RFWave: ऑडियो वेवफ़ॉर्म पुनर्निर्माण के लिए मल्टी-बैंड रेक्टिफाइड फ्लो
ऑडियो वेवफ़ॉर्म पुनर्निर्माण की समस्या, जिसमें यथार्थवादी, बोधगम्य ध्वनियों में निम्न-आयामी विशेषताओं को बदलना शामिल है, बढ़ी हुई डिजिटल इंटरैक्शन की बढ़ती मांग से उभरी है। यह तकनीक वर्चुअल असिस्टेंट, मनोरंजन प्रणाली...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
ऑडियो वेवफ़ॉर्म पुनर्निर्माण की समस्या, जिसमें यथार्थवादी, बोधगम्य ध्वनियों में निम्न-आयामी विशेषताओं को बदलना शामिल है, बढ़ी हुई डिजिटल इंटरैक्शन की बढ़ती मांग से उभरी है। यह तकनीक वर्चुअल असिस्टेंट, मनोरंजन प्रणाली और टेक्स्ट-टू-स्पीच संश्लेषण जैसे विविध अनुप्रयोगों के लिए महत्वपूर्ण है, जहाँ उच्च-गुणवत्ता वाली, स्वाभाविक लगने वाली आवाज़ और संगीत उत्पन्न करना सर्वोपरि है। ऐतिहासिक रूप से, उन्नत जनरेटिव मॉडलों के आगमन के साथ यह क्षेत्र पारंपरिक सिग्नल प्रोसेसिंग विधियों (कवाहारा एट अल., 1999; मोरिसे एट अल., 2016) से आगे बढ़ गया।
शुरुआती महत्वपूर्ण प्रगति दो मुख्य प्रतिमानों से आई: ऑटोरेग्रेसिव मॉडल और जनरेटिव एडवरसैरियल नेटवर्क (GANs) (गुडफेलो एट अल., 2014)। ऑटोरेग्रेसिव मॉडल, उच्च-गुणवत्ता वाला ऑडियो उत्पन्न करने में सक्षम होने के बावजूद, अपनी धीमी पीढ़ी की गति से गंभीर रूप से सीमित थे। यह धीमी गति व्यक्तिगत नमूना बिंदुओं की क्रमिक भविष्यवाणी से उत्पन्न हुई (ओर्ड एट अल., 2016; काल्चब्रेनर एट अल., 2018; वेलिन और स्कोग्लंड, 2019), जिससे वास्तविक समय के अनुप्रयोग अव्यावहारिक हो गए। GANs ने समानांतर में नमूना बिंदुओं की भविष्यवाणी करके तेज़ पीढ़ी की पेशकश की (कुमार एट अल., 2019; यामामोटो एट अल., 2020; कोंग एट अल., 2020a), लेकिन उन्होंने अपनी "दर्द बिंदु" की एक श्रृंखला पेश की। इनमें जटिल डिस्क्रिमिनेटर डिज़ाइन की आवश्यकता और प्रशिक्षण अस्थिरता या मोड कोलैप्स (थanh-Tung et al., 2018) जैसी समस्याएं शामिल थीं, जहाँ मॉडल डेटा की पूरी विविधता को सीखने में विफल हो सकता है।
हाल ही में, डिफ्यूजन मॉडल (सोंग एट अल., 2020; हो एट अल., 2020) एक आशाजनक विकल्प के रूप में उभरे, जो अधिक प्रशिक्षण स्थिरता और उच्च-गुणवत्ता वाले वेवफ़ॉर्म को पुनर्निर्मित करने की क्षमता प्रदान करते हैं (चेन एट अल., 2020; कोंग एट अल., 2020b; गिल ली एट अल., 2022)। हालाँकि, डिफ्यूजन मॉडल ने एक महत्वपूर्ण सीमा विरासत में प्राप्त की: वे GANs की तुलना में कम से कम एक परिमाण धीमे थे। यह धीमी गति मुख्य रूप से दो कारकों के कारण थी: (1) उच्च-गुणवत्ता वाले नमूने प्राप्त करने के लिए कई नमूना चरणों की आवश्यकता, और (2) व्यक्तिगत वेवफ़ॉर्म नमूना बिंदु स्तर पर उनका संचालन। बाद वाले में अक्सर फ्रेम दर और नमूना दर रिज़ॉल्यूशन को पाटने के लिए कई अपसैंपलिंग ऑपरेशन शामिल होते थे, जिससे अनुक्रम की लंबाई बढ़ जाती थी, GPU मेमोरी का उपयोग बढ़ जाता था, और महत्वपूर्ण कम्प्यूटेशनल मांगें होती थीं। डिफ्यूजन मॉडल में धीमी अनुमान गति की यह मौलिक सीमा मुख्य "दर्द बिंदु" है जिसे RFWave संबोधित करने का लक्ष्य रखता है, जो डिफ्यूजन मॉडल की स्थिरता और गुणवत्ता को बनाए रखते हुए GAN-आधारित गति से मेल खाने का प्रयास करता है।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष शब्द दिए गए हैं, जिन्हें एक नौसिखिया के लिए रोजमर्रा की उपमाओं में अनुवादित किया गया है:
- मेल-स्पेक्ट्रोग्राम (Mel-spectrogram): कल्पना कीजिए कि आपके पास संगीत पत्र का एक टुकड़ा है जो एक गीत को दृश्य रूप से दर्शाता है। एक मेल-स्पेक्ट्रोग्राम समान है, लेकिन यह ध्वनि की एक डिजिटल "तस्वीर" है जिसे कंप्यूटर समझ सकता है। यह दिखाता है कि विभिन्न आवृत्तियों की loudness समय के साथ कैसे बदलती है, एक विशेष स्केलिंग (मेल स्केल) के साथ जो मानव पिच को कैसे महसूस करते हैं, उसकी नकल करती है। यह मशीन के लिए एक संगीत स्कोर की तरह है, जो ध्वनि के महत्वपूर्ण हिस्सों को उजागर करता है।
- रेक्टिफाइड फ्लो (Rectified Flow): बिंदु A से बिंदु B तक की यात्रा के बारे में सोचें। सामान्य तौर पर, आप कई मोड़ों वाली घुमावदार सड़क ले सकते हैं। रेक्टिफाइड फ्लो बिंदु A (शोर डेटा) और बिंदु B (स्वच्छ ऑडियो) के बीच सबसे सीधी, सीधी रेखा पथ खोजने जैसा है। यह "सीधी राजमार्ग" यात्रा को बहुत तेज़ और अधिक कुशल बनाता है, जिससे मॉडल को कम चरणों में शोर को ध्वनि में बदलने की अनुमति मिलती है।
- डिफ्यूजन मॉडल (Diffusion Models): एक बहुत ही धुंधली तस्वीर की कल्पना करें जो प्रत्येक चरण के साथ धीरे-धीरे स्पष्ट और तेज हो जाती है जिसे आप इसे "डीनोइज़" करने के लिए लेते हैं। डिफ्यूजन मॉडल समान रूप से काम करते हैं: वे यादृच्छिक शोर (पूरी तरह से धुंधली छवि की तरह) से शुरू करते हैं और धीरे-धीरे, चरण-दर-चरण, एक डिफ्यूजन प्रक्रिया को उलट कर इसे एक सुसंगत, उच्च-गुणवत्ता वाले ऑडियो वेवफ़ॉर्म में बदलते हैं। यह एक कलाकार की तरह है जो धीरे-धीरे कैनवास में विवरण जोड़ता है जब तक कि एक उत्कृष्ट कृति उभर न जाए।
- मोड कोलैप्स (Mode Collapse) (GANs में): एक ऐसे शेफ की कल्पना करें जिससे विभिन्न प्रकार के व्यंजन पकाने के लिए कहा गया था लेकिन उसने केवल एक विशिष्ट व्यंजन बनाना सीखा, अन्य सभी व्यंजनों को अनदेखा कर दिया। GANs जैसे जनरेटिव मॉडल में, मोड कोलैप्स का मतलब है कि मॉडल विविध आउटपुट उत्पन्न करने में विफल रहता है और इसके बजाय केवल समान, उच्च-गुणवत्ता वाले नमूनों का एक सीमित सेट उत्पन्न करता है। यह ऐसा है जैसे शेफ हमेशा एक ही उत्तम पास्ता बनाता है, भले ही स्टेक या सलाद के लिए कहा जाए, क्योंकि यह केवल वही है जो वह अच्छी तरह से करना जानता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $Z_t$ | परिवर्तन प्रक्रिया के दौरान किसी दिए गए समय $t$ पर डेटा की विकसित स्थिति। |
| $v(Z_t, t)$ | "वेग" क्षेत्र जो बताता है कि समय $t$ पर डेटा $Z_t$ कैसे बदलता है, इसे लक्ष्य की ओर निर्देशित करता है। |
| $\pi_0$ | प्रारंभिक संभाव्यता वितरण, जो आम तौर पर यादृच्छिक शोर का प्रतिनिधित्व करता है। |
| $\pi_1$ | लक्ष्य संभाव्यता वितरण, जो वांछित वास्तविक ऑडियो डेटा का प्रतिनिधित्व करता है। |
| $X_0$ | एक प्रारंभिक डेटा नमूना, आमतौर पर यादृच्छिक शोर, $\pi_0$ से लिया गया। |
| $X_1$ | एक लक्ष्य डेटा नमूना, जो ग्राउंड ट्रुथ ऑडियो वेवफ़ॉर्म या स्पेक्ट्रोग्राम का प्रतिनिधित्व करता है, $\pi_1$ से लिया गया। |
| $X_t$ | समय $t$ पर एक मध्यवर्ती डेटा नमूना, $X_0$ और $X_1$ के बीच इंटरपोलेशन का प्रतिनिधित्व करता है। |
| $t$ | समय चर, जो 0 (परिवर्तन की शुरुआत) से 1 (परिवर्तन का अंत) तक प्रगति करता है। |
| $C$ | सशर्त इनपुट, जैसे मेल-स्पेक्ट्रोग्राम या असतत ध्वनिक टोकन, जो ऑडियो पीढ़ी का मार्गदर्शन करता है। |
| $N$ | फास्ट फूरियर ट्रांसफॉर्म (FFT) का आकार, जो आवृत्ति रिज़ॉल्यूशन निर्धारित करता है। |
| $d_s$ | किसी विशिष्ट सबबैंड के जटिल स्पेक्ट्रम के भीतर आवृत्ति डिब्बे की संख्या। |
| $F$ | स्पेक्ट्रोग्राम में फ़्रेमों की कुल संख्या, जो समय खंडों का प्रतिनिधित्व करती है। |
| $i_{sb}$ | एक विशिष्ट सबबैंड की पहचान करने वाला सूचकांक। |
| $i_{bw}$ | एनकोडेक टोकन के लिए बैंडविड्थ सूचकांक, विभिन्न संपीड़न स्तरों के लिए उपयोग किया जाता है। |
| $\sigma$ | ऊर्जा-संतुलित हानि में प्रयुक्त एक भार गुणांक, जो अक्सर ग्राउंड ट्रुथ वेग के मानक विचलन से प्राप्त होता है। |
| $S(v)$ | सीखे गए वेग क्षेत्र के प्रक्षेप पथों की "सीधेपन" का एक माप, जो परिवर्तन पथ की प्रत्यक्षता को इंगित करता है। |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पेपर द्वारा संबोधित मुख्य समस्या विभिन्न संपीड़ित अभ्यावेदन, जैसे मेल-स्पेक्ट्रोग्राम या असतत ध्वनिक टोकन से उच्च-निष्ठा ऑडियो वेवफ़ॉर्म को कुशलतापूर्वक पुनर्निर्मित करने की चुनौती है।
इस समस्या के लिए इनपुट/वर्तमान स्थिति में शामिल हैं:
* निम्न-आयामी ऑडियो सुविधाएँ, विशेष रूप से मेल-स्पेक्ट्रोग्राम या असतत ध्वनिक टोकन, जो ध्वनि के संक्षिप्त प्रतिनिधित्व हैं।
* मौजूदा जनरेटिव मॉडल, मुख्य रूप से डिफ्यूजन मॉडल और जनरेटिव एडवरसैरियल नेटवर्क (GANs), प्रत्येक की अपनी सीमाएँ हैं। डिफ्यूजन मॉडल, उच्च-गुणवत्ता वाला ऑडियो उत्पन्न करने में सक्षम होने के बावजूद, व्यक्तिगत वेवफ़ॉर्म नमूना बिंदु स्तर पर संचालित होते हैं और कई नमूना चरणों की आवश्यकता होती है, जिससे महत्वपूर्ण विलंबता होती है। GANs, तेज़ होने के बावजूद, अक्सर प्रशिक्षण अस्थिरता और मोड कोलैप्स से पीड़ित होते हैं, और जटिल डिस्क्रिमिनेटर डिज़ाइन की आवश्यकता होती है।
वांछित अंतिम बिंदु/लक्ष्य स्थिति प्राप्त करना है:
* इन निम्न-आयामी इनपुट से पुनर्निर्मित उच्च-निष्ठा ऑडियो वेवफ़ॉर्म।
* एक जनरेटिव मॉडल जो GAN-आधारित विधियों (अर्थात, वास्तविक समय या तेज़) की अनुमान गति से मेल खाता है, जबकि डिफ्यूजन मॉडल की प्रशिक्षण स्थिरता और उच्च नमूना गुणवत्ता को बनाए रखता है।
* नमूना चरणों की एक बहुत कम संख्या के साथ वेवफ़ॉर्म को पुनर्निर्मित करने की क्षमता (जैसे, केवल 10 चरण, जैसा कि RFWave द्वारा प्राप्त किया गया है)।
* बेहतर कम्प्यूटेशनल दक्षता, वास्तविक समय से काफी तेज़ गति से ऑडियो पीढ़ी को सक्षम करना (जैसे, GPU पर 160 गुना तक तेज़)।
* मेल-स्पेक्ट्रोग्राम और असतत ध्वनिक टोकन दोनों से ऑडियो को पुनर्निर्मित करने में बहुमुखी प्रतिभा।
वर्तमान स्थिति और वांछित अंतिम बिंदु के बीच सटीक लुप्त कड़ी या गणितीय अंतर एक जनरेटिव मॉडलिंग फ्रेमवर्क की अनुपस्थिति है जो एक साथ डिफ्यूजन मॉडल की उच्च अवधारणात्मक गुणवत्ता और प्रशिक्षण स्थिरता और ऑडियो वेवफ़ॉर्म पुनर्निर्माण के लिए GANs की उच्च कम्प्यूटेशनल दक्षता और कम विलंबता प्राप्त कर सके। पिछले डिफ्यूजन मॉडल गणितीय रूप से कई चरणों में एक सिग्नल को धीरे-धीरे डीनोइज़ करने के लिए तैयार किए गए हैं, जिससे वे स्वाभाविक रूप से धीमे हो जाते हैं। GANs, तेज़ होने के बावजूद, स्थिर प्रशिक्षण और सुसंगत गुणवत्ता के लिए मजबूत गणितीय गारंटी का अभाव है। यह पेपर रेक्टिफाइड फ्लो का लाभ उठाकर इस अंतर को पाटने का प्रयास करता है, जिसका उद्देश्य शोर और डेटा वितरण के बीच एक सीधा, सीधा परिवहन प्रक्षेप पथ सीखना है, जिससे आवश्यक नमूना चरणों को कम किया जा सके। विशेष रूप से, रेक्टिफाइड फ्लो एक वेग क्षेत्र $v(Z_t, t)$ सीखता है जो प्रारंभिक शोर वितरण $\pi_0$ से लक्ष्य डेटा वितरण $\pi_1$ तक एक शोर नमूना $Z_t$ के विकास को नियंत्रित करता है, जैसे कि $\frac{dZ_t}{dt} = v(Z_t, t)$। सीखने का उद्देश्य एक सीधी-रेखा प्रक्षेप पथ से विचलन को कम करना है:
$$ \min E_{(X_0, X_1)\sim\gamma} \int_0^1 || \frac{d}{dt}X_t - v(X_t, t) ||^2 dt $$
जहां $X_t = (1-t)X_0 + tX_1$ एक रैखिक इंटरपोलेशन का प्रतिनिधित्व करता है। यह गणितीय सूत्रीकरण कम, अधिक प्रत्यक्ष चरणों को सक्षम करके अनुमान प्रक्रिया को तेज करने की कुंजी है।
पिछले शोधकर्ताओं को फंसाने वाला दर्दनाक ट्रेड-ऑफ या दुविधा ऑडियो गुणवत्ता/प्रशिक्षण स्थिरता और अनुमान गति/कम्प्यूटेशनल दक्षता के बीच मौलिक संघर्ष है। एक पहलू में सुधार आम तौर पर दूसरे को खराब करता है:
* डिफ्यूजन मॉडल: उत्कृष्ट ऑडियो गुणवत्ता और स्थिर प्रशिक्षण प्रदान करते हैं, लेकिन कुख्यात रूप से धीमे होते हैं। "व्यक्तिगत नमूना बिंदु स्तर" पर उनका संचालन और "कई नमूना चरणों" (अक्सर सैकड़ों या हजारों) की आवश्यकता उच्च विलंबता और कम्प्यूटेशनल मांगों की ओर ले जाती है।
* GANs: नमूना बिंदुओं को समानांतर में भविष्यवाणी करके तेज़ पीढ़ी की गति प्रदान करते हैं, लेकिन प्रशिक्षण की कठिनाई और मोड कोलैप्स जैसी समस्याओं से ग्रस्त हैं, जिससे उन्हें मज़बूती से प्रशिक्षित करना कठिन हो जाता है और कभी-कभी निम्न गुणवत्ता या कम विविध आउटपुट होते हैं।
इस दुविधा का मतलब है कि शोधकर्ताओं को पहले उच्च-गुणवत्ता, स्थिर लेकिन धीमे मॉडल, या तेज़ लेकिन संभावित रूप से अस्थिर और निम्न-गुणवत्ता वाले मॉडल के बीच चयन करना पड़ता था। पेपर इस ट्रेड-ऑफ को तोड़ने का लक्ष्य रखता है।
बाधाएँ और विफलता मोड
उच्च-निष्ठा, वास्तविक समय ऑडियो वेवफ़ॉर्म पुनर्निर्माण की समस्या कई कठोर, यथार्थवादी बाधाओं और अंतर्निहित विफलता मोड के कारण अविश्वसनीय रूप से कठिन है:
-
कम्प्यूटेशनल लागत और GPU मेमोरी सीमाएँ:
- नमूना बिंदु-स्तरीय संचालन: पिछले डिफ्यूजन मॉडल ऑडियो को व्यक्तिगत नमूना बिंदु स्तर पर संसाधित करते हैं। इसके लिए "फ्रेम दर रिज़ॉल्यूशन से नमूना दर रिज़ॉल्यूशन में संक्रमण के लिए कई अपसैंपलिंग ऑपरेशनों" की आवश्यकता होती है, जिससे अनुक्रम की लंबाई बढ़ जाती है और परिणामस्वरूप GPU मेमोरी का उपयोग और कम्प्यूटेशनल मांगें बढ़ जाती हैं" (पृष्ठ 2)। उच्च-रिज़ॉल्यूशन ऑडियो (जैसे, 44.1 kHz या 48 kHz) के लिए, प्रति सेकंड लाखों नमूनों को संसाधित करना कम्प्यूटेशनल रूप से निषेधात्मक और मेमोरी-गहन है। उदाहरण के लिए, PriorGrad केवल 30 GB GPU मेमोरी के भीतर 44.1 kHz पर 6-सेकंड ऑडियो क्लिप पर प्रशिक्षित कर सकता है, जो इस गंभीर मेमोरी बाधा को उजागर करता है (पृष्ठ 4)।
- कई नमूना चरण: डिफ्यूजन मॉडल को आम तौर पर उच्च-गुणवत्ता वाले ऑडियो उत्पन्न करने के लिए सैकड़ों या हजारों नमूना चरणों की आवश्यकता होती है, जो सीधे अनुमान गति और कम्प्यूटेशनल लोड को प्रभावित करते हैं। यह उन्हें "GANs की तुलना में कम से कम एक परिमाण धीमा" बनाता है (पृष्ठ 1)।
-
वास्तविक समय विलंबता आवश्यकताएँ: कई व्यावहारिक अनुप्रयोगों (जैसे, वर्चुअल असिस्टेंट, वास्तविक समय संचार) के लिए अत्यंत कम विलंबता की आवश्यकता होती है। मौजूदा डिफ्यूजन मॉडल, सबसे तेज़ वाले भी, केवल "वास्तविक समय से लगभग 10 से 20 गुना तेज़" (पृष्ठ 3) होते हैं, जो बड़े पैमाने पर ध्वनिक मॉडल के साथ संयुक्त होने पर भी, वास्तविक वास्तविक समय इंटरैक्शन के लिए अपर्याप्त है।
-
प्रशिक्षण अस्थिरता और मोड कोलैप्स (GANs के लिए): जबकि GANs गति प्रदान करते हैं, उनका प्रशिक्षण कुख्यात रूप से कठिन है। "जटिल डिस्क्रिमिनेटर डिज़ाइन" और "अस्थिरता या मोड कोलैप्स" (पृष्ठ 1) जैसी समस्याएं का मतलब है कि वे पूर्ण डेटा वितरण को सीखने में विफल हो सकते हैं, जिससे कम विविध या निम्न-गुणवत्ता वाले आउटपुट होते हैं।
-
मल्टी-बैंड प्रोसेसिंग में त्रुटि संचय: मल्टी-बैंड रणनीतियों का उपयोग करते समय, "उच्च बैंड को निम्न बैंड पर कंडीशनिंग से त्रुटि संचय हो सकता है, जिसका अर्थ है कि निम्न बैंड में अशुद्धियाँ अनुमान के दौरान उच्च बैंड को प्रतिकूल रूप से प्रभावित कर सकती हैं" (पृष्ठ 4)। इसका मतलब है कि आवृत्ति स्पेक्ट्रम के एक हिस्से में त्रुटियाँ फैल सकती हैं और दूसरों को दूषित कर सकती हैं।
-
शांत क्षेत्रों में निम्न-आयतन शोर: माध्य वर्ग त्रुटि (MSE) हानि के साथ प्रशिक्षित मॉडल के लिए एक सामान्य विफलता मोड "अपेक्षित शांत क्षेत्रों में निम्न-आयतन शोर" की उपस्थिति है (पृष्ठ 5)। ऐसा इसलिए होता है क्योंकि शांत भागों में छोटी त्रुटियाँ समग्र MSE में न्यूनतम योगदान करती हैं, जिससे मॉडल उच्च-आयाम वाले क्षेत्रों में बड़ी त्रुटियों को कम करने को प्राथमिकता देता है, जिससे शांत वर्गों में बोधगम्य शोर होता है।
-
सबबैंड के बीच असंगति: जब विभिन्न आवृत्ति सबबैंड को स्वतंत्र रूप से अनुमानित किया जाता है, तो "उनके बीच असंगति" का जोखिम होता है (पृष्ठ 6), जिससे पुनर्निर्मित वेवफ़ॉर्म में सबबैंड सीमाओं पर श्रव्य कलाकृतियाँ होती हैं।
-
पृष्ठभूमि शोर में कलाकृतियाँ: STFT हानि जैसे विशिष्ट हानि कार्यों के बिना, मॉडल "पृष्ठभूमि शोर की उपस्थिति में ऊर्ध्वाधर पैटर्न" या अन्य "कलाकृतियाँ" उत्पन्न कर सकते हैं (चित्र A.8, पृष्ठ 6), जो कथित गुणवत्ता को खराब करते हैं।
-
गैर-रैखिक परिवहन प्रक्षेप पथ: रेक्टिफाइड फ्लो की प्रभावशीलता "सीधे परिवहन प्रक्षेप पथ" (पृष्ठ 2) सीखने पर निर्भर करती है। यदि सीखा गया वेग क्षेत्र रैखिकता से काफी विचलित होता है, तो यूलर विधि को ODE को सटीक रूप से अनुमानित करने के लिए अधिक चरणों की आवश्यकता होगी, जिससे दक्षता लाभ समाप्त हो जाएगा। यह सीखे गए वेग क्षेत्र को एक नाजुक कार्य बनाता है।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
RFWave द्वारा संबोधित मुख्य समस्या जनरेटिव मॉडल में ऑडियो पुनर्निर्माण गुणवत्ता और पीढ़ी की गति के बीच महत्वपूर्ण ट्रेड-ऑफ है। पारंपरिक अत्याधुनिक (SOTA) विधियों, उन्नत होने के बावजूद, प्रत्येक ने महत्वपूर्ण सीमाएँ प्रस्तुत कीं जिन्होंने उन्हें एक साथ उच्च-निष्ठा और वास्तविक समय प्रदर्शन प्राप्त करने के लिए अपर्याप्त बना दिया।
लेखकों ने महसूस किया कि मानक डिफ्यूजन मॉडल, उच्च-गुणवत्ता वाले ऑडियो उत्पन्न करने में अपनी महारत और स्थिर प्रशिक्षण की पेशकश के बावजूद, मौलिक रूप से दो कारकों से बाधित थे: (1) व्यक्तिगत वेवफ़ॉर्म नमूना बिंदु स्तर पर उनका संचालन, और (2) वांछित गुणवत्ता प्राप्त करने के लिए कई नमूना चरणों की आवश्यकता। इससे गंभीर विलंबता समस्याएँ और उच्च GPU मेमोरी खपत हुई, जिससे वे GANs की तुलना में कम से कम एक परिमाण धीमे हो गए और वास्तविक समय अनुप्रयोगों के लिए अव्यावहारिक हो गए। पेपर स्पष्ट रूप से इस अहसास को बताता है: "जबकि डिफ्यूजन मॉडल इस कार्य में निपुण हैं, वे व्यक्तिगत नमूना बिंदु स्तर पर अपने संचालन और कई नमूना चरणों की आवश्यकता के कारण विलंबता मुद्दों से बाधित होते हैं।" (सार)। इस अपर्याप्तता को इस अवलोकन से और रेखांकित किया गया था कि सबसे तेज़ डिफ्यूजन विधियाँ भी वास्तविक समय से केवल 10 से 20 गुना तेज़ थीं, जो वास्तविक दुनिया के अनुप्रयोगों की मांगों से बहुत दूर थी।
जनरेटिव एडवरसैरियल नेटवर्क (GANs), समानांतर में नमूना बिंदुओं की भविष्यवाणी करके तेज़ पीढ़ी की गति में सक्षम होने के बावजूद, अंतर्निहित प्रशिक्षण अस्थिरता और मोड कोलैप्स जैसी समस्याओं से पीड़ित थे, अक्सर जटिल डिस्क्रिमिनेटर डिज़ाइन की आवश्यकता होती थी। ऑटोरेग्रेसिव मॉडल, जनरेटिव मॉडल का एक और वर्ग, नमूना बिंदुओं की क्रमिक भविष्यवाणी के कारण इसी तरह से अस्वीकार कर दिया गया था, जिससे अस्वीकार्य रूप से धीमी पीढ़ी की गति हुई।
रेक्टिफाइड फ्लो, एक मल्टी-बैंड, फ्रेम-स्तरीय प्रसंस्करण रणनीति के साथ मिलकर, केवल व्यवहार्य समाधान के रूप में उभरा क्योंकि यह सीधे इन मौलिक सीमाओं को संबोधित करता है। यह डिफ्यूजन मॉडल की उच्च नमूना गुणवत्ता और प्रशिक्षण स्थिरता प्राप्त करने के लिए एक तंत्र प्रदान करता है, साथ ही व्यावहारिक मेमोरी बाधाओं के भीतर GANs की पीढ़ी गति से मेल खाता है और उससे भी आगे निकल जाता है। एब्लेशन अध्ययन भी इसकी पुष्टि करता है, यह दर्शाता है कि "उच्च-गुणवत्ता वाले ऑडियो नमूने कुशलतापूर्वक उत्पन्न करने के लिए रेक्टिफाइड फ्लो हमारे मॉडल के लिए महत्वपूर्ण है" (पृष्ठ 9), क्योंकि अधिक चरणों के साथ पारंपरिक डिफ्यूजन शोर शेड्यूल कम पड़ गए।
तुलनात्मक श्रेष्ठता
RFWave केवल प्रदर्शन मेट्रिक्स से परे, पिछली स्वर्ण मानकों पर भारी गुणात्मक श्रेष्ठता प्रदर्शित करता है।
सबसे पहले, गति के संदर्भ में, RFWave GPU पर वास्तविक समय से 160 गुना तक की अनुमान गति प्राप्त करता है (सार)। यह डिफ्यूजन मॉडल की तुलना में एक नाटकीय सुधार है, जो आम तौर पर वास्तविक समय से 10-20 गुना संचालित होते हैं, और कई GAN-आधारित विधियों से भी आगे निकल जाते हैं। उदाहरण के लिए, तालिका 7 RFWave के GPU xRT (वास्तविक समय के गुना) को BigVGAN के 72.68 और PriorGrad के 16.67 की तुलना में 162.59 पर दिखाती है। यह संरचनात्मक लाभ रेक्टिफाइड फ्लो की सीधी परिवहन प्रक्षेप पथ सीखने की क्षमता से उत्पन्न होता है, जो केवल 10 नमूना चरणों के साथ उच्च-गुणवत्ता वाले पुनर्निर्माण को सक्षम करता है, जो अन्य डिफ्यूजन मॉडल की तुलना में काफी कम संख्या है।
दूसरे, गुणवत्ता के संबंध में, RFWave लगातार वस्तुनिष्ठ मेट्रिक्स (जैसे, MOS, PESQ, ViSQOL) और व्यक्तिपरक मूल्यांकन (तालिका 1) दोनों में PriorGrad और FreGrad जैसे डिफ्यूजन-आधारित बेसलाइन से बेहतर प्रदर्शन करता है। जबकि यह BigVGAN और Vocos जैसे GANs के साथ इन-डोमेन डेटा के लिए समान प्रदर्शन करता है, इसकी श्रेष्ठता आउट-ऑफ-डोमेन डेटा (MUSDB18 डेटासेट) के साथ स्पष्ट हो जाती है। यहां, RFWave "महत्वपूर्ण लाभ" (पृष्ठ 8) दिखाता है, जो स्पष्ट, अच्छी तरह से परिभाषित उच्च-आवृत्ति हार्मोनिक्स उत्पन्न करता है, GANs के विपरीत जो "क्षैतिज रेखाएं" उत्पन्न करते हैं जिससे "धात्विक ध्वनि गुणवत्ता" होती है (चित्र A.7)। यह RFWave के बेहतर सामान्यीकरण और मजबूती का संकेत देता है।
तीसरे, RFWave कहीं अधिक कम्प्यूटेशनल दक्षता और मेमोरी जटिलता प्रदान करता है। व्यक्तिगत वेवफ़ॉर्म नमूना बिंदुओं के बजाय शॉर्ट-टाइम फूरियर ट्रांसफॉर्म (STFT) फ्रेम स्तर पर संचालित करके, यह GPU मेमोरी उपयोग को काफी कम कर देता है। यह संरचनात्मक लाभ RFWave को समान मेमोरी संसाधनों के साथ 177-सेकंड ऑडियो क्लिप को संभालने की अनुमति देता है, जो PriorGrad (एक नमूना-बिंदु डिफ्यूजन वोकोडर) केवल 6-सेकंड क्लिप के लिए उपयोग करता है (पृष्ठ 4)। तालिका 7 इसे और स्पष्ट करती है, जिसमें RFWave 780 MB GPU मेमोरी का उपयोग करता है जबकि PriorGrad 4976 MB और MBD 5480 MB का उपयोग करता है। यह फ्रेम-स्तरीय प्रसंस्करण "कई अपसैंपलिंग ऑपरेशनों" और बढ़ी हुई अनुक्रम लंबाई से बचता है जो नमूना-बिंदु मॉडल को सताते हैं, जिससे अन्यथा GPU मेमोरी उपयोग और कम्प्यूटेशनल मांगें बढ़ जाती हैं।
अंत में, मल्टी-बैंड रणनीति एक प्रमुख संरचनात्मक लाभ है। विभिन्न सबबैंड को समवर्ती रूप से उत्पन्न करके और उन्हें एक एकल एकीकृत मॉडल के साथ समानांतर में मॉडल करके, RFWave त्रुटियों के संचय को रोकता है जो तब हो सकता है जब उच्च बैंड को क्रमिक रूप से निम्न बैंड पर कंडीशन किया जाता है। यह न केवल ऑडियो गुणवत्ता सुनिश्चित करता है बल्कि संश्लेषण गति को भी बढ़ाता है। तीन उन्नत हानि कार्यों (ऊर्जा-संतुलित, ओवरलैप, और STFT हानि) और एक अनुकूलित "समान सीधेपन" नमूना रणनीति के समावेश से समग्र गुणवत्ता और मजबूती और बढ़ जाती है, विशेष रूप से निम्न-आयतन क्षेत्रों को संभालने में, सबबैंड संक्रमण सुनिश्चित करना और कलाकृतियों को कम करना।
बाधाओं के साथ संरेखण
चुना गया रेक्टिफाइड फ्लो दृष्टिकोण, इसके वास्तुशिल्प नवाचारों के साथ मिलकर, उच्च-निष्ठा, वास्तविक समय ऑडियो वेवफ़ॉर्म पुनर्निर्माण की कठोर, बहुआयामी आवश्यकताओं के साथ पूरी तरह से संरेखित होता है।
-
उच्च-निष्ठा ऑडियो गुणवत्ता: समस्या के लिए असाधारण ऑडियो गुणवत्ता की आवश्यकता होती है। RFWave डिफ्यूजन-प्रकार के मॉडल की अंतर्निहित गुणवत्ता-संरक्षण क्षमताओं का लाभ उठाकर इसे प्राप्त करता है, जिसे रेक्टिफाइड फ्लो की सीधी, उच्च-गुणवत्ता वाली मैपिंग सीखने की क्षमता से और बढ़ाया जाता है। तीन उन्नत हानि कार्य (ऊर्जा-संतुलित, ओवरलैप, और STFT हानि) और "समान सीधेपन" नमूना रणनीति विशेष रूप से अवधारणात्मक गुणवत्ता में सुधार, शांत क्षेत्रों में शोर को दबाने, सबबैंड संक्रमण सुनिश्चित करने और उच्च-आवृत्ति विवरणों को संरक्षित करने के लिए डिज़ाइन की गई हैं। यह एक मजबूत जनरेटिव फ्रेमवर्क का "विवाह" लक्षित गुणवत्ता संवर्द्धन के साथ सुनिश्चित करता है कि आउटपुट सिर्फ अच्छा नहीं है, बल्कि "उत्कृष्ट" है (सार)।
-
वास्तविक समय पीढ़ी गति: एक महत्वपूर्ण बाधा पिछले डिफ्यूजन मॉडल की विलंबता को दूर करना था। रेक्टिफाइड फ्लो के सीधे परिवहन प्रक्षेप पथ नमूना चरणों में एक नाटकीय कमी को सक्षम करते हैं - केवल 10 चरणों तक - जो धीमी अनुमान समस्या का एक सीधा समाधान है। इसके अलावा, व्यक्तिगत नमूना बिंदु स्तर के बजाय STFT फ्रेम स्तर पर संचालित करना, समानांतर प्रसंस्करण को सक्षम बनाता है, जिससे कम्प्यूटेशनल गति काफी बढ़ जाती है। यह संयोजन वास्तविक समय से 160 गुना तक की पीढ़ी गति में परिणत होता है, जो वास्तविक समय प्रयोज्यता आवश्यकता को सीधे पूरा करता है।
-
कुशल संसाधन उपयोग: नमूना-बिंदु स्तर प्रसंस्करण की उच्च GPU मेमोरी और कम्प्यूटेशनल मांगें एक बड़ी बाधा थीं। RFWave का फ्रेम-स्तरीय संचालन इस बाधा के लिए एक आदर्श फिट है, जो "अधिक कुशल प्रसंस्करण और GPU मेमोरी उपयोग को कम करता है" (पृष्ठ 2)। यह मॉडल को समान मेमोरी के साथ बहुत लंबे ऑडियो क्लिप (जैसे, 177 सेकंड) को संभालने की अनुमति देता है, जो अन्य मॉडल छोटे क्लिप (जैसे, 6 सेकंड) को संभालते हैं, जिससे यह विविध अनुप्रयोगों के लिए व्यावहारिक हो जाता है।
-
प्रशिक्षण स्थिरता: GANs प्रशिक्षण अस्थिरता और मोड कोलैप्स से जूझते थे। डिफ्यूजन-प्रकार के मॉडल के रूप में, RFWave स्वाभाविक रूप से डिफ्यूजन मॉडल की "प्रशिक्षण के दौरान स्थिरता" से लाभान्वित होता है, इस प्रकार GAN-आधारित विकल्पों की एक प्रमुख बाधा से बचा जाता है।
-
इनपुट प्रतिनिधित्व में बहुमुखी प्रतिभा: समस्या के लिए विभिन्न इनपुट से वेवफ़ॉर्म को पुनर्निर्मित करने में लचीलेपन की आवश्यकता होती है। RFWave को मेल-स्पेक्ट्रोग्राम और असतत ध्वनिक टोकन दोनों से वेवफ़ॉर्म को पुनर्निर्मित करने के लिए डिज़ाइन किया गया है, जिससे इसकी बहुमुखी प्रतिभा और विभिन्न ऑडियो पीढ़ी कार्यों में प्रयोज्यता बढ़ जाती है।
यह सावधानीपूर्वक डिजाइन सुनिश्चित करता है कि RFWave केवल एक प्रदर्शनकारी मॉडल नहीं है, बल्कि एक ऐसा मॉडल है जिसे कुशल और उच्च-गुणवत्ता वाले ऑडियो पुनर्निर्माण की कठोर, बहुआयामी आवश्यकताओं को पूरा करने के लिए विशेष रूप से बनाया गया है।
विकल्पों का अस्वीकरण
पेपर ऑडियो वेवफ़ॉर्म पुनर्निर्माण के लिए अन्य लोकप्रिय दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है:
-
पारंपरिक डिफ्यूजन मॉडल (जैसे, DiffWave, WaveGrad, PriorGrad, FreGrad, Multi-Band Diffusion): इन मॉडलों को मुख्य रूप से उनकी धीमी पीढ़ी की गति और उच्च कम्प्यूटेशनल मांगों के कारण अस्वीकार कर दिया गया था। पेपर कहता है कि वे "व्यक्तिगत नमूना बिंदु स्तर पर अपने संचालन और कई नमूना चरणों की आवश्यकता के कारण विलंबता मुद्दों से बाधित होते हैं" (सार)। विशेष रूप से, वे "GANs की तुलना में कम से कम एक परिमाण धीमे" और "वास्तविक समय से केवल लगभग 10 से 20 गुना तेज़" (परिचय, पृष्ठ 3) हैं, जो उनकी वास्तविक समय प्रयोज्यता को सीमित करता है। RFWave सीधे नमूना चरणों को 10 तक कम करने के लिए रेक्टिफाइड फ्लो का उपयोग करके और मेमोरी और कम्प्यूटेशनल ओवरहेड को कम करने के लिए STFT फ्रेम स्तर पर संचालित करके इसे संबोधित करता है, जिससे वास्तविक समय की 160x गति प्राप्त होती है। एब्लेशन अध्ययन स्पष्ट रूप से दिखाता है कि 50 चरणों के साथ एक मानक डिफ्यूजन शोर अनुसूची (DDPM) का उपयोग करने से प्रदर्शन में "बेसलाइन से कम" रहा (तालिका 6), जो रेक्टिफाइड फ्लो की आवश्यकता को रेखांकित करता है।
-
जनरेटिव एडवरसैरियल नेटवर्क (GANs) (जैसे, HiFi-GAN, BigVGAN, Vocos, APNet2): जबकि GANs तेज़ पीढ़ी की गति प्रदान करते हैं, उन्हें उनकी अंतर्निहित प्रशिक्षण अस्थिरता और मोड कोलैप्स जैसी समस्याओं (परिचय) के कारण अस्वीकार कर दिया गया था। GANs को अक्सर "जटिल डिस्क्रिमिनेटर डिज़ाइन" की आवश्यकता होती है और वे "विनाशकारी भूलने" (Thanh-Tung et al., 2018) से जूझ सकते हैं। इसके अलावा, आउट-ऑफ-डोमेन डेटा के लिए, BigVGAN और Vocos जैसे GAN-आधारित मॉडल "स्पेक्ट्रोग्राम के उच्च-आवृत्ति क्षेत्रों में क्षैतिज रेखाएं" उत्पन्न करते हैं, जिससे "धात्विक ध्वनि गुणवत्ता" होती है जो स्वाभाविकता को कम करती है (पृष्ठ 8, चित्र A.7)। RFWave, एक डिफ्यूजन-प्रकार के मॉडल के रूप में, डिफ्यूजन मॉडल की "प्रशिक्षण के दौरान स्थिरता" विरासत में प्राप्त करता है, जबकि आउट-ऑफ-डोमेन सामान्यीकरण में GANs को पार करता है और उनकी गति से मेल खाता है या उससे अधिक होता है।
-
ऑटोरेग्रेसिव मॉडल (जैसे, WaveNet): इन मॉडलों को नमूना बिंदुओं की क्रमिक भविष्यवाणी के परिणामस्वरूप उनकी धीमी पीढ़ी की गति के कारण अनुपयुक्त माना गया (परिचय)। यह क्रमिक प्रकृति उन्हें वास्तविक समय ऑडियो संश्लेषण के लिए स्वाभाविक रूप से अक्षम बनाती है, जो समस्या की एक प्रमुख आवश्यकता है। RFWave का फ्रेम स्तर पर समानांतर प्रसंस्करण और कम नमूना चरण इस सीमा के विपरीत एक सीधा प्रस्ताव प्रदान करते हैं।
-
नमूना-बिंदु स्तर प्रसंस्करण: यह दृष्टिकोण, कई शुरुआती डिफ्यूजन और ऑटोरेग्रेसिव मॉडल में आम है, इसे अस्वीकार कर दिया गया था क्योंकि यह "फ्रेम दर रिज़ॉल्यूशन से नमूना दर रिज़ॉल्यूशन में संक्रमण के लिए कई अपसैंपलिंग ऑपरेशनों" की ओर ले जाता है, जिससे अनुक्रम की लंबाई बढ़ जाती है और परिणामस्वरूप GPU मेमोरी का उपयोग और कम्प्यूटेशनल मांगें बढ़ जाती हैं" (परिचय)। RFWave का STFT फ्रेम-स्तरीय संचालन में बदलाव सीधे इन मेमोरी और कम्प्यूटेशनल बाधाओं को कम करता है।
गणितीय और तार्किक तंत्र
मास्टर समीकरण
RFWave को शक्ति प्रदान करने वाला पूर्ण कोर समीकरण, विशेष रूप से इसके ऊर्जा-संतुलित संवर्द्धन के साथ, प्रशिक्षण के दौरान अनुकूलित उद्देश्य फ़ंक्शन है। यह समीकरण परिभाषित करता है कि मॉडल शोर को लक्ष्य ऑडियो प्रतिनिधित्व में बदलने वाले वेग क्षेत्र को कैसे सीखता है।
$$
\min_{v} E_{X_0 \sim \pi_0, (X_1, C) \sim D} \left[ \int_0^1 \left\| \frac{(X_1 - X_0)}{\sigma} - v(X_t, t | C)/\sigma \right\|^2 dt \right]
$$
$\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$ और $X_t = (1 - t)X_0 + tX_1$ के साथ।
पद-दर-पद विच्छेदन
आइए प्रत्येक घटक की गणितीय परिभाषा, भौतिक/तार्किक भूमिका और लेखक की डिजाइन पसंद को समझने के लिए इस मास्टर समीकरण का विश्लेषण करें।
-
$v$: यह वेग क्षेत्र का प्रतिनिधित्व करता है जिसे तंत्रिका नेटवर्क सीखता है।
- गणितीय परिभाषा: यह एक फ़ंक्शन $v: \mathbb{R}^d \times [0, 1] \times \mathcal{C} \to \mathbb{R}^d$ है, जहाँ $\mathbb{R}^d$ डेटा स्पेस है, $[0, 1]$ समय अंतराल है, और $\mathcal{C}$ सशर्त इनपुट का स्थान है। RFWave में, यह एक गहरे तंत्रिका नेटवर्क (विशेष रूप से, एक ConvNeXtV2 बैकबोन) द्वारा पैरामीट्रिज्ड है।
- भौतिक/तार्किक भूमिका: यह मॉडल का मुख्य आउटपुट है। यह किसी दिए गए मध्यवर्ती स्थिति $X_t$ और समय $t$ पर डेटा स्पेस में तात्कालिक "वेग" या दिशा की भविष्यवाणी करता है, जिसे $C$ पर सशर्त किया गया है। नेटवर्क का लक्ष्य शोर से डेटा तक सीधी-रेखा आंदोलन की भविष्यवाणी करना सीखना है।
- डिजाइन पसंद: एक तंत्रिका नेटवर्क का उपयोग किया जाता है क्योंकि यह उच्च-आयामी इनपुट ($X_t, t, C$) से उच्च-आयामी आउटपुट ($v$) तक जटिल, गैर-रैखिक मैपिंग सीख सकता है।
-
$E_{X_0 \sim \pi_0, (X_1, C) \sim D}$: यह नमूनों पर अपेक्षा (औसत) को दर्शाता है।
- गणितीय परिभाषा: यह $(X_0, X_1)$ और सशर्त इनपुट $C$ के जोड़ों पर एक सांख्यिकीय औसत है। $X_0$ को एक पूर्व शोर वितरण $\pi_0$ (जैसे, मानक गॉसियन शोर) से नमूना लिया जाता है, और $(X_1, C)$ को वास्तविक डेटा वितरण $D$ से नमूना लिया जाता है (जैसे, $X_1$ एक लक्ष्य जटिल स्पेक्ट्रोग्राम है, $C$ एक मेल-स्पेक्ट्रोग्राम है)।
- भौतिक/तार्किक भूमिका: यह सुनिश्चित करता है कि मॉडल विशिष्ट उदाहरणों को याद करने के बजाय शोर इनपुट और लक्ष्य डेटा की एक विस्तृत श्रृंखला पर सामान्यीकरण करना सीखता है। कई नमूनों पर हानि का औसत प्रशिक्षण को मजबूत बनाता है।
-
$\int_0^1 \dots dt$: यह समय चर $t$ पर एक निश्चित अभिन्न है।
- गणितीय परिभाषा: यह $t=0$ से $t=1$ तक निरंतर समय अंतराल पर तात्कालिक वर्ग त्रुटि को जोड़ता है।
- भौतिक/तार्किक भूमिका: रेक्टिफाइड फ्लो शोर से डेटा तक एक निरंतर प्रक्षेप पथ का वर्णन करता है। इस पूरे पथ पर हानि को एकीकृत करना यह सुनिश्चित करता है कि सीखा गया वेग क्षेत्र केवल असतत स्नैपशॉट पर ही नहीं, बल्कि सभी मध्यवर्ती बिंदुओं पर सुसंगत और सटीक हो। यह निरंतर सूत्रीकरण ODE-आधारित जनरेटिव मॉडल के लिए मौलिक है।
-
$\left\| \cdot \right\|^2$: यह वर्ग $L_2$ मानदंड (यूक्लिडियन दूरी) है।
- गणितीय परिभाषा: एक वेक्टर $z$ के लिए, $\|z\|^2 = \sum_i z_i^2$ । यह अंतर वेक्टर के वर्ग परिमाण को मापता है।
- भौतिक/तार्किक भूमिका: यह पद सामान्यीकृत ग्राउंड ट्रुथ वेग और सामान्यीकृत अनुमानित वेग के बीच वर्ग त्रुटि (MSE) की गणना करता है। इस वर्ग अंतर को कम करना प्रतिगमन कार्यों में एक मानक दृष्टिकोण है, जो मॉडल की भविष्यवाणियों को यथासंभव वास्तविक मानों के करीब प्रोत्साहित करता है। यह इसके अवकलनीयता और उत्तल गुणों के लिए चुना गया है, जो ग्रेडिएंट-आधारित अनुकूलन के लिए फायदेमंद हैं।
-
$X_1$: यह लक्ष्य डेटा का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: लक्ष्य डेटा वितरण $\pi_1$ से एक नमूना, जो मॉडल द्वारा पुनर्निर्मित करने का लक्ष्य रखने वाला ग्राउंड ट्रुथ ऑडियो वेवफ़ॉर्म या जटिल स्पेक्ट्रोग्राम है।
- भौतिक/तार्किक भूमिका: यह वांछित आउटपुट है, "स्वच्छ" ऑडियो प्रतिनिधित्व जिस पर पीढ़ी प्रक्रिया को अभिसरण करना चाहिए।
-
$X_0$: यह प्रारंभिक शोर का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: एक पूर्व शोर वितरण $\pi_0$ से एक नमूना, आमतौर पर मानक गॉसियन शोर $N(0,1)$।
- भौतिक/तार्किक भूमिका: यह जनरेटिव प्रक्रिया का प्रारंभिक बिंदु है, एक यादृच्छिक इनपुट जिसे मॉडल सार्थक ऑडियो में बदल देगा।
-
$C$: यह सशर्त इनपुट है।
- गणितीय परिभाषा: मेल-स्पेक्ट्रोग्राम या असतत ध्वनिक टोकन।
- भौतिक/तार्किक भूमिका: यह पीढ़ी के लिए मार्गदर्शक जानकारी प्रदान करता है। उदाहरण के लिए, यदि लक्ष्य मेल-स्पेक्ट्रोग्राम को ऑडियो वेवफ़ॉर्म में परिवर्तित करना है, तो $C$ वह मेल-स्पेक्ट्रोग्राम होगा। यह नियंत्रित और निर्देशित ऑडियो संश्लेषण की अनुमति देता है।
-
$X_t = (1 - t)X_0 + tX_1$: यह इंटरपोलेटेड स्थिति है।
- गणितीय परिभाषा: समय $t$ पर $X_0$ और $X_1$ के बीच एक रैखिक इंटरपोलेशन।
- भौतिक/तार्किक भूमिका: यह पद शोर ($t=0$ पर $X_0$) से डेटा ($t=1$ पर $X_1$) तक सीधी-रेखा पथ के साथ मध्यवर्ती बिंदु को परिभाषित करता है। मॉडल इन मध्यवर्ती अवस्थाओं पर वेग की भविष्यवाणी करना सीखता है।
-
$\frac{(X_1 - X_0)}{\sigma}$: यह सामान्यीकृत ग्राउंड ट्रुथ वेग है।
- गणितीय परिभाषा: लक्ष्य डेटा और प्रारंभिक शोर के बीच सीधा अंतर, $\sigma$ द्वारा स्केल किया गया। यह आदर्श, सामान्यीकृत तात्कालिक वेग का प्रतिनिधित्व करता है यदि प्रक्षेप पथ पूरी तरह से रैखिक था।
- भौतिक/तार्किक भूमिका: यह आदर्श वेग है जिसे तंत्रिका नेटवर्क $v$ को अनुमानित करना सीखना चाहिए। $\sigma$ द्वारा विभाजन एक महत्वपूर्ण ऊर्जा-संतुलन सामान्यीकरण है।
-
$v(X_t, t | C)/\sigma$: यह सामान्यीकृत अनुमानित वेग है।
- गणितीय परिभाषा: तंत्रिका नेटवर्क $v$ का आउटपुट, $X_t$, $t$, और $C$ को इनपुट के रूप में लेना, $\sigma$ द्वारा भी स्केल किया गया।
- भौतिक/तार्किक भूमिका: यह मॉडल का तात्कालिक वेग का अनुमान है, जिसे ऊर्जा-संतुलन गुणांक द्वारा सामान्यीकृत किया गया है। प्रशिक्षण प्रक्रिया का लक्ष्य इस पद को सामान्यीकृत ग्राउंड ट्रुथ वेग से मेल खाना है।
-
$\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$: यह ऊर्जा-संतुलन भार गुणांक है।
- गणितीय परिभाषा: प्रत्येक आवृत्ति सबबैंड के लिए समय-अक्ष के साथ गणना किए गए ग्राउंड ट्रुथ वेग $(X_1 - X_0)$ के मानक विचलन।
- भौतिक/तार्किक भूमिका: यह पद निम्न-आयतन शोर वाले क्षेत्रों में निम्न-आयतन शोर की समस्या को दूर करने के लिए पेश किया गया है। ग्राउंड ट्रुथ और अनुमानित दोनों वेगों को $\sigma$ से विभाजित करके, हानि फ़ंक्शन प्रभावी रूप से ऊर्जा के आधार पर त्रुटियों को अलग-अलग भारित करता है। जब $\sigma$ छोटा होता है (कम-ऊर्जा/शांत क्षेत्र), तो पद $1/\sigma$ बड़ा हो जाता है, इन क्षेत्रों में त्रुटियों के कुल हानि में योगदान को बढ़ाता है। यह मॉडल को शांत भागों में शोर को सटीक रूप से दबाने पर अधिक ध्यान देने के लिए मजबूर करता है, जिससे बोधगम्य निम्न-आयतन कलाकृतियों की पीढ़ी को रोका जा सके।
चरण-दर-चरण प्रवाह
आइए अनुमान (पीढ़ी) प्रक्रिया के दौरान एक एकल अमूर्त डेटा बिंदु के जीवनचक्र का पता लगाएं, यह मानते हुए कि मॉडल पहले से ही प्रशिक्षित है। हम आवृत्ति-डोमेन दृष्टिकोण पर विचार करेंगे जहां $X_t$ और $v_t$ आवृत्ति डोमेन में रहते हैं, क्योंकि यह अनुमान के दौरान अधिक कुशल है।
- प्रारंभिक शोर इंजेक्शन (प्रक्षेप पथ की शुरुआत, $t=0$): प्रक्रिया एक मानक गॉसियन शोर वितरण, $N(0,1)$ से एक प्रारंभिक स्थिति, $X_0$ का नमूना लेकर शुरू होती है। यह $X_0$ लक्ष्य ऑडियो के समान आयामों का एक जटिल स्पेक्ट्रोग्राम है। हमें सशर्त इनपुट $C$ (जैसे, एक मेल-स्पेक्ट्रोग्राम) भी प्राप्त होता है जो पीढ़ी का मार्गदर्शन करता है।
- पुनरावृत्त वेग भविष्यवाणी और स्थिति अद्यतन (यूलर एकीकरण): मॉडल तब असतत समय चरणों की एक श्रृंखला से गुजरता है, $t_i$, $t=0$ से $t=1$ तक। प्रत्येक चरण $i$ के लिए:
- वर्तमान स्थिति: हमारे पास वर्तमान अनुमानित स्थिति, $X_{t_i}$ है, जो $X_0$ से शुरू होती है।
- सबबैंड विभाजन (यदि लागू हो): यदि मॉडल मल्टी-बैंड संरचना का उपयोग करता है, तो $X_{t_i}$ को सबबैंड में विभाजित किया जाता है। प्रत्येक सबबैंड के शोर नमूने ($X_{t_i}^{\text{sb}}$) को ConvNeXtV2 बैकबोन में फीड किया जाता है।
- वेग भविष्यवाणी: तंत्रिका नेटवर्क $v$ (ConvNeXtV2 बैकबोन) वर्तमान स्थिति $X_{t_i}$ (या इसके सबबैंड $X_{t_i}^{\text{sb}}$), वर्तमान समय $t_i$, और सशर्त इनपुट $C$ (और संभावित रूप से सबबैंड सूचकांक $i_{\text{sb}}$ और बैंडविड्थ सूचकांक $i_{\text{bw}}$) को तात्कालिक वेग $v(X_{t_i}, t_i | C)$ की भविष्यवाणी करने के लिए लेता है।
- यूलर चरण: अनुमानित वेग $v(X_{t_i}, t_i | C)$ का उपयोग तब स्थिति को अद्यतन करने के लिए किया जाता है। यूलर विधि जैसे संख्यात्मक ODE सॉल्वर का उपयोग करके, अगली स्थिति $X_{t_{i+1}}$ की गणना $X_{t_{i+1}} = X_{t_i} + v(X_{t_i}, t_i | C) \cdot \Delta t$ के रूप में की जाती है, जहाँ $\Delta t = t_{i+1} - t_i$ समय चरण अंतराल है। यह प्रभावी रूप से डेटा बिंदु को अनुमानित वेग वेक्टर के साथ ले जाता है।
- सबबैंड विलय (यदि लागू हो): यदि सबबैंड को स्वतंत्र रूप से संसाधित किया गया था, तो उनके अनुमानित वेगों को एक पूर्ण-बैंड वेग बनाने के लिए वापस विलय कर दिया जाता है, जिसका उपयोग यूलर चरण के लिए किया जाता है।
- अंतिम स्पेक्ट्रोग्राम पुनर्निर्माण ($t=1$): यह पुनरावृत्त प्रक्रिया कुछ नमूना चरणों (जैसे, RFWave में 10 चरण) तक जारी रहती है जब तक कि $t$ 1 तक नहीं पहुंच जाता। अंतिम स्थिति, $X_1$, पुनर्निर्मित जटिल स्पेक्ट्रोग्राम है।
- वेवफ़ॉर्म रूपांतरण: चूंकि $X_1$ आवृत्ति डोमेन में एक जटिल स्पेक्ट्रोग्राम है, इसलिए इसे अंतिम उच्च-निष्ठा ऑडियो वेवफ़ॉर्म में परिवर्तित करने के लिए एक एकल व्युत्क्रम शॉर्ट-टाइम फूरियर ट्रांसफॉर्म (ISTFT) ऑपरेशन लागू किया जाता है। पेपर नोट करता है कि आवृत्ति-डोमेन मॉडल के लिए, अंत में केवल एक ISTFT की आवश्यकता होती है, जो एक प्रमुख दक्षता लाभ है।
यह अनुक्रम एक यादृच्छिक शोर इनपुट को सशर्त इनपुट और सीखे गए वेग क्षेत्र द्वारा निर्देशित एक संरचित, उच्च-गुणवत्ता वाले ऑडियो वेवफ़ॉर्म में बदल देता है।
अनुकूलन गतिशीलता
RFWave तंत्र अतिरिक्त हानि शब्दों द्वारा संवर्धित, ऊर्जा-संतुलित रेक्टिफाइड फ्लो उद्देश्य फ़ंक्शन को कम करके सीखता है, अपडेट करता है और अभिसरण करता है, स्टोकेस्टिक ग्रेडिएंट डिसेंट के माध्यम से।
-
हानि परिदृश्य आकार देना: प्राथमिक हानि फ़ंक्शन (समीकरण 5) एक हानि परिदृश्य को परिभाषित करता है जहां "घाटियाँ" सटीक वेग भविष्यवाणियों के अनुरूप होती हैं। रेक्टिफाइड फ्लो सूत्रीकरण स्वाभाविक रूप से सीधी-रेखा प्रक्षेप पथ सीखने को प्रोत्साहित करता है, जो शोर अनुसूचियों को सीखने वाले डिफ्यूजन मॉडल की तुलना में एक चिकना और अधिक प्रबंधनीय हानि परिदृश्य बनाने की प्रवृत्ति रखता है। महत्वपूर्ण $\sigma$ पद, जो ऊर्जा-संतुलन गुणांक का प्रतिनिधित्व करता है, इस परिदृश्य को गतिशील रूप से नया आकार देता है। निम्न-ऊर्जा क्षेत्रों (जैसे, मौन) में, $\sigma$ छोटा होता है, जिससे पद $1/\sigma$ बड़ा हो जाता है। यह प्रभावी रूप से इन क्षेत्रों में त्रुटियों के योगदान को कुल हानि में बढ़ाता है, जिससे छोटे विचलन के लिए तेज ग्रेडिएंट बनते हैं। यह सुनिश्चित करता है कि मॉडल को शांत अंशों में शोर को सटीक रूप से दबाने के लिए भारी दंडित किया जाता है, जिससे सामान्य समस्या को रोका जा सके। इसके विपरीत, उच्च-ऊर्जा क्षेत्रों में, $\sigma$ बड़ा होता है, जिससे इन प्रमुख क्षेत्रों को अन्य भागों के महत्व को पूरी तरह से ओवरशैडो करने से रोका जा सके। यह गतिशील भारण पूरे ऑडियो स्पेक्ट्रम में एक अधिक संतुलित सीखने के उद्देश्य बनाता है।
-
ग्रेडिएंट व्यवहार: प्रशिक्षण के दौरान, मॉडल अपने तंत्रिका नेटवर्क मापदंडों के संबंध में हानि फ़ंक्शन के ग्रेडिएंट की गणना करता है। ये ग्रेडिएंट इंगित करते हैं कि त्रुटि को कम करने के लिए मापदंडों को कैसे समायोजित किया जाए।
- $L_2$ मानदंड सुनिश्चित करता है कि ग्रेडिएंट अनुमानित वेग $v(X_t, t | C)$ को ग्राउंड ट्रुथ वेग $(X_1 - X_0)$ के साथ संरेखित करने के लिए धकेलते हैं।
- $\sigma$ पद सीधे ग्रेडिएंट परिमाण को प्रभावित करता है। निम्न $\sigma$ मानों के लिए, उन क्षेत्रों में त्रुटियों से जुड़े ग्रेडिएंट स्केल किए जाते हैं, जिससे मॉडल को मौन भागों में वेगों की अधिक सटीकता से भविष्यवाणी करना सीखना पड़ता है। यह शोर दमन के लिए एक सीधा तंत्र है।
- अतिरिक्त हानि कार्य: RFWave तीन उन्नत हानि कार्यों को शामिल करता है: ऊर्जा-संतुलित हानि (पहले से ही $\sigma$ के माध्यम से चर्चा की गई), ओवरलैप हानि, और STFT हानि। ये अतिरिक्त हानियाँ आगे ग्रेडिएंट संकेत प्रदान करती हैं:
- ओवरलैप हानि: यह हानि प्रशिक्षण के दौरान आसन्न सबबैंड के ओवरलैपिंग वर्गों के बीच स्थिरता बनाए रखने के लिए लागू की जाती है। यह अनुमान के दौरान सबबैंड को विलय करते समय चिकनी संक्रमण और असंतोष को रोकने के लिए ग्रेडिएंट उत्पन्न करता है।
- STFT हानि: स्पेक्ट्रल कन्वर्जेंस (SC) हानि और लॉग-स्केल STFT-परिमाण हानि ($L_1$ मानदंड लॉग-परिमाण पर) से मिलकर, यह पद अनुमानित लक्ष्य $\tilde{X}_1$ पर संचालित होता है। SC हानि (फ्रॉबेनियस मानदंड) बड़े स्पेक्ट्रल घटकों पर केंद्रित है, जबकि लॉग-स्केल STFT-परिमाण हानि छोटे-आयाम वाले घटकों पर जोर देती है। ये हानियाँ मॉडल को स्पेक्ट्रली सटीक ऑडियो उत्पन्न करने के लिए निर्देशित करने वाले ग्रेडिएंट प्रदान करती हैं, जिससे कलाकृतियाँ कम होती हैं और समग्र ध्वनि गुणवत्ता में सुधार होता है। इन अतिरिक्त हानियों के लिए भार (जैसे, 0.01) को मुख्य रेक्टिफाइड फ्लो हानि के साथ उनके प्रभाव को संतुलित करने के लिए चुना जाता है।
-
पुनरावृत्त स्थिति अद्यतन और अभिसरण: तंत्रिका नेटवर्क मापदंडों को सभी हानि घटकों से एकत्रित ग्रेडिएंट द्वारा संचालित, AdamW जैसे ऑप्टिमाइज़र का उपयोग करके पुनरावृत्त रूप से अद्यतन किया जाता है। एक कोसाइन एनीलिंग लर्निंग रेट शेड्यूल नियोजित किया जाता है, जो एक उच्च दर (जैसे, 2e-4) पर शुरू होता है और धीरे-धीरे एक न्यूनतम (जैसे, 2e-6) तक घटता है। यह शेड्यूल मॉडल को प्रशिक्षण की शुरुआत में बड़े समायोजन करने और फिर स्थिर अभिसरण के लिए अपने मापदंडों को ठीक करने में मदद करता है। मॉडल अभिसरण करता है जब अनुमानित वेग क्षेत्र $v$ किसी भी मध्यवर्ती स्थिति $X_t$ को सही सीधी-रेखा वेग $(X_1 - X_0)$ तक सटीक रूप से मैप करता है, $C$ पर सशर्त, पूरे समय अंतराल में। "समान सीधेपन" नमूना रणनीति, हालांकि मुख्य रूप से एक अनुमान तकनीक है, अप्रत्यक्ष रूप से अभिसरण का समर्थन करती है, यह सुनिश्चित करके कि मॉडल को लगातार सभी यूलर चरणों में चुनौती दी जाती है, जिससे संभावित रूप से एक अधिक मजबूती से सीखा गया वेग क्षेत्र प्राप्त होता है।
मॉडल संरचना
मॉडल संरचना को चित्र 1 में दर्शाया गया है। सभी आवृत्ति बैंड, प्रत्येक एक अद्वितीय सबबैंड सूचकांक द्वारा प्रतिष्ठित, एक ही मॉडल साझा करते हैं। एक दिए गए नमूने के सबबैंड को प्रसंस्करण के लिए एक एकल बैच में एक साथ समूहीकृत किया जाता है, जो एक साथ प्रशिक्षण या अनुमान की सुविधा प्रदान करता है। यह अनुमान विलंबता को काफी कम करता है। इसके अलावा, सबबैंड को स्वतंत्र रूप से मॉडल करने से त्रुटि संचय कम होता है। जैसा कि (रोमन एट अल., 2023) में चर्चा की गई है, उच्च बैंड को निम्न बैंड पर कंडीशनिंग से त्रुटि संचय हो सकता है, जिसका अर्थ है कि निम्न बैंड में अशुद्धियाँ अनुमान के दौरान उच्च बैंड को प्रतिकूल रूप से प्रभावित कर सकती हैं।
मॉडल एक शोर नमूना (Xt) को उसके वेग (vt) पर मैप करता है। प्रत्येक सबबैंड के लिए, सबबैंड के शोर नमूने (Xsb) को समय (t), सबबैंड सूचकांक (ist), सशर्त इनपुट (C', मेल-स्पेक्ट्रोग्राम या एनकोडेक (Défossez et al., 2022) टोकन), और एक वैकल्पिक एनकोडेक बैंडविड्थ सूचकांक (ibw) पर सशर्त उसके वेग (vs) की भविष्यवाणी करने के लिए ConvNeXtV2 बैकबोन में फीड किया जाता है। ConvNeXtV2 बैकबोन की विस्तृत संरचना चित्र 1 में दिखाई गई है। हम (किंग्मा एट अल., 2021) में वर्णित फूरियर सुविधाओं का उपयोग करते हैं। Xsb, C, और फूरियर सुविधाओं को चैनल आयाम के साथ जोड़ा जाता है और फिर एक रैखिक परत से गुजारा जाता है, जो इनपुट बनाता है जिसे ConvNeXtV2 ब्लॉक की एक श्रृंखला में फीड किया जाता है। साइनसोइडल टी एम्बेडिंग, वैकल्पिक ibw एम्बेडिंग के साथ, प्रत्येक ConvNeXtV2 ब्लॉक के इनपुट में तत्व-वार जोड़ा जाता है। ibw का उपयोग एनकोडेक टोकन के डिकोडिंग के दौरान किया जाता है, जिससे एक एकल मॉडल विभिन्न बैंडविड्थ के साथ एनकोडेक टोकन का समर्थन कर सके। इसके अलावा, ist को एक अनुकूली परत सामान्यीकरण मॉड्यूल के माध्यम से शामिल किया जाता है, जो (Siuzdak, 2023; Xu et al., 2019) में वर्णित सीखने योग्य एम्बेडिंग का उपयोग करता है। अन्य घटक ConvNeXtV2 वास्तुकला के भीतर वालों के समान हैं, विवरण (Woo et al., 2023) में पाए जा सकते हैं।
हमारी कार्यप्रणाली दो मॉडलिंग विकल्प प्रदान करती है। पहला गॉसियन शोर को सीधे समय डोमेन में वेवफ़ॉर्म पर मैप करना शामिल है, जिसमें X0, X1, Xt और vt सभी समय डोमेन में रहते हैं। दूसरा विकल्प गॉसियन शोर को जटिल स्पेक्ट्रोग्राम पर मैप करता है, जिससे X0, X1, Xt और vt आवृत्ति डोमेन में रहते हैं। विशेष रूप से, Xish और vist लगातार आवृत्ति डोमेन में दर्शाए जाते हैं, जैसा कि निम्नलिखित पैराग्राफ में विस्तृत है, यह सुनिश्चित करते हुए कि तंत्रिका नेटवर्क फ्रेम स्तर पर चलता है। फ्रेम-स्तरीय सुविधाओं को संसाधित करके, हमारा मॉडल PriorGrad जैसे डिफ्यूजन वोकोडर की तुलना में अधिक मेमोरी दक्षता प्राप्त करता है, जो वेवफ़ॉर्म नमूना बिंदुओं के स्तर पर संचालित होते हैं। जबकि PriorGrad (gil Lee et al., 2022) 30 GB GPU मेमोरी के भीतर 44.1 kHz पर 6-सेकंड² ऑडियो क्लिप पर प्रशिक्षित कर सकता है, हमारा मॉडल समान मेमोरी संसाधनों के साथ 177-सेकंड क्लिप को संभाल सकता है।
Xt को टाइम डोमेन और वेवफ़ॉर्म इक्वलाइजेशन के साथ संचालन चूंकि हमारा मॉडल फ्रेम स्तर पर कार्य करने के लिए डिज़ाइन किया गया है, जब Xt और vt टाइम डोमेन में होते हैं (विशेष रूप से, X₁ वेवफ़ॉर्म है और Xo समान आकार का शोर है, जिसमें Xt और vt (3) से प्राप्त होते हैं), STFT और ISTFT का उपयोग, जैसा कि चित्र 1 में दर्शाया गया है, आवश्यक हो जाता है। Xt और vt का आयाम [1, T]³ का पालन करता है, जहां T नमूना बिंदुओं में वेवफ़ॉर्म लंबाई है। STFT ऑपरेशन के बाद, हम पूर्ण-बैंड जटिल स्पेक्ट्रोग्राम को समान रूप से विभाजित करके सबबैंड निकालते हैं, जिससे Xis प्राप्त होता है। प्रत्येक सबबैंड Xisb
यूलर विधि के लिए समय बिंदु चुनना
लियू एट अल. (2023) यूलर विधि के लिए समान चरण अंतराल का उपयोग करते हैं, जैसा कि (4) में दर्शाया गया है। यहां, हम परिवहन प्रक्षेप पथों की सीधेपन के आधार पर नमूनाकरण के लिए समय बिंदुओं का चयन करने का प्रस्ताव करते हैं। समय बिंदुओं को इस प्रकार चुना जाता है कि प्रत्येक चरण में सीधेपन में वृद्धि समान हो। सीखे गए वेग क्षेत्र v की सीधेपन को S(v) = ∫ E || (X1 - Xo) – v(Xt, t | C) ||² dt के रूप में परिभाषित किया गया है, जो प्रक्षेप पथ के साथ वेग के विचलन का वर्णन करता है। एक छोटा S(v) का अर्थ है सीधी प्रक्षेप पथ। यह दृष्टिकोण सुनिश्चित करता है कि प्रत्येक यूलर चरण की कठिनाई सुसंगत बनी रहे, जिसके लिए मॉडल को अधिक चुनौतीपूर्ण क्षेत्रों में अधिक कदम उठाने की आवश्यकता होती है। समान संख्या में नमूना चरणों का उपयोग करके, यह विधि समान अंतराल दृष्टिकोण से बेहतर प्रदर्शन करती है। कार्यान्वयन विवरण परिशिष्ट अनुभाग A.5 में प्रदान किए गए हैं, जबकि एल्गोरिथम परिशिष्ट अनुभाग A.9.2 में प्रस्तुत किया गया है। हम इस दृष्टिकोण को समान सीधेपन कहते हैं।
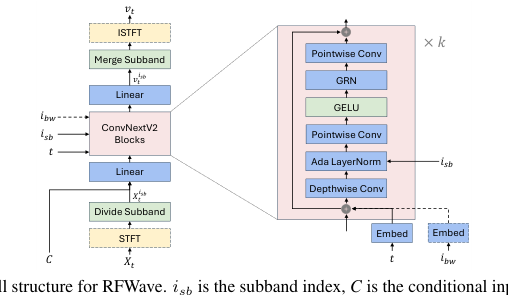 Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
RFWave के प्रदर्शन को कठोरता से मान्य करने के लिए, लेखकों ने विभिन्न ऑडियो डोमेन और इनपुट प्रकारों में स्थापित "पीड़ित" बेसलाइन के खिलाफ अपने मॉडल को खड़ा करते हुए एक व्यापक प्रयोगात्मक सेटअप तैयार किया।
मेल-स्पेक्ट्रोग्राम इनपुट के लिए, दो प्राथमिक मूल्यांकन परिदृश्य तैयार किए गए थे:
1. डिफ्यूजन-आधारित वोकोडर के साथ तुलना: RFWave मॉडल को तीन विविध डेटासेट पर अलग-अलग प्रशिक्षित किया गया था: LibriTTS (भाषण के लिए), MTG-Jamendo (संगीत के लिए), और Opencpop (स्वर संगीत के लिए)। इन मॉडलों का तब उनके संबंधित परीक्षण सेटों पर मूल्यांकन किया गया था। इस श्रेणी में बेसलाइन अत्याधुनिक डिफ्यूजन मॉडल थे: PriorGrad और FreGrad।
2. GAN-आधारित वोकोडर के साथ तुलना: LibriTTS पर एक RFWave मॉडल प्रशिक्षित किया गया था। इसके प्रदर्शन का तब LibriTTS परीक्षण सेट (इन-डोमेन) पर और, महत्वपूर्ण रूप से, MUSDB18 डेटासेट (आउट-ऑफ-डोमेन) पर सामान्यीकरण और मजबूती का परीक्षण करने के लिए मूल्यांकन किया गया था। यहां बेसलाइन व्यापक रूप से उपयोग किए जाने वाले GAN मॉडल थे: Vocos और BigVGAN।
असतत एनकोडेक टोकन इनपुट के लिए, एक सार्वभौमिक RFWave मॉडल को कॉमन वॉयस 7.0, DNS चैलेंज 4, MTG-Jamendo, FSD50K, और AudioSet सहित बड़े पैमाने पर, मिश्रित डेटासेट पर प्रशिक्षित किया गया था। इस सार्वभौमिक मॉडल का तब 15 बाहरी स्रोतों से 900 ऑडियो नमूनों के एक कस्टम-निर्मित एकीकृत परीक्षण डेटासेट पर एनकोडेक और मल्टी-बैंड डिफ्यूजन (MBD) के खिलाफ मूल्यांकन किया गया था, जिसमें भाषण, स्वर और ध्वनि प्रभाव शामिल थे। इस व्यापक मूल्यांकन का उद्देश्य विभिन्न ऑडियो प्रकारों में RFWave की बहुमुखी प्रतिभा को साबित करना था।
मूल्यांकन मेट्रिक्स: वस्तुनिष्ठ और व्यक्तिपरक दोनों उपायों को नियोजित किया गया था।
* वस्तुनिष्ठ मेट्रिक्स में ViSQOL (अवधारणात्मक गुणवत्ता, 22.05/24 kHz के लिए भाषण-मोड का उपयोग करके और 44.1 kHz वेवफ़ॉर्म के लिए ऑडियो-मोड), PESQ (भाषण गुणवत्ता का अवधारणात्मक मूल्यांकन), V/UV F1 (स्वर/अस्वर वर्गीकरण के लिए F1 स्कोर), और आवधिकता (आवधिकता त्रुटि) शामिल थे।
* व्यक्तिपरक मूल्यांकन में 5-बिंदु मीन ओपिनियन स्कोर (MOS) स्केल (1: 'खराब/अप्राकृतिक' से 5: 'उत्कृष्ट/प्राकृतिक') का उपयोग करके भीड़-सोर्स मूल्यांकन शामिल था। प्रत्येक तुलना के लिए, 30 श्रोताओं ने ग्राउंड ट्रुथ, RFWave, और बेसलाइन मॉडल सहित 20-40 समूहों के ऑडियो नमूनों को यादृच्छिक क्रम में रेट किया।
कार्यान्वयन विवरण: RFWave मॉडल ने डिफ़ॉल्ट रूप से एक समय-डोमेन दृष्टिकोण का उपयोग किया, जिसमें तीन उन्नत हानि कार्यों (ऊर्जा-संतुलित, ओवरलैप, और STFT हानि) और 8 ब्लॉक के साथ एक ConvNeXtV2 बैकबोन शामिल था। जटिल स्पेक्ट्रोग्राम को 8 समान रूप से फैले सबबैंड में विभाजित किया गया था। एक प्रमुख वास्तुशिल्प विकल्प केवल 10 नमूना चरणों का उपयोग था। एब्लेशन अध्ययन भी व्यक्तिगत घटकों के प्रभाव को अलग करने के लिए आयोजित किए गए थे, जैसे कि आवृत्ति बनाम समय डोमेन मॉडलिंग, प्रत्येक हानि फ़ंक्शन का वृद्धिशील जोड़, "समान सीधेपन" नमूना रणनीति, विभिन्न बैकबोन आर्किटेक्चर (ResNet बनाम ConvNeXtV2), और मॉडल आकार। अनुमान गति का बेंचमार्क एक NVIDIA GeForce RTX 4090 GPU पर बैच आकार 1 के साथ किया गया था।
साक्ष्य क्या साबित करता है
पेपर में प्रस्तुत अनुभवजन्य साक्ष्य निश्चित और निर्विवाद प्रमाण प्रदान करते हैं कि RFWave के मुख्य तंत्र वास्तविकता में काम करते हैं, जो ऑडियो गुणवत्ता और कम्प्यूटेशनल दक्षता दोनों में इसके बेहतर प्रदर्शन को प्रदर्शित करते हैं।
डिफ्यूजन-आधारित बेसलाइन को हराना:
RFWave ने मेल-स्पेक्ट्रोग्राम से पुनर्निर्माण करते समय सभी वस्तुनिष्ठ और व्यक्तिपरक मेट्रिक्स में अपने डिफ्यूजन-आधारित "पीड़ितों", PriorGrad और FreGrad को क्रूरतापूर्वक पछाड़ दिया (तालिका 1)। उदाहरण के लिए, RFWave ने औसतन 3.95 ± 0.09 का MOS प्राप्त किया, जो PriorGrad के 3.75 ± 0.09 और FreGrad के 2.99 ± 0.14 से काफी अधिक है। वस्तुनिष्ठ रूप से, RFWave के 4.202 के PESQ ने PriorGrad के 3.612 और FreGrad के 3.640 को बौना कर दिया। इस श्रेष्ठता के लिए निश्चित प्रमाण RFWave की "स्पष्ट और अधिक सुसंगत हार्मोनिक्स, विशेष रूप से उच्च-आवृत्ति रेंज में" उत्पन्न करने की क्षमता है, जैसा कि परिशिष्ट A.6 (चित्र A.3, A.4, A.5) में स्पेक्ट्रोग्राम द्वारा नेत्रहीन पुष्टि की गई है, जहां बेसलाइन में मामूली असंतोष या धुंधले उच्च-आवृत्ति घटक दिखाई देते थे। यह सीधे तौर पर कम नमूना चरणों के साथ उच्च-गुणवत्ता वाले ऑडियो प्राप्त करने में रेक्टिफाइड फ्लो की प्रभावशीलता को मान्य करता है।
GAN-आधारित बेसलाइन को चुनौती देना:
जबकि GANs गति के लिए जाने जाते हैं, RFWave ने इन-डोमेन गुणवत्ता और बेहतर आउट-ऑफ-डोमेन सामान्यीकरण का प्रदर्शन किया। इन-डोमेन LibriTTS परीक्षण सेट पर, RFWave का MOS (3.82 ± 0.12) BigVGAN (3.78 ± 0.11) और Vocos (3.74 ± 0.10) (तालिका 2) के बराबर था। हालाँकि, असली जीत आउट-ऑफ-डोमेन MUSDB18 डेटासेट (तालिका 3) में आई, जहाँ RFWave ने औसतन 3.67 ± 0.05 का MOS प्राप्त किया, जो BigVGAN के 3.51 ± 0.05 और Vocos के 3.10 ± 0.06 से काफी बेहतर है। यहाँ का कठोर प्रमाण चित्र A.7 में दृश्य विश्लेषण है, जो दिखाता है कि BigVGAN और Vocos जैसे GAN-आधारित मॉडल "स्पेक्ट्रोग्राम के उच्च-आवृत्ति क्षेत्रों में क्षैतिज रेखाएं" उत्पन्न करते हैं, जिससे "धात्विक ध्वनि गुणवत्ता" होती है। RFWave, इसके विपरीत, लगातार "स्पष्ट और अच्छी तरह से परिभाषित उच्च-आवृत्ति हार्मोनिक्स" उत्पन्न करता है, जो एक डिफ्यूजन-प्रकार के मॉडल के रूप में इसकी मजबूती और सामान्यीकरण क्षमताओं को साबित करता है।
एनकोडेक टोकन पुनर्निर्माण पर हावी होना:
असतत एनकोडेक टोकन इनपुट के लिए, RFWave (CFG2 के साथ) लगातार अधिकांश मेट्रिक्स (MOS, PESQ, V/UV F1, आवधिकता) और विभिन्न बैंडविड्थ में इष्टतम स्कोर प्राप्त करता है, जो एनकोडेक और MBD (तालिका 4) दोनों से बेहतर प्रदर्शन करता है। उदाहरण के लिए, 6.0 kbps पर, RFWave का MOS 3.10 ± 0.15 के एनकोडेक और 3.43 ± 0.15 के MBD की तुलना में 3.69 ± 0.16 था। यह संपीड़ित अभ्यावेदन से उच्च-गुणवत्ता वाले ऑडियो को पुनर्निर्मित करने में RFWave की बहुमुखी प्रतिभा और दक्षता को दर्शाता है।
एब्लेशन अध्ययन सत्यापन:
एब्लेशन अध्ययन (तालिका 5) ने RFWave के व्यक्तिगत घटकों की प्रभावशीलता में महत्वपूर्ण अंतर्दृष्टि प्रदान की:
* समय-डोमेन मॉडल लगातार अपने आवृत्ति-डोमेन समकक्ष (जैसे, PESQ 4.127 बनाम 3.872) से बेहतर प्रदर्शन करता है, जो बेहतर उच्च-आवृत्ति विवरण संरक्षण के लिए पसंद को मान्य करता है।
* ऊर्जा-संतुलित हानि को शांत क्षेत्रों में निम्न-आयतन शोर को कम करने के लिए दिखाया गया था, समग्र प्रदर्शन में सुधार हुआ (जैसे, PESQ 4.127 से 4.181 तक), जो सापेक्ष त्रुटि को कम करने में इसकी भूमिका साबित करता है।
* ओवरलैप हानि, PESQ में थोड़ी गिरावट के बावजूद, "चिकनी सबबैंड संक्रमण" और स्थिरता बनाए रखने के लिए आवश्यक थी, जैसा कि इसके बिना ध्यान देने योग्य संक्रमणों द्वारा नेत्रहीन पुष्टि की गई है (चित्र A.9)।
* STFT हानि ने पृष्ठभूमि शोर (चित्र A.8) में कलाकृतियों को प्रभावी ढंग से कम किया, PESQ को 4.158 से 4.211 तक सुधारा, हालांकि इसके परिमाण पर जोर देने के कारण ViSQOL और आवधिकता में थोड़ी गिरावट आई।
* समान सीधेपन नमूना रणनीति ने प्रदर्शन में काफी सुधार किया "मुफ्त में" (PESQ 4.275, आवधिकता 0.100), समान अंतराल चरणों पर इसकी प्रभावशीलता साबित हुई।
* रेक्टिफाइड फ्लो तंत्र को कुशल उच्च-गुणवत्ता वाले पीढ़ी के लिए "महत्वपूर्ण" दिखाया गया था, क्योंकि 50 चरणों के साथ एक DDPM दृष्टिकोण खराब प्रदर्शन करता था (तालिका 6)। ConvNeXtV2 बैकबोन ने भी ResNet की तुलना में बेहतर प्रदर्शन किया, जिससे दक्षता और गुणवत्ता दोनों में वृद्धि हुई।
अभूतपूर्व कम्प्यूटेशनल दक्षता:
शायद सबसे आश्चर्यजनक सबूत RFWave की कहीं अधिक कम्प्यूटेशनल दक्षता (तालिका 7) है। इसने केवल 10 नमूना चरणों के साथ एक एकल NVIDIA GeForce RTX 4090 GPU पर वास्तविक समय से 162.59 गुना (xRT) की अनुमान गति प्राप्त की। यह डिफ्यूजन बेसलाइन (PriorGrad 16.67 xRT, FreGrad 7.50 xRT, MBD 4.82 xRT) की तुलना में एक परिमाण तेज है और BigVGAN (72.68 xRT) से दोगुना से भी अधिक तेज है। इसके अलावा, RFWave ने BigVGAN (1436 MB) की तुलना में कम GPU मेमोरी (780 MB) का उपभोग किया। यह गति लाभ, उच्च नमूना दरों (जैसे, 44.1 kHz पर 152.58 xRT) पर भी बनाए रखा गया, निर्णायक रूप से साबित करता है कि RFWave डिफ्यूजन मॉडल की विलंबता बाधा को दूर करता है, जिससे यह वास्तविक दुनिया, वास्तविक समय अनुप्रयोगों के लिए व्यावहारिक हो जाता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि RFWave ऑडियो वेवफ़ॉर्म पुनर्निर्माण में एक महत्वपूर्ण छलांग प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
एक सूक्ष्म सीमा देखी गई है कि ViSQOL मीट्रिक GAN-आधारित मॉडल के प्रति पक्षपाती है। यद्यपि RFWave अक्सर उच्च MOS और अन्य वस्तुनिष्ठ स्कोर प्राप्त करता है, ViSQOL कभी-कभी GANs का पक्ष लेता है, जो मानव अवधारणात्मक गुणवत्ता को पूरी तरह से प्रतिबिंबित नहीं कर सकता है। यह बताता है कि वर्तमान वस्तुनिष्ठ मेट्रिक्स सिंथेटिक ऑडियो में गुणवत्ता की सभी बारीकियों को पूरी तरह से कैप्चर नहीं कर सकते हैं, खासकर उपन्यास जनरेटिव दृष्टिकोण के लिए। एक और दिलचस्प ट्रेड-ऑफ STFT हानि के साथ देखा गया था: जबकि यह कलाकृतियों को प्रभावी ढंग से कम करता है, यह परिमाण पर जोर देने के कारण ViSQOL और आवधिकता को थोड़ा खराब कर सकता है। यह ऑडियो निष्ठा के विभिन्न पहलुओं को संतुलित करने में एक चुनौती को उजागर करता है। इसके अलावा, जबकि RFWave GANs की तुलना में मजबूत आउट-ऑफ-डोमेन सामान्यीकरण प्रदर्शित करता है, एक वास्तव में सार्वभौमिक वोकोडर का अंतिम लक्ष्य अनदेखे ऑडियो स्थितियों और विशेषताओं के एक और भी व्यापक स्पेक्ट्रम को संभालना है, जो एक निरंतर चुनौती बनी हुई है। प्रशिक्षण के लिए आवश्यक कम्प्यूटेशनल संसाधन, विशेष रूप से बड़े पैमाने पर एनकोडेक मिश्रित डेटासेट (जैसे, 10 दिनों के लिए 4x A100 GPU) के लिए, छोटे अनुसंधान समूहों या व्यक्तिगत डेवलपर्स के लिए एक व्यावहारिक बाधा का भी प्रतिनिधित्व करते हैं।
आगे देखते हुए, इन निष्कर्षों को विकसित करने और विकसित करने के लिए कई रोमांचक चर्चा विषय उभरते हैं:
- अनुकूली हानि फ़ंक्शन डिजाइन: STFT हानि ट्रेड-ऑफ को देखते हुए, क्या हम हानि कार्यों के लिए गतिशील या संदर्भ-जागरूक भारण का पता लगा सकते हैं? उदाहरण के लिए, एक अनुकूली तंत्र जो कुछ आवृत्ति बैंडों में या विशिष्ट ऑडियो घटनाओं के दौरान चरण जानकारी को प्राथमिकता देता है, कलाकृतियों को फिर से पेश किए बिना और भी बेहतर अवधारणात्मक गुणवत्ता प्रदान कर सकता है। इसमें सीखने योग्य भार गुणांक या एक बहु-उद्देश्यीय अनुकूलन ढांचा शामिल हो सकता है।
- "समान सीधेपन" नमूनाकरण से परे: "समान सीधेपन" विधि एक चतुर अनुमान है, लेकिन क्या होगा यदि इष्टतम नमूना प्रक्षेप पथ लेटेंट स्पेस के सभी क्षेत्रों में सख्ती से "समान रूप से सीधा" न हो? भविष्य का काम इष्टतम, गैर-समान नमूना अनुसूचियों की खोज के लिए अधिक उन्नत अनुकूली ODE सॉल्वर या सुदृढीकरण सीखने के दृष्टिकोण की जांच कर सकता है जो निष्ठा को अधिकतम करते हुए चरणों को और कम करते हैं, संभावित रूप से विशिष्ट ऑडियो विशेषताओं के अनुरूप अनुसूची को भी तैयार करते हैं।
- चरम आउट-ऑफ-डिस्ट्रीब्यूशन डेटा के लिए उन्नत सामान्यीकरण: जबकि RFWave उत्कृष्ट प्रदर्शन करता है, वास्तविक दुनिया का ऑडियो अविश्वसनीय रूप से विविध और अक्सर शोरगुल वाला होता है। हम इन मॉडलों को अत्यधिक दूषित, अत्यंत कम-संसाधन, या पूरी तरह से उपन्यास ऑडियो प्रकारों के प्रति और भी अधिक मजबूत कैसे बना सकते हैं? इसमें तेजी से अनुकूलन के लिए मेटा-लर्निंग, विशाल अनलेबल ऑडियो पर स्व-पर्यवेक्षित शिक्षण, या स्पष्ट शोर मॉडलिंग क्षमताओं को शामिल करना शामिल हो सकता है।
- बाधित हार्डवेयर पर वास्तविक समय परिनियोजन: एक उच्च-स्तरीय GPU पर वास्तविक समय से 160x प्राप्त करना बहुत अच्छा है, लेकिन मोबाइल उपकरणों या एम्बेडेड सिस्टम पर सर्वव्यापी अनुप्रयोगों के लिए, आगे अनुकूलन की आवश्यकता है। इसमें मॉडल क्वांटिज़ेशन, प्रूनिंग, नॉलेज डिस्टिलेशन, या विशेष आर्किटेक्चर को डिजाइन करना शामिल हो सकता है जो एज हार्डवेयर पर स्वाभाविक रूप से अधिक कुशल हों, वास्तविक समय ऑडियो संश्लेषण में क्या संभव है, इसकी सीमाओं को आगे बढ़ाते हुए।
- मल्टी-मोडल और इंटरैक्टिव ऑडियो जनरेशन: वर्तमान कार्य मेल-स्पेक्ट्रोग्राम और असतत टोकन पर केंद्रित है। RFWave को सीधे अन्य तौर-तरीकों जैसे टेक्स्ट, वीडियो, या यहां तक कि उपयोगकर्ता-परिभाषित मापदंडों (जैसे, भावनात्मक संकेत, स्थानिक ऑडियो गुण) को शामिल करने के लिए विस्तारित करने से नई रचनात्मक अनुप्रयोगों और अधिक सहज मानव-कंप्यूटर इंटरैक्शन को अनलॉक किया जा सकता है। कल्पना करें कि एक वीडियो दृश्य के मूड या उपयोगकर्ता के इशारे इनपुट से पूरी तरह मेल खाने वाला ऑडियो उत्पन्न हो रहा है।
- अवधारणात्मक रूप से संरेखित मेट्रिक्स का विकास: देखी गई ViSQOL पूर्वाग्रह एक व्यापक आवश्यकता को रेखांकित करता है। हम नए वस्तुनिष्ठ मेट्रिक्स कैसे विकसित कर सकते हैं जो अधिक मजबूत, कम पक्षपाती हों, और सिंथेटिक ऑडियो में "स्वाभाविकता" और "गुणवत्ता" की धारणा के साथ अधिक निकटता से संरेखित हों, खासकर जब मॉडल तेजी से जटिल और उपन्यास ध्वनियाँ उत्पन्न करते हैं? इसमें मानव-इन-द-लूप प्रतिक्रिया या उन्नत साइकोअकॉस्टिक मॉडलिंग का लाभ उठाना शामिल हो सकता है।
- नैतिक निहितार्थ और सुरक्षा उपाय: जैसे-जैसे ऑडियो संश्लेषण वास्तविक रिकॉर्डिंग से अप्रभेद्य हो जाता है, नैतिक निहितार्थ, जैसे कि डीपफेक का निर्माण या गलत सूचना में दुरुपयोग, बढ़ते हैं। भविष्य के शोध को सिंथेटिक ऑडियो की वॉटरमार्किंग के तरीकों की खोज करके, मजबूत पहचान तंत्र विकसित करके, या मॉडल डिजाइन और परिनियोजन प्रक्रिया में सीधे नैतिक दिशानिर्देशों को एकीकृत करके इन चिंताओं को सक्रिय रूप से संबोधित करना चाहिए। यह उन्नत जनरेटिव AI का एक महत्वपूर्ण, अक्सर अनदेखा किया जाने वाला, पहलू है।