RFWave: 오디오 파형 복원을 위한 다중 대역 정류 흐름
Recent advancements in generative modeling have significantly enhanced the reconstruction of audio waveforms from various representations.
배경 및 학문적 계보
기원 및 학문적 계보
저차원 특징을 사실적이고 인지 가능한 소리로 변환하는 오디오 파형 복원 문제는 향상된 디지털 상호작용에 대한 수요 증가에서 비롯되었다. 이 기술은 가상 비서, 엔터테인먼트 시스템, 텍스트 음성 변환 합성 등 고품질의 자연스러운 음성 및 음악 생성이 무엇보다 중요한 다양한 응용 분야에서 필수적이다. 역사적으로 이 분야는 고급 생성 모델의 등장과 함께 전통적인 신호 처리 방법을 넘어섰다(Kawahara et al., 1999; Morise et al., 2016).
초기 주요 발전은 두 가지 주요 패러다임에서 이루어졌다: 자기회귀 모델과 생성적 적대 신경망(GAN)(Goodfellow et al., 2014)이다. 자기회귀 모델은 고품질 오디오를 생성할 수 있었지만 생성 속도가 매우 느리다는 심각한 한계가 있었다. 이 느린 속도는 개별 샘플 포인트를 순차적으로 예측하는 데서 비롯되었으며(Oord et al., 2016; Kalchbrenner et al., 2018; Valin & Skoglund, 2019), 실시간 응용에는 비현실적이었다. GAN은 샘플 포인트를 병렬로 예측하여 더 빠른 생성을 제공했지만(Kumar et al., 2019; Yamamoto et al., 2020; Kong et al., 2020a), 자체적인 "고충점"을 도입했다. 여기에는 복잡한 판별자 설계의 필요성과 훈련 불안정 또는 모드 붕괴(Thanh-Tung et al., 2018)와 같은 문제가 포함되었는데, 이는 모델이 데이터의 전체 다양성을 학습하지 못할 수 있음을 의미한다.
최근에는 확산 모델(Song et al., 2020; Ho et al., 2020)이 유망한 대안으로 등장하여 훈련 안정성을 높이고 고품질 파형을 복원할 수 있는 능력을 제공했다(Chen et al., 2020; Kong et al., 2020b; gil Lee et al., 2022). 그러나 확산 모델은 상당한 한계를 물려받았는데, 이는 GAN보다 적어도 한 자릿수 느리다는 것이다. 이 느린 속도는 주로 두 가지 요인에 기인했다: (1) 고품질 샘플을 달성하기 위해 수많은 샘플링 단계가 필요하다는 점, (2) 개별 파형 샘플 포인트 수준에서 작동한다는 점이다. 후자는 종종 프레임 속도와 샘플 속도 해상도를 연결하기 위해 여러 업샘플링 작업을 포함하여 시퀀스 길이 증가, GPU 메모리 사용량 증가, 상당한 계산 요구 사항으로 이어졌다. 확산 모델의 느린 추론 속도라는 이 근본적인 한계는 RFWave가 해결하고자 하는 핵심 "고충점"이며, 확산 모델의 안정성과 품질을 유지하면서 GAN 기반 속도에 맞추기 위해 노력한다.
직관적인 도메인 용어
다음은 논문의 전문 용어를 초보자를 위한 일상적인 비유로 번역한 것이다.
- 멜 스펙트로그램 (Mel-spectrogram): 노래를 시각적으로 표현하는 악보 한 장이 있다고 상상해 보라. 멜 스펙트로그램은 이와 유사하지만, 컴퓨터가 이해할 수 있는 소리의 디지털 "그림"이다. 시간 경과에 따른 다양한 주파수의 음량이 어떻게 변하는지를 보여주며, 인간이 음높이를 인식하는 방식을 모방한 특수 스케일(멜 스케일)을 사용한다. 이는 기계용 악보와 같아서 소리의 중요한 부분을 강조한다.
- 정류 흐름 (Rectified Flow): A 지점에서 B 지점으로의 여정을 생각해 보라. 일반적으로 구불구불한 길을 여러 번 꺾어서 갈 수 있다. 정류 흐름은 A 지점(잡음 데이터)과 B 지점(깨끗한 오디오) 사이의 가장 직접적이고 직선적인 경로를 찾는 것과 같다. 이 "직선 고속도로"는 여정을 훨씬 빠르고 효율적으로 만들어 모델이 더 적은 단계로 잡음을 소리로 변환할 수 있게 한다.
- 확산 모델 (Diffusion Models): 점차 선명하고 날카로워지는 매우 흐릿한 사진을 상상해 보라. 확산 모델은 유사하게 작동한다: 무작위 잡음(완전히 흐릿한 이미지와 같음)으로 시작하여 확산 과정을 역전시킴으로써 점진적으로 단계별로 일관성 있고 고품질의 오디오 파형으로 변환한다. 마치 예술가가 캔버스에 세부 사항을 천천히 추가하여 걸작이 나타날 때까지 작업하는 것과 같다.
- 모드 붕괴 (Mode Collapse, GAN에서): 다양한 요리를 만들어 달라는 요청을 받았지만 완벽하게 한 가지 요리만 만드는 법을 배우고 다른 모든 레시피는 무시하는 요리사를 상상해 보라. GAN과 같은 생성 모델에서 모드 붕괴는 모델이 다양한 출력을 생성하지 못하고 대신 유사하고 고품질인 샘플의 제한된 세트만 생성하는 것을 의미한다. 마치 스테이크나 샐러드를 요청받았을 때도 요리사가 가장 잘 할 수 있는 것만 알기 때문에 항상 완벽한 파스타만 만드는 것과 같다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $Z_t$ | 변환 과정 중 주어진 시간 $t$에서의 데이터의 진화 상태. |
| $v(Z_t, t)$ | 시간 $t$에서 데이터 $Z_t$가 어떻게 변화하는지를 지시하는 "속도" 필드로, 목표를 향해 안내한다. |
| $\pi_0$ | 초기 확률 분포, 일반적으로 무작위 잡음을 나타낸다. |
| $\pi_1$ | 목표 확률 분포, 원하는 실제 오디오 데이터를 나타낸다. |
| $X_0$ | 일반적으로 $\pi_0$에서 추출된 무작위 잡음인 초기 데이터 샘플. |
| $X_1$ | $\pi_1$에서 추출된 실제 오디오 파형 또는 스펙트로그램의 기준점인 목표 데이터 샘플. |
| $X_t$ | 시간 $t$에서의 중간 데이터 샘플, $X_0$와 $X_1$ 사이의 보간을 나타낸다. |
| $t$ | 시간 변수, 0(변환 시작)에서 1(변환 끝)까지 진행된다. |
| $C$ | 오디오 생성을 안내하는 멜 스펙트로그램 또는 이산 음향 토큰과 같은 조건부 입력. |
| $N$ | 푸리에 변환(FFT)의 크기, 주파수 해상도를 결정한다. |
| $d_s$ | 특정 하위 대역의 복소 스펙트럼 내 주파수 빈의 수. |
| $F$ | 스펙트로그램의 총 프레임 수, 시간 세그먼트를 나타낸다. |
| $i_{sb}$ | 특정 하위 대역을 식별하는 인덱스. |
| $i_{bw}$ | EnCodec 토큰에 대한 대역폭 인덱스, 다른 압축 수준에 사용된다. |
| $\sigma$ | 에너지 균형 손실에서 사용되는 가중치 계수, 종종 기준점 속도의 표준 편차에서 파생된다. |
| $S(v)$ | 학습된 속도 필드의 궤적의 "직선성" 측정값, 변환 경로가 얼마나 직접적인지를 나타낸다. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
이 논문에서 다루는 핵심 문제는 멜 스펙트로그램 또는 이산 음향 토큰과 같은 다양한 압축 표현에서 고충실도 오디오 파형을 효율적으로 복원하는 과제이다.
이 문제에 대한 입력/현재 상태는 다음과 같다:
* 저차원 오디오 특징, 특히 멜 스펙트로그램 또는 이산 음향 토큰으로, 이는 소리의 압축된 표현이다.
* 주로 확산 모델과 생성적 적대 신경망(GAN)과 같은 기존 생성 모델로, 각각 고유한 한계를 가지고 있다. 확산 모델은 고품질 오디오를 생성할 수 있지만 개별 파형 샘플 포인트 수준에서 작동하고 수많은 샘플링 단계가 필요하여 상당한 지연 시간을 초래한다. GAN은 더 빠르지만 종종 훈련 불안정 및 모드 붕괴로 어려움을 겪으며 복잡한 판별자 설계를 필요로 한다.
원하는 최종 상태/목표 상태는 다음과 같다:
* 이러한 저차원 입력에서 복원된 고충실도 오디오 파형.
* GAN 기반 방법(즉, 실시간 또는 그 이상)의 추론 속도를 달성하면서 확산 모델의 훈련 안정성과 높은 샘플 품질 특성을 유지하는 생성 모델.
* 매우 적은 수의 샘플링 단계(예: RFWave에서 달성된 10단계)로 파형을 복원하는 능력.
* 실시간보다 훨씬 빠른 속도(예: GPU에서 최대 160배 빠른 속도)로 오디오 생성을 가능하게 하는 우수한 계산 효율성.
* 멜 스펙트로그램과 이산 음향 토큰 모두에서 오디오를 복원하는 다용성.
현재 상태와 원하는 최종 상태 사이의 정확한 누락된 연결 또는 수학적 격차는 확산 모델의 고품질 지각 품질 및 훈련 안정성과 GAN의 고속 계산 효율성 및 저지연 시간을 동시에 달성할 수 있는 생성 모델링 프레임워크의 부재이다. 이전 확산 모델은 여러 단계를 거쳐 신호를 점진적으로 노이즈 제거하도록 수학적으로 공식화되어 본질적으로 느리다. GAN은 빠르지만 안정적인 훈련과 일관된 품질에 대한 강력한 수학적 보증이 부족하다. 이 논문은 잡음과 데이터 분포 사이의 직접적이고 직선적인 운송 궤적을 학습하여 샘플링 단계를 줄이는 것을 목표로 하는 정류 흐름을 활용하여 이 격차를 해소하려고 시도한다. 구체적으로, 정류 흐름은 초기 잡음 분포 $\pi_0$에서 목표 데이터 분포 $\pi_1$로의 잡음 샘플 $Z_t$의 진화를 지배하는 속도 필드 $v(Z_t, t)$를 학습하여 $\frac{dZ_t}{dt} = v(Z_t, t)$가 된다. 학습 목표는 직선 궤적에서의 편차를 최소화한다:
$$ \min E_{(X_0, X_1)\sim\gamma} \int_0^1 || \frac{d}{dt}X_t - v(X_t, t) ||^2 dt $$
여기서 $X_t = (1-t)X_0 + tX_1$는 선형 보간을 나타낸다. 이 수학적 공식은 더 적고 직접적인 단계를 가능하게 하여 추론 프로세스를 가속화하는 핵심이다.
이전 연구자들을 가두었던 고통스러운 절충 또는 딜레마는 오디오 품질/훈련 안정성과 추론 속도/계산 효율성 사이의 근본적인 충돌이다. 한 측면을 개선하면 일반적으로 다른 측면이 저하된다:
* 확산 모델: 우수한 오디오 품질과 안정적인 훈련을 제공하지만 악명 높게 느리다. "개별 샘플 포인트 수준"에서의 작동과 "수많은 샘플링 단계"의 필요성(종종 수백 또는 수천 단계)은 높은 지연 시간과 계산 요구 사항으로 이어진다.
* GAN: 샘플 포인트를 병렬로 예측하여 빠른 생성 속도를 제공하지만, "복잡한 판별자 설계 및 불안정 또는 모드 붕괴와 같은 문제"로 어려움을 겪어 안정적으로 훈련하기가 더 어렵고 때로는 품질이 낮거나 덜 다양한 출력을 초래한다.
이 딜레마는 연구자들이 이전에는 고품질, 안정적이지만 느린 모델 또는 빠르지만 잠재적으로 불안정하고 품질이 낮은 모델 중에서 선택해야 했음을 의미한다. 이 논문은 이 절충을 깨는 것을 목표로 한다.
제약 조건 및 실패 모드
고충실도 실시간 오디오 파형 복원 문제는 몇 가지 가혹하고 현실적인 제약 조건과 내재된 실패 모드로 인해 매우 어렵다:
-
계산 비용 및 GPU 메모리 제한:
- 샘플 포인트 수준 작동: 이전 확산 모델은 개별 샘플 포인트 수준에서 오디오를 처리한다. 이는 "프레임 속도 해상도에서 샘플 속도 해상도로 전환하기 위한 여러 업샘플링 작업이 필요하여 시퀀스 길이가 증가하고 결과적으로 GPU 메모리 사용량과 계산 요구 사항이 증가한다"(2페이지). 고해상도 오디오(예: 44.1kHz 또는 48kHz)의 경우 초당 수백만 개의 샘플을 처리하는 것은 계산상 불가능하고 메모리 집약적이다. 예를 들어, PriorGrad는 30GB의 GPU 메모리 내에서 44.1kHz의 6초 오디오 클립만 훈련할 수 있으며, 이는 이 심각한 메모리 제약을 강조한다(4페이지).
- 수많은 샘플링 단계: 확산 모델은 일반적으로 고품질 오디오를 생성하기 위해 수백 또는 수천 단계의 샘플링이 필요하며, 이는 추론 속도와 계산 부하에 직접적인 영향을 미친다. 이는 GAN보다 "적어도 한 자릿수 느리게" 만든다(1페이지).
-
실시간 지연 시간 요구 사항: 많은 실제 응용 프로그램(예: 가상 비서, 실시간 통신)은 극도로 낮은 지연 시간을 요구한다. 기존 확산 모델조차도 "실시간보다 약 10~20배 빠르다"(3페이지)는 점은 대규모 음향 모델과 결합될 때 진정한 실시간 상호 작용에는 충분하지 않다.
-
훈련 불안정 및 모드 붕괴 (GAN의 경우): GAN은 속도를 제공하지만 훈련이 악명 높게 어렵다. "복잡한 판별자 설계"와 "불안정 또는 모드 붕괴"와 같은 문제(1페이지)는 전체 데이터 분포를 학습하지 못할 수 있음을 의미하며, 이는 덜 다양하거나 품질이 낮은 출력을 초래한다.
-
다중 대역 처리에서의 오류 누적: 다중 대역 전략을 사용할 때 "더 높은 대역을 더 낮은 대역에 조건화하는 것은 오류 누적으로 이어질 수 있으며, 이는 추론 중에 더 낮은 대역의 부정확성이 더 높은 대역에 악영향을 미칠 수 있다"(4페이지). 이는 주파수 스펙트럼의 한 부분의 오류가 전파되어 다른 부분을 손상시킬 수 있음을 의미한다.
-
무음 영역의 저음량 잡음: 평균 제곱 오차(MSE) 손실로 훈련된 모델의 일반적인 실패 모드는 "예상되는 무음 영역의 저음량 잡음"의 존재이다(5페이지). 이는 무음 부분의 작은 오류가 전체 MSE에 최소한의 기여를 하므로 모델이 고진폭 영역의 더 큰 오류를 줄이는 것을 우선시하여 조용한 부분에서 인지 가능한 잡음을 초래하기 때문이다.
-
하위 대역 간의 불일치: 서로 다른 주파수 하위 대역이 독립적으로 예측될 때 "그들 사이의 불일치"의 위험이 있으며, 이는 복원된 파형의 하위 대역 경계에서 가청 아티팩트로 이어진다(6페이지).
-
배경 잡음의 아티팩트: STFT 손실과 같은 특정 손실 함수 없이는 모델이 "배경 잡음이 있는 상태에서 수직 패턴" 또는 기타 "아티팩트"를 생성할 수 있으며(그림 A.8, 6페이지), 지각 품질을 저하시킨다.
-
비선형 운송 궤적: 정류 흐름의 효과는 "직선 운송 궤적"을 학습하는 데 달려 있다(2페이지). 학습된 속도 필드가 선형성에서 크게 벗어나면 오일러 방법은 ODE를 정확하게 근사하기 위해 더 많은 단계가 필요하여 효율성 이점을 무효화한다. 이는 속도 필드 학습을 섬세한 작업으로 만든다.
왜 이 접근 방식인가
선택의 불가피성
RFWave가 다루는 핵심 문제는 생성 모델에서 오디오 복원 품질과 생성 속도 사이의 중요한 절충이다. 전통적인 최첨단(SOTA) 방법은 고급이었지만 각각 동시에 고충실도와 실시간 성능을 달성하기에 불충분한 상당한 한계를 제시했다.
저자들은 표준 확산 모델이 고품질 오디오 생성 능력과 안정적인 훈련에도 불구하고 본질적으로 두 가지 요인에 의해 방해받는다는 것을 깨달았다: (1) 개별 파형 샘플 포인트 수준에서의 작동, (2) 원하는 품질을 달성하기 위해 수많은 샘플링 단계가 필요하다는 점이다. 이는 심각한 지연 시간 문제와 높은 GPU 메모리 소비로 이어져 GAN보다 적어도 한 자릿수 느리고 실시간 응용에는 비현실적이었다. 논문은 이 불충분함을 명시적으로 언급한다: "확산 모델은 이 작업에 능숙하지만, 개별 샘플 포인트 수준에서의 작동과 수많은 샘플링 단계의 필요성으로 인해 지연 시간 문제로 방해받는다." (초록). 이 불충분함은 가장 빠른 확산 방법조차 실시간보다 10~20배만 빠르다는 관찰에 의해 더욱 강조되었으며, 이는 실제 응용 프로그램의 요구 사항과는 거리가 멀다.
샘플 포인트를 병렬로 예측하여 더 빠른 생성 속도를 제공하는 생성적 적대 신경망(GAN)은 본질적인 훈련 불안정성과 모드 붕괴와 같은 문제로 어려움을 겪었으며, 종종 복잡한 판별자 설계를 필요로 했다. 또 다른 생성 모델 계열인 자기회귀 모델도 샘플 포인트를 순차적으로 예측하여 용납할 수 없을 정도로 느린 생성 속도를 초래했기 때문에 거부되었다.
정류 흐름과 다중 대역, 프레임 수준 처리 전략의 조합은 이러한 근본적인 한계를 직접적으로 해결하기 때문에 유일하게 실행 가능한 해결책으로 부상했다. 이는 확산 모델의 높은 샘플 품질과 훈련 안정성을 달성하는 동시에 실용적인 메모리 제약 내에서 GAN의 생성 속도를 일치시키고 심지어 능가하는 메커니즘을 제공한다. 비교 연구는 또한 "정류 흐름이 우리 모델이 고품질 오디오 샘플을 효율적으로 생성하는 데 중요하다"(9페이지)고 강조하며, 더 많은 단계를 가진 전통적인 확산 잡음 스케줄은 부족했다.
비교 우위
RFWave는 단순한 성능 지표를 훨씬 뛰어넘는 압도적인 질적 우위를 이전의 금본위제에 보여준다.
첫째, 속도 측면에서 RFWave는 GPU에서 실시간보다 최대 160배 빠른 추론 속도를 달성한다(초록). 이는 일반적으로 실시간보다 10~20배 빠른 확산 모델보다 훨씬 뛰어나며 많은 GAN 기반 방법보다도 뛰어나다. 예를 들어, 표 7은 RFWave의 GPU xRT(실시간 배수)를 162.59로 보여주며, 이는 BigVGAN의 72.68 및 PriorGrad의 16.67과 비교된다. 이 구조적 이점은 정류 흐름이 직선 운송 궤적을 학습하여 단 10개의 샘플링 단계로 고품질 복원을 가능하게 하는 능력에서 비롯되며, 이는 다른 확산 모델보다 훨씬 적은 수이다.
둘째, 품질에 관해서는 RFWave는 객관적 지표(예: MOS, PESQ, ViSQOL)와 주관적 평가(표 1) 모두에서 PriorGrad 및 FreGrad와 같은 확산 기반 기준선을 일관되게 능가한다. GAN인 BigVGAN 및 Vocos와 동일한 수준의 성능을 보이지만, 도메인 외 데이터(MUSDB18 데이터셋)에서는 그 우수성이 분명해진다. 여기서 RFWave는 "상당한 이점"(8페이지)을 보여주며, GAN이 "수평선"을 생성하여 "금속성 음질"을 초래하는 것과 달리 더 명확하고 잘 정의된 고주파 하모닉스를 생성한다. 이는 RFWave의 우수한 일반화 및 견고성을 나타낸다.
셋째, RFWave는 훨씬 우수한 계산 효율성 및 메모리 복잡성을 제공한다. 개별 파형 샘플 포인트 대신 STFT(Short-Time Fourier Transform) 프레임 수준에서 작동함으로써 GPU 메모리 사용량을 대폭 줄인다. 이 구조적 이점은 RFWave가 PriorGrad(샘플 포인트 확산 보코더)가 6초 클립에 사용하는 것과 동일한 메모리 리소스로 177초 오디오 클립을 처리할 수 있게 한다(4페이지). 표 7은 RFWave가 780MB의 GPU 메모리를 사용하는 반면 PriorGrad는 4976MB, MBD는 5480MB를 사용하는 것을 보여준다. 이 프레임 수준 처리는 샘플 포인트 모델을 괴롭히는 "여러 업샘플링 작업"과 시퀀스 길이 증가를 피하여 GPU 메모리 사용량과 계산 요구 사항을 증가시킨다.
마지막으로, 다중 대역 전략은 핵심 구조적 이점이다. 서로 다른 하위 대역을 동시에 생성하고 단일 통합 모델로 병렬로 모델링함으로써 RFWave는 더 높은 대역이 순차적으로 더 낮은 대역에 조건화될 때 발생할 수 있는 오류 누적을 방지한다. 이는 오디오 품질을 보장할 뿐만 아니라 합성 속도를 향상시킨다. 세 가지 향상된 손실 함수(에너지 균형, 오버랩 및 STFT 손실)와 최적화된 "균등 직선성" 샘플링 전략의 통합은 전반적인 품질과 견고성을 더욱 향상시키며, 특히 저음량 영역 처리, 하위 대역 전환 보장 및 아티팩트 감소에 효과적이다.
제약 조건과의 일치
선택된 정류 흐름 접근 방식은 아키텍처 혁신과 결합되어 고충실도, 실시간 오디오 파형 복원의 엄격한 요구 사항과 완벽하게 일치한다.
-
고충실도 오디오 품질: 이 문제는 뛰어난 오디오 품질을 요구한다. RFWave는 확산 유형 모델의 고유한 품질 보존 기능을 활용하고 정류 흐름의 직접적이고 고품질 매핑을 학습하는 능력을 통해 이를 달성한다. 세 가지 향상된 손실 함수(에너지 균형, 오버랩 및 STFT 손실)와 "균등 직선성" 샘플링 전략은 특히 저음량 영역의 잡음을 억제하고 하위 대역 전환을 보장하며 고주파 세부 정보를 보존하여 지각 품질을 개선하기 위해 특별히 설계되었다. 이러한 강력한 생성 프레임워크와 대상 품질 향상의 "결합"은 출력이 단순히 좋지 않고 "뛰어나다"는 것을 보장한다(초록).
-
실시간 생성 속도: 중요한 제약 조건은 이전 확산 모델의 지연 시간을 극복하는 것이었다. 정류 흐름의 직선 운송 궤적은 샘플링 단계를 10단계까지 대폭 줄여 추론 속도 문제에 대한 직접적인 해결책이다. 또한, 개별 샘플 포인트 수준이 아닌 STFT 프레임 수준에서 작동함으로써 하위 대역의 병렬 처리가 가능하여 계산이 크게 가속화된다. 이 조합은 실시간보다 최대 160배 빠른 생성 속도를 제공하여 실시간 적용 요구 사항을 직접적으로 충족한다.
-
효율적인 리소스 활용: 샘플 포인트 수준 처리의 높은 GPU 메모리 및 계산 요구 사항은 주요 병목 현상이었다. RFWave의 프레임 수준 작동은 이 제약 조건에 완벽하게 적합하여 "더 효율적인 처리와 GPU 메모리 사용량 감소"를 가능하게 한다(2페이지). 이를 통해 모델은 다른 모델이 짧은 클립(예: 6초)을 처리하는 데 사용하는 것과 동일한 메모리로 훨씬 더 긴 오디오 클립(예: 177초)을 처리할 수 있어 다양한 응용 프로그램에 실용적이다.
-
훈련 안정성: GAN은 훈련 불안정성과 모드 붕괴로 어려움을 겪었다. 확산 유형 모델로서 RFWave는 본질적으로 확산 모델이 제공하는 "훈련 중 안정성"의 이점을 누려 GAN 기반 대안의 주요 함정을 피한다.
-
입력 표현의 다용성: 이 문제는 다양한 입력에서 파형을 복원하는 유연성을 요구한다. RFWave는 멜 스펙트로그램과 이산 음향 토큰 모두에서 파형을 복원하도록 설계되어 다양한 오디오 생성 작업에 대한 다용성과 적용 가능성을 향상시킨다.
이러한 신중한 설계는 RFWave가 단순히 성능이 뛰어난 모델이 아니라 효율적이고 고품질의 오디오 복원의 가혹하고 다면적인 요구 사항을 충족하도록 목적에 맞게 제작되었음을 보장한다.
대안의 거부
이 논문은 다른 인기 있는 오디오 파형 복원 접근 방식을 거부하는 명확한 이유를 제공한다:
-
전통적인 확산 모델 (예: DiffWave, WaveGrad, PriorGrad, FreGrad, Multi-Band Diffusion): 이러한 모델은 주로 느린 생성 속도와 높은 계산 요구 사항으로 인해 거부되었다. 논문은 "개별 샘플 포인트 수준에서의 작동과 수많은 샘플링 단계의 필요성으로 인한 지연 시간 문제로 방해받는다"(초록). 구체적으로, 이들은 "GAN보다 적어도 한 자릿수 느리며" "실시간보다 약 10~20배만 빠르다"(서론, 3페이지)는 점은 실시간 적용 가능성을 제한한다. RFWave는 정류 흐름을 사용하여 샘플링 단계를 10단계로 줄이고 STFT 프레임 수준에서 작동하여 메모리 및 계산 오버헤드를 줄여 실시간 속도의 160배를 달성함으로써 이를 직접적으로 해결한다. 비교 연구는 50단계의 표준 확산 잡음 스케줄(DDPM)을 사용한 것이 성능에서 "기준선에 미치지 못했다"(표 6)고 명시적으로 보여주며, 정류 흐름의 필요성을 강조한다.
-
생성적 적대 신경망 (GAN) (예: HiFi-GAN, BigVGAN, Vocos, APNet2): GAN은 더 빠른 생성 속도를 제공하지만, 본질적인 훈련 불안정성과 모드 붕괴와 같은 문제로 인해 거부되었다(서론). GAN은 종종 "복잡한 판별자 설계"를 필요로 하며 "파멸적인 망각"(Thanh-Tung et al., 2018)으로 어려움을 겪을 수 있다. 또한, 도메인 외 데이터의 경우 BigVGAN 및 Vocos와 같은 GAN 기반 모델은 "스펙트로그램의 고주파 영역에 수평선"을 생성하는 경향이 있어 "금속성 음질"을 초래하여 자연스러움을 저하시킨다(8페이지, 그림 A.7). 확산 유형 모델로서 RFWave는 GAN의 도메인 외 일반화 능력을 능가하고 속도를 일치시키거나 능가하면서 확산 모델의 "훈련 중 안정성"을 상속한다.
-
자기회귀 모델 (예: WaveNet): 이러한 모델은 샘플 포인트를 순차적으로 예측하여 발생하는 느린 생성 속도로 인해 부적합한 것으로 간주되었다(서론). 이 순차적 특성은 실시간 오디오 합성에 본질적으로 비효율적이며, 이는 문제의 핵심 요구 사항이다. RFWave의 프레임 수준에서의 병렬 처리와 줄어든 샘플링 단계는 이 한계에 대한 직접적인 대응을 제공한다.
-
샘플 포인트 수준 처리: 많은 초기 확산 및 자기회귀 모델에서 일반적인 이 접근 방식은 "프레임 속도 해상도에서 샘플 속도 해상도로 전환하기 위한 여러 업샘플링 작업이 필요하여 시퀀스 길이가 증가하고 결과적으로 GPU 메모리 사용량과 계산 요구 사항이 증가한다"(서론)는 이유로 거부되었다. RFWave의 STFT 프레임 수준 작동으로의 전환은 이러한 메모리 및 계산 병목 현상을 직접적으로 완화한다.
수학적 및 논리적 메커니즘
마스터 방정식
RFWave를 구동하는 핵심 방정식은 에너지 균형 강화와 함께 훈련 중에 최소화되는 목표 함수이다. 이 방정식은 모델이 잡음을 대상 오디오 표현으로 변환하는 속도 필드를 학습하는 방법을 정의한다.
$$
\min_{v} E_{X_0 \sim \pi_0, (X_1, C) \sim D} \left[ \int_0^1 \left\| \frac{(X_1 - X_0)}{\sigma} - v(X_t, t | C)/\sigma \right\|^2 dt \right]
$$
여기서 $\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$이고 $X_t = (1 - t)X_0 + tX_1$이다.
항별 분석
이 마스터 방정식을 분해하여 각 구성 요소의 수학적 정의, 물리적/논리적 역할 및 저자의 설계 선택을 이해해 보자.
-
$v$: 이는 신경망이 학습하는 속도 필드를 나타낸다.
- 수학적 정의: 이는 데이터 공간 $\mathbb{R}^d$, 시간 간격 $[0, 1]$, 조건부 입력 공간 $\mathcal{C}$에 대한 함수 $v: \mathbb{R}^d \times [0, 1] \times \mathcal{C} \to \mathbb{R}^d$이다. RFWave에서는 이것이 신경망(특히 ConvNeXtV2 백본)으로 매개변수화된다.
- 물리적/논리적 역할: 이것이 모델의 핵심 출력이다. 주어진 중간 상태 $X_t$와 시간 $t$에서 데이터 공간의 순간적인 "속도" 또는 방향을 조건부 입력 $C$에 따라 예측한다. 신경망의 목표는 잡음에서 데이터로의 직선 이동을 예측하는 방법을 학습하는 것이다.
- 설계 선택: 신경망은 고차원 입력($X_t, t, C$)에서 고차원 출력($v$)으로 복잡하고 비선형적인 매핑을 학습할 수 있기 때문에 사용된다.
-
$E_{X_0 \sim \pi_0, (X_1, C) \sim D}$: 이는 샘플에 대한 기대값(평균)을 나타낸다.
- 수학적 정의: 이는 $(X_0, X_1)$ 쌍과 조건부 입력 $C$에 대한 통계적 평균이다. $X_0$는 사전 잡음 분포 $\pi_0$(예: 표준 가우시안 잡음)에서 샘플링되고, $(X_1, C)$는 실제 데이터 분포 $D$(예: $X_1$은 대상 복소 스펙트로그램, $C$는 멜 스펙트로그램)에서 샘플링된다.
- 물리적/논리적 역할: 이는 모델이 특정 예제를 암기하는 것이 아니라 광범위한 잡음 입력과 대상 데이터에 대해 일반화하는 방법을 학습하도록 보장한다. 여러 샘플에 대한 평균 손실은 훈련을 견고하게 만든다.
-
$\int_0^1 \dots dt$: 이는 시간 변수 $t$에 대한 정적분이다.
- 수학적 정의: 이는 $t=0$에서 $t=1$까지의 연속 시간 간격에 걸쳐 순간 제곱 오차를 합산한다.
- 물리적/논리적 역할: 정류 흐름은 잡음에서 데이터로의 연속적인 궤적을 설명한다. 이 전체 경로에 걸쳐 손실을 적분하면 학습된 속도 필드가 이산적인 스냅샷뿐만 아니라 모든 중간 지점에서 일관되고 정확하도록 보장된다. 이 연속적인 공식화는 ODE 기반 생성 모델의 기본이다.
-
$\left\| \cdot \right\|^2$: 이는 제곱 $L_2$ 노름(유클리드 거리)이다.
- 수학적 정의: 벡터 $z$에 대해 $\|z\|^2 = \sum_i z_i^2$이다. 이는 차이 벡터의 제곱 크기를 측정한다.
- 물리적/논리적 역할: 이 항은 정규화된 기준점 속도와 정규화된 예측 속도 간의 평균 제곱 오차(MSE)를 계산한다. 이 제곱 차이를 최소화하는 것은 회귀 작업에서 표준 접근 방식이며, 모델의 예측이 실제 값에 최대한 가깝도록 권장한다. 이는 미분 가능성과 볼록 속성으로 인해 기울기 기반 최적화에 유리하다.
-
$X_1$: 이는 대상 데이터를 나타낸다.
- 수학적 정의: 대상 데이터 분포 $\pi_1$의 샘플로, 모델이 복원하고자 하는 기준점 오디오 파형 또는 복소 스펙트로그램이다.
- 물리적/논리적 역할: 이는 원하는 출력, 즉 생성 프로세스가 수렴해야 하는 "깨끗한" 오디오 표현이다.
-
$X_0$: 이는 초기 잡음을 나타낸다.
- 수학적 정의: 일반적으로 표준 가우시안 잡음 $N(0,1)$인 사전 잡음 분포 $\pi_0$의 샘플이다.
- 물리적/논리적 역할: 이는 생성 프로세스의 시작점으로, 모델이 의미 있는 오디오로 변환할 무작위 입력이다.
-
$C$: 이는 조건부 입력이다.
- 수학적 정의: 멜 스펙트로그램 또는 이산 음향 토큰.
- 물리적/논리적 역할: 이는 생성을 위한 안내 정보를 제공한다. 예를 들어, 멜 스펙트로그램을 오디오 파형으로 변환하는 것이 목표라면 $C$는 해당 멜 스펙트로그램이 된다. 이는 제어되고 지시된 오디오 합성을 가능하게 한다.
-
$X_t = (1 - t)X_0 + tX_1$: 이는 보간된 상태이다.
- 수학적 정의: 시간 $t$에서의 $X_0$와 $X_1$ 사이의 선형 보간이다.
- 물리적/논리적 역할: 이 항은 잡음($t=0$에서의 $X_0$)에서 데이터($t=1$에서의 $X_1$)로의 직선 경로를 따라 중간 지점을 정의한다. 모델은 이러한 중간 상태에서의 속도를 예측하는 방법을 학습한다.
-
$\frac{(X_1 - X_0)}{\sigma}$: 이는 정규화된 기준점 속도이다.
- 수학적 정의: 대상 데이터와 초기 잡음 사이의 직접적인 차이를 $\sigma$로 나눈 값이다. 이는 궤적이 완벽하게 선형이었다면 순간적인 정규화된 속도를 나타낸다.
- 물리적/논리적 역할: 이는 신경망 $v$가 근사하도록 학습해야 하는 이상적인 속도이다. $\sigma$로 나누는 것은 중요한 에너지 균형 정규화이다.
-
$v(X_t, t | C)/\sigma$: 이는 정규화된 예측 속도이다.
- 수학적 정의: $X_t, t, C$를 입력으로 받는 신경망 $v$의 출력으로, $\sigma$로도 스케일링된다.
- 물리적/논리적 역할: 이는 에너지 균형 계수로 정규화된 순간 속도에 대한 모델의 예측이다. 훈련 프로세스는 이 항을 정규화된 기준점 속도와 일치시키는 것을 목표로 한다.
-
$\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$: 이는 에너지 균형 가중치 계수이다.
- 수학적 정의: 각 주파수 하위 대역에 대해 시간 축을 따라 계산된 기준점 속도 $(X_1 - X_0)$의 표준 편차이다.
- 물리적/논리적 역할: 이 항은 저음량 잡음 영역의 문제를 해결하기 위해 도입되었다. 기준점 속도와 예측 속도 모두를 $\sigma$로 나눔으로써 손실 함수는 에너지 영역에 따라 오류의 기여도를 효과적으로 가중치를 부여한다. $\sigma$가 작을 때(저에너지/무음 영역), $1/\sigma$ 항이 커져 해당 영역의 오류 기여도가 전체 손실에 미치는 영향을 증폭시킨다. 이는 모델이 조용한 부분의 잡음을 정확하게 억제하는 데 더 많은 주의를 기울이도록 강제하여 인지 가능한 저음량 아티팩트 생성을 방지한다.
단계별 흐름
모델이 이미 훈련되었다고 가정하고, 단일 추상 데이터 포인트의 수명 주기를 추론(생성) 프로세스 중에 추적해 보자. 추론 중에 더 효율적인 주파수 영역 접근 방식을 고려할 것이다.
- 초기 잡음 주입 (궤적 시작, $t=0$): 프로세스는 표준 가우시안 잡음 분포 $N(0,1)$에서 샘플링된 초기 상태 $X_0$로 시작된다. 이 $X_0$는 대상 오디오와 동일한 차원의 복소 스펙트로그램이다. 또한 생성에 도움이 되는 조건부 입력 $C$(예: 멜 스펙트로그램)를 받는다.
- 반복 속도 예측 및 상태 업데이트 (오일러 적분): 모델은 $t=0$에서 $t=1$까지의 일련의 이산 시간 단계 $t_i$를 통해 진행된다. 각 단계 $i$에 대해:
- 현재 상태: 현재 추정 상태 $X_{t_i}$를 가지고 있으며, 이는 $X_0$로 시작한다.
- 하위 대역 분할 (해당하는 경우): 모델이 다중 대역 구조를 사용하는 경우 $X_{t_i}$는 하위 대역으로 분할된다. 각 하위 대역의 잡음 샘플($X_{t_i}^{\text{sb}}$)은 ConvNeXtV2 백본에 공급된다.
- 속도 예측: 신경망 $v$(ConvNeXtV2 백본)는 현재 상태 $X_{t_i}$(또는 해당 하위 대역 $X_{t_i}^{\text{sb}}$), 현재 시간 $t_i$, 조건부 입력 $C$(및 잠재적으로 하위 대역 인덱스 $i_{\text{sb}}$ 및 대역폭 인덱스 $i_{\text{bw}}$)를 입력으로 받아 순간 속도 $v(X_{t_i}, t_i | C)$를 예측한다.
- 오일러 단계: 예측된 속도 $v(X_{t_i}, t_i | C)$는 상태를 업데이트하는 데 사용된다. 오일러 방법과 같은 수치 ODE 솔버를 사용하여 다음 상태 $X_{t_{i+1}}$는 $X_{t_{i+1}} = X_{t_i} + v(X_{t_i}, t_i | C) \cdot \Delta t$로 계산되며, 여기서 $\Delta t = t_{i+1} - t_i$는 시간 단계 간격이다. 이는 효과적으로 데이터 포인트를 예측된 속도 벡터를 따라 이동시킨다.
- 하위 대역 병합 (해당하는 경우): 하위 대역이 독립적으로 처리되었다면, 예측된 속도가 다시 병합되어 전체 대역 속도를 형성하고, 이는 오일러 단계에 사용된다.
- 최종 스펙트로그램 복원 ($t=1$): 이 반복 프로세스는 RFWave에서 10단계와 같이 적은 수의 샘플링 단계를 거쳐 $t$가 1에 도달할 때까지 계속된다. 최종 상태 $X_1$은 복원된 복소 스펙트로그램이다.
- 파형 변환: $X_1$은 주파수 영역의 복소 스펙트로그램이므로, 최종 고충실도 오디오 파형으로 변환하기 위해 단일 역 단시간 푸리에 변환(ISTFT) 연산이 적용된다. 논문은 주파수 영역 모델의 경우 마지막에 단 한 번의 ISTFT만 필요하며, 이는 핵심 효율성 이점이라고 언급한다.
이 순서는 무작위 잡음 입력을 조건부 입력과 학습된 속도 필드에 의해 안내되는 구조화되고 고품질의 오디오 파형으로 변환한다.
최적화 역학
RFWave 메커니즘은 추가 손실 항으로 보강된 에너지 균형 정류 흐름 목표 함수를 최소화함으로써 학습, 업데이트 및 수렴한다.
-
손실 지형 성형: 주요 손실 함수(방정식 5)는 "계곡"이 정확한 속도 예측에 해당하는 손실 지형을 정의한다. 정류 흐름 공식화는 본질적으로 직선 궤적을 학습하도록 권장하며, 이는 복잡한 잡음 스케줄을 학습하는 확산 모델에 비해 더 부드럽고 다루기 쉬운 손실 지형을 만드는 경향이 있다. 중요한 $\sigma$ 항(에너지 균형 계수)은 이 지형을 동적으로 재구성한다. 저에너지 영역(예: 무음)에서는 $\sigma$가 작아져 $1/\sigma$ 항이 커진다. 이는 해당 영역의 오류 기여도를 손실에 증폭시켜 작은 편차에 대해 더 가파른 기울기를 만든다. 이는 모델이 조용한 부분의 잡음을 정확하게 억제하도록 강제하여 일반적인 저음량 아티팩트 생성 문제를 방지한다. 반대로, 고에너지 영역에서는 $\sigma$가 커져 이러한 지배적인 영역이 다른 부분의 중요성을 완전히 가리지 않도록 한다. 이 동적 가중치는 전체 오디오 스펙트럼에 걸쳐 더 균형 잡힌 학습 목표를 만든다.
-
기울기 동작: 훈련 중에 모델은 손실 함수를 신경망 매개변수에 대해 계산한다. 이러한 기울기는 오류를 줄이기 위해 매개변수를 조정하는 방법을 나타낸다.
- $L_2$ 노름은 기울기가 예측 속도 $v(X_t, t | C)$를 기준점 속도 $(X_1 - X_0)$에 정렬하도록 푸시하도록 보장한다.
- $\sigma$ 항은 기울기 크기에 직접 영향을 미친다. 낮은 $\sigma$ 값의 경우 해당 영역의 오류와 관련된 기울기가 스케일링되어 모델이 무음 부분의 속도를 더 정확하게 예측하도록 강제한다. 이는 무음 부분의 잡음을 줄이기 위한 직접적인 메커니즘이다.
- 추가 손실 함수: RFWave는 세 가지 향상된 손실 함수(에너지 균형, 오버랩 및 STFT 손실)를 통합한다. 이러한 추가 손실은 추가 기울기 신호를 제공한다:
- 오버랩 손실: 이 손실은 훈련 중에 인접한 하위 대역의 겹치는 섹션 간의 일관성을 유지하기 위해 적용된다. 이는 하위 대역이 추론 중에 나중에 병합될 때 부드러운 전환과 불연속성 방지를 보장하는 기울기를 생성한다.
- STFT 손실: 스펙트럼 수렴(SC) 손실과 로그 스케일 STFT-크기 손실로 구성된 이 항은 근사 대상 $\tilde{X}_1$에서 작동한다. SC 손실(프로베니우스 노름)은 큰 스펙트럼 구성 요소에 초점을 맞추고, 로그 스케일 STFT-크기 손실($L_1$ 노름)은 작은 진폭 구성 요소에 중점을 둔다. 이러한 손실은 모델이 스펙트럼적으로 정확한 오디오를 생성하도록 안내하는 기울기를 제공하여 아티팩트를 줄이고 전반적인 음질을 개선한다. 이러한 추가 손실의 가중치(예: 0.01)는 주요 정류 흐름 손실과의 영향 균형을 맞추기 위해 선택된다.
-
반복 상태 업데이트 및 수렴: 신경망 매개변수는 모든 손실 구성 요소의 집계 기울기에 의해 구동되는 AdamW와 같은 옵티마이저를 사용하여 반복적으로 업데이트된다. 코사인 어닐링 학습률 스케줄이 사용되며, 높은 비율(예: 2e-4)로 시작하여 최소(예: 2e-6)로 점진적으로 감소한다. 이 스케줄은 모델이 훈련 초기에 큰 조정을 하고 안정적인 수렴을 위해 매개변수를 미세 조정하도록 돕는다. 모델은 예측된 속도 필드 $v$가 시간 간격 전체에 걸쳐 $C$에 조건화된 모든 중간 상태 $X_t$를 실제 직선 속도 $(X_1 - X_0)$로 정확하게 매핑할 때 수렴한다. "균등 직선성" 샘플링 전략은 주로 추론 기술이지만, 모든 오일러 단계에 걸쳐 모델이 일관되게 도전을 받도록 보장함으로써 수렴을 간접적으로 지원하여 잠재적으로 더 견고하게 학습된 속도 필드를 초래한다.
모델 구조
모델 구조는 그림 1에 나와 있다. 각 고유한 하위 대역 인덱스로 구별되는 모든 주파수 대역은 동일한 모델을 공유한다. 주어진 샘플의 하위 대역은 처리를 위해 단일 배치로 그룹화되며, 이는 동시 훈련 또는 추론을 용이하게 한다. 이는 추론 지연 시간을 크게 줄인다. 또한, 하위 대역을 독립적으로 모델링하면 오류 누적이 줄어든다. (Roman et al., 2023)에서 논의된 바와 같이, 더 높은 대역을 더 낮은 대역에 조건화하는 것은 오류 누적으로 이어질 수 있으며, 이는 더 낮은 대역의 부정확성이 추론 중에 더 높은 대역에 악영향을 미칠 수 있음을 의미한다.
모델은 잡음 샘플(Xt)을 속도(vt)로 매핑한다. 각 하위 대역에 대해 하위 대역의 잡음 샘플(Xsb)은 ConvNeXtV2 백본에 공급되어 시간(t), 하위 대역 인덱스(ist), 조건부 입력(C', 멜 스펙트로그램 또는 EnCodec(Défossez et al., 2022) 토큰) 및 선택적 EnCodec 대역폭 인덱스(ibw)에 조건화된 속도(vs)를 예측한다. ConvNeXtV2 백본의 자세한 구조는 그림 1에 나와 있다. (Kingma et al., 2021)에서 설명한 푸리에 특징을 사용한다. Xsb, C 및 푸리에 특징은 채널 차원을 따라 연결된 다음 선형 레이어를 통과하여 ConvNeXtV2 블록 시리즈에 공급되는 입력을 형성한다. 사인파 t 임베딩은 선택적 ibw 임베딩과 함께 각 ConvNeXtV2 블록의 입력에 요소별로 추가된다. ibw는 EnCodec 토큰의 디코딩 중에 사용되며, 단일 모델이 다양한 대역폭의 EnCodec 토큰을 지원할 수 있게 한다. 또한, ist는 (Siuzdak, 2023; Xu et al., 2019)에서 설명한 바와 같이 학습 가능한 임베딩을 사용하는 적응형 레이어 정규화 모듈을 통해 통합된다. 다른 구성 요소는 ConvNeXtV2 아키텍처 내의 구성 요소와 동일하며, 자세한 내용은 (Woo et al., 2023)에서 찾을 수 있다.
우리 방법론은 두 가지 모델링 옵션을 제공한다. 첫 번째는 가우시안 잡음을 파형에 직접 시간 영역으로 매핑하는 것을 포함하며, 여기서 X0, X1, Xt 및 vt는 모두 시간 영역에 있다. 두 번째 옵션은 가우시안 잡음을 복소 스펙트로그램으로 매핑하여 X0, X1, Xt 및 vt를 주파수 영역에 배치한다. 주목할 점은 Xish와 vist는 다음 단락에서 자세히 설명된 바와 같이 일관되게 주파수 영역으로 표현되어 신경망이 프레임 수준에서 실행되도록 보장한다는 것이다. 프레임 수준 특징을 처리함으로써 우리 모델은 파형 샘플 포인트 수준에서 작동하는 PriorGrad와 같은 확산 보코더보다 더 나은 메모리 효율성을 달성한다. PriorGrad(gil Lee et al., 2022)는 30GB의 GPU 메모리 내에서 44.1kHz의 6초² 오디오 클립을 훈련할 수 있지만, 우리 모델은 동일한 메모리 리소스로 177초 클립을 처리할 수 있다.
Xt를 시간 영역에서 작동하고 파형 균등화 Since 우리 모델은 프레임 수준에서 작동하도록 설계되었으며, Xt와 vt가 시간 영역에 있을 때(특히, X₁은 파형이고 Xo는 동일한 모양의 잡음이며, Xt와 vt는 (3)에서 파생됨), 그림 1에 설명된 STFT 및 ISTFT의 사용이 필요하다. Xt와 vt의 차원은 [1, T]³를 따르며, 여기서 T는 샘플 포인트의 파형 길이이다. STFT 연산 후, 우리는 하위 대역을 추출하여 전체 대역 복소 스펙트로그램을 균등하게 분할하여 Xis를 얻는다. 각 하위 대역 Xisb
오일러 방법의 시간 포인트 선택
Liu et al. (2023)은 (4)에 설명된 바와 같이 오일러 방법에 대해 동일한 단계 간격을 사용한다. 여기서는 운송 궤적의 직선성을 기반으로 시간 포인트를 선택할 것을 제안한다. 시간 포인트는 각 단계에서 직선성의 증가가 동일하도록 선택된다. 학습된 속도 필드 v의 직선성은 S(v) = ∫ E || (X1 - Xo) – v(Xt, t | C) ||² dt로 정의되며, 이는 궤적을 따라 속도의 편차를 설명한다. 더 작은 S(v)는 더 직선적인 궤적을 의미한다. 이 접근 방식은 각 오일러 단계의 어려움이 일관되게 유지되도록 보장하며, 모델이 더 어려운 영역에서 더 많은 단계를 취하도록 요구한다. 동일한 수의 샘플링 단계를 사용하면 이 방법은 동일한 간격 접근 방식보다 우수하다. 구현 세부 사항은 부록 섹션 A.5에 제공되며, 알고리즘은 부록 섹션 A.9.2에 제시된다. 우리는 이 접근 방식을 균등 직선성이라고 부른다.
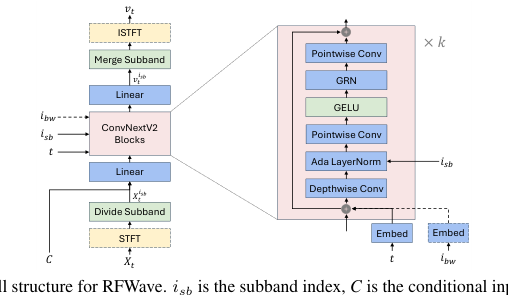 Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
결과, 한계 및 결론
실험 설계 및 기준선
RFWave의 성능을 엄격하게 검증하기 위해 저자들은 다양한 오디오 도메인 및 입력 유형에 걸쳐 확립된 "피해자" 기준선과 경쟁하는 포괄적인 실험 설계를 구성했다.
멜 스펙트로그램 입력의 경우 두 가지 주요 평가 시나리오가 설계되었다:
1. 확산 기반 보코더와의 비교: RFWave 모델은 세 가지 다양한 데이터셋(음성용 LibriTTS, 음악용 MTG-Jamendo, 보컬 음악용 Opencpop)에 대해 별도로 훈련되었다. 그런 다음 이러한 모델은 해당 테스트 세트에서 평가되었다. 이 범주의 기준선은 최첨단 확산 모델인 PriorGrad와 FreGrad였다.
2. GAN 기반 보코더와의 비교: RFWave 모델은 LibriTTS에서 훈련되었다. 그런 다음 LibriTTS 테스트 세트(도메인 내)와, 특히 MUSDB18 데이터셋(도메인 외)에서 일반화 및 견고성 테스트를 위해 성능을 평가했다. 여기 기준선은 널리 사용되는 GAN 모델인 Vocos와 BigVGAN이었다.
이산 EnCodec 토큰 입력의 경우, 범용 RFWave 모델은 Common Voice 7.0, DNS Challenge 4, MTG-Jamendo, FSD50K 및 AudioSet를 포함하는 대규모 혼합 데이터셋에서 훈련되었다. 그런 다음 이 범용 모델은 음성, 보컬 및 음향 효과를 포함하는 15개의 외부 소스에서 가져온 900개의 오디오 샘플로 구성된 맞춤형 통합 테스트 데이터셋에서 EnCodec 및 Multi-Band Diffusion(MBD)과 비교하여 평가되었다. 이 광범위한 평가는 RFWave의 다양한 오디오 유형에 대한 다용성을 입증하는 것을 목표로 했다.
평가 지표: 객관적 및 주관적 측정 모두 사용되었다.
* 객관적 지표에는 ViSQOL(지각 품질, 22.05/24kHz 파형의 음성 모드 및 44.1kHz 파형의 오디오 모드 사용), PESQ(지각 음성 품질 평가), V/UV F1(음성/무음 분류 F1 점수) 및 주기성(주기 오류)이 포함되었다.
* 주관적 평가는 5점 만점의 평균 의견 점수(MOS) 척도(1: '나쁨/부자연스러움' ~ 5: '우수함/자연스러움')를 사용한 크라우드 소싱 평가를 포함했다. 각 비교에 대해 30명의 청취자가 기준점, RFWave 및 기준선 모델을 포함한 20~40개의 오디오 샘플 그룹을 무작위 순서로 평가했다.
구현 세부 사항: RFWave 모델은 기본적으로 시간 영역 접근 방식을 사용했으며, 세 가지 향상된 손실 함수(에너지 균형, 오버랩 및 STFT 손실)와 8개 블록의 ConvNeXtV2 백본을 통합했다. 복소 스펙트로그램은 8개의 균등하게 분포된 하위 대역으로 분할되었다. 핵심 아키텍처 선택은 추론에 단 10개의 샘플링 단계만 사용하는 것이었다. 비교 연구도 개별 구성 요소의 영향을 분석하기 위해 수행되었다. 즉, 주파수 대 시간 영역 모델링, 각 손실 함수의 점진적 추가, "균등 직선성" 샘플링 전략, 다른 백본 아키텍처(ResNet 대 ConvNeXtV2) 및 모델 크기이다. 추론 속도는 배치 크기 1로 NVIDIA GeForce RTX 4090 GPU에서 벤치마킹되었다.
증거가 증명하는 것
논문에서 제시된 경험적 증거는 RFWave의 핵심 메커니즘이 실제로 작동한다는 결정적이고 부인할 수 없는 증거를 제공하며, 오디오 품질과 계산 효율성 모두에서 우수한 성능을 보여준다.
확산 기반 기준선 격파:
RFWave는 멜 스펙트로그램에서 복원할 때 모든 객관적 및 주관적 지표에서 확산 기반 "피해자"인 PriorGrad 및 FreGrad를 무자비하게 능가했다(표 1). 예를 들어, RFWave는 평균 MOS 3.95 ± 0.09를 달성하여 PriorGrad의 3.75 ± 0.09 및 FreGrad의 2.99 ± 0.14보다 훨씬 높았다. 객관적으로 RFWave의 PESQ 4.202는 PriorGrad의 3.612 및 FreGrad의 3.640을 압도했다. 이 우수성에 대한 결정적인 증거는 RFWave가 부록 A.6(그림 A.3, A.4, A.5)의 스펙트로그램에서 시각적으로 확인된 "더 명확하고 일관된 하모닉스, 특히 고주파 범위에서"를 생성할 수 있다는 점이며, 여기서 기준선은 사소한 불연속성 또는 흐릿한 고주파 구성 요소를 보였다. 이는 적은 샘플링 단계로 고품질 오디오를 달성하는 데 정류 흐름의 효과를 직접적으로 검증한다.
GAN 기반 기준선 도전:
GAN은 속도로 알려져 있지만, RFWave는 도메인 내 품질과 우수한 도메인 외 일반화 능력을 보여주었다. 도메인 내 LibriTTS 테스트 세트에서 RFWave의 MOS(3.82 ± 0.12)는 BigVGAN(3.78 ± 0.11) 및 Vocos(3.74 ± 0.10)와 비슷했다(표 2). 그러나 진정한 승리는 도메인 외 MUSDB18 데이터셋(표 3)에서 나왔는데, 여기서 RFWave는 평균 MOS 3.67 ± 0.05를 달성하여 BigVGAN의 3.51 ± 0.05 및 Vocos의 3.10 ± 0.06을 크게 능가했다. 여기서 핵심 증거는 BigVGAN 및 Vocos와 같은 GAN 기반 모델이 "스펙트로그램의 고주파 영역에 수평선을" 생성하는 경향이 있어 "금속성 음질"을 초래하는 그림 A.7의 시각적 분석이다. 대조적으로 RFWave는 일관되게 "명확하고 잘 정의된 고주파 하모닉스"를 생성하여 확산 유형 모델로서의 견고성과 일반화 능력을 입증했다.
EnCodec 토큰 복원 지배:
이산 EnCodec 토큰 입력의 경우, RFWave(CFG2 사용)는 대부분의 지표(MOS, PESQ, V/UV F1, 주기성) 및 다양한 대역폭에서 일관되게 최적의 점수를 달성하여 EnCodec 및 MBD(표 4)를 능가했다. 예를 들어, 6.0kbps에서 RFWave의 MOS는 EnCodec의 3.10 ± 0.15 및 MBD의 3.43 ± 0.15에 비해 3.69 ± 0.16이었다. 이는 압축된 표현에서 고품질 오디오를 복원하는 데 있어 RFWave의 다용성과 효율성을 입증한다.
비교 연구 검증:
비교 연구(표 5)는 RFWave의 개별 구성 요소의 효과에 대한 중요한 통찰력을 제공했다:
* 시간 영역 모델은 주파수 영역 모델보다 일관되게 우수했다(예: PESQ 4.127 대 3.872). 이는 더 나은 고주파 세부 정보 보존에 대한 선택을 검증한다.
* 에너지 균형 손실은 무음 영역의 저음량 잡음을 완화하여 전반적인 성능을 개선했다(예: PESQ 4.127에서 4.181로). 이는 상대 오류 최소화 역할의 증거이다.
* 오버랩 손실은 PESQ가 약간 하락했지만 "부드러운 하위 대역 전환"과 일관성 유지를 위해 필수적이었으며, 이는 없는 경우 눈에 띄는 전환으로 시각적으로 확인되었다(그림 A.9).
* STFT 손실은 배경 잡음의 아티팩트를 효과적으로 줄여(그림 A.8) PESQ를 4.158에서 4.211로 개선했지만, 크기에 중점을 두어 ViSQOL 및 주기성에 약간의 절충이 있었다.
* 균등 직선성 샘플링 전략은 "무료"(PESQ 4.275, 주기성 0.100)로 성능을 크게 향상시켜 동일한 간격 단계보다 효과적임을 입증했다.
* 정류 흐름 메커니즘은 50단계의 DDPM 접근 방식이 성능이 저조했기 때문에(표 6) 효율적인 고품질 생성을 위해 "중요"한 것으로 나타났다. ConvNeXtV2 백본도 ResNet보다 우수하여 효율성과 품질을 모두 향상시켰다.
전례 없는 계산 효율성:
아마도 가장 놀라운 증거는 RFWave의 훨씬 우수한 계산 효율성(표 7)일 것이다. 단일 NVIDIA GeForce RTX 4090 GPU에서 단 10개의 샘플링 단계로 실시간보다 162.59배 빠른(xRT) 추론 속도를 달성했다. 이는 확산 기준선(PriorGrad 16.67 xRT, FreGrad 7.50 xRT, MBD 4.82 xRT)보다 한 자릿수 빠르고 BigVGAN(72.68 xRT)보다 두 배 이상 빠르다. 또한, RFWave는 BigVGAN(1436MB)보다 적은 GPU 메모리(780MB)를 소비했다. 더 높은 샘플링 속도(예: 44.1kHz에서 152.58 xRT)에서도 유지되는 이 속도 이점은 RFWave가 확산 모델의 지연 시간 장벽을 극복하여 실제 실시간 응용 프로그램에 실용적임을 확실하게 입증한다.
한계 및 향후 방향
RFWave는 오디오 파형 복원에서 상당한 발전을 이루었지만, 현재의 한계를 인정하고 향후 개발 방향을 고려하는 것이 중요하다.
관찰된 미묘한 한계 중 하나는 ViSQOL 지표의 편향이다. RFWave는 종종 더 높은 MOS 및 기타 객관적 점수를 달성하지만, ViSQOL은 GAN을 선호하는 경우가 있는데, 이는 인간의 지각 품질을 완전히 반영하지 못할 수 있다. 이는 현재 객관적 지표가 새로운 생성 접근 방식에 대한 모든 오디오 품질의 뉘앙스를 완벽하게 포착하지 못할 수 있음을 시사한다. 또 다른 흥미로운 절충은 STFT 손실에서 관찰되었다: 아티팩트를 효과적으로 줄이지만, 크기에 중점을 두어 위상보다 ViSQOL과 주기성을 약간 저하시킬 수 있다. 이는 오디오 충실도의 다른 측면을 균형 잡는 데 있어 과제를 강조한다. 또한, RFWave는 GAN에 비해 강력한 도메인 외 일반화 능력을 보여주지만, 진정한 범용 보코더의 궁극적인 목표는 훨씬 더 넓은 범위의 보지 못한 오디오 조건 및 특성을 처리하는 것을 의미하며, 이는 지속적인 과제로 남아 있다. 훈련에 필요한 계산 리소스, 특히 대규모 EnCodec 혼합 데이터셋(예: 10일 동안 4x A100 GPU)의 경우, 소규모 연구 그룹이나 개인 개발자에게 실질적인 장벽을 나타낸다.
앞으로 몇 가지 흥미로운 논의 주제가 이러한 발견을 더욱 발전시키고 진화시키기 위해 등장한다:
- 적응형 손실 함수 설계: STFT 손실 절충을 고려할 때, 손실 함수에 대한 동적 또는 컨텍스트 인식 가중치를 탐색할 수 있을까? 예를 들어, 특정 주파수 대역 또는 특정 오디오 이벤트 중에 위상 정보에 우선순위를 부여하는 적응형 메커니즘은 아티팩트를 다시 도입하지 않고도 더 나은 지각 품질을 얻을 수 있다. 여기에는 학습된 가중치 계수 또는 다중 목표 최적화 프레임워크가 포함될 수 있다.
- 균등 직선성 샘플링 너머: "균등 직선성" 방법은 영리한 휴리스틱이지만, 잠재 공간의 모든 영역에서 최적의 샘플링 궤적이 엄격하게 "균등하게 직선적"이지 않다면 어떻게 될까? 향후 연구에서는 더 고급 적응형 ODE 솔버 또는 강화 학습 접근 방식을 조사하여 충실도를 극대화하면서 단계를 최소화하는 최적의 비균일 샘플링 일정을 발견하고, 잠재적으로 특정 오디오 특성에 맞게 일정을 조정할 수 있다.
- 극단적인 도메인 외 데이터에 대한 일반화 강화: RFWave는 뛰어나지만, 실제 오디오는 매우 다양하고 종종 잡음이 많다. 이러한 모델을 매우 손상된, 극도로 저자원 또는 완전히 새로운 오디오 유형에 대해 더욱 견고하게 만들려면 어떻게 해야 할까? 여기에는 신속한 적응을 위한 메타 학습, 방대한 레이블 없는 오디오에 대한 자기 지도 학습 또는 명시적인 잡음 모델링 기능 통합이 포함될 수 있다.
- 제약된 하드웨어에서의 실시간 배포: 고급 GPU에서 실시간보다 160배 빠른 속도를 달성하는 것은 훌륭하지만, 모바일 장치 또는 임베디드 시스템의 보편적인 응용 프로그램의 경우 추가 최적화가 필요하다. 여기에는 모델 양자화, 가지치기, 지식 증류 또는 엣지 하드웨어에서 본질적으로 더 효율적인 특수 아키텍처 설계를 탐색하는 것이 포함될 수 있으며, 실시간 오디오 합성의 가능성을 확장한다.
- 다중 모드 및 대화형 오디오 생성: 현재 작업은 멜 스펙트로그램과 이산 토큰에 초점을 맞춘다. RFWave를 텍스트, 비디오 또는 사용자 정의 매개변수(예: 감정 단서, 공간 오디오 속성)와 같은 다른 양식과 직접 통합하면 새로운 창의적 응용 프로그램과 더 직관적인 인간-컴퓨터 상호 작용이 가능해질 수 있다. 비디오 장면의 분위기나 사용자의 제스처 입력과 완벽하게 일치하는 오디오를 생성한다고 상상해 보라.
- 지각적으로 정렬된 지표 개발: 관찰된 ViSQOL 편향은 더 넓은 분야의 필요성을 강조한다. 합성 오디오의 "자연스러움" 및 "품질"에 대한 인간의 인식과 더 밀접하게 일치하는 더 강력하고 편향되지 않은 새로운 객관적 지표를 어떻게 개발할 수 있을까? 여기에는 인간 참여 피드백 또는 고급 심리 음향 모델링 활용이 포함될 수 있다.
- 윤리적 영향 및 안전 장치: 오디오 합성이 실제 녹음과 구별할 수 없게 됨에 따라, 딥페이크 생성 또는 허위 정보에서의 오용과 같은 윤리적 영향이 증가한다. 향후 연구는 합성 오디오의 워터마킹, 강력한 탐지 메커니즘 개발 또는 모델 설계 및 배포 프로세스에 윤리적 지침을 직접 통합하는 방법을 탐색하여 이러한 우려를 사전에 해결해야 한다. 이것은 종종 간과되는 생성 AI 발전의 중요한 측면이다.