CENet: Сеть улучшения контекста для сегментации медицинских изображений
Исторически точное выделение анатомических структур, органов и поражений на медицинских изображениях было исключительно ручной задачей.
Предыстория и академическое происхождение
Исторически точное выделение анатомических структур, органов и поражений на медицинских изображениях было исключительно ручной задачей. Рентгенологи должны были кропотливо обводить границы пиксель за пикселем — процесс, который был невероятно трудоемким и дорогостоящим, фактически обходящимся в сотни долларов (например, 150 долларов за снимок на оплату труда) и обусловившим острую необходимость в автоматизированных системах. Эта проблема породила область автоматической сегментации медицинских изображений. Революцию в этой области произвели Fully Convolutional Networks (FCNs), и в частности архитектура U-Net, которая представила структуру кодировщика-декодировщика. Кодировщик сжимает изображение, чтобы понять, "что" находится на снимке, в то время как декодировщик расширяет его, чтобы точно определить, "где" это находится. Однако по мере развития медицинской визуализации возникла критическая проблема: как научить машину одновременно понимать широкий, глобальный контекст всей органной системы, сохраняя при этом микроскопические, мелкозернистые детали границ крошечной опухоли?
Фундаментальное ограничение предыдущих подходов заключается в постоянной борьбе между захватом общей картины и сохранением мелких деталей. Традиционные сверточные нейронные сети (CNN) имеют ограниченное "поле зрения", что означает, что они испытывают трудности с пониманием глобальных взаимосвязей на больших изображениях. Для решения этой проблемы исследователи представили Vision Transformers (ViTs), которые рассматривают все изображение одновременно. Однако ViTs вычислительно массивны и печально известны своей неспособностью улавливать локальные детали краев. Когда предыдущие модели, даже гибридные, пытались передать мелкозернистые детали границ через сеть для решения этой проблемы, они страдали от серьезной болевой точки: "сверхусиления". Без надлежащих механизмов контроля усиление деталей краев также усиливает фоновый шум, что приводит к деградации на стадии декодировщика. Существующие модели просто компрометируют детали границ в процессе понижения дискретизации (downsampling), делая высокоточную, многомасштабную сегментацию сложных органов практически невозможной. Это вынудило авторов создать CENet для интеллектуального усиления границ без перегрузки сети шумом.
Вот несколько узкоспециализированных терминов из статьи, переведенных в интуитивно понятные концепции:
- Skip Connections (Пропускающие соединения): В нейронных сетях это архитектурные "ярлыки", которые обходят определенные слои, чтобы подавать необработанную, детализированную информацию непосредственно на более поздние этапы модели.
- Аналогия из повседневной жизни: Представьте, что вы переводите очень подробный роман объемом 1000 страниц в краткое изложение на 10 страниц, а затем просите автора переписать полный роман, используя только это краткое изложение. Он потеряет все богатые детали. Пропускающее соединение похоже на то, как если бы вы передали автору оригинальные наброски персонажей и описания обстановки во время переписывания, гарантируя, что мелкие детали не будут утеряны при переводе.
- Receptive Field (Рецептивное поле): Конкретная, ограниченная область входного изображения, на которую в данный момент "смотрит" определенная часть нейронной сети.
- Аналогия из повседневной жизни: Представьте, что вы смотрите на огромное, замысловатое фреску через картонную трубку от бумажных полотенец. Маленький круг фрески, который вы можете видеть в данный момент, — это ваше рецептивное поле. Чтобы понять всю историю фрески, вам нужна гораздо более широкая трубка.
- Downsampling (Понижение дискретизации): Процесс намеренного уменьшения пространственного разрешения изображения для сжатия информации и извлечения высокоуровневого, семантического смысла.
- Аналогия из повседневной жизни: Это похоже на увеличение масштаба на цифровой карте на вашем телефоне. При уменьшении масштаба вы теряете названия отдельных улиц и кофеен (мелкие детали), но наконец-то можете увидеть форму всего штата или страны (глобальный контекст).
- Self-Attention Mechanism (Механизм самовнимания): Математический метод, который позволяет модели взвешивать важность различных частей входных данных относительно друг друга, решая, на чем сосредоточиться.
- Аналогия из повседневной жизни: Представьте, что вы находитесь на шумной, многолюдной коктейльной вечеринке. Ваш мозг естественным образом отфильтровывает фоновую музыку и звон бокалов, чтобы сосредоточиться исключительно на голосе человека, с которым вы разговариваете. Механизм самовнимания делает именно это для данных, решая, на какие пиксели наиболее важно "обратить внимание".
Ключевые математические обозначения
| Обозначение | Описание |
|---|---|
| $F$ | Входная карта признаков, обрабатываемая сетью. |
| $\mathcal{D}(F, s)$ | Операция многомасштабного понижения дискретизации, применяемая к карте признаков на масштабе $s$. |
| $\mathcal{U}(F, s)$ | Операция повышения дискретизации (upsampling), применяемая к карте признаков на масштабе $s$. |
| $s_1, s_2, s_0$ | Конкретные параметры масштаба, используемые для изменения размера карт признаков (например, $0.75, 0.5, 1.0$). |
| $F_{u1}, F_{u2}$ | Результирующие карты признаков после повышения дискретизации на разных масштабах. |
| $F_{\text{edge}}$ | Изолированные, уточненные детали границ, математически определяемые как $\|F_{u1} - F_{u2}\|$. |
| $\lambda$ | Обучаемый вектор весовых параметров ($\lambda \in \mathbb{R}^d$), используемый для масштабирования признаков границ. |
| $\tilde{F}$ | Финальная улучшенная карта признаков после добавления взвешенных деталей границ обратно к исходному входу. |
| $\mathbf{g}$ | Глобальный дескрипторный вектор, генерируемый операциями пулинга для захвата статистики по каналам. |
| $\mathbf{s}$ | Веса каналов, генерируемые блоком калибровки каналов (CCU) для адаптивного перевзвешивания признаков. |
| $F'$ | Перевзвешенная выходная карта признаков после применения внимания к каналам ($F \odot \mathbf{s}$). |
| $F'_i$ | Разделенные части карты признаков, используемые в агрегаторе многомасштабного контекста (MCA). |
| $f_{dk}$ | Оператор глубинной свертки (depth-wise convolution) с определенным размером ядра и коэффициентом дилатации $d_k$. |
| $\mathcal{C}_{\text{avg}}, \mathcal{C}_{\text{max}}, \mathcal{C}_{\text{std}}$ | Операции среднего пулинга, максимального пулинга и пулинга стандартного отклонения по каналам. |
| $G$ | Пространственный дескриптор, созданный путем объединения различных операций пулинга в модуле пространственной калибровки. |
| $S$ | Комбинированный выход, используемый для перекалибровки карты признаков посредством поэлементного умножения. |
Определение проблемы и ограничения
Представьте, что вы пытаетесь точно обрисовать сложный, постоянно меняющий свою форму остров на сильно пикселизированной спутниковой карте. В области анализа медицинских изображений исходными данными (Input) является необработанный медицинский набор данных — такой как КТ-скан, МРТ или дермоскопическая фотография кожного поражения. Желаемым конечным результатом (Output) является точное, попиксельное выделение анатомических структур, органов или патологических поражений. Математический разрыв, который данная статья пытается преодолеть, заключается в значительной потере информации, происходящей при сжатии изображения для понимания его общего контекста, что неизбежно разрушает мелкозернистые пространственные координаты, необходимые для построения точных границ. Авторам нужен способ математически изолировать и внедрить эти недостающие детали границ — которые они рассчитывают как абсолютную разницу между многомасштабными апсемплированными признаками, $F_{edge} = |F_{u1} - F_{u2}|$ — не утонув в нерелевантных данных.
В глубоком обучении исправление одной проблемы почти всегда нарушает другую, и предыдущие исследователи оказались в ловушке разочаровывающей дилеммы. Если использовать сверточные нейронные сети (CNN), модель становится превосходной в понимании локальных текстур, но не может уловить глобальный контекст из-за ограниченного рецептивного поля сверточных ядер. Для решения этой проблемы исследователи обратились к Vision Transformers (ViTs), которые используют механизм самовнимания для одновременного анализа всего изображения. Однако ViTs вводят болезненный компромисс: хотя они прекрасно улавливают глобальный контекст, они значительно хуже моделируют локальные представления границ. Более того, если попытаться вручную заставить сеть уделять внимание мелкозернистым признакам границ для исправления этого, возникает новая проблема: отсутствие надлежащих механизмов контроля усиливает фоновый шум, что приводит к "переусиленным" представлениям, которые фактически ухудшают производительность сети на этапе декодирования. Вы вынуждены выбирать между размытыми границами, отсутствием глобального понимания или шумной, нестабильной архитектурой.
Авторы столкнулись с несколькими суровыми, реалистичными препятствиями, которые делают эту конкретную проблему чрезвычайно сложной для решения:
- Квадратичная вычислительная сложность: Несмотря на мощность Трансформеров, их механизмы самовнимания масштабируются квадратично с размером входных данных, что часто выражается как $O(N^2)$. Это создает массивное вычислительное узкое место и сталкивается со строгими аппаратными ограничениями по памяти, что делает их крайне неэффективными для крупномасштабных, высокоразрешающих медицинских приложений.
- Деструктивное понижение дискретизации: Иерархическая структура современных нейронных сетей сильно полагается на понижение дискретизации для извлечения признаков. Это физическое ограничение неизбежно компрометирует детали границ и мелкозернистые семантические представления, которые математически трудно восстановить после их потери.
- Экстремальная морфологическая вариабельность: Медицинские структуры не являются жесткими. Органы и поражения сильно деформируемы, демонстрируя разнообразные формы, внешний вид и патологические состояния у разных пациентов. Фиксированное рецептивное поле просто не может адаптироваться к этой многомасштабной вариабельности.
- Накопление шума в пропускных соединениях: Для восстановления потерянных деталей сети используют "пропускные соединения" (skip connections) для обхода сжатия. Однако без способа фильтрации этих данных нерелевантный фоновый шум напрямую передается в декодер. Авторы отмечают, что это создает серьезное ограничение, при котором чрезмерно усиленные представления накапливают шум, требуя сложных математических вмешательств для адаптивного шумоподавления признаков без стирания критически важных деталей границ.
Почему этот подход
При анализе сегментации медицинских изображений авторы CENet столкнулись с весьма специфической и фрустрирующей проблемой. Они осознали, что традиционные state-of-the-art (SOTA) архитектуры фундаментально несостоятельны в суровых реалиях клинических сканов. Сверточные нейронные сети (CNN), такие как U-Net, ограничены локальными рецептивными полями своих ядер — они просто не способны уловить глобальный контекст крупного, деформируемого органа. С другой стороны, Vision Transformers (ViT) стали новым золотым стандартом для захвата глобального контекста посредством механизма self-attention. Однако авторы выявили именно тот момент, когда ViT потерпели неудачу: они значительно уступают в моделировании локальных мелкозернистых деталей (например, точной границы поражения) и обладают критическим квадратичным вычислительным усложнением, что делает их крайне неэффективными для крупномасштабных медицинских приложений с высоким разрешением.
Даже когда предыдущие исследователи пытались объединить эти подходы в гибридные модели CNN-Transformer, возникала новая проблема. Принудительное внедрение мелкозернистых краевых признаков в декодер без строгих механизмов контроля просто перегружало сеть шумом, что приводило к деградации на стадии декодера. Авторы поняли, что грубый подход нежизнеспособен; им требовалась высококонтролируемая, математически строгая система фильтрации. Именно поэтому Context Enhancement Network (CENet) стала единственным жизнеспособным решением.
Для решения этой задачи они разработали "союз" между жесткими ограничениями медицинской визуализации — где границы размыты, а органы сильно варьируются по размеру — и уникальной архитектурой двойной фильтрации. Они внедрили Dual Selective Enhancement Block (DSEB) в skip connections. Вместо слепого пропуска признаков из энкодера в декодер, DSEB активно изолирует и усиливает краевые детали с помощью Feature Edge Amplifier (FEA). Это достигается путем расчета разницы между признаками на разных масштабах:
$$F_{edge} = |F_{u1} - F_{u2}|$$
где $F_{u1}$ и $F_{u2}$ — это апсемплированные признаки из различных масштабов даунсемплинга. Эта изолированная карта краев затем вводится обратно в исходную карту признаков:
$$\tilde{F} = F + \lambda F_{edge}$$
где $\lambda \in \mathbb{R}^d$ выступает в качестве весового параметра.
Но именно здесь проявляется сравнительное превосходство. Если усиливать края, обычно усиливается и высокоразмерный шум. Для борьбы с этим авторы интегрировали Differential Attention (DiffAtt). Вычисляя отдельные карты внимания и вычитая их, они эффективно отменяют избыточное внимание и несбалансированную важность токенов. Это действует как активные наушники с шумоподавлением для нейронной сети.
Кроме того, декодер использует Context Feature Attention Module (CFAM), чтобы предотвратить перегрузку сети чрезмерно усиленными представлениями. Он использует Channel Calibration Unit (CCU) для сжатия и адаптивного перевзвешивания каналов с использованием глобального дескриптора $\mathbf{g}$:
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
За этим следует Multi-scale Contextual Aggregator (MCA), который разделяет признаки и обрабатывает их через параллельные глубинные свертки с расширением (dilated depth-wise convolutions). Это структурное преимущество позволяет сети одновременно рассматривать несколько масштабов без массивного раздувания параметров, характерного для традиционных плотных слоев.
Честно говоря, в статье не приводится точная математическая нотация Big-O, показывающая, насколько снижена сложность по памяти по сравнению со стандартными ViT, но авторы явно отвергают стандартные Трансформеры из-за их квадратичной неэффективности. Используя глубинные свертки и снижение размерности каналов, CENet достигает качественно превосходящего, легковесного представления, которое легко превосходит более тяжелые модели.
Наконец, в статье точно объясняется, почему терпят неудачу другие популярные подходы. Хотя авторы явно не упоминают отказ от GAN или диффузионных моделей — чтобы быть абсолютно прозрачными, эти генеративные модели, вероятно, и так испытывают трудности с требуемой здесь детерминированной точностью — они подвергают резкой критике существующие локализованные механизмы self-attention и гибридные модели. Эти альтернативы слишком сильно фокусируются на "признаках тела", а не на "информации о краях", и им не хватает адаптивного шумоподавления, необходимого для обработки накопления шума. Включение взвешенного Non-local Block (wNLB) в конце CFAM в CENet идеально моделирует дальние пространственные зависимости для подавления избыточно привлеченных, нерелевантных деталей (например, волос на дерматоскопических изображениях), доказывая, что контролируемое, контекстно-зависимое усиление значительно превосходит предыдущий золотой стандарт.
Математический и логический механизм
Чтобы понять гениальность сети Context Enhancement Network (CENet), сначала необходимо разобраться в фундаментальном противостоянии при сегментации медицинских изображений. Представьте, что вы пытаетесь точно обвести контур опухоли или органа (например, почки) на размытом, полутоновом медицинском снимке. Если вы слишком сильно увеличите изображение, вы увидите точные края, но потеряете ориентацию в теле (потеря глобального контекста). Если вы уменьшите масштаб, вы будете точно знать, где находитесь, но тонкие границы размоются до пикселей (потеря локальных деталей).
Исторически сверточные нейронные сети (CNN) были экспертами "крупного плана", работающими с крошечным скользящим окном, в то время как Vision Transformers (ViT) были экспертами "общего плана", рассматривающими все изображение, но испытывающими трудности с тонкими, локализованными границами. Более того, когда инженеры пытались их объединить, сети часто страдали от "переусиления" — усиления фонового шума наряду с фактическими органами, что приводило к ухудшению предсказаний.
Авторы CENet решили эту проблему, разработав высококонтролируемую многомасштабную архитектуру, действующую как умная лупа. Она избирательно усиливает границы, используя сложный механизм вентилей для подавления нерелевантного шума.
Вот математический разбор того, как им это удалось.
Основные уравнения
Сердцем CENet являются два взаимосвязанных математических механизма. Первый — это Dual Selective Enhancement Block (DSEB), который восстанавливает детали границ. Второй — Multi-scale Contextual Aggregator (MCA), который интеллектуально объединяет различные уровни масштабирования без перегрузки сети шумом.
Механизм усиления границ:
$$ \tilde{F} = F + \lambda F_{edge} $$
Механизм вентилирования контекста на основе многомасштабности:
$$ F_{MCA} = \Big( \text{SiLU}(f_{1\times1}(F_{cat})) \odot \text{SiLU}(f_{1\times1}(F')) \Big) + F $$
Разбираем уравнения
Давайте разберем каждый винтик и пружинку в этих механизмах.
Из механизма границ:
* $F$: Исходная входная карта признаков. Физически это базовый уровень реальности изображения на определенном слое — необработанный, неизмененный сигнал.
* $F_{edge}$: Выделенные детали границ. Авторы вычисляют это путем понижения и повышения дискретизации изображения в различных масштабах и взятия абсолютной разницы ($|F_{u1} - F_{u2}|$). Логически это действует как фильтр высоких частот, улавливая только резкие переходы (границы органов).
* $\lambda$: Обучаемый весовой параметр (вектор в $\mathbb{R}^d$). Он действует как регулятор громкости для границ, позволяя сети решать, насколько усиление границ действительно необходимо для каждого конкретного канала.
* $+$ (Сложение): Почему сложение, а не умножение? Сложение действует как наложение. Мы берем базовое изображение ($F$) и накладываем на него усиленные границы ($\lambda F_{edge}$). Если бы мы использовали умножение, любая область без границы (где $F_{edge} \approx 0$) стерла бы все изображение, превратив внутреннюю часть органов в абсолютно черную!
Из механизма вентилирования контекста:
* $F_{cat}$: Конкатенированные многомасштабные признаки. Сеть разделяет изображение и рассматривает его через различные "расширенные" линзы (рассматривая соседей на расстоянии 3, 5 и 8 пикселей), а затем объединяет их. Это представляет "глобальный контекст" или лес.
* $F'$: Карта признаков, калиброванная по каналам. Это исходный сигнал, веса которого были изменены так, чтобы приоритет отдавался наиболее важным каналам признаков. Это представляет "локальную деталь" или деревья.
* $f_{1\times1}$: Попиксельная свертка. Математически это линейное преобразование по глубине карты признаков. Логически это действует как бармен, смешивающий различные каналы информации, не изменяя пространственную ширину или высоту изображения.
* $\text{SiLU}$: Функция активации Sigmoid Linear Unit. Она позволяет сильным положительным сигналам проходить линейно, но плавно сжимает отрицательные сигналы к нулю. Она действует как мягкий, непрерывный привратник.
* $\odot$ (Поэлементное умножение): Поэлементное умножение. Это самый критический оператор. Почему умножение, а не сложение? Умножение действует как логический вентиль "И" (фильтр). Левая часть уравнения оценивает контекст ($F_{cat}$), а правая часть оценивает локальные признаки ($F'$). Умножая их, сеть пропускает сигнал только в том случае, если и локальные детали, и глобальный контекст подтверждают его важность. Это активно подавляет нерелевантный фоновый шум.
* $+$ (Остаточное сложение): После того как сложный механизм вентилирования определил, что следует усилить, результат добавляется обратно к исходному входу $F$. Это остаточное соединение. Оно гарантирует, что сеть никогда не забывает исходное изображение, действуя как страховочная сетка против чрезмерной обработки.
Пошаговый поток
Давайте проследим точный жизненный цикл одной абстрактной точки данных — скажем, высокоразмерного вектора, представляющего крошечный пиксель на границе желудка.
- Базовый ввод: Пиксель границы желудка поступает в блок DSEB как часть карты признаков $F$.
- Извлечение границ: Сеть сжимает и расширяет изображение вокруг этого пикселя. Поскольку он находится на границе, пиксель немного смещается в процессе. Сеть вычитает две версии, выделяя резкий переход. Наш пиксель теперь светится на карте $F_{edge}$.
- Внедрение границ: Сеть масштабирует это свечение на $\lambda$ и добавляет его обратно к исходному пикселю ($+$). Граница желудка теперь четкая и хорошо определенная ($\tilde{F}$).
- Сбор контекста: Пиксель перемещается в декодер CFAM. Он разделяется на клоны. Один клон смотрит на свои непосредственные окрестности; другой смотрит на расстояние 8 пикселей, чтобы понять: "Ага, я рядом с печенью". Эти перспективы объединяются в $F_{cat}$.
- Опрос вентилем: Контекст ($F_{cat}$) и собственная калиброванная идентичность пикселя ($F'$) оба смешиваются $f_{1\times1}$ и сглаживаются $\text{SiLU}$. Они встречаются на операторе умножения ($\odot$). Контекст говорит: "Это действительная граница органа", выдавая высокое значение (например, 0.9). Локальный признак говорит: "Я — резкая граница", выдавая высокое значение (например, 0.8). Они умножаются ($0.9 \times 0.8 = 0.72$), переживая фильтр. (Если бы этот пиксель был просто случайным волоском на коже, контекст выдал бы 0.01, и умножение мгновенно уничтожило бы шум).
- Финальная рекомбинация: Этот уточненный, одобренный контекстом сигнал добавляется ($+$) обратно к необработанному пикселю $F$. Точка данных выходит из модуля, идеально усиленная и готовая для финальной карты сегментации.
Динамика оптимизации
Как эта механическая сборочная линия фактически учится сегментировать органы?
Процесс обучения управляется градиентами, текущими назад от функции потерь (в частности, BDoU Loss, которая сильно штрафует сеть, если она ошибается с границами).
Архитектура формирует очень благоприятный ландшафт потерь. Благодаря интенсивному использованию остаточных сложений ($+$), градиенты имеют "быстрый проход" — магистраль для прямого течения от конца сети до самых ранних слоев без затухания.
Тем временем механизм вентилирования ($\odot$) действует как динамический маршрутизатор градиентов. Во время обратного распространения, если вентиль SiLU для определенной области был закрыт (близок к нулю) во время прямого прохода, поскольку он был сочтен нерелевантным шумом, градиент, текущий назад по этому пути, также умножается на ноль. Это эффективно замораживает обучение для "мертвого веса" и заставляет оптимизатор концентрировать всю свою мощность обновления на весах, ответственных за значимые области (органы и границы).
Наконец, чтобы предотвратить чрезмерное возбуждение сети и создание неуправляемых обратных связей (где усиленные признаки продолжают усиливаться до тех пор, пока не взорвутся в шум), авторы разместили взвешенный Non-Local Block (wNLB) в конце модуля. Это действует как пространственный регуляризатор. Он рассматривает все изображение одновременно и сглаживает любые изолированные пики чрезмерного усиления, обеспечивая стабильность траектории оптимизации, плавность и сходимость к высокоточной, идеальной по границам сегментации.
Результаты, ограничения и заключение
Чтобы по-настоящему оценить Сеть Усиления Контекста (Context Enhancement Network, CENet), нам сначала необходимо понять фундаментальную проблему сегментации медицинских изображений. Представьте, что вам поручено точно обвести границы страны на очень детализированной, но слегка размытой спутниковой карте. В медицинской сфере это "обведение" — это попиксельная сегментация, то есть определение точных границ органов, опухолей или поражений по необработанным данным КТ, МРТ или дерматологическим снимкам.
Исторически для этого ученые использовали сверточные нейронные сети (Convolutional Neural Networks, CNN). CNN действуют как увеличительное стекло: они отлично справляются с анализом локальных текстур, но плохо понимают глобальный контекст (общую картину). Недавно на сцену вышли Vision Transformers (ViTs). ViTs действуют как вид со спутника: они прекрасно понимают глобальный контекст, но часто размывают мелкие локальные детали границ. Когда инженеры пытаются объединить эти два подхода или сжимают изображения для экономии вычислительной мощности (downsampling), деликатные границы органов нарушаются.
Основная мотивация данной статьи — решить разочаровывающий парадокс: если вы пытаетесь математически заставить сеть уделять больше внимания тонким краям, вы неизбежно усиливаете фоновый шум (подобно помехам на экране телевизора или волоскам на дерматологическом снимке). Авторам потребовалось создать систему, которая могла бы усиливать границы сложных, деформируемых органов без "чрезмерного усиления" или деградации процесса обучения сети.
Математическое ядро: Какая проблема была решена и как?
Авторы спроектировали CENet для перехвата и уточнения потока визуальной информации с помощью двух блестящих математических вмешательств: Блока Двойного Селективного Усиления (Dual Selective Enhancement Block, DSEB) и Модуля Внимания к Контекстным Признакам (Contextual Feature Attention Module, CFAM).
1. Изоляция краев (DSEB)
Вместо того чтобы просто угадывать, где находятся края, DSEB математически изолирует их с помощью Усилителя Краев Признаков (Feature Edge Amplifier, FEA). Сеть принимает входную карту признаков $F$ и масштабирует ее вниз, а затем обратно вверх с различными коэффициентами ($s_1 = 0.75$ и $s_2 = 0.5$).
$$F_{u1} = U(\mathcal{D}(F, s_1), s_0), \quad F_{u2} = U(\mathcal{D}(F, s_2), s_0)$$
Здесь $\mathcal{D}$ обозначает downsampling, а $U$ — upsampling. Поскольку эти две версии изображения были сжаты по-разному, вычитание их друг из друга компенсирует широкие, плоские области (например, середину органа), оставляя только резкие, высокочастотные детали краев:
$$F_{edge} = |F_{u1} - F_{u2}|$$
Эта чистая "карта краев" затем взвешивается обучаемым параметром $\lambda$ и добавляется обратно к исходной карте признаков:
$$\tilde{F} = F + \lambda F_{edge}$$
2. Укрощение шума (CFAM)
После усиления краев сеть рискует быть перегруженной шумом. CFAM действует как многоступенчатая система фильтрации, чтобы предотвратить искажение конечного результата чрезмерно усиленными представлениями.
Сначала он использует Блок Калибровки Каналов (Channel Calibration Unit, CCU), чтобы определить, какие "каналы" (слои визуальных данных) действительно важны. Это делается путем агрегирования данных тремя различными способами — среднее, максимум и стандартное отклонение — для создания глобального дескриптора $\mathbf{g}$:
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
Этот дескриптор генерирует набор весов $\mathbf{s}$, которые масштабируют исходные признаки: $F' = F \odot \mathbf{s}$.
Позже в CFAM Модуль Пространственной Калибровки (Spatial Calibration Module, SRM) выполняет аналогичный трюк для пространственных положений, используя параллельные свертки для захвата как попиксельных взаимодействий, так и взаимодействий в окрестности:
$$S = \sigma(f_{1\times1}(G) + f_k^{dw}(G))$$
$$F_{recal} = F_{MCA} \odot S$$
Объединяя усиление краев DSEB с беспощадной фильтрацией шума CFAM, авторы решили парадокс: они достигли гиперрезких границ без помех.
Экспериментальная архитектура: Доказательство утверждений
Авторы не просто бросили свою модель на набор данных и похвастались 1% увеличением точности. Они разработали крайне враждебную среду для беспощадной проверки своих математических утверждений.
Жертвы (базовые модели):
Они противопоставили CENet огромному списку передовых моделей. В число "жертв" вошли чистые CNN (U-Net, DeepLabv3+), чистые Трансформеры (Swin-Unet, MissFormer) и мощные гибридные модели (TransUNet, MSA$^2$Net, UCTransNet).
Окончательные доказательства:
Чтобы доказать, что их модель не просто запоминала один конкретный тип изображений, они протестировали ее на совершенно разных медицинских областях: внутренней радиологии (3D КТ и МРТ почек, желудков и сердец) и внешней дерматоскопии (2D фотографии поражений кожи). CENet превзошла базовые модели во всех категориях, достигнув впечатляющего показателя DICE 92.18% на наборе данных сердечно-сосудистых заболеваний ACDC.
Но неоспоримым, "дымящимся пистолетом" были не метрики, а тепловые карты визуальных признаков и абляционное исследование. Авторы буквально открыли "мозг" сети, чтобы показать, куда она смотрит.
1. До DSEB: Внимание сети было рассеянным и размытым.
2. После DSEB: Внимание резко сфокусировалось на границах органов.
3. После wNLB (механизм шумоподавления): Сеть активно подавляла нерелевантные детали. На наборе данных поражений кожи визуально видно, как сеть игнорирует физические волоски на коже пациента, фокусируясь исключительно на границе поражения.
Кроме того, они систематически разобрали собственную модель (отключая DSEB, FEA и CFAM по одному). Абляционное исследование доказало, что без специфической математической комбинации усиления краев и подавления шума производительность модели резко падала.
Темы для будущих дискуссий
Основываясь на блестящих механизмах, представленных в этой статье, вот несколько направлений для дальнейших исследований и критических дебатов:
- Стоимость многомасштабной обработки по сравнению с клинической реальностью:
CENet в значительной степени полагается на многомасштабное downsampling, upsampling и дилатированные свертки. Хотя модель обладает высокой точностью, как это влияет на время инференса? Если больница захочет развернуть ее на стандартной клинической GPU за 150 долларов, а не на NVIDIA A100, станут ли сложные механизмы гейтинга CFAM узким местом? Мы должны обсудить, как преобразовать эти сложные математические операции в более легкие, работающие в реальном времени архитектуры для диагностики в отделениях неотложной помощи. - Дилемма "размытой границы":
Модуль DSEB предполагает, что резкая граница всегда является истинной (ground truth). Однако в онкологии некоторые агрессивные, инфильтрирующие опухоли (например, глиобластома в мозге) по своей природе не имеют резких границ; они переходят в здоровую ткань. Как механизм абсолютной разности ($|F_{u1} - F_{u2}|$) будет вести себя, когда биологическая истина представляет собой градиент, а не край? Может ли эта математическая строгость случайно заставить сеть "галлюцинировать" жесткую границу там, где ее нет? - Эволюция к непрерывным 3D пространственным зависимостям:
Текущая модель обрабатывает 3D МРТ и КТ-сканы как серию 2D срезов. Хотя wNLB (weighted Non-local Block) захватывает пространственные зависимости на большом расстоянии в пределах среза, он игнорирует ось Z (глубину). Как математически развить Блок Калибровки Каналов (CCU) и Модуль Пространственной Калибровки (SRM) для обработки истинных объемных тензоров без экспоненциального взрыва вычислительной сложности?
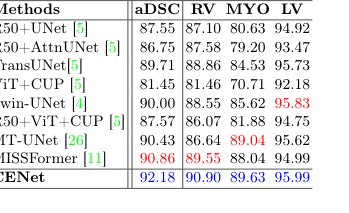 Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
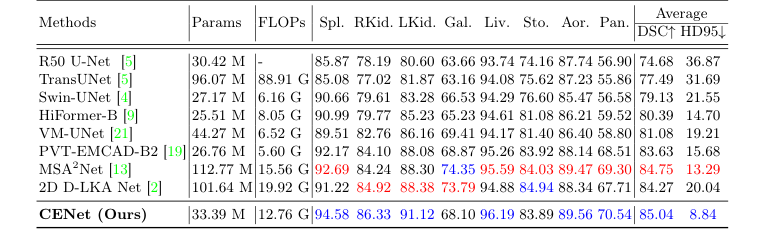 Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
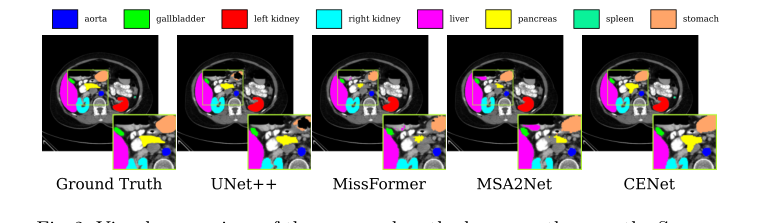 Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset
Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset