメインで束縛された表現を作成する。
- 逆ハーダマール変換とスケーリング: この要素ごとの積 $x_j \odot y_j$ は、ハーダマール行列 $H$ を適用し、$1/d$ でスケーリングすることによって逆変換される。結果は $B(\pi(x_j), \pi(y_j)) = \frac{1}{d} H(x_j \odot y_j)$ となる。
-
複合表現の形成: これら個別に束縛されたベクトル $B(\pi(x_j), \pi(y_j))$ のすべて $p$ 個が合計される。この線形合計は、単一の高次元ベクトル $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$ を作成し、これはすべての $p$ 個の関連付けのバンドルを表す。
-
クエリ射影(束縛解除用): 複合表現 $\chi_p$ から特定の概念、例えば $x_i$ を取得したい場合、関連付けられたクエリベクトル $y_i$ を使用する。このクエリベクトル $y_i$ も同じ射影ステップを経る:$\pi(y_i) = \frac{1}{d} Hy_i$。
-
束縛解除操作(式 4): 束縛解除プロセス $B^*(\chi_p, \pi(y_i)^\dagger)$ が展開される。
- 複合体の変換: ハーダマール変換 $H$ が複合表現 $\chi_p$ に適用される。$H$ の線形性と $\chi_p$ の構造により、これは $H(\chi_p) = \sum_{j=1}^p (x_j \odot y_j)$ に単純化される。これにより、バンドル全体が個々の束縛ペアが要素ごとの積として明確に表されるドメインに変換される。
- クエリの変換: ハーダマール変換 $H$ が射影されたクエリベクトル $\pi(y_i)$ に適用され、$H(\pi(y_i)) = y_i$ に単純化される。
- 逆クエリ: この変換されたクエリの要素ごとの逆数 $1/y_i$ が計算される。これはハーダマールドメインでの「束縛解除キー」として機能する。
- 要素ごとの束縛解除: 変換された複合表現 $\sum_{j=1}^p (x_j \odot y_j)$ は、次に逆クエリ $1/y_i$ と要素ごとに乗算される。このステップは、$y_i$ 成分を「除算」しようとし、理想的には $x_i$ を分離する。
- 逆ハーダマール変換とスケーリング: この要素ごとの乗算の結果は、ハーダマール行列 $H$ を適用し、$1/d$ でスケーリングすることによって逆変換される。これにより、中間束縛解除結果 $B^*(\chi_p, \pi(y_i)^\dagger)$ が得られる。
-
逆射影(最終出力): 本稿では、この中間結果から「元のデータ」(すなわち、元の $x_i$)を取得するために、逆射影ステップが適用されると述べている。この最終ステップは、中間結果を式 5 の形式に効果的に単純化し、これはおおよそ $x_i$ である($p=1$ の場合)、または $x_i + \eta''$ ($\eta''$ は低減されたノイズ成分、 $p>1$ の場合)である。
最適化ダイナミクス
ハーダマール誘導線形束縛(HLB)メカニズムは、本稿で説明されているように、それ自体は学習アルゴリズムではなく、むしろ非常に効率的で数値的に安定するように設計された、固定された数学的に導出された操作のセットである。したがって、その「最適化ダイナミクス」は、勾配による内部パラメータの反復更新を伴わない。代わりに、そのダイナミクスは、それがより大きな、微分可能なシステムでどのように学習を促進するかという設計に固有のものである。
-
固定された決定論的操作: HLBのコアの束縛および束縛解除関数は、ハーダマール行列と要素ごとの操作に基づく決定論的な変換である。HLB操作自体には、勾配降下法または他の学習規則によって更新される学習可能な重み、バイアス、またはその他のパラメータはない。ハーダマール行列は、事前に定義された静的なコンポーネントである。
-
固有の数値的安定性: HLBの重要なダイナミック特性は、組み込みの数値的安定性である。ハーダマール変換は、設計上、$\pm 1$ 値の操作のみを含み、HRRのような他のVSA手法で不安定性を引き起こす可能性のある複素数と非有理数乗算を回避する。さらに、ベクトル初期化に使用される正規分布混合(MiND)(式 6)は、ベクトルがゼロの期待値を持つがゼロではない絶対平均を持つことを保証する。この設計選択は、束縛解除プロセス中のゼロに近い値による除算を防ぎ、そうでなければ数値的爆発を引き起こす。
-
ノイズ低減メカニズム: 射影ステップ($\pi(x) = \frac{1}{d} Hx$)は、検索精度を向上させるためのHLBの内部ダイナミクスの重要な部分である。この射影を入力ベクトルに適用してから束縛することにより、メカニズムは、複数の項目がバンドルされたときに発生する蓄積ノイズ($\eta''$)を積極的に低減する。これは静的で事前に定義されたノイズ低減戦略であり、学習されたものではないが、システムのパフォーマンスと堅牢性に大きく影響する。
-
システム統合のための微分可能性: HLB自体は学習しないが、「微分可能なシステム」との互換性があるように明示的に設計されている。これは、HLBを構成する数学的操作(行列乗算、要素ごとの積、合計)がすべて微分可能であることを意味する。したがって、HLBがより大きなニューラルネットワークアーキテクチャに埋め込まれた場合(コネクショニストシンボリック疑似秘密およびXtreme Multi-Label分類タスクで実証されているように)、システム全体を標準的な勾配ベース最適化アルゴリズム(例:XML分類のための式 11 のコサイン類似性損失)を使用してエンドツーエンドでトレーニングできる。HLBメカニズムは、これらの学習システム内でシンボリック情報を表現および操作するための安定した効率的な方法を提供する。これにより、周囲のネットワークパラメータが定義された損失ランドスケープに基づいて最適化される。HLB操作自体は、変更なしに勾配を通過させるだけである。
結果、限界、結論
実験設計とベースライン
著者らは、古典的なベクトル記号アーキテクチャ(VSA)タスクと現代のディープラーニングアプリケーションの両方で、ハーダマール誘導線形束縛(HLB)を検証するために細心の注意を払って実験を設計し、確立されたベースラインと徹底的に比較した。
古典的なVSAタスクでは、2つの主要なシナリオが構築された。
-
基本的な束縛/束縛解除精度: この実験は、複合表現から束縛されたベクトルを正しく取得するHLBの能力を証明することを目的とした。セットアップは、1000個のランダムベクトルのプールを作成することを含んだ。このプールから、$p$ 個のベクトルのペア($p$ は1から25の範囲)がサンプリングされ、VSAの束縛操作 $B(x_i, y_i)$ を使用して束縛され、複合表現 $s = \sum_{i=1}^p B(x_i, y_i)$ を形成するために合計された。犠牲となるベースラインモデルには、ホログラフィック削減表現(HRR)[32]、ベクトル誘導変換束縛(VTB)[12]、および乗算加算置換(MAP)[10] が含まれた。各複合体 $s$ に対して、実験は元のバンドルの一部であったすべての左側成分 $x_q$ を反復処理し、束縛解除操作 $B^*(s, x_q)$ を使用して対応する $y_q$ を取得しようとした。取得が成功したと見なされたのは、ドット積 $B^*(s, x_q)^T y_q$ が他のすべての $j \neq q$ に対して $B^*(s, x_q)^T y_j$ よりも大きい場合であった。このプロセスは50回の試行で繰り返され、決定的な証拠は、さまざまなベクトル次元 $d$(特にVTBの制約に対応するために完全な平方数)にわたって、束縛された項目の数 $p$ に対する精度の曲線下面積(AUC)として提示された。
-
逐次束縛/束縛解除安定性: このタスクは、類似性スコアの質と、繰り返し束縛操作下でのベクトルの大きさの安定性を評価した。2つのサブシナリオがテストされた。
- ランダム束縛: 初期ベクトル $b_0$ は、新しいランダムベクトル $x_t$ と $p$ ラウンドで逐次的に変更され、$b_{t+1} = B(b_t, x_t)$ が生成された。目標は、各 $x_t$ を束縛解除して前の $b_t$ を回復することであった。
- 自動束縛: 単一のランダムベクトル $x$ が、進化する状態と繰り返し束縛された:$b_{t+1} = B(b_t, x)$。
この実験のベースラインはHRR、VTB、およびMAP-Cであった。求められた重要な証拠は、類似性スコア $B^*(b_{t+1}, x_t)^T b_t$ が存在する項目に対して理想的に1のままであるか、およびベクトルの大きさ $||B^*(b_{t+1}, x_t)||_2$ が一定に保たれ、$p$ が増加するにつれて一般的なVSAの落とし穴である爆発または消失値を回避するかどうかであった。
ディープラーニングアプリケーションでは、HLBは2つの最近のニューロシンボリックタスクに統合された。
-
コネクショニストシンボリック疑似秘密(CSPS)[3]: このタスクは、VSAを使用してヒューリスティックなセキュリティを探求し、「ワンタイムパッド」を模倣して、信頼できない第三者に計算をオフロードする際に、入力と出力を曖昧にすることを探求した。実験では、ランダムなVSAベクトル $s$(「秘密」)を入力 $x$ に束縛して、曖昧な表現 $B(s, x)$ を作成することを含んだ。第三者のネットワークはこの曖昧な入力を処理し、出力 $y$ を返し、それをローカルで秘密 $B^*(y, s)$ で束縛解除して最終的な回答を得た。ベースラインはHRR、VTB、MAP-C、およびMAP-Bであった。実験は、32GBメモリを搭載した単一のNVIDIA TESLA P100 GPUで実行された。
- 精度: 主要なメトリックは、5つの標準画像データセット(MNIST、SVHN、CIFAR-10、CIFAR-100、およびMini-ImageNet)でのTop@1およびTop@5分類精度であった。
- セキュリティ: 情報隠蔽の主張を徹底的に証明するために、調整ランド指数(ARI)が計算された。詮索する第三者は、さまざまなクラスタリングアルゴリズム(K-means、ガウス混合モデル、Birch、HDBSCAN)を使用して、曖昧な入力 $B(x, s)$ と出力 $y$ をクラスタリングしようとした。ゼロに近いARIスコアは、攻撃者の観点からランダムなラベル割り当てを示す、情報隠蔽の成功の決定的な証拠であった。
-
Xtreme Multi-Label(XML)分類 [9]: このタスクは、単一の入力が多数の可能なクラス($C \gg d$、ここで $d$ は入力次元)に分類される必要があるシナリオを扱った。これは電子商取引で一般的である。VSAは、スパースな出力空間を表現するために使用された。実験設定は[9]のネットワーク詳細に従い、元のVSAをHLBおよびベースラインVSA(HRR、VTB、MAP)に置き換えた。評価は、8つの多様なデータセット(BIBTEX、DELICIOUS、MEDIAMILL、EURLEX-4K、EURLEX-4.3K、WIKI10-31K、AMAZON-13K、DELICIOUS-200K)で実行された。主要なメトリックは、正規化割引累積ゲイン(nDCG)と傾向スコア付きnDCG(PSnDCG)であり、これらは多ラベル分類パフォーマンスの評価に標準的である。
証拠が証明すること
経験的な証拠は、理論的な主張を強く支持し、HLBの広範なVSAアプリケーションにおける優れたまたは競争力のあるパフォーマンスを実証している。
理論的検証:
本稿は、HLBのコア数学的メカニズムが意図したとおりに機能することを示す説得力のある証拠を提供している。元のベクトル $x_i$ とその取得されたバージョン $\hat{x}_i$ の間のコサイン類似度 $\phi$ がおおよそ $1/\sqrt{p}$ であるという理論的関係(定理 3.2)は、ヒートマップ(図 1)とプロット(図 6)によって経験的に検証されている。これは、提案された類似性拡張の有効性を確認している。さらに、複合表現のノルムに対する理論的予測、$||X_p||_2 \approx \mu^2 \sqrt{p} \cdot d$ (定理 B.1)も、実験結果(図 5)によって密接に一致しているが、$p$ が増加するにつれて近似によりいくらかの変動がある。決定的に、HLBに導入された射影ステップは、蓄積ノイズを低減することが明確に示されている。射影なしの場合とありの場合のノイズ成分を比較したヒートマップ(図 4)は、射影なしの最大ノイズが射影あり(7.18)よりも著しく高い(19.38)ことを明確に示しており、このアーキテクチャ上の選択が検索精度の向上に効果的であることを証明している。
古典的なVSAタスク:
基本的な束縛/束縛解除精度タスクでは、HLBは一貫してHRRおよびVTBと同等、あるいはそれ以上のパフォーマンスを示し、さまざまな次元でMAPを明確に上回っている(図 2)。曲線下面積(AUC)スコアとして提示されたこのハードな証拠は、HLBの束縛および束縛解除操作が堅牢で基本的なVSA操作に効果的であることを証明している。さらに印象的なのは、逐次束縛/束縛解除安定性タスク(図 3)では、HLBは存在する項目に対して理想的な類似性スコア1を維持し、決定的に、束縛されたベクトルの数 $p$ に関係なく一定のベクトル大きさを維持することで際立っている。これは、HRR、VTB、およびMAPのようなベースラインが類似性スコアの減衰または大きさの爆発/消失を示すことに対する重要な利点である。この安定性は、HLBが他のVSAに一般的な主要な数値安定性の問題に対処していることの否定できない証拠であり、複雑なシンボリック処理のためのより信頼性の高い基盤となっている。
ディープラーニングタスク:
HLBの有効性は、ディープラーニングコンテキストに堅牢に拡張される。コネクショニストシンボリック疑似秘密(CSPS)タスクでは、HLBは5つのデータセットすべて(MNIST、SVHN、CIFAR-10、CIFAR-100、Mini-ImageNet)で分類精度においてすべての以前のVSA手法を大幅に上回るだけでなく、情報隠蔽も向上させている(表 2)。調整ランド指数(ARI)スコア(表 3)は、HLBに対してSVHN、CIFARs、およびMini-ImageNetで一貫してゼロに近いため、詮索する第三者が入力または出力をクラスタリングすることがはるかに困難になり、二重の利点(精度向上とセキュリティ強化)を証明している。MNISTはすべての手法でARIのいくらかの退化を示したが、これはCSPSセキュリティの既知の問題として認識されている。この二重の改善は、HLBの実用的な有用性に対する強力な証拠である。
Xtreme Multi-Label(XML)分類では、HLBは新しい最先端(SOTA)を確立している。表 4 は、特徴とラベルの観点から「容易」から「困難」まで、8つの多様なデータセットにわたるnDCGおよびPSnDCGスコアを示している。HLBは、両方のメトリックですべてのデータセットで最高のスコアを達成しており、高次元でスパースな出力空間を効率的かつ効果的に処理する能力の優位性を示している。複数のデータセットとメトリックにわたるこの包括的な勝利は、HLBのコアメカニズムが複雑で現実世界のディープラーニングシナリオで具体的なパフォーマンス向上につながるという決定的な、否定できない証拠を提供している。
限界と将来の方向性
提案されたハーダマール誘導線形束縛(HLB)は印象的なパフォーマンスと理論的な健全性を示しているが、特定の限界を認識し、これらの発見をさらに進化させるための将来の開発の方向性を考慮することが重要である。
限界:
1つの暗黙的な限界は、明示的に述べられていないが、数学的導出に起因する。HLBの基盤であるハーダマール行列は、通常、ベクトル次元 $d$ が2のべき乗であることを必要とする。これは多くの計算コンテキストで一般的であるが、任意の次元を持つアプリケーションにはパディングやその他の回避策が必要になる可能性があり、非効率性や複雑性を導入する可能性がある。本稿ではまた、定理 B.1(式 17 のノイズ項 $\xi$ の無視)で行われた近似により、束縛ペアの数 $p$ が増加するにつれて複合表現のノルムの変動が増加することを示唆している(図 5)。全体的な傾向は維持されているが、これは極端に大きな $p$ の場合、近似がそれほど正確ではなくなり、システムの予測可能性に影響を与えたり、より洗練されたノイズ処理が必要になったりする可能性があることを示唆している。
さらに、CSPSで提供されるセキュリティは、ヒューリスティックであり、暗号学的に保証されたものではない。MNISTデータセットのARI結果は、いくらかの退化を示しており、そのようなセキュリティが絶対的ではないことを思い出させる。これは、厳格で証明可能なセキュリティを必要とするアプリケーションでは、CSPSフレームワーク内のHLBだけでは不十分である可能性があることを示唆している。最後に、束縛ステップ自体は効率的な $O(d)$ の複雑性を誇るが、本稿では、特に $d$ または $p$ が極端な値にスケールする場合、大規模なディープラーニングシステムに統合されたHLBの全体的な計算フットプリント(例:メモリ使用量、非常に大規模なモデルのトレーニング時間、またはエネルギー消費)を深く掘り下げていない。
将来の方向性:
-
任意の次元と代替変換への一般化:
- 議論: 非効率的な単純パディングに頼ることなく、2のべき乗ではないベクトル次元にHLBの利点をどのように拡張できるか?近似的なハーダマール変換を非べき乗次元用に探求したり、同様の計算上の利点と望ましいVSA特性を提供するが次元の柔軟性が高い他の直交変換を調査したりできるか?これはHLBの適用範囲を大幅に広げる可能性がある。
- 視点: 理論的な観点から、これはハーダマール基底の厳密な数学的優雅さに挑戦するが、実用的な工学的ソリューションへの扉を開く。アプリケーションの観点から、それは多様な既存のデータセットやモデルへの統合の潜在的な障壁を取り除く。
-
ニューロシンボリックAIにおける証明可能なセキュリティへの道:
- 議論: CSPSセキュリティがヒューリスティックであると考えると、より堅牢な暗号プリミティブとHLBを統合するための次のステップは何か?HLBの線形特性と効率的な束縛解除は、準同型暗号スキームや安全なマルチパーティ計算プロトコルと組み合わせることで、証明可能なセキュリティ保証を提供するニューロシンボリックシステムを設計するために活用できるか?これはヒューリスティックセキュリティを超えて、真に信頼できるAIへと移行するだろう。
- 視点: これは機密性の高いアプリケーションにとって重要な領域である。セキュリティに焦点を当てた研究者は、形式検証方法を探求するだろうが、AIの実践者は、セキュリティとパフォーマンスのバランスをとる実用的な効率的な実装を探すだろう。
-
動的な $p$ 推定と適応的類似性拡張:
- 議論: 本稿は、類似性拡張ステップのために $p$(束縛ペアの数)を知るか推定することの重要性を強調している。複雑で動的なニューロシンボリックシステムでは、$p$ が常に明示的に知られているとは限らない。複合表現自体から動的に $p$ を推測できる適応メカニズムまたは学習済み推定器を開発するにはどうすればよいか?これにより、リアルタイムでコンテキストを意識した類似性補正が可能になるか?
- 視点: これはVSAベースシステムの自律性と堅牢性を向上させるだろう。機械学習の専門家は $p$ 推定のためのニューラルネットワークアーキテクチャを提案するかもしれないが、認知科学者は構成的表現における不確実性を処理する生物学的システムとの類似性を引き出すかもしれない。
-
非対称束縛と高度な構成性の探求:
- 議論: HLBは対称であるが、本稿ではVTBの非対称性について言及している。「主体-行動-対象」の関係など、非対称束縛を本質的に必要とするシンボリック関係または認知タスクの特定のタイプは何か?ハーダマール誘導フレームワークは、計算効率と数値的安定性を維持しながら、非対称束縛操作をサポートするように拡張または変更できるか?これは、指向性関係とより複雑な意味構造の表現のための新しい機能を開く可能性がある。
- 視点: これはVSAの表現力に踏み込む。言語学者または認知AI研究者は、非対称束縛を要求する特定の文法または論理構造を特定し、数学的フレームワークをより豊かなシンボリック表現を収容するように推進するかもしれない。
-
高度なディープラーニングアーキテクチャとのより深い統合:
- 議論: HLBはCSPSとXMLで有望な結果を示している。それを最先端のディープラーニングアーキテクチャに、より深くネイティブに統合するにはどうすればよいか?HLBベースの束縛および束縛解除操作は、Transformerモデル(例:アテンションメカニズムまたは位置エンコーディング用)、グラフニューラルネットワーク、または再帰型ニューラルネットワークのコンポーネントを置き換えまたは補強し、それらに強力なシンボリック推論能力と改善された構成的汎化能力を付与できるか?
- 視点: これはシンボリックAIとコネクショニストAIの間のギャップを埋めることである。ニューラルアーキテクチャ設計者は新しいレイヤー設計を探求するかもしれないが、理論計算科学者はそのようなハイブリッドシステムの計算グラフと情報フローを分析するかもしれない。
-
敵対的攻撃と現実世界のノイズに対する堅牢性:
- 議論: 射影ステップはノイズを低減するが、HLBは、特に安全クリティカルなアプリケーションにおいて、さまざまな形態の敵対的攻撃または現実世界のセンサーノイズに対してどの程度堅牢か?初期化戦略、ノイズを意識したトレーニング、または誤り訂正符号のようなさらなるメカニズムは、HLBと統合して、ノイズの多いまたは敵対的な環境での回復力と信頼性を向上させることができるか?
- 視点: これは展開にとって重要である。セキュリティ研究者は攻撃ベクトルと防御に焦点を当てるだろうが、エンジニアは実用的なノイズモデルとハードウェアレベルの回復力を考慮するだろう。
-
ハードウェアアクセラレーションとエネルギー効率の高い実装:
- 議論: HLBの束縛のための $O(d)$ 複雑性と、ハーダマール変換(高速アルゴリズムに適している)への依存性を考慮すると、特殊なハードウェアアクセラレーションの機会は何であるか?HLBは、エッジAIデバイスまたは大規模なシンボリック処理システム向けの超低消費電力と高スループットを達成するために、ニューロモルフィックチップ、FPGA、またはその他のカスタムハードウェアに効率的に実装できるか?
- 視点: これはハードウェア-ソフトウェア共同設計の課題である。コンピュータアーキテクトは並列化とメモリアクセスパターンを調査するだろうが、持続可能性の提唱者はエネルギー効率の高いAIの可能性を強調するだろう。
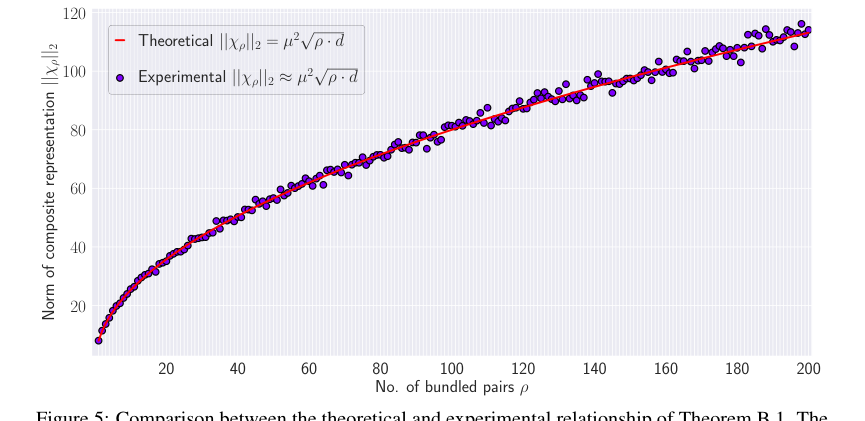 Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
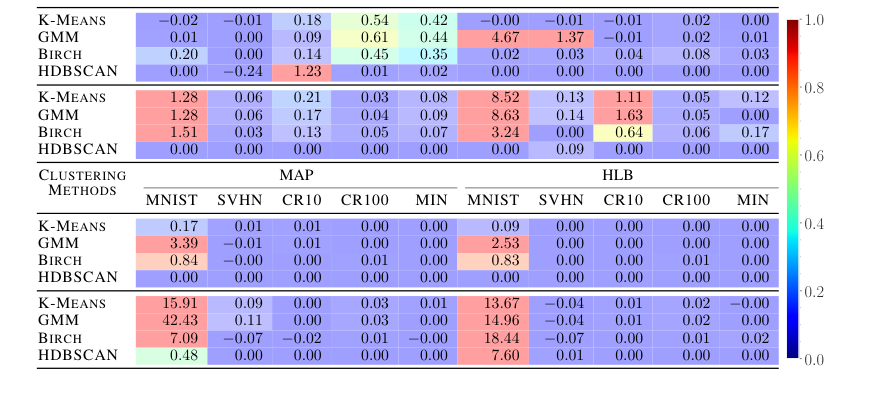 Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
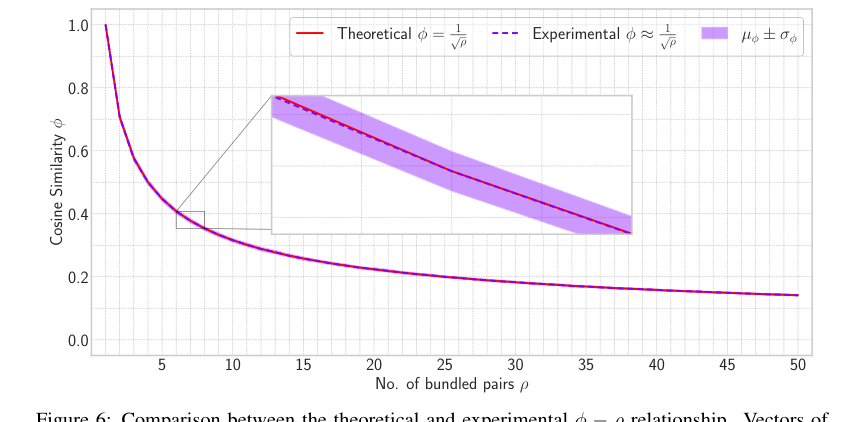 Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion
Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion