扩散模型在视觉、语言和控制中的非渐进式推理摊销
Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem.
背景与学术渊源
起源与学术渊源
本文所解决的问题精确地源于扩散模型近期在计算机视觉、自然语言处理和强化学习等多个领域的成功及其广泛应用。尽管这些模型通过学习逆转渐进式加噪过程,在生成高质量数据方面表现出色,但它们在下游任务中的应用通常需要更复杂的推理形式:从后验分布中采样。
历史上,扩散模型最早由 Sohl-Dickstein 等人在 2015 年 [68] 提出,是一类层次化生成模型,用于学习建模复杂的数据分布。其核心思想是定义一个前向扩散过程,该过程逐渐向数据添加噪声,将其转化为一个简单、易于处理的分布(如高斯噪声)。然后,训练一个神经网络来学习逆向过程,通过逐步去噪数据来生成新的样本。
当这些预训练的扩散模型被用作先验 $p(x)$,并且在期望输出必须满足一个额外的、通常很复杂的约束 $r(x)$ 的场景中时,具体问题就出现了。这个约束可以是分类器的似然度(例如,生成特定类别的图像)、强化学习中的奖励函数(例如,生成最大化奖励的动作),或者用于填充缺失文本的语言模型的似然度。目标就变成从乘积分布 $p_{\text{post}}(x) \propto p(x)r(x)$ 中采样,该分布代表了贝叶斯后验。这个问题尤其具有挑战性,因为扩散模型的层次化特性使得从这种后验中精确采样变得难以处理,特别是当 $r(x)$ 是一个不提供简单解析解的“黑盒”函数时。
先前方法的根本局限性或“痛点”在于它们无法准确有效地执行这种难以处理的后验推理。现有方法通常分为几类,每类都有显著的缺点:
* 线性近似或随机优化:这些方法通常只提供近似解 [73, 33, 31, 11, 22, 48],可能无法忠实地捕捉真实的后验分布。
* 引导项估计:像分类器引导 [12] 这样的技术试图通过在加噪数据上训练一个分类器来估计一个“引导”项。然而,这种方法受到限制,因为它需要特定的加噪数据,并且在这些数据不可用时,它会诉诸于近似或蒙特卡洛估计 [70, 14, 10]。这些近似值在扩展到高维问题时众所周知地难以处理,而高维问题在现代生成任务中很常见。
* 强化学习 (RL) 方法:最近针对此问题的基于 RL 的方法 [8, 16],虽然有前景,但已被证明是有偏的并遭受模式崩溃。模式崩溃意味着模型无法生成多样化的样本,而是陷入只生成少数高奖励示例,从而未能充分探索真实的后验分布。这种在从完整后验分布中采样时的多样性和准确性不足,是扩散模型在复杂下游任务中可靠且通用应用的主要障碍。
直观的领域术语
以下是论文中的几个专业领域术语,通过直观的类比进行翻译:
- 扩散模型 (Diffusion Models):想象你有一张非常模糊、充满噪点的照片。扩散模型就像一位技艺精湛的数字艺术家,他确切地知道如何逐步去除模糊和噪点,直到恢复出原始的清晰照片。它通过研究图像最初是如何变得模糊的来学习这种“去模糊”过程。
- 后验推理 (Posterior Inference):这就像试图找到一种特定的稀有鸟类。你有一本通用的野外指南,告诉你关于所有鸟类的信息(“先验”知识)。但随后,你从当地专家那里得到一个提示:“这种鸟只出现在一种特定树附近”(“约束”)。后验推理就是结合你的通用鸟类知识和这个新的、具体的提示,来缩小搜索范围,找到这种特定鸟类最可能出现的位置的过程。
- 模式崩溃 (Mode Collapse):想象一位厨师被要求为派对烘烤各种蛋糕。如果厨师只烤巧克力蛋糕,即使派对参与者也想要香草、草莓和柠檬蛋糕,那就是模式崩溃。厨师已经“崩溃”到一种蛋糕(巧克力)上,并且没有探索到期望选项的全部范围,即使巧克力蛋糕非常好。
- 相对轨迹平衡 (Relative Trajectory Balance, RTB):考虑一个走钢丝的人试图穿越一根非常长、摇晃的绳子。RTB 不是仅仅关注到达另一边(这可能导致摔倒),而是像拥有一个复杂的传感器系统,不断地将行人的前进运动与假定的后退运动进行比较,相对于一条稳定、已知的路径。这种持续的、相对的比较有助于行人保持完美的平衡并可靠地到达目的地,而不会偏离或卡住。
- 黑盒约束 $r(x)$ (Black-box constraint $r(x)$):想象你在玩一个视频游戏,试图设计一个角色。你可以改变各种特征,但有一个神秘的“评委”只会给你的角色的吸引力打分,而不会解释为什么他们会给出这个分数。你无法看到评委的内心;你只得到一个数字。这个评委就是一个黑盒约束——你知道它的输出,但不知道它的内部工作原理。
符号表
| 符号 | 描述 |
|---|---|
| $p_{\theta}(x)$ | 预训练的扩散生成模型(先验),由 $\theta$ 参数化。 |
| $r(x)$ | 一个正的、黑盒的约束或似然函数。 |
| $p_{\text{post}}(x)$ | 目标后验分布, $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$。 |
| $P_{\Phi}^{\text{post}}(\tau)$ | 在后验扩散模型下轨迹 $\tau$ 的概率,由 $\Phi$ 参数化。 |
| $p_{\theta}(\tau)$ | 在先验扩散模型下轨迹 $\tau$ 的概率,由 $\theta$ 参数化。 |
| $\tau = (X_0, X_{\Delta t}, \dots, X_1)$ | 从初始噪声 $X_0$ 到最终数据 $X_1$ 的扩散轨迹。 |
| $X_t$ | 扩散过程中中间时间步 $t$ 的数据点。 |
| $u_{\Phi}^{\text{post}}(x_t, t)$ | 后验 SDE 的漂移项,由参数为 $\Phi$ 的神经网络学习。 |
| $u_{\theta}(x_t, t)$ | 先验 SDE 的漂移项,由参数为 $\theta$ 的神经网络学习。 |
| $\mathcal{L}_{\text{RTB}}(\tau; \Phi)$ | 相对轨迹平衡 (RTB) 损失函数。 |
| $Z$ | 后验分布的归一化常数。 |
| $T$ | 扩散过程中离散时间步的总数。 |
| $\Delta t$ | 单个时间步的时长, $\Delta t = 1/T$。 |
| $B$ | 用于批量梯度计算的累积批次大小。 |
| $E[\log r(x)]$ | 期望对数奖励,衡量样本满足约束的程度的指标。 |
| FID | Fréchet Inception Distance,衡量图像质量和与目标分布相似度的指标。 |
| BERTScore | 衡量文本生成质量的指标,比较生成文本与参考文本。 |
| BLEU-4 | 衡量文本生成质量的指标,基于 n-gram 重叠。 |
| GLEU-4 | 衡量文本生成质量的指标,与 BLEU 类似但与人类判断的相关性更好。 |
问题定义与约束
核心问题表述与困境
本文的核心问题是当扩散模型用作下游任务的先验时,其难以处理的后验推理。具体来说,作者旨在弥合拥有强大的生成扩散模型作为先验与需要从约束版本先验中采样之间的差距。
起点(输入/当前状态)是一个预训练的扩散生成模型,表示为 $p_{\theta}(x)$,它有效地建模了复杂的数据分布(例如,图像、文本、动作)。与此先验并行的是一个黑盒约束或似然函数 $r(x)$,它代表了额外的条件或偏好。目标是对这两个分布的乘积进行推理。
期望终点(输出/目标状态)是一个新的、训练好的扩散模型 $p_{\phi}^{\text{post}}$,它可以无偏地从真实的后验分布 $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$ 中采样。这意味着训练好的模型应该准确地反映先验和约束的组合影响,从而实现灵活准确的条件生成或策略学习。
精确缺失的环节或数学鸿沟是直接从后验 $p_{\text{post}}(x)$ 中采样固有的难以处理性。扩散模型通过深度随机变换链生成样本,使得在黑盒 $r(x)$ 下从 $p_{\theta}(x)r(x)$ 中精确采样变得难以处理。先前的方法要么只提供近似解,要么仅限于受限情况,要么引入了偏差并遭受模式崩溃等问题。本文试图通过提出一种新颖的训练目标——相对轨迹平衡 (RTB)——来弥合这一差距,当满足该目标时,可以确保训练好的后验扩散模型 $p_{\phi}^{\text{post}}$ 从期望的分布中采样。在数学上,本文旨在训练 $p_{\phi}^{\text{post}}$ 以使其满足相对轨迹平衡约束:
$$Z p_{\phi}^{\text{post}}(X_0, X_{\Delta t}, \dots, X_1) = r(X_1) p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$$
其中 $Z$ 是归一化常数,$X_0, \dots, X_1$ 代表一个去噪轨迹,而 $p_{\theta}(X_0, X_{\Delta t}, \dots, X_1)$ 是轨迹在先验下的联合概率。
困扰先前研究人员的痛苦权衡或困境主要是准确性/无偏性与可处理性/计算效率之间的权衡。现有解决方案通常落入以下陷阱之一:
1. 近似 vs. 偏差:依赖于线性近似或随机优化的方法是可处理的,但通常会产生有偏的结果或难以扩展到高维问题。例如,分类器引导虽然在某些情况下有效,但提供了真实后验漂移的有偏近似。
2. 奖励最大化 vs. 模式覆盖:基于强化学习 (RL) 的方法,它们微调扩散模型以最大化奖励函数,经常遭受模式崩溃。它们可能通过专注于少数高奖励模式来获得高奖励,但代价是多样性显著下降,并且对完整后验分布的表示不准确。这意味着改进一个方面(奖励)通常会破坏另一个方面(多样性)。
3. On-policy vs. Off-policy 训练:On-policy 训练(从当前模型采样轨迹)可能效率低下,并且难以发现后验的所有模式。虽然 off-policy 探索可以改善模式覆盖,但它带来了训练稳定性和样本效率方面的挑战。
约束与失败模式
扩散模型中难以处理的推理摊销问题因几个严酷的、现实的障碍而变得异常困难:
-
计算约束:
- 精确后验采样难以处理:根本挑战在于,从扩散先验和黑盒约束 $r(x)$ 的乘积中精确采样在计算上是难以处理的,特别是考虑到扩散模型的层次化特性。
- 高维性:许多现有的推理技术,包括蒙特卡洛估计和线性近似,都“难以扩展到高维问题”,例如在视觉、语言和控制任务中遇到的问题。
- 硬件内存限制:对于大型扩散模型,计算和存储长去噪轨迹中所有步骤的梯度,由于硬件内存限制而“不可行”。这需要内存高效的技术,如随机子采样或批量梯度计算,这可能会引入梯度方差增加等权衡。
- 训练时间:学习后验采样器所需的基于仿真的训练可能“缓慢且内存密集”,正如在局限性部分所指出的。论文中所有实验的总估计计算时间为 3000 小时在强大的 GPU 上,这表明了显著的计算成本。
-
数据驱动约束:
- 缺乏无偏后验样本:依赖于真实后验样本直接监督的训练方法通常是不可行的,因为假定这些样本不可用。例如,分类器引导需要一个在加噪数据上的可微分分类器,这通常是难以推导或学习的,除非能获得无偏数据。
- 引导项数据稀疏性:当用于在加噪数据上训练分类器的数据不可用时,研究人员必须诉诸于近似,这可能会引入偏差。
- 对不完美先验模型的敏感性:提出的损失函数可能对“不完美拟合的先验模型”敏感,这会影响训练稳定性和性能。
-
数学与逻辑约束:
- 不可微约束:约束函数 $r(x)$ 通常是“黑盒”,这意味着它可能不可微,这使基于梯度的优化复杂化。虽然本文探讨了 $r(x_1)$ 可微的情况,但一般问题表述必须考虑不可微场景。
- 近似中的偏差:先前的方法,如分类器引导或带有每步 KL 正则化的 RL,引入了固有的偏差,阻止它们渐近地达到真实的后验。
- 模式崩溃:RL-based 微调方法,特别是那些没有足够正则化的方法,容易发生模式崩溃,即模型只采样后验模式的子集,导致生成样本缺乏多样性。
- 边际 KL 散度难以处理:在文本到图像生成等 RL 微调的背景下,微调模型与先验之间的边际 KL 散度对于扩散模型来说是难以处理的,迫使依赖于每步 KL 惩罚等近似,这可能会引入偏差。
为什么选择这种方法
选择的必然性
采用相对轨迹平衡 (RTB) 不仅仅是一个选择,而是由扩散模型用作下游任务先验时后验推理的固有难以处理性所驱动的必然。本文明确指出,“扩散模型已成为有效的分布估计器……但它们作为下游任务先验的使用带来了难以处理的后验推理问题。”(摘要,第 1 页)。核心问题源于“扩散模型中生成过程的层次化特性”,这使得“在黑盒函数 $r(x)$ 下从后验 $p(x)r(x)$ 中精确采样是难以处理的”(第 2 页)。
传统的“SOTA”方法不足以应对这一特定挑战。现有方法要么只提供近似解,要么仅限于受限情况。例如,常见的推理技术依赖于线性近似 [73, 33, 31, 11] 或随机优化 [22, 48],这些方法固有地引入了近似。另一种流行策略是通过在加噪数据上训练分类器来估计“引导”项 [12]。然而,当这些加噪数据不可用时,该方法就会失效,迫使依赖于进一步的近似或蒙特卡洛估计 [70, 14, 10],这些估计在扩展到高维问题方面极其困难。此外,最近为此问题提出的强化学习 (RL) 方法 [8, 16] 已知是有偏的且易受模式崩溃影响,正如图 1(第 3 页)所直观展示的。
作者意识到需要一种根本不同的方法来实现从这些难以处理的后验中渐近无偏采样。这导致了 RTB 的开发,它源于扩散模型的生成流网络视角。这种视角为一种可以克服先前方法局限性的目标提供了理论基础,为在其他技术要么近似、失败或遭受模式崩溃等关键问题的情况下实现无偏后验采样提供了途径。
比较优势
相对轨迹平衡 (RTB) 通过几个结构和操作优势,超越了先前黄金标准,这些优势超出了单纯的性能指标。
首先,RTB 是一个“渐近无偏的目标,它以无数据的方式恢复漂移的差异(以及对数卷积似然的梯度)”(第 5 页)。这与分类器引导相比是一个显著的结构优势,分类器引导虽然为后验漂移提供了精确解,但需要一个在加噪数据上的可微分分类器,而该分类器通常难以推导或学习,除非能获得无偏数据样本。RTB 规避了这种数据依赖性,提供了更鲁棒和通用的解决方案。
其次,该方法表现出优越的内存效率和可扩展性。一个关键的见解是,“该目标相对于 $\phi$ 的梯度不需要(反向传播)到产生轨迹 $x_0 \to \dots \to x_1$ 的采样过程中”(第 5 页)。这一特性带来了两个关键优势:
1. Off-policy 优化:RTB 可以作为 off-policy 目标进行优化,这意味着用于训练的轨迹可以从与目标后验本身不同的分布中采样。这种灵活性对于“确保模式覆盖”(第 5 页)至关重要,并且是容易模式崩溃的 on-policy RL 方法的一个显著优势(图 C.2,第 19 页)。
2. 批量梯度累积:RTB 的梯度计算不需要存储整个计算图的所有时间步。相反,“只有累积批次大小 B,而不是轨迹长度 T,受内存预算的限制”(第 27 页)。这使得在不增加随机子采样引入的梯度方差的情况下,将训练扩展到大量扩散步骤成为可能,并且在固定内存预算下,训练时间随步数线性增长。这极大地降低了内存复杂性,使其在高维问题上具有压倒性优势,因为在高维问题上存储完整轨迹是不可行的。
最后,RTB 的多功能性是一个定性优势。本文展示了其在视觉(分类器引导图像生成、文本到图像生成)、语言(使用离散扩散 LLM 进行填充)和连续控制(离线强化学习)等不同领域的广泛适用性。如此广泛的成功应用突显了其处理各种扩散先验和黑盒约束的结构优势。
与约束的对齐
所选的 RTB 方法与问题的严苛要求完美契合,形成了“婚姻”,将问题定义与解决方案的独特属性紧密结合。
问题中定义的主要约束是需要从“乘积分布中采样,其中预训练的扩散模型充当先验 $p(x)$,并乘以一个辅助约束 $r(x)$”(第 2 页)。RTB 明确设计用于“训练从扩散模型先验下的后验分布中采样的扩散模型”(§2.2),直接解决了这一核心要求。
此外,辅助约束 $r(x)$ 通常是“黑盒约束或似然函数”(摘要,第 1 页),这意味着其函数形式可能很复杂或不可微。RTB 被设计为处理“任意正约束 $r(x_1)$”(第 5 页)和“任意黑盒似然”(第 10 页),使其非常适合约束函数不易进行传统梯度优化方法的场景。
问题还强调了“难以处理的后验推理”(摘要,第 1 页)是主要障碍。RTB 提供了一个“渐近无偏的训练目标”(第 2 页),提供了一种理论上可靠的方法来解决这种难以处理性,而不是依赖于可能引入偏差的近似。
对于依赖于其他变量的条件问题(例如,$r(x_1; y) = p(y | x_1)$),RTB 允许后验漂移根据 $y$ 进行条件化,从而实现“摊销推理”和“泛化到训练中未见的新 $y$”(第 5 页)。这一特性对于需要跨不同条件进行有效推理的实际应用至关重要。
最后,需要“扩展到高维问题”(第 2 页)和“大型扩散模型”(第 5 页)带来了显著的内存和计算约束。RTB 的内存高效训练,通过批量梯度累积和随机子采样,直接解决了这些实际限制。如 §H.1 所讨论的,在不增加内存预算的情况下,将训练扩展到大量扩散步骤的能力,非常适合现代生成模型苛刻的性质。
拒绝替代方案
本文为解决扩散模型中难以处理的后验推理摊销这一特定问题,提供了清晰的理由,拒绝了几种流行的方案:
-
传统推理技术(线性近似、随机优化):作者指出,“该问题的常见解决方案涉及基于线性近似 [73, 33, 31, 11] 或随机优化 [22, 48] 的推理技术”(第 2 页)。这些方法被认为不足,因为它们“仅近似解决或仅在受限情况下解决”(摘要,第 1 页),未能提供 RTB 所追求的渐近无偏采样。
-
分类器引导 (CG) / 扩散后验采样 (DPS) / 损失引导扩散蒙特卡洛 (LGD-MC):这些试图估计“引导”项的方法因几个原因而受到批评:
- 它们“导致有偏结果”(图 1,第 3 页)。
- 它们依赖于“在加噪数据上训练分类器 [12]”,这在“数据不可用时”是有问题的(第 2 页)。
- 在加噪数据上推导可微分分类器“通常是难以处理的”(第 5 页),并且学习它需要“无偏数据样本”,而这正是问题旨在生成的。
- 在实验中,“基于分类器引导的方法,如 DP 和 LGD-MC,表现出高多样性,但未能适当地建模后验分布(最低的 log r(x))”(第 7 页)。它们还实现了“较低的分类器平均奖励”,并且未能“适当地建模后验分布”(第 21 页)。
-
强化学习 (RL) 方法(例如,DPOK、DDPO):尽管 RL 方法 [8, 16] 已被提出用于此问题,但它们存在关键缺陷:
- 它们“有偏且易于模式崩溃(图 1)”(第 2 页)。图 E.1(第 20 页)进一步说明了纯 RL 微调中的“早期模式崩溃”和“奖励剥削”。
- “纯 RL 微调(无 KL 正则化)表现出模式崩溃的特征,以获得高奖励为代价,多样性和 FID 分数显著下降”(第 7 页)。
- 用于微调扩散模型的 RL 方法通常是“on-policy”(第 19 页),这使得它们“容易模式崩溃”(图 C.2,第 19 页)。
- DPOK 和 DDPO 等方法使用每步惩罚来优化边际 KL 的上限,这会引入偏差。相比之下,RTB“可以避免这种近似中的偏差,并直接学习从后验 $p(x_1 | z)$ 生成无偏样本”(第 7 页)。
本文没有明确讨论拒绝生成对抗网络 (GAN) 用于此特定问题。重点在于改进扩散模型框架内的后验推理,其中扩散模型已被确立为先验。因此,直接比较或拒绝 GAN 作为先验模型本身的替代生成模型超出了本次分析的范围。
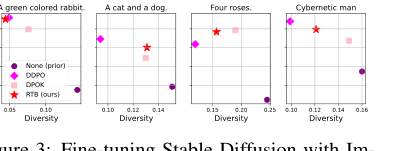 Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
Figure 3. Fine-tuning Stable Diffusion with Im- ageReward. We report mean log 𝑟(x1, z) and diver- sity, measured as the mean cosine distance between CLIP embeddings for a batch of 100 generated im- ages.2
数学与逻辑机制
主方程
驱动本文的绝对核心方程是相对轨迹平衡 (RTB) 损失函数。该目标驱动后验扩散模型从期望的目标分布中采样。损失定义为比率的平方对数,旨在将该比率带到一。
$$ \mathcal{L}_{\text{RTB}}(\tau; \Phi) := \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right)^2 $$
这里,$\tau = (X_0, X_{\Delta t}, \dots, X_1)$ 代表扩散过程中的完整轨迹。轨迹概率 $P(\tau)$ 本身是初始分布和离散时间步上的条件转移概率的乘积,如论文方程 (3) 所示:
$$ P(\tau) = p(X_0) \prod_{i=1}^T P(X_{i\Delta t} | X_{(i-1)\Delta t}) $$
按项解剖
让我们剖析主方程,以理解每个组件的作用。为清晰起见,我们将主要关注对数内的项,因为将其最小化到零是直接目标。
-
$\mathcal{L}_{\text{RTB}}$:
- 数学定义:相对轨迹平衡 (RTB) 损失函数。
- 物理/逻辑作用:这是模型在训练期间寻求最小化的主要目标函数。将此损失驱动到零可确保满足相对轨迹平衡约束(论文中的方程 8)。这反过来又保证了后验扩散模型 $P_{\Phi}^{\text{post}}$ 学习从目标后验分布 $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$ 中采样。
- 为何平方? 将对数比率平方是损失函数设计中的标准技术(类似于均方误差)。它确保损失始终非负,并提供一个平滑、可微分的目标,这对于基于梯度的优化至关重要。它比小的偏差更严厉地惩罚与目标比率(为 1)的较大偏差,鼓励精确收敛。
-
$\tau = (X_0, X_{\Delta t}, \dots, X_1)$:
- 数学定义:扩散过程中的特定轨迹,代表从初始噪声状态 $X_0$ 到最终去噪数据点 $X_1$ 的状态序列,经过中间状态 $X_{i\Delta t}$(在离散时间步)。
- 物理/逻辑作用:这是 RTB 机制的基本操作单元。整个学习过程基于模型生成这些序列路径以满足约束的程度来评估和调整模型。
-
$\Phi$:
- 数学定义:后验扩散模型 $P_{\Phi}^{\text{post}}$ 的可学习参数集。这些参数通常定义了底层随机微分方程 (SDE) 的漂移项 $u_{\Phi}^{\text{post}}(x_t, t)$,该漂移项通常实现为神经网络。
- 物理/逻辑作用:这些是控制后验模型如何生成样本的神经网络的权重和偏差。优化过程调整 $\Phi$ 以使后验采样与期望的目标分布对齐。
-
$Z$:
- 数学定义:一个标量归一化常数,具体为 $Z = \int q(x_1)r(x_1) dx_1$,如命题 1 所推导。为了数值稳定性,其对数 $\log Z$ 通常被学习或估计。
- 物理/逻辑作用:该项对于确保目标后验分布 $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$ 被正确归一化至关重要。由于约束函数 $r(X_1)$ 可能是一个未归一化的似然度或奖励, $Z$ 会缩放整体概率使其积分为 1。它对于匹配绝对概率,而不仅仅是相对比例至关重要。
-
$r(X_1)$:
- 数学定义:一个正的、黑盒的约束函数或似然函数,在最终数据点 $X_1$ 处进行评估。
- 物理/逻辑作用:该项代表将扩散过程引导至期望特征的“奖励”或“引导”信号。例如,它可以是特定类别的分类器似然度 $p(c|X_1)$,或者强化学习中的奖励函数 $\exp(\beta Q(s,a))$。它编码了我们希望生成的数据所拥有的特定属性。
-
$p_{\theta}(\tau)$:
- 数学定义:轨迹 $\tau$ 在先验扩散模型下的概率,由 $\theta$ 参数化。这通常是初始分布 $p(X_0)$ 和每个步骤的条件转移概率 $P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$ 的乘积。
- 物理/逻辑作用:这代表了“基线”或“无条件”生成过程。它是一个预训练的扩散模型,在没有任何特定约束的情况下生成数据。RTB 目标使用它作为参考点来定义后验模型的相对平衡。
-
$P_{\Phi}^{\text{post}}(\tau)$:
- 数学定义:轨迹 $\tau$ 在后验扩散模型下的概率,由 $\Phi$ 参数化。与 $p_{\theta}(\tau)$ 类似,它是 $p(X_0)$(通常与先验共享)和条件转移概率 $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$ 的乘积。
- 物理/逻辑作用:这代表了我们正在积极学习从中采样期望后验分布的生成过程。其参数 $\Phi$ 在训练期间被调整,以使它的轨迹与约束 $r(X_1)$ 相对于先验 $p_{\theta}(\tau)$ 对齐。
-
$\log(\cdot)$:
- 数学定义:自然对数。
- 物理/逻辑作用:对数将概率的乘积转换为对数概率的和,这在数值上更稳定,并且通常更容易优化。它还将概率的比率转换为对数概率的差值,这是信息论中的常用技术(例如,KL 散度)。目标是使对数比率为零,意味着比率本身为一。
-
$\sum_{i=1}^T$:
- 数学定义:对从 1 到 $T$ 的离散时间步 $i$ 的求和。
- 物理/逻辑作用:该算子聚合了扩散轨迹所有离散步骤上的条件转移概率的对数比率。扩散过程被建模为 $T$ 个离散步骤的序列,并且整体轨迹概率是这些步长概率的乘积。对数将此乘积转换为和,使得每个步骤的贡献加到整体对数比率上。
- 为何求和而不是积分? 本文明确将扩散过程建模为 SDE 的“时间离散化版本”,其中轨迹是离散状态 $X_0, X_{\Delta t}, \dots, X_1$ 的序列。因此,求和是组合这些离散转移概率的自然选择,反映了实现的扩散步骤的离散性质。
-
$P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- 数学定义:在后验扩散模型下,给定前一状态 $X_{(i-1)\Delta t}$ 到达状态 $X_{i\Delta t}$ 的条件概率。对于高斯扩散模型,这通常是一个高斯分布 $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$。
- 物理/逻辑作用:该项描述了后验模型如何从一个时间步演变到下一个时间步。学习到的漂移项 $u_{\Phi}^{\text{post}}$(由 $\Phi$ 参数化)决定了这个高斯转移的均值,有效地引导样本生成朝着期望的后验方向。
-
$P_{\theta}(X_{i\Delta t} | X_{(i-1)\Delta t})$:
- 数学定义:在先验扩散模型下,给定前一状态 $X_{(i-1)\Delta t}$ 到达状态 $X_{i\Delta t}$ 的条件概率。与后验类似,它是一个高斯分布 $N(X_{i\Delta t} | X_{(i-1)\Delta t} + u_{\theta}(X_{(i-1)\Delta t})\Delta t, \sigma^2 \Delta t I)$。
- 物理/逻辑作用:该项描述了预训练的先验扩散模型的步长演变。它作为后验模型转移的参考。后验与先验转移概率的比率表明后验模型在每一步“偏离”先验的程度以满足约束。
分步流程
让我们追踪一个抽象数据点通过这个数学引擎的精确生命周期。
-
噪声的起源 ($X_0$):过程始于一个抽象的数据点,最初是一个纯高斯噪声向量 $X_0$,从一个固定的、简单的分布(如 $\mathcal{N}(0, I)$)中采样。将其视为将要从中诞生杰作的原始、未成形的粘土。
-
生成装配线(轨迹 $\tau$):
- 生成一个完整的轨迹 $\tau = (X_0, X_{\Delta t}, \dots, X_1)$。该轨迹可以由当前的后验模型(on-policy 采样)或由替代的、探索性的分布(off-policy 采样)生成。
- 在每个离散时间步 $i$ 从 1 到 $T$,正在进行中的样本 $X_{(i-1)\Delta t}$ 进入一个“处理单元”。在这里,一个神经网络(后验扩散模型的一部分,由 $\Phi$ 参数化)预测一个“漂移”或“去噪方向” $u_{\Phi}^{\text{post}}(X_{(i-1)\Delta t}, (i-1)\Delta t)$。
- 基于这个预测的漂移和一个少量的高斯噪声,样本根据条件概率 $P_{\Phi}^{\text{post}}(X_{i\Delta t} | X_{(i-1)\Delta t})$ 被转化为下一个状态 $X_{i\Delta t}$。这就像一个传送带,物品在上面被逐步改进和塑形。
- 这个步长转换持续进行,直到在时间 $T$ 产生最终的去噪数据点 $X_1$。
-
质量控制检查 ($r(X_1)$):一旦最终数据点 $X_1$ 从装配线上下来,它就会立即被送到“质量控制”站。在这里,黑盒约束函数 $r(X_1)$ 评估 $X_1$ 在多大程度上满足期望的标准。这可能是一个奖励分数、一个类别似然度,或者任何其他质量衡量标准。这对于确定生成过程的成功至关重要。
-
平衡表(对数比率计算):
- 现在,整个轨迹 $\tau$(从 $X_0$ 到 $X_1$)被分析。该轨迹在后验模型下发生的概率 $P_{\Phi}^{\text{post}}(\tau)$ 通过将初始噪声概率与路径上的所有条件转移概率相乘来计算。
- 同时,也计算相同轨迹在先验扩散模型下发生的概率 $p_{\theta}(\tau)$。这个先验充当一个中立的参考。
- 然后,将这些概率与归一化常数 $Z$ 和约束 $r(X_1)$ 结合起来,形成一个关键比率:$\frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$。
- 取该比率的自然对数。这个对数比率是系统旨在驱动到零的核心“平衡”度量。如果它为零,则后验模型相对于先验和约束是完美平衡的。
-
绩效审查(损失计算):计算出的对数比率被平方,得到该特定轨迹的 $\mathcal{L}_{\text{RTB}}$ 损失。该损失量化了后验模型当前生成过程中的“不平衡”或“误差”。
-
调整机制(参数更新):计算出的损失值随后用于生成相对于后验模型参数 $\Phi$ 的梯度。这些梯度充当精确指令,告诉模型如何调整其内部机制(神经网络权重)以减少损失。这种调整使得后验模型更有可能生成满足相对平衡约束的轨迹,从而有效地学习生成高质量、受约束的样本。这个迭代过程会精炼模型,就像一位熟练的工程师微调一台复杂的机器一样。
优化动力学
相对轨迹平衡 (RTB) 机制通过基于梯度的 $\mathcal{L}_{\text{RTB}}$ 损失优化,迭代地精炼后验扩散模型 $P_{\Phi}^{\text{post}}$ 的参数 $\Phi$ 来学习、更新和收敛。
-
损失景观与目标:$\mathcal{L}_{\text{RTB}}$ 损失函数,作为一个平方对数比率,定义了一个损失景观,其全局最小值是零。在该最小值处,相对轨迹平衡约束 $Z P_{\Phi}^{\text{post}}(\tau) = r(X_1) p_{\theta}(\tau)$ 对所有轨迹 $\tau$ 都得到满足。这意味着后验模型 $P_{\Phi}^{\text{post}}$ 已学会从目标分布 $p_{\text{post}}(x_1) \propto p_{\theta}(X_1)r(X_1)$ 中采样。虽然底层的神经网络参数化使得景观是非凸的,但对数和平方运算提供了适合梯度下降的平滑目标。本文提到使用经验方差(相对于小批量)和损失裁剪等实际策略来稳定训练并导航这个复杂的景观,尤其是在先验模型不完美或约束函数 $r(X_1)$ 导致尖锐分布时。
-
梯度行为与学习信号:学习过程的核心在于 $\mathcal{L}_{\text{RTB}}$ 损失相对于后验模型参数 $\Phi$ 的梯度。作者强调的一个关键优势是,该梯度不需要通过生成轨迹 $\tau$ 的整个采样过程进行反向传播。相反,它主要包括后验轨迹的对数概率的梯度 $\nabla_{\Phi} \log P_{\Phi}^{\text{post}}(\tau)$,并乘以当前对数比率偏差。
$$ \nabla_{\Phi} \mathcal{L}_{\text{RTB}}(\tau; \Phi) = 2 \left( \log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)} \right) \nabla_{\Phi} \left( \log P_{\Phi}^{\text{post}}(\tau) \right) $$
该梯度充当“校正信号”。如果项 $\log \frac{Z P_{\Phi}^{\text{post}}(\tau)}{r(X_1) p_{\theta}(\tau)}$ 为正(意味着 $P_{\Phi}^{\text{post}}(\tau)$ 相对于目标过高),梯度会推动 $\Phi$ 来减小 $\log P_{\Phi}^{\text{post}}(\tau)$,使得该轨迹在后验下不太可能出现。反之,如果该项为负,梯度会推动 $\Phi$ 来增大 $\log P_{\Phi}^{\text{post}}(\tau)$,使得该轨迹在后验下更可能出现。这种调整的幅度与当前模型与满足平衡约束的距离成正比。这种机制允许后验模型学习“放大”导致 $r(X_1)$ 高值的轨迹,同时与先验 $p_{\theta}(\tau)$ 保持一致的关系。 -
状态更新与收敛:
- 迭代状态更新:参数 $\Phi$ 使用优化算法(如 AdamW)在许多训练步骤中进行迭代更新。在每一步中,采样一个轨迹批次。对于每个轨迹,计算 $\mathcal{L}_{\text{RTB}}$ 损失,并累积梯度。然后优化器使用这些累积梯度来调整 $\Phi$,将其移动到参数空间中损失较低的区域。
- Off-policy 探索:RTB 与 off-policy 训练的兼容性是其显著优势。这意味着用于学习的轨迹可以从与当前后验模型 $P_{\Phi}^{\text{post}}$ 不同的分布中采样。这种灵活性对于有效的模式覆盖至关重要,允许模型探索更广泛的潜在轨迹并避免模式崩溃,这是生成模型只学习生成有限的高奖励样本的常见陷阱。通过利用多样化的轨迹(例如,来自回放缓冲区或探索性修改),模型可以学会覆盖目标后验分布的完整范围。
- 渐近正确性:本文将 RTB 确立为“渐近无偏的训练目标”。这一理论保证意味着,在获得足够的数据和训练的情况下,模型有望收敛到真实的后验分布。平方对数比率的连续减小,以及对归一化常数 $Z$ 的正确处理,将系统驱动到一个满足相对平衡约束的状态,从而实现精确的后验采样。
结果、局限性与结论
实验设计与基线
作者精心设计了一系列跨越不同领域的实验,以严格验证相对轨迹平衡 (RTB) 在扩散模型中摊销难以处理的后验推理的有效性。核心思想是展示 RTB 从复杂后验分布 $p_{\text{post}}(x) \propto p_{\theta}(x)r(x)$ 中采样的能力,其中 $p_{\theta}(x)$ 是扩散先验,$r(x)$ 是黑盒约束或似然函数。
视觉:分类器引导的图像生成
对于视觉任务,目标是学习一个用于类别条件图像生成的扩散后验 $p_{\text{post}}(x|c) \propto p_{\theta}(x)p(c|x)$。
- 数据集:在两个 10 类图像数据集上进行了实验:MNIST(28x28,放大到 32x32 单通道数字)和 CIFAR-10(32x32 3 通道图像)。
- 先验与约束:使用了来自 [27] 的现成无条件扩散先验作为 $p_{\theta}(x)$,标准的分类器 $p(c|x)$ 作为约束 $r(x)$。
- 训练架构:使用 RTB 对后验扩散模型 $p_{\phi}^{\text{post}}$ 进行微调,该模型初始化为先验 $p_{\theta}$ 的副本。通过 LoRA 权重 [28] 实现参数高效微调,约占先验模型参数总数的 3%。RTB 目标在从当前后验模型 on-policy 采样的轨迹上进行优化。
- 基线:RTB 的性能与两类基线进行了比较:
- 基于 RL 的微调:DPOK [16] 和 DDPO [8]。
- 分类器引导:DPS [11] 和 LGD-MC [70]。
- 实验设置:测试了三种不同的场景:MNIST 单数字后验、CIFAR-10 单类别后验,以及更具挑战性的 MNIST 多数字后验(生成偶数或奇数,其中 $r(x) = \max_{i \in \{0,2,4,6,8\}} p(c=i|x)$)。
- 指标:性能通过期望对数奖励 $E[\log r(x)]$(越高越好)、Fréchet Inception Distance (FID)(越低越好,衡量与真实样本的接近程度)和多样性(Inceptionv3 特征空间中的平均成对余弦距离,越高越好)进行评估。FID 计算为真实后验分布的相似度估计,受每类样本总数(CIFAR-10/MNIST 数字为 5k-6k,偶数/奇数为 30k)的限制。
- 计算量:所有视觉实验均在单个 NVIDIA V100 GPU 上运行。
语言建模:文本填充
为了评估 RTB 在离散扩散模型上的表现,选择了文本填充任务,模型需要根据故事的前三句话 $x$ 和最后一句 $y$ 来生成缺失的第四句话 $z$。目标后验为 $p_{\text{post}}(z|x,y) \propto p(z|x)p_{\text{reward}}(y|x,z)$。
- 语料库:使用了 ROCStories 语料库 [50],该语料库包含 5 句话的故事。
- 先验与约束:SEDD (Score Entropy Discrete Diffusion) 语言模型 [43] 作为先验 $p(z|x)$。奖励函数 $p_{\text{reward}}(y|x,z)$ 是一个自回归 GPT-2 Large 模型 [57],使用 trl 库 [81] 在故事数据集上进行了微调。
- 训练细节:RTB 目标应用于离散扩散模型。为了控制计算成本(内存和速度),作者采用了随机 TB 技巧(通过轨迹步数的子集传播梯度)和损失裁剪。对于此条件问题,使用了相对 VarGrad 目标,并对奖励似然度进行了温度调节。
- 基线:
- 使用 $x$ 对扩散 LM 进行简单提示(Prompt (x))。
- 使用 $x, y$ 进行简单提示(Prompt (x, y))。
- 来自 [29] 的自回归语言模型基线,包括 GFlowNet 微调和监督微调。
- 指标:生成填充文本的质量通过 BERTScore [90]、BLEU-4 [54] 和 GLEU-4 [86] 进行衡量,并与数据集中的参考填充文本进行比较。
- 计算量:实验在单个 NVIDIA A100-Large GPU 上进行。
连续控制:离线强化学习
RTB 应用于离线强化学习中的 KL 约束策略搜索问题,旨在找到一个最优策略 $\pi^*(a|s) \propto \mu(a|s)\exp(\beta Q(s,a))$。
- 数据集:使用了 D4RL 套件 [18],特别是 halfcheetah、hopper 和 walker2d MuJoCo [76] 的运动任务。每个任务都包括“medium”、“medium-expert”和“medium-replay”数据集,代表了行为先验中不同程度的次优性。
- 先验与约束:一个状态条件噪声预测 DDPM [27] 作为行为扩散策略 $\mu(a|s)$。约束由 $\exp(\beta Q(s,a))$ 定义,其中 $Q(s,a)$ 是使用 IQL [36] 训练的 Q 函数。
- 训练细节:RTB 微调了行为扩散策略以从 $\pi^*$ 中采样,其权重从行为策略中初始化。采用了 Langevin 动力学归纳偏置 [11],并训练了一个额外的 MLP 来处理能量缩放网络。使用了 VarGrad 目标 [61] 来隐式估计 $\log Z(s)$。通过使用包含高奖励情节样本的离线数据集,利用了 off-policy 探索,导致了“混合训练”(off-policy 和 on-policy)。
- 基线:与一套全面的最先进离线 RL 基线进行了比较:行为克隆 (BC)、CQL [37]、IQL [36]、Diffuser (D) [30]、Decision Diffuser (DD) [2]、D-QL [83]、IDQL [25] 和 QGPO [44]。
- 指标:主要指标是训练策略的平均奖励,报告为 5 次随机种子运行的均值 $\pm$ 标准差。
- 计算量:所有离线 RL 实验均在单个 NVIDIA A100-Large GPU 上进行。
证据证明了什么
实验证据明确表明,相对轨迹平衡 (RTB) 提供了一种强大且通用的方法,用于扩散模型中的摊销后验推理,在视觉、语言和连续控制任务中优于或匹配最先进的基线。RTB 的核心机制——渐近无偏训练以从乘积分布中采样——通过其在奖励和多样性之间取得平衡,以及在其他方法失败时准确建模复杂后验的能力,得到了无情的证明。
视觉:无偏推理的决定性证据
- 奖励与多样性的卓越平衡:在分类器引导的图像生成(表 2)中,RTB 在高期望对数奖励($E[\log r(x)]$)和高多样性(平均成对余弦距离)之间始终实现了卓越的平衡,同时保持了低 FID 分数(与真实样本的接近度)。例如,在 CIFAR-10 上,RTB 实现了 -2.1625 的 $E[\log r(x)]$ 和 0.4717 的 FID,显著优于分类器引导方法如 DPS(-3.6025 $E[\log r(x)]$)和 LGD-MC(-3.0988 $E[\log r(x)]$),尽管后者的多样性很高。
-
击败模式崩溃:本文最引人注目的视觉证据(图 1)显示 RTB 样本与真实的后验分布(9 个活跃模式的高斯混合)非常相似(图 1c)。相比之下,纯 RL 方法(无 KL 正则化,DDPO)遭受了严重的模式崩溃(图 1e),尽管奖励很高,但只关注了少数模式。即使是具有调整 KL 正则化的 RL(DPOK)也产生了不准确的推理(图 1d),而分类器引导(CG)则导致了有偏结果(图 1f)。这种视觉上不可否认的证据证明了 RTB 避免模式崩溃并准确覆盖后验分布的能力。
-
高质量、多样化的样本:图 2 和图 4 展示了 RTB 微调模型为各种提示(例如,“一只绿色的兔子”、“一只猫和一只狗”、“四朵玫瑰”)生成的图像的高视觉质量和多样性。这些定性结果强化了定量指标,表明 RTB 的核心机制转化为感知上更好、更多样化的输出。
-
渐近无偏:本文强调 RTB 是一个渐近无偏的目标,可以恢复真实的漂移差异,这与依赖于后验分数函数有偏近似的分类器引导不同。这种理论优势在实验结果中得到了体现,RTB 持续实现更好的后验建模。
语言建模:填充任务中的强劲表现
- 超越自回归基线:对于文本填充(表 3),RTB 配合离散扩散先验,在所有非 SFT 基线中获得了最高的 BERTScore (0.156)、BLEU-4 (0.025) 和 GLEU-4 (0.045)。这表明 RTB 能够生成更连贯和一致的填充文本,显著优于简单的提示基线,甚至优于最强的自回归 GFlowNet 微调基线(BERTScore 0.102)。这有力地表明 RTB 处理离散扩散模型的机制有效地提高了条件文本生成能力。
连续控制:最先进的离线 RL
- 匹配最先进的奖励:在离线强化学习(表 4)中,RTB 在 D4RL 基准测试中取得了最先进或有竞争力的结果。例如,在
hopper-medium-replay上,RTB 得分为 100.40,与 DD (100.00) 和 D-QL (100.70) 等其他领先方法相当或更高。这证明了 RTB 可以通过从 KL 约束后验中采样来有效地学习最优策略,即使在行为先验次优的情况下也是如此。 - 对次优先验的鲁棒性:RTB 在“medium-replay”任务中表现尤为出色,这些任务的特点是行为先验高度次优,因此行为先验较差。这种鲁棒性是关键证据,表明 RTB 的 off-policy 训练能力使其即使在初始先验不理想的情况下也能有效学习,这是现实世界 RL 场景中的常见挑战。
- Off-policy 探索的优势:表 G.1 进一步巩固了 RTB 的 off-policy 能力的优势,表明“混合训练”(结合 off-policy 和 on-policy 样本)在三分之二的 medium-replay 任务上优于纯 on-policy 训练。这直接支持了 RTB 利用多样化轨迹的灵活性可以提高训练效率和性能的说法。
总而言之,这些不同领域的证据提供了一个引人注目的叙述:RTB 在摊销后验采样方面的原则性方法,基于相对轨迹平衡,通过有效应对奖励最大化和模式覆盖之间的权衡,持续产生卓越或有竞争力的结果,而这种权衡常常困扰着其他推理方法。
局限性与未来方向
尽管相对轨迹平衡 (RTB) 为扩散模型中的摊销后验推理提供了一个强大且通用的框架,但作者坦诚地承认了几个局限性,并提出了令人兴奋的未来研究方向。
局限性
- 计算成本和内存密集性:主要局限性在于 RTB 通过基于仿真的训练来学习后验,这可能既缓慢又内存密集。尽管本文引入了随机子采样和批量梯度计算等技术来减轻 RTB 本身的内存使用,但训练轨迹仿真的基本性质仍然是一个瓶颈。这对于大规模模型或高维数据尤其相关。
- 高梯度方差:RTB 目标是在完整轨迹上计算的。这意味着损失函数没有为轨迹内的单个步骤提供局部信用分配信号。因此,梯度可能表现出高方差,这会阻碍训练的稳定性和效率。
- 对不完美拟合的理论保证缺失:本文指出,关于先验模型不完美拟合所产生的误差、摊销的影响以及时间离散化(类似于扩散采样器 [7] 的现有分析)的理论保证尚未完全建立。此类保证将提供对 RTB 在非理想条件下的行为的更深入理解。
- 不适用于可微分模拟方法:为 RTB 开发的内存节省技术(随机子采样、批量梯度计算)并非普遍适用。具体来说,基于可微分模拟的扩散采样器(例如,路径积分采样器 (PIS) 和去噪扩散采样器 (DDS))仍然需要存储 SDE 积分的整个计算图,导致内存需求随轨迹长度线性增长。
未来方向
研究成果为几个有前景的研究方向打开了大门,推动了扩散模型和强化学习的边界:
- 增强的 Off-policy 训练和探索:本文强调了 RTB 与 off-policy 轨迹的兼容性。未来的工作可以更深入地研究利用先进的 off-policy 训练技术,如局部搜索 [34, 65],以进一步提高样本效率,最重要的是,提高模式覆盖率。这可能涉及更复杂的探索策略,以发现后验分布中难以到达的模式。
- 探索基于仿真的目标:作者建议探索其他基于仿真的目标,类似于 [89] 中用于摊销采样问题的方法。这可能会产生提供计算成本、梯度方差和性能之间不同权衡的替代公式。
- 开发无模拟的扩展:研究无模拟的扩展,例如时间局部化的目标 [45],可能解决与完整轨迹训练相关的计算和内存密集性问题。这将是使 RTB 更具可扩展性的重要一步。
- 应用于具有黑盒似然的逆问题:RTB 处理任意黑盒似然函数的独特能力使其成为各种逆问题的理想选择。这包括:
- 3D 对象合成:使用渲染器 [例如,56, 82] 计算的似然度来从 2D 观测生成 3D 对象。
- 成像问题:将 RTB 应用于天文学 [例如,1] 和医学成像 [例如,73] 中的复杂任务,其中似然函数可能很复杂且不可微。
- 分子结构预测:利用 RTB 来解决分子生物学 [例如,84] 中的挑战性问题,目标是从实验数据中推断分子结构。
- 分子动力学领域的突破:一个特别令人兴奋的前景是 RTB 在模拟分子动力学方面取得突破的潜力。通过将模拟稀有事件轨迹这一出了名的挑战性任务转化为对稀有事件样本放大分布的后验推理问题,RTB 可以为理解复杂的化学过程提供一种新颖的方法。Seong 等人 [66] 使用 TB 和奖励乘以先验似然度(有效地是 RTB)的初步工作支持了这一方向。
- 理论分析的严谨性:未来的工作应侧重于为 RTB 提供严格的理论保证,特别是关于不完美先验模型的影响、摊销的影响以及时间离散化的含义。这将加强对该方法基础理解。
更广泛的影响讨论
作者还周到地讨论了他们工作的更广泛的社会影响。与所有生成模型领域的进步一样,RTB 可能被“恶意行为者”滥用,用于训练生成有害内容或虚假信息的模型。然而,他们也强调了积极的潜力:RTB 可用于减轻预训练模型中存在的偏差,并应用于各种科学问题,从而促进不同的观点,并激发对强大生成式人工智能技术负责任的开发和部署的批判性思考。
 Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
Figure 1. Sampling densities learned by various posterior inference methods. The prior is a diffusion model sampling a mixture of 25 Gaussians (a) and the posterior is the product of the prior with a constraint that masks all but 9 of the modes (b). Our method (RTB) samples close to the true posterior (c). RL methods with tuned KL regularization yield inaccurate inference (d), while without KL regularization, they mode-collapse (e). A classifier guidance (CG) approximation (f) results in biased outcomes. For details, see §C
 Figure 2. Samples from RTB fine-tuned diffusion posteriors
Figure 2. Samples from RTB fine-tuned diffusion posteriors
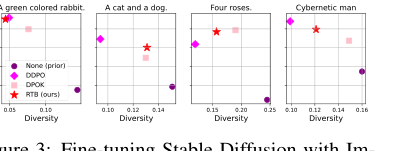 Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
Figure 4. Images generated from prior (top row), DPOK (middle row) and RTB (bottom row) for 4 different prompts. Images in the same column share the random DDIM seed. More images in §H.2
 Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted
Table 4. Average rewards of trained policies on D4RL locomotion tasks (mean±std over 5 random seeds). Following past work, numbers within 5% of maximum in every row are highlighted
与其他领域的同构性
结构骨架
本质上,本文提出了一种机制,通过平衡相对于已知先验的正向和反向轨迹概率,来训练生成模型以高效地从复杂目标分布中采样。