機能構造接続ネットワークを用いたクロスモーダル脳グラフTransformerによる脳疾患診断
Multi-modal brain networks represent the complex connectivity between different brain regions from both functional and structural perspectives, which is of great significance for brain disease diagnosis.
背景と学術的系譜
この問題がどこから来るのかを理解するためには、神経科学者や計算科学者が、アルツハイマー病(AD)や自閉スペクトラム症(ASD)のような複雑な脳疾患の診断に歴史的にどのように取り組んできたかを見る必要がある。神経画像処理の初期段階では、研究者は異常を探すために単一種類の脳スキャンに依存していた。やがて、脳は高度に複雑で相互接続されたネットワークとして機能するという認識が広まった。これにより、2つの異なる視点が用いられるようになった。機能的接続性(異なる脳領域がどのように共に活性化するか、fMRIで測定)と構造的接続性(それらを物理的に接続する実際の神経線維、DTIで測定)である。脳疾患はしばしば物理的な配線とコミュニケーションパターンの両方を同時に破壊するため、これら2つのモダリティを融合するという特定の問題が生じた。それらを正確に診断するには、どちらか一方を孤立して見るのではなく、構造と機能の間の深く結合した関係を理解する必要がある。
著者がこの論文を書くことを余儀なくされた根本的な限界は何だったのか?以前のアプローチは、これら2種類のデータを組み合わせようとした際に大きな壁にぶつかった。グラフニューラルネットワーク(GNN)は人気があったが、隣接ノード間で局所的に情報しか伝達せず、脳における広範囲にわたる長距離依存性を完全に無視していた。これを修正するために、最近のモデルのいくつかはTransformerを導入したが、これは全体像を把握するのに優れている。しかし、既存のマルチモーダルモデルは、機能的データと構造的データを2つの別個の並列ビューとして扱い、最終的な特徴量を最後に単純に融合するだけだった。それらは構造的接続性の支援的役割を完全に無視していた。具体的には、物理的な配線が機能的なコミュニケーションをどのように指示または誘導すべきかということである。著者は、物理的な構造を明示的に使用して、機能的データに対するモデルの「注意」を誘導しない限り、以前のモデルは重要な診断情報をテーブルに残したままにしていることに気づいた。
以下に、この論文で使用されているいくつかの高度に専門的な用語を、日常的な概念に翻訳したものを示す。
- 機能的接続性ネットワーク(fMRI): これは、異なる都市間のリアルタイムの電話通信トラフィックと考えてほしい。電話回線自体は示さないが、どの都市が全く同じ時間に頻繁に互いに通信しているかを示す。
- 構造的接続性ネットワーク(DTI): これは物理的なインフラストラクチャ、つまりそれらの都市間に構築された実際の光ファイバーケーブルまたはコンクリート道路である。たとえ2つの都市が現在通信していなくても、物理的な道路は存在する。
- 関心領域(ROI): 国の地図を見ていると想像してほしい。ROIは単に特定の都市または州である。脳では、研究者が活動または接続性を監視する特定解剖学的領域(海馬など)である。
- クロスモーダルTopKプーリング: 大規模な全国地図を、危機を監視するための最も重要な都市トップ$k$個だけに縮小しようとしている政府委員会のことを想像してほしい。単に人口規模(1つのモダリティ)を見るだけでなく、物理的な道路インフラと電話トラフィック(クロスモーダル)の両方を評価して最も重要な都市を選択し、分析を簡素化するために残りを破棄する。
この問題を解決するために使用された主要な数学的記法を整理しよう。
| 記法 | タイプ | 説明 |
|---|---|---|
| $\mathbf{X}_{s}$ | 変数 | DTI画像から得られた構造的接続性行列。 |
| $\mathbf{X}_{s,(i,j)}$ | 変数 | ROI $i$ と ROI $j$ 間の物理的な線維接続数。 |
| $\mathbf{M}^0$ | パラメータ | Transformerを誘導するために、フィルタリングされた構造的特徴量から再構築された初期拡張マスク。 |
| $\mathbf{X}_f^{l-1}$ | 変数 | $l$層目の入力ノード特徴量行列(機能的接続性を表す)。 |
| $\mathbf{M}^{l-1}$ | 変数 | $l$層目の拡張マスク。物理的な配線に基づいて注意メカニズムを誘導するために使用される。 |
| $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$ | パラメータ | マルチヘッド自己注意メカニズムにおけるQuery、Key、Valueの学習可能な重み行列。 |
| $\mathbf{S}^l$ | 変数 | プーリングにおける各ノードのクロスモーダル重要性を反映する最終スコアベクトル。 |
| $\mathbf{i}$ | 変数 | プーリングプロセス後に選択されたトップ$k$ノードを格納するインデックスベクトル。 |
問題定義と制約
この論文が取り組む正確な問題を理解するためには、まずどこから出発し、どこへ行きたいのかを定義する必要がある。
出発点(入力): 神経画像から抽出された2種類の異なる脳ネットワークデータから開始する。
1. 機能的接続性(FC): fMRIスキャンから派生し、異なる脳領域がどのように「発火」するかを捉える。数学的には、$N^0$個の異なる関心領域(ROI)間のピアソン相関係数を計算することによって得られる初期ノード特徴量行列 $\mathbf{X}^0_f \in \mathbb{R}^{N^0 \times N^0}$ として表される。
2. 構造的接続性(SC): DTIスキャンから派生し、これらの領域を接続する実際の物理的な「配線」または神経線維束を表し、行列 $\mathbf{X}_s \in \mathbb{R}^{N^0 \times N^0}$ として表される。
目標状態(出力): 最終的な目標は、患者が特定の脳疾患(アルツハイマー病や自閉スペクトラム症など)を有するか、または正常対照であるかを判断するための、非常に正確な分類確率 $P(c)$ を出力することである。
数学的なギャップ: ここでの欠けているリンクは、物理的な配線(構造)を機能的な発火(活動)に効果的に数学的に織り込む方法である。以前の研究者は、両方のネットワークから独立して特徴量を抽出し、最後にそれらを連結する(特徴量次元での融合)だけだった。それらは、2つの間の深い、結合された相互依存性を捉えることに失敗した。この論文の著者は、構造的接続性が機能的接続性への数学的注意を誘導および強化するための物理的なマップとして機能する必要があることに気づいた。
しかし、このギャップを埋めることは、以前の研究者を閉じ込めてきた苦痛なジレンマをもたらす。
ジレンマ:
脳ネットワーク分析において、疾患を診断するには、遠隔の脳領域がどのように通信するかを理解する必要がある。これは、モデルが「長距離依存性」を捉えなければならないことを意味する。
ここにトレードオフがある:グラフニューラルネットワーク(GNN)を使用すると、脳の局所的な物理的トポロジーをうまく捉えることができるが、GNNはオーバー・スムージングと呼ばれる現象により、長距離依存性を捉えるのが著しく苦手である。一方、標準的なTransformerアーキテクチャを使用すると、自己注意メカニズムは長距離依存性を捉えるのに優れている。しかし、標準的なTransformerは「トポロジーに盲目」であり、すべての脳領域が等しく接続されていると見なし、脳の実際の物理的な神経線維の高速道路を完全に無視する。
Transformerに脳のトポロジーを一から学習させようとすると、深刻な計算上の肥大化とノイズに遭遇する。あなたは行き詰まる:GNNを使用して長距離の機能的な誤発火を失うか、Transformerを使用して物理的な構造的制約を失うか。
厳しい壁と制約:
このジレンマを解決するために、著者はこの問題を非常に困難にする、いくつかの厳しい現実的な壁に直面した。
- 極端なデータスキューネス: 生の構造的接続性行列 $\mathbf{X}_s$ をニューラルネットワークに単純にフィードすることはできない。2つの脳領域間の物理的な線維接続数 $\mathbf{X}_{s,(i,j)}$ は、絶対ゼロから数千まで変化する、非常に偏った分布を持つ。これを数学的に安定させるために、著者はサンプル平均が正規分布に適合するように、厳密な対数変換 $\mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1)$ を適用し、その後標準正規化を行うことを余儀なくされた。
- 次元の呪いとノイズ: 脳は多くのROI(ノード)に分割されている。複数のモダリティにわたるすべてのROIに対する密な注意計算は計算コストが高く、すべての脳領域が特定の疾患に関連しているわけではないため、大量のノイズを導入する。グラフサイズを削減する必要がある。
- クロスモーダルプーリング制約: グラフサイズの削減はノードの削除(プーリング)を必要とする。しかし、診断に必要な正確なバイオマーカーを誤って捨てずにノードを削除するにはどうすればよいか?機能的データのみを見てノードを削除すると、重大な構造的損傷を持つ領域を破棄してしまう可能性がある。ここでの制約は、ノードの重要性を、保持または破棄を決定する前に、機能的および構造的両方の観点から同時に評価する必要があるということである。正直に言うと、以前の単一モダリティプーリング方法が構造的損傷を無視することをどのように正当化したのか完全には確信が持てないが、この論文では、構造的マスクと機能的特徴量の両方を学習可能なベクトルに投影して統一されたクロスモーダルスコア $\mathbf{S}^l$ を計算することにより、これを克服している。
なぜこのアプローチなのか
従来のメソッドの崩壊点
著者がこの特定のアーキテクチャを選択した理由を理解するには、従来のメソッドが壁にぶつかった正確な瞬間を見る必要がある。脳ネットワーク分析では、脳の異なる領域(ノード)が互いにどのように通信するかを見ることで、アルツハイマー病や自閉症のような疾患を診断することが目標である。
長らく、グラフニューラルネットワーク(GNN)がそのためのゴールドスタンダードだった。しかし、著者は根本的な欠陥に気づいた。GNNは「局所情報伝播」メカニズムで動作する。それらは直接の隣接ノードとしか通信しない。しかし、人間の脳は高度に複雑であり、疾患はしばしば長距離依存性を破壊する。つまり、脳の前部にある領域が後部の領域と誤って通信する可能性がある。あなたがクロスカントリーの高速道路システムをナビゲートする必要があるときに、ローカルな都市地図に150ドルを費やすことはないだろう。それと同様に、GNNは全脳分析にはあまりにも近視眼的だった。
Transformerは、その自己注意メカニズムにより、グラフ全体を一度に見ることでこれを解決する。しかし、標準的なTransformer(BrainNetTFなど)は新しい問題を引き起こした。それらは機能的MRI(fMRI)データのみを見て、物理的な神経線維配線(DTIデータ)を完全に無視していた。他のマルチモーダル手法は、機能的データと構造的データを「マルチビュー」データとして並行して処理することでこれを修正しようとした。著者は、これが物理的な配線の支援的役割を無視しているため、不十分であることに気づいた。2つのデータセットを単に混ぜ合わせることはできない。物理的な配線が機能的な活動を明示的に誘導しなければならない。この認識により、クロスモーダル脳グラフTransformer(CBGT)が唯一実行可能なソリューションとなった。
構造的利点とベンチマークロジック
単にチャート上のより高い精度数値を達成するだけでなく、この方法はグラフの複雑さとノイズの処理方法において質的に優れている。脳ネットワークは信じられないほどノイズが多く、高次元である。各層ですべての接続を処理しようとすると、計算オーバーヘッドと無関係なデータに溺れてしまう。
これを解決するために、著者は「クロスモーダルTopKプーリング」モジュールを導入した。巨大で静的なグラフに依存するのではなく、モデルは機能的および構造的スコアの両方を融合することによって、各脳領域(ROI)の重要性を動的に評価する。
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
このスコアベクトル $\mathbf{S}^l$ に基づいて、モデルは最も重要なノードのみをトップ$k$個選択する。
$$ \mathbf{i} = \text{topk}(\mathbf{S}^l, k) $$
この論文ではこれを厳密な $O(N^2)$ から $O(N)$ メモリ削減として明示的にフレーム化していないが、構造的利点はまさにそれである。それは層ごとにグラフサイズを劇的に縮小する。非本質的な脳領域を除外することにより、最も重要なバイオマーカー(例:楔前部または海馬)のみを保持し、モデルを、ノイズの多いグラフ全体を記憶することを強制した以前の方法よりも圧倒的に優れているものにする。
問題と解決策の完璧な結婚
この問題における最も厳しい制約は、Transformerに機能的な活動を見ているときに物理的な脳配線を気にするように数学的に強制する方法を見つけることだった。
著者は、この制約と彼らの解決策との間に、拡張マスク $\mathbf{M}^{l-1}$ と呼ばれるものを生成することによって、見事な「結婚」を達成した。まず、XGBoostを使用して構造的データから重要でない物理的接続を除外し、最も影響力のある物理的経路のみを残す。次に、この構造的マスクをTransformerの機能的自己注意メカニズムの心臓部に直接注入する。
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
その方程式の右側、要素ごとの乗算($\odot$)をよく見てほしい。要素ごとの乗算の左側は、2つの脳領域が機能的にどれだけ同期して発火しているかを示す標準的な注意スコアである。これを $(1 + \mathbf{M}^{l-1})$ で乗算することにより、物理的な神経線維接続も強い場合にのみ、モデルは注意スコアを数学的に増幅する。これは、構造が機能に指示するようにするための完全にエレガントな方法である。
取られなかった道
この論文は、GNNが拒否された理由(長距離依存性を捉える能力の欠如)と、標準的なマルチモーダル融合が拒否された理由(構造と機能を別個だが同等として扱うのではなく、相互依存として扱う)を明確に説明している。
正直に言うと、著者が全く言及していないため、GANやDiffusionモデルのような生成モデルがここでどのように機能するかは完全には確信が持てない。しかし、論理的には、GANとDiffusionモデルはノイズから新しいデータ分布を生成するように設計されている。ここで定義された問題は厳密に識別的なグラフ分類タスク(例:アルツハイマー病対正常対照の診断)である。グラフを分類するためにDiffusionモデルを使用することは、計算コストが法外に高く、特定の局所的な脳バイオマーカーを特定するという目標に対してアーキテクチャ的に整合しないだろう。したがって、クロスモーダルプーリングを備えた識別的なTransformerは、取るべき最も直接的で論理的な道だった。
数学的・論理的メカニズム
この論文がもたらす深遠な飛躍を理解するためには、まず人間の脳を二層ネットワーク、すなわち「ハードウェア」と「ソフトウェア」の組み合わせとして理解する必要がある。
神経画像処理において、「ハードウェア」は拡散テンソルイメージング(DTI)によって測定され、異なる脳領域を接続する実際の物理的な神経線維をマッピングする。これは構造的接続性と呼ばれる。「ソフトウェア」は機能的磁気共鳴画像法(fMRI)によって測定され、どの脳領域が同時に発火しているかを見るために血流を追跡する。これは機能的接続性と呼ばれる。
長年、アルツハイマー病や自閉症のような脳疾患を診断しようとする医師やAI研究者は、大きな制約に直面していた。彼らはハードウェア、ソフトウェアのいずれかを見るか、あるいは単に2つのデータセットを乱雑に混ぜ合わせるだけだった。標準的なグラフニューラルネットワーク(GNN)は近視眼的であり、直接隣接する脳領域しか見ない。一方、Transformerは長距離依存性(脳の前部にある領域が後部の領域にどのように影響するか)を見るのに優れているが、マップがないと脳の巨大な機能的データのノイズに簡単に迷子になる。
この論文の著者は、クロスモーダル脳グラフTransformer(CBGT)を作成することによってこれを解決した。彼らは数学的にAIに、物理的なハードウェア(構造的接続性)を、ソフトウェア(機能的接続性)をよりよく理解するためのガイドとなる青写真として使用することを強制する。
以下に、このクロスモーダル融合に命を吹き込む絶対的なコア数学エンジンを示す。
$$ \mathbf{T}^{l,z} = \text{softmax} \left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left( \mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1} \right)^\top}{\sqrt{d_K^{l,z}}} \odot \left( 1 + \mathbf{M}^{l-1} \right) \right) $$
$$ \mathbf{h}^{l,z} = \mathbf{T}^{l,z} \mathbf{W}_V^{l,z} \mathbf{X}_f^{l-1} $$
これらの数式を一つずつ分解して、どのようにモデルに命を吹き込んでいるかを理解しよう。
- $\mathbf{X}_f^{l-1}$:これはレイヤー$l-1$の入力ノード特徴量行列である。物理的には、「ソフトウェア」信号、つまり異なる領域の機能的な脳活動を表す。
- $\mathbf{W}_Q^{l,z}, \mathbf{W}_K^{l,z}, \mathbf{W}_V^{l,z}$:これらは、アテンションヘッド$z$におけるQuery、Key、Valueの学習可能な重み行列である。論理的には、それらは翻訳者として機能する。行列乗算を使用して、生の脳信号を、領域が質問(Query)、回答(Key)、および実質(Value)を提供できる新しい数学的空間に回転および投影する。
- $(\dots)^\top$:転置演算子。Key行列を転置して、Query行列と乗算できるようにする。このドット積は、2つの脳領域の活動間の生の類似性または「整合性」を測定する。
- $\sqrt{d_K^{l,z}}$:Keyベクトルの次元の平方根。これは熱力学的なサーモスタットとして機能する。大きなベクトルを乗算すると、結果の数値が爆発し、ソフトマックス関数を学習が停止する平坦で死んだゾーンに押し込む可能性がある。除算は、分散を縮小し、数学的エンジンをスムーズに実行するために使用される。
- $\mathbf{M}^{l-1}$:構造的接続性ネットワークから派生した拡張マスク。これは「ハードウェア」マップであり、XGBoostアルゴリズムによって事前にフィルタリングされ、最も重要な物理的な神経接続のみが保持される。
- $1 + \mathbf{M}^{l-1}$:構造的バイアス。なぜここで加算を使用するのか?数値の$1$はベースラインとして機能する。$\mathbf{M}$が$0$(2つの領域を接続する物理的な線維がないことを意味する)の場合、項は単純に$1$になる。これにより、ベースラインの機能情報が消去されないことが保証される。物理的な接続が存在する場合、$\mathbf{M}$は$1$に加算され、接続が増幅される。
- $\odot$:アダマール積(要素ごとの乗算)。これは拡大鏡として機能する。構造的な青写真を使用して、機能的な注意スコアを直接スケーリングする。乗算が加算の代わりにここで使用されるのは、構造的マスクが比例乗数として機能し、物理的な脳のアーキテクチャがそれをサポートする場所に注意を正確にスケーリングするためである。
- $\text{softmax}$:正規化関数。厳密な予算管理者として機能し、すべての生の、ブーストされた類似性スコアが正確に$1.0$(または100%)に合計されるように強制する。生の数学を確率分布に変換する。
- $\mathbf{T}^{l,z}$:最終的な注意行列。これはルーティングネットワークであり、各脳領域が他のどの脳領域にどれだけ耳を傾けるべきかを正確に伝えるマスター台帳である。
- $\mathbf{h}^{l,z}$:出力隠れ状態。これは、脳領域が互いに通信した後に更新され、リッチになった信号である。
これを実際に確認するために、単一の抽象的なデータポイント、例えば海馬からの信号の正確なライフサイクルをこの数式を通してトレースしてみよう。
まず、海馬の生の機能信号($\mathbf{X}_f$)が組み立てラインに入り、$\mathbf{W}_Q$ と乗算されてQueryベクトルが生成される。これは本質的に虚空に向かって叫んでいるようなものだ。「私と同期して発火しているのは誰?」同時に、前頭前野のような他のすべての脳領域は、Keyベクトル($\mathbf{W}_K \mathbf{X}_f$)を生成する。海馬のQueryは前頭前野のKeyと乗算される。それらの機能信号が一致する場合、結果のスコアは高くなる。
次に、この生のスコアは$\sqrt{d_K}$で割られて冷却され、数学的なオーバーフローを防ぐ。ここでクロスモーダルマジックが登場する。システムは構造マスク$\mathbf{M}$をチェックする。海馬と前頭前野を実際に物理的な神経線維が接続しているか?もしそうなら、マスク$\mathbf{M}$は高い値を示し、要素ごとの乗算$\odot (1 + \mathbf{M})$はその接続スコアを大幅にブーストする。物理的な線維がない場合、スコアは$1$で乗算され、変更されない。
softmax関数は、これらのすべてのスコアをクリップして圧縮し、パーセンテージにする。例えば、海馬が前頭前野に注意の80%を払うと決定したとする。最後に、海馬は前頭前野のValueベクトル($\mathbf{W}_V \mathbf{X}_f$)の80%を吸収し、自身の内部状態を$\mathbf{h}$に更新する。海馬は、脳のハードウェアの制約に基づいて、ソフトウェアを正常に更新した。
このメカニズムは実際にどのように学習し、収束するのか?ここでの最適化ダイナミクスは美しく制約されている。モデルは、モデルの最終的な疾患診断がどれほど間違っているかを測定するクロスエントロピー損失関数によって、非常に最後に教師あり学習される。
逆伝播中、勾配は最終的な分類から、トップKプーリング層(動的に無用な脳領域を削除し、最も重要なバイオマーカーのみを保持するように学習する)を通り、Transformer層へと逆流する。構造マスク$\odot (1 + \mathbf{M})$のため、損失ランドスケープは根本的に再形成される。標準的なTransformerでは、モデルがランダムでノイズの多い機能的な相関(例:偶然に2つの脳領域が同期して発火する)に容易に過学習するため、損失ランドスケープは混沌としている。
しかし、構造マスクは損失ランドスケープにおける深い、滑らかな谷として機能する。それは物理的な事前情報として機能し、勾配が実際の生物学的経路に沿ってずっと強く流れるように強制する。Adamオプティマイザは、重み行列($\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V$)を反復的に更新するが、それは常に脳の物理的な現実に導かれている。時間とともに、モデルは統計的なパターンだけでなく、生物学的に妥当なマルチモーダルバイオマーカーに収束し、アルツハイマー病や自閉症のような状態を前例のない精度で診断することを可能にする。
結果、限界、結論
巨大で賑やかな大都市がどのように機能するかを理解しようとしていると想像してほしい。2つの地図がある。最初の地図は、異なる地域を結ぶ物理的な高速道路と鉄道線路を示している。これは都市の構造的接続性である。2番目の地図は、それらの地域間の電話通話とテキストメッセージの量を示している。これは機能的接続性である。
数十年にわたり、神経科学者は人間の脳を非常に似た方法で見つめてきた。拡散テンソルイメージング(DTI)を使用して、物理的な神経線維(高速道路)をマッピングし、機能的磁気共鳴画像法(fMRI)を使用して、脳活動のコヒーレンス(電話通話)をマッピングする。アルツハイマー病や自閉症のような複雑な脳疾患を診断したい場合、両方を見る必要がある。高額なスキャンを購入して、データの半分を無視するようなことはしないだろう。
しかし、AI駆動型神経科学における根本的な問題は、これら2つの地図をどのように組み合わせるかであった。既存のモデルは通常、処理パイプラインの最後に特徴量を単純に混ぜ合わせるだけだった。それらは、物理的な高速道路が電話通話の経路を決定するということを理解できていなかった。さらに、物理的に離れた脳領域がしばしば激しく通信する(長距離依存性)。従来のグラフニューラルネットワーク(GNN)は、直接の隣接ノードしか見ないため、全体像を見るのが非常に苦手である。Transformerは全体像を見るのに優れているが、通常は物理的なグラフ構造を完全に無視する。
この論文は、AIに物理的な構造マップを、機能活動マップに注意を集中させるためのレンズとして使用することを強制する、見事なアーキテクチャであるクロスモーダル脳グラフTransformer(CBGT)を導入する。
数学的中心:どのような問題が解決されたか?
著者は特定の制約を解決する必要があった。どのようにして、Transformerの自己注意メカニズムに物理的な神経線維を気にするように数学的に強制するか?
まず、構造データをクリーンアップする必要があった。DTI線維数は非常に偏っている。一部の領域には接続がゼロで、他の領域には数千の接続がある。これを正規化するために、対数変換を適用した。
$$ \mathbf{X}_{s,(i,j)} = \log_{10}(\mathbf{X}_{s,(i,j)} + 1) $$
この行列を標準化した後、機械学習アルゴリズム(XGBoost)を使用してノイズを除外し、最も重要な物理的接続のみを特定し、「拡張マスク」$\mathbf{M}^0$を作成した。正直に言うと、論文ではハードしきい値 $p=3$ を設定するためにグリッドサーチに依存しているが、この特定のステップでXGBoostを選択した理由が、微分可能なニューラルレイヤーではなく、堅牢な特徴選択器として機能するのかは完全にはわからない。
真の天才は、クロスモーダルTransformerレイヤーにある。標準的なTransformerでは、注意はクエリとキーを比較することによって計算される。ここでは、著者は構造マスク$\mathbf{M}^{l-1}$を機能的注意計算に直接注入する。
$$ \mathbf{T}^{l,z} = \text{softmax}\left( \frac{\mathbf{W}_Q^{l,z} \mathbf{X}_f^{l-1} \left(\mathbf{W}_K^{l,z} \mathbf{X}_f^{l-1}\right)^\top}{\sqrt{d_K^{l,z}}} \odot (1 + \mathbf{M}^{l-1}) \right) $$
直感的には、項 $(1 + \mathbf{M}^{l-1})$ は構造的乗数として機能する。2つの脳領域が強い物理的接続(高い$\mathbf{M}$)を共有する場合、モデルはそれらの機能的相関に対する注意($\mathbf{T}$)を人工的にブーストする。これは構造と機能をエレガントに結婚させる。
最後に、疾患を診断するために、モデルは脳全体を均等に見ることはできない。特定の損傷した地域(バイオマーカー)を見つける必要がある。彼らはクロスモーダルTopKプーリングメカニズムを設計した。これは、構造的マスクと機能的ノード特徴量の両方を学習可能なベクトルに投影し、それらを連結し、多層パーセプトロン(MLP)に通して統一された重要性スコアを生成する。
$$ \mathbf{S}^l = \sigma(\mathbf{S}^l \cdot \mathbf{W}^l + \mathbf{b}^l) $$
モデルはその後、このクロスモーダルスコアに基づいてトップ$k$個の最も重要な領域のみを保持し、これらの洗練された表現をソフト投票分類器に渡すことによって、グラフを ruthlessly に枝刈りする。
実験的アーキテクチャ:容赦ない証明と「犠牲者」
著者は単に数学が機能すると主張しただけでなく、2つの全く異なる神経学的戦場、すなわちアルツハイマー病(ADNIデータセット)と自閉スペクトラム症(ABIDEデータセット)全体でそれを否定できないように証明するための実験を設計した。
彼らの後に残された「犠牲者」は、最先端モデルの誰でも知っている名前だった。彼らは、単一種類のスキャンのみを見た単一モダリティベースライン(SVM、GAT、BrainGNN、BrainIB、BrainNetTF、ALTER)を打ち破り、さらに重要なことに、構造と機能を融合しようとするが、それを不器用に融合する既存のマルチモーダルモデル(BrainNN、MME-GCN、Cross-GNN)を粉砕した。例えば、軽度認知障害(MCI)と正常対照(NC)を区別するという困難なタスクにおいて、CBGTはすべての他のクロスモーダル手法を3.9%の精度で大幅に上回った。
しかし、彼らのコアメカニズムが機能したという決定的な、否定できない証拠は、高い精度だけでなく、アブレーションスタディと解釈分析であった。
構造マスクを取り除いた(モデルをバニラ単一モダリティTransformerに戻した)とき、アルツハイマー病分類の精度は4.9%急落した。これは、構造マスクが単なるギミックではなく、モデルの負荷支持柱であったことを証明した。さらに、AIの注意を物理的な脳にマッピングしたとき、モデルは自閉症患者が精神状態を推測しようとしたときに長らく臨床文献で活性化されていないと証明されている領域である、楔前部(PCUN)と直腸(REC)に焦点を当てることを独立して学習した。数学は単に損失関数を最適化しただけでなく、生物学的現実を再発見した。
将来の進化のための議論トピック
この見事な基盤に基づいて、将来の探求のためのいくつかの深い方向性を以下に示す。
- エンドツーエンド微分可能な構造的スパース性:
現在、モデルは構造マスク $\mathbf{M}^0$ を抽出するために、離散的な前処理ステップとしてXGBoostに依存している。これはパイプラインのエンドツーエンド微分可能性を壊す。これを、逆伝播中に構造グラフを動的に枝刈りすることを学習する微分可能なスパースアテンションメカニズム(SparsemaxやGumbel-Softmaxルーターなど)に置き換えることはできるか?これは、モデルの新しい、明白でない物理的バイオマーカーを発見する能力にどのように影響するか? - 機能的接続性における時間的ダイナミクス:
この論文では、機能的接続性を静的な行列(スキャン全体のピアソン相関)として扱っている。しかし、脳活動は非常に動的であり、「電話通話」はバーストで発生する。機能的入力 $\mathbf{X}_f$ を時空間シーケンスに進化させ、時間的Transformerを適用する場合、静的な構造マスクを使用して動的な機能的シーケンスを数学的に制約するにはどうすればよいか? - 学際的な一般化:
ここでのコア数学的前提、すなわち動的で完全に接続されたグラフを、スパースでハードワイヤードな物理的トポロジー行列によって乗法的に埋め込むことによって制約し、その後二重基準の次元削減を行うメカニズムは、脳に限定されない。これは都市工学に展開できるか?例えば、リアルタイムGPS移動データ(機能)上の注意をマスクするために物理的な道路ネットワーク(構造)を使用することによって、交通渋滞を予測できるか?「ノード」が90の脳領域から90,000の都市交差点にスケールアップした場合、どのような制約が生じるか?
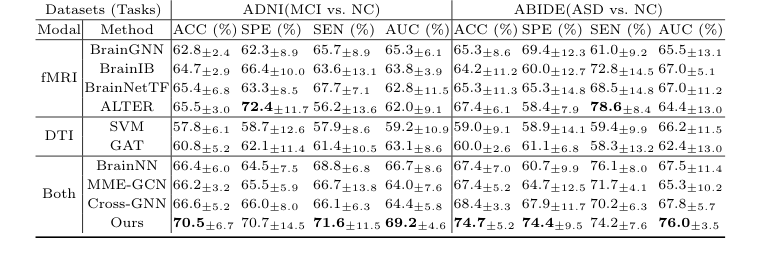 Table 2. Ablation Study Results on Different Datasets
Table 2. Ablation Study Results on Different Datasets
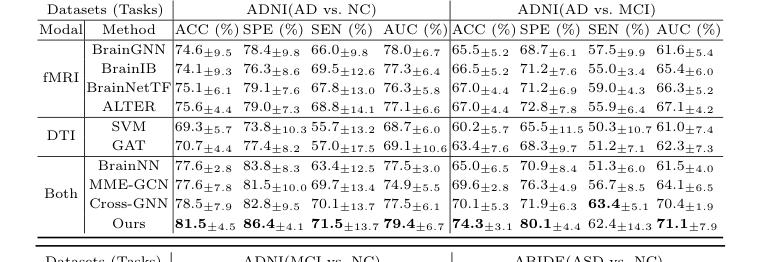 Table 1. Comparative Experiments of Classification Tasks on Different Datasets
Table 1. Comparative Experiments of Classification Tasks on Different Datasets