비전, 언어 및 제어를 위한 확산 모델에서 난해한 추론의 감가상각
Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 문제는 컴퓨터 비전, 자연어 처리, 강화 학습 등 다양한 영역에서 강력한 생성 모델로서 최근 성공을 거두고 널리 채택된 확산 모델(diffusion models)에서 정확히 비롯됩니다. 이러한 모델은 점진적인 노이즈 추가 과정을 역으로 학습하여 고품질 데이터를 생성하는 데 뛰어나지만, 다운스트림 작업(downstream tasks)에 적용할 때는 종종 더 복잡한 형태의 추론, 즉 사후 분포(posterior distribution)에서 샘플링하는 것이 필요합니다.
역사적으로 2015년 Sohl-Dickstein 등이 처음 소개한 [68] 확산 모델은 복잡한 데이터 분포를 모델링하는 계층적 생성 모델의 한 종류입니다. 핵심 아이디어는 데이터에 점진적으로 노이즈를 추가하여 간단하고 다루기 쉬운 분포(예: 가우시안 노이즈)로 변환하는 순방향 확산 과정을 정의하는 것입니다. 그런 다음 신경망을 훈련하여 역방향 과정을 학습하고, 데이터를 단계별로 효과적으로 노이즈 제거하여 새로운 샘플을 생성합니다.
이러한 사전 훈련된 확산 모델이 원하는 출력이 추가적이고 종종 복잡한 제약 조건 $r(x)$을 만족해야 하는 시나리오에서 사전 분포(prior) $p(x)$로 사용될 때 특정 문제가 발생합니다. 이 제약 조건은 분류기의 가능도(예: 특정 클래스의 이미지 생성), 강화 학습에서의 보상 함수(예: 보상을 최대화하는 행동 생성), 또는 누락된 텍스트를 채우기 위한 언어 모델의 가능도일 수 있습니다. 목표는 베이지안 사후 분포를 나타내는 곱셈 분포 $p_{\text{post}}(x) \propto p(x)r(x)$에서 샘플링하는 것입니다. 확산 모델의 계층적 특성으로 인해 이러한 사후 분포에서 정확한 샘플링이 특히 어렵습니다. 특히 $r(x)$가 분석적 해를 쉽게 제공하지 않는 "블랙박스(black-box)" 함수인 경우 더욱 그렇습니다.
이전 접근 방식의 근본적인 한계 또는 "고충점(pain point)"은 이러한 난해한 사후 추론을 정확하고 효율적으로 수행할 수 없다는 것입니다. 기존 방법은 일반적으로 몇 가지 범주로 나뉘며, 각 범주에는 상당한 단점이 있습니다.
* 선형 근사 또는 확률적 최적화: 이러한 방법은 종종 근사적인 해만 제공하며 [73, 33, 31, 11, 22, 48], 실제 사후 분포를 충실하게 포착하지 못할 수 있습니다.
* 가이던스 항 추정: 분류기 가이던스 [12]와 같은 기법은 노이즈가 추가된 데이터에 대한 분류기를 훈련하여 "가이던스" 항을 추정하려고 시도합니다. 그러나 이 접근 방식은 특정 노이즈 데이터가 필요하며, 이러한 데이터가 없을 경우 근사 또는 몬테카를로 추정치 [70, 14, 10]에 의존한다는 한계가 있습니다. 이러한 근사치는 현대 생성 작업에서 흔히 발생하는 고차원 문제에 확장하기가 악명 높게 어렵습니다.
* 강화 학습(RL) 방법: 이 문제에 대한 최근 RL 기반 접근 방식 [8, 16]은 유망하지만 편향(biased)되어 있고 모드 붕괴(mode collapse)를 겪는 것으로 나타났습니다. 모드 붕괴는 모델이 다양한 샘플을 생성하지 못하고 몇 가지 높은 보상 예제만 생성하는 데 stuck되는 것을 의미하며, 따라서 실제 사후 분포를 완전히 탐색하지 못합니다. 복잡한 다운스트림 작업에서 확산 모델의 안정적이고 다재다능한 응용에 있어 전체 사후 분포에서 샘플링하는 데 있어 다양성과 정확성이 부족한 것은 주요 장애물입니다.
직관적인 도메인 용어
다음은 논문의 몇 가지 전문 도메인 용어를 직관적인 비유로 번역한 것입니다.
- 확산 모델(Diffusion Models): 매우 흐릿하고 노이즈가 많은 사진이 있다고 상상해 보세요. 확산 모델은 마치 숙련된 디지털 아티스트가 점진적으로 흐릿함과 노이즈를 단계별로 제거하여 원래의 선명한 사진을 복원하는 방법을 정확히 아는 것과 같습니다. 이는 애초에 이미지가 어떻게 노이즈가 되는지를 연구함으로써 이 "흐릿함 제거" 과정을 학습합니다.
- 사후 추론(Posterior Inference): 특정 종류의 희귀한 새를 찾는 것과 같다고 생각하세요. 모든 새에 대해 알려주는 일반적인 현장 가이드(사전 지식)가 있습니다. 그런데 지역 전문가로부터 "이 새는 특정 종류의 나무 근처에서만 나타난다"는 팁을 받습니다(제약 조건). 사후 추론은 일반적인 새 지식과 이 새로운 특정 팁을 결합하여 검색 범위를 좁히고 그 특정 새가 나타날 가능성이 가장 높은 위치를 찾는 과정입니다.
- 모드 붕괴(Mode Collapse): 파티를 위해 다양한 종류의 케이크를 구워달라는 요청을 받은 요리사를 상상해 보세요. 파티 참석자들이 바닐라, 딸기, 레몬 케이크도 원하는데 요리사가 초콜릿 케이크만 굽는다면 그것이 모드 붕괴입니다. 요리사는 하나의 케이크 종류(초콜릿)로 "붕괴"되었고, 초콜릿 케이크가 아주 맛있더라도 원하는 옵션의 전체 범위를 탐색하지 못하고 있습니다.
- 상대 궤적 균형(Relative Trajectory Balance, RTB): 매우 길고 흔들리는 줄 위를 건너려는 줄타기 곡예사를 고려해 보세요. 단순히 반대편으로 가는 것에만 집중하면 넘어질 수 있습니다. RTB는 마치 정교한 센서 시스템이 곡예사의 전진 움직임을 안정적이고 알려진 경로에 상대적으로 비교하는 것과 같습니다. 이 지속적인 상대 비교는 곡예사가 완벽한 균형을 유지하고 목적지에 안정적으로 도달하도록 돕고, 벗어나거나 stuck되는 것을 방지합니다.
- 블랙박스 제약 조건 $r(x)$: 캐릭터를 디자인하려는 비디오 게임을 하고 있다고 상상해 보세요. 다양한 기능을 변경할 수 있지만, 점수를 설명하지 않고 캐릭터의 매력에 대한 점수만 주는 신비로운 "심사위원"이 있습니다. 심사위원의 마음속을 볼 수는 없습니다. 단지 숫자만 얻을 뿐입니다. 이 심사위원은 블랙박스 제약 조건입니다. 출력은 알지만 내부 작동 방식은 모릅니다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $p_{\theta}(x)$ | 사전 훈련된 확산 생성 모델(사전 분포), $\theta$로 매개변수화됨. |
| $r(x)$ | 양수, 블랙박스 제약 조건 또는 가능도 함수. |
| $p_{\text{post}}(x)$ | 목표 사후 분포, $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$. |
| $P_{\Phi}^{\text{post}}(\tau)$ | 사후 확산 모델, $\Phi$로 매개변수화된 궤적 $\tau$에서의 확률. |
| $p_{\theta}(\tau)$ | 사전 확산 모델, $\theta$로 매개변수화된 궤적 $\tau$에서의 확률. |
| $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ | 초기 노이즈 $X_0$에서 최종 데이터 $X_1$까지의 확산 궤적. |
| $X_t$ | 확산 과정의 중간 시간 단계 $t$에서의 데이터 포인트. |
| $u_{\Phi}^{\text{post}}(x_t, t)$ | 매개변수 $\Phi$를 가진 신경망으로 학습된 사후 SDE의 드리프트 항. |
| $u_{\theta}(x_t, t)$ | 매개변수 $\theta$를 가진 신경망으로 학습된 사전 SDE의 드리프트 항. |
| $\mathcal{L}_{\text{RTB}}(\tau; \Phi)$ | 상대 궤적 균형(RTB) 손실 함수. |
| $Z$ | 사후 분포의 정규화 상수. |
| $T$ | 확산 과정의 총 이산 시간 단계 수. |
| $\Delta t$ | 단일 시간 단계의 지속 시간, $\Delta t = 1/T$. |
| $B$ | 배치 경사도 계산을 위한 누적 배치 크기. |
| $E[\log r(x)]$ | 샘플이 제약 조건을 얼마나 잘 만족하는지에 대한 지표인 기대 로그 보상. |
| FID | Fréchet Inception Distance, 이미지 품질 및 대상 분포와의 유사성에 대한 지표. |
| BERTScore | 생성된 텍스트를 참조 텍스트와 비교하는 텍스트 생성 품질 지표. |
| BLEU-4 | n-그램 중복을 기반으로 하는 텍스트 생성 품질 지표. |
| GLEU-4 | BLEU와 유사하지만 인간 판단과의 상관관계가 더 좋은 텍스트 생성 품질 지표. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 중심 문제는 확산 모델이 다운스트림 작업의 사전 분포로 사용될 때 발생하는 난해한 사후 추론입니다. 구체적으로, 저자들은 강력한 생성 확산 모델을 사전 분포로 가지고 있지만 해당 사전 분포의 제약 조건이 있는 버전을 샘플링해야 하는 필요성 사이의 격차를 해소하는 것을 목표로 합니다.
시작점(입력/현재 상태)은 복잡한 데이터 분포(예: 이미지, 텍스트, 행동)를 효과적으로 모델링하는 사전 훈련된 확산 생성 모델 $p_{\theta}(x)$입니다. 이 사전 분포와 함께 추가 조건이나 선호도를 나타내는 블랙박스 제약 조건 또는 가능도 함수 $r(x)$가 있습니다. 목표는 이 두 분포의 곱에 대한 추론을 수행하는 것입니다.
원하는 종점(출력/목표 상태)은 진정한 사후 분포 $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$에서 편향 없이 샘플링할 수 있는 새로운 훈련된 확산 모델 $p_{\phi}^{\text{post}}$입니다. 이는 훈련된 모델이 사전 분포와 제약 조건의 결합된 영향을 정확하게 반영하여 유연하고 정확한 조건부 생성 또는 정책 학습을 가능하게 해야 함을 의미합니다.
정확히 누락된 연결 또는 수학적 격차는 이 사후 분포 $p_{\text{post}}(x)$에서 직접 샘플링하는 본질적인 난해함입니다. 확산 모델은 확률적 변환의 깊은 체인을 통해 샘플을 생성하므로, 블랙박스 $r(x)$ 하에서 $p_{\theta}(x)r(x)$에서 정확한 샘플링은 난해합니다. 이전 방법들은 근사적인 해를 제공하거나, 제한된 경우에만 작동하거나, 편향을 도입하고 모드 붕괴와 같은 문제를 겪습니다. 본 논문은 상대 궤적 균형(RTB)이라는 새로운 훈련 목표를 제안함으로써 이 격차를 해소하려고 시도하며, 이 목표가 만족되면 훈련된 사후 확산 모델 $p_{\phi}^{\text{post}}$가 원하는 분포에서 샘플링하도록 보장합니다. 수학적으로, 논문은 $p_{\phi}^{\text{post}}$를 훈련하여 상대 궤적 균형 제약 조건을 만족하도록 합니다.
$$Z p_{\phi}^{\text{post}}(X_0, X_{\Delta t}, \dots, X_1) = r(X_1) p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$$
여기서 $Z$는 정규화 상수이고, $X_0, \dots, X_1$은 노이즈 제거 궤적을 나타내며, $p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$는 사전 분포에서의 궤적의 결합 확률입니다.
이전 연구자들을 가두었던 고통스러운 절충 또는 딜레마는 주로 정확성/편향 없음과 다루기 쉬움/계산 효율성 사이의 문제입니다. 기존 해결책은 종종 이러한 함정 중 하나에 빠집니다.
1. 근사 vs. 편향: 선형 근사 또는 확률적 최적화에 의존하는 방법은 다루기 쉽지만 종종 편향된 결과를 산출하거나 고차원 문제에 확장하기 어렵습니다. 예를 들어, 분류기 가이던스는 일부 경우에 효과적이지만 실제 사후 드리프트의 편향된 근사를 제공합니다.
2. 보상 최대화 vs. 모드 커버리지: 보상 함수를 최대화하기 위해 확산 모델을 미세 조정하는 강화 학습(RL) 기반 방법은 빈번하게 모드 붕괴를 겪습니다. 높은 보상을 얻기 위해 몇 가지 높은 보상 모드에 집중할 수 있지만, 다양성이 현저히 떨어지고 전체 사후 분포의 부정확한 표현을 대가로 합니다. 이는 한 측면(보상)을 개선하는 것이 종종 다른 측면(다양성)을 망가뜨린다는 것을 의미합니다.
3. 온폴리시 vs. 오프폴리시 훈련: 궤적이 현재 모델에서 샘플링되는 온폴리시 훈련은 비효율적일 수 있으며 모든 사후 모드를 발견하는 데 어려움을 겪을 수 있습니다. 오프폴리시 탐색은 모드 커버리지를 개선할 수 있지만, 훈련 안정성과 샘플 효율성에 대한 자체적인 문제를 야기합니다.
제약 조건 및 실패 모드
확산 모델에서 난해한 추론을 감가상각하는 문제는 몇 가지 가혹하고 현실적인 벽으로 인해 매우 어렵습니다.
-
계산 제약 조건:
- 정확한 사후 샘플링의 난해함: 근본적인 과제는 확산 사전 분포와 블랙박스 제약 조건 $r(x)$의 곱에서 정확한 샘플링이 계산적으로 난해하다는 것입니다. 특히 확산 모델의 계층적 특성을 고려할 때 더욱 그렇습니다.
- 고차원성: 몬테카를로 추정치 및 선형 근사를 포함한 많은 기존 추론 기법은 "고차원 문제에 확장하기 어렵습니다". 이는 비전, 언어 및 제어 작업에서 발생하는 문제입니다.
- 하드웨어 메모리 제한: 대규모 확산 모델의 경우, 긴 노이즈 제거 궤적의 모든 단계에 대한 경사도를 계산하고 저장하는 것은 하드웨어 메모리 제한으로 인해 "실현 불가능합니다". 이는 확률적 부분 샘플링 또는 배치 경사도 계산과 같은 메모리 효율적인 기법을 필요로 하며, 이는 경사도 분산 증가와 같은 절충을 야기할 수 있습니다.
- 훈련 시간: 사후 샘플러 학습을 위한 시뮬레이션 기반 훈련은 "느리고 메모리 집약적"일 수 있으며, 이는 제한 사항 섹션에서 언급되었습니다. 논문의 모든 실험에 대한 총 예상 컴퓨팅 시간은 강력한 GPU에서 3000시간으로, 상당한 계산 비용을 나타냅니다.
-
데이터 기반 제약 조건:
- 편향 없는 사후 샘플 부족: 실제 사후 샘플에서 직접적인 감독에 의존하는 훈련 방법은 이러한 샘플을 사용할 수 없다고 가정하기 때문에 종종 비현실적입니다. 예를 들어, 분류기 가이던스는 노이즈가 추가된 데이터에 대한 미분 가능한 분류기를 필요로 하는데, 이는 일반적으로 편향 없는 데이터에 대한 접근 없이는 유도하거나 학습하기가 난해합니다.
- 가이던스 항에 대한 데이터 희소성: 노이즈가 추가된 데이터에 대한 분류기 훈련을 위한 데이터가 없을 경우, 연구자들은 근사치를 사용해야 하며, 이는 편향을 도입할 수 있습니다.
- 불완전한 사전 모델에 대한 민감도: 제안된 손실 함수는 "불완전하게 적합된 사전 모델"에 민감할 수 있으며, 이는 훈련 안정성과 성능에 영향을 미칠 수 있습니다.
-
수학적 및 논리적 제약 조건:
- 미분 불가능한 제약 조건: 제약 조건 함수 $r(x)$는 종종 "블랙박스"이므로 미분 불가능할 수 있으며, 이는 경사도 기반 최적화를 복잡하게 만듭니다. 논문은 $r(x_1)$이 미분 가능한 경우를 탐색하지만, 일반적인 문제 공식화는 미분 불가능한 시나리오를 고려해야 합니다.
- 근사의 편향: 단계별 KL 정규화를 사용한 RL과 같은 이전 방법들은 진정한 사후 분포에 점근적으로 도달하는 것을 방지하는 내재된 편향을 도입합니다.
- 모드 붕괴: 특히 충분한 정규화가 없는 RL 기반 미세 조정 방법은 모델이 실제 사후 분포의 일부 모드만 샘플링하는 모드 붕괴에 취약하며, 생성 샘플의 다양성이 부족합니다.
- 주변 KL 발산의 난해함: 텍스트-이미지 생성에 대한 RL 기반 미세 조정과 같은 맥락에서, 미세 조정된 모델과 사전 분포 간의 주변 KL 발산은 확산 모델에 대해 난해하므로, 편향을 도입할 수 있는 단계별 KL 페널티와 같은 근사치에 의존해야 합니다.
왜 이 접근 방식인가
선택의 불가피성
상대 궤적 균형(RTB)의 채택은 확산 모델이 다운스트림 작업의 사전 분포로 사용될 때 사후 추론의 본질적인 난해함으로 인해 단순한 선택이 아니라 필수였습니다. 본 논문은 "확산 모델은 효과적인 분포 추정자로 부상했지만... 다운스트림 작업에서 사전 분포로 사용하는 것은 난해한 사후 추론 문제를 제기합니다." (초록, 1쪽)라고 명시적으로 언급합니다. 핵심 문제는 "확산 모델의 생성 과정의 계층적 특성"으로 인해 "블랙박스 함수 $r(x)$ 하에서 사후 분포 $p(x)r(x)$에서 정확한 샘플링이 난해합니다." (2쪽)라는 것입니다.
전통적인 "SOTA(State-of-the-Art)" 방법들은 이 특정 과제에 대해 불충분함이 입증되었습니다. 기존 접근 방식은 근사적인 해를 제공하거나 제한된 경우에만 작동합니다. 예를 들어, 일반적인 추론 기법은 선형 근사 [73, 33, 31, 11] 또는 확률적 최적화 [22, 48]에 의존하며, 이는 본질적으로 근사를 도입합니다. 또 다른 인기 있는 전략은 노이즈가 추가된 데이터에 대한 분류기를 훈련하여 '가이던스' 항을 추정하는 것입니다 [12]. 그러나 이 방법은 이러한 노이즈 데이터가 없을 때 실패하여 추가적인 근사 또는 몬테카를로 추정치 [70, 14, 10]에 의존하게 되는데, 이는 고차원 문제에 확장하기가 악명 높게 어렵습니다. 또한, 이 문제에 대해 제안된 최근 강화 학습(RL) 방법 [8, 16]은 편향되어 있고 모드 붕괴에 취약한 것으로 알려져 있으며, 이는 그림 1(3쪽)에서 시각적으로 입증되었습니다.
저자들은 이러한 난해한 사후 분포에서 점근적으로 편향 없는 샘플링을 달성하기 위해 근본적으로 다른 접근 방식이 필요하다는 것을 깨달았습니다. 이것이 확산 모델에 대한 생성 흐름 네트워크 관점에서 파생된 RTB의 개발로 이어졌습니다. 이 관점은 이전 방법의 한계를 극복할 수 있는 목표에 대한 이론적 기반을 제공하며, 다른 기술이 근사하거나 실패하거나 모드 붕괴와 같은 심각한 문제를 겪는 곳에서 편향 없는 사후 샘플링으로 가는 길을 제공합니다.
비교 우위
상대 궤적 균형(RTB)은 단순한 성능 지표를 넘어 여러 구조적 및 운영적 이점을 통해 이전의 금본위제(gold standard)에 비해 질적인 우수성을 보여줍니다.
첫째, RTB는 "데이터 없이 드리프트의 차이(따라서 로그 합성 가능도의 기울기)를 복구하는 점근적으로 편향 없는 목표"입니다 (5쪽). 이는 미분 가능한 분류기에 대한 정확한 해를 제공하지만 종종 난해한 실제 노이즈 데이터에 대한 분류기를 필요로 하는 분류기 가이던스에 비해 상당한 구조적 이점입니다. RTB는 이러한 데이터 의존성을 우회하여 보다 강력하고 일반적인 솔루션을 제공합니다.
둘째, 이 방법은 우수한 메모리 효율성과 확장성을 보여줍니다. 중요한 통찰력은 "이 목표의 $\phi$에 대한 경사도가 x0 → ... → x1을 생성한 샘플링 프로세스를 통해 미분(역전파)할 필요가 없다"는 것입니다 (5쪽). 이 속성은 두 가지 주요 이점을 제공합니다.
1. 오프폴리시 최적화: RTB는 오프폴리시 목표로 최적화될 수 있습니다. 즉, 훈련을 위한 궤적은 대상 사후 분포 자체와 다른 분포에서 샘플링될 수 있습니다. 이 유연성은 "모드 커버리지를 보장"하는 데 중요하며 (5쪽) 모드 붕괴에 취약한 온폴리시 RL 방법보다 뚜렷한 이점입니다(그림 C.2, 19쪽).
2. 배치 경사도 누적: RTB의 경사도 계산은 전체 계산 그래프를 모든 시간 단계에 대해 저장할 필요가 없습니다. 대신, "메모리 예산에 의해 제약되는 것은 궤적 길이 T가 아니라 누적 배치 크기 B뿐입니다" (27쪽). 이를 통해 확률적 부분 샘플링을 통한 경사도 분산 증가 없이도 긴 확산 단계로 훈련을 확장할 수 있으며, 고정된 메모리 예산 하에서 훈련 시간은 단계 수에 선형적으로 증가합니다. 이는 전체 궤적을 저장하는 것이 불가능한 고차원 문제에 대해 메모리 복잡성을 크게 줄여줍니다.
마지막으로, RTB의 다재다능함은 질적인 강점입니다. 본 논문은 비전(분류기 가이던스 이미지 생성, 텍스트-이미지 생성), 언어(이산 확산 LLM을 사용한 인필링), 연속 제어(오프라인 강화 학습)를 포함한 다양한 영역에서 광범위한 적용 가능성을 보여줍니다. 이러한 다양한 성공적인 응용은 다양한 형태의 확산 사전 분포와 블랙박스 제약 조건을 처리하는 데 있어 구조적 이점을 강조합니다.
제약 조건과의 정렬
선택된 RTB 방법은 문제의 가혹한 요구 사항과 완벽하게 일치하며, 문제 정의와 솔루션의 고유한 속성 사이에 강력한 "결합"을 형성합니다.
문제에서 정의된 주요 제약 조건은 "사전 훈련된 확산 모델이 사전 분포 $p(x)$ 역할을 하고 보조 제약 조건 $r(x)$와 곱해지는 곱셈 분포에서 샘플링해야 하는" 필요성입니다 (2쪽). RTB는 "확산 모델 사전 분포 하에서 사후 분포에서 샘플링하는 확산 모델을 훈련하기 위해" 명시적으로 설계되었습니다 (§2.2). 이는 이 핵심 요구 사항을 직접적으로 해결합니다.
또한, 보조 제약 조건 $r(x)$는 종종 "블랙박스 제약 조건 또는 가능도 함수" (초록, 1쪽)이며, 이는 기능 형태가 복잡하거나 미분 불가능할 수 있음을 의미합니다. RTB는 제약 조건 함수가 전통적인 경사도 기반 방법에 쉽게 적용되지 않는 시나리오에 매우 적합하게 "임의의 양수 제약 조건 $r(x_1)$" (5쪽) 및 "임의의 블랙박스 가능도" (10쪽)를 처리하도록 공식화되었습니다.
문제는 또한 "난해한 사후 추론" (초록, 1쪽)을 주요 장애물로 강조합니다. RTB는 편향을 도입할 수 있는 근사치에 의존하는 대신, 이 난해함을 해결하기 위한 이론적으로 건전한 방법을 제공하는 "점근적으로 편향 없는 훈련 목표" (2쪽)를 제공합니다.
조건부 문제의 경우, 제약 조건이 다른 변수에 의존하는 경우(예: $r(x_1; y) = p(y | x_1)$), RTB는 사후 드리프트를 $y$에 대해 조건화할 수 있도록 하여 "감가상각 추론" 및 "훈련 중에 보지 못한 새로운 $y$에 대한 일반화"를 가능하게 합니다 (5쪽). 이 속성은 다양한 조건에 걸쳐 효율적인 추론을 요구하는 실제 응용에 중요합니다.
마지막으로, "고차원 문제" (2쪽) 및 "대규모 확산 모델" (5쪽)로 확장해야 하는 필요성은 상당한 메모리 및 계산 제약 조건을 부과합니다. RTB의 배치 경사도 누적 및 확률적 부분 샘플링을 통한 메모리 효율적인 훈련은 이러한 실제 제한 사항을 직접적으로 해결합니다. 현대 생성 모델의 까다로운 특성에 완벽하게 맞춰, 메모리 예산을 늘리지 않고 대규모 확산 단계로 훈련을 확장하는 능력은 §H.1에서 논의된 바와 같이 완벽하게 적합합니다.
대안의 거부
본 논문은 확산 모델에서 난해한 사후 추론을 감가상각하는 특정 문제에 대해 몇 가지 인기 있는 접근 방식을 거부하는 명확한 이유를 제공합니다.
-
전통적인 추론 기법(선형 근사, 확률적 최적화): 저자들은 "이 문제에 대한 일반적인 해결책은 선형 근사 [73, 33, 31, 11] 또는 확률적 최적화 [22, 48]에 기반한 추론 기법을 포함합니다" (2쪽)라고 언급합니다. 이러한 방법들은 "근사적으로 또는 제한된 경우에만 해결" (초록, 1쪽)하므로 RTB가 목표로 하는 점근적으로 편향 없는 샘플링을 제공하지 못하기 때문에 불충분한 것으로 간주됩니다.
-
분류기 가이던스(CG) / 확산 사후 샘플링(DPS) / 손실 가이던스 확산 몬테카를로(LGD-MC): '가이던스' 항을 추정하려고 시도하는 이러한 방법들은 여러 가지 이유로 비판받습니다.
- 그들은 "편향된 결과를 초래합니다" (그림 1, 3쪽).
- 그들은 "노이즈가 추가된 데이터에 대한 분류기 훈련"에 의존하며, 이는 "해당 데이터가 없을 때" 문제가 됩니다 (2쪽).
- 노이즈가 추가된 데이터에 대한 미분 가능한 분류기를 유도하는 것은 "일반적으로 난해하지 않습니다" (5쪽)이며, 이를 학습하려면 정확히 문제가 생성하려고 하는 "편향 없는 데이터 샘플"이 필요합니다.
- 실험적으로, "DPS 및 LGD-MC와 같은 분류기 가이던스 기반 방법은 높은 다양성을 보이지만, 사후 분포를 적절하게 모델링하지 못합니다(가장 낮은 로그 r(x))" (7쪽). 또한 "더 낮은 분류기 평균 보상"을 달성하고 "사후 분포를 적절하게 모델링하지 못합니다" (21쪽).
-
강화 학습(RL) 방법(예: DPOK, DDPO): 이 문제에 대해 RL 방법 [8, 16]이 제안되었지만, 심각한 결함이 있습니다.
- 그들은 "편향되어 있고 모드 붕괴에 취약합니다(그림 1)" (2쪽). 그림 E.1(20쪽)은 순수 RL 미세 조정에서 "조기 모드 붕괴" 및 "보상 착취"를 더 자세히 보여줍니다.
- "순수 RL 미세 조정(KL 정규화 없음)은 모드 붕괴 특성을 보이며, 훨씬 낮은 다양성과 FID 점수를 대가로 높은 보상을 달성합니다" (7쪽).
- 확산 모델 미세 조정을 위한 RL 방법은 일반적으로 "온폴리시" (19쪽)이며, 이는 "모드 붕괴에 취약합니다" (그림 C.2, 19쪽).
- DPOK 및 DDPO와 같은 방법은 단계별 페널티를 사용하여 주변 KL의 상한을 최적화하며, 이는 편향을 도입합니다. 대조적으로 RTB는 "이러한 근사의 편향을 피하고 사후 분포 $p(x_1 | z)$에서 편향 없는 샘플을 직접 생성하도록 학습할 수 있습니다" (7쪽).
본 논문은 이 특정 문제에 대해 생성적 적대 신경망(GAN)을 거부하는 것에 대해 명시적으로 논의하지 않습니다. 초점은 확산 모델 프레임워크 내에서 사후 추론을 개선하는 데 있으며, 여기서 확산 모델은 이미 사전 분포로서 확립되어 있습니다. 따라서 사전 분포 자체로서 GAN을 직접 비교하거나 거부하는 것은 이 특정 분석의 범위를 벗어납니다.
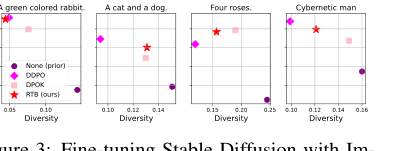 Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
수학적 및 논리적 메커니즘
마스터 방정식
이 논문의 동력이 되는 절대적인 핵심 방정식은 상대 궤적 균형(RTB) 손실 함수입니다. 이 목표는 사후 확산 모델이 원하는 대상 분포에서 샘플링하도록 유도합니다. 손실은 비율의 제곱 로그로 정의되며, 이 비율을 1로 만드는 것을 목표로 합니다.
$$ \mathcal{L}_{\text{RTB}}(\tau; \Phi) := \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right)^2 $$
여기서 $\tau = (X_0, X_{\Delta t}, \dots, X_1)$는 확산 과정의 전체 궤적을 나타냅니다. 궤적 확률 $P(\tau)$ 자체는 초기 분포와 이산 시간 단계에 걸친 조건부 전이 확률의 곱으로 구성되며, 논문의 방정식 (3)에 나와 있습니다.
$$ P(\tau) = p(X_0) \prod_{i=1}^T P(X_{i\Delta t} | X_{(i-1)\Delta t}) $$
항별 분석
각 구성 요소의 역할을 이해하기 위해 마스터 방정식을 분해해 보겠습니다. 명확성을 위해 로그 안의 항에 주로 초점을 맞출 것입니다. 왜냐하면 이 항을 0으로 만드는 것이 직접적인 목표이기 때문입니다.
-
$\mathcal{L}_{\text{RTB}}$:
- 수학적 정의: 상대 궤적 균형(RTB) 손실 함수.
- 물리적/논리적 역할: 이것은 모델이 훈련 중에 최소화하려고 하는 주요 목표 함수입니다. 이 손실을 0으로 만드는 것은 상대 궤적 균형 제약 조건(논문의 방정식 8)이 만족되도록 보장합니다. 이는 차례로 사후 확산 모델 $P_{\Phi}^{\text{post}}$가 원하는 대상 사후 분포 $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$에서 샘플링하는 것을 학습하도록 보장합니다.
- 왜 제곱하는가?: 로그 비율의 제곱은 손실 함수 설계에서 표준 기술(평균 제곱 오차와 유사)입니다. 항상 음수가 아닌 손실을 보장하고 경사도 기반 최적화에 필수적인 부드럽고 미분 가능한 목표를 제공합니다. 대상 비율(1)에서 더 큰 편차를 더 작은 편차보다 더 심각하게 페널티를 부여하여 정확한 수렴을 장려합니다.
-
$\tau = (X_0, X_{\Delta t}, \dots, X_1)$:
- 수학적 정의: 확산 과정의 특정 궤적으로, 초기 노이즈 상태 $X_0$에서 최종 노이즈 제거된 데이터 포인트 $X_1$까지, 중간 상태 $X_{i\Delta t}$를 이산 시간 단계에 걸쳐 통과하는 상태 시퀀스를 나타냅니다.
- 물리적/논리적 역할: 이것은 RTB 메커니즘의 기본 작동 단위입니다. 전체 학습 과정은 이 순차적인 경로를 얼마나 잘 생성하는지를 평가하고 조정합니다.
-
$\Phi$:
- 수학적 정의: 사후 확산 모델 $P_{\Phi}^{\text{post}}$의 학습 가능한 매개변수 집합입니다. 이러한 매개변수는 일반적으로 확률 미분 방정식(SDE)의 드리프트 항 $u_{\Phi}^{\text{post}}(x_t, t)$를 정의하며, 이는 종종 신경망으로 구현됩니다.
- 물리적/논리적 역할: 이것은 모델이 샘플을 생성하는 방식을 제어하는 신경망의 가중치와 편향입니다. 최적화 과정은 $\Phi$를 조정하여 사후 샘플링을 원하는 대상 분포에 맞춥니다.
-
$Z$:
- 수학적 정의: 스칼라 정규화 상수, 특히 명제 1에서 파생된 $Z = \int q(x_1)r(x_1) dx_1$입니다. 수치적 안정성을 위해 로그 $ \log Z$가 학습되거나 추정되는 경우가 많습니다.
- 물리적/논리적 역할: 이 항은 대상 사후 분포 $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$가 올바르게 정규화되도록 보장하는 데 필수적입니다. 제약 조건 함수 $r(X_1)$가 정규화되지 않은 가능도 또는 보상일 수 있으므로, $Z$는 전체 확률을 1로 적분하도록 조정합니다. 이는 상대적 비율뿐만 아니라 절대 확률을 일치시키는 데 중요합니다.
-
$r(X_1)$:
- 수학적 정의: 최종 데이터 포인트 $X_1$에서 평가되는 양수, 블랙박스 제약 조건 함수 또는 가능도 함수입니다.
- 물리적/논리적 역할: 이 항은 확산 과정을 원하는 특성으로 유도하는 "보상" 또는 "가이던스" 신호를 나타냅니다. 예를 들어, 특정 클래스에 대한 분류기의 가능도 $p(c|X_1)$이거나 강화 학습에서의 보상 함수 $\exp(\beta Q(s,a))$일 수 있습니다. 생성된 데이터가 가져야 하는 특정 속성을 인코딩합니다.
-
$p_{\theta}(\tau)$:
- 수학적 정의: 사전 확산 모델, $\theta$로 매개변수화된 궤적 $\tau$의 확률입니다. 이는 일반적으로 초기 분포 $p(X_0)$와 조건부 전이 확률 $P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$의 곱입니다.
- 물리적/논리적 역할: 이것은 "기준선" 또는 "무조건부" 생성 프로세스를 나타냅니다. 특정 제약 조건 없이 데이터를 생성하는 사전 훈련된 확산 모델입니다. RTB 목표는 이를 참조점으로 사용하여 사후 모델의 전이에 대한 상대적 균형을 정의합니다.
-
$P_{\Phi}^{\text{post}}(\tau)$:
- 수학적 정의: 사후 확산 모델, $\Phi$로 매개변수화된 궤적 $\tau$의 확률입니다. $p_{\theta}(\tau)$와 유사하게, 이는 $p(X_0)$(종종 사전 분포와 공유됨)와 조건부 전이 확률 $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$의 곱입니다.
- 물리적/논리적 역할: 이것은 원하는 사후 분포에서 샘플링하도록 학습 중인 생성 프로세스를 나타냅니다. 그 매개변수 $\Phi$는 훈련 중에 조정되어 궤적이 제약 조건 $r(X_1)$를 사전 $p_{\theta}(\tau)$에 상대적으로 만족하도록 합니다.
-
$\log(\cdot)$:
- 수학적 정의: 자연 로그입니다.
- 물리적/논리적 역할: 로그는 확률의 곱을 로그 확률의 합으로 변환하여 수치적으로 더 안정적이고 종종 최적화하기 쉽습니다. 또한 확률의 비율을 로그 확률의 차이로 변환하며, 이는 정보 이론(예: KL 발산)에서 일반적인 기술입니다. 목표는 로그 비율을 0으로 만드는 것이며, 이는 비율 자체가 1임을 의미합니다.
-
$\sum_{i=1}^T$:
- 수학적 정의: 1부터 $T$까지의 이산 시간 단계 $i$에 대한 합계입니다.
- 물리적/논리적 역할: 이 연산자는 확산 궤적의 모든 이산 단계에 걸쳐 조건부 전이 확률의 로그 비율을 집계합니다. 확산 과정은 $T$개의 이산 단계의 시퀀스로 모델링되며, 전체 궤적 확률은 이러한 단계별 확률의 곱입니다. 로그는 이 곱을 합으로 변환하여 각 단계의 기여가 전체 로그 비율에 가산되도록 합니다.
- 왜 합계인가, 적분이 아닌가?: 본 논문은 확산 과정을 SDE의 "시간 이산화 버전"으로 명시적으로 모델링하며, 여기서 궤적은 이산 상태 $X_0, X_{\Delta t}, \dots, X_1$의 시퀀스입니다. 따라서 합계는 이러한 이산 전이의 확률을 결합하는 자연스러운 선택이며, 구현된 확산 단계의 이산적 특성을 반영합니다.
-
$P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- 수학적 정의: 사후 확산 모델 하에서 이전 상태 $X_{(i-1)\Delta t}$가 주어졌을 때 상태 $X_{i\Delta t}$로 전이하는 조건부 확률입니다. 가우시안 확산 모델의 경우, 이는 일반적으로 가우시안 분포 $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$입니다.
- 물리적/논리적 역할: 이 항은 사후 모델이 시간 단계마다 어떻게 발전하는지를 설명합니다. 학습된 드리프트 항 $u_{\Phi}^{\text{post}}$($\Phi$로 매개변수화됨)는 이 가우시안 전이의 평균을 결정하며, 효과적으로 샘플 생성을 사후 분포로 유도합니다.
-
$P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- 수학적 정의: 사전 확산 모델 하에서 이전 상태 $X_{(i-1)\Delta t}$가 주어졌을 때 상태 $X_{i\Delta t}$로 전이하는 조건부 확률입니다. 사후 분포와 유사하게, 이는 가우시안 분포 $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\theta}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$입니다.
- 물리적/논리적 역할: 이 항은 사전 훈련된 사전 확산 모델의 단계별 발전을 설명합니다. 이는 사후 모델의 전이에 대한 참조 역할을 합니다. 사후 대 사전 전이 확률의 비율은 사후 모델이 제약 조건을 만족시키기 위해 각 단계에서 사전에서 얼마나 "벗어나는지"를 나타냅니다.
단계별 흐름
이 수학적 엔진을 통해 추상적인 데이터 포인트의 정확한 수명 주기를 추적해 보겠습니다.
-
노이즈의 탄생 ($X_0$): 프로세스는 처음에 순수한 가우시안 노이즈 벡터인 $X_0$에서 시작하며, 이는 $\mathcal{N}(0, I)$와 같이 고정되고 간단한 분포에서 샘플링됩니다. 이는 걸작이 탄생할 원시적이고 형성되지 않은 점토와 같습니다.
-
생성 조립 라인 (궤적 $\tau$):
- 전체 궤적 $\tau = (X_0, X_{\Delta t}, \dots, X_1)$가 생성됩니다. 이 궤적은 현재 사후 모델(온폴리시 샘플링) 또는 대안적인 탐색 분포(오프폴리시 샘플링)에서 생성될 수 있습니다.
- 각 이산 시간 단계 $i$ (1부터 $T$까지)에서, 진행 중인 샘플 $X_{(i-1)\Delta t}$는 "처리 장치"에 들어갑니다. 여기서 신경망(사후 확산 모델의 일부, $\Phi$로 매개변수화됨)은 "드리프트" 또는 "노이즈 제거 방향" $u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t}, (i-1)\Delta t)$을 예측합니다.
- 이 예측된 드리프트와 소량의 가우시안 노이즈를 기반으로, 샘플은 조건부 확률 $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$에 따라 다음 상태 $X_{i\Delta t}$로 변환됩니다. 이는 항목이 점진적으로 개선되고 모양이 만들어지는 컨베이어 벨트와 같습니다.
- 이 단계별 변환은 시간 $T$에서 최종 노이즈 제거된 데이터 포인트 $X_1$이 생성될 때까지 계속됩니다.
-
품질 관리 검사 ($r(X_1)$): 최종 데이터 포인트 $X_1$이 조립 라인에서 나오면 즉시 "품질 관리" 스테이션으로 보내집니다. 여기서 블랙박스 제약 조건 함수 $r(X_1)$는 $X_1$이 원하는 기준을 얼마나 잘 충족하는지 평가합니다. 이는 보상 점수, 클래스 가능도 또는 품질에 대한 기타 측정 기준일 수 있습니다. 이 값은 생성 프로세스의 성공을 결정하는 데 중요합니다.
-
균형표 (로그 비율 계산):
- 이제 전체 궤적 $\tau$( $X_0$에서 $X_1$까지)가 분석됩니다. 사후 모델 하에서 이 특정 궤적이 발생할 확률 $P_{\Phi}^{\text{post}}(\tau)$는 초기 노이즈 확률에 경로를 따라 모든 조건부 전이 확률을 곱하여 계산됩니다.
- 병렬로, 동일한 궤적이 사전 확산 모델 $p_{\theta}(\tau)$ 하에서 발생할 확률도 계산됩니다. 이 사전은 중립적인 참조 역할을 합니다.
- 이러한 확률은 정규화 상수 $Z$ 및 제약 조건 $r(X_1)$와 결합되어 중요한 비율을 형성합니다: $\frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$.
- 이 비율의 자연 로그가 취해집니다. 이 로그 비율은 시스템이 0으로 만들려고 하는 핵심 "균형" 지표입니다. 0이면 사후 모델이 사전 및 제약 조건에 대해 완벽하게 균형을 이룬 것입니다.
-
성능 검토 (손실 계산): 계산된 로그 비율은 이 특정 궤적에 대한 $\mathcal{L}_{\text{RTB}}$ 손실을 산출하기 위해 제곱됩니다. 이 손실은 사후 모델의 현재 생성 프로세스에서의 "불균형" 또는 "오류"를 정량화합니다.
-
조정 메커니즘 (매개변수 업데이트): 계산된 손실 값은 사후 모델 매개변수 $\Phi$에 대한 경사도를 생성하는 데 사용됩니다. 이러한 경사도는 모델이 손실을 줄이기 위해 내부 메커니즘(신경망 가중치)을 어떻게 조정해야 하는지를 알려주는 정확한 지침 역할을 합니다. 이 조정은 사후 모델이 제약 조건 균형을 만족시키는 궤적을 생성할 가능성을 높여, 고품질의 제약 조건이 있는 샘플을 생성하도록 효과적으로 학습합니다. 이 반복적인 프로세스는 숙련된 엔지니어가 복잡한 기계를 미세 조정하는 것처럼 모델을 정제합니다.
최적화 역학
상대 궤적 균형(RTB) 메커니즘은 $\mathcal{L}_{\text{RTB}}$ 손실의 경사도 기반 최적화를 통해 사후 확산 모델 $P_{\Phi}^{\text{post}}$의 매개변수 $\Phi$를 반복적으로 정제함으로써 학습, 업데이트 및 수렴합니다.
-
손실 지형 및 목표: $\mathcal{L}_{\text{RTB}}$ 손실 함수는 제곱 로그 비율이므로, 전역 최소값이 0인 손실 지형을 정의합니다. 이 최소값에서 상대 궤적 균형 제약 조건 $Z P_{\Phi}^{\text{post}}(\tau) = r(X_1) p_{\theta}(\tau)$가 모든 궤적 $\tau$에 대해 완벽하게 만족됩니다. 이는 사후 모델 $P_{\Phi}^{\text{post}}$가 대상 분포 $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$에서 샘플링하는 것을 학습했음을 의미합니다. 기본 신경망 매개변수화로 인해 지형이 비볼록하지만, 로그 및 제곱 연산은 경사 하강법에 적합한 부드러운 목표를 제공합니다. 본 논문은 미니배치에 대한 경험적 분산 및 손실 클리핑과 같은 실용적인 전략을 사용하여 훈련을 안정화하고 이 복잡한 지형을 탐색한다고 언급하며, 특히 사전 모델이 불완전하거나 제약 조건 함수 $r(X_1)$가 날카로운 분포를 초래하는 경우에 그렇습니다.
-
경사도 동작 및 학습 신호: $\mathcal{L}_{\text{RTB}}$ 손실의 사후 모델 매개변수 $\Phi$에 대한 경사도는 학습 과정의 핵심입니다. RTB의 주요 장점은 이 경사도가 궤적 $\tau$를 생성한 전체 샘플링 프로세스를 통해 역전파할 필요가 없다는 것입니다. 대신, 주로 사후 궤적의 로그 가능도 경사도 $\nabla_{\Phi} \log P_{\Phi}^{\text{post}}(\tau)$를 현재 로그 비율 편차로 스케일링하는 것을 포함합니다.
$$ \nabla_{\Phi} \mathcal{L}_{\text{RTB}}(\tau; \Phi) = 2 \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right) \nabla_{\Phi} \left( \log P_{\Phi}^{\text{post}}(\tau) \right) $$
이 경사도는 "수정 신호" 역할을 합니다. $\log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$ 항이 양수이면 (즉, $P_{\Phi}^{\text{post}}(\tau)$가 대상에 비해 너무 높으면) 경사도는 $\Phi$를 밀어 $\log P_{\Phi}^{\text{post}}(\tau)$를 감소시켜 해당 궤적을 사후 분포에서 덜 가능하게 만듭니다. 반대로 항이 음수이면 경사도는 $\Phi$를 밀어 $\log P_{\Phi}^{\text{post}}(\tau)$를 증가시켜 해당 궤적을 더 가능하게 만듭니다. 이 조정의 크기는 현재 모델이 균형 제약 조건을 만족하는 정도와 비례합니다. 이 메커니즘은 사후 모델이 사전 $p_{\theta}(\tau)$와의 일관된 관계를 유지하면서 $r(X_1)$의 높은 값으로 이어지는 궤적을 "증폭"하도록 학습할 수 있도록 합니다. -
상태 업데이트 및 수렴:
- 반복적 상태 업데이트: 매개변수 $\Phi$는 AdamW와 같은 최적화 알고리즘을 사용하여 여러 훈련 단계에 걸쳐 반복적으로 업데이트됩니다. 각 단계에서 궤적 배치가 샘플링됩니다. 각 궤적에 대해 $\mathcal{L}_{\text{RTB}}$ 손실이 계산되고 경사도가 누적됩니다. 그런 다음 최적화 프로그램은 이러한 누적 경사도를 사용하여 $\Phi$를 조정하여 매개변수 공간에서 더 낮은 손실 영역으로 이동합니다.
- 오프폴리시 탐색: RTB의 중요한 강점은 오프폴리시 궤적과의 호환성입니다. 이는 학습에 사용되는 궤적이 현재 사후 모델 $P_{\Phi}^{\text{post}}$와 다른 분포에서 샘플링될 수 있음을 의미합니다. 이 유연성은 효율적인 모드 커버리지에 중요하며, 모델이 잠재적인 궤적의 더 넓은 범위를 탐색하고 생성 모델이 제한된 보상 샘플만 학습하는 일반적인 함정인 모드 붕괴를 피할 수 있도록 합니다. 다양한 궤적(예: 리플레이 버퍼 또는 탐색 수정)을 활용함으로써 모델은 대상 사후 분포의 전체 스펙트럼을 커버하도록 학습할 수 있습니다.
- 점근적 정확성: 본 논문은 RTB를 "점근적으로 편향 없는 훈련 목표"로 확립합니다. 이 이론적 보장은 충분한 데이터와 훈련이 주어지면 모델이 실제 사후 분포로 수렴할 것으로 예상된다는 것을 의미합니다. 제곱 로그 비율의 지속적인 감소와 정규화 상수 $Z$의 올바른 처리는 시스템을 상대 균형 제약 조건이 충족되는 상태로 이끌어 정확한 사후 샘플링으로 이어집니다.
결과, 한계 및 결론
실험 설계 및 기준선
저자들은 확산 모델에서 난해한 사후 추론을 감가상각하는 데 있어 상대 궤적 균형(RTB)의 효능을 엄격하게 검증하기 위해 다양한 영역에 걸쳐 일련의 실험을 세심하게 설계했습니다. 핵심 아이디어는 $p_{\theta}(x)$가 확산 사전 분포이고 $r(x)$가 블랙박스 제약 조건 또는 가능도 함수인 복잡한 사후 분포 $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$에서 샘플링하는 RTB의 능력을 입증하는 것이었습니다.
비전: 분류기 가이던스 이미지 생성
비전 작업의 경우, 클래스 조건부 이미지 생성을 위해 사후 확산 $p_{\text{post}}(x|c) \propto p_{\theta}(x)p(c|x)$를 학습하는 것이 목표였습니다.
- 데이터셋: MNIST(28x28, 32x32 단일 채널 숫자 이미지로 업스케일링) 및 CIFAR-10(32x32 3채널 이미지)의 두 가지 10개 클래스 이미지 데이터셋에서 실험이 수행되었습니다.
- 사전 분포 및 제약 조건: [27]의 오프더셸프 무조건부 확산 사전 분포가 $p_{\theta}(x)$로 사용되었고, 표준 분류기가 $p(c|x)$로 제약 조건 $r(x)$ 역할을 했습니다.
- 훈련 아키텍처: 사후 확산 모델 $p_{\phi}^{\text{post}}$는 RTB를 사용하여 미세 조정되었으며, 사전 $p_{\theta}$의 복사본으로 초기화되었습니다. 매개변수 효율적인 미세 조정은 LoRA 가중치 [28]를 사용하여 달성되었으며, 이는 사전 모델 매개변수 수의 약 3%를 차지했습니다. RTB 목표는 현재 사후 모델에서 샘플링된 궤적을 사용하여 최적화되었습니다.
- 기준선: RTB의 성능은 두 가지 범주의 기준선과 비교되었습니다.
- RL 기반 미세 조정: DPOK [16] 및 DDPO [8].
- 분류기 가이던스: DPS [11] 및 LGD-MC [70].
- 실험 설정: 세 가지 별도의 시나리오가 테스트되었습니다. MNIST 단일 숫자 사후, CIFAR-10 단일 클래스 사후, 그리고 더 어려운 MNIST 다중 숫자 사후(짝수 또는 홀수 숫자 생성, 여기서 $r(x) = \max_{i \in \{0,2,4,6,8\}} p(c=i|x)$).
- 지표: 성능은 기대 로그 보상 $E[\log r(x)]$ (높을수록 좋음), 실제 샘플과의 근접성을 위한 Fréchet Inception Distance(FID) (낮을수록 좋음), 다양성(Inceptionv3 특징 공간에서의 평균 쌍별 코사인 거리, 높을수록 좋음)을 사용하여 평가되었습니다. FID는 실제 사후 분포의 유사성 점수 추정치로 계산되었으며, 클래스당 총 샘플 수(CIFAR-10/MNIST 숫자 5k-6k, 짝수/홀수 30k)로 제한되었습니다.
- 컴퓨팅: 모든 비전 실험은 단일 NVIDIA V100 GPU에서 실행되었습니다.
언어 모델링: 텍스트 인필링
이산 확산 모델에 대한 RTB를 평가하기 위해, 이야기의 처음 세 문장 $x$와 마지막 문장 $y$가 주어졌을 때 네 번째 문장 $z$를 생성해야 하는 텍스트 인필링 작업이 선택되었습니다. 목표 사후 분포는 $p_{\text{post}}(z|x,y) \propto p(z|x)p_{\text{reward}}(y|x,z)$였습니다.
- 말뭉치: 5문장 이야기로 구성된 ROCStories 말뭉치 [50]가 사용되었습니다.
- 사전 분포 및 제약 조건: SEDD(Score Entropy Discrete Diffusion) 언어 모델 [43]이 사전 $p(z|x)$ 역할을 했습니다. 보상 함수 $p_{\text{reward}}(y|x,z)$는 trl 라이브러리 [81]를 사용하여 이야기 데이터셋에 미세 조정된 자기회귀 GPT-2 Large 모델 [57]이었습니다.
- 훈련 세부 정보: RTB 목표는 이산 확산 모델에 적용되었습니다. 계산 비용(메모리 및 속도)을 관리하기 위해 저자들은 확률적 TB 트릭(궤적 단계에 대한 경사도 전파)과 손실 클리핑을 사용했습니다. 이 조건부 문제에 대해 상대 VarGrad 목표가 사용되었으며, 보상 가능도에 대한 템퍼링도 함께 사용되었습니다.
- 기준선:
- $x$로 확산 LM을 간단히 프롬프트하는 것 (Prompt (x)).
- $x, y$로 간단히 프롬프트하는 것 (Prompt (x, y)).
- [29]의 자기회귀 언어 모델 기준선, GFlowNet 미세 조정 및 지도 학습 미세 조정을 포함합니다.
- 지표: 생성된 인필의 품질은 BERTScore [90], BLEU-4 [54], GLEU-4 [86]를 사용하여 측정되었으며, 데이터셋의 참조 인필과 비교되었습니다.
- 컴퓨팅: 실험은 단일 NVIDIA A100-Large GPU에서 수행되었습니다.
연속 제어: 오프라인 강화 학습
RTB는 오프라인 강화 학습에서 KL 제약 정책 검색 문제에 적용되었으며, 최적 정책 $\pi^*(a|s) \propto \mu(a|s)\exp(\beta Q(s,a))$를 찾는 것을 목표로 했습니다.
- 데이터셋: D4RL 제품군 [18]이 사용되었으며, 특히 halfcheetah, hopper 및 walker2d MuJoCo [76] 이동 작업이 사용되었습니다. 각 작업에는 "medium", "medium-expert", "medium-replay" 데이터셋이 포함되어 있으며, 이는 행동 사전의 부분 최적화 수준을 나타냅니다.
- 사전 분포 및 제약 조건: 상태 조건부 노이즈 예측 DDPM [27]이 확산 행동 정책 $\mu(a|s)$ 역할을 했습니다. 제약 조건은 IQL [36]을 사용하여 훈련된 Q 함수인 $\exp(\beta Q(s,a))$로 정의되었습니다.
- 훈련 세부 정보: RTB는 확산 행동 정책을 미세 조정하여 $\pi^*$에서 샘플링했으며, 그 가중치는 훈련된 행동 정책에서 초기화되었습니다. Langevin 역학 귀납적 편향 [11]이 통합되었고, 에너지 스케일링 네트워크를 위해 추가 MLP가 훈련되었습니다. VarGrad 목표 [61]가 $\log Z(s)$를 암묵적으로 추정하는 데 사용되었습니다. 오프폴리시 탐색은 높은 보상 에피소드에서 샘플을 포함하는 오프라인 데이터셋을 사용하여 활용되었으며, 이는 "혼합 훈련"(오프폴리시 및 온폴리시)으로 이어졌습니다.
- 기준선: 상태-최신 오프라인 RL 기준선의 포괄적인 세트가 비교되었습니다. Behavior Cloning (BC), CQL [37], IQL [36], Diffuser (D) [30], Decision Diffuser (DD) [2], D-QL [83], IDQL [25], QGPO [44].
- 지표: 주요 지표는 훈련된 정책의 평균 보상이었으며, 5개의 무작위 시드에 대한 평균 ± 표준 편차로 보고되었습니다.
- 컴퓨팅: 모든 오프라인 RL 실험은 단일 NVIDIA A100-Large GPU에서 수행되었습니다.
증거가 증명하는 것
실험 증거는 상대 궤적 균형(RTB)이 비전, 언어 및 연속 제어 작업 전반에 걸쳐 상태 최신 기준선을 능가하거나 일치하는 확산 모델에서 난해한 사후 추론을 위한 강력하고 다재다능한 방법을 제공한다는 것을 부인할 수 없게 입증합니다. RTB의 핵심 메커니즘인 점근적으로 편향 없는 샘플링은 보상과 다양성의 균형을 맞추고 다른 방법이 실패한 복잡한 사후 분포를 정확하게 모델링하는 능력에 의해 무자비하게 입증되었습니다.
비전: 편향 없는 추론에 대한 결정적 증거
- 보상 및 다양성의 우수한 균형: 분류기 가이던스 이미지 생성(표 2)에서 RTB는 높은 기대 로그 보상($E[\log r(x)]$)과 높은 다양성(평균 쌍별 코사인 거리) 사이에서 일관되게 우수한 균형을 달성했으며, 낮은 FID 점수(실제 샘플과의 근접성)를 유지했습니다. 예를 들어, CIFAR-10에서 RTB는 $E[\log r(x)]$ -2.1625와 FID 0.4717을 달성했으며, 이는 높은 다양성에도 불구하고 더 낮은 보상을 가진 DPS (-3.6025 $E[\log r(x)]$) 및 LGD-MC (-3.0988 $E[\log r(x)]$)와 같은 분류기 가이던스 방법보다 훨씬 우수했습니다.
-
모드 붕괴 극복: 본 논문의 가장 설득력 있는 시각적 증거(그림 1)는 RTB 샘플이 9개의 활성 모드를 가진 가우시안 혼합물인 실제 사후 분포(그림 1c)와 매우 유사함을 보여줍니다. 대조적으로, KL 정규화가 없는 순수 RL 방법(DDPO)은 심각한 모드 붕괴를 겪었습니다(그림 1e). 심지어 조정된 KL 정규화를 가진 RL(DPOK)도 부정확한 추론을 초래했으며(그림 1d), 분류기 가이던스(CG)는 편향된 결과를 초래했습니다(그림 1f). 이 시각적으로 부인할 수 없는 증거는 RTB가 모드 붕괴를 피하고 사후 분포를 정확하게 커버하는 능력을 증명합니다.
-
고품질, 다양한 샘플: 그림 2와 그림 4는 다양한 프롬프트(예: "녹색 토끼", "고양이와 개", "장미 네 송이")에 대해 RTB 미세 조정 모델로 생성된 이미지의 높은 시각적 품질과 다양성을 보여줍니다. 이러한 질적 결과는 정량적 지표를 강화하여 RTB의 핵심 메커니즘이 인지적으로 더 나은 결과와 더 다양한 결과로 이어진다는 것을 보여줍니다.
-
점근적으로 편향 없음: 본 논문은 RTB가 점근적으로 편향 없는 목표이며 실제 사후 점수 함수의 편향된 근사에 의존하는 분류기 가이던스와 달리 드리프트의 실제 차이를 복구한다고 강조합니다. 이 이론적 이점은 RTB가 사후 분포 모델링을 일관되게 개선한다는 실험 결과에서 나타납니다.
언어 모델링: 인필링에서의 강력한 성능
- 자기회귀 기준선 능가: 텍스트 인필링(표 3)의 경우, 이산 확산 사전 분포를 가진 RTB는 모든 비-SFT 기준선 중에서 가장 높은 BERTScore(0.156), BLEU-4(0.025), GLEU-4(0.045)를 달성했습니다. 이는 RTB가 더 일관되고 일관된 인필을 생성하는 능력을 보여주며, 단순 프롬프트 기준선 및 가장 강력한 자기회귀 GFlowNet 미세 조정 기준선(BERTScore 0.102)보다 훨씬 뛰어납니다. 이는 RTB의 이산 확산 모델 처리 메커니즘이 조건부 텍스트 생성을 효과적으로 개선한다는 강력한 지표입니다.
연속 제어: 상태 최신 오프라인 RL
- 상태 최신 보상 일치: 오프라인 강화 학습(표 4)에서 RTB는 D4RL 벤치마크 전반에 걸쳐 상태 최신 또는 경쟁력 있는 결과를 달성했습니다. 예를 들어,
hopper-medium-replay에서 RTB는 100.40을 기록하여 DD(100.00) 및 D-QL(100.70)과 같은 다른 선도적인 방법과 일치하거나 능가했습니다. 이는 RTB가 부분 최적화된 행동 사전이 있더라도 KL 제약 사후 분포에서 샘플링하여 효과적으로 최적 정책을 학습할 수 있음을 증명합니다. - 부분 최적 사전 분포에 대한 견고성: RTB는 특히 부분 최적 데이터와 따라서 열악한 행동 사전으로 특징지어지는 "medium-replay" 작업에서 강력한 성능을 보였습니다. 이러한 견고성은 RTB의 오프폴리시 훈련 기능이 초기 사전이 이상적이지 않은 실제 RL 시나리오에서 흔히 발생하는 문제에도 불구하고 효과적으로 학습할 수 있도록 한다는 중요한 증거입니다.
- 오프폴리시 탐색의 이점: 표 G.1은 RTB의 오프폴리시 기능의 이점을 더욱 공고히 하여, "혼합 훈련"(오프폴리시 및 온폴리시 샘플 결합)이 세 가지 medium-replay 작업 중 두 가지에서 순수 온폴리시 훈련보다 우수함을 보여줍니다. 이는 RTB의 다양한 궤적을 활용하는 유연성이 훈련 효율성과 성능을 향상시킨다는 주장을 직접적으로 뒷받침합니다.
본질적으로, 이러한 다양한 영역에 걸친 증거는 설득력 있는 이야기를 제공합니다. RTB의 상대 궤적 균형에 기반한 원칙적인 감가상각 사후 샘플링 접근 방식은 종종 다른 추론 방법을 괴롭히는 보상 최대화와 모드 커버리지 간의 절충을 효과적으로 탐색함으로써 일관되게 우수하거나 경쟁력 있는 결과를 산출합니다.
한계 및 향후 방향
상대 궤적 균형(RTB)은 확산 모델에서 난해한 사후 추론을 위한 강력하고 다재다능한 프레임워크를 제시하지만, 저자들은 솔직하게 몇 가지 한계를 인정하고 흥미로운 미래 연구 방향을 제안합니다.
한계
- 계산 비용 및 메모리 집약도: 주요 한계는 RTB가 시뮬레이션 기반 훈련을 통해 사후 분포를 학습한다는 것입니다. 이는 느리고 메모리 집약적일 수 있습니다. 본 논문은 RTB 자체의 메모리 사용량을 완화하기 위해 확률적 부분 샘플링 및 배치 경사도 계산과 같은 기법을 도입했지만, 훈련을 위한 궤적 시뮬레이션의 근본적인 특성은 병목 현상으로 남아 있습니다. 이는 특히 대규모 모델 또는 고차원 데이터에 관련이 있습니다.
- 높은 경사도 분산: RTB 목표는 전체 궤적에 대해 계산됩니다. 이는 손실 함수가 궤적 내 개별 단계에 대한 지역적 신용 할당 신호를 제공하지 않음을 의미합니다. 결과적으로 경사도는 높은 분산을 보일 수 있으며, 이는 훈련 안정성과 효율성을 방해할 수 있습니다.
- 불완전한 적합에 대한 이론적 보장 부족: 본 논문은 사전 모델의 불완전한 적합으로 인한 오류, 감가상각의 효과, 시간 이산화의 영향(기존 확산 샘플러 분석 [7]과 유사)에 대한 이론적 보장이 아직 완전히 확립되지 않았다고 언급합니다. 이러한 보장은 비이상적인 조건 하에서의 RTB 동작에 대한 더 깊은 이해를 제공할 것입니다.
- 미분 가능한 시뮬레이션 방법에는 적용 불가: RTB에 대해 개발된 메모리 절약 기법(확률적 부분 샘플링, 배치 경사도 계산)은 보편적으로 적용 가능하지 않습니다. 특히, 미분 가능한 시뮬레이션(예: Path Integral Sampler (PIS) 및 Denoising Diffusion Samplers (DDS))에 기반한 확산 샘플러는 여전히 전체 SDE 적분 계산 그래프를 저장해야 하므로 궤적 길이에 선형적으로 확장되는 메모리 요구 사항이 발생합니다.
향후 방향
발견된 내용은 여러 유망한 연구 방향을 열어 확산 모델과 강화 학습의 경계를 넓힙니다.
- 향상된 오프폴리시 훈련 및 탐색: 본 논문은 RTB가 오프폴리시 궤적과 호환된다는 점을 강조합니다. 향후 연구는 샘플 효율성과, 가장 중요하게는 모드 커버리지를 더욱 개선하기 위해 고급 오프폴리시 훈련 기법(예: 지역 검색 [34, 65])을 활용하는 데 더 깊이 파고들 수 있습니다. 이는 사후 분포의 도달하기 어려운 모드를 발견하기 위한 보다 정교한 탐색 전략을 포함할 수 있습니다.
- 시뮬레이션 기반 목표 탐색: 저자들은 감가상각 샘플링 문제에 대해 [89]에서 사용된 것과 유사한 다른 시뮬레이션 기반 목표를 탐색할 것을 제안합니다. 이는 계산 비용, 경사도 분산 및 성능 간의 다른 절충을 제공하는 대안적인 공식으로 이어질 수 있습니다.
- 시뮬레이션 없는 확장 개발: 시간적으로 국소적인 목표 [45]와 같은 시뮬레이션 없는 확장을 조사하면 전체 궤적 기반 훈련과 관련된 계산 및 메모리 집약도 문제를 해결할 수 있습니다. 이는 RTB를 더 확장 가능하게 만드는 중요한 단계가 될 것입니다.
- 블랙박스 가능도 함수를 가진 역 문제에 대한 적용: RTB의 임의의 블랙박스 가능도 함수를 처리하는 고유한 능력은 다양한 역 문제에 이상적인 후보입니다. 여기에는 다음이 포함됩니다.
- 3D 객체 합성: 렌더러 [예: 56, 82]를 통해 계산된 가능도를 사용하여 2D 관찰에서 3D 객체를 생성합니다.
- 이미징 문제: 천문학 [예: 1] 및 의료 영상 [예: 73]의 복잡한 작업에 RTB를 적용하며, 여기서 가능도 함수는 복잡하고 미분 불가능할 수 있습니다.
- 분자 구조 예측: 실험 데이터에서 분자 구조를 추론하는 것을 목표로 하는 분자 생물학 [예: 84]의 어려운 문제에 대해 RTB를 활용합니다.
- 분자 역학의 돌파구: 특히 흥미로운 전망은 분자 역학 모델링에서 돌파구를 촉진할 수 있는 RTB의 잠재력입니다. 화학 시뮬레이션에서 희귀 이벤트 궤적 샘플링이라는 악명 높은 어려운 작업을 희귀 이벤트 샘플의 증폭된 분포에 대한 사후 추론 문제로 변환함으로써 RTB는 복잡한 화학 공정을 이해하는 새로운 접근 방식을 제공할 수 있습니다. 보상에 사전 가능도를 곱한 TB(효과적으로 RTB)를 사용한 Seong 등 [66]의 예비 작업은 이 방향을 뒷받침합니다.
- 이론 분석의 엄격성: 향후 연구는 특히 불완전한 사전 모델의 영향, 감가상각의 효과 및 시간 이산화의 영향과 관련하여 RTB에 대한 엄격한 이론적 보장을 제공하는 데 중점을 두어야 합니다. 이는 방법의 기초적인 이해를 강화할 것입니다.
광범위한 영향 논의
저자들은 또한 작업의 사회적 영향에 대해 신중하게 논의합니다. 생성 모델링의 다른 발전과 마찬가지로 RTB는 "악의적인 행위자"가 유해한 콘텐츠나 잘못된 정보를 생성하는 모델을 훈련하는 데 잠재적으로 오용될 수 있습니다. 그러나 그들은 또한 긍정적인 잠재력을 강조합니다. RTB는 사전 훈련된 모델에 존재하는 편향을 완화하는 데 사용될 수 있으며 다양한 과학 문제에 적용되어 다양한 관점을 육성하고 책임감 있는 개발 및 배포에 대한 비판적 사고를 자극합니다.
 Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
 Figure 2. Samples from RTB fine-tuned diffusion posteriors
Figure 2. Samples from RTB fine-tuned diffusion posteriors
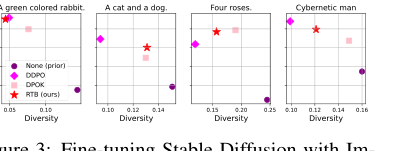 Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
 Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted
Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted