Адаптивная нормализация окраски для кросс-доменной медицинской гистологии
Проблема, рассматриваемая в данной статье, проистекает из критической роли патологического исследования в диагностике заболеваний, которое традиционно опирается на ручную оценку цифровых гистологических изображений.
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, проистекает из критической роли патологического исследования в диагностике заболеваний, которое традиционно опирается на ручную оценку цифровых гистологических изображений. Хотя ручной анализ предоставляет ценную информацию о морфологии тканей и клеточных аномалиях, он является трудоемким, времязатратным и подверженным вариабельности между различными наблюдателями [20, 19]. Появление глубокого обучения открыло перспективный путь к автоматизации этого анализа, но быстро столкнулось со значительным препятствием: несогласованностью цветов в цифровых гистологических изображениях.
Эта вариабельность цветов, являющаяся серьезной проблемой для обобщаемости моделей, обусловлена несколькими факторами: (i) различиями в химических реакциях и времени экспозиции красителей в процессе окрашивания, (ii) вариациями в подготовке образцов и (iii) разнообразными условиями визуализации на различном сканирующем оборудовании [15]. В то время как опытные патологи могут интуитивно компенсировать эти вариации, модели глубокого обучения крайне чувствительны к таким "сдвигам домена", что приводит к значительному снижению производительности и плохой обобщаемости при применении к данным, полученным в условиях, отличных от тех, на которых они обучались [3]. Эта "болевая точка" заставила академическое сообщество, особенно в области медицинской патологии, разрабатывать стратегии нормализации цвета окраски для обеспечения единообразного внешнего вида изображений в различных наборах данных.
Предыдущие подходы к нормализации окраски, хотя и пытались смягчить эти проблемы, страдали от ряда фундаментальных ограничений. Традиционные методы часто требовали тщательного выбора "шаблонного" изображения из обучающего домена для согласования статистик цвета, что требовало предварительных знаний и могло приводить к артефактам. Физические методы, такие как те, что используют закон Бугера-Ламберта-Бера и неотрицательное матричное разложение (NMF), улучшили этот подход, учитывая базовый процесс формирования изображения. Однако они по-прежнему обычно полагались на предопределенные шаблоны или требовали дополнительных предварительных знаний, таких как матрица спектров поглощения специфических красителей или точное количество различных цветовых компонентов [18]. Кроме того, использование анализа главных компонент (PCA) в некоторых методах на основе NMF имело недостатки, поскольку оно предполагает ортогональные компоненты, что не всегда реалистично для компонентов окраски. Более современные методы на основе глубокого обучения, такие как генеративно-состязательные сети (GAN), могли выравнивать распределения цветов, но часто вносили синтетические артефакты или "галлюцинировали" клеточные структуры, что представляло риски для медицинской диагностики [12]. Другие методы глубокого обучения часто были слишком общими, не учитывая специфическую физику гистологического окрашивания [10]. Авторы данной статьи стремились преодолеть эти ограничения, предложив обучаемое, физически обоснованное и не требующее шаблонов решение, способное адаптивно разделять информацию об окраске.
Интуитивные термины домена
- Сдвиг домена (Domain Shift): Представьте, что вы научили собаку распознавать красный мяч. Если вы затем покажете ей синий мяч, она может растеряться, потому что "домен" (цвет мяча) изменился. В цифровой патологии это означает, что модель глубокого обучения, обученная на изображениях из одной лаборатории (с определенной окраской и визуализацией), может плохо работать на изображениях из другой лаборатории с несколько иными условиями.
- Нормализация окраски (Stain Normalization): Думайте об этом как об использовании фотофильтра, чтобы все ваши снимки имели одинаковый последовательный вид, даже если они были сделаны при разном освещении. В гистологии это процесс корректировки цветов гистологических срезов, чтобы они выглядели так, как будто были окрашены по одному и тому же протоколу, что делает их сопоставимыми для автоматизированного анализа.
- Закон Бугера-Ламберта-Бера (Beer-Lambert Law): Это базовое правило оптики, похожее на то, как работают солнцезащитные очки. Оно показывает, сколько света проходит через материал (например, окрашенную ткань) в зависимости от толщины материала и количества светопоглощающего вещества (красителя). Это имеет решающее значение для понимания того, как красители придают ткани ее характерный цвет.
- Неотрицательное матричное разложение (Nonnegative Matrix Factorization, NMF): Представьте фруктовый салат, где вы хотите точно определить, какие фрукты использовались и в каких количествах, зная, что не может быть "отрицательного" количества какого-либо фрукта. NMF — это математический метод, который разлагает сложное изображение (например, окрашенный гистологический срез) на его фундаментальные, неотрицательные компоненты, такие как отдельные красители и их концентрации в каждом пикселе.
- Развертывание алгоритма (Algorithmic Unrolling): Рассмотрите сложный итеративный расчет, например, многократную настройку фокуса телескопа до получения резкого изображения. "Развертывание" означает взятие каждого шага этого итеративного процесса и преобразование его в отдельный слой нейронной сети. Это позволяет всей последовательности корректировок обучаться и оптимизироваться сквозным образом, а не быть фиксированным, отдельным процессом.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, проистекает из присущей вариабельности цветов в цифровых гистологических изображениях, что является критическим вопросом для надежности и обобщаемости моделей глубокого обучения в медицинской диагностике.
Входные данные / Текущее состояние: Входными данными является цифровое гистологическое изображение, представленное как $X \in \mathbb{R}^{c \times p}$, где $c$ — количество цветовых интенсивностей (обычно 3 для RGB), а $p$ — количество пикселей. Это изображение $X$ демонстрирует значительные несоответствия цветов из-за различных факторов: различия в протоколах окрашивания, химических реакциях, времени экспозиции красителей, вариабельности подготовки образцов и разнообразных условий визуализации на различном сканирующем оборудовании. Это несоответствие цветов приводит к "сдвигу домена", означающему, что модели глубокого обучения, обученные на данных из одного набора условий, плохо работают при применении к данным из другого.
Желаемое конечное состояние / Целевое состояние: Желаемым результатом является "нормализованное по окраске" изображение или, точнее, представление "структурной информации, инвариантной к окраске", полученное из входного изображения. Это нормализованное представление должно эффективно удалять вариабельность цветов, сохраняя при этом базовую морфологию тканей и клеточные аномалии. Конечная цель состоит в том, чтобы подать это надежное, инвариантное к окраске представление в последующие задачи глубокого обучения, такие как обнаружение объектов и классификация изображений, позволяя этим моделям эффективно обобщаться на различные домены и достигать последовательной, высокой производительности независимо от внешнего вида окраски исходного изображения.
Отсутствующее звено / Математический пробел: Точным отсутствующим звеном является надежный, адаптивный и физически обоснованный метод математического разделения информации об окраске от структурного содержания изображения. Предыдущие подходы, мотивированные законом Бугера-Ламберта-Бера, моделируют интенсивность изображения $X$ как функцию падающего света $x_0$, матрицы цветового внешнего вида $S$ и матрицы оптической плотности $D$:
$$X = (x_0 \mathbf{1}^T) \odot e^{-SD^T}$$
где $\mathbf{1}$ — вектор из единиц, а $\odot$ обозначает поэлементное матричное произведение. Математический пробел заключается в надежной оценке $x_0$, $S$ и $D$ из данного входного изображения $X$ таким образом, чтобы это было:
1. Адаптивно: Не требовало предварительных знаний о протоколах окрашивания или шаблонных изображениях.
2. Физически обоснованно: Уважало неотрицательность цветовых спектров и оптических плотностей.
3. Обучаемо: Могло быть интегрировано сквозным образом с архитектурами глубокого обучения.
4. Сохраняющее структуру: Избегало введения синтетических артефактов.
Статья направлена на устранение этого пробела путем усовершенствования существующих моделей неотрицательного матричного разложения (NMF), которые часто являются невыпуклыми и требуют тщательной настройки параметров, в обучаемую, развернутую сетевую архитектуру.
Дилемма: Предыдущие исследователи оказались в ловушке нескольких болезненных компромиссов:
* Зависимость от шаблона против адаптивности: Многие существующие методы нормализации окраски сильно полагаются на "шаблонное изображение" или требуют априорных знаний (например, спектров поглощения специфических красителей, количества цветовых компонентов). Хотя эти методы могут быть эффективны для специфических, четко определенных доменов, они не адаптируются к новым или произвольным протоколам окрашивания без ручного вмешательства или тщательного выбора шаблона, что серьезно ограничивает их обобщаемость.
* Физическая точность против генерации артефактов: Методы, строго следующие физике окрашивания (например, основанные на законе Бугера-Ламберта-Бера и NMF), часто используют эвристики (например, анализ главных компонент для $S$ и $D$), которые вносят недостатки, такие как требование ортогональности, что нереалистично для компонентов окраски. И наоборот, более общие подходы глубокого обучения, такие как генеративно-состязательные сети (GAN), могут выравнивать распределения цветов, но склонны к "галлюцинации" клеточных структур или введению синтетических артефактов, что недопустимо и опасно в медицинской диагностике.
* Фиксированные параметры против обучаемости: Более ранние модели NMF (например, уравнение 3) требуют ручной настройки параметров, таких как сила разрежения $\lambda$ и ранг $r$ (количество цветовых компонентов). Эта ручная настройка сложна, особенно когда количество цветовых компонентов неизвестно, и препятствует беспрепятственной интеграции в сквозные конвейеры глубокого обучения, где параметры обучаются автоматически.
Ограничения и режимы отказа
Проблема адаптивной нормализации окраски чрезвычайно сложна из-за нескольких суровых, реалистичных стен, с которыми столкнулись авторы:
-
Физические ограничения:
- Соответствие закону Бугера-Ламберта-Бера: Любая эффективная модель должна точно представлять физический процесс ослабления света красителями. Это означает соблюдение мультипликативного характера поглощения света и разложения на концентрации красителей и свойства поглощения.
- Неотрицательность: Как цветовые спектры ($S$), так и оптические плотности ($D$) являются физически неотрицательными величинами. Применение этого ограничения имеет решающее значение для осмысленного разложения, но усложняет задачи оптимизации.
- Информация, инвариантная к окраске: Основная задача — извлечь структурную информацию, которая действительно независима от внешнего вида окраски. Это требует надежного разделения цветовой информации от морфологических деталей, что нетривиально, учитывая их взаимосвязь в необработанных изображениях.
-
Вычислительные ограничения:
- Невыпуклая оптимизация: Базовая задача NMF, особенно с матричным произведением $SD^T$, является невыпуклой. Это означает, что стандартные алгоритмы оптимизации могут застрять в локальных минимумах, что затрудняет поиск глобально оптимальных решений.
- Сквозная обучаемость: Для практического развертывания с современными моделями глубокого обучения процесс нормализации окраски должен быть дифференцируемым и способным обучаться сквозным образом. Многие традиционные методы включают недифференцируемые шаги или эвристики, что препятствует их беспрепятственной интеграции в фреймворки глубокого обучения.
- Вычислительная эффективность: Обработка больших целых гистологических изображений (whole slide images, WSI) в режиме реального времени или близком к нему для клинических приложений требует вычислительно эффективных алгоритмов. Сложные итеративные процедуры оптимизации могут быть непомерно медленными.
-
Ограничения, основанные на данных:
- Экстремальный сдвиг домена: Наборы данных гистологической патологии демонстрируют значительную вариабельность цветов не только между различными лабораториями или сканерами, но даже в пределах одной лаборатории с течением времени. Этот "сдвиг домена" является основной причиной сбоев моделей глубокого обучения, требуя метода нормализации, который может обрабатывать большие и непредсказуемые вариации.
- Отсутствие предварительных знаний: Во многих сценариях реального мира подробные априорные знания о конкретных протоколах окрашивания, спектрах поглощения красителей или точном количестве цветовых компонентов в образце недоступны. Надежный метод должен работать эффективно без таких явных входных данных.
- Избегание артефактов: В отличие от общего переноса стиля изображения, анализ медицинских изображений не терпит введения "синтетических артефактов" или "галлюцинированных" структур во время нормализации. Такие искажения могут привести к ошибочному диагнозу, делая сохранение структуры первостепенным ограничением.
-
Режимы отказа предыдущих подходов (которые становятся ограничениями для нового решения):
- Смещение, вызванное шаблоном: Опора на фиксированное шаблонное изображение может привести к смещению и ограничить адаптивность, поскольку выбранный шаблон может не быть репрезентативным для всех целевых доменов.
- Чувствительность к параметрам: Предыдущие модели NMF требовали тщательного ручного выбора параметров регуляризации и количества компонентов ($r$), что часто является процессом проб и ошибок и может привести к субоптимальным результатам, если выбрано неправильно.
- Предположение об ортогональности: Методы, такие как PCA, используемые в некоторых предыдущих работах для оценки компонентов окраски, накладывают ограничение ортогональности, которое не является физически реалистичным для биологических красителей, что приводит к неточным разложениям.
- Неоднозначность перестановки: Разложение $S$ и $D$ может страдать от неоднозначности перестановки, когда столбцы могут быть переставлены, что приводит к "значительным искажениям цвета", если не обрабатывается должным образом.
Почему такой подход
Неизбежность выбора
Разработка BeerLaNet была обусловлена явными и постоянными недостатками существующих методов нормализации окраски при столкновении со сложными реалиями цифровой патологии. Основная проблема, как подчеркивается в статье, заключается в "сдвиге домена", вызванном значительной вариабельностью цветов из-за различий в протоколах окрашивания и условиях визуализации. Эта вариабельность серьезно ухудшает производительность моделей глубокого обучения, препятствуя их обобщаемости.
Традиционные методы нормализации окраски, такие как те, что основаны на статистическом сопоставлении или разложении цветового пространства (например, Reinhard, Macenko, Vahadane), оказались недостаточными в основном потому, что они сильно зависят от "соответствующих репрезентативных шаблонов" или "предварительных знаний о домене". Это часто включает требование специфических спектров поглощения красителей или предопределенного количества цветовых компонентов. Такие зависимости делают эти методы хрупкими и склонными к "значительным искажениям цвета", когда шаблон выбран плохо или при столкновении с неизвестными протоколами окрашивания. Авторы осознали, что метод, требующий таких явных предварительных знаний или тщательного ручного выбора шаблонов и параметров, не может быть единственным жизнеспособным решением для действительно адаптивной и надежной системы.
Альтернативы на основе глубокого обучения, такие как генеративно-состязательные сети (GAN) для переноса стиля (например, StainGAN), также имели критические недостатки. Хотя они способны выравнивать распределения цветов, GAN часто "вносят синтетические артефакты или "галлюцинируют" клеточные структуры", что представляет недопустимые риски в медицинской диагностике, где точность исходной морфологии имеет первостепенное значение. Другие методы глубокого обучения, использующие механизмы внимания, были признаны "в значительной степени общими" и не учитывали базовую физику формирования изображения, что ограничивало их надежность и интерпретируемость.
В тот момент, когда авторы осознали, что эти SOTA методы недостаточны, они заметили, что существующие физически обоснованные модели матричного разложения, хотя и концептуально обоснованы, страдали от практических ограничений. В частности, модель разреженного неотрицательного матричного разложения (NMF) в уравнении (3) была невыпуклой и требовала априорного указания количества цветовых компонентов ($r$), что является сложной задачей, когда это количество неизвестно (например, когда образцы содержат дополнительные цветовые компоненты, такие как гемоглобин). Кроме того, использование анализа главных компонент (PCA) в более ранних физических методах было проблематичным, поскольку оно предполагает ортогональные столбцы, что нереалистично для разделения красителей. Это сочетание проблем — зависимость от шаблона, генерация артефактов, отсутствие физически обоснованной адаптивности и требования к фиксированным параметрам — сделало очевидным, что необходим принципиально новый, интегрированный подход.
Сравнительное превосходство
BeerLaNet достигает качественного превосходства над предыдущими золотыми стандартами благодаря нескольким структурным преимуществам, выходящим за рамки простых метрик производительности. Во-первых, его Адаптивное разделение окраски позволяет ему распространяться на "произвольные протоколы окрашивания", обучаясь "представлениям изображений, инвариантным к окраске, без необходимости каких-либо предварительных знаний о протоколе окрашивания". Это является существенным преимуществом перед шаблонными методами, которые по своей сути ограничены качеством и репрезентативностью выбранных шаблонов. Способность BeerLaNet работать без шаблонов и без предварительных знаний о специфических красителях или компонентах делает его гораздо более надежным и обобщаемым в различных клинических условиях.
Во-вторых, метод является Обучаемым и физически обоснованным, построенным на основе неотрицательного матричного разложения (NMF) и развертывания алгоритма. Эта комбинация является ключевой структурной инновацией. Преобразуя традиционно невыпуклую задачу оптимизации в обучаемую глубокую сеть путем развертывания модифицированной формулировки NMF (уравнение 4), BeerLaNet. Это позволяет осуществлять обучаемую адаптацию параметров регуляризации ($\gamma, \lambda$) и инициализаций ($S_{init}$), которые ранее были фиксированными или эвристически выбирались. Это основанное на данных обучение, основанное на законе Бугера-Ламберта-Бера, гарантирует, что процесс разложения окраски является как физически точным, так и высокоадаптивным, избегая подводных камней общих цветовых преобразований, игнорирующих базовую физику визуализации.
Включение дополнительной $l_2$ регуляризации в модифицированную формулировку NMF (4) является еще одним структурным преимуществом. Эта регуляризация способствует получению решений с низким рангом, позволяя модели инициализировать количество цветовых компонентов ($r$) больше, чем ожидалось, а затем адаптировать ранг решения к данным. Это элегантно решает проблему априорного указания $r$, делая модель более гибкой и надежной к вариациям в составе образца.
Наконец, Гибкая интеграция BeerLaNet в качестве модуля "подключи и работай" означает, что его можно беспрепятственно комбинировать с любой базовой сетью для последующих задач. Эта архитектурная конструкция гарантирует, что нормализация окраски является не отдельным шагом предварительной обработки, а неотъемлемой, обучаемой частью всего конвейера глубокого обучения, оптимизируя нормализацию специально для конечной задачи (например, обнаружения объектов или классификации). Эта сквозная обучаемость является значительным структурным преимуществом перед методами, которые работают изолированно и не могут адаптировать свой процесс нормализации на основе обратной связи от последующих задач.
Соответствие ограничениям
Дизайн BeerLaNet идеально соответствует суровым требованиям нормализации окраски в медицинской гистологии, образуя прочный "брак" между проблемой и решением.
-
Ограничение: Преодоление несоответствия цветов и сдвига домена: Основная цель — обобщение на различные условия окрашивания и визуализации. BeerLaNet решает эту проблему с помощью "Адаптивного разделения окраски", которое обучается "представлениям, инвариантным к окраске", без необходимости предварительных знаний о протоколе окрашивания. Это напрямую устраняет первопричину сдвига домена, извлекая базовую биологическую информацию, независимую от вариаций цвета.
-
Ограничение: Избегание артефактов и галлюцинаций: Крайне важно для медицинской диагностики. BeerLaNet достигает этого благодаря своей "физической обоснованности". Его основа на законе Бугера-Ламберта-Бера гарантирует, что разложение окраски основано на фактическом взаимодействии света и ткани, делая преобразования физически правдоподобными и менее склонными к введению синтетических артефактов по сравнению с чисто основанными на данных, общими моделями глубокого обучения, такими как GAN.
-
Ограничение: Устранение зависимости от шаблона и предварительных знаний: Традиционные методы испытывали трудности с необходимостью использования специфических шаблонов или априорных знаний (например, спектров поглощения, количества компонентов). "Обучаемая и физически обоснованная" природа BeerLaNet в сочетании с развертыванием алгоритма позволяет ему обучаться этим параметрам на основе данных. Регуляризация $l_2$ позволяет модели адаптировать количество компонентов ($r$) к данным, устраняя необходимость ручного указания. Это делает метод полностью не требующим шаблонов и независимым от явных предварительных знаний.
-
Ограничение: Поддержка разнообразных протоколов окрашивания: Многие предыдущие методы были сосредоточены в основном на окрашивании H&E. BeerLaNet явно "распространяется на произвольные протоколы окрашивания", что делает его более универсальным решением для широкого спектра красителей, используемых в патологии.
-
Ограничение: Беспрепятственная интеграция с последующими задачами: Решение должно быть практичным для реальных диагностических конвейеров. BeerLaNet разработан как модуль "Гибкой интеграции", компонент "подключи и работай", который может быть объединен с "произвольными базовыми сетями для последующих задач, таких как обнаружение объектов и классификация". Это гарантирует, что процесс нормализации оптимизирован в контексте конечной диагностической задачи, повышая общую производительность системы.
Отклонение альтернатив
Статья предоставляет четкое обоснование отклонения альтернативных подходов, как традиционных, так и основанных на глубоком обучении.
Традиционные методы (например, Reinhard, Macenko, Vahadane): Эти методы были отклонены в первую очередь из-за их присущей зависимости от шаблонных изображений и предварительных знаний. Как указано, они "сильно полагаются на выбор соответствующих репрезентативных шаблонов" и "могут требовать предварительных знаний о домене", таких как матрица спектров поглощения специфических красителей или количество различных цветовых компонентов. Эта зависимость делает их хрупкими; если шаблон не является репрезентативным или предварительные знания неточны, эти методы могут привести к "значительным искажениям цвета". Кроме того, они часто требуют тщательного ручного выбора параметров, таких как сила регуляризации ($\lambda$) и ранг матричного разложения ($r$). Экспериментальные результаты в Таблице 1 количественно подтверждают это отклонение, показывая, что эти методы часто демонстрируют "большое падение производительности" на наборах данных с большими сдвигами домена, такими как набор данных малярии, что указывает на плохую обобщаемость.
Методы на основе глубокого обучения (например, StainGAN, LStainNorm):
* GAN (например, StainGAN): Эти методы были отклонены из-за критического недостатка для медицинских приложений: они "часто могут вносить синтетические артефакты или "галлюцинировать" клеточные структуры, что представляет риски для медицинской диагностики [12]". В области, где точность диагностики и верность биологической реальности имеют первостепенное значение, любой метод, компрометирующий целостность изображения, недопустим.
* Механизмы внимания (например, LStainNorm): Эти методы были признаны "в значительной степени общими и не обязательно учитывают соответствующий процесс формирования изображения [10]". Это подразумевает отсутствие обоснования в базовой физике окрашивания, что может ограничить их надежность и интерпретируемость по сравнению с физически обоснованным подходом BeerLaNet.
Экспериментальные результаты далее подтверждают эти отклонения. В статье отмечается, что "методы с общим дизайном, которые не включают характеристики, специфичные для окраски, могут хорошо работать на данных с небольшим сдвигом домена (Camelyon17-WILDS, клетки крови) но не обобщаются на большие цветовые сдвиги, наблюдаемые в наборе данных малярии". Это прямо контрастирует с последовательной и превосходной производительностью BeerLaNet на различных задачах и наборах данных, особенно с большими сдвигами домена, подчеркивая ограничения альтернатив в реальных, сложных сценариях.
Математический и логический механизм
Мастер-уравнение
Ядром метода BeerLaNet, которое определяет его возможности нормализации окраски, является задача оптимизации, выведенная из модели разреженного неотрицательного матричного разложения (NMF). Эта модель сама по себе основана на законе Бугера-Ламберта-Бера, который описывает, как свет ослабляется красителями. Конкретная целевая функция, которую BeerLaNet разворачивает и оптимизирует, задается следующим образом:
$$ \min_{x_0,S,D} \frac{1}{2} ||x_0\mathbf{1}^T - X - SD^T||_F^2 + \lambda \sum_{i=1}^r (||s_i||_2^2 + ||d_i||_1 + ||d_i||_2^2) \text{ при условии } S,D \ge 0. $$
Это уравнение стремится найти оптимальную интенсивность фонового света ($x_0$), цветовые профили красителей ($S$) и концентрации красителей ($D$), которые наилучшим образом объясняют входное изображение, одновременно способствуя желаемым свойствам, таким как разреженность и решения с низким рангом.
Поэлементный разбор
Давайте разберем это мастер-уравнение, чтобы понять роль каждого компонента:
-
$X$: Это матрица входного изображения, обычно размером $C \times P$, где $C$ — количество цветовых каналов (например, 3 для RGB), а $P$ — общее количество пикселей. Каждый столбец $X$ представляет цветовые интенсивности для одного пикселя. Важно отметить, что, исходя из вывода логарифмической формы закона Бугера-Ламберта-Бера (уравнение 2 в статье), эта $X$ неявно представляет собой поэлементный логарифм наблюдаемых интенсивностей изображения.
- Математическое определение: Матрица $C \times P$, представляющая логарифмические цветовые интенсивности входного изображения.
- Физическая/логическая роль: Это необработанные, наблюдаемые данные, которые модель пытается разложить. Цель состоит в том, чтобы объяснить это наблюдаемое изображение как комбинацию фонового света и эффектов окраски.
- Почему используется: Это прямое представление данных изображения в формате, подходящем для матричного разложения.
-
$x_0$: Это вектор в $\mathbb{R}^C$, представляющий интенсивность падающего света или фоновое освещение.
- Математическое определение: $C$-мерный вектор.
- Физическая/логическая роль: В контексте закона Бугера-Ламберта-Бера $x_0$ моделирует интенсивность источника света до его взаимодействия с окрашенной тканью. Он учитывает вариации условий освещения.
- Почему используется: Это фундаментальный компонент закона Бугера-Ламберта-Бера, позволяющий модели адаптироваться к различным условиям освещения.
-
$\mathbf{1}^T$: Это вектор-строка из единиц размером $1 \times P$.
- Математическое определение: Матрица $1 \times P$, где все элементы равны 1.
- Физическая/логическая роль: При умножении на $x_0$ он эффективно транслирует интенсивность фонового света $x_0$ на все пиксели, создавая матрицу, где каждый пиксель предположительно освещен $x_0$.
- Почему используется: Для равномерного применения интенсивности фонового света ко всем пикселям для матричных операций.
-
$x_0\mathbf{1}^T$: Этот член представляет матрицу падающего света для всех пикселей.
- Математическое определение: Матрица $C \times P$, где каждый столбец является вектором $x_0$.
- Физическая/логическая роль: Это матрица "неослабленного" света, представляющая свет, который был бы наблюдаем, если бы не было красителей.
- Почему используется: Она формирует базовую линию, от которой вычитается ослабление, вызванное окраской, в соответствии с логарифмическим законом Бугера-Ламберта-Бера.
-
$S$: Это матрица цветового внешнего вида размером $C \times r$, где $r$ — количество цветовых компонентов. Каждый столбец $s_i \in \mathbb{R}^C$ представляет цветовой спектр (характеристики поглощения) $i$-го цветового компонента (например, специфического красителя, такого как гематоксилин или эозин).
- Математическое определение: Матрица $C \times r$.
- Физическая/логическая роль: Эта матрица захватывает уникальный "отпечаток" каждого красителя, описывая, как он поглощает свет в различных цветовых каналах. Это важно для разделения различных цветов красителей.
- Почему используется: Позволяет модели изучать спектральные свойства красителей непосредственно из данных, без необходимости предварительных знаний о специфических красителях.
-
$D$: Это матрица оптической плотности размером $P \times r$. Каждый столбец $d_i \in \mathbb{R}^P$ содержит оптическую плотность (концентрацию) $i$-го цветового компонента на каждом пикселе.
- Математическое определение: Матрица $P \times r$.
- Физическая/логическая роль: Эта матрица представляет пространственное распределение и концентрацию каждого компонента окраски по изображению. Это "структурная информация, инвариантная к окраске", которую BeerLaNet стремится извлечь, поскольку она описывает где и сколько каждого красителя присутствует, независимо от его цвета.
- Почему используется: Это другой основной компонент закона Бугера-Ламберта-Бера, представляющий количество каждого красителя, присутствующего в каждом пикселе.
-
$SD^T$: Это матричное произведение размером $C \times P$, представляющее общий вклад оптической плотности от всех красителей во всех пикселях, преобразованный обратно в цветовое пространство.
- Математическое определение: Матрица $C \times P$, полученная в результате произведения $S$ и $D^T$.
- Физическая/логическая роль: В логарифмическом законе Бугера-Ламберта-Бера этот член представляет общее ослабление, вызванное красителями. Это "эффект окраски", который необходимо смоделировать и, впоследствии, удалить для нормализации.
- Почему используется: Это математическое представление того, как цветовые профили красителей ($S$) распределяются ($D$) для вызова ослабления света.
-
$||x_0\mathbf{1}^T - X - SD^T||_F^2$: Это член точности данных, в частности, квадрат нормы Фробениуса остаточной матрицы.
- Математическое определение: Сумма квадратов всех элементов матрицы $(x_0\mathbf{1}^T - X - SD^T)$.
- Физическая/логическая роль: Этот член измеряет, насколько хорошо реконструкция изображения моделью (основанная на $x_0, S, D$) соответствует фактическому входному изображению $X$. Минимизация этого члена означает, что модель пытается найти $x_0, S, D$ такие, чтобы их комбинация точно объясняла наблюдаемое изображение.
- Почему используется: Квадрат нормы Фробениуса является стандартным и дифференцируемым способом количественной оценки различий между матрицами, что делает его подходящим для оптимизации на основе градиента. Фактор $\frac{1}{2}$ является обычным соглашением для упрощения его производной.
-
$\lambda$: Это неотрицательный скалярный параметр регуляризации.
- Математическое определение: Скалярное значение.
- Физическая/логическая роль: Он контролирует силу членов регуляризации. Большее $\lambda$ придает больший вес стимулированию разреженности и свойств низкого ранга в $S$ и $D$, потенциально за счет идеальной реконструкции данных. Он действует как балансирующий регулятор.
- Почему используется: Для предотвращения переобучения и стимулирования выученных компонентов окраски иметь желаемые математические свойства, и он становится обучаемым в BeerLaNet.
-
$\sum_{i=1}^r (\dots)$: Обозначает суммирование по $r$ цветовым компонентам.
- Математическое определение: Сумма от $i=1$ до $r$.
- Физическая/логическая роль: Агрегирует штрафы за регуляризацию для каждого отдельного компонента красителя ($s_i$ и $d_i$) в один общий штраф.
- Почему используется: Для равномерного применения регуляризации ко всем идентифицированным компонентам окраски.
-
$||s_i||_2^2$: Это квадрат L2-нормы $i$-го столбца $S$.
- Математическое определение: Сумма квадратов элементов вектора $s_i$.
- Физическая/логическая роль: Этот член регулирует величину векторов цветовых спектров. Он стимулирует элементы $s_i$ быть малыми, предотвращая чрезмерный вклад любого отдельного цветового канала в профиль красителя. Он также способствует получению решений с низким рангом для $S$.
- Почему используется: Помогает найти более компактный и осмысленный набор компонентов окраски, как упомянуто в статье, путем стимулирования решений с низким рангом.
-
$||d_i||_1$: Это L1-норма $i$-го столбца $D$.
- Математическое определение: Сумма абсолютных значений элементов вектора $d_i$.
- Физическая/логическая роль: Этот член стимулирует разреженность в матрице оптической плотности $D$. Он побуждает многие элементы $d_i$ быть равными точно нулю, что означает, что определенный компонент красителя присутствует только в нескольких пикселях. Это соответствует предположению, что "релевантные гистологические признаки, представляющие интерес, разрежены в пространстве".
- Почему используется: L1-регуляризация является стандартным методом для достижения разреженности, что помогает изолировать различные области окраски и делает интерпретацию $D$ более осмысленной.
-
$||d_i||_2^2$: Это квадрат L2-нормы $i$-го столбца $D$.
- Математическое определение: Сумма квадратов элементов вектора $d_i$.
- Физическая/логическая роль: Подобно $||s_i||_2^2$, этот член регулирует величину векторов оптической плотности. Он предотвращает чрезмерно высокие концентрации красителя в любом отдельном пикселе и способствует получению решений с низким рангом для $D$.
- Почему используется: Для стимулирования решений с низким рангом и предотвращения чрезмерно больших значений в $D$, способствуя численной стабильности и лучшей обобщаемости.
-
$\text{s.t. } S,D \ge 0$: Это ограничения неотрицательности.
- Математическое определение: Все элементы в матрицах $S$ и $D$ должны быть больше или равны нулю.
- Физическая/логическая роль: Это критическое физическое ограничение. Концентрации красителей (оптические плотности в $D$) и коэффициенты поглощения света (в $S$) не могут быть отрицательными. Отрицательные значения были бы физически бессмысленными. Это определяющая характеристика неотрицательного матричного разложения (NMF).
- Почему используется: Для обеспечения того, чтобы выученные компоненты окраски и их концентрации были физически интерпретируемыми и соответствовали базовому закону Бугера-Ламберта-Бера, который основан на неотрицательных величинах.
Выбор сложения для объединения членов точности данных и регуляризации является стандартным в оптимизации, позволяя сбалансировать соответствие данным и стимулирование желаемых свойств. Суммирование используется вместо интегралов, поскольку проблема связана с дискретными сущностями: пикселями, цветовыми каналами и компонентами окраски.
Пошаговый поток
BeerLaNet работает путем "развертывания" процесса оптимизации мастер-уравнения в серию итеративных шагов, подобно конвейеру. Давайте проследим, как абстрактные данные (вектор цвета одного пикселя $x_j$ из входного изображения $X$) будут проходить через этот механизм для одной итерации $k$:
- Ввод данных: В модуль BeerLaNet подается все входное изображение $X$ (матрица $C \times P$). На этом этапе у нас есть начальные или предыдущие оценки фонового света $x_0^{(k-1)}$, матрицы цветовых профилей красителей $S^{(k-1)}$ и матрицы оптической плотности $D^{(k-1)}$.
- Обновление фонового света ($x_0$): Первая станция на нашем конвейере обновляет фоновый свет $x_0$. Вектор цвета каждого пикселя $x_j$ (из $X$) концептуально объединяется с текущей оценкой его вклада окраски (полученной из $S^{(k-1)}$ и $D^{(k-1)}$). Эти объединенные значения затем усредняются по всем пикселям для получения новой, уточненной оценки $x_0^{(k)}$. Этот шаг по существу определяет общий падающий свет, который при ослаблении текущей моделью окраски наилучшим образом реконструирует наблюдаемое изображение.
- Обновление оптической плотности ($D$): Далее система фокусируется на обновлении матрицы оптической плотности $D$.
- Расчет размера шага: Вычисляется динамический размер шага $\tau_D$, который определяет, насколько агрессивно $D$ будет обновляться в этой итерации.
- Градиентный спуск: Для каждого пикселя его текущие концентрации красителей (представленные строкой в $D^{(k-1)}$) корректируются. Эта корректировка основана на том, насколько хорошо текущие $S$ и $D$ объясняют входное изображение $X$ и недавно обновленный $x_0^{(k)}$. Градиент подталкивает $D$ к значениям, минимизирующим ошибку реконструкции.
- Проксимальные операторы (Разреженность и неотрицательность): После шага градиента к каждому столбцу $d_i$ матрицы $D$ применяются серии операций "обрезки" и "сжатия". Это проксимальные операторы. Они обеспечивают два критических свойства:
- Неотрицательность: Любые отрицательные значения концентрации немедленно обрезаются до нуля, обеспечивая физическую реалистичность.
- Разреженность: Регуляризация L1-нормой стимулирует, чтобы многие значения концентрации становились точно нулевыми. Это означает, что для данного пикселя, если концентрация компонента красителя очень низка, она фактически удаляется, делая представление разреженным и выделяя только доминирующие красители.
- L2-регуляризация: Дополнительный L2-проксимальный оператор далее регулирует величину $d_i$, предотвращая чрезмерно высокие концентрации и способствуя получению решений с низким рангом.
- Замечание аналитика: Честно говоря, я не до конца уверен в точной форме проксимальных операторов для $D$ и $S$, как описано в Алгоритме 1 (строки 10 и 17). Такие члены, как $\lambda\gamma\tau||s_i||_2^2$ или $\lambda\gamma\tau_S(d_1+d_2)$, не являются стандартными для проксимальных операторов L1 или L2 целевой функции (4) и, похоже, содержат небольшое расхождение или очень специализированную формулировку, не полностью детализированную в тексте. Однако намерение явно состоит в обеспечении неотрицательности, разреженности (для $D$) и регуляризации величины (для обоих $S$ и $D$).
- Обновление цветового профиля красителя ($S$): Затем процесс переходит к обновлению матрицы цветовых профилей красителей $S$.
- Расчет размера шага: Вычисляется динамический размер шага $\tau_S$ для $S$.
- Градиентный спуск: Каждый цветовой профиль красителя (столбец в $S^{(k-1)}$) корректируется в зависимости от того, насколько хорошо текущие $S$ и обновленные $D^{(k)}$ объясняют изображение $X$ и фон $x_0^{(k)}$. Это уточняет спектральные характеристики каждого красителя.
- Проксимальные операторы (Величина и неотрицательность): Аналогично $D$, к каждому столбцу $s_i$ матрицы $S$ применяются проксимальные операторы:
- Неотрицательность: Гарантирует, что коэффициенты поглощения физически осмысленны (неотрицательны).
- L2-регуляризация: Уменьшает величину цветовых векторов, способствуя низкоранговому свойству $S$ и предотвращая чрезмерно доминирующий спектральный вклад любого отдельного цветового канала.
- Конец итерации: Это завершает одну развернутую итерацию. Уточненные $x_0^{(k)}, S^{(k)}, D^{(k)}$ теперь готовы к следующей итерации или, если $K$ итераций завершены, к финальному выводу.
- Вывод и последующая интеграция: После $K$ итераций извлекается окончательная матрица $D$, представляющая структурную информацию, инвариантную к окраске. Эта матрица $P \times r$ затем преобразуется в изображение с $r$ каналами (где каждый канал соответствует пространственному распределению одного компонента окраски). Это $r$-канальное изображение затем пропускается через сверточный слой $1 \times 1$ для преобразования обратно в 3-канальное изображение, которое затем может быть беспрепятственно интегрировано в любую базовую сеть глубокого обучения (например, YOLO или ResNet) для последующих задач, таких как обнаружение объектов или классификация.
Обзор нашего подхода показан на рис. 1, а полные детали нашего метода приведены в Алгоритме 1.
Динамика оптимизации
Механизм, с помощью которого BeerLaNet "обучается" и сходится, заключается в развернутом итеративном проксимальном градиентном спуске, который затем обучается сквозным образом.
- Итеративный проксимальный градиентный спуск: Основная стратегия оптимизации итеративна. Она решает невыпуклую целевую функцию, попеременно оптимизируя один набор параметров ($x_0$, затем $D$, затем $S$), сохраняя остальные фиксированными. Для каждой переменной она сочетает стандартный шаг градиентного спуска (для минимизации гладкого члена точности данных) с проксимальным оператором (для обработки негладких членов регуляризации и ограничений неотрицательности). Это итеративное уточнение помогает модели ориентироваться в сложном ландшафте потерь.
- Невыпуклый ландшафт потерь: Присутствие произведения $SD^T$ делает целевую функцию невыпуклой. Это означает, что ландшафт потерь не является простой чашеобразной формой; он может иметь несколько "долин" или локальных минимумов. Хотя итеративный проксимальный градиентный спуск эффективен, он не гарантирует нахождение абсолютно лучшего (глобального) минимума. Однако на практике он часто находит хорошие решения.
- Градиенты и обновления: Во время фаз градиентного спуска для $D$ и $S$ алгоритм вычисляет градиенты члена точности данных. Эти градиенты указывают направление, в котором ошибка реконструкции наиболее резко возрастает. Затем алгоритм делает шаг в противоположном направлении, итеративно уменьшая эту ошибку. Динамические размеры шага ($\tau_D, \tau_S$) имеют решающее значение; они адаптируются к локальной кривизне ландшафта потерь, позволяя делать большие шаги, когда ландшафт плоский, и меньшие шаги, когда он крутой, способствуя более быстрому и стабильному сближению.
- Роль проксимальных операторов: Проксимальные операторы жизненно важны для формирования решения. Для $D$ L1-норма стимулирует разреженность, эффективно устанавливая малые концентрации красителей в ноль, что упрощает карту окраски. Для обоих $S$ и $D$ L2-нормы и ограничения неотрицательности гарантируют, что выученные профили красителей и концентрации физически осмысленны и ведут себя хорошо, предотвращая нереалистичные значения или переобучение.
- Обучаемые параметры и сквозное обучение: Ключевой инновацией BeerLaNet является то, что некоторые критические гиперпараметры оптимизации (такие как $\lambda$, $\gamma$ и начальная $S_{init}$) становятся обучаемыми. Вместо ручной настройки этих параметров весь процесс развернутой оптимизации встраивается в архитектуру нейронной сети. Затем потери от конечной последующей задачи (например, точность обнаружения объектов) обратно распространяются через все $K$ развернутых слоев. Это означает, что градиенты проходят полностью назад для обновления не только весов последующей базовой сети, но и параметров регуляризации и начальных оценок окраски в BeerLaNet. Это сквозное обучение позволяет модулю BeerLaNet адаптировать свой внутренний процесс нормализации окраски для прямой оптимизации производительности конечной задачи, делая его высокоадаптивным и надежным.
- Поведение сходимости: С каждой развернутой итерацией оценки $x_0, S, D$ постепенно уточняются. Количество развернутых итераций, $K$, действует как глубина модуля BeerLaNet. Обратное распространение через эти развернутые слои направляет итеративный процесс к решению, которое не только оптимально для цели NMF, но и специально для конечной цели последующей задачи, что приводит к улучшенной обобщаемости на различных доменах окраски.
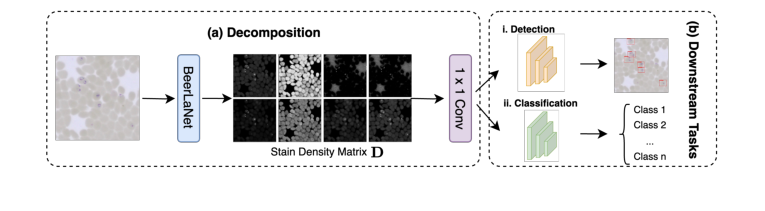 Figure 1. Overview of our proposed BeerLaNet method
Figure 1. Overview of our proposed BeerLaNet method
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки способности BeerLaNet обеспечивать адаптивную нормализацию окраски и улучшать кросс-доменную обобщаемость авторы разработали комплексную экспериментальную установку для двух основных диагностических задач: обнаружение объектов и классификация изображений. Они противопоставили BeerLaNet набору установленных базовых моделей, как классических, так и основанных на глубоком обучении, на различных наборах данных патологии.
Для обнаружения объектов оценка была сосредоточена на обнаружении паразитов малярии и клеток крови. Задача обнаружения паразитов малярии использовала общедоступный набор данных [5], состоящий из 24 720 изображений тонких мазков, окрашенных по методу May Grunwald-Giemsa (MGG), с аннотациями для лейкоцитов, эритроцитов, тромбоцитов и различных видов паразитов. Для оценки использовался отдельный, внутренне собранный тестовый набор из 264 изображений тонких мазков с микроскопа Zeiss Axioscan. Для обнаружения клеток крови использовались два общедоступных набора данных: BCCD [17] для обучения (366 изображений) и BCDD [1] для тестирования (100 изображений). BeerLaNet был интегрирован с базовой моделью YOLOv8 [9] для этих задач.
Для классификации изображений были решены две различные задачи: классификация паразитов малярии и классификация рака молочной железы. Набор данных для классификации малярии представлял собой разнообразную коллекцию с четырех платформ микроскопии (Hamamatsu NanoZoomer, Zeiss Axioscan, Olympus CX43, Morphle Hemolens), включающую тонкие мазки крови, окрашенные по методу Гимзы. Он включал обучающий набор из 2 486 обрезанных изображений отдельных клеток и два тестовых набора (343 и 261 образец) с различных платформ визуализации, предназначенных для оценки обобщаемости между доменами. Задача заключалась в классификации обнаруженных паразитов по стадиям жизненного цикла. Для классификации рака молочной железы использовался набор данных Camelyon17-WILDS [2], состоящий из участков изображений размером 96x96 пикселей из целых гистологических изображений лимфатических узлов с метками наличия опухоли. Этот набор данных охватывал пять больниц, что неизбежно приводило к значительным сдвигам домена. BeerLaNet был интегрирован с базовой моделью ResNet-18 [8] для задач классификации.
"Жертвы" (базовые модели), с которыми сравнивался BeerLaNet, включали три классических метода нормализации гистологии: Reinhard [13], Macenko [11] и Vahadane [18]. Кроме того, были включены два метода на основе глубокого обучения, StainGAN [16] и LStainNorm [10]. Для базовых моделей, требующих шаблонного изображения для нормализации, одно изображение было случайным образом выбрано из обучающего набора данных.
Ключевые детали реализации BeerLaNet включали установку количества цветовых компонентов ($r$) равным 8, а количество внутренних развернутых итераций ($K$) — 10. Параметры обучения варьировались в зависимости от задачи, с размерами пакетов 8 (обнаружение) или 128 (классификация) и скоростями обучения 0.01 или 1e-4. Примечательно, что для набора данных классификации малярии использовался двухэтапный конвейер шумоподавления (медианный и гауссовский фильтры) для смягчения артефактов сжатия. Все экспериментальные результаты усреднялись по трем случайным начальным значениям для обеспечения надежности.
Метрики оценки были выбраны для отражения специфических требований задачи: mAP50 и mAP50-95 для обнаружения и Accuracy (Acc) для классификации. Специализированная Relaxed Accuracy (RAcc) была введена для классификации паразитов малярии, рассматривая предсказания как успешные, если они находились в пределах одной стадии жизненного цикла от истинного значения, признавая непрерывный характер роста паразитов. Для предоставления окончательной, неоспоримой меры последовательной производительности по всем задачам и наборам данных авторы ввели метрику Average Percent Underperformance (APU). Эта метрика количественно оценивает среднее процентное различие между производительностью метода и лучшей производительностью для каждой комбинации задачи-метрики, предоставляя целостное представление об обобщаемости.
изображения, демонстрирующие вариативность домена между обучающими и тестовыми данными, показаны на рис. 2.
Что доказывают доказательства
Экспериментальные доказательства, обобщенные в Таблице 1, убедительно доказывают, что основной механизм BeerLaNet — физически обоснованное, обучаемое разделение окраски посредством развертывания алгоритма — эффективно работает на практике и обеспечивает превосходную кросс-доменную обобщаемость по сравнению с базовыми моделями.
BeerLaNet достиг лучшей производительности как в обнаружении паразитов малярии (mAP50 95,07% и mAP50-95 57,10%), так и в классификации паразитов малярии (Acc 48,66% и RAcc 90,33%). Он также занял второе место по производительности в обнаружении клеток крови (mAP50 86,80% и mAP50-95 51,33%). Хотя он не всегда был абсолютным лидером по каждой отдельной метрике (например, Macenko достиг немного более высокой точности на C17test), окончательное доказательство превосходства BeerLaNet заключается в его последовательной и надежной производительности во всех разнообразных задачах и наборах данных, количественно оцененной метрикой Average Percent Underperformance (APU).
BeerLaNet значительно превзошел все сравниваемые методы по APU, достигнув 2,00 для задач обнаружения и 1,86 для задач классификации. Это критически важные доказательства. Например, Macenko, достигнув лучшей точности на наборе данных Camelyon-17 WILDS C17test (95,92%), испытал существенное падение более чем на 10 процентных пунктов на наборе данных C17val (85,77%). Аналогичные значительные падения производительности наблюдались практически у всех других базовых методов на различных задачах или наборах данных. Эта непоследовательность подчеркивает их уязвимость к сдвигам домена.
Базовые модели, особенно те, что имели общий дизайн или полагались на фиксированные шаблоны, испытывали трудности с обобщением при столкновении с большими цветовыми вариациями, такими как присутствующие в наборе данных малярии (как визуально предполагается на рис. 2). Их производительность часто была высокой на наборах данных с относительно незначительными цветовыми сдвигами (например, Camelyon17-WILDS или клетки крови), но резко падала в более сложных условиях. В отличие от этого, BeerLaNet поддерживал очень конкурентоспособную производительность, даже когда не был абсолютным лидером, демонстрируя свою способность адаптироваться к широкому диапазону условий окрашивания и визуализации без предварительных знаний или выбора шаблона. Эта последовательная, высокоуровневая производительность, безжалостно раскрытая метрикой APU, является неоспоримым доказательством того, что физически обоснованный, сквозным образом обучаемый подход BeerLaNet эффективно разделяет структурную информацию, инвариантную к окраске, что приводит к надежной кросс-доменной обобщаемости в медицинской гистологии.
Ограничения и будущие направления
Хотя BeerLaNet демонстрирует замечательную надежность и последовательную производительность в различных задачах медицинской гистологии, важно признать его присущие ограничения и рассмотреть направления для будущего развития.
Одно тонкое ограничение, как отмечают авторы, заключается в том, что BeerLaNet не всегда является абсолютно лучшим методом для каждого отдельного конкретного набора данных или метрики. Например, Macenko достиг немного более высокой точности на наборе данных Camelyon-17 WILDS C17test. Хотя сила BeerLaNet заключается в его последовательной высокой производительности в целом (что подтверждается его превосходным APU), это предполагает, что все еще существует пространство для специализированной оптимизации, которая могла бы еще больше повысить его производительность на конкретных, менее сложных сдвигах домена. В статье также не детализируется явным образом вычислительная нагрузка развернутой сетевой архитектуры по сравнению с более простыми базовыми моделями, что может быть практическим соображением для чрезвычайно больших целых гистологических изображений или приложений реального времени.
Заглядывая вперед, авторы предлагают изучить применение BeerLaNet к дополнительным последующим задачам, таким как сегментация и другие гистопатологические домены. Это естественное расширение, учитывая его дизайн "подключи и работай".
Помимо этого, возникает несколько тем для обсуждения для дальнейшего развития и эволюции этих выводов:
- Обобщаемость на новые красители и модальности визуализации: Статья подчеркивает способность BeerLaNet обрабатывать "произвольные протоколы окрашивания". Насколько хорошо он будет работать на совершенно новых красителях или модальностях визуализации (например, флуоресцентная микроскопия, масс-спектрометрическая визуализация), которые значительно отличаются от окрасок H&E или Гимзы, в основном используемых в экспериментах? Будущая работа могла бы включать строгие испытания на более широком спектре невиданных ранее типов окрашивания, чтобы действительно подтвердить его "адаптивное" утверждение.
- Интерпретируемость и клиническая полезность разделенных компонентов: BeerLaNet извлекает структурную информацию, инвариантную к окраске (матрица D). Может ли это разделенное представление быть непосредственно интерпретировано патологами или использовано для количественного анализа, помимо улучшения производительности последующих задач? Разработка инструментов для визуализации и количественной оценки этих компонентов может предоставить новые диагностические сведения и повысить доверие к патологии, управляемой ИИ.
- Динамическая адаптация гиперпараметров: Количество цветовых компонентов ($r$) и развернутых итераций ($K$) устанавливаются как фиксированные гиперпараметры. Могут ли они быть динамически адаптированы на основе характеристик входного изображения или сложности протокола окрашивания? Адаптивный механизм мог бы далее оптимизировать производительность и снизить потребность в ручной настройке.
- Интеграция с мультимодальными данными: Гистопатология часто включает интеграцию информации из различных источников (например, молекулярные данные, история болезни). Как нормализация окраски BeerLaNet может быть объединена с фреймворками мультимодального обучения для предоставления более полной диагностической картины?
- Надежность к деградации качества изображения: Хотя вариабельность окраски устранена, реальные патологические изображения могут страдать от других деградаций, таких как не в фокусе области, пыль или артефакты сжатия (частично решены для классификации малярии). Может ли фреймворк физически обоснованного развертывания быть расширен для совместной нормализации окрасок и коррекции других распространенных проблем качества изображения?
- Этические соображения и предотвращение артефактов: В медицинской диагностике введение синтетических артефактов или "галлюцинация" клеточных структур является критической проблемой, как отмечалось для некоторых методов на основе GAN. Хотя BeerLaNet стремится избежать этого, необходима непрерывная проверка и, возможно, даже формальные процессы сертификации, чтобы гарантировать, что процесс нормализации никогда непреднамеренно не замаскирует или не изменит диагностически релевантные признаки, даже если общая точность повысится.
- Вычислительная эффективность для целых гистологических изображений: Обработка гигапиксельных целых гистологических изображений (WSI) требует значительных вычислительных ресурсов. Хотя BeerLaNet обучается сквозным образом, его развернутый механизм NMF все еще может быть ресурсоемким. Будущие исследования могли бы сосредоточиться на оптимизации его вычислительной эффективности, возможно, посредством более легких развернутых архитектур или эффективных аппаратных реализаций, чтобы обеспечить анализ WSI в реальном времени.
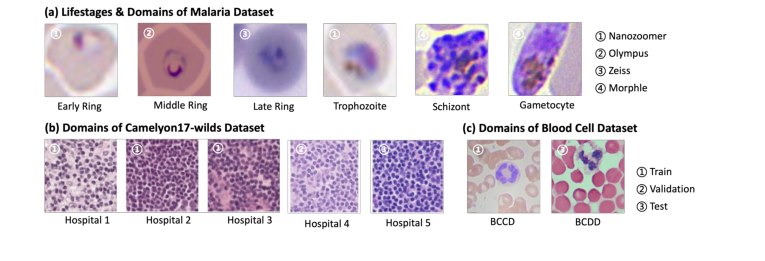 Figure 2. Example images from our tested datasets
Figure 2. Example images from our tested datasets
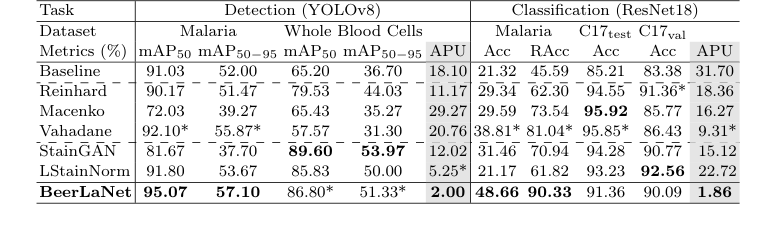 Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
Связи с другими областями
Математический каркас
Чисто математическим ядром данной работы является структурированная задача неотрицательного матричного разложения (NMF) с комбинированными регуляризациями $l_1$ и $l_2$, которая решается с использованием развернутого итеративного проксимального градиентного спуска. Этот фреймворк направлен на разложение входной матрицы на две неотрицательные факторные матрицы, способствуя разреженности и свойствам низкого ранга в факторах.
Смежные области исследований
Неотрицательное матричное разложение (NMF)
Основа модели BeerLaNet лежит в неотрицательном матричном разложении, широко используемом методе для снижения размерности и извлечения признаков в различных областях. В частности, целевая функция в уравнении 4, которая стремится минимизировать $||x_0\mathbf{1}^T - X - SD^T||_F^2$ при условии $S, D \ge 0$ и дополнительных регуляризаций, является прямой вариацией задачи NMF. Здесь логарифмически преобразованные данные изображения разлагаются на матрицу цветовых профилей красителей $S$ и матрицу оптической плотности $D$. Эта математическая структура, где матрица аппроксимируется произведением двух неотрицательных матриц, является центральной для приложений, таких как тематическое моделирование в обработке текстов, спектральное разделение в гиперспектральной визуализации и разделение источников в обработке звука. Например, в спектральном разделении NMF используется для разложения спектра смешанного пикселя на набор спектров чистых материалов (конечных членов) и их соответствующих обилий, что очень похоже на разделение цветов красителей и их плотностей в гистологических изображениях. Фундаментальной работой в области NMF является работа Ли и Синга (1999, Nature), поистине новаторская статья.
Развертывание алгоритма / Глубокое развертывание
Метод использует развертывание алгоритма, также известное как глубокое развертывание, для преобразования итеративного процесса оптимизации для структурированной задачи NMF в обучаемую архитектуру глубокой нейронной сети. Шаги итеративного проксимального градиентного спуска, описанные в Алгоритме 1, которые обновляют $x_0$, $D$ и $S$ путем выполнения шагов градиента и применения проксимальных операторов для ограничений регуляризации и неотрицательности, непосредственно развертываются в фиксированное количество слоев сети. Этот подход позволяет сквозное обучение параметров, таких как силы регуляризации ($\gamma, \lambda$) и инициализации ($S_{init}$), посредством обратного распространения, используя преимущества глубокого обучения при сохранении интерпретируемости и теоретических гарантий базового алгоритма оптимизации. Этот метод нашел успех в различных задачах обработки сигналов и обратных задач, таких как разреженное кодирование, реконструкция сжатого зондирования и восстановление изображений, где итеративные алгоритмы преобразуются в эффективные, обучаемые глубокие модели (например, Gregor & LeCun, 2010, ICML), очень умная идея.