能量引导的连续熵中心估计(Energy-Guided Continuous Entropic Barycenter Estimation)用于一般成本函数
This paper introduces a new, simpler way to average probability distributions that keeps their shape, with guaranteed quality and real-world applications.
背景与学术渊源
起源与学术渊源
本文所解决的 Optimal Transport (OT) 中心问题,源于在几何上有意义的方式平均概率分布的基本需求。虽然在向量空间中平均标量或向量是直接的,但当处理概率分布时,这项任务变得复杂得多。简单的凸组合通常无法保留重要的几何特征,因此需要一种更复杂的方法来定义“中心”或平均值。
这个问题最早出现在 Optimal Transport 的学术领域,该领域通过定义一种将一个分布转换为另一个分布的“成本”,为比较和平均概率分布提供了一个强大的框架。Agueh 和 Carlier [1] 于 2011 年提出的 OT 中心概念,旨在寻找一个中心分布,该分布能最小化到给定源分布集合的传输成本总和。
在过去十年中,对有效中心计算的实际需求推动了大量的研究。最初的努力主要集中在离散 OT 中心设置,其中分布由有限的点集表示。然而,处理连续概率分布的连续设置被证明更具挑战性。先前连续 OT 中心的求解器存在几个关键限制:
- 特定的成本函数: 许多现有方法仅为特定的 OT 成本函数设计,最著名的是二次欧几里得成本 ($l_2(x, y) \stackrel{\text{def}}{=} ||x - y||^2$)。这限制了它们在狭窄问题范围内的适用性,因为现实世界场景通常涉及非欧几里得或更复杂的成本函数。
- 非平凡的先验选择: 一些方法需要复杂的先验选择或为中心分布设置固定的先验,这可能难以确定并限制模型的灵活性。
- 表达能力和生成能力的限制: 某些方法表达分布之间复杂关系或从学习到的中心生成新样本的能力有限,阻碍了它们在生成建模任务中的应用。
- 无法恢复 OT 计划: 一些方法将中心参数化为生成模型,但未能恢复底层的 Optimal Transport 计划,而这些计划对于理解每个源分布如何映射到中心至关重要。
本文旨在通过提出一种新颖的算法来克服这些限制,该算法可以近似连续的 Entropic OT (EOT) 中心,能够处理任意 OT 成本函数,而无需固定的先验或限制表达能力,并且重要的是,它能够恢复条件 OT 计划。
直观的领域术语
为了帮助初学者理解核心概念,这里提供一些专业术语的日常类比翻译:
- Optimal Transport (OT): 想象你有几堆泥土(概率分布),你想将它们重塑成新的土堆。Optimal Transport 就像是找到最有效的方法,将所有泥土从原始土堆移动到形成新的土堆,同时最小化涉及的总“工作量”或“成本”。
- Barycenter (中心): 如果你有几个分散的烟雾团(概率分布),中心就像是找到一个“平均”或“质心”烟雾团,它在平均意义上最接近所有原始烟雾团,同时考虑将一个烟雾团转换为另一个烟雾团的“努力”(Optimal Transport 成本)。它是平衡所有其他分布“拉力”的中心点。
- Entropic Optimal Transport (EOT): 这是 Optimal Transport 的一个“更柔和”或“更模糊”的版本。EOT 不会严格地将每一粒泥土沿着最直接的路径移动,而是允许在运输过程中进行一些混合或随机性。这使得问题在计算上更容易解决,就像允许一些泥土稍微扩散一样,同时仍然可以获得一个良好、几何上合理的平均值。
- Weak OT Dual Formulation (弱 OT 对偶形式): 想象一个复杂的问题,比如设计一座完美的桥梁。与其直接建造和测试每座可能的桥梁,“对偶形式”就像是找到一个更简单、等价的问题,涉及优化桥梁上的力和应力。在 OT 中,这意味着我们不直接跟踪每一个“泥土颗粒”,而是找到两个“势函数”,通过优化它们,间接告诉我们移动泥土的最有效方法。这通常更容易解决。
- Energy-Based Models (EBMs) (基于能量的模型): 想象一个地形,山谷代表数据点可能出现的地方,山丘代表不太可能出现的地方。EBMs 学习这个“能量地形”来理解数据的分布方式。我们的方法使用类似的想法:它将中心问题构建为在复杂空间中寻找最低“能量”配置,从而允许我们利用成熟的 EBM 训练技术来找到解决方案。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文的核心问题是估计连续 Entropic Optimal Transport (EOT) 中心,用于一组概率分布。
输入/当前状态:
起始点涉及 $K$ 个源概率分布的集合,表示为 $P_k \in \mathcal{P}_{ac}(\mathcal{X}_k)$,其中 $\mathcal{P}_{ac}(\mathcal{X}_k)$ 表示定义在紧致子集 $\mathcal{X}_k \subset \mathbb{R}^{D_k}$ 上的绝对连续概率分布。对于每个源分布 $P_k$,都有一个相关的连续成本函数 $c_k(\cdot, \cdot) : \mathcal{X}_k \times \mathcal{Y} \to \mathbb{R}$,它量化了在 $\mathcal{X}_k$ 中的点与中心空间 $\mathcal{Y}$ 中的点之间传输质量的“成本”。此外,还给定一组正权重 $\lambda_k > 0$,满足条件 $\sum_{k=1}^K \lambda_k = 1$。至关重要的是,在实际场景中,这些源分布 $P_k$ 并非显式已知,而只能通过有限的经验样本集 $X_k = \{x_1^k, x_2^k, \dots, x_{N_k}^k\} \sim P_k$ 来访问。现有的连续 OT 中心求解器通常难以处理一般的成本函数,需要特定的先验选择,或具有有限的表达能力和生成能力。
期望终点(输出/目标状态):
最终目标是识别 EOT 中心 $Q^* \in \mathcal{P}(\mathcal{Y})$,这是一个概率分布,它最小化了与所有源分布 $P_k$ 的加权 EOT 差异之和。数学上,这被表述为:
$$L^* \stackrel{\text{def}}{=} \inf_{Q \in \mathcal{P}(\mathcal{Y})} \sum_{k=1}^K \lambda_k \text{EOT}_{c_k, \epsilon}(P_k, Q)$$
这里,$\text{EOT}_{c_k, \epsilon}(P_k, Q)$ 表示 $P_k$ 和 $Q$ 之间的熵最优传输成本,由参数 $\epsilon > 0$ 进行正则化。除了找到 $Q^*$ 之外,本文还旨在近似最优条件传输计划 $\pi_{f_k}^*(\cdot|x_k)$,该计划将每个源 $P_k$ 的点映射到中心 $Q^*$。这些恢复的计划应能够进行“样本外估计”,这意味着它们可以为来自 $P_k$ 的新的、未见过样本 $x_{\text{new}}$ 生成 $\pi_{f_k}^*(\cdot|x_{\text{new}})$ 的样本。进一步的雄心是学习中心在预训练生成模型的图像流形上,这对于实际应用具有重要意义。
缺失的环节与困境:
确切的缺失环节是一个通用、鲁棒且计算上可行的算法,用于估计连续 EOT 中心,该算法能够处理任意成本函数,并仅使用源分布的经验样本有效运行。先前的研究陷入了一个痛苦的权衡:在连续 OT 中心问题中实现更大的通用性和表达能力,通常会带来显著的计算挑战或需要限制性假设。例如,提高通用性以处理任意成本函数通常会导致难以处理的优化问题,因为许多先前的方法依赖于特定、更简单的成本(如二次欧几里得 $l_2$ 成本),因为它们具有有利的理论性质。这些更简单的成本允许更有效的算法,但限制了适用性。此外,虽然连续设置功能更强大,但它也“比离散设置更具挑战性”,现有解决方案通常在表达能力方面存在局限性,或者需要非平凡的先验选择或中心的特定参数化,这可能难以确定或限制了方法的范围。在高维数据空间(如图像)中也出现了另一个困境:EOT 中心的直接计算通常由于熵正则化和对 MCMC 的依赖而导致“模糊偏差”或“噪声图像”。虽然将搜索空间限制在数据流形上可以缓解这个问题,但它带来了与流形学习和成本函数适应相关的自身复杂性。
约束与失效模式
连续 EOT 中心估计问题由于几个严峻的现实约束而变得困难:
- 直接优化的计算不可行性: EOT 中心(方程 5)的目标函数涉及对所有概率分布 $\mathcal{P}(\mathcal{Y})$ 的空间进行 $\inf$ 操作,这是一个无限维空间。直接优化通常是不可行的,需要重新表述问题。
- 缺乏解析解: 对于大多数实际场景,包括高斯分布的情况,熵中心问题(对于 $\epsilon > 0$ 和未正则化的 $\epsilon = 0$ 情况)没有已知的直接解析解。这迫使依赖于数值近似方法。
- 经验数据限制: 在实际应用中,源分布 $P_k$ 很少显式可用。相反,只能访问有限的经验样本(数据集)$X_k$。这意味着算法必须对数据稀疏性和噪声具有鲁棒性,并能够进行样本外泛化。
- 高维性: 处理复杂数据类型,如 RGB 图像(例如,CelebA 的 $3 \times 64 \times 64$ 维度),会给学习和采样带来显著的计算和内存需求,使得直接方法不可行。
- 任意成本函数: 本文旨在支持“任意 OT 成本函数”,这是一个重大的约束。许多现有方法专门针对更简单的成本(如 $l_2$),这些成本具有特定的理论性质,可以简化计算。通用成本消除了这些简化,增加了复杂性。
- 非欧几里得几何: 该问题明确考虑了“非欧几里得成本函数”,这意味着标准的欧几里得距离度量通常不足。这需要更灵活、更强大的模型来捕捉复杂的几何关系。
- MCMC 采样限制: 所提出的方法依赖于马尔可夫链蒙特卡洛 (MCMC) 程序(特别是未调整的 Langevin 算法,ULA)进行采样。
- 高计算成本: MCMC 采样本质上是“耗时的”,影响训练和推理延迟(表 3)。
- 收敛问题: 基本的 ULA 算法“可能难以收敛到期望的分布”,导致次优结果。
- 可微分性要求: MCMC 通常需要能量函数(以及因此的成本函数 $c_k$)是可微分的。不可微分的成本将需要更复杂、无梯度的采样程序。
- 局部最小值: MCMC 推理可能会“陷入能量景观的局部最小值”,导致学习到的传输计划在保留期望的图像内容或其他特征方面失败(第 5.3 节)。
- 归一化常数不可行: 对偶目标函数中归一化常数 $Z_{c_k}(f_k, x_k)$ 的直接计算通常是“不可行的”,需要近似来估计梯度。
- 数据空间中的“模糊偏差”: 当在数据空间(例如,图像像素)中直接计算 EOT 中心时,熵正则化可能导致“噪声图像”或“模糊偏差”,使得结果中心的可解释性或视觉合理性降低。
- 流形约束的复杂性: 虽然将中心搜索限制在数据流形上(例如,使用预训练的 StyleGAN)有助于缓解模糊问题,但这增加了训练和集成此类生成模型以及将成本函数适应流形潜在空间本身的复杂性。
- 泛化和近似误差: 确保学习到的模型能够很好地泛化到未见过的数据,并且神经网络近似是准确的,这是一个重大的理论挑战。对于一般的 Lipschitz 成本,估计误差可能会受到“维度灾难”的影响,在高维情况下难以实现快速收敛速率。
为什么选择这种方法
选择的必然性
作者选择能量引导的连续熵中心估计方法并非仅仅是偏好,而是由于现有连续 Optimal Transport (OT) 中心问题方法的固有局限性所驱动的必然选择。从第 3 节和表 1 中对先前艺术品缺点的详细讨论中,可以明显看出这一认识的精确时刻。
传统的“SOTA”方法,如标准的 CNN、基础扩散模型或 Transformer,被认为是不够的,因为:
1. 特定的成本函数: 相当一部分先前连续 OT 求解器,包括 [59, 55, 32, 82] 等著作,仅为二次欧几里得成本 $l_2(x, y) = ||x - y||^2$ 设计。这种限制严重限制了它们在现实世界场景中的适用性,而这些场景通常需要任意的、非欧几里得成本函数来捕捉分布之间复杂的几何关系。本文明确指出,“相比之下,我们提出的方法旨在处理具有任意成本函数 $c_1, \dots, c_K$ 的 EOT 问题。”(第 4 页)。
2. 固定的先验和非平凡的选择: 一些方法,如 [72],需要非平凡的先验选择或要求为中心选择一个固定的先验,这可能是一个复杂且不鲁棒的过程。本方法避免了这一约束。
3. 缺乏 OT 计划恢复: 至关重要的是,某些方法,如 [17],未能恢复 OT 计划,而这是第 2.3 节定义的学习设置的基本要求,该设置侧重于样本外估计和生成能力。
4. 计算复杂性和参数化: 其他变分方法,如 [14],增加了优化复杂性,并需要中心分布的特定参数化,使其通用性或直观性降低。
作者意识到需要一种新颖的方法来解决这些集体局限性,特别是需要一个求解器,该求解器能够处理任意成本函数,恢复 OT 计划,并在连续设置中在没有限制性先验的情况下运行。
比较优势
该方法通过几个结构性优势,超越了先前黄金标准,这些优势超出了简单的性能指标:
- 任意成本函数和非欧几里得成本: 与许多仅限于二次欧几里得成本的先前工作不同,该方法是为任意 OT 成本函数设计的,包括非欧几里得成本。这种灵活性是一个深刻的结构优势,使其能够应用于更广泛的复杂问题,例如涉及图像流形或专业地质模拟的问题(第 5 节,B.2)。
- 与基于能量的模型 (EBMs) 的无缝集成: 该方法的核心在于通过 EOT 的弱对偶形式结合一致性条件,对 Entropic Optimal Transport (EOT) 中心问题进行优雅的重构。这种重构自然地与 EBM 的训练过程对齐,允许使用经过良好调整的算法,并提供“避免了 min-max、强化学习和其他复杂技术技巧的直观优化方案”(摘要,第 1 页)。这避免了通常与对抗训练(如 GANs)或策略梯度方法相关的复杂性。
- 鲁棒的泛化和近似保证: 本文建立了强大的理论基础,包括恢复的 EOT 计划的泛化界和通用近似保证(第 4.3 节)。具体而言,对于基于特征的二次成本,该方法实现了 $O(N^{-1/2})$ 的估计误差,这被描述为“标准快速且无维度的收敛速率”(定理 4.5 (b),第 6 页)。这提供了对方法统计一致性和可靠性的严格理解,这是竞争性连续中心求解器通常缺乏的特征。
- 处理高维噪声和流形学习: 对于像图像这样的复杂数据,数据空间中的直接 EOT 中心可能会遭受“模糊偏差”并产生噪声图像。该方法通过引入新颖的“流形约束”设置(第 4.4 节)来定性地更好地处理这个问题。通过将搜索空间限制在预训练生成模型(例如 StyleGAN)生成的图像流形上,它产生了更具可解释性和更合理性的中心分布,有效缓解了高维图像平均固有的噪声和伪影。这是实际应用中结果质量的重大改进。
与约束的对齐
所选择的能量引导方法完美地符合问题的严苛要求,形成了“问题需求与解决方案独特属性的结合”:
- 连续 OT 和样本外估计: 该问题明确要求解决连续 OT 中心任务并提供样本外估计,这意味着能够为新数据点生成条件计划 $\pi^*(\cdot|x_{\text{new}})$ 的样本。所提出的方法通过学习定义条件分布 $\mu_{f_k}^*(\cdot|x_k)$(方程 4,第 3 页)的神经网络势函数 $f_k$ 直接解决此问题。然后可以使用标准的 MCMC 技术生成样本,从而满足样本外估计的要求(第 4.2 节)。
- 任意成本函数: 关键约束是需要处理任意成本函数,超越 $l_2$ 特定方法的限制。对偶形式和 EBM 框架自然地容纳了任何可微分的成本函数 $c_k(x,y)$,如使用非欧几里得“扭曲”成本和流形约束成本的实验所示(第 5.1 节,5.2 节)。
- 数据可访问性(经验样本): 该问题假设源分布 $P_k$ 只能通过有限数量的 i.i.d. 经验样本 $X_k$ 来访问。所提出的算法设计为直接使用这些样本运行,在训练期间使用蒙特卡洛近似来估计梯度(算法 1,第 5 页)。
- 复杂空间中的有意义的中心: 对于图像数据,像素空间中的直接平均通常是不可取的,因为存在“模糊偏差”。流形约束 EOT 中心(第 4.4 节)通过将搜索空间限制在预定义的 数据流形上(例如,由 StyleGAN 生成)直接解决此问题。这确保了结果中心集中在合理的流形上,产生视觉上更优越且更具可解释性的结果,如图 4 和图 5 所示。这是对实际问题约束的一个巧妙解决方案。
替代方案的拒绝
本文提供了明确的理由来拒绝几种替代方法,强调了所提出方法独特的优势:
- 离散 OT 求解器: 作者明确指出,“离散 OT 不适合连续 OT 设置所需的样本外估计”(第 2.3 节,第 3 页)。虽然离散 OT 方法具有扎实的理论基础和收敛保证,但它们不能直接适用于连续学习设置,因为目标是为看不见的数据近似条件计划(第 B.1 节,第 22 页)。
- 具有 $l_2$ 成本的连续 OT 求解器: 许多现有的连续 OT 中心求解器“仅为二次欧几里得成本 $l_2(x, y) = ||x - y||^2$ 设计”(第 3 节,第 4 页)。这被拒绝是因为现实世界应用通常需要任意成本函数,包括非欧几里得成本,以捕捉复杂的数据关系。所提出的方法处理通用成本的能力是对这一限制的直接回应。
- 需要固定先验或缺乏计划恢复的连续 OT 求解器: 一些方法,如 [72],需要为中心进行“非平凡的先验选择”,这可能很麻烦。另一些方法,如 [17],则“不恢复 OT 计划”,这与本文学习条件传输计划以用于生成任务的目标不符(第 3 节,第 4 页)。
- 具有 $H(Q)$ 项的双重正则化 EOT 中心: 本文讨论了双重正则化 EOT 中心(方程 40,第 24 页),其中中心分布 $Q$ 的附加熵项 $H(Q)$ 存在。此替代方案被拒绝,因为“存在 $H(Q)$ 项与我们的方法明显不同,并且似乎不适合我们的求解器”(第 25 页)。原因是添加 $H(Q)$ 将需要单独、高度非平凡地计算第二边际 $H(\pi_k(y))$ 的熵,而这从原始样本中是不可行的,并且基于 EBM 的技术无法在此场景中推导出梯度(第 25 页)。
- 其他基于 GAN 的中心方法(例如 [95]): 虽然 [95] 也将搜索空间限制在 GAN 流形上,但他们的方法根本不同,并且“实际上不适用于”本文的问题设置(第 B.1 节,第 23 页)。他们考虑 K 个图像(通过强度直方图表示为 2D 分布),并使用离散 OT 求解器搜索 GAN 流形上的单个图像。相比之下,本文使用连续 OT 求解器来查找 K 个高维图像分布(由随机样本表示)的中心,该求解器恢复 OT 计划。目标和方法是不同的,使得 [95] 的方法不适用于当前问题。
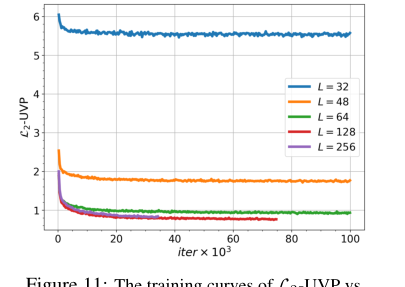 Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
Figure 11. The training curves of L2-UVP vs. iterations for OUR proposed method for the barycenter of Gaussian distributions depending on number of Langevin steps L
数学与逻辑机制
核心方程
为本文的熵中心估计方法提供动力的绝对核心数学引擎是算法旨在最大化的对偶目标函数。该目标函数源自熵最优传输 (EOT) 问题的弱对偶形式,并由神经网络参数化。优化的具体方程为:
$$ \mathcal{L}(\theta) \stackrel{\text{def}}{=} \sum_{k=1}^K \lambda_k \left\{ -\epsilon \mathbb{E}_{x_k \sim P_k} \left[ \log Z_{c_k}(f_{\theta,k}, x_k) \right] \right\} \quad (8) $$
其中 $Z_{c_k}(f_{\theta,k}, x_k)$ 是归一化常数(或分区函数),定义为:
$$ Z_{c_k}(f_{\theta,k}, x_k) \stackrel{\text{def}}{=} \int_{\mathcal{Y}} \exp\left(\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}\right) dy \quad (21) $$
逐项解剖
让我们逐一分解这些方程,以理解它们的作用:
- $\mathcal{L}(\theta)$: 这是算法旨在最大化的目标函数。其值反映了当前势函数集(由 $\theta$ 参数化)与 EOT 中心问题的对偶形式的匹配程度。最大化此对偶目标等同于最小化原始 EOT 中心问题。
- $\theta$: 这代表神经网络 $f_{\theta,k}$ 的所有可学习参数的集合。在学习过程中,这些参数会进行调整以优化目标。
- $K$: 这是我们要平均的源概率分布 $P_k$ 的总数。例如,如果我们平均三个图像数据集,则 $K=3$。
- $\lambda_k$: 这些是每个源分布 $P_k$ 的预定义正权重,满足 $\sum_{k=1}^K \lambda_k = 1$。它们决定了每个源分布对最终中心的相对重要性或贡献。如果所有 $\lambda_k$ 都相等,则为简单平均;否则为加权平均。
- $\sum_{k=1}^K$: 这是求和算子,用于聚合所有 $K$ 个源分布的贡献。作者使用加法是因为 EOT 中心问题被表述为每个源分布与中心之间的个体 EOT 差异之和。
- $\epsilon$: 这是熵正则化参数,一个正标量。它控制传输计划的“平滑度”或“随机性”。较大的 $\epsilon$ 会导致更分散、不那么“锐利”的传输计划(以及更平滑的损失景观),而较小的 $\epsilon$ 会使传输更确定,接近经典 Optimal Transport。它在统计力学中充当“温度”参数。
- $\mathbb{E}_{x_k \sim P_k}[\dots]$: 这表示对从第 $k$ 个源概率分布 $P_k$ 中抽取的样本 $x_k$ 的期望。在实践中,该期望通过从 $P_k$ 中抽取样本批次来近似。
- $P_k$: 这是第 $k$ 个源概率分布。这些是算法旨在平均的输入分布。在现实世界场景中,这些通常只能通过经验样本(数据集)来访问。
- $x_k$: 这是从第 $k$ 个源分布 $P_k$ 中抽取的样本(数据点)。
- $\log$: 这是自然对数函数。此处使用它是因为弱熵 c-变换 $f_k^{c_k}(x_k)$ 定义为 $-\epsilon \log Z_{c_k}(f_k, x_k)$。此变换对于将积分转换为更易于优化的形式以及将其与基于能量的模型相关联至关重要。
- $Z_{c_k}(f_{\theta,k}, x_k)$: 这是条件概率分布 $\mu_{x_k}^{f_{\theta,k}}(y)$ 的归一化常数或分区函数。它确保条件分布积分到 1。其值取决于势函数 $f_{\theta,k}$ 和成本 $c_k$ 对于给定的 $x_k$。
- $\int_{\mathcal{Y}} \dots dy$: 这是对目标空间 $\mathcal{Y}$ 的积分。它对所有可能的 $y$ 点的“能量”贡献进行求和,以计算归一化常数。作者使用积分是因为问题设置在连续的概率分布域中。
- $\exp(\dots)$: 这是指数函数。它将“能量”项 $(f_{\theta,k}(y) - c_k(x_k, y))/\epsilon$ 转换为非负值,该值可以解释为未归一化的概率密度。这是统计力学和基于能量模型中的标准组成部分。
- $f_{\theta,k}(y)$: 这是第 $k$ 个分布的势函数,在目标点 $y$ 处进行评估。这些函数由神经网络 $f_{\theta,k}$ 参数化,是模型的主要可学习组件。它们代表了从第 $k$ 个源到目标点 $y$ 的“价值”或“效用”。
- $c_k(x_k, y)$: 这是将质量从源点 $x_k$ 传输到目标点 $y$ 的成本函数。它量化了在 $x_k$ 和 $y$ 之间移动的“成本”或“不相似性”。本文强调了其处理一般(甚至非欧几里得)成本函数的能力。
- $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$: 该项代表从 $x_k$ 传输到 $y$ 的缩放后的“能量”或“对数概率”,由势函数 $f_{\theta,k}$ 和正则化参数 $\epsilon$ 调节。势函数 $f_{\theta,k}(y)$ 可以被认为是到达 $y$ 的“奖励”,而 $c_k(x_k, y)$ 是传输的“惩罚”。除以 $\epsilon$ 会缩放此能量,对于小的 $\epsilon$ 使分布更锐利,对于大的 $\epsilon$ 使分布更平坦。
- 指数内的减法 $f_{\theta,k}(y) - c_k(x_k, y)$ 是组合势和成本的一种自然方式,因为它反映了对于给定的 $x_k$,目标点 $y$ 的净“吸引力”。
分步流程
想象一个抽象的数据点,例如来自第一个源分布 $P_1$ 的 $x_1$,在训练迭代中通过这个数学引擎进行处理。
- 数据点输入:从第一个源分布 $P_1$ 中抽取一个样本 $x_1$。这个 $x_1$ 是数据集中的一个具体实例。
- 势函数评估:对于这个 $x_1$,以及目标空间 $\mathcal{Y}$ 中一系列可能的目标点 $y$,神经网络 $f_{\theta,1}$ 计算其势函数 $f_{\theta,1}(y)$。同时,评估成本函数 $c_1(x_1, y)$,量化从 $x_1$ 移动到每个 $y$ 的“努力”。
- 能量计算:将这些值组合起来:$f_{\theta,1}(y) - c_1(x_1, y)$。这个差值代表了从 $x_1$ 传输到 $y$ 的“净效用”。然后将此效用按正则化参数 $\epsilon$ 进行缩放,得到 $\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}$。
- 非归一化概率:将缩放后的效用进行指数化:$\exp\left(\frac{f_{\theta,1}(y) - c_1(x_1, y)}{\epsilon}\right)$。这给出了从 $x_1$ 传输到 $y$ 的“可能性”的未归一化度量。
- 归一化(分区函数):为了使其成为关于 $y$ 的一个合适的条件概率分布(表示为 $\mu_{x_1}^{f_{\theta,1}}(y)$),我们需要对其进行归一化。这通过对整个目标空间 $\mathcal{Y}$ 中的未归一化概率进行积分来得到 $Z_{c_1}(f_{\theta,1}, x_1)$。这个积分通常在计算上是难以处理的,因此使用 MCMC 等技术来估计其梯度。
- 对数似然贡献:然后取该归一化常数的自然对数 $\log Z_{c_1}(f_{\theta,1}, x_1)$。该项乘以 $-\epsilon$ 后,有效地成为弱熵 c-变换 $f_1^{c_1}(x_1)$。
- 加权求和:此过程(步骤 2-6)对 $P_1$ 中的其他样本重复(以近似期望 $\mathbb{E}_{x_1 \sim P_1}[\dots]$),并对所有其他源分布 $P_k$ 的样本重复。然后将每个分布的贡献按其 $\lambda_k$ 系数加权并求和,形成总目标 $\mathcal{L}(\theta)$。
- 梯度计算:计算 $\mathcal{L}(\theta)$ 相对于神经网络参数 $\theta$ 的梯度。该梯度指示参数空间中将增加目标函数的方向。由于 $Z_{c_k}$ 的直接计算很困难,因此通过从条件分布 $\mu_{x_k}^{f_{\theta,k}}(y)$ 使用 MCMC 程序进行采样来近似 $\log Z_{c_k}$ 的梯度。
- 参数更新:最后,使用优化算法(如随机梯度上升)沿着计算出的梯度指示的方向更新神经网络 $f_{\theta,k}$ 的参数 $\theta$。这种迭代更新有助于模型逐渐调整其势函数,以更好地满足 EOT 中心条件。
优化动力学
该机制通过随机梯度上升迭代地最大化对偶目标函数 $\mathcal{L}(\theta)$ 来进行学习。以下是学习、更新和收敛的展开过程:
- 神经网络参数化:关键的见解是将未知的势函数 $f_k$ 表示为神经网络 $f_{\theta,k}$,其中 $\theta$ 是这些网络的权重和偏置。这允许灵活、高维的函数逼近。
- 一致性条件处理:对偶形式(方程 6)包含一个重要的约束:$\sum_{k=1}^K \lambda_k f_k = 0$。作者巧妙地通过将 $f_{\theta,k}$ 参数化为 $g_{\theta,k} - \sum_{j=1}^K \lambda_j g_{\theta,j}$ 来处理此问题,其中 $g_{\theta,k}$ 是各个神经网络。这种特定的构造自动确保加权势之和为零,从而无需显式约束优化。
- 梯度上升:由于目标函数是对偶形式,目标是最大化 $\mathcal{L}(\theta)$。这通过梯度上升来实现。计算梯度 $\frac{\partial}{\partial \theta} \mathcal{L}(\theta)$,并在该梯度的方向上更新参数 $\theta$。
- 通过 MCMC 进行梯度估计:最困难的部分是在梯度公式(方程 9)中计算期望 $\mathbb{E}_{y \sim \mu_{x_k}^{f_{\theta,k}}} \left[ \frac{\partial}{\partial \theta} f_{\theta,k}(y) \right]$。条件分布 $\mu_{x_k}^{f_{\theta,k}}(y)$ 的未归一对数密度由 $\frac{f_{\theta,k}(y) - c_k(x_k, y)}{\epsilon}$ 给出。为了从该分布中采样,本文采用了马尔可夫链蒙特卡洛 (MCMC) 程序,特别是未调整的 Langevin 算法 (ULA)。
- ULA 步骤:对于从 $P_k$ 中抽取的每个 $x_k$,ULA 生成一系列样本 $y_t$,这些样本最终近似了 $\mu_{x_k}^{f_{\theta,k}}$ 的样本。ULA 的更新规则为:
$$y_{t+1}^{(1)} = y_t^{(1)} + \frac{\eta}{2\epsilon} \nabla_y (f_{\theta,k}(y) - c_k(x_k, y))|_{y=y_t^{(1)}} + \sqrt{\eta} \xi_t$$
其中 $\eta$ 是步长,$\xi_t$ 是从标准正态分布中抽取的随机噪声项。该过程模拟了一个在由 $f_{\theta,k}(y) - c_k(x_k, y)$ 定义的能量景观中移动的粒子,逐渐收敛到目标分布。
- ULA 步骤:对于从 $P_k$ 中抽取的每个 $x_k$,ULA 生成一系列样本 $y_t$,这些样本最终近似了 $\mu_{x_k}^{f_{\theta,k}}$ 的样本。ULA 的更新规则为:
- 损失景观:对偶目标函数是凹的(如命题 A.1 (iii) 中关于弱 c-变换的陈述,该命题扩展到 $\mathcal{L}(\theta)$)。这种凹性意味着没有非全局最大值,这使得优化问题比非凹目标函数显著简化。熵正则化参数 $\epsilon$ 进一步平滑了该景观,使得基于梯度的算法更容易导航并避免陷入未正则化情况下可能存在的虚假模式。
- 迭代精炼:随着每次迭代,抽取新的样本 $x_k$,运行 MCMC 生成 $y$ 样本,估计 $\mathcal{L}(\theta)$ 的梯度,并更新 $\theta$。这个迭代过程精炼了神经网络势函数 $f_{\theta,k}$,使其收敛到定义 EOT 中心的最优势函数。然后最大化目标函数,并通过这些势函数隐式地学习中心。
- 收敛:本文提供了关于恢复的计划的质量以及神经网络的通用近似能力的理论保证(定理 4.2、4.5、4.6),表明只要有足够的数据和网络容量,学习到的势函数就可以准确地近似真实的 EOT 计划,从而近似中心。然而,实际收敛速度和质量受到 MCMC 参数( Langevin 步数 $L$、步长 $\eta$)和批次大小的影响,如实验部分所述。
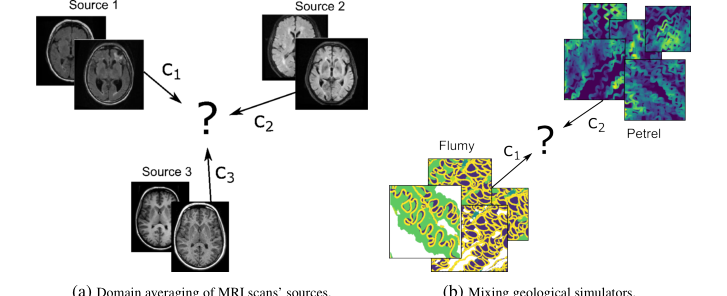 Figure 6. A schematical presentation of potential applications of barycenter solvers
Figure 6. A schematical presentation of potential applications of barycenter solvers
结果、局限性与结论
实验设计与基线
作者精心设计了一系列实验,以在各种场景下严格验证他们提出的能量引导连续熵中心 (EOT) 求解器,从低维玩具问题到高维图像流形。验证策略的核心,尤其是在真实中心未知的情况下,是通过将计算出的 EOT 中心(对于足够小的正则化参数 $\epsilon$)与解析可导出的未正则化中心($\epsilon=0$)进行比较。这种方法通过展示定性和定量的一致性或在适用情况下的优越性能,无情地证明了其数学声明的有效性。
对于2D 玩具分布,特别是“扭曲”示例,实验设计了三个彗星状的 2D 分布 ($P_1, P_2, P_3$),权重均匀。测试了两种不同的成本函数:非欧几里得“扭曲成本”$c_k(x_k, y) = ||u(x_k) - u(y)||^2$ 和标准欧几里得 $l^2$ 成本 $c_k(x, y) = ||x - y||^2$,两者正则化参数均为 $\epsilon = 10^{-2}$。这里的“受害者”或基线是扭曲成本的解析导出的真实未正则化中心(一个居中高斯分布)以及使用 POT 包 [33] 中的 free_support_barycenter 求解器估计的 $l^2$ 中心。这允许与已知或成熟的解决方案进行直接比较。在3D 球体实验中,求解器使用非二次成本函数 $c_k(x_k, y) = \frac{1}{2} \arccos^2(x_k, y)$ 和 $\epsilon = 10^{-2}$,估计了 3D 球体上四个 von Mises 分布的中心。这里真实中心未知,因此评估主要是定性的,侧重于学习到的中心的合理性。
对于图像数据,实验涉及 MNIST 0/1 数字和 Ave, celeba! 数据集。对于 MNIST,任务是在 $32 \times 32$ 的灰度图像空间中,以相等的权重平均 0/1 数字的分布。MNIST 的真实未正则化 $l^2$ 中心是像素平均值,作者将其与学习未正则化中心的现有求解器 SCWB [32] 和 WIN [55] 进行了比较。至关重要的是,他们引入了一个流形约束设置,其中中心的搜索空间被限制在预训练的 StyleGAN [50] 流形上,甚至用无关样本“污染”该流形以测试鲁棒性。成本函数被修改为 $c_{k,G}(x_k, z) = ||x_k - G(z)||^2$,其中 $\epsilon = 10^{-2}$。Ave, celeba! 数据集实验涉及平均三个退化的面部子集,其中真实未正则化 $l^2$ 中心是 Celeba 面部本身的分布。这也在流形约束设置中进行了评估,$\epsilon = 10^{-4}$,并与 SCWB [32] 和 WIN [55] 进行了比较。
最后,对于高斯分布,作者进行了定量评估,使用了不同维度($D = 2, 4, 8, 16, 64$)的三个高斯分布,权重为 $(\frac{1}{4}, \frac{1}{2}, \frac{1}{4})$,正则化参数为 $\epsilon = 0.01, 1$。真实未正则化中心 $Q^*$ 通过 WIN 存储库的迭代过程进行估计,WIN 求解器 [55] 本身作为基线。主要指标是双极投影的 $L_2$-UVP(未解释方差百分比)。还进行了消融研究,以了解批次大小和 Langevin 步数的影响。还进行了单细胞实验,侧重于随时间推移细胞群的插值,维度为 $D = 50, 100, 1000$。这里的指标是 MMD(最大均值差异),基线包括 LightSB-M [2]、SFM-sink [3] 和 EGNOT [1]。
证据证明的内容
实验证据明确证明,所提出的能量引导连续熵中心 (EOT) 求解器能够为一般成本函数有效地近似连续 EOT 中心,克服了先前方法的局限性。
3D 球体实验(图 1)提供了定性证据,表明该方法适用于非标准、非二次的实验设置,即使在真实中心未知的情况下也能产生合理的中心。这证明了该方法在简单欧几里得空间之外的灵活性和鲁棒性。
对于2D 扭曲示例,定性结果(图 12)显示了无可辩驳的证据,表明我们的求解器在 $\epsilon = 10^{-2}$ 时,能够准确地恢复非欧几里得扭曲成本的真实未正则化中心。计算出的中心(图 12b)在视觉上与解析导出的高斯真实值(图 12a)完美匹配。这是对核心机制能够处理复杂非欧几里得成本的关键验证。对于 $l^2$ 成本,我们的 EOT 中心(图 12d)也与真实的 $l^2$ 中心(图 12c)很好地匹配,进一步证实了其通用适用性。学习到的扭曲成本与 $l^2$ 成本的条件计划的不同结构突显了该方法对成本函数定义的底层几何形状的敏感性。
在MNIST 0/1 实验中,数据空间 EOT 中心(图 5,“OURS (Data Space)”)中观察到的“模糊偏差”和噪声与熵正则化 OT 和 MCMC 采样的性质一致。然而,流形约束设置(图 5,“OURS (Manifold Constrained)”)明确证明了所提出技术的力量。通过将搜索限制在 StyleGAN 流形上,求解器产生了清晰、可解释的中心,有效地忽略了来自流形的“污染”样本。这是一个关键证据,表明流形约束成功地缓解了直接数据空间 EOT 中心估计固有的噪声问题。
Ave, celeba! 数据集评估提供了令人信服的定量证据。与基线模型 SCWB [32] 和 WIN [55] 相比,我们的求解器实现了显著更低的 FID 分数(表 2)。例如,我们方法在 $k=1$ 时的 FID 为 8.4(标准差为 0.3),远超 SCWB 的 56.7 和 WIN 的 49.3。这种显著的改进,特别是在流形约束设置中,是核心机制与生成模型结合后产生卓越感知质量和更准确的图像分布中心估计的决定性证据。定性结果(图 4)也显示了“定性上良好”的传输图像,尽管偶尔会出现归因于 MCMC 的内容保留失败。
对于高斯分布,$L_2$-UVP 指标(表 7)提供了关于求解器准确性的硬性证据。对于小的 $\epsilon = 0.01$ 和高达 $D=16$ 的维度,我们的算法产生的 $L_2$-UVP 分数甚至优于专门为未正则化情况设计的 WIN 求解器。例如,在 $D=2$ 时,我们的 $L_2$-UVP 为 0.02,而 WIN 为 0.03。这表明对于适当的正则化,我们的 EOT 求解器可以达到最先进的准确性,甚至超过专门针对未正则化情况的方法。关于批次大小(表 9)和 Langevin 步数(图 11)的消融研究进一步证实了该方法性能对这些参数的敏感性,正如 MCMC 方法所预期的那样,更大的批次大小和足够的 Langevin 步数可以提高质量。
最后,单细胞实验(表 8)表明,我们的通用熵中心方法在各种维度和设置下,几乎与领先的基线(例如,在 $D=50$ 时,OURS 为 2.32,LightSB-M 为 2.33)相匹配。这表明它有潜力成为人口插值等问题的鲁棒、开箱即用的基础模型。
局限性与未来方向
尽管提出的能量引导连续熵中心求解器取得了显著进展,但认识到其固有的局限性并考虑有前途的未来研究方向至关重要。
一个主要的方法学局限性源于在训练和推理过程中对马尔可夫链蒙特卡洛 (MCMC) 程序(如未调整的 Langevin 算法 ULA)的依赖。ULA 本身可能难以收敛到期望的分布 $\mu^\ddagger$,尤其是在复杂的能量景观中。MCMC 采样本质上也是耗时的,这影响了该方法的可扩展性,特别是对于更大的批次大小或更高维的问题,如计算复杂性分析(表 3,附录 C)中所述。未来的工作绝对应该探索更有效的采样程序,借鉴先进的 MCMC 技术,例如涉及回放缓冲区 [46]、辅助变量 [43] 或神经传输 [47, 71, 99, 108, 66, 26] 的技术。这可以显著降低计算负担并提高收敛稳定性。
另一个理论局限性是,目前对泛化界和通用近似保证(§4.3)的分析并未考虑由梯度下降过程和 MCMC 采样本身引起的优化误差。这是一个复杂的机器学习理论领域,超出了本文的范围,但它代表了更深入理论理解的关键方向。未来的研究可以致力于通过开发一个更全面的理论框架来整合这些实际优化挑战来弥合这一差距。
从问题设置的角度来看,在图像数据空间中使用熵正则化可能导致“模糊偏差”和噪声中心图像,如 MNIST 0/1 数据空间实验(图 5)中所观察到的。虽然流形约束方法通过利用预训练的生成模型(如 StyleGAN)有效地缓解了这一点,但它引入了对这些外部模型质量和适用性的依赖。那么问题就出现了:我们如何确保所选择的流形真正代表底层数据结构,以及该方法对“污染”或不完美的流形有多鲁棒?未来的工作可以研究自适应流形学习技术或联合学习流形和中心的模型,而不是依赖于固定的、预训练的生成模型。
一个重要的前瞻性讨论话题围绕着将能量引导方法扩展到双重正则化 EOT 中心,其中正则化参数 $\lambda$ 和 $\tau$ 不一定等于 $\epsilon$(附录 B.3)。当前的求解器是为 Schrödinger 中心情况($\lambda = \tau = \epsilon$)量身定制的,其中熵项 $H(Q)$ 从目标函数中消失。引入非零的 $H(Q)$ 项将需要单独、非平凡地计算第二边际 $\pi_k(y)$ 的熵,而这目前从原始 MCMC 样本中是不可行的。开发新的技术来估计或近似该熵项,或者重新表述对偶目标以避免其直接计算,将解锁更广泛的 EOT 中心问题类别。
另一个关键的未来发展领域在于为实际应用设计合适的成本函数和数据流形,特别是在医学(域偏移问题)和地质学(混合模拟器)等领域。本文强调,在这些领域有效应用中心需要领域专业知识来定义有意义的成本函数 $c_k$ 并选择或构建合适的数据流形 $M$。这表明需要跨学科合作,将机器学习专家与领域专家聚集在一起,共同开发特定任务的解决方案。例如,在医学成像领域,探索如何利用新兴的大型生成模型(例如 DALL-E [85]、StableDiffusion [87])来参数化医学数据流形,可能会开辟新的分析途径。
重要性采样 (IS) 训练程序(附录 D)的替代方案显示出快速收敛的潜力,但带来了自身的挑战:需要准确选择提议分布 $q$ 以降低估计方差。在实际场景中,这通常很难做到。未来的研究可以侧重于开发自适应或学习的提议分布用于 IS,可能将其与 MCMC 或其他技术相结合,以创建更鲁棒、更有效的 EOT 中心训练算法。
最后,可扩展性和计算效率仍然是关键挑战。虽然当前方法适用于大规模设置,但推理时间,特别是由于 MCMC,可能相当可观。探索硬件加速 MCMC、分布式计算策略或减少 Langevin 步数而不会显著降低质量的近似(如消融研究所暗示的)将是有价值的。目标应该是使这些连续中心求解器对工业和社会重要问题更加易于访问和实用,真正利用它们作为最优传输任务的“基础模型”。
 Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
Figure 1. Entropic barycenter Q∗(5) of N = 4 von Mises distributions Pn on the sphere (see M5.1) estimated with our barycenter solver (Algorithm 1). The used transport costs are ck(xk, y) = 1
 Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
Figure 12. 2D twister example. Trained with importance sampling: The true barycenter of 3 comets vs. the one computed by our solver with ϵ = 10−2. Two costs ck are considered: the twisted cost (12a, 12b) and ℓ2 (12c, 12d). We employ the simulation-free importance sampling procedure for training
 Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
Figure 5. Qualitative comparison of barycenters of MNIST 0/1 digit classes computed with barycenter solvers in the image space w.r.t. the pixel-wise ℓ2. Solvers SCWB and WIN only learn the unregularized barycenter (ϵ = 0) directly in the data space. In turn, our solver learns the EOT barycenter in data space as well as it can learn EOT barycenter restricted to the StyleGAN manifold (ϵ = 10−2)
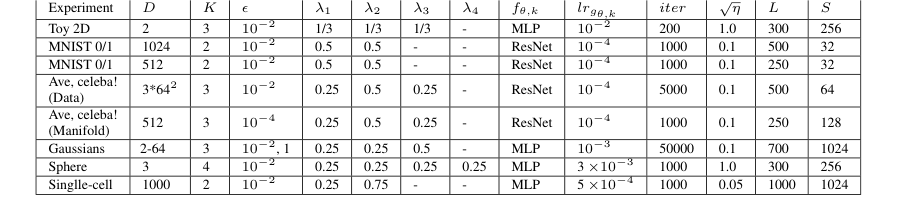 Table 4. Hyperparameters that we use in the experiments with our Algorithm 1
Table 4. Hyperparameters that we use in the experiments with our Algorithm 1
与其他领域的同构性
结构骨架
本质上,本文提出了一种数学和计算框架,用于从一组输入概率分布中找到一个具有代表性的“平均”概率分布(中心),方法是最小化正则化最优传输成本。