CENet: 의료 영상 분할을 위한 컨텍스트 강화 네트워크
CENet boosts medical image segmentation by enhancing boundaries and preserving details across diverse image types.
배경 및 학문적 계보
역사적으로 의료 영상에서 해부학적 구조, 장기 및 병변의 정확한 경계 구분은 전적으로 수작업으로 이루어졌다. 영상의학과 의사들은 픽셀 단위로 경계를 꼼꼼하게 그려야 했으며, 이는 엄청난 시간과 비용이 소요되는 과정이었다. 스캔당 150달러에 달하는 인건비는 자동화 시스템에 대한 시급한 필요성을 야기했다. 이러한 문제는 자동 의료 영상 분할 분야를 탄생시켰다. 이 분야는 완전 합성곱 신경망(FCN)과 특히 인코더-디코더 구조를 도입한 U-Net 아키텍처에 의해 혁신되었다. 인코더는 스캔에 "무엇"이 있는지 이해하기 위해 이미지를 압축하는 반면, 디코더는 "어디"에 있는지 정확히 파악하기 위해 이미지를 확장한다. 그러나 의료 영상이 발전함에 따라 중요한 과제가 등장했다. 기계에게 전체 장기 시스템의 광범위한 전역적 맥락을 동시에 이해하도록 가르치면서 미세한 종양의 미세한 경계 세부 정보를 완벽하게 보존하도록 하는 방법은 무엇인가?
이전 접근 방식의 근본적인 한계는 큰 그림을 포착하는 것과 미세한 세부 정보를 유지하는 것 사이의 끊임없는 줄다리기였다. 전통적인 합성곱 신경망(CNN)은 제한된 "시야"를 가지는데, 이는 큰 이미지에 걸친 전역적 관계를 이해하는 데 어려움을 겪는다는 것을 의미한다. 이를 해결하기 위해 연구자들은 한 번에 전체 이미지를 보는 Vision Transformer(ViT)를 도입했다. 그러나 ViT는 계산량이 방대하고 국부적인 에지 세부 정보를 포착하는 데 악명이 높다. 이전 모델, 심지어 하이브리드 모델조차도 이를 해결하기 위해 미세한 경계 세부 정보를 네트워크를 통해 전달하려고 시도했을 때 심각한 문제점인 "과도한 증폭"을 겪었다. 적절한 제어 메커니즘 없이는 에지 세부 정보를 증폭하는 것이 배경 노이즈를 증폭시켜 디코더 단계의 성능 저하를 초래했다. 기존 모델은 다운샘플링 과정에서 단순히 경계 세부 정보를 타협하여 복잡한 장기의 매우 정확하고 다중 스케일 분할을 거의 불가능하게 만들었다. 이로 인해 저자들은 네트워크를 노이즈로 뒤덮지 않고 지능적으로 경계를 강화하기 위해 CENet을 만들 수밖에 없었다.
논문에서 발췌한 몇 가지 고도로 전문화된 도메인 용어를 직관적인 개념으로 번역하면 다음과 같다.
- Skip Connections (스킵 연결): 신경망에서 특정 계층을 우회하여 원시적이고 상세한 정보를 모델의 후반 단계로 직접 전달하는 아키텍처적 지름길이다.
- 일상적 비유: 매우 상세한 1,000페이지 분량의 소설을 10페이지 요약으로 번역한 다음, 저자에게 오직 그 요약만을 사용하여 전체 소설을 다시 작성하도록 요청하는 것을 상상해 보라. 그러면 풍부한 세부 정보가 손실될 것이다. 스킵 연결은 저자가 원본 캐릭터 스케치와 배경 설명을 전달하여 번역 과정에서 세부 정보가 손실되지 않도록 하는 것과 같다.
- Receptive Field (수용 영역): 신경망의 특정 부분이 특정 순간에 입력 이미지의 "보고 있는" 특정 제한된 영역이다.
- 일상적 비유: 종이 타월 튜브를 통해 거대하고 복잡한 벽화를 보는 것을 생각해 보라. 한 번에 볼 수 있는 벽화의 작은 원이 수용 영역이다. 벽화의 전체 스토리를 이해하려면 훨씬 더 넓은 튜브가 필요하다.
- Downsampling (다운샘플링): 정보를 압축하고 높은 수준의 의미론적 의미를 추출하기 위해 의도적으로 이미지의 공간 해상도를 줄이는 과정이다.
- 일상적 비유: 휴대폰에서 디지털 지도를 확대/축소하는 것과 같다. 확대/축소할 때 개별 거리나 커피숍의 이름(미세한 세부 정보)은 잃지만, 마침내 전체 주 또는 국가의 모양(전역적 맥락)을 볼 수 있게 된다.
- Self-Attention Mechanism (셀프 어텐션 메커니즘): 모델이 입력 데이터의 다른 부분의 중요도를 서로 상대적으로 가중치를 부여하여 무엇에 집중할지 결정할 수 있도록 하는 수학적 방법이다.
- 일상적 비유: 시끄럽고 붐비는 칵테일 파티에 있다고 상상해 보라. 당신의 뇌는 대화하는 사람의 목소리에 완전히 집중하기 위해 배경 음악과 잔 부딪히는 소리를 자연스럽게 무시한다. 셀프 어텐션은 데이터에 대해 정확히 이 작업을 수행하여 어떤 픽셀에 "귀 기울여야" 하는지 결정한다.
주요 수학적 표기
| 표기 | 설명 |
|---|---|
| $F$ | 네트워크에서 처리되는 입력 특징 맵. |
| $\mathcal{D}(F, s)$ | 스케일 $s$에서 특징 맵에 적용되는 다중 스케일 다운샘플링 연산. |
| $\mathcal{U}(F, s)$ | 스케일 $s$에서 특징 맵에 적용되는 업샘플링 연산. |
| $s_1, s_2, s_0$ | 특징 맵 크기 조정에 사용되는 특정 스케일 매개변수 (예: $0.75, 0.5, 1.0$). |
| $F_{u1}, F_{u2}$ | 다른 스케일에서 결과로 나오는 업샘플링된 특징 맵. |
| $F_{\text{edge}}$ | 분리되고 정제된 에지 세부 정보, 수학적으로 $\|F_{u1} - F_{u2}\|$로 정의됨. |
| $\lambda$ | 에지 특징의 스케일을 조정하는 데 사용되는 학습 가능한 가중치 매개변수 벡터 ($\lambda \in \mathbb{R}^d$). |
| $\tilde{F}$ | 가중치가 부여된 에지 세부 정보를 원래 입력에 다시 추가한 후의 최종 강화된 특징 맵. |
| $\mathbf{g}$ | 채널별 통계를 캡처하기 위해 풀링 연산으로 생성된 전역 설명자 벡터. |
| $\mathbf{s}$ | 채널 보정 유닛(CCU)에서 생성된 채널 가중치로, 특징을 적응적으로 재가중한다. |
| $F'$ | 채널 어텐션 적용 후 재가중된 출력 특징 맵 ($F \odot \mathbf{s}$). |
| $F'_i$ | 다중 스케일 컨텍스트 집계기(MCA)에서 사용되는 특징 맵의 분할된 부분. |
| $f_{dk}$ | 특정 커널 크기와 팽창률 $d_k$를 갖는 깊이별 합성곱 연산자. |
| $\mathcal{C}_{\text{avg}}, \mathcal{C}_{\text{max}}, \mathcal{C}_{\text{std}}$ | 채널별 평균 풀링, 최대 풀링 및 표준 편차 풀링 연산. |
| $G$ | 공간 보정 모듈에서 다른 풀링 연산을 결합하여 생성된 공간 설명자. |
| $S$ | 요소별 곱셈을 통해 특징 맵을 재보정하는 데 사용되는 결합된 출력. |
문제 정의 및 제약 조건
의료 영상 분석 분야에서 입력(Input)은 CT 스캔, MRI, 피부 병변의 피부경 검사 사진과 같은 원시 의료 데이터셋이며, 원하는 출력(Output)은 해부학적 구조, 장기 또는 병리학적 병변의 픽셀 단위 정밀한 윤곽선이다. 본 논문이 해결하고자 하는 수학적 간극은 이미지의 전체적인 맥락을 이해하기 위해 압축될 때 발생하는 심각한 정보 손실이며, 이는 정확한 경계를 그리는 데 필요한 미세한 공간 좌표를 본질적으로 파괴한다. 저자들은 관련 없는 데이터에 시스템이 압도되지 않으면서, 이러한 누락된 경계 세부 정보를 수학적으로 분리하고 주입할 방법을 필요로 한다. 이는 다중 스케일 업샘플링된 특징 간의 절대값 차이, $F_{edge} = |F_{u1} - F_{u2}|$로 계산된다.
딥러닝에서 하나의 문제를 해결하면 거의 항상 다른 문제가 발생하며, 이전 연구자들은 좌절스러운 딜레마에 빠져 있었다. 컨볼루션 신경망(CNN)을 사용하면 모델은 지역적 질감을 이해하는 데 뛰어나지만, 컨볼루션 커널의 제한된 수용장(receptive field)으로 인해 전역적 맥락을 파악하는 데 실패한다. 이를 해결하기 위해 연구자들은 Vision Transformers(ViTs)로 전환했으며, 이는 자체 주의(self-attention)를 사용하여 전체 이미지를 한 번에 살펴본다. 그러나 ViTs는 고통스러운 절충점을 도입한다. 전역적 맥락을 아름답게 포착하는 반면, 지역적 경계 표현을 모델링하는 데 심각하게 성능이 저하된다. 더욱이, 이를 해결하기 위해 네트워크가 미세한 경계 특징에 주의를 기울이도록 수동으로 강제하려고 하면 새로운 문제가 발생한다. 적절한 제어 메커니즘의 부족은 배경 노이즈를 증폭시켜, 디코딩 단계에서 네트워크 성능을 실제로 저하시키는 "과도하게 강화된" 표현으로 이어진다. 흐릿한 경계, 전역적 이해 부족, 또는 노이즈가 많고 불안정한 아키텍처 중에서 선택해야 하는 상황에 놓인다.
저자들은 이 특정 문제를 해결하기 매우 어렵게 만드는 몇 가지 가혹하고 현실적인 문제에 직면했다.
- 이차 계산 복잡성: 트랜스포머는 강력하지만, 자체 주의 메커니즘은 입력 크기에 따라 이차적으로 확장되며, 이는 종종 $O(N^2)$로 표현된다. 이는 막대한 계산 병목 현상을 야기하고 엄격한 하드웨어 메모리 제한에 부딪히게 하여, 대규모 고해상도 의료 애플리케이션에 매우 비효율적이다.
- 파괴적인 다운샘플링: 현대 신경망의 계층적 구조는 특징 추출을 위해 다운샘플링에 크게 의존한다. 이러한 물리적 제약은 본질적으로 경계 세부 정보와 미세한 의미론적 표현을 손상시키며, 일단 손실되면 수학적으로 복구하기 어렵다.
- 극심한 형태학적 가변성: 의료 구조는 고정되어 있지 않다. 장기와 병변은 매우 변형 가능하며, 환자마다 다양한 모양, 외형 및 병리학적 상태를 나타낸다. 고정된 수용장은 이러한 다중 스케일 가변성에 적응할 수 없다.
- 스킵 연결에서의 노이즈 축적: 손실된 세부 정보를 복구하기 위해 네트워크는 압축을 우회하기 위해 "스킵 연결(skip connections)"을 사용한다. 그러나 이 데이터를 필터링할 방법이 없으면 관련 없는 배경 노이즈가 디코더로 직접 전달된다. 저자들은 이것이 과도하게 강화된 표현이 노이즈를 축적하여, 중요한 경계 세부 정보를 지우지 않고 특징을 적응적으로 노이즈 제거하기 위한 복잡한 수학적 개입을 필요로 하는 심각한 제약을 생성한다고 지적한다.
이 접근 방식은 왜
의료 영상 분할 분야를 분석할 때, CENet의 저자들은 매우 구체적이고 좌절스러운 난관에 봉착했다. 그들은 기존의 최신(SOTA) 아키텍처들이 임상 스캔의 혹독한 현실에 근본적으로 결함이 있음을 인지했다. U-Net과 같은 합성곱 신경망(CNN)은 커널의 국소 수용 필드에 의해 본질적으로 제한되며, 이는 거대하고 변형 가능한 장기의 전역적 맥락을 파악할 수 없다는 것을 의미한다. 반면에, Vision Transformer(ViT)는 자체 주의 메커니즘을 통해 전역적 맥락을 포착하는 새로운 황금 표준으로 부상했다. 그러나 저자들은 ViT가 실패하는 정확한 순간을 식별했다: 국소적인 미세 디테일(병변의 정확한 경계와 같은)을 모델링하는 데 심각하게 성능이 저하되며, 대규모 고해상도 의료 애플리케이션에 매우 비효율적인 치명적인 이차 계산 복잡성을 가진다는 것이다.
이전 연구자들이 이들을 혼합하여 하이브리드 CNN-Transformer 모델을 만들려고 시도했을 때조차도 새로운 문제가 발생했다. 엄격한 제어 메커니즘 없이 미세한 에지 특징을 디코더로 강제하는 것은 네트워크에 노이즈를 범람시켜 디코더 단계의 성능 저하를 초래했다. 저자들은 무차별적인 접근 방식이 실행 가능하지 않다는 것을 깨달았으며, 고도로 제어되고 수학적으로 엄격한 필터링 시스템이 필요했다. 이것이 바로 Context Enhancement Network(CENet)가 유일하게 실행 가능한 해결책이었던 이유이다.
이를 해결하기 위해 그들은 의료 영상의 혹독한 제약 조건—경계가 불분명하고 장기의 크기가 매우 다양함—과 독특한 이중 필터링 아키텍처 간의 "결합"을 설계했다. 그들은 스킵 연결에 Dual Selective Enhancement Block(DSEB)을 도입했다. 인코더에서 디코더로 특징을 무분별하게 전달하는 대신, DSEB는 Feature Edge Amplifier(FEA)를 사용하여 에지 디테일을 능동적으로 분리하고 증폭시킨다. 이는 서로 다른 스케일에서의 특징 간의 차이를 계산함으로써 이루어진다:
$$F_{edge} = |F_{u1} - F_{u2}|$$
여기서 $F_{u1}$과 $F_{u2}$는 서로 다른 다운샘플링 스케일에서 업샘플링된 특징이다. 이 분리된 에지 맵은 원래 특징 맵으로 다시 주입된다:
$$\tilde{F} = F + \lambda F_{edge}$$
여기서 $\lambda \in \mathbb{R}^d$는 가중치 파라미터로 작용한다.
하지만 여기서 비교 우위가 진정으로 빛을 발한다. 에지를 증폭하면 일반적으로 고차원 노이즈도 증폭된다. 이를 방지하기 위해 저자들은 Differential Attention(DiffAtt)을 통합했다. 별도의 어텐션 맵을 계산하고 빼줌으로써, 그들은 중복된 어텐션과 불균형한 토큰 중요도를 효과적으로 상쇄한다. 이는 신경망을 위한 능동적인 노이즈 캔슬링 헤드폰과 같이 작용한다.
더 나아가, 디코더는 Context Feature Attention Module(CFAM)을 활용하여 네트워크가 과도하게 증폭된 표현으로 인해 막히는 것을 방지한다. 이는 글로벌 디스크립터 $\mathbf{g}$를 사용하여 채널을 압축하고 적응적으로 재가중하는 Channel Calibration Unit(CCU)을 사용한다:
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
이어서 Multi-scale Contextual Aggregator(MCA)가 특징을 분할하고 병렬 확장된 깊이별 합성곱을 통해 처리한다. 이러한 구조적 이점은 네트워크가 기존의 밀집 레이어의 막대한 파라미터 증가 없이 여러 스케일을 동시에 볼 수 있도록 한다.
솔직히 말해서, 이 논문은 표준 ViT에 비해 메모리 복잡성이 얼마나 감소하는지에 대한 정확한 Big-O 수학적 표기법을 명시적으로 제공하지는 않지만, 이차적인 비효율성 때문에 표준 Transformer를 명시적으로 거부한다. 깊이별 합성곱과 채널 감소를 활용함으로써, CENet은 더 무거운 모델을 쉽게 능가하는 질적으로 우수한 경량 표현을 달성한다.
마지막으로, 이 논문은 다른 인기 있는 접근 방식이 왜 실패하는지를 정확하게 설명한다. GAN이나 Diffusion 모델을 명시적으로 거부하지는 않지만—완전히 투명하게 말하자면, 그러한 생성 모델들은 여기서 요구되는 결정론적 정밀도에 어차피 어려움을 겪을 가능성이 높다—그들은 기존의 국소화된 자체 어텐션 및 하이브리드 모델을 심하게 비판한다. 이러한 대안들은 "에지 정보"보다는 "바디 특징"에 너무 집중하며, 노이즈 축적을 처리하는 데 필요한 적응형 노이즈 제거 기능이 부족하다. CFAM의 끝에 가중치 Non-local Block(wNLB)을 CENet에 포함시킨 것은 장거리 공간 의존성을 완벽하게 모델링하여 과도하게 어텐션된 관련 없는 디테일(피부과 검진 이미지의 털과 같은)을 억제함으로써, 제어되고 맥락을 인식하는 증폭이 이전의 황금 표준보다 압도적으로 우수함을 증명한다.
수학 및 논리 메커니즘
의료 영상 분할에서 발생하는 근본적인 상충 관계를 이해하기 위해서는 먼저 Context Enhancement Network (CENet)의 탁월함을 파악해야 한다. 흐릿하고 회색조의 의료 영상에서 종양이나 장기(예: 신장)의 정확한 윤곽을 추적한다고 상상해보자. 너무 확대하면 정확한 경계는 보이지만 신체 내에서 어디에 있는지 파악하기 어려워진다(global context 손실). 반대로 축소하면 위치는 정확히 알 수 있지만 미세한 경계가 픽셀 속으로 흐릿해진다(local detail 손실).
역사적으로 Convolutional Neural Networks (CNNs)는 아주 작은 슬라이딩 윈도우를 통해 살펴보는 "확대된" 전문가였던 반면, Vision Transformers (ViTs)는 전체 이미지를 보지만 미세하고 국소적인 경계에 어려움을 겪는 "축소된" 전문가였다. 더 나아가, 엔지니어들이 이 둘을 결합하려 했을 때, 네트워크는 종종 실제 장기뿐만 아니라 배경 잡음까지 증폭시키는 "과도한 강화(over-enhancement)"로 인해 예측 성능이 저하되는 문제를 겪었다.
CENet의 저자들은 이를 스마트 확대경처럼 작동하는 고도로 제어된 다중 스케일 아키텍처를 설계함으로써 해결했다. 이 아키텍처는 관련 없는 잡음을 억제하기 위해 정교한 게이팅 메커니즘을 사용하면서 선택적으로 경계를 강화한다.
이러한 성과를 달성한 수학적 분석은 다음과 같다.
핵심 방정식
CENet의 핵심은 두 개의 상호 연결된 수학적 엔진에 의존한다. 첫 번째는 경계 세부 정보를 복구하는 Dual Selective Enhancement Block (DSEB)이며, 두 번째는 노이즈로 네트워크를 압도하지 않고 다양한 확대 수준을 지능적으로 융합하는 Multi-scale Contextual Aggregator (MCA)이다.
경계 강화 엔진:
$$ \tilde{F} = F + \lambda F_{edge} $$
다중 스케일 컨텍스트 게이팅 엔진:
$$ F_{MCA} = \Big( \text{SiLU}(f_{1\times1}(F_{cat})) \odot \text{SiLU}(f_{1\times1}(F')) \Big) + F $$
방정식 해부
이 메커니즘의 모든 기어와 스프링을 분해해보자.
경계 엔진에서:
* $F$: 원본 입력 특징 맵(feature map). 물리적으로 이는 특정 레이어에서의 이미지의 기준 현실, 즉 원시적이고 편집되지 않은 신호이다.
* $F_{edge}$: 분리된 경계 세부 정보. 저자들은 이를 다양한 스케일에서 이미지를 다운샘플링하고 업샘플링한 후 절대값 차이($|F_{u1} - F_{u2}|$)를 계산하여 얻는다. 논리적으로 이는 고역 통과 필터(high-pass filter) 역할을 하여 날카로운 전환(장기의 경계)만을 포착한다.
* $\lambda$: 학습 가능한 가중치 파라미터($\mathbb{R}^d$의 벡터). 이는 경계에 대한 볼륨 조절기 역할을 하여 네트워크가 각 특정 채널에 대해 실제로 얼마나 많은 경계 강화가 필요한지 결정하도록 한다.
* $+$ (덧셈): 곱셈 대신 덧셈을 사용하는 이유? 덧셈은 오버레이(overlay) 역할을 한다. 기준 이미지($F$)를 가져와 강화된 경계($\lambda F_{edge}$)를 그 위에 그리는 것이다. 만약 곱셈을 사용했다면, 경계가 없는 영역(여기서 $F_{edge} \approx 0$)은 전체 이미지를 지워버려 장기 내부를 완전히 검게 만들었을 것이다!
컨텍스트 게이팅 엔진에서:
* $F_{cat}$: 연결된 다중 스케일 특징. 네트워크는 이미지를 분할하고 다양한 "확장된(dilated)" 렌즈(3, 5, 8 픽셀 떨어진 이웃을 보는)를 통해 이를 살펴본 후 함께 쌓는다. 이는 "전역 컨텍스트(global context)" 또는 숲을 나타낸다.
* $F'$: 채널 보정된 특징 맵. 이는 가장 중요한 특징 채널이 우선순위를 갖도록 재가중된 원본 신호이다. 이는 "국소 세부 정보(local detail)" 또는 나무를 나타낸다.
* $f_{1\times1}$: 점별 컨볼루션(point-wise convolution). 수학적으로는 특징 맵의 깊이에 걸친 선형 변환이다. 논리적으로는 바텐더 역할을 하여 이미지의 공간적 너비나 높이를 변경하지 않고 다양한 정보 채널을 혼합한다.
* $\text{SiLU}$: Sigmoid Linear Unit 활성화 함수. 강한 양수 신호는 선형적으로 통과시키고 음수 신호는 0으로 부드럽게 압축한다. 이는 부드럽고 연속적인 게이트키퍼 역할을 한다.
* $\odot$ (Hadamard Product): 요소별 곱셈. 이것이 가장 중요한 연산자이다. 덧셈 대신 곱셈을 사용하는 이유? 곱셈은 논리적인 AND 게이트(필터) 역할을 한다. 방정식의 왼쪽은 컨텍스트($F_{cat}$)를 평가하고, 오른쪽은 국소 특징($F'$)을 평가한다. 이를 곱함으로써 네트워크는 국소 세부 정보와 전역 컨텍스트 모두가 중요하다고 판단할 때만 신호가 통과하도록 허용한다. 이는 관련 없는 배경 잡음을 적극적으로 음소거한다.
* $+$ (잔차 덧셈): 복잡한 게이팅 메커니즘이 무엇을 강화할지 결정한 후, 원본 입력 $F$에 다시 더해진다. 이는 잔차 연결(residual connection)이다. 이는 네트워크가 원본 이미지를 절대 잊지 않도록 하여 과도한 처리를 방지하는 안전망 역할을 한다.
단계별 흐름
위장 경계의 작은 픽셀을 나타내는 고차원 벡터와 같은 단일 추상 데이터 포인트의 정확한 수명 주기를 추적해보자.
- 기준 진입: 위장 경계 픽셀이 특징 맵 $F$의 일부로 DSEB 블록에 진입한다.
- 경계 추출: 네트워크는 이 픽셀 주변의 이미지를 축소하고 확장한다. 경계에 있기 때문에 이 과정에서 픽셀이 약간 이동한다. 네트워크는 두 버전을 빼서 날카로운 전환을 분리한다. 이제 우리 픽셀은 $F_{edge}$ 맵에서 빛나고 있다.
- 경계 주입: 네트워크는 이 빛을 $\lambda$로 스케일링하고 원본 픽셀에 다시 더한다($+$). 이제 위장 경계는 선명하고 잘 정의된다($\tilde{F}$).
- 컨텍스트 수집: 픽셀이 CFAM 디코더로 이동한다. 복제본으로 분할된다. 한 복제본은 즉각적인 이웃을 보고, 다른 복제본은 8픽셀 떨어진 곳을 보며 "아, 간 옆에 있구나"라고 인지한다. 이러한 관점들이 $F_{cat}$으로 쌓인다.
- 게이팅 심문: 컨텍스트($F_{cat}$)와 픽셀 자체의 보정된 정체성($F'$)은 모두 $f_{1\times1}$에 의해 혼합되고 $\text{SiLU}$에 의해 부드럽게 처리된다. 이들은 곱셈 연산자($\odot$)에서 만난다. 컨텍스트는 "이것은 유효한 장기 경계이다"라고 말하며 높은 값(예: 0.9)을 출력한다. 국소 특징은 "나는 날카로운 경계이다"라고 말하며 높은 값(예: 0.8)을 출력한다. 이들은 곱해진다($0.9 \times 0.8 = 0.72$) 필터를 통과한다. (만약 이 픽셀이 단순히 피부의 무작위 털이었다면, 컨텍스트는 0.01을 출력하고 곱셈은 즉시 잡음을 제거했을 것이다.)
- 최종 재결합: 이 정제되고 컨텍스트 승인을 받은 신호는 원시 픽셀 $F$에 다시 더해진다($+$). 데이터 포인트는 모듈을 빠져나가며 완벽하게 강화되어 최종 분할 맵을 준비한다.
최적화 역학
이 기계적 조립 라인은 실제로 어떻게 장기를 분할하는 법을 배울까?
학습 과정은 손실 함수(특히 경계를 잘못 예측할 경우 네트워크에 큰 페널티를 부과하는 BDoU Loss)로부터 역방향으로 흐르는 그래디언트(gradient)에 의해 주도된다.
아키텍처는 매우 유리한 손실 지형(loss landscape)을 형성한다. 잔차 덧셈($+$)의 광범위한 사용으로 인해 그래디언트는 네트워크 끝에서 초기 레이어까지 소실되지 않고 직접 흐를 수 있는 "고속도로"를 갖는다.
한편, 게이팅 메커니즘($\odot$)은 동적 그래디언트 라우터 역할을 한다. 역전파(backpropagation) 중에 특정 영역의 SiLU 게이트가 순방향 패스에서 관련 없는 잡음으로 간주되어 0에 가까웠다면, 해당 경로를 통해 역방향으로 흐르는 그래디언트도 0으로 곱해진다. 이는 효과적으로 무가치한 부분의 학습을 동결시키고 최적화기가 모든 업데이트 파워를 중요한 영역(장기 및 경계)을 담당하는 가중치에 집중하도록 강제한다.
마지막으로, 네트워크가 너무 흥분하여 폭주하는 피드백 루프(강화된 특징이 계속 강화되어 잡음으로 폭발하는)를 생성하는 것을 방지하기 위해, 저자들은 모듈 끝에 가중치 비지역 블록(weighted Non-Local Block, wNLB)을 배치했다. 이는 공간 정규화기(spatial regularizer) 역할을 한다. 이는 전체 이미지를 한 번에 살펴보고 과도한 강화로 인한 고립된 스파이크를 부드럽게 하여 최적화 궤적이 안정적이고 부드럽게 유지되며 매우 정확하고 경계가 완벽한 분할로 수렴하도록 보장한다.
결과, 한계점 및 결론
CENet(Context Enhancement Network)을 제대로 이해하기 위해서는 먼저 의료 영상 분할(medical image segmentation)의 근본적인 문제를 파악해야 한다. 매우 상세하지만 다소 흐릿한 위성 지도에서 한 국가의 정확한 국경선을 추적하는 임무를 맡았다고 상상해보자. 의료 분야에서 이러한 "추적"은 픽셀 단위 분할, 즉 원시 CT, MRI 또는 피부 스캔에서 장기, 종양 또는 병변의 정확한 경계를 식별하는 것이다.
역사적으로 과학자들은 이를 위해 합성곱 신경망(CNN)을 사용했다. CNN은 돋보기와 같아서 국소적인 질감을 보는 데는 뛰어나지만 전역적인 맥락("큰 그림")을 이해하는 데는 매우 취약하다. 최근에는 비전 트랜스포머(ViT)가 등장했다. ViT는 위성 보기와 같아서 전역적인 맥락을 완벽하게 이해하지만 종종 미세한 국소 경계 세부 정보를 흐릿하게 만든다. 엔지니어들이 이 두 가지 접근 방식을 결합하려고 하거나 계산 능력을 절약하기 위해 이미지를 축소(다운샘플링)할 때, 장기의 섬세한 경계가 손상된다.
이 논문의 핵심 동기는 좌절스러운 역설을 해결하는 것이다. 즉, 네트워크가 미세한 가장자리에 더 많은 주의를 기울이도록 수학적으로 강제하려고 하면 필연적으로 배경 잡음(TV의 정전기나 피부 스캔의 털과 같은)이 증폭된다는 것이다. 저자들은 "과도한 강화"를 유발하거나 네트워크의 학습 과정을 저하시키지 않으면서 복잡하고 변형 가능한 장기의 가장자리를 강화할 수 있는 시스템을 구축해야 했다.
수학적 핵심: 어떤 문제를 어떻게 해결했는가?
저자들은 DSEB(Dual Selective Enhancement Block)와 CFAM(Contextual Feature Attention Module)이라는 두 가지 뛰어난 수학적 개입을 통해 시각 정보의 흐름을 가로채고 정제하도록 CENet을 설계했다.
1. 가장자리 분리 (DSEB)
가장자리가 어디인지 단순히 추측하는 대신, DSEB는 FEA(Feature Edge Amplifier)를 사용하여 수학적으로 가장자리를 분리한다. 네트워크는 입력 특징 맵 $F$를 받아 서로 다른 비율($s_1 = 0.75$ 및 $s_2 = 0.5$)로 축소했다가 다시 확대한다.
$$F_{u1} = U(\mathcal{D}(F, s_1), s_0), \quad F_{u2} = U(\mathcal{D}(F, s_2), s_0)$$
여기서 $\mathcal{D}$는 다운샘플링이고 $U$는 업샘플링이다. 이미지의 이 두 버전은 다르게 압축되었기 때문에, 이를 빼면 장기의 중앙과 같이 넓고 평평한 영역은 상쇄되고 날카롭고 고주파인 가장자리 세부 정보만 남게 된다.
$$F_{edge} = |F_{u1} - F_{u2}|$$
이 순수한 "가장자리 맵"은 학습된 매개변수 $\lambda$에 의해 가중치가 부여된 후 원래 특징 맵에 다시 추가된다.
$$\tilde{F} = F + \lambda F_{edge}$$
2. 잡음 억제 (CFAM)
가장자리가 강화된 후, 네트워크는 잡음에 압도될 위험이 있다. CFAM은 과도하게 강화된 표현이 최종 출력을 망치는 것을 방지하기 위해 다단계 필터링 시스템 역할을 한다.
먼저, CCU(Channel Calibration Unit)를 사용하여 실제로 중요한 "채널"(시각 데이터의 계층)을 파악한다. 이는 평균, 최대값, 표준 편차의 세 가지 다른 방식으로 데이터를 풀링하여 전역 기술자 $\mathbf{g}$를 생성함으로써 수행된다.
$$\mathbf{g} = [\mathcal{P}_{avg}(F); \mathcal{P}_{max}(F); \mathcal{P}_{std}(F)]$$
이 기술자는 원래 특징을 스케일링하는 가중치 집합 $\mathbf{s}$를 생성한다: $F' = F \odot \mathbf{s}$.
나중에 CFAM에서 SRM(Spatial Calibration Module)은 병렬 컨볼루션을 사용하여 픽셀 단위 및 이웃 상호 작용을 모두 캡처하여 공간 위치에 대해 유사한 작업을 수행한다.
$$S = \sigma(f_{1\times1}(G) + f_k^{dw}(G))$$
$$F_{recal} = F_{MCA} \odot S$$
DSEB의 가장자리 부스팅과 CFAM의 철저한 잡음 필터링을 결합함으로써 저자들은 역설을 해결했다. 즉, 잡음 없이 초고해상도 경계를 달성했다.
실험 아키텍처: 주장을 증명하다
저자들은 단순히 데이터셋에 모델을 적용하고 1%의 정확도 향상을 자랑하는 데 그치지 않았다. 그들은 수학적 주장을 철저히 검증하기 위해 매우 적대적인 시험장을 설계했다.
희생양 (베이스라인):
CENet을 최첨단 모델의 방대한 명단과 비교했다. 희생양에는 순수 CNN(U-Net, DeepLabv3+), 순수 트랜스포머(Swin-Unet, MissFormer), 그리고 강력한 하이브리드 모델(TransUNet, MSA$^2$Net, UCTransNet)이 포함되었다.
결정적 증거:
모델이 특정 유형의 이미지만 암기한 것이 아님을 증명하기 위해 완전히 다른 의료 도메인에서 테스트했다. 내부 영상의학(신장, 위, 심장의 3D CT 및 MRI 스캔)과 외부 피부병리학(피부 병변의 2D 사진)이다. CENet은 ACDC 심장 데이터셋에서 92.18%의 엄청난 DICE 점수를 달성하며 모든 베이스라인을 능가했다.
하지만 부인할 수 없는 결정적인 증거는 메트릭이 아니라 시각적 특징 히트맵과 어블레이션 연구였다. 저자들은 네트워크의 "뇌"를 말 그대로 열어 그것이 어디를 보고 있는지 보여주었다.
1. DSEB 이전: 네트워크의 주의는 확산되고 산만했다.
2. DSEB 이후: 주의는 장기의 가장자리로 팽팽하게 집중되었다.
3. wNLB (잡음 제거 메커니즘) 이후: 네트워크는 관련 없는 세부 정보를 적극적으로 억제했다. 피부 병변 데이터셋에서는 네트워크가 환자의 피부 털을 무시하고 병변 경계에만 집중하는 것을 시각적으로 볼 수 있다.
또한, 그들은 자신의 모델을 체계적으로 해체했다(DSEB, FEA, CFAM을 하나씩 끄면서). 어블레이션 연구는 가장자리 증폭과 잡음 억제의 특정 수학적 조합 없이는 모델의 성능이 붕괴됨을 입증했다.
향후 논의 주제
이 논문에서 소개된 뛰어난 메커니즘을 바탕으로 향후 탐구 및 비판적 토론을 위한 몇 가지 영역은 다음과 같다.
- 다중 스케일 처리의 비용 대 임상 현실:
CENet은 다중 스케일 다운샘플링, 업샘플링 및 확장 컨볼루션에 크게 의존한다. 정확도가 높지만 추론 시간에 어떤 영향을 미치는가? 병원에서 NVIDIA A100이 아닌 표준 150달러 임상 GPU에 이를 배포하고 싶다면 CFAM의 복잡한 게이팅 메커니즘이 병목 현상이 될 것인가? 이러한 무거운 수학적 연산을 응급실 진단을 위한 가볍고 실시간 아키텍처로 증류하는 방법에 대해 논의해야 한다. - "흐릿한 경계" 딜레마:
DSEB 모듈은 날카로운 경계가 항상 정답이라고 가정한다. 그러나 종양학에서는 뇌의 교모세포종과 같이 공격적이고 침윤적인 특정 종양은 본질적으로 날카로운 경계가 부족하며 건강한 조직으로 희미해진다. 절대값 차이 메커니즘($|F_{u1} - F_{u2}|$)은 생물학적 정답이 가장자리가 아닌 기울기일 때 어떻게 작동할 수 있는가? 이러한 수학적 엄격함이 존재하지 않는 곳에 강한 경계를 환각하도록 네트워크를 실수로 강제할 수 있는가? - 연속적인 3D 공간 종속성으로의 진화:
현재 모델은 3D MRI 및 CT 스캔을 2D 슬라이스의 연속으로 처리한다. wNLB(weighted Non-local Block)는 슬라이스 내에서 장거리 공간 종속성을 포착하지만 Z축(깊이)은 무시한다. 계산 복잡성의 기하급수적인 폭발을 일으키지 않고 진정한 볼륨 텐서를 처리하도록 CCU(Channel Calibration Unit) 및 SRM(Spatial Calibration Module)을 수학적으로 어떻게 발전시킬 수 있는가?
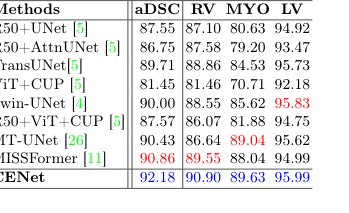 Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
Table 2. Evaluation results on the skin benchmarks (PH2 and HAM10000) and ACDC dataset
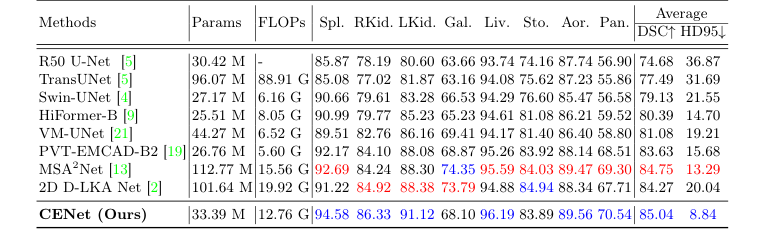 Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
Table 1. Evaluation results on the Synapse dataset (blue indicates the best and red the second best results)
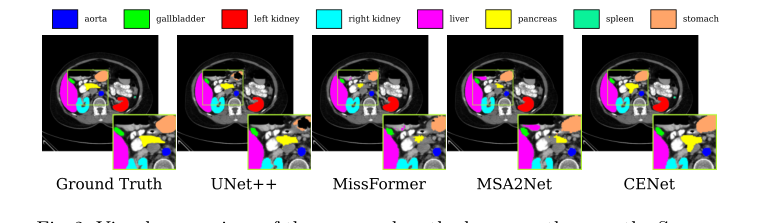 Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset
Figure 2. Visual comparison of the proposed method versus others on the Synapse dataset