일반 비용에 대한 에너지 기반 연속 엔트로픽 중심점 추정
This paper introduces a new, simpler way to average probability distributions that keeps their shape, with guaranteed quality and real-world applications.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 최적 수송(Optimal Transport, OT) 중심점 문제는 확률 분포를 기하학적으로 의미 있는 방식으로 평균화해야 하는 근본적인 필요성에서 비롯된다. 선형 공간에서 스칼라나 벡터를 평균화하는 것은 간단하지만, 확률 분포를 다룰 때는 훨씬 더 복잡해진다. 단순한 볼록 조합은 종종 필수적인 기하학적 특징을 보존하지 못하므로, "중심" 또는 평균을 정의하기 위한 보다 정교한 접근 방식이 필요하다.
이 특정 문제는 확률 분포를 비교하고 평균화하기 위한 강력한 프레임워크를 제공하는 최적 수송 분야에서 처음 등장했으며, 한 분포를 다른 분포로 변환하는 데 드는 "비용"을 정의한다. Agueh와 Carlier [1]가 2011년에 소개한 OT 중심점 개념은 주어진 소스 분포 모음으로의 수송 비용의 합을 최소화하는 중심 분포를 찾는 것을 목표로 한다.
지난 10년 동안 효과적인 중심점 계산에 대한 실질적인 수요는 상당한 연구를 촉진했다. 초기 노력은 주로 분포가 점의 유한 집합으로 표현되는 이산 OT 중심점 설정에 초점을 맞췄다. 그러나 연속 확률 분포를 다루는 연속 설정은 훨씬 더 어려운 것으로 입증되었다. 이전의 연속 OT 중심점 솔버는 몇 가지 주요 한계점을 가지고 있었다.
- 특정 비용 함수: 많은 기존 방법은 특히 이차 유클리드 비용($l_2(x, y) \stackrel{\text{def}}{=} ||x - y||^2$)과 같은 특정 OT 비용 함수에 대해서만 설계되었다. 이는 실제 시나리오에서 비유클리드 또는 더 복잡한 비용 함수를 자주 사용하기 때문에 문제에 대한 적용 범위를 제한했다.
- 비자명한 사전 선택: 일부 접근 방식은 중심점 분포에 대한 복잡한 사전 선택 또는 고정 사전 정보를 요구했는데, 이는 결정하기 어렵고 모델의 유연성을 제한할 수 있다.
- 표현력 및 생성 능력 제한: 특정 방법은 분포 간의 복잡한 관계를 표현하거나 학습된 중심점에서 새로운 샘플을 생성하는 능력이 제한되어 생성 모델링 작업에서의 유용성을 저해했다.
- OT 계획 복구 불가: 일부 접근 방식은 중심점을 생성 모델로 매개변수화했지만, 개별 소스 분포가 중심점으로 어떻게 매핑되는지를 이해하는 데 중요한 기본 최적 수송 계획을 복구하지 못했다.
본 논문은 임의의 OT 비용 함수를 처리할 수 있는 연속 엔트로픽 OT(EOT) 중심점 근사를 위한 새로운 알고리즘을 제안함으로써 이러한 한계를 극복하는 것을 목표로 한다. 이 알고리즘은 고정된 사전 정보를 요구하거나 표현력을 제한하지 않으며, 중요하게도 조건부 OT 계획을 복구한다.
직관적인 도메인 용어
기초 독자가 핵심 개념을 이해하도록 돕기 위해 일상적인 비유로 번역된 전문 용어는 다음과 같다.
- 최적 수송 (OT): 여러 더미의 흙(확률 분포)이 있고 이를 새로운 더미로 재구성하고 싶다고 상상해 보라. 최적 수송은 관련된 총 "작업" 또는 "비용"을 최소화하면서 원래 더미에서 새로운 더미를 형성하기 위해 모든 흙을 옮기는 가장 효율적인 방법을 찾는 것과 같다.
- 중심점 (Barycenter): 여러 개의 흩어진 연기 구름(확률 분포)이 있다면, 중심점은 "평균" 또는 "질량 중심" 연기 구름을 찾는 것과 같다. 이는 "노력"(최적 수송 비용)을 고려하여 모든 원래 구름에 대해 평균적으로 가장 가까운 중심 구름이며, 한 구름을 다른 구름으로 변환하는 것이다. 이는 모든 다른 분포로부터의 "끌어당김"을 균형 잡는 중심점이다.
- 엔트로픽 최적 수송 (EOT): 이는 최적 수송의 "더 부드러운" 또는 "더 흐릿한" 버전이다. 모든 흙 입자를 가장 직접적인 경로를 따라 옮기는 대신, EOT는 수송 중에 약간의 혼합 또는 무작위성을 허용한다. 이는 계산상 문제를 더 쉽게 만들며, 일부 흙이 약간 퍼지도록 허용하면서도 좋고 기하학적으로 합리적인 평균을 달성하는 것과 같다.
- 약한 OT 쌍대 공식 (Weak OT Dual Formulation): 복잡한 문제, 예를 들어 완벽한 다리 설계와 같다고 생각하라. 가능한 모든 다리를 직접 구축하고 테스트하는 대신, "쌍대 공식"은 다리에 대한 힘과 응력을 최적화하는 것과 관련된 더 간단하고 동등한 문제를 찾는 것과 같다. OT에서는 모든 "흙 입자"를 직접 추적하는 대신, 간접적으로 가장 효율적인 흙 이동 방법을 알려주는 두 개의 "잠재 함수"를 찾는 것이다. 이는 종종 해결하기 더 쉽다.
- 에너지 기반 모델 (EBMs): 데이터 포인트가 있을 가능성이 높은 곳을 계곡으로, 가능성이 낮은 곳을 언덕으로 나타내는 풍경을 상상해 보라. EBM은 데이터가 어떻게 분포되는지 이해하기 위해 이 "에너지 풍경"을 학습한다. 우리의 방법은 유사한 아이디어를 사용한다. 중심점 문제를 복잡한 공간에서 가장 낮은 "에너지" 구성을 찾는 것으로 프레임화하여, 솔루션을 찾기 위해 잘 확립된 EBM 훈련 기술을 활용할 수 있다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 확률 분포 모음의 연속 엔트로픽 최적 수송(EOT) 중심점을 추정하는 것이다.
입력/현재 상태:
시작점은 $K$개의 소스 확률 분포 모음이며, 이는 $\mathcal{X}_k \subset \mathbb{R}^{D_k}$의 컴팩트 부분 집합에 정의된 절대 연속 확률 분포를 나타내는 $\mathcal{P}_{ac}(\mathcal{X}_k)$로 표시된다. 각 소스 분포 $P_k$에 대해, $\mathcal{X}_k$의 점과 중심점 공간 $\mathcal{Y}$의 점 사이의 질량 수송 "비용"을 정량화하는 연속 비용 함수 $c_k(\cdot, \cdot) : \mathcal{X}_k \times \mathcal{Y} \to \mathbb{R}$가 연관되어 있다. 또한, $\sum_{k=1}^K \lambda_k = 1$ 조건을 만족하는 양수 가중치 $\lambda_k > 0$의 집합이 주어진다. 실질적인 시나리오에서는 이러한 소스 분포 $P_k$가 명시적으로 알려져 있지 않고, 유한한 경험적 샘플 집합 $X_k = \{x_1^k, x_2^k, \dots, x_{N_k}^k\} \sim P_k$을 통해서만 접근할 수 있다. 기존의 연속 OT 중심점 솔버는 종종 일반적인 비용 함수를 처리하는 데 어려움을 겪거나, 특정 사전 선택을 요구하거나, 표현력 및 생성 기능이 제한적이다.
원하는 최종 상태 (출력/목표 상태):
궁극적인 목표는 모든 소스 분포 $P_k$에 대한 EOT 불일치의 가중 합을 최소화하는 확률 분포인 EOT 중심점 $Q^* \in \mathcal{P}(\mathcal{Y})$를 식별하는 것이다. 수학적으로 이는 다음과 같이 공식화된다.
$$L^* \stackrel{\text{def}}{=} \inf_{Q \in \mathcal{P}(\mathcal{Y})} \sum_{k=1}^K \lambda_k \text{EOT}_{c_k, \epsilon}(P_k, Q)$$
여기서 $\text{EOT}_{c_k, \epsilon}(P_k, Q)$는 양의 매개변수 $\epsilon > 0$으로 정규화된 $P_k$와 $Q$ 사이의 엔트로픽 최적 수송 비용을 나타낸다. $Q^*$를 찾는 것 외에도, 본 논문은 각 소스 $P_k$의 점을 중심점 $Q^*$로 매핑하는 최적 조건부 수송 계획 $\pi_{f_k}^*(\cdot|x_k)$를 근사하는 것을 목표로 한다. 이러한 복구된 계획은 "샘플 외 추정"을 가능하게 하여, 새로운, 보지 못한 샘플 $x_{\text{new}}$에 대해 $\pi_{f_k}^*(\cdot|x_{\text{new}})$로부터 샘플을 생성할 수 있도록 한다. 또 다른 야심찬 목표는 사전 훈련된 생성 모델의 이미지 다양체에서 중심점을 학습하는 것으로, 이는 실제 응용에 상당한 영향을 미친다.
누락된 연결 고리 및 딜레마:
정확한 누락된 연결 고리는 경험적 샘플만으로 효과적으로 작동하고 임의의 비용 함수를 처리할 수 있는 일반적이고 강력하며 계산적으로 실행 가능한 연속 EOT 중심점 추정 알고리즘이다. 이전 연구는 고통스러운 절충안에 갇혀 있었다. 연속 OT 중심점 문제에서 더 큰 일반성과 표현력을 달성하는 것은 일반적으로 상당한 계산적 어려움을 야기하거나 제한적인 가정을 요구한다. 예를 들어, 임의의 비용 함수를 처리하기 위해 일반성을 개선하면 많은 이전 방법이 유리한 이론적 속성을 가진 특정, 더 간단한 비용(예: 이차 유클리드 $l_2$ 비용)에 의존하기 때문에 해결할 수 없는 최적화 문제가 발생한다. 이러한 더 간단한 비용은 더 효율적인 알고리즘을 가능하게 하지만 적용 범위를 제한한다. 또한, 연속 설정은 이산 설정보다 "훨씬 더 어렵지만" 기존 솔루션은 종종 표현력에 한계가 있거나 비자명한 사전 선택 또는 중심점의 특정 매개변수화를 요구하며, 이는 결정하기 어렵거나 방법의 범위를 제한할 수 있다. 또 다른 딜레마는 이미지와 같은 고차원 데이터 공간에서 발생한다. EOT 중심점의 직접 계산은 종종 엔트로피 정규화와 MCMC에 대한 의존성으로 인해 "노이즈가 많은 이미지" 또는 "흐릿한 편향"을 초래한다. 검색 공간을 데이터 다양체로 제한하면 이를 완화할 수 있지만, 다양체 학습 및 비용 함수 적응과 관련된 자체적인 복잡성을 도입한다.
제약 조건 및 실패 모드
연속 EOT 중심점 추정 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 본질적으로 어렵다.
- 직접 최적화의 계산적 비실행성: EOT 중심점의 목적 함수(방정식 5)는 모든 확률 분포 $\mathcal{P}(\mathcal{Y})$의 공간에 대한 $\inf$를 포함하며, 이는 무한 차원 공간이다. 이를 직접 최적화하는 것은 일반적으로 실행 불가능하므로 문제를 재구성해야 한다.
- 해석적 해 부재: 대부분의 실질적인 시나리오, 가우시안 분포를 포함한 경우에도 엔트로픽 중심점 문제( $\epsilon > 0$ 및 정규화되지 않은 $\epsilon = 0$ 경우 모두)에 대한 직접적인 해석적 해는 알려져 있지 않다. 이는 수치적 근사 방법에 의존하게 만든다.
- 경험적 데이터 제한: 소스 분포 $P_k$는 실제 응용에서 거의 명시적으로 사용되지 않는다. 대신, 유한한 경험적 샘플(데이터셋) $X_k$만 접근할 수 있다. 이는 알고리즘이 데이터 희소성 및 노이즈에 강하고 샘플 외 일반화 능력이 있어야 함을 의미한다.
- 고차원성: RGB 이미지(예: CelebA의 $3 \times 64 \times 64$ 차원)와 같은 복잡한 데이터 유형을 다루는 것은 학습 및 샘플링에 상당한 계산 및 메모리 요구 사항을 도입하여 직접적인 접근 방식을 비실행 가능하게 만든다.
- 임의의 비용 함수: 본 논문은 "임의의 OT 비용 함수"를 지원하는 것을 목표로 하며, 이는 상당한 제약 조건이다. 많은 기존 방법은 특정 이론적 속성을 가지고 있어 계산을 단순화하는 더 간단한 비용(예: $l_2$)에 특화되어 있다. 일반 비용은 이러한 단순화를 제거하여 복잡성을 증가시킨다.
- 비유클리드 기하학: 문제는 명시적으로 "비유클리드 비용 함수"를 고려하며, 이는 표준 유클리드 거리 측정값이 종종 부적절함을 의미한다. 이는 복잡한 기하학적 관계를 포착하기 위해 더 유연하고 강력한 모델을 필요로 한다.
- MCMC 샘플링 제한: 제안된 방법은 샘플링을 위해 마르코프 연쇄 몬테카를로(MCMC) 절차(특히 조정되지 않은 랭킨 알고리즘, ULA)에 의존한다.
- 높은 계산 비용: MCMC 샘플링은 본질적으로 "시간이 많이 소요"되어 훈련 및 추론 지연 시간(표 3)에 영향을 미친다.
- 수렴 문제: 기본 ULA 알고리즘은 "원하는 분포로 제대로 수렴하지 못할 수 있으며", 최적이 아닌 결과로 이어진다.
- 미분 가능성 요구 사항: MCMC는 일반적으로 에너지 함수(따라서 비용 함수 $c_k$)가 미분 가능해야 한다. 미분 불가능한 비용은 더 복잡하고 기울기 없는 샘플링 절차를 필요로 한다.
- 지역 최소값: MCMC 추론은 "에너지 풍경의 지역 최소값에 갇힐 수 있으며", 학습된 수송 계획이 원하는 이미지 내용이나 다른 특징을 보존하는 데 실패하게 만든다(섹션 5.3).
- 정규화 상수 비실행성: 쌍대 목적 함수의 정규화 상수 $Z_{c_k}(f_k, x_k)$의 직접적인 계산은 종종 "실행 불가능"하여 기울기 추정을 위한 근사를 필요로 한다.
- 데이터 공간의 "흐릿한 편향": 고차원 데이터 공간(예: 이미지 픽셀)에서 EOT 중심점을 직접 계산하면 엔트로피 정규화로 인해 "노이즈가 많은 이미지" 또는 "흐릿한 편향"이 발생하여 결과 중심점이 해석하기 어렵거나 시각적으로 그럴듯하지 않게 된다.
- 다양체 제약 조건 복잡성: 중심점 검색을 데이터 다양체로 제한하는 것(예: 사전 훈련된 StyleGAN 사용)은 흐릿함을 완화하는 데 도움이 되지만, 이러한 생성 모델의 훈련 및 통합과 관련된 추가 복잡성을 도입하고 비용 함수를 다양체의 잠재 공간에 적응시킨다.
- 일반화 및 근사 오류: 학습된 모델이 보지 못한 데이터에 대해 잘 일반화되고 신경망 근사가 정확함을 보장하는 것은 상당한 이론적 과제이다. 추정 오류는 일반 립시츠 비용의 경우 "차원의 저주"로 인해 고차원에서 빠른 수렴 속도를 달성하기 어렵게 만든다.
왜 이 접근 방식인가
선택의 불가피성
저자들은 연속 최적 수송(OT) 중심점 문제에 대한 기존 방법의 내재된 한계로 인해 에너지 기반 연속 엔트로픽 중심점 추정 접근 방식을 선택했다. 이러한 인식의 정확한 순간은 섹션 3과 표 1의 상세한 논의에서 분명히 드러나며, 이는 이전 기술의 단점을 강조한다.
전통적인 "SOTA" 방법, 예를 들어 표준 CNN, 기본 확산 모델 또는 트랜스포머는 다음과 같은 이유로 불충분하다고 간주되었다.
1. 특정 비용 함수: [59, 55, 32, 82]와 같은 이전 연속 OT 솔버의 상당 부분은 이차 유클리드 비용 $l_2(x, y) = ||x - y||^2$에 대해서만 설계되었다. 이 제한은 분포 간의 복잡한 기하학적 관계를 포착하는 데 필수적인 임의의 비유클리드 비용 함수가 필요한 실제 시나리오에 대한 적용 가능성을 심각하게 제한한다. 본 논문은 명시적으로 "대조적으로, 제안된 접근 방식은 임의의 비용 함수 $c_1, \dots, c_K$를 가진 EOT 문제를 처리하도록 설계되었다"고 명시한다. (4페이지)
2. 고정된 사전 정보 및 비자명한 선택: [72]와 같은 일부 방법은 중심점에 대한 비자명한 사전 선택을 요구하거나 고정된 사전 정보를 선택해야 했으며, 이는 복잡하고 견고하지 않은 절차일 수 있다. 제안된 방법은 이 제약 조건을 피한다.
3. OT 계획 복구 부족: 결정적으로, [17]과 같은 특정 접근 방식은 OT 계획을 복구하지 않았으며, 이는 섹션 2.3의 학습 설정에 대한 기본 요구 사항으로, 샘플 외 추정 및 생성 능력에 초점을 맞춘다.
4. 계산 복잡성 및 매개변수화: [14]와 같은 다른 변분 방법은 최적화 복잡성을 증가시키고 중심점 분포의 특정 매개변수화를 요구하여 덜 일반적이거나 직관적이지 않게 만들었다.
저자들은 연속 설정에서 임의의 비용 함수를 처리하고, OT 계획을 복구하며, 제한적인 사전 정보 없이 작동할 수 있는 솔버에 대한 필요성을 해결하기 위해 새로운 접근 방식이 필요하다는 것을 깨달았다.
비교 우위
이 방법은 단순한 성능 지표를 넘어 여러 구조적 장점을 통해 이전의 황금 표준에 비해 질적으로 우수함을 보여준다.
- 임의의 비용 함수 및 비유클리드 비용: 이차 유클리드 비용에 국한된 많은 이전 작업과 달리, 이 접근 방식은 비유클리드 비용을 포함한 임의의 OT 비용 함수를 위해 설계되었다. 이 유연성은 이미지 다양체 또는 전문 지질학적 시뮬레이션과 같은 훨씬 더 넓은 범위의 복잡한 문제에 대한 적용을 가능하게 하는 심오한 구조적 이점이다(섹션 5, B.2).
- 에너지 기반 모델(EBM)과의 원활한 통합: 방법의 핵심은 EOT의 약한 쌍대 형식과 합동 조건을 결합한 엔트로픽 최적 수송(EOT) 중심점 문제의 우아한 재구성에 있다. 이 재구성은 EBM의 훈련 절차와 자연스럽게 일치하여, 잘 조정된 알고리즘을 사용할 수 있게 하고 "복잡한 기술적 트릭 없이 직관적인 최적화 체계를 제공한다"(초록, 1페이지). 이는 GAN 또는 정책 경사 방법과 같은 적대적 훈련과 관련된 복잡성을 피한다.
- 견고한 일반화 및 근사 보장: 본 논문은 학습된 EOT 계획에 대한 일반화 경계 및 보편적 근사 보장을 포함한 강력한 이론적 기초를 확립한다(섹션 4.3). 특히, 특징 기반 이차 비용의 경우, 이 방법은 "표준적이고 빠르며 차원 독립적인 수렴 속도"로 설명되는 $O(N^{-1/2})$의 추정 오류를 달성한다(정리 4.5 (b), 6페이지). 이는 경쟁적인 연속 중심점 솔버에서 종종 부족한 방법의 통계적 일관성과 신뢰성에 대한 엄격한 이해를 제공한다.
- 고차원 노이즈 및 다양체 학습 처리: 이미지와 같은 복잡한 데이터의 경우, 데이터 공간에서의 직접적인 EOT 중심점은 "흐릿한 편향"으로 고통받고 노이즈가 많은 이미지를 생성할 수 있다. 이 방법은 "다양체 제약" 설정(섹션 4.4)을 도입하여 이를 질적으로 더 잘 처리한다. 사전 훈련된 생성 모델(예: StyleGAN)에 의해 생성된 이미지 다양체에서 중심점을 학습함으로써, 고차원 이미지 평균화에 내재된 노이즈 및 아티팩트를 효과적으로 완화하여 더 해석 가능하고 그럴듯한 중심점 분포를 생성한다. 이는 실제 응용을 위한 결과 품질에서 중요한 개선이다.
제약 조건과의 일치
선택된 에너지 기반 접근 방식은 문제의 가혹한 요구 사항과 완벽하게 일치하여 "문제의 요구 사항과 솔루션의 고유한 속성 간의 결합"을 형성한다.
- 연속 OT 및 샘플 외 추정: 문제는 명시적으로 연속 OT 중심점 작업을 해결하고 샘플 외 추정을 제공해야 한다. 즉, 새로운 데이터 포인트에 대한 조건부 계획 $\pi^*(\cdot|x_{\text{new}})$에서 샘플을 생성하는 능력이다. 제안된 방법은 신경망 잠재 함수 $f_k$를 학습하여 조건부 분포 $\mu_{f_k}^*(\cdot|x_k)$(방정식 4, 3페이지)를 정의함으로써 이를 직접적으로 해결한다. 그런 다음 표준 MCMC 기술을 사용하여 샘플을 생성할 수 있으며, 이는 샘플 외 추정 요구 사항을 충족한다(섹션 4.2).
- 임의의 비용 함수: 핵심 제약 조건은 $l_2$ 특정 방법의 한계를 넘어 임의의 비용 함수를 처리할 필요성이다. 쌍대 공식과 EBM 프레임워크는 차별화 가능한 모든 비용 함수 $c_k(x,y)$를 자연스럽게 수용하며, 이는 비유클리드 "꼬인" 비용 및 다양체 제약 비용을 실험하여 입증되었다(섹션 5.1, 5.2).
- 데이터 접근성 (경험적 샘플): 문제는 소스 분포 $P_k$가 제한된 수의 i.i.d. 경험적 샘플 $X_k$를 통해서만 접근할 수 있다고 가정한다. 제안된 알고리즘은 이러한 샘플과 직접 작동하도록 설계되었으며, 훈련 중 기울기 추정을 위해 몬테카를로 근사를 사용한다(알고리즘 1, 5페이지).
- 복잡한 공간에서의 의미 있는 중심점: 이미지 데이터의 경우, 픽셀 공간에서의 직접적인 평균화는 "흐릿한 편향"으로 인해 종종 바람직하지 않다. 다양체 제약 EOT 중심점(섹션 4.4)은 사전 훈련된 생성 모델(예: StyleGAN)에 의해 생성된 데이터 다양체로 검색 공간을 제한함으로써 이를 직접적으로 해결한다. 이는 결과 중심점이 그럴듯한 다양체에 집중되도록 보장하여, 그림 4 및 5에서 볼 수 있듯이 시각적으로 우수하고 더 해석 가능한 결과를 산출한다. 이는 실질적인 문제 제약에 대한 영리한 해결책이다.
대안의 거부
본 논문은 제안된 방법의 고유한 장점을 강조하면서 여러 대안적 접근 방식을 거부하는 명확한 이유를 제공한다.
- 이산 OT 솔버: 저자들은 명시적으로 "이산 OT는 연속 OT 설정에서 요구되는 샘플 외 추정에 적합하지 않다"(섹션 2.3, 3페이지)고 명시한다. 이산 OT 방법은 건전한 이론적 기초와 수렴 보장을 가지고 있지만, 보지 못한 데이터에 대한 조건부 계획을 근사하는 것이 목표인 연속 학습 설정에 직접 적용할 수 없다(섹션 B.1, 22페이지).
- $l_2$ 비용을 가진 연속 OT 솔버: 많은 기존 연속 OT 중심점 솔버는 "$l_2(x, y) = ||x - y||^2$의 이차 유클리드 비용에 대해서만 설계되었다"(섹션 3, 4페이지). 이는 실제 응용에서 복잡한 데이터 관계를 포착하기 위해 임의의 비유클리드 비용을 포함한 임의의 비용 함수를 요구하기 때문에 거부된다. 제안된 방법의 일반 비용 처리 능력은 이러한 제한에 대한 직접적인 대응이다.
- 고정된 사전 정보를 요구하거나 계획 복구가 부족한 연속 OT 솔버: [72]와 같은 일부 방법은 중심점에 대해 "비자명한 사전 선택"을 요구하며, 이는 번거로울 수 있다. [17]과 같은 다른 방법은 "OT 계획을 복구하지 않으며", 이는 본 논문의 생성 작업을 위한 조건부 수송 계획 학습 목표와 근본적으로 일치하지 않는다(섹션 3, 4페이지).
- $H(Q)$ 항을 가진 이중 정규화 EOT 중심점: 본 논문은 중심점 분포 $Q$에 대한 추가 엔트로피 항 $H(Q)$가 있는 이중 정규화 EOT 중심점(방정식 40, 24페이지)을 논의한다. 이 대안은 " $H(Q)$ 항의 존재는 우리 것과 눈에 띄게 다르며 우리 솔버에 적합하지 않은 것 같다"(25페이지)고 명시되어 거부된다. 그 이유는 $H(Q)$를 추가하면 두 번째 주변 분포 $H(\pi_k(y))$의 엔트로피를 별도로, 매우 비자명하게 계산해야 하는데, 이는 원시 샘플에서 추정하기가 실행 불가능하며 EBM과 같은 기술은 이 시나리오에서 기울기를 도출할 수 없기 때문이다(25페이지).
- 기타 GAN 기반 중심점 방법 (예: [95]): [95]는 검색 공간을 GAN 다양체로 제한하지만, 그 접근 방식은 근본적으로 다르며 "실제로 적용할 수 없다"(섹션 B.1, 23페이지)고 명시되어 있다. 그들은 K개의 이미지(강도 히스토그램을 통해 2D 분포로 표현됨)를 고려하고 이산 OT 솔버를 사용하여 GAN 다양체에서 단일 이미지를 검색한다. 대조적으로, 본 논문은 연속 OT 솔버를 사용하여 K개의 고차원 이미지 분포(무작위 샘플로 표현됨)의 중심점을 찾고 OT 계획을 복구한다. 목표와 방법론은 다르므로 [95]의 접근 방식은 현재 문제에 적합하지 않다.
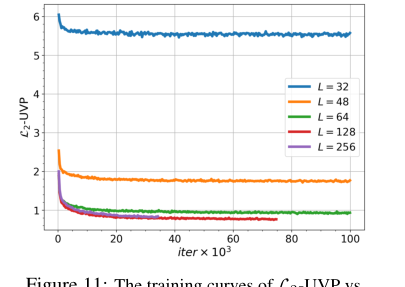 Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
수학적 및 논리적 메커니즘
마스터 방정식
이 논문의 엔트로픽 중심점 추정 접근 방식을 뒷받침하는 절대적인 핵심 수학적 엔진은 알고리즘이 최대화하려는 쌍대 목적 함수이다. 이 목적 함수는 엔트로픽 최적 수송(EOT) 문제의 약한 쌍대 형식에서 파생되었으며 신경망으로 매개변수화된다. 최적화되는 특정 방정식은 다음과 같다.
$$ \mathcal{L}(\theta) \stackrel{\text{def}}{=} \sum_{k=1}^K \lambda_k \left\{ -\epsilon \mathbb{E}_{x_k \sim P_k} \left[ \log Z_{c_k}(f_{\theta,k}, x_k) \right] \right\} \quad (8) $$
여기서 $Z_{c_k}(f_{\theta,k}, x_k)$는 다음과 같이 정의되는 정규화 상수(또는 분배 함수)이다.
$$ Z_{c_k}(f_{\theta,k}, x_k) \stackrel{\text{def}}{=} \int_{\mathcal{Y}} \exp\left(\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}\right) dy \quad (21) $$
항별 분석
이 방정식들을 조각별로 분석하여 그 역할을 이해해 보자.
- $\mathcal{L}(\theta)$: 이 함수는 알고리즘이 최대화하려는 목적 함수이다. 그 값은 현재 잠재 함수 집합( $\theta$로 매개변수화됨)이 EOT 중심점 문제의 쌍대 형식과 얼마나 잘 일치하는지를 반영한다. 이 쌍대 목적 함수를 최대화하는 것은 원시 EOT 중심점 문제를 최소화하는 것과 동등하다.
- $\theta$: 이는 신경망 $f_{\theta,k}$의 모든 학습 가능한 매개변수 집합을 나타낸다. 이러한 매개변수는 목적 함수를 최적화하기 위해 학습 과정 중에 조정된다.
- $K$: 이는 우리가 평균화하려는 $K$개의 소스 확률 분포 $P_k$의 총 개수이다. 예를 들어, 세 개의 이미지 데이터셋을 평균화하는 경우 $K=3$이다.
- $\lambda_k$: 이는 각 소스 분포 $P_k$에 대한 미리 정의된 양수 가중치이며, $\sum_{k=1}^K \lambda_k = 1$을 만족한다. 이는 각 소스 분포의 최종 중심점에 대한 상대적 중요성 또는 기여도를 결정한다. 모든 $\lambda_k$가 같으면 단순 평균이고, 그렇지 않으면 가중 평균이다.
- $\sum_{k=1}^K$: 이는 모든 $K$개의 소스 분포로부터의 기여도를 집계하는 합계 연산자이다. EOT 중심점 문제는 각 소스 분포와 중심점 사이의 개별 EOT 불일치의 합으로 공식화되기 때문에 저자는 덧셈을 사용한다.
- $\epsilon$: 이는 엔트로피 정규화 매개변수이며, 양수 스칼라이다. 이는 수송 계획의 "부드러움" 또는 "무작위성"을 제어한다. $\epsilon$이 클수록 더 확산되고 덜 "날카로운" 수송 계획(및 더 부드러운 손실 곡면)이 생성되고, $\epsilon$이 작을수록 수송이 더 결정론적이 되어 고전적인 최적 수송에 가까워진다. 이는 통계 역학에서 "온도" 매개변수 역할을 한다.
- $\mathbb{E}_{x_k \sim P_k}[\dots]$: 이는 $k$-번째 소스 확률 분포 $P_k$에서 추출된 샘플 $x_k$에 대한 기대값을 나타낸다. 실제로는 이 기대값이 $P_k$에서 샘플 배치(batch)를 추출하여 몬테카를로 샘플링을 통해 근사된다.
- $P_k$: 이는 알고리즘이 평균화하려는 $k$-번째 소스 확률 분포이다. 실제 시나리오에서는 일반적으로 경험적 샘플(데이터셋)을 통해서만 접근할 수 있다.
- $x_k$: 이는 $k$-번째 소스 분포 $P_k$에서 추출된 샘플(데이터 포인트)이다.
- $\log$: 이는 자연 로그 함수이다. 약한 엔트로픽 c-변환 $f_k^{c_k}(x_k)$가 $-\epsilon \log Z_{c_k}(f_k, x_k)$로 정의되기 때문에 여기서 사용된다. 이 변환은 적분을 최적화를 위한 더 관리하기 쉬운 형태로 변환하고 에너지 기반 모델과 관련시키는 데 중요하다.
- $Z_{c_k}(f_{\theta,k}, x_k)$: 이는 주어진 $x_k$에 대한 잠재 함수 $f_{\theta,k}$ 및 비용 $c_k$에 따라 조건부 확률 분포 $\mu_{x_k}^{f_{\theta,k}}(y)$의 정규화 상수 또는 분배 함수이다. 이는 조건부 분포가 1로 적분되도록 보장한다. 그 값은 잠재 함수 $f_{\theta,k}$와 비용 $c_k$에 따라 달라진다.
- $\int_{\mathcal{Y}} \dots dy$: 이는 목표 공간 $\mathcal{Y}$에 대한 적분이다. 이는 정규화 상수를 계산하기 위해 모든 가능한 목표 지점 $y$에 걸쳐 "에너지" 기여도를 합산한다. 저자는 문제가 확률 분포의 연속 영역에 설정되어 있기 때문에 적분을 사용한다.
- $\exp(\dots)$: 이는 지수 함수이다. "에너지" 항 $(f_{\theta,k}(y) - c_k(x_k, y))/\epsilon$을 확률 밀도로 해석될 수 있는 음수가 아닌 값으로 변환한다. 이는 통계 역학 및 에너지 기반 모델의 표준 구성 요소이다.
- $f_{\theta,k}(y)$: 이는 목표 지점 $y$에서의 $k$-번째 분포의 잠재 함수이다. 이러한 함수는 신경망 $f_{\theta,k}$로 매개변수화되며 모델의 주요 학습 가능한 구성 요소이다. 이는 $k$-번째 소스의 관점에서 목표 지점 $y$의 "가치" 또는 "유용성"을 나타낸다.
- $c_k(x_k, y)$: 이는 소스 지점 $x_k$에서 목표 지점 $y$로 질량을 수송하는 비용 함수이다. 이는 $x_k$와 $y$ 사이의 이동 "비용"을 정량화한다. 본 논문은 일반적인(심지어 비유클리드) 비용 함수를 처리할 수 있는 능력을 강조한다.
- $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$: 이 항은 잠재 함수 $f_{\theta,k}$와 정규화 $\epsilon$에 의해 변조된 $x_k$에서 $y$로의 수송의 "순 유용성" 또는 "로그 확률"을 나타낸다. 잠재 함수 $f_{\theta,k}(y)$는 $y$에 도달하는 "보상"으로 생각할 수 있고, $c_k(x_k, y)$는 수송에 대한 "벌점"이다. $\epsilon$으로 나누는 것은 이 에너지를 스케일링하여, 작은 $\epsilon$의 경우 분포를 더 날카롭게 하고 큰 $\epsilon$의 경우 더 평평하게 만든다.
- 지수 안의 $f_{\theta,k}(y) - c_k(x_k, y)$ 빼기는 잠재 함수와 비용을 결합하는 자연스러운 방법으로, 주어진 $x_k$에 대한 목표 지점 $y$의 순 "매력도"를 반영한다.
단계별 흐름
훈련 반복 중에 단일 추상 데이터 포인트, 예를 들어 첫 번째 소스 분포 $P_1$의 $x_1$이 이 수학적 엔진을 통과한다고 상상해 보라.
- 데이터 포인트 입력: 첫 번째 소스 분포 $P_1$에서 샘플 $x_1$이 추출된다. 이 $x_1$은 데이터셋의 구체적인 인스턴스이다.
- 잠재 함수 평가: 이 $x_1$에 대해, 그리고 대상 공간 $\mathcal{Y}$의 가능한 대상 지점 범위에 대해, 신경망 $f_{\theta,1}$은 잠재 함수 $f_{\theta,1}(y)$를 계산한다. 동시에 비용 함수 $c_1(x_1, y)$가 평가되어 각 $y$로의 이동 "노력"을 정량화한다.
- 에너지 계산: 이러한 값들이 결합된다: $f_{\theta,1}(y) - c_1(x_1, y)$. 이 차이는 $x_1$에서 $y$로의 수송의 "순 유용성"을 나타낸다. 이 유용성은 정규화 매개변수 $\epsilon$으로 스케일링되어 $\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}$을 생성한다.
- 정규화되지 않은 확률: 스케일링된 유용성은 지수화된다: $\exp\left(\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}\right)$. 이는 $x_1$에서 $y$로의 수송이 얼마나 "가능성이 있는지"에 대한 정규화되지 않은 척도를 제공한다.
- 정규화 (분배 함수): 이를 $y$에 대한 올바른 조건부 확률 분포( $\mu_{x_1}^{f_{\theta,1}}(y)$로 표시됨)로 만들기 위해 정규화해야 한다. 이는 전체 대상 공간 $\mathcal{Y}$에 걸쳐 정규화되지 않은 확률을 적분하여 $Z_{c_1}(f_{\theta,1}, x_1)$을 얻음으로써 수행된다. 이 적분은 종종 계산상 실행 불가능하므로, MCMC와 같은 기술을 사용하여 기울기가 추정된다.
- 로그 확률 기여: 이 정규화 상수의 자연 로그 $\log Z_{c_1}(f_{\theta,1}, x_1)$가 취해진다. 이 항은 $-\epsilon$을 곱하면 약한 엔트로픽 c-변환 $f_1^{c_1}(x_1)$이 된다.
- 가중 합계: 이 과정(단계 2-6)은 다른 $P_1$ 샘플에 대해( $\mathbb{E}_{x_1 \sim P_1}[\dots]$를 근사하기 위해) 그리고 다른 소스 분포 $P_k$의 샘플에 대해 반복된다. 그런 다음 각 분포의 기여도는 $\lambda_k$ 계수로 가중치를 부여하고 합산하여 총 목적 함수 $\mathcal{L}(\theta)$를 형성한다.
- 기울기 계산: 신경망 매개변수 $\theta$에 대한 $\mathcal{L}(\theta)$의 기울기가 계산된다. 이 기울기는 목적 함수를 증가시키는 매개변수 공간의 방향을 나타낸다. $Z_{c_k}$의 직접적인 계산은 어렵기 때문에, $\log Z_{c_k}$의 기울기는 MCMC 절차를 사용하여 조건부 분포 $\mu_{x_k}^{f_{\theta,k}}(y)$에서 $y$를 샘플링함으로써 근사된다.
- 매개변수 업데이트: 마지막으로, 신경망 $f_{\theta,k}$의 매개변수 $\theta$는 계산된 기울기에 의해 표시된 방향으로 최적화 알고리즘(확률적 경사 상승과 같은)을 사용하여 업데이트된다. 이 반복적인 업데이트는 신경망 잠재 함수가 EOT 중심점 조건을 더 잘 만족하도록 점진적으로 조정하는 데 도움이 된다.
최적화 역학
메커니즘은 확률적 경사 상승을 통해 쌍대 목적 함수 $\mathcal{L}(\theta)$를 반복적으로 최대화함으로써 학습한다. 학습, 업데이트 및 수렴이 어떻게 발생하는지는 다음과 같다.
- 신경망 매개변수화: 핵심 통찰력은 알 수 없는 잠재 함수 $f_k$를 신경망 $f_{\theta,k}$로 표현하는 것이며, 여기서 $\theta$는 이러한 신경망의 가중치와 편향이다. 이를 통해 유연하고 고차원적인 함수 근사가 가능하다.
- 합동 조건 처리: 쌍대 공식(6)은 중요한 제약 조건인 $\sum_{k=1}^K \lambda_k f_k = 0$을 포함한다. 저자들은 개별 신경망 $g_{\theta,k}$를 사용하여 $f_{\theta,k}$를 $g_{\theta,k} - \sum_{j=1}^K \lambda_j g_{\theta,j}$로 매개변수화함으로써 이를 독창적으로 처리한다. 이 특정 구성은 가중 잠재 함수의 합이 0이 되도록 자동으로 보장하여 명시적인 제약 조건 최적화의 필요성을 제거한다.
- 경사 상승: 목적 함수가 쌍대 공식이기 때문에 목표는 $\mathcal{L}(\theta)$를 최대화하는 것이다. 이는 경사 상승을 사용하여 달성된다. 기울기 $\frac{\partial}{\partial \theta} \mathcal{L}(\theta)$가 계산되고 매개변수 $\theta$는 이 기울기의 방향으로 업데이트된다.
- MCMC를 통한 기울기 추정: 가장 어려운 부분은 기울기 공식(방정식 9) 내에서 기대값 $\mathbb{E}_{y \sim \mu_{x_k}^{f_{\theta,k}}} \left[ \frac{\partial}{\partial \theta} f_{\theta,k}(y) \right]$을 계산하는 것이다. 조건부 분포 $\mu_{x_k}^{f_{\theta,k}}(y)$는 정규화되지 않은 로그 밀도가 $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$로 주어지는 것을 가진다. 이 분포에서 샘플링하기 위해, 본 논문은 마르코프 연쇄 몬테카를로(MCMC) 절차, 특히 조정되지 않은 랭킨 알고리즘(ULA)을 사용한다.
- ULA 단계: $P_k$에서 샘플링된 각 $x_k$에 대해 ULA는 결국 $\mu_{x_k}^{f_{\theta,k}}$에서 샘플을 근사하는 일련의 샘플 $y_t$를 생성한다. ULA의 업데이트 규칙은 다음과 같다.
$$y_{t+1}^{(1)} = y_t^{(1)} + \frac{\eta}{2\epsilon} \nabla_y (f_{\theta,k}(y) - c_k(x_k, y))|_{y=y_t^{(1)}} + \sqrt{\eta} \xi_t$$
여기서 $\eta$는 스텝 크기이고, $\xi_t$는 표준 정규 분포에서 추출된 무작위 노이즈 항이다. 이 과정은 $f_{\theta,k}(y) - c_k(x_k, y)$에 의해 정의된 에너지 풍경에서 움직이는 입자를 시뮬레이션하여 대상 분포로 점진적으로 수렴한다.
- ULA 단계: $P_k$에서 샘플링된 각 $x_k$에 대해 ULA는 결국 $\mu_{x_k}^{f_{\theta,k}}$에서 샘플을 근사하는 일련의 샘플 $y_t$를 생성한다. ULA의 업데이트 규칙은 다음과 같다.
- 손실 곡면: 쌍대 목적 함수는 오목하다(약한 c-변환에 대한 명제 A.1 (iii)에서 언급되었으며, 이는 $\mathcal{L}(\theta)$로 확장된다). 이 오목성 때문에 전역 최대값이 아닌 지역 최대값은 존재하지 않으므로, 비오목 목적 함수에 비해 최적화 문제를 크게 단순화한다. 엔트로피 정규화 매개변수 $\epsilon$은 이 곡면을 더욱 부드럽게 하여 경사 기반 방법이 잘못된 모드(정규화되지 않은 경우 존재할 수 있음)에 갇히지 않고 탐색하기 쉽게 만든다.
- 반복적 개선: 각 반복에서 새로운 샘플 $x_k$가 추출되고, MCMC가 실행되어 $y$ 샘플을 생성하고, $\mathcal{L}(\theta)$의 기울기가 추정되고, $\theta$가 업데이트된다. 이 반복적인 과정은 신경망 잠재 함수 $f_{\theta,k}$를 점진적으로 개선하여 EOT 중심점 조건을 만족하도록 수렴시킨다. 그런 다음 목적 함수가 최대화되고, 이러한 잠재 함수를 통해 중심점이 암묵적으로 학습된다.
- 수렴: 본 논문은 복구된 OT 계획의 품질과 신경망의 보편적 근사 능력에 관한 이론적 보장(정리 4.2, 4.5, 4.6)을 제공하며, 충분한 데이터와 네트워크 용량을 가진 경우 학습된 잠재 함수가 진정한 EOT 계획을 정확하게 근사할 수 있음을 시사한다. 그러나 실제 수렴 속도와 품질은 MCMC 매개변수(랭킨 단계 수 $L$, 스텝 크기 $\eta$) 및 배치 크기에 의해 영향을 받으며, 실험 섹션에서 논의된다.
 Figure 6. A schematical presentation of potential applications of barycenter solvers
Figure 6. A schematical presentation of potential applications of barycenter solvers
결과, 한계 및 결론
실험 설계 및 기준선
저자들은 저차원 장난감 문제부터 고차원 이미지 다양체에 이르기까지 다양한 시나리오에서 제안된 에너지 기반 연속 엔트로픽 중심점(EOT) 솔버를 엄격하게 검증하기 위해 일련의 실험을 세심하게 설계했다. 특히 실제 정답 중심점을 알 수 없을 때 검증의 핵심 전략은 충분히 작은 정규화 매개변수 $\epsilon$에 대한 계산된 EOT 중심점을 분석적으로 도출 가능한 정규화되지 않은 중심점($\epsilon=0$)과 비교하는 것이었다. 이 접근 방식은 수학적 주장을 무자비하게 입증했으며, 가능한 경우 일치하거나 우수한 성능을 보여주었다.
2D 장난감 분포의 경우, 특히 "트위스터" 예제에서, 세 개의 혜성 모양 2D 분포($P_1, P_2, P_3$)와 균일한 가중치를 사용하여 실험이 설계되었다. 두 가지 다른 비용 함수가 테스트되었다. 비유클리드 "꼬인 비용" $c_k(x_k, y) = ||u(x_k) - u(y)||^2$ 및 표준 유클리드 $l^2$ 비용 $c_k(x, y) = ||x - y||^2$이며, 둘 다 정규화 $\epsilon = 10^{-2}$를 사용했다. 여기서 "희생자" 또는 기준선은 꼬인 비용에 대한 분석적으로 도출된 실제 정규화되지 않은 중심점과 POT 패키지 [33]의 free_support_barycenter 솔버를 사용하여 추정된 $l^2$ 중심점이었다. 이를 통해 알려지거나 잘 확립된 솔루션과 직접 비교할 수 있었다. 3D 구체 실험에서는 솔버가 3D 구체상의 네 개의 폰 미세스 분포에 대한 중심점을 추정했으며, 비이차 비용 함수 $c_k(x_k, y) = \frac{1}{2} \arccos^2(x_k, y)$와 $\epsilon = 10^{-2}$를 사용했다. 여기서 실제 정답은 알려지지 않았으므로 평가는 주로 학습된 중심점의 합리성에 초점을 맞춘 질적 평가였다.
이미지 데이터의 경우, 실험은 MNIST 0/1 숫자와 Ave, celeba! 데이터셋을 포함했다. MNIST의 경우, 32x32 흑백 이미지 공간에서 0/1 숫자의 분포를 평균화하는 작업이었다. MNIST에 대한 실제 정규화되지 않은 $l^2$ 중심점은 단순한 픽셀별 평균이며, 저자들은 정규화되지 않은 중심점을 학습하는 SCWB [32] 및 WIN [55]와 같은 기존 솔버와 비교했다. 결정적으로, 그들은 검색 공간을 사전 훈련된 StyleGAN [50] 다양체로 제한하는 다양체 제약 설정을 도입했으며, 견고성을 테스트하기 위해 이 다양체를 관련 없는 샘플로 "오염"시키기까지 했다. 비용 함수는 $c_{k,G}(x_k, z) = ||x_k - G(z)||^2$로 수정되었으며, $\epsilon = 10^{-2}$였다. Ave, celeba! 데이터셋 실험은 세 개의 손상된 얼굴 하위 집합을 평균화하는 것을 포함했으며, 여기서 실제 정규화되지 않은 $l^2$ 중심점은 Celeba 얼굴 자체의 분포이다. 이 역시 $\epsilon = 10^{-4}$로 다양체 제약 설정에서 SCWB [32] 및 WIN [55]와 비교하여 평가되었다.
마지막으로, 가우시안 분포의 경우, 저자들은 다양한 차원($D = 2, 4, 8, 16, 64$)에서 가중치 $(\frac{1}{4}, \frac{1}{2}, \frac{1}{4})$와 정규화 $\epsilon = 0.01, 1$을 사용하여 세 개의 가우시안 분포에 대한 정량적 평가를 수행했다. 실제 정규화되지 않은 중심점 $Q^*$는 WIN 저장소에서 반복 절차를 통해 추정되었으며, WIN 솔버 [55] 자체가 기준선 역할을 했다. 주요 지표는 중심점 투영의 $L_2$-UVP(설명되지 않은 분산 비율)였다. 또한 배치 크기와 랭킨 단계 수의 영향을 이해하기 위한 축소 연구도 수행되었다. 단일 세포 실험도 수행되었으며, 시간 경과에 따른 세포 집단 보간에 초점을 맞추었고, 차원은 $D = 50, 100, 1000$이었다. 여기서 지표는 MMD(최대 평균 불일치)였으며, 기준선에는 LightSB-M [2], SFM-sink [3], EGNOT [1]이 포함되었다.
증거가 증명하는 것
실험 증거는 제안된 에너지 기반 연속 엔트로픽 중심점(EOT) 솔버가 일반 비용 함수에 대한 연속 EOT 중심점을 효과적으로 근사하며, 이전 방법의 한계를 극복한다는 것을 확실하게 증명한다.
3D 구체 실험(그림 1)은 비표준, 비이차 실험 설정에 적용할 수 있으며, 실제 정답을 알 수 없을 때도 합리적인 중심점을 생성한다는 질적 증거를 제공한다. 이는 방법의 유연성과 견고성이 단순한 유클리드 공간을 넘어선다는 것을 보여준다.
2D 트위스터 예제의 경우, 질적 결과(그림 12)는 $\epsilon = 10^{-2}$를 사용한 우리 솔버가 비유클리드 꼬인 비용에 대한 실제 정규화되지 않은 중심점을 정확하게 복구한다는 부인할 수 없는 증거를 보여준다. 계산된 중심점(그림 12b)은 분석적으로 도출된 가우시안 실제 정답(그림 12a)과 시각적으로 완벽하게 일치한다. 이는 핵심 메커니즘이 복잡한 비유클리드 비용을 처리할 수 있다는 강력한 검증이다. $l^2$ 비용의 경우, 우리의 EOT 중심점(그림 12d)도 실제 $l^2$ 중심점(그림 12c)과 잘 일치하여 일반 적용 가능성을 다시 한번 확인한다. 꼬인 비용과 $l^2$ 비용에 대한 학습된 조건부 계획의 뚜렷한 구조는 방법이 비용 함수에 의해 정의된 기본 기하학에 민감하다는 것을 강조한다.
MNIST 0/1 실험에서 데이터 공간 EOT 중심점(그림 5, "OURS (Data Space)")에서 관찰된 "흐릿한 편향"과 노이즈는 엔트로피 정규화 OT 및 MCMC 샘플링의 특성과 일치한다. 그러나 다양체 제약 설정(그림 5, "OURS (Manifold Constrained)")은 제안된 기술의 힘을 결정적으로 증명한다. StyleGAN 다양체로 검색 공간을 제한함으로써 솔버는 깨끗하고 해석 가능한 중심점을 생성하여 "오염된" 샘플을 효과적으로 무시한다. 이는 다양체 제약이 직접적인 데이터 공간 EOT 중심점 추정에 내재된 노이즈 문제를 성공적으로 완화한다는 중요한 증거이다.
Ave, celeba! 데이터셋 평가는 설득력 있는 정량적 증거를 제공한다. 우리 솔버는 기준선 모델 SCWB [32] 및 WIN [55]에 비해 훨씬 낮은 FID 점수(표 2)를 달성했다. 예를 들어, $k=1$에 대한 우리 방법의 FID는 8.4(표준 편차 0.3)였으며, 이는 SCWB의 56.7과 WIN의 49.3을 훨씬 능가했다. 특히 다양체 제약 설정에서 이러한 상당한 개선은 핵심 메커니즘이 생성 모델과 결합될 때 복잡한 이미지 분포에 대한 우수한 지각 품질과 더 정확한 중심점 추정을 제공한다는 결정적인 증거이다. 질적 결과(그림 4)도 "질적으로 좋은" 수송된 이미지를 보여주지만, MCMC에 기인한 가끔의 내용 보존 실패가 있다.
가우시안 분포의 경우, 정량적 $L_2$-UVP 지표(표 7)는 솔버의 정확성에 대한 확실한 증거를 제공한다. 작은 $\epsilon = 0.01$ 및 $D=16$까지의 차원에서, 우리 알고리즘은 정규화되지 않은 경우에 대해 특별히 설계된 WIN 솔버보다도 더 나은 $L_2$-UVP 점수를 산출했다. 예를 들어, $D=2$에서 우리의 $L_2$-UVP는 WIN의 0.03에 비해 0.02였다. 이는 적절한 정규화의 경우, 우리의 EOT 솔버가 정규화되지 않은 설정을 전문으로 하는 방법을 능가하는 최첨단 정확도를 달성할 수 있음을 보여준다. 배치 크기(표 9) 및 랭킨 단계(그림 11)에 대한 축소 연구는 방법의 성능이 이러한 매개변수에 민감하며, 더 큰 배치 크기와 충분한 랭킨 단계가 예상대로 MCMC 기반 접근 방식에서 성능 향상으로 이어진다는 것을 추가로 확인한다.
마지막으로, 단일 세포 실험(표 8)은 우리의 일반 목적 엔트로픽 중심점 접근 방식이 다양한 차원 및 설정에서 선도적인 기준선(예: $D=50$에서 OURS의 2.32 대 LightSB-M의 2.33)의 성능에 거의 근접함을 보여준다. 이는 집단 보간과 같은 문제에 대한 견고하고 즉시 사용 가능한 기반 모델로서의 잠재력을 시사한다.
한계 및 향후 방향
제안된 에너지 기반 연속 엔트로픽 중심점 솔버가 상당한 발전을 보여주지만, 내재된 한계를 인식하고 미래 연구를 위한 유망한 방향을 고려하는 것이 중요하다.
주요 방법론적 한계 중 하나는 훈련 및 추론 모두에서 마르코프 연쇄 몬테카를로(MCMC) 절차에 의존한다는 것이다. 사용된 기본 조정되지 않은 랭킨 알고리즘(ULA)은 특히 복잡한 에너지 풍경에서 원하는 분포 $\mu^\ddagger$로의 수렴이 좋지 않을 수 있다. MCMC 샘플링은 또한 본질적으로 시간이 많이 소요되어, 특히 더 큰 배치 크기 또는 더 높은 차원의 문제에 대해 방법의 확장성에 영향을 미친다(계산 복잡성 분석(표 3, 부록 C)에서 언급됨). 미래 작업은 재현 버퍼 [46], 보조 변수 [43] 또는 신경 수송 [47, 71, 99, 108, 66, 26]과 같은 고급 MCMC 기술에서 영감을 얻은 더 효율적인 샘플링 절차를 탐색해야 한다. 이는 계산 부담을 크게 줄이고 수렴 안정성을 향상시킬 수 있다.
또 다른 이론적 한계는 일반화 경계 및 보편적 근사 보장에 대한 현재 분석(§4.3)이 경사 하강 과정 및 MCMC 샘플링 자체에서 발생하는 최적화 오류를 고려하지 않는다는 것이다. 이는 이 논문의 범위를 벗어나는 기계 학습 이론의 복잡한 영역이지만, 더 깊은 이론적 이해를 위한 중요한 방향을 나타낸다. 미래 연구는 이러한 실질적인 최적화 문제를 통합하는 보다 포괄적인 이론적 프레임워크를 개발함으로써 이 격차를 해소하는 것을 목표로 할 수 있다.
문제 설정 관점에서, 이미지 데이터 공간에서 엔트로피 정규화를 사용하면 MNIST 0/1 데이터 공간 실험(그림 5)에서 관찰된 것처럼 "흐릿한 편향"과 노이즈가 많은 중심점 이미지가 발생할 수 있다. 다양체 제약 접근 방식은 StyleGAN과 같은 사전 훈련된 생성 모델을 활용하여 이를 효과적으로 완화하지만, 이러한 외부 모델의 품질과 적합성에 대한 의존성을 도입한다. 그러면 질문이 생긴다. 선택된 다양체가 기본 데이터 구조를 진정으로 대표하는지 어떻게 보장할 수 있으며, 이 방법은 "오염된" 또는 불완전한 다양체에 얼마나 견고한가? 미래 작업은 적응형 다양체 학습 기술 또는 다양체와 중심점을 공동으로 학습하는 방법을 조사할 수 있다.
중요한 미래 지향적 논의 주제는 $\lambda$ 및 $\tau$가 반드시 $\epsilon$과 같지 않은 이중 정규화 EOT 중심점으로 에너지 기반 방법론을 확장하는 것이다(부록 B.3). 현재 솔버는 엔트로피 항 $H(Q)$가 목적 함수에서 사라지는 슈뢰딩거 중심점 경우($\lambda = \tau = \epsilon$)에 맞춰져 있다. 비영수 $H(Q)$ 항을 통합하려면 두 번째 주변 분포 $\pi_k(y)$의 엔트로피를 별도로, 비자명하게 계산해야 하는데, 이는 현재 MCMC 샘플에서 추정하기가 실행 불가능하다. 이 엔트로피 항을 추정하거나 근사하는 새로운 기술을 개발하거나, 직접적인 계산을 피하기 위해 쌍대 목적 함수를 재구성하면 더 넓은 범위의 EOT 중심점 문제를 해결할 수 있다.
또 다른 중요한 미래 개발 영역은 특히 의학(도메인 이동 문제) 및 지질학(시뮬레이터 혼합)과 같은 분야의 실제 응용을 위한 적절한 비용 함수 및 데이터 다양체 설계에 있다. 본 논문은 이러한 분야에서 중심점을 효과적으로 적용하려면 의미 있는 비용 함수 $c_k$를 정의하고 적합한 데이터 다양체 $M$을 선택하거나 구성하기 위해 도메인별 지식이 필요하다고 강조한다. 이는 기계 학습 전문가와 도메인 전문가를 협력하여 작업별 솔루션을 공동 개발하도록 하는 학제 간 협력의 필요성을 시사한다. 예를 들어, 의료 영상에서 신흥 대규모 생성 모델(예: DALL-E [85], StableDiffusion [87])을 사용하여 의료 데이터를 매개변수화하는 방법을 탐색하면 새로운 분석 경로를 열 수 있다.
대안적 중요 샘플링(IS) 훈련 절차(부록 D)는 더 빠른 수렴을 약속하지만, 추정기 분산을 줄이기 위해 제안 분포 $q$의 정확한 선택이 필요하다는 자체적인 과제를 도입한다. 이는 실제 시나리오에서 종종 어렵다. 미래 연구는 IS를 위한 적응형 또는 학습된 제안 분포를 개발하는 데 초점을 맞출 수 있으며, 잠재적으로 이를 MCMC 또는 다른 기술과 결합하여 EOT 중심점에 대한 더 견고하고 효율적인 훈련 알고리즘을 만들 수 있다.
마지막으로, 확장성 및 계산 효율성은 여전히 주요 과제이다. 현재 방법은 대규모 설정에서 작동하지만, 특히 MCMC로 인해 추론 시간이 상당할 수 있다. 하드웨어 가속 MCMC, 분산 컴퓨팅 전략 또는 품질 저하 없이 랭킨 단계 수를 줄이는 근사치(축소 연구에서 암시된 대로)를 탐색하는 것은 가치가 있을 것이다. 목표는 이러한 연속 중심점 솔버를 산업 및 사회적으로 중요한 문제에 대해 더 접근 가능하고 실용적으로 만들어, 최적 수송 작업에 대한 "기반 모델"로서의 잠재력을 진정으로 활용하는 것이어야 한다.
 Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
 Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
 Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
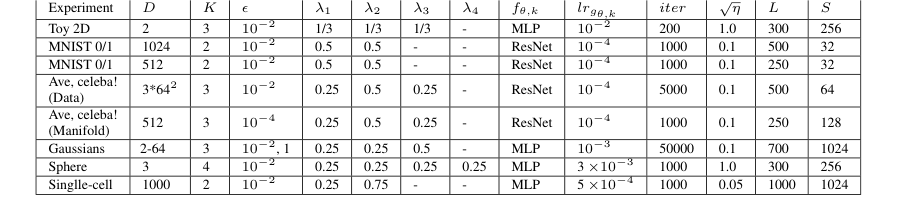 Table 4. Hyperparameters that we use in the experiments with our Algorithm 1
Table 4. Hyperparameters that we use in the experiments with our Algorithm 1