RFWave: Многодиапазонный выпрямленный поток для реконструкции аудиосигналов
Проблема реконструкции аудиосигналов, заключающаяся в преобразовании низкоразмерных признаков в реалистичные, воспринимаемые звуки, возникла из растущего спроса на улучшенное цифровое взаимодействие.
Предпосылки и академическая преемственность
Происхождение и академическая преемственность
Проблема реконструкции аудиосигналов, заключающаяся в преобразовании низкоразмерных признаков в реалистичные, воспринимаемые звуки, возникла из растущего спроса на улучшенное цифровое взаимодействие. Эта технология имеет решающее значение для разнообразных приложений, таких как виртуальные ассистенты, развлекательные системы и синтез речи по тексту, где генерация высококачественного, естественно звучащего голоса и музыки имеет первостепенное значение. Исторически эта область вышла за рамки традиционных методов обработки сигналов (Kawahara et al., 1999; Morise et al., 2016) с появлением передовых генеративных моделей.
Ранние значительные достижения пришли из двух основных парадигм: авторегрессионных моделей и генеративно-состязательных сетей (GAN) (Goodfellow et al., 2014). Авторегрессионные модели, хотя и способны производить высококачественное аудио, были сильно ограничены своей медленной скоростью генерации. Эта медлительность была вызвана их последовательным предсказанием отдельных точек выборки (Oord et al., 2016; Kalchbrenner et al., 2018; Valin & Skoglund, 2019), что делало приложения реального времени непрактичными. GAN обеспечили более быструю генерацию, предсказывая точки выборки параллельно (Kumar et al., 2019; Yamamoto et al., 2020; Kong et al., 2020a), но они привнесли свой собственный набор "болевых точек". К ним относилась необходимость в сложных конструкциях дискриминаторов и проблемы, такие как нестабильность обучения или коллапс мод (Thanh-Tung et al., 2018), когда модель могла не освоить полное разнообразие данных.
В последнее время диффузионные модели (Song et al., 2020; Ho et al., 2020) появились как многообещающая альтернатива, предлагая большую стабильность обучения и способность реконструировать высококачественные сигналы (Chen et al., 2020; Kong et al., 2020b; gil Lee et al., 2022). Однако диффузионные модели унаследовали существенное ограничение: они были как минимум на порядок медленнее GAN. Эта медлительность была в основном обусловлена двумя факторами: (1) требованием многочисленных шагов выборки для достижения высококачественных образцов и (2) их работой на уровне отдельных точек выборки сигнала. Последнее часто включало множество операций повышающей дискретизации для согласования частоты кадров и частоты дискретизации, что приводило к увеличению длины последовательности, более высокому потреблению памяти GPU и существенным вычислительным требованиям. Это фундаментальное ограничение медленной скорости вывода в диффузионных моделях является основной "болевой точкой", которую RFWave стремится устранить, стремясь соответствовать скоростям, основанным на GAN, сохраняя при этом стабильность и качество диффузионных моделей.
Интуитивные термины предметной области
Вот некоторые специализированные термины из статьи, переведенные в повседневные аналогии для начинающих:
- Мел-спектрограмма: Представьте, что у вас есть нотная запись, которая визуально представляет песню. Мел-спектрограмма похожа, но это цифровое "изображение" звука, которое может понять компьютер. Оно показывает, как громкость различных частот меняется со временем, со специальным масштабированием (шкала Мел), имитирующим то, как люди воспринимают высоту тона. Это похоже на музыкальную партитуру для машины, выделяющую важные части звука.
- Выпрямленный поток (Rectified Flow): Представьте себе путешествие из точки А в точку Б. Обычно вы можете выбрать извилистую дорогу с множеством поворотов. Выпрямленный поток похож на поиск самого прямого, прямолинейного пути между точкой А (зашумленные данные) и точкой Б (чистое аудио). Эта "прямая магистраль" делает путешествие намного быстрее и эффективнее, позволяя модели преобразовывать шум в звук за меньшее количество шагов.
- Диффузионные модели: Представьте себе очень размытую фотографию, которая постепенно становится четче и резче с каждым шагом, который вы делаете для "удаления шума". Диффузионные модели работают аналогично: они начинают со случайного шума (как полностью размытое изображение) и медленно, шаг за шагом, преобразуют его в связный, высококачественный аудиосигнал, обращая процесс диффузии. Это похоже на то, как художник медленно добавляет детали на холст, пока не появится шедевр.
- Коллапс мод (в GAN): Представьте себе повара, которого попросили приготовить разнообразные блюда, но он научился готовить только одно конкретное блюдо идеально, игнорируя все остальные рецепты. В генеративных моделях, таких как GAN, коллапс мод означает, что модель не генерирует разнообразные выходные данные, а вместо этого производит только ограниченный набор похожих, высококачественных образцов. Это похоже на то, как повар всегда готовит одну и ту же идеальную пасту, даже когда его просят приготовить стейк или салат, потому что это единственное, что он умеет делать хорошо.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $Z_t$ | Эволюционирующее состояние данных в данный момент времени $t$ в процессе преобразования. |
| $v(Z_t, t)$ | Поле "скорости", определяющее, как данные $Z_t$ изменяются во времени $t$, направляя их к цели. |
| $\pi_0$ | Начальное распределение вероятностей, обычно представляющее случайный шум. |
| $\pi_1$ | Целевое распределение вероятностей, представляющее желаемые реальные аудиоданные. |
| $X_0$ | Начальный образец данных, обычно случайный шум, взятый из $\pi_0$. |
| $X_1$ | Целевой образец данных, представляющий истинный аудиосигнал или спектрограмму, взятый из $\pi_1$. |
| $X_t$ | Промежуточный образец данных во времени $t$, представляющий интерполяцию между $X_0$ и $X_1$. |
| $t$ | Переменная времени, которая прогрессирует от $0$ (начало преобразования) до $1$ (конец преобразования). |
| $C$ | Условный вход, такой как мел-спектрограмма или дискретные акустические токены, который управляет генерацией аудио. |
| $N$ | Размер быстрой преобразования Фурье (FFT), определяющий разрешение по частоте. |
| $d_s$ | Количество частотных бинов в комплексном спектре определенной подполосы. |
| $F$ | Общее количество кадров в спектрограмме, представляющее временные сегменты. |
| $i_{sb}$ | Индекс, идентифицирующий определенную подполосу. |
| $i_{bw}$ | Индекс полосы пропускания для токенов EnCodec, используемый для различных уровней сжатия. |
| $\sigma$ | Весовой коэффициент, используемый в потерях с энергетическим балансом, часто выводимый из стандартного отклонения истинной скорости. |
| $S(v)$ | Мера "прямолинейности" траекторий обученного поля скорости, указывающая, насколько прямым является путь преобразования. |
Определение проблемы и ограничения
Основная постановка задачи и дилемма
Основная проблема, решаемая данной статьей, заключается в эффективной реконструкции высококачественных аудиосигналов из различных сжатых представлений, таких как мел-спектрограммы или дискретные акустические токены.
Входные данные/Текущее состояние для этой проблемы включают:
* Низкоразмерные аудиопризнаки, в частности мел-спектрограммы или дискретные акустические токены, которые являются компактными представлениями звука.
* Существующие генеративные модели, в основном диффузионные модели и генеративно-состязательные сети (GAN), каждая со своими ограничениями. Диффузионные модели, хотя и способны производить высококачественное аудио, работают на уровне отдельных точек выборки сигнала и требуют многочисленных шагов выборки, что приводит к значительному времени задержки. GAN, хотя и быстрее, часто страдают от нестабильности обучения и коллапса мод, а также требуют сложных конструкций дискриминаторов.
Желаемая конечная точка/Целевое состояние заключается в достижении:
* Высококачественных аудиосигналов, реконструированных из этих низкоразмерных входных данных.
* Генеративной модели, которая соответствует скорости вывода методов на основе GAN (т.е. в реальном времени или быстрее), сохраняя при этом стабильность обучения и высокое качество образцов, характерное для диффузионных моделей.
* Возможности реконструировать сигналы с резко уменьшенным количеством шагов выборки (например, всего 10 шагов, как достигнуто RFWave).
* Превосходной вычислительной эффективности, обеспечивающей генерацию аудио со скоростью, значительно превышающей реальное время (например, до 160 раз быстрее на GPU).
* Универсальности в реконструкции аудио как из мел-спектрограмм, так и из дискретных акустических токенов.
Точное недостающее звено или математический пробел между текущим состоянием и желаемой конечной точкой — это отсутствие фреймворка генеративного моделирования, который мог бы одновременно достичь высокого перцептивного качества и стабильности обучения диффузионных моделей и высокой вычислительной эффективности и низкой задержки GAN для реконструкции аудиосигналов. Предыдущие диффузионные модели математически сформулированы для постепенного удаления шума из сигнала за множество шагов, что делает их по своей сути медленными. GAN, хотя и быстрые, не имеют надежных математических гарантий стабильного обучения и постоянного качества. Данная статья пытается устранить этот пробел, используя Rectified Flow, который стремится изучить прямой, прямолинейный транспортный путь между распределениями шума и данных, тем самым уменьшая требуемые шаги выборки. В частности, Rectified Flow изучает поле скорости $v(Z_t, t)$, которое управляет эволюцией зашумленного образца $Z_t$ от начального распределения шума $\pi_0$ к целевому распределению данных $\pi_1$ таким образом, что $\frac{dZ_t}{dt} = v(Z_t, t)$. Цель обучения минимизирует отклонение от прямолинейной траектории:
$$ \min E_{(X_0, X_1)\sim\gamma} \int_0^1 || \frac{d}{dt}X_t - v(X_t, t) ||^2 dt $$
где $X_t = (1-t)X_0 + tX_1$ представляет собой линейную интерполяцию. Эта математическая формулировка является ключом к ускорению процесса вывода, позволяя выполнять меньше, более прямых шагов.
Болезненный компромисс или дилемма, в ловушке которой оказались предыдущие исследователи, — это фундаментальный конфликт между качеством аудио/стабильностью обучения и скоростью вывода/вычислительной эффективностью. Улучшение одного аспекта обычно ухудшает другой:
* Диффузионные модели: Обеспечивают отличное качество аудио и стабильное обучение, но печально медленны. Их работа на "уровне отдельных точек выборки" и необходимость "многочисленных шагов выборки" (часто сотни или тысячи) приводят к высокой задержке и вычислительным требованиям.
* GAN: Обеспечивают высокую скорость генерации, предсказывая точки выборки параллельно, но страдают от "сложных конструкций дискриминаторов и проблем, таких как нестабильность или коллапс мод", что делает их более трудными для надежного обучения и иногда приводит к более низкому качеству или менее разнообразным выходным данным.
Эта дилемма означает, что исследователям ранее приходилось выбирать между высококачественной, стабильной, но медленной моделью, или быстрой, но потенциально нестабильной и менее качественной моделью. Данная статья стремится разорвать этот компромисс.
Ограничения и режимы отказа
Проблема высококачественной реконструкции аудиосигналов в реальном времени чрезвычайно сложна из-за нескольких жестких, реалистичных ограничений и присущих ей режимов отказа:
-
Вычислительные затраты и ограничения памяти GPU:
- Работа на уровне точек выборки: Предыдущие диффузионные модели обрабатывают аудио на уровне отдельных точек выборки. Это требует "множества операций повышающей дискретизации для перехода от разрешения частоты кадров к разрешению частоты дискретизации, увеличивая длину последовательности и, как следствие, приводя к более высокому потреблению памяти GPU и вычислительным требованиям" (стр. 2). Для аудио высокого разрешения (например, 44,1 кГц или 48 кГц) обработка миллионов выборок в секунду вычислительно непомерна и требует больших объемов памяти. Например, PriorGrad может обучаться только на аудиоклипах длительностью 6 секунд при частоте 44,1 кГц в пределах 30 ГБ памяти GPU, что подчеркивает это серьезное ограничение памяти (стр. 4).
- Многочисленные шаги выборки: Диффузионные модели обычно требуют сотен или тысяч шагов выборки для генерации высококачественного аудио, что напрямую влияет на скорость вывода и вычислительную нагрузку. Это делает их "как минимум на порядок медленнее по сравнению с GAN" (стр. 1).
-
Требования к задержке в реальном времени: Многие практические приложения (например, виртуальные ассистенты, связь в реальном времени) требуют чрезвычайно низкой задержки. Существующие диффузионные модели, даже самые быстрые, работают "всего примерно в 10-20 раз быстрее реального времени" (стр. 3), что недостаточно для истинного взаимодействия в реальном времени, особенно в сочетании с крупномасштабными акустическими моделями.
-
Нестабильность обучения и коллапс мод (для GAN): Хотя GAN обеспечивают скорость, их обучение печально трудно. "Сложные конструкции дискриминаторов" и проблемы, такие как "нестабильность или коллапс мод" (стр. 1), означают, что они могут не освоить полное распределение данных, что приводит к менее разнообразным или менее качественным выходным данным.
-
Накопление ошибок при многополосной обработке: При использовании многополосных стратегий "обусловливание более высоких полос более низкими может привести к накоплению ошибок, что означает, что неточности в более низких полосах могут неблагоприятно сказаться на более высоких полосах во время вывода" (стр. 4). Это означает, что ошибки в одной части частотного спектра могут распространяться и повреждать другие.
-
Низкоуровневый шум в тихих регионах: Распространенным режимом отказа для моделей, обученных с использованием потерь среднеквадратичной ошибки (MSE), является наличие "низкоуровневого шума в ожидаемых тихих регионах" (стр. 5). Это происходит потому, что небольшие ошибки в тихих частях минимально вносят вклад в общую MSE, заставляя модель отдавать приоритет уменьшению больших ошибок в областях с высокой амплитудой, что приводит к слышимому шуму в тихих участках.
-
Несоответствия между подполосами: Когда разные частотные подполосы предсказываются независимо, существует риск "несоответствий между ними" (стр. 6), что приводит к слышимым артефактам на границах подполос в реконструированном сигнале.
-
Артефакты в фоновом шуме: Без специальных функций потерь, таких как потери STFT, модели могут генерировать "вертикальные паттерны" или другие "артефакты в присутствии фонового шума" (Рисунок A.8, стр. 6), ухудшая воспринимаемое качество.
-
Нелинейные траектории переноса: Эффективность Rectified Flow зависит от изучения "прямолинейных траекторий переноса" (стр. 2). Если обученное поле скорости значительно отклоняется от линейности, метод Эйлера потребует больше шагов для точного аппроксимирования ОДУ, сводя на нет преимущества эффективности. Это делает изучение поля скорости деликатной задачей.
Почему этот подход
Неизбежность выбора
Основная проблема, решаемая RFWave, — это критический компромисс между качеством реконструкции аудио и скоростью генерации в генеративных моделях. Традиционные передовые (SOTA) методы, несмотря на их продвинутость, каждый представлял собой существенные ограничения, которые делали их недостаточными для одновременного достижения как высокой точности, так и производительности в реальном времени.
Авторы осознали, что стандартные диффузионные модели, несмотря на их мастерство в генерации высококачественного аудио и обеспечении стабильного обучения, были фундаментально ограничены двумя факторами: (1) их работой на уровне отдельных точек выборки сигнала и (2) необходимостью многочисленных шагов выборки для достижения желаемого качества. Это привело к серьезным проблемам с задержкой и высокому потреблению памяти GPU, что сделало их как минимум на порядок медленнее GAN и непрактичными для приложений реального времени. В статье явно указано это осознание: "Хотя диффузионные модели преуспевают в этой задаче, они ограничены проблемами задержки из-за их работы на уровне отдельных точек выборки и необходимости многочисленных шагов выборки." (Аннотация). Эта недостаточность была дополнительно подчеркнута наблюдением, что даже самые быстрые диффузионные методы работали только в 10-20 раз быстрее реального времени, что далеко от требований реальных приложений.
Генеративно-состязательные сети (GAN), хотя и способны к более быстрой генерации, страдали от присущей им нестабильности обучения и проблем, таких как коллапс мод, часто требуя сложных конструкций дискриминаторов. Авторегрессионные модели, еще один класс генеративных моделей, были аналогично отвергнуты из-за их последовательного предсказания точек выборки, что привело к неприемлемо медленным скоростям генерации.
Rectified Flow, в сочетании с многополосной, покадровой стратегией обработки, стал единственным жизнеспособным решением, поскольку он напрямую решает эти фундаментальные ограничения. Он предлагает механизм для достижения высокого качества выборки и стабильности обучения диффузионных моделей, одновременно соответствуя и даже превосходя скорость генерации GAN, и все это в рамках практических ограничений памяти. Исследование абляции дополнительно подтверждает это, показывая, что "Rectified Flow критически важен для того, чтобы наша модель эффективно генерировала высококачественные образцы аудио" (стр. 9), поскольку традиционные диффузионные графики шума с большим количеством шагов оказались недостаточными.
Сравнительное превосходство
RFWave демонстрирует подавляющее качественное превосходство над предыдущими золотыми стандартами, выходящее далеко за рамки простых метрик производительности.
Во-первых, с точки зрения скорости, RFWave достигает скорости вывода до 160 раз быстрее реального времени на GPU (Аннотация). Это драматическое улучшение по сравнению с диффузионными моделями, которые обычно работают в 10-20 раз быстрее реального времени, и даже превосходит многие методы на основе GAN. Например, Таблица 7 показывает GPU xRT (кратное реальному времени) RFWave на уровне 162,59 по сравнению с 72,68 у BigVGAN и 16,67 у PriorGrad. Это структурное преимущество обусловлено способностью Rectified Flow изучать прямолинейные траектории переноса, что позволяет реконструировать высокое качество всего за 10 шагов выборки, что значительно меньше, чем у других диффузионных моделей.
Во-вторых, в отношении качества, RFWave последовательно превосходит диффузионные базовые модели, такие как PriorGrad и FreGrad, как по объективным метрикам (например, MOS, PESQ, ViSQOL), так и по субъективным оценкам (Таблица 1). В то время как он работает наравне с GAN, такими как BigVGAN и Vocos, для данных в пределах домена, его превосходство становится очевидным при работе с данными вне домена (набор данных MUSDB18). Здесь RFWave демонстрирует "значительные преимущества" (стр. 8), генерируя более четкие, хорошо определенные высокочастотные гармоники, в отличие от GAN, которые склонны генерировать "горизонтальные линии", приводящие к "металлическому качеству звука" (Рисунок A.7). Это указывает на превосходную обобщающую способность и устойчивость RFWave.
В-третьих, RFWave предлагает значительно превосходящую вычислительную эффективность и сложность памяти. Работая на уровне кадров преобразования Фурье в коротких временных интервалах (STFT), а не на уровне отдельных точек выборки сигнала, он резко снижает потребление памяти GPU. Это структурное преимущество позволяет RFWave обрабатывать аудиоклипы длительностью 177 секунд с теми же ресурсами памяти, которые PriorGrad (вокодер диффузии по точкам выборки) использует только для 6-секундных клипов (стр. 4). Таблица 7 далее иллюстрирует это: RFWave потребляет 780 МБ памяти GPU по сравнению с 4976 МБ у PriorGrad и 5480 МБ у MBD. Эта покадровая обработка позволяет избежать "множества операций повышающей дискретизации" и увеличения длины последовательности, которые преследуют модели по точкам выборки, что в противном случае привело бы к более высокому потреблению памяти GPU и вычислительным требованиям.
Наконец, многополосная стратегия является ключевым структурным преимуществом. Генерируя различные подполосы одновременно и моделируя их параллельно с помощью одной унифицированной модели, RFWave предотвращает накопление ошибок, которое может возникнуть при последовательном обусловливании более высоких полос более низкими. Это не только обеспечивает качество звука, но и повышает скорость синтеза. Включение трех улучшенных функций потерь (с энергетическим балансом, перекрытием и STFT) и оптимизированной стратегии выборки "равной прямолинейности" дополнительно повышает общее качество и устойчивость, особенно при обработке низкоуровневых регионов, обеспечивая плавные переходы между подполосами и уменьшая артефакты.
Соответствие ограничениям
Выбранный подход Rectified Flow в сочетании с его архитектурными инновациями идеально соответствует строгим требованиям высококачественной реконструкции аудиосигналов в реальном времени.
-
Высококачественное аудио: Проблема требует исключительного качества звука. RFWave достигает этого, используя присущие диффузионным моделям возможности сохранения качества, дополнительно усиленные способностью Rectified Flow изучать прямые, высококачественные отображения. Три улучшенные функции потерь (с энергетическим балансом, перекрытием и STFT) и стратегия выборки "равной прямолинейности" специально разработаны для улучшения перцептивного качества, подавления шума в тихих регионах, обеспечения плавных переходов между подполосами и сохранения высокочастотных деталей. Этот "брак" надежного генеративного фреймворка с целевыми улучшениями качества гарантирует, что выходные данные не просто хороши, а "выдающиеся" (Аннотация).
-
Скорость генерации в реальном времени: Критическим ограничением было преодоление задержки предыдущих диффузионных моделей. Прямолинейные траектории переноса Rectified Flow позволяют резко сократить количество шагов выборки — до всего 10 шагов, что является прямым решением проблемы медленного вывода. Кроме того, работа на уровне кадров STFT, а не на уровне отдельных точек выборки, позволяет параллельно обрабатывать подполосы, значительно ускоряя вычисления. Эта комбинация приводит к скорости генерации до 160 раз быстрее реального времени, напрямую удовлетворяя требование применимости в реальном времени.
-
Эффективное использование ресурсов: Высокие требования к памяти GPU и вычислительные требования обработки на уровне точек выборки были основным узким местом. Покадровая работа RFWave идеально подходит для этого ограничения, обеспечивая "более эффективную обработку и снижение потребления памяти GPU" (стр. 2). Это позволяет модели обрабатывать гораздо более длинные аудиоклипы (например, 177 секунд) с той же памятью, что и другие модели для коротких клипов (например, 6 секунд), делая ее практичной для различных приложений.
-
Стабильность обучения: GAN испытывали трудности с нестабильностью обучения и коллапсом мод. Будучи моделью типа диффузии, RFWave изначально выигрывает от "стабильности во время обучения" (Введение), которую предлагают диффузионные модели, тем самым избегая ключевой ловушки альтернатив на основе GAN.
-
Универсальность входных представлений: Проблема требует гибкости в реконструкции сигналов из различных входных данных. RFWave разработан для реконструкции сигналов как из мел-спектрограмм, так и из дискретных акустических токенов, повышая его универсальность и применимость в различных задачах генерации аудио.
Эта тщательная разработка гарантирует, что RFWave является не просто производительной моделью, а моделью, специально разработанной для удовлетворения жестких, многогранных требований эффективной и высококачественной реконструкции аудио.
Отклонение альтернатив
Статья предоставляет четкое обоснование отклонения других популярных подходов к реконструкции аудиосигналов:
-
Традиционные диффузионные модели (например, DiffWave, WaveGrad, PriorGrad, FreGrad, Multi-Band Diffusion): Эти модели были отклонены в первую очередь из-за их медленной скорости генерации и высоких вычислительных требований. В статье говорится, что они "ограничены проблемами задержки из-за их работы на уровне отдельных точек выборки и необходимости многочисленных шагов выборки" (Аннотация). В частности, они "как минимум на порядок медленнее по сравнению с GAN" и работают "всего примерно в 10-20 раз быстрее реального времени" (Введение, стр. 3), что ограничивает их применимость в реальном времени. RFWave напрямую решает эту проблему, используя Rectified Flow для сокращения шагов выборки до 10 и работая на уровне кадров STFT для снижения накладных расходов на память и вычисления, достигая скорости 160x реального времени. Исследование абляции явно показывает, что использование стандартного графика шума диффузии (DDPM) с 50 шагами "не достигло базового уровня" по производительности (Таблица 6), подчеркивая необходимость Rectified Flow.
-
Генеративно-состязательные сети (GAN) (например, HiFi-GAN, BigVGAN, Vocos, APNet2): Хотя GAN обеспечивают более высокую скорость генерации, они были отклонены из-за их присущей нестабильности обучения и проблем, таких как коллапс мод (Введение). GAN часто требуют "сложных конструкций дискриминаторов" и могут страдать от "катастрофического забывания" (Thanh-Tung et al., 2018). Кроме того, для данных вне домена модели на основе GAN, такие как BigVGAN и Vocos, склонны генерировать "горизонтальные линии в высокочастотных областях спектрограмм", приводящие к "металлическому качеству звука", которое снижает естественность (стр. 8, Рисунок A.7). RFWave, как модель типа диффузии, наследует "стабильность обучения" диффузионных моделей, превосходя при этом GAN в обобщении вне домена и соответствуя или превосходя их скорость.
-
Авторегрессионные модели (например, WaveNet): Эти модели были признаны непригодными из-за их медленной скорости генерации, обусловленной последовательным предсказанием точек выборки (Введение). Эта последовательная природа делает их по своей сути неэффективными для синтеза аудио в реальном времени, что является ключевым требованием для данной задачи. Параллельная обработка RFWave на уровне кадров и сокращенные шаги выборки предлагают прямое противодействие этому ограничению.
-
Обработка на уровне точек выборки: Этот подход, распространенный во многих ранних диффузионных и авторегрессионных моделях, был отклонен, поскольку он приводит к "множеству операций повышающей дискретизации для перехода от разрешения частоты кадров к разрешению частоты дискретизации, увеличивая длину последовательности и, как следствие, приводя к более высокому потреблению памяти GPU и вычислительным требованиям" (Введение). Сдвиг RFWave к обработке на уровне кадров STFT напрямую устраняет эти узкие места в памяти и вычислениях.
Математический и логический механизм
Основное уравнение
Абсолютно ключевым уравнением, которое обеспечивает работу RFWave, особенно с его улучшением с энергетическим балансом, является целевая функция, минимизируемая во время обучения. Это уравнение определяет, как модель изучает поле скорости, которое преобразует шум в целевое аудиопредставление.
$$
\min_{v} E_{X_0 \sim \pi_0, (X_1, C) \sim D} \left[ \int_0^1 \left\| \frac{(X_1 - X_0)}{\sigma} - v(X_t, t | C)/\sigma \right\|^2 dt \right]
$$
с $\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$ и $X_t = (1 - t)X_0 + tX_1$.
Поэлементный анализ
Давайте разберем это основное уравнение, чтобы понять математическое определение, физическую/логическую роль каждого компонента и выбор авторов.
-
$v$: Это представляет собой поле скорости, которое изучает нейронная сеть.
- Математическое определение: Это функция $v: \mathbb{R}^d \times [0, 1] \times \mathcal{C} \to \mathbb{R}^d$, где $\mathbb{R}^d$ — пространство данных, $[0, 1]$ — временной интервал, а $\mathcal{C}$ — пространство условных входов. В RFWave оно параметризуется глубокой нейронной сетью (в частности, основой ConvNeXtV2).
- Физическая/логическая роль: Это основной выход модели. Он предсказывает мгновенную "скорость" или направление в пространстве данных в заданном промежуточном состоянии $X_t$ и времени $t$, обусловленное $C$. Цель сети — научиться предсказывать прямолинейное движение от шума к данным.
- Выбор дизайна: Нейронная сеть используется потому, что она может изучать сложные, нелинейные отображения от высокоразмерных входов ($X_t, t, C$) к высокоразмерным выходам ($v$).
-
$E_{X_0 \sim \pi_0, (X_1, C) \sim D}$: Это обозначает ожидание (среднее) по образцам.
- Математическое определение: Это статистическое среднее по парам $(X_0, X_1)$ и условным входам $C$. $X_0$ выбирается из априорного распределения шума $\pi_0$ (например, стандартный гауссовский шум), а $(X_1, C)$ выбираются из распределения реальных данных $D$ (например, $X_1$ — целевая комплексная спектрограмма, $C$ — мел-спектрограмма).
- Физическая/логическая роль: Это гарантирует, что модель учится обобщать на широкий спектр шумовых входов и целевых данных, а не просто запоминать конкретные примеры. Усреднение потерь по многим образцам делает обучение устойчивым.
-
$\int_0^1 \dots dt$: Это определенный интеграл по переменной времени $t$.
- Математическое определение: Он суммирует мгновенную квадратичную ошибку по непрерывному временному интервалу от $t=0$ до $t=1$.
- Физическая/логическая роль: Rectified Flow описывает непрерывную траекторию от шума к данным. Интегрирование потерь по всему этому пути гарантирует, что обученное поле скорости является последовательным и точным во всех промежуточных точках, а не только в дискретных моментах. Эта непрерывная формулировка является основополагающей для генеративных моделей на основе ОДУ.
-
$\left\| \cdot \right\|^2$: Это квадрат $L_2$-нормы (евклидово расстояние).
- Математическое определение: Для вектора $z$, $\|z\|^2 = \sum_i z_i^2$. Он измеряет квадрат величины вектора разности.
- Физическая/логическая роль: Этот член вычисляет среднеквадратичную ошибку (MSE) между нормализованной истинной скоростью и нормализованной предсказанной скоростью. Минимизация этой квадратичной разности является стандартным подходом в задачах регрессии, побуждая модель делать предсказания как можно ближе к истинным значениям. Он выбран из-за его дифференцируемости и выпуклых свойств, которые полезны для оптимизации на основе градиента.
-
$X_1$: Это представляет собой целевые данные.
- Математическое определение: Образец из целевого распределения данных $\pi_1$, который является истинным аудиосигналом или комплексной спектрограммой, которую модель стремится реконструировать.
- Физическая/логическая роль: Это желаемый выход, "чистое" аудиопредставление, к которому должен сходиться генеративный процесс.
-
$X_0$: Это представляет собой начальный шум.
- Математическое определение: Образец из априорного распределения шума $\pi_0$, обычно стандартного гауссовского шума $N(0,1)$.
- Физическая/логическая роль: Это начальная точка генеративного процесса, случайный вход, который модель преобразует в осмысленный звук.
-
$C$: Это условный вход.
- Математическое определение: Мел-спектрограммы или дискретные акустические токены.
- Физическая/логическая роль: Это предоставляет управляющую информацию для генерации. Например, если цель состоит в преобразовании мел-спектрограммы в аудиосигнал, $C$ будет этой мел-спектрограммой. Это позволяет контролируемый и направленный синтез аудио.
-
$X_t = (1 - t)X_0 + tX_1$: Это интерполированное состояние.
- Математическое определение: Линейная интерполяция между $X_0$ и $X_1$ во времени $t$.
- Физическая/логическая роль: Этот член определяет промежуточную точку на прямолинейном пути от шума ($X_0$ при $t=0$) к данным ($X_1$ при $t=1$). Модель изучает предсказание скорости в этих промежуточных состояниях.
-
$\frac{(X_1 - X_0)}{\sigma}$: Это нормализованная истинная скорость.
- Математическое определение: Прямая разница между целевыми данными и начальным шумом, масштабированная на $\sigma$. Это представляет собой истинную, нормализованную мгновенную скорость, если бы траектория была идеально линейной.
- Физическая/логическая роль: Это идеальная скорость, которую нейронная сеть $v$ должна научиться аппроксимировать. Деление на $\sigma$ является критической нормализацией для энергетического баланса.
-
$v(X_t, t | C)/\sigma$: Это нормализованная предсказанная скорость.
- Математическое определение: Выход нейронной сети $v$, принимающей $X_t$, $t$ и $C$ в качестве входных данных, также масштабированный на $\sigma$.
- Физическая/логическая роль: Это предсказание моделью мгновенной скорости, нормализованное коэффициентом энергетического баланса. Процесс обучения направлен на то, чтобы этот член соответствовал нормализованной истинной скорости.
-
$\sigma = \sqrt{\text{Var}_t(X_1 - X_0)}$: Это коэффициент весового баланса энергии.
- Математическое определение: Стандартное отклонение истинной скорости $(X_1 - X_0)$ вдоль размерности признака, вычисленное по оси времени для каждой частотной подполосы.
- Физическая/логическая роль: Этот член введен для решения проблемы низкоуровневого шума в тихих регионах. Делением как истинной, так и предсказанной скорости на $\sigma$, функция потерь эффективно взвешивает ошибки по-разному в зависимости от энергии региона. Когда $\sigma$ мала (низкоэнергетические/тихие регионы), член $1/\sigma$ становится большим, усиливая вклад ошибок в этих регионах в общие потери. Это заставляет модель уделять больше внимания точному подавлению шума в тихих частях, предотвращая генерацию слышимых низкоуровневых артефактов.
Пошаговый поток
Давайте проследим жизненный цикл одного абстрактного образца данных во время процесса вывода (генерации), предполагая, что модель уже обучена. Мы рассмотрим подход в частотной области, где $X_t$ и $v_t$ находятся в частотной области, поскольку это более эффективно во время вывода.
- Введение начального шума (Начало траектории, $t=0$): Процесс начинается с выборки начального состояния, $X_0$, из стандартного распределения гауссовского шума, $N(0,1)$. Этот $X_0$ представляет собой комплексную спектрограмму тех же размеров, что и целевое аудио. Мы также получаем условный вход $C$ (например, мел-спектрограмму), который управляет генерацией.
- Итеративное предсказание скорости и обновление состояния (Интегрирование Эйлера): Затем модель проходит через серию дискретных временных шагов, $t_i$, от $t=0$ до $t=1$. Для каждого шага $i$:
- Текущее состояние: У нас есть текущее оцененное состояние, $X_{t_i}$, которое начинается как $X_0$.
- Разделение на подполосы (если применимо): Если модель использует многополосную структуру, $X_{t_i}$ делится на подполосы. Каждый зашумленный образец подполосы ($X_{t_i}^{\text{sb}}$) подается в основу ConvNeXtV2.
- Предсказание скорости: Нейронная сеть $v$ (основа ConvNeXtV2) принимает текущее состояние $X_{t_i}$ (или его подполосы $X_{t_i}^{\text{sb}}$), текущее время $t_i$ и условный вход $C$ (и, возможно, индекс подполосы $i_{\text{sb}}$ и индекс полосы пропускания $i_{\text{bw}}$) для предсказания мгновенной скорости $v(X_{t_i}, t_i | C)$.
- Шаг Эйлера: Предсказанная скорость $v(X_{t_i}, t_i | C)$ затем используется для обновления состояния. Используя численный решатель ОДУ, такой как метод Эйлера, следующее состояние $X_{t_{i+1}}$ вычисляется как $X_{t_{i+1}} = X_{t_i} + v(X_{t_i}, t_i | C) \cdot \Delta t$, где $\Delta t = t_{i+1} - t_i$ — интервал временного шага. Это эффективно перемещает точку данных вдоль предсказанного вектора скорости.
- Объединение подполос (если применимо): Если подполосы обрабатывались независимо, их предсказанные скорости объединяются обратно для формирования полнополосной скорости, которая затем используется для шага Эйлера.
- Финальная реконструкция спектрограммы (t=1): Этот итеративный процесс продолжается в течение небольшого количества шагов выборки (например, 10 шагов в RFWave) до тех пор, пока $t$ не достигнет 1. Конечное состояние, $X_1$, представляет собой реконструированную комплексную спектрограмму.
- Преобразование сигнала: Поскольку $X_1$ является комплексной спектрограммой в частотной области, к ней применяется одна операция обратного преобразования Фурье в коротких временных интервалах (ISTFT) для преобразования ее в окончательный высококачественный аудиосигнал. В статье отмечается, что для модели в частотной области только один ISTFT требуется в самом конце, что является ключевым преимуществом в эффективности.
Эта последовательность преобразует случайный шумовой вход в структурированный, высококачественный аудиосигнал, управляемый условным входом и обученным полем скорости.
Динамика оптимизации
Механизм RFWave обучается, обновляется и сходится путем минимизации целевой функции Rectified Flow с энергетическим балансом, дополненной дополнительными терминами потерь, с помощью стохастического градиентного спуска.
-
Формирование ландшафта потерь: Основная функция потерь (Уравнение 5) определяет ландшафт потерь, где "долины" соответствуют точным предсказаниям скорости. Формулировка Rectified Flow по своей сути способствует изучению прямолинейных траекторий, что, как правило, создает более гладкий и управляемый ландшафт потерь по сравнению с диффузионными моделями, которые изучают сложные графики шума. Критически важный член $\sigma$, представляющий коэффициент энергетического баланса, динамически изменяет форму этого ландшафта. В низкоэнергетических регионах (например, тишина) $\sigma$ мала, что делает член $1/\sigma$ большим. Это эффективно усиливает вклад ошибок в этих регионах в общие потери, создавая более крутые градиенты для малых отклонений. Это гарантирует, что модель строго наказывается за генерацию даже слабого шума в тихих отрывках, предотвращая распространенную проблему низкоуровневых артефактов. И наоборот, в высокоэнергетических регионах $\sigma$ больше, что предотвращает полное затмение этих доминирующих регионов важностью других частей аудио. Это динамическое взвешивание создает более сбалансированную цель обучения по всему аудиоспектру.
-
Поведение градиента: Во время обучения модель вычисляет градиенты функции потерь по отношению к параметрам своей нейронной сети. Эти градиенты указывают, как корректировать параметры для уменьшения ошибки.
- $L_2$-норма гарантирует, что градиенты подталкивают предсказанную скорость $v(X_t, t | C)$ к согласованию с истинной скоростью $(X_1 - X_0)$.
- Член $\sigma$ напрямую влияет на величину градиентов. Для низких значений $\sigma$ градиенты, связанные с ошибками в этих регионах, масштабируются вверх, заставляя модель более точно изучать предсказание скоростей в тихих частях. Это прямой механизм подавления шума.
- Дополнительные функции потерь: RFWave включает три улучшенные функции потерь: потери с энергетическим балансом (уже обсуждались через $\sigma$), потери перекрытия и потери STFT. Эти дополнительные потери вводят дополнительные градиентные сигналы:
- Потери перекрытия: Эти потери применяются во время обучения для поддержания согласованности между перекрывающимися участками смежных подполос. Они генерируют градиенты, которые обеспечивают плавные переходы и предотвращают разрывы при последующем объединении подполос во время вывода.
- Потери STFT: Состоящие из потерь спектральной сходимости (SC) и потерь магнитуды STFT в логарифмическом масштабе, этот член действует на аппроксимированную цель $\tilde{X}_1$. Потери SC (норма Фробениуса) фокусируются на больших спектральных компонентах, в то время как потери магнитуды STFT в логарифмическом масштабе ($L_1$-норма на логарифмических магнитудах) подчеркивают компоненты малой амплитуды. Эти потери предоставляют градиенты, которые направляют модель к генерации спектрально точного аудио, уменьшая артефакты и улучшая общее качество звука. Веса для этих дополнительных потерь (например, 0,01) выбраны для балансировки их влияния с основными потерями Rectified Flow.
-
Итеративные обновления состояния и сходимость: Параметры нейронной сети обновляются итеративно с использованием оптимизатора, такого как AdamW, на основе агрегированных градиентов от всех компонентов потерь. Используется расписание скорости обучения с аннулированием косинуса, начиная с более высокой скорости (например, 2e-4) и постепенно уменьшаясь до минимума (например, 2e-6). Это расписание помогает модели вносить большие корректировки в начале обучения, а затем точно настраивать свои параметры для стабильной сходимости. Модель сходится, когда предсказанное поле скорости $v$ точно отображает любое промежуточное состояние $X_t$ на истинную прямолинейную скорость $(X_1 - X_0)$, обусловленное $C$, по всему временному интервалу. Стратегия выборки "равной прямолинейности", хотя и является в первую очередь методом вывода, также косвенно поддерживает сходимость, гарантируя, что модель последовательно испытывает трудности на всех шагах Эйлера, потенциально приводя к более надежно обученному полю скорости.
Структура модели
Структура модели показана на Рисунке 1. Все частотные полосы, каждая из которых отличается уникальным индексом подполосы, используют одну и ту же модель. Подполосы данного образца группируются вместе в один пакет для обработки, что облегчает одновременное обучение или вывод. Это значительно снижает задержку вывода. Более того, независимое моделирование подполос уменьшает накопление ошибок. Как обсуждалось в (Roman et al., 2023), обусловливание более высоких полос более низкими может привести к накоплению ошибок, что означает, что неточности в более низких полосах могут неблагоприятно сказаться на более высоких полосах во время вывода.
Модель отображает зашумленный образец (Xt) в его скорость (vt). Для каждой подполосы зашумленный образец подполосы (Xsb) подается в основу ConvNeXtV2 для предсказания его скорости (vs), обусловленной временем (t), индексом подполосы (ist), условным входом (C', мел-спектрограммой или токенами EnCodec (Défossez et al., 2022)) и необязательным индексом полосы пропускания EnCodec (ibw). Подробная структура основы ConvNeXtV2 показана на Рисунке 1. Мы используем Фурье-признаки, как описано в (Kingma et al., 2021). Xsb, C и Фурье-признаки объединяются по канальному измерению, а затем пропускаются через линейный слой, образуя вход, который подается в серию блоков ConvNeXtV2. Синусоидальное вложение t, наряду с необязательным вложением ibw, поэлементно добавляется к входу каждого блока ConvNeXtV2. ibw используется при декодировании токенов EnCodec, позволяя одной модели поддерживать токены EnCodec с различными полосами пропускания. Кроме того, ist включается через модуль адаптивной нормализации слоя, который использует обучаемые вложения, как описано в (Siuzdak, 2023; Xu et al., 2019). Другие компоненты идентичны компонентам архитектуры ConvNeXtV2, подробности можно найти в (Woo et al., 2023).
Наша методология предлагает два варианта моделирования. Первый включает отображение гауссовского шума непосредственно в сигнал во временной области, где X0, X1, Xt и vt находятся во временной области. Второй вариант отображает гауссовский шум в комплексную спектрограмму, помещая X0, X1, Xt и vt в частотную область. Примечательно, что Xish и vist последовательно представлены в частотной области, как подробно описано в следующих параграфах, гарантируя, что нейронная сеть работает на уровне кадров. Обрабатывая признаки на уровне кадров, наша модель достигает большей эффективности памяти по сравнению с диффузионными вокодерами, такими как PriorGrad, которые работают на уровне точек выборки сигнала. В то время как PriorGrad (gil Lee et al., 2022) может обучаться на аудиоклипах длительностью 6 секунд² при частоте 44,1 кГц в пределах 30 ГБ памяти GPU, наша модель способна обрабатывать клипы длительностью 177 секунд с теми же ресурсами памяти.
Работа с Xt во временной области и эквализация сигнала Поскольку наша модель предназначена для работы на уровне кадров, когда Xt и vt находятся во временной области (в частности, X₁ — это сигнал, а Xo — шум той же формы, с Xt и vt, полученными из (3)), использование STFT и ISTFT, как показано на Рисунке 1, становится необходимым. Размерность Xt и vt соответствует [1, T]³, где T — длина сигнала в точках выборки. После операции STFT мы извлекаем подполосы, равномерно разделяя полнополосную комплексную спектрограмму, получая Xis. Каждая подполоса Xisb
Выбор временных точек для метода Эйлера
Liu et al. (2023) используют равные интервалы шагов для метода Эйлера, как показано в (4). Здесь мы предлагаем выбирать временные точки для выборки на основе прямолинейности траекторий переноса. Временные точки выбираются таким образом, чтобы увеличение прямолинейности было одинаковым для каждого шага. Прямолинейность обученного поля скорости v определяется как S(v) = ∫ E || (X1 - Xo) – v(Xt, t | C) ||² dt, что описывает отклонение скорости вдоль траектории. Меньшее значение S(v) означает более прямые траектории. Этот подход гарантирует, что сложность каждого шага Эйлера остается постоянной, требуя от модели больше шагов в более сложных регионах. При использовании одинакового количества шагов выборки этот метод превосходит подход с равными интервалами. Детали реализации приведены в Приложении А.5, а алгоритм — в Приложении А.9.2. Мы называем этот подход "равной прямолинейностью".
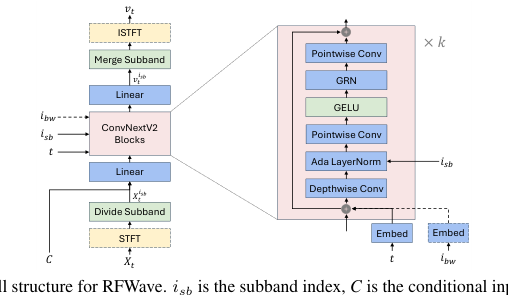 Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
Figure 1. The overall structure for RFWave. isb is the subband index, C is the conditional input, which can be an Encodec token or Mel-spectrogram, and ibw is the EnCodec bandwidth index. Modules enclosed in a dashed box, as well as dashed arrows, are considered optional
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки производительности RFWave авторы разработали комплексную экспериментальную установку, противопоставив свою модель ряду установленных "жертвенных" базовых моделей в различных аудиодоменах и типах входных данных.
Для входных данных мел-спектрограмм были разработаны два основных сценария оценки:
1. Сравнение с диффузионными вокодерами: Модели RFWave обучались отдельно на трех разнообразных наборах данных: LibriTTS (для речи), MTG-Jamendo (для музыки) и Opencpop (для вокальной музыки). Затем эти модели оценивались на соответствующих тестовых наборах. Базовыми моделями в этой категории были передовые диффузионные модели: PriorGrad и FreGrad.
2. Сравнение с вокодерами на основе GAN: Модель RFWave обучалась на LibriTTS. Затем ее производительность оценивалась на тестовом наборе LibriTTS (в пределах домена) и, что особенно важно, на наборе данных MUSDB18 (вне домена) для проверки обобщающей способности и устойчивости. Базовыми моделями здесь были широко используемые модели GAN: Vocos и BigVGAN.
Для дискретных входных данных токенов EnCodec универсальная модель RFWave обучалась на крупномасштабном смешанном наборе данных, включающем Common Voice 7.0, DNS Challenge 4, MTG-Jamendo, FSD50K и AudioSet. Затем эта универсальная модель оценивалась против EnCodec и Multi-Band Diffusion (MBD) на специально созданном унифицированном тестовом наборе данных из 900 аудиообразцов из 15 внешних источников, охватывающих речь, вокал и звуковые эффекты. Эта широкая оценка была направлена на доказательство универсальности RFWave для различных типов аудио.
Метрики оценки: Использовались как объективные, так и субъективные меры.
* Объективные метрики включали ViSQOL (перцептивное качество, используя речевой режим для сигналов 22,05/24 кГц и аудиорежим для сигналов 44,1 кГц), PESQ (Perceptual Evaluation of Speech Quality), V/UV F1 (F1-оценка для классификации озвученных/неозвученных) и Periodicity (ошибка периодичности).
* Субъективная оценка включала краудсорсинговые оценки с использованием 5-балльной шкалы среднего мнения (MOS) (1: "плохое/неестественное" до 5: "отличное/естественное"). Для каждого сравнения 30 слушателей оценивали 20-40 групп аудиообразцов, включая истинные данные, RFWave и базовые модели, в случайном порядке.
Детали реализации: Модель RFWave использовала временной подход по умолчанию, включая три улучшенные функции потерь (с энергетическим балансом, перекрытием и STFT) и основу ConvNeXtV2 с 8 блоками. Комплексная спектрограмма была разделена на 8 подполос с равным интервалом. Ключевым архитектурным выбором было использование всего 10 шагов выборки для вывода. Также были проведены исследования абляции для анализа влияния отдельных компонентов, таких как моделирование в частотной против временной области, постепенное добавление каждой функции потерь, стратегия выборки "равной прямолинейности", различные архитектуры основы (ResNet против ConvNeXtV2) и размеры моделей. Скорость вывода была измерена на GPU NVIDIA GeForce RTX 4090 с размером пакета 1.
Что доказывают свидетельства
Эмпирические данные, представленные в статье, предоставляют окончательные и неоспоримые доказательства работы основных механизмов RFWave на практике, демонстрируя его превосходную производительность как по качеству аудио, так и по вычислительной эффективности.
Победа над диффузионными базовыми моделями:
RFWave безжалостно превзошел своих диффузионных "жертв", PriorGrad и FreGrad, по всем объективным и субъективным метрикам при реконструкции из мел-спектрограмм (Таблица 1). Например, RFWave достиг среднего MOS $3,95 \pm 0,09$, что значительно выше, чем у PriorGrad ($3,75 \pm 0,09$) и FreGrad ($2,99 \pm 0,14$). Объективно, PESQ RFWave на уровне $4,202$ превосходил PESQ PriorGrad ($3,612$) и FreGrad ($3,640$). Окончательным доказательством этого превосходства является способность RFWave генерировать "более четкие и последовательные гармоники, особенно в высокочастотных диапазонах", что визуально подтверждается спектрограммами в Приложении А.6 (Рисунки A.3, A.4, A.5), где базовые модели демонстрировали незначительные разрывы или размытые высокочастотные компоненты. Это напрямую подтверждает эффективность Rectified Flow в достижении высококачественного аудио с меньшим количеством шагов выборки.
Конкуренция с базовыми моделями GAN:
Хотя GAN известны своей скоростью, RFWave продемонстрировал сопоставимое качество в пределах домена и превосходное обобщение вне домена. На тестовом наборе LibriTTS в пределах домена MOS RFWave ($3,82 \pm 0,12$) был наравне с BigVGAN ($3,78 \pm 0,11$) и Vocos ($3,74 \pm 0,10$) (Таблица 2). Однако истинный триумф пришел на наборе данных MUSDB18 вне домена (Таблица 3), где RFWave достиг среднего MOS $3,67 \pm 0,05$, значительно превосходя BigVGAN ($3,51 \pm 0,05$) и Vocos ($3,10 \pm 0,06$). Здесь неоспоримым доказательством является визуальный анализ на Рисунке A.7, который показывает, что модели на основе GAN, такие как BigVGAN и Vocos, склонны генерировать "горизонтальные линии в высокочастотных областях спектрограмм", приводящие к "металлическому качеству звука". RFWave, в отличие от этого, последовательно генерировал "четкие и хорошо определенные высокочастотные гармоники", доказывая свою устойчивость и обобщающие способности как модель типа диффузии.
Доминирование в реконструкции токенов EnCodec:
Для дискретных входных данных токенов EnCodec RFWave (с CFG2) последовательно достигал оптимальных результатов по большинству метрик (MOS, PESQ, V/UV F1, Periodicity) и различным полосам пропускания, превосходя как EnCodec, так и MBD (Таблица 4). Например, при скорости 6,0 кбит/с MOS RFWave составил $3,69 \pm 0,16$ по сравнению с $3,10 \pm 0,15$ у EnCodec и $3,43 \pm 0,15$ у MBD. Это демонстрирует универсальность и эффективность RFWave в реконструкции высококачественного аудио из сжатых представлений.
Валидация исследования абляции:
Исследования абляции (Таблица 5) предоставили решающую информацию об эффективности отдельных компонентов RFWave:
* Временная модель последовательно превосходила свою частотную counterpart (например, PESQ $4,127$ против $3,872$), подтверждая выбор для лучшей детализации высокочастотных деталей.
* Потери с энергетическим балансом показали, что они смягчают низкоуровневый шум в тихих регионах, улучшая общую производительность (например, PESQ с $4,127$ до $4,181$), доказывая свою роль в минимизации относительной ошибки.
* Потери перекрытия, несмотря на небольшое снижение PESQ, были необходимы для "плавных переходов между подполосами" и поддержания согласованности, как визуально подтверждено заметными переходами без них (Рисунок A.9).
* Потери STFT эффективно уменьшали артефакты в фоновом шуме (Рисунок A.8), улучшая PESQ с $4,158$ до $4,211$, хотя и с небольшим компромиссом в ViSQOL и периодичности из-за акцента на магнитуду.
* Стратегия выборки "равной прямолинейности" значительно улучшила производительность "бесплатно" (PESQ $4,275$, Periodicity $0,100$), доказывая ее эффективность по сравнению с равными интервалами.
* Механизм Rectified Flow оказался "критически важным" для эффективной высококачественной генерации, поскольку подход DDPM с 50 шагами показал низкую производительность (Таблица 6). Основа ConvNeXtV2 также оказалась превосходящей ResNet, улучшая как эффективность, так и качество.
Беспрецедентная вычислительная эффективность:
Пожалуй, самым поразительным доказательством является значительно превосходящая вычислительная эффективность RFWave (Таблица 7). Он достиг скорости вывода в 162,59 раза быстрее реального времени (xRT) на одном GPU NVIDIA GeForce RTX 4090 всего за 10 шагов выборки. Это на порядок быстрее, чем диффузионные базовые модели (PriorGrad $16,67$ xRT, FreGrad $7,50$ xRT, MBD $4,82$ xRT), и более чем в два раза быстрее, чем BigVGAN ($72,68$ xRT). Кроме того, RFWave потреблял меньше памяти GPU ($780$ МБ), чем BigVGAN ($1436$ МБ). Это преимущество в скорости, сохраняющееся даже при более высоких частотах дискретизации (например, $152,58$ xRT при 44,1 кГц), окончательно доказывает, что RFWave преодолевает барьер задержки диффузионных моделей, делая его практичным для реальных приложений в реальном времени.
Ограничения и будущие направления
Хотя RFWave представляет собой значительный шаг вперед в реконструкции аудиосигналов, важно признать его текущие ограничения и рассмотреть направления для будущего развития.
Одно тонкое ограничение, наблюдаемое в метрике ViSQOL, заключается в ее предвзятости к моделям на основе GAN. Хотя RFWave часто достигает более высоких оценок MOS и других объективных показателей, ViSQOL иногда отдает предпочтение GAN, что может не полностью отражать человеческое перцептивное качество. Это предполагает, что текущие объективные метрики могут не полностью улавливать все нюансы качества звука, особенно для новых генеративных подходов. Другой интересный компромисс наблюдался с потерями STFT: хотя они эффективно уменьшают артефакты, они могут незначительно ухудшать ViSQOL и периодичность из-за акцента на магнитуде над фазой. Это подчеркивает проблему балансировки различных аспектов точности аудио. Кроме того, хотя RFWave демонстрирует сильное обобщение вне домена по сравнению с GAN, конечная цель действительно универсального вокодера подразумевает обработку еще более широкого спектра невиданных ранее аудиоусловий и характеристик, что остается постоянной проблемой. Вычислительные ресурсы, необходимые для обучения, особенно для крупномасштабного смешанного набора данных EnCodec (например, 4x GPU A100 в течение 10 дней), также представляют собой практический барьер для небольших исследовательских групп или индивидуальных разработчиков.
Заглядывая вперед, возникает несколько интересных тем для обсуждения для дальнейшего развития и эволюции этих выводов:
- Адаптивный дизайн функций потерь: Учитывая компромисс потерь STFT, можно ли исследовать динамическое или контекстно-зависимое взвешивание функций потерь? Например, адаптивный механизм, который отдает приоритет фазовой информации в определенных частотных диапазонах или во время конкретных аудиособытий, может дать еще лучшее перцептивное качество без повторного введения артефактов. Это может включать обучаемые весовые коэффициенты или фреймворк многоцелевой оптимизации.
- Выборка за пределами "равной прямолинейности": Метод "равной прямолинейности" является умным эвристическим методом, но что, если оптимальная траектория выборки не является строго "равно прямолинейной" во всех областях латентного пространства? Будущие исследования могут изучить более продвинутые адаптивные решатели ОДУ или подходы обучения с подкреплением для обнаружения оптимальных, неравномерных графиков выборки, которые дополнительно минимизируют шаги при максимизации точности, потенциально даже адаптируя график к конкретным аудиохарактеристикам.
- Улучшенное обобщение для экстремальных данных вне домена: Хотя RFWave преуспевает, реальное аудио чрезвычайно разнообразно и часто зашумлено. Как сделать эти модели еще более устойчивыми к сильно искаженным, чрезвычайно низкоресурсным или совершенно новым типам аудио? Это может включать метаобучение для быстрой адаптации, самообучение на огромном количестве неразмеченного аудио или включение явных возможностей моделирования шума.
- Развертывание в реальном времени на ограниченном оборудовании: Достижение 160x реального времени на высокопроизводительном GPU — это фантастика, но для повсеместных приложений на мобильных устройствах или встраиваемых системах требуются дальнейшие оптимизации. Это может включать изучение квантования моделей, их обрезки, дистилляции знаний или проектирование специализированных архитектур, которые изначально более эффективны на периферийном оборудовании, раздвигая границы возможного в синтезе аудио в реальном времени.
- Мультимодальная и интерактивная генерация аудио: Текущая работа сосредоточена на мел-спектрограммах и дискретных токенах. Расширение RFWave для прямого включения других модальностей, таких как текст, видео или даже пользовательские параметры (например, эмоциональные сигналы, свойства пространственного аудио), может открыть новые творческие приложения и более интуитивное взаимодействие человека с компьютером. Представьте себе генерацию аудио, которое идеально соответствует настроению видеосцены или жестам пользователя.
- Разработка перцептивно согласованных метрик: Наблюдаемая предвзятость ViSQOL подчеркивает более широкую потребность в этой области. Как мы можем разработать новые объективные метрики, которые будут более надежными, менее предвзятыми и более тесно связанными с человеческим восприятием "естественности" и "качества" синтезированного аудио, особенно по мере того, как модели генерируют все более сложные и новые звуки? Это может включать использование обратной связи от человека или продвинутое психоакустическое моделирование.
- Этические последствия и меры предосторожности: Поскольку синтез аудио становится неотличимым от реальных записей, растут этические последствия, такие как создание дипфейков или злоупотребление в дезинформации. Будущие исследования должны проактивно решать эти проблемы, исследуя методы водяных знаков синтезированного аудио, разрабатывая надежные механизмы обнаружения или интегрируя этические руководящие принципы непосредственно в процесс проектирования и развертывания моделей. Это критически важный, часто упускаемый из виду аспект развития генеративного ИИ.