Производная от преобразования Адамара линейная векторно-символьная архитектура
Проблема, рассматриваемая в данной статье, берет свое начало в области векторно символьных архитектур (VSA), уникального подхода к разработке нейросимвольного ИИ.
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, берет свое начало в области векторно-символьных архитектур (VSA), уникального подхода к разработке нейросимвольного ИИ. Эта академическая родословная может быть точно прослежена до Смоленского [38], который инициировал подход VSA с помощью тензорного произведения представлений (TPR). В TPR концепции представлены как высокоразмерные векторы, и эти векторы "связываются" путем вычисления внешнего произведения для формирования новых, составных концепций. Эта основополагающая работа возникла как способ обеспечить символьные манипуляции в рамках коннекционистского фреймворка, позволяя представлять логические утверждения и структуры [13].
Исторически сложилось так, что большинство VSA были разработаны до широкого распространения глубокого обучения и автоматического дифференцирования. Их основное внимание уделялось эффективности в системах, разработанных вручную, часто вдохновленных задачами классического ИИ или когнитивной наукой. Однако этот ранний фокус привел к ряду фундаментальных ограничений, или "болевых точек", при попытке интегрировать VSA в современные дифференцируемые системы:
- Вычислительная сложность: Ранние методы VSA, такие как TPR, страдали от непрактичной вычислительной сложности. Например, связывание $p$ элементов с помощью TPR приводило к сложности $O(d^p)$, где $d$ — размерность вектора. Даже более общие линейные VSA, которые представляют связывание как матричную операцию, обычно имели сложность $O(d^2)$, что делало их слишком медленными для приложений реального времени или крупномасштабных приложений.
- Численная нестабильность: Другие популярные методы VSA, такие как голографические редуцированные представления (HRR) [32], полагаются на преобразование Фурье (FT) и циклические свертки. Хотя эти операции мощны, они включают иррациональные умножения и комплексные числа, что может привести к численной нестабильности на практике. Предыдущие работы [9] пытались использовать шаги проекции для смягчения этой проблемы, но основная проблема оставалась.
- Субоптимальная производительность в дифференцируемых системах: Многие существующие методы VSA не были разработаны с учетом свойств, необходимых для бесшовной интеграции в фреймворки глубокого обучения. Им часто не хватало благоприятной вычислительной эффективности и численной стабильности при использовании с градиентным спуском и автоматическим дифференцированием, что приводило к более низким, чем желалось, показателям производительности в современных нейросимвольных задачах ИИ.
Данная статья устраняет эти ограничения, выводя новую VSA, линейное связывание на основе Адамара (HLB), которое призвано обеспечить сложность $O(d)$ для связывания, улучшенную численную стабильность и лучшую производительность в дифференцируемых приложениях глубокого обучения, используя свойства преобразования Адамара Уолша.
Интуитивные термины предметной области
Чтобы сделать концепции этой статьи доступными, давайте разберем некоторые специализированные термины с помощью повседневных аналогий:
- Векторно-символьные архитектуры (VSA): Представьте, что у вас есть набор уникальных "векторов-мыслей" в вашем мозгу, где каждый вектор представляет базовую концепцию, такую как "кошка", "счастливый" или "красный". VSA — это как особый ментальный язык, который позволяет вам комбинировать эти векторы-мысли для формирования новых, более сложных идей, таких как "счастливая кошка" или "красная машина", а затем позже "спросить" свой мозг, чтобы извлечь части этих сложных идей. Это способ для компьютеров манипулировать концепциями, как мы это делаем словами, но используя числа.
- Связывание (Binding): Это процесс объединения двух или более векторов концепций для создания нового вектора, который представляет их взаимосвязь или состав. Думайте об этом как о смешивании двух ингредиентов в рецепте, скажем, "муки" и "воды", чтобы получить "тесто". "Тесто" — это новая сущность, которая содержит оба исходных ингредиента, но в комбинированной форме. В VSA связывание "кошка" и "счастливый" создает новый вектор для "счастливой кошки".
- Развязывание (Unbinding): Это обратный процесс связыванию. Имея комбинированный вектор концепции (например, "тесто") и один из его исходных компонентов ("мука"), развязывание позволяет извлечь другой компонент ("вода"). Это похоже на то, как если бы вы взяли вектор "счастливая кошка" и вектор "счастливый", а затем смогли бы извлечь вектор "кошка". Эта операция имеет решающее значение для запроса и извлечения информации из составных представлений.
- Преобразование Адамара (Hadamard Transform): Представьте себе особый вид цифрового процесса "перемешивания" или "кодирования". В отличие от более сложного преобразования Фурье, которое имеет дело с волнами и мнимыми числами, преобразование Адамара гораздо проще. Оно использует только сложение и вычитание, а его выходные значения всегда равны +1 или -1. Это делает его очень быстрым и численно стабильным, как сверхэффективный, простой компрессор данных, который легко обратим.
- Нейросимвольный ИИ (Neuro-symbolic AI): Это подход к искусственному интеллекту, который пытается получить лучшее из обоих миров: интуитивные способности нейронных сетей к обучению на основе закономерностей (как люди распознают лица) и логическое, основанное на правилах рассуждение традиционного символьного ИИ (как компьютеры следуют инструкциям). Это ИИ, который может как "чувствовать", так и "думать" структурированным образом, стремясь преодолеть ограничения каждого подхода при использовании по отдельности.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $B(x, y)$ | Операция связывания, которая соединяет две концепции/вектора $x$ и $y$ для получения нового вектора $z$. |
| $B^*(x, y)$ | Операция развязывания, которая извлекает один компонент связанного вектора, имея другой компонент. |
| $x, y, z$ | Общие векторы, представляющие концепции или точки данных в пространстве VSA. |
| $d$ | Размерность векторов в VSA, т.е. $x \in \mathbb{R}^d$. |
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в ограничениях существующих векторно-символьных архитектур (VSA) при применении к современным системам глубокого обучения.
Исходная точка (вход/текущее состояние):
Текущие VSA работают путем связывания двух векторов, $x, y \in R^d$, представляющих концепции, в новый составной вектор $z \in R^d$ с использованием операции связывания $B(x, y) = z$. Обратная операция развязывания, $B^*(x, y)$, позволяет извлечь компонент. Хотя эти архитектуры предлагают привлекательные платформы для нейросимвольных методов благодаря своим естественным манипуляциям в стиле символьного ИИ (коммутативность, ассоциативность, обратная операция), они были в значительной степени разработаны до широкого распространения глубокого обучения и автоматического дифференцирования. Следовательно, многие существующие методы VSA демонстрируют ряд критических недостатков:
1. Высокая вычислительная сложность: Многие VSA, особенно те, которые рассматриваются как линейные операции $B(a,b) = a^T G b$ и $B^*(a,b) = a^T F b$ (где $G$ и $F$ — матрицы $d \times d$), имеют вычислительную сложность $O(d^2)$ для шага связывания. Хотя это может быть уменьшено до $O(d)$ для диагональных матриц, это часто не так для более сложных, выразительных связываний. Тензорное произведение представлений (TPR), например, имеет непрактичную сложность $O(d^p)$ для связывания $p$ элементов.
2. Численная нестабильность: Методы, такие как голографические редуцированные представления (HRR), которые полагаются на преобразование Фурье и комплексные числа, подвержены численной нестабильности из-за "иррациональных умножений" при работе с действительными векторами.
3. Субоптимальная производительность в дифференцируемых системах: Существующие VSA не были явно разработаны для обучения на основе градиентов, что означает, что их свойства (например, коммутативность) могут не сохраняться, если их базовые матрицы обучаются с помощью градиентного спуска без дополнительных ограничений. Их производительность в приложениях глубокого обучения часто ниже желаемой.
Желаемая конечная точка (выход/целевое состояние):
Статья направлена на представление новой VSA, названной линейным связыванием на основе Адамара (HLB), которая преодолевает эти ограничения. Цель состоит в разработке VSA, которая является:
1. Вычислительно эффективной: Обеспечивает сложность $O(d)$ для шага связывания, что значительно быстрее, чем $O(d^2)$ или $O(d \log d)$ (что обычно связано с самим преобразованием Адамара, но здесь derivation приводит к линейной сложности).
2. Численно стабильной: Избегает проблем нестабильности комплексных VSA, работая исключительно с действительными числами и простой арифметикой (сложение, вычитание и значения $\{-1, 1\}$).
3. Высокоэффективной: Показывает сравнимую или лучшую производительность по сравнению с существующими VSA как в классических задачах VSA, так и в современных приложениях глубокого обучения.
4. Совместимой с дифференцируемыми системами: Разработана с нуля для бесшовной интеграции и хорошей производительности в дифференцируемых системах, поддерживая нейросимвольный ИИ.
5. Симметричной: Операция связывания $B(x,y)$ должна быть симметричной, т.е. $B(x,y) = B(y,x)$, что является желательным свойством для многих приложений VSA.
Отсутствующее звено или математический пробел:
Точным отсутствующим звеном является вывод механизма связывания и развязывания VSA, который использует благоприятные свойства преобразования Адамара для достижения линейной вычислительной сложности и численной стабильности, сохраняя при этом основные возможности символьных манипуляций и будучи пригодным для дифференцируемого обучения. Предыдущие попытки либо страдали от сложности, нестабильности, либо не имели явной разработки для интеграции глубокого обучения. Статья заполняет этот пробел, заменяя преобразование Фурье (используемое в HRR) преобразованием Адамара и тщательно разрабатывая операции связывания и развязывания для использования его уникальных характеристик, таких как рекурсивная структура и свойство самообратности.
Болезненный компромисс или дилемма:
Предыдущие исследователи, пытавшиеся решить эту проблему, оказались в ловушке нескольких болезненных компромиссов:
* Выразительность против вычислительных затрат: Достижение богатых, композиционных представлений (например, связывание многих элементов) часто приводит к экспоненциальному росту вычислительной сложности, как видно из стоимости $O(d^p)$ TPR. Это заставляет выбирать между высоковыразительными символьными структурами и практичными вычислениями.
* Символьная точность против обучаемости: Хотя VSA предлагают мощные символьные свойства, адаптация их для обучения на основе градиентов в глубоких нейронных сетях часто рискует компрометировать эти самые свойства. Обучение базовых матриц $G$ и $F$ без дополнительных ограничений может нарушить желаемую коммутативность или ассоциативность. Это создает дилемму между сохранением "нейросимвольных свойств" и оптимизацией для современных парадигм машинного обучения.
* Математическая элегантность против численной надежности: Использование математически элегантных инструментов, таких как преобразование Фурье для циклической свертки (как в HRR), вводит комплексные числа и иррациональные умножения, которые могут привести к численной нестабильности при реализации с действительными векторами в практических системах. Это заставляет выбирать между теоретической чистотой и надежной, реальной производительностью.
Ограничения и сбои
Проблема делает ее чрезвычайно сложной из-за нескольких суровых, реалистичных стен, с которыми сталкиваются авторы:
- Стена вычислительной сложности: Необходимость сложности $O(d)$ для шага связывания является строгим ограничением. Многие существующие VSA имеют сложность $O(d^2)$ или $O(d \log d)$, что является значительным барьером для масштабируемости для высокоразмерных векторов ($d$). Это ограничивает их применимость в крупномасштабных моделях глубокого обучения, где эффективность имеет первостепенное значение.
- Численная нестабильность: Основной сбой для существующих VSA, таких как HRR, — это численная нестабильность. Она возникает из-за операций, включающих комплексные числа и иррациональные умножения, которые могут привести к ошибкам с плавающей запятой и ненадежным результатам, особенно при работе с действительными векторами. Предлагаемое решение должно по своей сути избегать этого.
- Накопление шума в составных представлениях: Когда несколько концепций связываются в один составной вектор (т.е. упаковываются $p \ge 2$ элементов), неизбежно накапливается шум. Этот шум снижает точность операции развязывания, затрудняя надежное извлечение отдельных компонентов. Без механизма смягчения этого ограничения полезность VSA для сложных символьных структур сильно ограничена. В статье показано, что без шага проекции шумовой компонент $\eta'$ значительно выше, чем $\eta''$ с проекцией.
- Проблемы инициализации векторов: Чтобы операции связывания и развязывания работали правильно, векторы должны иметь ожидаемое значение ноль. Однако, если компоненты вектора инициализированы так, что значения близки к нулю, последующее деление на эти векторы запроса во время развязывания может "дестабилизировать шумовую компоненту и создать численную нестабильность". Это конкретное ограничение инициализации требует тщательного выбора дизайна, что приводит к введению смеси нормальных распределений (MiND).
- Стабильность величины при множественных связываниях: Идеальная VSA должна поддерживать стабильную величину своих составных векторов, то есть величина не должна "взрываться/исчезать по мере увеличения $p$" (количество связанных элементов). Это распространенный сбой для приближенных процедур развязывания в других VSA, где оценки сходства убывают или величины становятся нестабильными с увеличением $p$.
- Ограничения памяти оборудования: Экспериментальная установка, использующая один GPU NVIDIA TESLA P100 с 32 ГБ памяти, неявно накладывает ограничение, что любая предложенная VSA должна быть достаточно энергоэффективной по памяти, чтобы работать в таких типичных средах оборудования для глубокого обучения.
- Экстремальная разреженность в многоклассовой классификации: В приложениях, таких как экстремальная многоклассовая классификация (XML), количество возможных классов ($L \ge 100 000$) значительно превышает размерность входных данных ($d \approx 5000$), и только небольшая доля классов является релевантной для данного входного сигнала (часто менее 100). Эта экстремальная разреженность делает традиционные линейные слои вычислительно неподъемными ($O(L)$ сложность), требуя VSA, которая может эффективно представлять это огромное, разреженное выходное пространство (снижая сложность до $O(K)$, где $K$ — количество присутствующих классов).
Почему этот подход
Неизбежность выбора
Принятие линейного связывания на основе Адамара (HLB) было не просто предпочтением, а необходимостью, обусловленной присущими ограничениями существующих векторно-символьных архитектур (VSA) при применении к современным контекстам глубокого обучения. Авторы признали, что традиционные VSA-"SOTA" методы, такие как голографические редуцированные представления (HRR), векторно-производные трансформационные связывания (VTB) и умножение-сложение-перестановка (MAP), были принципиально недостаточны для их целей, особенно в отношении численной стабильности, вычислительной эффективности и бесшовной интеграции с дифференцируемыми системами.
Критическое осознание возникло из наблюдения, что, хотя VSA предлагают привлекательную платформу для нейросимвольных методов, многие существующие подходы были разработаны до широкого распространения глубокого обучения и автоматического дифференцирования. Например, HRR, который полагается на преобразование Фурье (FT) и циклическую свертку, страдает от численной нестабильности из-за своей зависимости от комплексных чисел и иррациональных умножений (стр. 3). Это затрудняет его использование в системах, требующих надежных численных операций, особенно когда задействованы градиенты.
Преобразование Адамара, напротив, по своей сути избегает этих проблем. Оно работает исключительно с действительными числами, выполняя только сложение и вычитание, тем самым устраняя иррациональные умножения и арифметику комплексных чисел (стр. 3). Это свойство делает его уникально жизнеспособным решением для поддержания численной стабильности, что является первостепенной задачей в дифференцируемых системах, где небольшие численные ошибки могут распространяться и дестабилизировать обучение. Кроме того, свойство матрицы Адамара быть самообратной упрощает дизайн операции развязывания $B^*$, делая общую систему более элегантной и надежной.
Сравнительное превосходство
HLB демонстрирует качественное превосходство над предыдущими золотыми стандартами по нескольким ключевым аспектам, выходящим за рамки простых метрик производительности.
Во-первых, с точки зрения вычислительной сложности, HLB достигает впечатляющей сложности $O(d)$ для своего шага связывания (стр. 1). Это значительное структурное преимущество по сравнению с $O(d^2)$ сложностью общих линейных операций (которые многие VSA можно рассматривать как) или даже $O(d \log d)$ сложностью, обычно ассоциируемой с самим преобразованием Адамара Уолша (стр. 2). Эта линейная сложность достигается путем переопределения функции связывания как поэлементного произведения в домене Адамара, $B'(x, y) = x \odot y$ (стр. 5), что делает его исключительно эффективным для высокоразмерных векторов.
Во-вторых, численная стабильность является основным преимуществом. Как упоминалось, преобразование Адамара использует исключительно значения $\{-1, 1\}$ и действительную арифметику, полностью обходя проблемы численной нестабильности, распространенные в методах на основе преобразования Фурье, таких как HRR, которые включают комплексные числа и иррациональные умножения (стр. 2, 3). Эта присущая стабильность имеет решающее значение для надежной работы, особенно в глубоком обучении, где модели чувствительны к числовой точности.
В-третьих, HLB демонстрирует превосходную обработку шума. Статья представляет шаг проекции (Определение 3.2, стр. 4), который значительно уменьшает накопленный шум при развязывании. Эмпирические результаты (Рисунок 4, стр. 15) ясно показывают, что шумовая компонента с этой проекцией ($\eta''$) существенно ниже, чем без нее ($\eta'$), что приводит к улучшенной точности извлечения. Это структурное улучшение напрямую решает распространенную проблему в VSA, где шум накапливается при множественных связываниях.
Наконец, HLB демонстрирует замечательную последовательность и стабильность величины и оценок сходства. Рисунок 3 (стр. 7) иллюстрирует, что HLB последовательно возвращает идеальную оценку сходства 1 для присутствующих элементов и поддерживает постоянную величину независимо от количества связанных векторов. Это предотвращает "взрывные/исчезающие" значения, наблюдаемые в HRR, VTB и MAP, что является критическим свойством для разработки стабильных решений VSA и обеспечения надежного извлечения информации. Эта стабильность приписывается свойствам смеси нормальных распределений (MiND), используемой для инициализации векторов (Свойства 3.1, стр. 5).
Соответствие ограничениям
Выбранный метод HLB идеально соответствует неявным и явным ограничениям разработки VSA, подходящей для современного нейросимвольного ИИ.
- Вычислительная эффективность: Основное ограничение для VSA, особенно в глубоком обучении, — это низкие вычислительные накладные расходы. Сложность связывания HLB $O(d)$ напрямую решает эту проблему, делая его осуществимым для высокоразмерных данных и крупномасштабных приложений (стр. 1, 5).
- Численная стабильность: Требование надежных численных операций удовлетворяется основой HLB на преобразовании Адамара, которое избегает комплексных чисел и иррациональной арифметики, обеспечивая стабильность (стр. 2, 3).
- Производительность в дифференцируемых системах: В статье явно заявлена цель VSA, которая "хорошо работает в дифференцируемых системах" (Аннотация, стр. 1). Линейные операции HLB, действительная природа и численная стабильность делают его изначально совместимым с оптимизацией на основе градиентов, краеугольным камнем глубокого обучения.
- Нейросимвольные свойства: VSA ценятся за их возможности символьных манипуляций (коммутативность, ассоциативность, обратная операция). Преобразование Адамара "уже ассоциативно и дистрибутивно" (стр. 2), что упрощает дизайн для сохранения этих существенных свойств без дополнительных сложных ограничений.
- Управление шумом: Проблема накопления шума в составных представлениях является значительной проблемой. Инициализация MiND HLB (Уравнение 6, стр. 5) и явный шаг проекции (Определение 3.2, стр. 4) разработаны для минимизации и управления этим шумом, обеспечивая точное извлечение даже при большом количестве связанных элементов.
Этот "брак" между суровыми требованиями проблемы и уникальными свойствами HLB очевиден в его дизайнерских решениях, от выбора преобразования до шагов инициализации и проекции.
Отклонение альтернатив
Статья предоставляет четкое обоснование для отклонения других популярных подходов VSA и, косвенно, общих методов глубокого обучения для данного контекста проблемы.
- Существующие VSA (HRR, VTB, MAP):
- Численная нестабильность: HRR, ключевой базовый метод, явно критикуется за его "численную нестабильность из-за иррациональных умножений комплексных чисел" (стр. 3). Это является прямой причиной поиска альтернативы, такой как HLB, которая использует операции с действительными числами.
- Вычислительная сложность: В статье отмечается, что многие VSA, если бы они были реализованы как общие линейные операции, имели бы сложность $O(d^2)$, что слишком высоко (стр. 1). Тензорное произведение представлений (TPR) отвергается как "непрактичное из-за сложности $O(d^p)$" для связывания нескольких элементов (стр. 2). Сложность HLB $O(d)$ предлагает существенное улучшение.
- Производительность в дифференцируемых системах: Общая критика "большинства VSA" заключается в том, что они "были разработаны до того, как глубокое обучение и автоматическое дифференцирование стали популярными, и вместо этого сосредоточились на эффективности в системах, разработанных вручную" и "показали проблемы с численной стабильностью, вычислительной сложностью или иначе более низкую, чем желалось, производительность в контексте дифференцируемой системы" (стр. 1). Это подчеркивает их непригодность для основной области применения статьи.
- Проблемы с шумом и стабильностью: Рисунок 3 (стр. 7) эмпирически демонстрирует, что HRR, VTB и MAP-C/B страдают от убывающих оценок сходства и взрывающихся/исчезающих величин по мере увеличения количества связанных векторов. Способность HLB поддерживать постоянную величину и идеальные оценки сходства напрямую решает эти сбои в альтернативах.
- Общее глубокое обучение (например, стандартные CNN, базовые диффузионные модели, трансформеры): Хотя прямо не "отвергаются" в прямом сравнении, фокус статьи на "нейросимвольном ИИ" (Аннотация, стр. 1) подразумевает, что чисто коннекционистские модели лишены присущих символьных манипуляционных способностей, которые предоставляют VSA. Для таких задач, как "коннекционистские символьные псевдосекреты" (CSPS) или "экстремальная многоклассовая классификация" (XML), символьные свойства VSA используются для получения конкретных преимуществ:
- CSPS: Для безопасного вычисления с выгрузкой, гомоморфное шифрование (HE) считается "более дорогим, чем само выполнение нейронной сети", что сводит на нет его полезность (стр. 8). VSA предлагают эвристическую альтернативу для скрытия входных/выходных данных при одновременном снижении локальных вычислений. Чистые нейронные сети не предоставляли бы этот механизм "шифрования/дешифрования".
- XML: VSA используются для "обхода этой стоимости" вычислительной сложности $O(L)$ (где $L$ — количество классов), используя символьные манипуляции для снижения ее до $O(K)$ (где $K$ — количество присутствующих классов, $K \ll L$) (стр. 9). Стандартные архитектуры глубокого обучения обычно требовали бы большого выходного слоя, что влечет за собой стоимость $O(L)$, которой VSA призваны избежать.
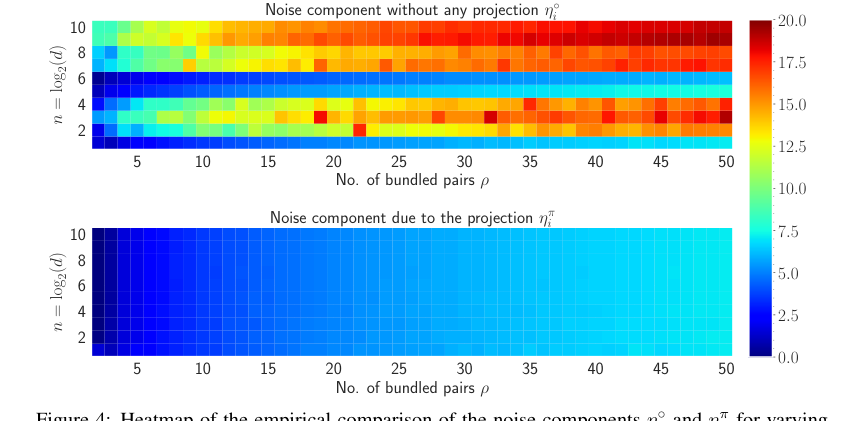 Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
Математический и логический механизм
Мастер-уравнение
Суть механизма линейного связывания на основе Адамара (HLB) заключается в определении операций связывания и развязывания, которые используют преобразование Адамара Уолша. Абсолютно основные уравнения, определяющие эту логику преобразования, — это функция связывания и функция развязывания, особенно при применении к спроецированным входам для повышения производительности и стабильности.
Операция связывания $B(x,y)$ для двух векторов $x, y \in \mathbb{R}^d$ определяется как:
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) \quad \text{(Уравнение 2)} $$
При работе с составным представлением, образованным суммированием нескольких связанных пар, и после применения шага проекции к входным векторам, операция развязывания $B^*(\chi_p, \pi(y_i)^\dagger)$ дает промежуточный результат. Функция проекции $\pi(v)$ определяется как $\pi(v) = \frac{1}{d} Hv$. Составное представление $\chi_p$ формируется путем суммирования $p$ спроецированных связанных пар: $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$. Операция развязывания, примененная к этому составному представлению со спроецированным вектором запроса $\pi(y_i)$, дается:
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) \quad \text{(Уравнение 4)} $$
Затем статья показывает, что после дополнительного шага обратной проекции этот промежуточный результат упрощается до окончательного извлеченного вывода, который приблизительно равен $x_i$ (исходный вектор, связанный с $y_i$) плюс шумовой член $\eta''$ при $p > 1$.
Поэлементный разбор
Давайте разберем компоненты этих мастер-уравнений, чтобы понять их математические определения, физическую/логическую роль и выбор авторов.
Разбор уравнения связывания (Уравнение 2)
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) $$
- $B(x,y)$:
- Математическое определение: Выходной вектор, полученный в результате операции связывания между входными векторами $x$ и $y$.
- Физическая/логическая роль: Это основная функция, которая ассоциирует две концепции, представленные векторами $x$ и $y$, в один новый вектор. Это фундаментальный строительный блок для создания композиционных представлений в VSA.
- Почему этот выбор: Эта конкретная форма выводится путем замены преобразования Фурье в циклической свертке (используемой в голографических редуцированных представлениях, HRR) на преобразование Адамара, с целью повышения вычислительной эффективности и численной стабильности.
- $x, y$:
- Математическое определение: Входные векторы размерности $d$, $x, y \in \mathbb{R}^d$.
- Физическая/логическая роль: Каждый вектор представляет собой отдельную концепцию, символ или часть информации в рамках фреймворка VSA.
- Почему этот выбор: VSA по своей сути работают с высокоразмерными действительными векторами для кодирования и манипулирования символьной информацией.
- $d$:
- Математическое определение: Размерность входных векторов $x$ и $y$.
- Физическая/логическая роль: Действует как нормализующий множитель.
- Почему этот выбор: Деление на $d$ является обычной практикой в VSA для поддержания величины результирующего связанного вектора в разумных пределах, предотвращая взрыв значений и обеспечивая приблизительные свойства ортогональности. Оно также компенсирует масштабирующий множитель, вводимый двойным применением преобразования Адамара ($H(Hv) = dv$).
- $H$:
- Математическое определение: Матрица Адамара размера $d \times d$. Эта матрица состоит только из элементов $+1$ и $-1$ и рекурсивно определяется (например, $H_1 = [1]$, $H_{2n} = \begin{pmatrix} H_n & H_n \\ H_n & -H_n \end{pmatrix}$).
- Физическая/логическая роль: Выполняет преобразование Адамара над вектором.
- Почему этот выбор: Преобразование Адамара выбрано из-за его вычислительной эффективности (линейная сложность $O(d)$ в данной derivation, или $O(d \log d)$ для общего быстрого преобразования Адамара Уолша), численной стабильности (только значения $\pm 1$, избегая комплексных чисел или иррациональных умножений) и его удобного свойства, что его транспонирование является его собственным обратным ($H^T = H$ и $H H = dI$), что упрощает дизайн обратных операций.
- $Hx$:
- Математическое определение: Преобразование Адамара вектора $x$.
- Физическая/логическая роль: Преобразует входной вектор $x$ из его исходной области в область Адамара.
- Почему этот выбор: Это преобразование имеет решающее значение для операции связывания. Преобразуя векторы в область Адамара, поэлементное умножение может достичь эффекта связывания, аналогичного циклической свертке в исходной области (которая обычно выполняется путем поэлементного умножения в области Фурье для HRR).
- $Hy$:
- Математическое определение: Преобразование Адамара вектора $y$.
- Физическая/логическая роль: Преобразует входной вектор $y$ в область Адамара.
- Почему этот выбор: Та же причина, что и для $Hx$.
- $\odot$:
- Математическое определение: Поэлементное произведение (также известное как произведение Адамара).
- Физическая/логическая роль: Этот оператор выполняет фактическое связывание преобразованных векторов в области Адамара.
- Почему этот выбор: В области Адамара поэлементное умножение служит механизмом связывания, аналогично тому, как оно работает в области Фурье для циклической свертки. Эта операция вычислительно эффективна и сохраняет желаемые алгебраические свойства для VSA.
- $H(\dots)$:
- Математическое определение: Обратное преобразование Адамара. Поскольку $H$ является своим собственным обратным (с точностью до масштабирующего множителя $d$), двойное применение $H$ фактически инвертирует предыдущее преобразование.
- Физическая/логическая роль: Преобразует связанный вектор обратно из области Адамара в исходное векторное пространство.
- Почему этот выбор: Чтобы гарантировать, что результирующий связанный вектор $B(x,y)$ находится в том же векторном пространстве, что и исходные входные данные, позволяя выполнять согласованные операции, такие как суммирование с другими векторами.
Разбор уравнения развязывания (Уравнение 4)
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) $$
- $B^*(\chi_p, \pi(y_i)^\dagger)$:
- Математическое определение: Выходной вектор, полученный в результате операции развязывания, примененной к составному представлению $\chi_p$ с использованием обратного значения спроецированного вектора запроса $\pi(y_i)$.
- Физическая/логическая роль: Это обратная операция к связыванию, предназначенная для извлечения конкретной концепции (в идеале $\pi(x_i)$) из упакованного представления.
- Почему этот выбор: Эта операция является фундаментальной для извлечения знаний в VSA, позволяя системе "спросить", что было связано с данным запросом.
- $\chi_p$:
- Математическое определение: Составное представление, образованное суммированием $p$ отдельных связанных пар, где каждый входной вектор был предварительно обработан функцией проекции $\pi$. Математически, $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$.
- Физическая/логическая роль: Один вектор, который компактно хранит несколько ассоциаций или концепций.
- Почему этот выбор: VSA позволяют суммировать связанные векторы для представления составных структур или наборов ассоциаций, используя линейность векторного сложения.
- $\pi(x_j), \pi(y_j)$:
- Математическое определение: Спроецированные входные векторы, где $\pi(v) = \frac{1}{d} Hv$.
- Физическая/логическая роль: Предварительно обработанные версии исходных векторов концепций $x_j, y_j$.
- Почему этот выбор: Шаг проекции нормализует векторы и преобразует их в область Адамара. Это помогает смягчить численную нестабильность и уменьшить накопление шума, что особенно важно при упаковке нескольких элементов вместе.
- $\sum_{j=1}^p (\dots)$:
- Математическое определение: Суммирование по $p$ отдельным членам, каждый из которых является поэлементным произведением спроецированных входных векторов.
- Физическая/логическая роль: Агрегирует отдельные связанные представления (в промежуточной форме) в один составной вектор.
- Почему этот выбор: Линейность сложения позволяет упаковывать несколько связанных пар в один вектор, что является ключевой особенностью VSA для представления сложных структур.
- $\odot$:
- Математическое определение: Поэлементное произведение.
- Физическая/логическая роль: Внутри суммы оно выполняет связывание спроецированных входов в области Адамара. Вне суммы оно выполняет развязывание путем умножения на обратное значение запроса.
- Почему этот выбор: Поэлементное умножение является выбранным механизмом связывания/развязывания в области Адамара из-за его эффективности и алгебраических свойств.
- $H(\sum \dots)$:
- Математическое определение: Преобразование Адамара, примененное к сумме поэлементных произведений спроецированных входов.
- Физическая/логическая роль: Это промежуточное преобразование Адамара, примененное к составному представлению.
- Почему этот выбор: Этот шаг является частью процесса развязывания, преобразуя сумму в область, подходящую для поэлементного деления (умножения на обратное).
- $\frac{1}{H \pi(y_i)}$:
- Математическое определение: Поэлементное обратное значение преобразования Адамара спроецированного вектора запроса $\pi(y_i)$.
- Физическая/логическая роль: Этот член действует как "ключ развязывания" в области Адамара.
- Почему этот выбор: Для выполнения обратной операции фактически "делят" на вектор запроса. В области Адамара это достигается путем поэлементного умножения на обратное значение преобразования Адамара запроса. Использование обратного значения выводится из свойства $Hx \cdot Hx^\dagger = 1$.
- $H(\dots)$:
- Математическое определение: Обратное преобразование Адамара.
- Физическая/логическая роль: Преобразует результат обратно из области Адамара в исходное векторное пространство.
- Почему этот выбор: Чтобы получить извлеченный вектор в том же пространстве, что и исходные входные векторы, делая его интерпретируемым и пригодным для дальнейших операций VSA.
- $\frac{1}{d}$:
- Математическое определение: Масштабирующий множитель.
- Физическая/логическая роль: Нормализует величину извлеченного вектора.
- Почему этот выбор: Аналогично операции связывания, это масштабирование обеспечивает постоянные величины векторов и компенсирует масштабирование, вводимое преобразованием Адамара, поддерживая численную стабильность.
Пошаговый поток
Давайте проследим жизненный цикл абстрактной точки данных, скажем $x_1$, по мере ее связывания с $y_1$ в составное представление $\chi_p$ (вместе с $p-1$ другими парами) и последующего развязывания.
-
Инициализация концепции: Мы начинаем с необработанных векторов концепций, например, $x_1, y_1, \dots, x_p, y_p$, все находящиеся в $\mathbb{R}^d$. Эти векторы обычно инициализируются путем выборки из смеси нормальных распределений (MiND) $\Omega(\mu, 1/d)$, что гарантирует, что они имеют ожидаемое значение ноль, но ненулевое абсолютное среднее. Эта инициализация является основополагающим шагом для численной стабильности.
-
Проекция входа: Перед любым связыванием каждый отдельный вектор концепции (например, $x_j$ и $y_j$) проходит шаг проекции. Для любого вектора $v$ это включает применение преобразования Адамара и масштабирования: $\pi(v) = \frac{1}{d} Hv$. Это преобразует необработанные входные векторы в "спроецированную" форму, $\pi(x_j)$ и $\pi(y_j)$, которые нормализованы и находятся в области Адамара. Эта предварительная обработка имеет решающее значение для уменьшения шума в дальнейшем.
-
Индивидуальное связывание (на пару): Для каждой пары спроецированных векторов концепций, скажем $(\pi(x_j), \pi(y_j))$, выполняется операция связывания HLB $B(\pi(x_j), \pi(y_j))$:
- Преобразование Адамара (неявно): Определение $\pi(v)$ означает, что $H(\pi(v)) = H(\frac{1}{d} Hv) = \frac{1}{d} H(Hv) = v$. Таким образом, когда $B(\pi(x_j), \pi(y_j))$ вычисляется с использованием Уравнения 2, члены $H(\pi(x_j))$ и $H(\pi(y_j))$ фактически становятся $x_j$ и $y_j$.
- Поэлементное связывание: Затем векторы $x_j$ и $y_j$ объединяются путем поэлементного произведения: $x_j \odot y_j$. Это основной ассоциативный шаг, создающий связанное представление в домене, подобном Адамару.
- Обратное преобразование Адамара и масштабирование: Это поэлементное произведение $x_j \odot y_j$ затем преобразуется обратно путем применения матрицы Адамара $H$ и масштабируется на $1/d$. Результатом является $B(\pi(x_j), \pi(y_j)) = \frac{1}{d} H(x_j \odot y_j)$.
-
Формирование составного представления: Все $p$ этих индивидуально связанных векторов $B(\pi(x_j), \pi(y_j))$ суммируются. Это линейное суммирование создает один высокоразмерный вектор $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$, который теперь представляет собой пакет всех $p$ ассоциаций.
-
Проекция запроса (для развязывания): Когда мы хотим извлечь конкретную концепцию, скажем $x_i$, из составного $\chi_p$, мы используем связанный с ней вектор запроса $y_i$. Этот вектор запроса $y_i$ также проходит тот же шаг проекции: $\pi(y_i) = \frac{1}{d} Hy_i$.
-
Операция развязывания (Уравнение 4): Затем разворачивается процесс развязывания $B^*(\chi_p, \pi(y_i)^\dagger)$:
- Преобразование составного: Преобразование Адамара $H$ применяется к составному представлению $\chi_p$. Благодаря линейности $H$ и структуре $\chi_p$, это упрощается до $H(\chi_p) = \sum_{j=1}^p (x_j \odot y_j)$. Это переносит весь пакет в область, где отдельные связанные пары четко представлены как поэлементные произведения.
- Преобразование запроса: Преобразование Адамара $H$ применяется к спроецированному вектору запроса $\pi(y_i)$, что упрощается до $H(\pi(y_i)) = y_i$.
- Обратный запрос: Вычисляется поэлементное обратное значение этого преобразованного запроса, $1/y_i$. Это действует как "ключ развязывания" в области Адамара.
- Поэлементное развязывание: Преобразованное составное представление $\sum_{j=1}^p (x_j \odot y_j)$ затем поэлементно умножается на обратное значение запроса $1/y_i$. Этот шаг пытается "разделить" компонент $y_i$, в идеале изолируя $x_i$.
- Обратное преобразование Адамара и масштабирование: Результат этого поэлементного умножения затем преобразуется обратно путем применения матрицы Адамара $H$ и масштабируется на $1/d$. Это дает промежуточный результат развязывания $B^*(\chi_p, \pi(y_i)^\dagger)$.
-
Обратная проекция (окончательный вывод): В статье утверждается, что для получения "исходных данных" (т.е. исходного $x_i$) из этого промежуточного результата применяется шаг обратной проекции. Этот окончательный шаг фактически упрощает промежуточный результат до формы, показанной в Уравнении 5, которая приблизительно равна $x_i$, если была связана только одна пара ($p=1$), или $x_i + \eta''$ (где $\eta''$ — уменьшенная шумовая компонента), если было связано несколько пар ($p>1$).
Динамика оптимизации
Механизм линейного связывания на основе Адамара (HLB), как описано в статье, сам по себе не является алгоритмом обучения; скорее, это фиксированный, математически выведенный набор операций, разработанный для высокой эффективности и численной стабильности. Следовательно, его "динамика оптимизации" не включает итеративные обновления внутренних параметров с помощью градиентов. Вместо этого его динамика присуща его дизайну и тому, как он облегчает обучение в более крупных, дифференцируемых системах:
-
Фиксированные, детерминированные операции: Основные функции связывания и развязывания HLB являются детерминированными преобразованиями, основанными на матрице Адамара и поэлементных операциях. В самих операциях HLB нет обучаемых весов, смещений или других параметров, которые обновляются с помощью градиентного спуска или любого другого правила обучения. Матрица Адамара является предопределенным, статическим компонентом.
-
Присущая численная стабильность: Ключевым динамическим свойством HLB является его встроенная численная стабильность. Преобразование Адамара по своей сути включает только операции со значениями $\pm 1$, избегая комплексных чисел и иррациональных умножений, которые могут привести к нестабильности в других методах VSA, таких как HRR. Кроме того, смесь нормальных распределений (MiND), используемая для инициализации векторов (Уравнение 6), гарантирует, что векторы имеют ожидаемое значение ноль, но ненулевое абсолютное среднее. Этот выбор дизайна предотвращает деление на значения, близкие к нулю, во время процесса развязывания, что иначе вызвало бы численные взрывы.
-
Механизм снижения шума: Шаг проекции ($\pi(x) = \frac{1}{d} Hx$) является критически важной частью внутренней динамики HLB для улучшения точности извлечения. Применяя эту проекцию к входным векторам перед связыванием, механизм активно уменьшает накопленный шум ($\eta''$), который возникает при упаковке нескольких элементов вместе. Это статическая, предопределенная стратегия снижения шума, а не обучаемая, но она значительно влияет на производительность и надежность системы.
-
Дифференцируемость для интеграции в систему: Хотя сам HLB не обучается, он явно разработан для совместимости с "дифференцируемыми системами". Это означает, что математические операции, составляющие HLB (матричные умножения, поэлементные произведения, суммы), все дифференцируемы. Следовательно, когда HLB встраивается в более крупную архитектуру нейронной сети (как показано в задачах Connectionist Symbolic Pseudo Secrets и Xtreme Multi-Label Classification), вся система по-прежнему может обучаться сквозным образом с использованием стандартных алгоритмов оптимизации на основе градиентов (например, стохастического градиентного спуска). Механизм HLB обеспечивает стабильный и эффективный способ представления и манипулирования символьной информацией внутри этих обучающих систем, позволяя окружающим параметрам сети оптимизироваться на основе определенного ландшафта потерь (например, потерь косинусного сходства в Уравнении 11 для XML-классификации). Сами операции HLB просто пропускают градиенты без изменений.
Результаты, ограничения и заключение
Дизайн эксперимента и базовые методы
Авторы тщательно разработали эксперименты для проверки линейного связывания на основе Адамара (HLB) как в классических задачах векторно-символьных архитектур (VSA), так и в современных приложениях глубокого обучения, безжалостно противопоставляя его установленным базовым методам.
Для классических задач VSA были сконструированы два основных сценария:
-
Базовая точность связывания/развязывания: Этот эксперимент был направлен на доказательство способности HLB корректно извлекать связанный вектор из составного представления. Сценарий включал создание пула из 1000 случайных векторов. Из этого пула были выбраны $p$ пар векторов (где $p$ варьировалось от 1 до 25), связаны с помощью операции связывания VSA $B(x_i, y_i)$ и затем суммированы для формирования составного представления $s = \sum_{i=1}^p B(x_i, y_i)$. В качестве "жертв" базовых методов были выбраны голографические редуцированные представления (HRR) [32], векторно-производные трансформационные связывания (VTB) [12] и умножение-сложение-перестановка (MAP) [10]. Для каждого составного $s$ эксперимент итерировал по всем левым компонентам $x_q$, которые были частью исходного пакета, и пытался извлечь их соответствующие $y_q$ с помощью операции развязывания $B^*(s, x_q)$. Извлечение считалось корректным, если скалярное произведение $B^*(s, x_q)^T y_q$ было больше, чем $B^*(s, x_q)^T y_j$ для всех других $j \neq q$. Этот процесс повторялся в течение 50 испытаний, и окончательным доказательством служила площадь под кривой (AUC) точности в зависимости от количества связанных элементов $p$, для различных размерностей векторов $d$ (в частности, для полных квадратов, чтобы соответствовать ограничениям VTB).
-
Стабильность последовательного связывания/развязывания: Эта задача оценивала качество оценки сходства и стабильность величины векторов при повторных операциях связывания. Были протестированы два подсценария:
- Случайное связывание: Начальный вектор $b_0$ последовательно модифицировался путем связывания его с новым случайным вектором $x_t$ в течение $p$ раундов, что приводило к $b_{t+1} = B(b_t, x_t)$. Цель состояла в том, чтобы развязать каждый $x_t$ и восстановить предыдущий $b_t$.
- Автоматическое связывание: Один случайный вектор $x$ последовательно связывался с развивающимся состоянием: $b_{t+1} = B(b_t, x)$.
Базовыми методами для этого эксперимента были HRR, VTB и MAP-C. Важным доказательством, которое искали, было то, остается ли оценка сходства $B^*(b_{t+1}, x_t)^T b_t$ идеально равной 1 (для присутствующего элемента) и остается ли величина векторов $||B^*(b_{t+1}, x_t)||_2$ постоянной, избегая распространенных проблем VSA с взрывающимися или исчезающими значениями по мере увеличения $p$.
Для приложений глубокого обучения HLB был интегрирован в две недавние нейросимвольные задачи:
-
Коннекционистские символьные псевдосекреты (CSPS) [3]: Эта задача исследовала использование VSA для эвристической безопасности, имитируя "одноразовый блокнот" для скрытия входных и выходных данных при выгрузке вычислений ненадежным третьим сторонам. Эксперимент включал связывание случайного вектора VSA $s$ ("секрет") с входным сигналом $x$ для создания скрытого представления $B(s, x)$. Сторонняя сеть обрабатывала это скрытое входное значение, возвращая выход $y$, который затем локально развязывался с секретом $B^*(y, s)$ для получения окончательного ответа. Базовыми методами были HRR, VTB, MAP-C и MAP-B. Эксперименты проводились на одном GPU NVIDIA TESLA P100 с 32 ГБ памяти.
- Точность: Основной метрикой была точность классификации Top@1 и Top@5 на пяти стандартных наборах данных изображений: MNIST, SVHN, CIFAR-10, CIFAR-100 и Mini-ImageNet.
- Безопасность: Чтобы безжалостно доказать утверждение о сокрытии информации, был рассчитан скорректированный индекс Рэнда (ARI). Шпионская третья сторона пыталась кластеризовать скрытые входные данные $B(x, s)$ и выходные данные $y$ с использованием различных алгоритмов кластеризации (K-means, Gaussian Mixture Model, Birch, HDBSCAN). Оценка ARI, близкая к нулю, служила окончательным доказательством успешного сокрытия информации, указывая на случайное назначение меток с точки зрения атакующего.
-
Экстремальная многоклассовая классификация (XML) [9]: Эта задача решала сценарии, когда один входной сигнал должен быть классифицирован по огромному количеству возможных классов ($C \gg d$, где $d$ — размерность входных данных), что часто встречается в электронной коммерции. VSA использовалась для представления разреженного выходного пространства. Экспериментальная установка следовала сетевым деталям из [9], заменяя их исходную VSA на HLB и базовые VSA (HRR, VTB, MAP). Оценка проводилась на восьми разнообразных наборах данных (BIBTEX, DELICIOUS, MEDIAMILL, EURLEX-4K, EURLEX-4.3K, WIKI10-31K, AMAZON-13K, DELICIOUS-200K). Ключевыми метриками были нормализованное дисконтированное кумулятивное усиление (nDCG) и nDCG с учетом пропусков (PSnDCG), которые являются стандартными для оценки производительности многоклассовой классификации.
Что доказывают доказательства
Эмпирические доказательства убедительно подтверждают теоретические утверждения и демонстрируют превосходную или конкурентоспособную производительность HLB в широком спектре приложений VSA.
Теоретическое подтверждение:
Статья предоставляет убедительные доказательства того, что основные математические механизмы HLB работают как задумано. Теоретическая связь, согласно которой косинусное сходство $\phi$ между исходным вектором $x_i$ и его извлеченным вариантом $\hat{x}_i$ приблизительно равно $1/\sqrt{p}$ (Теорема 3.2), эмпирически подтверждается тепловыми картами (Рисунок 1) и графиками (Рисунок 6). Это подтверждает эффективность предложенного усиления сходства. Кроме того, теоретическое предсказание для нормы составного представления, $||X_p||_2 \approx \mu^2 \sqrt{p} \cdot d$ (Теорема B.1), также тесно соответствует экспериментальным результатам (Рисунок 5), хотя и с некоторыми вариациями по мере увеличения $p$ из-за приближений. Критически важно, что шаг проекции, введенный в HLB, определенно показал снижение накопленного шума. Тепловые карты, сравнивающие шумовые компоненты с проекцией и без нее (Рисунок 4), ясно иллюстрируют, что максимальный шум без проекции значительно выше (19.38) по сравнению с проекцией (7.18), доказывая, что этот архитектурный выбор эффективен для повышения точности извлечения.
Классические задачи VSA:
В задаче базовой точности связывания/развязывания HLB последовательно показывает производительность, сравнимую или даже превосходящую HRR и VTB, при этом явно превосходя MAP для различных размерностей (Рисунок 2). Эти жесткие доказательства, представленные в виде оценок AUC, доказывают, что операции связывания и развязывания HLB надежны и эффективны для фундаментальных операций VSA. Более впечатляюще, в задаче стабильности последовательного связывания/развязывания (Рисунок 3) HLB выделяется тем, что поддерживает идеальную оценку сходства 1 для присутствующих элементов и, что критически важно, постоянную величину вектора независимо от количества связанных элементов $p$. Это значительное преимущество перед базовыми методами, такими как HRR, VTB и MAP, которые демонстрируют убывающие оценки сходства или взрывающиеся/исчезающие величины. Эта стабильность является неоспоримым доказательством того, что HLB решает ключевую проблему численной стабильности, распространенную в других VSA, делая его более надежной основой для сложной символьной обработки.
Задачи глубокого обучения:
Эффективность HLB надежно распространяется и на контексты глубокого обучения. В задаче Коннекционистских символьных псевдосекретов (CSPS) HLB не только значительно превосходит все предыдущие методы VSA по точности классификации на всех пяти наборах данных (MNIST, SVHN, CIFAR-10, CIFAR-100, Mini-ImageNet), как показано в Таблице 2, но и достигает превосходного сокрытия информации. Оценки скорректированного индекса Рэнда (ARI) (Таблица 3) для HLB последовательно ближе к нулю для SVHN, CIFARs и Mini-ImageNet, что указывает на то, что третьей стороне-шпиону было бы гораздо труднее кластеризовать входные или выходные данные, тем самым доказывая его двойную выгоду от улучшенной точности и повышенной безопасности. Хотя MNIST показал некоторую дегенерацию в ARI для всех методов, это признается как известная проблема для безопасности CSPS. Это двойное улучшение является сильным свидетельством практической полезности HLB.
Для экстремальной многоклассовой классификации (XML) HLB устанавливает новый стандарт (SOTA). Таблица 4 представляет оценки nDCG и PSnDCG на восьми разнообразных наборах данных, от "легких" до "сложных" с точки зрения признаков и меток. HLB достигает лучших оценок на всех наборах данных для обеих метрик, демонстрируя свою превосходную способность эффективно и результативно обрабатывать высокоразмерные, разреженные выходные пространства. Эта всесторонняя победа на множестве наборов данных и метрик предоставляет окончательное, неоспоримое доказательство того, что основной механизм HLB приводит к ощутимым улучшениям производительности в сложных, реальных сценариях глубокого обучения.
Ограничения и будущие направления
Хотя предложенное линейное связывание на основе Адамара (HLB) демонстрирует впечатляющую производительность и теоретическую обоснованность, важно признать определенные ограничения и рассмотреть направления для дальнейшего развития, чтобы расширить эти выводы.
Ограничения:
Одно неявное ограничение, хотя и не явно сформулированное как таковое, возникает из математического вывода. Матрица Адамара, краеугольный камень HLB, обычно требует, чтобы размерности векторов $d$ были степенями двойки. Хотя это часто встречается во многих вычислительных контекстах, это может потребовать дополнения или других обходных путей для приложений с произвольными размерностями, потенциально внося неэффективность или сложности. В статье также отмечается, что приближение, сделанное в Теореме B.1 (отбрасывание шумового члена $\xi$ в Уравнении 17), приводит к увеличению вариации нормы составного представления по мере роста числа упакованных пар $p$ (Рисунок 5). Хотя общая тенденция сохраняется, это предполагает, что для чрезвычайно больших $p$ приближение может стать менее точным, потенциально влияя на предсказуемость системы или требуя более сложного управления шумом.
Кроме того, безопасность, предлагаемая CSPS, хотя и значительно улучшена HLB, описывается как эвристическая, а не криптографически гарантированная. Результаты ARI для набора данных MNIST, показывающие некоторую дегенерацию, служат напоминанием о том, что такая безопасность не является абсолютной. Это подразумевает, что для приложений, требующих строгой, доказуемой безопасности, HLB в рамках фреймворка CSPS может быть недостаточным сам по себе. Наконец, хотя шаг связывания сам по себе может похвастаться эффективной сложностью $O(d)$, статья не углубляется в общие вычислительные накладные расходы (например, использование памяти, время обучения для очень больших моделей или энергопотребление) HLB при интеграции в крупномасштабные системы глубокого обучения, особенно по мере того, как $d$ или $p$ масштабируются до экстремальных значений.
Будущие направления:
-
Обобщение на произвольные размерности и альтернативные преобразования:
- Обсуждение: Как преимущества HLB могут быть распространены на размерности векторов, не являющиеся степенями двойки, без использования простого дополнения, которое может быть неэффективным? Можно ли исследовать "приближенные" преобразования Адамара для размерностей, не являющихся степенями двойки, или изучить другие ортогональные преобразования, которые предлагают аналогичные вычислительные преимущества и желаемые свойства VSA, но более гибки в отношении размерности? Это могло бы значительно расширить применимость HLB.
- Перспектива: С теоретической точки зрения это бросает вызов строгой математической элегантности базиса Адамара, но открывает двери для практических инженерных решений. С точки зрения приложений, это устраняет потенциальный барьер для интеграции в разнообразные существующие наборы данных и модели.
-
К доказательной безопасности в нейросимвольном ИИ:
- Обсуждение: Учитывая, что безопасность CSPS является эвристической, каковы следующие шаги для интеграции HLB с более надежными криптографическими примитивами? Можно ли использовать линейные свойства HLB и эффективное развязывание для разработки нейросимвольных систем, предлагающих доказуемые гарантии безопасности, возможно, путем объединения его с схемами гомоморфного шифрования или протоколами безопасных многосторонних вычислений? Это вывело бы за рамки эвристической безопасности к действительно надежному ИИ.
- Перспектива: Это критически важная область для конфиденциальных приложений. Исследователь, ориентированный на безопасность, мог бы изучить методы формальной верификации, в то время как практикующий специалист по ИИ мог бы искать практичные, эффективные реализации, которые балансируют безопасность и производительность.
-
Динамическая оценка $p$ и адаптивное усиление сходства:
- Обсуждение: В статье подчеркивается важность знания или оценки $p$ (количество упакованных пар) для шага усиления сходства. В сложных, динамических нейросимвольных системах $p$ не всегда может быть явно известно. Как можно разработать адаптивные механизмы или обучаемые оценщики, которые могут динамически выводить $p$ из самого составного представления, позволяя в реальном времени, контекстно-зависимую коррекцию сходства?
- Перспектива: Это повысит автономность и надежность систем на основе VSA. Эксперт по машинному обучению мог бы предложить архитектуры нейронных сетей для оценки $p$, в то время как когнитивный ученый мог бы провести параллели с тем, как биологические системы справляются с неопределенностью в композиционных представлениях.
-
Исследование несимметричного связывания и продвинутой композиционности:
- Обсуждение: Хотя HLB симметричен, в статье упоминается несимметричная природа VTB. Какие конкретные типы символьных отношений или когнитивных задач, естественно, выигрывают от несимметричного связывания (например, отношения "агент-действие-объект")? Можно ли расширить или модифицировать фреймворк на основе Адамара для поддержки несимметричных операций связывания, сохраняя при этом его вычислительную эффективность и численную стабильность? Это могло бы открыть новые возможности для представления направленных отношений и более сложных семантических структур.
- Перспектива: Это углубляется в выразительность VSA. Лингвист или исследователь когнитивного ИИ мог бы выявить конкретные грамматические или логические структуры, требующие несимметричного связывания, подталкивая математический фреймворк к более богатым символьным представлениям.
-
Более глубокая интеграция с передовыми архитектурами глубокого обучения:
- Обсуждение: HLB показал многообещающие результаты в CSPS и XML. Как его можно более глубоко и нативно интегрировать в передовые архитектуры глубокого обучения? Могут ли операции связывания и развязывания на основе HLB заменить или дополнить компоненты в трансформерных моделях (например, для механизмов внимания или позиционных кодировок), графовых нейронных сетях или рекуррентных нейронных сетях, чтобы наделить их более сильными способностями к символьному рассуждению и улучшенной композиционной генерализации?
- Перспектива: Это вопрос о преодолении разрыва между символьным и коннекционистским ИИ. Дизайнер нейронных архитектур мог бы исследовать новые конструкции слоев, в то время как теоретик информатики мог бы анализировать вычислительные графы и потоки информации в таких гибридных системах.
-
Устойчивость к атакам и шуму реального мира:
- Обсуждение: Хотя шаг проекции снижает шум, насколько устойчив HLB к различным формам атак и шуму реального мира, особенно в критически важных приложениях? Какие дальнейшие механизмы, такие как стратегии надежной инициализации, обучение с учетом шума или коды коррекции ошибок, могут быть интегрированы с HLB для повышения его устойчивости и надежности в шумных или враждебных средах?
- Перспектива: Это важно для развертывания. Исследователь безопасности сосредоточился бы на векторах атак и защите, в то время как инженер рассмотрел бы практические модели шума и устойчивость на аппаратном уровне.
-
Аппаратное ускорение и энергоэффективные реализации:
- Обсуждение: Учитывая сложность HLB $O(d)$ для связывания и его зависимость от преобразований Адамара (которые поддаются быстрым алгоритмам), каковы возможности для специализированного аппаратного ускорения? Может ли HLB быть эффективно реализован на нейроморфных чипах, FPGA или другом специализированном оборудовании для достижения сверхнизкого энергопотребления и высокой пропускной способности для периферийных ИИ-устройств или крупномасштабных систем символьной обработки?
- Перспектива: Это задача совместного проектирования аппаратного и программного обеспечения. Компьютерный архитектор исследовал бы параллелизм и шаблоны доступа к памяти, в то время как сторонник устойчивого развития подчеркнул бы потенциал энергоэффективного ИИ.
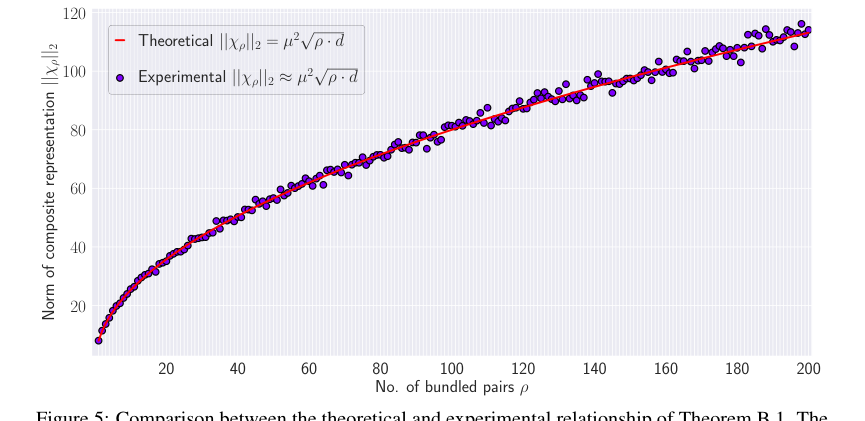 Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
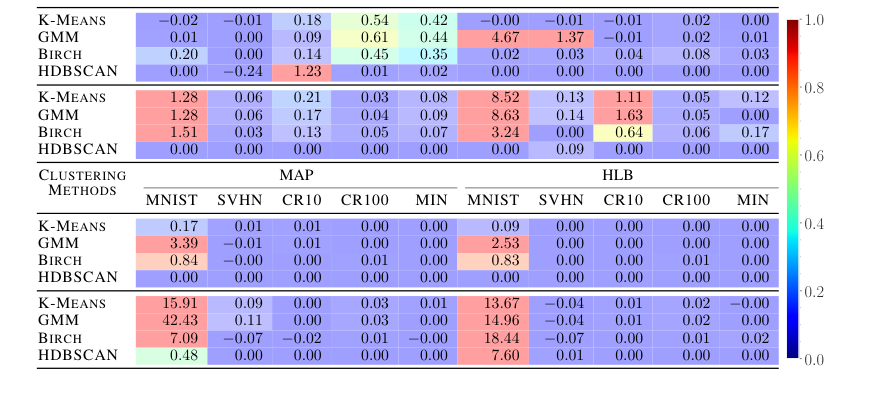 Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
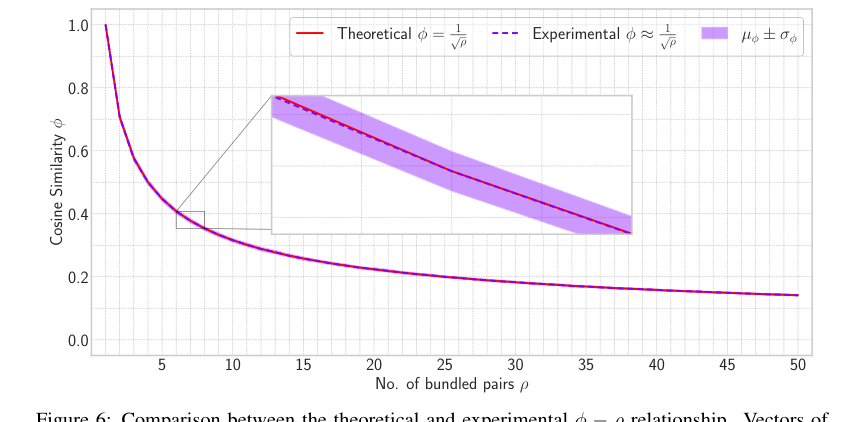 Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion
Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion