一般的なコストに対するエネルギー誘導型連続エントロピー重心推定
This paper introduces a new, simpler way to average probability distributions that keeps their shape, with guaranteed quality and real-world applications.
背景と学術的系譜
起源と学術的系譜
本論文で取り組む問題である最適輸送(OT)重心問題は、確率分布を幾何学的に意味のある方法で平均化するという根本的な必要性から生じる。スカラーやベクトルを線形空間で平均化することは容易であるが、確率分布を扱う場合、タスクは著しく複雑になる。単純な凸結合は、しばしば本質的な幾何学的特徴を保持できず、中心または平均を定義するためのより洗練されたアプローチが必要となる。
この特定の問題は、最適輸送の学術分野で最初に登場した。最適輸送は、ある分布を別の分布に変換するための「コスト」を定義することにより、確率分布の比較と平均化のための堅牢なフレームワークを提供する。AguehとCarlier [1] によって2011年に導入されたOT重心の概念は、与えられたソース分布のコレクションへの輸送コストの合計を最小化する中心分布を見つけることを目的としている。
過去10年間、効果的な重心計算の実用的な需要は、実質的な研究を推進してきた。初期の取り組みは、主に離散OT重心の設定に焦点を当てていた。そこでは、分布は点の有限集合として表現される。しかし、連続確率分布を扱う連続設定は、はるかに困難であることが証明された。以前の連続OT重心ソルバーは、いくつかの主要な制限に悩まされていた。
- 特定のコスト関数: 多くの既存の方法は、特に二次ユークリッドコスト($l_2(x, y) \stackrel{\text{def}}{=} ||x - y||^2$)などの特定のOTコスト関数専用に設計されていた。これは、現実世界のシナリオが非ユークリッドまたはより複雑なコスト関数をしばしば含むため、それらの適用範囲を狭い範囲の問題に限定した。
- 非自明なa priori選択: いくつかの手法は、重心分布に対して複雑なa priori選択または固定された事前分布を必要とした。これは決定が容易ではなく、モデルの柔軟性を制限する可能性がある。
- 表現力と生成能力の制限: 特定の手法は、分布間の複雑な関係を表現したり、学習された重心から新しいサンプルを生成したりする能力が限られており、生成モデリングタスクでの有用性を妨げていた。
- OT計画の回復不能: いくつかの手法は、重心を生成モデルとしてパラメータ化したが、個々のソース分布が重心にどのようにマッピングされるかを理解するために不可欠な、基盤となる最適輸送計画を回復しなかった。
本論文は、任意のOTコスト関数を処理でき、固定された事前分布を必要とせず、表現力を制限せず、そして重要なことに、条件付きOT計画を回復できる、連続エントロピーOT(EOT)重心の近似のための新しいアルゴリズムを提案することにより、これらの制限を克服することを目指している。
直感的なドメイン用語
ゼロベースの読者が中心的な概念を理解できるように、専門用語を日常的なアナロジーに翻訳したものを以下に示す。
- 最適輸送(OT): いくつかの土の山(確率分布)があり、それらを新しい山に再形成したいと想像してください。最適輸送は、元の山からすべての土を移動して新しい山を形成する最も効率的な方法を見つけるようなもので、関与する総「労力」または「コスト」を最小化します。
- 重心: いくつかの散らばった煙の雲(確率分布)がある場合、重心は、元の雲すべてに平均して最も近い「平均」または「質量中心」の煙の雲を見つけるようなものです。「努力」(最適輸送コスト)を考慮して、ある雲を別の雲に変換します。それは、他のすべての分布からの「引力」をバランスさせる中心点です。
- エントロピー最適輸送(EOT): これは、最適輸送の「より柔らかい」または「よりぼやけた」バージョンです。すべての土の粒子を最も直接的な経路に沿って厳密に移動するのではなく、EOTは輸送中にわずかな混合またはランダム性を許容します。これにより、問題は計算上解決しやすくなります。土の一部が少し広がることを許可するようなものですが、それでも良好で幾何学的に意味のある平均を達成します。
- 弱いOT双対定式化: 複雑な問題、例えば完璧な橋の設計を考えてみてください。すべての可能な橋を直接構築してテストするのではなく、「双対定式化」は、橋にかかる力と応力を最適化することを含む、同等の単純な問題を見つけるようなものです。OTでは、すべての「土の粒子」を直接追跡するのではなく、最適化すると最も効率的な土の移動方法を間接的に教えてくれる2つの「ポテンシャル関数」を見つけます。これはしばしば解決が容易です。
- エネルギーベースモデル(EBM): データポイントが存在しやすい場所を谷、存在しにくい場所を丘として表す風景を想像してください。EBMはこの「エネルギーランドスケープ」を学習して、データの分布を理解します。私たちの方法は同様のアイデアを使用します。重心問題を複雑な空間での最も低い「エネルギー」構成を見つける問題としてフレーム化し、解決策を見つけるために確立されたEBMトレーニング技術を活用できるようにします。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
中核問題定式化とジレンマ
本論文で取り組む中核問題は、確率分布のコレクションに対する連続エントロピー最適輸送(EOT)重心の推定である。
入力/現在の状態:
開始点は、$K$個のソース確率分布のコレクションであり、$P_k \in \mathcal{P}_{ac}(\mathcal{X}_k)$と表記される。ここで、$\mathcal{P}_{ac}(\mathcal{X}_k)$は、コンパクトなサブセット$\mathcal{X}_k \subset \mathbb{R}^{D_k}$上に定義された絶対連続確率分布を表す。各ソース分布$P_k$に対して、$\mathcal{X}_k$の点と重心空間$\mathcal{Y}$の点との間の質量輸送の「コスト」を定量化する連続コスト関数$c_k(\cdot, \cdot) : \mathcal{X}_k \times \mathcal{Y} \to \mathbb{R}$が関連付けられている。さらに、正の重み$\lambda_k > 0$のセットが与えられ、条件$\sum_{k=1}^K \lambda_k = 1$を満たす。実用的なシナリオでは、これらのソース分布$P_k$は明示的には知られておらず、有限個の経験サンプル、$X_k = \{x_1^k, x_2^k, \dots, x_{N_k}^k\} \sim P_k$からのみアクセス可能である。既存の連続OT重心ソルバーは、一般的なコスト関数に苦労したり、特定のa priori選択を必要としたり、表現力や生成能力が限られていたりすることが多い。
望ましい終点(出力/目標状態):
最終的な目標は、EOT重心$Q^* \in \mathcal{P}(\mathcal{Y})$を特定することである。これは、すべてのソース分布$P_k$に対するEOT乖離の加重和を最小化する確率分布である。数学的には、これは次のように定式化される。
$$L^* \stackrel{\text{def}}{=} \inf_{Q \in \mathcal{P}(\mathcal{Y})} \sum_{k=1}^K \lambda_k \text{EOT}_{c_k, \epsilon}(P_k, Q)$$
ここで、$\text{EOT}_{c_k, \epsilon}(P_k, Q)$は、パラメータ$\epsilon > 0$で正則化された、$P_k$と$Q$の間のエントロピー最適輸送コストを表す。単に$Q^*$を見つけるだけでなく、本論文は、各ソース$P_k$の点を重心$Q^*$にマッピングする最適な条件付き輸送計画$\pi_{f_k}^*(\cdot|x_k)$を近似することを目指している。これらの回復された計画は、「アウトオブサンプル推定」を可能にするべきである。つまり、新しい、未知のサンプル$x_{\text{new}}$($P_k$から)に対して、それらは$\pi_{f_k}^*(\cdot|x_{\text{new}})$からのサンプルを生成できる。さらなる野心は、事前学習された生成モデルの画像多様体上で重心を学習することであり、これは実世界のアプリケーションに大きな影響を与える。
失われたリンクとジレンマ:
正確な失われたリンクは、任意のコスト関数を処理でき、経験サンプルのみで効果的に動作する、連続EOT重心を推定するための一般的で堅牢かつ計算上実行可能なアルゴリズムである。以前の研究は、痛みを伴うトレードオフに囚われていた。連続OT重心問題における一般性と表現力の向上は、通常、計算上の大きな課題をもたらすか、または制限的な仮定を必要とする。例えば、任意のコスト関数を処理するための一般性の向上は、多くの先行手法が有利な理論的特性を持つため、より単純なコスト(二次ユークリッド$l_2$コストなど)に依存しているため、解決不可能な最適化問題につながることが多い。これらのより単純なコストは、より効率的なアルゴリズムを可能にするが、適用範囲を制限する。さらに、連続設定はより強力であるが、「離散設定よりもさらに困難」であり、既存の解決策はしばしば表現力の制限、または非自明なa priori選択や重心の特定のパラメータ化を必要とし、これらは決定が困難であったり、手法の範囲を制限したりする可能性がある。高次元データ空間(画像など)では、EOT重心の直接計算は、エントロピー正則化とMCMCへの依存により、しばしば「ノイズの多い画像」または「ぼかしバイアス」につながる。検索空間をデータ多様体に制限するとこれを緩和できるが、多様体学習とコスト関数の適応に関連する独自の複雑さが導入される。
制約と失敗モード
連続EOT重心推定の問題は、いくつかの厳しい現実的な制約により、本質的に困難である。
- 直接最適化の計算上の非現実性: EOT重心の目的関数(式5)は、すべての確率分布$\mathcal{P}(\mathcal{Y})$の空間における$\inf$を含む。これは無限次元空間である。これを直接最適化することは一般に不可能であり、問題の再定式化が必要となる。
- 解析解の欠如: ほとんどの実用的なシナリオでは、ガウス分布の場合を含むが、エントロピー重心問題($\epsilon > 0$と正則化されていない$\epsilon = 0$の両方の場合)に対する直接的な解析解は知られていない。これは数値近似法への依存を強制する。
- 経験的データ制限: ソース分布$P_k$は、現実世界のアプリケーションではめったに明示的に利用できない。代わりに、有限の経験サンプル(データセット)$X_k$のみがアクセス可能である。これは、アルゴリズムがデータの疎性やノイズに対して堅牢であり、アウトオブサンプル汎化を実行できる必要があることを意味する。
- 高次元性: RGB画像(例: CelebAの$3 \times 64 \times 64$次元)のような複雑なデータ型を扱うことは、学習とサンプリングのための計算およびメモリの要求を大幅に増加させ、直接的なアプローチを不可能にする。
- 任意のコスト関数: 本論文は「任意のOTコスト関数」をサポートすることを目指しており、これは実質的な制約である。多くの既存の手法は、計算を単純化する特定の理論的特性を持つ、より単純なコスト($l_2$など)に特化している。一般的なコストはこれらの単純化を削除し、複雑さを増す。
- 非ユークリッド幾何学: 問題は明示的に「非ユークリッドコスト関数」を考慮している。これは、標準的なユークリッド距離尺度がしばしば不十分であることを意味する。これには、複雑な幾何学的関係を捉えるためにより柔軟で強力なモデルが必要となる。
- MCMCサンプリングの制限: 提案手法は、サンプリングのためにマルコフ連鎖モンテカルロ(MCMC)手順(特に調整なしランジュバンアルゴリズム、ULA)に依存している。
- 高い計算コスト: MCMCサンプリングは本質的に「時間のかかる」ものであり、トレーニングと推論のレイテンシに影響を与える(表3)。
- 収束の問題: 基本的なULAアルゴリズムは「望ましい分布にうまく収束しない可能性があり」、最適でない結果につながる。
- 微分可能性の要件: MCMCは通常、エネルギー関数(したがってコスト関数$c_k$)が微分可能であることを必要とする。微分不可能なコストは、より複雑な勾配フリーサンプリング手順を必要とするだろう。
- 局所的最小値: MCMC推論は「エネルギーランドスケープの局所的最小値に引っかかる可能性があり」、学習された輸送計画が望ましい画像コンテンツまたは他の特徴の保持に失敗する原因となる(セクション5.3)。
- 正規化定数の非現実性: 双対目的関数内の正規化定数$Z_{c_k}(f_k, x_k)$の直接計算はしばしば「非現実的」であり、勾配推定のために近似が必要となる。
- データ空間における「ぼかしバイアス」: EOT重心が高次元データ空間(例: 画像ピクセル)で直接計算されると、エントロピー正則化により「ノイズの多い画像」または「ぼかしバイアス」が生じる可能性があり、結果として得られる重心の解釈可能性や視覚的な妥当性が低下する。
- 多様体制約の複雑さ: 重心の探索空間をデータ多様体(例: 事前学習済みStyleGANを使用した)に制限すると、このような生成モデルのトレーニングと統合、およびコスト関数を多様体の潜在空間に適応させるという追加の複雑さが導入される。
- 汎化と近似誤差: 学習されたモデルが未知のデータに対してうまく汎化し、ニューラルネットワーク近似が正確であることを保証することは、重大な理論的課題である。推定誤差は、一般的なリプシッツコストの場合、「次元の呪い」の影響を受ける可能性があり、高次元での高速な収束率の達成を困難にする。
なぜこのアプローチなのか
選択の必然性
著者らがエネルギー誘導型連続エントロピー重心推定アプローチを選択したのは、単なる好みではなく、連続最適輸送(OT)重心問題における既存手法の固有の制限によって駆動された必然性であった。この認識の正確な瞬間は、セクション3と表1の詳細な議論から明らかであり、それらは先行技術の欠点を強調している。
従来の「SOTA」手法、例えば標準的なCNN、基本的な拡散モデル、またはTransformerは、次のような理由で不十分と見なされた。
1. 特定のコスト関数: 連続OTソルバーの大部分([59, 55, 32, 82]などの論文を含む)は、二次ユークリッドコスト$l_2(x, y) = ||x - y||^2$専用に設計されていた。この制限は、複雑な幾何学的関係を捉えるために任意の非ユークリッドコスト関数が不可欠な現実世界のシナリオへの適用を著しく制限する。本論文では、「対照的に、我々が提案するアプローチは、任意のコスト関数$c_1, \dots, c_K$を持つEOT問題を処理するように設計されている。」(p. 4)と明記されている。
2. 固定された事前分布と非自明な選択: いくつかの手法(例: [72])は、重心に対して非自明なa priori選択を必要としたり、固定された事前分布を選択したりする必要があった。これは複雑でロバストでない手順である可能性がある。提案手法はこの制約を回避する。
3. OT計画回復の欠如: 決定的なことに、いくつかの手法(例: [17])はOT計画を回復せず、これはセクション2.3で定義された学習設定、特にアウトオブサンプル推定と生成能力に焦点を当てたものにとって基本的な要件である。
4. 計算上の複雑さとパラメータ化: 他の変分法(例: [14])は、最適化の複雑さを増加させ、重心分布の特定のパラメータ化を必要とし、それらを一般性または直感性の低いものにした。
著者らは、連続設定で任意のコスト関数を処理し、OT計画を回復し、制限的な事前分布なしで動作するソルバーの必要性、特にこれらの集合的な制限に対処するために新しいアプローチが必要であると認識した。
比較優位性
この手法は、単純なパフォーマンス指標を超えたいくつかの構造的利点を通じて、以前のゴールドスタンダードに対する質的な優位性を示す。
- 任意のコスト関数と非ユークリッドコスト: 多くの先行研究が二次ユークリッドコストに限定されていたのに対し、このアプローチは、非ユークリッドコストを含む任意のOTコスト関数用に設計されている。この柔軟性は、画像多様体や特殊な地質シミュレーションを含む、はるかに広範な複雑な問題への適用を可能にする、深遠な構造的利点である(セクション5、B.2)。
- エネルギーベースモデル(EBM)とのシームレスな統合: 手法の核心は、EOTの弱い双対形式と合同条件を組み合わせたエントロピー最適輸送(EOT)重心問題の優雅な再定式化にある。この再定式化は、EBMのトレーニング手順と自然に一致し、調整されたアルゴリズムの使用を可能にし、「ミニマックス、強化学習、その他の複雑な技術的トリックを回避する直感的な最適化スキーム」(要旨、p. 1)を提供する。これにより、敵対的トレーニング(GANなど)や方策勾配法に関連する複雑さが回避される。
- ロバストな汎化と近似保証: 本論文は、回復されたEOT計画(セクション4.3)に対する汎化バウンドと普遍的近似保証を含む、強力な理論的基盤を確立している。特に、特徴ベースの二次コストの場合、手法は$O(N^{-1/2})$の推定誤差を達成し、これは「標準的で高速かつ次元に依存しない収束率」として説明されている(定理4.5 (b)、p. 6)。これは、手法の統計的一貫性と信頼性に関する厳密な理解を提供する。これは、競合する連続重心ソルバーではしばしば欠けている特徴である。
- 高次元ノイズと多様体学習の処理: 画像のような複雑なデータの場合、データ空間での直接的なEOT重心は、「ぼかしバイアス」に苦しみ、ノイズの多い画像を生成する可能性がある。この手法は、新しい「多様体制約付き」設定(セクション4.4)を導入することにより、これを質的にうまく処理する。事前学習済み生成モデル(例: StyleGAN)によって生成された画像多様体上で重心を学習することにより、高次元画像平均化に固有のノイズとアーティファクトを効果的に緩和し、より解釈可能で妥当な重心分布を生成する。これは、実用的なアプリケーションにおける結果の質における重要な改善である。
制約との整合性
選択されたエネルギー誘導型アプローチは、問題の厳しい要件に完全に適合し、「問題の要求とソリューションの独自のプロパティとの結婚」を形成する。
- 連続OTとアウトオブサンプル推定: 問題は、連続OT重心タスクの解決とアウトオブサンプル推定(新しいデータポイントに対する条件付き計画$\pi^*(\cdot|x_{\text{new}})$からのサンプルの生成能力)を提供することを明確に要求している。提案手法は、条件付き分布$\mu_{f_k}^*(\cdot|x_k)$(式4、p. 3)を定義するニューラルネットワークポテンシャル$f_k$を学習することにより、これを直接的に処理する。その後、標準的なMCMC技術を使用してサンプルを生成でき、アウトオブサンプル推定要件を満たす(セクション4.2)。
- 任意のコスト関数: 主要な制約は、任意のコスト関数を処理する必要があることであり、$l_2$固有の手法の制限を超えている。双対定式化とEBMフレームワークは、実験で非ユークリッド「ツイスト」コストや多様体制約付きコストで実証されているように、微分可能な任意のコスト関数$c_k(x,y)$を自然に受け入れる(セクション5.1、5.2)。
- データアクセス可能性(経験サンプル): 問題は、ソース分布$P_k$が限られた数のi.i.d.経験サンプル$X_k$からのみアクセス可能であると仮定している。提案アルゴリズムは、トレーニング中の勾配推定のためのモンテカルロ近似を使用して、これらのサンプルを直接操作するように設計されている(アルゴリズム1、p. 5)。
- 複雑な空間での意味のある重心: 画像データの場合、ピクセル空間での直接的な平均化は、「ぼかしバイアス」のために望ましくないことが多い。多様体制約付きEOT重心(セクション4.4)は、検索空間を事前定義されたデータ多様体(StyleGANによって生成されたものなど)に制限することにより、これを直接的に処理する。これにより、結果として得られる重心が妥当な多様体に集中し、視覚的に優れた、より解釈可能な結果が得られることが保証される。これは、実用的な問題に対する巧妙な解決策である。
代替案の却下
本論文は、提案手法の独自の利点を強調して、いくつかの代替アプローチを却下する明確な理由を提供している。
- 離散OTソルバー: 著者らは、「離散OTは、連続OT設定で要求されるアウトオブサンプル推定には適していない」(セクション2.3、p. 3)と明確に述べている。離散OT手法は堅固な理論的基盤と収束保証を持っているが、未知のデータに対する条件付き計画の近似を目的とする連続学習設定には直接適応できない(セクションB.1、p. 22)。
- $l_2$コストを持つ連続OTソルバー: 多くの既存の連続OT重心ソルバーは、「二次ユークリッドコスト$l_2(x, y) = ||x - y||^2$専用に設計されている」(セクション3、p. 4)。これは、現実世界のアプリケーションが複雑なデータ関係を捉えるために、非ユークリッドコストを含む任意のコスト関数をしばしば要求するため、却下される。提案手法の一般的なコストを処理する能力は、この制限に対する直接的な応答である。
- 固定された事前分布を必要とするか、計画回復を欠く連続OTソルバー: いくつかの手法(例: [72])は、重心に対して「非自明なa priori選択」を必要とし、これは煩雑である可能性がある。他の手法(例: [17])は、「OT計画を回復しない」が、これは本論文の生成タスクのための条件付き輸送計画学習という目標とは根本的に一致しない(セクション3、p. 4)。
- $H(Q)$項を持つ二重正則化EOT重心: 本論文では、二重正則化EOT重心(式40、p. 24)について議論している。そこでは、正則化パラメータ$\lambda$と$\tau$が重心分布$Q$のエントロピー項$H(Q)$を追加する。この代替案は、「$H(Q)$項の存在は我々のものとは著しく異なり、我々のソルバーには適していないように思われる」(p. 25)ため却下される。その理由は、$H(Q)$を追加すると、第二辺縁分布$H(\pi_k(y))$のエントロピーの別途、非常に非自明な計算が必要になり、これは生サンプルから推定することが不可能であり、EBMのような技術ではこのシナリオで勾配を導出できないからである(p. 25)。
- 他のGANベースの重心手法(例: [95]): [95]は検索空間をGAN多様体に制限しているが、そのアプローチは根本的に異なり、「実際には適用できない」(セクションB.1、p. 23)とされている。彼らはK個の画像(強度ヒストグラムを介して2D分布として表される)を考慮し、GAN多様体上の単一画像を離散OTソルバーを使用して検索する。対照的に、本論文は、K個の高次元画像分布(ランダムサンプルによって表される)の重心を、OT計画を回復する連続OTソルバーを使用して検索する。目的と方法論は異なるため、[95]の手法は現在の問題には適していない。
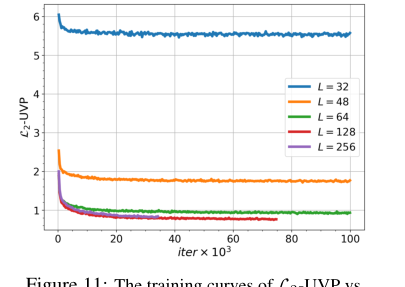 Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
数学的・論理的メカニズム
マスター方程式
本論文のアプローチの核となる数学的エンジンは、アルゴリズムが最大化しようとする双対目的関数である。この目的は、エントロピー最適輸送(EOT)問題の弱い双対定式化から導出され、ニューラルネットワークによってパラメータ化される。最適化される特定の式は次のように与えられる。
$$ \mathcal{L}(\theta) \stackrel{\text{def}}{=} \sum_{k=1}^K \lambda_k \left\{ -\epsilon \mathbb{E}_{x_k \sim P_k} \left[ \log Z_{c_k}(f_{\theta,k}, x_k) \right] \right\} \quad (8) $$
ここで、$Z_{c_k}(f_{\theta,k}, x_k)$は正規化定数(または分配関数)であり、次のように定義される。
$$ Z_{c_k}(f_{\theta,k}, x_k) \stackrel{\text{def}}{=} \int_{\mathcal{Y}} \exp\left(\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}\right) dy \quad (21) $$
項ごとの解剖
これらの式の各部分を分解して、その役割を理解しよう。
- $\mathcal{L}(\theta)$: これはアルゴリズムが最大化しようとする目的関数である。その値は、ポテンシャル関数の現在のセット($\theta$でパラメータ化される)がEOT重心問題の双対定式化にどれだけよく一致するかを反映する。この双対目的を最大化することは、原始EOT重心問題を最小化することと同等である。
- $\theta$: これは、ニューラルネットワーク$f_{\theta,k}$のすべての学習可能なパラメータのコレクションを表す。これらのパラメータは、目的を最適化するために学習プロセス中に調整される。
- $K$: これは、平均化したいソース確率分布$P_k$の合計数である。例えば、3つの画像データセットを平均化している場合、$K=3$である。
- $\lambda_k$: これらは、各ソース分布$P_k$の事前に定義された正の重みであり、$\sum_{k=1}^K \lambda_k = 1$を満たす。それらは、最終的な重心に対する各ソース分布の相対的な重要性または寄与を決定する。すべての$\lambda_k$が等しい場合、それは単純な平均であり、そうでなければ加重平均である。
- $\sum_{k=1}^K$: これは、すべての$K$個のソース分布からの寄与を集計する合計演算子である。著者は、EOT重心問題が各ソース分布と重心との間の個々のEOT乖離の合計として定式化されているため、加算を使用する。
- $\epsilon$: これはエントロピー正則化パラメータであり、正のスカラーである。これは、輸送計画の「滑らかさ」または「ランダム性」を制御する。$\epsilon$が大きいほど、より拡散した、より「シャープでない」輸送計画(およびより滑らかな損失ランドスケープ)になり、$\epsilon$が小さいほど、輸送はより決定論的になり、古典的な最適輸送に近づく。これは統計力学における「温度」パラメータとして機能する。
- $\mathbb{E}_{x_k \sim P_k}[\dots]$: これは、$k$番目のソース確率分布$P_k$からサンプリングされたサンプル$x_k$に対する期待値を表す。実際には、この期待値は、$P_k$からサンプルのバッチを描画することによってモンテカルロサンプリングを使用して近似される。
- $P_k$: これは$k$番目のソース確率分布である。これらは、アルゴリズムが平均化しようとする入力分布である。現実世界のシナリオでは、これらは通常、経験サンプル(データセット)からのみアクセス可能である。
- $x_k$: これは、$k$番目のソース分布$P_k$からサンプリングされたサンプル(データポイント)である。
- $\log$: これは自然対数関数である。ここでは、弱いエントロピーc変換、$f_k^{c_k}(x_k)$が$-\epsilon \log Z_{c_k}(f_k, x_k)$として定義されているため使用される。この変換は、積分を最適化のためのより管理しやすい形式に変換し、エネルギーベースモデルとの関連付けに重要である。
- $Z_{c_k}(f_{\theta,k}, x_k)$: これは、条件付き確率分布$\mu_{x_k}^{f_{\theta,k}}(y)$の正規化定数または分配関数である。これは、条件付き分布が1に積分することを保証する。その値は、ポテンシャル関数$f_{\theta,k}$とコスト$c_k$に依存し、与えられた$x_k$に対して計算される。
- $\int_{\mathcal{Y}} \dots dy$: これはターゲット空間$\mathcal{Y}$上の積分である。これは、正規化定数を計算するために、すべての可能なターゲットポイント$y$にわたる「エネルギー」寄与を合計する。著者は、問題が確率分布の連続ドメインで設定されているため、積分を使用する。
- $\exp(\dots)$: これは指数関数である。これは、「エネルギー」項$(f_{\theta,k}(y) - c_k(x_k, y))/\epsilon$を、正規化されていない確率密度として解釈できる非負の値に変換する。これは統計力学とエネルギーベースモデルにおける標準的なコンポーネントである。
- $f_{\theta,k}(y)$: これは、ターゲットポイント$y$で評価された、$k$番目の分布のポテンシャル関数である。これらの関数はニューラルネットワーク$f_{\theta,k}$によってパラメータ化され、モデルの主要な学習可能なコンポーネントである。それらは、$k$番目のソースの観点から、ターゲットポイント$y$の「値」または「効用」を表す。
- $c_k(x_k, y)$: これは、ソースポイント$x_k$からターゲットポイント$y$への質量の輸送のコスト関数である。これは、$x_k$と$y$の間を移動する「コスト」または非類似性を定量化する。本論文は、一般的な(非ユークリッドでさえも)コスト関数を処理する能力を強調している。
- $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$: この項は、$x_k$から$y$への輸送のスケーリングされた「エネルギー」または「対数確率」を表し、ポテンシャル$f_{\theta,k}$と正則化$\epsilon$によって変調される。ポテンシャル$f_{\theta,k}(y)$は、ターゲットポイント$y$に対する「報酬」と見なすことができ、一方$c_k(x_k, y)$は輸送に対する「ペナルティ」である。$\epsilon$による除算は、このエネルギーをスケーリングし、小$\epsilon$では分布をシャープにし、大$\epsilon$ではフラットにする。
- 指数内の減算$f_{\theta,k}(y) - c_k(x_k, y)$は、ポテンシャルとコストを組み合わせる自然な方法である。これは、与えられた$x_k$に対するターゲットポイント$y$の正味の「魅力」を反映しているためである。
ステップバイステップフロー
トレーニングイテレーション中に、この数学的エンジンを通過する単一の抽象データポイント、例えば最初のソース分布$P_1$からの$x_1$を想像してみましょう。
- データポイント入力: ソース分布$P_1$からサンプル$x_1$が描画される。この$x_1$はデータセットからの具体的なインスタンスである。
- ポテンシャル評価: この$x_1$と、ターゲット空間$\mathcal{Y}$の可能なターゲットポイントの範囲$y$に対して、ニューラルネットワーク$f_{\theta,1}$がそのポテンシャル$f_{\theta,1}(y)$を計算する。同時に、コスト関数$c_1(x_1, y)$が評価され、$x_1$から各$y$への移動の「労力」が定量化される。
- エネルギー計算: これらの値が組み合わされる: $f_{\theta,1}(y) - c_1(x_1, y)$。この差は、$x_1$から$y$への輸送の「正味の効用」を表す。この効用は正則化パラメータ$\epsilon$でスケーリングされ、$\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}$が得られる。
- 正規化されていない確率: スケーリングされた効用が指数関数化される: $\exp\left(\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}\right)$。これは、$x_1$から$y$への輸送の「可能性」の正規化されていない尺度を与える。
- 正規化(分配関数): これを適切な条件付き確率分布($\mu_{x_1}^{f_{\theta,1}}(y)$と表記される)にするために、正規化する必要がある。これは、正規化されていない確率をターゲット空間$\mathcal{Y}$全体にわたって積分して$Z_{c_1}(f_{\theta,1}, x_1)$を得ることによって行われる。この積分はしばしば計算上不可能であるため、その勾配はMCMCのような技術を使用して推定される。
- 対数尤度寄与: この正規化定数の自然対数、$\log Z_{c_1}(f_{\theta,1}, x_1)$が取られる。この項は、$ -\epsilon$で乗算されると、効果的に弱いエントロピーc変換$f_1^{c_1}(x_1)$となる。
- 加重合計: このプロセス(ステップ2-6)は、$P_1$からの他のサンプルに対して(期待値$\mathbb{E}_{x_1 \sim P_1}[\dots]$を近似するため)および他のすべてのソース分布$P_k$からのサンプルに対して繰り返される。各分布の寄与は、その$\lambda_k$係数で重み付けされ、合計されて、総目的関数$\mathcal{L}(\theta)$が形成される。
- 勾配計算: $\mathcal{L}(\theta)$のニューラルネットワークパラメータ$\theta$に対する勾配が計算される。この勾配は、目的関数を増加させるパラメータ空間の方向を示す。$Z_{c_k}$の直接計算は困難であるため、$\log Z_{c_k}$の勾配は、MCMC手順を使用して条件付き分布$\mu_{x_k}^{f_{\theta,k}}(y)$から$y$をサンプリングすることによって近似される。
- パラメータ更新: 最後に、ニューラルネットワーク$f_{\theta,k}$のパラメータ$\theta$は、計算された勾配によって示された方向に、最適化アルゴリズム(確率的勾配上昇法など)を使用して更新される。この反復更新は、モデルがEOT重心条件を満たすようにニューラルネットワークポテンシャルを徐々に調整するのに役立つ。
最適化ダイナミクス
メカニズムは、確率的勾配上昇法を通じて双対目的関数$\mathcal{L}(\theta)$を反復的に最大化することによって学習する。学習、更新、および収束がどのように展開されるかを以下に示す。
- ニューラルネットワークパラメータ化: 主要な洞察は、未知のポテンシャル関数$f_k$をニューラルネットワーク$f_{\theta,k}$として表現することである。ここで、$\theta$はこれらのネットワークの重みとバイアスである。これにより、柔軟な高次元関数近似が可能になる。
- 合同条件の処理: 双対定式化(6)には、重要な制約が含まれている: $\sum_{k=1}^K \lambda_k f_k = 0$。著者らは、個々のニューラルネットワーク$g_{\theta,k}$としてパラメータ化された$f_{\theta,k}$を$g_{\theta,k} - \sum_{j=1}^K \lambda_j g_{\theta,j}$としてパラメータ化することにより、これを巧妙に処理する。この特定の構成は、加重ポテンシャルの合計がゼロであることを自動的に保証し、明示的な制約最適化の必要性を排除する。
- 勾配上昇: 目的関数は双対定式化であるため、目標は$\mathcal{L}(\theta)$を最大化することである。これは勾配上昇を使用して達成される。勾配$\frac{\partial}{\partial \theta} \mathcal{L}(\theta)$が計算され、パラメータ$\theta$は、この勾配の方向に更新される。
- MCMCによる勾配推定: 最も困難な部分は、勾配式(式9)内の期待値$\mathbb{E}_{y \sim \mu_{x_k}^{f_{\theta,k}}} \left[ \frac{\partial}{\partial \theta} f_{\theta,k}(y) \right]$を計算することである。条件付き分布$\mu_{x_k}^{f_{\theta,k}}(y)$は、正規化されていない対数密度を$\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$として持つ。この分布からサンプリングするために、本論文はマルコフ連鎖モンテカルロ(MCMC)手順、特に調整なしランジュバンアルゴリズム(ULA)を採用する。
- ULAステップ: $P_k$からサンプリングされた各$x_k$に対して、ULAは最終的に$\mu_{x_k}^{f_{\theta,k}}$のサンプルを近似する一連のサンプル$y_t$を生成する。ULAの更新ルールは次のとおりである。
$$y_{t+1}^{(1)} = y_t^{(1)} + \frac{\eta}{2\epsilon} \nabla_y (f_{\theta,k}(y) - c_k(x_k, y))|_{y=y_t^{(1)}} + \sqrt{\eta} \xi_t$$
ここで、$\eta$はステップサイズであり、$\xi_t$は標準正規分布から描画されたランダムノイズ項である。このプロセスは、$f_{\theta,k}(y) - c_k(x_k, y)$によって定義されるエネルギーランドスケープを移動する粒子をシミュレートし、ターゲット分布に徐々に収束する。
- ULAステップ: $P_k$からサンプリングされた各$x_k$に対して、ULAは最終的に$\mu_{x_k}^{f_{\theta,k}}$のサンプルを近似する一連のサンプル$y_t$を生成する。ULAの更新ルールは次のとおりである。
- 損失ランドスケープ: 双対目的関数は凹である(弱いc変換に関する命題A.1 (iii)で述べられており、$\mathcal{L}(\theta)$に拡張される)。この凹性により、局所的最大値が同時に大域的最大値でもあるという局所的極大値が存在しないため、非凹目的関数と比較して最適化問題が大幅に単純化される。エントロピー正則化パラメータ$\epsilon$は、このランドスケープをさらに滑らかにし、正則化されていない場合存在する可能性のある偽のモードに引っかかるのを回避するために、勾配ベースの手法がナビゲートしやすくなる。
- 反復的洗練: 各イテレーションで、新しいサンプル$x_k$が描画され、MCMCが実行されて$y$サンプルが生成され、$\mathcal{L}(\theta)$の勾配が推定され、$\theta$が更新される。この反復プロセスは、ニューラルネットワークポテンシャル$f_{\theta,k}$を洗練させ、EOT重心条件を満たすように収束させる。その後、目的関数が最大化され、これらのポテンシャルを通じて重心が暗黙的に学習される。
- 収束: 本論文は、回復された計画の質とニューラルネットワークの普遍的近似能力に関する理論的保証(定理4.2、4.5、4.6)を提供しており、十分なデータとネットワーク容量があれば、学習されたポテンシャルが真のEOT計画、したがって重心を正確に近似できることを示唆している。しかし、実用的な収束速度と質は、MCMCパラメータ(ステップ数$L$、ステップサイズ$\eta$)とバッチサイズに影響され、実験セクションで議論されている。
 Figure 6. A schematical presentation of potential applications of barycenter solvers
Figure 6. A schematical presentation of potential applications of barycenter solvers
結果、制限、および結論
実験設計とベースライン
著者らは、低次元のトイ問題から高次元の画像多様体まで、多様なシナリオにわたって提案されたエネルギー誘導型連続エントロピー重心(EOT)ソルバーを厳密に検証するために一連の実験を設計した。特に真の重心が不明な場合の検証の主な戦略は、計算されたEOT重心(十分な小さい正則化パラメータ$\epsilon$の場合)を、解析的に導出可能な正則化されていない重心($\epsilon=0$)と比較することであった。このアプローチは、定性的および定量的な一致または該当する場合の優れたパフォーマンスを示すことにより、それらの数学的主張を徹底的に証明した。
2Dトイ分布、特に「ツイスター」例では、3つの彗星形の2D分布($P_1, P_2, P_3$)と均一な重みを持つように実験が設計された。2つの異なるコスト関数がテストされた。非ユークリッド「ツイストコスト」$c_k(x_k, y) = ||u(x_k) - u(y)||^2$と標準ユークリッド$l^2$コスト$c_k(x, y) = ||x - y||^2$であり、どちらも正則化$\epsilon = 10^{-2}$を使用した。「犠牲者」またはベースラインは、ツイストコストの解析的に導出された真の正則化されていない重心(中心ガウス分布)と、POTパッケージ[33]のfree_support_barycenterソルバーを使用して推定された$l^2$重心であった。これにより、既知または確立された解決策との直接比較が可能になった。3D球体実験では、ソルバーは、非二次コスト関数$c_k(x_k, y) = \frac{1}{2} \arccos^2(x_k, y)$と$\epsilon = 10^{-2}$を使用して、3D球体上の4つのフォンミーゼス分布の重心を推定した。ここでは真の重心は不明であったため、評価は主に質的なものであり、学習された重心の妥当性に焦点を当てた。
画像データの場合、実験にはMNIST 0/1数字とAve, celeba!データセットが含まれた。MNISTの場合、タスクは、$32 \times 32$グレースケール画像空間で、0/1数字の分布の重心を平均化することであった。MNISTの真の正則化されていない$l^2$重心は単純なピクセルごとの平均であり、著者らはSCWB [32]やWIN [55]のような既存のソルバーと比較した。決定的なことに、彼らは多様体制約付き設定を導入した。そこでは、重心の検索空間が事前学習済みStyleGAN [50]多様体に制限され、この多様体を無関係なサンプルで「汚染」して堅牢性をテストした。コスト関数は$c_{k,G}(x_k, z) = ||x_k - G(z)||^2$に修正され、$\epsilon = 10^{-2}$とした。Ave, celeba!データセット実験では、顔の3つの劣化サブセットの平均化が含まれ、真の正則化されていない$l^2$重心はCeleba顔分布自体である。これも$\epsilon = 10^{-4}$で、SCWB [32]とWIN [55]と比較して、多様体制約付き設定で評価された。
最後に、ガウス分布の場合、著者らは様々な次元($D = 2, 4, 8, 16, 64$)で重み$(\frac{1}{4}, \frac{1}{2}, \frac{1}{4})$と正則化$\epsilon = 0.01, 1$を持つ3つのガウス分布を使用して定量的な評価を実施した。真の正則化されていない重心$Q^*$は、WINリポジトリからの反復手順によって推定され、WINソルバー[55]自体がベースラインとして機能した。主な指標は、重心射影の$L_2$-UVP(説明されていない分散の割合)であった。アブレーションスタディも、バッチサイズとランジュバンステップ数の影響を理解するために実施された。単一細胞実験も実施され、次元$D = 50, 100, 1000$で、時間経過に伴う細胞集団の補間を中心に据えた。ここでは、指標はMMD(最大平均不一致)であり、ベースラインにはLightSB-M [2]、SFM-sink [3]、およびEGNOT [1]が含まれた。
証拠が証明すること
実験的証拠は、提案されたエネルギー誘導型連続エントロピー重心(EOT)ソルバーが、一般的なコスト関数に対する連続EOT重心を効果的に近似し、先行手法の制限を克服することを断定的に証明している。
2Dツイスター例(図12)では、定性的な結果は、$\epsilon = 10^{-2}$を持つ我々のソルバーが、非ユークリッドツイストコストの真の正則化されていない重心を正確に回復することを示す、否定できない証拠を提供している。計算された重心(図12b)は、解析的に導出されたガウス真値(図12a)と視覚的に完全に一致する。これは、コアメカニズムが複雑な非ユークリッドコストを処理する能力の強力な検証である。$l^2$コストの場合、我々のEOT重心(図12d)も真の$l^2$重心(図12c)とよく一致しており、その一般的な適用可能性をさらに確認している。ツイストコストと$l^2$コストで学習された条件付き計画の異なる構造は、コスト関数によって定義される基盤となる幾何学に対する手法の感度を強調している。
MNIST 0/1実験では、データ空間EOT重心(図5、「OURS (Data Space)」)で観察された「ぼかしバイアス」とノイズは、エントロピー正則化OTとMCMCサンプリングの性質と一致している。しかし、多様体制約付き設定(図5、「OURS (Manifold Constrained)」)は、提案手法の力を決定的に証明している。StyleGANのような生成モデルに制約を課すことにより、ソルバーはクリーンで解釈可能な重心を生成し、多様体からの「汚染された」サンプルを効果的に無視する。これは、多様体制約が直接的なデータ空間EOT重心推定に固有のノイズ問題をうまく緩和するという重要な証拠である。
Ave, celeba!データセット評価は、説得力のある定量的な証拠を提供する。我々のソルバーは、ベースラインモデルSCWB [32]およびWIN [55]と比較して、大幅に低いFIDスコア(表2)を達成した。例えば、$k=1$に対する我々の手法のFIDは8.4(標準偏差0.3)であり、SCWBの56.7およびWINの49.3を劇的に上回った。特に多様体制約付き設定におけるこの大幅な改善は、生成モデルと組み合わせたコアメカニズムが、複雑な画像分布に対して優れた知覚品質とより正確な重心推定をもたらすという決定的な証拠である。定性的な結果(図4)も、「定性的に良好な」輸送画像を示しているが、MCMCに起因するコンテンツ保持の失敗が時折発生している。
ガウス分布の場合、定量的な$L_2$-UVPメトリック(表7)は、ソルバーの精度に関する確固たる証拠を提供する。小$\epsilon = 0.01$および次元$D=16$まででは、我々のアルゴリズムは、正則化されていないケース専用に設計されたWINソルバーよりも優れた$L_2$-UVPスコアを達成した。例えば、$D=2$では、我々の$L_2$-UVPは0.02であり、WINの0.03と比較された。これは、適切な正則化の場合、我々のEOTソルバーが最先端の精度を達成できることを示しており、正則化されていない設定専用の手法さえも上回っている。バッチサイズ(表9)とランジュバンステップ数(図11)に関するアブレーションスタディは、手法のパフォーマンスがこれらのパラメータに敏感であることをさらに確認しており、より大きなバッチサイズと十分なランジュバンステップ数が品質の向上につながる。これはMCMCベースの手法に期待されることである。
最後に、単一細胞実験(表8)は、我々の汎用エントロピー重心アプローチが、様々な次元と設定で、主要なベースラインのパフォーマンスにほぼ匹敵することを示している(例: $D=50$でOURSの2.32対LightSB-Mの2.33)。これは、集団補間のような問題に対する堅牢で、すぐに使える基盤モデルとしての可能性を示唆している。
制限と将来の方向性
提案されたエネルギー誘導型連続エントロピー重心ソルバーは顕著な進歩を示しているが、その固有の制限を認識し、将来の研究のための有望な方向性を考慮することは重要である。
主な方法論的制限の1つは、トレーニングと推論の両方におけるマルコフ連鎖モンテカルロ(MCMC)手順への依存に起因する。使用されている基本的な調整なしランジュバンアルゴリズム(ULA)は、特に複雑なエネルギーランドスケープにおいて、望ましい分布$\mu^\ddagger$への収束が悪いという問題を抱える可能性がある。MCMCサンプリングは本質的に時間のかかるものであり、特に大きなバッチサイズや高次元の問題の場合、手法の拡張性に影響を与える(表3、付録Cの計算複雑性分析で指摘されている)。将来の研究では、再利用バッファ[46]、補助変数[43]、またはニューラル輸送[47, 71, 99, 108, 66, 26]などの高度なMCMC技術に着想を得た、より効率的なサンプリング手順を探索すべきである。これにより、計算負荷が大幅に軽減され、収束安定性が向上する可能性がある。
もう1つの理論的制限は、汎化バウンドと普遍的近似保証(§4.3)の現在の分析が、勾配降下プロセスとMCMCサンプリング自体から生じる最適化誤差を考慮していないことである。これはこの論文の範囲とは異なる機械学習理論の複雑な領域であるが、より深い理論的理解のための重要な方向性を表している。将来の研究では、これらの実際的な最適化課題を統合する、より包括的な理論的フレームワークを開発することにより、このギャップを埋めることを目指すべきである。
問題設定の観点から、画像データ空間でのエントロピー正則化の使用は、「ぼかしバイアス」とノイズの多い重心画像につながる可能性がある。これは、MNIST 0/1データ空間実験(図5)で観察された。多様体制約付きアプローチは、StyleGANのような事前学習済み生成モデルを活用することでこれを効果的に緩和するが、これらの外部モデルの品質と適合性への依存性が導入される。その場合、問題は、選択された多様体が基盤となるデータ構造を真に代表していることをどのように保証できるか、そしてこの手法が「汚染された」または不完全な多様体に対してどれほど堅牢であるかということになる。将来の研究では、適応的多様体学習技術、または多様体と重心を共同で学習する方法を調査すべきである。固定された事前学習済み生成モデルに依存するのではなく。
将来に向けた重要な議論のトピックは、二重正則化EOT重心へのエネルギー誘導型方法論の拡張に関するものである。そこでは、正則化パラメータ$\lambda$と$\tau$が$\epsilon$と等しいとは限らない(付録B.3)。現在のソルバーは、エントロピー項$H(Q)$が目的関数から消えるシュレーディンガー重心ケース($\lambda = \tau = \epsilon$)に特化している。ゼロでない$H(Q)$項を組み込むには、第二辺縁分布$\pi_k(y)$のエントロピーの別途、非自明な計算が必要になる。これは現在、生のMCMCサンプルからは不可能である。このエントロピー項を推定または近似するための新しい技術を開発するか、またはその直接計算を回避するために双対目的を再定式化することは、より広範なEOT重心問題のクラスを解き放くだろう。
もう1つの重要な将来の開発分野は、特に医学(ドメインシフト問題)や地質学(シミュレータの混合)などの分野における、実世界のアプリケーションのための適切なコスト関数とデータ多様体の設計にある。本論文は、これらの分野で重心を効果的に適用するには、意味のあるコスト関数$c_k$を定義し、適切なデータ多様体$M$を選択または構築するために、ドメイン固有の知識が必要であることを強調している。これは、機械学習専門家とドメイン専門家との学際的な協力が必要であることを示唆しており、タスク固有のソリューションを共同で開発する。例えば、医用画像処理では、新兴の巨大生成モデル(例: DALL-E [85]、StableDiffusion [87])を使用して医療データをパラメータ化する方法を調査することは、新しい分析の可能性を開く可能性がある。
代替の重要度サンプリング(IS)トレーニング手順(付録D)は、より高速な収束の可能性を示しているが、推定器の分散を減らすための提案分布$q$の正確な選択が必要となるという独自の課題を導入する。これは、現実世界のシナリオではしばしば困難である。将来の研究では、ISのための適応的または学習された提案分布の開発に焦点を当てるべきであり、おそらくそれをMCMCまたは他の技術と組み合わせて、EOT重心のためのより堅牢で効率的なトレーニングアルゴリズムを作成する。
最後に、拡張性と計算効率は依然として主要な課題である。現在の手法は大規模なセットアップで機能するが、特にMCMCによる推論時間は相当なものになる可能性がある。ハードウェアアクセラレーションされたMCMC、分散コンピューティング戦略、または品質に大きな影響を与えることなくランジュバンステップ数を削減する近似(アブレーションスタディで示唆されているように)を探索することは価値があるだろう。目標は、これらの連続重心ソルバーを産業および社会的に重要な問題に対してよりアクセス可能で実用的なものにし、最適輸送タスクの「基盤モデル」としての潜在能力を真に活用することである。
 Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
 Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
 Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
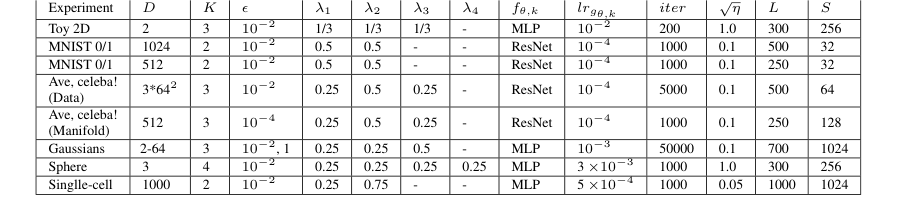 Table 4. Hyperparameters that we use in the experiments with our Algorithm 1
Table 4. Hyperparameters that we use in the experiments with our Algorithm 1