跨域医学组织学自适应染色归一化
Deep learning advances have revolutionized automated digital pathology analysis.
背景与学术渊源
起源与学术渊源
本文所解决的问题源于病理学检查在疾病诊断中的关键作用,而传统上这种检查依赖于对数字病理图像进行人工评估。尽管人工审查能提供关于组织形态学和细胞异常的重要见解,但其本质上是劳动密集型、耗时且容易受到不同观察者之间变异性的影响 [20, 19]。深度学习的出现为自动化分析提供了充满希望的途径,但很快遇到了一个重大障碍:数字病理图像的颜色不一致性。
这种颜色变异性是模型泛化能力面临的主要挑战,其根源在于多种因素:(i) 染色过程中染料化学反应和暴露时间差异,(ii) 样本制备的变异,以及 (iii) 不同扫描硬件下成像条件的差异 [15]。经验丰富的人类病理学家可以直观地补偿这些变异,但深度学习模型对此类“域偏移”高度敏感,当应用于与训练数据不同条件下采集的数据时,会导致性能显著下降和泛化能力差 [3]。这一“痛点”迫使学术界,特别是在医学病理学领域,开发染色颜色归一化策略,以确保跨不同数据集的图像外观一致性。
以往的染色归一化方法,尽管试图缓解这些问题,但存在一些根本性的局限性。传统方法通常需要仔细选择训练域中的“模板”图像来匹配颜色统计信息,这需要先验知识并可能引入伪影。基于物理的方法,例如利用比尔-兰伯特定律和非负矩阵分解 (NMF),通过考虑图像形成的底层过程而有所改进。然而,它们通常仍然依赖于预定义的模板或需要额外的先验知识,例如特定染料的吸收光谱矩阵或不同颜色成分的确切数量 [18]。此外,一些基于 NMF 的方法中使用了主成分分析 (PCA),存在不足之处,因为它假设成分是正交的,而这对于染色成分来说并不总是现实的。更近期的深度学习方法,如生成对抗网络 (GAN),可以对齐颜色分布,但常常引入合成伪影或“幻觉”的细胞结构,在医学诊断中存在风险 [12]。其他深度学习技术则往往过于通用,未能考虑到组织学染色的特定物理原理 [10]。本文的作者旨在通过提出一种可训练、受物理学启发的、无模板的解决方案来克服这些局限性,该方案能够自适应地解耦染色信息。
直观的领域术语
- 域偏移 (Domain Shift):想象一下你训练了一条狗识别红色的球。如果你随后给它看一个蓝色的球,它可能会感到困惑,因为“域”(球的颜色)发生了偏移。在数字病理学中,这意味着一个在一家实验室(具有特定染色和成像)的图像上训练的深度学习模型,在另一家实验室具有略微不同条件的图像上表现可能不佳。
- 染色归一化 (Stain Normalization):可以将其视为使用照片滤镜,使所有照片都具有相同的、一致的外观,即使它们是在不同的光照条件下拍摄的。在组织学中,这是一个调整组织切片颜色以使其看起来像是使用完全相同的方案进行染色的过程,从而使其可用于自动化分析。
- 比尔-兰伯特定律 (Beer-Lambert Law):这是光学中的基本定律,类似于太阳镜的作用。它根据材料的厚度和吸光物质(染料)的含量,告诉我们有多少光能够穿过材料(如染色组织)。它对于理解染料如何赋予组织其特征颜色至关重要。
- 非负矩阵分解 (Nonnegative Matrix Factorization, NMF):想象一个水果沙拉,你想弄清楚具体用了哪些水果以及它们的用量,并且知道任何水果的用量都不能是“负数”。NMF 是一种数学技术,它将复杂的图像(如染色组织切片)分解为其基本、非负的组成部分,例如单独的染料及其在每个像素处的浓度。
- 算法展开 (Algorithmic Unrolling):考虑一个复杂的迭代计算,就像反复调整望远镜的焦点直到图像清晰一样。“展开”意味着将该迭代过程的每一步转化为神经网络中的一个独立层。这使得整个调整序列可以被端到端地学习和优化,而不是一个固定的、独立的过程。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决的核心问题源于数字病理图像固有的颜色变异性,这是深度学习模型在医学诊断中可靠性和泛化能力的关键问题。
输入/当前状态:输入是数字病理图像,表示为 $X \in \mathbb{R}^{c \times p}$,其中 $c$ 是颜色强度数量(通常 RGB 为 3),$p$ 是像素数量。该图像 $X$ 由于多种因素而表现出显著的颜色不一致性:染色方案的差异、化学反应、染料暴露时间、样本制备变异以及不同扫描硬件的成像条件。这种颜色不一致性导致“域偏移”,意味着在一种条件数据上训练的深度学习模型在应用于另一种条件数据时性能会下降。
期望终点/目标状态:期望的输出是“染色归一化”图像,或者更精确地说,是从输入图像派生出的“染色不变结构信息”表示。这种归一化表示应能有效去除颜色变异性,同时保留底层的组织形态学和细胞异常。最终目标是将这种鲁棒的、染色不变的表示输入到下游的深度学习任务中,如目标检测和图像分类,从而使这些模型能够有效地跨域泛化,并无论原始图像的染色外观如何都能实现一致的高性能。
缺失环节/数学鸿沟:确切的缺失环节是一种鲁棒、自适应且受物理学启发的数学方法,用于将图像的染色信息与结构内容解耦。以往的方法,受比尔-兰伯特定律的启发,将图像强度 $X$ 建模为入射光 $x_0$、颜色外观矩阵 $S$ 和光密度矩阵 $D$ 的函数:
$$X = (x_0 \mathbf{1}^T) \odot e^{-SD^T}$$
其中 $\mathbf{1}$ 是全一向量,$\odot$ 表示逐元素矩阵乘积。数学鸿沟在于可靠地从给定输入图像 $X$ 中估计 $x_0$、$S$ 和 $D$,并且这种估计是:
1. 自适应的:不需要染色方案或模板图像的先验知识。
2. 受物理学启发的:尊重颜色光谱和光密度的非负性。
3. 可训练的:可以与深度学习架构进行端到端集成。
4. 结构保持的:避免引入合成伪影。
本文旨在通过改进现有的非负矩阵分解 (NMF) 模型来弥合这一鸿沟,这些模型通常是非凸的且需要仔细的参数调整,将其转化为一个可训练的、展开的网络架构。
困境:以往的研究人员被几种痛苦的权衡所困扰:
* 模板依赖性 vs. 自适应性:许多现有的染色归一化方法严重依赖于“模板图像”或需要先验知识(例如,特定染料的吸收光谱、颜色成分的数量)。虽然这些方法对于特定、定义明确的域可能有效,但它们在没有手动干预或仔细选择模板的情况下,无法适应新的或任意的染色方案,严重限制了它们的泛化能力。
* 受物理学启发的准确性 vs. 伪影生成:严格遵循染色物理学(如基于比尔-兰伯特定律和 NMF 的方法)的方法通常采用启发式方法(例如,用于 $S$ 和 $D$ 的主成分分析),这些方法会引入缺陷,例如需要正交性,而这对于染色成分来说是不现实的。相反,更通用的深度学习方法,如生成对抗网络 (GAN),可以对齐颜色分布,但容易“幻觉”细胞结构或引入合成伪影,这在医学诊断中是不可接受且危险的。
* 固定参数 vs. 可学习性:早期的 NMF 模型(例如,方程 3)需要手动调整参数,如稀疏正则化强度 $\lambda$ 和秩 $r$(颜色成分的数量)。这种手动调整具有挑战性,尤其是在颜色成分数量未知的情况下,并且阻碍了与参数自动学习的端到端深度学习管道的无缝集成。
约束与失效模式
自适应染色归一化问题由于作者遇到的几个严峻的现实障碍而变得异常困难:
-
物理约束:
- 遵守比尔-兰伯特定律:任何有效模型都必须准确地表示染料对光衰减的物理过程。这意味着要尊重光吸收的乘法性质以及分解为染色浓度和吸收特性的能力。
- 非负性:颜色光谱 ($S$) 和光密度 ($D$) 都是物理上非负的量。强制执行此约束对于有意义的分解至关重要,但它增加了优化问题的复杂性。
- 染色不变信息:核心挑战是提取真正独立于染色外观的结构信息。这需要将颜色信息与形态学细节进行鲁棒分离,鉴于它们在原始图像中的交织性质,这并非易事。
-
计算约束:
- 非凸优化:底层的 NMF 问题,特别是带有 $SD^T$ 矩阵乘积的问题,是非凸的。这意味着标准优化算法可能会陷入局部最小值,从而难以找到全局最优解。
- 端到端可训练性:为了与现代深度学习模型进行实际部署,染色归一化过程必须是可微分的,并且能够进行端到端训练。许多传统方法涉及不可微分的步骤或启发式方法,阻碍了它们与深度学习框架的无缝集成。
- 计算效率:为临床应用实时或近实时地处理大型全切片图像需要计算效率高的算法。复杂的迭代优化过程可能慢得令人望而却步。
-
数据驱动约束:
- 极端域偏移:数字病理学数据集不仅在不同实验室或扫描仪之间表现出显著的颜色变异性,甚至在同一实验室的不同时间段内也存在变异性。这种“域偏移”是深度学习模型失败的主要原因,需要一种能够处理大且不可预测变化的归一化方法。
- 缺乏先验知识:在许多实际场景中,关于特定染色方案、染料吸收光谱或标本中颜色成分确切数量的详细先验知识是不可用的。鲁棒的方法必须在没有此类显式输入的情况下有效运行。
- 伪影避免:与一般图像风格迁移不同,医学图像分析不能容忍在归一化过程中引入“合成伪影”或“幻觉”结构。此类失真可能导致误诊,使结构保持成为首要约束。
-
先前方法的失效模式(成为新解决方案的约束):
- 模板引起的偏差:依赖于固定模板图像可能会引入偏差并限制自适应性,因为所选模板可能不代表所有目标域。
- 参数敏感性:先前的 NMF 模型需要仔细手动选择正则化参数和组件数量 ($r$),这通常是一个试错过程,如果选择不当可能导致次优结果。
- 正交性假设:PCA 等方法(在一些先前工作中用于估计染色成分)施加了对生物染色不切实际的正交约束,导致分解不准确。
- 排列模糊性:$S$ 和 $D$ 的分解可能存在排列模糊性,即列可能被交换,如果处理不当会导致“显著的颜色失真”。
为什么选择这种方法
选择的必然性
BeerLaNet 的开发源于现有染色归一化方法在面对数字病理学复杂现实时,其明显且持续的不足之处。正如论文所强调的,核心问题是由于染色方案和成像条件差异引起的显著颜色变异性所导致的“域偏移”。这种变异性严重降低了深度学习模型的性能,阻碍了其泛化能力。
传统的染色归一化技术,例如那些依赖统计匹配或颜色空间分解的方法(如 Reinhard、Macenko、Vahadane),被发现不足,主要原因是它们严重依赖于“适当的代表性模板”或“领域先验知识”。这通常包括要求特定的染料吸收光谱或预定义的颜色成分数量。这种依赖性使得这些方法变得脆弱,并且在模板选择不当或面对未知染色方案时容易出现“显著的颜色失真”。作者意识到,一种需要这种显式先验知识或仔细手动选择模板和参数的方法,无法成为真正自适应和鲁棒系统的唯一可行解决方案。
基于深度学习的替代方法,如用于风格迁移的生成对抗网络 (GAN)(例如 StainGAN),也存在关键缺陷。虽然它们能够对齐颜色分布,但 GAN 常常“引入合成伪影或‘幻觉’细胞结构”,这在医学诊断中存在不可接受的风险,因为形态学的保真度至关重要。其他使用注意力机制的深度学习技术被认为“很大程度上是通用的”,并且未能考虑到图像形成的底层物理原理,限制了它们的鲁棒性和可解释性。
作者们意识到这些 SOTA 方法不足的确切时刻是,他们观察到现有的受物理学启发的矩阵分解模型,尽管概念上合理,但存在实际限制。具体来说,方程 (3) 中的稀疏非负矩阵分解 (NMF) 模型是非凸的,并且需要先验指定颜色成分的数量 ($r$),这是一个具有挑战性的任务,尤其是在该数量未知时(例如,当标本包含额外的着色成分如血红蛋白时)。此外,早期基于物理的方法中使用主成分分析 (PCA) 是存在问题的,因为它假设列是正交的,而这对于染色分离来说是不现实的。这些问题的结合——模板依赖性、伪影生成、缺乏受物理学启发的自适应性以及固定参数要求——使得开发一种根本上新颖的、集成的解决方案变得清晰。
比较优势
BeerLaNet 通过多种结构优势实现了超越先前黄金标准的定性优势,这些优势超越了单纯的性能指标。首先,其自适应染色解耦使其能够扩展到“任意染色方案”,学习“图像的染色不变表示,而无需任何染色方案的先验知识”。这比那些本质上受其所选模板的质量和代表性限制的基于模板的方法具有显著优势。BeerLaNet 无模板且无需特定染料或成分先验知识即可运行的能力,使其在各种临床环境中更加鲁棒和通用。
其次,该方法是可训练且受物理学启发的,构建于非负矩阵分解 (NMF) 和算法展开之上。这种组合是一项关键的结构创新。通过算法展开修改后的 NMF 公式(方程 4),BeerLaNet 将一个传统的非凸优化问题转化为一个端到端可训练的深度网络。这使得正则化参数 ($\gamma, \lambda$) 和初始化 ($S_{init}$) 的可学习适应成为可能,而这些参数以前是固定的或通过启发式选择的。这种基于数据的学习,以比尔-兰伯特定律为基础,确保了染色分解过程既物理准确又高度自适应,避免了忽略底层成像物理学的通用颜色转换的陷阱。
在修改后的 NMF 公式 (4) 中加入额外的 $l_2$ 正则化是另一个结构优势。这种正则化促进了低秩解,使得模型能够将颜色成分数量 ($r$) 初始化得比预期更大,然后根据数据自适应地调整解的秩。这巧妙地解决了 $r$ 的先验指定问题,使模型更加灵活和鲁棒,能够应对标本成分的变化。
最后,BeerLaNet 的灵活集成作为即插即用模块,意味着它可以无缝地与任何骨干网络结合用于下游任务。这种架构设计确保染色归一化不是一个独立的预处理步骤,而是整个深度学习管道中一个集成、可学习的部分,从而针对最终任务(例如,目标检测或分类)优化归一化。这种端到端的可训练性是独立运行且无法根据下游任务反馈调整其归一化过程的方法的显著结构优势。
与约束的对齐
BeerLaNet 的设计完美地契合了医学组织学中染色归一化的严苛要求,形成了“问题与解决方案”的强大“结合”。
-
约束:克服颜色不一致性和域偏移:主要目标是跨越不同的染色和成像条件进行泛化。BeerLaNet 通过其“自适应染色解耦”来解决此问题,该方法在无需染色方案先验知识的情况下学习“染色不变表示”。这通过提取独立于颜色变化的底层生物信息,直接解决了域偏移的根本原因。
-
约束:避免伪影和幻觉:对医学诊断至关重要。BeerLaNet 通过“受物理学启发”来实现这一点。其基础是比尔-兰伯特定律,确保染色分解基于实际的光-组织相互作用,与纯粹的数据驱动、通用深度学习模型(如 GAN)相比,引入合成伪影的可能性更小。
-
约束:消除模板依赖性和先验知识:传统方法在需要特定模板或先验知识(例如,吸收光谱、颜色成分数量)方面存在困难。BeerLaNet 的“可训练且受物理学启发”的性质,加上算法展开,使其能够从数据中学习这些参数。 $l_2$ 正则化使模型能够根据数据自适应地调整组件数量 ($r$),消除了手动指定的需要。这使得该方法完全无模板且独立于明确的先验知识。
-
约束:支持多样的染色方案:许多先前的方法主要关注 H&E 染色。BeerLaNet 明确“扩展到任意染色方案”,使其成为病理学中各种染色更通用的解决方案。
-
约束:与下游任务无缝集成:解决方案必须对实际诊断流程实用。BeerLaNet 被设计为一个“灵活集成”模块,一个“即插即用”组件,可以与“任意骨干网络结合用于目标检测和分类等下游任务”。这确保了归一化过程在最终诊断任务的背景下得到优化,从而提高了整体系统性能。
替代方案的拒绝
本文提供了拒绝替代方案(包括传统方法和深度学习方法)的清晰理由。
传统方法(例如,Reinhard、Macenko、Vahadane):这些方法被拒绝的主要原因是它们固有的模板图像和先验知识依赖性。如所述,它们“严重依赖于选择合适的代表性模板”并且“可能需要领域先验知识”,例如特定染料的吸收光谱矩阵或颜色成分的数量。这种依赖性使它们变得脆弱;如果模板不具代表性或先验知识不准确,这些方法可能导致“显著的颜色失真”。此外,它们通常需要仔细手动选择正则化强度 ($\lambda$) 和矩阵分解秩 ($r$) 等参数。表 1 中的实验结果在数量上支持了这些拒绝,表明这些方法在具有更大域变化的(例如,疟疾数据集)数据集上通常表现出“性能大幅下降”,表明泛化能力差。
基于深度学习的方法(例如,StainGAN、LStainNorm):
* GANs(例如,StainGAN):这些方法被拒绝是由于医学应用中的一个关键缺陷:它们“常常会引入合成伪影或‘幻觉’细胞结构,在医学诊断中存在风险 [12]”。在一个图像保真度至关重要的领域,任何损害图像完整性的方法都是不可接受的。
* 注意力机制(例如,LStainNorm):这些方法被认为“很大程度上是通用的,并且不一定考虑相关的图像形成过程 [10]”。这意味着它们缺乏对染色底层物理学的支撑,与 BeerLaNet 的受物理学启发的处理方法相比,这可能会限制它们的鲁棒性和可解释性。
实验结果进一步验证了这些拒绝。论文指出,“具有通用设计且不包含染色特定特征的方法可能在小域偏移数据(Camelyon17-WILDS、全血细胞)上表现良好,但在面对疟疾数据集中的大颜色偏移时会失效。”这直接与 BeerLaNet 在各种任务和数据集上(尤其是在域偏移显著的情况下)始终如一且优越的性能形成对比,突显了替代方法在现实、挑战性场景中的局限性。
数学与逻辑机制
主方程
BeerLaNet 方法的核心,驱动其染色归一化能力,是一个源自稀疏非负矩阵分解 (NMF) 模型的优化问题。该模型本身基于比尔-兰伯特定律,该定律描述了染料如何衰减光线。BeerLaNet 展开并优化的具体目标函数为:
$$ \min_{x_0,S,D} \frac{1}{2} ||x_0\mathbf{1}^T - X - SD^T||_F^2 + \lambda \sum_{i=1}^r (||s_i||_2^2 + ||d_i||_1 + ||d_i||_2^2) \text{ s.t. } S,D \ge 0. $$
该方程旨在找到最优的背景光强度 ($x_0$)、染色颜色轮廓 ($S$) 和染色浓度 ($D$),以最好地解释输入图像,同时还促进稀疏性和低秩解等期望的性质。
逐项解剖
让我们剖析这个主方程,以理解每个组件的作用:
-
$X$:这是输入图像矩阵,通常大小为 $C \times P$,其中 $C$ 是颜色通道数(例如,RGB 为 3),$P$ 是总像素数。$X$ 的每一列代表单个像素的颜色强度。至关重要的是,根据比尔-兰伯特定律的对数形式(论文中的方程 2)的推导,这个 $X$ 隐式地代表了观察到的图像强度的逐元素对数。
- 数学定义:一个 $C \times P$ 矩阵,表示输入图像的对数颜色强度。
- 物理/逻辑作用:它是模型试图分解的原始、观察到的数据。目标是解释这个观察到的图像,将其作为背景光和染色效应的组合。
- 为何使用:它是图像数据的直接表示,适合矩阵分解。
-
$x_0$:这是一个 $\mathbb{R}^C$ 中的向量,表示入射光强度或背景照明。
- 数学定义:一个 $C$ 维向量。
- 物理/逻辑作用:在比尔-兰伯特定律的背景下,$x_0$ 对光线在与染色组织相互作用之前的强度进行建模。它考虑了照明条件的变化。
- 为何使用:它是比尔-兰伯特定律的一个基本组成部分,允许模型适应不同的照明场景。
-
$\mathbf{1}^T$:这是一个全为 1 的行向量,维度为 $1 \times P$。
- 数学定义:一个 $1 \times P$ 矩阵,所有元素均为 1。
- 物理/逻辑作用:当与 $x_0$ 相乘时,它有效地将背景光强度 $x_0$ 广播到所有像素,创建一个矩阵,其中每个像素都被假定由 $x_0$ 照明。
- 为何使用:为了将背景光强度均匀地应用于所有像素以进行矩阵运算。
-
$x_0\mathbf{1}^T$:这个项表示所有像素的入射光矩阵。
- 数学定义:一个 $C \times P$ 矩阵,其中每一列是向量 $x_0$。
- 物理/逻辑作用:这是“未衰减”的光矩阵,表示如果没有染色,将观察到的光。
- 为何使用:根据对数比尔-兰伯特定律,它是从染色引起的衰减中减去的基线。
-
$S$:这是颜色外观矩阵,大小为 $C \times r$,其中 $r$ 是颜色成分的数量。每一列 $s_i \in \mathbb{R}^C$ 表示第 $i$ 个颜色成分(例如,特定染料如苏木精或伊红)的颜色光谱(吸收特性)。
- 数学定义:一个 $C \times r$ 矩阵。
- 物理/逻辑作用:该矩阵捕获每种染料独特的“指纹”,描述了它在不同颜色通道中的光吸收方式。它对于解耦不同的染色颜色至关重要。
- 为何使用:它允许模型直接从数据中学习染料的光谱特性,而无需特定染料的先验知识。
-
$D$:这是光密度矩阵,大小为 $P \times r$。每一列 $d_i \in \mathbb{R}^P$ 包含第 $i$ 个颜色成分在每个像素处的光密度(浓度)。
- 数学定义:一个 $P \times r$ 矩阵。
- 物理/逻辑作用:该矩阵表示每个染色成分在图像中的空间分布和浓度。它是 BeerLaNet 旨在提取的“染色不变结构信息”,因为它描述了每种染料在哪里以及多少存在,独立于其颜色。
- 为何使用:它是比尔-兰伯特定律的另一个核心组成部分,表示每个像素处存在的每种染料的数量。
-
$SD^T$:这个矩阵乘积,大小为 $C \times P$,表示所有像素处所有染料的总光密度贡献,转换回颜色空间。
- 数学定义:由 $S$ 和 $D^T$ 相乘得到的 $C \times P$ 矩阵。
- 物理/逻辑作用:在对数比尔-兰伯特定律中,这一项表示由染色引起的总衰减。它是需要建模并随后移除以进行归一化的“染色效应”。
- 为何使用:它是染色颜色轮廓 ($S$) 如何分布 ($D$) 以引起光衰减的数学表示。
-
$||x_0\mathbf{1}^T - X - SD^T||_F^2$:这是数据保真度项,特别是残差矩阵的平方 Frobenius 范数。
- 数学定义:矩阵 $(x_0\mathbf{1}^T - X - SD^T)$ 所有元素的平方和。
- 物理/逻辑作用:这一项衡量模型对图像的重建(基于 $x_0, S, D$)与实际输入图像 $X$ 的匹配程度。最小化这一项意味着模型正在尝试找到 $x_0, S, D$,使得它们的组合能够准确地解释观察到的图像。
- 为何使用:平方 Frobenius 范数是量化矩阵之间差异的标准且可微分的方法,适合基于梯度的优化。$\frac{1}{2}$ 因子是简化其导数的常见约定。
-
$\lambda$:这是一个非负标量正则化参数。
- 数学定义:一个标量值。
- 物理/逻辑作用:它控制正则化项的强度。较大的 $\lambda$ 会更强调促进 $S$ 和 $D$ 中的稀疏性和低秩特性,可能会以牺牲完美数据重建为代价。它充当一个平衡旋钮。
- 为何使用:用于防止过拟合并鼓励学习到的染色成分具有期望的数学特性,并且在 BeerLaNet 中是可学习的。
-
$\sum_{i=1}^r (\dots)$:这表示对 $r$ 个颜色成分的求和。
- 数学定义:从 $i=1$ 到 $r$ 的求和。
- 物理/逻辑作用:它将每个单独染色成分($s_i$ 和 $d_i$)的正则化惩罚聚合为总惩罚。
- 为何使用:将正则化均匀地应用于所有识别出的染色成分。
-
$||s_i||_2^2$:这是 $S$ 的第 $i$ 列的平方 L2 范数。
- 数学定义:向量 $s_i$ 中元素平方和。
- 物理/逻辑作用:该项正则化了颜色光谱向量的幅度。它鼓励 $s_i$ 的元素变小,防止任何单一颜色通道对染料的轮廓产生过大的贡献。它还促进了 $S$ 的低秩解。
- 为何使用:如论文所述,通过促进低秩解,有助于找到更紧凑且有意义的染色成分集。
-
$||d_i||_1$:这是 $D$ 的第 $i$ 列的 L1 范数。
- 数学定义:向量 $d_i$ 的绝对值之和。
- 物理/逻辑作用:该项促进了光密度矩阵 $D$ 中的稀疏性。它鼓励 $d_i$ 的许多元素变为零,这意味着特定染色成分仅存在于少数像素中。这与“相关的组织学特征在空间上是稀疏的”这一假设一致。
- 为何使用:L1 正则化是诱导稀疏性的标准技术,有助于分离不同的染色区域,并使 $D$ 的解释更有意义。
-
$||d_i||_2^2$:这是 $D$ 的第 $i$ 列的平方 L2 范数。
- 数学定义:向量 $d_i$ 的平方和。
- 物理/逻辑作用:与 $||s_i||_2^2$ 类似,该项正则化了光密度向量的幅度。它防止任何单个像素具有过高的染色浓度,并有助于促进 $D$ 的低秩解。
- 为何使用:用于促进低秩解并防止 $D$ 中的值过大,有助于数值稳定和更好的泛化。
-
$\text{s.t. } S,D \ge 0$:这些是非负约束。
- 数学定义:矩阵 $S$ 和 $D$ 中的所有元素必须大于或等于零。
- 物理/逻辑作用:这是一个关键的物理约束。染色浓度($D$ 中的光密度)和光吸收系数($S$ 中的)不能为负。负值在物理上没有意义。这是非负矩阵分解 (NMF) 的一个定义特征。
- 为何使用:确保学习到的染色成分及其浓度在物理上具有可解释性,并符合基于非负量的底层比尔-兰伯特定律。
数据保真度和正则化项组合的加法选择是优化中的标准做法,允许在拟合数据和促进期望属性之间取得平衡。使用求和而不是积分是因为问题涉及离散实体:像素、颜色通道和染色成分。
分步流程
BeerLaNet 通过将优化过程“展开”成一系列迭代步骤来运行,就像装配线一样。让我们追踪一个抽象数据点(来自输入图像 $X$ 的单个像素的颜色向量 $x_j$)如何流经该机制,进行一次迭代 $k$:
- 输入进入:整个输入图像 $X$(一个 $C \times P$ 矩阵)被馈送到 BeerLaNet 模块。在此阶段,我们有背景光 $x_0^{(k-1)}$、染色颜色矩阵 $S^{(k-1)}$ 和光密度矩阵 $D^{(k-1)}$ 的初始或先前估计。
- 背景光更新 ($x_0$):我们装配线上的第一个站点更新背景光 $x_0$。每个像素的颜色向量 $x_j$(来自 $X$)与当前估计的染色贡献(从 $S^{(k-1)}$ 和 $D^{(k-1)}$ 导出)相结合。然后将这些组合值跨所有像素平均,以产生 $x_0^{(k)}$ 的新、精炼估计。此步骤基本上确定了整体入射光,当被当前染色模型衰减时,能够最好地重建观察到的图像。
- 光密度更新 ($D$):接下来,系统专注于更新光密度矩阵 $D$。
- 步长计算:计算动态步长 $\tau_D$,它决定了 $D$ 在本次迭代中应该以多大的幅度更新。
- 梯度下降:对于每个像素,其当前染色浓度(由 $D^{(k-1)}$ 中的一行表示)会进行调整。这种调整基于当前 $S$ 和 $D$ 在多大程度上解释了输入图像 $X$ 和新更新的 $x_0^{(k)}$。梯度将 $D$ 推向最小化重建误差的值。
- 近端算子(稀疏性与非负性):梯度步骤之后,会对 $D$ 的每个列 $d_i$ 应用一系列“裁剪”和“收缩”操作。这些是近端算子。它们强制执行两个关键属性:
- 非负性:任何负浓度值都会立即被裁剪为零,确保物理现实性。
- 稀疏性:L1 范数正则化鼓励许多浓度值变为零。这意味着对于给定像素,如果染色成分的浓度非常低,它将被有效移除,从而使表示稀疏并突出显示主要的染色。
- L2 正则化:额外的 L2 近端算子进一步正则化了 $d_i$ 的幅度,防止浓度过高并促进低秩解。
- 分析师注:老实说,我不太确定算法 1(第 10 行和第 17 行)中描述的 $D$ 和 $S$ 的近端算子的确切形式。像 $\lambda\gamma\tau||s_i||_2^2$ 或 $\lambda\gamma\tau_S(d_1+d_2)$ 这样的项不是目标函数 (4) 的 L1 或 L2 近端算子的标准项,并且似乎包含轻微的差异或一个未在文本中完全详细说明的高度专业化的公式。然而,意图显然是强制执行非负性、稀疏性(对于 $D$)和幅度正则化(对于 $S$ 和 $D$)。
- 染色颜色更新 ($S$):然后过程转向更新染色颜色矩阵 $S$。
- 步长计算:为 $S$ 计算动态步长 $\tau_S$。
- 梯度下降:每种染色的颜色轮廓($S^{(k-1)}$ 中的一列)会根据当前 $S$ 和新更新的 $D^{(k)}$ 在多大程度上解释图像 $X$ 和背景 $x_0^{(k)}$ 进行调整。这会精炼每种染料的光谱特性。
- 近端算子(幅度和非负性):与 $D$ 类似,近端算子应用于 $S$ 的每个列 $s_i$:
- 非负性:确保吸收系数在物理上具有可解释性(非负)。
- L2 正则化:缩小颜色向量的幅度,有助于 $S$ 的低秩特性,并防止任何单一颜色通道对光谱贡献产生过大的影响。
- 迭代结束:这完成了一次展开迭代。精炼后的 $x_0^{(k)}, S^{(k)}, D^{(k)}$ 已准备好进行下一次迭代,或者如果完成了 $K$ 次迭代,则准备输出。
- 输出与下游集成:经过 $K$ 次迭代后,提取最终的 $D$ 矩阵,它代表了染色不变的结构信息。然后将这个 $P \times r$ 矩阵重塑为 $r$ 通道图像(其中每个通道对应于一种染色成分的空间分布)。然后将这个 $r$ 通道图像通过一个 $1 \times 1$ 卷积层,将其映射回一个 3 通道图像,然后可以将其无缝集成到任何深度学习骨干网络(如 YOLO 或 ResNet)中,用于目标检测或分类等下游任务。
我们方法的概述如图 1 所示,我们方法的完整细节见算法 1。
优化动力学
BeerLaNet “学习”和收敛的机制是通过一个展开的交替近端梯度下降算法,然后进行端到端训练。
- 交替近端梯度下降:核心优化策略是迭代的。它通过交替优化一组参数(首先是 $x_0$,然后是 $D$,然后是 $S$),同时保持其他参数固定来处理非凸目标函数。对于每个变量,它将标准的梯度下降步骤(以最小化平滑数据保真度项)与近端算子(以处理非平滑正则化项和非负约束)相结合。这种迭代精炼有助于模型导航复杂损失景观。
- 非凸损失景观:$SD^T$ 乘积的存在使得目标函数非凸。这意味着损失景观不是一个简单的碗状形状;它可能包含多个“山谷”或局部最小值。虽然交替近端梯度下降是有效的,但它不能保证找到绝对最佳的(全局)最小值。然而,在实践中,它通常能找到好的解决方案。
- 梯度与更新:在 $D$ 和 $S$ 的梯度下降阶段,算法计算数据保真度项的梯度。这些梯度指向重建误差最陡峭的增加方向。然后算法沿着相反的方向迈出一步,迭代地减小这个误差。动态步长 ($\tau_D, \tau_S$) 至关重要;它们会适应损失景观的局部曲率,当景观平坦时允许更大的步长,当景观陡峭时允许更小的步长,从而有助于更快、更稳定的收敛。
- 近端算子的作用:近端算子对于塑造解决方案至关重要。对于 $D$,L1 范数鼓励稀疏性,有效地将小的染色浓度设置为零,从而简化了染色图。对于 $S$ 和 $D$,L2 范数和非负约束确保了学习到的染色轮廓和浓度在物理上具有可解释性且行为良好,防止了不切实际的值或过拟合。
- 可学习参数与端到端训练:BeerLaNet 的一个关键创新是使一些关键的优化超参数(如 $\lambda$, $\gamma$, 和初始 $S_{init}$)可学习。不是手动调整这些参数,而是将整个展开的优化过程嵌入到一个神经网络架构中。最终下游任务(例如,目标检测准确性)的损失会通过所有 $K$ 个展开的层进行反向传播。这意味着梯度会一直回传,不仅更新下游骨干网络的权重,还更新 BeerLaNet 内的正则化参数和初始染色估计。这种端到端训练使得 BeerLaNet 模块能够调整其内部染色归一化过程,以直接优化最终任务的性能,使其高度自适应和鲁棒。
- 收敛行为:随着每个展开迭代的进行,$x_0, S, D$ 的估计会逐渐精炼。展开迭代次数 $K$ 就像 BeerLaNet 模块的深度一样。通过这些展开层的反向传播引导迭代过程朝着一个不仅对 NMF 目标最优,而且专门针对下游任务的最终目标最优的解决方案,从而提高跨不同染色域的泛化能力。
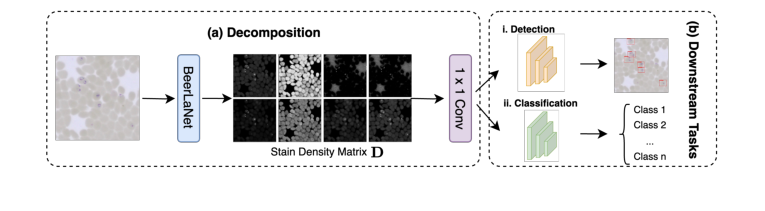 Figure 1. Overview of our proposed BeerLaNet method
Figure 1. Overview of our proposed BeerLaNet method
结果、局限性与结论
实验设计与基线
为了严格验证 BeerLaNet 在提供自适应染色归一化和增强跨域泛化能力方面的有效性,作者们在两个主要诊断任务:目标检测和图像分类上构建了一个全面的实验设置。他们将 BeerLaNet 与一系列经典的、以及基于深度学习的基线模型进行了比较,这些模型涵盖了各种病理数据集。
对于目标检测,评估集中在疟疾寄生虫检测和全血细胞检测上。疟疾检测任务使用了公开数据集 [5],包含 24,720 张 May Grunwald-Giemsa (MGG) 染色的薄血涂片图像,并标注了白细胞、红细胞、血小板和各种寄生虫物种。另外,使用了一个内部整理的 264 张薄血涂片图像的测试数据集,来自 Zeiss Axioscan 显微镜,用于评估。对于全血细胞检测,使用了两个公开数据集:BCCD [17] 用于训练(366 张图像)和 BCDD [1] 用于测试(100 张图像)。BeerLaNet 与 YOLOv8 骨干网络 [9] 集成用于这些任务。
对于图像分类,解决了两个不同的挑战:疟疾寄生虫分类和乳腺癌分类。疟疾分类数据集是从四个显微镜平台(Hamamatsu NanoZoomer、Zeiss Axioscan、Olympus CX43、Morphle Hemolens)收集的,包含吉姆萨染色的薄血涂片。它包括一个包含 2,486 张单细胞裁剪图像的训练集和两个测试集(343 张和 261 张样本),来自不同的成像平台,旨在评估跨域泛化能力。任务涉及按生命阶段对检测到的寄生虫进行分类。对于乳腺癌分类,使用了 Camelyon17-WILDS 数据集 [2],该数据集包含来自淋巴结全切片图像的 96x96 图像块,并带有肿瘤存在标签。该数据集跨越五个医院,固有地引入了显著的域偏移。BeerLaNet 与 ResNet-18 骨干网络 [8] 集成用于分类任务。
BeerLaNet 的比较对象(基线模型)包括三种经典的组织学归一化方法:Reinhard [13]、Macenko [11] 和 Vahadane [18]。此外,还包括两种基于深度学习的方法:StainGAN [16] 和 LStainNorm [10]。对于需要模板图像进行归一化的基线,从训练数据集中随机选择一张图像作为模板。
BeerLaNet 的关键实现细节包括将颜色成分数量 ($r$) 设置为 8,展开迭代次数 ($K$) 设置为 10。训练参数因任务而异,批次大小为 8(检测)或 128(分类),学习率为 0.01 或 1e-4。值得注意的是,对疟疾分类数据集应用了两步去噪流程(中值滤波和高斯滤波),以减轻压缩伪影。所有实验结果均取三个随机种子下的平均值,以确保鲁棒性。
评估指标的选择反映了特定任务的要求:检测任务使用 mAP50 和 mAP50-95,分类任务使用准确率 (Acc)。为疟疾寄生虫分类引入了一种特殊的宽松准确率 (RAcc),考虑到预测结果在生命阶段上与地面真实值相差一个阶段也算成功,这承认了寄生虫生长的连续性。为了提供一个明确、无可辩驳的跨所有任务和数据集的一致性能度量,作者们引入了平均百分比欠佳率 (APU) 指标。该指标量化了每种方法在每个任务-指标组合下的性能与表现最佳方法之间的平均百分比差异,提供了对泛化能力的整体视角。
图 2 展示了训练和测试数据之间域差异的示例图像。
证据证明的内容
如表 1 所总结的实验证据,有力地证明了 BeerLaNet 的核心机制——受物理学启发、可训练的染色解耦通过算法展开——在现实中有效,并且与基线相比提供了卓越的跨域泛化能力。
BeerLaNet 在疟疾寄生虫检测(mAP50 为 95.07%,mAP50-95 为 57.10%)和疟疾寄生虫分类(Acc 为 48.66%,RAcc 为 90.33%)方面均取得了最佳性能。它在全血细胞检测(mAP50 为 86.80%,mAP50-95 为 51.33%)方面也获得了第二高的性能。尽管并非在每个单一指标上都是绝对最佳的(例如,Macenko 在 C17test 上取得了稍高的准确率),但 BeerLaNet 在所有不同任务和数据集上一致且鲁棒的性能是其卓越性的决定性证据,这通过平均百分比欠佳率 (APU) 指标量化。
BeerLaNet 在 APU 方面显著优于所有比较方法,在检测任务上为 2.00,在分类任务上为 1.86。这是一个关键的证据。例如,Macenko 在 Camelyon-17 WILDS C17test 数据集上取得了最佳准确率(95.92%),但在 C17val 数据集上性能下降了超过 10 个百分点(85.77%)。在几乎所有其他基线方法在不同任务或数据集上都观察到了类似的显著性能下降。这种不一致性凸显了它们对域偏移的脆弱性。
基线方法,特别是那些具有通用设计或依赖固定模板的方法,在面对更大的颜色变化时(如疟疾数据集中存在的,如图 2 直观所示)难以泛化。它们的性能通常在颜色变化相对较小的(如 Camelyon17-WILDS 或全血细胞)数据集上表现良好,但在更具挑战性的条件下会急剧下降。相比之下,BeerLaNet 即使在不是绝对最佳的情况下,也保持了非常具有竞争力的性能,证明了它在无需先验知识或模板选择的情况下适应各种染色和成像条件的能力。这种一致的、高水平的性能,被 APU 指标无情地揭示出来,是 BeerLaNet 的受物理学启发、端到端可训练方法有效解耦染色不变结构信息,从而在医学组织学中实现鲁棒跨域泛化的无可辩驳的证据。
局限性与未来方向
尽管 BeerLaNet 在各种医学组织学任务中展现出卓越的鲁棒性和一致的性能,但认识到其固有的局限性并考虑未来发展方向至关重要。
一个微妙的局限性是,正如作者所指出的,BeerLaNet 在每一个特定数据集或指标上并非总是绝对最佳性能的方法。例如,Macenko 在 Camelyon-17 WILDS C17test 数据集上取得了稍高的准确率。尽管 BeerLaNet 的优势在于其在整个范围内一致的高性能(由其优越的 APU 量化),但这表明仍有进一步的专业优化空间,可以在特定、不太具挑战性的域偏移上进一步提升其性能。论文也没有明确详细说明展开网络架构相对于更简单的基线在计算开销方面,这对于极大的全切片图像或实时应用可能是一个实际的考虑因素。
展望未来,作者们提议探索 BeerLaNet 在分割和其他组织病理学领域等其他下游任务中的应用。鉴于其即插即用设计,这是一个自然的延伸。
除此之外,还出现了几个讨论话题,用于进一步发展和演变这些发现:
- 对新型染色和成像模态的泛化能力:论文强调了 BeerLaNet 处理“任意染色方案”的能力。它在与实验中主要使用的 H&E 或吉姆萨染色有显著差异的全新染色或成像模态(例如,荧光显微镜、质谱成像)上的表现如何?未来的工作可以包括在更广泛的范围内的未见染色类型上进行严格测试,以真正验证其“自适应”声明。
- 解耦成分的可解释性与临床效用:BeerLaNet 提取染色不变的结构信息(D 矩阵)。这种解耦的表示是否可以直接被病理学家解释或用于改进下游任务性能之外的定量分析?开发可视化和量化这些成分的工具可以提供新的诊断见解,并增强对人工智能驱动的病理学诊断的信任。
- 超参数的动态适应:颜色成分数量 ($r$) 和展开迭代次数 ($K$) 被设定为固定超参数。这些是否可以根据输入图像的特征或染色方案的复杂性进行动态调整?自适应机制可以进一步优化性能并减少手动调整的需要。
- 与多模态数据的集成:组织病理学通常涉及整合来自各种来源的信息(例如,分子数据、患者病史)。BeerLaNet 的染色归一化如何与多模态学习框架结合,以提供更全面的诊断图景?
- 对图像质量退化的鲁棒性:虽然解决了染色变异性,但真实的病理图像可能遭受其他退化,如失焦区域、灰尘或压缩伪影(部分针对疟疾分类进行了处理)。是否可以将受物理学启发的展开框架扩展到同时归一化染色并校正其他常见的图像质量问题?
- 伦理考量与伪影预防:在医学诊断中,引入合成伪影或“幻觉”细胞结构是一个关键问题,正如一些 GAN 方法所指出的那样。虽然 BeerLaNet 旨在避免这种情况,但仍需要持续的验证,甚至可能需要正式的认证流程,以确保归一化过程不会无意中模糊或改变诊断相关的特征,即使整体准确性有所提高。
- 全切片成像的计算效率:处理吉字节级全切片图像 (WSI) 在计算上要求很高。尽管 BeerLaNet 是端到端可训练的,但其展开的 NMF 机制可能仍然需要大量资源。未来的研究可以专注于优化其计算效率,可能通过更轻量级的展开架构或高效的硬件实现,以实现 WSI 的实时分析。
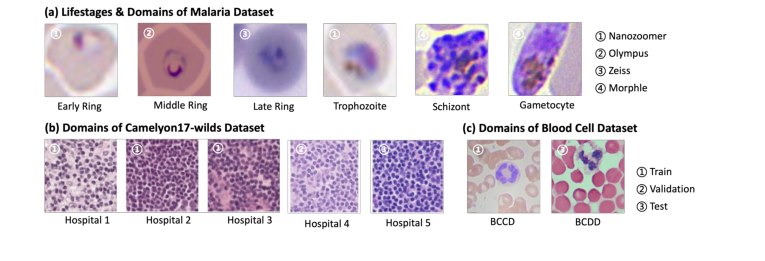 Figure 2. Example images from our tested datasets
Figure 2. Example images from our tested datasets
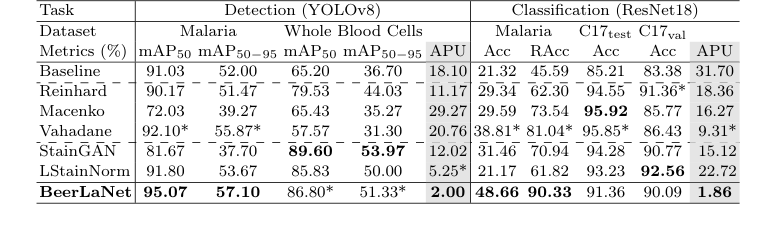 Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
Table 1. Comparison of Stain Normalization Techniques. The best and the second-best results are boldfaced or starred (*), respectively. (C17 denotes Camelyon17-WILDS)
与其他领域的联系
数学骨架
这项工作纯粹的数学核心是结构化的非负矩阵分解 (NMF) 问题,具有组合的 $l_1$ 和 $l_2$ 范数正则化,通过展开的交替近端梯度下降算法进行求解。该框架旨在将输入矩阵分解为两个非负因子矩阵,从而促进因子中的稀疏性和低秩特性。
相邻研究领域
非负矩阵分解 (NMF)
BeerLaNet 模型的基础在于非负矩阵分解,这是一种在各个领域广泛使用的降维和特征提取技术。具体而言,方程 4 中的目标函数,旨在最小化 $||x_0\mathbf{1}^T - X - SD^T||_F^2$ 并受 $S, D \ge 0$ 和附加正则化的约束,是 NMF 问题的直接变体。在这里,对数变换的图像数据被分解为染色颜色矩阵 $S$ 和光密度矩阵 $D$。这种将矩阵近似为两个非负矩阵乘积的数学结构,在文本分析的主题建模、高光谱成像的光谱解混以及音频处理的源分离等应用中至关重要。例如,在光谱解混中,NMF 用于将混合像素光谱分解为一组纯材料光谱(端元)及其相应的丰度,这与组织学图像中分离染色颜色及其密度高度相似。NMF 的基础工作由 Lee 和 Seung 于 1999 年在《Nature》上发表,这是一篇真正开创性的论文。
算法展开 / 深度展开
该方法采用算法展开(也称为深度展开),将结构化 NMF 问题的迭代优化过程转化为一个可训练的深度神经网络架构。算法 1 中概述的交替近端梯度下降步骤,通过梯度步骤和应用近端算子进行正则化和非负约束来更新 $x_0$、$D$ 和 $S$,直接展开为固定数量的网络层。这种方法允许通过反向传播对正则化强度 ($\gamma, \lambda$) 和初始化 ($S_{init}$) 等参数进行端到端训练,从而利用深度学习的优势,同时保持底层优化算法的可解释性和理论保证。这项技术在各种信号处理和逆问题中取得了成功,例如稀疏编码、压缩感知重建和图像恢复,其中迭代算法被转换为高效、可学习的深度模型(例如,Gregor & LeCun,2010,ICML),这是一个非常巧妙的想法。