Кросс-модальный трансформер для графов мозга на основе сети функционально-структурной связности для диагностики заболеваний мозга
Чтобы понять, откуда берется эта проблема, нам нужно обратиться к тому, как нейробиологи и специалисты по компьютерным наукам исторически подходили к диагностике сложных заболеваний мозга, таких как болезнь...
Предыстория и академическая родословная
Чтобы понять, откуда берется эта проблема, нам нужно обратиться к тому, как нейробиологи и специалисты по компьютерным наукам исторически подходили к диагностике сложных заболеваний мозга, таких как болезнь Альцгеймера (БА) или расстройства аутистического спектра (РАС). В ранние дни нейровизуализации исследователи полагались на один тип сканирования мозга для выявления аномалий. В конечном итоге область осознала, что мозг функционирует как высокосложная, взаимосвязанная сеть. Это привело к использованию двух различных перспектив: функциональной связности (как различные области мозга активируются совместно, измеряется фМРТ) и структурной связности (фактические физические нервные волокна, соединяющие их, измеряется ДТИ). Конкретная проблема слияния этих двух модальностей возникла потому, что заболевания мозга часто одновременно нарушают как физическую проводку, так и паттерны коммуникации. Точная диагностика требует понимания глубоко связанной взаимосвязи между структурой и функцией, а не рассмотрения каждой из них в отдельности.
Каково было фундаментальное ограничение, которое заставило авторов написать эту статью? Предыдущие подходы столкнулись с серьезным препятствием при попытке объединить эти два типа данных. Графовые нейронные сети (GNN) были популярны, но они передавали информацию только локально между соседними узлами, полностью упуская из виду широкомасштабные, дальние зависимости в мозге. Чтобы решить эту проблему, некоторые недавние модели ввели трансформеры, которые отлично справляются с видением общей картины. Однако существующие мультимодальные модели просто рассматривали функциональные и структурные данные как два отдельных, параллельных представления и лишь сливали их конечные признаки вместе в конце. Они полностью пренебрегли вспомогательной ролью структурной связности — в частности, тем, как физическая проводка должна диктовать или направлять функциональную коммуникацию. Авторы осознали, что без использования физической структуры для явного направления "внимания" модели к функциональным данным, предыдущие модели оставляли критически важную диагностическую информацию без внимания.
Вот несколько высокоспециализированных терминов из статьи, переведенных на общепринятые понятия:
- Сеть функциональной связности (фМРТ): Представьте себе это как трафик телефонных звонков в реальном времени между разными городами. Это не показывает сами телефонные линии, но показывает, какие города часто разговаривают друг с другом в один и тот же момент времени.
- Сеть структурной связности (ДТИ): Это физическая инфраструктура — фактические оптоволоконные кабели или бетонные магистрали, построенные между этими городами. Даже если два города сейчас не разговаривают, физическая магистраль существует.
- Область интереса (ROI): Представьте, что вы смотрите на карту страны; ROI — это просто конкретный город или штат. В мозге это определенная анатомическая область (например, гиппокамп), за активностью или связями которой следят исследователи.
- Кросс-модальный TopK Pooling: Представьте себе правительственный комитет, пытающийся уменьшить масштаб огромной национальной карты до $k$ наиболее критических городов для мониторинга кризиса. Вместо того чтобы просто смотреть на размер населения (одна модальность), они оценивают как физическую инфраструктуру магистралей, так и телефонный трафик (кросс-модальный), чтобы выбрать наиболее важные города, отбрасывая остальные для упрощения анализа.
Давайте организуем ключевые математические обозначения, используемые для решения этой проблемы.
| Обозначение | Тип | Описание |
|---|---|---|
| $\mathbf{X}_{s}$ | Переменная | Матрица структурной связности, полученная из изображений ДТИ. |
| $\mathbf{X}_{s,(i,j)}$ | Переменная | Количество физических соединений волокон между ROI $i$ и ROI $j$. |
| $\mathbf{M}^0$ | Параметр | Начальная усиленная маска, реконструированная из отфильтрованных структурных признаков для управления трансформером. |
| $\mathbf{X}_f^{l-1}$ | Переменная | Входная матрица признаков узлов (представляющая функциональную связность) на $l$-м слое. |
| $\mathbf{M}^{l-1}$ | Переменная | Усиленная маска на $l$-м слое, используемая для управления механизмом внимания на основе физической проводки. |
| $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$ | Параметр | Обучаемые матрицы весов для Запроса (Query), Ключа (Key) и Значения (Value) в механизме многоголового самовнимания. |
| $\mathbf{S}^l$ | Переменная | Финальный вектор оценок, отражающий кросс-модальную важность каждого узла для пулинга. |
| $\mathbf{i}$ | Переменная | Вектор индексов, хранящий $k$ выбранных узлов после процесса пулинга. |
Определение проблемы и ограничения
Чтобы понять точную проблему, которую решает эта статья, нам сначала нужно определить, с чего мы начинаем и куда хотим прийти.
Исходная точка (входные данные): Мы начинаем с двух различных типов данных сетевой активности мозга, извлеченных из нейровизуализации.
1. Функциональная связность (FC): Полученная из снимков фМРТ, она фиксирует, как различные области мозга "активируются" совместно. Математически она представлена как начальная матрица признаков узлов $\mathbf{X}^0_f \in \mathbb{R}^{N^0 \times N^0}$, полученная путем расчета коэффициента корреляции Пирсона между $N^0$ различными областями интереса (ROI).
2. Структурная связность (SC): Полученная из снимков ДТИ, она представляет собой фактическую физическую "проводку" или тракты нервных волокон, соединяющие эти области, представленные матрицей $\mathbf{X}_s \in \mathbb{R}^{N^0 \times N^0}$.
Целевое состояние (выходные данные): Конечная цель — получить высокоточную вероятность классификации $P(c)$ для определения, имеет ли пациент определенное заболевание мозга (например, болезнь Альцгеймера или расстройство аутистического спектра) или является нормальным контролем.
Математический разрыв: Отсутствующее звено здесь — это то, как эффективно математически вплести физическую проводку (структуру) в функциональную активность (активацию). Предыдущие исследователи просто извлекали признаки из обеих сетей независимо и конкатенировали их в конце (слияние в размерностях признаков). Они не смогли уловить глубокую, связанную взаимозависимость между ними. Авторы этой статьи осознали, что структурная связность должна действовать как физическая карта для управления и усиления математического внимания, уделяемого функциональной связности.
Однако преодоление этого разрыва порождает болезненную дилемму, которая поставила в тупик предыдущих исследователей.
Дилемма:
В анализе сетей мозга диагностика заболевания требует понимания того, как общаются удаленные области мозга. Это означает, что модель должна улавливать "дальние зависимости".
Вот компромисс: если вы используете графовые нейронные сети (GNN), вы успешно улавливаете локальную физическую топологию мозга, но GNN печально известны своей неспособностью улавливать дальние зависимости из-за явления, называемого пересглаживанием (over-smoothing). С другой стороны, если вы используете стандартную архитектуру трансформера, механизм самовнимания отлично справляется с улавливанием дальних зависимостей. Однако стандартные трансформеры "слепы к топологии" — они рассматривают каждую область мозга как равно соединенную, полностью игнорируя фактические физические магистрали нервных волокон мозга.
Если вы попытаетесь заставить трансформер изучать топологию мозга с нуля, вы столкнетесь с серьезным вычислительным раздуванием и шумом. Вы в тупике: использовать GNN и потерять дальние функциональные сбои, или использовать трансформеры и потерять физические структурные ограничения.
Жесткие стены и ограничения:
Чтобы решить эту дилемму, авторы столкнулись с несколькими жесткими, реалистичными проблемами, которые делают эту задачу невероятно сложной:
- Экстремальная асимметрия данных: Вы не можете просто подать необработанную матрицу структурной связности $\mathbf{X}_s$ в нейронную сеть. Количество физических соединений волокон между двумя областями мозга, $\mathbf{X}_{s,(i,j)}$, имеет чрезвычайно асимметричное распределение, варьирующееся от абсолютного нуля до нескольких тысяч. Чтобы сделать это математически стабильным, авторы были вынуждены применить строгое логарифмическое преобразование $\mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1)$, за которым последовала стандартная нормализация, просто чтобы средние значения выборки соответствовали нормальному распределению.
- Проклятие размерности и шум: Мозг парцеллирован на множество ROI (узлов). Вычисление плотного внимания по всем ROI в нескольких модальностях является вычислительно затратным и вносит огромный шум, поскольку не все области мозга имеют отношение к конкретному заболеванию. Размер графа должен быть уменьшен.
- Ограничение кросс-модального пулинга: Уменьшение размера графа требует отбрасывания узлов (пулинг). Но как отбросить узлы, случайно не выбросив именно тот биомаркер, который необходим для диагностики? Если вы смотрите только на функциональные данные для отбрасывания узлов, вы можете выбросить область с критическим структурным повреждением. Ограничение здесь заключается в том, что важность узла должна оцениваться одновременно с обеих функциональной и структурной точек зрения, прежде чем принимать решение о его сохранении или отбрасывании. Честно говоря, я не совсем уверен, как предыдущие унимодальные методы пулинга оправдывали игнорирование структурного повреждения, но эта статья преодолевает это, проецируя как структурную маску, так и функциональные признаки на обучаемые векторы для расчета единой кросс-модальной оценки $\mathbf{S}^l$, представляющей конечную важность узла.
Почему этот подход
Точка отказа традиционных методов
Чтобы понять, почему авторы выбрали именно эту архитектуру, нам нужно взглянуть на тот момент, когда традиционные методы уперлись в стену. В анализе сетей мозга цель состоит в диагностике таких заболеваний, как Альцгеймер или Аутизм, путем изучения того, как различные области мозга (узлы) общаются друг с другом.
Долгое время графовые нейронные сети (GNN) были золотым стандартом для этого. Однако авторы осознали фундаментальный недостаток: GNN работают по механизму "локальной передачи информации". Они общаются только со своими непосредственными соседями. Но человеческий мозг чрезвычайно сложен, и заболевания часто нарушают дальние зависимости, что означает, что область в передней части мозга может неправильно общаться с областью в задней части. Точно так же, как вы бы не потратили 150 долларов США на карту местного города, когда вам нужно ориентироваться по системе междугородних автомагистралей, GNN были просто слишком близоруки для анализа всего мозга.
Трансформеры с их механизмами самовнимания решают эту проблему, рассматривая весь граф одновременно. Но стандартные трансформеры (например, BrainNetTF) ввели новую проблему: они смотрели только на данные функциональной магнитно-резонансной томографии (фМРТ), полностью игнорируя физическую проводку нервных волокон (данные ДТИ). Другие мультимодальные методы пытались исправить это, обрабатывая функциональные и структурные данные бок о бок как "многовидовые" данные. Авторы осознали, что этого недостаточно, потому что это игнорировало вспомогательную роль физической проводки. Нельзя просто смешивать два набора данных; физическая проводка должна явно направлять функциональную активность. Это осознание сделало кросс-модальный трансформер для графов мозга (CBGT) единственным жизнеспособным решением.
Структурное преимущество и логика бенчмаркинга
Помимо простого достижения более высоких показателей точности на графике, этот метод качественно превосходит другие благодаря тому, как он обрабатывает сложность графа и шум. Сети мозга чрезвычайно шумны и имеют высокую размерность. Если вы попытаетесь обработать каждое соединение на каждом слое, вы утонете в вычислительных накладных расходах и нерелевантных данных.
Чтобы решить эту проблему, авторы представили модуль "Кросс-модальный TopK Pooling". Вместо того чтобы полагаться на огромный, статический граф, модель динамически оценивает важность каждой области мозга (ROI), объединяя как функциональные, так и структурные оценки:
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
На основе этого вектора оценок $\mathbf{S}^l$ модель выбирает только $k$ наиболее критических узлов:
$$ \mathbf{i} = \text{topk}(\mathbf{S}^l, k) $$
Хотя статья явно не формулирует это как строгое сокращение памяти с $O(N^2)$ до $O(N)$ в нотации Big-O, структурное преимущество именно в этом: оно резко сокращает размер графа слой за слоем. Отфильтровывая несущественные области мозга, оно сохраняет только наиболее критические биомаркеры (например, предклинье или гиппокамп), делая модель подавляюще превосходящей предыдущие методы, которые заставляли сеть запоминать весь шумный граф.
Идеальное сочетание проблемы и решения
Самым жестким ограничением в этой проблеме было нахождение способа математически заставить трансформер учитывать физическую проводку мозга при рассмотрении функциональной активности.
Авторы достигли блестящего "брака" между этим ограничением и своим решением путем создания Усиленной Маски, обозначенной как $\mathbf{M}^{l-1}$. Сначала они использовали XGBoost для фильтрации неважных физических соединений из структурных данных, оставляя только наиболее влиятельные физические пути. Затем они ввели эту структурную маску непосредственно в ядро механизма самовнимания трансформера для функциональных данных:
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
Внимательно посмотрите на правую часть этого уравнения: $\odot (1 + \mathbf{M}^{l-1})$. Левая часть поэлементного умножения ($\odot$) — это стандартная оценка внимания, показывающая, насколько две области мозга функционально активируются совместно. Умножая ее на $(1 + \mathbf{M}^{l-1})$, модель математически усиливает оценку внимания только если существует также сильное физическое соединение нервных волокон. Это совершенно элегантный способ заставить структуру диктовать функцию.
Неизбранный путь
В статье явно объясняется, почему GNN были отклонены (неспособность улавливать дальние зависимости) и почему стандартное мультимодальное слияние было отклонено (рассмотрение структуры и функции как отдельных, но равных, а не взаимозависимых).
Честно говоря, я не совсем уверен, как бы показали себя генеративные модели, такие как GAN или диффузионные модели, поскольку авторы вообще их не упоминают. Однако логически GAN и диффузионные модели предназначены для генерации новых распределений данных из шума. Проблема, определенная здесь, является строго дискриминативной задачей классификации графов (например, диагностика болезни Альцгеймера против нормального контроля). Использование диффузионной модели для классификации графа было бы вычислительно чрезмерным и архитектурно несоответствующим цели идентификации специфических, локализованных биомаркеров мозга. Следовательно, дискриминативный трансформер с кросс-модальным пулингом был наиболее прямым и логичным путем.
Математический и логический механизм
Чтобы понять глубокий скачок, который совершает эта статья, нам сначала нужно понять человеческий мозг как двухслойную сеть: комбинацию "аппаратного" и "программного обеспечения".
В нейровизуализации "аппаратное обеспечение" измеряется с помощью диффузионной тензорной визуализации (ДТИ), которая картирует фактические физические нервные волокна, соединяющие различные области мозга. Это называется структурной связностью. "Программное обеспечение" измеряется с помощью функциональной магнитно-резонансной томографии (фМРТ), которая отслеживает кровоток, чтобы увидеть, какие области мозга активируются одновременно. Это называется функциональной связностью.
Годами врачи и исследователи ИИ, пытающиеся диагностировать заболевания мозга (такие как Альцгеймер или Аутизм), сталкивались с огромным ограничением: они либо смотрели на аппаратное обеспечение, либо на программное обеспечение, либо просто неуклюже смешивали два набора данных. Стандартные графовые нейронные сети (GNN) близоруки — они смотрят только на непосредственные соседние области мозга. Трансформеры, с другой стороны, блестяще видят дальние зависимости (как область в передней части мозга влияет на область в задней), но они легко теряются в шуме огромных функциональных данных мозга, если у них нет карты.
Авторы этой статьи решили эту проблему, создав Кросс-модальный трансформер для графов мозга (CBGT). Они математически заставляют ИИ использовать физическое аппаратное обеспечение (структурную связность) как направляющий шаблон для лучшего понимания программного обеспечения (функциональной связности).
Вот абсолютное ядро математического движка, которое обеспечивает это кросс-модальное слияние.
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot \left( 1 + \mathbf{M}^{l-1} \right) \right) $$
$$ \mathbf{h}^{l,z} = \mathbf{T}^{l,z} \mathbf{W}_V^{l,z} \mathbf{X}_f^{l-1} $$
Давайте разберем эти уравнения по частям, чтобы понять, как они оживляют модель.
- $\mathbf{X}_f^{l-1}$: Это входная матрица признаков узлов на слое $l-1$. Физически она представляет "программные" сигналы — функциональную активность мозга различных областей.
- $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$: Это обучаемые матрицы весов для запроса (Query), ключа (Key) и значения (Value) в голове внимания $z$. Логически они действуют как переводчики. Они используют матричное умножение для вращения и проецирования необработанных сигналов мозга в новое математическое пространство, где области могут задавать вопросы (Query), предоставлять ответы (Key) и предлагать содержание (Value).
- $(\dots)^\top$: Оператор транспонирования. Он переворачивает матрицу ключей, чтобы ее можно было умножить на матрицу запросов. Это скалярное произведение измеряет сырую схожесть или "согласованность" между активностью двух областей мозга.
- $\sqrt{d_K^{l,z}}$: Квадратный корень из размерности векторов ключей. Это действует как термостат. Когда вы умножаете большие векторы, результирующие числа могут взрываться, загоняя функцию softmax в плоские, мертвые зоны, где обучение прекращается. Деление используется здесь для уменьшения дисперсии и поддержания работы математического движка.
- $\mathbf{M}^{l-1}$: Усиленная маска, полученная из сети структурной связности. Это "аппаратная" карта, предварительно отфильтрованная алгоритмом XGBoost для сохранения только наиболее критических физических нервных соединений.
- $1 + \mathbf{M}^{l-1}$: Структурный смещение (bias). Почему здесь используется сложение? Число $1$ действует как базовый уровень. Если $\mathbf{M}$ равно $0$ (что означает отсутствие физического соединения между двумя областями), член просто становится $1$. Это гарантирует, что базовая функциональная информация не будет стерта. Если физическое соединение существует, $\mathbf{M}$ добавляется к $1$, усиливая соединение.
- $\odot$: Произведение Адамара (поэлементное умножение). Это действует как увеличительное стекло. Оно масштабирует оценки функционального внимания напрямую, используя структурный шаблон. Умножение вместо сложения используется здесь для того, чтобы структурная маска действовала как пропорциональный множитель — увеличивая внимание именно там, где это поддерживает физическая архитектура мозга.
- $\text{softmax}$: Функция нормализации. Она действует как строгий бюджетировщик, заставляя все сырые, усиленные оценки схожести суммироваться ровно до $1.0$ (или 100%). Она преобразует сырую математику в распределение вероятностей.
- $\mathbf{T}^{l,z}$: Финальная матрица внимания. Это маршрутизирующая сеть, главный реестр, который точно указывает каждой области мозга, сколько внимания ей следует уделять каждой другой области.
- $\mathbf{h}^{l,z}$: Выходное скрытое состояние. Это обновленный, обогащенный сигнал областей мозга после их взаимодействия друг с другом.
Чтобы увидеть это в действии, давайте проследим точный жизненный цикл одной абстрактной точки данных — скажем, сигнала из гиппокампа — проходящей через это уравнение.
Сначала необработанный функциональный сигнал гиппокампа ($\mathbf{X}_f$) поступает на сборочную линию и умножается на $\mathbf{W}_Q$, чтобы сформировать вектор запроса. Он, по сути, кричит в пустоту: "Кто синхронно активируется со мной?" Одновременно все другие области мозга, такие как префронтальная кора, генерируют свои векторы ключей ($\mathbf{W}_K \mathbf{X}_f$). Запрос гиппокампа умножается на ключ префронтальной коры. Если их функциональные сигналы совпадают, результирующая оценка высока.
Затем эта сырая оценка делится на $\sqrt{d_K}$, чтобы охладить ее и предотвратить математический переполнение. Теперь происходит кросс-модальная магия. Система проверяет структурную маску $\mathbf{M}$. Существует ли фактическое физическое нервное волокно, соединяющее гиппокамп с префронтальной корой? Если да, то маска $\mathbf{M}$ имеет высокое значение, и поэлементное умножение $\odot (1 + \mathbf{M})$ значительно усиливает их оценку соединения. Если физического провода нет, оценка умножается на $1$, оставаясь неизменной.
Функция softmax затем обрезает и сжимает все эти оценки до процентов. Допустим, гиппокамп решает уделить 80% своего внимания префронтальной коре. Наконец, гиппокамп поглощает 80% вектора значения префронтальной коры ($\mathbf{W}_V \mathbf{X}_f$), обновляя свое собственное внутреннее состояние до $\mathbf{h}$. Гиппокамп успешно обновил свое программное обеспечение на основе ограничений аппаратного обеспечения мозга.
Как этот механизм на самом деле учится и сходится? Динамика оптимизации здесь красиво ограничена. Модель контролируется на самом последнем этапе функцией потерь кросс-энтропии, которая измеряет, насколько ошибочен конечный диагноз заболевания, поставленный моделью.
Во время обратного распространения градиенты текут назад от конечной классификации, через слой TopK pooling (который динамически учится отбрасывать бесполезные области мозга и сохранять только наиболее критические биомаркеры) и в слои трансформера. Благодаря структурной маске $\odot (1 + \mathbf{M})$, ландшафт потерь фундаментально преобразуется. В стандартном трансформере ландшафт потерь хаотичен, потому что модель может легко переобучиться на случайные, шумные функциональные корреляции (например, две области мозга активируются случайно).
Однако структурная маска действует как глубокая, гладкая долина в ландшафте потерь. Она действует как физический априорный фактор, заставляя градиенты течь гораздо сильнее вдоль фактических биологических путей. Оптимизатор Adam итеративно обновляет матрицы весов ($\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V$), но он постоянно руководствуется физической реальностью мозга. Со временем модель сходится не только на статистических закономерностях, но и на биологически правдоподобных мультимодальных биомаркерах, что позволяет ей диагностировать такие состояния, как болезнь Альцгеймера и Аутизм, с беспрецедентной точностью.
Результаты, ограничения и заключение
Представьте, что вы пытаетесь понять, как работает огромный, шумный мегаполис. У вас есть две карты. Первая карта показывает физические автомагистрали и железнодорожные пути, соединяющие разные районы — это структурная связность города. Вторая карта показывает объем телефонных звонков и текстовых сообщений, отправляемых между этими районами — это функциональная связность.
Десятилетиями нейробиологи смотрели на человеческий мозг очень похожим образом. Используя диффузионную тензорную визуализацию (ДТИ), они картируют физические нервные волокна (магистрали), а с помощью функциональной магнитно-резонансной томографии (фМРТ) они картируют когерентность активности мозга (телефонные звонки). Если вы хотите диагностировать сложные заболевания мозга, такие как Альцгеймер или Аутизм, вам нужно смотреть на оба. Вы бы не потратили 150 долларов на высокотехнологичное сканирование, чтобы потом проигнорировать половину данных.
Однако фундаментальная проблема в нейронауке, управляемой ИИ, заключалась в том, как объединить эти две карты. Существующие модели обычно просто смешивают признаки в конце своего конвейера обработки. Они не понимают, что физические магистрали определяют, как путешествуют телефонные звонки. Кроме того, области мозга, которые физически далеко друг от друга, часто интенсивно общаются (дальние зависимости). Традиционные графовые нейронные сети (GNN) ужасно видят общую картину, потому что они смотрят только на непосредственных соседей. Трансформеры отлично видят общую картину, но они обычно полностью игнорируют физическую структуру графа.
Эта статья представляет Кросс-модальный трансформер для графов мозга (CBGT) — блестящую архитектуру, которая заставляет ИИ использовать физическую структурную карту как линзу для фокусировки своего внимания на карте функциональной активности.
Математическое ядро: Какая проблема была решена?
Авторам нужно было решить конкретное ограничение: как математически заставить механизм самовнимания трансформера учитывать физические нервные волокна?
Сначала им пришлось очистить структурные данные. Количество волокон ДТИ сильно асимметрично — некоторые области имеют нулевые соединения, другие — тысячи. Для нормализации они применили логарифмическое преобразование:
$$ \mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1) $$
После стандартизации этой матрицы они использовали алгоритм машинного обучения (XGBoost) для фильтрации шума и идентификации только наиболее критических физических соединений, создав "усиленную маску", обозначенную как $\mathbf{M}^0$. Честно говоря, я не совсем уверен, почему они выбрали XGBoost вместо дифференцируемого нейронного слоя для этого конкретного шага, поскольку статья использует поиск по сетке для установки жесткого порога $p=3$, но он служит надежным селектором признаков.
Истинный гений заключается в кросс-модальном слое трансформера. В стандартном трансформере внимание рассчитывается путем сравнения запросов и ключей. Здесь авторы вставляют структурную маску $\mathbf{M}^{l-1}$ непосредственно в расчет функционального внимания:
$$ \mathbf{T}^{l,z} = \text{softmax}\left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left(\mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1}\right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
Интуитивно, член $(1 + \mathbf{M}^{l-1})$ действует как структурный множитель. Если две области мозга имеют сильное физическое соединение (высокое $\mathbf{M}$), модель искусственно усиливает внимание ($\mathbf{T}$), которое она уделяет их функциональной корреляции. Это элегантно объединяет структуру и функцию.
Наконец, для диагностики заболевания модель не может рассматривать весь мозг одинаково; ей нужно найти конкретные поврежденные области (биомаркеры). Они разработали механизм Кросс-модального TopK Pooling. Он проецирует как структурную маску, так и функциональные признаки узлов в обучаемые векторы, конкатенирует их и пропускает через многослойный перцептрон (MLP) для генерации единой оценки важности:
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
Затем модель безжалостно обрезает граф, сохраняя только $k$ наиболее важных областей на основе этой кросс-модальной оценки, передавая эти уточненные представления классификатору с мягким голосованием.
Экспериментальная архитектура: Безжалостное доказательство и "жертвы"
Авторы не просто заявили, что их математика работает; они разработали эксперимент, чтобы неоспоримо доказать это на двух совершенно разных неврологических полях битвы: болезнь Альцгеймера (набор данных ADNI) и расстройства аутистического спектра (набор данных ABIDE).
"Жертвами", оставшимися позади, были многие передовые модели. Они победили унимодальные базовые модели, которые рассматривали только один тип сканирования (SVM, GAT, BrainGNN, BrainIB, BrainNetTF, ALTER), и, что более важно, они разгромили существующие мультимодальные модели (BrainNN, MME-GCN, Cross-GNN), которые пытаются объединить структуру и функцию, но делают это неуклюже. Например, в сложной задаче различения легкого когнитивного нарушения (MCI) от нормального контроля (NC), CBGT превзошел все другие кросс-модальные методы на массивные 3,9% по точности.
Но окончательным, неоспоримым доказательством того, что их основной механизм работал, была не просто высокая точность — это было Анализ Абляции и Интерпретации.
Когда они убрали структурную маску (вернув модель к обычному унимодальному трансформеру), точность классификации болезни Альцгеймера упала на 4,9%. Это доказало, что структурная маска была не просто трюком; это был несущий столб модели. Более того, когда они сопоставили внимание ИИ с физическим мозгом, модель самостоятельно научилась фокусироваться на предклинье (PCUN) и ректусе (REC) у пациентов с РАС — областях, которые, как давно доказала клиническая литература, деактивируются, когда пациенты с РАС пытаются вывести состояния разума. Математика не просто оптимизировала функцию потерь; она заново открыла биологическую реальность.
Темы для обсуждения для будущей эволюции
Основываясь на этом блестящем фундаменте, вот несколько глубоких направлений для будущих исследований:
- Сквозная дифференцируемая структурная разреженность:
В настоящее время модель полагается на XGBoost как на дискретный шаг предварительной обработки для извлечения структурной маски $\mathbf{M}^0$. Это нарушает сквозную дифференцируемость конвейера. Можем ли мы заменить это дифференцируемым механизмом разреженного внимания (например, Sparsemax или маршрутизатором Gumbel-Softmax), который учится динамически обрезать структурный граф во время обратного распространения? Как это повлияет на способность модели открывать новые, неочевидные физические биомаркеры? - Временная динамика в функциональной связности:
Эта статья рассматривает функциональную связность как статическую матрицу (корреляция Пирсона по всему сканированию). Однако активность мозга высокодинамична; "телефонные звонки" происходят всплесками. Если мы преобразуем функциональный вход $\mathbf{X}_f$ в пространственно-временную последовательность и применим временной трансформер, как мы можем математически ограничить динамическую функциональную последовательность статической структурной маской? - Кросс-дисциплинарная обобщаемость:
Основная математическая предпосылка здесь — использование статического, физического графа для маскирования и управления вниманием к динамическому, функциональному графу — не ограничена мозгом. Может ли эта точная архитектура быть развернута в городском инжиниринге? Например, прогнозирование транспортных пробок, используя физическую дорожную сеть (структуру) для маскирования внимания к данным GPS-движения в реальном времени (функцию). Какие ограничения возникнут, когда размер "узлов" увеличится с 90 областей мозга до 90 000 городских перекрестков?
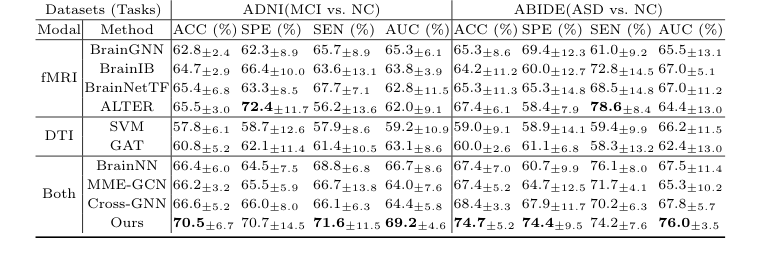 Table 2. Ablation Study Results on Different Datasets
Table 2. Ablation Study Results on Different Datasets
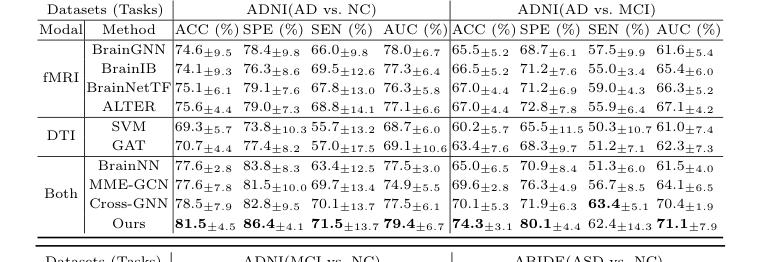 Table 1. Comparative Experiments of Classification Tasks on Different Datasets
Table 1. Comparative Experiments of Classification Tasks on Different Datasets