सामान्य लागतों के लिए ऊर्जा-संचालित सतत एन्ट्रोपिक बैरीसेंटर अनुमान
इस पत्र में संबोधित की गई समस्या, इष्टतम परिवहन (OT) बैरीसेंटर समस्या, संभाव्यता वितरणों को ज्यामितीय रूप से सार्थक तरीके से औसत करने की मौलिक आवश्यकता से उत्पन्न होती है। जबकि रैखिक स्थानों में स्केलर या वैक्टर का...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित की गई समस्या, इष्टतम परिवहन (OT) बैरीसेंटर समस्या, संभाव्यता वितरणों को ज्यामितीय रूप से सार्थक तरीके से औसत करने की मौलिक आवश्यकता से उत्पन्न होती है। जबकि रैखिक स्थानों में स्केलर या वैक्टर का औसत सीधा है, संभाव्यता वितरणों से निपटने पर कार्य काफी अधिक जटिल हो जाता है। सरल उत्तल संयोजन अक्सर आवश्यक ज्यामितीय विशेषताओं को संरक्षित करने में विफल रहते हैं, जिससे "केंद्र" या औसत को परिभाषित करने के लिए एक अधिक परिष्कृत दृष्टिकोण की आवश्यकता होती है।
यह विशिष्ट समस्या पहली बार इष्टतम परिवहन के अकादमिक क्षेत्र में उभरी, जो एक वितरण को दूसरे में बदलने के लिए "लागत" को परिभाषित करके संभाव्यता वितरणों की तुलना और औसत करने के लिए एक मजबूत ढाँचा प्रदान करती है। Agueh और Carlier [1] द्वारा 2011 में पेश की गई OT बैरीसेंटर की अवधारणा, एक केंद्रीय वितरण खोजने का प्रयास करती है जो स्रोत वितरणों के दिए गए संग्रह के लिए परिवहन लागतों के योग को कम करती है।
पिछले एक दशक में, प्रभावी बैरीसेंटर गणना की व्यावहारिक मांग ने पर्याप्त शोध को प्रेरित किया है। प्रारंभिक प्रयासों ने मुख्य रूप से असतत OT बैरीसेंटर सेटिंग पर ध्यान केंद्रित किया, जहां वितरणों को बिंदुओं के परिमित सेट द्वारा दर्शाया जाता है। हालांकि, सतत सेटिंग, जो सतत संभाव्यता वितरणों से संबंधित है, कहीं अधिक चुनौतीपूर्ण साबित हुई। पिछले सतत OT बैरीसेंटर सॉल्वर कई प्रमुख सीमाओं से ग्रस्त थे:
- विशिष्ट लागत फलन: कई मौजूदा विधियों को विशेष रूप से विशिष्ट OT लागत फलनों के लिए डिज़ाइन किया गया था, विशेष रूप से द्विघात यूक्लिडियन लागत ($l_2(x, y) \stackrel{\text{def}}{=} ||x - y||^2$)। इसने उनकी प्रयोज्यता को समस्याओं की एक संकीर्ण सीमा तक सीमित कर दिया, क्योंकि वास्तविक दुनिया के परिदृश्यों में अक्सर गैर-यूक्लिडियन या अधिक जटिल लागत फलन शामिल होते हैं।
- गैर-तुच्छ ए प्रियोरी चयन: कुछ दृष्टिकोणों को बैरीसेंटर वितरण के लिए जटिल ए प्रियोरी चयन या निश्चित पूर्व-निर्धारण की आवश्यकता होती है, जिसे निर्धारित करना गैर-तुच्छ हो सकता है और मॉडल के लचीलेपन को सीमित कर सकता है।
- अभिव्यक्ति और जनरेटिव क्षमता को सीमित करना: कुछ विधियों में वितरणों के बीच जटिल संबंधों को व्यक्त करने या सीखे गए बैरीसेंटर से नए नमूने उत्पन्न करने की सीमित क्षमता थी, जिससे जनरेटिव मॉडलिंग कार्यों में उनकी उपयोगिता बाधित हुई।
- OT योजनाओं को पुनः प्राप्त करने में असमर्थता: कुछ दृष्टिकोणों ने बैरीसेंटर को एक जनरेटिव मॉडल के रूप में पैरामीट्रिज्ड किया लेकिन अंतर्निहित इष्टतम परिवहन योजनाओं को पुनः प्राप्त नहीं किया, जो यह समझने के लिए महत्वपूर्ण हैं कि व्यक्तिगत स्रोत वितरण बैरीसेंटर पर कैसे मैप होते हैं।
यह पत्र इन सीमाओं को दूर करने का लक्ष्य रखता है, जो सतत एन्ट्रोपिक OT (EOT) बैरीसेंटर का अनुमान लगाने के लिए एक उपन्यास एल्गोरिथम का प्रस्ताव करता है जो मनमानी OT लागत फलनों को संभाल सकता है, बिना निश्चित पूर्व-निर्धारण की आवश्यकता के या अभिव्यक्ति को सीमित किए, और महत्वपूर्ण रूप से, यह सशर्त OT योजनाओं को पुनः प्राप्त करता है।
सहज डोमेन शब्द
एक शून्य-आधारित पाठक को मुख्य अवधारणाओं को समझने में मदद करने के लिए, यहाँ कुछ विशेष शब्दों का रोजमर्रा के सादृश्य में अनुवाद किया गया है:
- इष्टतम परिवहन (OT): कल्पना करें कि आपके पास मिट्टी के कई ढेर हैं (संभाव्यता वितरण) और आप उन्हें एक नए ढेर में बदलना चाहते हैं। इष्टतम परिवहन सबसे कुशल तरीका खोजने जैसा है जिससे मूल ढेरों से सभी मिट्टी को ले जाकर नया ढेर बनाया जा सके, जिसमें शामिल कुल "कार्य" या "लागत" को कम किया जा सके।
- बैरीसेंटर: यदि आपके पास धुएं के कई बिखरे हुए बादल हैं (संभाव्यता वितरण), तो बैरीसेंटर एक "औसत" या "द्रव्यमान का केंद्र" धुआं बादल खोजने जैसा है जो मूल बादलों के औसत से सबसे करीब है, एक बादल को दूसरे में बदलने के "प्रयास" (इष्टतम परिवहन लागत) को ध्यान में रखते हुए। यह वह केंद्रीय बिंदु है जो अन्य सभी वितरणों से "खिंचाव" को संतुलित करता है।
- एन्ट्रोपिक इष्टतम परिवहन (EOT): यह इष्टतम परिवहन का एक "नरम" या "धुंधला" संस्करण है। हर कण को सबसे सीधे रास्ते पर ले जाने के बजाय, EOT परिवहन के दौरान थोड़ी मिश्रण या यादृच्छिकता की अनुमति देता है। यह समस्या को कम्प्यूटेशनल रूप से हल करना आसान बनाता है, जैसे कि कुछ मिट्टी को थोड़ा फैलने देना, फिर भी एक अच्छा, ज्यामितीय रूप से समझदार औसत प्राप्त करना।
- कमजोर OT द्वैत सूत्रीकरण: एक जटिल समस्या के बारे में सोचें, जैसे कि एक आदर्श पुल डिजाइन करना। हर संभव पुल को सीधे बनाने और परीक्षण करने के बजाय, एक "द्वैत सूत्रीकरण" एक सरल, समतुल्य समस्या खोजने जैसा है जिसमें पुल पर बलों और तनावों का अनुकूलन शामिल है। OT में, इसका मतलब है कि हम सीधे हर "मिट्टी के कण" को ट्रैक नहीं करते हैं, बल्कि दो "संभावित फलन" पाते हैं जो, अनुकूलित होने पर, हमें मिट्टी को ले जाने का सबसे कुशल तरीका अप्रत्यक्ष रूप से बताते हैं। इसे हल करना अक्सर आसान होता है।
- ऊर्जा-आधारित मॉडल (EBMs): एक परिदृश्य की कल्पना करें जहाँ घाटियाँ उन स्थानों का प्रतिनिधित्व करती हैं जहाँ डेटा बिंदु होने की संभावना है, और पहाड़ियाँ उन स्थानों का प्रतिनिधित्व करती हैं जहाँ होने की संभावना नहीं है। EBMs डेटा कैसे वितरित होता है, यह समझने के लिए इस "ऊर्जा परिदृश्य" को सीखते हैं। हमारी विधि एक समान विचार का उपयोग करती है: यह बैरीसेंटर समस्या को एक जटिल स्थान में सबसे कम "ऊर्जा" विन्यास खोजने के रूप में तैयार करती है, जिससे हमें समाधान खोजने के लिए अच्छी तरह से स्थापित EBM प्रशिक्षण तकनीकों का लाभ उठाने की अनुमति मिलती है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या संभाव्यता वितरणों के एक संग्रह के लिए सतत एन्ट्रोपिक इष्टतम परिवहन (EOT) बैरीसेंटर का अनुमान लगाना है।
इनपुट/वर्तमान स्थिति:
शुरुआती बिंदु में $K$ स्रोत संभाव्यता वितरणों का एक संग्रह शामिल है, जिसे $P_k \in \mathcal{P}_{ac}(\mathcal{X}_k)$ के रूप में दर्शाया गया है, जहाँ $\mathcal{P}_{ac}(\mathcal{X}_k)$ कॉम्पैक्ट सबसेट $\mathcal{X}_k \subset \mathbb{R}^{D_k}$ पर परिभाषित पूर्णतः सतत संभाव्यता वितरणों का प्रतिनिधित्व करता है। प्रत्येक स्रोत वितरण $P_k$ के लिए, एक संबद्ध सतत लागत फलन $c_k(\cdot, \cdot) : \mathcal{X}_k \times \mathcal{Y} \to \mathbb{R}$ होता है, जो $\mathcal{X}_k$ में बिंदुओं और बैरीसेंटर स्थान $\mathcal{Y}$ में बिंदुओं के बीच द्रव्यमान के परिवहन की "लागत" को मापता है। इसके अतिरिक्त, सकारात्मक भार $\lambda_k > 0$ का एक सेट दिया गया है, जो $\sum_{k=1}^K \lambda_k = 1$ की शर्त को संतुष्ट करता है। महत्वपूर्ण रूप से, व्यावहारिक परिदृश्यों में, ये स्रोत वितरण $P_k$ स्पष्ट रूप से ज्ञात नहीं होते हैं, बल्कि केवल अनुभवजन्य नमूनों के परिमित सेट, $X_k = \{x_1^k, x_2^k, \dots, x_{N_k}^k\} \sim P_k$ के माध्यम से सुलभ होते हैं। मौजूदा सतत OT बैरीसेंटर सॉल्वर अक्सर सामान्य लागत फलनों के साथ संघर्ष करते हैं, विशिष्ट ए प्रियोरी चयन की आवश्यकता होती है, या सीमित अभिव्यक्ति और जनरेटिव क्षमताएं होती हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
अंतिम लक्ष्य EOT बैरीसेंटर $Q^* \in \mathcal{P}(\mathcal{Y})$ की पहचान करना है, जो सभी स्रोत वितरणों $P_k$ के लिए भारित EOT विसंगतियों के योग को कम करने वाला एक संभाव्यता वितरण है। गणितीय रूप से, इसे इस प्रकार तैयार किया गया है:
$$L^* \stackrel{\text{def}}{=} \inf_{Q \in \mathcal{P}(\mathcal{Y})} \sum_{k=1}^K \lambda_k \text{EOT}_{c_k, \epsilon}(P_k, Q)$$
यहाँ, $\text{EOT}_{c_k, \epsilon}(P_k, Q)$ एक पैरामीटर $\epsilon > 0$ द्वारा नियमित एन्ट्रोपिक इष्टतम परिवहन लागत को $P_k$ और $Q$ के बीच दर्शाता है। केवल $Q^*$ खोजने से परे, पत्र का उद्देश्य इष्टतम सशर्त परिवहन योजनाओं $\pi_{f_k}^*(\cdot|x_k)$ का अनुमान लगाना है जो प्रत्येक स्रोत $P_k$ से बिंदुओं को बैरीसेंटर $Q^*$ तक मैप करती हैं। इन पुनः प्राप्त योजनाओं को "आउट-ऑफ-सैंपल अनुमान" को सक्षम करना चाहिए, जिसका अर्थ है कि वे $P_k$ से नए, अनदेखे नमूनों $x_{\text{new}}$ के लिए $\pi_{f_k}^*(\cdot|x_{\text{new}})$ से नमूने उत्पन्न कर सकते हैं। एक और महत्वाकांक्षा पूर्व-प्रशिक्षित जनरेटिव मॉडल के छवि मैनिफोल्ड पर बैरीसेंटर सीखना है, जिसका वास्तविक दुनिया के अनुप्रयोगों के लिए महत्वपूर्ण निहितार्थ हैं।
लुप्त कड़ी और दुविधा:
सटीक लुप्त कड़ी एक सामान्य, मजबूत और कम्प्यूटेशनल रूप से व्यवहार्य एल्गोरिथम है जो सतत EOT बैरीसेंटर का अनुमान लगाता है जो मनमानी लागत फलनों को संभाल सकता है और केवल अनुभवजन्य नमूनों से प्रभावी ढंग से काम कर सकता है। पिछले शोध एक दर्दनाक व्यापार-बंद में फंस गए थे: सतत OT बैरीसेंटर समस्याओं में अधिक सामान्यता और अभिव्यक्ति प्राप्त करने से आम तौर पर महत्वपूर्ण कम्प्यूटेशनल चुनौतियाँ पेश होती हैं या प्रतिबंधात्मक धारणाओं की आवश्यकता होती है। उदाहरण के लिए, मनमानी लागत फलनों को संभालने के लिए सामान्यता में सुधार से अक्सर अनसुलझे अनुकूलन समस्याएं होती हैं, क्योंकि कई पूर्व विधियाँ उनके अनुकूल सैद्धांतिक गुणों के कारण विशिष्ट, सरल लागतों (जैसे द्विघात यूक्लिडियन $l_2$ लागत) पर निर्भर करती हैं। ये सरल लागतें अधिक कुशल एल्गोरिदम की अनुमति देती हैं, लेकिन प्रयोज्यता को सीमित करती हैं। इसके अलावा, जबकि सतत सेटिंग अधिक शक्तिशाली है, यह असतत सेटिंग की तुलना में "और भी अधिक चुनौतीपूर्ण" है, जिसमें मौजूदा समाधानों में अक्सर अभिव्यक्ति में सीमाएं होती हैं या बैरीसेंटर के गैर-तुच्छ ए प्रियोरी चयन या विशिष्ट पैरामीट्रिजेशन की आवश्यकता होती है, जिसे निर्धारित करना मुश्किल हो सकता है या विधि के दायरे को सीमित कर सकता है। उच्च-आयामी डेटा स्पेस, जैसे कि छवियों में एक और दुविधा उत्पन्न होती है: EOT बैरीसेंटर की प्रत्यक्ष गणना अक्सर "शोर वाली छवियां" या "धुंधला पूर्वाग्रह" का परिणाम देती है, जो एन्ट्रॉपी नियमितीकरण और MCMC पर निर्भरता के कारण होती है। जबकि डेटा मैनिफोल्ड पर खोज स्थान को प्रतिबंधित करने से यह कम हो सकता है, यह मैनिफोल्ड लर्निंग और लागत फलनों के अनुकूलन से संबंधित अपनी जटिलताओं को प्रस्तुत करता है।
बाधाएँ और विफलता मोड
सतत EOT बैरीसेंटर अनुमान की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण स्वाभाविक रूप से कठिन है:
- प्रत्यक्ष अनुकूलन की कम्प्यूटेशनल अनसुलझता: EOT बैरीसेंटर के लिए उद्देश्य फलन (समीकरण 5) में सभी संभाव्यता वितरणों $\mathcal{P}(\mathcal{Y})$ के स्थान पर एक $\inf$ शामिल है, जो एक अनंत-आयामी स्थान है। इसे सीधे अनुकूलित करना आम तौर पर अनसुलझा होता है, जिससे समस्या के सूत्रीकरण की आवश्यकता होती है।
- विश्लेषणात्मक समाधानों का अभाव: अधिकांश व्यावहारिक परिदृश्यों के लिए, जिसमें गॉसियन वितरण के मामले भी शामिल हैं, एन्ट्रोपिक बैरीसेंटर समस्या ( $\epsilon > 0$ और अनियंत्रित $\epsilon = 0$ दोनों मामलों के लिए) के लिए कोई ज्ञात प्रत्यक्ष विश्लेषणात्मक समाधान नहीं है। यह संख्यात्मक अनुमान विधियों पर निर्भरता को मजबूर करता है।
- अनुभवजन्य डेटा सीमा: वास्तविक दुनिया के अनुप्रयोगों में स्रोत वितरण $P_k$ शायद ही कभी स्पष्ट रूप से उपलब्ध होते हैं। इसके बजाय, केवल परिमित अनुभवजन्य नमूने (डेटासेट) $X_k$ सुलभ होते हैं। इसका मतलब है कि एल्गोरिदम को डेटा विरलता और शोर के प्रति मजबूत होना चाहिए, और आउट-ऑफ-सैंपल सामान्यीकरण में सक्षम होना चाहिए।
- उच्च-आयामीता: जटिल डेटा प्रकारों, जैसे RGB छवियों (जैसे, CelebA के लिए $3 \times 64 \times 64$ आयाम) के साथ काम करने से सीखने और नमूनाकरण के लिए महत्वपूर्ण कम्प्यूटेशनल और मेमोरी मांगें उत्पन्न होती हैं, जिससे प्रत्यक्ष दृष्टिकोण अव्यवहारिक हो जाते हैं।
- मनमानी लागत फलन: पत्र का उद्देश्य "मनमानी OT लागत फलनों" का समर्थन करना है, जो एक महत्वपूर्ण बाधा है। कई मौजूदा विधियाँ सरल लागतों (जैसे $l_2$) के लिए विशिष्ट हैं, जिनमें विशिष्ट सैद्धांतिक गुण होते हैं जो गणना को सरल बनाते हैं। सामान्य लागतें इन सरलीकरणों को हटा देती हैं, जटिलता बढ़ा देती हैं।
- गैर-यूक्लिडियन ज्यामिति: समस्या स्पष्ट रूप से "गैर-यूक्लिडियन लागत फलनों" पर विचार करती है, जिसका अर्थ है कि मानक यूक्लिडियन दूरी मेट्रिक्स अक्सर अपर्याप्त होते हैं। इसके लिए जटिल ज्यामितीय संबंधों को पकड़ने के लिए अधिक लचीले और शक्तिशाली मॉडल की आवश्यकता होती है।
- MCMC नमूनाकरण सीमाएँ: प्रस्तावित विधि नमूनाकरण के लिए मार्कोव चेन मोंटे कार्लो (MCMC) प्रक्रियाओं (विशेष रूप से अनएडजस्टेड लांगविन एल्गोरिथम, ULA) पर निर्भर करती है।
- उच्च कम्प्यूटेशनल लागत: MCMC नमूनाकरण स्वाभाविक रूप से "समय लेने वाला" है, जो प्रशिक्षण और अनुमान विलंबता (तालिका 3) को प्रभावित करता है।
- अभिसरण मुद्दे: मूल ULA एल्गोरिथम "वांछित वितरण में खराब रूप से अभिसरण कर सकता है," जिससे उप-इष्टतम परिणाम प्राप्त होते हैं।
- विभेदक क्षमता की आवश्यकता: MCMC को आम तौर पर ऊर्जा फलनों (और इस प्रकार लागत फलनों $c_k$) को विभेदक होने की आवश्यकता होती है। गैर-विभेदक लागतों के लिए अधिक जटिल, ग्रेडिएंट-मुक्त नमूनाकरण प्रक्रियाओं की आवश्यकता होगी।
- स्थानीय न्यूनतम: MCMC अनुमान "ऊर्जा परिदृश्य के स्थानीय न्यूनतम में फंस सकता है," जिससे सीखे गए परिवहन योजनाओं को वांछित छवि सामग्री या अन्य विशेषताओं को संरक्षित करने में विफल होने का कारण बनता है (धारा 5.3)।
- अव्यवहार्य सामान्यीकरण स्थिरांक: द्वैत उद्देश्य फलन के भीतर सामान्यीकरण स्थिरांक $Z_{c_k}(f_k, x_k)$ की प्रत्यक्ष गणना अक्सर "अव्यवहार्य" होती है, जिसके लिए ग्रेडिएंट अनुमान के लिए अनुमानों की आवश्यकता होती है।
- डेटा स्पेस में "धुंधला पूर्वाग्रह": जब उच्च-आयामी डेटा स्पेस (जैसे, छवि पिक्सेल) में EOT बैरीसेंटर की गणना सीधे की जाती है, तो एन्ट्रॉपी नियमितीकरण "शोर वाली छवियों" या "धुंधला पूर्वाग्रह" का कारण बन सकता है, जिससे परिणामी बैरीसेंटर कम व्याख्यात्मक या देखने में plausible हो जाता है।
- मैनिफोल्ड बाधा जटिलता: जबकि बैरीसेंटर खोज को डेटा मैनिफोल्ड तक सीमित करना (जैसे, पूर्व-प्रशिक्षित StyleGAN का उपयोग करके) धुंधलापन को कम करने में मदद करता है, यह मैनिफोल्ड लर्निंग और लागत फलनों के अनुकूलन से संबंधित जटिलताओं को प्रस्तुत करता है।
- सामान्यीकरण और अनुमान त्रुटियाँ: यह सुनिश्चित करना कि सीखे गए मॉडल अनदेखे डेटा के लिए अच्छी तरह से सामान्यीकृत हों और तंत्रिका नेटवर्क अनुमान सटीक हों, एक महत्वपूर्ण सैद्धांतिक चुनौती है। सामान्य लिप्सचिट्ज़ लागतों के लिए अनुमान त्रुटि "आयामों के अभिशाप" से पीड़ित हो सकती है, जिससे उच्च आयामों में तेज अभिसरण दरों को प्राप्त करना मुश्किल हो जाता है।
यह दृष्टिकोण क्यों
पसंद की अनिवार्यता
लेखकों का एनर्जी-गाइडेड कंटीन्यूअस एंट्रोपिक बैरीसेंटर एस्टिमेशन दृष्टिकोण का चुनाव केवल एक प्राथमिकता नहीं बल्कि सतत इष्टतम परिवहन (OT) बैरीसेंटर समस्याओं के लिए मौजूदा तरीकों की अंतर्निहित सीमाओं से प्रेरित एक आवश्यकता थी। इस अहसास का सटीक क्षण धारा 3 और तालिका 1 में विस्तृत चर्चा से स्पष्ट है, जो पिछले कला के दोषों को उजागर करते हैं।
पारंपरिक "SOTA" विधियों, जैसे कि मानक CNN, बुनियादी डिफ्यूजन मॉडल, या ट्रांसफॉर्मर, को अपर्याप्त माना गया क्योंकि:
1. विशिष्ट लागत फलन: पिछले सतत OT सॉल्वर का एक महत्वपूर्ण हिस्सा, जिसमें [59, 55, 32, 82] के कार्य शामिल हैं, विशेष रूप से द्विघात यूक्लिडियन लागत $l_2(x, y) = ||x - y||^2$ के लिए डिज़ाइन किए गए थे। यह सीमा वास्तविक दुनिया के परिदृश्यों तक उनकी प्रयोज्यता को गंभीर रूप से प्रतिबंधित करती है जहाँ वितरणों के बीच जटिल ज्यामितीय संबंधों को पकड़ने के लिए मनमानी, गैर-यूक्लिडियन लागत फलनों आवश्यक हैं। पत्र स्पष्ट रूप से कहता है, "इसके विपरीत, हमारा प्रस्तावित दृष्टिकोण मनमानी लागत फलनों $c_1, \dots, c_K$ के साथ EOT समस्या को संभालने के लिए डिज़ाइन किया गया है।" (पृष्ठ 4)।
2. निश्चित पूर्व-निर्धारण और गैर-तुच्छ चयन: कुछ विधियों, जैसे [72], को बैरीसेंटर के लिए गैर-तुच्छ ए प्रियोरी चयन की आवश्यकता होती है या एक निश्चित पूर्व-निर्धारण की आवश्यकता होती है, जो एक जटिल और गैर-मजबूत प्रक्रिया हो सकती है। प्रस्तावित विधि इस बाधा से बचती है।
3. OT योजना पुनर्प्राप्ति का अभाव: महत्वपूर्ण रूप से, कुछ दृष्टिकोण, जैसे [17], OT योजनाओं को पुनः प्राप्त नहीं करते हैं, जो धारा 2.3 में परिभाषित सीखने की व्यवस्था के लिए एक मौलिक आवश्यकता है, जो आउट-ऑफ-सैंपल अनुमान और जनरेटिव क्षमता पर केंद्रित है।
4. कम्प्यूटेशनल जटिलता और पैरामीट्रिजेशन: अन्य भिन्नता विधियाँ, जैसे [14], ने अनुकूलन जटिलता को बढ़ाया और बैरीसेंटर वितरण के विशिष्ट पैरामीट्रिजेशन की आवश्यकता थी, जिससे वे कम सामान्य या सहज हो गए।
लेखकों ने महसूस किया कि सतत सेटिंग में मनमानी लागत फलनों को संभालने, OT योजनाओं को पुनः प्राप्त करने और प्रतिबंधात्मक पूर्व-निर्धारण के बिना काम करने के लिए एक सॉल्वर की आवश्यकता को संबोधित करने के लिए एक उपन्यास दृष्टिकोण की आवश्यकता थी।
तुलनात्मक श्रेष्ठता
यह विधि कई संरचनात्मक लाभों के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करती है, जो सरल प्रदर्शन मेट्रिक्स से परे फैली हुई है:
- मनमानी लागत फलन और गैर-यूक्लिडियन लागत: कई पूर्व कार्यों के विपरीत जो द्विघात यूक्लिडियन लागतों तक सीमित थे, यह दृष्टिकोण मनमानी OT लागत फलनों के लिए डिज़ाइन किया गया है, जिसमें गैर-यूक्लिडियन भी शामिल हैं। यह लचीलापन एक गहरा संरचनात्मक लाभ है, जो इसे जटिल समस्याओं की एक बहुत व्यापक श्रेणी के लिए इसकी प्रयोज्यता को सक्षम करता है, जैसे कि छवि मैनिफोल्ड या विशेष भूवैज्ञानिक सिमुलेशन (धारा 5, बी.2) से संबंधित।
- ऊर्जा-आधारित मॉडल (EBMs) के साथ निर्बाध एकीकरण: विधि का मूल EOT का एक कमजोर द्वैत रूप और एक सर्वांगसमता शर्त के संयोजन का उपयोग करके एन्ट्रोपिक इष्टतम परिवहन (EOT) बैरीसेंटर समस्या के एक सुरुचिपूर्ण सूत्रीकरण में निहित है। यह सूत्रीकरण स्वाभाविक रूप से EBMs की प्रशिक्षण प्रक्रियाओं के साथ संरेखित होता है, जिससे अच्छी तरह से ट्यून किए गए एल्गोरिदम का उपयोग करने की अनुमति मिलती है और "मिन-मैक्स, रीइन्फोर्स और अन्य जटिल तकनीकी चालों से बचने वाली एक सहज अनुकूलन योजना" (सार, पृष्ठ 1) प्रदान की जाती है। यह GANs) या नीति ग्रेडिएंट विधियों के रूप में प्रतिकूल प्रशिक्षण से जुड़ी जटिलताओं से बचता है।
- मजबूत सामान्यीकरण और अनुमान गारंटी: पत्र सैद्धांतिक नींव स्थापित करता है, जिसमें पुनः प्राप्त EOT योजनाओं (धारा 4.3) के लिए सामान्यीकरण सीमाएं और सार्वभौमिक अनुमान गारंटी शामिल हैं। विशेष रूप से, सुविधा-आधारित द्विघात लागतों के लिए, विधि $O(N^{-1/2})$ का अनुमान त्रुटि प्राप्त करती है, जिसे "मानक तेज और आयाम-मुक्त अभिसरण दर" (प्रमेय 4.5 (b), पृष्ठ 6) के रूप में वर्णित किया गया है। यह विधि की सांख्यिकीय स्थिरता और विश्वसनीयता की कठोर समझ प्रदान करता है, एक ऐसी विशेषता जो अक्सर प्रतिस्पर्धी सतत बैरीसेंटर सॉल्वर में गायब होती है।
- उच्च-आयामी शोर और मैनिफोल्ड लर्निंग को संभालना: छवियों जैसे जटिल डेटा के लिए, डेटा स्पेस में प्रत्यक्ष EOT बैरीसेंटर "धुंधला पूर्वाग्रह" से पीड़ित हो सकते हैं और शोर वाली छवियां उत्पन्न कर सकते हैं। यह विधि एक उपन्यास "मैनिफोल्ड-बाधित" सेटअप (धारा 4.4) पेश करके इसे गुणात्मक रूप से बेहतर ढंग से संभालती है। पूर्व-प्रशिक्षित जनरेटिव मॉडल (जैसे, StyleGAN) द्वारा उत्पन्न एक छवि मैनिफोल्ड पर बैरीसेंटर सीखकर, यह अधिक व्याख्यात्मक और plausible बैरीसेंटर वितरण उत्पन्न करता है, जो उच्च-आयामी छवि औसत में निहित शोर और कलाकृतियों को प्रभावी ढंग से कम करता है। यह व्यावहारिक अनुप्रयोगों के लिए परिणामों की गुणवत्ता में एक महत्वपूर्ण सुधार है।
बाधाओं के साथ संरेखण
चुना गया ऊर्जा-संचालित दृष्टिकोण समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो "समस्या की मांगों और समाधान के अद्वितीय गुणों के बीच एक विवाह" बनाता है:
- सतत OT और आउट-ऑफ-सैंपल अनुमान: समस्या स्पष्ट रूप से सतत OT बैरीसेंटर कार्यों को हल करने और आउट-ऑफ-सैंपल अनुमान प्रदान करने की आवश्यकता है, जिसका अर्थ है कि नए डेटा बिंदुओं के लिए सशर्त योजनाओं $\pi^*(\cdot|x_{\text{new}})$ से नमूने उत्पन्न करने की क्षमता। प्रस्तावित विधि सीधे इस समस्या का समाधान करती है, तंत्रिका नेटवर्क क्षमताएं $f_k$ सीखकर जो सशर्त वितरण $\mu_{f_k}^*(\cdot|x_k)$ (समीकरण 4, पृष्ठ 3) को परिभाषित करती हैं। नमूने तब मानक MCMC तकनीकों का उपयोग करके उत्पन्न किए जा सकते हैं, जो आउट-ऑफ-सैंपल अनुमान आवश्यकता (धारा 4.2) को पूरा करते हैं।
- मनमानी लागत फलन: एक प्रमुख बाधा मनमानी लागत फलनों को संभालने की आवश्यकता है, जो $l_2$-विशिष्ट विधियों की सीमाओं से परे जाती है। द्वैत सूत्रीकरण और EBM ढाँचा स्वाभाविक रूप से किसी भी विभेदक लागत फलन $c_k(x,y)$ को समायोजित करता है, जैसा कि गैर-यूक्लिडियन "ट्विस्टेड" लागतों और मैनिफोल्ड-बाधित लागतों के साथ प्रयोगों द्वारा प्रदर्शित किया गया है (धारा 5.1, 5.2)।
- डेटा पहुंच (अनुभवजन्य नमूने): समस्या मानती है कि स्रोत वितरण $P_k$ केवल सीमित संख्या में i.i.d. अनुभवजन्य नमूनों $X_k$ के माध्यम से सुलभ हैं। प्रस्तावित एल्गोरिथम को सीधे इन नमूनों के साथ संचालित करने के लिए डिज़ाइन किया गया है, प्रशिक्षण के दौरान ग्रेडिएंट अनुमान के लिए मोंटे कार्लो अनुमानों का उपयोग करता है (एल्गोरिथम 1, पृष्ठ 5)।
- जटिल स्थानों में सार्थक बैरीसेंटर: छवि डेटा के लिए, पिक्सेल स्पेस में प्रत्यक्ष औसत अक्सर "धुंधला पूर्वाग्रह" के कारण अवांछनीय होता है। मैनिफोल्ड-बाधित EOT बैरीसेंटर (धारा 4.4) सीधे इस समस्या से निपटता है, खोज स्थान को एक पूर्व-परिभाषित डेटा मैनिफोल्ड (जैसे, StyleGAN द्वारा उत्पन्न) तक सीमित करके। यह सुनिश्चित करता है कि परिणामी बैरीसेंटर एक plausible मैनिफोल्ड पर केंद्रित हों, जो देखने में बेहतर और अधिक व्याख्यात्मक परिणाम देते हैं, जैसा कि चित्र 4 और 5 में दिखाया गया है। यह एक व्यावहारिक समस्या बाधा का एक चतुर समाधान है।
विकल्पों का अस्वीकरण
पत्र कई वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है, जो प्रस्तावित विधि के अद्वितीय लाभों पर जोर देता है:
- असतत OT सॉल्वर: लेखकों ने स्पष्ट रूप से कहा है कि "सतत OT सेटअप में आवश्यक आउट-ऑफ-सैंपल अनुमान के लिए असतत OT अच्छी तरह से अनुकूल नहीं हैं" (धारा 2.3, पृष्ठ 3)। जबकि असतत OT विधियों में ध्वनि सैद्धांतिक नींव और अभिसरण गारंटी होती है, उन्हें सीधे सतत सीखने की व्यवस्था के अनुकूल नहीं बनाया जा सकता है जहाँ लक्ष्य अनदेखे डेटा के लिए सशर्त योजनाओं का अनुमान लगाना है (धारा बी.1, पृष्ठ 22)।
- $l_2$ लागतों के साथ सतत OT सॉल्वर: कई मौजूदा सतत OT बैरीसेंटर सॉल्वर "विशेष रूप से द्विघात यूक्लिडियन लागत $l_2(x, y) = ||x - y||^2$" के लिए डिज़ाइन किए गए हैं (धारा 3, पृष्ठ 4)। इसे अस्वीकार कर दिया गया है क्योंकि वास्तविक दुनिया के अनुप्रयोगों में अक्सर जटिल डेटा संबंधों को पकड़ने के लिए मनमानी लागत फलनों, जिसमें गैर-यूक्लिडियन भी शामिल हैं, की मांग होती है। सामान्य लागतों को संभालने की प्रस्तावित विधि की क्षमता इस सीमा का एक सीधा जवाब है।
- निश्चित पूर्व-निर्धारण की आवश्यकता वाले सतत OT सॉल्वर या योजना पुनर्प्राप्ति का अभाव: कुछ विधियों, जैसे [72], को बैरीसेंटर के लिए "गैर-तुच्छ ए प्रियोरी चयन" की आवश्यकता होती है, जो बोझिल हो सकता है। अन्य, जैसे [17], "OT योजनाओं को पुनः प्राप्त नहीं करते हैं," जो जनरेटिव कार्यों के लिए सशर्त परिवहन योजनाओं को सीखने के पत्र के उद्देश्य से एक मौलिक बेमेल है (धारा 3, पृष्ठ 4)।
- $H(Q)$ पद के साथ दोहरे-नियमित EOT बैरीसेंटर: पत्र दोहरे-नियमित EOT बैरीसेंटर (समीकरण 40, पृष्ठ 24) पर चर्चा करता है जहाँ बैरीसेंटर वितरण $Q$ के लिए एक अतिरिक्त एन्ट्रॉपी पद $H(Q)$ मौजूद है। इस विकल्प को अस्वीकार कर दिया गया है क्योंकि " $H(Q)$ पद की उपस्थिति हमारे से काफी भिन्न है और हमारे सॉल्वर के लिए उपयुक्त नहीं लगती है" (पृष्ठ 25)। इसका कारण यह है कि $H(Q)$ जोड़ने के लिए दूसरे मार्जिनल $H(\pi_k(y))$ की एक अलग, अत्यधिक गैर-तुच्छ गणना की आवश्यकता होगी, जिसे कच्चे नमूनों से अनुमान लगाना अव्यवहार्य है, और EBM-जैसी तकनीकें इस परिदृश्य में ग्रेडिएंट प्राप्त नहीं कर सकती हैं (पृष्ठ 25)।
- अन्य GAN-आधारित बैरीसेंटर विधियाँ (जैसे, [95]): जबकि [95] भी खोज स्थान को GAN मैनिफोल्ड तक सीमित करता है, उनका दृष्टिकोण मौलिक रूप से भिन्न है और इस पत्र में समस्या सेटअप के लिए "वास्तव में लागू नहीं है" (धारा बी.1, पृष्ठ 23)। वे K छवियों (तीव्रता हिस्टोग्राम के माध्यम से 2D वितरण के रूप में दर्शाए गए) पर विचार करते हैं और असतत OT सॉल्वर का उपयोग करके GAN मैनिफोल्ड पर एक एकल छवि की खोज करते हैं। इसके विपरीत, यह पत्र सतत OT सॉल्वर का उपयोग करके K उच्च-आयामी छवि वितरणों के बैरीसेंटर की तलाश करता है जो OT योजनाओं को पुनः प्राप्त करता है। उद्देश्य और पद्धतियाँ भिन्न हैं, जिससे [95] का दृष्टिकोण वर्तमान समस्या के लिए अनुपयुक्त हो जाता है।
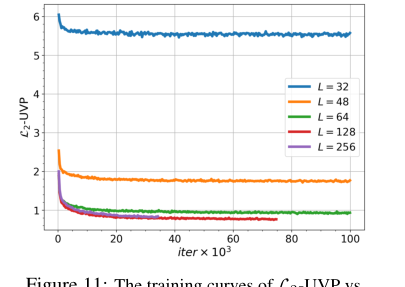 Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पत्र के एन्ट्रोपिक बैरीसेंटर अनुमान के लिए ऊर्जा-संचालित दृष्टिकोण को शक्ति प्रदान करने वाला पूर्ण मुख्य गणितीय इंजन द्वैत उद्देश्य फलन है जिसे एल्गोरिथम अधिकतम करने का प्रयास करता है। यह उद्देश्य एन्ट्रोपिक इष्टतम परिवहन (EOT) समस्या के कमजोर द्वैत सूत्रीकरण से प्राप्त होता है और तंत्रिका नेटवर्क द्वारा पैरामीट्रिज्ड होता है। विशिष्ट समीकरण जिसे अनुकूलित किया गया है, वह इस प्रकार दिया गया है:
$$ \mathcal{L}(\theta) \stackrel{\text{def}}{=} \sum_{k=1}^K \lambda_k \left\{ -\epsilon \mathbb{E}_{x_k \sim P_k} \left[ \log Z_{c_k}(f_{\theta,k}, x_k) \right] \right\} \quad (8) $$
जहाँ $Z_{c_k}(f_{\theta,k}, x_k)$ सामान्यीकरण स्थिरांक (या विभाजन फलन) है जिसे इस प्रकार परिभाषित किया गया है:
$$ Z_{c_k}(f_{\theta,k}, x_k) \stackrel{\text{def}}{=} \int_{\mathcal{Y}} \exp\left(\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}\right) dy \quad (21) $$
पद-दर-पद विच्छेदन
आइए उनके भूमिकाओं को समझने के लिए इन समीकरणों को एक-एक करके तोड़ें:
- $\mathcal{L}(\theta)$: यह उद्देश्य फलन है जिसे एल्गोरिथम अधिकतम करने का लक्ष्य रखता है। इसका मान दर्शाता है कि संभावित फलनों का वर्तमान सेट ( $\theta$ द्वारा पैरामीट्रिज्ड) EOT बैरीसेंटर समस्या के द्वैत सूत्रीकरण के साथ कितनी अच्छी तरह संरेखित होता है। इस द्वैत उद्देश्य को अधिकतम करना प्राथमिक EOT बैरीसेंटर समस्या को कम करने के बराबर है।
- $\theta$: यह तंत्रिका नेटवर्क $f_{\theta,k}$ के सभी सीखने योग्य मापदंडों का संग्रह दर्शाता है। इन मापदंडों को उद्देश्य को अनुकूलित करने के लिए सीखने की प्रक्रिया के दौरान समायोजित किया जाता है।
- $K$: यह स्रोत संभाव्यता वितरणों $P_k$ की कुल संख्या है जिनका हम औसत निकालना चाहते हैं। उदाहरण के लिए, यदि हम तीन छवि डेटासेट का औसत निकाल रहे हैं, तो $K=3$ है।
- $\lambda_k$: ये प्रत्येक स्रोत वितरण $P_k$ के लिए पूर्वनिर्धारित सकारात्मक भार हैं, जैसे कि $\sum_{k=1}^K \lambda_k = 1$। वे अंतिम बैरीसेंटर में प्रत्येक स्रोत वितरण के सापेक्ष महत्व या योगदान को निर्धारित करते हैं। यदि सभी $\lambda_k$ बराबर हैं, तो यह एक साधारण औसत है; अन्यथा, यह एक भारित औसत है।
- $\sum_{k=1}^K$: यह एक योग ऑपरेटर है जो सभी $K$ स्रोत वितरणों से योगदान को एकत्रित करता है। लेखक जोड़ का उपयोग करते हैं क्योंकि EOT बैरीसेंटर समस्या को प्रत्येक स्रोत वितरण और बैरीसेंटर के बीच व्यक्तिगत EOT विसंगतियों के योग के रूप में तैयार किया गया है।
- $\epsilon$: यह एन्ट्रोपिक नियमितीकरण पैरामीटर है, एक सकारात्मक स्केलर। यह परिवहन योजनाओं की "चिकनाई" या "यादृच्छिकता" को नियंत्रित करता है। एक बड़ा $\epsilon$ अधिक विसरित, कम "तेज" परिवहन योजनाओं (और एक चिकनी हानि परिदृश्य) की ओर ले जाता है, जबकि एक छोटा $\epsilon$ परिवहन को अधिक नियतात्मक बनाता है, जो शास्त्रीय इष्टतम परिवहन के करीब पहुंचता है। यह सांख्यिकीय यांत्रिकी में "तापमान" पैरामीटर के रूप में कार्य करता है।
- $\mathbb{E}_{x_k \sim P_k}[\dots]$: यह $k$-वें स्रोत संभाव्यता वितरण $P_k$ से निकाले गए नमूनों $x_k$ पर अपेक्षा को दर्शाता है। व्यवहार में, इस अपेक्षा का अनुमान मोंटे कार्लो नमूनाकरण का उपयोग करके $P_k$ से नमूनों के एक बैच को निकालकर किया जाता है।
- $P_k$: यह $k$-वां स्रोत संभाव्यता वितरण है। ये इनपुट वितरण हैं जिनका एल्गोरिथम औसत निकालने का लक्ष्य रखता है। वास्तविक दुनिया के परिदृश्यों में, ये आम तौर पर केवल अनुभवजन्य नमूनों (डेटासेट) के माध्यम से सुलभ होते हैं।
- $x_k$: यह $k$-वें स्रोत वितरण $P_k$ से निकाला गया एक नमूना (डेटा बिंदु) है।
- $\log$: यह प्राकृतिक लघुगणक फलन है। इसका उपयोग यहाँ किया जाता है क्योंकि कमजोर एन्ट्रोपिक सी-ट्रांसफॉर्म, $f_k^{c_k}(x_k)$, को $-\epsilon \log Z_{c_k}(f_k, x_k)$ के रूप में परिभाषित किया गया है। यह परिवर्तन इसे एक अधिक प्रबंधनीय रूप में बदलने के लिए महत्वपूर्ण है और इसे ऊर्जा-आधारित मॉडल से संबंधित करने के लिए।
- $Z_{c_k}(f_{\theta,k}, x_k)$: यह सशर्त संभाव्यता वितरण $\mu_{x_k}^{f_{\theta,k}}(y)$ के लिए सामान्यीकरण स्थिरांक या विभाजन फलन है। यह सुनिश्चित करता है कि सशर्त वितरण 1 तक एकीकृत हो। इसका मान संभावित फलन $f_{\theta,k}$ और लागत $c_k$ पर निर्भर करता है, जो दिए गए $x_k$ के लिए है।
- $\int_{\mathcal{Y}} \dots dy$: यह लक्ष्य स्थान $\mathcal{Y}$ पर एक समाकलन है। यह सामान्यीकरण स्थिरांक की गणना करने के लिए सभी संभावित लक्ष्य बिंदुओं $y$ पर "ऊर्जा" योगदानों को जोड़ता है। लेखक एक समाकलन का उपयोग करते हैं क्योंकि समस्या संभाव्यता वितरणों के सतत डोमेन में निर्धारित है।
- $\exp(\dots)$: यह घातीय फलन है। यह "ऊर्जा" पद $(f_{\theta,k}(y) - c_k(x_k, y))/\epsilon$ को एक गैर-नकारात्मक मान में बदलता है जिसे एक अनियंत्रित घनत्व के रूप में व्याख्यायित किया जा सकता है। यह सांख्यिकीय यांत्रिकी और ऊर्जा-आधारित मॉडल में एक मानक घटक है।
- $f_{\theta,k}(y)$: यह $k$-वें वितरण के लिए संभावित फलन है, जिसका मूल्यांकन लक्ष्य बिंदु $y$ पर किया जाता है। ये फलन तंत्रिका नेटवर्क $f_{\theta,k}$ द्वारा पैरामीट्रिज्ड होते हैं और मॉडल के प्राथमिक सीखने योग्य घटक होते हैं। वे स्रोत $k$ के दृष्टिकोण से लक्ष्य बिंदु $y$ के "मान" या "उपयोगिता" का प्रतिनिधित्व करते हैं।
- $c_k(x_k, y)$: यह स्रोत बिंदु $x_k$ से लक्ष्य बिंदु $y$ तक द्रव्यमान के परिवहन के लिए लागत फलन है। यह $x_k$ और $y$ के बीच चलने की "लागत" को मापता है। पत्र सामान्य (यहां तक कि गैर-यूक्लिडियन) लागत फलनों को संभालने की अपनी क्षमता पर प्रकाश डालता है।
- $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$: यह पद स्केल्ड "ऊर्जा" या "लॉग-संभाव्यता" का प्रतिनिधित्व करता है, जो संभावित $f_{\theta,k}$ और लागत $c_k$ द्वारा संशोधित होता है। संभावित $f_{\theta,k}(y)$ को $y$ पर उतरने के लिए "पुरस्कार" के रूप में सोचा जा सकता है, जबकि $c_k(x_k, y)$ परिवहन के लिए "दंड" है। $\epsilon$ द्वारा विभाजन इस ऊर्जा को स्केल करता है, छोटे $\epsilon$ के लिए वितरण को तेज और बड़े $\epsilon$ के लिए समतल बनाता है।
- घातांक के भीतर $f_{\theta,k}(y) - c_k(x_k, y)$ का घटाव संयुक्त करने का एक प्राकृतिक तरीका है, क्योंकि यह किसी दिए गए $x_k$ के लिए $y$ के लक्ष्य बिंदु की शुद्ध "आकर्षण" को दर्शाता है।
चरण-दर-चरण प्रवाह
एक प्रशिक्षण पुनरावृति के दौरान इस गणितीय इंजन के माध्यम से यात्रा करते हुए, एक एकल अमूर्त डेटा बिंदु, जैसे $x_1$, $P_1$ से, की कल्पना करें।
- डेटा बिंदु प्रवेश: पहले स्रोत वितरण $P_1$ से एक नमूना $x_1$ निकाला जाता है। यह $x_1$ डेटासेट से एक ठोस उदाहरण है।
- संभावित मूल्यांकन: इस $x_1$ के लिए, और लक्ष्य स्थान $\mathcal{Y}$ में संभावित लक्ष्य बिंदुओं की एक श्रृंखला के लिए, तंत्रिका नेटवर्क $f_{\theta,1}$ अपनी क्षमता $f_{\theta,1}(y)$ की गणना करता है। साथ ही, लागत फलन $c_1(x_1, y)$ का मूल्यांकन किया जाता है, जो प्रत्येक $y$ तक ले जाने के "प्रयास" को मापता है।
- ऊर्जा गणना: इन मानों को संयोजित किया जाता है: $f_{\theta,1}(y) - c_1(x_1, y)$। यह अंतर $x_1$ से $y$ तक परिवहन की "शुद्ध उपयोगिता" का प्रतिनिधित्व करता है। इस उपयोगिता को फिर नियमितीकरण पैरामीटर $\epsilon$ से स्केल किया जाता है, जिससे $\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}$ प्राप्त होता है।
- अनियंत्रित संभाव्यता: स्केल्ड उपयोगिता को घातांकित किया जाता है: $\exp\left(\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}\right)$। यह $x_1$ से $y$ तक परिवहन करने की "संभावना" का एक अनियंत्रित माप देता है।
- सामान्यीकरण (विभाजन फलन): इसे $y$ पर एक उचित सशर्त संभाव्यता वितरण ( $\mu_{x_1}^{f_{\theta,1}}(y)$ के रूप में दर्शाया गया) बनाने के लिए, हमें इसे सामान्य करने की आवश्यकता है। यह $Z_{c_1}(f_{\theta,1}, x_1)$ प्राप्त करने के लिए पूरे लक्ष्य स्थान $\mathcal{Y}$ पर अनियंत्रित संभावनाओं को एकीकृत करके किया जाता है। यह समाकलन अक्सर कम्प्यूटेशनल रूप से अनसुलझा होता है, इसलिए इसके ग्रेडिएंट का अनुमान MCMC जैसी तकनीकों का उपयोग करके लगाया जाता है।
- लॉग-संभाव्यता योगदान: इस सामान्यीकरण स्थिरांक, $\log Z_{c_1}(f_{\theta,1}, x_1)$ के प्राकृतिक लघुगणक को फिर लिया जाता है। यह पद, $-\epsilon$ से गुणा होने पर, प्रभावी रूप से कमजोर एन्ट्रोपिक सी-ट्रांसफॉर्म $f_1^{c_1}(x_1)$ बन जाता है।
- भारित योग: यह प्रक्रिया (चरण 2-6) $P_1$ से अन्य नमूनों के लिए (अपेक्षा $\mathbb{E}_{x_1 \sim P_1}[\dots]$ का अनुमान लगाने के लिए) और अन्य सभी स्रोत वितरणों $P_k$ से नमूनों के लिए दोहराई जाती है। प्रत्येक वितरण के योगदान को फिर उसके $\lambda_k$ गुणांक से भारित किया जाता है और कुल उद्देश्य $\mathcal{L}(\theta)$ बनाने के लिए जोड़ा जाता है।
- ग्रेडिएंट गणना: तंत्रिका नेटवर्क मापदंडों $\theta$ के संबंध में $\mathcal{L}(\theta)$ का ग्रेडिएंट गणना की जाती है। यह ग्रेडिएंट पैरामीटर स्पेस में दिशा इंगित करता है जो उद्देश्य फलन को बढ़ाएगा। चूंकि $Z_{c_k}$ की प्रत्यक्ष गणना कठिन है, $\log Z_{c_k}$ का ग्रेडिएंट सशर्त वितरण $\mu_{x_k}^{f_{\theta,k}}(y)$ से नमूनाकरण करके अनुमानित किया जाता है, जो MCMC प्रक्रिया का उपयोग करके किया जाता है।
- पैरामीटर अद्यतन: अंत में, तंत्रिका नेटवर्क $f_{\theta,k}$ के पैरामीटर $\theta$ को गणना किए गए ग्रेडिएंट द्वारा इंगित दिशा में एक अनुकूलन एल्गोरिथम (जैसे स्टोकेस्टिक ग्रेडिएंट एसेंट) का उपयोग करके अद्यतन किया जाता है। यह पुनरावृत्त अद्यतन तंत्रिका नेटवर्क क्षमता को EOT बैरीसेंटर शर्तों को बेहतर ढंग से संतुष्ट करने के लिए धीरे-धीरे समायोजित करने में मदद करता है।
अनुकूलन गतिशीलता
तंत्रिका नेटवर्क क्षमता $f_k$ को तंत्रिका नेटवर्क, $f_{\theta,k}$, के रूप में पैरामीट्रिज्ड करके, जहाँ $\theta$ इन नेटवर्कों के भार और पूर्वाग्रह हैं। यह लचीले, उच्च-आयामी फ़ंक्शन सन्निकटन की अनुमति देता है।
-
सर्वांगसमता शर्त को संभालना: द्वैत सूत्रीकरण (6) में एक महत्वपूर्ण बाधा शामिल है: $\sum_{k=1}^K \lambda_k f_k = 0$ । लेखकों ने चतुराई से $f_{\theta,k}$ को $g_{\theta,k} - \sum_{j=1}^K \lambda_j g_{\theta,j}$ के रूप में पैरामीट्रिज्ड करके इसे संभाला है, जहाँ $g_{\theta,k}$ व्यक्तिगत तंत्रिका नेटवर्क हैं। यह विशिष्ट निर्माण स्वचालित रूप से सुनिश्चित करता है कि भारित क्षमताओं का योग शून्य है, जिससे स्पष्ट बाधा अनुकूलन की आवश्यकता समाप्त हो जाती है।
-
ग्रेडिएंट एसेंट: चूंकि उद्देश्य फलन एक द्वैत सूत्रीकरण है, लक्ष्य $\mathcal{L}(\theta)$ को अधिकतम करना है। यह ग्रेडिएंट एसेंट का उपयोग करके प्राप्त किया जाता है। ग्रेडिएंट $\frac{\partial}{\partial \theta} \mathcal{L}(\theta)$ की गणना की जाती है, और मापदंडों $\theta$ को इस ग्रेडिएंट की दिशा में अद्यतन किया जाता है।
-
MCMC के माध्यम से ग्रेडिएंट अनुमान: सबसे चुनौतीपूर्ण हिस्सा ग्रेडिएंट सूत्र (समीकरण 9) के भीतर अपेक्षा $\mathbb{E}_{y \sim \mu_{x_k}^{f_{\theta,k}}} \left[ \frac{\partial}{\partial \theta} f_{\theta,k}(y) \right]$ की गणना करना है। सशर्त वितरण $\mu_{x_k}^{f_{\theta,k}}(y)$ में एक अनियंत्रित लॉग-घनत्व होता है जो $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$ द्वारा दिया जाता है। इस वितरण से नमूना लेने के लिए, पत्र एक मार्कोव चेन मोंटे कार्लो (MCMC) प्रक्रिया, विशेष रूप से अनएडजस्टेड लांगविन एल्गोरिथम (ULA) का उपयोग करता है।
- ULA चरण: $P_k$ से नमूना $x_k$ के प्रत्येक के लिए, ULA नमूनों $y_t$ का एक क्रम उत्पन्न करता है जो अंततः $\mu_{x_k}^{f_{\theta,k}}$ से नमूनों का अनुमान लगाता है। ULA के लिए अद्यतन नियम है:
$$y_{t+1}^{(1)} = y_t^{(1)} + \frac{\eta}{2\epsilon} \nabla_y (f_{\theta,k}(y) - c_k(x_k, y))|_{y=y_t^{(1)}} + \sqrt{\eta} \xi_t$$
जहाँ $\eta$ स्टेप साइज है, और $\xi_t$ एक मानक सामान्य वितरण से खींचा गया एक यादृच्छिक शोर पद है। यह प्रक्रिया $f_{\theta,k}(y) - c_k(x_k, y)$ द्वारा परिभाषित ऊर्जा परिदृश्य में चलने वाले एक कण का अनुकरण करती है, जो धीरे-धीरे लक्ष्य वितरण में परिवर्तित होती है।
- ULA चरण: $P_k$ से नमूना $x_k$ के प्रत्येक के लिए, ULA नमूनों $y_t$ का एक क्रम उत्पन्न करता है जो अंततः $\mu_{x_k}^{f_{\theta,k}}$ से नमूनों का अनुमान लगाता है। ULA के लिए अद्यतन नियम है:
-
हानि परिदृश्य: द्वैत उद्देश्य फलन अवतल है (प्रस्ताव ए.1 (iii) के अनुसार कमजोर सी-ट्रांसफॉर्म के लिए, जो $\mathcal{L}(\theta)$ तक विस्तारित होता है)। यह अवतलता का अर्थ है कि कोई स्थानीय अधिकतम नहीं हैं जो वैश्विक अधिकतम नहीं हैं, जो गैर-अवतल उद्देश्यों की तुलना में अनुकूलन समस्या को काफी सरल बनाता है। एन्ट्रॉपी नियमितीकरण पैरामीटर $\epsilon$ इस परिदृश्य को और चिकना करता है, जिससे ग्रेडिएंट-आधारित विधियों के लिए नेविगेट करना और उन भ्रामक मोड में फंसने से बचना आसान हो जाता है जो अनियंत्रित मामले में मौजूद हो सकते हैं।
-
पुनरावृत्त शोधन: प्रत्येक पुनरावृति के साथ, नए नमूने $x_k$ निकाले जाते हैं, $y$ नमूने उत्पन्न करने के लिए MCMC चलाया जाता है, $\mathcal{L}(\theta)$ के ग्रेडिएंट का अनुमान लगाया जाता है, और $\theta$ को अद्यतन किया जाता है। यह पुनरावृत्त प्रक्रिया तंत्रिका नेटवर्क क्षमताओं $f_{\theta,k}$ को परिष्कृत करती है, जिससे वे EOT बैरीसेंटर को परिभाषित करने वाले इष्टतम क्षमताओं की ओर अभिसरण करते हैं। उद्देश्य फलन को तब अधिकतम किया जाता है, और इन क्षमताओं के माध्यम से बैरीसेंटर को अप्रत्यक्ष रूप से सीखा जाता है।
-
अभिसरण: पत्र पुनः प्राप्त योजनाओं की गुणवत्ता और तंत्रिका नेटवर्क की सार्वभौमिक सन्निकटन क्षमताओं के संबंध में सैद्धांतिक गारंटी (प्रमेय 4.2, 4.5, 4.6) प्रदान करता है, यह सुझाव देता है कि पर्याप्त डेटा और नेटवर्क क्षमता के साथ, सीखे गए क्षमताएं वास्तविक EOT योजनाओं और इस प्रकार बैरीसेंटर का सटीक अनुमान लगा सकती हैं। हालांकि, व्यावहारिक अभिसरण गति और गुणवत्ता MCMC मापदंडों (लांगिन चरणों की संख्या $L$, स्टेप साइज $\eta$) और बैच आकार से प्रभावित होती है, जैसा कि प्रयोगात्मक अनुभाग में चर्चा की गई है।
 Figure 6. A schematical presentation of potential applications of barycenter solvers
Figure 6. A schematical presentation of potential applications of barycenter solvers
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और आधार रेखाएँ
लेखकों ने विभिन्न परिदृश्यों में अपने प्रस्तावित एनर्जी-गाइडेड कंटीन्यूअस एंट्रोपिक बैरीसेंटर (EOT) सॉल्वर को कठोरता से मान्य करने के लिए प्रयोगों की एक श्रृंखला को सावधानीपूर्वक डिजाइन किया, जो निम्न-आयामी खिलौना समस्याओं से लेकर उच्च-आयामी छवि मैनिफोल्ड तक थे। सत्यापन के लिए मुख्य रणनीति, विशेष रूप से जब ग्राउंड ट्रुथ बैरीसेंटर अज्ञात हो, तो गणना किए गए EOT बैरीसेंटर (पर्याप्त छोटे नियमितीकरण पैरामीटर $\epsilon$ के लिए) की तुलना विश्लेषणात्मक रूप से व्युत्पन्न अनियंत्रित बैरीसेंटर ($\epsilon=0$) से की गई। इस दृष्टिकोण ने गुणात्मक और मात्रात्मक समझौते या लागू होने पर बेहतर प्रदर्शन का प्रदर्शन करके उनकी गणितीय दावों को क्रूरता से साबित किया।
2D खिलौना वितरण के लिए, विशेष रूप से "ट्विस्टर" उदाहरण में, प्रयोग को तीन कॉमेट-आकार के 2D वितरणों ($P_1, P_2, P_3$) के साथ समान भार के साथ तैयार किया गया था। दो अलग-अलग लागत फलनों का परीक्षण किया गया: एक गैर-यूक्लिडियन "ट्विस्टेड कॉस्ट" $c_k(x_k, y) = ||u(x_k) - u(y)||^2$ और मानक यूक्लिडियन $l^2$ लागत $c_k(x, y) = ||x - y||^2$, दोनों नियमितीकरण $\epsilon = 10^{-2}$ के साथ। यहाँ "पीड़ित" या आधार रेखाएँ ट्विस्टेड लागत के लिए विश्लेषणात्मक रूप से व्युत्पन्न सत्य अनियंत्रित बैरीसेंटर (एक केंद्रित गॉसियन) और POT पैकेज [33] से free_support_barycenter सॉल्वर का उपयोग करके अनुमानित $l^2$ बैरीसेंटर थे। इसने ज्ञात या अच्छी तरह से स्थापित समाधानों के खिलाफ सीधी तुलना की अनुमति दी। 3D स्फीयर प्रयोग में, सॉल्वर ने एक गैर-द्विघात लागत फलन $c_k(x_k, y) = \frac{1}{2} \arccos^2(x_k, y)$ और $\epsilon = 10^{-2}$ का उपयोग करके 3D स्फीयर पर चार वॉन मिसेस वितरणों के बैरीसेंटर का अनुमान लगाया। यहाँ, ग्राउंड ट्रुथ अज्ञात था, इसलिए मूल्यांकन मुख्य रूप से गुणात्मक था, जो सीखे गए बैरीसेंटर की तर्कसंगतता पर केंद्रित था।
छवि डेटा के लिए, प्रयोगों में MNIST 0/1 अंक और Ave, celeba! डेटासेट शामिल थे। MNIST के लिए, कार्य $32 \times 32$ ग्रेस्केल छवि स्थान में समान भार के साथ 0/1 अंकों के वितरण का औसत निकालना था। MNIST के लिए सत्य अनियंत्रित $l^2$-बैरीसेंटर एक साधारण पिक्सेल-वार औसत है, और लेखकों ने SCWB [32] और WIN [55] जैसे मौजूदा सॉल्वर के खिलाफ तुलना की जो अनियंत्रित बैरीसेंटर सीखते हैं। महत्वपूर्ण रूप से, उन्होंने एक मैनिफोल्ड-बाधित सेटअप पेश किया जहाँ बैरीसेंटर के लिए खोज स्थान एक पूर्व-प्रशिक्षित StyleGAN [50] मैनिफोल्ड तक सीमित था, यहाँ तक कि इस मैनिफोल्ड को अप्रासंगिक नमूनों से "प्रदूषित" भी किया गया था ताकि मजबूती का परीक्षण किया जा सके। लागत फलन को $c_{k,G}(x_k, z) = ||x_k - G(z)||^2$ में संशोधित किया गया था, $\epsilon = 10^{-2}$ के साथ। Ave, celeba! डेटासेट प्रयोग में चेहरों के तीन खराब हुए उपसमूहों का औसत निकालना शामिल था, जहाँ सत्य अनियंत्रित $l^2$ बैरीसेंटर Celeba चेहरों का वितरण स्वयं है। इसका मूल्यांकन भी मैनिफोल्ड-बाधित सेटिंग में $\epsilon = 10^{-4}$ के साथ, SCWB [32] और WIN [55] के खिलाफ किया गया था।
अंत में, गॉसियन वितरण के लिए, लेखकों ने विभिन्न आयामों ($D = 2, 4, 8, 16, 64$) में भार $(\frac{1}{4}, \frac{1}{2}, \frac{1}{4})$ और नियमितीकरण $\epsilon = 0.01, 1$ के साथ तीन गॉसियन वितरणों का उपयोग करके एक मात्रात्मक मूल्यांकन किया। सत्य अनियंत्रित बैरीसेंटर $Q^*$ का अनुमान WIN रिपॉजिटरी से एक पुनरावृत्त प्रक्रिया के माध्यम से लगाया गया था, और WIN सॉल्वर [55] स्वयं एक आधार रेखा के रूप में कार्य करता था। प्राथमिक मीट्रिक $L_2$-UVP (अस्पष्टीकृत भिन्नता प्रतिशत) बैरीसेंट्रिक अनुमानों का था। बैच आकार और लांगिन चरणों की संख्या के प्रभाव को समझने के लिए एब्लेशन अध्ययन भी किए गए थे। एक एकल-सेल प्रयोग भी आयोजित किया गया था, जो समय के साथ सेल आबादी के इंटरपोलेशन पर केंद्रित था, जिसमें आयाम $D = 50, 100, 1000$ थे। यहाँ, मीट्रिक MMD (मैक्सिमम मीन डिसक्रेपेंसी) था, और आधार रेखाओं में LightSB-M [2], SFM-sink [3], और EGNOT [1] शामिल थे।
साक्ष्य क्या साबित करता है
प्रायोगिक साक्ष्य निश्चित रूप से साबित करते हैं कि प्रस्तावित एनर्जी-गाइडेड कंटीन्यूअस एंट्रोपिक बैरीसेंटर (EOT) सॉल्वर मनमानी लागत फलनों के लिए सतत EOT बैरीसेंटर का प्रभावी ढंग से अनुमान लगाता है, जो पिछली विधियों की सीमाओं को पार करता है।
3D स्फीयर प्रयोग (चित्र 1) गुणात्मक साक्ष्य प्रदान करता है कि दृष्टिकोण गैर-मानक, गैर-द्विघात प्रायोगिक सेटअपों पर लागू होता है, जो सत्य अज्ञात होने पर भी उचित बैरीसेंटर उत्पन्न करता है। यह ज्यामितीय स्थानों से परे विधि के लचीलेपन और मजबूती को प्रदर्शित करता है।
2D ट्विस्टर उदाहरण के लिए, गुणात्मक परिणाम (चित्र 12) निर्विवाद प्रमाण दिखाते हैं कि हमारा सॉल्वर, $\epsilon = 10^{-2}$ के साथ, गैर-यूक्लिडियन ट्विस्टेड लागत के लिए सत्य अनियंत्रित बैरीसेंटर को सटीक रूप से पुनः प्राप्त करता है। गणना किया गया बैरीसेंटर (चित्र 12b) विश्लेषणात्मक रूप से व्युत्पन्न गॉसियन ग्राउंड ट्रुथ (चित्र 12a) के साथ नेत्रहीन रूप से पूरी तरह से संरेखित होता है। यह मूल तंत्र की जटिल, गैर-यूक्लिडियन लागतों को संभालने की क्षमता का एक मजबूत सत्यापन है। $l^2$ लागत के लिए, हमारा EOT बैरीसेंटर (चित्र 12d) भी सत्य $l^2$ बैरीसेंटर (चित्र 12c) के साथ अच्छी तरह से संरेखित होता है, जो इसके सामान्य प्रयोज्यता की पुष्टि करता है। ट्विस्टेड बनाम $l^2$ लागतों के लिए सीखे गए सशर्त योजनाओं की विशिष्ट संरचनाएं अंतर्निहित ज्यामिति के प्रति विधि की संवेदनशीलता को उजागर करती हैं जो लागत फलन द्वारा परिभाषित होती है।
MNIST 0/1 प्रयोगों में, डेटा-स्पेस EOT बैरीसेंटर (चित्र 5, "OURS (Data Space)") में देखी गई "धुंधला पूर्वाग्रह" और शोर एन्ट्रॉपी-नियमित OT और MCMC नमूनाकरण की प्रकृति के अनुरूप हैं। हालांकि, मैनिफोल्ड-बाधित सेटअप (चित्र 5, "OURS (Manifold Constrained)") प्रस्तावित तकनीक की शक्ति को निश्चित रूप से साबित करता है। StyleGAN जैसे जनरेटिव मॉडल के मैनिफोल्ड तक खोज को सीमित करके, सॉल्वर स्वच्छ, व्याख्यात्मक बैरीसेंटर उत्पन्न करता है, जो प्रभावी रूप से मैनिफोल्ड से "प्रदूषित" नमूनों को अनदेखा करता है। यह एक महत्वपूर्ण साक्ष्य है कि मैनिफोल्ड बाधा सीधे डेटा-स्पेस EOT बैरीसेंटर अनुमान में निहित शोर समस्या को प्रभावी ढंग से कम करती है।
Ave, celeba! डेटासेट मूल्यांकन सम्मोहक मात्रात्मक साक्ष्य प्रदान करता है। हमारे सॉल्वर ने आधार रेखा मॉडल SCWB [32] और WIN [55] की तुलना में काफी कम FID स्कोर (तालिका 2) प्राप्त किए। उदाहरण के लिए, $k=1$ के लिए हमारे विधि का FID 8.4 (0.3 के मानक विचलन के साथ) था, जो SCWB के 56.7 और WIN के 49.3 से काफी बेहतर प्रदर्शन करता है। यह पर्याप्त सुधार, विशेष रूप से मैनिफोल्ड-बाधित सेटिंग में, निश्चित प्रमाण है कि मूल तंत्र, जनरेटिव मॉडल के साथ संयुक्त होने पर, जटिल छवि वितरणों के लिए बेहतर वैचारिक गुणवत्ता और अधिक सटीक बैरीसेंटर अनुमान प्रदान करता है। गुणात्मक परिणाम (चित्र 12) भी "गुणात्मक रूप से अच्छी" परिवहन की गई छवियां दिखाते हैं, कभी-कभी सामग्री संरक्षण विफलताओं के बावजूद MCMC के कारण।
गॉसियन वितरण के लिए, मात्रात्मक $L_2$-UVP मीट्रिक (तालिका 7) सॉल्वर की सटीकता का कठोर प्रमाण प्रदान करता है। छोटे $\epsilon = 0.01$ और $D=16$ तक के आयामों के लिए, हमारे एल्गोरिथम ने $L_2$-UVP स्कोर उत्पन्न किए जो अनियंत्रित मामले के लिए विशेष रूप से डिज़ाइन किए गए WIN सॉल्वर से भी बेहतर थे। उदाहरण के लिए, $D=2$ पर, हमारा $L_2$-UVP 0.02 था जो WIN के 0.03 की तुलना में था। यह दर्शाता है कि उपयुक्त नियमितीकरण के लिए, हमारा EOT सॉल्वर अत्याधुनिक सटीकता प्राप्त कर सकता है, यहां तक कि अनियंत्रित सेटिंग के लिए तैयार की गई विधियों से भी बेहतर प्रदर्शन करता है। बैच आकार (तालिका 9) और लांगिन चरणों (चित्र 11) पर एब्लेशन अध्ययन आगे पुष्टि करते हैं कि विधि का प्रदर्शन इन मापदंडों के प्रति संवेदनशील है, बड़े बैच आकार और पर्याप्त लांगिन चरणों के साथ बेहतर गुणवत्ता के कारण, जैसा कि MCMC-आधारित दृष्टिकोणों से अपेक्षित है।
अंत में, एकल-सेल प्रयोग (तालिका 8) से पता चलता है कि हमारा सामान्य-उद्देश्य एन्ट्रोपिक बैरीसेंटर दृष्टिकोण विभिन्न आयामों और सेटअपों में अग्रणी आधार रेखाओं (जैसे, $D=50$ पर OURS के लिए 2.32 बनाम LightSB-M के लिए 2.33) के प्रदर्शन से लगभग मेल खाता है। यह जनसंख्या इंटरपोलेशन जैसी समस्याओं के लिए एक मजबूत, आउट-ऑफ-द-बॉक्स फाउंडेशन मॉडल के रूप में इसकी क्षमता का सुझाव देता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि प्रस्तावित एनर्जी-गाइडेड कंटीन्यूअस एंट्रोपिक बैरीसेंटर सॉल्वर महत्वपूर्ण प्रगति प्रदर्शित करता है, इसकी अंतर्निहित सीमाओं को स्वीकार करना और भविष्य के शोध के लिए आशाजनक रास्ते पर विचार करना महत्वपूर्ण है।
पद्धतिगत सीमाओं में से एक प्रशिक्षण और अनुमान दोनों के दौरान मार्कोव चेन मोंटे कार्लो (MCMC) प्रक्रियाओं पर निर्भरता से उत्पन्न होती है। मूल अनएडजस्टेड लांगविन एल्गोरिथम (ULA) का उपयोग खराब अभिसरण से पीड़ित हो सकता है, खासकर जटिल ऊर्जा परिदृश्यों में। MCMC नमूनाकरण स्वाभाविक रूप से समय लेने वाला भी है, जो विधि की मापनीयता को प्रभावित करता है, विशेष रूप से बड़े बैच आकारों या उच्च-आयामी समस्याओं के लिए, जैसा कि कम्प्यूटेशनल जटिलता विश्लेषण (तालिका 3, परिशिष्ट सी) में नोट किया गया है। भविष्य के काम को निश्चित रूप से अधिक कुशल नमूनाकरण प्रक्रियाओं का पता लगाना चाहिए, जो उन्नत MCMC तकनीकों से प्रेरणा लेते हैं जैसे कि रीप्ले बफ़र्स [46], सहायक चर [43], या तंत्रिका परिवहन [47, 71, 99, 108, 66, 26] से। यह कम्प्यूटेशनल बोझ को काफी कम कर सकता है और अभिसरण स्थिरता में सुधार कर सकता है।
एक और सैद्धांतिक सीमा यह है कि सामान्यीकरण सीमाओं और सार्वभौमिक सन्निकटन गारंटी (§4.3) के वर्तमान विश्लेषण में ग्रेडिएंट डिसेंट प्रक्रिया और MCMC नमूनाकरण से उत्पन्न होने वाली अनुकूलन त्रुटियों को ध्यान में नहीं रखा गया है। यह मशीन लर्निंग सिद्धांत का एक जटिल क्षेत्र है, जो इस पत्र के दायरे से अलग है, लेकिन यह गहरी सैद्धांतिक समझ के लिए एक महत्वपूर्ण दिशा का प्रतिनिधित्व करता है। भविष्य का शोध इन व्यावहारिक अनुकूलन चुनौतियों को एकीकृत करने वाले एक अधिक व्यापक सैद्धांतिक ढांचे को विकसित करके इस अंतर को पाटने का लक्ष्य रख सकता है।
समस्या सेटअप परिप्रेक्ष्य से, छवि डेटा स्पेस में एन्ट्रॉपी नियमितीकरण का उपयोग "धुंधला पूर्वाग्रह" और शोर वाले बैरीसेंटर छवियों का कारण बन सकता है, जैसा कि MNIST 0/1 डेटा-स्पेस प्रयोग (चित्र 5) में देखा गया है। जबकि मैनिफोल्ड-बाधित दृष्टिकोण प्रभावी रूप से पूर्व-प्रशिक्षित जनरेटिव मॉडल जैसे StyleGAN का लाभ उठाकर इसे कम करता है, यह इन बाहरी मॉडल की गुणवत्ता और उपयुक्तता पर निर्भरता प्रस्तुत करता है। फिर सवाल उठता है: हम कैसे सुनिश्चित कर सकते हैं कि चुना गया मैनिफोल्ड वास्तव में अंतर्निहित डेटा संरचना का प्रतिनिधि है, और यह विधि "प्रदूषित" या अपूर्ण मैनिफोल्ड के प्रति कितनी मजबूत है? भविष्य के काम में अनुकूली मैनिफोल्ड लर्निंग तकनीकों या मैनिफोल्ड और बैरीसेंटर दोनों को सीखने की विधियों की जांच की जा सकती है, बजाय एक निश्चित, पूर्व-प्रशिक्षित जनरेटिव मॉडल पर निर्भर रहने के।
एक महत्वपूर्ण आगे की चर्चा का विषय दोहरे-नियमित EOT बैरीसेंटर तक ऊर्जा-संचालित पद्धति का विस्तार करना है जहाँ नियमितीकरण पैरामीटर $\lambda$ और $\tau$ आवश्यक रूप से $\epsilon$ के बराबर नहीं होते हैं (परिशिष्ट बी.3)। वर्तमान सॉल्वर श्रोडिंगर बैरीसेंटर मामले ($\lambda = \tau = \epsilon$) के लिए तैयार किया गया है, जहाँ एन्ट्रॉपी पद $H(Q)$ उद्देश्य से गायब हो जाता है। एक गैर-शून्य $H(Q)$ पद को शामिल करने के लिए दूसरे मार्जिनल $\pi_k(y)$ की एक अलग, अत्यधिक गैर-तुच्छ गणना की आवश्यकता होगी, जो वर्तमान में कच्चे MCMC नमूनों से अव्यवहार्य है। इस एन्ट्रॉपी पद का अनुमान लगाने या अनुमान लगाने की नई तकनीकों का विकास, या इसके प्रत्यक्ष गणना से बचने के लिए द्वैत उद्देश्य को फिर से तैयार करना, EOT बैरीसेंटर समस्याओं के एक व्यापक वर्ग को अनलॉक करेगा।
एक और महत्वपूर्ण विकास क्षेत्र वास्तविक दुनिया के अनुप्रयोगों, विशेष रूप से चिकित्सा (डोमेन शिफ्ट समस्याओं) और भूविज्ञान (सिम्युलेटर मिश्रण) जैसे क्षेत्रों के लिए उपयुक्त लागत फलनों और डेटा मैनिफोल्ड के डिजाइन में निहित है। पत्र इस बात पर प्रकाश डालता है कि इन डोमेन में बैरीसेंटर को प्रभावी ढंग से लागू करने के लिए डोमेन-विशिष्ट ज्ञान की आवश्यकता होती है ताकि सार्थक लागत फलन $c_k$ को परिभाषित किया जा सके और उपयुक्त डेटा मैनिफोल्ड $M$ का चयन या निर्माण किया जा सके। यह उभरते बड़े जनरेटिव मॉडल (जैसे, DALL-E [85], StableDiffusion [87]) का उपयोग करके चिकित्सा इमेजिंग में, उदाहरण के लिए, रासायनिक मैनिफोल्ड का प्रतिनिधित्व करने वाले तंत्रिका नेटवर्क का उपयोग करके, नए विश्लेषण मार्ग खोल सकता है।
वैकल्पिक महत्व नमूनाकरण (IS) प्रशिक्षण प्रक्रिया (परिशिष्ट डी) तेज अभिसरण के लिए वादा दिखाती है लेकिन अपनी चुनौती प्रस्तुत करती है: अनुमानक विचरण को कम करने के लिए प्रस्ताव वितरण $q$ के सटीक चयन की आवश्यकता। यह वास्तविक दुनिया के परिदृश्यों में अक्सर मुश्किल होता है। भविष्य का शोध IS के लिए अनुकूली या सीखे गए प्रस्ताव वितरणों को विकसित करने पर ध्यान केंद्रित कर सकता है, संभावित रूप से इसे MCMC या अन्य तकनीकों के साथ जोड़कर EOT बैरीसेंटर के लिए अधिक मजबूत और कुशल प्रशिक्षण एल्गोरिदम बनाने के लिए।
अंत में, मापनीयता और कम्प्यूटेशनल दक्षता प्रमुख चुनौतियाँ बनी हुई हैं। जबकि वर्तमान विधि बड़े पैमाने पर सेटअप के लिए काम करती है, अनुमान समय, विशेष रूप से MCMC के कारण, पर्याप्त हो सकता है। हार्डवेयर-त्वरित MCMC, वितरित कंप्यूटिंग रणनीतियों, या गुणवत्ता में महत्वपूर्ण गिरावट के बिना लांगिन चरणों की संख्या को कम करने वाले अनुमानों की खोज (जैसा कि एब्लेशन अध्ययनों द्वारा संकेतित है) मूल्यवान होगा। लक्ष्य इन सतत बैरीसेंटर सॉल्वर को औद्योगिक और सामाजिक रूप से महत्वपूर्ण समस्याओं के लिए अधिक सुलभ और व्यावहारिक बनाना होना चाहिए, जो इष्टतम परिवहन कार्यों के लिए "नींव मॉडल" के रूप में उनकी क्षमता का वास्तव में लाभ उठाता है।
 Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
 Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
 Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
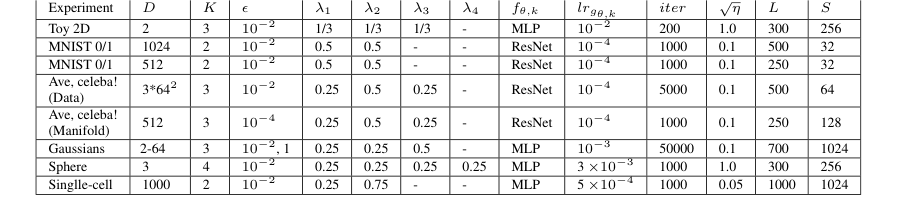 Table 4. Hyperparameters that we use in the experiments with our Algorithm 1
Table 4. Hyperparameters that we use in the experiments with our Algorithm 1