クロスドメイン医療組織学のための適応的染色正規化
Deep learning advances have revolutionized automated digital pathology analysis.
背景と学術的系譜
起源と学術的系譜
本論文で取り組む問題は、疾患診断における病理学的検査の極めて重要な役割に端を発する。この検査は伝統的に、デジタル病理画像の手動評価に依存してきた。手動レビューは組織形態学や細胞異常に関する重要な洞察を提供する一方で、本質的に労働集約的であり、時間を要し、観察者間でのばらつきが生じやすいという欠点がある[20, 19]。深層学習の登場は、この分析を自動化するための有望な道を開いたが、すぐに大きな障害に直面した。それはデジタル病理画像における色の不一致である。
この色のばらつきは、モデルの汎化性にとって主要な課題であり、いくつかの要因に起因する。(i) 染色プロセス中の色素の化学反応や露光時間の違い、(ii) サンプル調製におけるばらつき、(iii) 異なるスキャンハードウェア間での多様な画像取得条件[15]。経験豊富な病理医はこれらのばらつきを直感的に補正できるが、深層学習モデルはこのような「ドメインシフト」に非常に敏感であり、学習データとは異なる条件下で取得されたデータに適用された場合、性能の大幅な低下と汎化性の悪化を招く[3]。この「ペインポイント」は、学術分野、特に医学病理学において、多様なデータセット間で一貫した画像外観を保証するための染色色正規化戦略を開発することを余儀なくさせた。
染色正規化に対するこれまでのアプローチは、これらの問題を軽減しようと試みたものの、いくつかの根本的な限界に悩まされていた。従来のメソッドは、しばしば学習ドメインから「テンプレート」画像を慎重に選択し、色の統計を一致させる必要があったが、これは事前の知識を要求し、アーティファクトを導入する可能性があった。Beer-Lambert則や非負値行列因子分解(NMF)などを活用する物理ベースのメソッドは、画像形成プロセスの根底にあるものを考慮することで改善をもたらした。しかし、それらは依然として定義済みのテンプレートに依存するか、特定の色素の吸収スペクトル行列や、明確な色成分の正確な数のような追加の事前知識を必要とした[18]。さらに、一部のNMFベースのメソッドにおける主成分分析(PCA)の使用には欠点があった。PCAは直交成分を仮定するが、これは染色成分にとって常に現実的とは限らないからである。生成敵対ネットワーク(GANs)のような、より最近の深層学習ベースのメソッドは、色の分布を整列させることができたが、しばしば合成アーティファクトや「幻覚」した細胞構造を導入し、医学的診断においてリスクをもたらした[12]。他の深層学習技術は、しばしばあまりにも一般的であり、組織学的な染色の特定の物理学を考慮できなかった[10]。本論文の著者らは、学習可能で、物理学に基づき、テンプレートフリーなソリューションを提案することで、これらの限界を克服しようと試みた。このソリューションは、染色情報を適応的に分離することを可能にする。
直感的なドメイン用語
- ドメインシフト (Domain Shift): 赤いボールを認識するように犬を訓練したと想像してほしい。もしその後、青いボールを見せると、犬は混乱するかもしれない。なぜなら「ドメイン」(ボールの色)がシフトしたからである。デジタル病理学においては、これは、ある研究所(特定の染色と画像取得条件を持つ)の画像で訓練された深層学習モデルが、わずかに異なる条件を持つ別の研究所の画像では性能が低下する可能性があることを意味する。
- 染色正規化 (Stain Normalization): すべての写真を、異なる照明下で撮影されたものであっても、同じ一貫した外観になるようにする写真フィルターを使用するようなものだと考えてほしい。組織学においては、これは組織スライドの色を調整するプロセスであり、それらがすべて全く同じプロトコルで染色されたかのように見えるようにし、自動分析のために比較可能にする。
- Beer-Lambert則 (Beer-Lambert Law): これは光学の基本的な規則であり、サングラスの仕組みのようなものである。それは、材料の厚さと、光を吸収する物質(染色)の量に基づいて、材料をどれだけ光が通過するかを教えてくれる。これは、染色が組織にその特徴的な色を与える仕組みを理解する上で重要である。
- 非負値行列因子分解 (Nonnegative Matrix Factorization, NMF): 果物のサラダを思い浮かべてほしい。そのサラダに使われた果物とそれぞれの量を正確に知りたいが、どの果物も「負の量」では存在しないことを知っている。NMFは、複雑な画像(染色された組織スライドのようなもの)を、個々の染色とその各ピクセルにおける濃度のような、基本的な非負の成分に分解する数学的手法である。
- アルゴリズムのアンローリング (Algorithmic Unrolling): 画像が鮮明になるまで望遠鏡の焦点を繰り返し調整するような、複雑な反復計算を考えてほしい。「アンローリング」とは、その反復プロセスの各ステップを取り出し、それをニューラルネットワーク内の個別の層に変換することを意味する。これにより、調整のシーケンス全体が、固定された別個のプロセスではなく、エンドツーエンドで学習および最適化されることが可能になる。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
中心的な問題定式化とジレンマ
本論文が取り組む中心的な問題は、デジタル病理画像における固有の色変動に起因するものであり、これは医療診断における深層学習モデルの信頼性と汎化可能性にとって極めて重要な課題である。
入力/現状: 入力はデジタル病理画像であり、$X \in \mathbb{R}^{c \times p}$として表現される。ここで、$c$は色強度(通常RGBでは3)の数、$p$はピクセル数である。この画像$X$は、染色プロトコルの違い、化学反応、色素曝露時間、検体調製法のばらつき、および異なるスキャンハードウェア間での多様な撮像条件など、様々な要因により著しい色の不一致を示す。この色の不一致は「ドメインシフト」を引き起こし、ある条件のデータで学習された深層学習モデルは、別の条件のデータに適用された際に性能が低下することを意味する。
望ましい終点/目標状態: 望ましい出力は、「染色正規化」された画像、あるいはより正確には、入力画像から派生した「染色不変の構造情報」表現である。この正規化された表現は、色のばらつきを効果的に除去しつつ、基盤となる組織形態学および細胞異常を保持すべきである。最終的な目標は、このロバストで染色不変な表現を、物体検出や画像分類などの下流の深層学習タスクに供給し、これらのモデルが異なるドメイン間で効果的に汎化し、元の画像の染色外観に関わらず一貫した高い性能を達成できるようにすることである。
欠落しているリンク/数学的ギャップ: 正確な欠落リンクは、画像から染色情報を構造的コンテンツと数学的に分離するための、ロバストで適応的かつ物理学に基づいた手法である。Beer-Lambert則に着想を得た先行研究では、画像強度$X$を、入射光$x_0$、色外観行列$S$、および光学密度行列$D$の関数としてモデル化している。
$$X = (x_0 \mathbf{1}^T) \odot e^{-SD^T}$$
ここで、$\mathbf{1}$は全ての要素が1のベクトルであり、$\odot$は要素ごとの行列積を示す。数学的なギャップは、与えられた入力画像$X$から、$x_0$、$S$、$D$を以下の点で信頼性高く推定することにある。
1. 適応性: 染色プロトコルやテンプレート画像の事前知識を必要としない。
2. 物理学に基づいている: 色スペクトルおよび光学密度の非負性を尊重する。
3. 学習可能: 深層学習アーキテクチャとエンドツーエンドで統合できる。
4. 構造を保持する: 合成アーティファクトの導入を避ける。
本論文は、しばしば非凸であり慎重なパラメータ調整を必要とする既存の非負行列分解(NMF)モデルを、学習可能なアンロールネットワークアーキテクチャに洗練させることで、このギャップを埋めることを目指す。
ジレンマ: 先行研究者たちは、いくつかの苦痛なトレードオフに囚われてきた。
* テンプレート依存性 vs. 適応性: 多くの既存の染色正規化手法は、「テンプレート画像」に大きく依存するか、a priori知識(例:特定の色素の吸収スペクトル、色成分の数)を必要とする。これらの手法は、特定の明確に定義されたドメインでは効果的である可能性があるが、手動介入や慎重なテンプレート選択なしには新しいまたは任意の染色プロトコルに適応できず、汎化可能性を著しく制限する。
* 物理学に基づいた精度 vs. アーティファクト生成: 染色の物理学(Beer-Lambert則やNMFに基づくものなど)に厳密に従う手法は、しばしばヒューリスティクス(例:$S$および$D$のための主成分分析)を採用するが、これは染色成分にとって非現実的な直交性を要求するなど、欠陥を導入する。逆に、敵対的生成ネットワーク(GAN)のようなより汎用的な深層学習アプローチは、色分布を整合させることができるが、「幻覚」のような細胞構造や合成アーティファクトの導入を起こしやすく、医療診断においては許容できず危険である。
* 固定パラメータ vs. 学習可能性: より初期のNMFモデル(例:式3)は、スパース正則化強度$\lambda$やランク$r$(色成分の数)のようなパラメータの手動調整を必要とする。この手動調整は、色成分の数が不明な場合に特に困難であり、パラメータが自動的に学習されるエンドツーエンドの深層学習パイプラインへのシームレスな統合を妨げる。
制約と失敗モード
適応的な染色正規化の問題は、著者らが直面するいくつかの厳しい現実的な壁により、極めて困難である。
-
物理的制約:
- Beer-Lambert則の遵守: 効果的なモデルは、染色による光減衰の物理プロセスを正確に表現しなければならない。これは、光吸収の乗法的な性質と、染色濃度および吸収特性への分解を尊重することを意味する。
- 非負性: 色スペクトル($S$)と光学密度($D$)の両方は、物理的に非負の量である。この制約を課すことは、意味のある分解にとって重要であるが、最適化問題に複雑さを加える。
- 染色不変情報: 中核的な課題は、染色外観から真に独立した構造情報を抽出することである。これは、生の画像におけるそれらの絡み合った性質を考慮すると、色情報と形態学的詳細のロバストな分離を必要とし、容易ではない。
-
計算的制約:
- 非凸最適化: 基盤となるNMF問題、特に$SD^T$行列積を含むものは非凸である。これは、標準的な最適化アルゴリズムが局所的最小値に陥る可能性があり、大域的に最適な解を見つけることを困難にする。
- エンドツーエンド学習可能性: 最新の深層学習モデルとの実用的な展開のためには、染色正規化プロセスは微分可能であり、エンドツーエンドで学習可能でなければならない。多くの従来のメソッドは、非微分可能なステップやヒューリスティクスを含み、深層学習フレームワークへのシームレスな統合を妨げる。
- 計算効率: 臨床応用のため、大規模な全スライド画像をリアルタイムまたはそれに近い速度で処理するには、計算効率の高いアルゴリズムが要求される。複雑な反復最適化手順は、実行不可能に遅くなる可能性がある。
-
データ駆動型制約:
- 極端なドメインシフト: デジタル病理データセットは、異なるラボやスキャナー間だけでなく、同じラボ内でも時間とともに著しい色のばらつきを示す。この「ドメインシフト」は、深層学習モデルの失敗の主な原因であり、大規模で予測不可能な変動を処理できる正規化手法を必要とする。
- 事前知識の欠如: 多くの実世界のシナリオでは、特定の染色プロトコル、色素吸収スペクトル、または検体中の色成分の正確な数に関する詳細なa priori知識が入手できない。ロバストな手法は、そのような明示的な入力なしで効果的に動作しなければならない。
- アーティファクト回避: 一般的な画像スタイル変換とは異なり、医療画像解析は、正規化中に「合成アーティファクト」または「幻覚」した構造の導入を許容できない。そのような歪みは誤診につながる可能性があり、構造の保持を最優先の制約とする。
-
先行アプローチの失敗モード(新しいソリューションの制約となるもの):
- テンプレートによるバイアス: 固定テンプレート画像に依存することは、選択されたテンプレートがすべてのターゲットドメインを代表していない可能性があるため、バイアスを導入し適応性を制限する可能性がある。
- パラメータ感度: 先行するNMFモデルは、正則化パラメータと成分数($r$)の慎重な手動選択を必要としたが、これはしばしば試行錯誤のプロセスであり、正しく選択されない場合に最適でない結果につながる可能性がある。
- 直交性仮定: 一部の先行研究で使用されたPCAのような手法は、染色成分を推定するために直交性制約を課すが、これは生物学的染色にとって物理的に現実的ではなく、不正確な分解につながる。
- 順列曖昧性: $S$および$D$の分解は、列が入れ替わる可能性のある順列曖昧性に悩まされる可能性があり、正しく処理されない場合は「著しい色の歪み」につながる。
このアプローチの理由
選択の必然性
BeerLaNetの開発は、デジタル病理学の複雑な現実と対峙した際の既存の染色正規化手法の、明白かつ根強い欠点によって推進された。本論文で強調されている中心的な問題は、染色プロトコルや画像取得条件の違いによる著しい色のばらつきに起因する「ドメインシフト」である。このばらつきは、深層学習モデルの性能を著しく低下させ、その汎化能力を妨げる。
統計的マッチングや色空間分解(例:Reinhard, Macenko, Vahadane)に依存する従来の染色正規化技術は、主に「適切な代表的テンプレート」や「ドメインに関する事前知識」に大きく依存するため、不十分であることが判明した。これには、特定の染料吸収スペクトルや、あらかじめ定義された色成分の数が要求されることがしばしば含まれる。このような依存性は、テンプレートが不適切に選択された場合や、未知の染色プロトコルに直面した場合に、これらの手法を脆弱にし、「著しい色の歪み」を引き起こしやすくする。著者らは、このような明示的な事前知識や、テンプレートおよびパラメータの慎重な手動選択を必要とする手法は、真に適応的で堅牢なシステムにとって唯一の実行可能な解決策ではあり得ないことを認識した。
スタイル変換のための敵対的生成ネットワーク(GANs)のような深層学習ベースの代替手法(例:StainGAN)も、決定的な欠点を呈していた。色の分布を整列させる能力はあるものの、GANsはしばしば「合成アーティファクトや細胞構造の『幻覚』を導入する」ことがあり、形態への忠実性が最重要視される医療診断においては、許容できないリスクをもたらす。注意機構を用いた他の深層学習手法は、「概して汎用的」と見なされ、画像形成の根底にある物理学を考慮しておらず、その堅牢性と解釈可能性を制限していた。
著者らがこれらのSOTA手法の不十分さを認識した正確な瞬間は、既存の物理学に基づいた行列分解モデルが、概念的には妥当であるにもかかわらず、実用上の限界に苦しんでいることを観察した時であった。具体的には、式(3)のスパース非負行列分解(NMF)モデルは非凸であり、色成分の数($r$)をa prioriで指定する必要があったが、この数が未知の場合(例:検体にヘモグロビンなどの追加の色成分が含まれる場合)には困難な課題となる。さらに、以前の物理学ベースのモデルにおける主成分分析(PCA)の使用は、列の直交性を仮定するため問題があったが、これは染色分離においては非現実的である。テンプレートへの依存性、アーティファクトの生成、物理学に基づいた適応性の欠如、固定パラメータ要件といったこれらの問題の収束は、根本的に新しい統合的アプローチが必要であることを明確にした。
比較優位性
BeerLaNetは、単なる性能指標を超えたいくつかの構造的利点により、以前のゴールドスタンダードに対する質的な優位性を達成している。第一に、その適応的染色分離(Adaptive Stain Disentanglement)は、「任意の染色プロトコルに拡張」することを可能にし、「染色プロトコルの事前知識を一切必要とせずに、画像の色素不変表現(stain-invariant representations)を学習」する。これは、テンプレートの品質と代表性に本質的に限定されるテンプレートベースの手法に対する、画期的な利点である。BeerLaNetがテンプレートフリーで、特定の染料や成分の事前知識なしに動作できる能力は、多様な臨床設定において、はるかに堅牢で汎化性の高いものにする。
第二に、この手法は学習可能で物理学に基づいている(Trainable and Physics-Informed)ものであり、非負行列分解(NMF)とアルゴリズム展開(algorithmic unrolling)に基づいている。この組み合わせは、主要な構造的イノベーションである。修正されたNMF定式化(式4)のアルゴリズム展開を通じてモデルアーキテクチャを導出することにより、BeerLaNetは伝統的に非凸な最適化問題を、エンドツーエンドで学習可能な深層ネットワークへと変換する。これにより、以前は固定または経験的に選択されていた正則化パラメータ($\gamma, \lambda$)と初期化($S_{init}$)の学習可能な適応が可能になる。Beer-Lambert則に根ざしたこのデータ駆動型の学習は、染色分解プロセスが物理的に正確かつ高度に適応的であることを保証し、画像形成の根底にある物理学を無視する汎用的な色変換の落とし穴を回避する。
修正されたNMF定式化(4)への追加の$l_2$正則化の組み込みは、もう一つの構造的利点である。この正則化は低ランク解を促進し、モデルが色成分の数($r$)を予想よりも大きく初期化し、その後、解のランクをデータに適合させることを可能にする。これは、a prioriでの$r$の指定の問題をエレガントに解決し、モデルを標本組成の変動に対してより柔軟で堅牢にする。
最後に、BeerLaNetの柔軟な統合(Flexible Integration)は、プラグアンドプレイモジュールとして機能するため、下流タスクのための任意のバックボーンネットワークとシームレスに組み合わせることができる。このアーキテクチャ設計により、染色正規化は独立した前処理ステップではなく、深層学習パイプライン全体の不可欠で学習可能な一部となり、最終タスク(例:物体検出または分類)に特化して正規化を最適化する。このエンドツーエンドの学習可能性は、孤立して動作し、下流タスクからのフィードバックに基づいて正規化プロセスを適応させることができない手法に対する、重要な構造的利点である。
制約への整合性
BeerLaNetの設計は、医療組織学における染色正規化の厳しい要件と完全に整合しており、問題と解決策の間に強力な「結婚」を形成している。
-
制約:色の不整合とドメインシフトの克服:主な目標は、染色および画像取得条件の変動にわたる汎化である。BeerLaNetは、「適応的染色分離」を通じてこれを解決し、「染色プロトコルの事前知識を必要とせずに、色素不変表現」を学習する。これは、色のばらつきに依存しない根底にある生物学的情報を抽出することにより、ドメインシフトの根本原因に直接対処する。
-
制約:アーティファクトと幻覚の回避:医療診断に不可欠である。BeerLaNetは「物理学に基づいている」ことでこれを達成する。Beer-Lambert則に基づいていることは、染色分解が実際の光と組織の相互作用に基づいていることを保証し、変換を物理的に妥当にし、純粋にデータ駆動型の汎用深層学習モデル(GANsなど)と比較して合成アーティファクトを導入する可能性を低くする。
-
制約:テンプレート依存性と事前知識の排除:従来の多くの手法は、特定のテンプレートやa priori知識(例:吸収スペクトル、成分数)を必要とすることに苦労していた。BeerLaNetの「学習可能で物理学に基づいた」性質は、アルゴリズム展開と組み合わさることで、データからこれらのパラメータを学習することを可能にする。$l_2$正則化は、モデルが成分数($r$)をデータに適合させることを可能にし、手動指定の必要性をなくす。これにより、この手法は完全にテンプレートフリーで、明示的な事前知識に依存しないものとなる。
-
制約:多様な染色プロトコルのサポート:以前の手法の多くは、主にH&E染色に焦点を当てていた。BeerLaNetは、病理学で使用される多種多様な染色に対して、より普遍的に適用可能なソリューションとして、明示的に「任意の染色プロトコルに拡張」する。
-
制約:下流タスクとのシームレスな統合:解決策は、実際の診断パイプラインにとって実用的でなければならない。BeerLaNetは、「物体検出や分類などの下流タスクのための任意のバックボーンネットワーク」と組み合わせることができる「プラグアンドプレイ」コンポーネントとして、「柔軟な統合」モジュールとして設計されている。これにより、正規化プロセスが最終診断タスクの文脈で最適化され、システム全体のパフォーマンスが向上することが保証される。
代替案の却下
本論文は、伝統的および深層学習ベースの両方の代替アプローチを却下する明確な理由を提供している。
従来の技術(例:Reinhard, Macenko, Vahadane):これらの手法は、主にテンプレート画像と事前知識への固有の依存性により却下された。述べられているように、それらは「適切な代表的テンプレートの選択に強く依存」し、「特定の染料の吸収スペクトル行列や、異なる色成分の数などのドメインに関する事前知識を必要とする場合がある」。この依存性はそれらを脆弱にし、テンプレートが代表的でない場合や事前知識が不正確な場合、これらの手法は「著しい色の歪み」につながる可能性がある。さらに、それらはしばしば正則化強度($\lambda$)や行列分解のランク($r$)のようなパラメータの手動選択を必要とする。表1の実験結果は、これらの手法が、マラリアデータセットのようなドメイン変動が大きいデータセットでしばしば「性能の大幅な低下」を示すことを示しており、汎化能力の低さを示唆していることから、この却下を定量的に支持している。
深層学習ベースの手法(例:StainGAN, LStainNorm):
* GANs(例:StainGAN):医療用途における決定的な欠点である、「しばしば合成アーティファクトを導入したり、細胞構造を『幻覚』したりする可能性があり、医療診断にリスクをもたらす[12]」ために却下された。診断精度と生物学的現実への忠実性が最重要視される分野では、画像の一貫性を損なういかなる手法も許容できない。
* 注意機構(例:LStainNorm):「概して汎用的であり、必ずしも関連する画像形成プロセスを考慮しているわけではない[10]」と見なされた。これは、染色に関する根底にある物理学の基盤の欠如を示唆しており、BeerLaNetの物理学に基づいたアプローチと比較して、その堅牢性と解釈可能性を制限する可能性がある。
実験結果はこれらの却下をさらに検証している。本論文は、「染色固有の特性を組み込んでいない汎用的な設計の手法は、小規模なドメインシフトデータ(Camelyon17-WILDS、全血球)では良好な性能を示す可能性があるが、マラリアデータセットで観察される大規模な色のシフトには汎化できない」と述べている。これは、BeerLaNetの一貫した、そして優れた性能と直接対比され、特にドメインシフトが大きいデータセットにおいて、現実世界の困難なシナリオにおける代替案の限界を強調している。
数学的・論理的メカニズム
マスター方程式
BeerLaNetメソッドの中核であり、その染色正規化能力を駆動するものは、スパース非負行列因子分解(NMF)モデルから導出された最適化問題である。このモデル自体は、染料による光の減衰を記述するBeer-Lambert則に基づいている。BeerLaNetが展開し最適化する具体的な目的関数は以下のように与えられる。
$$ \min_{x_0,S,D} \frac{1}{2} ||x_0\mathbf{1}^T - X - SD^T||_F^2 + \lambda \sum_{i=1}^r (||s_i||_2^2 + ||d_i||_1 + ||d_i||_2^2) \text{ s.t. } S,D \ge 0. $$
この方程式は、入力画像を最もよく説明する最適な背景光強度 ($x_0$)、染色カラープロファイル ($S$)、および染色濃度 ($D$) を見つけることを目的とし、同時にスパース性や低ランク解といった望ましい特性を促進する。
用語解説
このマスター方程式を分解し、各構成要素の役割を理解しよう。
-
$X$: これは入力画像行列であり、通常 $C \times P$ のサイズを持つ。ここで、$C$ はカラーチャンネル数(例:RGBの場合は3)、$P$ はピクセル総数である。$X$ の各列は、単一ピクセルのカラー強度を表す。重要なのは、論文の式2にあるBeer-Lambert則の対数形式からの導出を考慮すると、この $X$ は暗黙的に観測された画像強度の要素ごとの対数を表していることである。
- 数学的定義: 入力画像の対数カラー強度を表す $C \times P$ 行列。
- 物理的/論理的役割: モデルが分解しようとする生の観測データである。目標は、この観測画像を背景光と染色の効果の組み合わせとして説明することである。
- 使用理由: 行列分解に適した形式での画像データの直接的な表現であるため。
-
$x_0$: これは入射光強度または背景照明を表す $\mathbb{R}^C$ のベクトルである。
- 数学的定義: $C$次元ベクトル。
- 物理的/論理的役割: Beer-Lambert則の文脈では、$x_0$ は染色組織と相互作用する前の光源の強度をモデル化する。照明条件の変化に対応する。
- 使用理由: Beer-Lambert則の基本的な構成要素であり、モデルが異なる照明シナリオに適応することを可能にするため。
-
$\mathbf{1}^T$: これはすべての要素が1である行ベクトルで、次元は $1 \times P$ である。
- 数学的定義: 全ての要素が1である $1 \times P$ 行列。
- 物理的/論理的役割: $x_0$ と乗算されると、背景光強度 $x_0$ をすべてのピクセルに効果的にブロードキャストし、各ピクセルが $x_0$ によって照明されていると仮定される行列を作成する。
- 使用理由: 行列演算のために背景光強度をすべてのピクセルに一様に適用するため。
-
$x_0\mathbf{1}^T$: この項は、すべてのピクセルにわたる入射光行列を表す。
- 数学的定義: 各列がベクトル $x_0$ である $C \times P$ 行列。
- 物理的/論理的役割: 染色がない場合に観測されるであろう光を表す、「減衰されていない」光行列である。
- 使用理由: 対数Beer-Lambert則に従い、染色によって引き起こされる減衰を差し引くためのベースラインを形成するため。
-
$S$: これはカラー外観行列で、サイズは $C \times r$ である。ここで、$r$ は着色成分の数である。各列 $s_i \in \mathbb{R}^C$ は、$i$番目の着色成分(例:ヘマトキシリンやエオシンのような特定の染色)のカラースペクトル(吸収特性)を表す。
- 数学的定義: $C \times r$ 行列。
- 物理的/論理的役割: この行列は、各染色のユニークな「指紋」を捉え、異なるカラーチャンネルにわたる光の吸収方法を記述する。異なる染色カラーを分離するために不可欠である。
- 使用理由: 特定の染料に関する事前知識を必要とせずに、データから直接染色のスペクトル特性を学習することをモデルに許可するため。
-
$D$: これは光学密度行列で、サイズは $P \times r$ である。各列 $d_i \in \mathbb{R}^P$ には、各ピクセルにおける $i$番目の着色成分の光学密度(濃度)が含まれる。
- 数学的定義: $P \times r$ 行列。
- 物理的/論理的役割: この行列は、画像全体にわたる各染色成分の空間分布と濃度を表す。これは、BeerLaNetが抽出を目指す「染色に不変な構造情報」であり、その色が独立して、各染色がどこに どれだけ存在するかを記述する。
- 使用理由: Beer-Lambert則のもう一つの中心的な構成要素であり、各ピクセルに存在する各染色の量を示すため。
-
$SD^T$: この行列積は、$C \times P$ のサイズを持ち、すべてのピクセルにわたるすべての染色の総光学密度寄与を、カラー空間に変換して表す。
- 数学的定義: $S$ と $D^T$ の積から得られる $C \times P$ 行列。
- 物理的/論理的役割: 対数Beer-Lambert則において、この項は染色によって引き起こされる総減衰を表す。これはモデル化され、その後正規化のために除去されるべき「染色効果」である。
- 使用理由: 染色カラープロファイル ($S$) がどのように分布 ($D$) されて光減衰を引き起こすかの数学的表現であるため。
-
$||x_0\mathbf{1}^T - X - SD^T||_F^2$: これはデータ忠実度項であり、具体的には残差行列のフロベニウスノルムの二乗である。
- 数学的定義: 行列 $(x_0\mathbf{1}^T - X - SD^T)$ のすべての要素の二乗の合計。
- 物理的/論理的役割: この項は、モデルによる画像の再構成($x_0, S, D$ に基づく)が実際の入力画像 $X$ とどれだけ一致するかを測定する。この項を最小化することは、モデルがその組み合わせが観測画像を正確に説明するように $x_0, S, D$ を見つけようとしていることを意味する。
- 使用理由: フロベニウスノルムの二乗は、行列間の差を定量化するための標準的で微分可能な方法であり、勾配ベースの最適化に適している。$\frac{1}{2}$ という係数は、その導関数を単純化するための一般的な慣習である。
-
$\lambda$: これは非負のスカラー正則化パラメータである。
- 数学的定義: スカラー値。
- 物理的/論理的役割: 正則化項の強さを制御する。$\lambda$ が大きいほど、完全なデータ再構成を犠牲にして、$S$ および $D$ におけるスパース性や低ランク特性の促進に重点が置かれる。これはバランスを取るノブとして機能する。
- 使用理由: 過学習を防ぎ、学習された染色成分が望ましい数学的特性を持つことを奨励するため。BeerLaNetでは学習可能になっている。
-
$\sum_{i=1}^r (\dots)$: これは $r$ 個の着色成分にわたる合計を示す。
- 数学的定義: $i=1$ から $r$ までの合計。
- 物理的/論理的役割: 各個別の染色成分 ($s_i$ および $d_i$) に対する正則化ペナルティを単一の総ペナルティに集計する。
- 使用理由: 同定されたすべての染色成分に正則化を一様に適用するため。
-
$||s_i||_2^2$: これは $S$ の $i$番目の列のL2ノルムの二乗である。
- 数学的定義: ベクトル $s_i$ の要素の二乗の合計。
- 物理的/論理的役割: この項は、カラースペクトルベクトルの大きさを正則化する。$s_i$ の要素が小さくなることを奨励し、単一のカラーチャンネルが染色のプロファイルに過度に大きな寄与を持つことを防ぐ。また、$S$ の低ランク解を促進する。
- 使用理由: 低ランク解を促進することにより、よりコンパクトで意味のある染色成分のセットを見つけるのに役立つため。
-
$||d_i||_1$: これは $D$ の $i$番目の列のL1ノルムである。
- 数学的定義: ベクトル $d_i$ の絶対値の合計。
- 物理的/論理的役割: この項は、光学密度行列 $D$ におけるスパース性を促進する。$d_i$ の多くの要素が正確にゼロになることを奨励し、これは特定の染色成分がごく一部のピクセルにのみ存在することを意味する。「関心のある関連組織学的特徴は空間的にスパースである」という仮定と一致する。
- 使用理由: L1正則化はスパース性を誘発するための標準的な技術であり、これにより個別の染色領域を分離し、$D$ の解釈をより意味のあるものにする。
-
$||d_i||_2^2$: これは $D$ の $i$番目の列のL2ノルムの二乗である。
- 数学的定義: ベクトル $d_i$ の要素の二乗の合計。
- 物理的/論理的役割: $||s_i||_2^2$ と同様に、この項は光学密度ベクトルの大きさを正則化する。単一のピクセルが過度に高い濃度の染色を持つことを防ぎ、$D$ の低ランク解を促進することに寄与する。
- 使用理由: 低ランク解を促進し、$D$ における過度に大きな値を防ぎ、数値的安定性とより良い汎化に貢献するため。
-
$\text{s.t. } S,D \ge 0$: これらは非負制約である。
- 数学的定義: 行列 $S$ および $D$ のすべての要素はゼロ以上でなければならない。
- 物理的/論理的役割: これは重要な物理的制約である。染色濃度($D$ における光学密度)および光吸収係数($S$ における)は負になり得ない。負の値は物理的に意味をなさない。これは非負行列分解(NMF)の定義的な特徴である。
- 使用理由: 学習された染色成分とその濃度が物理的に解釈可能であり、非負の量に基づいたBeer-Lambert則に準拠していることを保証するため。
データ忠実度項と正則化項を組み合わせるための加算の選択は、最適化において標準的であり、データへの適合と望ましい特性の促進とのバランスを可能にする。問題が離散的なエンティティ(ピクセル、カラーチャンネル、染色成分)を扱うため、積分ではなく合計が使用される。
ステップ・バイ・ステップの流れ
BeerLaNetは、マスター方程式の最適化プロセスを、アセンブリラインのように一連の反復ステップに「展開」することによって動作する。抽象的なデータポイント(入力画像 $X$ からの単一ピクセルのカラーベクトル $x_j$)が、1回の反復 $k$ でこのメカニズムをどのように流れるかを追ってみよう。
- 入力エントリー: 入力画像全体 $X$ ($C \times P$ 行列) がBeerLaNetモジュールに供給される。この段階では、背景光 $x_0^{(k-1)}$、染色カラー行列 $S^{(k-1)}$、および光学密度行列 $D^{(k-1)}$ の初期または前回の推定値がある。
- 背景光更新 ($x_0$): アセンブリラインの最初のステーションで背景光 $x_0$ が更新される。各ピクセルのカラーベクトル $x_j$ ($X$ から) は、現在の染色寄与の推定値($S^{(k-1)}$ および $D^{(k-1)}$ から導出される)と概念的に組み合わされる。これらの結合された値は、すべてのピクセルで平均化され、新しい洗練された $x_0^{(k)}$ の推定値が生成される。このステップは、現在の染色モデルによって減衰されたときに、観測画像を最もよく再構成する全体的な入射光を決定する。
- 光学密度更新 ($D$): 次に、システムは光学密度行列 $D$ の更新に焦点を当てる。
- ステップサイズの計算: 動的なステップサイズ $\tau_D$ が計算され、この反復で $D$ をどれだけ積極的に更新すべきかが決定される。
- 勾配降下: 各ピクセルについて、その現在の染色濃度($D^{(k-1)}$ の行で表される)が調整される。この調整は、現在の $S$ と $D$ が入力画像 $X$ と新しく更新された $x_0^{(k)}$ をどれだけうまく説明できるかに基づく。勾配は、$D$ を再構成誤差を最小化する値に向かってプッシュする。
- 近接演算子(スパース性・非負性): 勾配ステップの後、$D$ の各列 $d_i$ に一連の「クリッピング」および「シュリンキング」操作が適用される。これらは近接演算子である。これらは2つの重要な特性を強制する。
- 非負性: 負の濃度値は即座にゼロにクリップされ、物理的な現実性を保証する。
- スパース性: L1ノルム正則化は、多くの濃度値が正確にゼロになることを奨励する。これは、特定のピクセルについて、染色成分の濃度が非常に低い場合、それは効果的に除去され、表現がスパースになり、支配的な染色のみが強調されることを意味する。
- L2正則化: 追加のL2近接演算子が $d_i$ の大きさをさらに正則化し、過度に高い濃度を防ぎ、低ランク解を促進する。
- アナリスト注: 正直なところ、$D$ および $S$ の近接演算子の正確な形式については、アルゴリズム1(行10および17)に記載されている通り、完全には確信が持てない。項 $\lambda\gamma\tau||s_i||_2^2$ や $\lambda\gamma\tau_S(d_1+d_2)$ のようなものは、目的関数(4)のL1またはL2近接演算子としては標準的ではなく、テキストで完全に詳細化されていない、わずかな不一致または非常に特殊な定式化を含んでいるように見える。しかし、意図は、非負性、スパース性($D$ の場合)、および大きさの正則化($S$ および $D$ の両方)を強制することであることは明らかである。
- 染色カラー更新 ($S$): 次に、プロセスは染色カラー行列 $S$ の更新に進む。
- ステップサイズの計算: $S$ のための動的なステップサイズ $\tau_S$ が計算される。
- 勾配降下: 各染色のカラープロファイル($S^{(k-1)}$ の列)は、現在の $S$ と新しく更新された $D^{(k)}$ が画像 $X$ と背景 $x_0^{(k)}$ をどれだけうまく説明できるかに基づいて調整される。これにより、各染色のスペクトル特性が洗練される。
- 近接演算子(大きさ・非負性): $D$ と同様に、$S$ の各列 $s_i$ に近接演算子が適用される。
- 非負性: 吸収係数が物理的に意味のある値(非負)であることを保証する。
- L2正則化: カラーベクトルの大きさを縮小し、$S$ の低ランク特性に寄与し、単一のカラーチャンネルが過度に支配的なスペクトル寄与を持つことを防ぐ。
- 反復終了: これで1回の展開された反復が完了する。洗練された $x_0^{(k)}, S^{(k)}, D^{(k)}$ は、次の反復の準備ができるか、または $K$ 回の反復が完了した場合は最終出力の準備ができる。
- 出力と下流統合: $K$ 回の反復後、染色に不変な構造情報である最終的な $D$ 行列が抽出される。この $P \times r$ 行列は、その後 $r$ チャンネル画像(各チャンネルは1つの染色成分の空間分布に対応する)にリシェイプされる。この $r$ チャンネル画像は、その後 $1 \times 1$ 畳み込み層を通過して3チャンネル画像にマッピングされ、オブジェクト検出や分類などの下流タスクのために、YOLOやResNetのような任意のディープラーニングバックボーンネットワークにシームレスに統合できる。
アプローチの概要は図1に示されており、方法の詳細についてはアルゴリズム1を参照のこと。
最適化ダイナミクス
BeerLaNetが「学習」し収束するメカニズムは、展開された交互近接勾配降下アルゴリズムを通じて行われ、その後エンドツーエンドで学習される。
- 交互近接勾配降下: コアとなる最適化戦略は反復的である。非凸目的関数を、一方のパラメータセット(まず $x_0$、次に $D$、次に $S$)を他のパラメータを固定したまま交互に最適化することで処理する。各変数について、標準的な勾配降下ステップ(滑らかなデータ忠実度項を最小化するため)と近接演算子(非滑らかな正則化項と非負制約を処理するため)を組み合わせる。この反復的な洗練は、モデルが複雑な損失ランドスケープをナビゲートするのに役立つ。
- 非凸損失ランドスケープ: $SD^T$ 積の存在は、目的関数を非凸にする。これは、損失ランドスケープが単純なボウル状ではなく、複数の「谷」または局所的最小値を持つ可能性があることを意味する。交互近接勾配降下は効果的であるが、絶対的な最良(大域的)最小値を見つけることを保証するものではない。しかし、実際には良好な解を見つけることが多い。
- 勾配と更新: $D$ および $S$ の勾配降下フェーズ中、アルゴリズムはデータ忠実度項の勾配を計算する。これらの勾配は、再構成誤差が最も急激に増加する方向を示す。アルゴリズムはその後、反対方向にステップを取り、この誤差を反復的に低減する。動的なステップサイズ($\tau_D, \tau_S$)は重要である。これらは損失ランドスケープの局所的な曲率に適合し、ランドスケープが平坦な場合は大きなステップを、急峻な場合は小さなステップを可能にし、より高速で安定した収束を支援する。
- 近接演算子の役割: 近接演算子は、解の形状を整える上で不可欠である。$D$ の場合、L1ノルムはスパース性を促進し、小さな染色濃度を効果的にゼロに設定して染色マップを単純化する。$S$ および $D$ の両方の場合、L2ノルムと非負制約は、学習された染色プロファイルと濃度が物理的に意味があり、適切に振る舞うことを保証し、非現実的な値や過学習を防ぐ。
- 学習可能なパラメータとエンドツーエンド学習: BeerLaNetの重要な革新は、いくつかの重要な最適化ハイパーパラメータ($\lambda$, $\gamma$、および初期 $S_{init}$ など)を学習可能にすることである。これらを手動で調整する代わりに、展開された最適化プロセス全体がニューラルネットワークアーキテクチャ内に埋め込まれる。その後、最終的な下流タスク(例:オブジェクト検出精度)からの損失が、すべての $K$ 個の展開されたレイヤーを通じてバックプロパゲートされる。これは、勾配が下流バックボーンネットワークの重だけでなく、BeerLaNet内の正則化パラメータと初期染色推定値にも流れることを意味する。このエンドツーエンド学習により、BeerLaNetモジュールは、最終タスクのパフォーマンスを直接最適化するように内部染色正規化プロセスを適応させることができ、非常に適応性が高く堅牢になる。
- 収束挙動: 各展開された反復により、$x_0, S, D$ の推定値が段階的に洗練される。展開された反復回数 $K$ は、BeerLaNetモジュールの深さのように機能する。これらの展開されたレイヤーを通じたバックプロパゲーションは、NMF目的関数に対して最適であるだけでなく、特に下流タスクの最終目標に対して最適である解に向かって反復プロセスを導き、異なる染色ドメイン全体での汎化性能を向上させる。
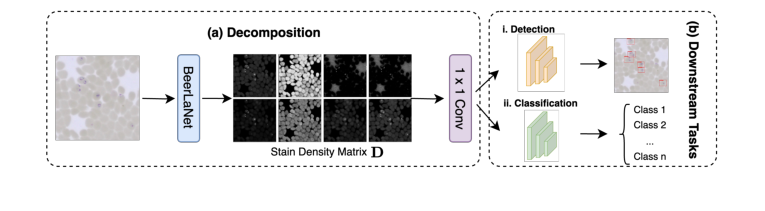 Figure 1. Overview of our proposed BeerLaNet method
Figure 1. Overview of our proposed BeerLaNet method
結果、限界、および結論
実験デザインとベースライン
BeerLaNet の適応的染色正規化能力とドメイン間汎化能力の向上を厳密に検証するため、著者らは 2 つの主要な診断タスク、すなわち物体検出と画像分類にわたる包括的な実験セットアップを設計した。BeerLaNet は、古典的および深層学習ベースの確立されたベースラインモデル群と、多様な病理データセットで比較された。
物体検出においては、評価はマラリア原虫検出と全血球検出に焦点を当てた。マラリア検出タスクでは、白血球、赤血球、血小板、および様々な寄生虫種がアノテーションされた、24,720 枚の May Grunwald-Giemsa (MGG) 染色薄層血液塗抹標本画像からなる公開データセット [5] を利用した。評価には、Zeiss Axioscan顕微鏡から取得された 264 枚の薄層血液塗抹標本画像からなる、別途内部でキュレーションされたテストデータセットを使用した。全血球検出には、学習用に BCCD [17] (366 枚の画像)、テスト用に BCDD [1] (100 枚の画像) の 2 つの公開データセットが採用された。これらのタスクには、BeerLaNet が YOLOv8 バックボーン [9] と統合された。
画像分類においては、マラリア原虫分類と乳がん分類という 2 つの異なる課題に取り組んだ。マラリア分類データセットは、4 つの顕微鏡プラットフォーム (Hamamatsu NanoZoomer, Zeiss Axioscan, Olympus CX43, Morphle Hemolens) から収集された多様なコレクションであり、Giemsa 染色薄層血液塗抹標本を特徴とする。これには、2,486 枚の単一細胞クロップ画像からなる学習セットと、ドメイン間の汎化を評価するために設計された、異なるイメージングプラットフォームからの 2 つのテストセット (343 枚および 261 サンプル) が含まれていた。タスクは、検出された原虫をライフステージ別に分類することを含んだ。乳がん分類には、リンパ節の全スライド画像から抽出された 96x96 の画像パッチで構成され、腫瘍の有無を示すラベルが付与された Camelyon17-WILDS データセット [2] が使用された。このデータセットは 5 つの病院にまたがっており、本質的に大きなドメインシフトを導入していた。分類タスクには、BeerLaNet が ResNet-18 バックボーン [8] と統合された。
BeerLaNet と比較された「犠牲者」(ベースラインモデル)には、3 つの古典的な組織染色正規化手法、すなわち Reinhard [13]、Macenko [11]、および Vahadane [18] が含まれた。さらに、2 つの深層学習ベースの手法、StainGAN [16] および LStainNorm [10] も含められた。正規化のためにテンプレート画像を必要とするベースラインについては、学習データセットからランダムに 1 枚の画像が選択された。
BeerLaNet の主要な実装詳細には、色成分数 ($r$) を 8、内部展開反復回数 ($K$) を 10 に設定することが含まれる。学習パラメータはタスクによって異なり、バッチサイズは 8 (検出) または 128 (分類)、学習率は 0.01 または 1e-4 であった。特に、圧縮アーティファクトを軽減するために、マラリア分類データセットには 2 段階のノイズ除去パイプライン (中央値フィルタおよびガウシアンフィルタ) が適用された。すべての実験結果は、堅牢性を確保するために 3 つのランダムシードで平均化された。
評価指標は、検出には mAP50 および mAP50-95、分類には Accuracy (Acc) を選択し、特定のタスク要件を反映させた。マラリア原虫分類には、予測が真のラベルから 1 つのライフステージ以内であれば成功と見なす、特殊な Relaxed Accuracy (RAcc) が導入され、原虫成長の連続的な性質を考慮した。すべてのタスクおよびデータセットにわたる一貫したパフォーマンスの決定的かつ否定できない尺度を提供するため、著者らは Average Percent Underperformance (APU) 指標を導入した。この指標は、各タスク・指標の組み合わせにおいて、ある手法のパフォーマンスと最高パフォーマンス手法との平均パーセント差を定量化し、汎化の全体像を提供する。学習データとテストデータのドメイン間のばらつきを示す例画像は図 2 に示されている。
証拠が示すもの
表 1 に要約された実験的証拠は、BeerLaNet の中核メカニズム、すなわち物理情報に基づいた、アルゴリズム展開による学習可能な染色分離が現実世界で効果的に機能し、ベースラインと比較して優れたドメイン間汎化を提供するという説得力のある証明を提供している。
BeerLaNet は、マラリア原虫検出 (mAP50 95.07%、mAP50-95 57.10%) およびマラリア原虫分類 (Acc 48.66%、RAcc 90.33%) の両方で最高のパフォーマンスを達成した。また、全血球検出 (mAP50 86.80%、mAP50-95 51.33%) でも 2 番目に高いパフォーマンスを確保した。すべての単一指標で常に絶対的なトップパフォーマーではなかったものの (例: Camelyon17test で Macenko がわずかに高い精度を達成)、BeerLaNet の優位性の決定的証拠は、Average Percent Underperformance (APU) 指標によって定量化された、すべての多様なタスクおよびデータセットにわたる 一貫した および 堅牢な パフォーマンスにある。
BeerLaNet は、APU の観点からすべての比較手法を大幅に上回り、検出タスクで 2.00、分類タスクで 1.86 を達成した。これは重要な証拠である。例えば、Camelyon-17 WILDS C17test データセットで最高の精度 (95.92%) を達成した Macenko は、C17val データセットでは 10 パーセントポイント以上の大幅な低下 (85.77%) を経験した。同様に、ほぼすべての他のベースライン手法で、異なるタスクまたはデータセットにわたって大幅なパフォーマンス低下が観察された。この一貫性のなさは、ドメインシフトに対するそれらの脆弱性を浮き彫りにしている。
特に汎用的な設計や固定テンプレートへの依存を持つベースラインは、マラリアデータセットに見られるような大きな色変化に直面した場合 (図 2 で視覚的に示唆されているように)、汎化に苦労した。それらのパフォーマンスは、比較的軽微な色シフトを持つデータセット (Camelyon17-WILDS や全血球など) ではしばしば良好であったが、より困難な条件下では劇的に低下した。対照的に、BeerLaNet は、絶対的な最高でなくても、非常に競争力のあるパフォーマンスを維持し、事前の知識やテンプレート選択なしに、幅広い染色および画像条件に適応する能力を示した。APU 指標によって厳密に明らかにされたこの一貫した高レベルのパフォーマンスは、BeerLaNet の物理情報に基づいた、エンドツーエンドで学習可能なアプローチが、染色に依存しない構造情報を効果的に分離し、医療組織学における堅牢なドメイン間汎化につながるという否定できない証拠である。
限界と今後の方向性
BeerLaNet は多様な医療組織学タスクにおいて顕著な堅牢性と一貫したパフォーマンスを示す一方で、その固有の限界を認識し、将来の開発の方向性を検討することが重要である。
著者らが指摘するように、1 つの微妙な限界は、BeerLaNet が すべての単一 の特定のデータセットまたは指標において、常に 絶対的な トップパフォーマーではないことである。例えば、Camelyon-17 WILDS C17test データセットでは Macenko がわずかに高い精度を達成した。BeerLaNet の強みは、全体にわたる 一貫した 高パフォーマンス (その優れた APU によって証明される) にあるが、これは、特に挑戦的ではないドメインシフトにおいて、パフォーマンスをさらに向上させる可能性のある特殊な最適化の余地があることを示唆している。また、論文では、より単純なベースラインと比較した場合の展開されたネットワークアーキテクチャの計算オーバーヘッドについて明示的に詳述しておらず、これは非常に大きな全スライド画像やリアルタイムアプリケーションにとって実用的な考慮事項となる可能性がある。
将来に向けて、著者らは BeerLaNet を セグメンテーション やその他の 組織病理学ドメイン といった追加のダウンストリームタスクに適用することを提案している。そのプラグアンドプレイ設計を考慮すると、これは自然な拡張である。
これら以外にも、これらの発見をさらに発展させ進化させるためのいくつかの議論のトピックが挙げられる。
- 新規染色および画像モダリティへの一般化可能性: 本論文は、BeerLaNet が「任意の染色プロトコル」を処理する能力を強調している。H&E または Giemsa 染色が主に実験で使用されたものとは大きく異なる、全く 新規な 染色や画像モダリティ (例: 蛍光顕微鏡、質量分析イメージング) に対して、どの程度パフォーマンスを発揮するだろうか?将来の研究では、その「適応性」の主張を真に検証するために、より広範な未知の染色タイプに対する厳密なテストを行うことが考えられる。
- 分離されたコンポーネントの解釈可能性と臨床的有用性: BeerLaNet は染色に依存しない構造情報 (D 行列) を抽出する。この分離された表現は、病理医によって直接解釈可能か、またはダウンストリームタスクのパフォーマンス向上を超えた定量的分析に使用できるか?これらのコンポーネントを可視化および定量化するためのツールを開発することは、新たな診断洞察を提供し、AI 主導の病理学への信頼を高める可能性がある。
- 動的なハイパーパラメータ適応: 色成分数 ($r$) および展開反復回数 ($K$) は固定されたハイパーパラメータとして設定されている。これらは、入力画像の特性や染色プロトコルの複雑さに基づいて動的に適応させることができるだろうか?適応的なメカニズムは、パフォーマンスをさらに最適化し、手動チューニングの必要性を減らす可能性がある。
- マルチモーダルデータとの統合: 組織病理学は、しばしば様々なソースからの情報の統合を伴う (例: 分子データ、患者履歴)。BeerLaNet の染色正規化をマルチモーダル学習フレームワークと組み合わせることで、より包括的な診断像を提供できるだろうか?
- 画像品質劣化に対する堅牢性: 染色のばらつきは対処されているが、実際の病理画像は、焦点外領域、塵、または圧縮アーティファクト (マラリア分類で部分的に対処されている) のような他の劣化に苦しむ可能性がある。物理情報に基づいた展開フレームワークは、染色を正規化し、他の一般的な画像品質の問題を補正するために共同で拡張できるだろうか?
- 倫理的考慮事項とアーティファクト防止: 医療診断において、合成アーティファクトの導入や細胞構造の「幻覚」は、一部の GAN ベースの手法で指摘されているように、重大な懸念事項である。BeerLaNet はこれを回避することを目指しているが、全体的な精度が向上した場合でも、正規化プロセスが決定的に関連する特徴を意図せず不明瞭にしたり変更したりしないことを保証するために、継続的な検証、さらには正式な認証プロセスが必要となる可能性がある。
- 全スライドイメージングのための計算効率: ギガピクセル全スライド画像 (WSI) の処理は計算負荷が高い。BeerLaNet はエンドツーエンドで学習可能であるが、その展開された NMF メカニズムは依然としてリソースを消費する可能性がある。将来の研究では、より軽量な展開アーキテクチャや効率的なハードウェア実装を通じて、計算効率を最適化することに焦点を当て、リアルタイム WSI 分析を可能にすることが考えられる。
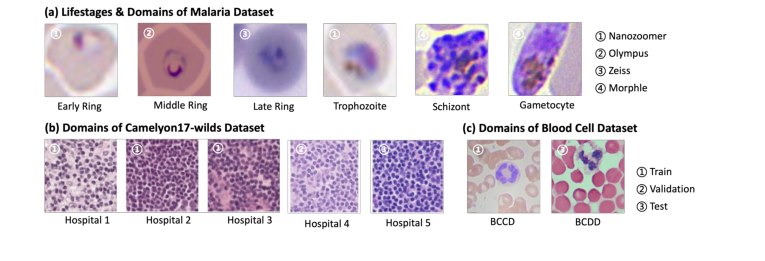 Figure 2. Example images from our tested datasets
Figure 2. Example images from our tested datasets
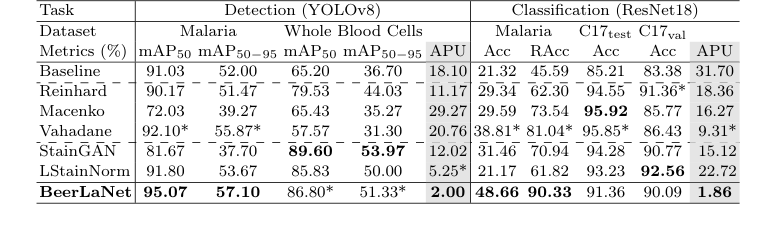 Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
他分野との関連
数学的骨子
本研究の純粋な数学的核は、結合された $l_1$ および $l_2$ ノルム正則化を持つ構造化非負行列分解(NMF)問題であり、これは展開型交互プロキシマル勾配降下法アルゴリズムを用いて解かれる。このフレームワークは、入力行列を2つの非負因子行列に分解することを目的とし、因子におけるスパース性および低ランク性を促進する。
隣接研究分野
非負行列分解(NMF)
BeerLaNetモデルの基盤は、様々な分野における次元削減および特徴抽出に広く用いられている技術である非負行列分解に置かれている。具体的には、式4の目的関数は、$S, D \ge 0$ および追加の正則化制約の下で $||x_0\mathbf{1}^T - X - SD^T||_F^2$ を最小化することを目指しており、これはNMF問題の直接的な変種である。ここでは、対数変換された画像データが、染色カラー行列 $S$ と光学密度行列 $D$ に分解される。行列が2つの非負行列の積によって近似されるというこの数学的構造は、テキスト分析におけるトピックモデリング、ハイパースペクトルイメージングにおけるスペクトル分解、および音声処理におけるソース分離などの応用において中心的である。例えば、スペクトル分解では、NMFは混合ピクセルスペクトルを純粋な材料スペクトル(エンドメンバー)のセットとその対応する存在量に分解するために使用され、これは組織画像における染色カラーとその密度の分離に高度に類似している。NMFにおける基礎的な研究は、LeeとSeung(1999, Nature)によるものであり、真に画期的な論文である。
アルゴリズム展開 / 深層展開(Deep Unfolding)
本手法は、アルゴリズム展開、別名深層展開(deep unfolding)を採用し、構造化NMF問題のための反復最適化プロセスを、学習可能な深層ニューラルネットワークアーキテクチャに変換する。アルゴリズム1に概説されている交互プロキシマル勾配降下法のステップは、$x_0$, $D$, $S$ を勾配ステップの実行と、正則化および非負性制約のためのプロキシマル演算子の適用によって更新するものであり、これは固定数のネットワーク層に直接展開される。このアプローチにより、正則化強度($\gamma, \lambda$)や初期化($S_{init}$)などのパラメータを、バックプロパゲーションを介してエンドツーエンドで学習することが可能になり、深層学習の利点を活用しつつ、基盤となる最適化アルゴリズムの解釈可能性と理論的保証を維持することができる。この技術は、スパースコーディング、圧縮センシング再構成、画像復元など、様々な信号処理および逆問題において成功を収めており、そこでは反復アルゴリズムが効率的で学習可能な深層モデルに変換されている(例:Gregor & LeCun, 2010, ICML)。これは非常に巧妙なアイデアである。