Амортизация недоступного вывода в диффузионных моделях для зрения, языка и управления
Проблема, рассматриваемая в данной статье, непосредственно вытекает из недавнего успеха и широкого распространения диффузионных моделей как мощных генеративных моделей в различных областях, включая компьютерное...
Предпосылки и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, непосредственно вытекает из недавнего успеха и широкого распространения диффузионных моделей как мощных генеративных моделей в различных областях, включая компьютерное зрение, обработку естественного языка и обучение с подкреплением. Хотя эти модели превосходно генерируют высококачественные данные, обучаясь обращать постепенный процесс зашумления, их применение в последующих задачах часто требует более сложной формы вывода: выборки из апостериорного распределения.
Исторически диффузионные модели, впервые представленные в 2015 году Солом-Дикштейном и др. [68], представляют собой класс иерархических генеративных моделей, которые обучаются моделировать сложные распределения данных. Основная идея заключается в определении прямого диффузионного процесса, который постепенно добавляет шум к данным, трансформируя их в простое, доступное для анализа распределение (например, гауссовский шум). Затем нейронная сеть обучается моделировать обратный процесс, эффективно удаляя шум из данных шаг за шагом для генерации новых выборок.
Конкретная проблема возникает, когда эти предварительно обученные диффузионные модели используются в качестве априорных $p(x)$ в сценариях, где желаемый результат также должен удовлетворять дополнительному, часто сложному, ограничению $r(x)$. Это ограничение может быть вероятностью классификатора (например, генерация изображения определенного класса), функцией вознаграждения в обучении с подкреплением (например, генерация действий, максимизирующих вознаграждение) или вероятностью языковой модели для заполнения недостающего текста. Задача затем состоит в выборке из произведения распределений $p_{\text{post}}(x) \propto p(x)r(x)$, которое представляет собой байесовское апостериорное распределение. Эта проблема особенно сложна, поскольку иерархическая природа диффузионных моделей делает точную выборку из таких апостериорных распределений недоступной, особенно когда $r(x)$ является "черным ящиком", не предлагающим простых аналитических решений.
Фундаментальное ограничение или "болевая точка" предыдущих подходов заключается в их неспособности выполнять этот недоступный апостериорный вывод точно и эффективно. Существующие методы обычно попадают в несколько категорий, каждая из которых имеет существенные недостатки:
* Линейные аппроксимации или стохастическая оптимизация: Эти методы часто дают только приближенные решения [73, 33, 31, 11, 22, 48], которые могут неточно отражать истинное апостериорное распределение.
* Оценка направляющего члена: Методы, такие как направляющая классификатора [12], пытаются оценить "направляющий" член, обучая классификатор на зашумленных данных. Однако этот подход ограничен, поскольку требует специфических зашумленных данных, а когда такие данные недоступны, он прибегает к аппроксимациям или оценкам Монте-Карло [70, 14, 10]. Эти аппроксимации notoriously трудно масштабировать до задач высокой размерности, которые распространены в современных генеративных задачах.
* Методы обучения с подкреплением (RL): Недавние подходы на основе RL [8, 16] для этой проблемы, хотя и многообещающие, оказались смещенными и страдали от коллапса мод. Коллапс мод означает, что модель не может генерировать разнообразные выборки, вместо этого застревая на генерации лишь нескольких примеров с высоким вознаграждением, тем самым не полностью исследуя истинное апостериорное распределение. Этот недостаток разнообразия и точности при выборке из полного апостериорного распределения является основным препятствием для надежных и универсальных приложений диффузионных моделей в сложных последующих задачах.
Интуитивные термины предметной области
Вот несколько специализированных терминов предметной области из статьи, переведенных в интуитивные аналогии:
- Диффузионные модели: Представьте, что у вас есть очень размытая, зашумленная фотография. Диффузионная модель — это как искусный цифровой художник, который точно знает, как постепенно удалять размытие и шум шаг за шагом, пока не проявится оригинальная, четкая фотография. Она изучает этот процесс "размытия" путем изучения того, как изображения становятся зашумленными в первую очередь.
- Апостериорный вывод: Подумайте об этом как о попытке найти определенный вид редкой птицы. У вас есть общий справочник, который рассказывает обо всех птицах (априорные знания). Но затем вы получаете подсказку от местного эксперта: "Эта птица появляется только возле определенного типа деревьев" (ограничение). Апостериорный вывод — это процесс объединения ваших общих знаний о птицах с этой новой, конкретной подсказкой, чтобы сузить поиск и найти наиболее вероятные места для именно этой птицы.
- Коллапс мод: Представьте себе шеф-повара, которого попросили испечь разнообразные торты для вечеринки. Если шеф-повар испечет только шоколадные торты, хотя гости вечеринки хотят также ванильные, клубничные и лимонные торты, это и есть коллапс мод. Шеф-повар "схлопнулся" на одном типе торта (шоколадном) и не исследует полный спектр желаемых вариантов, даже если шоколадный торт очень хорош.
- Относительный баланс траекторий (RTB): Представьте канатоходца, пытающегося пересечь очень длинный, шаткий канат. Вместо того чтобы просто сосредоточиться на достижении другой стороны, что может привести к падению, RTB — это как иметь сложную систему датчиков, которая постоянно сравнивает прямое движение ходока с гипотетическим обратным движением относительно стабильного, известного пути. Это непрерывное, относительное сравнение помогает ходоку поддерживать идеальный баланс и надежно достигать цели, не отклоняясь и не застревая.
- Ограничение "черный ящик" $r(x)$: Представьте, что вы играете в видеоигру, где пытаетесь создать персонажа. Вы можете изменять различные черты, но есть таинственный "судья", который просто ставит вам оценку за привлекательность вашего персонажа, не объясняя, почему он поставил такую оценку. Вы не можете заглянуть в разум судьи; вы просто получаете число. Этот судья — ограничение "черный ящик": вы знаете его результат, но не его внутреннюю работу.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $p_{\theta}(x)$ | Предварительно обученная генеративная диффузионная модель (априорная), параметризованная $\theta$. |
| $r(x)$ | Положительная, "черный ящик" функция ограничения или правдоподобия. |
| $p_{\text{post}}(x)$ | Целевое апостериорное распределение, $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$. |
| $P_{\Phi}^{\text{post}}(\tau)$ | Вероятность траектории $\tau$ при апостериорной диффузионной модели, параметризованной $\Phi$. |
| $p_{\theta}(\tau)$ | Вероятность траектории $\tau$ при априорной диффузионной модели, параметризованной $\theta$. |
| $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ | Диффузионная траектория от начального шума $X_0$ до конечных данных $X_1$. |
| $X_t$ | Точка данных на промежуточном временном шаге $t$ в диффузионном процессе. |
| $u_{\Phi}^{\text{post}}(x_t, t)$ | Дрейфовый член апостериорного SDE, обучаемый нейронной сетью с параметрами $\Phi$. |
| $u_{\theta}(x_t, t)$ | Дрейфовый член априорного SDE, обучаемый нейронной сетью с параметрами $\theta$. |
| $\mathcal{L}_{\text{RTB}}(\tau; \Phi)$ | Функция потерь относительного баланса траекторий (RTB). |
| $Z$ | Нормализационная константа для апостериорного распределения. |
| $T$ | Общее количество дискретных временных шагов в диффузионном процессе. |
| $\Delta t$ | Длительность одного временного шага, $\Delta t = 1/T$. |
| $B$ | Размер пакетной аккумуляции для пакетного вычисления градиента. |
| $E[\log r(x)]$ | Ожидаемый логарифм вознаграждения, метрика того, насколько хорошо выборки удовлетворяют ограничению. |
| FID | Fréchet Inception Distance, метрика качества изображений и их сходства с целевым распределением. |
| BERTScore | Метрика качества генерации текста, сравнивающая сгенерированный текст с эталонным. |
| BLEU-4 | Метрика качества генерации текста, основанная на перекрытии n-грамм. |
| GLEU-4 | Метрика качества генерации текста, похожая на BLEU, но с лучшей корреляцией с человеческой оценкой. |
Определение проблемы и ограничения
Основная постановка проблемы и дилемма
Центральная проблема, рассматриваемая в данной статье, заключается в недоступном апостериорном выводе в диффузионных моделях при их использовании в качестве априорных для последующих задач. В частности, авторы стремятся преодолеть разрыв между наличием мощной генеративной диффузионной модели в качестве априорной и необходимостью выборки из ограниченной версии этой априорной модели.
Отправная точка (Вход/Текущее состояние) — это предварительно обученная генеративная диффузионная модель $p_{\theta}(x)$, которая эффективно моделирует сложные распределения данных (например, изображения, текст, действия). Наряду с этой априорной моделью существует ограничение "черный ящик" или функция правдоподобия $r(x)$, которая представляет дополнительные условия или предпочтения. Цель состоит в том, чтобы выполнить вывод по произведению этих двух распределений.
Желаемая конечная точка (Выход/Целевое состояние) — это новая, обученная диффузионная модель $p_{\phi}^{\text{post}}$, которая может беспристрастно выбирать из истинного апостериорного распределения $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$. Это означает, что обученная модель должна точно отражать комбинированное влияние априорной модели и ограничения, позволяя гибкую и точную условную генерацию или обучение политики.
Точное недостающее звено или математический пробел — это присущая недоступность прямого выбора из этого апостериорного распределения $p_{\text{post}}(x)$. Диффузионные модели генерируют выборки посредством глубокой цепочки стохастических преобразований, что делает точную выборку из $p_{\theta}(x)r(x)$ при "черном ящике" $r(x)$ недоступной. Предыдущие методы либо дают только приближенные решения, работают в ограниченных случаях, либо вводят смещения и страдают от таких проблем, как коллапс мод. Статья пытается преодолеть это, предлагая новый тренировочный объект, относительный баланс траекторий (RTB), который при удовлетворении гарантирует, что обученная апостериорная диффузионная модель $p_{\phi}^{\text{post}}$ выбирает из желаемого распределения. Математически, статья стремится обучить $p_{\phi}^{\text{post}}$ таким образом, чтобы она удовлетворяла ограничению относительного баланса траекторий:
$$Z p_{\phi}^{\text{post}}(X_0, X_{\Delta t}, \dots, X_1) = r(X_1) p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$$
где $Z$ — нормализационная константа, $X_0, \dots, X_1$ представляет собой траекторию шумоподавления, а $p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$ — совместная вероятность траектории при априорной модели.
Болезненный компромисс или дилемма, которая ставила в тупик предыдущих исследователей, заключается в основном между точностью/беспристрастностью и доступностью/вычислительной эффективностью. Существующие решения часто попадают в одну из этих ловушек:
1. Аппроксимация против смещения: Методы, основанные на линейных аппроксимациях или стохастической оптимизации, доступны, но часто дают смещенные результаты или их трудно масштабировать до задач высокой размерности. Например, направляющая классификатора, хотя и эффективна в некоторых случаях, дает смещенную аппроксимацию истинного апостериорного дрейфа.
2. Максимизация вознаграждения против покрытия мод: Методы обучения с подкреплением (RL), которые дообучают диффузионные модели для максимизации функции вознаграждения, часто страдают от коллапса мод. Они могут достигать высоких вознаграждений, фокусируясь на нескольких режимах с высоким вознаграждением, но ценой значительно худшего разнообразия и неточного представления полного апостериорного распределения. Это означает, что улучшение одного аспекта (вознаграждение) часто нарушает другой (разнообразие).
3. Обучение на политике против обучения вне политики: Обучение на политике, при котором траектории выбираются из текущей модели, может быть неэффективным и испытывать трудности с обнаружением всех мод апостериорного распределения. Хотя исследование вне политики может улучшить покрытие мод, оно вносит свои собственные проблемы, связанные со стабильностью обучения и эффективностью выборки.
Ограничения и режимы отказа
Проблема амортизации недоступного вывода в диффузионных моделях делает ее чрезвычайно сложной из-за нескольких суровых, реалистичных стен:
-
Вычислительные ограничения:
- Недоступность точной апостериорной выборки: Фундаментальная проблема заключается в том, что точная выборка из произведения диффузионной априорной модели и ограничения "черный ящик" $r(x)$ вычислительно недоступна, особенно учитывая иерархическую природу диффузионных моделей.
- Высокая размерность: Многие существующие методы вывода, включая оценки Монте-Карло и линейные аппроксимации, "трудно масштабировать до задач высокой размерности", таких как те, с которыми сталкиваются в задачах зрения, языка и управления.
- Пределы памяти оборудования: Для больших диффузионных моделей вычисление и хранение градиентов для всех шагов длинной траектории шумоподавления является "непомерным" из-за ограничений памяти оборудования. Это требует эффективных по памяти методов, таких как стохастическая субвыборка или пакетное вычисление градиентов, которые могут вносить компромиссы, такие как увеличение дисперсии градиента.
- Время обучения: Симуляционное обучение, необходимое для изучения апостериорных выборщиков, может быть "медленным и требовательным к памяти", как отмечено в разделе ограничений. Общее оценочное время вычислений для всех экспериментов в статье составляет 3000 часов на мощных GPU, что указывает на значительную вычислительную стоимость.
-
Ограничения, основанные на данных:
- Отсутствие несмещенных апостериорных выборок: Методы обучения, основанные на прямой супервизии от истинных апостериорных выборок, часто невыполнимы, поскольку такие выборки не предполагаются доступными. Например, направляющая классификатора требует дифференцируемого классификатора на зашумленных данных, который, как правило, недоступен для вывода или обучения без доступа к несмещенным данным.
- Разреженность данных для направляющего члена: Когда данные для обучения классификатора на зашумленных данных недоступны, исследователи должны прибегать к аппроксимациям, которые могут вводить смещение.
- Чувствительность к несовершенным априорным моделям: Предложенная функция потерь может быть чувствительна к "несовершенно подогнанной априорной модели", что может повлиять на стабильность обучения и производительность.
-
Математические и логические ограничения:
- Недифференцируемые ограничения: Функция ограничения $r(x)$ часто является "черным ящиком", что означает, что она может быть недифференцируемой, что усложняет оптимизацию на основе градиента. Хотя статья исследует случаи, когда $r(x_1)$ дифференцируема, общая постановка проблемы должна учитывать недифференцируемые сценарии.
- Смещение в аппроксимациях: Предыдущие методы, такие как направляющая классификатора или RL с регуляризацией KL на каждом шаге, вводят присущие смещения, которые не позволяют им асимптотически достигать истинного апостериорного распределения.
- Недоступность маргинальной KL-дивергенции: В контекстах, таких как дообучение RL для генерации изображений по тексту, маргинальная KL-дивергенция между дообученной моделью и априорной моделью недоступна для диффузионных моделей, что вынуждает полагаться на аппроксимации, такие как штрафы KL на каждом шаге, которые могут вводить смещение.
Почему этот подход
Неизбежность выбора
Принятие относительного баланса траекторий (RTB) было не просто выбором, а необходимостью, обусловленной присущей недоступностью апостериорного вывода в диффузионных моделях при их использовании в качестве априорных для последующих задач. В статье прямо указано, что "Диффузионные модели стали эффективными оценщиками распределений... но их использование в качестве априорных в последующих задачах представляет собой недоступную проблему апостериорного вывода." (Аннотация, стр. 1). Основная проблема вытекает из "иерархической природы генеративного процесса в диффузионных моделях", что делает "точную выборку из апостериорных распределений $p(x)r(x)$ при использовании функции 'черный ящик' $r(x)$ недоступной" (стр. 2).
Традиционные "SOTA" методы оказались недостаточными для этой конкретной задачи. Существующие подходы либо предлагают только приближенные решения, либо ограничены специфическими случаями. Например, распространенные методы вывода полагаются на линейные аппроксимации [73, 33, 31, 11] или стохастическую оптимизацию [22, 48], которые по своей сути вводят аппроксимации. Другая популярная стратегия включает оценку "направляющего" члена путем обучения классификатора на зашумленных данных [12]. Однако этот метод терпит неудачу, когда такие зашумленные данные недоступны, вынуждая полагаться на дальнейшие аппроксимации или оценки Монте-Карло [70, 14, 10], которые notoriously трудно масштабировать до задач высокой размерности. Кроме того, недавние методы обучения с подкреплением (RL) [8, 16], предложенные для этой проблемы, известны тем, что они смещены и подвержены коллапсу мод, как наглядно продемонстрировано на Рисунке 1 (стр. 3).
Авторы осознали, что для достижения асимптотически беспристрастной выборки из этих недоступных апостериорных распределений требуется принципиально иной подход. Это привело к разработке RTB, который выводится из перспективы генеративных сетей потоков для диффузионных моделей. Эта перспектива обеспечивает теоретическую основу для объекта, который может преодолеть ограничения предыдущих методов, предлагая путь к беспристрастной апостериорной выборке, где другие методы либо аппроксимируют, терпят неудачу или страдают от критических проблем, таких как коллапс мод.
Сравнительное превосходство
Относительный баланс траекторий (RTB) демонстрирует качественное превосходство над предыдущими золотыми стандартами благодаря нескольким структурным и операционным преимуществам, выходящим за рамки простых метрик производительности.
Во-первых, RTB является "асимптотически беспристрастным объектом, который восстанавливает разницу в дрейфах (и, следовательно, градиент логарифма свертки правдоподобия) без данных" (стр. 5). Это значительное структурное преимущество перед направляющей классификатора, которая, хотя и дает точное решение для апостериорного дрейфа, требует дифференцируемого классификатора на зашумленных данных, который часто недоступен для вывода или обучения без несмещенных выборок данных. RTB обходит эту зависимость от данных, предлагая более надежное и общее решение.
Во-вторых, метод демонстрирует превосходную эффективность памяти и масштабируемость. Важным наблюдением является то, что "градиент этого объекта по отношению к $\phi$ не требует дифференцирования (обратного распространения ошибки) в процесс выборки, который произвел траекторию $x_0 \rightarrow \dots \rightarrow x_1$" (стр. 5). Это свойство дает два ключевых преимущества:
1. Оптимизация вне политики: RTB может быть оптимизирован как объект вне политики, что означает, что траектории для обучения могут быть выбраны из распределения, отличного от самого целевого апостериорного распределения. Эта гибкость имеет решающее значение для "обеспечения покрытия мод" (стр. 5) и является явным преимуществом перед методами RL на политике, которые подвержены коллапсу мод (Рис. C.2, стр. 19).
2. Пакетное накопление градиентов: Вычисление градиента для RTB не требует хранения всего графа вычислений для всех временных шагов. Вместо этого "только размер пакетной аккумуляции B, а не длина траектории T, ограничен бюджетом памяти" (стр. 27). Это позволяет масштабировать обучение до большого количества шагов диффузии без увеличения дисперсии градиента за счет стохастической субвыборки, при этом время обучения растет линейно с количеством шагов при фиксированном бюджете памяти. Это значительно снижает сложность памяти, делая его подавляюще превосходящим для задач высокой размерности, где хранение полных траекторий является непомерным.
Наконец, универсальность RTB является качественным преимуществом. Статья демонстрирует его широкую применимость в различных областях, включая зрение (генерация изображений с направляющей классификатора, генерация изображений по тексту), язык (заполнение текста с дискретными диффузионными LLM) и непрерывное управление (автономное обучение с подкреплением). Такой широкий спектр успешных применений подчеркивает его структурное преимущество в обработке различных форм диффузионных априорных моделей и ограничений "черный ящик".
Соответствие ограничениям
Выбранный метод RTB идеально соответствует жестким требованиям проблемы, образуя прочный "брак" между определением проблемы и уникальными свойствами решения.
Основное ограничение, как определено в проблеме, заключается в необходимости выборки из "произведений распределений, где предварительно обученная диффузионная модель служит априорной моделью $p(x)$, которая умножается на вспомогательное ограничение $r(x)$" (стр. 2). RTB специально разработан для "обучения диффузионных моделей, которые выбирают из апостериорных распределений при априорной диффузионной модели" (§2.2), напрямую решая эту основную задачу.
Кроме того, вспомогательное ограничение $r(x)$ часто является "функцией ограничения или правдоподобия 'черный ящик'" (Аннотация, стр. 1), что означает, что его функциональная форма может быть сложной или недифференцируемой. RTB сформулирован для обработки "произвольного положительного ограничения $r(x_1)$" (стр. 5) и "произвольных правдоподобий 'черный ящик'" (стр. 10), что делает его высоко подходящим для сценариев, где функция ограничения нелегко поддается традиционным методам, основанным на градиенте.
Проблема также подчеркивает "недоступный апостериорный вывод" (Аннотация, стр. 1) как основное препятствие. RTB предоставляет "асимптотически беспристрастный тренировочный объект" (стр. 2), предлагая теоретически обоснованный способ решения этой недоступности, вместо того чтобы полагаться на аппроксимации, которые могут вводить смещение.
Для условных задач, где ограничения зависят от других переменных (например, $r(x_1; y) = p(y | x_1)$), RTB позволяет апостериорному дрейфу быть условным на $y$, обеспечивая "амортизированный вывод" и "обобщение на новые $y$, не виденные в обучении" (стр. 5). Это свойство имеет решающее значение для практических приложений, требующих эффективного вывода при меняющихся условиях.
Наконец, необходимость масштабирования до "задач высокой размерности" (стр. 2) и "больших диффузионных моделей" (стр. 5) налагает значительные ограничения по памяти и вычислениям. Эффективное по памяти обучение RTB, посредством пакетного накопления градиентов и стохастической субвыборки, напрямую решает эти практические ограничения. Способность масштабировать обучение с большим количеством шагов диффузии без увеличения бюджета памяти, как обсуждается в §H.1, идеально подходит для требовательного характера современных генеративных моделей.
Отклонение альтернатив
В статье представлены четкие обоснования для отклонения нескольких популярных подходов для конкретной проблемы амортизации недоступного апостериорного вывода в диффузионных моделях:
-
Традиционные методы вывода (линейные аппроксимации, стохастическая оптимизация): Авторы отмечают, что "распространенные решения этой проблемы включают методы вывода, основанные на линейных аппроксимациях [73, 33, 31, 11] или стохастической оптимизации [22, 48]" (стр. 2). Эти методы считаются недостаточными, поскольку они "решают только приблизительно или в ограниченных случаях" (Аннотация, стр. 1), не обеспечивая асимптотически беспристрастной выборки, к которой стремится RTB.
-
Направляющая классификатора (CG) / Выборка апостериорного распределения диффузии (DPS) / Диффузионный Монте-Карло с направляющей потерь (LGD-MC): Эти методы, которые пытаются оценить "направляющий" член, критикуются по нескольким причинам:
- Они "приводят к смещенным результатам" (Рис. 1, стр. 3).
- Они полагаются на "обучение классификатора на зашумленных данных [12]", что проблематично, "когда такие данные недоступны" (стр. 2).
- Вывод дифференцируемого классификатора на зашумленных данных "в общем случае недоступен" (стр. 5), а его обучение требует "несмещенных выборок данных", которые именно и стремится генерировать проблема.
- Экспериментально, "методы, основанные на направляющей классификатора, такие как DP и LGD-MC, демонстрируют высокое разнообразие, но не моделируют должным образом апостериорное распределение (наименьший логарифм $r(x)$)" (стр. 7). Они также достигают "более низких средних вознаграждений классификатора" и не "моделируют должным образом апостериорное распределение" (стр. 21).
-
Методы обучения с подкреплением (RL) (например, DPOK, DDPO): Хотя методы RL [8, 16] были предложены для этой проблемы, они страдают от критических недостатков:
- Они "смещены и подвержены коллапсу мод (Рис. 1)" (стр. 2). Рисунок E.1 (стр. 20) далее иллюстрирует "ранний коллапс мод" и "эксплуатацию вознаграждения" при чистом дообучении RL.
- "Чистое дообучение RL (без регуляризации KL) демонстрирует характеристики коллапса мод, достигая высоких вознаграждений в обмен на значительно худшее разнообразие и оценки FID" (стр. 7).
- Методы RL для дообучения диффузионных моделей обычно являются "на политике" (стр. 19), что делает их "подверженными коллапсу мод" (Рис. C.2, стр. 19).
- Методы, такие как DPOK и DDPO, оптимизируют верхнюю границу маргинальной KL-дивергенции с использованием штрафа на каждом шаге, что вводит смещение. RTB, напротив, "может избежать смещения в такой аппроксимации и напрямую научиться генерировать несмещенные выборки из апостериорного распределения $p(x_1 | z)$" (стр. 7).
В статье не обсуждается явное отклонение генеративно-состязательных сетей (GAN) для этой конкретной проблемы. Основное внимание уделяется улучшению апостериорного вывода в рамках диффузионной модели, где диффузионные модели уже зарекомендовали себя как априорные. Следовательно, прямое сравнение или отклонение GAN как альтернативной генеративной модели для самого априорного распределения выходит за рамки данного анализа.
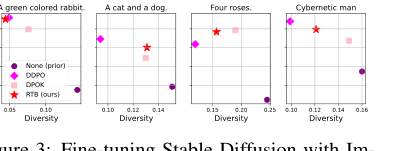 Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
Математический и логический механизм
Основное уравнение
Абсолютно ключевым уравнением, лежащим в основе этой статьи, является функция потерь относительного баланса траекторий (RTB). Этот объект заставляет апостериорную диффузионную модель выбирать из желаемого целевого распределения. Потери определяются как квадрат логарифма отношения, стремясь привести это отношение к единице.
$$ \mathcal{L}_{\text{RTB}}(\tau; \Phi) := \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right)^2 $$
Здесь $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ представляет собой полную траекторию в диффузионном процессе. Вероятности траекторий $P(\tau)$ сами по себе являются произведениями начального распределения и условных вероятностей переходов по дискретным временным шагам, как показано в Уравнении (3) статьи:
$$ P(\tau) = p(X_0) \prod_{i=1}^T P(X_{i\Delta t} | X_{(i-1)\Delta t}) $$
Пошаговый анализ по частям
Давайте разберем основное уравнение, чтобы понять роль каждой компоненты. Для ясности мы в основном сосредоточимся на термине внутри логарифма, поскольку его минимизация до нуля является прямой целью.
-
$\mathcal{L}_{\text{RTB}}$:
- Математическое определение: Функция потерь относительного баланса траекторий (RTB).
- Физическая/логическая роль: Это основной объект потерь, который модель стремится минимизировать во время обучения. Приведение этих потерь к нулю гарантирует удовлетворение ограничения относительного баланса траекторий (Уравнение 8 статьи). Это, в свою очередь, гарантирует, что апостериорная диффузионная модель $P_{\Phi}^{\text{post}}$ обучается выбирать из желаемого целевого апостериорного распределения $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$.
- Почему возведение в квадрат? Возведение логарифма отношения в квадрат является стандартным методом при проектировании функций потерь (аналогично среднеквадратичной ошибке). Оно гарантирует, что потери всегда неотрицательны и обеспечивает гладкий, дифференцируемый объект, что крайне важно для оптимизации на основе градиента. Оно наказывает большие отклонения от целевого отношения (равного 1) более значительно, чем меньшие, способствуя точному сближению.
-
$\tau = (X_0, X_{\Delta t}, \dots, X_1)$:
- Математическое определение: Конкретная траектория в диффузионном процессе, представляющая последовательность состояний от начального зашумленного состояния $X_0$ до конечной, шумоподавленной точки данных $X_1$, проходя через промежуточные состояния $X_{i\Delta t}$ на дискретных временных шагах.
- Физическая/логическая роль: Это фундаментальная единица операции для механизма RTB. Весь процесс обучения оценивает и корректирует модель на основе того, насколько хорошо она генерирует эти последовательные пути через пространство данных.
-
$\Phi$:
- Математическое определение: Набор обучаемых параметров для апостериорной диффузионной модели, $P_{\Phi}^{\text{post}}$. Эти параметры обычно определяют дрейфовый член $u_{\Phi}^{\text{post}}(x_t, t)$ лежащего в основе стохастического дифференциального уравнения (SDE), который часто реализуется как нейронная сеть.
- Физическая/логическая роль: Это веса и смещения нейронной сети, которые управляют тем, как апостериорная модель генерирует выборки. Процесс оптимизации корректирует $\Phi$ для согласования апостериорной выборки с желаемым целевым распределением.
-
$Z$:
- Математическое определение: Скалярная нормализационная константа, в частности $Z = \int q(x_1)r(x_1) dx_1$, как выведено в Предложении 1. Для численной устойчивости ее логарифм, $\log Z$, часто обучается или оценивается.
- Физическая/логическая роль: Этот член необходим для обеспечения правильной нормализации целевого апостериорного распределения $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$. Поскольку функция ограничения $r(X_1)$ может быть ненормализованным правдоподобием или вознаграждением, $Z$ масштабирует общую вероятность до интеграла, равного 1. Это важно для соответствия абсолютным вероятностям, а не только относительным пропорциям.
-
$r(X_1)$:
- Математическое определение: Положительная, "черный ящик" функция ограничения или правдоподобия, вычисленная для конечной точки данных $X_1$.
- Физическая/логическая роль: Этот член представляет собой "сигнал вознаграждения" или "направляющий" сигнал, который направляет диффузионный процесс к желаемым характеристикам. Например, это может быть правдоподобие классификатора $p(c|X_1)$ для определенного класса $c$, или функция вознаграждения $\exp(\beta Q(s,a))$ в обучении с подкреплением. Он кодирует специфические свойства, которыми должны обладать сгенерированные данные.
-
$p_{\theta}(\tau)$:
- Математическое определение: Вероятность траектории $\tau$ при априорной диффузионной модели, параметризованной $\theta$. Это обычно произведение начального распределения $p(X_0)$ и условных вероятностей переходов $P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$ для каждого шага.
- Физическая/логическая роль: Это представляет собой "базовый" или "безусловный" генеративный процесс. Это предварительно обученная диффузионная модель, которая генерирует данные без каких-либо специфических ограничений. Объект RTB использует это как точку отсчета для определения относительного баланса для апостериорной модели.
-
$P_{\Phi}^{\text{post}}(\tau)$:
- Математическое определение: Вероятность траектории $\tau$ при апостериорной диффузионной модели, параметризованной $\Phi$. Аналогично $p_{\theta}(\tau)$, это произведение $p(X_0)$ (часто совместно с априорной моделью) и условных вероятностей переходов $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$.
- Физическая/логическая роль: Это представляет собой генеративный процесс, из которого мы активно учимся выбирать желаемое апостериорное распределение. Его параметры $\Phi$ обновляются во время обучения, чтобы его траектории соответствовали ограничению $r(X_1)$ относительно априорной модели $p_{\theta}(\tau)$.
-
$\log(\cdot)$:
- Математическое определение: Натуральный логарифм.
- Физическая/логическая роль: Логарифм преобразует произведения вероятностей в суммы логарифмов вероятностей, что численно более устойчиво и часто легче оптимизируется. Он также преобразует отношения вероятностей в разности логарифмов вероятностей, что является распространенной техникой в теории информации (например, KL-дивергенция). Объект стремится сделать логарифм отношения равным нулю, что означает, что само отношение равно единице.
-
$\sum_{i=1}^T$:
- Математическое определение: Сумма по дискретным временным шагам $i$ от 1 до $T$.
- Физическая/логическая роль: Этот оператор агрегирует логарифмы отношений условных вероятностей переходов по всем дискретным шагам диффузионной траектории. Диффузионный процесс моделируется как последовательность $T$ дискретных шагов, а общая вероятность траектории является произведением этих пошаговых вероятностей. Логарифм преобразует это произведение в сумму, делая вклад каждого шага аддитивным к общему логарифму отношения.
- Почему сумма вместо интеграла? Статья явно моделирует диффузионный процесс как "дискретизированную по времени версию" SDE, где траектории представляют собой последовательности дискретных состояний $X_0, X_{\Delta t}, \dots, X_1$. Следовательно, сумма является естественным выбором для объединения вероятностей этих дискретных переходов, отражая дискретную природу реализованных диффузионных шагов.
-
$P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- Математическое определение: Условная вероятность перехода к состоянию $X_{i\Delta t}$ при условии предыдущего состояния $X_{(i-1)\Delta t}$ в апостериорной диффузионной модели. Для гауссовских диффузионных моделей это обычно гауссовское распределение $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$.
- Физическая/логическая роль: Этот член описывает, как апостериорная модель эволюционирует от одного временного шага к другому. Обученный дрейфовый член $u_{\Phi}^{\text{post}}$ (параметризованный $\Phi$) определяет среднее значение этого гауссовского перехода, эффективно направляя генерацию выборки к желаемому апостериорному распределению.
-
$P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- Математическое определение: Условная вероятность перехода к состоянию $X_{i\Delta t}$ при условии предыдущего состояния $X_{(i-1)\Delta t}$ в априорной диффузионной модели. Аналогично апостериорной модели, это гауссовское распределение $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\theta}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$.
- Физическая/логическая роль: Этот член описывает пошаговую эволюцию предварительно обученной априорной диффузионной модели. Он служит эталоном для переходов апостериорной модели. Отношение вероятностей апостериорной модели к априорной указывает, насколько апостериорная модель "отклоняется" от априорной на каждом шаге, чтобы удовлетворить ограничение.
Пошаговый поток
Давайте проследим точный жизненный цикл одной абстрактной точки данных, когда она проходит через этот математический механизм.
-
Генезис шума ($X_0$): Процесс начинается с абстрактной точки данных, изначально представляющей собой вектор чистого гауссовского шума $X_0$, выбранный из фиксированного, простого распределения, такого как $\mathcal{N}(0, I)$. Представьте это как сырую, неоформленную глину, из которой будет создаваться шедевр.
-
Конвейер генерации (траектория $\tau$):
- Генерируется полная траектория $\tau = (X_0, X_{\Delta t}, \dots, X_1)$. Эта траектория может быть сгенерирована текущей апостериорной моделью (выборка на политике) или альтернативным, исследовательским распределением (выборка вне политики).
- На каждом дискретном временном шаге $i$ от 1 до $T$ образец в процессе обработки, $X_{(i-1)\Delta t}$, поступает в "блок обработки". Здесь нейронная сеть (часть апостериорной диффузионной модели, параметризованная $\Phi$) предсказывает "дрейф" или "направление шумоподавления", $u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t}, (i-1)\Delta t)$.
- На основе этого предсказанного дрейфа и небольшого количества гауссовского шума образец преобразуется в следующее состояние, $X_{i\Delta t}$, в соответствии с условной вероятностью $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$. Это похоже на конвейерную ленту, где предмет постепенно совершенствуется и формируется.
- Это пошаговое преобразование продолжается до тех пор, пока на шаге $T$ не будет получен конечный, шумоподавленный образец данных, $X_1$.
-
Проверка контроля качества ($r(X_1)$): Как только конечная точка данных $X_1$ сходит с конвейера, она немедленно отправляется на станцию "контроля качества". Здесь функция ограничения "черный ящик" $r(X_1)$ оценивает, насколько хорошо $X_1$ соответствует желаемым критериям. Это может быть оценка вознаграждения, правдоподобие класса или любая другая мера качества. Это значение имеет решающее значение для определения успеха генеративного процесса.
-
Балансовый лист (расчет логарифма отношения):
- Теперь анализируется вся траектория $\tau$ (от $X_0$ до $X_1$). Вероятность этой конкретной траектории, полученной по апостериорной модели, $P_{\Phi}^{\text{post}}(\tau)$, вычисляется путем умножения вероятности начального шума на все условные вероятности переходов по пути.
- Параллельно вычисляется вероятность той же траектории, полученной по априорной диффузионной модели, $p_{\theta}(\tau)$. Эта априорная модель служит нейтральным эталоном.
- Затем эти вероятности объединяются с нормализационной константой $Z$ и ограничением $r(X_1)$ для формирования критического отношения: $\frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$.
- Берется натуральный логарифм этого отношения. Этот логарифм отношения является основным метрическим "балансом", который система стремится привести к нулю. Если он равен нулю, апостериорная модель идеально сбалансирована относительно априорной модели и ограничения.
-
Обзор производительности (вычисление потерь): Вычисленный логарифм отношения возводится в квадрат, чтобы получить потери $\mathcal{L}_{\text{RTB}}$ для данной траектории. Эти потери количественно определяют "дисбаланс" или "ошибку" в текущем генеративном процессе апостериорной модели.
-
Механизм корректировки (обновление параметров): Полученное значение потерь затем используется для генерации градиентов по отношению к параметрам апостериорной модели $\Phi$. Эти градиенты действуют как точные инструкции, указывая модели, как скорректировать свои внутренние механизмы (веса нейронной сети), чтобы уменьшить потери. Эта корректировка делает апостериорную модель более вероятной для генерации траекторий, которые удовлетворяют ограничению относительного баланса, эффективно обучаясь производить высококачественные, ограниченные выборки. Этот итеративный процесс совершенствует модель, подобно тому, как опытный инженер настраивает сложную машину.
Динамика оптимизации
Механизм относительного баланса траекторий (RTB) обучается, обновляется и сходится путем итеративной корректировки параметров $\Phi$ апостериорной диффузионной модели $P_{\Phi}^{\text{post}}$ посредством оптимизации на основе градиента функции потерь $\mathcal{L}_{\text{RTB}}$.
-
Ландшафт потерь и объект оптимизации: Функция потерь $\mathcal{L}_{\text{RTB}}$, будучи квадратом логарифма отношения, определяет ландшафт потерь, где глобальный минимум равен нулю. В этом минимуме ограничение относительного баланса траекторий $Z P_{\Phi}^{\text{post}}(\tau) = r(X_1) p_{\theta}(\tau)$ идеально удовлетворяется для всех траекторий $\tau$. Это означает, что апостериорная модель $P_{\Phi}^{\text{post}}$ научилась выбирать из целевого распределения $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$. Хотя лежащие в основе параметризации нейронных сетей делают ландшафт невыпуклым, логарифмические и квадратичные операции обеспечивают гладкий объект, подходящий для градиентной оптимизации. В статье упоминаются практические стратегии, такие как использование эмпирической дисперсии по мини-пакетам и обрезка потерь для стабилизации обучения и навигации по этому сложному ландшафту, особенно когда априорная модель несовершенна или функция ограничения $r(X_1)$ приводит к резким распределениям.
-
Поведение градиента и сигнал обучения: Ядром процесса обучения является градиент потерь $\mathcal{L}_{\text{RTB}}$ по отношению к параметрам апостериорной модели $\Phi$. Ключевым преимуществом, отмеченным авторами, является то, что этот градиент не требует обратного распространения ошибки через весь процесс выборки, который сгенерировал траекторию $\tau$. Вместо этого он в основном включает градиент логарифма вероятности апостериорной траектории, $\nabla_{\Phi} \log P_{\Phi}^{\text{post}}(\tau)$, масштабированный текущим отклонением логарифма отношения.
$$ \nabla_{\Phi} \mathcal{L}_{\text{RTB}}(\tau; \Phi) = 2 \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right) \nabla_{\Phi} \left( \log P_{\Phi}^{\text{post}}(\tau) \right) $$
Этот градиент действует как "корректирующий сигнал". Если член $\log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$ положителен (что означает, что $P_{\Phi}^{\text{post}}(\tau)$ слишком высок относительно цели), градиент толкает $\Phi$ к уменьшению $\log P_{\Phi}^{\text{post}}(\tau)$, делая эту траекторию менее вероятной при апостериорной модели. И наоборот, если член отрицателен, градиент толкает $\Phi$ к увеличению $\log P_{\Phi}^{\text{post}}(\tau)$, делая траекторию более вероятной. Величина этой корректировки пропорциональна тому, насколько текущая модель далека от удовлетворения ограничения баланса. Этот механизм позволяет апостериорной модели научиться "усиливать" траектории, которые приводят к высоким значениям $r(X_1)$, сохраняя при этом согласованную связь с априорной моделью $p_{\theta}(\tau)$. -
Обновления состояния и сходимость:
- Итеративные обновления состояния: Параметры $\Phi$ обновляются итеративно с использованием оптимизатора, такого как AdamW, в течение многих шагов обучения. На каждом шаге выбирается пакет траекторий. Для каждой траектории вычисляются потери $\mathcal{L}_{\text{RTB}}$, и градиенты накапливаются. Затем оптимизатор использует эти накопленные градиенты для корректировки $\Phi$, перемещая его к областям с меньшими потерями в пространстве параметров.
- Исследование вне политики: Значительным преимуществом RTB является его совместимость с обучением вне политики. Это означает, что траектории, используемые для обучения, могут быть выбраны из распределения, отличного от текущей апостериорной модели $P_{\Phi}^{\text{post}}$. Эта гибкость имеет решающее значение для эффективного покрытия мод, позволяя модели исследовать более широкий спектр потенциальных траекторий и избегать коллапса мод, распространенной ловушки, когда генеративные модели учатся производить только ограниченный набор выборок с высоким вознаграждением. Используя разнообразные траектории (например, из буферов воспроизведения или исследовательских модификаций), модель может научиться охватывать полный спектр целевого апостериорного распределения.
- Асимптотическая корректность: Статья устанавливает RTB как "асимптотически беспристрастный тренировочный объект". Эта теоретическая гарантия подразумевает, что при наличии достаточных данных и обучения ожидается, что модель сойдется к истинному апостериорному распределению. Непрерывное уменьшение квадрата логарифма отношения в сочетании с правильной обработкой нормализационной константы $Z$ приводит систему к состоянию, когда выполняется ограничение относительного баланса, что приводит к точной апостериорной выборке.
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые линии
Авторы тщательно разработали набор экспериментов в различных областях для строгого подтверждения эффективности относительного баланса траекторий (RTB) в амортизации недоступного апостериорного вывода в диффузионных моделях. Основная идея заключалась в демонстрации способности RTB выбирать из сложных апостериорных распределений, $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$, где $p_{\theta}(x)$ — диффузионная априорная модель, а $r(x)$ — ограничение "черный ящик" или функция правдоподобия.
Зрение: генерация изображений с направляющей классификатора
Для задач компьютерного зрения целью было обучение апостериорного диффузионного распределения $p_{\text{post}}(x|c) \propto p_{\theta}(x)p(c|x)$ для условной генерации изображений по классам.
- Наборы данных: Эксперименты проводились на двух наборах данных изображений с 10 классами: MNIST (32x32 одноканальные цифры, масштабированные с 28x28) и CIFAR-10 (32x32 трехканальные изображения).
- Априорные модели и ограничения: Готовые безусловные диффузионные априорные модели из [27] использовались для $p_{\theta}(x)$, а стандартные классификаторы $p(c|x)$ служили ограничениями $r(x)$.
- Архитектура обучения: Апостериорная диффузионная модель $p_{\phi}^{\text{post}}$ была дообучена с использованием RTB, инициализированная как копия априорной модели $p_{\theta}$. Эффективное дообучение параметров достигалось с использованием весов LoRA [28], которые составляли примерно 3% от общего числа параметров априорной модели. Объект RTB оптимизировался на траекториях, выбранных на политике из текущей апостериорной модели.
- Базовые линии: Производительность RTB сравнивалась с двумя категориями базовых линий:
- Дообучение на основе RL: DPOK [16] и DDPO [8].
- Направляющая классификатора: DPS [11] и LGD-MC [70].
- Экспериментальные настройки: Были протестированы три различных сценария: апостериорное распределение для одной цифры MNIST, апостериорное распределение для одного класса CIFAR-10 и более сложный случай апостериорного распределения для нескольких цифр MNIST (генерация четных или нечетных цифр, где $r(x) = \max_{i \in \{0,2,4,6,8\}} p(c=i|x)$).
- Метрики: Производительность оценивалась с использованием ожидаемого логарифма вознаграждения $E[\log r(x)]$ (чем выше, тем лучше), Fréchet Inception Distance (FID) для близости к истинным выборкам (чем ниже, тем лучше) и разнообразия (среднее попарное косинусное расстояние в пространстве признаков Inceptionv3, чем выше, тем лучше). FID вычислялся как оценка сходства истинного апостериорного распределения по данным, ограниченная общим количеством выборок на класс (5k-6k для цифр MNIST/CIFAR-10, 30k для четных/нечетных).
- Вычисления: Все эксперименты по зрению проводились на одном GPU NVIDIA V100.
Языковое моделирование: заполнение текста
Для оценки RTB на дискретных диффузионных моделях была выбрана задача заполнения текста, где модель должна была сгенерировать недостающее четвертое предложение $z$ при условии первых трех предложений $x$ и последнего предложения $y$ истории. Целевым апостериорным распределением было $p_{\text{post}}(z|x,y) \propto p(z|x)p_{\text{reward}}(y|x,z)$.
- Корпус: Использовался корпус ROCStories [50], состоящий из историй из 5 предложений.
- Априорная модель и ограничение: Языковая модель SEDD (Score Entropy Discrete Diffusion) [43] служила априорной моделью $p(z|x)$. Функция вознаграждения $p_{\text{reward}}(y|x,z)$ представляла собой авторегрессионную модель GPT-2 Large [57], дообученную на наборе данных историй с использованием библиотеки trl [81].
- Детали обучения: Объект RTB применялся к дискретным диффузионным моделям. Для управления вычислительными расходами (память и скорость) авторы использовали стохастический трюк TB (распространение градиентов через подмножество шагов траектории) и обрезку потерь. Для этой условной задачи использовался относительный объект VarGrad, а также темперирование правдоподобия вознаграждения.
- Базовые линии:
- Простое промптингование диффузионной LM с $x$ (Prompt (x)).
- Простое промптингование с $x, y$ (Prompt (x, y)).
- Авторегрессионные базовые линии языковых моделей из [29], включая дообучение GFlowNet и супервизионное дообучение.
- Метрики: Качество сгенерированных заполнений оценивалось с использованием BERTScore [90], BLEU-4 [54] и GLEU-4 [86] путем сравнения с эталонными заполнениями из набора данных.
- Вычисления: Эксперименты проводились на одном GPU NVIDIA A100-Large.
Непрерывное управление: автономное обучение с подкреплением
RTB применялся к задаче поиска политики с KL-ограничением в автономном обучении с подкреплением, целью которого было найти оптимальную политику $\pi^*(a|s) \propto \mu(a|s)\exp(\beta Q(s,a))$.
- Наборы данных: Использовался набор данных D4RL [18], в частности, задачи локамоции MuJoCo [76] halfcheetah, hopper и walker2d. Каждая задача включала наборы данных "medium", "medium-expert" и "medium-replay", представляющие различную степень субоптимальности априорной политики поведения.
- Априорная модель и ограничение: Диффузионная политика поведения DDPM [27] с условием на состояние служила априорной моделью поведения $\mu(a|s)$. Ограничение определялось как $\exp(\beta Q(s,a))$, где $Q(s,a)$ — это Q-функция, обученная с использованием IQL [36].
- Детали обучения: RTB дообучал диффузионную политику поведения для выбора из $\pi^*$, при этом ее веса инициализировались из обученной политики поведения. Использовался индуктивный байесовский принцип ланжевеновской динамики [11], и для сети масштабирования энергии обучался дополнительный MLP. Для неявной оценки $\log Z(s)$ использовался объект VarGrad [61]. Использовалось исследование вне политики путем использования автономного набора данных, который содержал выборки из эпизодов с высоким вознаграждением, что приводило к "смешанному обучению" (вне политики и на политике).
- Базовые линии: Были сравнены комплексные базовые линии обучения с подкреплением вне политики на современном уровне: Behavior Cloning (BC), CQL [37], IQL [36], Diffuser (D) [30], Decision Diffuser (DD) [2], D-QL [83], IDQL [25] и QGPO [44].
- Метрики: Основной метрикой было среднее вознаграждение обученных политик, представленное как среднее $\pm$ стандартное отклонение по 5 случайным семенам.
- Вычисления: Все эксперименты по автономному обучению с подкреплением проводились на одном GPU NVIDIA A100-Large.
Что доказывают свидетельства
Экспериментальные свидетельства недвусмысленно демонстрируют, что относительный баланс траекторий (RTB) обеспечивает надежный и универсальный метод для амортизированного апостериорного вывода в диффузионных моделях, превосходя или соответствуя базовым линиям на современном уровне в задачах компьютерного зрения, языка и непрерывного управления. Основной механизм RTB — асимптотически беспристрастное обучение для выборки из произведений распределений — был безжалостно доказан его способностью балансировать вознаграждение и разнообразие, а также точно моделировать сложные апостериорные распределения, где другие методы терпели неудачу.
Зрение: убедительные доказательства беспристрастного вывода
- Превосходный баланс вознаграждения и разнообразия: В генерации изображений с направляющей классификатора (Таблица 2) RTB последовательно достигал превосходного баланса между высоким ожидаемым логарифмом вознаграждения ($E[\log r(x)]$) и высоким разнообразием (среднее попарное косинусное расстояние), сохраняя при этом низкие значения FID (близость к истинным выборкам). Например, на CIFAR-10 RTB достиг $E[\log r(x)]$ -2.1625 и FID 0.4717, что значительно лучше, чем у методов направляющей классификатора, таких как DPS (-3.6025 $E[\log r(x)]$) и LGD-MC (-3.0988 $E[\log r(x)]$), которые имели более низкие вознаграждения, несмотря на высокое разнообразие.
-
Преодоление коллапса мод: Наиболее убедительные визуальные свидетельства статьи (Рисунок 1) показывают, что выборки RTB очень похожи на истинное апостериорное распределение (Рисунок 1c), которое представляет собой смесь гауссовских распределений с 9 активными модами. В отличие от этого, чистые методы RL без регуляризации KL (DDPO) страдали от сильного коллапса мод (Рисунок 1e), фокусируясь только на нескольких модах, несмотря на высокие вознаграждения. Даже RL с настроенной регуляризацией KL (DPOK) давал неточные выводы (Рисунок 1d), а направляющая классификатора (CG) приводила к смещенным результатам (Рисунок 1f). Эти визуально неоспоримые свидетельства доказывают способность RTB избегать коллапса мод и точно покрывать апостериорное распределение.
-
Высококачественные, разнообразные выборки: Рисунок 2 и Рисунок 4 демонстрируют высокое визуальное качество и разнообразие изображений, сгенерированных моделями, дообученными с помощью RTB, для различных запросов (например, "Кролик зеленого цвета", "Кошка и собака", "Четыре розы"). Эти качественные результаты подкрепляют количественные метрики, демонстрируя, что основной механизм RTB приводит к более качественным и разнообразным выходным данным.
-
Асимптотически беспристрастный: В статье подчеркивается, что RTB является асимптотически беспристрастным объектом обучения, который восстанавливает истинную разницу в дрейфах, в отличие от направляющей классификатора, которая полагается на смещенную аппроксимацию апостериорной функции оценки. Это теоретическое преимущество подтверждается экспериментальными результатами, где RTB последовательно достигает лучшего моделирования апостериорного распределения.
Языковое моделирование: высокая производительность при заполнении текста
- Превосходство над авторегрессионными базовыми линиями: Для заполнения текста (Таблица 3) RTB с дискретной диффузионной априорной моделью достиг наивысших значений BERTScore (0.156), BLEU-4 (0.025) и GLEU-4 (0.045) среди всех базовых линий, кроме SFT. Это демонстрирует способность RTB генерировать более согласованные и последовательные заполнения, значительно превосходя простые базовые линии промптингования и даже самую сильную авторегрессионную базовую линию дообучения GFlowNet (BERTScore 0.102). Это является сильным показателем того, что механизм RTB для обработки дискретных диффузионных моделей эффективно улучшает условную генерацию текста.
Непрерывное управление: автономное обучение с подкреплением на современном уровне
- Соответствие вознаграждениям на современном уровне: В автономном обучении с подкреплением (Таблица 4) RTB достиг результатов на современном уровне или конкурентоспособных на эталонных тестах D4RL. Например, на
hopper-medium-replayRTB показал результат 100.40, что соответствует или превосходит другие ведущие методы, такие как DD (100.00) и D-QL (100.70). Это доказывает, что RTB может эффективно изучать оптимальные политики, выбирая из апостериорного распределения с KL-ограничением, даже при субоптимальных априорных политиках поведения. - Устойчивость к субоптимальным априорным моделям: RTB показал особенно сильные результаты в задачах "medium-replay", которые характеризуются высокой степенью субоптимальности данных и, следовательно, худшими априорными моделями поведения. Эта устойчивость является критически важным свидетельством, показывающим, что возможности RTB по обучению вне политики позволяют ему эффективно обучаться даже при неидеальной начальной априорной модели, что является распространенной проблемой в реальных сценариях RL.
- Преимущества исследования вне политики: Таблица G.1 далее подтвердила преимущество возможностей RTB по обучению вне политики, показав, что "смешанное обучение" (комбинирование выборок вне политики и на политике) превосходило чистое обучение на политике в двух из трех задач medium-replay. Это напрямую подтверждает утверждение о том, что гибкость RTB в использовании разнообразных траекторий улучшает эффективность обучения и производительность.
По сути, свидетельства из этих разнообразных областей представляют убедительный нарратив: принципиальный подход RTB к амортизированной апостериорной выборке, основанный на относительном балансе траекторий, последовательно дает превосходные или конкурентоспособные результаты, эффективно управляя компромиссами между максимизацией вознаграждения и покрытием мод, проблемой, которая часто преследует другие методы вывода.
Ограничения и будущие направления
Хотя относительный баланс траекторий (RTB) представляет собой мощную и универсальную основу для амортизированного апостериорного вывода в диффузионных моделях, авторы откровенно признают несколько ограничений и предлагают захватывающие направления для будущих исследований.
Ограничения
- Вычислительная стоимость и интенсивность памяти: Основное ограничение заключается в том, что RTB обучает апостериорное распределение посредством симуляционного обучения, которое может быть как медленным, так и требовательным к памяти. Хотя в статье представлены методы, такие как стохастическая субвыборка и пакетное вычисление градиентов, для снижения использования памяти для самого RTB, фундаментальная природа симуляции траекторий для обучения остается узким местом. Это особенно актуально для крупномасштабных моделей или данных высокой размерности.
- Высокая дисперсия градиента: Объект RTB вычисляется на полных траекториях. Это означает, что функция потерь не предоставляет локальный сигнал кредитного присвоения для отдельных шагов в пределах траектории. Следовательно, градиенты могут демонстрировать высокую дисперсию, что может препятствовать стабильности и эффективности обучения.
- Отсутствие теоретических гарантий при несовершенных соответствиях: В статье отмечается, что теоретические гарантии относительно ошибки, возникающей из-за несовершенного соответствия априорной модели, эффектов амортизации и влияния дискретизации по времени (аналогично существующим анализам для диффузионных выборщиков [7]), еще не полностью установлены. Такие гарантии дадут более глубокое понимание поведения RTB в неидеальных условиях.
- Неприменимость к методам дифференцируемой симуляции: Методы экономии памяти, разработанные для RTB (стохастическая субвыборка, пакетное вычисление градиентов), не являются универсально применимыми. В частности, диффузионные выборщики, основанные на дифференцируемой симуляции (например, Path Integral Sampler (PIS) и Denoising Diffusion Samplers (DDS)), по-прежнему требуют хранения всего графа вычислений интеграции SDE, что приводит к требованиям к памяти, масштабирующимся линейно с длиной траектории.
Будущие направления
Результаты открывают несколько перспективных направлений исследований, расширяющих границы диффузионных моделей и обучения с подкреплением:
- Улучшенное обучение вне политики и исследование: Статья подчеркивает совместимость RTB с траекториями вне политики. Будущие работы могут глубже изучить использование передовых методов обучения вне политики, таких как локальный поиск [34, 65], для дальнейшего повышения эффективности выборки и, что крайне важно, покрытия мод. Это может включать более сложные стратегии исследования для обнаружения труднодоступных мод апостериорного распределения.
- Исследование симуляционных объектов: Авторы предлагают исследовать другие симуляционные объекты, аналогичные тем, что используются в [89], для задач амортизированной выборки. Это может привести к альтернативным формулировкам, предлагающим различные компромиссы в отношении вычислительной стоимости, дисперсии градиента и производительности.
- Разработка расширений без симуляции: Исследование расширений без симуляции, таких как объекты, локальные по времени [45], может потенциально решить проблемы вычислительной интенсивности и интенсивности памяти, связанные с обучением на основе полных траекторий. Это стало бы значительным шагом к повышению масштабируемости RTB.
- Применение к обратным задачам с правдоподобиями "черный ящик": Уникальная способность RTB обрабатывать произвольные правдоподобия "черный ящик" делает его идеальным кандидатом для широкого спектра обратных задач. Это включает:
- Синтез 3D-объектов: Использование правдоподобий, вычисленных с помощью рендереров [например, 56, 82], для генерации 3D-объектов из 2D-наблюдений.
- Задачи обработки изображений: Применение RTB к сложным задачам в астрономии [например, 1] и медицинской визуализации [например, 73], где функции правдоподобия могут быть сложными и недифференцируемыми.
- Предсказание молекулярной структуры: Использование RTB для решения сложных задач в молекулярной биологии [например, 84], где цель состоит в выводе молекулярных структур из экспериментальных данных.
- Прорывы в молекулярной динамике: Особо захватывающей перспективой является потенциал RTB для содействия прорывам в моделировании молекулярной динамики. Преобразуя чрезвычайно сложную задачу выборки редких событий в химических симуляциях в проблему апостериорного вывода по усиленным распределениям редких событий, RTB может предложить новый подход к пониманию сложных химических процессов. Предварительная работа Сеонга и др. [66] с использованием TB с вознаграждением, умноженным на априорное правдоподобие (эффективно RTB), поддерживает это направление.
- Строгость в теоретическом анализе: Будущая работа должна быть сосредоточена на предоставлении строгих теоретических гарантий для RTB, особенно в отношении влияния несовершенной априорной модели, эффектов амортизации и последствий дискретизации по времени. Это укрепит фундаментальное понимание метода.
Обсуждение более широкого воздействия
Авторы также вдумчиво рассматривают более широкие социальные последствия своей работы. Как и другие достижения в области генеративного моделирования, RTB потенциально может быть использован "злоумышленниками" для обучения моделей, производящих вредоносный контент или дезинформацию. Однако они также подчеркивают позитивный потенциал: RTB может быть использован для смягчения смещений, присутствующих в предварительно обученных моделях, и применяться к различным научным проблемам, способствуя разнообразию точек зрения и стимулируя критическое мышление об ответственном развитии и развертывании таких мощных генеративных технологий ИИ.
 Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
 Figure 2. Samples from RTB fine-tuned diffusion posteriors
Figure 2. Samples from RTB fine-tuned diffusion posteriors
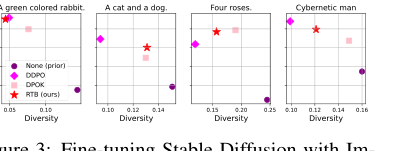 Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
 Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted
Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted