विज़न, भाषा और नियंत्रण के लिए डिफ्यूजन मॉडल में इंट्रैक्टेबल अनुमान को कम करना
इस पत्र में संबोधित समस्या सटीक रूप से कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और सुदृढीकरण सीखने सहित विभिन्न डोमेन में शक्तिशाली जनरेटिव मॉडल के रूप में डिफ्यूजन मॉडल की हालिया सफलता और व्यापक रूप से अपनाने से...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या सटीक रूप से कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और सुदृढीकरण सीखने सहित विभिन्न डोमेन में शक्तिशाली जनरेटिव मॉडल के रूप में डिफ्यूजन मॉडल की हालिया सफलता और व्यापक रूप से अपनाने से उत्पन्न होती है। जबकि ये मॉडल क्रमिक शोर प्रक्रिया को उलटने की प्रक्रिया सीखकर उच्च-गुणवत्ता वाले डेटा उत्पन्न करने में उत्कृष्टता प्राप्त करते हैं, डाउनस्ट्रीम कार्यों में उनका अनुप्रयोग अक्सर अधिक जटिल अनुमान की आवश्यकता होती है: पश्च वितरण से नमूनाकरण।
ऐतिहासिक रूप से, डिफ्यूजन मॉडल, जिसे पहली बार 2015 में सोहल-डिकस्टीन एट अल. [68] द्वारा पेश किया गया था, पदानुक्रमित जनरेटिव मॉडल का एक वर्ग है जो जटिल डेटा वितरण को मॉडल करना सीखते हैं। मुख्य विचार एक फॉरवर्ड डिफ्यूजन प्रक्रिया को परिभाषित करना है जो धीरे-धीरे डेटा में शोर जोड़ती है, इसे एक सरल, सुगम वितरण (जैसे गॉसियन शोर) में बदल देती है। फिर, एक न्यूरल नेटवर्क को रिवर्स प्रक्रिया सीखने के लिए प्रशिक्षित किया जाता है, जो नए नमूने उत्पन्न करने के लिए चरण दर चरण डेटा को प्रभावी ढंग से डीनोइज़ करता है।
यह विशिष्ट समस्या तब उत्पन्न होती है जब इन पूर्व-प्रशिक्षित डिफ्यूजन मॉडल का उपयोग प्रायोर $p(x)$ के रूप में उन परिदृश्यों में किया जाता है जहां वांछित आउटपुट को एक अतिरिक्त, अक्सर जटिल, बाधा $r(x)$ को भी संतुष्ट करना चाहिए। यह बाधा एक क्लासिफायर की संभावना (जैसे, एक विशिष्ट वर्ग की छवि उत्पन्न करना), सुदृढीकरण सीखने में एक इनाम फ़ंक्शन (जैसे, इनाम को अधिकतम करने वाली क्रियाएं उत्पन्न करना), या लापता पाठ को भरने के लिए एक भाषा मॉडल की संभावना हो सकती है। लक्ष्य तब उत्पाद वितरण $p_{\text{post}}(x) \propto p(x)r(x)$ से नमूनाकरण करना बन जाता है, जो बायेसियन पश्च का प्रतिनिधित्व करता है। यह समस्या विशेष रूप से चुनौतीपूर्ण है क्योंकि डिफ्यूजन मॉडल की पदानुक्रमित प्रकृति ऐसे पश्चों से सटीक नमूनाकरण को इंट्रैक्टेबल बनाती है, खासकर जब $r(x)$ एक "ब्लैक-बॉक्स" फ़ंक्शन है जो आसान विश्लेषणात्मक समाधान प्रदान नहीं करता है।
पिछले दृष्टिकोणों की मौलिक सीमा या "दर्द बिंदु" इस इंट्रैक्टेबल पश्च अनुमान को सटीक और कुशलता से करने में उनकी अक्षमता है। मौजूदा विधियां आम तौर पर कई श्रेणियों में आती हैं, प्रत्येक महत्वपूर्ण कमियों के साथ:
* रैखिक सन्निकटन या स्टोकेस्टिक अनुकूलन: ये विधियां अक्सर केवल अनुमानित समाधान [73, 33, 31, 11, 22, 48] प्रदान करती हैं, जो वास्तविक पश्च वितरण को निष्ठापूर्वक कैप्चर नहीं कर सकती हैं।
* गाइडेंस टर्म अनुमान: क्लासिफायर गाइडेंस [12] जैसी तकनीकें शोर वाले डेटा पर एक क्लासिफायर को प्रशिक्षित करके "गाइडेंस" टर्म का अनुमान लगाने का प्रयास करती हैं। हालांकि, यह दृष्टिकोण सीमित है क्योंकि इसके लिए विशिष्ट शोर वाले डेटा की आवश्यकता होती है, और जब ऐसा डेटा अनुपलब्ध होता है, तो यह सन्निकटन या मोंटे कार्लो अनुमानों [70, 14, 10] पर निर्भर करता है। ये सन्निकटन आधुनिक जनरेटिव कार्यों में आम उच्च-आयामी समस्याओं को स्केल करने के लिए कुख्यात रूप से कठिन हैं।
* सुदृढीकरण सीखने (RL) विधियां: इस समस्या के लिए हालिया RL-आधारित दृष्टिकोण [8, 16], जबकि आशाजनक हैं, पक्षपाती पाए गए हैं और मोड कोलैप्स से पीड़ित हैं। मोड कोलैप्स का मतलब है कि मॉडल विविध नमूने उत्पन्न करने में विफल रहता है, इसके बजाय केवल कुछ उच्च-इनाम उदाहरण उत्पन्न करने में फंस जाता है, इस प्रकार पूर्ण पश्च वितरण का पूरी तरह से पता नहीं लगाता है। पूर्ण पश्च वितरण से नमूनाकरण में विविधता और सटीकता की यह कमी जटिल डाउनस्ट्रीम कार्यों में डिफ्यूजन मॉडल के विश्वसनीय और बहुमुखी अनुप्रयोगों के लिए एक बड़ी बाधा है।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष डोमेन शब्द दिए गए हैं, जिनका अनुवाद सहज उपमाओं में किया गया है:
- डिफ्यूजन मॉडल: कल्पना कीजिए कि आपके पास एक बहुत धुंधली, शोर वाली तस्वीर है। एक डिफ्यूजन मॉडल एक कुशल डिजिटल कलाकार की तरह है जो ठीक से जानता है कि धीरे-धीरे धुंधलापन और शोर को चरण दर चरण कैसे हटाया जाए, जब तक कि मूल, स्पष्ट तस्वीर सामने न आ जाए। यह इस "अन-ब्लरिंग" प्रक्रिया को सीखता है कि छवियां पहली जगह में शोर वाली कैसे बनती हैं।
- पश्च अनुमान: इसे एक विशेष प्रकार की दुर्लभ चिड़िया को खोजने की कोशिश करने के रूप में सोचें। आपके पास एक सामान्य फील्ड गाइड है जो आपको सभी पक्षियों के बारे में बताता है ("प्रायोर" ज्ञान)। लेकिन फिर, आपको एक स्थानीय विशेषज्ञ से एक टिप मिलती है: "यह पक्षी केवल एक विशेष प्रकार के पेड़ के पास दिखाई देता है" (यह "बाधा" है)। पश्च अनुमान आपके सामान्य पक्षी ज्ञान को इस नई, विशिष्ट टिप के साथ मिलाकर अपनी खोज को सीमित करने और उस विशेष पक्षी के लिए सबसे संभावित स्थानों को खोजने की प्रक्रिया है।
- मोड कोलैप्स: एक ऐसे शेफ की कल्पना करें जिसे पार्टी के लिए विभिन्न प्रकार के केक बेक करने के लिए कहा गया है। यदि शेफ केवल चॉकलेट केक बेक करता है, भले ही पार्टी के मेहमान वेनिला, स्ट्रॉबेरी और लेमन केक भी चाहते हों, तो यह मोड कोलैप्स है। शेफ ने केक के एक ही प्रकार (चॉकलेट) पर "कोलैप्स" कर दिया है और वांछित विकल्पों की पूरी श्रृंखला का पता नहीं लगा रहा है, भले ही चॉकलेट केक बहुत अच्छा हो।
- सापेक्ष प्रक्षेप पथ संतुलन (RTB): एक बहुत लंबे, डगमगाते रस्सी को पार करने की कोशिश कर रहे एक टाइटरोप वॉकर पर विचार करें। केवल दूसरी तरफ जाने पर ध्यान केंद्रित करने के बजाय, जिससे गिर सकता है, RTB एक परिष्कृत सेंसर सिस्टम की तरह है जो लगातार वॉकर की आगे की गति की तुलना एक काल्पनिक पीछे की गति से करता है, एक स्थिर, ज्ञात पथ के सापेक्ष। यह निरंतर, सापेक्ष तुलना वॉकर को सही संतुलन बनाए रखने और गंतव्य तक मज़बूती से पहुंचने में मदद करती है, बिना विचलित हुए या फंसे।
- ब्लैक-बॉक्स बाधा $r(x)$: कल्पना कीजिए कि आप एक वीडियो गेम खेल रहे हैं जहाँ आप एक चरित्र डिजाइन करने की कोशिश कर रहे हैं। आप विभिन्न सुविधाओं को बदल सकते हैं, लेकिन एक रहस्यमय "निर्णायक" है जो आपके चरित्र की अपील के लिए आपको केवल एक स्कोर देता है, यह बताए बिना कि उन्होंने वह स्कोर क्यों दिया। आप निर्णायक के दिमाग के अंदर नहीं देख सकते; आपको बस एक संख्या मिलती है। यह निर्णायक एक ब्लैक-बॉक्स बाधा है - आप इसका आउटपुट जानते हैं, लेकिन इसके आंतरिक कामकाज को नहीं।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $p_{\theta}(x)$ | एक पूर्व-प्रशिक्षित डिफ्यूजन जनरेटिव मॉडल (प्रायोर), $\theta$ द्वारा पैरामीट्रिज्ड। |
| $r(x)$ | एक सकारात्मक, ब्लैक-बॉक्स बाधा या संभावना फ़ंक्शन। |
| $p_{\text{post}}(x)$ | लक्ष्य पश्च वितरण, $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$। |
| $P_{\Phi}^{\text{post}}(\tau)$ | पश्च डिफ्यूजन मॉडल, $\Phi$ द्वारा पैरामीट्रिज्ड, के तहत एक प्रक्षेप पथ $\tau$ की संभावना। |
| $p_{\theta}(\tau)$ | प्रायोर डिफ्यूजन मॉडल, $\theta$ द्वारा पैरामीट्रिज्ड, के तहत एक प्रक्षेप पथ $\tau$ की संभावना। |
| $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ | प्रारंभिक शोर $X_0$ से अंतिम डेटा $X_1$ तक एक डिफ्यूजन प्रक्षेप पथ। |
| $X_t$ | डिफ्यूजन प्रक्रिया में एक मध्यवर्ती समय चरण $t$ पर एक डेटा बिंदु। |
| $u_{\Phi}^{\text{post}}(x_t, t)$ | पश्च SDE का ड्रिफ्ट टर्म, $\Phi$ पैरामीटर वाले एक न्यूरल नेटवर्क द्वारा सीखा गया। |
| $u_{\theta}(x_t, t)$ | प्रायोर SDE का ड्रिफ्ट टर्म, $\theta$ पैरामीटर वाले एक न्यूरल नेटवर्क द्वारा सीखा गया। |
| $\mathcal{L}_{\text{RTB}}(\tau; \Phi)$ | सापेक्ष प्रक्षेप पथ संतुलन (RTB) हानि फ़ंक्शन। |
| $Z$ | पश्च वितरण के लिए एक सामान्यीकरण स्थिरांक। |
| $T$ | डिफ्यूजन प्रक्रिया में असतत समय चरणों की कुल संख्या। |
| $\Delta t$ | एक एकल समय चरण की अवधि, $\Delta t = 1/T$। |
| $B$ | बैच वाले ग्रेडिएंट गणना के लिए संचय बैच आकार। |
| $E[\log r(x)]$ | अपेक्षित लॉग इनाम, नमूनों द्वारा बाधा को कितनी अच्छी तरह संतुष्ट किया जाता है, इसका एक मीट्रिक। |
| FID | फ्रेट इनसेप्शन डिस्टेंस, छवि गुणवत्ता और लक्ष्य वितरण के साथ समानता के लिए एक मीट्रिक। |
| BERTScore | पाठ निर्माण गुणवत्ता के लिए एक मीट्रिक, उत्पन्न पाठ की संदर्भ पाठ से तुलना करता है। |
| BLEU-4 | पाठ निर्माण गुणवत्ता के लिए एक मीट्रिक, एन-ग्राम ओवरलैप पर आधारित। |
| GLEU-4 | पाठ निर्माण गुणवत्ता के लिए एक मीट्रिक, BLEU के समान लेकिन मानव निर्णय के साथ बेहतर सहसंबंध के साथ। |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित केंद्रीय समस्या डिफ्यूजन मॉडल में इंट्रैक्टेबल पश्च अनुमान है जब उन्हें डाउनस्ट्रीम कार्यों के लिए प्रायोर के रूप में उपयोग किया जाता है। विशेष रूप से, लेखक एक शक्तिशाली जनरेटिव डिफ्यूजन मॉडल को प्रायोर के रूप में रखने और उसके बाधित संस्करण से नमूनाकरण की आवश्यकता के बीच की खाई को पाटने का लक्ष्य रखते हैं।
प्रारंभ बिंदु (इनपुट/वर्तमान स्थिति) एक पूर्व-प्रशिक्षित डिफ्यूजन जनरेटिव मॉडल है, जिसे $p_{\theta}(x)$ के रूप में दर्शाया गया है, जो प्रभावी रूप से जटिल डेटा वितरण (जैसे, चित्र, पाठ, क्रियाएं) को मॉडल करता है। इस प्रायोर के साथ, एक ब्लैक-बॉक्स बाधा या संभावना फ़ंक्शन, $r(x)$ है, जो अतिरिक्त शर्तों या प्राथमिकताओं का प्रतिनिधित्व करता है। लक्ष्य इन दो वितरणों के उत्पाद पर अनुमान लगाना है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) एक नया, प्रशिक्षित डिफ्यूजन मॉडल, $p_{\phi}^{\text{post}}$ है, जो अनबायस्ड रूप से वास्तविक पश्च वितरण $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$ से नमूनाकरण कर सकता है। इसका मतलब है कि प्रशिक्षित मॉडल को प्रायोर और बाधा के संयुक्त प्रभाव को सटीक रूप से प्रतिबिंबित करना चाहिए, जिससे लचीला और सटीक सशर्त पीढ़ी या नीति सीखने की अनुमति मिल सके।
सटीक लुप्त कड़ी या गणितीय अंतर इस पश्च $p_{\text{post}}(x)$ से सीधे नमूनाकरण की अंतर्निहित इंट्रैक्टेबिलिटी है। डिफ्यूजन मॉडल स्टोकेस्टिक परिवर्तनों की एक गहरी श्रृंखला के माध्यम से नमूने उत्पन्न करते हैं, जिससे ब्लैक-बॉक्स $r(x)$ के तहत $p_{\theta}(x)r(x)$ से सटीक नमूनाकरण इंट्रैक्टेबल हो जाता है। पिछले तरीके या तो केवल अनुमानित समाधान प्रदान करते हैं, प्रतिबंधित मामलों में काम करते हैं, या पूर्वाग्रह पेश करते हैं और मोड कोलैप्स जैसे मुद्दों से पीड़ित होते हैं। पत्र एक उपन्यास प्रशिक्षण उद्देश्य, सापेक्ष प्रक्षेप पथ संतुलन (RTB) का प्रस्ताव करके इस अंतर को पाटने का प्रयास करता है, जो, जब संतुष्ट होता है, तो यह सुनिश्चित करता है कि प्रशिक्षित पश्च डिफ्यूजन मॉडल $p_{\phi}^{\text{post}}$ वांछित वितरण से नमूनाकरण करता है। गणितीय रूप से, पत्र $p_{\phi}^{\text{post}}$ को प्रशिक्षित करने का प्रयास करता है ताकि वह सापेक्ष प्रक्षेप पथ संतुलन बाधा को संतुष्ट करे:
$$Z p_{\phi}^{\text{post}}(X_0, X_{\Delta t}, \dots, X_1) = r(X_1) p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$$
जहां $Z$ एक सामान्यीकरण स्थिरांक है, $X_0, \dots, X_1$ एक डीनोइज़िंग प्रक्षेप पथ का प्रतिनिधित्व करता है, और $p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$ प्रायोर के तहत एक प्रक्षेप पथ की संयुक्त संभावना है।
पिछले शोधकर्ताओं को फंसाने वाला दर्दनाक समझौता या दुविधा मुख्य रूप से सटीकता/अनबायस्डनेस और सुगमता/कम्प्यूटेशनल दक्षता के बीच है। मौजूदा समाधान अक्सर इनमें से एक जाल में पड़ जाते हैं:
1. सन्निकटन बनाम पूर्वाग्रह: रैखिक सन्निकटन या स्टोकेस्टिक अनुकूलन पर निर्भर विधियां सुगम हैं लेकिन अक्सर पक्षपाती परिणाम देती हैं या उच्च-आयामी समस्याओं को स्केल करने में चुनौतीपूर्ण होती हैं। उदाहरण के लिए, क्लासिफायर गाइडेंस, कुछ मामलों में प्रभावी होने के बावजूद, वास्तविक पश्च ड्रिफ्ट का एक पक्षपाती सन्निकटन प्रदान करता है।
2. इनाम अधिकतमकरण बनाम मोड कवरेज: सुदृढीकरण सीखने (RL) आधारित विधियां, जो एक इनाम फ़ंक्शन को अधिकतम करने के लिए डिफ्यूजन मॉडल को फाइन-ट्यून करती हैं, अक्सर मोड कोलैप्स से पीड़ित होती हैं। वे उच्च-इनाम मोड के कुछ पर ध्यान केंद्रित करके उच्च पुरस्कार प्राप्त कर सकते हैं, लेकिन काफी खराब विविधता और पूर्ण पश्च वितरण के गलत प्रतिनिधित्व की कीमत पर। यह विविधता और पूर्ण पश्च वितरण से नमूनाकरण में सटीकता की कमी का मतलब है कि विश्वसनीय और बहुमुखी अनुप्रयोगों के लिए एक प्रमुख बाधा है।
बाधाएँ और विफलता मोड
डिफ्यूजन मॉडल में इंट्रैक्टेबल अनुमान को कम करने की समस्या को कई कठोर, यथार्थवादी दीवारों से बेहद मुश्किल बना दिया गया है:
-
कम्प्यूटेशनल बाधाएँ:
- सटीक पश्च नमूनाकरण की इंट्रैक्टेबिलिटी: मौलिक चुनौती यह है कि डिफ्यूजन प्रायोर और एक ब्लैक-बॉक्स बाधा $r(x)$ के उत्पाद से सटीक नमूनाकरण कम्प्यूटेशनल रूप से इंट्रैक्टेबल है, खासकर डिफ्यूजन मॉडल की पदानुक्रमित प्रकृति को देखते हुए।
- उच्च-आयामीता: कई मौजूदा अनुमान तकनीकें, जिनमें मोंटे कार्लो अनुमान और रैखिक सन्निकटन शामिल हैं, "उच्च-आयामी समस्याओं को स्केल करने में चुनौतीपूर्ण" हैं, जैसे कि दृष्टि, भाषा और नियंत्रण कार्यों में सामना की जाने वाली।
- हार्डवेयर मेमोरी सीमाएँ: बड़े डिफ्यूजन मॉडल के लिए, एक लंबे डीनोइज़िंग प्रक्षेप पथ में सभी चरणों के लिए ग्रेडिएंट की गणना और भंडारण हार्डवेयर मेमोरी सीमाओं के कारण "निषिद्ध" है। इसके लिए स्टोकेस्टिक सबसैंपलिंग या बैच वाले ग्रेडिएंट गणना जैसी मेमोरी-कुशल तकनीकों की आवश्यकता होती है, जो ग्रेडिएंट विचरण में वृद्धि जैसे व्यापार-बंद पेश कर सकती हैं।
- प्रशिक्षण समय: पश्च सैंपलर सीखने के लिए आवश्यक सिमुलेशन-आधारित प्रशिक्षण "धीमा और मेमोरी-गहन" हो सकता है, जैसा कि सीमा अनुभाग में उल्लेख किया गया है। पत्र में सभी प्रयोगों के लिए अनुमानित कुल कम्प्यूट समय शक्तिशाली जीपीयू पर 3000 घंटे है, जो महत्वपूर्ण कम्प्यूटेशनल लागत को इंगित करता है।
-
डेटा-संचालित बाधाएँ:
- अनबायस्ड पश्च नमूनों की कमी: प्रत्यक्ष पर्यवेक्षण से प्रशिक्षण विधियां जो वास्तविक पश्च नमूनों से प्राप्त होती हैं, अक्सर अव्यवहारिक होती हैं क्योंकि ऐसे नमूनों को उपलब्ध नहीं माना जाता है। उदाहरण के लिए, क्लासिफायर गाइडेंस के लिए शोर वाले डेटा पर एक डिफरेंशिएबल क्लासिफायर की आवश्यकता होती है, जो आम तौर पर अनबायस्ड डेटा तक पहुंच के बिना प्राप्त करना या सीखना इंट्रैक्टेबल होता है।
- गाइडेंस टर्म के लिए डेटा की विरलता: जब शोर वाले डेटा पर क्लासिफायर को प्रशिक्षित करने के लिए डेटा अनुपलब्ध होता है, तो शोधकर्ताओं को सन्निकटन पर निर्भर रहना पड़ता है, जो पूर्वाग्रह पेश कर सकता है।
- अपूर्ण प्रायोर मॉडल के प्रति संवेदनशीलता: प्रस्तावित हानि फ़ंक्शन "अपूर्ण रूप से फिट प्रायोर मॉडल" के प्रति संवेदनशील हो सकता है, जो प्रशिक्षण स्थिरता और प्रदर्शन को प्रभावित कर सकता है।
-
गणितीय और तार्किक बाधाएँ:
- गैर-डिफरेंशिएबल बाधाएँ: बाधा फ़ंक्शन $r(x)$ अक्सर एक "ब्लैक-बॉक्स" होता है, जिसका अर्थ है कि यह डिफरेंशिएबल नहीं हो सकता है, जिससे ग्रेडिएंट-आधारित अनुकूलन जटिल हो जाता है। यद्यपि पत्र उन मामलों की पड़ताल करता है जहां $r(x_1)$ डिफरेंशिएबल है, सामान्य समस्या सूत्रीकरण को गैर-डिफरेंशिएबल परिदृश्यों को ध्यान में रखना चाहिए।
- सन्निकटन में पूर्वाग्रह: क्लासिफायर गाइडेंस या प्रति-चरण केएल नियमितीकरण के साथ आरएल जैसे पिछले तरीके, अंतर्निहित पूर्वाग्रह पेश करते हैं जो उन्हें वास्तविक पश्च तक एसिम्प्टोटिक रूप से प्राप्त करने से रोकते हैं।
- मोड कोलैप्स: आरएल-आधारित फाइन-ट्यूनिंग विधियां, विशेष रूप से पर्याप्त नियमितीकरण के बिना, मोड कोलैप्स के शिकार होती हैं, जहां मॉडल केवल वास्तविक पश्च मोड के एक उपसमूह का नमूना लेता है, जिससे उत्पन्न नमूनों में विविधता की कमी होती है।
- सीमांत केएल विचलन की इंट्रैक्टेबिलिटी: पाठ-से-छवि निर्माण के लिए आरएल-आधारित फाइन-ट्यूनिंग जैसे संदर्भों में, फाइन-ट्यून किए गए मॉडल और प्रायोर के बीच सीमांत केएल विचलन डिफ्यूजन मॉडल के लिए इंट्रैक्टेबल है, जिससे प्रति-चरण केएल दंड जैसे सन्निकटन पर निर्भरता होती है, जो पूर्वाग्रह पेश कर सकता है।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) को अपनाना केवल एक विकल्प नहीं बल्कि एक आवश्यकता थी, जो डाउनस्ट्रीम कार्यों के लिए प्रायोर के रूप में डिफ्यूजन मॉडल का उपयोग करते समय पश्च अनुमान की अंतर्निहित इंट्रैक्टेबिलिटी से प्रेरित थी। पत्र स्पष्ट रूप से बताता है कि "डिफ्यूजन मॉडल प्रभावी वितरण अनुमानक के रूप में उभरे हैं... लेकिन डाउनस्ट्रीम कार्यों में प्रायोर के रूप में उनका उपयोग एक इंट्रैक्टेबल पश्च अनुमान समस्या प्रस्तुत करता है।" (सार, पृष्ठ 1)। मुख्य मुद्दा "डिफ्यूजन मॉडल में जनरेटिव प्रक्रिया की पदानुक्रमित प्रकृति" से उत्पन्न होता है, जो "ब्लैक-बॉक्स फ़ंक्शन $r(x)$ के तहत पश्च $p(x)r(x)$ से सटीक नमूनाकरण को इंट्रैक्टेबल बनाता है" (पृष्ठ 2)।
पारंपरिक "SOTA" विधियां इस विशिष्ट चुनौती के लिए अपर्याप्त साबित हुईं। मौजूदा दृष्टिकोण या तो केवल अनुमानित समाधान प्रदान करते हैं या प्रतिबंधित मामलों तक सीमित होते हैं। उदाहरण के लिए, सामान्य अनुमान तकनीकों में रैखिक सन्निकटन [73, 33, 31, 11] या स्टोकेस्टिक अनुकूलन [22, 48] पर निर्भरता शामिल है, जो स्वाभाविक रूप से सन्निकटन पेश करते हैं। एक अन्य लोकप्रिय रणनीति शोर वाले डेटा पर एक क्लासिफायर को प्रशिक्षित करके 'गाइडेंस' टर्म का अनुमान लगाना है [12]। हालांकि, यह विधि तब विफल हो जाती है जब ऐसा शोर वाला डेटा अनुपलब्ध होता है, जिससे आगे सन्निकटन या मोंटे कार्लो अनुमानों [70, 14, 10] पर निर्भरता होती है जो उच्च-आयामी समस्याओं को स्केल करने के लिए कुख्यात रूप से कठिन होते हैं। इसके अलावा, हालिया सुदृढीकरण सीखने (RL) विधियां [8, 16] जो इस समस्या के लिए प्रस्तावित हैं, पूर्वाग्रह से ग्रस्त और मोड कोलैप्स के शिकार होने के लिए जानी जाती हैं, जैसा कि चित्र 1 (पृष्ठ 3) में नेत्रहीन रूप से प्रदर्शित किया गया है।
लेखकों ने महसूस किया कि इन इंट्रैक्टेबल पश्चों से एसिम्प्टोटिक रूप से अनबायस्ड नमूनाकरण प्राप्त करने के लिए एक मौलिक रूप से भिन्न दृष्टिकोण की आवश्यकता थी। इससे RTB का विकास हुआ, जो डिफ्यूजन मॉडल पर जनरेटिव फ्लो नेटवर्क परिप्रेक्ष्य से प्राप्त होता है। यह परिप्रेक्ष्य एक ऐसे उद्देश्य के लिए सैद्धांतिक आधार प्रदान करता है जो पिछले तरीकों की सीमाओं को दूर कर सकता है, इंट्रैक्टेबल पश्च नमूनाकरण के लिए एक मार्ग प्रदान करता है जहां अन्य तकनीकें या तो अनुमान लगाती हैं, विफल होती हैं, या मोड कोलैप्स जैसे महत्वपूर्ण मुद्दों से पीड़ित होती हैं।
तुलनात्मक श्रेष्ठता
रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) केवल प्रदर्शन मेट्रिक्स से परे, कई संरचनात्मक और परिचालन लाभों के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है।
सबसे पहले, RTB एक "एसिम्प्टोटिक रूप से अनबायस्ड उद्देश्य है जो डेटा-मुक्त तरीके से ड्रिफ्ट्स में अंतर (और इस प्रकार लॉग-संयोजित संभावना के ग्रेडिएंट) को पुनर्प्राप्त करता है" (पृष्ठ 5)। यह क्लासिफायर गाइडेंस की तुलना में एक महत्वपूर्ण संरचनात्मक लाभ है, जो पश्च ड्रिफ्ट के लिए एक सटीक समाधान प्रदान करते हुए, शोर वाले डेटा पर एक डिफरेंशिएबल क्लासिफायर पर निर्भर करता है जिसे अक्सर अनबायस्ड डेटा नमूनों के बिना प्राप्त करना या सीखना इंट्रैक्टेबल होता है। RTB इस डेटा निर्भरता को दरकिनार करता है, एक अधिक मजबूत और सामान्य समाधान प्रदान करता है।
दूसरे, विधि बेहतर मेमोरी दक्षता और स्केलेबिलिटी प्रदर्शित करती है। एक महत्वपूर्ण अंतर्दृष्टि यह है कि "$\phi$ के संबंध में इस उद्देश्य के ग्रेडिएंट को $\tau$ द्वारा उत्पादित नमूनाकरण प्रक्रिया में (बैकप्रॉपैगेशन) विभेदन की आवश्यकता नहीं होती है" (पृष्ठ 5)। यह संपत्ति दो प्रमुख लाभ प्रदान करती है:
1. ऑफ-पॉलिसी अनुकूलन: RTB को ऑफ-पॉलिसी उद्देश्य के रूप में अनुकूलित किया जा सकता है, जिसका अर्थ है कि प्रशिक्षण के लिए प्रक्षेप पथों को लक्ष्य पश्च से भिन्न वितरण से नमूना किया जा सकता है। यह लचीलापन "मोड कवरेज सुनिश्चित करने" (पृष्ठ 5) के लिए महत्वपूर्ण है और ऑन-पॉलिसी आरएल विधियों से एक अलग लाभ है जो मोड कोलैप्स (चित्र C.2, पृष्ठ 19) के शिकार होते हैं।
2. बैच ग्रेडिएंट संचय: RTB के लिए ग्रेडिएंट गणना के लिए सभी समय-चरणों के लिए पूरे कम्प्यूटेशन ग्राफ को संग्रहीत करने की आवश्यकता नहीं होती है। इसके बजाय, "केवल संचय बैच आकार B, प्रक्षेप पथ लंबाई T नहीं, मेमोरी बजट द्वारा सीमित है" (पृष्ठ 27)। यह स्टोकेस्टिक सबसैंपलिंग के माध्यम से ग्रेडिएंट विचरण में वृद्धि के बिना बड़ी संख्या में डिफ्यूजन चरणों तक स्केलिंग प्रशिक्षण की अनुमति देता है, जिसमें एक निश्चित मेमोरी बजट के तहत प्रशिक्षण समय चरणों की संख्या के साथ रैखिक रूप से बढ़ता है। यह मेमोरी जटिलता को नाटकीय रूप से कम करता है, जिससे यह उच्च-आयामी समस्याओं के लिए अत्यधिक श्रेष्ठ हो जाता है जहां पूर्ण प्रक्षेप पथों को संग्रहीत करना निषिद्ध है।
अंत में, RTB की बहुमुखी प्रतिभा एक गुणात्मक शक्ति है। पत्र विभिन्न डोमेन में इसकी व्यापक प्रयोज्यता को प्रदर्शित करता है, जिसमें विजन (क्लासिफायर-गाइडेड इमेज जनरेशन, टेक्स्ट-टू-इमेज जनरेशन), भाषा (असतत डिफ्यूजन एलएलएम के साथ इनफिलिंग), और निरंतर नियंत्रण (ऑफलाइन सुदृढीकरण सीखने) शामिल हैं। सफल अनुप्रयोगों की यह विस्तृत श्रृंखला विभिन्न प्रकार के डिफ्यूजन प्रायोर और ब्लैक-बॉक्स बाधाओं को संभालने में इसकी संरचनात्मक लाभ को रेखांकित करती है।
बाधाओं के साथ संरेखण
चुनी गई RTB विधि समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, जो समस्या परिभाषा और समाधान के अद्वितीय गुणों के बीच एक मजबूत "विवाह" बनाती है।
समस्या में परिभाषित प्राथमिक बाधा, "उत्पाद वितरण से नमूनाकरण करने की आवश्यकता है, जहां एक पूर्व-प्रशिक्षित डिफ्यूजन मॉडल एक प्रायोर $p(x)$ के रूप में कार्य करता है जिसे एक सहायक बाधा $r(x)$ से गुणा किया जाता है" (पृष्ठ 2)। RTB विशेष रूप से "डिफ्यूजन मॉडल प्रायोर के तहत पश्च वितरण से नमूनाकरण करने वाले डिफ्यूजन मॉडल को प्रशिक्षित करने" (§2.2) के लिए डिज़ाइन किया गया है, जो इस मुख्य आवश्यकता को सीधे संबोधित करता है।
इसके अलावा, सहायक बाधा $r(x)$ अक्सर एक "ब्लैक-बॉक्स बाधा या संभावना फ़ंक्शन" (सार, पृष्ठ 1) होती है, जिसका अर्थ है कि इसका कार्यात्मक रूप जटिल या गैर-डिफरेंशिएबल हो सकता है। RTB "मनमाना सकारात्मक बाधा $r(x_1)$" (पृष्ठ 5) और "मनमाना ब्लैक-बॉक्स संभावनाओं" (पृष्ठ 10) को संभालने के लिए तैयार किया गया है, जिससे यह उन परिदृश्यों के लिए अत्यधिक उपयुक्त है जहां बाधा फ़ंक्शन पारंपरिक ग्रेडिएंट-आधारित विधियों के लिए आसानी से उत्तरदायी नहीं है।
समस्या "इंट्रैक्टेबल पश्च अनुमान" (सार, पृष्ठ 1) को एक प्रमुख बाधा के रूप में भी उजागर करती है। RTB एक "एसिम्प्टोटिक रूप से अनबायस्ड प्रशिक्षण उद्देश्य" (पृष्ठ 2) प्रदान करता है, जो पूर्वाग्रह पेश कर सकने वाले सन्निकटन पर निर्भर रहने के बजाय इस इंट्रैक्टेबिलिटी से निपटने का एक सैद्धांतिक रूप से ध्वनि तरीका प्रदान करता है।
सशर्त समस्याओं के लिए, जहां बाधाएं अन्य चर पर निर्भर करती हैं (जैसे, $r(x_1; y) = p(y | x_1)$), RTB पश्च ड्रिफ्ट को $y$ पर सशर्त करने की अनुमति देता है, जिससे "अमोर्टीकृत अनुमान" और "प्रशिक्षण में नहीं देखे गए नए $y$ के लिए सामान्यीकरण" (पृष्ठ 5) सक्षम होता है। यह संपत्ति विभिन्न स्थितियों में भिन्न होने वाले कुशल अनुमान की आवश्यकता वाले व्यावहारिक अनुप्रयोगों के लिए महत्वपूर्ण है।
अंत में, "उच्च-आयामी समस्याओं" (पृष्ठ 2) और "बड़े डिफ्यूजन मॉडल" (पृष्ठ 5) तक स्केल करने की आवश्यकता महत्वपूर्ण मेमोरी और कम्प्यूटेशनल बाधाएं लगाती है। RTB का मेमोरी-कुशल प्रशिक्षण, बैच वाले ग्रेडिएंट संचय और स्टोकेस्टिक सबसैंपलिंग के माध्यम से, सीधे इन व्यावहारिक सीमाओं को संबोधित करता है। बड़ी संख्या में डिफ्यूजन चरणों के साथ मेमोरी बजट में वृद्धि के बिना प्रशिक्षण को स्केल करने की क्षमता, जैसा कि §H.1 में चर्चा की गई है, आधुनिक जनरेटिव मॉडल की मांग वाली प्रकृति के लिए एक आदर्श फिट है।
विकल्पों का अस्वीकरण
पत्र डिफ्यूजन मॉडल में इंट्रैक्टेबल पश्च अनुमान को कम करने की विशिष्ट समस्या के लिए कई लोकप्रिय दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है:
-
पारंपरिक अनुमान तकनीकें (रैखिक सन्निकटन, स्टोकेस्टिक अनुकूलन): लेखक नोट करते हैं कि "इस समस्या के सामान्य समाधानों में रैखिक सन्निकटन [73, 33, 31, 11] या स्टोकेस्टिक अनुकूलन [22, 48] पर आधारित अनुमान तकनीकें शामिल हैं" (पृष्ठ 2)। इन विधियों को अपर्याप्त माना जाता है क्योंकि वे "केवल अनुमानित रूप से या प्रतिबंधित मामलों में हल करती हैं" (सार, पृष्ठ 1), एसिम्प्टोटिक रूप से अनबायस्ड नमूनाकरण प्रदान करने में विफल रहती हैं जिसका RTB लक्ष्य है।
-
क्लासिफायर गाइडेंस (CG) / डिफ्यूजन पोस्टीरियर सैंपलिंग (DPS) / लॉस-गाइडेड डिफ्यूजन मोंटे कार्लो (LGD-MC): ये विधियां, जो 'गाइडेंस' टर्म का अनुमान लगाने का प्रयास करती हैं, कई कारणों से आलोचना की जाती हैं:
- वे "पक्षपाती परिणाम देते हैं" (चित्र 1, पृष्ठ 3)।
- वे "शोर वाले डेटा पर एक क्लासिफायर को प्रशिक्षित करने" [12] पर निर्भर करते हैं, जो तब समस्याग्रस्त होता है "जब ऐसा डेटा उपलब्ध नहीं होता है" (पृष्ठ 2)।
- शोर वाले डेटा पर एक डिफरेंशिएबल क्लासिफायर प्राप्त करना "सामान्य रूप से, इंट्रैक्टेबल नहीं है" (पृष्ठ 5), और इसे सीखने के लिए "अनबायस्ड डेटा नमूनों की आवश्यकता होती है", जो ठीक वही हैं जो समस्या उत्पन्न करने का लक्ष्य रखती है।
- प्रायोगिक रूप से, "क्लासिफायर-गाइडेंस-आधारित विधियां, जैसे DP और LGD-MC, उच्च विविधता प्रदर्शित करती हैं, लेकिन पश्च वितरण (सबसे कम लॉग r(x)) को ठीक से मॉडल करने में विफल रहती हैं" (पृष्ठ 7)। वे "कम क्लासिफायर औसत पुरस्कार" भी प्राप्त करते हैं और "पश्च वितरण को ठीक से मॉडल करने" में विफल रहते हैं (पृष्ठ 21)।
-
सुदृढीकरण सीखने (RL) विधियां (जैसे, DPOK, DDPO): जबकि इस समस्या के लिए आरएल विधियां [8, 16] प्रस्तावित की गई हैं, वे महत्वपूर्ण खामियों से ग्रस्त हैं:
- वे "पक्षपाती हैं और मोड कोलैप्स (चित्र 1) के शिकार हैं" (पृष्ठ 2)। चित्र E.1 (पृष्ठ 20) आगे "प्रारंभिक मोड कोलैप्स" और शुद्ध आरएल फाइन-ट्यूनिंग में "इनाम शोषण" को दर्शाता है।
- "शुद्ध आरएल फाइन-ट्यूनिंग (कोई केएल नियमितीकरण नहीं) मोड कोलैप्स विशेषताओं को प्रदर्शित करता है, जो काफी खराब विविधता और एफआईडी स्कोर के बदले में उच्च पुरस्कार प्राप्त करता है" (पृष्ठ 7)।
- डिफ्यूजन मॉडल को फाइन-ट्यून करने के लिए आरएल विधियां आम तौर पर "ऑन-पॉलिसी" (पृष्ठ 19) होती हैं, जो उन्हें "मोड कोलैप्स के शिकार" बनाती हैं (चित्र C.2, पृष्ठ 19)।
- DPOK और DDPO जैसी विधियां प्रति-चरण दंड का उपयोग करके सीमांत केएल पर एक ऊपरी सीमा को अनुकूलित करती हैं, जो पूर्वाग्रह पेश करती है। इसके विपरीत, RTB, "इस तरह के सन्निकटन में पूर्वाग्रह से बच सकता है और सीधे पश्च $p(x_1 | z)$ से अनबायस्ड नमूने उत्पन्न करना सीख सकता है" (पृष्ठ 7)।
पत्र इस विशिष्ट समस्या के लिए जनरेटिव एडवरसैरियल नेटवर्क (GANs) को अस्वीकार करने पर स्पष्ट रूप से चर्चा नहीं करता है। ध्यान डिफ्यूजन मॉडल ढांचे के भीतर पश्च अनुमान में सुधार पर है, जहां डिफ्यूजन मॉडल पहले से ही प्रायोर के रूप में स्थापित हैं। इसलिए, प्रायोर के रूप में GANs की सीधी तुलना या अस्वीकृति इस विशेष विश्लेषण के दायरे से बाहर है।
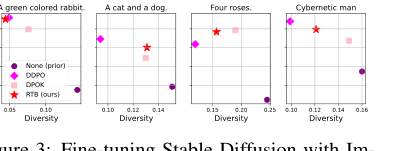 Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पत्र को शक्ति प्रदान करने वाला पूर्ण मुख्य समीकरण रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) हानि फ़ंक्शन है। यह उद्देश्य पश्च डिफ्यूजन मॉडल को लक्ष्य वितरण से नमूनाकरण करने के लिए प्रेरित करता है। हानि एक अनुपात के लघुगणक के वर्ग के रूप में परिभाषित की गई है, जिसका लक्ष्य इस अनुपात को एक तक लाना है।
$$ \mathcal{L}_{\text{RTB}}(\tau; \Phi) := \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right)^2 $$
यहां, $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ डिफ्यूजन प्रक्रिया में एक पूर्ण प्रक्षेप पथ का प्रतिनिधित्व करता है। प्रक्षेप पथ की संभावनाएं $P(\tau)$ स्वयं प्रारंभिक वितरण और असतत समय चरणों पर सशर्त संक्रमण संभावनाओं के उत्पाद हैं, जैसा कि पत्र के समीकरण (3) में दिखाया गया है:
$$ P(\tau) = p(X_0) \prod_{i=1}^T P(X_{i\Delta t} | X_{(i-1)\Delta t}) $$
पद-दर-पद विच्छेदन
आइए प्रत्येक घटक की भूमिका को समझने के लिए मास्टर समीकरण का विश्लेषण करें। स्पष्टता के लिए, हम मुख्य रूप से लघुगणक के अंदर शब्द पर ध्यान केंद्रित करेंगे, क्योंकि इसे शून्य तक कम करना सीधा लक्ष्य है।
-
$\mathcal{L}_{\text{RTB}}$:
- गणितीय परिभाषा: सापेक्ष प्रक्षेप पथ संतुलन (RTB) हानि फ़ंक्शन।
- भौतिक/तार्किक भूमिका: यह प्राथमिक उद्देश्य फ़ंक्शन है जिसे मॉडल प्रशिक्षण के दौरान कम करने का प्रयास करता है। इस हानि को शून्य तक ले जाने से यह सुनिश्चित होता है कि सापेक्ष प्रक्षेप पथ संतुलन बाधा (पत्र का समीकरण 8) संतुष्ट है। यह, बदले में, यह सुनिश्चित करता है कि पश्च डिफ्यूजन मॉडल $P_{\Phi}^{\text{post}}$ वांछित लक्ष्य पश्च वितरण $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$ से नमूनाकरण करना सीखता है।
- वर्गीकरण क्यों? हानि फ़ंक्शन डिजाइन में वर्ग करना एक मानक तकनीक है (मीन स्क्वेयर्ड एरर के समान)। यह सुनिश्चित करता है कि हानि हमेशा गैर-नकारात्मक हो और एक चिकना, डिफरेंशिएबल उद्देश्य प्रदान करता है, जो ग्रेडिएंट-आधारित अनुकूलन के लिए महत्वपूर्ण है। यह लक्ष्य अनुपात (जो 1 है) से बड़े विचलन को छोटे लोगों की तुलना में अधिक महत्वपूर्ण रूप से दंडित करता है, सटीक अभिसरण को प्रोत्साहित करता है।
-
$\tau = (X_0, X_{\Delta t}, \dots, X_1)$:
- गणितीय परिभाषा: डिफ्यूजन प्रक्रिया में एक विशिष्ट प्रक्षेप पथ, जो प्रारंभिक शोर वाले राज्य $X_0$ से अंतिम, डीनोइज़्ड डेटा बिंदु $X_1$ तक राज्यों के अनुक्रम का प्रतिनिधित्व करता है, जो मध्यवर्ती राज्यों $X_{i\Delta t}$ से असतत समय चरणों पर गुजरता है।
- भौतिक/तार्किक भूमिका: यह RTB तंत्र के संचालन की मौलिक इकाई है। पूरी सीखने की प्रक्रिया मूल्यांकन करती है और मॉडल को इन अनुक्रमिक पथों को डेटा स्पेस के माध्यम से उत्पन्न करने के तरीके के आधार पर समायोजित करती है।
-
$\Phi$:
- गणितीय परिभाषा: पश्च डिफ्यूजन मॉडल, $P_{\Phi}^{\text{post}}$ के लिए सीखने योग्य मापदंडों का सेट। ये पैरामीटर आम तौर पर अंतर्निहित स्टोकेस्टिक डिफरेंशियल समीकरण (SDE) के ड्रिफ्ट टर्म $u_{\Phi}^{\text{post}}(x_t, t)$ को परिभाषित करते हैं, जिसे अक्सर एक न्यूरल नेटवर्क के रूप में लागू किया जाता है।
- भौतिक/तार्किक भूमिका: ये न्यूरल नेटवर्क के वजन और बायस हैं जो नियंत्रित करते हैं कि पश्च मॉडल नमूने कैसे उत्पन्न करता है। अनुकूलन प्रक्रिया $\Phi$ को समायोजित करती है ताकि पश्च नमूनाकरण को वांछित लक्ष्य वितरण के साथ संरेखित किया जा सके।
-
$Z$:
- गणितीय परिभाषा: एक स्केलर सामान्यीकरण स्थिरांक, विशेष रूप से $Z = \int q(x_1)r(x_1) dx_1$ जैसा कि प्रस्ताव 1 में प्राप्त किया गया है। संख्यात्मक स्थिरता के लिए, इसके लघुगणक, $\log Z$, को अक्सर सीखा या अनुमानित किया जाता है।
- भौतिक/तार्किक भूमिका: यह स्थिरांक यह सुनिश्चित करने के लिए आवश्यक है कि लक्ष्य पश्च वितरण $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$ सही ढंग से सामान्यीकृत हो। चूंकि बाधा फ़ंक्शन $r(X_1)$ एक अननॉर्मलाइज्ड संभावना या इनाम हो सकता है, $Z$ समग्र संभावना को 1 तक एकीकृत करने के लिए स्केल करता है। यह केवल सापेक्ष अनुपातों के बजाय निरपेक्ष संभावनाओं से मेल खाने के लिए महत्वपूर्ण है।
-
$r(X_1)$:
- गणितीय परिभाषा: अंतिम डेटा बिंदु $X_1$ पर मूल्यांकित एक सकारात्मक, ब्लैक-बॉक्स बाधा या संभावना फ़ंक्शन।
- भौतिक/तार्किक भूमिका: यह "इनाम" या "गाइडेंस" संकेत का प्रतिनिधित्व करता है जो डिफ्यूजन प्रक्रिया को वांछित विशेषताओं की ओर निर्देशित करता है। उदाहरण के लिए, यह एक विशिष्ट वर्ग के लिए एक क्लासिफायर की संभावना $p(c|X_1)$ हो सकती है, या सुदृढीकरण सीखने में एक इनाम फ़ंक्शन $\exp(\beta Q(s,a))$ हो सकती है। यह उन विशिष्ट गुणों को एन्कोड करता है जिन्हें हम चाहते हैं कि उत्पन्न डेटा में हों।
-
$p_{\theta}(\tau)$:
- गणितीय परिभाषा: प्रायोर डिफ्यूजन मॉडल, $\theta$ द्वारा पैरामीट्रिज्ड, के तहत एक प्रक्षेप पथ $\tau$ की संभावना। यह आम तौर पर प्रारंभिक वितरण $p(X_0)$ और सशर्त संक्रमण संभावनाओं $P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$ के उत्पाद का एक उत्पाद है।
- भौतिक/तार्किक भूमिका: यह "आधार रेखा" या "अनकंडीशनल" जनरेटिव प्रक्रिया का प्रतिनिधित्व करता है। यह एक पूर्व-प्रशिक्षित डिफ्यूजन मॉडल है जो किसी भी विशिष्ट बाधा के बिना डेटा उत्पन्न करता है। RTB उद्देश्य इस प्रायोर को एक संदर्भ बिंदु के रूप में उपयोग करता है ताकि पश्च मॉडल के संक्रमण को परिभाषित किया जा सके।
-
$P_{\Phi}^{\text{post}}(\tau)$:
- गणितीय परिभाषा: पश्च डिफ्यूजन मॉडल, $\Phi$ द्वारा पैरामीट्रिज्ड, के तहत एक प्रक्षेप पथ $\tau$ की संभावना। $p_{\theta}(\tau)$ के समान, यह $p(X_0)$ (अक्सर प्रायोर के साथ साझा) और सशर्त संक्रमण संभावनाओं $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$ का उत्पाद है।
- भौतिक/तार्किक भूमिका: यह जनरेटिव प्रक्रिया का प्रतिनिधित्व करता है जिसे हम सक्रिय रूप से वांछित पश्च वितरण से नमूनाकरण करना सीख रहे हैं। इसके पैरामीटर $\Phi$ को बाधा $r(X_1)$ के सापेक्ष पश्च मॉडल के संक्रमण को संरेखित करने के लिए प्रशिक्षण के दौरान समायोजित किया जाता है।
-
$\log(\cdot)$:
- गणितीय परिभाषा: प्राकृतिक लघुगणक।
- भौतिक/तार्किक भूमिका: लघुगणक संभावनाओं के उत्पादों को लॉग-संभावनाओं के योग में बदल देता है, जो संख्यात्मक रूप से अधिक स्थिर होता है और अक्सर अनुकूलित करना आसान होता है। यह संभावनाओं के अनुपातों को लॉग-संभावनाओं के अंतर में भी बदल देता है, जो सूचना सिद्धांत (जैसे, केएल विचलन) में एक सामान्य तकनीक है। उद्देश्य लॉग-अनुपात को शून्य बनाना है, जिसका अर्थ है कि अनुपात स्वयं एक है।
-
$\sum_{i=1}^T$:
- गणितीय परिभाषा: असतत समय चरणों $i$ से 1 से $T$ तक एक योग।
- भौतिक/तार्किक भूमिका: यह ऑपरेटर डिफ्यूजन प्रक्षेप पथ के सभी असतत चरणों में सशर्त संक्रमण संभावनाओं के लॉग-अनुपातों को एकत्रित करता है। डिफ्यूजन प्रक्रिया को $T$ असतत चरणों के अनुक्रम के रूप में मॉडल किया जाता है, और समग्र प्रक्षेप पथ संभावना इन चरण-वार संभावनाओं के उत्पादों से बनी होती है। लघुगणक इस उत्पाद को एक योग में परिवर्तित करता है, जिससे प्रत्येक चरण का योगदान समग्र लॉग-अनुपात में योगात्मक हो जाता है।
- योग के बजाय समाकलन क्यों? पत्र स्पष्ट रूप से डिफ्यूजन प्रक्रिया को एक SDE के "समय-विभेदीकृत संस्करण" के रूप में मॉडल करता है, जहां प्रक्षेप पथ असतत राज्यों $X_0, X_{\Delta t}, \dots, X_1$ के अनुक्रम होते हैं। इसलिए, इन असतत संक्रमणों की संभावनाओं को संयोजित करने के लिए एक योग एक स्वाभाविक विकल्प है, जो लागू डिफ्यूजन चरणों की असतत प्रकृति को दर्शाता है।
-
$P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- गणितीय परिभाषा: पश्च डिफ्यूजन मॉडल के तहत पिछले राज्य $X_{(i-1)\Delta t}$ को देखते हुए राज्य $X_{i\Delta t}$ में संक्रमण की सशर्त संभावना। गॉसियन डिफ्यूजन मॉडल के लिए, यह आम तौर पर एक गॉसियन वितरण $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$ होता है।
- भौतिक/तार्किक भूमिका: यह शब्द बताता है कि पश्च मॉडल एक समय चरण से अगले तक कैसे विकसित होता है। सीखा हुआ ड्रिफ्ट टर्म $u_{\Phi}^{\text{post}}$ (पैरामीट्रिज्ड $\Phi$ द्वारा) इस गॉसियन संक्रमण के माध्य को निर्धारित करता है, प्रभावी रूप से नमूना पीढ़ी को वांछित पश्च की ओर निर्देशित करता है।
-
$P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- गणितीय परिभाषा: प्रायोर डिफ्यूजन मॉडल के तहत पिछले राज्य $X_{(i-1)\Delta t}$ को देखते हुए राज्य $X_{i\Delta t}$ में संक्रमण की सशर्त संभावना। पश्च के समान, यह एक गॉसियन वितरण $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\theta}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$ है।
- भौतिक/तार्किक भूमिका: यह शब्द पूर्व-प्रशिक्षित प्रायोर डिफ्यूजन मॉडल के चरण-वार विकास का वर्णन करता है। यह पश्च मॉडल के संक्रमण के लिए एक संदर्भ के रूप में कार्य करता है। पश्च से प्रायोर संक्रमण संभावनाओं का अनुपात इंगित करता है कि पश्च मॉडल बाधा को संतुष्ट करने के लिए प्रत्येक चरण में प्रायोर से कितना "विचलित" होता है।
चरण-दर-चरण प्रवाह
आइए इस गणितीय इंजन से गुजरने वाले एक अमूर्त डेटा बिंदु के जीवनचक्र का पता लगाएं।
-
शोर की उत्पत्ति ($X_0$): प्रक्रिया एक अमूर्त डेटा बिंदु से शुरू होती है, जो शुरू में शुद्ध गॉसियन शोर का एक वेक्टर होता है, $X_0$, एक निश्चित, सरल वितरण जैसे $\mathcal{N}(0, I)$ से नमूना लिया जाता है। इसे कच्चे, अकारित मिट्टी के रूप में सोचें जिससे एक उत्कृष्ट कृति निकलेगी।
-
जनरेटिव असेंबली लाइन (प्रक्षेप पथ $\tau$):
- एक पूर्ण प्रक्षेप पथ $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ उत्पन्न होता है। इस प्रक्षेप पथ को वर्तमान पश्च मॉडल (ऑन-पॉलिसी नमूनाकरण) या एक वैकल्पिक, खोजपूर्ण वितरण (ऑफ-पॉलिसी नमूनाकरण) द्वारा उत्पन्न किया जा सकता है।
- प्रत्येक असतत समय चरण $i$ से 1 से $T$ तक, प्रगति में नमूना, $X_{(i-1)\Delta t}$, एक "प्रसंस्करण इकाई" में प्रवेश करता है। यहां, एक न्यूरल नेटवर्क (पश्च डिफ्यूजन मॉडल का हिस्सा, $\Phi$ द्वारा पैरामीट्रिज्ड) एक "ड्रिफ्ट" या "डीनोइज़िंग दिशा," $u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t}, (i-1)\Delta t)$ की भविष्यवाणी करता है।
- इस अनुमानित ड्रिफ्ट और गॉसियन शोर की एक छोटी मात्रा के आधार पर, नमूना अगले राज्य, $X_{i\Delta t}$ में सशर्त संभावना $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$ के अनुसार परिवर्तित हो जाता है। यह एक कन्वेयर बेल्ट की तरह है जहां आइटम को लगातार परिष्कृत और आकार दिया जाता है।
- यह चरण-वार परिवर्तन तब तक जारी रहता है जब तक कि अंतिम, डीनोइज़्ड डेटा बिंदु, $X_1$, समय $T$ पर उत्पन्न नहीं हो जाता।
-
गुणवत्ता नियंत्रण जांच ($r(X_1)$): एक बार जब अंतिम डेटा बिंदु $X_1$ असेंबली लाइन से बाहर निकल जाता है, तो इसे तुरंत "गुणवत्ता नियंत्रण" स्टेशन पर भेजा जाता है। यहां, ब्लैक-बॉक्स बाधा फ़ंक्शन $r(X_1)$ मूल्यांकन करता है कि $X_1$ वांछित मानदंडों को कितनी अच्छी तरह पूरा करता है। यह इनाम स्कोर, वर्ग संभावना, या गुणवत्ता का कोई अन्य माप हो सकता है। जनरेटिव प्रक्रिया की सफलता निर्धारित करने के लिए यह महत्वपूर्ण है।
-
संतुलन पत्रक (लॉग-अनुपात गणना):
- अब, पूरे प्रक्षेप पथ $\tau$ ( $X_0$ से $X_1$ तक) का विश्लेषण किया जाता है। पश्च मॉडल के तहत इस विशिष्ट प्रक्षेप पथ की संभावना, $P_{\Phi}^{\text{post}}(\tau)$, प्रारंभिक शोर संभावना को पथ के साथ सभी सशर्त संक्रमण संभावनाओं से गुणा करके गणना की जाती है।
- समानांतर में, प्रायोर डिफ्यूजन मॉडल, $p_{\theta}(\tau)$ के तहत समान प्रक्षेप पथ की संभावना भी गणना की जाती है। यह प्रायोर एक तटस्थ संदर्भ के रूप में कार्य करता है।
- इन संभावनाओं को सामान्यीकरण स्थिरांक $Z$ और बाधा $r(X_1)$ के साथ जोड़कर एक महत्वपूर्ण अनुपात बनाया जाता है: $\frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$।
- इस अनुपात का प्राकृतिक लघुगणक लिया जाता है। यह लॉग-अनुपात मुख्य "संतुलन" मीट्रिक है जिसे सिस्टम शून्य तक ले जाने का लक्ष्य रखता है। यदि यह शून्य है, तो पश्च मॉडल प्रायोर और बाधा के सापेक्ष पूरी तरह से संतुलित है।
-
प्रदर्शन समीक्षा (हानि गणना): गणना की गई लॉग-अनुपात को इस विशेष प्रक्षेप पथ के लिए $\mathcal{L}_{\text{RTB}}$ हानि उत्पन्न करने के लिए वर्ग किया जाता है। यह हानि पश्च मॉडल की वर्तमान जनरेटिव प्रक्रिया में "असंतुलन" या "त्रुटि" को मापती है।
-
समायोजन तंत्र (पैरामीटर अद्यतन): गणना की गई हानि मान का उपयोग पश्च मॉडल के मापदंडों $\Phi$ के संबंध में ग्रेडिएंट उत्पन्न करने के लिए किया जाता है। ये ग्रेडिएंट सटीक निर्देश के रूप में कार्य करते हैं, मॉडल को बताते हैं कि हानि को कम करने के लिए अपने आंतरिक तंत्र (न्यूरल नेटवर्क वजन) को कैसे समायोजित किया जाए। यह समायोजन पश्च मॉडल को उन प्रक्षेप पथों को उत्पन्न करने की अधिक संभावना बनाता है जो सापेक्ष संतुलन बाधा को संतुष्ट करते हैं, प्रभावी ढंग से उच्च-गुणवत्ता, बाधित नमूनों का उत्पादन करना सीखते हैं। यह पुनरावृत्ति प्रक्रिया मॉडल को परिष्कृत करती है, ठीक उसी तरह जैसे एक कुशल इंजीनियर एक जटिल मशीन को फाइन-ट्यून करता है।
अनुकूलन गतिशीलता
रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) तंत्र $\mathcal{L}_{\text{RTB}}$ हानि के ग्रेडिएंट-आधारित अनुकूलन के माध्यम से पश्च डिफ्यूजन मॉडल $P_{\Phi}^{\text{post}}$ के मापदंडों $\Phi$ को पुनरावृत्त रूप से परिष्कृत करके सीखता है, अपडेट करता है और अभिसरण करता है।
-
हानि परिदृश्य और उद्देश्य: $\mathcal{L}_{\text{RTB}}$ हानि फ़ंक्शन, एक वर्ग लॉग-अनुपात होने के नाते, एक हानि परिदृश्य को परिभाषित करता है जहां वैश्विक न्यूनतम शून्य है। इस न्यूनतम पर, सापेक्ष प्रक्षेप पथ संतुलन बाधा $Z P_{\Phi}^{\text{post}}(\tau) = r(X_1) p_{\theta}(\tau)$ सभी प्रक्षेप पथों $\tau$ के लिए पूरी तरह से संतुष्ट है। इसका मतलब है कि पश्च मॉडल $P_{\Phi}^{\text{post}}$ ने लक्ष्य वितरण $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$ से नमूनाकरण करना सीख लिया है। जबकि अंतर्निहित न्यूरल नेटवर्क पैरामीट्रिज़ेशन परिदृश्य को गैर-उत्तल बनाते हैं, लघुगणकीय और वर्ग संचालन एक चिकना उद्देश्य प्रदान करते हैं जो ग्रेडिएंट डिसेंट के लिए उपयुक्त है। पत्र व्यावहारिक रणनीतियों का उल्लेख करता है जैसे कि मिनीबैच पर अनुभवजन्य विचरण और हानि क्लिपिंग का उपयोग करना ताकि प्रशिक्षण को स्थिर किया जा सके और इस जटिल परिदृश्य को नेविगेट किया जा सके, खासकर जब प्रायोर मॉडल अपूर्ण हो या बाधा फ़ंक्शन $r(X_1)$ तेज वितरण की ओर ले जाता है।
-
ग्रेडिएंट व्यवहार और सीखने का संकेत: सीखने की प्रक्रिया का मूल पश्च मॉडल मापदंडों $\Phi$ के संबंध में $\mathcal{L}_{\text{RTB}}$ हानि का ग्रेडिएंट है। लेखकों द्वारा उजागर किया गया एक प्रमुख लाभ यह है कि इस ग्रेडिएंट को प्रक्षेप पथ $\tau$ उत्पन्न करने वाली नमूनाकरण प्रक्रिया के माध्यम से पूरे बैकप्रॉपैगेशन की आवश्यकता नहीं होती है। इसके बजाय, इसमें मुख्य रूप से पश्च प्रक्षेप पथ के लॉग-संभावना के ग्रेडिएंट, $\nabla_{\Phi} \log P_{\Phi}^{\text{post}}(\tau)$ शामिल होता है, जिसे वर्तमान लॉग-अनुपात विचलन द्वारा स्केल किया जाता है।
$$ \nabla_{\Phi} \mathcal{L}_{\text{RTB}}(\tau; \Phi) = 2 \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right) \nabla_{\Phi} \left( \log P_{\Phi}^{\text{post}}(\tau) \right) $$
यह ग्रेडिएंट एक "सुधार संकेत" के रूप में कार्य करता है। यदि पद $\log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$ सकारात्मक है (मतलब $P_{\Phi}^{\text{post}}(\tau)$ लक्ष्य की तुलना में बहुत अधिक है), तो ग्रेडिएंट $\Phi$ को $\log P_{\Phi}^{\text{post}}(\tau)$ को घटाने के लिए धकेलता है, जिससे वह प्रक्षेप पथ पश्च के तहत कम संभावना वाला हो जाता है। इसके विपरीत, यदि पद नकारात्मक है, तो ग्रेडिएंट $\Phi$ को $\log P_{\Phi}^{\text{post}}(\tau)$ को बढ़ाने के लिए धकेलता है, जिससे प्रक्षेप पथ अधिक संभावना वाला हो जाता है। इस समायोजन का परिमाण इस बात के समानुपाती होता है कि वर्तमान मॉडल संतुलन बाधा को संतुष्ट करने से कितनी दूर है। यह तंत्र पश्च मॉडल को उन प्रक्षेप पथों को "बढ़ावा" देना सीखने की अनुमति देता है जो $r(X_1)$ के उच्च मानों की ओर ले जाते हैं, जबकि प्रायोर $p_{\theta}(\tau)$ के साथ एक सुसंगत संबंध बनाए रखते हैं। -
राज्य अद्यतन और अभिसरण:
- पुनरावृत्ति राज्य अद्यतन: मापदंडों $\Phi$ को कई प्रशिक्षण चरणों में एडमडब्ल्यू जैसे अनुकूलन एल्गोरिथम का उपयोग करके पुनरावृत्त रूप से अद्यतन किया जाता है। प्रत्येक चरण में, प्रक्षेप पथों का एक बैच नमूना लिया जाता है। प्रत्येक प्रक्षेप पथ के लिए, $\mathcal{L}_{\text{RTB}}$ हानि की गणना की जाती है, और ग्रेडिएंट जमा किए जाते हैं। फिर अनुकूलक इन जमा ग्रेडिएंट का उपयोग $\Phi$ को समायोजित करने के लिए करता है, इसे पैरामीटर स्पेस में कम हानि वाले क्षेत्रों की ओर ले जाता है।
- ऑफ-पॉलिसी अन्वेषण: RTB की एक महत्वपूर्ण ताकत ऑफ-पॉलिसी प्रशिक्षण के साथ इसकी संगतता है। इसका मतलब है कि सीखने के लिए उपयोग किए जाने वाले प्रक्षेप पथों को वर्तमान पश्च मॉडल $P_{\Phi}^{\text{post}}$ से भिन्न वितरण से नमूना किया जा सकता है। यह लचीलापन मोड कवरेज को कुशल बनाने के लिए महत्वपूर्ण है, जिससे मॉडल संभावित प्रक्षेप पथों की एक विस्तृत श्रृंखला का पता लगा सकता है और मोड कोलैप्स से बच सकता है, एक सामान्य नुकसान जहां जनरेटिव मॉडल केवल उच्च-इनाम नमूनों के एक सीमित सेट का उत्पादन करना सीखते हैं। विविध प्रक्षेप पथों (जैसे, रिप्ले बफ़र्स या खोजपूर्ण संशोधनों से) का लाभ उठाकर, मॉडल लक्ष्य पश्च वितरण के पूर्ण स्पेक्ट्रम को कवर करना सीख सकता है।
- एसिम्प्टोटिक शुद्धता: पत्र RTB को एक "एसिम्प्टोटिक रूप से अनबायस्ड प्रशिक्षण उद्देश्य" के रूप में स्थापित करता है। यह सैद्धांतिक गारंटी निहित करती है कि, पर्याप्त डेटा और प्रशिक्षण को देखते हुए, मॉडल से वास्तविक पश्च वितरण में अभिसरण करने की उम्मीद की जाती है। वर्ग लॉग-अनुपात में निरंतर कमी, सामान्यीकरण स्थिरांक $Z$ के उचित संचालन के साथ, सिस्टम को एक ऐसी स्थिति की ओर ले जाती है जहां सापेक्ष संतुलन बाधा पूरी होती है, जिससे सटीक पश्च नमूनाकरण होता है।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
लेखकों ने डिफ्यूजन मॉडल में इंट्रैक्टेबल पश्च अनुमान को कम करने में रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) की प्रभावकारिता को कठोरता से मान्य करने के लिए प्रयोगों के एक सूट को सावधानीपूर्वक डिजाइन किया। मुख्य विचार RTB की क्षमता को प्रदर्शित करना था ताकि जटिल पश्च वितरण, $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$ से नमूनाकरण किया जा सके, जहां $p_{\theta}(x)$ एक डिफ्यूजन प्रायोर है और $r(x)$ एक ब्लैक-बॉक्स बाधा या संभावना फ़ंक्शन है।
विजन: क्लासिफायर-गाइडेड इमेज जनरेशन
दृष्टि कार्यों के लिए, लक्ष्य वर्ग-सशर्त छवि पीढ़ी के लिए एक डिफ्यूजन पश्च $p_{\text{post}}(x|c) \propto p_{\theta}(x)p(c|x)$ सीखना था।
- डेटासेट: प्रयोग दो 10-वर्ग छवि डेटासेट पर किए गए: MNIST (28x28, 32x32 एकल-चैनल अंकों तक बढ़ाया गया) और CIFAR-10 (32x32 3-चैनल छवियां)।
- प्रायोर और बाधाएँ: $p_{\theta}(x)$ के लिए [27] से ऑफ-द-शेल्फ अनकंडीशनल डिफ्यूजन प्रायोर का उपयोग किया गया था, और मानक क्लासिफायर $p(c|x)$ ने बाधा $r(x)$ के रूप में काम किया।
- प्रशिक्षण वास्तुकला: पश्च डिफ्यूजन मॉडल $p_{\phi}^{\text{post}}$ को RTB का उपयोग करके फाइन-ट्यून किया गया था, जिसे प्रायोर $p_{\theta}$ की एक प्रति के रूप में इनिशियलाइज़ किया गया था। पैरामीटर-कुशल फाइन-ट्यूनिंग LoRA भार [28] का उपयोग करके प्राप्त की गई थी, जो प्रायोर मॉडल के पैरामीटर गणना के लगभग 3% के लिए जिम्मेदार थी। RTB उद्देश्य को वर्तमान पश्च मॉडल से ऑन-पॉलिसी नमूना किए गए प्रक्षेप पथों पर अनुकूलित किया गया था।
- बेसलाइन: RTB के प्रदर्शन को दो श्रेणियों के बेसलाइन के मुकाबले बेंचमार्क किया गया था:
- आरएल-आधारित फाइन-ट्यूनिंग: DPOK [16] और DDPO [8]।
- क्लासिफायर गाइडेंस: DPS [11] और LGD-MC [70]।
- प्रायोगिक सेटिंग्स: तीन अलग-अलग परिदृश्यों का परीक्षण किया गया: MNIST एकल-अंक पश्च, CIFAR-10 एकल-वर्ग पश्च, और एक अधिक चुनौतीपूर्ण MNIST बहु-अंक पश्च (सम या विषम अंक उत्पन्न करना, जहां $r(x) = \max_{i \in \{0,2,4,6,8\}} p(c=i|x)$)।
- मेट्रिक्स: प्रदर्शन का मूल्यांकन अपेक्षित लॉग इनाम $E[\log r(x)]$ (उच्चतर बेहतर), फ्रेट इनसेप्शन डिस्टेंस (FID) (सच्चे नमूनों के करीब, निम्नतर बेहतर), और विविधता (इंसेप्शनv3 फीचर स्पेस में औसत जोड़ीदार कोसाइन दूरी, उच्चतर बेहतर) का उपयोग करके किया गया था। FID को वास्तविक पश्च वितरण के समानता स्कोर अनुमान के रूप में गणना की गई थी, जो प्रति-वर्ग नमूनों की कुल संख्या (CIFAR-10/MNIST अंकों के लिए 5k-6k, सम/विषम के लिए 30k) द्वारा सीमित थी।
- कम्प्यूट: सभी विजन प्रयोग एक एकल NVIDIA V100 GPU पर चलाए गए थे।
भाषा मॉडलिंग: टेक्स्ट इनफिलिंग
असतत डिफ्यूजन मॉडल पर RTB का आकलन करने के लिए, टेक्स्ट इनफिलिंग का कार्य चुना गया था, जहां मॉडल को कहानी के पहले तीन वाक्यों $x$ और अंतिम वाक्य $y$ को देखते हुए एक लापता चौथे वाक्य $z$ उत्पन्न करना था। लक्ष्य पश्च $p_{\text{post}}(z|x,y) \propto p(z|x)p_{\text{reward}}(y|x,z)$ था।
- कॉर्पस: ROCStories कॉर्पस [50], जिसमें 5-वाक्य की कहानियां शामिल हैं, का उपयोग किया गया था।
- प्रायोर और बाधाएँ: एक SEDD (स्कोर एंट्रॉपी डिस्क्रीट डिफ्यूजन) भाषा मॉडल [43] ने प्रायोर $p(z|x)$ के रूप में काम किया। इनाम फ़ंक्शन $p_{\text{reward}}(y|x,z)$ कहानियों के डेटासेट पर trl लाइब्रेरी [81] का उपयोग करके फाइन-ट्यून किया गया एक ऑटोरेग्रेसिव GPT-2 लार्ज मॉडल [57] था।
- प्रशिक्षण विवरण: RTB उद्देश्य को असतत डिफ्यूजन मॉडल पर लागू किया गया था। कम्प्यूटेशनल व्यय (मेमोरी और गति) को प्रबंधित करने के लिए, लेखकों ने स्टोकेस्टिक टीबी ट्रिक (प्रक्षेप पथ चरणों के सबसेट के माध्यम से ग्रेडिएंट्स का प्रसार) और हानि क्लिपिंग का उपयोग किया। इस सशर्त समस्या के लिए एक सापेक्ष VarGrad उद्देश्य का उपयोग किया गया था, साथ ही इनाम संभावना पर टेम्परिंग भी।
- बेसलाइन:
- $x$ के साथ डिफ्यूजन एलएम का सरल प्रॉम्प्टिंग (प्रॉम्प्ट (x))।
- $x, y$ के साथ सरल प्रॉम्प्टिंग (प्रॉम्प्ट (x, y))।
* [29] से ऑटोरेग्रेसिव भाषा मॉडल बेसलाइन, जिसमें GFlowNet फाइन-ट्यूनिंग और पर्यवेक्षित फाइन-ट्यूनिंग शामिल हैं।
- मेट्रिक्स: उत्पन्न इनफिल की गुणवत्ता को BERTScore [90], BLEU-4 [54], और GLEU-4 [86] का उपयोग करके मापा गया था, जिनकी तुलना डेटासेट से संदर्भ इनफिल से की गई थी।
- कम्प्यूट: प्रयोग एक एकल NVIDIA A100-Large GPU पर किए गए थे।
निरंतर नियंत्रण: ऑफलाइन सुदृढीकरण सीखना
RTB को ऑफलाइन सुदृढीकरण सीखने में केएल-बाधित नीति खोज समस्या पर लागू किया गया था, जिसका लक्ष्य इष्टतम नीति $\pi^*(a|s) \propto \mu(a|s)\exp(\beta Q(s,a))$ खोजना था।
- डेटासेट: D4RL सुइट [18] का उपयोग किया गया था, विशेष रूप से हाफचीता, हॉपर और वॉकर2डी म्यूजोको [76] लोकोमोशन कार्य। प्रत्येक कार्य में "मीडियम", "मीडियम-एक्सपर्ट", और "मीडियम-रिप्ले" डेटासेट शामिल थे, जो व्यवहार प्रायोर में उप-इष्टतमता के विभिन्न स्तरों का प्रतिनिधित्व करते थे।
- प्रायोर और बाधाएँ: एक राज्य-सशर्त शोर-भविष्यवाणी करने वाला DDPM [27] व्यवहार डिफ्यूजन नीति $\mu(a|s)$ के रूप में कार्य करता था। बाधा $\exp(\beta Q(s,a))$ द्वारा परिभाषित की गई थी, जहां $Q(s,a)$ IQL [36] का उपयोग करके प्रशिक्षित एक क्यू-फ़ंक्शन था।
- प्रशिक्षण विवरण: RTB ने व्यवहार डिफ्यूजन नीति को $\pi^*$ से नमूनाकरण करने के लिए फाइन-ट्यून किया, इसके भार को प्रशिक्षित व्यवहार नीति से इनिशियलाइज़ किया गया था। लैंगविन डायनेमिक्स इंडक्टिव बायस [11] को शामिल किया गया था, और ऊर्जा स्केलिंग नेटवर्क के लिए एक अतिरिक्त एमएलपी को प्रशिक्षित किया गया था। $\log Z(s)$ का अनुमान लगाने के लिए एक VarGrad उद्देश्य [61] का उपयोग किया गया था। ऑफलाइन डेटा का उपयोग करके ऑफ-पॉलिसी अन्वेषण का लाभ उठाया गया था, जिसमें उच्च-इनाम एपिसोड से नमूने शामिल थे, जिससे "मिश्रित प्रशिक्षण" (ऑफ-पॉलिसी और ऑन-पॉलिसी) हुआ।
- बेसलाइन: अत्याधुनिक ऑफलाइन आरएल बेसलाइन के एक व्यापक सेट की तुलना की गई थी: व्यवहार क्लोनिंग (बीसी), सीक्यूएल [37], आईक्यूएल [36], डिफ्यूज़र (डी) [30], डिसीजन डिफ्यूज़र (डीडी) [2], डी-क्यूएल [83], आईडीक्यूएल [25], और क्यूजीपीओ [44]।
- मेट्रिक्स: प्राथमिक मीट्रिक प्रशिक्षित नीतियों का औसत इनाम था, जिसे 5 यादृच्छिक बीजों पर माध्य $\pm$ मानक विचलन के रूप में रिपोर्ट किया गया था।
- कम्प्यूट: सभी ऑफलाइन आरएल प्रयोग एक एकल NVIDIA A100-Large GPU पर किए गए थे।
साक्ष्य क्या साबित करते हैं
प्रायोगिक साक्ष्य निर्विवाद रूप से प्रदर्शित करते हैं कि रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) डिफ्यूजन मॉडल में अमोर्टीकृत पश्च अनुमान के लिए एक मजबूत और बहुमुखी विधि प्रदान करता है, जो विजन, भाषा और निरंतर नियंत्रण कार्यों में अत्याधुनिक बेसलाइन से बेहतर या मिलान करता है। RTB का मुख्य तंत्र—एसिम्प्टोटिक रूप से अनबायस्ड प्रशिक्षण उत्पाद वितरण से नमूनाकरण के लिए—पुरस्कार और विविधता को संतुलित करने, और सटीक रूप से जटिल पश्चों को मॉडल करने की इसकी क्षमता से निर्दयतापूर्वक साबित हुआ, जहां अन्य तरीके विफल रहे।
विजन: अनबायस्ड अनुमान का निश्चित प्रमाण
- पुरस्कार और विविधता का बेहतर संतुलन: क्लासिफायर-गाइडेड इमेज जनरेशन (तालिका 2) में, RTB ने उच्च विविधता (औसत जोड़ीदार कोसाइन दूरी) के साथ उच्च अपेक्षित लॉग इनाम ($E[\log r(x)]$) के बीच लगातार एक बेहतर संतुलन हासिल किया, जबकि कम FID स्कोर (सच्चे नमूनों के करीब) बनाए रखा। उदाहरण के लिए, CIFAR-10 पर, RTB ने -2.1625 का $E[\log r(x)]$ और 0.4717 का FID स्कोर हासिल किया, जो क्लासिफायर गाइडेंस विधियों जैसे DPS (-3.6025 $E[\log r(x)]$) और LGD-MC (-3.0988 $E[\log r(x)]$) से काफी बेहतर है, जिनमें उच्च विविधता के बावजूद कम पुरस्कार थे।
-
मोड कोलैप्स को हराना: पत्र का सबसे सम्मोहक दृश्य साक्ष्य (चित्र 1) RTB नमूनों को वास्तविक पश्च वितरण (चित्र 1c) के करीब से मेल खाता हुआ दिखाता है, जो 9 सक्रिय मोड के साथ गॉसियन का मिश्रण है। इसके विपरीत, केएल नियमितीकरण के बिना शुद्ध आरएल विधियां (DDPO) गंभीर मोड कोलैप्स (चित्र 1e) से पीड़ित थीं, उच्च पुरस्कारों के बावजूद केवल कुछ मोड पर ध्यान केंद्रित कर रही थीं। यहां तक कि ट्यून्ड केएल नियमितीकरण (DPOK) के साथ आरएल ने भी गलत अनुमान (चित्र 1d) दिया, और क्लासिफायर गाइडेंस (CG) के परिणामस्वरूप पक्षपाती परिणाम (चित्र 1f) हुए। यह नेत्रहीन निर्विवाद साक्ष्य RTB की मोड कोलैप्स से बचने और पश्च वितरण को सटीक रूप से कवर करने की क्षमता को साबित करता है।
-
उच्च-गुणवत्ता, विविध नमूने: चित्र 2 और चित्र 4 विभिन्न संकेतों (जैसे, "एक हरे रंग का खरगोश", "एक बिल्ली और एक कुत्ता", "चार गुलाब") के लिए RTB फाइन-ट्यून किए गए मॉडल द्वारा उत्पन्न छवियों की उच्च दृश्य गुणवत्ता और विविधता को प्रदर्शित करते हैं। ये गुणात्मक परिणाम मात्रात्मक मेट्रिक्स को सुदृढ़ करते हैं, यह प्रदर्शित करते हुए कि RTB का मुख्य तंत्र कथित रूप से बेहतर और अधिक विविध आउटपुट में तब्दील होता है।
-
एसिम्प्टोटिक रूप से अनबायस्ड: पत्र इस बात पर प्रकाश डालता है कि RTB एक एसिम्प्टोटिक रूप से अनबायस्ड प्रशिक्षण उद्देश्य है जो पश्च स्कोर फ़ंक्शन के पक्षपाती सन्निकटन पर निर्भर करने के बजाय, वास्तविक ड्रिफ्ट अंतर को पुनर्प्राप्त करता है। यह सैद्धांतिक लाभ प्रायोगिक परिणामों में परिलक्षित होता है, जहां RTB लगातार बेहतर पश्च मॉडलिंग प्राप्त करता है।
भाषा मॉडलिंग: इनफिलिंग में मजबूत प्रदर्शन
- ऑटोरेग्रेसिव बेसलाइन से बेहतर: टेक्स्ट इनफिलिंग (तालिका 3) के लिए, असतत डिफ्यूजन प्रायोर के साथ RTB ने सभी गैर-एसएफटी बेसलाइन में उच्चतम BERTScore (0.156), BLEU-4 (0.025), और GLEU-4 (0.045) प्राप्त किया। यह RTB की अधिक सुसंगत और सुसंगत इनफिल उत्पन्न करने की क्षमता को प्रदर्शित करता है, जो सरल प्रॉम्प्टिंग बेसलाइन और यहां तक कि सबसे मजबूत ऑटोरेग्रेसिव GFlowNet फाइन-ट्यूनिंग बेसलाइन (BERTScore 0.102) से काफी बेहतर है। यह एक मजबूत संकेतक है कि असतत डिफ्यूजन मॉडल को संभालने के लिए RTB का तंत्र प्रभावी रूप से सशर्त पाठ निर्माण में सुधार करता है।
निरंतर नियंत्रण: अत्याधुनिक ऑफलाइन आरएल
- अत्याधुनिक पुरस्कारों से मेल खाना: ऑफलाइन सुदृढीकरण सीखने (तालिका 4) में, RTB ने D4RL बेंचमार्क में अत्याधुनिक या प्रतिस्पर्धी परिणाम प्राप्त किए। उदाहरण के लिए,
hopper-medium-replayपर, RTB ने 100.40 स्कोर किया, जो अन्य अग्रणी विधियों जैसे DD (100.00) और D-QL (100.70) के बराबर या उससे अधिक है। यह साबित करता है कि RTB केएल-बाधित पश्च से नमूनाकरण करके इष्टतम नीतियों को प्रभावी ढंग से सीख सकता है, भले ही उप-इष्टतम व्यवहार प्रायोर के साथ। - उप-इष्टतम प्रायोर के प्रति मजबूती: RTB ने विशेष रूप से "मीडियम-रिप्ले" कार्यों में मजबूत प्रदर्शन किया, जो अत्यधिक उप-इष्टतम डेटा और इस प्रकार खराब व्यवहार प्रायोर की विशेषता है। यह मजबूती एक महत्वपूर्ण प्रमाण है, यह दर्शाता है कि RTB की ऑफ-पॉलिसी प्रशिक्षण क्षमताएं इसे प्रभावी ढंग से सीखने की अनुमति देती हैं, भले ही प्रारंभिक प्रायोर आदर्श न हो, जो वास्तविक दुनिया के आरएल परिदृश्यों में एक सामान्य चुनौती है।
- ऑफ-पॉलिसी अन्वेषण के लाभ: तालिका G.1 ने RTB की ऑफ-पॉलिसी क्षमताओं के लाभ को और मजबूत किया, यह दिखाते हुए कि "मिश्रित प्रशिक्षण" (ऑफ-पॉलिसी और ऑन-पॉलिसी नमूनों को मिलाकर) ने तीन में से दो मीडियम-रिप्ले कार्यों पर शुद्ध ऑन-पॉलिसी प्रशिक्षण से बेहतर प्रदर्शन किया। यह सीधे इस दावे का समर्थन करता है कि विविध प्रक्षेप पथों का लाभ उठाने में RTB का लचीलापन प्रशिक्षण दक्षता और प्रदर्शन में सुधार करता है।
संक्षेप में, इन विविध डोमेन से साक्ष्य एक सम्मोहक कथा प्रदान करते हैं: RTB का अमोर्टीकृत पश्च नमूनाकरण के लिए सैद्धांतिक दृष्टिकोण, सापेक्ष प्रक्षेप पथ संतुलन में निहित, पुरस्कार अधिकतमकरण और मोड कवरेज के बीच व्यापार-बंद को प्रभावी ढंग से नेविगेट करके लगातार बेहतर या प्रतिस्पर्धी परिणाम देता है, एक चुनौती जो अक्सर अन्य अनुमान विधियों को प्रभावित करती है।
सीमाएँ और भविष्य की दिशाएँ
जबकि रिलेटिव ट्रैजेक्टरी बैलेंस (RTB) डिफ्यूजन मॉडल में अमोर्टीकृत पश्च अनुमान के लिए एक शक्तिशाली और बहुमुखी ढांचा प्रस्तुत करता है, लेखक ईमानदारी से कई सीमाओं को स्वीकार करते हैं और अनुसंधान की रोमांचक दिशाओं का प्रस्ताव करते हैं।
सीमाएँ
- कम्प्यूटेशनल लागत और मेमोरी तीव्रता: एक प्राथमिक सीमा यह है कि RTB सिमुलेशन-आधारित प्रशिक्षण के माध्यम से पश्च सीखता है, जो धीमा और मेमोरी-गहन दोनों हो सकता है। यद्यपि पत्र ने RTB के लिए मेमोरी उपयोग को कम करने के लिए स्टोकेस्टिक सबसैंपलिंग और बैच वाले ग्रेडिएंट गणना जैसी तकनीकों को पेश किया है, प्रशिक्षण के लिए प्रक्षेप पथों को अनुकरण करने की मौलिक प्रकृति एक बाधा बनी हुई है। यह विशेष रूप से बड़े पैमाने के मॉडल या उच्च-आयामी डेटा के लिए प्रासंगिक है।
- उच्च ग्रेडिएंट विचरण: RTB उद्देश्य को पूर्ण प्रक्षेप पथों पर गणना की जाती है। इसका मतलब है कि हानि फ़ंक्शन एक प्रक्षेप पथ के भीतर व्यक्तिगत चरणों के लिए स्थानीय क्रेडिट असाइनमेंट सिग्नल प्रदान नहीं करता है। परिणामस्वरूप, ग्रेडिएंट में उच्च विचरण हो सकता है, जो प्रशिक्षण स्थिरता और दक्षता में बाधा डाल सकता है।
- अपूर्ण फिट पर सैद्धांतिक गारंटी की कमी: पत्र नोट करता है कि प्रायोर मॉडल के अपूर्ण फिट, अमॉर्टाइजेशन के प्रभाव और समय विभेदन (डिफ्यूजन सैंपलर [7] के लिए मौजूदा विश्लेषण के अनुरूप) के प्रभावों से होने वाली त्रुटि के संबंध में सैद्धांतिक गारंटी अभी तक पूरी तरह से स्थापित नहीं हुई है। ऐसी गारंटी गैर-आदर्श परिस्थितियों में RTB के व्यवहार की गहरी समझ प्रदान करेगी।
- डिफरेंशिएबल सिमुलेशन विधियों पर लागू न होना: RTB के लिए विकसित मेमोरी-बचत तकनीकें (स्टोकेस्टिक सबसैंपलिंग, बैच ग्रेडिएंट गणना) सार्वभौमिक रूप से लागू नहीं होती हैं। विशेष रूप से, डिफरेंशिएबल सिमुलेशन (जैसे, पाथ इंटीग्रल सैंपलर (PIS) और डीनोइज़िंग डिफ्यूजन सैंपलर (DDS)) पर आधारित डिफ्यूजन सैंपलर को अभी भी SDE एकीकरण के पूरे कम्प्यूटेशन ग्राफ को संग्रहीत करने की आवश्यकता होती है, जिससे मेमोरी आवश्यकताएं प्रक्षेप पथ लंबाई के साथ रैखिक रूप से स्केल होती हैं।
भविष्य की दिशाएँ
निष्कर्ष कई आशाजनक अनुसंधान दिशाओं को खोलते हैं, जो डिफ्यूजन मॉडल और सुदृढीकरण सीखने की सीमाओं को आगे बढ़ाते हैं:
- उन्नत ऑफ-पॉलिसी प्रशिक्षण और अन्वेषण: पत्र RTB की ऑफ-पॉलिसी प्रक्षेप पथों के साथ संगतता पर प्रकाश डालता है। भविष्य के काम में नमूना दक्षता और, महत्वपूर्ण रूप से, मोड कवरेज में और सुधार के लिए उन्नत ऑफ-पॉलिसी प्रशिक्षण तकनीकों, जैसे स्थानीय खोज [34, 65] का लाभ उठाने में गहराई से उतरना शामिल हो सकता है। इसमें पश्च वितरण के कठिन-से-पहुंच मोड की खोज के लिए अधिक परिष्कृत अन्वेषण रणनीतियाँ शामिल हो सकती हैं।
- सिमुलेशन-आधारित उद्देश्यों का अन्वेषण: लेखकों ने [89] में प्रयुक्त उद्देश्यों के समान, अमोर्टीकृत नमूनाकरण समस्याओं के लिए अन्य सिमुलेशन-आधारित उद्देश्यों का पता लगाने का सुझाव दिया है। इससे वैकल्पिक सूत्रीकरण हो सकते हैं जो कम्प्यूटेशनल लागत, ग्रेडिएंट विचरण और प्रदर्शन के मामले में विभिन्न व्यापार-बंद प्रदान करते हैं।
- सिमुलेशन-मुक्त विस्तार का विकास: समय में स्थानीय [45] जैसे सिमुलेशन-मुक्त विस्तारों की जांच संभावित रूप से पूर्ण प्रक्षेप पथ-आधारित प्रशिक्षण से जुड़ी कम्प्यूटेशनल और मेमोरी तीव्रता के मुद्दों को संबोधित कर सकती है। यह RTB को अधिक स्केलेबल बनाने की दिशा में एक महत्वपूर्ण कदम होगा।
- ब्लैक-बॉक्स संभावनाओं के साथ व्युत्क्रम समस्याओं पर अनुप्रयोग: RTB की मनमानी ब्लैक-बॉक्स संभावनाओं को संभालने की अनूठी क्षमता इसे विभिन्न प्रकार की व्युत्क्रम समस्याओं के लिए एक आदर्श उम्मीदवार बनाती है। इसमें शामिल हैं:
- 3डी ऑब्जेक्ट संश्लेषण: 2डी अवलोकनों से 3डी ऑब्जेक्ट उत्पन्न करने के लिए रेंडरर्स [जैसे, 56, 82] के माध्यम से गणना की गई संभावनाओं का उपयोग करना।
- इमेजिंग समस्याएं: खगोल विज्ञान [जैसे, 1] और चिकित्सा इमेजिंग [जैसे, 73] में जटिल कार्यों पर RTB लागू करना, जहां संभावना फ़ंक्शन जटिल और गैर-डिफरेंशिएबल हो सकते हैं।
- आणविक संरचना भविष्यवाणी: आणविक जीव विज्ञान [जैसे, 84] में चुनौतीपूर्ण समस्याओं के लिए RTB का उपयोग करना, जहां लक्ष्य प्रयोगात्मक डेटा से आणविक संरचनाओं का अनुमान लगाना है।
- आणविक गतिशीलता में सफलताएँ: एक विशेष रूप से रोमांचक संभावना आणविक गतिशीलता मॉडलिंग में सफलताओं को सुविधाजनक बनाने में RTB की क्षमता है। रासायनिक सिमुलेशन में दुर्लभ-घटना प्रक्षेप पथों के नमूनाकरण के कुख्यात रूप से चुनौतीपूर्ण कार्य को दुर्लभ-घटना नमूनों के प्रवर्धित वितरण पर पश्च अनुमान समस्या में परिवर्तित करके, RTB जटिल रासायनिक प्रक्रियाओं को समझने के लिए एक उपन्यास दृष्टिकोण प्रदान कर सकता है। Seong et al. [66] द्वारा इनाम को प्रायोर संभावना से गुणा करके (प्रभावी रूप से RTB) टीबी का उपयोग करके प्रारंभिक कार्य इस दिशा का समर्थन करता है।
- सैद्धांतिक विश्लेषण में कठोरता: भविष्य के काम को RTB के लिए कठोर सैद्धांतिक गारंटी प्रदान करने पर ध्यान केंद्रित करना चाहिए, विशेष रूप से अपूर्ण प्रायोर मॉडल के प्रभाव, अमॉर्टाइजेशन के प्रभाव और समय विभेदन के निहितार्थों के संबंध में। यह विधि की मूलभूत समझ को मजबूत करेगा।
व्यापक प्रभाव चर्चा
लेखकों ने अपने काम के व्यापक सामाजिक निहितार्थों को भी विचारपूर्वक संबोधित किया है। जनरेटिव मॉडलिंग में अन्य प्रगति की तरह, RTB का संभावित रूप से "दुर्भावनापूर्ण अभिनेताओं" द्वारा हानिकारक सामग्री या गलत सूचना उत्पन्न करने वाले मॉडल को प्रशिक्षित करने के लिए दुरुपयोग किया जा सकता है। हालांकि, वे सकारात्मक क्षमता पर भी जोर देते हैं: RTB का उपयोग पूर्व-प्रशिक्षित मॉडल में मौजूद पूर्वाग्रहों को कम करने के लिए किया जा सकता है और विभिन्न वैज्ञानिक समस्याओं पर लागू किया जा सकता है, जिससे विविध दृष्टिकोणों को बढ़ावा मिलता है और ऐसे शक्तिशाली जनरेटिव एआई प्रौद्योगिकियों के जिम्मेदार विकास और परिनियोजन के बारे में महत्वपूर्ण सोच को बढ़ावा मिलता है।
 Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
 Figure 2. Samples from RTB fine-tuned diffusion posteriors
Figure 2. Samples from RTB fine-tuned diffusion posteriors
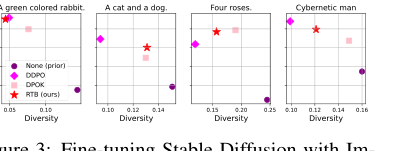 Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
 Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted
Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted