फंक्शन-स्ट्रक्चर कनेक्टिविटी नेटवर्क के माध्यम से क्रॉस-मोडल ब्रेन ग्राफ ट्रांसफार्मर: मस्तिष्क रोग निदान के लिए
यह समस्या कहाँ से उत्पन्न हुई, इसे समझने के लिए हमें यह देखना होगा कि तंत्रिका विज्ञानी और कंप्यूटर वैज्ञानिक ऐतिहासिक रूप से अल्जाइमर रोग (AD) या ऑटिज्म स्पेक्ट्रम डिसऑर्डर (ASD) जैसे जटिल मस्तिष्क रोगों का निदान...
पृष्ठभूमि और अकादमिक वंशावली
यह समस्या कहाँ से उत्पन्न हुई, इसे समझने के लिए हमें यह देखना होगा कि तंत्रिका विज्ञानी और कंप्यूटर वैज्ञानिक ऐतिहासिक रूप से अल्जाइमर रोग (AD) या ऑटिज्म स्पेक्ट्रम डिसऑर्डर (ASD) जैसे जटिल मस्तिष्क रोगों का निदान करने का प्रयास कैसे करते रहे हैं। न्यूरोइमेजिंग के शुरुआती दिनों में, शोधकर्ता विसंगतियों को देखने के लिए एकल प्रकार के मस्तिष्क स्कैन पर निर्भर करते थे। अंततः, इस क्षेत्र ने महसूस किया कि मस्तिष्क एक अत्यधिक जटिल, परस्पर जुड़ी हुई नेटवर्क के रूप में कार्य करता है। इससे दो अलग-अलग दृष्टिकोणों का उपयोग हुआ: कार्यात्मक कनेक्टिविटी (विभिन्न मस्तिष्क क्षेत्र एक साथ कैसे सक्रिय होते हैं, fMRI द्वारा मापा जाता है) और संरचनात्मक कनेक्टिविटी (उन्हें जोड़ने वाले वास्तविक भौतिक तंत्रिका फाइबर, DTI द्वारा मापा जाता है)। इन दो तौर-तरीकों को फ्यूज करने की विशिष्ट समस्या इसलिए उत्पन्न हुई क्योंकि मस्तिष्क रोग अक्सर भौतिक वायरिंग और संचार पैटर्न दोनों को एक साथ बाधित करते हैं। उनका सटीक निदान करने के लिए संरचना और कार्य के बीच गहरे युग्मित संबंध को समझने की आवश्यकता होती है, न कि किसी एक को अलग से देखने की।
वह मौलिक सीमा क्या थी जिसने लेखकों को यह पेपर लिखने के लिए मजबूर किया? इन दो प्रकार के डेटा को संयोजित करने का प्रयास करते समय पिछले दृष्टिकोण एक बड़ी बाधा से टकराए। ग्राफ न्यूरल नेटवर्क (GNNs) लोकप्रिय थे, लेकिन वे केवल पड़ोसी नोड्स के बीच स्थानीय रूप से जानकारी प्रसारित करते थे, जिससे मस्तिष्क में व्यापक, लंबी दूरी की निर्भरताओं को पूरी तरह से नजरअंदाज कर दिया जाता था। इसे ठीक करने के लिए, कुछ हालिया मॉडलों ने ट्रांसफार्मर पेश किए, जो बड़ी तस्वीर देखने में उत्कृष्ट हैं। हालांकि, मौजूदा मल्टी-मोडल मॉडल ने कार्यात्मक और संरचनात्मक डेटा को केवल दो अलग-अलग, समानांतर दृश्यों के रूप में माना और अंत में केवल उनकी अंतिम विशेषताओं को एक साथ फ्यूज किया। उन्होंने संरचनात्मक कनेक्टिविटी की सहायक भूमिका को पूरी तरह से नजरअंदाज कर दिया—विशेष रूप से, भौतिक वायरिंग को कार्यात्मक संचार को कैसे निर्देशित या मार्गदर्शन करना चाहिए। लेखकों ने महसूस किया कि मॉडल के कार्यात्मक डेटा पर "ध्यान" को स्पष्ट रूप से निर्देशित करने के लिए भौतिक संरचना का उपयोग किए बिना, पिछले मॉडल महत्वपूर्ण नैदानिक जानकारी को मेज पर छोड़ रहे थे।
यहां पेपर से कुछ अत्यधिक विशिष्ट शब्द दिए गए हैं, जिन्हें रोजमर्रा की अवधारणाओं में अनुवादित किया गया है:
- कार्यात्मक कनेक्टिविटी नेटवर्क (fMRI): इसे विभिन्न शहरों के बीच वास्तविक समय की फोन कॉल ट्रैफिक के रूप में सोचें। यह स्वयं फोन लाइनें नहीं दिखाता है, लेकिन यह बताता है कि कौन से शहर ठीक उसी समय एक-दूसरे से बार-बार बात कर रहे हैं।
- संरचनात्मक कनेक्टिविटी नेटवर्क (DTI): यह भौतिक बुनियादी ढांचा है—उन शहरों के बीच निर्मित वास्तविक फाइबर-ऑप्टिक केबल या कंक्रीट राजमार्ग। भले ही दो शहर अभी बात नहीं कर रहे हों, भौतिक राजमार्ग मौजूद है।
- रुचि का क्षेत्र (ROI): किसी देश के नक्शे को देखने की कल्पना करें; एक ROI बस एक विशिष्ट शहर या राज्य है। मस्तिष्क में, यह एक विशिष्ट शारीरिक क्षेत्र (जैसे हिप्पोकैम्पस) है जिस पर शोधकर्ता गतिविधि या कनेक्शन के लिए निगरानी करते हैं।
- क्रॉस-मोडल TopK पूलिंग: एक सरकारी समिति की कल्पना करें जो किसी संकट के लिए निगरानी के लिए शीर्ष $k$ सबसे महत्वपूर्ण शहरों तक एक विशाल राष्ट्रीय मानचित्र को छोटा करने की कोशिश कर रही है। केवल जनसंख्या आकार (एक तौर-तरीका) को देखने के बजाय, वे सबसे महत्वपूर्ण शहरों का चयन करने के लिए भौतिक राजमार्ग बुनियादी ढांचे और फोन ट्रैफिक (क्रॉस-मोडल) दोनों का मूल्यांकन करते हैं, अपने विश्लेषण को सरल बनाने के लिए बाकी को छोड़ देते हैं।
आइए इस समस्या को हल करने के लिए उपयोग किए जाने वाले प्रमुख गणितीय नोटेशन को व्यवस्थित करें।
| नोटेशन | प्रकार | विवरण |
|---|---|---|
| $\mathbf{X}_{s}$ | चर | DTI छवियों से प्राप्त संरचनात्मक कनेक्टिविटी मैट्रिक्स। |
| $\mathbf{X}_{s,(i,j)}$ | चर | ROI $i$ और ROI $j$ के बीच भौतिक फाइबर कनेक्शन की संख्या। |
| $\mathbf{M}^0$ | पैरामीटर | ट्रांसफार्मर को निर्देशित करने के लिए फ़िल्टर की गई संरचनात्मक विशेषताओं से पुनर्निर्मित प्रारंभिक संवर्धित मास्क। |
| $\mathbf{X}_f^{l-1}$ | चर | $l$-वें परत पर इनपुट नोड फीचर मैट्रिक्स (कार्यात्मक कनेक्टिविटी का प्रतिनिधित्व करता है)। |
| $\mathbf{M}^{l-1}$ | चर | $l$-वें परत पर संवर्धित मास्क, जिसका उपयोग भौतिक वायरिंग के आधार पर ध्यान तंत्र को निर्देशित करने के लिए किया जाता है। |
| $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$ | पैरामीटर | मल्टी-हेड सेल्फ-अटेंशन मैकेनिज्म में क्वेरी, की और वैल्यू के लिए सीखने योग्य भार मैट्रिक्स। |
| $\mathbf{S}^l$ | चर | अंतिम स्कोर वेक्टर जो पूलिंग के लिए प्रत्येक नोड के क्रॉस-मोडल महत्व को दर्शाता है। |
| $\mathbf{i}$ | चर | पूलिंग प्रक्रिया के बाद चयनित शीर्ष $k$ नोड्स को संग्रहीत करने वाला इंडेक्स वेक्टर। |
समस्या परिभाषा और बाधाएँ
यह पेपर जिस सटीक समस्या से निपटता है, उसे समझने के लिए, हमें पहले यह परिभाषित करना होगा कि हम कहाँ से शुरू कर रहे हैं और कहाँ जाना चाहते हैं।
प्रारंभ बिंदु (इनपुट): हम न्यूरोइमेजिंग से निकाले गए दो अलग-अलग प्रकार के मस्तिष्क नेटवर्क डेटा से शुरू करते हैं।
1. कार्यात्मक कनेक्टिविटी (FC): fMRI स्कैन से प्राप्त, यह कैप्चर करता है कि विभिन्न मस्तिष्क क्षेत्र एक साथ "फायर" कैसे करते हैं। गणितीय रूप से, इसे एक प्रारंभिक नोड फीचर मैट्रिक्स $\mathbf{X}^0_f \in \mathbb{R}^{N^0 \times N^0}$ के रूप में दर्शाया जाता है, जो $N^0$ विभिन्न रुचि के क्षेत्रों (ROIs) के बीच पियर्सन सहसंबंध गुणांक की गणना करके प्राप्त किया जाता है।
2. संरचनात्मक कनेक्टिविटी (SC): DTI स्कैन से प्राप्त, यह इन क्षेत्रों को जोड़ने वाले वास्तविक भौतिक "वायरिंग" या तंत्रिका फाइबर पथों का प्रतिनिधित्व करता है, जिसे एक मैट्रिक्स $\mathbf{X}_s \in \mathbb{R}^{N^0 \times N^0}$ के रूप में दर्शाया जाता है।
लक्ष्य स्थिति (आउटपुट): अंतिम उद्देश्य एक विशिष्ट मस्तिष्क रोग (जैसे अल्जाइमर रोग या ऑटिज्म स्पेक्ट्रम डिसऑर्डर) होने या सामान्य नियंत्रण होने का निर्धारण करने के लिए एक अत्यधिक सटीक वर्गीकरण संभावना $P(c)$ आउटपुट करना है।
गणितीय अंतर: यहां गायब कड़ी यह है कि भौतिक वायरिंग (संरचना) को कार्यात्मक फायरिंग (गतिविधि) में प्रभावी ढंग से गणितीय रूप से कैसे बुना जाए। पिछले शोधकर्ताओं ने दोनों नेटवर्क से स्वतंत्र रूप से विशेषताओं को निकाला और उन्हें अंत में (फीचर आयामों में फ्यूजन) जोड़ा। वे दोनों के बीच गहरे, युग्मित अंतर्निर्भरता को पकड़ने में विफल रहे। इस पेपर के लेखकों ने महसूस किया कि संरचनात्मक कनेक्टिविटी को कार्यात्मक कनेक्टिविटी पर गणितीय ध्यान को निर्देशित और बढ़ाने के लिए एक भौतिक मानचित्र के रूप में कार्य करना चाहिए।
हालांकि, इस अंतर को पाटने से एक दर्दनाक दुविधा उत्पन्न होती है जिसने पिछले शोधकर्ताओं को फंसाया है।
दुविधा:
मस्तिष्क नेटवर्क विश्लेषण में, किसी बीमारी का निदान करने के लिए दूरस्थ मस्तिष्क क्षेत्रों के संचार के तरीके को समझना आवश्यक है। इसका मतलब है कि मॉडल को "लंबी दूरी की निर्भरताओं" को कैप्चर करना चाहिए।
यहां व्यापार-बंद है: यदि आप ग्राफ न्यूरल नेटवर्क (GNNs) का उपयोग करते हैं, तो आप मस्तिष्क की स्थानीय भौतिक टोपोलॉजी को सफलतापूर्वक कैप्चर करते हैं, लेकिन GNNs ओवर-स्मूथिंग नामक घटना के कारण लंबी दूरी की निर्भरताओं को कैप्चर करने में कुख्यात रूप से खराब होते हैं। दूसरी ओर, यदि आप एक मानक ट्रांसफार्मर आर्किटेक्चर का उपयोग करते हैं, तो सेल्फ-अटेंशन मैकेनिज्म लंबी दूरी की निर्भरताओं को कैप्चर करने में उत्कृष्ट है। हालांकि, मानक ट्रांसफार्मर "टोपोलॉजी-ब्लाइंड" होते हैं—वे हर मस्तिष्क क्षेत्र को समान रूप से जुड़ा हुआ मानते हैं, मस्तिष्क के वास्तविक भौतिक तंत्रिका फाइबर राजमार्गों को पूरी तरह से नजरअंदाज करते हैं।
यदि आप एक ट्रांसफार्मर को खरोंच से मस्तिष्क की टोपोलॉजी सीखने के लिए मजबूर करने का प्रयास करते हैं, तो आप गंभीर कम्प्यूटेशनल ब्लोट और शोर का सामना करते हैं। आप फंसे हुए हैं: GNNs का उपयोग करें और लंबी दूरी की कार्यात्मक गलत फायरिंग खो दें, या ट्रांसफार्मर का उपयोग करें और भौतिक संरचनात्मक बाधाओं को खो दें।
कठोर दीवारें और बाधाएँ:
इस दुविधा को हल करने के लिए, लेखकों को कई कठोर, यथार्थवादी दीवारों का सामना करना पड़ा जो इस समस्या को अविश्वसनीय रूप से कठिन बनाती हैं:
- अत्यधिक डेटा तिरछापन: आप केवल कच्चे संरचनात्मक कनेक्टिविटी मैट्रिक्स $\mathbf{X}_s$ को न्यूरल नेटवर्क में फीड नहीं कर सकते। दो मस्तिष्क क्षेत्रों के बीच भौतिक फाइबर कनेक्शन की संख्या, $\mathbf{X}_{s,(i,j)}$, शून्य से लेकर कई हजारों तक की एक जंगली तिरछी वितरण रखती है। इसे गणितीय रूप से स्थिर बनाने के लिए, लेखकों को एक सख्त लघुगणकीय परिवर्तन $\mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1)$ लागू करने के लिए मजबूर किया गया, जिसके बाद मानक सामान्यीकरण किया गया ताकि नमूना माध्य एक सामान्य वितरण के अनुरूप हो।
- आयामों का अभिशाप और शोर: मस्तिष्क कई ROIs (नोड्स) में विभाजित है। कई तौर-तरीकों में सभी ROIs में सघन ध्यान की गणना करना कम्प्यूटेशनल रूप से महंगा है और भारी शोर पैदा करता है, क्योंकि सभी मस्तिष्क क्षेत्र किसी विशिष्ट बीमारी के लिए प्रासंगिक नहीं होते हैं। ग्राफ आकार को कम किया जाना चाहिए।
- क्रॉस-मोडल पूलिंग बाधा: ग्राफ आकार को कम करने के लिए नोड्स (पूलिंग) को छोड़ने की आवश्यकता होती है। लेकिन आप नोड्स को अनजाने में निदान के लिए आवश्यक सटीक बायोमार्कर को फेंक कर कैसे छोड़ सकते हैं? यदि आप नोड्स को छोड़ने के लिए केवल कार्यात्मक डेटा को देखते हैं, तो आप महत्वपूर्ण संरचनात्मक क्षति वाले क्षेत्र को छोड़ सकते हैं। यहां बाधा यह है कि नोड के महत्व का मूल्यांकन दोनों कार्यात्मक और संरचनात्मक दृष्टिकोणों से एक साथ किया जाना चाहिए, इससे पहले कि उसे रखने या छोड़ने का निर्णय लिया जाए। ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि पिछले यूनिमोडल पूलिंग विधियों ने संरचनात्मक क्षति को नजरअंदाज करने को कैसे उचित ठहराया, लेकिन यह पेपर दोनों को सीखने योग्य वैक्टर पर संरचनात्मक मास्क और कार्यात्मक विशेषताओं को प्रोजेक्ट करके इसे दूर करता है ताकि एक एकीकृत क्रॉस-मोडल स्कोर $\mathbf{S}^l$ की गणना की जा सके जो अंतिम नोड महत्व का प्रतिनिधित्व करता है।
यह दृष्टिकोण क्यों
पारंपरिक विधियों का टूटने का बिंदु
यह समझने के लिए कि लेखकों ने यह विशिष्ट वास्तुकला क्यों चुनी, हमें उस सटीक क्षण को देखना होगा जब पारंपरिक विधियाँ एक दीवार से टकराईं। मस्तिष्क नेटवर्क विश्लेषण में, लक्ष्य अल्जाइमर या ऑटिज्म जैसी बीमारियों का निदान करना है, यह देखकर कि मस्तिष्क के विभिन्न क्षेत्र (नोड्स) एक-दूसरे के साथ कैसे संवाद करते हैं।
लंबे समय तक, ग्राफ न्यूरल नेटवर्क (GNNs) इसके लिए स्वर्ण मानक थे। हालांकि, लेखकों ने एक मौलिक दोष महसूस किया: GNNs "स्थानीय सूचना प्रसार" तंत्र पर काम करते हैं। वे केवल अपने तत्काल पड़ोसियों से बात करते हैं। लेकिन मानव मस्तिष्क अत्यधिक जटिल है, और बीमारियाँ अक्सर लंबी दूरी की निर्भरताओं को बाधित करती हैं—जिसका अर्थ है कि मस्तिष्क के सामने का एक क्षेत्र पीछे के क्षेत्र के साथ गलत संचार कर सकता है। जैसे आप क्रॉस-कंट्री राजमार्ग प्रणाली को नेविगेट करने की आवश्यकता होने पर स्थानीय शहर के नक्शे पर $150 USD खर्च नहीं करेंगे, GNNs पूरे मस्तिष्क विश्लेषण के लिए बस बहुत दूरदर्शी थे।
सेल्फ-अटेंशन मैकेनिज्म वाले ट्रांसफार्मर, पूरे ग्राफ को एक साथ देखकर इसे हल करते हैं। लेकिन मानक ट्रांसफार्मर (जैसे BrainNetTF) ने एक नई समस्या पेश की: उन्होंने केवल कार्यात्मक एमआरआई (fMRI) डेटा को देखा, भौतिक तंत्रिका फाइबर वायरिंग (DTI डेटा) को पूरी तरह से नजरअंदाज कर दिया। अन्य मल्टी-मोडल विधियों ने कार्यात्मक और संरचनात्मक डेटा को "मल्टी-व्यू" डेटा के रूप में अगल-बगल संसाधित करके इसे ठीक करने का प्रयास किया। लेखकों ने महसूस किया कि यह अपर्याप्त था क्योंकि इसने भौतिक वायरिंग की सहायक भूमिका को नजरअंदाज कर दिया। आप बस दो डेटासेट को एक साथ नहीं मिला सकते; भौतिक वायरिंग को स्पष्ट रूप से कार्यात्मक गतिविधि का मार्गदर्शन करना चाहिए। इस अहसास ने क्रॉस-मोडल ब्रेन ग्राफ ट्रांसफार्मर (CBGT) को एकमात्र व्यवहार्य समाधान बना दिया।
संरचनात्मक लाभ और बेंचमार्किंग तर्क
सिर्फ एक चार्ट पर उच्च सटीकता संख्या प्राप्त करने से परे, यह विधि गुणात्मक रूप से श्रेष्ठ है क्योंकि यह ग्राफ जटिलता और शोर को कैसे संभालती है। मस्तिष्क नेटवर्क अविश्वसनीय रूप से शोरगुल वाले और उच्च-आयामी होते हैं। यदि आप प्रत्येक परत पर प्रत्येक कनेक्शन को संसाधित करने का प्रयास करते हैं, तो आप कम्प्यूटेशनल ओवरहेड और अप्रासंगिक डेटा में डूब जाते हैं।
इसे हल करने के लिए, लेखकों ने एक "क्रॉस-मोडल TopK पूलिंग" मॉड्यूल पेश किया। एक विशाल, स्थिर ग्राफ पर निर्भर रहने के बजाय, मॉडल कार्यात्मक और संरचनात्मक दोनों स्कोर को फ्यूज करके प्रत्येक मस्तिष्क क्षेत्र (ROI) के महत्व का गतिशील रूप से मूल्यांकन करता है:
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
इस स्कोर वेक्टर $\mathbf{S}^l$ के आधार पर, मॉडल केवल शीर्ष $k$ सबसे महत्वपूर्ण नोड्स का चयन करता है:
$$ \mathbf{i} = \text{topk}(\mathbf{S}^l, k) $$
जबकि पेपर स्पष्ट रूप से इसे बिग-ओ नोटेशन में एक सख्त $O(N^2)$ से $O(N)$ मेमोरी कमी के रूप में फ्रेम नहीं करता है, संरचनात्मक लाभ बिल्कुल वही है: यह परत दर परत ग्राफ आकार को काफी कम कर देता है। गैर-आवश्यक मस्तिष्क क्षेत्रों को फ़िल्टर करके, यह केवल सबसे महत्वपूर्ण बायोमार्कर (जैसे प्रीक्यून्यूस या हिप्पोकैम्पस) को संरक्षित करता है, जिससे मॉडल पिछले तरीकों की तुलना में अत्यधिक श्रेष्ठ हो जाता है जिन्होंने नेटवर्क को पूरे शोरगुल वाले ग्राफ को याद रखने के लिए मजबूर किया।
समस्या और समाधान का उत्तम विवाह
इस समस्या में सबसे कठोर बाधा एक ऐसा तरीका खोजना था जिससे ट्रांसफार्मर को कार्यात्मक गतिविधि को देखते समय भौतिक मस्तिष्क वायरिंग की परवाह करने के लिए गणितीय रूप से मजबूर किया जा सके।
लेखकों ने इस बाधा और उनके समाधान के बीच एक शानदार "विवाह" हासिल किया, जो एक संवर्धित मास्क, जिसे $\mathbf{M}^{l-1}$ के रूप में दर्शाया गया है, के निर्माण के माध्यम से हुआ। सबसे पहले, उन्होंने संरचनात्मक डेटा से महत्वहीन भौतिक कनेक्शनों को फ़िल्टर करने के लिए XGBoost का उपयोग किया, केवल सबसे प्रभावशाली भौतिक पथों को छोड़ दिया। फिर, उन्होंने इस संरचनात्मक मास्क को सीधे ट्रांसफार्मर के कार्यात्मक सेल्फ-अटेंशन मैकेनिज्म के दिल में इंजेक्ट किया:
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
उस समीकरण के दाईं ओर ध्यान से देखें: $\odot (1 + \mathbf{M}^{l-1})$। तत्व-वार गुणन ($\odot$) का बायां पक्ष मानक ध्यान स्कोर दिखाता है कि दो मस्तिष्क क्षेत्र कार्यात्मक रूप से एक साथ कितनी बार फायर कर रहे हैं। इसे $(1 + \mathbf{M}^{l-1})$ से गुणा करके, मॉडल गणितीय रूप से ध्यान स्कोर को केवल तभी बढ़ाता है जब उनके बीच एक मजबूत भौतिक तंत्रिका फाइबर भी जुड़ा हो। यह संरचना को कार्य को निर्देशित करने के लिए एक पूरी तरह से सुरुचिपूर्ण तरीका है।
न लिया गया मार्ग
पेपर स्पष्ट रूप से बताता है कि GNNs को क्यों अस्वीकार किया गया (लंबी दूरी की निर्भरताओं को कैप्चर करने में असमर्थता) और मानक मल्टी-मोडल फ्यूजन को क्यों अस्वीकार किया गया (संरचना और कार्य को अलग लेकिन समान मानना, न कि अंतर्निहित)।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि GANs या डिफ्यूजन मॉडल जैसे जनरेटिव मॉडल यहां कैसा प्रदर्शन करेंगे, क्योंकि लेखक उनका बिल्कुल भी उल्लेख नहीं करते हैं। हालांकि, तार्किक रूप से, GANs और डिफ्यूजन मॉडल शोर से नए डेटा वितरण उत्पन्न करने के लिए डिज़ाइन किए गए हैं। यहां परिभाषित समस्या सख्ती से एक विभेदक ग्राफ वर्गीकरण कार्य है (जैसे, अल्जाइमर बनाम सामान्य नियंत्रण का निदान करना)। डिफ्यूजन मॉडल का उपयोग करके ग्राफ को वर्गीकृत करना कम्प्यूटेशनल रूप से अत्यधिक महंगा होगा और विशिष्ट, स्थानीयकृत मस्तिष्क बायोमार्कर की पहचान के लक्ष्य के साथ वास्तुकलात्मक रूप से असंगत होगा। इसलिए, क्रॉस-मोडल पूलिंग के साथ एक विभेदक ट्रांसफार्मर सबसे सीधा और तार्किक मार्ग था।
गणितीय और तार्किक तंत्र
यह पेपर जो गहरा छलांग लगाता है, उसे समझने के लिए, हमें पहले मानव मस्तिष्क को एक दोहरी-स्तरित नेटवर्क के रूप में समझना होगा: "हार्डवेयर" और "सॉफ्टवेयर" का एक संयोजन।
न्यूरोइमेजिंग में, "हार्डवेयर" को डिफ्यूजन टेंसर इमेजिंग (DTI) द्वारा मापा जाता है, जो विभिन्न मस्तिष्क क्षेत्रों को जोड़ने वाले वास्तविक, भौतिक तंत्रिका फाइबर को मैप करता है। इसे संरचनात्मक कनेक्टिविटी कहा जाता है। "सॉफ्टवेयर" को कार्यात्मक मैग्नेटिक रेजोनेंस इमेजिंग (fMRI) द्वारा मापा जाता है, जो रक्त प्रवाह को ट्रैक करता है ताकि यह देखा जा सके कि कौन से मस्तिष्क क्षेत्र एक साथ फायर कर रहे हैं। इसे कार्यात्मक कनेक्टिविटी कहा जाता है।
वर्षों से, डॉक्टर और एआई शोधकर्ता जो मस्तिष्क रोगों (जैसे अल्जाइमर या ऑटिज्म) का निदान करने की कोशिश कर रहे थे, एक बड़ी बाधा का सामना कर रहे थे: वे या तो हार्डवेयर, सॉफ्टवेयर को देखते थे, या बस दोनों डेटासेट को अनाड़ीपन से एक साथ मिला देते थे। मानक ग्राफ न्यूरल नेटवर्क (GNNs) दूरदर्शी नहीं होते हैं—वे केवल तत्काल पड़ोसी मस्तिष्क क्षेत्रों को देखते हैं। दूसरी ओर, ट्रांसफार्मर लंबी दूरी की निर्भरताओं (जैसे मस्तिष्क के सामने का एक क्षेत्र पीछे के क्षेत्र को कैसे प्रभावित करता है) को देखने में उत्कृष्ट होते हैं, लेकिन यदि उनके पास नक्शा न हो तो वे मस्तिष्क के विशाल कार्यात्मक डेटा के शोर में आसानी से खो जाते हैं।
इस पेपर के लेखकों ने इसे क्रॉस-मोडल ब्रेन ग्राफ ट्रांसफार्मर (CBGT) बनाकर हल किया। वे गणितीय रूप से एआई को भौतिक हार्डवेयर (संरचनात्मक कनेक्टिविटी) को सॉफ्टवेयर (कार्यात्मक कनेक्टिविटी) को बेहतर ढंग से समझने के लिए एक मार्गदर्शक ब्लूप्रिंट के रूप में उपयोग करने के लिए मजबूर करते हैं।
यहां पूर्ण गणितीय इंजन है जो इस क्रॉस-मोडल फ्यूजन को शक्ति प्रदान करता है।
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot \left( 1 + \mathbf{M}^{l-1} \right) \right) $$
$$ \mathbf{h}^{l,z} = \mathbf{T}^{l,z} \mathbf{W}_V^{l,z} \mathbf{X}_f^{l-1} $$
आइए इन समीकरणों को टुकड़े-टुकड़े करके समझें कि वे मॉडल में जीवन कैसे भरते हैं।
- $\mathbf{X}_f^{l-1}$: यह परत $l-1$ पर इनपुट नोड फीचर मैट्रिक्स है। भौतिक रूप से, यह "सॉफ्टवेयर" संकेतों का प्रतिनिधित्व करता है—विभिन्न क्षेत्रों की कार्यात्मक मस्तिष्क गतिविधि।
- $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$: ये ध्यान हेड $z$ में क्वेरी, की और वैल्यू के लिए सीखने योग्य भार मैट्रिक्स हैं। तार्किक रूप से, वे अनुवादक के रूप में कार्य करते हैं। वे कच्चे मस्तिष्क संकेतों को एक नए गणितीय स्थान में घुमाने और प्रोजेक्ट करने के लिए मैट्रिक्स गुणन का उपयोग करते हैं जहां क्षेत्र प्रश्न पूछ सकते हैं (क्वेरी), उत्तर प्रदान कर सकते हैं (की), और पदार्थ (वैल्यू) प्रदान कर सकते हैं।
- $(\dots)^\top$: ट्रांसपोज़ ऑपरेटर। यह की मैट्रिक्स को फ्लिप करता है ताकि इसे क्वेरी मैट्रिक्स के विरुद्ध गुणा किया जा सके। यह डॉट उत्पाद दो मस्तिष्क क्षेत्रों की गतिविधियों के बीच कच्चे समानता या "संरेखण" को मापता है।
- $\sqrt{d_K^{l,z}}$: की वैक्टर के आयाम का वर्गमूल। यह एक थर्मोडायनामिक थर्मोस्टेट के रूप में कार्य करता है। जब आप बड़े वैक्टर को गुणा करते हैं, तो परिणामी संख्याएं फट सकती हैं, जिससे सॉफ्टमैक्स फ़ंक्शन सपाट, मृत क्षेत्रों में चला जाता है जहां सीखना बंद हो जाता है। गणितीय इंजन को सुचारू रूप से चलाने के लिए विचरण को सिकोड़ने के लिए विभाजन का उपयोग किया जाता है।
- $\mathbf{M}^{l-1}$: संरचनात्मक कनेक्टिविटी नेटवर्क से प्राप्त संवर्धित मास्क। यह "हार्डवेयर" नक्शा है, जिसे XGBoost एल्गोरिथम द्वारा पहले से फ़िल्टर किया गया है ताकि केवल सबसे महत्वपूर्ण भौतिक तंत्रिका कनेक्शनों को रखा जा सके।
- $1 + \mathbf{M}^{l-1}$: संरचनात्मक पूर्वाग्रह। यहां जोड़ का उपयोग क्यों करें? संख्या $1$ एक आधार रेखा के रूप में कार्य करती है। यदि $\mathbf{M}$ $0$ है (जिसका अर्थ है कि दो क्षेत्रों को जोड़ने वाला कोई भौतिक तार नहीं है), तो पद बस $1$ बन जाता है। यह सुनिश्चित करता है कि आधार कार्यात्मक जानकारी मिटाई न जाए। यदि कोई भौतिक कनेक्शन है, तो $\mathbf{M}$ $1$ में जुड़ जाता है, कनेक्शन को बढ़ाता है।
- $\odot$: हैडमार्ड उत्पाद (तत्व-वार गुणन)। यह एक आवर्धक कांच के रूप में कार्य करता है। यह संरचनात्मक ब्लूप्रिंट का उपयोग करके कार्यात्मक ध्यान स्कोर को सीधे स्केल करता है। जोड़ के बजाय यहां गुणन का उपयोग किया जाता है ताकि संरचनात्मक मास्क एक आनुपातिक गुणक के रूप में कार्य करे—ठीक उसी जगह ध्यान को बढ़ाना जहां मस्तिष्क की भौतिक वास्तुकला इसका समर्थन करती है।
- $\text{softmax}$: एक सामान्यीकरण फ़ंक्शन। यह एक सख्त बजटर के रूप में कार्य करता है, सभी कच्चे, बढ़े हुए समानता स्कोर को ठीक $1.0$ (या 100%) तक जोड़ने के लिए मजबूर करता है। यह कच्चे गणित को एक संभाव्यता वितरण में परिवर्तित करता है।
- $\mathbf{T}^{l,z}$: अंतिम ध्यान मैट्रिक्स। यह रूटिंग नेटवर्क है, एक मास्टर लेजर जो हर मस्तिष्क क्षेत्र को बताता है कि उसे हर दूसरे क्षेत्र को कितना सुनना चाहिए।
- $\mathbf{h}^{l,z}$: आउटपुट हिडन स्टेट। यह मस्तिष्क क्षेत्रों का अद्यतन, समृद्ध संकेत है, जो एक-दूसरे के साथ संवाद करने के बाद प्राप्त होता है।
इसे क्रियान्वित होते हुए देखने के लिए, आइए एक एकल अमूर्त डेटा बिंदु—मान लीजिए, हिप्पोकैम्पस से संकेत—के सटीक जीवनचक्र को इस समीकरण से गुजरते हुए देखें।
सबसे पहले, हिप्पोकैम्पस ($\mathbf{X}_f$) का कच्चा कार्यात्मक संकेत असेंबली लाइन में प्रवेश करता है और एक क्वेरी वेक्टर बनाने के लिए $\mathbf{W}_Q$ से गुणा किया जाता है। यह अनिवार्य रूप से शून्य में चिल्ला रहा है: "मुझसे सिंक में कौन फायर कर रहा है?" साथ ही, प्रीफ्रंटल कॉर्टेक्स जैसे सभी अन्य मस्तिष्क क्षेत्र अपने की वैक्टर ($\mathbf{W}_K \mathbf{X}_f$) उत्पन्न करते हैं। हिप्पोकैम्पस की क्वेरी को प्रीफ्रंटल कॉर्टेक्स की की के विरुद्ध गुणा किया जाता है। यदि उनके कार्यात्मक संकेत मेल खाते हैं, तो परिणामी स्कोर अधिक होता है।
इसके बाद, इस कच्चे स्कोर को गणितीय ओवरफ्लो को रोकने के लिए $\sqrt{d_K}$ से विभाजित करके ठंडा किया जाता है। अब क्रॉस-मोडल जादू आता है। सिस्टम संरचनात्मक मास्क $\mathbf{M}$ की जाँच करता है। क्या हिप्पोकैम्पस को प्रीफ्रंटल कॉर्टेक्स से जोड़ने वाला एक वास्तविक, भौतिक तंत्रिका फाइबर है? यदि हाँ, तो मास्क $\mathbf{M}$ का मान अधिक होता है, और तत्व-वार गुणन $\odot (1 + \mathbf{M})$ उनके कनेक्शन स्कोर को बहुत बढ़ाता है। यदि कोई भौतिक तार मौजूद नहीं है, तो स्कोर को $1$ से गुणा किया जाता है, जिससे यह अपरिवर्तित रहता है।
softmax फ़ंक्शन फिर इन सभी स्कोर को प्रतिशत में क्लिप और स्क्वैश करता है। मान लीजिए कि हिप्पोकैम्पस प्रीफ्रंटल कॉर्टेक्स पर 80% ध्यान देने का निर्णय लेता है। अंत में, हिप्पोकैम्पस प्रीफ्रंटल कॉर्टेक्स के वैल्यू वेक्टर ($\mathbf{W}_V \mathbf{X}_f$) का 80% अवशोषित करता है, अपनी आंतरिक स्थिति को $\mathbf{h}$ बनने के लिए अद्यतन करता है। हिप्पोकैम्पस ने अब मस्तिष्क के हार्डवेयर की बाधाओं के आधार पर अपने सॉफ्टवेयर को सफलतापूर्वक अद्यतन किया है।
यह तंत्र वास्तव में कैसे सीखता है और अभिसरण करता है? यहां अनुकूलन की गतिशीलता खूबसूरती से बाधित है। मॉडल को अंत में एक क्रॉस-एंट्रॉपी लॉस फ़ंक्शन द्वारा पर्यवेक्षित किया जाता है, जो मापता है कि मॉडल का अंतिम रोग निदान कितना गलत है।
बैकप्रॉपैगेशन के दौरान, ग्रेडिएंट अंतिम वर्गीकरण से, एक TopK पूलिंग परत (जो गतिशील रूप से बेकार मस्तिष्क क्षेत्रों को छोड़ने और केवल सबसे महत्वपूर्ण बायोमार्कर को रखने के लिए सीखती है) के माध्यम से, और ट्रांसफार्मर परतों में वापस प्रवाहित होते हैं। संरचनात्मक मास्क $\odot (1 + \mathbf{M})$ के कारण, लॉस लैंडस्केप मौलिक रूप से नया आकार लेता है। एक मानक ट्रांसफार्मर में, लॉस लैंडस्केप अराजक होता है क्योंकि मॉडल यादृच्छिक, शोरगुल वाले कार्यात्मक सहसंबंधों (जैसे, संयोग से एक साथ फायर करने वाले दो मस्तिष्क क्षेत्र) पर आसानी से ओवरफिट हो सकता है।
हालांकि, संरचनात्मक मास्क लॉस लैंडस्केप में एक गहरी, चिकनी घाटी के रूप में कार्य करता है। यह एक भौतिक पूर्ववर्ती के रूप में कार्य करता है, जिससे ग्रेडिएंट वास्तविक जैविक मार्गों के साथ बहुत अधिक मजबूती से प्रवाहित होते हैं। एडम ऑप्टिमाइज़र भार मैट्रिक्स ($\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V$) को पुनरावृत्त रूप से अद्यतन करता है, लेकिन यह लगातार मस्तिष्क की भौतिक वास्तविकता द्वारा निर्देशित होता है। समय के साथ, मॉडल केवल सांख्यिकीय पैटर्न पर ही नहीं, बल्कि जैविक रूप से प्रशंसनीय मल्टी-मोडल बायोमार्कर पर भी अभिसरण करता है, जिससे यह अल्जाइमर और ऑटिज्म जैसी स्थितियों का अभूतपूर्व सटीकता के साथ निदान कर पाता है।
परिणाम, सीमाएँ और निष्कर्ष
कल्पना कीजिए कि आप एक विशाल, हलचल भरे महानगर के काम करने के तरीके को समझने की कोशिश कर रहे हैं। आपके पास दो नक्शे हैं। पहला नक्शा विभिन्न पड़ोसों को जोड़ने वाले भौतिक राजमार्गों और ट्रेन ट्रैक दिखाता है—यह शहर की संरचनात्मक कनेक्टिविटी है। दूसरा नक्शा उन पड़ोसों के बीच फोन कॉल और टेक्स्ट संदेशों की मात्रा दिखाता है—यह कार्यात्मक कनेक्टिविटी है।
दशकों से, तंत्रिका विज्ञानी मानव मस्तिष्क को बहुत समान तरीके से देख रहे हैं। डिफ्यूजन टेंसर इमेजिंग (DTI) का उपयोग करके, वे भौतिक तंत्रिका फाइबर (राजमार्ग) को मैप करते हैं, और कार्यात्मक मैग्नेटिक रेजोनेंस इमेजिंग (fMRI) का उपयोग करके, वे मस्तिष्क गतिविधि की सुसंगतता (फोन कॉल) को मैप करते हैं। यदि आप अल्जाइमर या ऑटिज्म जैसे जटिल मस्तिष्क रोगों का निदान करना चाहते हैं, तो आपको दोनों को देखना होगा। आप डेटा के आधे हिस्से को अनदेखा करने के लिए \$150 का हाई-टेक स्कैन खर्च नहीं करेंगे।
हालांकि, एआई-संचालित तंत्रिका विज्ञान में मौलिक समस्या इन दो मानचित्रों को कैसे संयोजित किया जाए, रही है। मौजूदा मॉडल आमतौर पर अपने प्रसंस्करण पाइपलाइन के अंत में विशेषताओं को एक साथ मिलाते हैं। वे यह समझने में विफल रहते हैं कि भौतिक राजमार्ग फोन कॉल के यात्रा के तरीके को निर्धारित करते हैं। इसके अलावा, भौतिक रूप से दूर के मस्तिष्क क्षेत्र अक्सर गहन संचार करते हैं (लंबी दूरी की निर्भरताएं)। पारंपरिक ग्राफ न्यूरल नेटवर्क (GNNs) बड़ी तस्वीर देखने में भयानक होते हैं क्योंकि वे केवल तत्काल पड़ोसियों को देखते हैं। ट्रांसफार्मर बड़ी तस्वीर के लिए महान हैं, लेकिन वे आमतौर पर पूरी तरह से भौतिक ग्राफ संरचना को नजरअंदाज करते हैं।
यह पेपर क्रॉस-मोडल ब्रेन ग्राफ ट्रांसफार्मर (CBGT) पेश करता है, एक शानदार वास्तुकला जो एआई को कार्यात्मक गतिविधि मानचित्र पर अपने ध्यान को केंद्रित करने के लिए भौतिक संरचनात्मक मानचित्र का उपयोग करने के लिए मजबूर करती है।
गणितीय कोर: कौन सी समस्या हल की गई?
लेखकों को एक विशिष्ट बाधा को हल करने की आवश्यकता थी: गणितीय रूप से एक ट्रांसफार्मर के सेल्फ-अटेंशन मैकेनिज्म को भौतिक तंत्रिका फाइबर की परवाह करने के लिए कैसे मजबूर किया जाए?
सबसे पहले, उन्हें संरचनात्मक डेटा को साफ करना पड़ा। DTI फाइबर गणना अत्यधिक तिरछी होती है—कुछ क्षेत्रों में शून्य कनेक्शन होते हैं, दूसरों में हजारों। इसे सामान्य करने के लिए, उन्होंने एक लघुगणकीय परिवर्तन लागू किया:
$$ \mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1) $$
इस मैट्रिक्स को मानकीकृत करने के बाद, उन्होंने शोर को फ़िल्टर करने और केवल सबसे महत्वपूर्ण भौतिक कनेक्शनों की पहचान करने के लिए एक मशीन लर्निंग एल्गोरिथम (XGBoost) का उपयोग किया, जिससे एक "संवर्धित मास्क" बनाया गया जिसे $\mathbf{M}^0$ के रूप में दर्शाया गया है। ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि उन्होंने इस सटीक चरण के लिए विभेदक तंत्रिका परत के बजाय XGBoost को विशेष रूप से क्यों चुना, क्योंकि पेपर एक ग्रिड खोज का उपयोग करता है ताकि एक हार्ड थ्रेशोल्ड $p=3$ सेट किया जा सके, लेकिन यह एक मजबूत फीचर चयनकर्ता के रूप में कार्य करता है।
वास्तविक प्रतिभा क्रॉस-मोडल ट्रांसफार्मर परत में निहित है। एक मानक ट्रांसफार्मर में, ध्यान को क्वेरी और की की तुलना करके गणना की जाती है। यहां, लेखकों ने संरचनात्मक मास्क $\mathbf{M}^{l-1}$ को सीधे कार्यात्मक ध्यान गणना में इंजेक्ट किया है:
$$ \mathbf{T}^{l,z} = \text{softmax}\left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left(\mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1}\right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
सहज रूप से, $(1 + \mathbf{M}^{l-1})$ पद एक संरचनात्मक गुणक के रूप में कार्य करता है। यदि दो मस्तिष्क क्षेत्रों में एक मजबूत भौतिक कनेक्शन (उच्च $\mathbf{M}$) साझा होता है, तो मॉडल उनके कार्यात्मक सहसंबंध पर ध्यान ($\mathbf{T}$) को कृत्रिम रूप से बढ़ाता है। यह संरचना और कार्य को सुरुचिपूर्ण ढंग से जोड़ता है।
अंत में, एक बीमारी का निदान करने के लिए, मॉडल पूरे मस्तिष्क को समान रूप से नहीं देख सकता है; उसे विशिष्ट क्षतिग्रस्त पड़ोस (बायोमार्कर) खोजने की आवश्यकता है। उन्होंने एक क्रॉस-मोडल TopK पूलिंग तंत्र डिजाइन किया। यह संरचनात्मक मास्क और कार्यात्मक नोड सुविधाओं दोनों को सीखने योग्य वैक्टर में प्रोजेक्ट करता है, उन्हें जोड़ता है, और एक एकीकृत महत्व स्कोर उत्पन्न करने के लिए उन्हें एक मल्टी-लेयर परसेप्ट्रॉन (MLP) के माध्यम से पास करता है:
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
मॉडल फिर ग्राफ को क्रूरतापूर्वक छांटता है, इस क्रॉस-मोडल स्कोर के आधार पर केवल शीर्ष $k$ सबसे महत्वपूर्ण क्षेत्रों को रखता है, इन परिष्कृत अभ्यावेदन को एक सॉफ्ट-वोटिंग क्लासिफायरियर को पास करता है।
प्रयोगात्मक वास्तुकला: क्रूर प्रमाण और "पीड़ित"
लेखकों ने सिर्फ यह दावा नहीं किया कि उनका गणित काम करता है; उन्होंने इसे दो पूरी तरह से अलग न्यूरोलॉजिकल युद्धक्षेत्रों: अल्जाइमर रोग (ADNI डेटासेट) और ऑटिज्म स्पेक्ट्रम डिसऑर्डर (ABIDE डेटासेट) में निर्विवाद रूप से साबित करने के लिए एक प्रयोग की वास्तुकला तैयार की।
उनके पीछे छोड़े गए "पीड़ित" अत्याधुनिक मॉडलों का एक "कौन है कौन" थे। उन्होंने यूनिमोडल बेसलाइन को हराया जिन्होंने केवल एक प्रकार के स्कैन (SVM, GAT, BrainGNN, BrainIB, BrainNetTF, ALTER) को देखा और, अधिक महत्वपूर्ण बात, उन्होंने मौजूदा मल्टी-मोडल मॉडल (BrainNN, MME-GCN, Cross-GNN) को कुचल दिया जो संरचना और कार्य को फ्यूज करने का प्रयास करते हैं लेकिन इसे अनाड़ी ढंग से करते हैं। उदाहरण के लिए, माइल्ड कॉग्निटिव इंपेयरमेंट (MCI) को सामान्य नियंत्रण (NC) से अलग करने के कार्य में, CBGT ने सटीकता में भारी 3.9% से सभी अन्य क्रॉस-मोडल विधियों को पीछे छोड़ दिया।
लेकिन इस बात का निश्चित, निर्विवाद प्रमाण कि उनका मुख्य तंत्र काम करता था, केवल उच्च सटीकता नहीं थी—यह एब्लेशन स्टडी और इंटरप्रिटेशन एनालिसिस थी।
जब उन्होंने संरचनात्मक मास्क को हटा दिया (मॉडल को एक वैनिला यूनिमोडल ट्रांसफार्मर में वापस कर दिया), तो अल्जाइमर वर्गीकरण के लिए सटीकता 4.9% तक गिर गई। इसने साबित कर दिया कि संरचनात्मक मास्क सिर्फ एक गिमिक नहीं था; यह मॉडल का भार-वाहक स्तंभ था। इसके अलावा, जब उन्होंने एआई के ध्यान को भौतिक मस्तिष्क पर मैप किया, तो मॉडल ने स्वतंत्र रूप से ऑटिज्म रोगियों के लिए प्रीक्यून्यूस (PCUN) और रेक्टस (REC) पर ध्यान केंद्रित करना सीखा था—ऐसे क्षेत्र जिन्हें नैदानिक साहित्य ने लंबे समय से साबित किया है कि ASD रोगियों द्वारा मानसिक अवस्थाओं का अनुमान लगाने का प्रयास करते समय निष्क्रिय कर दिया जाता है। गणित ने केवल एक लॉस फ़ंक्शन को अनुकूलित नहीं किया; इसने जैविक वास्तविकता को फिर से खोजा।
भविष्य के विकास के लिए चर्चा विषय
इस शानदार नींव के आधार पर, भविष्य के अन्वेषण के लिए यहां कई गहरे रास्ते दिए गए हैं:
- एंड-टू-एंड डिफरेंशिएबल स्ट्रक्चरल स्पार्सिटी:
वर्तमान में, मॉडल संरचनात्मक मास्क $\mathbf{M}^0$ निकालने के लिए एक असतत, पूर्व-प्रसंस्करण चरण के रूप में XGBoost पर निर्भर करता है। यह पाइपलाइन की एंड-टू-एंड विभेदकता को तोड़ता है। क्या हम इसे एक विभेदक स्पार्स अटेंशन मैकेनिज्म (जैसे Sparsemax या Gumbel-Softmax राउटर) से बदल सकते हैं जो बैकप्रॉपैगेशन के दौरान संरचनात्मक ग्राफ को गतिशील रूप से छांटना सीखता है? यह मॉडल की उपन्यास, गैर-स्पष्ट भौतिक बायोमार्कर की खोज करने की क्षमता को कैसे बदलेगा? - कार्यात्मक कनेक्टिविटी में लौकिक गतिशीलता:
यह पेपर कार्यात्मक कनेक्टिविटी को एक स्थिर मैट्रिक्स (पूरे स्कैन पर पियर्सन सहसंबंध) के रूप में मानता है। हालांकि, मस्तिष्क गतिविधि अत्यधिक गतिशील होती है; "फोन कॉल" बर्स्ट में होते हैं। यदि हम कार्यात्मक इनपुट $\mathbf{X}_f$ को एक स्थानिक-लौकिक अनुक्रम में विकसित करते हैं और एक लौकिक ट्रांसफार्मर लागू करते हैं, तो हम एक स्थिर संरचनात्मक मास्क का उपयोग करके एक गतिशील कार्यात्मक अनुक्रम को गणितीय रूप से कैसे बाधित कर सकते हैं? - क्रॉस-डिसिप्लिनरी सामान्यीकरण:
यहां मुख्य गणितीय आधार—एक गतिशील, पूरी तरह से जुड़े ग्राफ पर ध्यान को मास्क और निर्देशित करने के लिए एक स्थिर, भौतिक ग्राफ का उपयोग करना—मस्तिष्क तक सीमित नहीं है। क्या इस सटीक वास्तुकला को शहरी इंजीनियरिंग में तैनात किया जा सकता है? उदाहरण के लिए, वास्तविक समय जीपीएस आंदोलन डेटा (कार्य) पर ध्यान को मास्क करने के लिए भौतिक सड़क नेटवर्क (संरचना) का उपयोग करके यातायात ग्रिडलॉक की भविष्यवाणी करना। जब "नोड्स" 90 मस्तिष्क क्षेत्रों से 90,000 शहर चौराहों तक स्केल करते हैं तो क्या बाधाएं उत्पन्न होंगी?
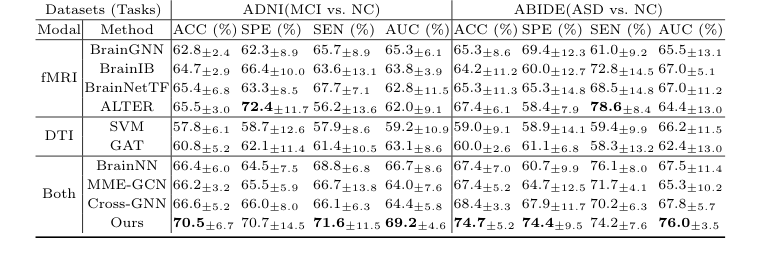 Table 2. Ablation Study Results on Different Datasets
Table 2. Ablation Study Results on Different Datasets
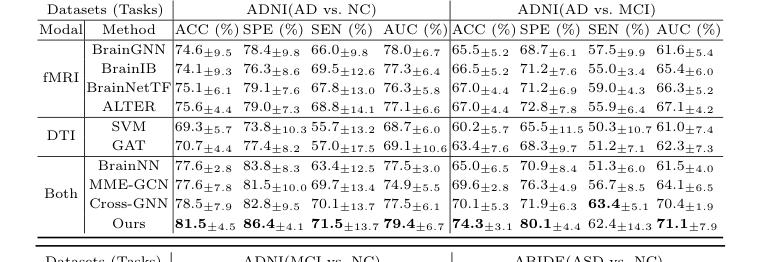 Table 1. Comparative Experiments of Classification Tasks on Different Datasets
Table 1. Comparative Experiments of Classification Tasks on Different Datasets