RFWave: 音声波形再構成のためのマルチバンド整流フロー
Recent advancements in generative modeling have significantly enhanced the reconstruction of audio waveforms from various representations.
背景と学術的系譜
起源と学術的系譜
低次元の特徴量から現実的で知覚可能な音への変換を行う音声波形再構成の問題は、デジタルインタラクションの需要の高まりから生まれました。この技術は、仮想アシスタント、エンターテイメントシステム、テキスト音声合成など、高品質で自然な音声や音楽の生成が最重要視される多様なアプリケーションにおいて不可欠です。歴史的に、この分野は、高度な生成モデルの登場により、従来の信号処理手法(Kawahara et al., 1999; Morise et al., 2016)を超えて進化してきました。
初期の重要な進歩は、自己回帰モデルと敵対的生成ネットワーク(GANs)(Goodfellow et al., 2014)という2つの主要なパラダイムからもたらされました。自己回帰モデルは、高品質な音声を生成する能力がありましたが、生成速度が非常に遅いという深刻な制限がありました。この遅さは、個々のサンプル点を逐次的に予測することに起因しており(Oord et al., 2016; Kalchbrenner et al., 2018; Valin & Skoglund, 2019)、リアルタイムアプリケーションの実用性を妨げていました。GANsは、サンプル点を並列に予測することで高速な生成を提供しましたが(Kumar et al., 2019; Yamamoto et al., 2020; Kong et al., 2020a)、それ自体が独自の「悩みどころ」をもたらしました。これには、複雑な識別器の設計の必要性や、トレーニングの不安定性、モード崩壊(Thanh-Tung et al., 2018)といった問題が含まれ、モデルがデータの完全な多様性を学習できない場合があります。
より最近では、拡散モデル(Song et al., 2020; Ho et al., 2020)が有望な代替手段として登場し、トレーニングの安定性が向上し、高品質な波形を再構成する能力を提供しました(Chen et al., 2020; Kong et al., 2020b; gil Lee et al., 2022)。しかし、拡散モデルは重大な制限を引き継いでいました。それは、GANsよりも少なくとも1桁遅いという点です。この遅さは主に2つの要因に起因していました。(1) 高品質なサンプルを得るために多数のサンプリングステップが必要であること、(2) 個々の波形サンプル点レベルで動作することです。後者は、フレームレートとサンプルレートの解像度を橋渡しするために複数のアップサンプリング操作を伴うことが多く、シーケンス長の増加、GPUメモリ使用量の増加、および実質的な計算要求につながりました。拡散モデルにおけるこの遅い推論速度という根本的な制限は、RFWaveが対処しようとしている中心的な「悩みどころ」であり、拡散モデルの安定性と品質を維持しながらGANベースの速度に匹敵することを目指しています。
直感的なドメイン用語
ここでは、この論文の専門用語を、初心者向けの日常的なアナロジーに翻訳します。
- メルスペクトログラム (Mel-spectrogram): 曲を視覚的に表現した楽譜があると想像してください。メルスペクトログラムはそれに似ていますが、コンピュータが理解できる音のデジタル「画像」です。時間の経過とともに異なる周波数のラウドネスがどのように変化するかを示しており、人間のピッチ知覚を模倣した特別なスケーリング(メルスケール)が施されています。これは機械のための音楽スコアのようなもので、音の重要な部分を強調します。
- 整流フロー (Rectified Flow): A地点からB地点への旅を想像してください。通常、曲がりくねった道を通るかもしれません。整流フローは、A地点(ノイズデータ)とB地点(クリーンオーディオ)の間の最も直接的で直線的な経路を見つけるようなものです。この「直線高速道路」は、旅をはるかに速く効率的にし、モデルがより少ないステップでノイズを音に変換できるようにします。
- 拡散モデル (Diffusion Models): 非常にぼやけた写真が、それを「ノイズ除去」するために取る各ステップで徐々に鮮明になっていく様子を想像してください。拡散モデルも同様に機能します。ランダムノイズ(完全にぼやけた画像のようなもの)から始まり、拡散プロセスを逆転させることによって、ステップバイステップでゆっくりと、一貫性のある高品質な音声波形に変換します。それは、アーティストがキャンバスに徐々にディテールを追加して傑作が現れるまでを描くようなものです。
- モード崩壊 (Mode Collapse) (GANsにおいて): 様々な料理を作るように頼まれたが、他のすべてのレシピを無視して、1つの特定の料理だけを完璧に作る方法を学んだシェフを想像してください。生成モデル(GANsなど)におけるモード崩壊とは、モデルが多様な出力を生成できず、代わりに類似した高品質なサンプルの限定されたセットしか生成しないことを意味します。それは、シェフがステーキやサラダを頼まれても、できることといえばそれだけなので、いつも完璧なパスタばかり作ってしまうようなものです。
記法表
| 記法 | 説明 |
|---|---|
| $Z_t$ | 変換プロセス中の任意の時間 $t$ におけるデータの進化状態。 |
| $v(Z_t, t)$ | 時間 $t$ におけるデータ $Z_t$ の変化を指示し、ターゲットに向かって導く「速度」場。 |
| $\pi_0$ | 初期確率分布、通常はランダムノイズを表す。 |
| $\pi_1$ | ターゲット確率分布、望ましい実際の音声データを表す。 |
| $X_0$ | $\pi_0$ からサンプリングされた初期データサンプル、通常はランダムノイズ。 |
| $X_1$ | $\pi_1$ からサンプリングされたターゲットデータサンプル、グラウンドトゥルース音声波形またはスペクトログラムを表す。 |
| $X_t$ | 時間 $t$ における中間データサンプル、$X_0$ と $X_1$ の間の補間を表す。 |
| $t$ | 時間変数、変換の開始(0)から終了(1)まで進行する。 |
| $C$ | 音声生成をガイドする、メルスペクトログラムや離散音響トークンなどの条件付き入力。 |
| $N$ | 高速フーリエ変換(FFT)のサイズ、周波数分解能を決定する。 |
| $d_s$ | 特定のサブバンドの複素スペクトル内の周波数ビン数。 |
| $F$ | スペクトログラムの総フレーム数、時間セグメントを表す。 |
| $i_{sb}$ | 特定のサブバンドを識別するインデックス。 |
| $i_{bw}$ | EnCodecトークンの帯域幅インデックス、異なる圧縮レベルに使用される。 |
| $\sigma$ | エネルギーバランス損失で使用される重み付け係数、通常はグラウンドトゥルース速度の標準偏差から導出される。 |
| $S(v)$ | 学習された速度場の軌道の「直線性」の尺度、変換パスの直接性を示す。 |
問題定義と制約
コア問題定式化とジレンマ
本論文で取り組むコア問題は、メルスペクトログラムや離散音響トークンなどの様々な圧縮表現から、高忠実度の音声波形を効率的に再構成するという課題です。
この問題の入力/現在の状態には以下が含まれます。
* 低次元の音声特徴量、特にメルスペクトログラムまたは離散音響トークン。これらは音のコンパクトな表現です。
* 既存の生成モデル、主に拡散モデルと敵対的生成ネットワーク(GANs)。それぞれに独自の限界があります。拡散モデルは高品質な音声を生成できますが、個々の波形サンプル点レベルで動作し、多数のサンプリングステップを必要とするため、実質的な遅延が生じます。GANsは高速ですが、トレーニングの不安定性やモード崩壊に苦しむことが多く、複雑な識別器の設計が必要です。
望ましい終点/目標状態は、以下を達成することです。
* これらの低次元入力から再構成された高忠実度の音声波形。
* GANベースの手法(すなわち、リアルタイムまたはそれ以上)の推論速度に匹敵し、同時に拡散モデルの特徴であるトレーニングの安定性と高いサンプル品質を維持する生成モデル。
* サンプリングステップ数を劇的に削減して(例:RFWaveで達成された10ステップのみで)波形を再構成する能力。
* リアルタイムよりも大幅に高速な音声生成を可能にする優れた計算効率(例:GPUで最大160倍高速)。
* メルスペクトログラムと離散音響トークンの両方から波形を再構成する際の汎用性。
現在の状態と望ましい終点との間の正確な欠落リンクまたは数学的ギャップは、音声波形再構成において、拡散モデルの高品質とトレーニング安定性 と GANsの高い計算効率と低遅延を同時に達成できる生成モデリングフレームワークの欠如です。以前の拡散モデルは、多くのステップにわたって信号を徐々にノイズ除去するように数学的に定式化されており、本質的に遅くなっています。GANsは高速ですが、安定したトレーニングと一貫した品質に対する堅牢な数学的保証を欠いています。本論文は、整流フローを活用してこのギャップを埋めようとしており、ノイズとデータ分布間の直接的で直線的な輸送軌道を学習することを目的としており、それによって必要なサンプリングステップを削減します。具体的には、整流フローは、ノイズ分布 $\pi_0$ からターゲットデータ分布 $\pi_1$ へのノイズサンプル $Z_t$ の進化を支配する速度場 $v(Z_t, t)$ を学習し、$\frac{dZ_t}{dt} = v(Z_t, t)$ とします。学習目標は、直線軌道からの逸脱を最小化します。
$$ \min E_{(X_0, X_1)\sim\gamma} \int_0^1 || \frac{d}{dt}X_t - v(X_t, t) ||^2 dt $$
ここで、$X_t = (1-t)X_0 + tX_1$ は線形補間を表します。この数学的定式化は、より少なく、より直接的なステップを可能にすることによって、推論プロセスを加速するための鍵となります。
過去の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、音声品質/トレーニング安定性と推論速度/計算効率の間の根本的な対立です。一方の側面を改善すると、通常はもう一方が低下します。
* 拡散モデル: 優れた音声品質と安定したトレーニングを提供しますが、著しく遅いです。それらの「個々のサンプル点レベル」での動作と「多数のサンプリングステップ」の必要性(しばしば数百または数千)は、高い遅延と計算要求につながります。
* GANs: サンプル点を並列に予測することで高速な生成速度を提供しますが、「複雑な識別器の設計と不安定性またはモード崩壊の問題」に悩まされており、信頼性の高いトレーニングが困難になり、時には品質が低下したり、出力が多様でなくなったりします。
このジレンマは、研究者が以前は高品質で安定しているが遅いモデル、または高速だが不安定で品質が低い可能性のあるモデルのいずれかを選択しなければならなかったことを意味します。本論文は、このトレードオフを打破することを目指しています。
制約と失敗モード
高忠実度、リアルタイム音声波形再構成の問題は、いくつかの厳しい現実的な制約と固有の失敗モードにより、非常に困難です。
-
計算コストとGPUメモリ制限:
- サンプル点レベルの操作: 以前の拡散モデルは、個々のサンプル点レベルで音声を処理します。これには「フレームレート解像度からサンプルレート解像度への移行のための複数のアップサンプリング操作が必要であり、シーケンス長が増加し、結果としてGPUメモリ使用量と計算要求が増加します」(p. 2)。高解像度オーディオ(例:44.1 kHzまたは48 kHz)の場合、毎秒数百万サンプルを処理することは計算上不可能であり、メモリ集約的です。例えば、PriorGradは30 GBのGPUメモリ内で44.1 kHzの6秒オーディオクリップしかトレーニングできません。これは、この深刻なメモリ制約を浮き彫りにしています(p. 4)。
- 多数のサンプリングステップ: 拡散モデルは通常、高品質なオーディオを生成するために数百または数千のサンプリングステップを必要とし、推論速度と計算負荷に直接影響します。これにより、それらは「GANsと比較して少なくとも1桁遅い」(p. 1)ものとなります。
-
リアルタイム遅延要件: 多くの実用的なアプリケーション(例:仮想アシスタント、リアルタイム通信)は、非常に低い遅延を要求します。既存の拡散モデルでさえ、最も高速なものでも「リアルタイムの約10〜20倍高速」にすぎず(p. 3)、大規模な音響モデルと組み合わせると、真のリアルタイム対話には不十分です。
-
トレーニングの不安定性とモード崩壊(GANsの場合): GANsは速度を提供しますが、そのトレーニングは非常に困難です。「複雑な識別器の設計」と「不安定性またはモード崩壊」の問題(p. 1)は、データ分布全体を学習できない可能性があり、多様性が低く品質が低い出力につながることを意味します。
-
マルチバンド処理におけるエラーの蓄積: マルチバンド戦略を使用する場合、「高位バンドを低位バンドに条件付けるとエラーの蓄積につながる可能性があり、これは低位バンドの不正確さが推論中に高位バンドに悪影響を与える可能性があることを意味します」(p. 4)。これは、周波数スペクトルの一部のエラーが伝播して他の部分を破損する可能性があることを意味します。
-
無音領域における低音量ノイズ: 平均二乗誤差(MSE)損失でトレーニングされたモデルの一般的な失敗モードは、「期待される無音領域における低音量ノイズ」の存在です(p. 5)。これは、無音部分の小さな誤差が全体のMSEへの寄与が最小限であるため発生し、モデルは高振幅領域の大きな誤差を減らすことを優先し、静かなセクションでの知覚可能なノイズにつながります。
-
サブバンド間の不整合: 異なる周波数サブバンドが独立して予測される場合、「それらの間の不整合」(p. 6)のリスクがあり、再構成された波形のサブバンド境界で聴覚的なアーティファクトが発生します。
-
バックグラウンドノイズにおけるアーティファクト: STFT損失のような特定の損失関数がない場合、モデルは「バックグラウンドノイズの存在下で垂直パターン」やその他の「アーティファクト」を生成する可能性があり(図A.8、p. 6)、知覚品質を低下させます。
-
非線形輸送軌道: 整流フローの効果は「直線輸送軌道」(p. 2)の学習に依存します。学習された速度場が線形性から大きく逸脱すると、オイラー法はODEを正確に近似するために多くのステップを必要とし、効率性の利点を無効にします。これにより、速度場の学習は繊細なタスクとなります。
なぜこのアプローチなのか
選択の必然性
RFWaveが取り組むコア問題は、生成モデルにおける音声波形再構成の品質と生成速度の間の重要なトレードオフです。従来の最先端(SOTA)手法は、高度であるにもかかわらず、それぞれが同時に高忠実度とリアルタイムパフォーマンスの両方を達成するには不十分な重大な制限を提示していました。
著者らは、標準的な拡散モデルが、高品質な音声を生成する能力と安定したトレーニングにもかかわらず、根本的に2つの要因によって妨げられていることに気づきました。(1) 個々の波形サンプル点レベルでの動作、および (2) 望ましい品質を達成するために多数のサンプリングステップが必要であること。これにより、深刻な遅延問題と高いGPUメモリ消費が発生し、GANsよりも少なくとも1桁遅くなり、リアルタイムアプリケーションには実用的ではありませんでした。論文では、この不十分さを明確に述べています。「拡散モデルはこのタスクに長けていますが、個々のサンプル点レベルでの動作と多数のサンプリングステップの必要性による遅延問題によって妨げられています。」(Abstract)。この不十分さは、最も高速な拡散手法でさえリアルタイムの10〜20倍しか高速ではないという観察によってさらに強調され、現実世界のアプリケーションの要求には程遠いものでした。
サンプル点を並列に予測することでより高速な生成速度を実現できる敵対的生成ネットワーク(GANs)は、固有のトレーニングの不安定性とモード崩壊の問題に悩まされていました。生成モデルの別のクラスである自己回帰モデルも、サンプル点の逐次予測により同様に却下され、許容できないほど遅い生成速度につながりました。
整流フローは、マルチバンド、フレームレベル処理戦略と組み合わされることで、これらの根本的な制限に直接対処するため、唯一実行可能なソリューションとして浮上しました。これは、拡散モデルの高いサンプル品質とトレーニング安定性を同時に達成しながら、GANsの生成速度に匹敵し、さらにはそれを超えるメカニズムを提供し、すべて実用的なメモリ制約内で実現します。アブレーションスタディはさらにこれを裏付けており、「RFWaveがモデルが高品質な音声サンプルを効率的に生成するために不可欠である」(p. 9)ことを示しており、より多くのステップを持つ従来の拡散ノイズスケジュールは不十分でした。
比較優位性
RFWaveは、単純なパフォーマンス指標を超えて、以前のゴールドスタンダードに対する圧倒的な定性的優位性を示しています。
まず、速度に関して、RFWaveはGPU上でリアルタイムの最大160倍の推論速度(Abstract)を達成します。これは、通常リアルタイムの10〜20倍で動作する拡散モデル、さらには多くのGANベースの手法さえも上回る劇的な改善です。例えば、表7は、RFWaveのGPU xRTを162.59とし、BigVGANの72.68、PriorGradの16.67と比較しています。この構造的な利点は、整流フローが直線的な輸送軌道を学習できる能力に由来しており、他の拡散モデルよりも大幅に少ない10サンプリングステップで高品質な再構成を可能にします。
次に、品質に関して、RFWaveは、客観的な指標(例:MOS、PESQ、ViSQOL)と主観的な評価(表1)の両方で、PriorGradやFreGradのような拡散ベースのベースラインを一貫して上回っています。GANsのようなBigVGANやVocosとドメイン内データでは同等にパフォーマンスを発揮しますが、ドメイン外データ(MUSDB18データセット)ではその優位性が際立ちます。ここでは、RFWaveは「顕著な利点」(p. 8)を示し、GANsが「水平線」を生成して「金属的な音質」につながる傾向があるのとは対照的に、より鮮明で明確な高周波ハーモニクスを生成します。これは、RFWaveの優れた汎化能力と堅牢性を示しています。
第三に、RFWaveは、はるかに優れた計算効率とメモリ複雑性を提供します。個々の波形サンプル点ではなく、短時間フーリエ変換(STFT)フレームレベルで動作することにより、GPUメモリ使用量を劇的に削減します。この構造的な利点により、RFWaveは、PriorGrad(サンプル点拡散ボコーダー)が6秒クリップに使用するのと同じメモリリソースで、177秒のオーディオクリップを処理できます(p. 4)。表7はこれをさらに例示しており、RFWaveは4976 MBのPriorGradや5480 MBのMBDと比較して780 MBのGPUメモリを消費しています。このフレームレベル処理は、シーケンス長の増加につながる「複数のアップサンプリング操作」を回避し、それ以外の場合はGPUメモリ使用量と計算要求の増加につながるサンプル点モデルの悩みを解消します。
最後に、マルチバンド戦略は重要な構造的利点です。異なる周波数サブバンドを同時に生成し、単一の統一モデルでそれらを並列にモデル化することにより、RFWaveは高位バンドが低位バンドに逐次的に条件付けられる場合に発生する可能性のあるエラーの蓄積を防ぎます。これにより、音声品質が保証されるだけでなく、合成速度も向上します。3つの強化された損失関数(エネルギーバランス、オーバーラップ、STFT損失)の組み込みと最適化された「等しい直線性」サンプリング戦略は、全体的な品質と堅牢性をさらに向上させ、特に低音量領域の処理において、サブバンド遷移の滑らかさを確保し、アーティファクトを低減します。
制約との整合性
選択された整流フローアプローチは、そのアーキテクチャ上の革新と組み合わされることで、高忠実度、リアルタイム音声波形再構成の厳格な要件に完全に適合しています。
-
高忠実度音声品質: 問題は、例外的な音声品質を要求します。RFWaveは、拡散タイプのモデルの固有の品質保持能力を活用し、整流フローが直接的で高品質なマッピングを学習できる能力によってさらに強化されることで、これを達成します。3つの強化された損失関数(エネルギーバランス、オーバーラップ、STFT損失)と「等しい直線性」サンプリング戦略は、知覚品質の向上、無音領域でのノイズ抑制、サブバンド遷移の滑らかさの確保、および高周波ディテールの維持を目的として特別に設計されています。この堅牢な生成フレームワークとターゲットを絞った品質強化の「結婚」により、出力は単に良いだけでなく、「傑出」(Abstract)したものになります。
-
リアルタイム生成速度: 重要な制約は、以前の拡散モデルの遅延を克服することでした。整流フローの直線的な輸送軌道は、サンプリングステップの劇的な削減(わずか10ステップまで)を可能にし、これは遅い推論問題への直接的な解決策です。さらに、個々のサンプル点レベルではなく、STFTフレームレベルで動作することにより、サブバンドの並列処理が可能になり、計算が大幅に加速されます。この組み合わせにより、リアルタイムの最大160倍の生成速度が実現され、リアルタイム適用の要件が直接満たされます。
-
効率的なリソース利用: サンプル点レベル処理の高いGPUメモリと計算要求は、主要なボトルネックでした。RFWaveのフレームレベル操作は、この制約に完全に適合しており、「より効率的な処理とGPUメモリ使用量の削減」(p. 2)を可能にします。これにより、モデルは他のモデルが短いクリップ(例:6秒)を処理するのと同じメモリで、はるかに長いオーディオクリップ(例:177秒)を処理でき、多様なアプリケーションに実用的になります。
-
トレーニングの安定性: GANsはトレーニングの不安定性とモード崩壊に苦労しました。拡散タイプのモデルとして、RFWaveは、拡散モデルが提供する「トレーニング中の安定性」(Introduction)の恩恵を本質的に受けており、GANベースの代替手段の主要な落とし穴を回避しています。
-
入力表現における汎用性: 問題は、様々な入力からの波形の再構成における柔軟性を要求します。RFWaveは、メルスペクトログラムと離散音響トークンの両方から波形を再構成するように設計されており、その汎用性と様々なオーディオ生成タスクへの適用性を向上させています。
この慎重な設計により、RFWaveは単なる高性能モデルではなく、効率的で高品質な音声再構成の厳しい多面的な要件を満たすために特別に構築されたモデルであることが保証されます。
代替案の却下
論文は、他の一般的な音声波形再構成アプローチを却下する明確な理由を提供しています。
-
従来の拡散モデル(例:DiffWave、WaveGrad、PriorGrad、FreGrad、Multi-Band Diffusion): これらのモデルは、主に生成速度の遅さと高い計算要求のために却下されました。論文では、それらは「個々のサンプル点レベルでの動作と多数のサンプリングステップの必要性による遅延問題によって妨げられている」(Abstract)と述べています。具体的には、それらは「GANsと比較して少なくとも1桁遅い」ものであり、「リアルタイムの約10〜20倍」にすぎず(Introduction, p. 3)、リアルタイムアプリケーションへの適用性を制限しています。RFWaveは、整流フローを使用してサンプリングステップを10に削減し、STFTフレームレベルで動作してメモリと計算オーバーヘッドを削減することにより、リアルタイム速度の160倍を達成することで、これを直接解決します。アブレーションスタディは、50ステップの標準的な拡散ノイズスケジュール(DDPM)を使用するとパフォーマンスが「ベースラインを下回った」(表6)ことを明確に示しており、整流フローの必要性を強調しています。
-
敵対的生成ネットワーク(GANs)(例:HiFi-GAN、BigVGAN、Vocos、APNet2): GANsはより高速な生成速度を提供しますが、それらは固有のトレーニングの不安定性とモード崩壊のような問題に悩まされていました(Introduction)。GANsはしばしば「複雑な識別器の設計」を必要とし、「壊滅的な忘却」(Thanh-Tung et al., 2018)に苦しむ可能性があります。さらに、ドメイン外データの場合、BigVGANやVocosのようなGANベースのモデルは、「スペクトログラムの高周波領域に水平線」を生成する傾向があり、「金属的な音質」につながり、自然さを損ないます(p. 8, 図A.7)。拡散タイプのモデルであるRFWaveは、GANsの速度に匹敵またはそれを超えながら、拡散モデルの「トレーニング中の安定性」を継承しています。
-
自己回帰モデル(例:WaveNet): これらのモデルは、サンプル点の逐次予測に起因する生成速度の遅さにより、不適切と見なされました(Introduction)。この逐次的な性質は、リアルタイム音声合成にとって本質的に非効率であり、これは問題の重要な要件です。RFWaveのフレームレベルでの並列処理とサンプリングステップの削減は、この制限に対する直接的な対抗策を提供します。
-
サンプル点レベル処理: 多くの初期拡散モデルや自己回帰モデルで一般的なこのアプローチは、「フレームレート解像度からサンプルレート解像度への移行のための複数のアップサンプリング操作が必要であり、シーケンス長が増加し、結果としてGPUメモリ使用量と計算要求が増加します」(Introduction)ため、却下されました。RFWaveのSTFTフレームレベル操作への移行は、これらのメモリと計算のボトルネックを直接軽減します。
数学的・論理的メカニズム
マスター方程式
RFWave、特にエネルギーバランス強化を伴うものを推進する絶対的なコア方程式は、トレーニング中に最小化される目的関数です。この方程式は、ノイズをターゲット音声表現に変換する速度場をモデルがどのように学習するかを定義します。
$$
\min_{v} E_{X_0 \sim \pi_0, (X_1, C) \sim D} \left[ \int_0^1 \left\| \frac{(X_1 - X_0)}{\sigma} - v(X_t, t | C)/\sigma \right\|^2 dt \right]
$$
ここで $\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$ および $X_t = (1 - t)X_0 + tX_1$ です。
用語ごとの解剖
このマスター方程式を分解して、各コンポーネントの数学的定義、物理的/論理的役割、および著者の設計上の選択を理解しましょう。
-
$v$: これは、ニューラルネットワークが学習する速度場を表します。
- 数学的定義: これは、データ空間 $\mathbb{R}^d$、時間区間 $[0, 1]$、および条件付き入力の空間 $\mathcal{C}$ における関数 $v: \mathbb{R}^d \times [0, 1] \times \mathcal{C} \to \mathbb{R}^d$ です。RFWaveでは、これはディープニューラルネットワーク(具体的にはConvNeXtV2バックボーン)によってパラメータ化されます。
- 物理的/論理的役割: これはモデルのコア出力です。中間状態 $X_t$ と時間 $t$ におけるデータ空間の瞬間的な「速度」または方向を、Cを条件として予測します。ネットワークの目標は、ノイズからデータへの直線的な移動を予測するように学習することです。
- 設計上の選択: ニューラルネットワークは、高次元入力($X_t, t, C$)から高次元出力($v$)への複雑で非線形なマッピングを学習できるため使用されます。
-
$E_{X_0 \sim \pi_0, (X_1, C) \sim D}$: これはサンプルの期待値(平均)を示します。
- 数学的定義: これは、$(X_0, X_1)$ のペアと条件付き入力 $C$ に対する統計的平均です。$X_0$ は事前ノイズ分布 $\pi_0$(例:標準ガウスノイズ)からサンプリングされ、$(X_1, C)$ は実際のデータ分布 $D$(例:$X_1$ はターゲット複素スペクトログラム、$C$ はメルスペクトログラム)からサンプリングされます。
- 物理的/論理的役割: これにより、モデルが特定の例を記憶するだけでなく、幅広いノイズ入力とターゲットデータにわたって一般化するように学習することが保証されます。多くのサンプルにわたって損失を平均化することで、トレーニングが堅牢になります。
-
$\int_0^1 \dots dt$: これは時間変数 $t$ に関する定積分です。
- 数学的定義: $t=0$ から $t=1$ までの連続時間区間にわたる瞬間的な二乗誤差を合計します。
- 物理的/論理的役割: 整流フローは、ノイズからデータへの連続的な軌道を記述します。この完全なパスにわたる損失の積分は、学習された速度場が離散的なスナップショットだけでなく、すべての中間点で一貫性があり正確であることを保証します。この連続的な定式化は、ODEベースの生成モデルの基本です。
-
$\left\| \cdot \right\|^2$: これは二乗 $L_2$ ノルム(ユークリッド距離)です。
- 数学的定義: ベクトル $z$ に対して、$\|z\|^2 = \sum_i z_i^2$ です。差ベクトルの二乗 magnitude を測定します。
- 物理的/論理的役割: この項は、正規化されたグラウンドトゥルース速度と正規化された予測速度の間の平均二乗誤差(MSE)を計算します。この二乗差を最小化することは、回帰タスクにおける標準的なアプローチであり、モデルの予測が真の値に可能な限り近くなるように促します。微分可能で凸な特性を持つため、勾配ベースの最適化に有益です。
-
$X_1$: これはターゲットデータを表します。
- 数学的定義: ターゲットデータ分布 $\pi_1$ からのサンプル。モデルが再構成を目指すグラウンドトゥルース音声波形または複素スペクトログラムです。
- 物理的/論理的役割: これは望ましい出力であり、生成プロセスが収束すべき「クリーンな」音声表現です。
-
$X_0$: これは初期ノイズを表します。
- 数学的定義: 事前ノイズ分布 $\pi_0$、通常は標準ガウスノイズ $N(0,1)$ からのサンプルです。
- 物理的/論理的役割: これは生成プロセスの開始点であり、モデルが意味のある音声に変換するランダムな入力です。
-
$C$: これは条件付き入力です。
- 数学的定義: メルスペクトログラムまたは離散音響トークン。
- 物理的/論理的役割: これは生成のためのガイド情報を提供します。例えば、メルスペクトログラムを音声波形に変換することが目標である場合、$C$ はそのメルスペクトログラムになります。これにより、制御された指向性のある音声合成が可能になります。
-
$X_t = (1 - t)X_0 + tX_1$: これは補間された状態です。
- 数学的定義: 時間 $t$ における $X_0$ と $X_1$ の間の線形補間です。
- 物理的/論理的役割: この項は、ノイズ($t=0$ の $X_0$)からデータ($t=1$ の $X_1$)への直線パスに沿った中間点を定義します。モデルは、これらの途中状態での速度を予測するように学習します。
-
$\frac{(X_1 - X_0)}{\sigma}$: これは正規化されたグラウンドトゥルース速度です。
- 数学的定義: ターゲットデータと初期ノイズの直接的な差を $\sigma$ でスケーリングしたものです。軌道が完全に線形であった場合の真の、正規化された瞬間速度を表します。
- 物理的/論理的役割: これはニューラルネットワーク $v$ が近似するように学習すべき理想的な速度です。$\sigma$ による除算は、重要なエネルギーバランス正規化です。
-
$v(X_t, t | C)/\sigma$: これは正規化された予測速度です。
- 数学的定義: $X_t$, $t$, $C$ を入力として取るニューラルネットワーク $v$ の出力で、$\sigma$ でスケーリングされています。
- 物理的/論理的役割: これは、エネルギーバランス係数で正規化された、瞬間速度のモデルの予測です。トレーニングプロセスは、この項を正規化されたグラウンドトゥルース速度に一致させることを目指します。
-
$\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$: これはエネルギーバランス重み付け係数です。
- 数学的定義: 各周波数サブバンドのタイム軸に沿って計算された、グラウンドトゥルース速度 $(X_1 - X_0)$ の特徴量次元における標準偏差です。
- 物理的/論理的役割: この項は、無音領域における低音量ノイズの問題に対処するために導入されています。グラウンドトゥルースと予測速度の両方を $\sigma$ で割ることにより、損失関数は領域のエネルギーに基づいてエラーの重みを効果的に変更します。$\sigma$ が小さい(低エネルギー/無音領域)場合、$1/\sigma$ の項が大きくなり、これらの領域のエラーの合計損失への寄与が増幅されます。これにより、モデルは静かな部分でのノイズを正確に抑制することにさらに注意を払うようになり、知覚可能な低音量アーティファクトの生成を防ぎます。
ステップバイステップフロー
モデルがすでにトレーニングされていると仮定して、単一の抽象データポイントのライフサイクルを推論(生成)プロセス中にトレースしましょう。推論中の効率性が高いため、周波数ドメインアプローチを考慮します。
- 初期ノイズ注入(軌道の開始、$t=0$): プロセスは、標準ガウスノイズ分布 $N(0,1)$ からの初期状態 $X_0$ をサンプリングすることから始まります。この $X_0$ は、ターゲットオーディオと同じ次元の複素スペクトログラムです。また、生成をガイドする条件付き入力 $C$(例:メルスペクトログラム)も受け取ります。
- 反復的な速度予測と状態更新(オイラー積分): モデルは、 $t=0$ から $t=1$ までの離散時間ステップ $t_i$ の一連のステップに進みます。各ステップ $i$ について:
- 現在の状態: 現在の推定状態 $X_{t_i}$ があり、これは $X_0$ から始まります。
- サブバンド分割(該当する場合): モデルがマルチバンド構造を使用している場合、$X_{t_i}$ はサブバンドに分割されます。各サブバンドのノイズサンプル($X_{t_i}^{\text{sb}}$)がConvNeXtV2バックボーンに供給されます。
- 速度予測: ニューラルネットワーク $v$ (ConvNeXtV2バックボーン)は、現在の状態 $X_{t_i}$(またはそのサブバンド $X_{t_i}^{\text{sb}}$)、現在の時間 $t_i$、および条件付き入力 $C$(およびオプションでサブバンドインデックス $i_{\text{sb}}$ と帯域幅インデックス $i_{\text{bw}}$)を受け取り、瞬間速度 $v(X_{t_i}, t_i | C)$ を予測します。
- オイラーステップ: 予測された速度 $v(X_{t_i}, t_i | C)$ を使用して状態が更新されます。オイラー法のような数値ODEソルバーを使用して、次の状態 $X_{t_{i+1}}$ は $X_{t_{i+1}} = X_{t_i} + v(X_{t_i}, t_i | C) \cdot \Delta t$ として計算されます。ここで $\Delta t = t_{i+1} - t_i$ は時間ステップ間隔です。これは、予測された速度ベクトルに沿ってデータポイントを効果的に移動させます。
- サブバンドマージ(該当する場合): サブバンドが独立して処理された場合、それらの予測された速度はマージされてフルバンド速度を形成し、それがオイラーステップに使用されます。
- 最終スペクトログラム再構成($t=1$): この反復プロセスは、 $t$ が1に達するまで、少数のサンプリングステップ(RFWaveでは例として10ステップ)で続行されます。最終状態 $X_1$ は、再構成された複素スペクトログラムです。
- 波形変換: $X_1$ は周波数ドメインの複素スペクトログラムであるため、単一の逆短時間フーリエ変換(ISTFT)操作が適用されて、最終的な高忠実度音声波形に変換されます。論文では、周波数ドメインモデルの場合、最後のステップで1回のISTFTのみが必要であり、これは主要な効率向上であると述べています。
このシーケンスは、ランダムノイズ入力を、条件付き入力と学習された速度場によってガイドされる、構造化された高品質音声波形に変換します。
最適化ダイナミクス
RFWaveメカニズムは、追加の損失項によって強化されたエネルギーバランス整流フロー目的関数を最小化することにより、確率的勾配降下法を通じて学習、更新、および収束します。
-
損失ランドスケープの整形: 主要な損失関数(式5)は、損失ランドスケープを定義し、その「谷」は正確な速度予測に対応します。整流フローの定式化は、本質的に直線軌道を学習することを奨励し、これは拡散モデルが複雑なノイズスケジュールを学習する場合と比較して、より滑らかで扱いやすい損失ランドスケープを作成する傾向があります。重要な $\sigma$ 項(エネルギーバランス係数)は、このランドスケープを動的に再整形します。低エネルギー領域(例:無音)では、$\sigma$ は小さく、項 $1/\sigma$ は大きくなります。これにより、これらの領域のエラーの損失への寄与が効果的に増幅され、わずかな逸脱に対する勾配が急になります。これにより、モデルは静かな部分でのノイズを正確に抑制することにさらに注意を払うようになり、一般的な低音量アーティファクトの問題を防ぎます。逆に、高エネルギー領域では $\sigma$ が大きくなり、これらの支配的な領域が他の部分の重要性を完全に覆い隠すのを防ぎます。この動的な重み付けは、オーディオ全体のスペクトル全体でよりバランスの取れた学習目的を作成します。
-
勾配の挙動: トレーニング中、モデルは損失関数に対するニューラルネットワークパラメータの勾配を計算します。これらの勾配は、エラーを減らすためにパラメータをどのように調整すべきかを示します。
- $L_2$ ノルムは、勾配が予測速度 $v(X_t, t | C)$ をグラウンドトゥルース速度 $(X_1 - X_0)$ に整列させることを保証します。
- $\sigma$ 項は勾配の大きさに直接影響します。低 $\sigma$ 値の場合、それらの領域のエラーに関連する勾配はスケールアップされ、モデルが無音部分での速度をより正確に予測するように強制されます。これはノイズ抑制のための直接的なメカニズムです。
- 追加の損失関数: RFWaveは3つの強化された損失関数を組み込んでいます:エネルギーバランス損失(すでに $\sigma$ を介して議論)、オーバーラップ損失、およびSTFT損失。これらの追加の損失は、さらなる勾配信号を導入します。
- オーバーラップ損失: この損失は、隣接するサブバンドの重なり合うセクション間の整合性を維持するためにトレーニング中に適用されます。サブバンドが推論中にマージされる際に、滑らかな遷移と不整合の防止を強制する勾配を生成します。
- STFT損失: スペクトル収束(SC)損失と対数スケールSTFTマグニチュード損失($L_1$ ノルム)からなるこの項は、近似ターゲット $\tilde{X}_1$ に適用されます。SC損失(フロベニウスノルム)は大きなスペクトル成分に焦点を当て、対数スケールSTFTマグニチュード損失は小さな振幅成分を強調します。これらの損失は、モデルがスペクトル的に正確なオーディオを生成するように導く勾配を提供し、アーティファクトを減らし、全体的な音質を向上させます。これらの追加損失の重み(例:0.01)は、メインの整流フロー損失との影響をバランスさせるために選択されます。
-
反復的な状態更新と収束: ニューラルネットワークパラメータは、AdamWのようなオプティマイザを使用して反復的に更新され、すべての損失コンポーネントからの集約された勾配によって駆動されます。コサインアニーリング学習率スケジュールが採用されており、高いレート(例:2e-4)で開始し、最小値(例:2e-6)まで徐々に減少します。このスケジュールは、モデルがトレーニングの早い段階で大きな調整を行い、その後、安定した収束のためにパラメータを微調整するのに役立ちます。モデルは、予測された速度場 $v$ が、時間間隔全体にわたって、Cを条件として、任意の途中状態 $X_t$ を真の直線速度 $(X_1 - X_0)$ に正確にマッピングするときに収束します。「等しい直線性」サンプリング戦略は、主に推論技術ですが、モデルがすべてのオイラーステップで一貫して挑戦されることを保証することにより、収束を間接的にサポートし、より堅牢に学習された速度場につながる可能性があります。
モデル構造
モデル構造を図1に示します。各周波数帯域は、一意のサブバンドインデックスによって区別され、同じモデルを共有します。特定のサンプルのサブバンドは、処理のために単一のバッチにグループ化されます。これにより、同時トレーニングまたは推論が容易になり、推論遅延が大幅に削減されます。さらに、サブバンドを独立してモデル化することで、エラーの蓄積が減少します。(Roman et al., 2023)で議論されているように、高位バンドを低位バンドに条件付けるとエラーの蓄積につながる可能性があり、これは低位バンドの不正確さが推論中に高位バンドに悪影響を与える可能性があることを意味します。
モデルは、ノイズサンプル(Xt)をその速度(vt)にマッピングします。各サブバンドについて、サブバンドのノイズサンプル(Xsb)がConvNeXtV2バックボーンに供給され、時間(t)、サブバンドインデックス(ist)、条件付き入力(C'、メルスペクトログラムまたはEnCodec(Défossez et al., 2022)トークン)、およびオプションのEnCodec帯域幅インデックス(ibw)を条件として、その速度(vs)を予測します。ConvNeXtV2バックボーンの詳細な構造は図1に示されています。Kingma et al. (2021) で説明されているように、フーリエ特徴量を使用します。Xsb、C、およびフーリエ特徴量はチャネル次元に沿って連結され、その後線形層を通過し、一連のConvNeXtV2ブロックに供給される入力を形成します。正弦波t埋め込みは、オプションのibw埋め込みとともに、各ConvNeXtV2ブロックの入力に要素ごとに追加されます。ibwはEnCodecトークンのデコード中に使用され、単一モデルがさまざまな帯域幅を持つEnCodecトークンをサポートできるようにします。さらに、istは適応レイヤー正規化モジュールを介して組み込まれ、学習可能な埋め込みを使用します(Siuzdak, 2023; Xu et al., 2019)。他のコンポーネントはConvNeXtV2アーキテクチャ内のものと同一であり、詳細は(Woo et al., 2023)で見つけることができます。
私たちの方法論は2つのモデリングオプションを提供します。最初のオプションは、ガウスノイズを時間領域で直接波形にマッピングすることを含み、ここでX0、X1、Xt、およびvtはすべて時間領域に存在します。2番目のオプションは、ガウスノイズを複素スペクトログラムにマッピングし、X0、X1、Xt、およびvtを周波数領域に配置します。特に、Xishとvistは、ニューラルネットワークがフレームレベルで実行されることを保証するために、後続の段落で詳述されているように、一貫して周波数領域で表されます。フレームレベルの特徴量を処理することにより、私たちのモデルは、波形サンプルポイントのレベルで動作するPriorGradのような拡散ボコーダーと比較して、より高いメモリ効率を達成します。PriorGrad(gil Lee et al., 2022)は、30 GBのGPUメモリ内で44.1 kHzの6秒²オーディオクリップをトレーニングできますが、私たちのモデルは同じメモリリソースで177秒のクリップを処理できます。
Xtを時間領域で操作し、波形等化を行う。私たちのモデルはフレームレベルで機能するように設計されているため、Xtとvtが時間領域にある場合(特に、X₁は波形であり、Xoは同じ形状のノイズであり、Xtとvtは(3)から導出される)、STFTとISTFTの使用(図1に示す)が必要になります。Xtとvtの次元は[1, T]³に準拠し、Tはサンプルポイントでの波形長です。STFT操作の後、フルバンド複素スペクトログラムを等しく分割してサブバンドを抽出し、Xisを取得します。各サブバンドXisb
オイラー法のための時間点選択
Liu et al. (2023) は、(4) に示すように、オイラー法に等しいステップ間隔を採用しています。ここでは、輸送軌道の直線性に基づいてサンプリングのための時間点を選択することを提案します。時間点は、各ステップで直線性の増加が等しくなるように選択されます。学習された速度場 v の直線性は $S(v) = \int E || (X1 - Xo) – v(Xt, t | C) ||² dt$ と定義され、速度の軌道に沿った逸脱を記述します。S(v) が小さいほど、軌道は直線的になります。このアプローチは、各オイラーステップの難易度が一貫していることを保証し、モデルにより多くのステップをより困難な領域で取ることを要求します。同じ数のサンプリングステップを使用すると、この方法は等間隔アプローチよりも優れています。実装の詳細は付録セクションA.5に記載されており、アルゴリズムは付録セクションA.9.2に示されています。このアプローチを等しい直線性と呼びます。
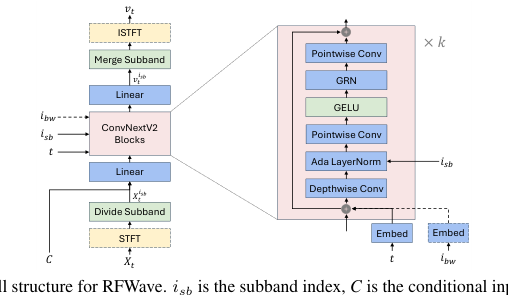 Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
結果、限界、結論
実験設計とベースライン
RFWaveのパフォーマンスを厳密に検証するために、著者らは、さまざまなオーディオドメインと入力タイプにわたって、確立された「犠牲者」ベースラインに対してモデルを比較する包括的な実験セットアップを設計しました。
メルスペクトログラム入力の場合、2つの主要な評価シナリオが設計されました。
1. 拡散ベースボコーダーとの比較: RFWaveモデルは、LibriTTS(音声用)、MTG-Jamendo(音楽用)、およびOpencpop(ボーカル音楽用)の3つの多様なデータセットで個別にトレーニングされました。これらのモデルは、それぞれのテストセットで評価されました。このカテゴリのベースラインは、最先端の拡散モデルであるPriorGradとFreGradでした。
2. GANベースボコーダーとの比較: RFWaveモデルはLibriTTSでトレーニングされました。その後、LibriTTSテストセット(ドメイン内)と、特にMUSDB18データセット(ドメイン外)で汎化能力と堅牢性をテストするために評価されました。ここでは、ベースラインは広く使用されているGANモデルであるVocosとBigVGANでした。
離散EnCodecトークン入力の場合、Common Voice 7.0、DNS Challenge 4、MTG-Jamendo、FSD50K、およびAudioSetを含む大規模な混合データセットでユニバーサルRFWaveモデルがトレーニングされました。このユニバーサルモデルは、その後、カスタム構築された統一テストデータセット(15の外部ソースからの900オーディオサンプル、音声、ボーカル、効果音をカバー)でEnCodecとMulti-Band Diffusion(MBD)に対して評価されました。この広範な評価は、RFWaveの多様なオーディオタイプにわたる汎用性を証明することを目的としていました。
評価指標: 客観的および主観的な測定の両方が採用されました。
* 客観的指標には、ViSQOL(知覚品質、22.05/24 kHzの音声モード、44.1 kHz波形のオーディオモードを使用)、PESQ(知覚音声品質評価)、V/UV F1(有声/無声分類のF1スコア)、およびPeriodicity(周期性誤差)が含まれていました。
* 主観的評価は、5点式平均オピニオンスコア(MOS)(1:'poor/unnatural'から5:'excellent/natural')を使用したクラウドソーシング評価を含みました。各比較について、30人のリスナーがグラウンドトゥルース、RFWave、およびベースラインモデルを含む20〜40グループのオーディオサンプルをランダムな順序で評価しました。
実装詳細: RFWaveモデルはデフォルトで時間領域アプローチを採用し、3つの強化された損失関数(エネルギーバランス、オーバーラップ、STFT損失)とConvNeXtV2バックボーン(8ブロック)を組み込みました。複素スペクトログラムは8つの等間隔サブバンドに分割されました。重要なアーキテクチャの選択は、わずか10サンプリングステップの推論でした。アブレーションスタディも、周波数対時間領域モデリング、各損失関数の段階的な追加、'等しい直線性'サンプリング戦略、異なるバックボーンアーキテクチャ(ResNet対ConvNeXtV2)、およびモデルサイズなどの個々のコンポーネントの影響を解明するために実施されました。推論速度は、バッチサイズ1でNVIDIA GeForce RTX 4090 GPUでベンチマークされました。
証拠が証明するもの
論文で提示された経験的証拠は、RFWaveのコアメカニズムが現実で機能していることを断定的かつ否定できない証明を提供し、音声品質と計算効率の両方でその優れたパフォーマンスを示しています。
拡散ベースベースラインの打破:
RFWaveは、メルスペクトログラムから再構成する際に、すべての客観的および主観的な指標で、拡散ベースの「犠牲者」であるPriorGradとFreGradを圧倒的に上回りました(表1)。例えば、RFWaveは平均MOS $3.95 \pm 0.09$ を達成し、PriorGradの $3.75 \pm 0.09$ とFreGradの $2.99 \pm 0.14$ を大幅に上回りました。客観的には、RFWaveのPESQ $4.202$ はPriorGradの $3.612$ とFreGradの $3.640$ をはるかに凌駕しました。この優位性の決定的な証拠は、RFWaveが「高周波範囲、特に高周波範囲で、より鮮明で一貫性のあるハーモニクスを生成する」能力にあり、付録A.6(図A.3、A.4、A.5)のスペクトログラムで視覚的に確認されており、ベースラインはマイナーな不連続性またはぼやけた高周波コンポーネントを示していました。これは、少ないサンプリングステップで高品質なオーディオを実現する整流フローの効果を直接検証します。
GANベースベースラインへの挑戦:
GANsは速度で知られていますが、RFWaveは同等のドメイン内品質と優れたドメイン外汎化能力を示しました。ドメイン内LibriTTSテストセットでは、RFWaveのMOS($3.82 \pm 0.12$)はBigVGAN($3.78 \pm 0.11$)とVocos($3.74 \pm 0.10$)(表2)と同等でした。しかし、真の勝利はドメイン外MUSDB18データセット(表3)で得られ、RFWaveは平均MOS $3.67 \pm 0.05$ を達成し、BigVGANの $3.51 \pm 0.05$ とVocosの $3.10 \pm 0.06$ を大幅に上回りました。ここでの決定的な証拠は、図A.7の視覚分析であり、BigVGANやVocosのようなGANベースのモデルは「スペクトログラムの高周波領域に水平線」を生成する傾向があり、「金属的な音質」につながることを示しています。対照的に、RFWaveは一貫して「鮮明で明確な高周波ハーモニクス」を生成し、拡散タイプモデルとしての堅牢性と汎化能力を証明しました。
EnCodecトークン再構成の支配:
離散EnCodecトークン入力の場合、RFWave(CFG2を使用)は、ほとんどの指標(MOS、PESQ、V/UV F1、Periodicity)とさまざまな帯域幅で一貫して最適なスコアを達成し、EnCodecとMBDの両方を上回りました(表4)。例えば、6.0 kbpsでは、RFWaveのMOSはEnCodecの $3.10 \pm 0.15$ とMBDの $3.43 \pm 0.15$ と比較して $3.69 \pm 0.16$ でした。これは、圧縮表現から高品質なオーディオを再構成する際のRFWaveの汎用性と効率性を示しています。
アブレーションスタディによる検証:
アブレーションスタディ(表5)は、RFWaveの個々のコンポーネントの効果に関する重要な洞察を提供しました。
* 時間領域モデルは、一貫して周波数領域の対応物(例:PESQ $4.127$ 対 $3.872$)を上回り、高周波ディテール保持の選択を検証しました。
* エネルギーバランス損失は、無音領域での低音量ノイズを軽減し、全体的なパフォーマンスを向上させることが示されました(例:PESQ $4.127$ から $4.181$ へ)。これは、相対エラーを最小化する役割を証明しました。
* オーバーラップ損失は、PESQのわずかな低下にもかかわらず、「滑らかなサブバンド遷移」と整合性の維持に不可欠であり、それがない場合の視覚的な確認(図A.9)によって裏付けられました。
* STFT損失は、バックグラウンドノイズにおけるアーティファクトを効果的に低減し(図A.8)、PESQを $4.158$ から $4.211$ に改善しましたが、マグニチュードへの強調によりViSQOLと周期性にわずかなトレードオフがありました。
* 等しい直線性サンプリング戦略は、パフォーマンスを「無料で」大幅に改善しました(PESQ $4.275$、周期性 $0.100$)。これは、等間隔ステップに対する有効性を証明しました。
* 整流フローメカニズムは、効率的な高品質生成に「不可欠」であることが示されました。なぜなら、50ステップのDDPMアプローチはパフォーマンスが悪かったからです(表6)。ConvNeXtV2バックボーンもResNetよりも優れており、効率と品質の両方を向上させました。
前例のない計算効率:
おそらく最も顕著な証拠は、RFWaveの圧倒的に優れた計算効率(表7)です。わずか10サンプリングステップで、単一のNVIDIA GeForce RTX 4090 GPUでリアルタイムの162.59倍(xRT)の推論速度を達成しました。これは、拡散ベースライン(PriorGrad $16.67$ xRT、FreGrad $7.50$ xRT、MBD $4.82$ xRT)よりも1桁速く、BigVGAN($72.68$ xRT)の2倍以上高速です。さらに、RFWaveはBigVGAN($1436$ MB)よりも少ないGPUメモリ($780$ MB)を消費しました。この速度の利点は、より高いサンプリングレート(例:44.1 kHzで $152.58$ xRT)でも維持されており、RFWaveが拡散モデルの遅延バリアを克服し、現実世界のリアルタイムアプリケーションに実用的であることを決定的に証明しています。
限界と将来の方向性
RFWaveは音声波形再構成における大きな飛躍を示していますが、現在の限界を認識し、将来の開発の方向性を検討することが重要です。
観察された微妙な限界の1つは、ViSQOL指標のGANベースモデルへの偏りです。RFWaveはしばしばより高いMOSや他の客観的スコアを達成しますが、ViSQOLはGANを好むことがあり、これは人間の知覚品質を完全に反映していない可能性があります。これは、現在の客観的指標が、特に新しい生成アプローチの合成オーディオの「自然さ」と「品質」のすべてのニュアンスを完全に捉えられない可能性があることを示唆しています。別の興味深いトレードオフは、STFT損失で見られました。アーティファクトを効果的に低減しますが、マグニチュードを位相よりも優先するため、ViSQOLと周期性をわずかに低下させる可能性があります。これは、オーディオ忠実度の異なる側面をバランスさせることの課題を浮き彫りにしています。さらに、RFWaveはGANと比較して優れたドメイン外汎化能力を示していますが、真にユニバーサルなボコーダーの究極の目標は、さらに広範な未知のオーディオ条件と特性を処理することを意味し、これは継続的な課題です。トレーニングに必要な計算リソース、特に大規模なEnCodec混合データセット(例:4x A100 GPUで10日間)は、小規模な研究グループや個人開発者にとっても実用的な障壁となります。
将来に向けて、これらの発見をさらに発展させ進化させるためのいくつかのエキサイティングな議論のトピックが登場します。
- 適応型損失関数設計: STFT損失のトレードオフを考慮すると、損失関数に動的またはコンテキスト認識重み付けを検討できますか?例えば、特定の周波数帯域または特定のオーディオイベント中に位相情報を優先する適応メカニズムは、アーティファクトを再導入することなく、さらに優れた知覚品質をもたらす可能性があります。これには、学習された重み付け係数や多目的最適化フレームワークが含まれる可能性があります。
- 等しい直線性サンプリングを超える: '等しい直線性'メソッドは巧妙なヒューリスティックですが、最適なサンプリング軌道がすべての潜在空間領域で厳密に「等しく直線的」でない場合はどうでしょうか?将来の研究では、忠実度を最大化しながらステップ数をさらに最小化する最適な、非均一なサンプリングスケジュールを発見するために、より高度な適応型ODEソルバーまたは強化学習アプローチを調査する可能性があります。これは、オーディオ特性に合わせたスケジュールを調整することさえ可能にするかもしれません。
- 極端なドメイン外データのための強化された汎化: RFWaveは優れていますが、現実世界のオーディオは信じられないほど多様で、しばしばノイズが多いです。これらのモデルを、非常に破損した、極端に低リソースの、または完全に新しいオーディオタイプに対してさらに堅牢にするにはどうすればよいでしょうか?これには、メタ学習による迅速な適応、膨大なラベルなしオーディオでの自己教師あり学習、または明示的なノイズモデリング機能の組み込みが含まれる可能性があります。
- 制約のあるハードウェアでのリアルタイム展開: ハイエンドGPUでリアルタイムの160倍を達成することは素晴らしいですが、モバイルデバイスや組み込みシステムでの普遍的なアプリケーションでは、さらなる最適化が必要です。これには、モデルの量子化、プルーニング、知識蒸留、またはエッジハードウェアで本質的に効率的な特殊アーキテクチャの設計の探索が含まれる可能性があり、リアルタイム音声合成の可能性の境界を押し広げます。
- マルチモーダルおよびインタラクティブオーディオ生成: 現在の研究はメルスペクトログラムと離散トークンに焦点を当てています。RFWaveをテキスト、ビデオ、またはユーザー定義パラメータ(例:感情的な手がかり、空間オーディオプロパティ)などの他のモダリティを直接組み込むように拡張すると、新しい創造的なアプリケーションとより直感的な人間とコンピュータの相互作用が可能になります。ビデオシーンのムードやユーザーのジェスチャー入力に完全に一致するオーディオを生成することを想像してください。
- 知覚的に整合した指標の開発: 観察されたViSQOLの偏りは、分野におけるより広範な必要性を強調しています。合成オーディオの「自然さ」と「品質」の知覚とより密接に一致する、より堅牢で偏りの少ない客観的指標をどのように開発できるでしょうか?これには、人間のフィードバックループまたは高度な心理音響モデリングの活用が含まれる可能性があります。
- 倫理的影響とセーフガード: 音声合成が実際の録音と区別がつかなくなるにつれて、ディープフェイクの作成や誤情報での悪用などの倫理的影響が増大します。将来の研究は、合成オーディオのウォーターマーキング、堅牢な検出メカニズムの開発、またはモデル設計と展開プロセスに倫理ガイドラインを直接統合する方法を模索することにより、これらの懸念に積極的に対処する必要があります。これは、しばしば見過ごされる、生成AIを進歩させる上で重要な側面です。