CENet:医用画像セグメンテーションのためのコンテキスト強調ネットワーク
CENet boosts medical image segmentation by enhancing boundaries and preserving details across diverse image types.
背景と学術的系譜
歴史的に、医用画像における解剖学的構造、臓器、病変の正確な境界線描画は、完全に手作業で行われていた。放射線技師は、ピクセルごとに慎重に境界線を描く必要があり、これは非常に時間と費用がかかるプロセスであった。例えば、1スキャンあたり150ドルの人件費がかかり、自動化システムの緊急の必要性を生み出した。この問題から、自動医用画像セグメンテーションの分野が誕生した。この分野は、エンコーダー・デコーダー構造を導入した全畳み込みネットワーク(FCN)と、特にU-Netアーキテクチャによって革命的に進歩した。エンコーダーはスキャン内の「何」を理解するために画像を圧縮し、デコーダーは「どこ」にあるかを特定するために画像を拡張する。しかし、医用画像技術が進歩するにつれて、重大な課題が現れた。機械に、臓器全体の広範なグローバルコンテキストを同時に理解させながら、小さな腫瘍の微細な境界の詳細を完全に保持させるにはどうすればよいか?
従来の、あるいは先行するアプローチの根本的な限界は、全体像の把握と微細な詳細の保持との間の絶え間ない綱引きである。従来の畳み込みニューラルネットワーク(CNN)は、「視野」が限られているため、大規模画像全体の関係性を理解するのに苦労する。これを解決するために、研究者たちは画像全体を一度に見るVision Transformer(ViT)を導入した。しかし、ViTは計算量が膨大であり、局所的なエッジの詳細を捉えるのが苦手であることが知られている。以前のモデル、ハイブリッドモデルでさえ、この問題を解決するために微細な境界の詳細をネットワークに通過させようとした際に、「過剰強調」という深刻な問題に悩まされた。適切な制御メカニズムがないと、エッジの詳細を増幅すると背景ノイズも増幅され、デコーダー段階での劣化につながる。既存のモデルは、ダウンサンプリングプロセス中に境界の詳細を単に妥協しており、複雑な臓器の高精度なマルチスケールセグメンテーションをほぼ不可能にしていた。このため、著者らは、ネットワークをノイズで溺れさせることなく、境界をインテリジェントに強調するためにCENetを作成する必要に迫られた。
以下に、論文から抽出された、直感的な概念に翻訳された、非常に専門的なドメイン用語をいくつか示す。
- スキップ接続 (Skip Connections): ニューラルネットワークにおいて、特定の層をバイパスして、生の、詳細な情報をモデルの後段に直接フィードするためのアーキテクチャ上のショートカットである。
- 日常的な例え: 1000ページの詳細な小説を10ページの要約に翻訳し、その要約だけを使って元の小説を書き直すように作者に依頼するのを想像してほしい。彼はすべての豊かな詳細を失うだろう。スキップ接続は、作者が書き直している間に、元のキャラクターのスケッチや設定の説明を渡すようなもので、翻訳中に細かいディテールが失われないようにする。
- 受容野 (Receptive Field): ニューラルネットワークの特定の部分が、現時点で入力画像の「見ている」特定の、制限された領域である。
- 日常的な例え: 段ボールのペーパータオルチューブを通して、巨大で複雑な壁画を見ていると考えてほしい。一度に見える壁画の小さな円があなたの受容野である。壁画全体の物語を理解するには、はるかに広いチューブが必要である。
- ダウンサンプリング (Downsampling): 情報を圧縮し、高レベルの意味論的な意味を抽出するために、画像の空間解像度を意図的に低下させるプロセスである。
- 日常的な例え: スマートフォンのデジタルマップでズームアウトするようなものである。ズームアウトすると、個々の通りの名前やコーヒーショップ(微細な詳細)は失われるが、ついに州や国の全体的な形(グローバルコンテキスト)を見ることができるようになる。
- 自己注意機構 (Self-Attention Mechanism): モデルが入力データの異なる部分間の重要度を相対的に重み付けし、何に焦点を当てるかを決定することを可能にする数学的方法である。
- 日常的な例え: 大音量で混雑したカクテルパーティーにいるのを想像してほしい。あなたの脳は、話している相手の声に集中するために、バックグラウンドミュージックやグラスの音を自然に無視する。自己注意は、データに対してまさにこれを行い、どのピクセルが「聞く」のに最も重要かを決定する。
主要な数学的記法
| 記法 | 説明 |
|---|---|
| $F$ | ネットワークによって処理される入力特徴マップ。 |
| $\mathcal{D}(F, s)$ | スケール $s$ で特徴マップに適用されるマルチスケールダウンサンプリング操作。 |
| $\mathcal{U}(F, s)$ | スケール $s$ で特徴マップに適用されるアップサンプリング操作。 |
| $s_1, s_2, s_0$ | 特徴マップのリサイズに使用される特定のスケールパラメータ(例: $0.75, 0.5, 1.0$)。 |
| $F_{u1}, F_{u2}$ | 異なるスケールで結果として得られるアップサンプリングされた特徴マップ。 |
| $F_{\text{edge}}$ | 数学的に $\|F_{u1} - F_{u2}\|$ と定義される、分離され洗練されたエッジの詳細。 |
| $\lambda$ | エッジ特徴をスケーリングするために使用される、学習可能な重み付けパラメータベクトル($\lambda \in \mathbb{R}^d$)。 |
| $\tilde{F}$ | 重み付けされたエッジ詳細を元の入力に追加した後の最終的な強調された特徴マップ。 |
| $\mathbf{g}$ | チャネルごとの統計情報をキャプチャするためにプーリング操作によって生成されるグローバル記述子ベクトル。 |
| $\mathbf{s}$ | チャネルキャリブレーションユニット(CCU)によって生成され、特徴を適応的に再重み付けするためのチャネル重み。 |
| $F'$ | チャネルアテンション($F \odot \mathbf{s}$)を適用した後の再重み付けされた出力特徴マップ。 |
| $F'_i$ | マルチスケールコンテキストアグリゲーター(MCA)で使用される特徴マップの分割された部分。 |
| $f_{dk}$ | 特定のカーネルサイズと膨張率 $d_k$ を持つ、深層ごとの畳み込み演算子。 |
| $\mathcal{C}_{\text{avg}}, \mathcal{C}_{\text{max}}, \mathcal{C}_{\text{std}}$ | チャネルごとの平均プーリング、最大プーリング、標準偏差プーリング操作。 |
| $G$ | スペーシャルキャリブレーションモジュールで異なるプーリング操作を組み合わせて作成されるスペーシャル記述子。 |
| $S$ | 要素ごとの乗算による特徴マップの再キャリブレーションに使用される結合された出力。 |
問題定義と制約
衛星画像のピクセルが粗い状態で、複雑に形を変える島の正確な輪郭をなぞろうとする状況を想像してほしい。医療画像解析の分野では、入力(Input)はCTスキャン、MRI、皮膚病変のダーモスコピー写真などの生データであり、出力(Output)は解剖学的構造、臓器、あるいは病変のピクセル単位での正確な輪郭線である。本論文が埋めようとしている数学的なギャップは、画像全体の文脈を理解するために圧縮された際に発生する深刻な情報損失であり、これは正確な境界を描くために必要な微細な空間座標を本質的に破壊する。著者らは、これらの失われたエッジの詳細を、マルチスケールアップサンプリングされた特徴量の絶対差として計算される $F_{edge} = |F_{u1} - F_{u2}|$ を用いて、無関係なデータにシステムが埋もれることなく、数学的に分離し注入する方法を必要としている。
ディープラーニングにおいて、一つの問題を解決すると、ほぼ必ず別の問題が発生し、先行研究者たちはフラストレーションの溜まるジレンマに陥っていた。畳み込みニューラルネットワーク(CNN)を使用すると、モデルは局所的なテクスチャの理解には優れるが、畳み込みカーネルの受容野が限定的であるため、グローバルな文脈を把握することができない。これを解決するために、研究者たちはVision Transformers(ViTs)に目を向けた。ViTsは自己注意機構を用いて画像全体を一度に見ることができる。しかし、ViTsは痛みを伴うトレードオフをもたらす。グローバルな文脈を美しく捉える一方で、局所的なエッジ表現のモデリングにおいて著しく性能が低下する。さらに、この問題を解決するために、ネットワークに微細な境界特徴に注意を払うよう手動で強制しようとすると、新たな問題が発生する。適切な制御機構の欠如が背景ノイズを増幅させ、「過剰に強調された」表現につながり、デコーディング段階でのネットワークの性能を実際に低下させる。ぼやけた境界、グローバルな理解の欠如、あるいはノイズが多く不安定なアーキテクチャのいずれかを選択せざるを得ない状況である。
著者らは、この特定の問題を解決することを極めて困難にしている、いくつかの厳しい現実的な壁に直面した。
- 二次計算量: Transformerは強力であるが、その自己注意機構は入力サイズに対して二次的にスケールする(しばしば $O(N^2)$ と表現される)。これは大規模な計算ボトルネックを生み出し、厳格なハードウェアメモリ制限に達するため、大規模で高解像度の医療アプリケーションには非常に非効率的である。
- 破壊的なダウンサンプリング: 現代のニューラルネットワークの階層構造は、特徴抽出のためにダウンサンプリングに大きく依存している。この物理的な制約は、本質的に境界の詳細と微細な意味表現を損なう。これらは失われた後に数学的に回復することが困難である。
- 極端な形態学的変動性: 医療構造は剛体ではない。臓器や病変は非常に変形しやすく、患者ごとに多様な形状、外観、病理学的状態を示す。固定された受容野では、このマルチスケール変動性に対応することはできない。
- スキップ接続におけるノイズ蓄積: 失われた詳細を回復するために、ネットワークは圧縮をバイパスするために「スキップ接続」を使用する。しかし、このデータをフィルタリングする方法がないと、無関係な背景ノイズが直接デコーダーに渡される。著者らは、過剰に強調された表現がノイズを蓄積し、重要な境界の詳細を消去することなく適応的に特徴量をノイズ除去するために複雑な数学的介入を必要とする、という深刻な制約が生じると指摘している。
このアプローチの理由
医療画像セグメンテーションの現状を分析する中で、CENetの著者らは非常に特異で、かつフラストレーションの溜まる壁に直面した。彼らは、従来の最先端(SOTA)アーキテクチャが、臨床スキャンという過酷な現実に対して根本的に欠陥があることに気づいたのである。U-Netのような畳み込みニューラルネットワーク(CNN)は、カーネルの局所的な受容野によって本質的に制限されており、大きくて変形しやすい臓器のグローバルなコンテキストを捉えることができない。一方、Vision Transformer(ViT)は、自己注意機構を通じてグローバルなコンテキストを捉える新たなゴールドスタンダードとして登場した。しかし、著者らはViTが失敗する正確な瞬間を特定した。すなわち、局所的な微細な詳細(病変の正確な境界など)のモデリングにおいて著しく性能が低下し、大規模で高解像度の医療アプリケーションには非効率的となる壊滅的な二次計算量を持つのである。
以前の研究者たちがこれらのモデルを組み合わせてハイブリッドCNN-Transformerモデルを構築しようとした際にも、新たな問題が生じた。厳密な制御機構なしに微細なエッジ特徴をデコーダーに押し込むことは、単にネットワークにノイズを氾濫させ、デコーダー段階での劣化を招いた。著者らは、力任せのアプローチは実行可能ではなく、高度に制御された、数学的に厳密なフィルタリングシステムが必要であると認識した。これが、Context Enhancement Network(CENet)が唯一実行可能なソリューションであった理由である。
この問題を解決するため、彼らは医療画像の厳しい制約――境界が曖昧で、臓器のサイズが大きく変動する――と、独自のデュアルフィルタリングアーキテクチャとの「結婚」を考案した。スキップ接続にDual Selective Enhancement Block(DSEB)を導入した。エンコーダーからデコーダーへ特徴量を盲目的に渡すのではなく、DSEBはFeature Edge Amplifier(FEA)を用いてエッジの詳細を積極的に分離・増幅する。これは、異なるスケールの特徴量間の差を計算することによって行われる。
$$F_{edge} = |F_{u1} - F_{u2}|$$
ここで、$F_{u1}$および$F_{u2}$は、異なるダウンサンプリングスケールからアップサンプリングされた特徴量である。この分離されたエッジマップは、元の特徴量マップに注入される。
$$\tilde{F} = F + \lambda F_{edge}$$
ここで、$\lambda \in \mathbb{R}^d$は重み付けパラメータとして機能する。
しかし、ここで比較優位性が真に輝く。エッジを増幅すると、通常は高次元のノイズも増幅してしまう。これを克服するため、著者らはDifferential Attention(DiffAtt)を統合した。別々の注意マップを計算してそれらを減算することにより、冗長な注意と不均衡なトークン重要性を効果的にキャンセルする。これは、ニューラルネットワークのためのアクティブノイズキャンセリングヘッドホンのように機能する。
さらに、デコーダーはContext Feature Attention Module(CFAM)を利用して、ネットワークが過度に増幅された表現に詰まるのを防ぐ。これは、グローバル記述子$\mathbf{g}$を用いてチャネルを圧縮し、適応的に再重み付けするChannel Calibration Unit(CCU)を使用する。
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
これに続いて、特徴量を分割し、並列の拡張されたdepth-wise畳み込みを通じて処理するMulti-scale Contextual Aggregator(MCA)が続く。この構造的利点により、ネットワークは、従来の密な層の巨大なパラメータ増加なしに、複数のスケールを同時に見ることができる。
率直に言って、この論文では標準的なViTと比較したメモリ複雑性の正確なBig-O表記は明示されていないが、彼らは二次的な非効率性のため標準的なTransformerを明確に却下している。depth-wise畳み込みとチャネル削減を利用することにより、CENetは質的に優れた軽量な表現を実現し、より重いモデルを容易に凌駕する。
最後に、この論文は他の一般的なアプローチがなぜ失敗するのかを正確に説明している。GANや拡散モデルを明確に却下しているわけではないが――完全に透明性を保つために、これらの生成モデルはここでは必要とされる決定論的な精度に苦労する可能性が高い――既存の局所的な自己注意機構やハイブリッドモデルを厳しく批判している。これらの代替案は、「エッジ情報」よりも「ボディ特徴」に過度に焦点を当てており、ノイズ蓄積に対処するために必要な適応的なノイズ除去を欠いている。CFAMの終端に重み付けされたNon-local Block(wNLB)をCENetに組み込むことは、長距離の空間的依存関係を完全にモデル化し、過度に注意が向けられた無関係な詳細(例えば、皮膚科画像における毛髪)を抑制し、制御されたコンテキスト認識型の増強が、以前のゴールドスタンダードよりも圧倒的に優れていることを証明している。
数学的・論理的メカニズム
Context Enhancement Network (CENet) の卓越性を理解するためには、まず医療画像セグメンテーションにおける根本的な綱引きを理解する必要がある。ぼやけたグレースケールの医療スキャンから、腫瘍や臓器(腎臓など)の正確な輪郭をトレースしようと想像してほしい。ズームしすぎると、正確なエッジは見えるが、体のどこにいるのかがわからなくなる(グローバルコンテキストの喪失)。ズームアウトすると、どこにいるかは正確にわかるが、細かい境界線がピクセルにぼやけてしまう(ローカル詳細の喪失)。
歴史的に、畳み込みニューラルネットワーク(CNN)は「ズームイン」の専門家であり、小さなスライディングウィンドウを通して見ていたのに対し、Vision Transformer(ViT)は「ズームアウト」の専門家であり、画像全体を見ていたが、細かい局所的な境界線に苦労していた。さらに、エンジニアがこれらを組み合わせようとしたとき、ネットワークはしばしば「過剰強調」に悩まされた。つまり、実際の臓器だけでなく背景ノイズも増幅し、予測の低下につながった。
CENetの著者らは、スマートな拡大鏡のように機能する、高度に制御されたマルチスケールアーキテクチャを設計することで、この問題を解決した。これは、関連性のないノイズを抑制するための洗練されたゲーティングメカニズムを使用しながら、選択的に境界を強調する。
以下に、著者らがこれを達成した数学的解剖を示す。
マスター方程式
CENetの心臓部は、2つの相互接続された数学的エンジンに依存している。1つ目は境界の詳細を救済するDual Selective Enhancement Block (DSEB)である。2つ目は、ネットワークをノイズで圧倒することなく、さまざまなズームレベルをインテリジェントに融合するMulti-scale Contextual Aggregator (MCA)である。
境界強調エンジン:
$$ \tilde{F} = F + \lambda F_{edge} $$
マルチスケールコンテキストゲーティングエンジン:
$$ F_{MCA} = \Big( \text{SiLU}(f_{1\times1}(F_{cat})) \odot \text{SiLU}(f_{1\times1}(F')) \Big) + F $$
方程式の分解
これらのメカニズムのすべての歯車とバネを分解してみよう。
境界エンジンから:
* $F$: 元の入力特徴マップ。物理的には、特定のレイヤーにおける画像のベースライン現実であり、生の、編集されていない信号である。
* $F_{edge}$: 分離されたエッジの詳細。著者らは、画像を異なるスケールでダウンサンプリングおよびアップサンプリングし、絶対差 ($|F_{u1} - F_{u2}|$) を取ることでこれを計算する。論理的には、これはハイパスフィルターとして機能し、シャープな遷移(臓器の境界)のみを捉える。
* $\lambda$: 学習可能な重み付けパラメータ($\mathbb{R}^d$ のベクトル)。これはエッジの音量ダイヤルとして機能し、ネットワークが各チャネルに対して実際にどの程度の境界強調が必要かを決定できるようにする。
* $+$ (加算): 乗算ではなく加算する理由。加算はオーバーレイとして機能する。ベースライン画像 ($F$) を取得し、その上に強調された境界 ($\lambda F_{edge}$) を描画している。乗算を使用した場合、エッジがない領域($F_{edge} \approx 0$)は画像全体を消去し、臓器の内部を真っ黒にしてしまうだろう!
コンテキストゲーティングエンジンから:
* $F_{cat}$: 連結されたマルチスケール特徴。ネットワークは画像を分割し、異なる「拡張」レンズ(3、5、8ピクセル離れた隣接を見る)を通して見てから、それらをスタックする。これは「グローバルコンテキスト」または森を表す。
* $F'$: チャネルキャリブレートされた特徴マップ。これは、最も重要な特徴チャネルが優先されるように再重み付けされた元の信号である。これは「ローカル詳細」または木を表す。
* $f_{1\times1}$: ポイントワイズ畳み込み。数学的には、特徴マップの深さにわたる線形変換である。論理的には、バーテンダーのように機能し、画像の空間的な幅や高さを変更せずに、さまざまなチャネルの情報を混合する。
* $\text{SiLU}$: Sigmoid Linear Unit 活性化関数。強い正の信号を線形に通過させるが、負の信号をゼロに向かって滑らかに圧縮する。ソフトで連続的なゲートキーパーとして機能する。
* $\odot$ (アダマール積): 要素ごとの乗算。これは最も重要な演算子である。加算ではなく乗算する理由。乗算は論理的な AND ゲート(フィルター)として機能する。方程式の左側はコンテキスト ($F_{cat}$) を評価し、右側はローカル特徴 ($F'$) を評価する。それらを乗算することにより、ネットワークは、ローカル詳細とグローバルコンテキストの両方がそれが重要であると合意した場合にのみ信号を通過させる。関連性のない背景ノイズを積極的にミュートする。
* $+$ (残差加算): 複雑なゲーティングメカニズムが強調するものを決定した後、元の入力 $F$ に加算して戻される。これは残差接続である。これにより、ネットワークが元の画像を忘れることはなく、過剰処理に対するセーフティネットとして機能する。
ステップバイステップフロー
胃の境界にある小さなピクセルを表す高次元ベクトルなどの、単一の抽象データポイントの正確なライフサイクルをトレースしてみよう。
- ベースラインエントリ: 胃の境界ピクセルが特徴マップ $F$ の一部として DSEB ブロックに入る。
- エッジ抽出: ネットワークはこのピクセルを中心に画像を縮小および拡大する。境界上にあるため、このプロセス中にピクセルはわずかにシフトする。ネットワークは2つのバージョンを減算し、シャープな遷移を分離する。このピクセルは現在、$F_{edge}$ マップで光っている。
- 境界注入: ネットワークはこの光を $\lambda$ でスケーリングし、元のピクセルに加算する ($+$)。胃の境界は現在、シャープで明確に定義されている ($\tilde{F}$)。
- コンテキスト収集: ピクセルは CFAM デコーダーに移動する。それはクローンに分割される。1つのクローンは近隣を見、別のクローンは8ピクセル離れた場所を見て、「ああ、私は肝臓の隣にいる」と認識する。これらの視点は $F_{cat}$ にスタックされる。
- ゲーティング尋問: コンテキスト ($F_{cat}$) とピクセル自身のキャリブレートされたアイデンティティ ($F'$) は、両方とも $f_{1\times1}$ によって混合され、$\text{SiLU}$ によって平滑化される。それらは乗算演算子 ($\odot$) で出会う。コンテキストは「これは有効な臓器の境界です」と言い、高い値(例:0.9)を出力する。ローカル特徴は「私はシャープなエッジです」と言い、高い値(例:0.8)を出力する。それらは乗算される($0.9 \times 0.8 = 0.72$)、フィルターを通過する。(もしこのピクセルが単なる皮膚のランダムな毛であれば、コンテキストは0.01を出力し、乗算はノイズを即座に殺すだろう)。
- 最終再結合: この洗練された、コンテキストによって承認された信号は、生のピクセル $F$ に($+$)加算して戻される。データポイントはモジュールを抜け、完璧に強調され、最終的なセグメンテーションマップの準備ができた。
最適化ダイナミクス
この機械的な組み立てラインは、実際にどのように臓器をセグメントすることを学習するのだろうか?
学習プロセスは、損失関数(特に、境界を間違えた場合にネットワークに重くペナルティを与える BDoU Loss)から逆方向に流れる勾配によって駆動される。
アーキテクチャは、非常に有利な損失ランドスケープを形成する。残差加算 ($+$) の多用により、勾配はネットワークの終端から初期レイヤーまで、消失することなく直接流れる「ファストパス」ハイウェイを持つ。
一方、ゲーティングメカニズム ($\odot$) は、動的な勾配ルーターとして機能する。バックプロパゲーション中、特定の領域の SiLU ゲートが、関連性のないノイズと見なされたため、フォワードパス中にゼロに近い状態(閉じられていた)であった場合、そのパスを流れる勾配もゼロで乗算される。これにより、デッドウェイトの学習が効果的に凍結され、オプティマイザーは、顕著な領域(臓器と境界)を担当する重みにすべての更新パワーを集中させることを強制される。
最後に、ネットワークが過度に興奮し、強調された特徴がノイズに爆発するまで増強され続ける暴走フィードバックループを作成するのを防ぐために、著者らはモジュールの終わりに重み付き非ローカルブロック(wNLB)を配置した。これは空間正則化器として機能する。画像全体を一度に見て、過剰強調の孤立したスパイクを平滑化し、最適化軌道が安定し、滑らかで、非常に正確で、境界が完璧なセグメンテーションに収束することを保証する。
結果、限界、および結論
Context Enhancement Network (CENet) を真に理解するためには、まず医療画像セグメンテーションの根本的な問題について理解する必要がある。詳細かつわずかにぼやけた衛星地図上で、ある国の正確な国境をなぞる作業を想像してほしい。医療分野において、この「なぞる」作業がピクセル単位のセグメンテーションであり、生データであるCT、MRI、または皮膚スキャンから、臓器、腫瘍、または病変の正確な境界を特定することである。
歴史的に、科学者たちはこの目的のために畳み込みニューラルネットワーク(CNN)を使用していた。CNNは虫眼鏡のように機能し、局所的なテクスチャを見ることに優れているが、グローバルなコンテキスト(「全体像」)を理解することは苦手である。最近になって、Vision Transformer(ViT)が登場した。ViTは衛星画像のように機能し、グローバルなコンテキストを完全に理解するが、しばしば細かい局所的な境界の詳細をぼかしてしまう。エンジニアがこれら2つのアプローチを組み合わせようとしたり、計算能力を節約するために画像を縮小(ダウンサンプリング)したりすると、臓器の繊細な境界が損なわれる。
本論文の核心的な動機は、悩ましいパラドックスを解決することである。それは、ネットワークにエッジの詳細に注意を払うように数学的に強制しようとすると、必然的にバックグラウンドノイズ(テレビの砂嵐や皮膚スキャンの毛のようなもの)が増幅されてしまうという問題である。著者らは、ネットワークの学習プロセスを劣化させることなく、「過剰な強調」を引き起こさずに、複雑で変形可能な臓器の境界を強調できるシステムを構築する必要があった。
数学的な核心:どのような問題が解決され、どのように解決されたか?
著者らは、Dual Selective Enhancement Block (DSEB) と Contextual Feature Attention Module (CFAM) という2つの優れた数学的介入を用いて、視覚情報の流れを傍受し、洗練させるようにCENetを設計した。
1. エッジの分離(DSEB)
DSEBは、単にエッジがどこにあるかを推測するのではなく、Feature Edge Amplifier (FEA) を使用して数学的にエッジを分離する。ネットワークは入力特徴マップ $F$ を受け取り、異なる比率($s_1 = 0.75$ および $s_2 = 0.5$)でダウンサンプリングしてからアップサンプリングする。
$$F_{u1} = U(\mathcal{D}(F, s_1), s_0), \quad F_{u2} = U(\mathcal{D}(F, s_2), s_0)$$
ここで、$\mathcal{D}$ はダウンサンプリング、$U$ はアップサンプリングを表す。これらの2つのバージョンの画像は異なる圧縮を受けているため、それらを減算することで、臓器の中央のような広くて平坦な領域はキャンセルされ、シャープで高周波のエッジの詳細のみが残る。
$$F_{edge} = |F_{u1} - F_{u2}|$$
この純粋な「エッジマップ」は、学習されたパラメータ $\lambda$ によって重み付けされ、元の特徴マップに追加される。
$$\tilde{F} = F + \lambda F_{edge}$$
2. ノイズの抑制(CFAM)
エッジが強調された後、ネットワークはノイズに圧倒されるリスクを負う。CFAMは、過度に強調された表現が最終的な出力を損なうのを防ぐために、多段階のフィルタリングシステムとして機能する。
まず、Channel Calibration Unit (CCU) を使用して、どの「チャネル」(視覚データの層)が実際に重要であるかを判断する。これは、平均、最大、標準偏差の3つの異なる方法でデータをプーリングすることにより、グローバル記述子 $\mathbf{g}$ を作成することで行われる。
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
この記述子は、元の特徴をスケーリングする重みセット $\mathbf{s}$ を生成する。$F' = F \odot \mathbf{s}$。
CFAMの後段では、Spatial Calibration Module (SRM) が空間位置に対して同様のトリックを実行し、並列畳み込みを使用してピクセル単位の相互作用と近傍の相互作用の両方を捉える。
$$S = \sigma(f_{1\times1}(G) + f_k^{dw}(G))$$
$$F_{recal} = F_{MCA} \odot S$$
DSEBによるエッジブーストとCFAMによる徹底的なノイズフィルタリングを組み合わせることで、著者らはパラドックスを解決した。つまり、静的なノイズなしに超シャープな境界を実現したのである。
実験的アーキテクチャ:主張の証明
著者らは単にモデルをデータセットに投入して精度が1%向上したと主張するだけではなかった。彼らは数学的な主張を徹底的に検証するために、非常に過酷な証明場を設計した。
犠牲者(ベースライン):
CENetを、最先端モデルの膨大なリストと対決させた。犠牲者には、純粋なCNN(U-Net、DeepLabv3+)、純粋なTransformer(Swin-Unet、MissFormer)、および強力なハイブリッドモデル(TransUNet、MSA$^2$Net、UCTransNet)が含まれていた。
決定的な証拠:
モデルが特定の種類の画像のみを記憶しているわけではないことを証明するために、彼らは全く異なる医療ドメインでテストを行った。内部放射線学(腎臓、胃、心臓の3D CTおよびMRIスキャン)と外部皮膚科学(皮膚病変の2D写真)である。CENetは、ACDC心臓データセットで92.18%という驚異的なDICEスコアを達成し、全般的にベースラインを上回った。
しかし、否定できない決定的な証拠はメトリクスではなく、視覚的な特徴ヒートマップとアブレーションスタディであった。著者らは文字通りネットワークの「脳」を開き、どこに注目しているかを示した。
1. DSEBの前: ネットワークの注意は拡散し、散らばっていた。
2. DSEBの後: 注意は臓器の境界に厳密に集中した。
3. wNLB(ノイズ除去メカニズム)の後: ネットワークは無関係な詳細を積極的に抑制した。皮膚病変データセットでは、ネットワークが患者の皮膚上の物理的な毛を無視して、病変の境界にのみ焦点を当てているのが視覚的に確認できる。
さらに、彼らは意図的にモデルを分解した(DSEB、FEA、CFAMを一つずつオフにした)。アブレーションスタディは、エッジ増幅とノイズ抑制の特定の数学的組み合わせなしでは、モデルのパフォーマンスが崩壊することを示した。
今後の議論トピック
本論文で導入された優れたメカニズムに基づき、将来の探求と批判的な議論のためのいくつかの方向性を以下に示す。
- マルチスケール処理のコスト vs. 臨床的現実:
CENetは、マルチスケールダウンサンプリング、アップサンプリング、および拡張畳み込みに大きく依存している。精度は高いが、推論時間にどのような影響を与えるか?病院が標準的な150ドルの臨床GPUではなく、NVIDIA A100でこれを展開したい場合、CFAMの複雑なゲーティングメカニズムがボトルネックになるだろうか?救急外来の診断のために、これらの重い数学的演算を軽量でリアルタイムなアーキテクチャに蒸留する方法について議論する必要がある。 - 「曖昧な境界」のジレンマ:
DSEBモジュールは、シャープな境界が常にグラウンドトゥルースであると仮定している。しかし、腫瘍学においては、一部の攻撃的で浸潤性の腫瘍(脳の神経膠芽腫など)は本質的にシャープな境界を欠いており、健康な組織に溶け込んでいる。絶対差メカニズム($|F_{u1} - F_{u2}|$)は、生物学的なグラウンドトゥルースがエッジではなく勾配である場合にどのように振る舞うだろうか?この数学的な厳密さが、存在しないハードボーダーをネットワークに誤って幻覚させる可能性があるだろうか? - 連続的な3D空間依存性への進化:
現在のモデルは、3D MRIおよびCTスキャンを2Dスライスのシリーズとして処理する。wNLB(weighted Non-local Block)はスライス内の長距離空間依存性を捉えるが、Z軸(奥行き)は無視している。計算複雑性の指数関数的な爆発を引き起こすことなく、真のボリュームテンソルを処理するために、Channel Calibration Unit (CCU) および Spatial Calibration Module (SRM) を数学的に進化させるにはどうすればよいか?
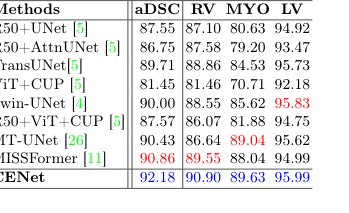 Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
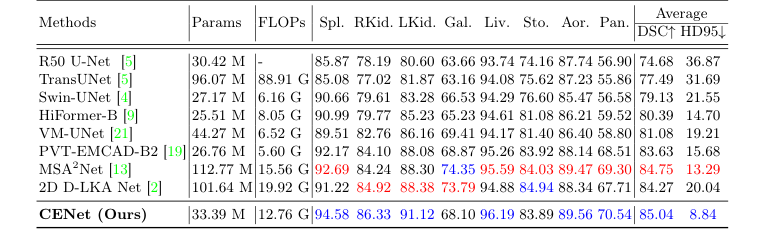 Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
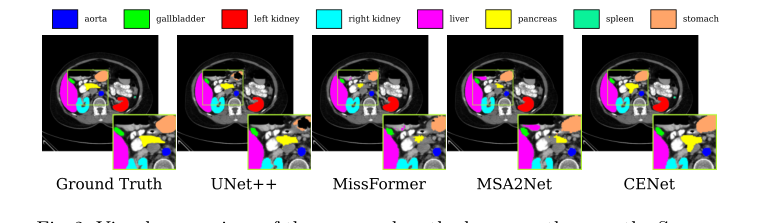 Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset
Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset