ऊष्मा-स्नान एल्गोरिथम शीतलन के माध्यम से क्वांटम मशीन लर्निंग में सुधार
इस पत्र में संबोधित समस्या क्वांटम सूचना प्रसंस्करण (QIP) और डेटा विज्ञान के प्रतिच्छेदन से उत्पन्न होती है, जिससे क्वांटम मशीन लर्निंग (QML) का क्षेत्र विकसित हुआ है। जबकि QML शास्त्रीय क्षमताओं से परे जटिल डेटा...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या क्वांटम सूचना प्रसंस्करण (QIP) और डेटा विज्ञान के प्रतिच्छेदन से उत्पन्न होती है, जिससे क्वांटम मशीन लर्निंग (QML) का क्षेत्र विकसित हुआ है। जबकि QML शास्त्रीय क्षमताओं से परे जटिल डेटा वितरण से निपटने के लिए अपार संभावनाएं रखता है, यह क्वांटम मापों की संभाव्य प्रकृति के कारण अंतर्निहित चुनौतियों का सामना करता है। यह संभाव्य प्रकृति का अर्थ है कि QML एल्गोरिदम के प्रशिक्षण और अनुमान दोनों चरण क्वांटम अवस्थाओं से जानकारी निकालने पर "परिमित नमूनाकरण त्रुटियों" के प्रति संवेदनशील होते हैं, जैसे कि प्रेक्षणीय मानों के अपेक्षा मान।
ऐतिहासिक रूप से, इन नमूनाकरण त्रुटियों को कम करने के प्रयासों, जैसे कि क्वांटम आयाम अनुमान (QAE) को अनुकूलित करना, ने द्विघात सुधार की पेशकश की। हालांकि, QAE प्रोटोकॉल के लिए जटिल ग्रोवर-जैसे संचालन के कई दौर की आवश्यकता होती है, जो कम्प्यूटेशनल रूप से गहन होते हैं और वर्तमान शोरगुल वाले मध्यवर्ती-पैमाने के क्वांटम (NISQ) उपकरणों पर उनकी व्यवहार्यता को गंभीर रूप से सीमित करते हैं। इसके अलावा, कई मशीन लर्निंग कार्यों, विशेष रूप से वर्गीकरण के लिए, QAE अत्यधिक सटीकता का स्तर प्रदान करता है। अक्सर, केवल मापे गए आँकड़े के संकेत को निर्धारित करना पर्याप्त होता है (जैसे, क्या वर्गीकरण स्कोर सकारात्मक है या नकारात्मक) न कि उसके सटीक परिमाण को। इस अहसास ने QAE के द्विघात सुधारों को पार करने में सक्षम अधिक व्यावहारिक और कुशल नमूनाकरण कमी तकनीकों की आवश्यकता को उजागर किया, जबकि NISQ हार्डवेयर की सीमाओं के साथ संगत भी रहा।
पिछली विधियों की मौलिक सीमा, या "दर्द बिंदु," जिसने लेखकों को इस कार्य को विकसित करने के लिए मजबूर किया, वह दोहरी है। सबसे पहले, QAE जैसी मौजूदा विधियाँ वर्तमान NISQ हार्डवेयर पर व्यावहारिक कार्यान्वयन के लिए बहुत अधिक संसाधन-गहन और जटिल (कई ग्रोवर-जैसे संचालन की आवश्यकता) हैं, जिससे वास्तविक समय अनुप्रयोग असंभव हो जाता है। दूसरे, पारंपरिक एल्गोरिथम शीतलन तकनीकें, जिन्होंने इस कार्य को प्रेरित किया, स्वाभाविक रूप से "एकदिशीय" हैं। उन्हें एक पूर्वनिर्धारित आधार स्थिति (जैसे, $|0\rangle$) की जनसंख्या बढ़ाने के लिए डिज़ाइन किया गया है, जिसके लिए वांछित आउटपुट के संकेत के पूर्व ज्ञान की आवश्यकता होती है। पर्यवेक्षित QML में, हालांकि, वर्गीकरण स्कोर का संकेत (जो लेबल या ग्रेडिएंट दिशा निर्धारित करता है) ठीक वही अज्ञात मात्रा है जिसे हम निर्धारित करने का लक्ष्य रखते हैं। पिछली शीतलन विधियों में "द्विदिशीय" क्षमता की इस कमी का मतलब था कि उन्हें सीधे QML वर्गीकरण समस्याओं पर लागू नहीं किया जा सकता था जहां पूर्वाग्रह दिशा शुरू में अज्ञात है। यह पत्र एक उपन्यास, संकेत-संरक्षण, द्विदिशीय शीतलन दृष्टिकोण पेश करके इन सीमाओं को सीधे संबोधित करता है।
सहज डोमेन शब्द
- क्वांटम मशीन लर्निंग (QML): कल्पना करें कि एक नियमित कंप्यूटर डेटा से पैटर्न सीख रहा है, जैसे कि एक छात्र परीक्षा के लिए अध्ययन कर रहा हो। QML उस छात्र को एक जादुई क्वांटम मस्तिष्क देने जैसा है जो जानकारी को पूरी तरह से नए तरीकों से संसाधित कर सकता है, जिससे वे बहुत तेज़ी से सीख सकते हैं या ऐसे पैटर्न खोज सकते हैं जिन्हें एक नियमित छात्र याद कर सकता है, खासकर बहुत जटिल डेटा के साथ।
- शोरगुल वाले मध्यवर्ती-पैमाने के क्वांटम (NISQ) उपकरण: NISQ उपकरणों को पहली पीढ़ी की इलेक्ट्रिक कारों के रूप में सोचें। वे क्रांतिकारी हैं और अविश्वसनीय क्षमता दिखाते हैं, लेकिन उनकी बैटरी लाइफ सीमित है, वे कुछ हद तक अविश्वसनीय हैं, और वे रिचार्ज या ठीक होने से पहले केवल कुछ कार्य ही कर सकते हैं। वे अभी तक लंबी सड़क यात्राओं के लिए तैयार नहीं हैं, लेकिन वे पूरी तरह कार्यात्मक क्वांटम वाहनों की दिशा में एक महत्वपूर्ण कदम हैं।
-
हीट-बाथ एल्गोरिथम कूलिंग (HBAC): एक गंदे डेस्क की कल्पना करें जहां महत्वपूर्ण दस्तावेज कचरे के साथ मिश्रित होते हैं। HBAC एक सावधानीपूर्वक सहायक की तरह है जो दो चरणों में, साफ-सफाई करता है: पहले, वे सभी महत्वपूर्ण दस्तावेजों को एक साफ ढेर में इकट्ठा करते हैं और कचरे को डेस्क के दूसरे हिस्से में धकेलते हैं (एंट्रॉपी संपीड़न)। दूसरा, वे डेस्क से कचरा फेंक देते हैं (थर्मलाइजेशन/रीसेट), जिससे महत्वपूर्ण दस्तावेज बहुत अधिक व्यवस्थित और सुलभ हो जाते हैं। यह एक प्रमुख समाधान है।
-
ध्रुवीकरण (एक क्यूबिट का): एक कंपास सुई की कल्पना करें। यदि यह पूरी तरह से संतुलित है, तो यह कहीं भी इंगित कर सकता है (कम ध्रुवीकरण)। यदि यह उत्तर की ओर दृढ़ता से खींचा जाता है, तो इसमें उत्तर की ओर उच्च ध्रुवीकरण होता है। एक क्वांटम बिट (क्यूबिट) के लिए, ध्रुवीकरण बताता है कि यह एक विशिष्ट स्थिति (जैसे '0') को दूसरे (जैसे '1') पर कितना दृढ़ता से पसंद करता है। उच्च ध्रुवीकरण का मतलब है क्यूबिट से एक बहुत स्पष्ट, अधिक विश्वसनीय 'हां' या 'नहीं' उत्तर।
- एंट्रॉपी संपीड़न: एक बड़े हॉल में बेतरतीब ढंग से बिखरे हुए लोगों के समूह पर विचार करें (उच्च एंट्रॉपी)। एंट्रॉपी संपीड़न एक चतुर कार्यक्रम आयोजक की तरह है जो किसी को भी हटाए बिना, सभी वीआईपी को एक निर्दिष्ट, आसानी से सुलभ क्षेत्र में निर्देशित करता है, जबकि बाकी उपस्थित लोग फैले रहते हैं। हॉल में लोगों की कुल संख्या (सूचना) समान है, लेकिन "महत्वपूर्ण" भाग अब बहुत अधिक केंद्रित और व्यवस्थित है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित केंद्रीय समस्या क्वांटम मशीन लर्निंग (QML) एल्गोरिदम, विशेष रूप से विविध क्वांटम बाइनरी क्लासिफायर (VQBCs) में अंतर्निहित परिमित नमूनाकरण त्रुटि है। यह त्रुटि क्वांटम मापों की संभाव्य प्रकृति से उत्पन्न होती है, जो QML के प्रशिक्षण और भविष्यवाणी दोनों चरणों के लिए मौलिक हैं।
इनपुट/वर्तमान स्थिति:
वर्तमान स्थिति में, QML एल्गोरिदम क्वांटम डेटा अभ्यावेदन को संसाधित करते हैं, और उनका आउटपुट (जैसे, एक वर्गीकरण लेबल या एक ग्रेडिएंट दिशा) एक मापे गए आँकड़े के संकेत में एन्कोड किया जाता है, विशेष रूप से एक लक्ष्य क्यूबिट के Z-ध्रुवीकरण $\alpha(x, \theta)$। यह ध्रुवीकरण एक एकल-क्यूबिट घनत्व ऑपरेटर $\rho_1(x, \theta) = \frac{I + \alpha(x, \theta)Z + \beta(x, \theta)X + \gamma(x, \theta)Y}{2}$ से प्राप्त होता है, जहां वर्गीकरण स्कोर $q(x, \theta) = \alpha(x, \theta)$ है। इस स्कोर का अनुमान लगाने के लिए, माप पुनरावृत्तियों (शॉट्स) की एक परिमित संख्या, जिसे $k$ द्वारा दर्शाया गया है, की जाती है। यह परिमित $k$ अनुमान त्रुटि की ओर ले जाता है। मजबूत भविष्यवाणी के लिए, अनुमानित अपेक्षा मान $\mu$ को $|\mu - \langle M \rangle| < |\langle M \rangle|$ को संतुष्ट करना चाहिए, जहां $\langle M \rangle$ वास्तविक अपेक्षा मान है। प्रशिक्षण के लिए, $q(x_j, \theta)$ के लिए अनुमान त्रुटि को हिंज हानि ग्रेडिएंट का सटीक आकलन करने के लिए $|q(x_j, \theta) - b|$ से छोटा होना चाहिए। इन कार्यों के लिए त्रुटि संभावनाएँ ऊपर से बंधी हुई हैं, उदाहरण के लिए, भविष्यवाणी के लिए:
$$ \text{Pr[error]} = \text{Pr}[|\mu - \langle M \rangle| \geq |\langle M \rangle|] \leq \frac{1 - \alpha^2(x, \theta^*)}{k\alpha^2(x, \theta^*)} $$
और प्रशिक्षण के लिए:
$$ \text{Pr[error]} = \frac{1 - \alpha^2(x_j, \theta)}{k(\alpha(x_j, \theta) - b)^2} $$
ये सीमाएँ दर्शाती हैं कि $|\alpha(x, \theta)|$ का एक छोटा परिमाण कम त्रुटि संभावना बनाए रखने के लिए एक बड़े संख्या में शॉट्स $k$ की आवश्यकता होती है। महत्वपूर्ण रूप से, QML संदर्भ में $\alpha(x, \theta)$ का संकेत पूर्व ज्ञान के बिना ज्ञात नहीं है, क्योंकि यह वही जानकारी (लेबल या ग्रेडिएंट दिशा) का प्रतिनिधित्व करता है जिसे एल्गोरिथम निर्धारित करने का लक्ष्य रखता है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
वांछित अंतिम बिंदु इन परिमित नमूनाकरण त्रुटियों को महत्वपूर्ण रूप से कम करना है, जिससे सटीक वर्गीकरण और ग्रेडिएंट अनुमान के लिए आवश्यक माप पुनरावृत्तियों $k$ की संख्या कम हो जाती है। यह लक्ष्य क्यूबिट के ध्रुवीकरण के परिमाण, $|\alpha(x, \theta)|$, को एक नए, संवर्धित मान $|\alpha'(x, \theta)|$ तक बढ़ाकर प्राप्त किया जाना है। मुख्य आवश्यकता यह है कि यह वृद्धि द्विदिशीय होनी चाहिए, जिसका अर्थ है कि ध्रुवीकरण का संकेत संरक्षित होना चाहिए जबकि उसका परिमाण बढ़ाया जाना चाहिए। एकल-क्यूबिट घनत्व मैट्रिक्स के लिए लक्ष्य परिवर्तन है:
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{साथ} \quad \begin{cases} \alpha' > \alpha & \text{यदि } \alpha > 0 \\ \alpha' < \alpha & \text{यदि } \alpha < 0 \end{cases} $$
इस प्रक्रिया को ग्रोवर पुनरावृत्तियों या क्वांटम चरण अनुमान जैसे कम्प्यूटेशनल रूप से महंगे संचालन पर भरोसा किए बिना प्रशिक्षण और भविष्यवाणी दोनों चरणों में नमूना दक्षता बढ़ानी चाहिए।
लुप्त कड़ी और दुविधा:
सटीक लुप्त कड़ी एक कुशल और संकेत-संरक्षण तंत्र है जो QML संदर्भ में एक लक्ष्य क्यूबिट के ध्रुवीकरण परिमाण को बढ़ाने के लिए है। पिछली एल्गोरिथम शीतलन तकनीकें, जैसे हीट-बाथ एल्गोरिथम कूलिंग (HBAC), "एकदिशीय" हैं; उन्हें एक पूर्वनिर्धारित आधार स्थिति (जैसे, $|0\rangle$) की जनसंख्या बढ़ाने के लिए डिज़ाइन किया गया है। इसके लिए वांछित आउटपुट (अर्थात, $\alpha(x, \theta)$ का संकेत) के पूर्व ज्ञान की आवश्यकता होती है, जो QML वर्गीकरण में ठीक वही अज्ञात जानकारी है। यह एक दर्दनाक दुविधा पैदा करता है: सटीकता में सुधार के लिए पारंपरिक शीतलन का उपयोग करने के लिए, किसी को पहले से ही उत्तर जानने की आवश्यकता होगी, जिससे वर्गीकरण के लिए शीतलन प्रक्रिया व्यर्थ हो जाएगी। यह पत्र एक उपन्यास "द्विदिशीय" शीतलन प्रोटोकॉल विकसित करके इस अंतर को पाटने का प्रयास करता है जो ध्रुवीकरण के प्रारंभिक संकेत की परवाह किए बिना काम करता है।
बाधाएँ और विफलता मोड
QML नमूना दक्षता बढ़ाने की समस्या को कई कठोर, यथार्थवादी बाधाओं द्वारा बेहद मुश्किल बना दिया गया है:
1. कम्प्यूटेशनल और हार्डवेयर बाधाएँ:
* NISQ उपकरण सीमाएँ: समाधान को शोरगुल वाले मध्यवर्ती-पैमाने के क्वांटम (NISQ) उपकरणों के साथ संगत होना चाहिए। इसका मतलब है कि जटिल, गहरे सर्किट और ग्रोवर पुनरावृत्तियों या क्वांटम चरण अनुमान जैसे संचालन से बचना चाहिए, जो सीमित क्यूबिट गणना, कम सुसंगतता समय और उच्च त्रुटि दरों के कारण अव्यवहारिक हैं।
* कम्प्यूटेशनल ओवरहेड: किसी भी प्रस्तावित विधि को वर्गीकरण स्कोर और ग्रेडिएंट का अनुमान लगाने से जुड़े कम्प्यूटेशनल ओवरहेड को कम करना चाहिए। त्रुटि को कम करने के लिए माप शॉट्स ($k$) की संख्या बढ़ाना कम्प्यूटेशनल लागत के साथ एक सीधा व्यापार-बंद है।
* क्यूबिट संसाधन सीमाएँ: वर्तमान हार्डवेयर पर उपलब्ध क्यूबिट की संख्या सीमित है। प्रोटोकॉल को संसाधन-कुशल होना चाहिए, आदर्श रूप से कुल आवश्यक क्यूबिट की संख्या को कम करने के लिए क्यूबिट को रीसायकल करके।
2. डेटा-संचालित और एल्गोरिथम बाधाएँ:
* अज्ञात ध्रुवीकरण संकेत (द्विदिशीयता आवश्यकता): मुख्य समस्या में उजागर के रूप में, लक्ष्य क्यूबिट के ध्रुवीकरण $\alpha(x, \theta)$ का संकेत पूर्व ज्ञान के बिना अज्ञात है। यह एक मौलिक बाधा है जो पारंपरिक, एकदिशीय एल्गोरिथम शीतलन प्रोटोकॉल को अनुपयुक्त बनाती है। शीतलन तंत्र को प्रारंभिक ध्रुवीकरण के सकारात्मक और नकारात्मक दोनों के लिए सही ढंग से काम करना चाहिए, बिना यह जाने कि कौन सा है।
* परिमित नमूनाकरण त्रुटियाँ: क्वांटम मापों की अंतर्निहित संभाव्य प्रकृति का मतलब है कि परिमित शॉट्स के आधार पर कोई भी अनुमान हमेशा कुछ त्रुटि के साथ होगा। लक्ष्य व्यावहारिक सीमाओं के भीतर इस त्रुटि को कम करना है, इसे पूरी तरह से समाप्त करना नहीं।
* बंजर पठार: हालांकि इस पत्र द्वारा सीधे हल नहीं किया गया है, विविध क्वांटम एल्गोरिदम में बंजर पठार (जहां ग्रेडिएंट क्यूबिट की संख्या के साथ घातीय रूप से गायब हो जाते हैं) की समस्या QML में एक ज्ञात चुनौती है। पत्र नोट करता है कि इसका दृष्टिकोण एक स्वतंत्र तंत्र है जिसका उपयोग मौजूदा बंजर पठार शमन रणनीतियों के साथ संयोजन में किया जा सकता है।
3. भौतिक शोर बाधाएँ:
* शोरगुल वाला क्वांटम वातावरण: वर्तमान क्वांटम हार्डवेयर विभिन्न प्रकार के शोर और डीकोहेरेंस के प्रति संवेदनशील है। प्रोटोकॉल को इन अपूर्णताओं के प्रति मजबूत होना चाहिए।
* विशिष्ट शोर मॉडल: पत्र विशेष रूप से सामान्यीकृत आयाम अवमूल्यन (GAD) और डिपोलराइजिंग चैनलों पर विचार करता है, जो NISQ उपकरणों में प्रमुख शोर तंत्र हैं। प्रोटोकॉल का डिज़ाइन, जो मुख्य रूप से विकर्ण अवस्थाओं के उप-स्थान के भीतर संचालित होता है, को सुसंगतता-क्षीण करने वाले शोर (जैसे, डीफेजिंग, चरण-अवमूल्यन, नियंत्रण-चरण उतार-चढ़ाव) के प्रति लचीलापन सुनिश्चित करना चाहिए जो विकर्ण तत्वों को प्रभावित नहीं करते हैं।
विफलता मोड:
यदि इन बाधाओं को पूरा नहीं किया जाता है, या समस्या का पर्याप्त रूप से समाधान नहीं किया जाता है, तो QML एल्गोरिदम कई विफलता मोड का सामना करेंगे:
* अशुद्ध वर्गीकरण: उच्च नमूनाकरण त्रुटियों से अविश्वसनीय भविष्यवाणियां होंगी, जहां अनुमानित लेबल वास्तविक लेबल से भिन्न हो सकता है।
* अप्रभावी प्रशिक्षण: उच्च नमूनाकरण त्रुटियों के कारण गलत ग्रेडिएंट अनुमान अनुकूलन प्रक्रिया में बाधा डालेंगे, जिससे मॉडल एक इष्टतम समाधान में परिवर्तित नहीं हो पाएगा।
* निषेधात्मक संसाधन खपत: अत्यधिक बड़ी संख्या में माप शॉट्स या जटिल क्वांटम संचालन पर निर्भरता QML को वर्तमान और निकट-अवधि के क्वांटम हार्डवेयर पर वास्तविक दुनिया के अनुप्रयोगों के लिए अव्यावहारिक और गैर-स्केलेबल बना देगी।
* शीतलन की गैर-लागूता: यदि शीतलन प्रोटोकॉल ध्रुवीकरण संकेत के पूर्व ज्ञान के बिना द्विदिशीय रूप से संचालित नहीं हो सकते हैं, तो उन्हें QML वर्गीकरण कार्यों में प्रभावी ढंग से एकीकृत नहीं किया जा सकता है जहां यह संकेत अज्ञात आउटपुट है।
* शोर के प्रति संवेदनशीलता: NISQ उपकरणों की शोर विशेषताओं के प्रति मजबूत नहीं होने वाले प्रोटोकॉल असंगत और अविश्वसनीय परिणाम देंगे, जिससे कोई भी सैद्धांतिक प्रदर्शन लाभ व्यर्थ हो जाएगा। पत्र विशेष रूप से यथार्थवादी NISQ शोर स्थितियों के तहत अपने प्रोटोकॉल का परीक्षण करता है, जिसमें विशिष्ट और सबसे खराब स्थिति वाले शासन शामिल हैं, ताकि वास्तविक हार्डवेयर में होने वाले शोर के खिलाफ मजबूती का प्रदर्शन किया जा सके।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
क्वांटम मशीन लर्निंग (QML) एल्गोरिदम में मुख्य चुनौती, विशेष रूप से वर्गीकरण कार्यों के लिए, क्वांटम मापों की संभाव्य प्रकृति से उत्पन्न होती है। प्रशिक्षण और अनुमान दोनों चरणों में संभाव्यता वितरण से जानकारी निकालने की आवश्यकता होती है, जो स्वाभाविक रूप से परिमित नमूनाकरण त्रुटियों का परिचय देती है। यह सीमा वर्गीकरण स्कोर और ग्रेडिएंट की विश्वसनीयता को सीधे प्रभावित करती है, जिसके लिए सटीक परिणाम प्राप्त करने के लिए पर्याप्त संख्या में पुनरावृत्तियों (शॉट्स) की आवश्यकता होती है।
पारंपरिक अत्याधुनिक (SOTA) क्वांटम विधियों, जैसे क्वांटम आयाम अनुमान (QAE), को इस विशिष्ट समस्या के लिए अपर्याप्त माना गया था। जबकि QAE सैद्धांतिक रूप से नमूनाकरण त्रुटियों में द्विघात कमी प्रदान करता है, जटिल ग्रोवर-जैसे संचालन [13,14] पर इसकी निर्भरता इसे शोरगुल वाले मध्यवर्ती-पैमाने के क्वांटम (NISQ) उपकरणों [15,16] के लिए काफी हद तक अव्यावहारिक और अव्यवहारिक बनाती है। इसके अलावा, QAE परिमाण का एक अत्यधिक सटीक अनुमान प्रदान करता है, जो अक्सर वर्गीकरण के लिए अत्यधिक होता है। बाइनरी वर्गीकरण के लिए, केवल मापे गए आँकड़े (ध्रुवीकरण) के संकेत की आवश्यकता होती है, न कि उसके सटीक परिमाण की।
लेखकों ने महसूस किया कि महत्वपूर्ण आवश्यकता वर्गीकरण स्कोर के ध्रुवीकरण के परिमाण, $|\alpha(x, \theta)|$ को बढ़ाने की थी, ताकि आवश्यक मापों की संख्या को कम किया जा सके। हालांकि, यह वृद्धि एकल मापी गई क्यूबिट पर एक साधारण स्थानीय एकात्मक प्रक्रिया द्वारा प्राप्त नहीं की जा सकती है, क्योंकि ऐसी प्रक्रिया इसकी स्थिति की शुद्धता को बदल देगी। इससे एल्गोरिथम शीतलन तकनीकों पर विचार किया गया।
जिस क्षण लेखकों ने मौजूदा विधियों की अपर्याप्तता को पहचाना, वह तब था जब उन्होंने पहचाना कि पारंपरिक एल्गोरिथम शीतलन प्रोटोकॉल, जिनका उद्देश्य एक पूर्वनिर्धारित आधार स्थिति की जनसंख्या को बढ़ाना है, मौलिक रूप से अनुपयुक्त थे। QML वर्गीकरण में, $\alpha(x, \theta)$ का संकेत (जो वर्ग लेबल या ग्रेडिएंट दिशा निर्धारित करता है) पूर्व ज्ञान के बिना अज्ञात है। इसलिए, किसी भी व्यवहार्य समाधान को एक द्विदिशीय प्रोटोकॉल होना चाहिए जो एकल-क्यूबिट घनत्व मैट्रिक्स को ध्रुवीकरण परिमाण बढ़ाने के लिए गतिशील रूप से बदलने में सक्षम हो, जबकि उसके अज्ञात संकेत को संरक्षित करे, जैसा कि परिवर्तन द्वारा व्यक्त किया गया है:
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{साथ} \quad \begin{cases} \alpha' > \alpha & \text{यदि } \alpha > 0 \\ \alpha' < \alpha & \text{यदि } \alpha < 0 \end{cases} $$
संकेत-संरक्षण, द्विदिशीय ध्रुवीकरण वृद्धि की यह आवश्यकता प्रस्तावित क्वांटम थर्मोडायनामिक शीतलन दृष्टिकोण को एकमात्र व्यवहार्य समाधान बनाती है।
तुलनात्मक श्रेष्ठता
यह क्वांटम थर्मोडायनामिक दृष्टिकोण, पर्यवेक्षित शिक्षण को शीतलन प्रक्रिया के रूप में पुन: प्रस्तुत करता है, जो केवल प्रदर्शन मेट्रिक्स से परे गुणात्मक श्रेष्ठता प्रदान करता है। इसके संरचनात्मक लाभ इसे कई प्रमुख पहलुओं में पिछले स्वर्ण मानकों से भारी श्रेष्ठ बनाते हैं:
-
कम कम्प्यूटेशनल ओवरहेड: विधि वर्गीकरण स्कोर और ग्रेडिएंट का अनुमान लगाने के लिए आवश्यक मापों की संख्या को महत्वपूर्ण रूप से कम करती है। लक्ष्य क्यूबिट के ध्रुवीकरण को बढ़ाकर, वांछित सटीकता प्राप्त करने के लिए कम शॉट्स की आवश्यकता होती है, जिससे समग्र कम्प्यूटेशनल ओवरहेड कम हो जाता है। यह उन विधियों पर एक सीधा लाभ है जिनके लिए व्यापक नमूनाकरण की आवश्यकता होती है।
-
बंजर पठार का शमन: क्लासिफायर संरचना या प्रशिक्षण प्रक्रियाओं को संशोधित करने वाली रणनीतियों के विपरीत, यह दृष्टिकोण परिमित नमूनाकरण त्रुटि को कम करने के लिए एक स्वतंत्र तंत्र के रूप में कार्य करता है। यह प्रभावी है चाहे सिस्टम बंजर पठार प्रदर्शित करे या नहीं, जो विविध क्वांटम एल्गोरिदम में एक आम चुनौती है [8,30]। यह अंतर्निहित QML मॉडल को बदले बिना एक मजबूत समाधान प्रदान करता है।
-
संसाधन दक्षता और अभिसरण दर: द्विदिशीय क्वांटम रेफ्रिजरेटर (BQR) प्रोटोकॉल एक चक्रीय संचालन का उपयोग करते हैं जहां संवर्धित क्यूबिट निकाले जाते हैं, और शेष $n-1$ क्यूबिट को बाद के शीतलन दौर के लिए कार्य निकाय के रूप में रीसायकल किया जाता है। यह रीसाइक्लिंग तंत्र कई संवर्धित क्यूबिट तैयार करने के लिए आवश्यक कुल क्यूबिट संसाधनों को काफी कम कर देता है ( $n + m N_{rounds}$ से $\sim m N_{rounds} + 1$ तक) और शीतलन प्रक्रिया के अभिसरण दर में काफी सुधार करता है।
-
हार्डवेयर व्यवहार्यता (k-स्थानीय BQR): k-स्थानीय BQR संस्करण का परिचय व्यावहारिक कार्यान्वयन के लिए एक महत्वपूर्ण संरचनात्मक लाभ है। संपीड़न संचालन को k-स्थानीय पड़ोस तक सीमित करके, प्रोटोकॉल वर्तमान NISQ उपकरणों पर काफी अधिक हार्डवेयर-अनुकूल और लागू करने में आसान हो जाता है, जबकि अभी भी अधिक सामान्य BQR प्रोटोकॉल के मुख्य प्रदर्शन लाभों को बरकरार रखता है। कुछ विन्यासों में, k-स्थानीय BQR त्रुटि-संभावना में कमी में प्रगतिशील सीमा एंट्रॉपी संपीड़न BQR से भी बेहतर प्रदर्शन कर सकता है।
-
शोर लचीलापन: प्रोटोकॉल का डिज़ाइन, जो पूरी तरह से विकर्ण अवस्थाओं के उप-स्थान के भीतर संचालित होता है (रीसेट, क्रमपरिवर्तन और सशर्त स्वैप विकर्णता को संरक्षित करते हैं), इसकी जनसंख्या गतिशीलता को छोटे स्टोकेस्टिक उतार-चढ़ाव के प्रति स्वाभाविक रूप से असंवेदनशील बनाता है। महत्वपूर्ण रूप से, क्वांटम कोहेरेंस पर विशेष रूप से कार्य करने वाली शोर प्रक्रियाओं (जैसे, डीफेजिंग, चरण-अवमूल्यन, नियंत्रण-चरण उतार-चढ़ाव) का परिणाम पर कोई मापने योग्य प्रभाव नहीं पड़ता है, क्योंकि वे विकास के दौरान विकर्ण अवस्थाओं को अपरिवर्तित छोड़ देते हैं। कोहेरेंस-क्षीण करने वाले शोर के खिलाफ यह आंतरिक मजबूती NISQ संगतता के लिए एक महत्वपूर्ण गुणात्मक लाभ है।
बाधाओं के साथ संरेखण
चुनी गई विधि QML में अंतर्निहित कठोर आवश्यकताओं और बाधाओं के साथ पूरी तरह से संरेखित होती है, जो समस्या और समाधान के बीच एक "विवाह" बनाती है:
-
परिमित नमूनाकरण त्रुटियाँ: इस कार्य का प्राथमिक उद्देश्य परिमित नमूनाकरण त्रुटियों को कम करना है। BQR प्रोटोकॉल सीधे लक्ष्य क्यूबिट के ध्रुवीकरण परिमाण को बढ़ाकर इसे संबोधित करते हैं, जो बदले में वांछित अनुमान सटीकता प्राप्त करने के लिए आवश्यक मापों की संख्या को कम करता है। यह वह केंद्रीय समस्या है जिसे विधि हल करने के लिए डिज़ाइन की गई है।
-
NISQ उपकरण संगतता: प्रोटोकॉल को विशेष रूप से NISQ उपकरणों के लिए डिज़ाइन किया गया है। ग्रोवर पुनरावृत्तियों और क्वांटम चरण अनुमान जैसे जटिल संचालन से बचने के साथ-साथ हार्डवेयर-अनुकूल k-स्थानीय संपीड़न इकाइयों के विकास के कारण, यह वर्तमान क्वांटम हार्डवेयर के लिए व्यावहारिक और कुशल है। यथार्थवादी NISQ शोर स्थितियों के तहत संख्यात्मक सिमुलेशन इसकी मजबूती और उपयुक्तता को और प्रदर्शित करते हैं।
-
अज्ञात ध्रुवीकरण संकेत: QML वर्गीकरण के लिए एक महत्वपूर्ण बाधा यह है कि वर्गीकरण स्कोर (ध्रुवीकरण) का संकेत पूर्व ज्ञान के बिना अज्ञात है। पारंपरिक एल्गोरिथम शीतलन यहाँ विफल हो जाता है। प्रस्तावित "द्विदिशीय शीतलन" विशेष रूप से प्रारंभिक संकेत की परवाह किए बिना ध्रुवीकरण परिमाण को बढ़ाने के लिए इंजीनियर किया गया है, इस प्रकार संकेत को संरक्षित करता है और पूर्व ज्ञान के बिना सही वर्गीकरण को सक्षम करता है।
-
कम्प्यूटेशनल ओवरहेड: विधि सटीक वर्गीकरण स्कोर और ग्रेडिएंट के लिए आवश्यक माप शॉट्स की संख्या को महत्वपूर्ण रूप से कम करके कम्प्यूटेशनल ओवरहेड को सीधे कम करती है। क्यूबिट के रीसाइक्लिंग से संसाधन उपयोग का और अनुकूलन होता है, जिससे समग्र प्रक्रिया बार-बार, स्वतंत्र मापों की तुलना में अधिक कुशल हो जाती है।
-
बंजर पठार: दृष्टिकोण नमूना त्रुटि को कम करने के लिए एक स्वतंत्र तंत्र प्रदान करता है, जो बंजर पठार की उपस्थिति में भी फायदेमंद है। इसके लिए विविध सर्किट संरचना या प्रशिक्षण रणनीति को बदलने की आवश्यकता नहीं है, इस प्रकार मौजूदा बंजर पठार शमन तकनीकों का पूरक है।
विकल्पों का अस्वीकरण
पत्र स्पष्ट रूप से या परोक्ष रूप से कई लोकप्रिय दृष्टिकोणों को उनकी मौलिक सीमाओं के कारण अस्वीकार करता है जो विशिष्ट समस्या बाधाओं को संबोधित करते हैं:
-
क्वांटम आयाम अनुमान (QAE): QAE को मुख्य रूप से उच्च संसाधन लागत और NISQ उपकरणों के लिए अव्यावहारिकता के कारण अस्वीकार कर दिया गया था। इसके लिए ग्रोवर-जैसे संचालन [13,14] के कई दौर की आवश्यकता होती है, जो वर्तमान क्वांटम हार्डवेयर [15,16] पर कुख्यात रूप से मांग वाले हैं। इसके अलावा, QAE परिमाण का अनुमान प्रदान करता है जो अक्सर वर्गीकरण कार्यों के लिए अत्यधिक होता है, जहां केवल ध्रुवीकरण के संकेत की आवश्यकता होती है। इसकी जटिलता इस विशेष समस्या के लिए लाभ से अधिक है।
-
पारंपरिक एल्गोरिथम शीतलन (AC) / हीट-बाथ एल्गोरिथम कूलिंग (HBAC): इन पारंपरिक शीतलन तकनीकों को एकदिशीय होने और लक्ष्य स्थिति के पूर्वाग्रह के पूर्व ज्ञान की आवश्यकता के कारण अस्वीकार कर दिया गया था। पारंपरिक AC प्रोटोकॉल को एक पूर्वनिर्धारित आधार स्थिति (जैसे, $|0\rangle$) की जनसंख्या बढ़ाने के लिए डिज़ाइन किया गया है। हालांकि, QML वर्गीकरण में, वर्गीकरण स्कोर $\alpha(x, \theta)$ का संकेत (जो सही लेबल निर्धारित करता है) पूर्व ज्ञान के बिना अज्ञात है। इसलिए, एक एकदिशीय शीतलन विधि जो एक ज्ञात पूर्वाग्रह दिशा मानती है, अज्ञात संकेत को संरक्षित करते हुए ध्रुवीकरण को बढ़ाने का लक्ष्य प्राप्त नहीं कर सकती है।
-
एकल क्यूबिट पर स्थानीय एकात्मक प्रक्रियाएँ: लेखकों ने नोट किया कि एकल मापे गए क्यूबिट पर केवल एक स्थानीय एकात्मक प्रक्रिया लागू करना अपर्याप्त होगा क्योंकि ऐसी प्रक्रिया क्यूबिट की स्थिति की शुद्धता को नहीं बदल सकती [धारा III]। ध्रुवीकरण बढ़ाने के लिए, क्यूबिट की एंट्रॉपी को कम करने की आवश्यकता होती है, जिसके लिए अन्य क्यूबिट के साथ बातचीत और एक विघटनकारी प्रक्रिया की आवश्यकता होती है, जो एकल-क्यूबिट एकात्मक परिवर्तन से परे जाती है।
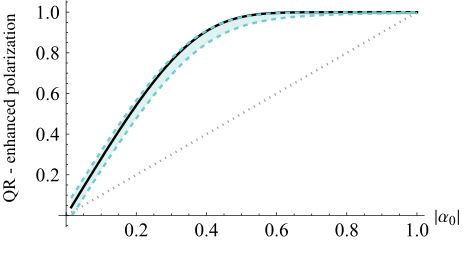 FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
गणितीय और तार्किक तंत्र
मास्टर समीकरण
क्वांटम मशीन लर्निंग (QML) में नमूना दक्षता बढ़ाने के लिए पत्र का मुख्य तंत्र द्विदिशीय क्वांटम रेफ्रिजरेटर (BQR) प्रोटोकॉल है। विशेष रूप से, प्रगतिशील सीमा एंट्रॉपी संपीड़न BQR (PBEC-BQR) एक चक्रीय प्रक्रिया का वर्णन करता है। इस तंत्र के एक पूर्ण दौर को पकड़ने वाला पूर्ण कोर समीकरण, यह दिखाते हुए कि कुल क्वांटम स्थिति कैसे विकसित होती है, इस प्रकार दिया गया है:
$$ \rho_T^{\text{QR round}}(\rho_T) := \text{Tr}_m[U_{\text{QR}}(n)\rho_T U_{\text{QR}}^\dagger(n)] \otimes \rho_a^{\otimes m} $$
यह समीकरण, जो पत्र में समीकरण (19) के रूप में पाया गया है, PBEC-BQR प्रोटोकॉल के एक दौर के बाद $n$-क्यूबिट रजिस्टर की कुल क्वांटम स्थिति $\rho_T$ के परिवर्तन का वर्णन करता है। यह एकात्मक एंट्रॉपी संपीड़न और विघटनकारी थर्मलाइजेशन दोनों चरणों को समाहित करता है।
पद-दर-पद विच्छेदन
आइए इस मास्टर समीकरण के प्रत्येक घटक को उसके गणितीय परिभाषा, भौतिक/तार्किक भूमिका और चुने गए गणितीय संचालन के पीछे के तर्क को समझने के लिए विच्छेदित करें।
-
$\rho_T$:
- गणितीय परिभाषा: यह घनत्व मैट्रिक्स है जो BQR के एक दौर से पहले $n$-क्यूबिट रजिस्टर की कुल क्वांटम स्थिति का प्रतिनिधित्व करता है। यह एक सकारात्मक-अर्ध-निश्चित हर्मिटियन ऑपरेटर है जिसका ट्रेस एक के बराबर है।
- भौतिक/तार्किक भूमिका: $\rho_T$ क्वांटम रेफ्रिजरेटर के एक दौर के लिए इनपुट स्थिति है। इसमें सभी $n$ क्यूबिट की क्वांटम जानकारी होती है, जिसमें लक्ष्य क्यूबिट जिसका ध्रुवीकरण बढ़ाया जाना है, सहायक क्यूबिट जो एंट्रॉपी पुनर्वितरण में सहायता करते हैं, और रीसेट क्यूबिट जो एंट्रॉपी को अवशोषित करेंगे। यह अनिवार्य रूप से शीतलन चक्र का "कार्यशील द्रव" है।
- क्यों उपयोग किया जाता है: घनत्व मैट्रिक्स क्वांटम यांत्रिकी में एक क्वांटम प्रणाली की स्थिति का वर्णन करने के लिए मानक औपचारिकता है, विशेष रूप से जब यह एक मिश्रित अवस्था (शुद्ध अवस्थाओं का एक सांख्यिकीय पहनावा) में हो या अन्य प्रणालियों के साथ उलझी हुई हो। यह यथार्थवादी क्वांटम प्रणालियों के मॉडलिंग के लिए महत्वपूर्ण है, विशेष रूप से उन प्रणालियों के साथ जो एक तापीय स्नान के साथ परस्पर क्रिया करती हैं।
-
$\rho_T^{\text{QR round}}(\rho_T)$:
- गणितीय परिभाषा: यह घनत्व मैट्रिक्स है जो BQR प्रोटोकॉल के एक पूर्ण दौर के बाद $n$-क्यूबिट रजिस्टर की कुल क्वांटम स्थिति का प्रतिनिधित्व करता है। यह परिवर्तन का आउटपुट राज्य है।
- भौतिक/तार्किक भूमिका: यह क्वांटम रेफ्रिजरेटर की अद्यतन स्थिति है जिसके बाद उसने शीतलन का एक चक्र पूरा किया है। प्रोटोकॉल का लक्ष्य यह है कि इस आउटपुट स्थिति के भीतर, लक्ष्य क्यूबिट के ध्रुवीकरण परिमाण में वृद्धि हुई है, जिससे यह "ठंडा" या अधिक पक्षपाती हो गया है। यह स्थिति चक्रीय संचालन में अगले दौर के लिए इनपुट के रूप में कार्य करती है।
- क्यों उपयोग किया जाता है: यह संकेतन स्पष्ट रूप से इंगित करता है कि स्थिति $\rho_T$ "QR दौर" ऑपरेशन द्वारा परिभाषित परिवर्तन से गुजरती है, जिससे एक नई स्थिति प्राप्त होती है।
-
$U_{\text{QR}}(n)$:
- गणितीय परिभाषा: यह $n$-क्यूबिट रजिस्टर पर कार्य करने वाला एक वैश्विक एकात्मक ऑपरेटर है। PBEC-BQR के लिए, यह स्थानीय एकात्मक संचालन के अनुक्रम से बना है, $U_{C_j}$, एक सीढ़ी-जैसी तरीके से लागू किया गया है (जैसे, $U_{\text{QR}}(n) = U_{C_n} (I_2 \otimes U_{C_{n-1}}) \dots (I_2^{\otimes (n-3)} \otimes U_{C_3})$ जैसा कि समीकरण (B7) में दिखाया गया है)।
- भौतिक/तार्किक भूमिका: यह एकात्मक संचालन "एंट्रॉपी संपीड़न" चरण करता है। यह पूरे $n$-क्यूबिट रजिस्टर में एंट्रॉपी को सुसंगत रूप से पुनर्वितरित करता है, प्रभावी रूप से लक्ष्य और सहायक क्यूबिट से एंट्रॉपी निकालता है और इसे रीसेट क्यूबिट में केंद्रित करता है। यहां मुख्य नवाचार इसकी द्विदिशीय प्रकृति है: यह लक्ष्य क्यूबिट के ध्रुवीकरण परिमाण ($|\alpha|$) को बढ़ाता है जबकि उसके मूल संकेत को संरक्षित करता है, उस संकेत के पूर्व ज्ञान की आवश्यकता के बिना। यह मुख्य "शीतलन" क्रिया है।
- क्यों उपयोग किया जाता है: एकात्मक संचालन क्वांटम यांत्रिकी में मौलिक हैं, जो प्रतिवर्ती परिवर्तन का प्रतिनिधित्व करते हैं जो एक बंद प्रणाली की कुल एंट्रॉपी को संरक्षित करते हैं। इस एकात्मक को सावधानीपूर्वक डिजाइन करके, लेखक एंट्रॉपी वितरण को हेरफेर कर सकते हैं, जिससे वांछित ध्रुवीकरण वृद्धि प्राप्त होती है। स्थानीय एकात्मक के अनुक्रम का उपयोग प्रोटोकॉल को एक एकल, जटिल वैश्विक एकात्मक की तुलना में अधिक प्रयोगात्मक रूप से व्यवहार्य बनाता है।
-
$U_{\text{QR}}^\dagger(n)$:
- गणितीय परिभाषा: यह एकात्मक ऑपरेटर $U_{\text{QR}}(n)$ का हर्मिटियन संयुग्म (एडजॉइंट) है।
- भौतिक/तार्किक भूमिका: क्वांटम यांत्रिकी में, जब एक एकात्मक ऑपरेटर $U$ घनत्व मैट्रिक्स $\rho$ पर कार्य करता है, तो परिवर्तन $U \rho U^\dagger$ द्वारा दिया जाता है। एडजॉइंट यह सुनिश्चित करता है कि परिवर्तित स्थिति एक मान्य घनत्व मैट्रिक्स (हर्मिटियन, सकारात्मक-अर्ध-निश्चित, और ट्रेस-संरक्षण) बनी रहे।
- क्यों उपयोग किया जाता है: घनत्व मैट्रिक्स पर एकात्मक परिवर्तन को सही ढंग से लागू करने के लिए यह एक गणितीय आवश्यकता है।
-
$\text{Tr}_m[\dots]$:
- गणितीय परिभाषा: यह $m$ रीसेट क्यूबिट पर आंशिक ट्रेस ऑपरेशन को दर्शाता है। यदि कुल प्रणाली दो उप-प्रणालियों, A और B से बनी है, और इसकी स्थिति $\rho_{AB}$ है, तो $\text{Tr}_B[\rho_{AB}]$ उप-प्रणाली A की कम घनत्व मैट्रिक्स प्राप्त करती है।
- भौतिक/तार्किक भूमिका: यह ऑपरेशन एंट्रॉपी को अवशोषित करने के बाद रीसेट क्यूबिट के $m$ को सिस्टम से प्रभावी "हटाने" या "त्यागने" का प्रतिनिधित्व करता है। यह विघटनकारी चरण का पहला भाग है, जो सिस्टम को थर्मलाइजेशन के लिए तैयार करता है।
- क्यों उपयोग किया जाता है: जब कुल प्रणाली एक मिश्रित या उलझी हुई अवस्था में होती है, तो उप-प्रणाली की कम स्थिति प्राप्त करने के लिए आंशिक ट्रेस सही गणितीय उपकरण है। यहां, यह हमें लक्ष्य और सहायक क्यूबिट की स्थिति पर ध्यान केंद्रित करने की अनुमति देता है, प्रभावी रूप से उन्हें "गर्म" रीसेट क्यूबिट से अलग करता है।
-
$\otimes$:
- गणितीय परिभाषा: यह टेंसर उत्पाद ऑपरेटर है, जिसका उपयोग स्वतंत्र उप-प्रणालियों की क्वांटम अवस्थाओं को संयोजित करने के लिए किया जाता है।
- भौतिक/तार्किक भूमिका: यह ऑपरेटर शेष $n-m$ क्यूबिट (पुराने रीसेट क्यूबिट को ट्रेस आउट करने के बाद) की कम स्थिति को $m$ ताज़ा, थर्मलाइज्ड रीसेट क्यूबिट ($\rho_a^{\otimes m}$) के साथ जोड़ता है। यह "थर्मलाइजेशन" या "रीसेट" चरण का प्रतिनिधित्व करता है, जहां संचित एंट्रॉपी को "ठंडे" क्यूबिट को बदलकर एक तापीय स्नान में निष्कासित किया जाता है। यह पुनर्भरण रेफ्रिजरेटर के चक्रीय संचालन के लिए महत्वपूर्ण है, जिससे यह लगातार एंट्रॉपी निकाल सकता है।
- क्यों उपयोग किया जाता है: टेंसर उत्पाद का उपयोग किया जाता है क्योंकि नए पेश किए गए रीसेट क्यूबिट को तापीय अवस्था $\rho_a$ में स्वतंत्र रूप से तैयार किया गया माना जाता है, और इस प्रकार उनकी स्थिति शेष $n-m$ क्यूबिट से असंबद्ध है।
-
$\rho_a^{\otimes m}$:
- गणितीय परिभाषा: यह $m$ समान क्यूबिट की स्थिति का प्रतिनिधित्व करता है, प्रत्येक को तापीय स्नान अवस्था $\rho_a$ में तैयार किया गया है। $\otimes m$ $\rho_a$ की $m$ प्रतियों के टेंसर उत्पाद को इंगित करता है।
- भौतिक/तार्किक भूमिका: ये "ताज़ा" या "ठंडे" क्यूबिट हैं जिन्हें "गर्म" रीसेट क्यूबिट को बदलने के लिए सिस्टम में पेश किया जाता है। वे तापीय स्नान के रूप में कार्य करते हैं, रीसेट क्यूबिट में केंद्रित एंट्रॉपी को अवशोषित करते हैं और उन्हें प्रभावी ढंग से कम-एंट्रॉपी स्थिति में रीसेट करते हैं। यह पुनःपूर्ति रेफ्रिजरेटर के चक्रीय संचालन के लिए महत्वपूर्ण है, जिससे यह लगातार एंट्रॉपी निकाल सकता है।
- क्यों उपयोग किया जाता है: यह पद शीतलन चक्र के विघटनकारी भाग को मॉडल करता है, जहां प्रणाली एंट्रॉपी को बाहर निकालने के लिए एक बाहरी वातावरण (तापीय स्नान) के साथ परस्पर क्रिया करती है। समान तापीय स्नान क्यूबिट की धारणा इस रीसेट प्रक्रिया के मॉडलिंग को सरल बनाती है।
चरण-दर-चरण प्रवाह
आइए इस क्वांटम रेफ्रिजरेशन तंत्र के एक दौर से गुजरने वाले एक अमूर्त डेटा बिंदु के सटीक जीवनचक्र का पता लगाएं, जिसे उसके प्रारंभिक ध्रुवीकरण $\alpha$ द्वारा दर्शाया गया है।
- प्रारंभिक स्थिति तैयारी: एक अमूर्त डेटा बिंदु, जिसे उसके फ़ीचर वेक्टर $x$ द्वारा दर्शाया गया है, को एक क्वांटम स्थिति के ध्रुवीकरण $\alpha$ में एन्कोड किया जाता है। यह स्थिति, $n-1$ अन्य क्यूबिट (सहायक और रीसेट क्यूबिट) के साथ, प्रारंभिक $n$-क्यूबिट रजिस्टर, $\rho_T$ बनाती है। सरलता के लिए, कल्पना करें कि लक्ष्य क्यूबिट पहला है, और शेष $n-1$ क्यूबिट कुछ प्रारंभिक स्थिति में तैयार किए गए हैं, अक्सर तापीय।
- एंट्रॉपी संपीड़न (एकात्मक चरण): पूरे $n$-क्यूबिट रजिस्टर, $\rho_T$, को एक सावधानीपूर्वक डिज़ाइन किए गए वैश्विक एकात्मक ऑपरेशन, $U_{\text{QR}}(n)$ के अधीन किया जाता है। इसे एक क्वांटम सॉर्टिंग मशीन के रूप में सोचें। यह एकात्मक सुसंगत रूप से सभी क्यूबिट में कम्प्यूटेशनल आधार अवस्थाओं की आबादी को फेरबदल करता है। इसका प्राथमिक कार्य लक्ष्य क्यूबिट और सहायक क्यूबिट से एंट्रॉपी निकालना है, इस "गर्मी" को $m$ "रीसेट" क्यूबिट के एक विशिष्ट उपसमूह में केंद्रित करना है। यहां जादू यह है कि यह एकात्मक "द्विदिशीय" है: इसे परवाह नहीं है कि लक्ष्य क्यूबिट का प्रारंभिक ध्रुवीकरण $\alpha$ सकारात्मक है या नकारात्मक। यह बस उसके परिमाण को बढ़ाता है, $\alpha$ को $\alpha'$ में बदलता है जैसे कि $|\alpha'| > |\alpha|$, जबकि $\alpha$ के मूल संकेत को संरक्षित करता है। यह लक्ष्य क्यूबिट को "ठंडा" या अधिक ध्रुवीकृत बनाता है।
- एंट्रॉपी निष्कासन (आंशिक ट्रेस): एकात्मक संचालन के बाद, $m$ रीसेट क्यूबिट, जो अब "गर्म" हो गए हैं, प्रभावी रूप से अलग हो गए हैं और सिस्टम से हटा दिए गए हैं। गणितीय रूप से, हम इन $m$ क्यूबिट पर एक आंशिक ट्रेस, $\text{Tr}_m[\dots]$ करते हैं। यह हमें शेष $n-m$ क्यूबिट के लिए एक कम क्वांटम स्थिति छोड़ देता है, जिसमें अब संवर्धित लक्ष्य क्यूबिट और सहायक क्यूबिट शामिल हैं। यह चरण "ठंडे" क्यूबिट की पुनःपूर्ति के लिए सिस्टम को तैयार करता है।
- थर्मलाइजेशन/रीसेट (क्यूबिट प्रतिस्थापन): दौर को पूरा करने और यह सुनिश्चित करने के लिए कि रेफ्रिजरेटर लगातार काम कर सके, $m$ बिल्कुल नए, "ठंडे" क्यूबिट, प्रत्येक को तापीय स्नान अवस्था $\rho_a$ में तैयार किया गया है, पेश किए जाते हैं। इन ताज़ा क्यूबिट को फिर टेंसर उत्पाद ($\otimes \rho_a^{\otimes m}$) के माध्यम से शेष $n-m$ क्यूबिट के साथ जोड़ा जाता है। यह क्रिया प्रभावी रूप से "तापीय स्नान" में संचित एंट्रॉपी को बाहर निकालकर रेफ्रिजरेटर की क्षमता को "रीसेट" करती है (ताज़ा क्यूबिट द्वारा दर्शाया गया)। प्रणाली अब एक $n$-क्यूबिट रजिस्टर पर वापस आ गई है, लेकिन एक लक्ष्य क्यूबिट के साथ जिसमें संवर्धित ध्रुवीकरण है।
- अगले दौर के लिए रीसाइक्लिंग: नवगठित $n$-क्यूबिट स्थिति BQR के अगले दौर के लिए इनपुट $\rho_T$ बन जाती है। संवर्धित लक्ष्य क्यूबिट को माप के लिए निकाला जा सकता है, या और भी अधिक ध्रुवीकरण वृद्धि प्राप्त करने के लिए इसे कई दौर ($N_{\text{rounds}}$) के लिए दोहराया जा सकता है। शेष $n-1$ क्यूबिट (सहायक और ताज़ा रीसेट क्यूबिट) को बाद के लक्ष्य क्यूबिट तैयार करने के लिए रीसायकल किया जाता है, जिससे प्रोटोकॉल संसाधन-कुशल हो जाता है।
यह पुनरावृत्ति प्रक्रिया सुनिश्चित करती है कि लक्ष्य क्यूबिट के ध्रुवीकरण को लगातार बढ़ाया जाता है, जिससे वर्गीकरण संकेत मजबूत और अधिक विश्वसनीय हो जाता है।
अनुकूलन गतिशीलता
BQR तंत्र क्वांटम मशीन लर्निंग के प्रदर्शन को सीधे परिमित नमूनाकरण त्रुटियों की चुनौती को संबोधित करके अनुकूलित करता है, जो क्वांटम मापों की संभाव्य प्रकृति से उत्पन्न होती हैं। यह मॉडल मापदंडों को पारंपरिक अर्थों में समायोजित करके नहीं, बल्कि वर्गीकरण स्कोर के सिग्नल-टू-नॉइज़ अनुपात को बढ़ाने के लिए क्वांटम अवस्थाओं को पूर्व-संसाधित करके ऐसा करता है।
- हानि परिदृश्य और ग्रेडिएंट विश्वसनीयता: QML में, वर्गीकरण स्कोर $q(x, \theta) = \alpha(x, \theta)$ का अनुमान परिमित मापों की संख्या से लगाया जाता है। प्रशिक्षण प्रक्रिया में आम तौर पर ग्रेडिएंट $\frac{dl}{d\theta}$ (समीकरण (8)) के आधार पर मॉडल मापदंडों $\theta$ को पुनरावृत्त रूप से अद्यतन करके एक हानि फ़ंक्शन (जैसे, हिंज हानि) को कम करना शामिल है। यदि ध्रुवीकरण $|\alpha(x, \theta)|$ का परिमाण छोटा है, तो परिमित मापों से सांख्यिकीय उतार-चढ़ाव आसानी से $\alpha$ के वास्तविक संकेत को अस्पष्ट कर सकते हैं, जिससे गलत वर्गीकरण लेबल या, महत्वपूर्ण रूप से, गलत निर्देशित ग्रेडिएंट अपडेट हो सकते हैं। यह "हानि परिदृश्य" को प्रभावी ढंग से बहुत सपाट या शोरगुल वाला बनाता है, जिससे कुशल अनुकूलन में बाधा आती है।
- ध्रुवीकरण वृद्धि "सिग्नल प्रवर्धन" के रूप में: BQR का मुख्य "अनुकूलन" इस ध्रुवीकरण के परिमाण को बढ़ाना है,
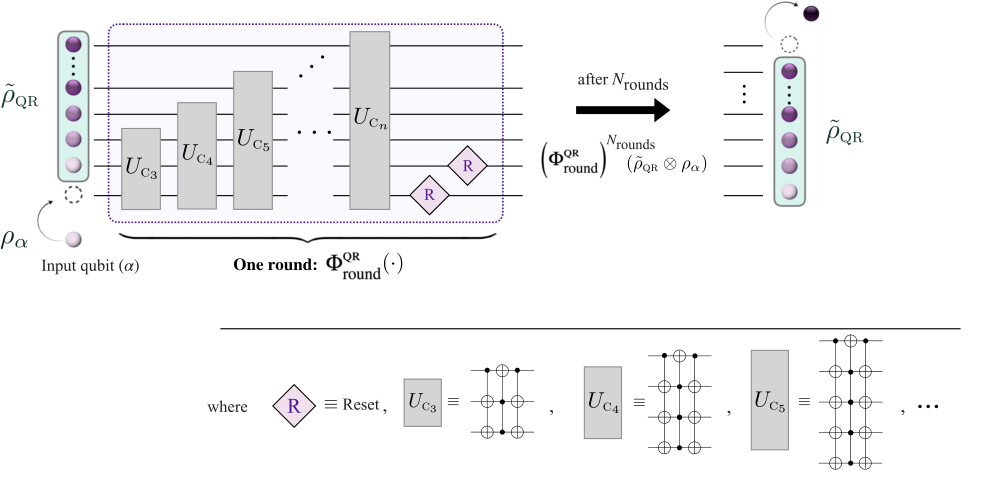 FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
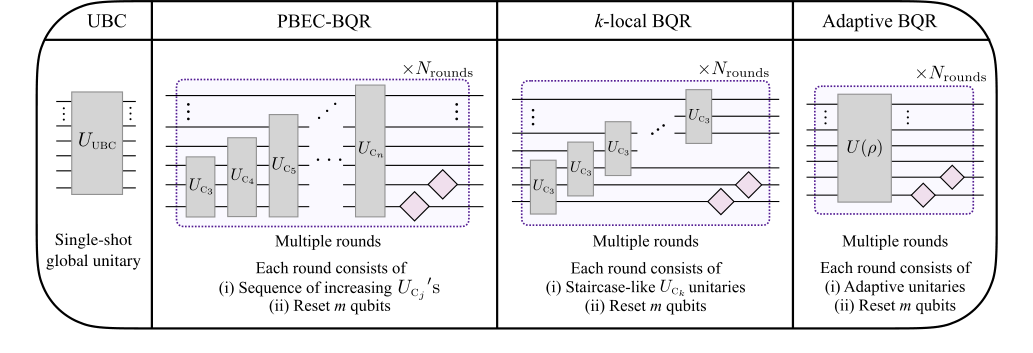 FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अपने गणितीय दावों को कठोरता से मान्य करने के लिए, लेखकों ने अपने द्विदिशीय क्वांटम रेफ्रिजरेटर (BQR) प्रोटोकॉल के व्यावहारिक वर्गीकरण प्रदर्शन पर ध्यान केंद्रित करते हुए, Qiskit और scikit-learn का उपयोग करके सिम्युलेटेड प्रयोगों की एक श्रृंखला को सावधानीपूर्वक डिज़ाइन किया। मुख्य उद्देश्य यह प्रदर्शित करना था कि BQR के माध्यम से माप क्यूबिट के ध्रुवीकरण को बढ़ाना सीधे क्वांटम मशीन लर्निंग में वर्गीकरण सटीकता में मूर्त सुधारों में तब्दील होता है, विशेष रूप से परिमित नमूनाकरण त्रुटियों को कम करके।
प्रायोगिक वास्तुकला एक रूढ़िवादी विकल्प पर केंद्रित थी: तीन-स्थानीय BQR प्रोटोकॉल (k=3), $n=5$ सिस्टम क्यूबिट, $m=2$ रीसेट क्यूबिट और $N_{rounds}=2$ शीतलन दौर के साथ संचालित। यह विशिष्ट विन्यास चुना गया था क्योंकि यदि यह अधिक व्यावहारिक, k-स्थानीय संस्करण भी बेसलाइन से बेहतर प्रदर्शन कर सकता है, तो पूर्ण BQR प्रोटोकॉल (जो मजबूत शीतलन प्रदान करता है) को और भी बेहतर प्रदर्शन करने की उम्मीद की जाएगी।
जिन "पीड़ितों" या बेसलाइन मॉडल के खिलाफ BQR का क्रूरतापूर्वक परीक्षण किया गया था, वे पारंपरिक नमूनाकरण विधियाँ थीं, जो किसी भी BQR वृद्धि का उपयोग नहीं करती थीं। निष्पक्ष तुलना सुनिश्चित करने और परिमित नमूनाकरण त्रुटि (जिसे BQR कम करने का लक्ष्य रखता है) के प्रभाव को अलग करने के लिए, बेसलाइन विधि को आनुपातिक रूप से अधिक माप शॉट्स आवंटित किए गए थे। विशेष रूप से, यदि BQR-संवर्धित क्लासिफायर $k_{BQR}$ माप शॉट्स (जैसे, यथार्थवादी NISQ बाधाओं को दर्शाने के लिए 10 या 100 शॉट्स) का उपयोग करता है, तो पारंपरिक बेसलाइन को $k_c = k_{BQR} \times m \times (N_{rounds} - 1) + n$ शॉट्स दिए गए थे। $k_{BQR}=10$ के लिए, इसका मतलब था कि बेसलाइन को $10 \times 2 \times (2-1) + 5 = 25$ शॉट्स प्राप्त हुए। $k_{BQR}=100$ के लिए, बेसलाइन को $100 \times 2 \times (2-1) + 5 = 205$ शॉट्स प्राप्त हुए। इस स्केलिंग ने सुनिश्चित किया कि दोनों दृष्टिकोणों ने तुलनीय क्यूबिट संसाधनों का उपभोग किया, जिससे किसी भी देखे गए प्रदर्शन अंतर को BQR की दक्षता का श्रेय दिया जा सके न कि केवल अधिक कच्चे मापों का।
QML मॉडल की अंतर्निहित अभिव्यक्ति या प्रशिक्षण क्षमता से नमूनाकरण त्रुटि के प्रभाव को अलग करने के लिए, समस्या सेटअप को सरल बनाया गया था। प्रयोगों ने एकल-क्यूबिट कम घनत्व मैट्रिक्स के रूप में अंतिम क्वांटम स्थिति तक सीधी पहुंच मानी, जहां इसका Z-ध्रुवीकरण सीधे वर्गीकरण संकेत को एन्कोड करता है। इसने कम मापों से भविष्यवाणियों की विश्वसनीयता में BQR कैसे सुधार करता है, इसका स्पष्ट मूल्यांकन करने की अनुमति दी।
प्रयोगों ने बाइनरी वर्गीकरण कार्यों के लिए विभिन्न प्रकार के डेटासेट का उपयोग किया, जिसमें सिंथेटिक डेटासेट (यूनिफ़ॉर्म और गॉसियन वितरण) और कई वास्तविक दुनिया के डेटासेट शामिल थे: आइरिस, वाइन, हस्तलिखित अंक (विशेष रूप से 2 बनाम 5), सोनार, और पीमा इंडियंस डायबिटीज। प्रत्येक डेटासेट के लिए, संतुलित कार्य बनाने के लिए प्रत्येक वर्ग से 50 डेटा बिंदुओं को यादृच्छिक रूप से नमूना लिया गया था, और इस संपूर्ण नमूनाकरण और मूल्यांकन प्रक्रिया को 100 बार दोहराया गया था ताकि एक मजबूत सांख्यिकीय पहनावा उत्पन्न हो सके।
महत्वपूर्ण रूप से, लेखकों ने यथार्थवादी शोरगुल वाले मध्यवर्ती-पैमाने के क्वांटम (NISQ) स्थितियों के तहत प्रोटोकॉल का भी परीक्षण किया। संख्यात्मक सिमुलेशन में सामान्यीकृत आयाम अवमूल्यन (GAD) और डिपोलराइजिंग चैनल शामिल थे, जो क्रमशः ऊर्जा विश्राम और स्टोकेस्टिक गेट त्रुटियों को मॉडल करते हैं। दो शोर शासन पर विचार किया गया: एक "विशिष्ट NISQ शासन" जिसमें मध्यम शोर पैरामीटर थे और एक "सबसे खराब स्थिति शासन" जिसमें प्रोटोकॉल की मजबूती का परीक्षण करने के लिए जानबूझकर अतिरंजित शोर ताकतें थीं। इस व्यापक प्रायोगिक डिजाइन का उद्देश्य BQR की प्रभावकारिता और व्यावहारिकता के निर्विवाद प्रमाण प्रदान करना था।
साक्ष्य क्या साबित करते हैं
पत्र में प्रस्तुत साक्ष्य निश्चित रूप से साबित करते हैं कि द्विदिशीय क्वांटम रेफ्रिजरेटर (BQR) प्रोटोकॉल, विशेष रूप से तीन-स्थानीय BQR, यथार्थवादी शोर स्थितियों के तहत भी, क्वांटम मशीन लर्निंग में नमूना दक्षता को महत्वपूर्ण रूप से बढ़ाता है और वर्गीकरण सटीकता में सुधार करता है। लक्ष्य क्यूबिट के ध्रुवीकरण के परिमाण को बढ़ाने का मुख्य तंत्र, जबकि इसके संकेत को संरक्षित करता है, वास्तव में काम करने के लिए दिखाया गया था, जिससे सटीक वर्गीकरण के लिए आवश्यक मापों की संख्या में पर्याप्त कमी आई।
सबसे सम्मोहक साक्ष्य तालिका I से आता है, जो सभी परीक्षण किए गए डेटासेट में वर्गीकरण सटीकता को सारांशित करता है। हर एक मामले में, BQR-संवर्धित क्लासिफायर ने लगातार पारंपरिक नमूना बेसलाइन को बेहतर प्रदर्शन किया। उदाहरण के लिए, यूनिफ़ॉर्म डेटासेट पर $k_{BQR}=10$ शॉट्स के साथ, BQR ने $95.8\% \pm 1.8\%$ की सटीकता हासिल की, जबकि बेसलाइन (25 शॉट्स के साथ) केवल $93.1\% \pm 2.3\%$ तक पहुंची। जब $k_{BQR}$ को 100 शॉट्स (बेसलाइन 205 शॉट्स पर) तक बढ़ाया गया, तो BQR ने $99.3\% \pm 0.7\%$ सटीकता हासिल की, जबकि बेसलाइन के $97.7\% \pm 1.3\%$ की तुलना में। बेहतर प्रदर्शन का यह पैटर्न सभी सिंथेटिक और वास्तविक दुनिया के डेटासेट में देखा गया, जिसमें आइरिस, वाइन, हस्तलिखित अंक, सोनार और डायबिटीज शामिल हैं। इन सुधारों की सांख्यिकीय सार्थकता को वेल्च के टी-टेस्ट द्वारा कठोरता से पुष्टि की गई थी, जिसने सभी मामलों में 0.05 से कम पी-मान उत्पन्न किए, यह दर्शाता है कि देखे गए लाभ यादृच्छिक संयोग के कारण नहीं थे।
कच्ची सटीकता से परे, पत्र अंतर्निहित तंत्र की सफलता का ग्राफिकल प्रमाण प्रदान करता है। चित्र 5 और 6 आदर्श, शोर-मुक्त सेटिंग में प्रगतिशील सीमा एंट्रॉपी संपीड़न-द्विदिशीय क्वांटम रेफ्रिजरेटर (PBEC-BQR) के लिए संवर्धित ध्रुवीकरण ($\alpha_{PBEC}'$) और त्रुटि-संभावना सीमा ($r_{PBEC}$) के कमी कारक को दर्शाते हैं। ये चित्र दिखाते हैं कि BQR ध्रुवीकरण परिमाण को काफी बढ़ाता है और त्रुटि सीमा को काफी कम करता है, विशेष रूप से मध्यवर्ती और उच्च-ध्रुवीकरण व्यवस्थाओं में। यह सीधे गणितीय दावे को मान्य करता है कि एंट्रॉपी में कमी से बेहतर सांख्यिकीय अनुमान होते हैं।
इसके अलावा, NISQ उपकरणों के लिए एक महत्वपूर्ण चिंता, शोर के प्रति BQR की मजबूती का पूरी तरह से प्रदर्शन किया गया था। चित्र 10 दिखाता है कि विशिष्ट NISQ-स्तर के शोर के तहत भी, BQR अभी भी महत्वपूर्ण ध्रुवीकरण वृद्धि प्राप्त करता है, एक स्थिर अवस्था में अभिसरण करता है जो आदर्श शोर-मुक्त प्रदर्शन के करीब रहता है। चित्र 11 इसे विशिष्ट NISQ शोर के तहत त्रुटि-संभावना सीमा ($r_{QR}$) की कमी कारक को मात्रात्मक रूप से दर्शाता है। आयाम अवमूल्यन (जो ध्रुवीकरण को एक दिशा की ओर ले जाता है) द्वारा पेश की गई कुछ विषमता के बावजूद, समग्र कमी कारक पर्याप्त बना हुआ है, यह साबित करता है कि प्रोटोकॉल अपूर्ण क्वांटम हार्डवेयर में भी नमूना त्रुटियों को प्रभावी ढंग से कम करता है। अंत में, चित्र 12 प्रोटोकॉल के लचीलेपन का एक शक्तिशाली प्रमाण प्रदान करता है, यह दिखाते हुए कि "सबसे खराब स्थिति" शोर शासन के तहत भी—जानबूझकर अतिरंजित शोर शक्तियों के साथ—BQR आदर्श मामले के समान प्रारंभिक ध्रुवीकरण की सीमा पर त्रुटि संभावना में कमी का उत्पादन जारी रखता है। यह निर्विवाद साक्ष्य पुष्टि करता है कि BQR का मुख्य तंत्र व्यवहार में काम करता है, जो QML में बढ़ी हुई सीखने के प्रदर्शन के लिए एक भौतिक रूप से आधारित और शोर-प्रतिरोधी मार्ग प्रदान करता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि द्विदिशीय क्वांटम रेफ्रिजरेटर (BQR) प्रोटोकॉल QML के लिए एक महत्वपूर्ण उन्नति प्रस्तुत करते हैं, लेखक ईमानदारी से कई सीमाओं को स्वीकार करते हैं और भविष्य के शोध के लिए सम्मोहक रास्ते प्रस्तावित करते हैं।
एक उल्लेखनीय सीमा कम-ध्रुवीकरण व्यवस्था में प्रदर्शन है। एकात्मक द्विदिशीय शीतलन (UBC) और BQR प्रोटोकॉल दोनों कोई सार्थक सुधार प्रदान नहीं करते हैं जब प्रारंभिक ध्रुवीकरण $\alpha$ शून्य के बहुत करीब होता है। जबकि लाभ का क्षेत्र प्रोटोकॉल मापदंडों को अनुकूलित करके विस्तारित किया जा सकता है, अत्यधिक कम-ध्रुवीकरण सीमा एक चुनौतीपूर्ण क्षेत्र बनी हुई है। यह बताता है कि कुछ प्रकार के डेटा या मॉडल अवस्थाओं के लिए, BQR के लाभ न्यूनतम हो सकते हैं, जिससे ऐसे परिदृश्यों में वैकल्पिक या पूरक रणनीतियों की आवश्यकता होती है।
एक और खुला प्रश्न PBEC-BQR प्रोटोकॉल की इष्टतमता से संबंधित है। पत्र निश्चित रूप से स्थापित नहीं करता है कि यह विशिष्ट शीतलन प्रोटोकॉल परिमित नमूनाकरण त्रुटियों को कम करने के लिए वास्तव में इष्टतम है या नहीं। यदि यह नहीं है, तो प्रोटोकॉल को और परिष्कृत करने के लिए भविष्य के काम की एक स्पष्ट दिशा है, जिससे संभावित रूप से और भी अधिक प्रदर्शन लाभ हो सकते हैं।
संसाधन के दृष्टिकोण से, जबकि BQR योजनाएं एकल वैश्विक एकात्मक UBC की तुलना में अधिक व्यावहारिक हैं, उन्हें अभी भी अतिरिक्त क्यूबिट की आवश्यकता होती है ताकि शीतलन के चक्रीय दौरों को बनाए रखा जा सके। यह एकल-शॉट UBC की तुलना में क्यूबिट ओवरहेड को जोड़ता है। भविष्य के काम को इस ओवरहेड को कम करने के तरीकों का पता लगाना चाहिए या क्यूबिट गणना, सर्किट गहराई और शीतलन प्रदर्शन के बीच व्यापार-बंद की जांच करनी चाहिए। पत्र यह भी नोट करता है कि सभी क्यूबिट पर एक एकल वैश्विक एकात्मक सबसे अच्छा ध्रुवीकरण वृद्धि प्राप्त करेगा, लेकिन इस तरह के संचालन को लागू करना अव्यावहारिक है। यह सैद्धांतिक इष्टतमता और क्वांटम कंप्यूटिंग में प्रयोगात्मक व्यवहार्यता के बीच चल रहे तनाव को उजागर करता है।
भविष्य के विकास के लिए एक महत्वपूर्ण क्षेत्र क्वांटम कर्नेल अनुमान पर प्रयोज्यता का विस्तार है। वर्तमान विधि मुख्य रूप से बाइनरी परिणामों के लिए संकेत अनुमान में सहायता करती है, जो क्वांटम कर्नेल मैट्रिक्स तत्वों का अनुमान लगाने के लिए सीधे पर्याप्त नहीं है। इन शीतलन तकनीकों को क्वांटम कर्नेल में परिमित नमूनाकरण त्रुटियों को कम करने के लिए अनुकूलित करना अद्वितीय चुनौतियां प्रस्तुत करता है, क्योंकि अनुमानित मात्राएं अधिक जटिल होती हैं। इसे संबोधित करने से क्वांटम थर्मोडायनामिक अंतर्दृष्टि के प्रभाव को QML अनुप्रयोगों के व्यापक स्पेक्ट्रम में विस्तारित किया जाएगा।
आगे देखते हुए, कई रोमांचक चर्चा विषय उभरते हैं:
- सुसंगतता और गैर-शास्त्रीय सहसंबंधों का उपयोग: पत्र में उल्लेख किया गया है कि शीतलन दक्षता में सुधार के लिए सिस्टम और स्नान क्यूबिट के भीतर सुसंगतता और गैर-शास्त्रीय सहसंबंधों का उपयोग कैसे किया जा सकता है, इसकी जांच की जाएगी। यह एक आकर्षक दिशा है, क्योंकि वर्तमान प्रोटोकॉल मुख्य रूप से विकर्ण उप-स्थान के भीतर संचालित होते हैं, जिससे वे डीफेजिंग शोर के प्रति मजबूत होते हैं लेकिन संभावित रूप से आगे वृद्धि के लिए अप्रयुक्त संसाधनों को छोड़ देते हैं।
- बंजर पठार शमन: BQR बंजर पठार प्रभाव को कैसे कम करता है, इसका एक विस्तृत मात्रात्मक विश्लेषण वारंट है। लेखकों का सुझाव है कि उनकी तकनीक का उपयोग बंजर पठार शमन के लिए मौजूदा रणनीतियों के साथ संयोजन में एक स्वतंत्र तंत्र के रूप में किया जा सकता है। इस अंतःक्रिया को समझना अधिक मजबूत और स्केलेबल QML एल्गोरिदम का कारण बन सकता है।
- डेटा रीअपलोडिंग और BQR सर्किट: डेटा रीअपलोडिंग तकनीकों के साथ BQR विधि का संबंध आकर्षक संभावनाएं खोलता है। BQR सर्किट का डेटा रीअपलोडिंग संस्करण बनाना सर्किट गहराई और क्यूबिट ओवरहेड के बीच एक व्यापक व्यापार-बंद विश्लेषण की अनुमति दे सकता है, जिससे संभावित रूप से अधिक संसाधन-कुशल कार्यान्वयन हो सकते हैं।
- बाइनरी वर्गीकरण से परे: जबकि वर्तमान कार्य बाइनरी वर्गीकरण पर केंद्रित है, एंट्रॉपी कमी के लिए अंतर्निहित थर्मोडायनामिक ढांचा संभावित रूप से अन्य QML कार्यों, जैसे प्रतिगमन या अधिक जटिल बहु-वर्ग समस्याओं के लिए अनुकूलित किया जा सकता है। इसके लिए "ध्रुवीकरण" और "संकेत" इन संदर्भों में कैसे सामान्यीकृत होते हैं, इस पर सावधानीपूर्वक विचार करने की आवश्यकता होगी।
- प्रायोगिक अहसास और हार्डवेयर अनुकूलन: NISQ शोर के तहत संख्यात्मक सिमुलेशन आशाजनक हैं, लेकिन विभिन्न क्वांटम हार्डवेयर प्लेटफार्मों (सुपरकंडक्टिंग, ट्रैप्ड-आयन, तटस्थ-परमाणु) पर वास्तविक प्रायोगिक अहसास अंतिम सत्यापन होगा। यह विशिष्ट हार्डवेयर आर्किटेक्चर और शोर विशेषताओं के लिए BQR सर्किट को अनुकूलित करने के लिए मूल्यवान प्रतिक्रिया भी प्रदान करेगा।
- QML के लिए शीतलन की सैद्धांतिक नींव: कार्य क्वांटम थर्मोडायनामिक्स और QML के बीच एक उपन्यास संबंध स्थापित करता है। सीखने के कार्यों के लिए शीतलन की मौलिक सीमाओं में आगे सैद्धांतिक अन्वेषण, और अन्य क्षेत्रों के साथ संभावित समरूपता (जैसा कि विहित अध्याय क्रम में संकेत दिया गया है), गहरी अंतर्दृष्टि प्रदान कर सकता है और पूरी तरह से नए एल्गोरिथम प्रतिमानों को प्रेरित कर सकता है।
ये विविध दृष्टिकोण इस बात पर प्रकाश डालते हैं कि BQR प्रोटोकॉल केवल वर्तमान QML चुनौतियों के लिए एक व्यावहारिक समाधान नहीं हैं, बल्कि अंतःविषय अनुसंधान के लिए एक उपजाऊ जमीन भी हैं, जो क्वांटम सूचना विज्ञान और मशीन लर्निंग की सीमाओं को आगे बढ़ाते हैं।
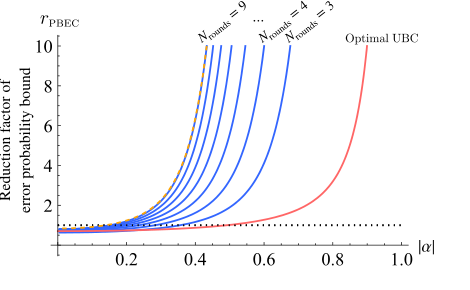 FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
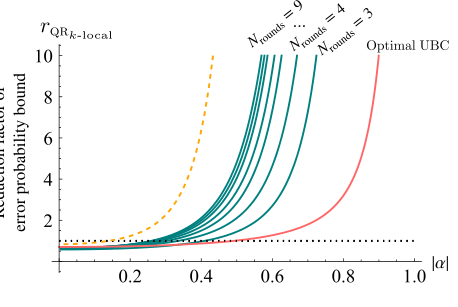 FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound
FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound