跨模态脑图谱Transformer:基于功能-结构连通性网络的大脑疾病诊断
Multi-modal brain networks represent the complex connectivity between different brain regions from both functional and structural perspectives, which is of great significance for brain disease diagnosis.
背景与学术渊源
要理解这个问题为何出现,我们必须回顾神经科学家和计算机科学家在诊断阿尔茨海默病(AD)或自闭症谱系障碍(ASD)等复杂大脑疾病的历史尝试。在神经影像学的早期,研究人员依赖单一类型的大脑扫描来寻找异常。最终,该领域认识到大脑是一个高度复杂、相互连接的网络。这促使了两种不同视角的出现:功能连通性(不同大脑区域如何协同激活,通过fMRI测量)和结构连通性(连接它们的实际神经纤维束,通过DTI测量)。融合这两种模态的特定问题应运而生,因为大脑疾病常常同时破坏物理连接和通信模式。准确诊断它们需要理解结构与功能之间深度耦合的关系,而不是孤立地看待其中任何一个。
迫使作者撰写本文的根本局限是什么?先前的方法在尝试结合这两种数据时遇到了重大瓶颈。图神经网络(GNNs)曾一度流行,但它们仅在相邻节点之间传递局部信息,完全忽略了大脑中广泛存在的长距离依赖关系。为了解决这个问题,一些近期模型引入了Transformer,它们在“全局视角”方面表现出色。然而,现有的多模态模型仅仅将功能和结构数据视为两个独立的、并行的视图,并在最后简单地融合它们的最终特征。它们完全忽视了结构连通性的支撑作用——具体来说,物理连接如何应该决定或指导功能通信。作者意识到,如果不利用物理结构来明确指导模型对功能数据的“注意力”,先前模型就会遗漏关键的诊断信息。
以下是论文中的几个高度专业化的术语,用日常概念解释:
- 功能连通性网络(fMRI): 可以将其视为不同城市之间实时通话流量。它不显示电话线路本身,但揭示了哪些城市在同一时间频繁地相互通信。
- 结构连通性网络(DTI): 这是物理基础设施——连接这些城市的实际光纤电缆或混凝土高速公路。即使两个城市目前没有通话,物理高速公路也存在。
- 兴趣区域(ROI): 想象一下看一张国家地图;ROI就是某个特定的城市或州。在大脑中,它是一个特定的解剖区域(如海马体),研究人员会监测其活动或连接。
- 跨模态TopK池化(Cross-modal TopK Pooling): 想象一个政府委员会试图缩小一张庞大的国家地图,只保留最关键的 $k$ 个城市用于危机监测。他们不只是看人口数量(一种模态),而是同时评估物理高速公路基础设施和电话流量(跨模态),以选择最重要的城市,丢弃其余的以简化分析。
让我们整理一下解决此问题所使用的关键数学符号。
| 符号 | 类型 | 描述 |
|---|---|---|
| $\mathbf{X}_{s}$ | 变量 | 从DTI图像获得的结构连通性矩阵。 |
| $\mathbf{X}_{s,(i,j)}$ | 变量 | ROI $i$ 和 ROI $j$ 之间的物理纤维连接数量。 |
| $\mathbf{M}^0$ | 参数 | 从滤波后的结构特征重建的初始增强掩码,用于指导Transformer。 |
| $\mathbf{X}_f^{l-1}$ | 变量 | 第 $l$ 层输入的节点特征矩阵(代表功能连通性)。 |
| $\mathbf{M}^{l-1}$ | 变量 | 第 $l$ 层的增强掩码,用于基于物理连接指导注意力机制。 |
| $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$ | 参数 | 多头自注意力机制中用于Query、Key和Value的可学习权重矩阵。 |
| $\mathbf{S}^l$ | 变量 | 最终得分向量,反映了每个节点用于池化的跨模态重要性。 |
| $\mathbf{i}$ | 变量 | 池化过程后存储前 $k$ 个选定节点索引的向量。 |
问题定义与约束
为了理解本文所解决的确切问题,我们首先需要定义起点和终点。
起点(输入): 我们从神经影像学中提取的两种不同类型的大脑网络数据开始。
1. 功能连通性(FC): 源自fMRI扫描,它捕捉不同大脑区域如何“协同放电”。在数学上,它表示为初始节点特征矩阵 $\mathbf{X}^0_f \in \mathbb{R}^{N^0 \times N^0}$,通过计算 $N^0$ 个不同兴趣区域(ROIs)之间的Pearson相关系数得到。
2. 结构连通性(SC): 源自DTI扫描,它代表连接这些区域的实际物理“线路”或神经纤维束,表示为矩阵 $\mathbf{X}_s \in \mathbb{R}^{N^0 \times N^0}$。
目标状态(输出): 最终目标是输出一个高度准确的分类概率 $P(c)$,以确定患者是否患有特定的脑部疾病(如阿尔茨海默病或自闭症谱系障碍),还是正常对照。
数学鸿沟: 缺失的环节是如何有效地在数学上将物理线路(结构)编织到功能放电(活动)中。先前的研究者只是独立地从两个网络中提取特征,并在最后将它们连接起来(特征维度上的融合)。他们未能捕捉两者之间深层、耦合的相互依赖性。本文作者意识到,结构连通性应该充当物理地图,来指导和增强对功能连通性的数学注意力。
然而,弥合这一鸿沟引入了一个困扰先前研究者的痛苦困境。
困境:
在大脑网络分析中,诊断疾病需要理解遥远的大脑区域如何通信。这意味着模型必须捕捉“长距离依赖”。
这是权衡:如果你使用图神经网络(GNNs),你可以成功地捕捉大脑的局部物理拓扑结构,但由于“过平滑”现象,GNN在捕捉长距离依赖方面出了名地糟糕。另一方面,如果你使用标准的Transformer架构,自注意力机制非常擅长捕捉长距离依赖。然而,标准的Transformer是“拓扑盲”的——它们认为每个大脑区域的连接都相等,完全忽略了实际的物理神经纤维高速公路。
如果你试图强迫Transformer从头开始学习大脑的拓扑结构,你会遇到严重的计算膨胀和噪声。你陷入了两难:使用GNN会丢失长距离功能性错误放电,或者使用Transformer会丢失物理结构约束。
严酷的壁垒与约束:
为了解决这个困境,作者们遇到了几个严酷的现实壁垒,使得这个问题异常困难:
- 极端的数据偏斜: 你不能仅仅将原始结构连通性矩阵 $\mathbf{X}_s$ 输入神经网络。两个大脑区域之间的物理纤维连接数 $\mathbf{X}_{s,(i,j)}$ 具有高度偏斜的分布,范围从零到数千。为了使其在数学上稳定,作者被迫应用严格的对数变换 $\mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1)$,然后进行标准化,以使样本均值符合正态分布。
- 维度灾难与噪声: 大脑被分割成许多ROIs(节点)。跨多个模态计算所有ROIs的密集注意力计算成本高昂,并且会引入大量噪声,因为并非所有大脑区域都与特定疾病相关。必须减小图的大小。
- 跨模态池化约束: 减小图的大小需要丢弃节点(池化)。但是,如何在不意外丢弃诊断所需的生物标志物的情况下丢弃节点?如果你只看功能数据来丢弃节点,你可能会丢弃一个具有严重结构损伤的区域。这里的约束是,在决定保留或丢弃节点之前,必须同时从功能和结构两个角度评估节点的重要性。老实说,我不太确定先前单模态池化方法如何证明忽略结构损伤的合理性,但本文通过将结构掩码和功能特征投影到可学习向量上来计算统一的跨模态分数 $\mathbf{S}^l$ 来表示最终节点重要性,从而克服了这一点。
为什么选择这种方法
传统方法的突破点
要理解作者为何选择这种特定的架构,我们必须审视传统方法达到瓶颈的确切时刻。在大脑网络分析中,目标是通过观察大脑不同区域(节点)如何相互通信来诊断阿尔茨海默病或自闭症等疾病。
长期以来,图神经网络(GNNs)一直是这方面的黄金标准。然而,作者们发现了一个根本性的缺陷:GNNs基于“局部信息传播”机制运行。它们只与直接的邻居交流。但人脑高度复杂,疾病常常会破坏长距离依赖——也就是说,大脑前部的区域可能与后部的区域发生错误通信。就像你不会花150美元买一张城市地图来导航跨国高速公路系统一样,GNN对于全脑分析来说过于短视。
Transformer凭借其自注意力机制,通过一次性查看整个图来解决这个问题。但标准的Transformer(如BrainNetTF)引入了一个新问题:它们只查看功能性MRI(fMRI)数据,完全忽略了物理神经纤维线路(DTI数据)。其他多模态方法试图通过将功能和结构数据作为“多视图”数据并行处理来解决这个问题。作者们意识到这还不够,因为它忽略了物理线路的支撑作用。你不能简单地将两个数据集混合在一起;物理线路必须明确地指导功能活动。这一认识使得跨模态脑图谱Transformer(CBGT)成为唯一可行的解决方案。
结构优势与基准测试逻辑
除了在图表上获得更高的准确率数字外,这种方法在处理图谱复杂性和噪声方面具有定性优势。大脑网络极其嘈杂且维度很高。如果你试图在每一层处理每一个连接,你就会淹没在计算开销和无关数据中。
为了解决这个问题,作者们引入了一个“跨模态TopK池化”模块。模型不是依赖于庞大、静态的图谱,而是通过融合功能和结构分数来动态评估每个大脑区域(ROI)的重要性:
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
基于这个得分向量 $\mathbf{S}^l$,模型只选择前 $k$ 个最关键的节点:
$$ \mathbf{i} = \text{topk}(\mathbf{S}^l, k) $$
虽然论文没有明确将其表述为严格的 $O(N^2)$ 到 $O(N)$ 的内存缩减(Big-O表示法),但结构优势正是如此:它逐层急剧缩小图谱的大小。通过过滤掉非必需的大脑区域,它只保留了最关键的生物标志物(如楔前叶或海马体),使得该模型在迫使网络记忆整个嘈杂图谱的先前方法上具有压倒性优势。
问题与解决方案的完美结合
这个问题中最严酷的约束是找到一种数学方法,在Transformer查看功能活动时强迫它关注物理大脑线路。
作者通过创建一个增强掩码 $\mathbf{M}^{l-1}$,实现了这一约束与他们解决方案的绝妙“结合”。首先,他们使用XGBoost过滤掉结构数据中不重要的物理连接,只留下最具影响力的物理通路。然后,他们将这个结构掩码直接注入到Transformer功能性自注意力机制的核心:
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
仔细看方程右侧:$\odot (1 + \mathbf{M}^{l-1})$。逐元素乘法($\odot$)的左侧是标准的注意力得分,显示两个大脑区域在功能上有多么协同放电。通过将其乘以 $(1 + \mathbf{M}^{l-1})$,模型在仅当存在强大的物理神经纤维连接它们时,才在数学上放大注意力得分。这是一种完美优雅的方式,让结构决定功能。
未选择的道路
论文明确解释了为什么拒绝GNNs(无法捕捉长距离依赖)以及为什么拒绝标准的跨模态融合(将结构和功能视为独立但相等,而非相互依赖)。
老实说,我不太确定生成模型如GANs或Diffusion模型在这里的表现如何,因为作者根本没有提及它们。然而,从逻辑上讲,GANs和Diffusion模型旨在从噪声中生成新的数据分布。这里定义的问题严格来说是一个判别式图分类任务(例如,诊断阿尔茨海默病 vs. 正常对照)。使用Diffusion模型来分类图谱在计算上是昂贵的,并且在架构上与识别特定、局部大脑生物标志物的目标不符。因此,一个具有跨模态池化的判别式Transformer是唯一直接且合乎逻辑的路径。
数学与逻辑机制
要理解本文所做的深刻飞跃,我们首先需要将人脑理解为一个双层网络:“硬件”和“软件”的组合。
在神经影像学中,“硬件”通过扩散张量成像(DTI)测量,它绘制了连接不同大脑区域的实际物理神经纤维。这被称为结构连通性。“软件”通过功能性磁共振成像(fMRI)测量,它跟踪血流量,以了解哪些大脑区域同时放电。这被称为功能连通性。
多年来,医生和人工智能研究人员在诊断脑部疾病(如阿尔茨海默病或自闭症)时面临着一个巨大的限制:他们要么只看硬件,要么只看软件,要么只是笨拙地将两个数据集混合在一起。标准的图神经网络(GNNs)目光短浅——它们只关注直接的邻近大脑区域。而Transformer则擅长观察长距离依赖(大脑前部的一个区域如何影响后部的一个区域),但如果它们没有地图,它们很容易在海量功能数据的噪声中迷失方向。
本文作者通过创建一个跨模态脑图谱Transformer(CBGT)解决了这个问题。他们通过数学方法迫使AI使用物理硬件(结构连通性)作为指导蓝图,以更好地理解软件(功能连通性)。
这是驱动这种跨模态融合的绝对核心数学引擎。
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot \left( 1 + \mathbf{M}^{l-1} \right) \right) $$
$$ \mathbf{h}^{l,z} = \mathbf{T}^{l,z} \mathbf{W}_V^{l,z} \mathbf{X}_f^{l-1} $$
让我们逐一解析这些方程,以理解它们如何赋予模型生命。
- $\mathbf{X}_f^{l-1}$:这是第 $l-1$ 层输入的节点特征矩阵。在物理上,它代表“软件”信号——不同区域的功能性大脑活动。
- $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$:这些是注意力头 $z$ 中Query、Key和Value的可学习权重矩阵。在逻辑上,它们充当翻译器。它们使用矩阵乘法将原始大脑信号旋转并投影到一个新的数学空间,其中区域可以提出问题(Query)、提供答案(Key)并提供实质内容(Value)。
- $(\dots)^\top$:转置算子。它翻转Key矩阵,使其能够与Query矩阵相乘。这个点积衡量了两个大脑区域活动之间原始相似性或“对齐度”。
- $\sqrt{d_K^{l,z}}$:Key向量维度的平方根。这充当了热力学恒温器。当你将大向量相乘时,产生的数字会爆炸,将softmax函数推入平坦、死寂的区域,导致学习停止。这里使用除法来缩小方差,保持数学引擎平稳运行。
- $\mathbf{M}^{l-1}$:从结构连通性网络派生的增强掩码。这是“硬件”地图,由XGBoost算法预先过滤,只保留最关键的物理神经连接。
- $1 + \mathbf{M}^{l-1}$:结构偏差。为什么在这里使用加法?数字 $1$ 充当基线。如果 $\mathbf{M}$ 为 $0$(意味着两个区域之间没有物理连接),则该项简单地变为 $1$。这确保了基线功能信息不会被抹去。如果确实存在物理连接,$\mathbf{M}$ 会加到 $1$ 上,从而放大连接。
- $\odot$:Hadamard积(逐元素乘法)。这充当了放大镜。它直接使用结构蓝图缩放功能性注意力得分。这里使用乘法而不是加法,是因为结构掩码充当比例乘数——在物理大脑结构支持它的地方精确地放大注意力。
- $\text{softmax}$:归一化函数。它充当严格的预算者,迫使所有原始的、增强的相似性得分总和恰好为 $1.0$(或100%)。它将原始数学转换为概率分布。
- $\mathbf{T}^{l,z}$:最终注意力矩阵。这是路由网络,一个主账本,告诉每个大脑区域它应该在多大程度上听取其他区域的意见。
- $\mathbf{h}^{l,z}$:输出隐藏状态。这是大脑区域在相互通信后更新的、丰富的信息。
为了在实践中看到这一点,让我们追踪一个抽象数据点——例如,来自海马体的信号——通过这个方程的精确生命周期。
首先,海马体的原始功能信号($\mathbf{X}_f$)进入流水线,并乘以 $\mathbf{W}_Q$ 来形成一个Query向量。它本质上是在向虚空呐喊:“谁和我同步放电?”同时,所有其他大脑区域,如前额叶皮层,生成它们的Key向量($\mathbf{W}_K \mathbf{X}_f$)。海马体的Query与前额叶皮层的Key相乘。如果它们的功能信号匹配,则结果得分很高。
接下来,这个原始得分除以 $\sqrt{d_K}$ 来冷却它,并防止数学溢出。现在是跨模态的魔力所在。系统检查结构掩码 $\mathbf{M}$。海马体和前额叶皮层之间是否存在实际的物理神经纤维连接?如果是,掩码 $\mathbf{M}$ 具有高值,逐元素乘法 $\odot (1 + \mathbf{M})$ 会大大提高它们的连接得分。如果没有物理连接,得分乘以 $1$,保持不变。
softmax函数然后裁剪并压缩所有这些得分,使其成为百分比。假设海马体决定将其80%的注意力放在前额叶皮层上。最后,海马体吸收前额叶皮层Value向量($\mathbf{W}_V \mathbf{X}_f$)的80%,更新其内部状态为 $\mathbf{h}$。海马体已经根据大脑硬件的约束成功更新了其软件。
这个机制如何实际学习和收敛?这里的优化动态受到精妙的约束。模型在最后由交叉熵损失函数进行监督,该函数衡量模型最终疾病诊断的错误程度。
在反向传播过程中,梯度从最终分类反向传播,经过TopK池化层(该层动态学习丢弃无用的脑区域并只保留最关键的生物标志物),然后进入Transformer层。由于结构掩码 $\odot (1 + \mathbf{M})$,损失景观被根本性地重塑。在标准的Transformer中,损失景观是混乱的,因为模型很容易过拟合随机的、嘈杂的功能性相关性(例如,两个大脑区域纯粹巧合地一起放电)。
然而,结构掩码在损失景观中充当了一个深邃、平滑的山谷。它充当了物理先验,迫使梯度沿着实际的生物通路流动得更强。Adam优化器迭代地更新权重矩阵($\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V$),但它始终受到大脑物理现实的指导。随着时间的推移,模型不仅收敛于统计模式,而且收敛于生物学上合理的跨模态生物标志物,使其能够以前所未有的准确性诊断阿尔茨海默病和自闭症等疾病。
结果、局限性与结论
想象一下,你正试图了解一个庞大、繁华的大都市是如何运作的。你有两张地图。第一张地图显示了连接不同社区的物理高速公路和火车轨道——这是城市的结构连通性。第二张地图显示了这些社区之间的电话通话和短信量——这是功能连通性。
几十年来,神经科学家一直以非常相似的方式看待人脑。使用扩散张量成像(DTI),他们绘制物理神经纤维(高速公路),并使用功能性磁共振成像(fMRI),他们绘制大脑活动的连贯性(电话通话)。如果你想诊断阿尔茨海默病或自闭症等复杂脑部疾病,你需要同时查看两者。你不会花150美元购买一个高科技扫描仪却忽略一半的数据。
然而,人工智能驱动的神经科学中的根本问题是如何组合这两张地图。现有模型通常只是在处理流程的最后将特征混合在一起。它们未能理解物理高速公路决定了电话如何传输。此外,物理上相距遥远的大脑区域经常进行强烈的交流(长距离依赖)。传统的图神经网络(GNNs)不善于看到全局图景,因为它们只看直接的邻居。Transformer擅长全局图景,但它们通常完全忽略物理图谱结构。
本文介绍了跨模态脑图谱Transformer(CBGT),一种出色的架构,它迫使AI使用物理结构地图作为透镜,来聚焦其对功能活动地图的注意力。
核心数学:解决了什么问题?
作者需要解决一个特定的约束:如何在数学上迫使Transformer的自注意力机制关注物理神经纤维?
首先,他们必须清理结构数据。DTI纤维计数高度偏斜——有些区域没有连接,有些区域有数千个连接。为了进行标准化,他们应用了对数变换:
$$ \mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1) $$
在标准化该矩阵后,他们使用机器学习算法(XGBoost)来过滤噪声并仅识别最重要的物理连接,从而创建一个称为 $\mathbf{M}^0$ 的“增强掩码”。老实说,我不太确定他们为什么选择XGBoost而不是可微分神经网络层来执行此特定步骤,因为论文依赖于网格搜索来设置硬阈值 $p=3$,但它充当了强大的特征选择器。
真正的天才在于跨模态Transformer层。在标准的Transformer中,注意力是通过比较查询和键来计算的。在这里,作者将结构掩码 $\mathbf{M}^{l-1}$ 直接注入到功能性注意力计算中:
$$ \mathbf{T}^{l,z} = \text{softmax}\left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left(\mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1}\right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
直观地说,项 $(1 + \mathbf{M}^{l-1})$ 起到了结构乘数的作用。如果两个大脑区域共享一个强大的物理连接(高 $\mathbf{M}$),模型会人为地提升它对它们功能相关性的注意力($\mathbf{T}$)。它巧妙地结合了结构和功能。
最后,为了诊断疾病,模型不能平等地看待整个大脑;它需要找到特定的受损区域(生物标志物)。他们设计了一个跨模态TopK池化机制。它将结构掩码和功能节点特征都投影到可学习向量,将它们连接起来,并通过多层感知器(MLP)生成统一的重要性得分:
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
然后,模型无情地修剪图谱,仅保留基于此跨模态得分的最重要的前 $k$ 个区域,将这些精炼的表示传递给一个软投票分类器。
实验架构:严酷的证明与“牺牲品”
作者们不仅声称他们的数学有效,而且设计了一个实验来无可辩驳地证明它在两个完全不同的神经学战场上:阿尔茨海默病(ADNI数据集)和自闭症谱系障碍(ABIDE数据集)。
他们“牺牲”的包括了最先进的模型。他们击败了只关注一种扫描类型的单模态基线(SVM、GAT、BrainGNN、BrainIB、BrainNetTF、ALTER),更重要的是,他们击败了现有的跨模态模型(BrainNN、MME-GCN、Cross-GNN),这些模型试图融合结构和功能,但处理方式笨拙。例如,在区分轻度认知障碍(MCI)和正常对照(NC)的困难任务中,CBGT在准确率上以3.9%的巨大优势超越了所有其他跨模态方法。
但他们核心机制奏效的决定性、无可辩驳的证据不仅仅是高准确率——而是消融研究和解释性分析。
当他们剥离结构掩码(将模型还原为标准的单模态Transformer)时,阿尔茨海默病分类的准确率下降了4.9%。这证明了结构掩码不仅仅是一个噱头;它是模型承重的主要支柱。此外,当他们将AI的注意力映射回物理大脑时,模型独立地学会了关注自闭症患者的楔前叶(PCUN)和额叶(REC)——这些区域在临床文献中早已被证明在ASD患者尝试推断心理状态时会失活。数学不仅仅优化了一个损失函数;它重新发现了生物学现实。
未来演进的讨论话题
基于这个出色的基础,以下是几个深入的未来探索方向:
- 端到端可微分结构稀疏性:
目前,模型依赖XGBoost作为离散的预处理步骤来提取结构掩码 $\mathbf{M}^0$。这打破了管道的端到端可微分性。我们能否用一个可微分的稀疏注意力机制(如Sparsemax或Gumbel-Softmax路由器)来替换它,该机制在反向传播过程中动态学习修剪结构图谱?这会如何改变模型发现新颖、非显而易见的物理生物标志物的能力? - 功能连通性的时间动态:
本文将功能连通性视为静态矩阵(整个扫描的Pearson相关性)。然而,大脑活动是高度动态的;“电话通话”是突发性的。如果我们把功能输入 $\mathbf{X}_f$ 演变成时空序列并应用时间Transformer,我们如何用静态结构掩码在数学上约束动态功能序列? - 跨学科泛化:
这里的核心数学前提——使用静态物理图谱来掩盖和指导对动态功能图谱的注意力——并不局限于大脑。这种确切的架构能否应用于城市工程?例如,通过使用物理道路网络(结构)来掩盖对实时GPS移动数据(功能)的注意力来预测交通拥堵。当“节点”从90个大脑区域扩展到90,000个城市交叉口时,会出现什么约束?
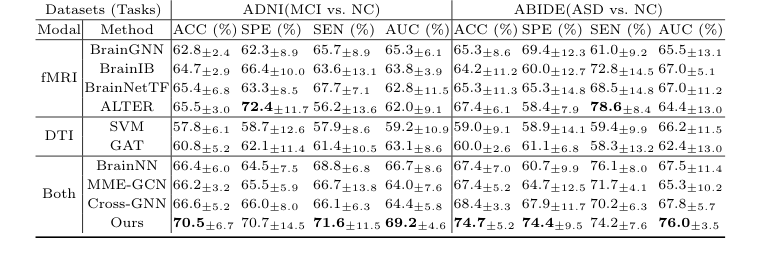 Table 2. Ablation Study Results on Different Datasets
Table 2. Ablation Study Results on Different Datasets
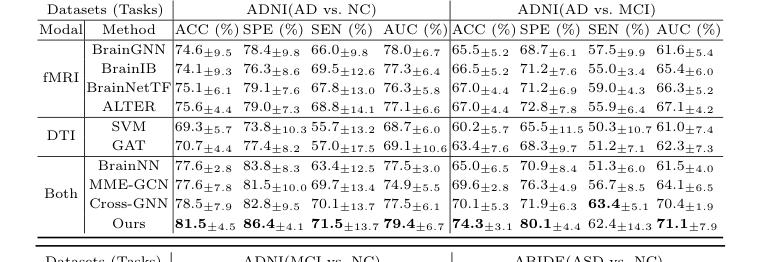 Table 1. Comparative Experiments of Classification Tasks on Different Datasets
Table 1. Comparative Experiments of Classification Tasks on Different Datasets
与其他领域的同构性
要理解本文,想象一座繁华的城市。物理道路和高速公路代表大脑的“结构连通性”(实际的生物线路,通过DTI扫描测量)。交通的动态流动——任何给定时间的汽车移动——代表“功能连通性”(实时大脑活动,通过fMRI扫描测量)。多年来,诊断阿尔茨海默病或自闭症等脑部疾病的科学家们分别查看道路和交通,或者只是在最后将最终报告混合在一起。他们难以克服的约束是,现有的AI模型未能理解两者之间深厚的物理相互依赖性:动态交通流量从根本上由物理道路的建造地点决定。
作者通过创建跨模态脑图谱Transformer解决了这个问题。在数学上,他们采用了标准的自注意力机制——它通常只寻找功能性交通($\mathbf{X}_f$)中的统计相关性——并迫使其戴上“结构眼镜”。他们提取了物理线路的滤波矩阵,称为增强掩码 $\mathbf{M}$。然后,他们将这个物理地图直接注入到注意力计算中:
$$ \mathbf{T}^{l,z} = \text{softmax}\left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left(\mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1}\right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
通过使用逐元素乘法算子 $\odot$,模型在两个大脑区域之间共享强大的物理连接($1 + \mathbf{M}^{l-1}$)时,在数学上放大了它们之间的注意力得分。最后,他们使用一个池化得分 $\mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l)$ 来缩小图谱以找到最关键的疾病生物标志物,该得分同时从结构和功能模态评估节点重要性。
在其纯粹的数学核心上,这是一种机制,通过乘法嵌入稀疏的、硬连线的物理拓扑矩阵,然后进行双重标准的降维,来约束系统的动态、全连接注意力权重。
这种潜在的逻辑在完全不同的领域揭示了令人着迷的“镜像图像”:
1) 全球宏观经济与金融
在全球金融领域,分析师不断试图预测市场崩溃。功能连通性是不同国家股市之间的统计相关性(价格如何协同变动)。结构连通性是这些国家之间实际的物理供应链和贸易协定。本文的核心逻辑完美地反映了区分真实因果市场变动与虚假统计噪声的长期经济问题,通过将动态价格相关性与硬性物理贸易量联系起来。
2) 城市电网工程
在电气工程中,功能连通性是全天不同城市区域动态的、波动的电力消耗。结构连通性是铜传输线的物理布局。工程师们难以仅凭动态负载数据来预测级联停电故障;本文的逻辑反映了通过加权动态电力消耗相关性与电网拓扑的硬性物理限制来找到最脆弱节点的解决方案。
如果一位量化交易员明天“窃取”了这个确切的方程会怎样?他们可以利用公司所有权结构或物理供应链依赖性作为结构掩码($\mathbf{M}$),而不是仅仅依赖于资产价格($\mathbf{X}_f$)之间短暂的统计相关性。这一突破将立即过滤掉市场噪声,创建一个高度稳健的交易算法,能够预测公司级联违约的发生,可能在突然的市场低迷期间为基金节省超过5亿美元。
通过展示物理支架如何指导对动态信号的解释,本文为通用结构库增加了一个重要的蓝图,再次证明了人类认知结构与互联系统数学之间的联系是由完全相同的普适定律所约束的。