CENet: मेडिकल इमेज सेगमेंटेशन के लिए कॉन्टेक्स्ट एन्हांसमेंट नेटवर्क
ऐतिहासिक रूप से, चिकित्सा छवियों में शारीरिक संरचनाओं, अंगों और घावों का सटीक सीमांकन एक विशुद्ध रूप से मैन्युअल कार्य था। रेडियोलॉजिस्ट को पिक्सेल दर पिक्सेल सीमाओं को सावधानीपूर्वक बनाना पड़ता था—एक ऐसी प्रक्रिया जो...
पृष्ठभूमि और अकादमिक वंश
ऐतिहासिक रूप से, चिकित्सा छवियों में शारीरिक संरचनाओं, अंगों और घावों का सटीक सीमांकन एक विशुद्ध रूप से मैन्युअल कार्य था। रेडियोलॉजिस्ट को पिक्सेल-दर-पिक्सेल सीमाओं को सावधानीपूर्वक बनाना पड़ता था—एक ऐसी प्रक्रिया जो अविश्वसनीय रूप से समय लेने वाली और महंगी थी, जिसमें श्रम के रूप में प्रति स्कैन सैकड़ों डॉलर (जैसे, \$150) लगते थे, और इसने स्वचालित प्रणालियों की तत्काल आवश्यकता को जन्म दिया। इस समस्या ने स्वचालित चिकित्सा छवि विभाजन के क्षेत्र को जन्म दिया। फुली कनवल्शनल नेटवर्क्स (FCNs) और विशेष रूप से U-Net आर्किटेक्चर द्वारा इस क्षेत्र में क्रांति ला दी गई, जिसने एक एनकोडर-डिकोडर संरचना पेश की। एनकोडर स्कैन में "क्या" है, यह समझने के लिए छवि को संपीड़ित करता है, जबकि डिकोडर इसे "कहां" है, यह इंगित करने के लिए विस्तारित करता है। हालांकि, जैसे-जैसे चिकित्सा इमेजिंग उन्नत हुई, एक महत्वपूर्ण चुनौती उभरी: आप एक मशीन को एक पूरे अंग प्रणाली के व्यापक, वैश्विक संदर्भ को एक साथ समझने के लिए कैसे सिखा सकते हैं, जबकि एक छोटे से ट्यूमर के सूक्ष्म, बारीक सीमा विवरण को पूरी तरह से संरक्षित कर सकते हैं?
पिछले दृष्टिकोणों की मौलिक सीमा बड़े चित्र को पकड़ने और बारीक विवरणों को बनाए रखने के बीच एक निरंतर खींचतान है। पारंपरिक कनवल्शनल न्यूरल नेटवर्क्स (CNNs) का एक सीमित "दृष्टि क्षेत्र" होता है, जिसका अर्थ है कि वे बड़ी छवियों में वैश्विक संबंधों को समझने के लिए संघर्ष करते हैं। इसे ठीक करने के लिए, शोधकर्ताओं ने विजन ट्रांसफॉर्मर्स (ViTs) पेश किए, जो एक साथ पूरी छवि को देखते हैं। हालांकि, ViTs कम्प्यूटेशनल रूप से विशाल हैं और स्थानीय किनारों के विवरण को पकड़ने में कुख्यात रूप से खराब हैं। जब पिछले मॉडल—यहां तक कि हाइब्रिड मॉडल भी—इस समस्या को हल करने के लिए बारीक सीमा विवरण को नेटवर्क के माध्यम से पास करने का प्रयास करते थे, तो वे एक गंभीर दर्द बिंदु से पीड़ित होते थे: "अति-संवर्धन।" उचित नियंत्रण तंत्र के बिना, किनारों के विवरण को बढ़ाना पृष्ठभूमि शोर को भी बढ़ाता है, जिससे डिकोडर-चरण का क्षरण होता है। मौजूदा मॉडल डाउनसैंपलिंग प्रक्रिया के दौरान बस सीमा विवरण से समझौता करते हैं, जिससे जटिल अंगों का अत्यधिक सटीक, बहु-स्तरीय विभाजन लगभग असंभव हो जाता है। इसने लेखकों को CENet बनाने के लिए मजबूर किया ताकि नेटवर्क को शोर में डूबाए बिना बुद्धिमानी से सीमाओं को बढ़ाया जा सके।
यहां पेपर से कुछ अत्यधिक विशिष्ट डोमेन शब्द दिए गए हैं, जिन्हें सहज ज्ञान युक्त अवधारणाओं में अनुवादित किया गया है:
- स्किप कनेक्शन्स (Skip Connections): न्यूरल नेटवर्क्स में, ये आर्किटेक्चरल शॉर्टकट होते हैं जो मॉडल के बाद के चरणों में कच्ची, विस्तृत जानकारी को सीधे फीड करने के लिए कुछ परतों को बायपास करते हैं।
- रोजमर्रा की उपमा: कल्पना कीजिए कि 1,000 पृष्ठों के एक अत्यधिक विस्तृत उपन्यास का 10 पृष्ठों के सारांश में अनुवाद किया जा रहा है, और फिर एक लेखक से केवल उस सारांश का उपयोग करके पूर्ण उपन्यास को फिर से लिखने के लिए कहा जा रहा है। वे सभी समृद्ध विवरण खो देंगे। एक स्किप कनेक्शन उस लेखक को मूल चरित्र स्केच और सेटिंग विवरण सौंपने जैसा है, जबकि वे फिर से लिखते हैं, यह सुनिश्चित करते हुए कि अनुवाद में बारीक विवरण खो न जाएं।
- रिसेप्टिव फील्ड (Receptive Field): इनपुट छवि का विशिष्ट, प्रतिबंधित क्षेत्र जिसे न्यूरल नेटवर्क का एक विशेष भाग किसी भी समय "देख" रहा होता है।
- रोजमर्रा की उपमा: एक कार्डबोर्ड पेपर टॉवल ट्यूब के माध्यम से एक विशाल, जटिल भित्ति चित्र को देखने के बारे में सोचें। भित्ति चित्र का वह छोटा वृत्त जो आप एक बार में देख सकते हैं, आपका रिसेप्टिव फील्ड है। भित्ति चित्र की पूरी कहानी को समझने के लिए, आपको एक बहुत व्यापक ट्यूब की आवश्यकता है।
- डाउनसैंपलिंग (Downsampling): जानकारी को संपीड़ित करने और उच्च-स्तरीय, अर्थ संबंधी अर्थ निकालने के लिए जानबूझकर छवि के स्थानिक रिज़ॉल्यूशन को कम करने की प्रक्रिया।
- रोजमर्रा की उपमा: यह आपके फोन पर एक डिजिटल मानचित्र पर ज़ूम आउट करने जैसा है। जैसे ही आप ज़ूम आउट करते हैं, आप व्यक्तिगत सड़कों और कॉफी की दुकानों के नाम (बारीक विवरण) खो देते हैं, लेकिन आप अंततः पूरे राज्य या देश (वैश्विक संदर्भ) के आकार को देखने में सक्षम होते हैं।
- सेल्फ-अटेंशन मैकेनिज्म (Self-Attention Mechanism): एक गणितीय विधि जो मॉडल को इनपुट डेटा के विभिन्न हिस्सों के महत्व को एक दूसरे के सापेक्ष तौलने की अनुमति देती है, यह तय करती है कि किस पर ध्यान केंद्रित करना है।
- रोजमर्रा की उपमा: एक शोरगुल वाली, भीड़ भरी कॉकटेल पार्टी में होने की कल्पना करें। आपका मस्तिष्क स्वाभाविक रूप से पृष्ठभूमि संगीत और बजते चश्मे को बाहर कर देता है ताकि आप जिस व्यक्ति से बात कर रहे हैं उसकी आवाज पर पूरी तरह से ध्यान केंद्रित कर सकें। सेल्फ-अटेंशन डेटा के लिए ठीक यही करता है, यह तय करता है कि किन पिक्सेल को "सुनना" सबसे महत्वपूर्ण है।
मुख्य गणितीय संकेतन
| संकेतन | विवरण |
|---|---|
| $F$ | नेटवर्क द्वारा संसाधित इनपुट फ़ीचर मैप। |
| $\mathcal{D}(F, s)$ | स्केल $s$ पर फ़ीचर मैप पर लागू मल्टी-स्केल डाउनसैंपलिंग ऑपरेशन। |
| $\mathcal{U}(F, s)$ | स्केल $s$ पर फ़ीचर मैप पर लागू अपसैंपलिंग ऑपरेशन। |
| $s_1, s_2, s_0$ | फ़ीचर मैप्स को रीसाइज़ करने के लिए उपयोग किए जाने वाले विशिष्ट स्केल पैरामीटर (जैसे, $0.75, 0.5, 1.0$)। |
| $F_{u1}, F_{u2}$ | विभिन्न पैमानों पर परिणामी अपसैंपल्ड फ़ीचर मैप्स। |
| $F_{\text{edge}}$ | अलग, परिष्कृत किनारे का विवरण, जिसे गणितीय रूप से $\|F_{u1} - F_{u2}\|$ के रूप में परिभाषित किया गया है। |
| $\lambda$ | किनारे की विशेषताओं को स्केल करने के लिए उपयोग किया जाने वाला एक सीखने योग्य भार पैरामीटर वेक्टर ($\lambda \in \mathbb{R}^d$)। |
| $\tilde{F}$ | भारित किनारे के विवरण को मूल इनपुट में वापस जोड़ने के बाद अंतिम संवर्धित फ़ीचर मैप। |
| $\mathbf{g}$ | चैनल-वार आँकड़ों को कैप्चर करने के लिए पूलिंग संचालन द्वारा उत्पन्न एक वैश्विक डिस्क्रिप्टर वेक्टर। |
| $\mathbf{s}$ | चैनल कैलिब्रेशन यूनिट (CCU) द्वारा उत्पन्न चैनल भार, जो विशेषताओं को अनुकूली रूप से पुनः भारित करने के लिए है। |
| $F'$ | चैनल अटेंशन ($F \odot \mathbf{s}$) लागू करने के बाद पुनः भारित आउटपुट फ़ीचर मैप। |
| $F'_i$ | मल्टी-स्केल कॉन्टेक्स्चुअल एग्रीगेटर (MCA) में उपयोग की जाने वाली फ़ीचर मैप के विभाजित हिस्से। |
| $f_{dk}$ | एक विशिष्ट कर्नेल आकार और प्रसार दर $d_k$ के साथ एक डेप्थ-वाइज कनवल्शनल ऑपरेटर। |
| $\mathcal{C}_{\text{avg}}, \mathcal{C}_{\text{max}}, \mathcal{C}_{\text{std}}$ | चैनल-वार औसत पूलिंग, मैक्स पूलिंग और मानक विचलन पूलिंग संचालन। |
| $G$ | स्पैटियल कैलिब्रेशन मॉड्यूल में विभिन्न पूलिंग ऑपरेशनों को मिलाकर बनाया गया एक स्थानिक डिस्क्रिप्टर। |
| $S$ | तत्व-वार गुणन के माध्यम से फ़ीचर मैप को पुन: कैलिब्रेट करने के लिए उपयोग किया जाने वाला संयुक्त आउटपुट। |
समस्या परिभाषा और बाधाएं
यह कल्पना करने जैसा है कि एक अत्यधिक पिक्सेलयुक्त उपग्रह मानचित्र पर एक जटिल, आकार बदलने वाले द्वीप की सटीक रूपरेखा का पता लगाने का प्रयास किया जा रहा है। चिकित्सा छवि विश्लेषण के क्षेत्र में, प्रारंभिक बिंदु (इनपुट) एक कच्चा चिकित्सा डेटासेट है—जैसे सीटी स्कैन, एमआरआई, या त्वचा के घाव की डर्मोस्कोपिक तस्वीर। वांछित अंतिम बिंदु (आउटपुट) शारीरिक संरचनाओं, अंगों, या रोग संबंधी घावों का एक सटीक, पिक्सेल-वार निरूपण है। यह पत्र जिस गणितीय अंतर को पाटने का प्रयास करता है, वह गंभीर सूचना हानि है जो तब होती है जब किसी छवि को उसके समग्र संदर्भ को समझने के लिए संपीड़ित किया जाता है, जो स्वाभाविक रूप से सटीक सीमाएँ खींचने के लिए आवश्यक महीन-ग्रेन स्थानिक निर्देशांक को नष्ट कर देता है। लेखकों को इन लापता किनारों के विवरण को गणितीय रूप से अलग करने और इंजेक्ट करने का एक तरीका चाहिए—जिसे वे मल्टी-स्केल अपसैंपल्ड फीचर्स के बीच पूर्ण अंतर के रूप में गणना करते हैं, $F_{edge} = |F_{u1} - F_{u2}|$—बिना सिस्टम को अप्रासंगिक डेटा में डुबोए।
डीप लर्निंग में, एक समस्या को ठीक करने से लगभग हमेशा दूसरी समस्या उत्पन्न होती है, और पिछले शोधकर्ता एक निराशाजनक दुविधा में फंस गए हैं। यदि आप कनवल्शनल न्यूरल नेटवर्क्स (CNNs) का उपयोग करते हैं, तो मॉडल स्थानीय बनावट को समझने में उत्कृष्ट हो जाता है लेकिन कनवल्शनल कर्नेल के सीमित रिसेप्टिव फील्ड के कारण वैश्विक संदर्भ को समझने में विफल रहता है। इसे ठीक करने के लिए, शोधकर्ताओं ने विजन ट्रांसफॉर्मर्स (ViTs) की ओर रुख किया, जो एक साथ पूरी छवि को देखने के लिए सेल्फ-अटेंशन का उपयोग करते हैं। हालांकि, ViTs एक दर्दनाक ट्रेड-ऑफ पेश करते हैं: जबकि वे वैश्विक संदर्भ को खूबसूरती से कैप्चर करते हैं, वे स्थानीय किनारों के निरूपण को मॉडल करने में गंभीर रूप से कम प्रदर्शन करते हैं। इसके अलावा, यदि आप इस समस्या को ठीक करने के लिए नेटवर्क को महीन-ग्रेन सीमा सुविधाओं पर ध्यान देने के लिए मैन्युअल रूप से मजबूर करने का प्रयास करते हैं, तो आप एक नई समस्या को ट्रिगर करते हैं: उचित नियंत्रण तंत्र की कमी पृष्ठभूमि शोर को बढ़ाती है, जिससे "अति-संवर्धित" निरूपण होता है जो वास्तव में डिकोडिंग चरण के दौरान नेटवर्क के प्रदर्शन को खराब करता है। आपको धुंधली सीमाओं, वैश्विक समझ की कमी, या शोरगुल वाली, अस्थिर वास्तुकला के बीच चयन करने के लिए मजबूर किया जाता है।
लेखकों को कई कठोर, यथार्थवादी बाधाओं का सामना करना पड़ा है जो इस विशिष्ट समस्या को हल करना बेहद मुश्किल बनाती हैं:
- द्विघात कम्प्यूटेशनल जटिलता (Quadratic Computational Complexity): जबकि ट्रांसफॉर्मर शक्तिशाली होते हैं, उनके सेल्फ-अटेंशन तंत्र इनपुट आकार के साथ द्विघात रूप से स्केल होते हैं, जिसे अक्सर $O(N^2)$ के रूप में व्यक्त किया जाता है। यह एक बड़े पैमाने पर कम्प्यूटेशनल बाधा उत्पन्न करता है और सख्त हार्डवेयर मेमोरी सीमाओं को हिट करता है, जिससे वे बड़े पैमाने पर, उच्च-रिज़ॉल्यूशन चिकित्सा अनुप्रयोगों के लिए अत्यधिक अक्षम हो जाते हैं।
- विनाशकारी डाउनसैंपलिंग (Destructive Downsampling): आधुनिक तंत्रिका नेटवर्क की पदानुक्रमित संरचना सुविधाओं को निकालने के लिए डाउनसैंपलिंग पर बहुत अधिक निर्भर करती है। यह भौतिक बाधा स्वाभाविक रूप से सीमा विवरण और महीन-ग्रेन सिमेंटिक निरूपण से समझौता करती है, जिन्हें एक बार खो जाने के बाद गणितीय रूप से पुनर्प्राप्त करना मुश्किल होता है।
- चरम रूपात्मक परिवर्तनशीलता (Extreme Morphological Variability): चिकित्सा संरचनाएं कठोर नहीं होती हैं। अंग और घाव अत्यधिक विरूपणीय होते हैं, जो विभिन्न रोगियों में विविध आकार, दिखावट और रोग संबंधी स्थितियां प्रस्तुत करते हैं। एक निश्चित रिसेप्टिव फील्ड इस बहु-स्केल परिवर्तनशीलता के अनुकूल नहीं हो सकता है।
- स्किप कनेक्शन में शोर संचय (Noise Accumulation in Skip Connections): खोए हुए विवरणों को पुनर्प्राप्त करने के लिए, नेटवर्क संपीड़न को बायपास करने के लिए "स्किप कनेक्शन" का उपयोग करते हैं। हालांकि, इस डेटा को फ़िल्टर करने के तरीके के बिना, अप्रासंगिक पृष्ठभूमि शोर सीधे डिकोडर में पारित हो जाता है। लेखक नोट करते हैं कि यह एक गंभीर बाधा उत्पन्न करता है जहां अत्यधिक संवर्धित निरूपण शोर जमा करते हैं, जिसके लिए महत्वपूर्ण सीमा विवरणों को मिटाए बिना सुविधाओं को अनुकूल रूप से डीनोइज़ करने के लिए जटिल गणितीय हस्तक्षेपों की आवश्यकता होती है।
यह तरीका क्यों
चिकित्सा छवि विभाजन (medical image segmentation) के परिदृश्य का विश्लेषण करते समय, CENet के लेखकों को एक बहुत ही विशिष्ट, निराशाजनक बाधा का सामना करना पड़ा। उन्होंने महसूस किया कि पारंपरिक अत्याधुनिक (state-of-the-art - SOTA) आर्किटेक्चर नैदानिक स्कैन (clinical scans) की कठोर वास्तविकताओं के लिए मौलिक रूप से त्रुटिपूर्ण थे। U-Net जैसे कनवल्शनल न्यूरल नेटवर्क (Convolutional Neural Networks - CNNs) अपने कर्नेल (kernels) के स्थानीय ग्रहणशील क्षेत्रों (local receptive fields) द्वारा स्वाभाविक रूप से सीमित होते हैं—वे बस एक बड़े, विकृत अंग (deformable organ) के वैश्विक संदर्भ (global context) को नहीं समझ सकते। दूसरी ओर, विज़न ट्रांसफॉर्मर (Vision Transformers - ViTs) स्व-ध्यान (self-attention) के माध्यम से वैश्विक संदर्भ को पकड़ने के लिए नए स्वर्ण मानक (gold standard) के रूप में उभरे। हालांकि, लेखकों ने उस सटीक क्षण की पहचान की जब ViTs विफल हो गए: वे स्थानीय सूक्ष्म विवरणों (local fine-grained details) (जैसे घाव की सटीक सीमा) को मॉडल करने में गंभीर रूप से कम प्रदर्शन करते हैं और एक दुर्बल करने वाली द्विघात कम्प्यूटेशनल जटिलता (quadratic computational complexity) रखते हैं जो उन्हें बड़े पैमाने पर, उच्च-रिज़ॉल्यूशन चिकित्सा अनुप्रयोगों के लिए अत्यधिक अक्षम बनाती है।
यहां तक कि जब पिछले शोधकर्ताओं ने इन दोनों को हाइब्रिड CNN-ट्रांसफॉर्मर मॉडल (hybrid CNN-Transformer models) में मिलाने की कोशिश की, तो एक नई समस्या उत्पन्न हुई। फाइन-ग्रेन्ड एज फीचर्स (fine-grained edge features) को सख्त नियंत्रण तंत्र (strict control mechanisms) के बिना डिकोडर (decoder) में जबरन डालने से नेटवर्क शोर (noise) से भर गया, जिससे डिकोडर-चरण का क्षरण (decoder-stage degradation) हुआ। लेखकों ने महसूस किया कि एक क्रूर-बल दृष्टिकोण (brute-force approach) व्यवहार्य नहीं था; उन्हें एक अत्यधिक नियंत्रित, गणितीय रूप से कठोर फ़िल्टरिंग प्रणाली (mathematically rigorous filtering system) की आवश्यकता थी। यही कारण है कि कॉन्टेक्स्ट एनहांसमेंट नेटवर्क (Context Enhancement Network - CENet) एकमात्र व्यवहार्य समाधान था।
इसे हल करने के लिए, उन्होंने चिकित्सा इमेजिंग की कठोर बाधाओं—जहां सीमाएं धुंधली होती हैं और अंग आकार में बहुत भिन्न होते हैं—और एक अद्वितीय दोहरे-फ़िल्टरिंग आर्किटेक्चर (dual-filtering architecture) के बीच एक "विवाह" तैयार किया। उन्होंने स्किप कनेक्शन (skip connections) में डुअल सेलेक्टिव एनहांसमेंट ब्लॉक (Dual Selective Enhancement Block - DSEB) पेश किया। एनकोडर (encoder) से डिकोडर तक सुविधाओं (features) को अंधाधुंध पास करने के बजाय, DSEB फीचर एज एम्पलीफायर (Feature Edge Amplifier - FEA) का उपयोग करके सक्रिय रूप से एज विवरणों को अलग करता है और बढ़ाता है। यह विभिन्न पैमानों पर सुविधाओं के बीच अंतर की गणना करके ऐसा करता है:
$$F_{edge} = |F_{u1} - F_{u2}|$$
जहां $F_{u1}$ और $F_{u2}$ विभिन्न डाउनसैंपलिंग पैमानों (downsampling scales) से अपसैंपल की गई विशेषताएं हैं। इस अलग की गई एज मैप (edge map) को फिर मूल फीचर मैप में वापस इंजेक्ट किया जाता है:
$$\tilde{F} = F + \lambda F_{edge}$$
जहां $\lambda \in \mathbb{R}^d$ एक भारित पैरामीटर (weighting parameter) के रूप में कार्य करता है।
लेकिन यहीं पर तुलनात्मक श्रेष्ठता (comparative superiority) वास्तव में चमकती है। यदि आप किनारों को बढ़ाते हैं, तो आप आमतौर पर उच्च-आयामी शोर (high-dimensional noise) को बढ़ाते हैं। इससे निपटने के लिए, लेखकों ने डिफरेंशियल अटेंशन (Differential Attention - DiffAtt) को एकीकृत किया। अलग-अलग अटेंशन मैप (attention maps) की गणना करके और उन्हें घटाकर, वे प्रभावी रूप से अनावश्यक ध्यान (redundant attention) और असंतुलित टोकन महत्व (imbalanced token importance) को रद्द कर देते हैं। यह न्यूरल नेटवर्क के लिए एक सक्रिय शोर-रद्द करने वाले हेडफ़ोन (active noise-canceling headphone) के रूप में कार्य करता है।
इसके अलावा, डिकोडर कॉन्टेक्स्ट फीचर अटेंशन मॉड्यूल (Context Feature Attention Module - CFAM) का उपयोग करता है ताकि नेटवर्क को अत्यधिक उन्नत अभ्यावेदन (overly enhanced representations) से चोक होने से रोका जा सके। यह एक चैनल कैलिब्रेशन यूनिट (Channel Calibration Unit - CCU) का उपयोग करता है ताकि एक वैश्विक डिस्क्रिप्टर (global descriptor) $\mathbf{g}$ का उपयोग करके चैनलों को संपीड़ित (compress) और अनुकूली रूप से पुनः भारित (adaptively reweight) किया जा सके:
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
इसके बाद मल्टी-स्केल कॉन्टेक्स्चुअल एग्रीगेटर (Multi-scale Contextual Aggregator - MCA) आता है जो सुविधाओं को विभाजित करता है और उन्हें समानांतर डाइलेटेड डेप्थ-वाइज कनवल्शन (parallel dilated depth-wise convolutions) के माध्यम से संसाधित करता है। यह संरचनात्मक लाभ नेटवर्क को पारंपरिक सघन परतों (traditional dense layers) के भारी पैरामीटर ब्लोट (massive parameter bloat) के बिना एक साथ कई पैमानों को देखने की अनुमति देता है।
ईमानदारी से कहूं तो, पेपर स्पष्ट रूप से मानक ViTs की तुलना में मेमोरी कॉम्प्लेक्सिटी (memory complexity) में कितनी कमी आई है, इसके लिए सटीक Big-O गणितीय संकेतन (mathematical notation) प्रदान नहीं करता है, लेकिन वे स्पष्ट रूप से अपनी द्विघात अक्षमता (quadratic inefficiency) के कारण मानक ट्रांसफॉर्मर को अस्वीकार करते हैं। डेप्थ-वाइज कनवल्शन और चैनल रिडक्शन का उपयोग करके, CENet एक गुणात्मक रूप से बेहतर, हल्का प्रतिनिधित्व (lightweight representation) प्राप्त करता है जो आसानी से भारी मॉडल (heavier models) को मात देता है।
अंत में, पेपर स्पष्ट रूप से बताता है कि अन्य लोकप्रिय दृष्टिकोण क्यों विफल होते हैं। हालांकि वे स्पष्ट रूप से GANs या डिफ्यूजन मॉडल (Diffusion models) को अस्वीकार करने का उल्लेख नहीं करते हैं—पूरी तरह से पारदर्शी होने के लिए, वे जनरेटिव मॉडल (generative models) संभवतः यहां आवश्यक नियतात्मक परिशुद्धता (deterministic precision) के साथ वैसे भी संघर्ष करेंगे—वे मौजूदा स्थानीयकृत स्व-ध्यान (localized self-attention) और हाइब्रिड मॉडल की कड़ी आलोचना करते हैं। वे विकल्प "एज जानकारी" के बजाय "बॉडी फीचर्स" पर बहुत अधिक ध्यान केंद्रित करते हैं और शोर संचय (noise accumulation) को संभालने के लिए आवश्यक अनुकूली डीनोइज़िंग (adaptive denoising) की कमी रखते हैं। CFAM के अंत में वेटेड नॉन-लोकल ब्लॉक (weighted Non-local Block - wNLB) का CENet का समावेश डर्मेटोस्कोपी छवियों (dermoscopy images) में बालों जैसी अत्यधिक-ध्यानित, अप्रासंगिक विवरणों को दबाने के लिए लंबी दूरी की स्थानिक निर्भरताओं (long-range spatial dependencies) को पूरी तरह से मॉडल करता है, यह साबित करते हुए कि नियंत्रित, संदर्भ-जागरूक संवर्धन (controlled, context-aware enhancement) पिछले स्वर्ण मानक की तुलना में अत्यधिक श्रेष्ठ है।
गणितीय और तार्किक तंत्र
मेडिकल इमेज सेगमेंटेशन में अंतर्निहित जटिलता को समझने के लिए, हमें पहले कॉन्टेक्स्ट एनहांसमेंट नेटवर्क (CENet) की उत्कृष्ट क्षमता को समझना होगा। कल्पना कीजिए कि एक धुंधली, ग्रेस्केल मेडिकल स्कैन से किसी ट्यूमर या अंग (जैसे किडनी) की सटीक रूपरेखा का पता लगाने का प्रयास किया जा रहा है। यदि आप बहुत अधिक ज़ूम इन करते हैं, तो आपको सटीक किनारे दिखाई देते हैं, लेकिन आप शरीर में कहाँ हैं, इसका पता खो देते हैं (ग्लोबल कॉन्टेक्स्ट का नुकसान)। यदि आप ज़ूम आउट करते हैं, तो आपको ठीक-ठीक पता होता है कि आप कहाँ हैं, लेकिन महीन सीमाएँ पिक्सेल में धुंधली हो जाती हैं (लोकल डिटेल का नुकसान)।
ऐतिहासिक रूप से, कनवल्शनल न्यूरल नेटवर्क्स (CNNs) "ज़ूम-इन" विशेषज्ञ थे, जो एक छोटी स्लाइडिंग विंडो के माध्यम से देखते थे, जबकि विज़न ट्रांसफॉर्मर्स (ViTs) "ज़ूम-आउट" विशेषज्ञ थे, जो पूरी छवि को देखते थे लेकिन महीन, स्थानीयकृत सीमाओं के साथ संघर्ष करते थे। इसके अलावा, जब इंजीनियरों ने उन्हें संयोजित करने का प्रयास किया, तो नेटवर्क अक्सर "ओवर-एनहांसमेंट" से पीड़ित होते थे - वास्तविक अंगों के साथ पृष्ठभूमि शोर को बढ़ाना, जिससे भविष्यवाणियों में गिरावट आती थी।
CENet के लेखकों ने इसे एक अत्यधिक नियंत्रित, मल्टी-स्केल आर्किटेक्चर डिज़ाइन करके हल किया है जो एक स्मार्ट आवर्धक लेंस की तरह काम करता है। यह अप्रासंगिक शोर को दबाने के लिए एक परिष्कृत गेटिंग तंत्र का उपयोग करते हुए चुनिंदा रूप से सीमाओं को बढ़ाता है।
यहां गणितीय विश्लेषण दिया गया है कि उन्होंने इसे कैसे प्राप्त किया।
मुख्य समीकरण
CENet का मूल दो परस्पर जुड़े गणितीय इंजनों पर निर्भर करता है। पहला डुअल सेलेक्टिव एनहांसमेंट ब्लॉक (DSEB) है, जो सीमा विवरण को पुनर्प्राप्त करता है। दूसरा मल्टी-स्केल कॉन्टेक्स्चुअल एग्रीगेटर (MCA) है, जो शोर से नेटवर्क को अभिभूत किए बिना विभिन्न ज़ूम स्तरों को बुद्धिमानी से फ्यूज करता है।
सीमा वृद्धि इंजन:
$$ \tilde{F} = F + \lambda F_{edge} $$
मल्टी-स्केल कॉन्टेक्स्ट गेटिंग इंजन:
$$ F_{MCA} = \Big( \text{SiLU}(f_{1\times1}(F_{cat})) \odot \text{SiLU}(f_{1\times1}(F')) \Big) + F $$
समीकरणों का विश्लेषण
आइए इन तंत्रों में प्रत्येक गियर और स्प्रिंग को अलग करें।
सीमा इंजन से:
* $F$: मूल इनपुट फीचर मैप। भौतिक रूप से, यह एक विशिष्ट परत पर छवि की आधारभूत वास्तविकता है - कच्चा, संपादित न किया गया सिग्नल।
* $F_{edge}$: अलग की गई सीमा विवरण। लेखक इसे विभिन्न पैमानों पर छवि को डाउनसैंपलिंग और अपसैंपलिंग करके और पूर्ण अंतर ($|F_{u1} - F_{u2}|$) लेकर गणना करते हैं। तार्किक रूप से, यह एक हाई-पास फिल्टर के रूप में कार्य करता है, जो केवल तेज संक्रमणों (अंगों की सीमाओं) को कैप्चर करता है।
* $\lambda$: एक सीखने योग्य भार पैरामीटर ( $\mathbb{R}^d$ में एक वेक्टर)। यह किनारों के लिए एक वॉल्यूम डायल के रूप में कार्य करता है, जिससे नेटवर्क यह तय कर पाता है कि प्रत्येक विशिष्ट चैनल के लिए कितनी सीमा वृद्धि वास्तव में आवश्यक है।
* $+$ (जोड़): गुणा के बजाय जोड़ क्यों? जोड़ एक ओवरले के रूप में कार्य करता है। हम आधारभूत छवि ($F$) ले रहे हैं और उस पर बढ़ी हुई सीमाओं ($\lambda F_{edge}$) को बना रहे हैं। यदि हमने गुणा का उपयोग किया होता, तो किनारे के बिना कोई भी क्षेत्र (जहां $F_{edge} \approx 0$) पूरी छवि को मिटा देता, जिससे अंगों के अंदर का हिस्सा पूरी तरह से काला हो जाता!
कॉन्टेक्स्ट गेटिंग इंजन से:
* $F_{cat}$: संयोजित मल्टी-स्केल फीचर्स। नेटवर्क छवि को विभाजित करता है और इसे विभिन्न "फैले हुए" लेंसों के माध्यम से देखता है (3, 5, और 8 पिक्सेल दूर पड़ोसियों को देखता है), फिर उन्हें एक साथ स्टैक करता है। यह "ग्लोबल कॉन्टेक्स्ट" या जंगल का प्रतिनिधित्व करता है।
* $F'$: चैनल-कैलिब्रेटेड फीचर मैप। यह मूल सिग्नल है जिसे पुनः भारित किया गया है ताकि सबसे महत्वपूर्ण फीचर चैनलों को प्राथमिकता दी जा सके। यह "लोकल डिटेल" या पेड़ों का प्रतिनिधित्व करता है।
* $f_{1\times1}$: एक पॉइंट-वाइज कनवल्शन। गणितीय रूप से, यह फीचर मैप की गहराई में एक रैखिक परिवर्तन है। तार्किक रूप से, यह एक बारटेंडर के रूप में कार्य करता है, जो छवि की स्थानिक चौड़ाई या ऊंचाई को बदले बिना सूचना के विभिन्न चैनलों को मिलाता है।
* $\text{SiLU}$: सिग्मॉइड लीनियर यूनिट एक्टिवेशन फ़ंक्शन। यह मजबूत सकारात्मक संकेतों को रैखिक रूप से गुजरने देता है लेकिन नकारात्मक संकेतों को शून्य की ओर सुचारू रूप से संकुचित करता है। यह एक नरम, निरंतर गेटकीपर के रूप में कार्य करता है।
* $\odot$ (हैडमार्ड उत्पाद): तत्व-वार गुणा। यह सबसे महत्वपूर्ण ऑपरेटर है। जोड़ के बजाय गुणा क्यों? गुणा एक तार्किक AND गेट (एक फिल्टर) के रूप में कार्य करता है। समीकरण का बायां पक्ष संदर्भ ($F_{cat}$) का मूल्यांकन करता है, और दायां पक्ष स्थानीय सुविधाओं ($F'$) का मूल्यांकन करता है। उन्हें गुणा करके, नेटवर्क केवल तभी सिग्नल को गुजरने देता है जब स्थानीय विवरण और ग्लोबल कॉन्टेक्स्ट दोनों सहमत हों कि यह महत्वपूर्ण है। यह सक्रिय रूप से अप्रासंगिक पृष्ठभूमि शोर को म्यूट करता है।
* $+$ (अवशिष्ट जोड़): जटिल गेटिंग तंत्र तय करने के बाद कि क्या बढ़ाना है, इसे मूल इनपुट $F$ में वापस जोड़ा जाता है। यह एक अवशिष्ट कनेक्शन है। यह सुनिश्चित करता है कि नेटवर्क मूल छवि को कभी न भूले, जो ओवर-प्रोसेसिंग के खिलाफ सुरक्षा जाल के रूप में कार्य करता है।
चरण-दर-चरण प्रवाह
आइए एक एकल अमूर्त डेटा बिंदु के सटीक जीवनचक्र का पता लगाएं - मान लीजिए, पेट की सीमा पर एक छोटे से पिक्सेल का प्रतिनिधित्व करने वाला एक उच्च-आयामी वेक्टर।
- आधारभूत प्रवेश: पेट की सीमा पिक्सेल फीचर मैप $F$ के हिस्से के रूप में DSEB ब्लॉक में प्रवेश करता है।
- किनारा निष्कर्षण: नेटवर्क इस पिक्सेल के चारों ओर छवि को सिकोड़ता और फैलाता है। चूंकि यह एक सीमा पर है, इस प्रक्रिया के दौरान पिक्सेल थोड़ा शिफ्ट हो जाता है। नेटवर्क तेज संक्रमण को अलग करते हुए दो संस्करणों को घटाता है। हमारा पिक्सेल अब $F_{edge}$ मैप में चमक रहा है।
- सीमा इंजेक्शन: नेटवर्क इस चमक को $\lambda$ से स्केल करता है और इसे मूल पिक्सेल ($+$) में वापस जोड़ता है। पेट की सीमा अब कुरकुरी और अच्छी तरह से परिभाषित ($\tilde{F}$) है।
- संदर्भ संग्रह: पिक्सेल CFAM डिकोडर में चला जाता है। इसे क्लोन में विभाजित किया गया है। एक क्लोन अपने तत्काल पड़ोसियों को देखता है; दूसरा 8 पिक्सेल दूर देखता है यह महसूस करने के लिए, "आह, मैं यकृत के बगल में हूँ।" इन दृष्टिकोणों को $F_{cat}$ में स्टैक किया गया है।
- गेटिंग पूछताछ: संदर्भ ($F_{cat}$) और पिक्सेल की अपनी कैलिब्रेटेड पहचान ($F'$) दोनों को $f_{1\times1}$ द्वारा मिश्रित किया जाता है और $\text{SiLU}$ द्वारा चिकना किया जाता है। वे गुणन ऑपरेटर ($\odot$) पर मिलते हैं। संदर्भ कहता है, "यह एक वैध अंग सीमा है," एक उच्च मान (जैसे, 0.9) आउटपुट करता है। स्थानीय सुविधा कहती है, "मैं एक तेज किनारा हूँ," एक उच्च मान (जैसे, 0.8) आउटपुट करती है। वे गुणा करते हैं ($0.9 \times 0.8 = 0.72$), फिल्टर से बच जाते हैं। (यदि यह पिक्सेल सिर्फ त्वचा पर एक यादृच्छिक बाल होता, तो संदर्भ 0.01 आउटपुट करता, और गुणन तुरंत शोर को मार देता)।
- अंतिम पुनर्संयोजन: यह परिष्कृत, संदर्भ-अनुमोदित सिग्नल कच्चे पिक्सेल $F$ में वापस जोड़ा जाता है ($+$)। डेटा बिंदु मॉड्यूल से बाहर निकलता है, पूरी तरह से बढ़ाया गया और अंतिम सेगमेंटेशन मैप के लिए तैयार है।
अनुकूलन गतिशीलता
यह यांत्रिक असेंबली लाइन वास्तव में अंगों को सेगमेंट करना कैसे सीखती है?
सीखने की प्रक्रिया लॉस फ़ंक्शन से पीछे की ओर बहने वाले ग्रेडिएंट्स द्वारा संचालित होती है (विशेष रूप से, BDoU लॉस, जो नेटवर्क को भारी दंडित करता है यदि यह सीमाओं को गलत करता है)।
आर्किटेक्चर एक अत्यधिक अनुकूल लॉस परिदृश्य को आकार देता है। अवशिष्ट जोड़ ($+$) के भारी उपयोग के कारण, ग्रेडिएंट्स के पास नेटवर्क के अंत से सीधे शुरुआती परतों तक बिना गायब हुए प्रवाहित होने के लिए एक "फास्ट-पास" राजमार्ग होता है।
इस बीच, गेटिंग तंत्र ($\odot$) एक गतिशील ग्रेडिएंट राउटर के रूप में कार्य करता है। बैकप्रॉपैगेशन के दौरान, यदि किसी विशिष्ट क्षेत्र के लिए SiLU गेट फॉरवर्ड पास के दौरान बंद (शून्य के करीब) था क्योंकि इसे अप्रासंगिक शोर माना गया था, तो उस पथ के माध्यम से वापस बहने वाला ग्रेडिएंट भी शून्य से गुणा हो जाता है। यह प्रभावी रूप से मृत भार के लिए सीखने को फ्रीज करता है और ऑप्टिमाइज़र को सभी अपडेटिंग शक्ति को उन भारों पर केंद्रित करने के लिए मजबूर करता है जो प्रमुख क्षेत्रों (अंगों और सीमाओं) के लिए जिम्मेदार हैं।
अंत में, नेटवर्क को बहुत अधिक उत्साहित होने और रनवे फीडबैक लूप बनाने से रोकने के लिए (जहां बढ़ी हुई सुविधाओं को तब तक बढ़ाया जाता रहता है जब तक वे शोर में विस्फोट न हो जाएं), लेखकों ने मॉड्यूल के अंत में एक भारित नॉन-लोकल ब्लॉक (wNLB) रखा। यह एक स्थानिक रेगुलराइज़र के रूप में कार्य करता है। यह एक साथ पूरी छवि को देखता है और ओवर-एनहांसमेंट के किसी भी अलग स्पाइक्स को चिकना करता है, यह सुनिश्चित करता है कि अनुकूलन प्रक्षेपवक्र स्थिर, चिकना बना रहे और अत्यधिक सटीक, सीमा-पूर्ण सेगमेंटेशन में परिवर्तित हो।
परिणाम, सीमाएँ और निष्कर्ष
CENet (Context Enhancement Network) की वास्तविक सराहना के लिए, हमें पहले मेडिकल इमेज सेगमेंटेशन की मौलिक समस्या को समझना होगा। कल्पना कीजिए कि आपको एक अत्यंत विस्तृत, फिर भी थोड़ी धुंधली, उपग्रह मानचित्र पर किसी देश की सटीक सीमाओं का पता लगाने का कार्य सौंपा गया है। चिकित्सा क्षेत्र में, यह "पता लगाना" पिक्सेल-वार सेगमेंटेशन है—कच्चे सीटी, एमआरआई, या त्वचा स्कैन से अंगों, ट्यूमर, या घावों की सटीक सीमाओं की पहचान करना।
ऐतिहासिक रूप से, वैज्ञानिकों ने इसके लिए कनवल्शनल न्यूरल नेटवर्क्स (CNNs) का उपयोग किया। CNNs एक आवर्धक कांच की तरह काम करते हैं; वे स्थानीय बनावटों को देखने में उत्कृष्ट होते हैं लेकिन वैश्विक संदर्भ ( "बड़ी तस्वीर" ) को समझने में भयानक होते हैं। हाल ही में, विजन ट्रांसफॉर्मर्स (ViTs) मैदान में उतरे। ViTs एक उपग्रह दृश्य की तरह काम करते हैं; वे वैश्विक संदर्भ को पूरी तरह से समझते हैं लेकिन अक्सर महीन, स्थानीय सीमा विवरणों को धुंधला कर देते हैं। जब इंजीनियर इन दो दृष्टिकोणों को संयोजित करने का प्रयास करते हैं, या जब वे कम्प्यूटेशनल शक्ति बचाने के लिए छवियों को सिकोड़ते हैं (डाउनसैंपलिंग), तो अंगों की नाजुक सीमाएं समझौता हो जाती हैं।
इस पत्र का मुख्य उद्देश्य एक निराशाजनक विरोधाभास को हल करना है: यदि आप किसी नेटवर्क को गणितीय रूप से महीन किनारों पर अधिक ध्यान देने के लिए मजबूर करने का प्रयास करते हैं, तो आप अनिवार्य रूप से पृष्ठभूमि शोर (जैसे टीवी पर स्थैतिक या त्वचा स्कैन पर बाल) को बढ़ाते हैं। लेखकों को एक ऐसी प्रणाली बनाने की आवश्यकता थी जो जटिल, विकृत अंगों की सीमाओं को बढ़ा सके बिना "अति-संवर्धन" के या नेटवर्क की सीखने की प्रक्रिया को खराब किए।
गणितीय कोर: क्या समस्या हल की गई और कैसे?
लेखकों ने दो शानदार गणितीय हस्तक्षेपों का उपयोग करके दृश्य सूचना के प्रवाह को रोकने और परिष्कृत करने के लिए CENet को आर्किटेक्ट किया: डुअल सेलेक्टिव एनहांसमेंट ब्लॉक (DSEB) और कॉन्टेक्स्चुअल फीचर अटेंशन मॉड्यूल (CFAM)।
1. किनारों को अलग करना (DSEB)
किनारे कहाँ हैं इसका केवल अनुमान लगाने के बजाय, DSEB गणितीय रूप से उन्हें फीचर एज एम्पलीफायर (FEA) का उपयोग करके अलग करता है। नेटवर्क इनपुट फीचर मैप $F$ लेता है और इसे विभिन्न अनुपातों ($s_1 = 0.75$ और $s_2 = 0.5$) पर नीचे और फिर से ऊपर स्केल करता है।
$$F_{u1} = U(\mathcal{D}(F, s_1), s_0), \quad F_{u2} = U(\mathcal{D}(F, s_2), s_0)$$
यहां, $\mathcal{D}$ डाउनसैंपलिंग है और $U$ अपसैंपलिंग है। क्योंकि छवि के ये दो संस्करण अलग-अलग संपीड़ित किए गए थे, उन्हें घटाने से चौड़े, सपाट क्षेत्र (जैसे अंग का मध्य भाग) रद्द हो जाते हैं और केवल तेज, उच्च-आवृत्ति वाले किनारे विवरण बचते हैं:
$$F_{edge} = |F_{u1} - F_{u2}|$$
यह शुद्ध "एज मैप" फिर एक सीखे हुए पैरामीटर $\lambda$ द्वारा भारित किया जाता है और मूल फीचर मैप में वापस जोड़ा जाता है:
$$\tilde{F} = F + \lambda F_{edge}$$
2. शोर को नियंत्रित करना (CFAM)
एक बार जब किनारों को बढ़ाया जाता है, तो नेटवर्क शोर से अभिभूत होने का जोखिम उठाता है। CFAM इन अत्यधिक संवर्धित अभ्यावेदन को अंतिम आउटपुट को खराब करने से रोकने के लिए एक बहु-चरणीय निस्पंदन प्रणाली के रूप में कार्य करता है।
सबसे पहले, यह पता लगाने के लिए कि कौन से "चैनल" (दृश्य डेटा की परतें) वास्तव में महत्वपूर्ण हैं, यह एक चैनल कैलिब्रेशन यूनिट (CCU) का उपयोग करता है। यह डेटा को तीन अलग-अलग तरीकों से पूल करके ऐसा करता है—औसत, अधिकतम, और मानक विचलन—एक वैश्विक डिस्क्रिप्टर $\mathbf{g}$ बनाने के लिए:
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
यह डिस्क्रिप्टर भारों का एक सेट $\mathbf{s}$ उत्पन्न करता है जो मूल विशेषताओं को स्केल करता है: $F' = F \odot \mathbf{s}$।
बाद में CFAM में, एक स्थानिक कैलिब्रेशन मॉड्यूल (SRM) स्थानिक स्थानों के लिए एक समान चाल चलता है, समानांतर कनवल्शन का उपयोग करके पिक्सेल-वार और पड़ोस की बातचीत दोनों को कैप्चर करता है:
$$S = \sigma(f_{1\times1}(G) + f_k^{dw}(G))$$
$$F_{recal} = F_{MCA} \odot S$$
DSEB के एज-बूस्टिंग को CFAM के क्रूर शोर-फ़िल्टरिंग के साथ जोड़कर, लेखकों ने विरोधाभास को हल किया: उन्होंने स्थैतिक के बिना अति-तेज सीमाएं प्राप्त कीं।
प्रयोगात्मक वास्तुकला: दावों को साबित करना
लेखकों ने केवल अपने मॉडल को एक डेटासेट पर नहीं फेंका और 1% सटीकता वृद्धि का दावा नहीं किया। उन्होंने अपने गणितीय दावों को क्रूरतापूर्वक मान्य करने के लिए एक अत्यधिक शत्रुतापूर्ण परीक्षण मैदान डिजाइन किया।
पीड़ित (बेसलाइन):
उन्होंने CENet को अत्याधुनिक मॉडलों की एक विशाल सूची के खिलाफ खड़ा किया। पीड़ितों में शुद्ध CNNs (U-Net, DeepLabv3+), शुद्ध ट्रांसफॉर्मर (Swin-Unet, MissFormer), और भारी-हिटिंग हाइब्रिड मॉडल (TransUNet, MSA$^2$Net, UCTransNet) शामिल थे।
निर्णायक साक्ष्य:
यह साबित करने के लिए कि उनका मॉडल केवल एक विशिष्ट प्रकार की छवि को याद नहीं कर रहा था, उन्होंने इसे पूरी तरह से अलग चिकित्सा डोमेन में परीक्षण किया: आंतरिक रेडियोलॉजी (गुर्दे, पेट और हृदय के 3D सीटी और एमआरआई स्कैन) और बाहरी डर्मोस्कोपी (त्वचा के घावों की 2डी तस्वीरें)। CENet ने सभी बेसलाइन को पार किया, ACDC कार्डियक डेटासेट पर एक विशाल 92.18% DICE स्कोर प्राप्त किया।
लेकिन निर्विवाद, धूम्रपान करने वाले बंदूक का सबूत मेट्रिक्स नहीं था—यह दृश्य फीचर हीटमैप और एब्लेशन अध्ययन था। लेखकों ने वास्तव में नेटवर्क के "मस्तिष्क" को खोला ताकि यह दिखाया जा सके कि यह कहाँ देख रहा था।
1. DSEB से पहले: नेटवर्क का ध्यान बिखरा हुआ और फैला हुआ था।
2. DSEB के बाद: ध्यान अंगों की सीमाओं पर कसकर केंद्रित हो गया।
3. wNLB (डीनोइज़िंग तंत्र) के बाद: नेटवर्क ने सक्रिय रूप से अप्रासंगिक विवरणों को दबा दिया। त्वचा घाव डेटासेट में, आप नेटवर्क को रोगी की त्वचा पर भौतिक बालों को अनदेखा करते हुए केवल घाव की सीमा पर ध्यान केंद्रित करते हुए देख सकते हैं।
इसके अलावा, उन्होंने व्यवस्थित रूप से अपने मॉडल को नष्ट कर दिया (DSEB, FEA, और CFAM को एक-एक करके बंद करके)। एब्लेशन अध्ययन ने साबित कर दिया कि एज-एम्प्लीफिकेशन और नॉइज़-सप्रेशन के विशिष्ट गणितीय संयोजन के बिना, मॉडल का प्रदर्शन ध्वस्त हो गया।
भविष्य की चर्चा के विषय
इस पत्र में प्रस्तुत शानदार यांत्रिकी के आधार पर, भविष्य के अन्वेषण और महत्वपूर्ण बहस के लिए कई रास्ते यहां दिए गए हैं:
- मल्टी-स्केल प्रोसेसिंग की लागत बनाम नैदानिक वास्तविकता:
CENet मल्टी-स्केल डाउनसैंपलिंग, अपसैंपलिंग और डाइलेटेड कनवल्शन पर बहुत अधिक निर्भर करता है। जबकि अत्यधिक सटीक, यह अनुमान समय को कैसे प्रभावित करता है? यदि कोई अस्पताल इसे NVIDIA A100 के बजाय एक मानक \$150 क्लिनिकल GPU पर तैनात करना चाहता है, तो क्या CFAM के जटिल गेटिंग तंत्र एक बाधा बन जाएंगे? हमें आपातकालीन कक्ष निदान के लिए इन भारी गणितीय परिचालनों को हल्के, वास्तविक समय के आर्किटेक्चर में आसवित करने के तरीके पर चर्चा करनी चाहिए। - "फजी बाउंड्री" दुविधा:
DSEB मॉड्यूल मानता है कि एक तेज सीमा हमेशा ग्राउंड ट्रुथ होती है। हालांकि, ऑन्कोलॉजी में, कुछ आक्रामक, घुसपैठ वाले ट्यूमर (जैसे मस्तिष्क में ग्लियोब्लास्टोमा) में स्वाभाविक रूप से तेज सीमाएं नहीं होती हैं; वे स्वस्थ ऊतक में फीके पड़ जाते हैं। जब जैविक ग्राउंड ट्रुथ एक किनारे के बजाय एक ग्रेडिएंट होता है तो निरपेक्ष अंतर तंत्र ($|F_{u1} - F_{u2}|$) कैसे व्यवहार कर सकता है? क्या यह गणितीय सख्ती गलती से नेटवर्क को वहां एक कठिन सीमा का मतिभ्रम करने के लिए मजबूर कर सकती है जहां कोई मौजूद नहीं है? - निरंतर 3D स्थानिक निर्भरताओं के लिए विकास:
वर्तमान मॉडल 3D एमआरआई और सीटी स्कैन को 2डी स्लाइस की एक श्रृंखला के रूप में संसाधित करता है। जबकि wNLB (वेटेड नॉन-लोकल ब्लॉक) एक स्लाइस के भीतर लंबी दूरी की स्थानिक निर्भरताओं को कैप्चर करता है, यह Z-अक्ष (गहराई) को अनदेखा करता है। हम चैनल कैलिब्रेशन यूनिट (CCU) और स्थानिक कैलिब्रेशन मॉड्यूल (SRM) को कम्प्यूटेशनल जटिलता के घातीय विस्फोट का कारण बने बिना वास्तविक वॉल्यूमेट्रिक टेंसर को संसाधित करने के लिए गणितीय रूप से कैसे विकसित कर सकते हैं?
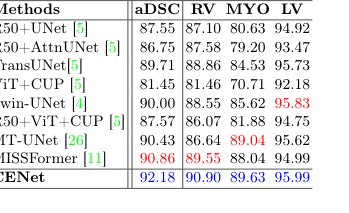 Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
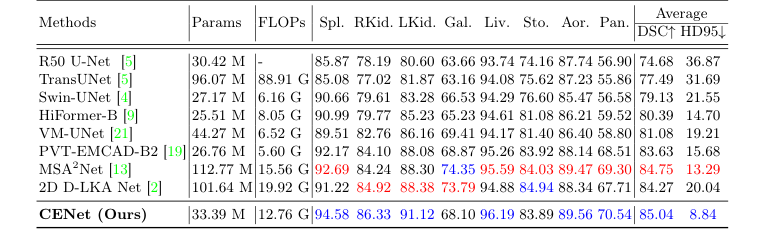 Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
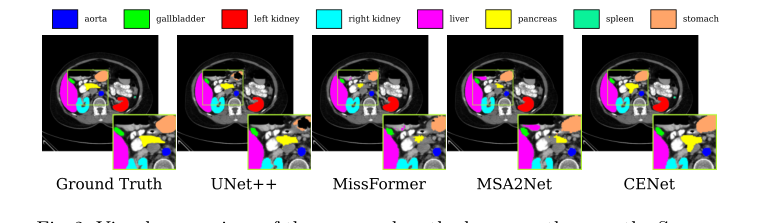 Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset
Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset