अनुकूली दाग़ सामान्यीकरण (Adaptive Stain Normalization) क्रॉस-डोमेन मेडिकल हिस्टोलॉजी के लिए
इस पत्र में संबोधित समस्या रोग निदान में पैथोलॉजिकल परीक्षा की महत्वपूर्ण भूमिका से उत्पन्न होती है, जो पारंपरिक रूप से डिजिटल पैथोलॉजी छवियों के मैन्युअल मूल्यांकन पर निर्भर करती है। जबकि मैन्युअल समीक्षा ऊतक आकारिकी...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या रोग निदान में पैथोलॉजिकल परीक्षा की महत्वपूर्ण भूमिका से उत्पन्न होती है, जो पारंपरिक रूप से डिजिटल पैथोलॉजी छवियों के मैन्युअल मूल्यांकन पर निर्भर करती है। जबकि मैन्युअल समीक्षा ऊतक आकारिकी (tissue morphology) और सेलुलर असामान्यताओं में महत्वपूर्ण अंतर्दृष्टि प्रदान करती है, यह स्वाभाविक रूप से श्रम-गहन, समय लेने वाली और विभिन्न पर्यवेक्षकों के बीच परिवर्तनशीलता के प्रति संवेदनशील है [20,19]। डीप लर्निंग के आगमन ने इस विश्लेषण को स्वचालित करने की दिशा में एक आशाजनक मार्ग प्रदान किया, लेकिन इसने जल्दी ही एक महत्वपूर्ण बाधा का सामना किया: डिजिटल पैथोलॉजी छवियों में रंग की असंगति।
यह रंग परिवर्तनशीलता, मॉडल सामान्यीकरण (model generalizability) के लिए एक प्रमुख चुनौती, कई कारकों से उत्पन्न होती है: (i) दाग़ने की प्रक्रिया के दौरान रासायनिक प्रतिक्रियाओं और डाई के संपर्क समय में अंतर, (ii) नमूना तैयार करने में भिन्नता, और (iii) विभिन्न स्कैनिंग हार्डवेयर में विविध इमेजिंग स्थितियाँ [15]। जबकि अनुभवी मानव पैथोलॉजिस्ट सहज रूप से इन भिन्नताओं की भरपाई कर सकते हैं, डीप लर्निंग मॉडल ऐसे "डोमेन शिफ्ट" के प्रति अत्यधिक संवेदनशील होते हैं, जिससे प्रदर्शन में महत्वपूर्ण गिरावट आती है और प्रशिक्षण डेटा की तुलना में विभिन्न परिस्थितियों में प्राप्त डेटा पर लागू होने पर खराब सामान्यीकरण होता है [3]। इस "दर्द बिंदु" ने अकादमिक क्षेत्र, विशेष रूप से मेडिकल पैथोलॉजी में, विविध डेटासेट में सुसंगत छवि उपस्थिति सुनिश्चित करने के लिए दाग़ रंग सामान्यीकरण (stain color normalization) के लिए रणनीतियाँ विकसित करने के लिए मजबूर किया।
दाग़ सामान्यीकरण के पिछले दृष्टिकोण, इन मुद्दों को कम करने का प्रयास करते हुए, कई मौलिक सीमाओं से ग्रस्त थे। पारंपरिक विधियों में अक्सर रंग आँकड़ों का मिलान करने के लिए प्रशिक्षण डोमेन से एक "टेम्पलेट" छवि के सावधानीपूर्वक चयन की आवश्यकता होती थी, जिसके लिए पूर्व ज्ञान की आवश्यकता होती थी और यह कलाकृतियाँ (artifacts) पेश कर सकता था। भौतिकी-आधारित विधियाँ, जैसे कि बीयर-लैम्बर्ट नियम (Beer-Lambert law) और नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (Nonnegative Matrix Factorization - NMF) का लाभ उठाने वाली, अंतर्निहित छवि निर्माण प्रक्रिया को ध्यान में रखकर इनमें सुधार हुआ। हालाँकि, वे अभी भी आम तौर पर पूर्वनिर्धारित टेम्पलेट्स पर निर्भर करते थे या अतिरिक्त पूर्व ज्ञान की आवश्यकता होती थी, जैसे कि विशिष्ट डाई के अवशोषण स्पेक्ट्रम मैट्रिक्स या अलग-अलग रंग घटकों की सटीक संख्या [18]। इसके अलावा, कुछ NMF-आधारित विधियों में प्रिंसिपल कंपोनेंट एनालिसिस (PCA) का उपयोग करने में कमियाँ थीं, क्योंकि यह ऑर्थोगोनल घटकों को मानता है, जो दाग़ घटकों के लिए हमेशा यथार्थवादी नहीं होता है। अधिक हालिया डीप लर्निंग-आधारित विधियाँ, जैसे जनरेटिव एडवरसैरियल नेटवर्क (GANs), रंग वितरण को संरेखित कर सकती हैं लेकिन अक्सर सिंथेटिक कलाकृतियाँ या "मतिभ्रमित" सेलुलर संरचनाएँ पेश करती हैं, जो चिकित्सा निदान में जोखिम पैदा करती हैं [12]। अन्य डीप लर्निंग तकनीकें अक्सर बहुत सामान्य होती थीं, जो हिस्टोलॉजिकल दाग़ की विशिष्ट भौतिकी को ध्यान में रखने में विफल रहती थीं [10]। इस पत्र के लेखकों का लक्ष्य इन सीमाओं को दूर करना था, एक प्रशिक्षण योग्य, भौतिकी-सूचित और टेम्पलेट-मुक्त समाधान प्रस्तावित करके जो अनुकूली रूप से दाग़ जानकारी को अलग कर सके।
सहज डोमेन शब्द
- डोमेन शिफ्ट (Domain Shift): कल्पना कीजिए कि आपने एक कुत्ते को लाल गेंद को पहचानने के लिए प्रशिक्षित किया है। यदि आप फिर उसे नीली गेंद दिखाते हैं, तो वह भ्रमित हो सकता है क्योंकि "डोमेन" (गेंद का रंग) शिफ्ट हो गया है। डिजिटल पैथोलॉजी में, इसका मतलब है कि एक प्रयोगशाला (विशिष्ट दाग़ और इमेजिंग के साथ) की छवियों पर प्रशिक्षित एक डीप लर्निंग मॉडल दूसरी प्रयोगशाला से थोड़ी अलग परिस्थितियों में प्राप्त छवियों पर खराब प्रदर्शन कर सकता है।
- दाग़ सामान्यीकरण (Stain Normalization): इसे एक फोटो फिल्टर का उपयोग करने जैसा समझें ताकि आपकी सभी तस्वीरें एक ही सुसंगत रूप में दिखाई दें, भले ही वे विभिन्न प्रकाश व्यवस्था में ली गई हों। हिस्टोलॉजी में, यह ऊतक स्लाइड के रंगों को समायोजित करने की एक प्रक्रिया है ताकि वे सभी ऐसे दिखाई दें जैसे कि उन्हें बिल्कुल एक ही प्रोटोकॉल का उपयोग करके दाग़ा गया हो, जिससे वे स्वचालित विश्लेषण के लिए तुलनीय हो सकें।
- बीयर-लैम्बर्ट नियम (Beer-Lambert Law): यह प्रकाशिकी में एक बुनियादी नियम है, जैसे कि धूप का चश्मा कैसे काम करता है। यह बताता है कि सामग्री (जैसे दाग़दार ऊतक) से कितना प्रकाश गुजरता है, यह सामग्री की मोटाई और प्रकाश-अवशोषित पदार्थ (दाग़) की मात्रा पर निर्भर करता है। यह समझने के लिए महत्वपूर्ण है कि दाग़ ऊतक को उसका विशिष्ट रंग कैसे देते हैं।
- नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF): एक फ्रूट सलाद की कल्पना करें जहाँ आप यह पता लगाना चाहते हैं कि कौन से फल और किस मात्रा में उपयोग किए गए थे, यह जानते हुए कि किसी भी फल की "नकारात्मक" मात्रा नहीं हो सकती है। NMF एक गणितीय तकनीक है जो एक जटिल छवि (जैसे दाग़दार ऊतक स्लाइड) को उसके मौलिक, गैर-नकारात्मक घटकों में तोड़ती है, जैसे कि व्यक्तिगत दाग़ और प्रत्येक पिक्सेल पर उनकी सांद्रता।
- एल्गोरिथम अनरोलिंग (Algorithmic Unrolling): एक जटिल पुनरावृत्तीय गणना पर विचार करें, जैसे कि छवि को तेज करने के लिए दूरबीन के फोकस को बार-बार समायोजित करना। "अनरोलिंग" का अर्थ है उस पुनरावृत्तीय प्रक्रिया के प्रत्येक चरण को लेना और उसे एक न्यूरल नेटवर्क के भीतर एक अलग परत में बदलना। यह समायोजन के पूरे अनुक्रम को एंड-टू-एंड सीखने और अनुकूलित करने की अनुमति देता है, बजाय इसके कि यह एक निश्चित, अलग प्रक्रिया हो।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र में संबोधित केंद्रीय समस्या डिजिटल पैथोलॉजी छवियों में अंतर्निहित रंग परिवर्तनशीलता से उत्पन्न होती है, जो चिकित्सा निदान में डीप लर्निंग मॉडल की विश्वसनीयता और सामान्यीकरण के लिए एक महत्वपूर्ण मुद्दा है।
इनपुट/वर्तमान स्थिति: इनपुट एक डिजिटल पैथोलॉजी छवि है, जिसे $X \in \mathbb{R}^{c \times p}$ के रूप में दर्शाया गया है, जहाँ $c$ रंग की तीव्रता की संख्या है (आमतौर पर RGB के लिए 3) और $p$ पिक्सेल की संख्या है। यह छवि $X$ विभिन्न कारकों के कारण महत्वपूर्ण रंग असंगतियों को प्रदर्शित करती है: दाग़ने की प्रक्रियाओं में अंतर, रासायनिक प्रतिक्रियाएं, डाई के संपर्क का समय, नमूना तैयार करने में परिवर्तनशीलता, और विभिन्न स्कैनिंग हार्डवेयर में विविध इमेजिंग स्थितियाँ। यह रंग असंगति "डोमेन शिफ्ट" की ओर ले जाती है, जिसका अर्थ है कि एक सेट की स्थितियों पर प्रशिक्षित डीप लर्निंग मॉडल दूसरी की स्थितियों पर लागू होने पर खराब प्रदर्शन करते हैं।
वांछित अंतिम बिंदु/लक्ष्य स्थिति: वांछित आउटपुट एक "दाग़-सामान्यीकृत" छवि है या, अधिक सटीक रूप से, इनपुट छवि से प्राप्त एक "दाग़-अपरिवर्तनीय संरचनात्मक जानकारी" प्रतिनिधित्व है। यह सामान्यीकृत प्रतिनिधित्व अंतर्निहित ऊतक आकारिकी और सेलुलर असामान्यताओं को संरक्षित करते हुए प्रभावी ढंग से रंग परिवर्तनशीलता को दूर करना चाहिए। अंतिम लक्ष्य इस मजबूत, दाग़-अपरिवर्तनीय प्रतिनिधित्व को डाउनस्ट्रीम डीप लर्निंग कार्यों, जैसे ऑब्जेक्ट डिटेक्शन और इमेज क्लासिफिकेशन, में फीड करना है, जिससे ये मॉडल विभिन्न डोमेन में प्रभावी ढंग से सामान्यीकृत हो सकें और मूल छवि की दाग़ उपस्थिति की परवाह किए बिना सुसंगत, उच्च प्रदर्शन प्राप्त कर सकें।
लुप्त कड़ी/गणितीय अंतर: सटीक लुप्त कड़ी एक मजबूत, अनुकूली और भौतिकी-सूचित विधि है जो छवि की संरचनात्मक सामग्री से दाग़ जानकारी को गणितीय रूप से अलग कर सके। बीयर-लैम्बर्ट नियम से प्रेरित पिछले दृष्टिकोण, छवि तीव्रता $X$ को आपतित प्रकाश $x_0$, एक रंग उपस्थिति मैट्रिक्स $S$, और एक ऑप्टिकल घनत्व मैट्रिक्स $D$ के फलन के रूप में मॉडल करते हैं:
$$X = (x_0 \mathbf{1}^T) \odot e^{-SD^T}$$
जहाँ $\mathbf{1}$ सभी एकों का एक वेक्टर है और $\odot$ तत्व-वार मैट्रिक्स उत्पाद को दर्शाता है। गणितीय अंतर एक दिए गए इनपुट छवि $X$ से $x_0$, $S$, और $D$ को मज़बूती से अनुमानित करने में निहित है जो इस प्रकार है:
1. अनुकूली (Adaptive): दाग़ने की प्रक्रियाओं या टेम्पलेट छवियों के पूर्व ज्ञान की आवश्यकता नहीं है।
2. भौतिकी-सूचित (Physics-informed): रंग स्पेक्ट्रा और ऑप्टिकल घनत्व की गैर-नकारात्मकता का सम्मान करता है।
3. प्रशिक्षण योग्य (Trainable): डीप लर्निंग आर्किटेक्चर के साथ एंड-टू-एंड एकीकृत किया जा सकता है।
4. संरचना-संरक्षण (Structure-preserving): सिंथेटिक कलाकृतियाँ पेश करने से बचता है।
पत्र का उद्देश्य मौजूदा नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF) मॉडल को परिष्कृत करके इस अंतर को पाटना है, जो अक्सर गैर-उत्तल (non-convex) होते हैं और सावधानीपूर्वक पैरामीटर ट्यूनिंग की आवश्यकता होती है, एक प्रशिक्षण योग्य, अनरोल्ड नेटवर्क आर्किटेक्चर में।
दुविधा: पिछले शोधकर्ताओं को कई दर्दनाक ट्रेड-ऑफ में फँसाया गया है:
* टेम्पलेट निर्भरता बनाम अनुकूलनशीलता: कई मौजूदा दाग़ सामान्यीकरण विधियाँ "टेम्पलेट छवि" पर बहुत अधिक निर्भर करती हैं या पूर्व ज्ञान की आवश्यकता होती है (जैसे, विशिष्ट डाई के अवशोषण स्पेक्ट्रा, रंग घटकों की संख्या)। जबकि ये विधियाँ विशिष्ट, अच्छी तरह से परिभाषित डोमेन के लिए प्रभावी हो सकती हैं, वे मैन्युअल हस्तक्षेप या सावधानीपूर्वक टेम्पलेट चयन के बिना नई या मनमानी दाग़ने की प्रक्रियाओं के अनुकूल होने में विफल रहती हैं, जिससे उनकी सामान्यीकरण क्षमता गंभीर रूप से सीमित हो जाती है।
* भौतिकी-सूचित सटीकता बनाम कलाकृति निर्माण: दाग़ की भौतिकी (जैसे बीयर-लैम्बर्ट नियम और NMF पर आधारित विधियाँ) का सख्ती से पालन करने वाली विधियाँ अक्सर अनुमानों (जैसे, $S$ और $D$ के लिए प्रिंसिपल कंपोनेंट एनालिसिस) का उपयोग करती हैं जो कमियाँ पेश करती हैं, जैसे कि ऑर्थोगोनैलिटी की आवश्यकता जो दाग़ घटकों के लिए अवास्तविक है। इसके विपरीत, अधिक सामान्य डीप लर्निंग दृष्टिकोण, जैसे जनरेटिव एडवरसैरियल नेटवर्क (GANs), रंग वितरण को संरेखित कर सकते हैं लेकिन "मतिभ्रमित" सेलुलर संरचनाओं या सिंथेटिक कलाकृतियों को पेश करने की प्रवृत्ति रखते हैं, जो चिकित्सा निदान में अस्वीकार्य और खतरनाक है।
* निश्चित पैरामीटर बनाम सीखने की क्षमता: पहले के NMF मॉडल (जैसे, समीकरण 3) को स्पार्स रेगुलराइज़ेशन स्ट्रेंथ $\lambda$ और रैंक $r$ (रंग घटकों की संख्या) जैसे मापदंडों के मैन्युअल ट्यूनिंग की आवश्यकता होती है। यह मैन्युअल ट्यूनिंग चुनौतीपूर्ण है, खासकर जब रंग घटकों की संख्या अज्ञात हो, और एंड-टू-एंड डीप लर्निंग पाइपलाइनों में निर्बाध एकीकरण को रोकता है जहाँ पैरामीटर स्वचालित रूप से सीखे जाते हैं।
बाधाएँ और विफलता मोड
मेडिकल हिस्टोलॉजी में अनुकूली दाग़ सामान्यीकरण की समस्या कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है जिनका लेखकों ने सामना किया:
-
भौतिक बाधाएँ:
- बीयर-लैम्बर्ट नियम का पालन: किसी भी प्रभावी मॉडल को दाग़ों द्वारा प्रकाश क्षीणन की भौतिक प्रक्रिया का सटीक रूप से प्रतिनिधित्व करना चाहिए। इसका मतलब है कि प्रकाश अवशोषण की गुणक प्रकृति और दाग़ सांद्रता और अवशोषण गुणों में अपघटन का सम्मान करना।
- गैर-नकारात्मकता: रंग स्पेक्ट्रा ($S$) और ऑप्टिकल घनत्व ($D$) दोनों भौतिक रूप से गैर-नकारात्मक मात्राएँ हैं। इस बाधा को लागू करना एक सार्थक अपघटन के लिए महत्वपूर्ण है, लेकिन यह अनुकूलन समस्याओं में जटिलता जोड़ता है।
- दाग़-अपरिवर्तनीय जानकारी: मुख्य चुनौती दाग़ उपस्थिति से स्वतंत्र संरचनात्मक जानकारी निकालना है। इसके लिए रंग जानकारी को आकारिकी विवरण से एक मजबूत अलगाव की आवश्यकता होती है, जो कच्चे छवियों में उनके परस्पर जुड़े होने को देखते हुए तुच्छ नहीं है।
-
कम्प्यूटेशनल बाधाएँ:
- गैर-उत्तल अनुकूलन: अंतर्निहित NMF समस्या, विशेष रूप से $SD^T$ मैट्रिक्स उत्पाद के साथ, गैर-उत्तल है। इसका मतलब है कि मानक अनुकूलन एल्गोरिदम स्थानीय न्यूनतम में फंस सकते हैं, जिससे वैश्विक इष्टतम समाधान खोजना मुश्किल हो जाता है।
- एंड-टू-एंड प्रशिक्षण क्षमता: आधुनिक डीप लर्निंग मॉडल के साथ व्यावहारिक परिनियोजन के लिए, दाग़ सामान्यीकरण प्रक्रिया को विभेदक (differentiable) होना चाहिए और एंड-टू-एंड प्रशिक्षित होने में सक्षम होना चाहिए। कई पारंपरिक विधियों में गैर-विभेदक चरण या अनुमान शामिल होते हैं, जो डीप लर्निंग फ्रेमवर्क में उनके निर्बाध एकीकरण को रोकते हैं।
- कम्प्यूटेशनल दक्षता: नैदानिक अनुप्रयोगों के लिए बड़े होल स्लाइड छवियों को वास्तविक समय या निकट-वास्तविक समय में संसाधित करने के लिए कम्प्यूटेशनल रूप से कुशल एल्गोरिदम की मांग होती है। जटिल पुनरावृत्तीय अनुकूलन प्रक्रियाएँ निषेधात्मक रूप से धीमी हो सकती हैं।
-
डेटा-संचालित बाधाएँ:
- चरम डोमेन शिफ्ट: डिजिटल पैथोलॉजी डेटासेट विभिन्न प्रयोगशालाओं या स्कैनर के बीच ही नहीं, बल्कि समय के साथ एक ही प्रयोगशाला के भीतर भी महत्वपूर्ण रंग परिवर्तनशीलता प्रदर्शित करते हैं। यह "डोमेन शिफ्ट" डीप लर्निंग मॉडल की विफलता का प्राथमिक कारण है, जिसके लिए एक सामान्यीकरण विधि की आवश्यकता होती है जो बड़े और अप्रत्याशित विविधताओं को संभाल सके।
- पूर्व ज्ञान का अभाव: कई वास्तविक दुनिया के परिदृश्यों में, विशिष्ट दाग़ने की प्रक्रियाओं, डाई अवशोषण स्पेक्ट्रा, या एक नमूने में रंग घटकों की सटीक संख्या के बारे में विस्तृत पूर्व ज्ञान उपलब्ध नहीं होता है। एक मजबूत विधि को ऐसे स्पष्ट इनपुट के बिना प्रभावी ढंग से काम करना चाहिए।
- कलाकृति से बचाव: सामान्य छवि शैली हस्तांतरण के विपरीत, चिकित्सा छवि विश्लेषण सामान्यीकरण के दौरान "सिंथेटिक कलाकृतियों" या "मतिभ्रमित" संरचनाओं को पेश करने को बर्दाश्त नहीं कर सकता है। ऐसे विकृतियों से गलत निदान हो सकता है, जिससे संरचना संरक्षण एक सर्वोपरि बाधा बन जाती है।
-
पिछले दृष्टिकोणों के विफलता मोड (जो एक नए समाधान के लिए बाधा बन जाते हैं):
- टेम्पलेट-प्रेरित पूर्वाग्रह: एक निश्चित टेम्पलेट छवि पर निर्भर रहने से पूर्वाग्रह उत्पन्न हो सकता है और अनुकूलनशीलता सीमित हो सकती है, क्योंकि चुना गया टेम्पलेट सभी लक्ष्य डोमेन का प्रतिनिधि नहीं हो सकता है।
- पैरामीटर संवेदनशीलता: पिछले NMF मॉडल को रंग घटकों ($r$) की संख्या और रेगुलराइज़ेशन मापदंडों के सावधानीपूर्वक, मैन्युअल चयन की आवश्यकता होती है, जो अक्सर एक परीक्षण-और-त्रुटि प्रक्रिया होती है और यदि सही ढंग से नहीं चुना गया तो उप-इष्टतम परिणाम दे सकती है।
- ऑर्थोगोनैलिटी धारणा: कुछ पिछले कार्यों में अनुमान लगाने के लिए उपयोग की जाने वाली PCA जैसी विधियाँ एक ऑर्थोगोनैलिटी बाधा लगाती हैं जो जैविक दाग़ों के लिए भौतिक रूप से यथार्थवादी नहीं है, जिससे गलत अपघटन होता है।
- क्रमपरिवर्तन अस्पष्टता: $S$ और $D$ के अपघटन में क्रमपरिवर्तन अस्पष्टता से ग्रस्त हो सकता है, जहाँ कॉलम स्वैप किए जा सकते हैं, जिससे यदि सही ढंग से संभाला न जाए तो "महत्वपूर्ण रंग विकृतियाँ" हो सकती हैं।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
BeerLaNet का विकास डिजिटल पैथोलॉजी की जटिल वास्तविकताओं का सामना करने पर मौजूदा दाग़ सामान्यीकरण विधियों की स्पष्ट और लगातार कमियों से प्रेरित था। मुख्य समस्या, जैसा कि पत्र में उजागर किया गया है, दाग़ने की प्रक्रियाओं और इमेजिंग स्थितियों में अंतर के कारण होने वाली महत्वपूर्ण रंग परिवर्तनशीलता के कारण "डोमेन शिफ्ट" है। यह परिवर्तनशीलता डीप लर्निंग मॉडल के प्रदर्शन को गंभीर रूप से खराब करती है, जिससे उनकी सामान्यीकरण क्षमता बाधित होती है।
पारंपरिक दाग़ सामान्यीकरण तकनीकें, जैसे कि सांख्यिकीय मिलान या रंग स्थान अपघटन (जैसे, Reinhard, Macenko, Vahadane) पर निर्भर रहने वाली, मुख्य रूप से अपर्याप्त पाई गईं क्योंकि वे "उपयुक्त प्रतिनिधि टेम्पलेट्स" या "डोमेन के पूर्व ज्ञान" पर बहुत अधिक निर्भर करती हैं। इसमें अक्सर विशिष्ट डाई अवशोषण स्पेक्ट्रा या रंग घटकों की पूर्वनिर्धारित संख्या की आवश्यकता शामिल होती है। ऐसी निर्भरताएँ इन विधियों को भंगुर बनाती हैं और "महत्वपूर्ण रंग विकृतियों" के प्रति संवेदनशील होती हैं जब टेम्पलेट खराब चुना जाता है या अज्ञात दाग़ने की प्रक्रियाओं का सामना करना पड़ता है। लेखकों को एहसास हुआ कि ऐसे स्पष्ट पूर्व ज्ञान या टेम्पलेट्स और मापदंडों के सावधानीपूर्वक मैन्युअल चयन की आवश्यकता वाली विधि वास्तव में अनुकूली और मजबूत प्रणाली के लिए एकमात्र व्यवहार्य समाधान नहीं हो सकती है।
डीप लर्निंग-आधारित विकल्प, जैसे शैली हस्तांतरण के लिए जनरेटिव एडवरसैरियल नेटवर्क (GANs) (जैसे, StainGAN), ने भी महत्वपूर्ण खामियाँ प्रस्तुत कीं। रंग वितरण को संरेखित करने में सक्षम होने के बावजूद, GANs अक्सर "सिंथेटिक कलाकृतियाँ पेश करते हैं या सेलुलर संरचनाओं को 'मतिभ्रमित' करते हैं," जो चिकित्सा निदान में अस्वीकार्य जोखिम पैदा करता है जहाँ मूल आकारिकी के प्रति निष्ठा सर्वोपरि है। ध्यान तंत्र का उपयोग करने वाली अन्य डीप लर्निंग तकनीकें "काफी हद तक सामान्य" मानी गईं और छवि निर्माण की अंतर्निहित भौतिकी को ध्यान में रखने में विफल रहीं, जिससे उनकी मजबूती और व्याख्यात्मकता सीमित हो गई।
लेखकों को उस सटीक क्षण का एहसास हुआ जब इन SOTA विधियों अपर्याप्त थीं, जब उन्होंने देखा कि मौजूदा भौतिकी-सूचित मैट्रिक्स फैक्टराइजेशन मॉडल, वैचारिक रूप से ध्वनि होने के बावजूद, व्यावहारिक सीमाओं से ग्रस्त थे। विशेष रूप से, समीकरण (3) में स्पार्स नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF) मॉडल गैर-उत्तल था और रंग घटकों ($r$) की संख्या का पूर्व विनिर्देशन आवश्यक था, एक चुनौतीपूर्ण कार्य जब यह संख्या अज्ञात हो (जैसे, जब नमूनों में हीमोग्लोबिन जैसे अतिरिक्त रंग घटक होते हैं)। इसके अलावा, पहले के भौतिकी-आधारित मॉडल में प्रिंसिपल कंपोनेंट एनालिसिस (PCA) का उपयोग समस्याग्रस्त था क्योंकि यह ऑर्थोगोनल कॉलम मानता है, जो दाग़ अलगाव के लिए अवास्तविक है। इन मुद्दों का यह संगम—टेम्पलेट निर्भरता, कलाकृति निर्माण, भौतिकी-सूचित अनुकूलनशीलता की कमी, और निश्चित पैरामीटर आवश्यकताएं—ने स्पष्ट कर दिया कि एक मौलिक रूप से नया, एकीकृत दृष्टिकोण आवश्यक था।
तुलनात्मक श्रेष्ठता
BeerLaNet कई संरचनात्मक लाभों के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्राप्त करता है जो केवल प्रदर्शन मेट्रिक्स से परे जाते हैं। सबसे पहले, इसका अनुकूली दाग़ अलगाव (Adaptive Stain Disentanglement) इसे "मनमानी दाग़ने की प्रक्रियाओं" तक विस्तारित करने की अनुमति देता है, "दाग़ने की प्रक्रिया के किसी भी पूर्व ज्ञान की आवश्यकता के बिना छवियों के दाग़-अपरिवर्तनीय प्रतिनिधित्व" सीखता है। यह टेम्पलेट-आधारित विधियों पर एक गहरा लाभ है जो स्वाभाविक रूप से उनके चुने हुए टेम्पलेट्स की गुणवत्ता और प्रतिनिधिता द्वारा सीमित हैं। टेम्पलेट-मुक्त और विशिष्ट डाई या घटकों के पूर्व ज्ञान के बिना संचालित करने की BeerLaNet की क्षमता इसे विविध नैदानिक सेटिंग्स में कहीं अधिक मजबूत और सामान्यीकृत बनाती है।
दूसरे, विधि प्रशिक्षण योग्य और भौतिकी-सूचित (Trainable and Physics-Informed) है, जो नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF) और एल्गोरिथम अनरोलिंग (algorithmic unrolling) पर निर्मित है। यह संयोजन एक प्रमुख संरचनात्मक नवाचार है। एक संशोधित NMF सूत्रीकरण (समीकरण 4) के एल्गोरिथम अनरोलिंग के माध्यम से मॉडल आर्किटेक्चर प्राप्त करके, BeerLaNet एक पारंपरिक रूप से गैर-उत्तल अनुकूलन समस्या को एंड-टू-एंड प्रशिक्षण योग्य डीप नेटवर्क में बदल देता है। यह रेगुलराइज़ेशन मापदंडों ($\gamma, \lambda$) और आरंभीकरण ($S_{init}$) के सीखने योग्य अनुकूलन की अनुमति देता है, जिन्हें पहले निश्चित या अनुमानित रूप से चुना गया था। भौतिकी-लैम्बर्ट नियम में निहित इस डेटा-संचालित सीखने से यह सुनिश्चित होता है कि दाग़ अपघटन प्रक्रिया भौतिक रूप से सटीक और अत्यधिक अनुकूली दोनों है, जो अंतर्निहित इमेजिंग भौतिकी की उपेक्षा करने वाले सामान्य रंग परिवर्तनों की खामियों से बचती है।
संशोधित NMF सूत्रीकरण (4) में एक अतिरिक्त $l_2$ रेगुलराइज़ेशन का समावेश एक और संरचनात्मक लाभ है। यह रेगुलराइज़ेशन निम्न-रैंक समाधानों को बढ़ावा देता है, जिससे मॉडल रंग घटकों की संख्या ($r$) को अपेक्षा से अधिक इनिशियलाइज़ कर सकता है और फिर समाधान के रैंक को डेटा के अनुकूल बना सकता है। यह सुरुचिपूर्ण ढंग से $r$ के पूर्व विनिर्देश की समस्या को हल करता है, जिससे मॉडल नमूना संरचना में भिन्नताओं के प्रति अधिक लचीला और मजबूत बनता है।
अंत में, BeerLaNet का लचीला एकीकरण (Flexible Integration) एक प्लग-एंड-प्ले मॉड्यूल के रूप में, यह सुनिश्चित करता है कि इसे किसी भी बैकबोन नेटवर्क के साथ डाउनस्ट्रीम कार्यों के लिए निर्बाध रूप से जोड़ा जा सके। यह आर्किटेक्चरल डिज़ाइन सुनिश्चित करता है कि दाग़ सामान्यीकरण एक स्टैंडअलोन प्रीप्रोसेसिंग चरण नहीं है, बल्कि पूरे डीप लर्निंग पाइपलाइन का एक अभिन्न, सीखने योग्य हिस्सा है, जो अंतिम कार्य (जैसे, ऑब्जेक्ट डिटेक्शन या वर्गीकरण) के लिए सामान्यीकरण को अनुकूलित करता है। यह एंड-टू-एंड प्रशिक्षण क्षमता अलग-अलग काम करने वाली विधियों पर एक महत्वपूर्ण संरचनात्मक लाभ है जो डाउनस्ट्रीम कार्य प्रतिक्रिया के आधार पर अपनी सामान्यीकरण प्रक्रिया को अनुकूलित नहीं कर सकती हैं।
बाधाओं के साथ संरेखण
BeerLaNet का डिज़ाइन मेडिकल हिस्टोलॉजी में दाग़ सामान्यीकरण की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो "समस्या और समाधान के बीच एक मजबूत 'विवाह' बनाता है।"
-
बाधा: रंग असंगति और डोमेन शिफ्ट को दूर करें: प्राथमिक लक्ष्य विभिन्न दाग़ने और इमेजिंग स्थितियों में सामान्यीकरण करना है। BeerLaNet इसे "अनुकूली दाग़ अलगाव" के माध्यम से संबोधित करता है, जो दाग़ने की प्रक्रिया के पूर्व ज्ञान की आवश्यकता के बिना "दाग़-अपरिवर्तनीय अभ्यावेदन" सीखता है। यह अंतर्निहित जैविक जानकारी को रंग विविधताओं से स्वतंत्र रूप से निकालकर डोमेन शिफ्ट के मूल कारण को सीधे संबोधित करता है।
-
बाधा: कलाकृतियों और मतिभ्रम से बचें: चिकित्सा निदान के लिए महत्वपूर्ण। BeerLaNet इसे "भौतिकी-सूचित" होने से प्राप्त करता है। बीयर-लैम्बर्ट नियम में इसकी नींव यह सुनिश्चित करती है कि दाग़ अपघटन प्रकाश-ऊतक संपर्क की वास्तविक भौतिकी पर आधारित है, जिससे परिवर्तन सामान्य डीप लर्निंग मॉडल जैसे GANs की तुलना में सिंथेटिक कलाकृतियों को पेश करने की संभावना कम होती है।
-
बाधा: टेम्पलेट निर्भरता और पूर्व ज्ञान को समाप्त करें: पारंपरिक विधियाँ विशिष्ट टेम्पलेट्स या पूर्व ज्ञान (जैसे, अवशोषण स्पेक्ट्रा, घटकों की संख्या) की आवश्यकता के साथ संघर्ष करती थीं। BeerLaNet की "प्रशिक्षण योग्य और भौतिकी-सूचित" प्रकृति, एल्गोरिथम अनरोलिंग के साथ मिलकर, इसे डेटा से इन मापदंडों को सीखने की अनुमति देती है। $l_2$ रेगुलराइज़ेशन मॉडल को डेटा के घटकों की संख्या ($r$) को अनुकूलित करने में सक्षम बनाता है, जिससे मैन्युअल विनिर्देश की आवश्यकता समाप्त हो जाती है। यह विधि को पूरी तरह से टेम्पलेट-मुक्त और स्पष्ट पूर्व ज्ञान से स्वतंत्र बनाता है।
-
बाधा: विविध दाग़ने की प्रक्रियाओं का समर्थन करें: कई पिछले तरीके मुख्य रूप से H&E दाग़ों पर केंद्रित थे। BeerLaNet स्पष्ट रूप से "मनमानी दाग़ने की प्रक्रियाओं तक विस्तारित होता है," जिससे यह पैथोलॉजी में उपयोग किए जाने वाले विभिन्न प्रकार के दाग़ों के लिए एक अधिक सार्वभौमिक रूप से लागू समाधान बन जाता है।
-
बाधा: डाउनस्ट्रीम कार्यों के साथ निर्बाध एकीकरण का समर्थन करें: समाधान नैदानिक पाइपलाइनों के लिए व्यावहारिक होना चाहिए। BeerLaNet को एक "लचीला एकीकरण" मॉड्यूल के रूप में डिज़ाइन किया गया है, एक "प्लग-एंड-प्ले" घटक जिसे "ऑब्जेक्ट डिटेक्शन और वर्गीकरण जैसे डाउनस्ट्रीम कार्यों के लिए मनमानी बैकबोन नेटवर्क" के साथ जोड़ा जा सकता है। यह सुनिश्चित करता है कि सामान्यीकरण प्रक्रिया अंतिम नैदानिक कार्य के संदर्भ में अनुकूलित हो, जिससे समग्र प्रणाली प्रदर्शन में वृद्धि हो।
विकल्पों का अस्वीकरण
पत्र पारंपरिक और डीप लर्निंग-आधारित दोनों तरह के वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है।
पारंपरिक विधियाँ (जैसे, Reinhard, Macenko, Vahadane): इन विधियों को मुख्य रूप से टेम्पलेट छवियों और पूर्व ज्ञान पर उनकी अंतर्निहित निर्भरता के कारण अस्वीकार कर दिया गया था। जैसा कि कहा गया है, वे "उपयुक्त प्रतिनिधि टेम्पलेट्स का चयन करने पर दृढ़ता से निर्भर करते हैं" और "डोमेन के पूर्व ज्ञान की आवश्यकता हो सकती है," जैसे कि विशिष्ट डाई के अवशोषण स्पेक्ट्रा या रंग घटकों की संख्या। यह निर्भरता उन्हें भंगुर बनाती है; यदि टेम्पलेट प्रतिनिधि नहीं है या पूर्व ज्ञान गलत है, तो ये विधियाँ "महत्वपूर्ण रंग विकृतियों" का कारण बन सकती हैं। इसके अलावा, उन्हें अक्सर रेगुलराइज़ेशन स्ट्रेंथ ($\lambda$) और मैट्रिक्स फैक्टराइजेशन के रैंक ($r$) जैसे मापदंडों के सावधानीपूर्वक मैन्युअल चयन की आवश्यकता होती है। तालिका 1 में प्रयोगात्मक परिणाम इस अस्वीकरण का मात्रात्मक रूप से समर्थन करते हैं, यह दिखाते हुए कि ये विधियाँ अक्सर मलेरिया डेटासेट पर डोमेन भिन्नता की अधिकता के साथ "प्रदर्शन में बड़ी गिरावट" प्रदर्शित करती हैं, जो खराब सामान्यीकरण का संकेत देती है।
डीप लर्निंग-आधारित विधियाँ (जैसे, StainGAN, LStainNorm):
* GANs (जैसे, StainGAN): चिकित्सा अनुप्रयोगों के लिए एक महत्वपूर्ण खामी के कारण इन्हें अस्वीकार कर दिया गया था: वे "अक्सर सिंथेटिक कलाकृतियाँ पेश कर सकते हैं या सेलुलर संरचनाओं को 'मतिभ्रमित' कर सकते हैं, जो चिकित्सा निदान में जोखिम पैदा करता है [12]।" एक ऐसे क्षेत्र में जहाँ नैदानिक सटीकता और जैविक वास्तविकता के प्रति निष्ठा सर्वोपरि है, कोई भी विधि जो छवि अखंडता से समझौता करती है, अस्वीकार्य है।
* ध्यान तंत्र (जैसे, LStainNorm): इन विधियों को "काफी हद तक सामान्य और आवश्यक रूप से प्रासंगिक छवि निर्माण प्रक्रिया को ध्यान में नहीं रखते हैं [10]।" इसका तात्पर्य दाग़ की अंतर्निहित भौतिकी में ग्राउंडिंग की कमी से है, जो BeerLaNet के भौतिकी-सूचित दृष्टिकोण की तुलना में उनकी मजबूती और व्याख्यात्मकता को सीमित कर सकता है।
प्रयोगात्मक परिणाम इन अस्वीकरणों को और मान्य करते हैं। पत्र नोट करता है कि "जेनेरिक डिज़ाइन वाली विधियाँ जो दाग़-विशिष्ट विशेषताओं को शामिल नहीं करती हैं, वे छोटे डोमेन शिफ्ट डेटा (Camelyon17-WILDS, पूरे रक्त कोशिकाएं) पर अच्छा प्रदर्शन कर सकती हैं लेकिन मलेरिया डेटासेट में देखी गई बड़ी रंग शिफ्टों के लिए सामान्यीकरण करने में विफल रहती हैं।" यह सीधे BeerLaNet के विविध कार्यों और डेटासेट में सुसंगत और बेहतर प्रदर्शन के विपरीत है, खासकर महत्वपूर्ण डोमेन शिफ्ट वाले, जो विकल्पों की सीमाओं को उजागर करता है।
गणितीय और तार्किक तंत्र
मास्टर समीकरण
BeerLaNet विधि का मूल, जो इसकी दाग़ सामान्यीकरण क्षमताओं को संचालित करता है, एक स्पार्स नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF) मॉडल से प्राप्त एक अनुकूलन समस्या है। यह मॉडल स्वयं बीयर-लैम्बर्ट नियम पर आधारित है, जो बताता है कि दाग़ों द्वारा प्रकाश कैसे क्षीण होता है। BeerLaNet द्वारा अनरोल और अनुकूलित किया गया विशिष्ट उद्देश्य फलन इस प्रकार दिया गया है:
$$ \min_{x_0,S,D} \frac{1}{2} ||x_0\mathbf{1}^T - X - SD^T||_F^2 + \lambda \sum_{i=1}^r (||s_i||_2^2 + ||d_i||_1 + ||d_i||_2^2) \text{ s.t. } S,D \ge 0. $$
यह समीकरण इनपुट छवि को सर्वोत्तम रूप से समझाने वाले इष्टतम पृष्ठभूमि प्रकाश तीव्रता ($x_0$), दाग़ रंग प्रोफाइल ($S$), और दाग़ सांद्रता ($D$) को खोजने का प्रयास करता है, साथ ही स्पार्सिटी और निम्न-रैंक समाधानों जैसे वांछनीय गुणों को भी बढ़ावा देता है।
पद-दर-पद ऑटोप्सी
आइए इस मास्टर समीकरण को समझने के लिए कि प्रत्येक घटक की क्या भूमिका है, उसका विश्लेषण करें:
-
$X$: यह इनपुट छवि मैट्रिक्स है, जो आमतौर पर $C \times P$ आकार का होता है, जहाँ $C$ रंग चैनलों की संख्या है (जैसे, RGB के लिए 3) और $P$ कुल पिक्सेल की संख्या है। $X$ का प्रत्येक कॉलम एक एकल पिक्सेल के लिए रंग तीव्रता का प्रतिनिधित्व करता है। महत्वपूर्ण रूप से, बीयर-लैम्बर्ट नियम के लघुगणकीय रूप (समीकरण 2) से व्युत्पत्ति को देखते हुए, यह $X$ अंततः देखी गई छवि तीव्रता के लघुगणक का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: इनपुट छवि की लघुगणकीय रंग तीव्रताओं का प्रतिनिधित्व करने वाला एक $C \times P$ मैट्रिक्स।
- भौतिक/तार्किक भूमिका: यह कच्चा, देखा गया डेटा है जिसे मॉडल विघटित करने का प्रयास करता है। लक्ष्य इस देखी गई छवि को पृष्ठभूमि प्रकाश और दाग़ प्रभावों के संयोजन के रूप में समझाना है।
- क्यों उपयोग किया जाता है: यह मैट्रिक्स फैक्टराइजेशन के लिए उपयुक्त प्रारूप में छवि डेटा का प्रत्यक्ष प्रतिनिधित्व है।
-
$x_0$: यह $\mathbb{R}^C$ में एक वेक्टर है जो आपतित प्रकाश तीव्रता या पृष्ठभूमि प्रदीप्ति का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: एक $C$-आयामी वेक्टर।
- भौतिक/तार्किक भूमिका: बीयर-लैम्बर्ट नियम के संदर्भ में, $x_0$ दाग़दार ऊतक के साथ संपर्क करने से पहले प्रकाश स्रोत की तीव्रता को मॉडल करता है। यह प्रदीप्ति स्थितियों में भिन्नताओं को ध्यान में रखता है।
- क्यों उपयोग किया जाता है: यह बीयर-लैम्बर्ट नियम का एक मौलिक घटक है, जो मॉडल को विभिन्न प्रकाश व्यवस्था के अनुकूल होने की अनुमति देता है।
-
$\mathbf{1}^T$: यह सभी एकों का एक पंक्ति वेक्टर है, जिसका आयाम $1 \times P$ है।
- गणितीय परिभाषा: एक $1 \times P$ मैट्रिक्स जहाँ सभी तत्व 1 हैं।
- भौतिक/तार्किक भूमिका: जब $x_0$ से गुणा किया जाता है, तो यह प्रभावी रूप से पृष्ठभूमि प्रकाश तीव्रता $x_0$ को सभी पिक्सेल तक प्रसारित करता है, एक मैट्रिक्स बनाता है जहाँ प्रत्येक पिक्सेल को $x_0$ द्वारा प्रदीप्त माना जाता है।
- क्यों उपयोग किया जाता है: मैट्रिक्स संचालन के लिए सभी पिक्सेल पर पृष्ठभूमि प्रकाश तीव्रता को समान रूप से लागू करने के लिए।
-
$x_0\mathbf{1}^T$: यह पद सभी पिक्सेल पर आपतित प्रकाश मैट्रिक्स का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: एक $C \times P$ मैट्रिक्स जहाँ प्रत्येक कॉलम वेक्टर $x_0$ है।
- भौतिक/तार्किक भूमिका: यह "अटूट" प्रकाश मैट्रिक्स है, जो उस प्रकाश का प्रतिनिधित्व करता है जो दाग़ न होने पर देखा जाएगा।
- क्यों उपयोग किया जाता है: लघुगणकीय बीयर-लैम्बर्ट नियम के अनुसार, दाग़-प्रेरित क्षीणन से घटाए जाने वाले आधार के रूप में कार्य करने के लिए।
-
$S$: यह रंग उपस्थिति मैट्रिक्स है, जिसका आकार $C \times r$ है, जहाँ $r$ रंगीन घटकों की संख्या है। प्रत्येक कॉलम $s_i \in \mathbb{R}^C$ $i$-वें रंगीन घटक (जैसे, हेमेटोक्सिलिन या इओसिन जैसे एक विशिष्ट दाग़) के रंग स्पेक्ट्रम (अवशोषण विशेषताओं) का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: एक $C \times r$ मैट्रिक्स।
- भौतिक/तार्किक भूमिका: यह मैट्रिक्स प्रत्येक दाग़ के अद्वितीय "फिंगरप्रिंट" को कैप्चर करता है, यह वर्णन करता है कि यह विभिन्न रंग चैनलों में प्रकाश को कैसे अवशोषित करता है। यह अलग-अलग दाग़ रंगों को अलग करने के लिए आवश्यक है।
- क्यों उपयोग किया जाता है: यह मॉडल को विशिष्ट डाई के पूर्व ज्ञान के बिना, सीधे डेटा से दाग़ों के स्पेक्ट्रल गुणों को सीखने की अनुमति देता है।
-
$D$: यह ऑप्टिकल घनत्व मैट्रिक्स है, जिसका आकार $P \times r$ है। प्रत्येक कॉलम $d_i \in \mathbb{R}^P$ प्रत्येक पिक्सेल पर $i$-वें रंगीन घटक का ऑप्टिकल घनत्व (सांद्रता) रखता है।
- गणितीय परिभाषा: एक $P \times r$ मैट्रिक्स।
- भौतिक/तार्किक भूमिका: यह मैट्रिक्स छवि में प्रत्येक दाग़ घटक के स्थानिक वितरण और सांद्रता का प्रतिनिधित्व करता है। यह "दाग़-अपरिवर्तनीय संरचनात्मक जानकारी" है जिसे BeerLaNet निकालने का लक्ष्य रखता है, क्योंकि यह बताता है कि प्रत्येक दाग़ कहाँ और कितना मौजूद है, इसकी उपस्थिति से स्वतंत्र।
- क्यों उपयोग किया जाता है: यह बीयर-लैम्बर्ट नियम का दूसरा मुख्य घटक है, जो प्रत्येक पिक्सेल पर मौजूद प्रत्येक दाग़ की मात्रा का प्रतिनिधित्व करता है।
-
$SD^T$: यह मैट्रिक्स उत्पाद, जिसका आकार $C \times P$ है, सभी पिक्सेल पर सभी दाग़ों से कुल ऑप्टिकल घनत्व योगदान का प्रतिनिधित्व करता है, जिसे रंग स्थान में वापस रूपांतरित किया गया है।
- गणितीय परिभाषा: $S$ और $D^T$ के उत्पाद से प्राप्त एक $C \times P$ मैट्रिक्स।
- भौतिक/तार्किक भूमिका: लघुगणकीय बीयर-लैम्बर्ट नियम में, यह पद दाग़ों के कारण होने वाले कुल क्षीणन का प्रतिनिधित्व करता है। यह "दाग़ प्रभाव" है जिसे सामान्यीकरण के लिए मॉडल और बाद में हटाया जाना चाहिए।
- क्यों उपयोग किया जाता है: यह इस बात का गणितीय प्रतिनिधित्व है कि दाग़ रंग प्रोफाइल ($S$) को वितरित ($D$) करके प्रकाश क्षीणन कैसे होता है।
-
$||x_0\mathbf{1}^T - X - SD^T||_F^2$: यह डेटा निष्ठा पद है, विशेष रूप से अवशिष्ट मैट्रिक्स का वर्ग फ्रोबेनियस नॉर्म।
- गणितीय परिभाषा: मैट्रिक्स $(x_0\mathbf{1}^T - X - SD^T)$ के सभी तत्वों के वर्गों का योग।
- भौतिक/तार्किक भूमिका: यह पद मापता है कि मॉडल का पुनर्निर्माण ( $x_0, S, D$ के आधार पर) वास्तविक इनपुट छवि $X$ से कितनी अच्छी तरह मेल खाता है। इस पद को कम करने का मतलब है कि मॉडल $x_0, S, D$ खोजने की कोशिश कर रहा है ताकि उनका संयोजन देखी गई छवि को सटीक रूप से समझा सके।
- क्यों उपयोग किया जाता है: वर्ग फ्रोबेनियस नॉर्म मैट्रिसेस के बीच अंतर को मापने का एक मानक और विभेदक तरीका है, जो इसे ग्रेडिएंट-आधारित अनुकूलन के लिए उपयुक्त बनाता है। $\frac{1}{2}$ कारक इसके व्युत्पन्न को सरल बनाने के लिए एक सामान्य परंपरा है।
-
$\lambda$: यह एक गैर-नकारात्मक स्केलर रेगुलराइज़ेशन पैरामीटर है।
- गणितीय परिभाषा: एक स्केलर मान।
- भौतिक/तार्किक भूमिका: यह रेगुलराइज़ेशन पदों की ताकत को नियंत्रित करता है। एक बड़ा $\lambda$ $S$ और $D$ में स्पार्सिटी और निम्न-रैंक गुणों को बढ़ावा देने पर अधिक जोर देता है, संभवतः पूर्ण डेटा पुनर्निर्माण की कीमत पर। यह एक संतुलनकारी नॉब के रूप में कार्य करता है।
- क्यों उपयोग किया जाता है: ओवरफिटिंग को रोकने और सीखे गए दाग़ घटकों को वांछनीय गणितीय गुण रखने के लिए प्रोत्साहित करने के लिए, और इसे BeerLaNet में सीखने योग्य बनाया गया है।
-
$\sum_{i=1}^r (\dots)$: यह $r$ रंगीन घटकों पर योग को दर्शाता है।
- गणितीय परिभाषा: $i=1$ से $r$ तक का योग।
- भौतिक/तार्किक भूमिका: यह प्रत्येक व्यक्तिगत दाग़ घटक ($s_i$ और $d_i$) के लिए रेगुलराइज़ेशन दंड को एक एकल कुल दंड में एकत्रित करता है।
- क्यों उपयोग किया जाता है: सीखे गए दाग़ घटकों के सभी पहचाने गए दाग़ घटकों पर समान रूप से रेगुलराइज़ेशन लागू करने के लिए।
-
$||s_i||_2^2$: यह $S$ के $i$-वें कॉलम का वर्ग L2 नॉर्म है।
- गणितीय परिभाषा: वेक्टर $s_i$ के तत्वों के वर्गों का योग।
- भौतिक/तार्किक भूमिका: यह पद रंग स्पेक्ट्रम वैक्टर के परिमाण को नियमित करता है। यह $s_i$ के तत्वों को छोटा करने के लिए प्रोत्साहित करता है, जिससे किसी भी एकल रंग चैनल का दाग़ के प्रोफाइल में अत्यधिक बड़ा योगदान हो सकता है। यह $S$ के लिए निम्न-रैंक समाधानों को भी बढ़ावा देता है।
- क्यों उपयोग किया जाता है: निम्न-रैंक समाधानों को बढ़ावा देकर और अधिक कॉम्पैक्ट और सार्थक दाग़ घटकों को खोजने में मदद करता है, जैसा कि पत्र में उल्लेख किया गया है।
-
$||d_i||_1$: यह $D$ के $i$-वें कॉलम का L1 नॉर्म है।
- गणितीय परिभाषा: वेक्टर $d_i$ के निरपेक्ष मानों का योग।
- भौतिक/तार्किक भूमिका: यह पद ऑप्टिकल घनत्व मैट्रिक्स $D$ में स्पार्सिटी को बढ़ावा देता है। यह $d_i$ के कई तत्वों को शून्य पर सेट करने के लिए प्रोत्साहित करता है, जिसका अर्थ है कि एक विशेष दाग़ घटक केवल कुछ पिक्सेल में मौजूद है। यह इस धारणा के अनुरूप है कि "रुचि की प्रासंगिक हिस्टोलॉजिकल विशेषताएँ स्थान में विरल हैं।"
- क्यों उपयोग किया जाता है: L1 रेगुलराइज़ेशन स्पार्सिटी को प्रेरित करने के लिए एक मानक तकनीक है, जो अलग-अलग दाग़ क्षेत्रों को अलग करने में मदद करती है और $D$ की व्याख्या को अधिक सार्थक बनाती है।
-
$||d_i||_2^2$: यह $D$ के $i$-वें कॉलम का वर्ग L2 नॉर्म है।
- गणितीय परिभाषा: वेक्टर $d_i$ के तत्वों के वर्गों का योग।
- भौतिक/तार्किक भूमिका: $||s_i||_2^2$ के समान, यह पद ऑप्टिकल घनत्व वैक्टर के परिमाण को नियमित करता है। यह किसी भी एकल पिक्सेल को दाग़ की अत्यधिक उच्च सांद्रता रखने से रोकता है और $D$ के लिए निम्न-रैंक समाधानों को बढ़ावा देने में योगदान देता है।
- क्यों उपयोग किया जाता है: निम्न-रैंक समाधानों को बढ़ावा देने और $D$ में अत्यधिक बड़े मानों को रोकने के लिए, संख्यात्मक स्थिरता और बेहतर सामान्यीकरण में योगदान।
-
$\text{s.t. } S,D \ge 0$: ये गैर-नकारात्मकता बाधाएँ हैं।
- गणितीय परिभाषा: मैट्रिक्स $S$ और $D$ में सभी तत्व शून्य से बड़े या उसके बराबर होने चाहिए।
- भौतिक/तार्किक भूमिका: यह एक महत्वपूर्ण भौतिक बाधा है। दाग़ सांद्रता ( $D$ में ऑप्टिकल घनत्व) और प्रकाश अवशोषण गुणांक ( $S$ में) नकारात्मक नहीं हो सकते। नकारात्मक मान भौतिक रूप से अर्थहीन होंगे। यह नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF) की एक परिभाषित विशेषता है।
- क्यों उपयोग किया जाता है: यह सुनिश्चित करने के लिए कि सीखे गए दाग़ घटक और उनकी सांद्रता भौतिक रूप से व्याख्या योग्य हैं और अंतर्निहित बीयर-लैम्बर्ट नियम का पालन करते हैं, जो गैर-नकारात्मक मात्राओं पर आधारित है।
डेटा निष्ठा और रेगुलराइज़ेशन पदों को संयोजित करने के लिए जोड़ का चुनाव अनुकूलन में मानक है, जिससे डेटा फिटिंग और वांछनीय गुणों को बढ़ावा देने के बीच संतुलन की अनुमति मिलती है। योग का उपयोग इंटीग्रल के बजाय किया जाता है क्योंकि समस्या असतत संस्थाओं से संबंधित है: पिक्सेल, रंग चैनल और दाग़ घटक।
चरण-दर-चरण प्रवाह
BeerLaNet मास्टर समीकरण के अनुकूलन प्रक्रिया को पुनरावृत्तीय चरणों की एक श्रृंखला में "अनरोल" करके संचालित होता है, जो एक असेंबली लाइन की तरह है। आइए देखें कि एक अमूर्त डेटा बिंदु (इनपुट छवि $X$ से एक एकल पिक्सेल के रंग वेक्टर $x_j$) इस तंत्र के माध्यम से एक पुनरावृति $k$ के लिए कैसे प्रवाहित होगा:
- इनपुट प्रवेश: एक पूरी इनपुट छवि $X$ ($C \times P$ मैट्रिक्स) को BeerLaNet मॉड्यूल में फीड किया जाता है। इस स्तर पर, हमारे पास पृष्ठभूमि प्रकाश $x_0^{(k-1)}$, दाग़ रंग मैट्रिक्स $S^{(k-1)}$, और ऑप्टिकल घनत्व मैट्रिक्स $D^{(k-1)}$ के प्रारंभिक या पिछले अनुमान हैं।
- पृष्ठभूमि प्रकाश अद्यतन ($x_0$): हमारी असेंबली लाइन पर पहला स्टेशन पृष्ठभूमि प्रकाश $x_0$ को अद्यतन करता है। प्रत्येक पिक्सेल के रंग वेक्टर $x_j$ ( $X$ से) को उसके दाग़ योगदान के वर्तमान अनुमान ( $S^{(k-1)}$ और $D^{(k-1)}$ से प्राप्त) के साथ वैचारिक रूप से जोड़ा जाता है। इन संयुक्त मानों को फिर $x_0^{(k)}$ के एक नए, परिष्कृत अनुमान का उत्पादन करने के लिए सभी पिक्सेल पर औसत किया जाता है। यह कदम अनिवार्य रूप से समग्र आपतित प्रकाश निर्धारित करता है जो, वर्तमान दाग़ मॉडल द्वारा क्षीण होने पर, देखी गई छवि को पुनर्निर्मित करने के लिए सबसे अच्छा है।
- ऑप्टिकल घनत्व अद्यतन ($D$): इसके बाद, सिस्टम ऑप्टिकल घनत्व मैट्रिक्स $D$ को अद्यतन करने पर केंद्रित है।
- चरण आकार गणना: एक गतिशील चरण आकार $\tau_D$ की गणना की जाती है, जो निर्धारित करता है कि इस पुनरावृति में $D$ को कितनी आक्रामक रूप से अद्यतन किया जाना चाहिए।
- ग्रेडिएंट डिसेंट: प्रत्येक पिक्सेल के लिए, इसकी वर्तमान दाग़ सांद्रता ( $D^{(k-1)}$ की एक पंक्ति द्वारा दर्शाई गई) को समायोजित किया जाता है। यह समायोजन इस बात पर आधारित है कि वर्तमान $S$ और $D$ इनपुट छवि $X$ और नव अद्यतन $x_0^{(k)}$ को कितनी अच्छी तरह समझाते हैं। ग्रेडिएंट $D$ को उन मानों की ओर धकेलता है जो पुनर्निर्माण त्रुटि को कम करते हैं।
- प्रॉक्सिमल ऑपरेटर (स्पार्सिटी और गैर-नकारात्मकता): ग्रेडिएंट चरण के बाद, $D$ के प्रत्येक कॉलम $d_i$ पर "क्लिपिंग" और "सिकुड़ने" की एक श्रृंखला लागू की जाती है। ये प्रॉक्सिमल ऑपरेटर हैं। वे दो महत्वपूर्ण गुणों को लागू करते हैं:
- गैर-नकारात्मकता: किसी भी नकारात्मक सांद्रता मान को तुरंत शून्य पर क्लिप किया जाता है, जिससे भौतिक यथार्थवाद सुनिश्चित होता है।
- स्पार्सिटी: L1 नॉर्म रेगुलराइज़ेशन सांद्रता मानों को शून्य पर सेट करने के लिए प्रोत्साहित करता है। इसका मतलब है कि एक दिए गए पिक्सेल के लिए, यदि किसी दाग़ घटक की सांद्रता बहुत कम है, तो उसे प्रभावी ढंग से हटा दिया जाता है, जिससे प्रतिनिधित्व विरल हो जाता है और केवल प्रमुख दाग़ों को उजागर किया जाता है।
- L2 रेगुलराइज़ेशन: एक अतिरिक्त L2 प्रॉक्सिमल ऑपरेटर $d_i$ के परिमाण को और नियमित करता है, अत्यधिक उच्च सांद्रता को रोकता है और निम्न-रैंक समाधानों को बढ़ावा देता है।
- विश्लेषक का नोट: ईमानदारी से कहूं तो, मुझे एल्गोरिथम 1 (पंक्ति 10 और 17) में वर्णित $D$ और $S$ के लिए प्रॉक्सिमल ऑपरेटरों के सटीक रूप के बारे में पूरी तरह से यकीन नहीं है। $\lambda\gamma\tau||s_i||_2^2$ या $\lambda\gamma\tau_S(d_1+d_2)$ जैसे पद उद्देश्य फलन (4) के L1 या L2 प्रॉक्सिमल ऑपरेटरों के लिए मानक नहीं हैं और पाठ में पूरी तरह से विस्तृत एक बहुत ही विशिष्ट सूत्रीकरण या थोड़ा विचलन प्रतीत होता है। हालाँकि, इरादा स्पष्ट रूप से गैर-नकारात्मकता, स्पार्सिटी ( $D$ के लिए), और परिमाण रेगुलराइज़ेशन (दोनों $S$ और $D$ के लिए) को लागू करना है।
- दाग़ रंग अद्यतन ($S$): प्रक्रिया फिर दाग़ रंग मैट्रिक्स $S$ को अद्यतन करने के लिए आगे बढ़ती है।
- चरण आकार गणना: $S$ के लिए एक गतिशील चरण आकार $\tau_S$ की गणना की जाती है।
- ग्रेडिएंट डिसेंट: प्रत्येक दाग़ के रंग प्रोफाइल ( $S^{(k-1)}$ में एक कॉलम) को समायोजित किया जाता है, जो इस बात पर आधारित होता है कि वर्तमान $S$ और नव अद्यतन $D^{(k)}$ छवि $X$ और पृष्ठभूमि $x_0^{(k)}$ को कितनी अच्छी तरह समझाते हैं। यह प्रत्येक दाग़ के स्पेक्ट्रल विशेषताओं को परिष्कृत करता है।
- प्रॉक्सिमल ऑपरेटर (परिमाण और गैर-नकारात्मकता): $D$ के समान, $S$ के प्रत्येक कॉलम $s_i$ पर प्रॉक्सिमल ऑपरेटर लागू किए जाते हैं:
- गैर-नकारात्मकता: सुनिश्चित करता है कि अवशोषण गुणांक भौतिक रूप से सार्थक (गैर-नकारात्मक) हैं।
- L2 रेगुलराइज़ेशन: रंग वैक्टर के परिमाण को कम करता है, $S$ के निम्न-रैंक गुण में योगदान देता है और किसी भी एकल रंग चैनल को अत्यधिक प्रमुख स्पेक्ट्रल योगदान रखने से रोकता है।
- पुनरावृति अंत: यह एक अनरोल्ड पुनरावृति को पूरा करता है। परिष्कृत $x_0^{(k)}, S^{(k)}, D^{(k)}$ अब अगली पुनरावृति के लिए तैयार हैं, या यदि $K$ पुनरावृति पूरी हो गई हैं, तो अंतिम आउटपुट के लिए।
- आउटपुट और डाउनस्ट्रीम एकीकरण: $K$ पुनरावृति के बाद, अंतिम $D$ मैट्रिक्स, जो दाग़-अपरिवर्तनीय संरचनात्मक जानकारी का प्रतिनिधित्व करता है, निकाला जाता है। इस $P \times r$ मैट्रिक्स को फिर एक $r$-चैनल छवि में पुनः आकार दिया जाता है (जहाँ प्रत्येक चैनल एक दाग़ घटक के स्थानिक वितरण से मेल खाता है)। इस $r$-चैनल छवि को फिर एक $1 \times 1$ कनवल्शन परत के माध्यम से पारित किया जाता है ताकि इसे 3-चैनल छवि में वापस मैप किया जा सके, जिसे तब किसी भी डीप लर्निंग बैकबोन नेटवर्क (जैसे YOLO या ResNet) में निर्बाध रूप से एकीकृत किया जा सकता है ताकि ऑब्जेक्ट डिटेक्शन या वर्गीकरण जैसे डाउनस्ट्रीम कार्यों के लिए उपयोग किया जा सके।
हमारे दृष्टिकोण का एक अवलोकन चित्र 1 में दर्शाया गया है, और हमारी विधि का पूरा विवरण एल्गोरिथम 1 में दिया गया है।
अनुकूलन गतिशीलता
जिस तंत्र द्वारा BeerLaNet "सीखता है" और अभिसरण करता है, वह एक अनरोल्ड वैकल्पिक प्रॉक्सिमल ग्रेडिएंट डिसेंट एल्गोरिथम के माध्यम से होता है, जिसे फिर एंड-टू-एंड प्रशिक्षित किया जाता है।
- वैकल्पिक प्रॉक्सिमल ग्रेडिएंट डिसेंट: मुख्य अनुकूलन रणनीति पुनरावृत्तीय है। यह चिकनी डेटा निष्ठा पद को कम करने के लिए एक मानक ग्रेडिएंट डिसेंट चरण (चिकनी डेटा निष्ठा पद को कम करने के लिए) को प्रॉक्सिमल ऑपरेटर (गैर-चिकनी रेगुलराइज़ेशन पदों और गैर-नकारात्मकता बाधाओं को संभालने के लिए) के साथ जोड़कर संरचित NMF समस्या से निपटता है। यह पुनरावृत्तीय शोधन मॉडल को जटिल हानि परिदृश्य को नेविगेट करने में मदद करता है।
- गैर-उत्तल हानि परिदृश्य: $SD^T$ उत्पाद की उपस्थिति उद्देश्य फलन को गैर-उत्तल बनाती है। इसका मतलब है कि हानि परिदृश्य एक साधारण कटोरे का आकार नहीं है; इसमें कई "घाटियाँ" या स्थानीय न्यूनतम हो सकते हैं। जबकि वैकल्पिक प्रॉक्सिमल ग्रेडिएंट डिसेंट प्रभावी है, यह पूर्ण सर्वोत्तम (वैश्विक) न्यूनतम खोजने की गारंटी नहीं देता है। हालांकि, व्यवहार में, यह अक्सर अच्छे समाधान पाता है।
- ग्रेडिएंट्स और अपडेट: $D$ और $S$ के लिए ग्रेडिएंट डिसेंट चरणों के दौरान, एल्गोरिथम डेटा निष्ठा पद के ग्रेडिएंट की गणना करता है। ये ग्रेडिएंट उस दिशा में इंगित करते हैं जहाँ पुनर्निर्माण त्रुटि सबसे तेजी से बढ़ती है। एल्गोरिथम फिर विपरीत दिशा में एक कदम उठाता है, इस त्रुटि को पुनरावृत्तीय रूप से कम करता है। गतिशील चरण आकार ($\tau_D, \tau_S$) महत्वपूर्ण हैं; वे हानि परिदृश्य की स्थानीय वक्रता के अनुकूल होते हैं, जिससे परिदृश्य सपाट होने पर बड़े कदम और खड़ी होने पर छोटे कदम उठाने की अनुमति मिलती है, जिससे तेज और अधिक स्थिर अभिसरण में सहायता मिलती है।
- प्रॉक्सिमल ऑपरेटरों की भूमिका: प्रॉक्सिमल ऑपरेटर समाधान को आकार देने के लिए महत्वपूर्ण हैं। $D$ के लिए, L1 नॉर्म स्पार्सिटी को प्रोत्साहित करता है, प्रभावी ढंग से छोटी दाग़ सांद्रता को शून्य पर सेट करता है, जो दाग़ मानचित्र को सरल बनाता है। $S$ और $D$ दोनों के लिए, L2 नॉर्म और गैर-नकारात्मकता बाधाएँ सुनिश्चित करती हैं कि सीखे गए दाग़ प्रोफाइल और सांद्रता भौतिक रूप से सार्थक और अच्छी तरह से व्यवहार किए जाते हैं, अवास्तविक मानों या ओवरफिटिंग को रोकते हैं।
- सीखने योग्य पैरामीटर और एंड-टू-एंड प्रशिक्षण: BeerLaNet का एक प्रमुख नवाचार कुछ महत्वपूर्ण अनुकूलन हाइपरपैरामीटर (जैसे $\lambda$, $\gamma$, और प्रारंभिक $S_{init}$) को सीखने योग्य बनाना है। इन मैन्युअल रूप से ट्यून करने के बजाय, पूरे अनरोल्ड अनुकूलन प्रक्रिया को एक न्यूरल नेटवर्क आर्किटेक्चर के भीतर एम्बेड किया गया है। अंतिम डाउनस्ट्रीम कार्य (जैसे, ऑब्जेक्ट डिटेक्शन सटीकता) से हानि फिर सभी $K$ अनरोल्ड परतों के माध्यम से वापस प्रचारित की जाती है। इसका मतलब है कि ग्रेडिएंट न केवल डाउनस्ट्रीम बैकबोन नेटवर्क के भार को अद्यतन करते हैं, बल्कि BeerLaNet के भीतर रेगुलराइज़ेशन पैरामीटर और प्रारंभिक दाग़ अनुमानों को भी अद्यतन करते हैं। यह एंड-टू-एंड प्रशिक्षण BeerLaNet मॉड्यूल को अंतिम कार्य के प्रदर्शन को सीधे अनुकूलित करने के लिए अपनी आंतरिक दाग़ सामान्यीकरण प्रक्रिया को अनुकूलित करने की अनुमति देता है, जिससे यह अत्यधिक अनुकूली और मजबूत बनता है।
- अभिसरण व्यवहार: प्रत्येक अनरोल्ड पुनरावृति के साथ, $x_0, S, D$ के अनुमानों को उत्तरोत्तर परिष्कृत किया जाता है। अनरोल्ड पुनरावृति की संख्या, $K$, BeerLaNet मॉड्यूल की गहराई की तरह कार्य करती है। इन अनरोल्ड परतों के माध्यम से बैकप्रॉपैगेशन पुनरावृत्तीय प्रक्रिया को एक ऐसे समाधान की ओर निर्देशित करता है जो न केवल NMF उद्देश्य के लिए इष्टतम है, बल्कि विशेष रूप से डाउनस्ट्रीम कार्य के अंतिम लक्ष्य के लिए है, जिससे विभिन्न दाग़ डोमेन में सामान्यीकरण में सुधार होता है।
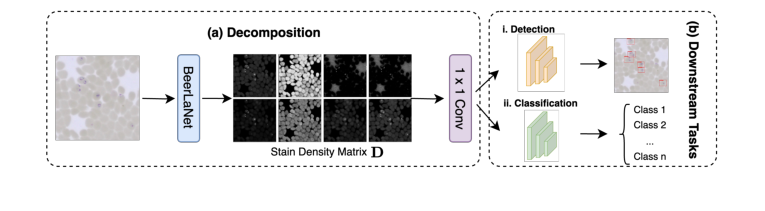 Figure 1. Overview of our proposed BeerLaNet method
Figure 1. Overview of our proposed BeerLaNet method
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अनुकूली दाग़ सामान्यीकरण प्रदान करने और क्रॉस-डोमेन सामान्यीकरण को बढ़ाने की BeerLaNet की क्षमता को कठोरता से मान्य करने के लिए, लेखकों ने दो प्राथमिक नैदानिक कार्यों: ऑब्जेक्ट डिटेक्शन और इमेज क्लासिफिकेशन में एक व्यापक प्रयोगात्मक सेटअप तैयार किया। उन्होंने विभिन्न पैथोलॉजी डेटासेट पर, शास्त्रीय और डीप लर्निंग-आधारित दोनों तरह के स्थापित बेसलाइन मॉडल के एक सूट के खिलाफ BeerLaNet को खड़ा किया।
ऑब्जेक्ट डिटेक्शन के लिए, मूल्यांकन मलेरिया परजीवी पहचान और पूरे रक्त कोशिका पहचान पर केंद्रित था। मलेरिया पहचान कार्य में 24,720 मई ग्रुनवाल्ड-गिम्सा (MGG)-दाग़दार पतली रक्त स्मीयर छवियों का एक सार्वजनिक डेटासेट [5] शामिल था, जिसे सफेद रक्त कोशिकाओं, लाल रक्त कोशिकाओं, प्लेटलेट्स और विभिन्न परजीवी प्रजातियों के लिए एनोटेट किया गया था। एक अलग, आंतरिक रूप से क्यूरेटेड परीक्षण डेटासेट जिसमें ज़ीस एक्सिओस्कैन माइक्रोस्कोप से 264 पतली रक्त स्मीयर छवियां थीं, का उपयोग मूल्यांकन के लिए किया गया था। पूरे रक्त कोशिका पहचान के लिए, दो सार्वजनिक डेटासेट का उपयोग किया गया था: प्रशिक्षण (366 छवियां) के लिए BCCD [17] और परीक्षण (100 छवियां) के लिए BCDD [1]। इन कार्यों के लिए BeerLaNet को YOLOv8 बैकबोन [9] के साथ एकीकृत किया गया था।
इमेज क्लासिफिकेशन के लिए, दो अलग-अलग चुनौतियों का समाधान किया गया: मलेरिया परजीवी वर्गीकरण और स्तन कैंसर वर्गीकरण। मलेरिया वर्गीकरण डेटासेट चार माइक्रोस्कोपी प्लेटफार्मों (हैमात्सु नैनोजूमर, ज़ीस एक्सिओस्कैन, ओलिंपस CX43, मॉर्फल हेमोलेंस) से एक विविध संग्रह था, जिसमें जिम्सा-दाग़दार पतली रक्त स्मीयर शामिल थे। इसमें 2,486 एकल-कोशिका क्रॉप की गई छवियों का एक प्रशिक्षण सेट और दो परीक्षण सेट (343 और 261 नमूने) विभिन्न इमेजिंग प्लेटफार्मों से थे, जिन्हें डोमेन में सामान्यीकरण का आकलन करने के लिए डिज़ाइन किया गया था। कार्य में पता लगाए गए परजीवियों को जीवन-चरण के अनुसार वर्गीकृत करना शामिल था। स्तन कैंसर वर्गीकरण के लिए, Camelyon17-WILDS डेटासेट [2] का उपयोग किया गया था, जिसमें लिम्फ नोड होल स्लाइड छवियों से 96x96 छवि पैच शामिल थे, जिसमें ट्यूमर उपस्थिति लेबल थे। यह डेटासेट पांच अस्पतालों में फैला हुआ था, जिसमें स्वाभाविक रूप से महत्वपूर्ण डोमेन शिफ्ट पेश किए गए थे। इन वर्गीकरण कार्यों के लिए BeerLaNet को ResNet-18 बैकबोन [8] के साथ एकीकृत किया गया था।
जिन "पीड़ितों" (बेसलाइन मॉडल) के खिलाफ BeerLaNet की तुलना की गई, उनमें तीन शास्त्रीय हिस्टोलॉजी सामान्यीकरण विधियाँ शामिल थीं: Reinhard [13], Macenko [11], और Vahadane [18]। इसके अतिरिक्त, दो डीप लर्निंग-आधारित विधियाँ, StainGAN [16] और LStainNorm [10], शामिल की गईं। टेम्पलेट छवि की आवश्यकता वाली बेसलाइन के लिए, प्रशिक्षण डेटासेट से एक छवि को यादृच्छिक रूप से चुना गया था।
BeerLaNet के लिए प्रमुख कार्यान्वयन विवरणों में रंगीन घटकों की संख्या ($r$) को 8 और आंतरिक अनरोल्ड पुनरावृति ($K$) को 10 पर सेट करना शामिल था। प्रशिक्षण पैरामीटर कार्य के अनुसार भिन्न होते थे, जिसमें बैच आकार 8 (डिटेक्शन) या 128 (क्लासिफिकेशन) और सीखने की दर 0.01 या 1e-4 थी। विशेष रूप से, मलेरिया वर्गीकरण डेटासेट पर संपीड़न कलाकृतियों को कम करने के लिए एक दो-चरणीय डीनोइज़िंग पाइपलाइन (मध्यिका और गाऊसी फिल्टर) लागू की गई थी। सभी प्रयोगात्मक परिणाम मजबूती सुनिश्चित करने के लिए तीन यादृच्छिक बीजों पर औसत किए गए थे।
कार्य आवश्यकताओं को दर्शाने के लिए मेट्रिक्स चुने गए थे: डिटेक्शन के लिए mAP50 और mAP50-95, और वर्गीकरण के लिए सटीकता (Acc)। मलेरिया परजीवी वर्गीकरण के लिए एक विशेष रिलैक्स्ड एक्यूरेसी (RAcc) पेश की गई थी, जो भविष्यवाणियों को सफल मानती थी यदि वे ग्राउंड ट्रुथ से एक जीवन-चरण के भीतर थीं, परजीवी वृद्धि की निरंतर प्रकृति को स्वीकार करती थी। सभी कार्यों और डेटासेट पर सुसंगत प्रदर्शन का एक निश्चित, निर्विवाद माप प्रदान करने के लिए, लेखकों ने एवरेज परसेंट अंडरपरफॉरमेंस (APU) मीट्रिक पेश किया। यह मीट्रिक प्रत्येक कार्य-मीट्रिक संयोजन के लिए सर्वश्रेष्ठ प्रदर्शन करने वाली विधि के प्रदर्शन और उसके बीच औसत प्रतिशत अंतर को मापता है, जो सामान्यीकरण का एक समग्र दृश्य प्रदान करता है।
प्रशिक्षण और परीक्षण डेटा के बीच डोमेन में भिन्नता दिखाने वाली उदाहरण छवियां चित्र 2 में प्रदर्शित की गई हैं।
साक्ष्य क्या साबित करते हैं
तालिका 1 में संक्षेप में प्रस्तुत किए गए प्रयोगात्मक साक्ष्य, इस बात का पुख्ता सबूत प्रदान करते हैं कि BeerLaNet का मुख्य तंत्र—भौतिकी-सूचित, प्रशिक्षण योग्य दाग़ अलगाव एल्गोरिथम अनरोलिंग के माध्यम से—वास्तव में व्यवहार में काम करता है और अपने बेसलाइन की तुलना में बेहतर क्रॉस-डोमेन सामान्यीकरण प्रदान करता है।
BeerLaNet ने मलेरिया परजीवी पहचान (mAP50 95.07% और mAP50-95 57.10%) और मलेरिया परजीवी वर्गीकरण (Acc 48.66% और RAcc 90.33%) दोनों में सर्वश्रेष्ठ प्रदर्शन हासिल किया। इसने पूरे रक्त कोशिका पहचान (mAP50 86.80% और mAP50-95 51.33%) में दूसरा सबसे अच्छा प्रदर्शन भी हासिल किया। जबकि यह हमेशा हर एक विशिष्ट मीट्रिक पर पूर्ण शीर्ष प्रदर्शनकर्ता नहीं था (जैसे, Macenko ने Camelyon-17 WILDS C17test डेटासेट पर थोड़ा अधिक सटीकता हासिल की), BeerLaNet की श्रेष्ठता का निश्चित प्रमाण सभी विविध कार्यों और डेटासेट में इसका सुसंगत और मजबूत प्रदर्शन है, जैसा कि एवरेज परसेंट अंडरपरफॉरमेंस (APU) मीट्रिक द्वारा मात्रात्मक रूप से मापा गया है।
BeerLaNet ने APU मीट्रिक के मामले में सभी तुलना विधियों को काफी पीछे छोड़ दिया, डिटेक्शन कार्यों के लिए 2.00 और वर्गीकरण कार्यों के लिए 1.86 हासिल किया। यह एक महत्वपूर्ण साक्ष्य है। उदाहरण के लिए, Macenko, Camelyon-17 WILDS C17test डेटासेट (95.92%) पर सर्वश्रेष्ठ सटीकता हासिल करने के बावजूद, C17val डेटासेट (85.77%) पर दस प्रतिशत अंकों से अधिक की पर्याप्त गिरावट का सामना करना पड़ा। लगभग सभी अन्य बेसलाइन विधियों में विभिन्न कार्यों या डेटासेट में समान महत्वपूर्ण प्रदर्शन गिरावट देखी गई। यह असंगति डोमेन शिफ्ट के प्रति उनकी भेद्यता को उजागर करती है।
बेसलाइन, विशेष रूप से जेनेरिक डिज़ाइन या निश्चित टेम्पलेट्स पर निर्भरता वाले, मलेरिया डेटासेट (जैसा कि चित्र 2 में नेत्रहीन रूप से सुझाया गया है) में मौजूद बड़ी रंग विविधताओं का सामना करने पर सामान्यीकरण करने के लिए संघर्ष करते थे। उनका प्रदर्शन अक्सर अपेक्षाकृत मामूली रंग शिफ्ट (जैसे Camelyon17-WILDS या पूरे रक्त कोशिकाएं) वाले डेटासेट पर मजबूत होता था लेकिन अधिक चुनौतीपूर्ण परिस्थितियों में नाटकीय रूप से विफल हो जाता था। इसके विपरीत, BeerLaNet ने पूर्व ज्ञान या टेम्पलेट चयन के बिना, विभिन्न दाग़ने और इमेजिंग स्थितियों के अनुकूल होने की अपनी क्षमता का प्रदर्शन करते हुए, सबसे अच्छा प्रदर्शन न होने पर भी बहुत प्रतिस्पर्धी प्रदर्शन बनाए रखा। यह सुसंगत, उच्च-स्तरीय प्रदर्शन, APU मीट्रिक द्वारा निर्दयतापूर्वक उजागर किया गया, यह निर्विवाद प्रमाण है कि BeerLaNet का भौतिकी-सूचित, एंड-टू-एंड प्रशिक्षण योग्य दृष्टिकोण प्रभावी ढंग से दाग़-अपरिवर्तनीय संरचनात्मक जानकारी को अलग करता है, जिससे मेडिकल हिस्टोलॉजी में मजबूत क्रॉस-डोमेन सामान्यीकरण होता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि BeerLaNet विभिन्न मेडिकल हिस्टोलॉजी कार्यों में उल्लेखनीय मजबूती और सुसंगत प्रदर्शन प्रदर्शित करता है, इसकी अंतर्निहित सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
एक सूक्ष्म सीमा, जैसा कि लेखकों द्वारा नोट किया गया है, यह है कि BeerLaNet हमेशा हर एकल विशिष्ट डेटासेट या मीट्रिक के लिए पूर्ण शीर्ष प्रदर्शन करने वाली विधि नहीं है। उदाहरण के लिए, Macenko ने Camelyon-17 WILDS C17test डेटासेट पर थोड़ा अधिक सटीकता हासिल की। जबकि BeerLaNet की ताकत सभी में सुसंगत उच्च प्रदर्शन में निहित है (इसके बेहतर APU द्वारा साक्ष्यित), यह बताता है कि विशेष अनुकूलन के लिए अभी भी जगह हो सकती है जो विशेष रूप से कम चुनौतीपूर्ण डोमेन शिफ्ट पर इसके प्रदर्शन को और बढ़ा सकती है। पत्र में कुछ बेसलाइन की तुलना में अनरोल्ड नेटवर्क आर्किटेक्चर के कम्प्यूटेशनल ओवरहेड का भी स्पष्ट रूप से विवरण नहीं दिया गया है, जो विशेष रूप से बड़े होल स्लाइड छवियों या वास्तविक समय अनुप्रयोगों के लिए एक व्यावहारिक विचार हो सकता है।
आगे देखते हुए, लेखक BeerLaNet के अनुप्रयोगों को सेगमेंटेशन और अन्य हिस्टोपैथोलॉजिकल डोमेन जैसे अतिरिक्त डाउनस्ट्रीम कार्यों में विस्तारित करने का प्रस्ताव करते हैं। यह इसके प्लग-एंड-प्ले डिज़ाइन को देखते हुए एक स्वाभाविक विस्तार है।
इनके अलावा, इन निष्कर्षों को विकसित करने और विकसित करने के लिए कई चर्चा विषय उभरते हैं:
- नई दाग़ों और इमेजिंग तौर-तरीकों के प्रति सामान्यीकरण क्षमता: पत्र "मनमानी दाग़ने की प्रक्रियाओं" को संभालने की BeerLaNet की क्षमता पर जोर देता है। यह पूरी तरह से नई दाग़ों या इमेजिंग तौर-तरीकों (जैसे, फ्लोरेसेंस माइक्रोस्कोपी, मास स्पेक्ट्रोमेट्री इमेजिंग) पर कितना अच्छा प्रदर्शन करेगा जो मुख्य रूप से प्रयोगों में उपयोग किए जाने वाले H&E या जिम्सा दाग़ों से काफी भिन्न होते हैं? इसकी "अनुकूली" दावे को वास्तव में मान्य करने के लिए भविष्य के काम में अनदेखी दाग़ प्रकारों के व्यापक स्पेक्ट्रम पर कठोर परीक्षण शामिल हो सकता है।
- अलग किए गए घटकों की व्याख्यात्मकता और नैदानिक उपयोगिता: BeerLaNet दाग़-अपरिवर्तनीय संरचनात्मक जानकारी ( $D$ मैट्रिक्स) निकालता है। क्या इस अलग किए गए प्रतिनिधित्व को सीधे पैथोलॉजिस्ट द्वारा व्याख्यायित किया जा सकता है या डाउनस्ट्रीम कार्य प्रदर्शन में सुधार से परे मात्रात्मक विश्लेषण के लिए उपयोग किया जा सकता है? इन घटकों को विज़ुअलाइज़ करने और मात्रात्मक बनाने के लिए उपकरण विकसित करने से नए नैदानिक अंतर्दृष्टि प्रदान हो सकती है और AI-संचालित पैथोलॉजी में विश्वास बढ़ सकता है।
- गतिशील हाइपरपैरामीटर अनुकूलन: रंगीन घटकों ($r$) और अनरोल्ड पुनरावृति ($K$) की संख्या को निश्चित हाइपरपैरामीटर के रूप में सेट किया गया है। क्या इनपुट छवि विशेषताओं या दाग़ने की प्रक्रिया की जटिलता के आधार पर इन्हें गतिशील रूप से अनुकूलित किया जा सकता है? एक अनुकूली तंत्र प्रदर्शन को और अनुकूलित कर सकता है और मैन्युअल ट्यूनिंग की आवश्यकता को कम कर सकता है।
- बहु-मोडल डेटा के साथ एकीकरण: हिस्टोपैथोलॉजी अक्सर विभिन्न स्रोतों (जैसे, आणविक डेटा, रोगी इतिहास) से जानकारी को एकीकृत करती है। BeerLaNet के दाग़ सामान्यीकरण को अधिक व्यापक नैदानिक चित्र प्रदान करने के लिए बहु-मोडल लर्निंग फ्रेमवर्क के साथ कैसे जोड़ा जा सकता है?
- छवि गुणवत्ता क्षरण के प्रति मजबूती: जबकि दाग़ परिवर्तनशीलता को संबोधित किया जाता है, वास्तविक दुनिया की पैथोलॉजी छवियों में धुंधले क्षेत्रों, धूल, या संपीड़न कलाकृतियों (मलेरिया वर्गीकरण के लिए आंशिक रूप से संबोधित) जैसे अन्य क्षरण से पीड़ित हो सकते हैं। क्या भौतिकी-सूचित अनरोलिंग ढांचे को दाग़ों को सामान्य करने और अन्य सामान्य छवि गुणवत्ता मुद्दों के लिए सुधार करने के लिए बढ़ाया जा सकता है?
- नैतिक विचार और कलाकृति रोकथाम: चिकित्सा निदान में, सिंथेटिक कलाकृतियों को पेश करना या सेलुलर संरचनाओं को "मतिभ्रमित" करना एक महत्वपूर्ण चिंता का विषय है, जैसा कि कुछ GAN-आधारित विधियों के लिए नोट किया गया है। जबकि BeerLaNet इससे बचने का लक्ष्य रखता है, यह सुनिश्चित करने के लिए निरंतर सत्यापन और शायद औपचारिक प्रमाणन प्रक्रियाओं की आवश्यकता है कि सामान्यीकरण प्रक्रिया कभी भी अनजाने में नैदानिक रूप से प्रासंगिक विशेषताओं को अस्पष्ट या परिवर्तित न करे, भले ही समग्र सटीकता में सुधार हो।
- होल स्लाइड इमेजिंग के लिए कम्प्यूटेशनल दक्षता: गीगापिक्सल होल स्लाइड छवियों (WSIs) को संसाधित करना कम्प्यूटेशनल रूप से मांग वाला है। जबकि BeerLaNet एंड-टू-एंड प्रशिक्षण योग्य है, इसका अनरोल्ड NMF तंत्र अभी भी संसाधन-गहन हो सकता है। भविष्य के शोध इसके कम्प्यूटेशनल दक्षता को अनुकूलित करने पर ध्यान केंद्रित कर सकते हैं, शायद अधिक हल्के अनरोलिंग आर्किटेक्चर या कुशल हार्डवेयर कार्यान्वयन के माध्यम से, वास्तविक समय WSI विश्लेषण को सक्षम करने के लिए।
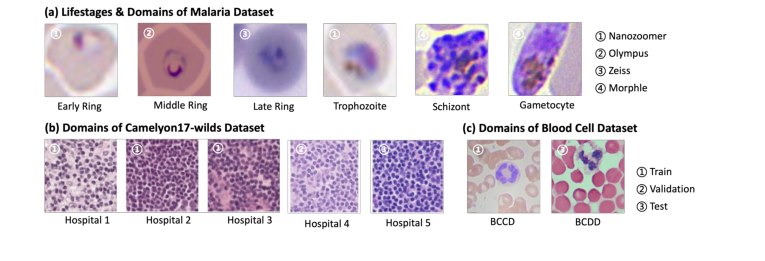 Figure 2. Example images from our tested datasets
Figure 2. Example images from our tested datasets
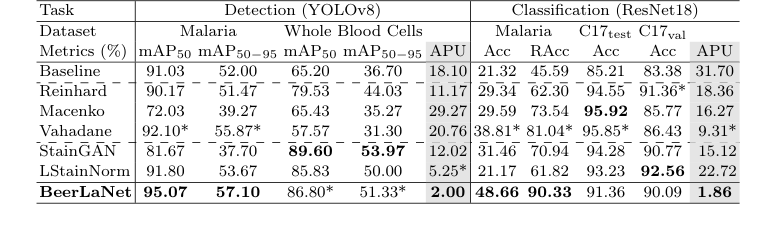 Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
अन्य क्षेत्रों से संबंध
गणितीय कंकाल
इस कार्य का शुद्ध गणितीय मूल एक संरचित नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF) समस्या है जिसमें संयुक्त $l_1$ और $l_2$ नॉर्म रेगुलराइज़ेशन शामिल हैं, जिसे एक अनरोल्ड वैकल्पिक प्रॉक्सिमल ग्रेडिएंट डिसेंट एल्गोरिथम का उपयोग करके हल किया जाता है। यह ढाँचा इनपुट मैट्रिक्स को दो गैर-नकारात्मक कारक मैट्रिसेस में विघटित करने का लक्ष्य रखता है, जो कारकों में स्पार्सिटी और निम्न-रैंक गुणों को बढ़ावा देता है।
आसन्न अनुसंधान क्षेत्र
नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन (NMF)
BeerLaNet मॉडल की नींव नॉन-नेगेटिव मैट्रिक्स फैक्टराइजेशन पर टिकी हुई है, जो विभिन्न क्षेत्रों में आयामीता में कमी और फीचर निष्कर्षण के लिए व्यापक रूप से उपयोग की जाने वाली तकनीक है। विशेष रूप से, समीकरण 4 में उद्देश्य फलन, जो $S, D \ge 0$ और अतिरिक्त रेगुलराइज़ेशन के अधीन $||x_0\mathbf{1}^T - X - SD^T||_F^2$ को कम करने का प्रयास करता है, NMF समस्या का एक सीधा प्रकार है। यहाँ, लॉग-परिवर्तित छवि डेटा को एक दाग़ रंग मैट्रिक्स $S$ और एक ऑप्टिकल घनत्व मैट्रिक्स $D$ में विघटित किया जाता है। यह गणितीय संरचना, जहाँ एक मैट्रिक्स को दो गैर-नकारात्मक मैट्रिसेस के उत्पाद द्वारा अनुमानित किया जाता है, पाठ विश्लेषण में विषय मॉडलिंग, हाइपरस्पेक्ट्रल इमेजिंग में स्पेक्ट्रल अनमिक्सिंग, और ऑडियो प्रोसेसिंग में स्रोत पृथक्करण जैसे अनुप्रयोगों के लिए केंद्रीय है। उदाहरण के लिए, स्पेक्ट्रल अनमिक्सिंग में, NMF का उपयोग मिश्रित पिक्सेल स्पेक्ट्रम को शुद्ध सामग्री स्पेक्ट्रा (एंडमेंबर्स) और उनके संबंधित बहुतायत के सेट में विघटित करने के लिए किया जाता है, जो हिस्टोलॉजी छवियों में दाग़ रंगों और उनके घनत्वों को अलग करने के समान है। NMF में एक मौलिक कार्य ली और सेउंग (1999, नेचर) का है, जो वास्तव में एक सेमिनल पेपर है।
एल्गोरिथम अनरोलिंग / डीप अनफोल्डिंग
विधि संरचित NMF समस्या के लिए पुनरावृत्तीय अनुकूलन प्रक्रिया को एक प्रशिक्षण योग्य डीप न्यूरल नेटवर्क आर्किटेक्चर में बदलने के लिए एल्गोरिथम अनरोलिंग, जिसे डीप अनफोल्डिंग के रूप में भी जाना जाता है, का उपयोग करती है। एल्गोरिथम 1 में उल्लिखित वैकल्पिक प्रॉक्सिमल ग्रेडिएंट डिसेंट चरण, जो $x_0$, $D$, और $S$ को ग्रेडिएंट चरण लेकर और रेगुलराइज़ेशन और गैर-नकारात्मकता बाधाओं के लिए प्रॉक्सिमल ऑपरेटरों को लागू करके अपडेट करते हैं, सीधे नेटवर्क परतों की एक निश्चित संख्या में अनरोल किए जाते हैं। यह दृष्टिकोण रेगुलराइज़ेशन स्ट्रेंथ ($\gamma, \lambda$) और आरंभीकरण ($S_{init}$) जैसे मापदंडों के एंड-टू-एंड प्रशिक्षण की अनुमति देता है, जो बैकप्रॉपैगेशन के माध्यम से होता है, अंतर्निहित अनुकूलन एल्गोरिथम की व्याख्यात्मकता और सैद्धांतिक गारंटी के लाभों का लाभ उठाता है। इस तकनीक को विभिन्न सिग्नल प्रोसेसिंग और व्युत्क्रम समस्याओं में सफलता मिली है, जैसे कि स्पार्स कोडिंग, संपीड़ित सेंसिंग पुनर्निर्माण, और छवि बहाली, जहाँ पुनरावृत्तीय एल्गोरिदम को कुशल, सीखने योग्य डीप मॉडल में परिवर्तित किया जाता है (जैसे, ग्रेगर और लेकुन, 2010, ICML), एक बहुत ही चतुर विचार।