열-욕조 알고리즘 냉각을 통한 양자 기계 학습 개선
This work introduces an approach rooted in quantum thermodynamics to enhance sampling efficiency in quantum machine learning (QML).
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 문제는 양자 정보 처리(QIP)와 데이터 과학의 교차점에서 발생하며, 양자 기계 학습(QML)이라는 분야를 탄생시켰다. QML은 고전적인 능력으로는 처리하기 어려운 복잡한 데이터 분포를 다루는 데 있어 엄청난 잠재력을 가지고 있지만, 양자 측정의 확률적 특성으로 인해 내재적인 어려움에 직면해 있다. 이러한 확률적 특성은 QML 알고리즘의 훈련 및 추론 단계 모두에서 양자 상태로부터 정보, 예를 들어 관측량의 기댓값 등을 추출할 때 "유한 샘플링 오류"에 취약하다는 것을 의미한다.
역사적으로 이러한 샘플링 오류를 완화하려는 시도는 양자 진폭 추정(QAE)을 적응시키는 것과 같이 이차적인 개선을 제공했다. 그러나 QAE 프로토콜은 여러 차례의 복잡한 그로버 유사 연산을 요구하며, 이는 계산 집약적이고 현재의 잡음 중간 규모 양자(NISQ) 장치에서의 실현 가능성을 심각하게 제한한다. 더욱이, 많은 기계 학습 작업, 특히 분류의 경우, QAE는 "과도한" 수준의 정밀도를 제공한다. 종종 측정된 통계량의 부호 (예: 분류 점수가 양수인지 음수인지)만을 결정하는 것으로 충분하며, 그 정확한 크기보다는 말이다. 이러한 인식은 QAE의 이차적 개선을 능가하면서도 NISQ 하드웨어의 한계와 호환될 수 있는 보다 실용적이고 효율적인 샘플링 감소 기술의 필요성을 강조했다.
저자들이 이 연구를 개발하도록 강요한 이전 접근 방식의 근본적인 한계, 즉 "고통점"은 두 가지이다. 첫째, QAE와 같은 기존 방법은 현재 NISQ 하드웨어에서의 실용적인 구현에 비해 너무 많은 리소스를 소모하고 복잡하다(많은 그로버 유사 연산 필요). 이는 실시간 적용을 불가능하게 만든다. 둘째, 이 연구에 영감을 준 기존의 알고리즘 냉각 기술은 본질적으로 "단방향"이다. 이는 미리 결정된 기저 상태(예: $|0\rangle$)의 모집단을 증가시키도록 설계되었으며, 원하는 출력의 부호를 사전에 알 필요가 있다. 그러나 지도 학습 QML에서는 분류 점수의 부호(레이블 또는 기울기 방향을 결정하는)가 우리가 결정하고자 하는 정확히 알려지지 않은 양이다. 이전 냉각 방법에서 이러한 "양방향" 기능의 부족은 편향 방향이 처음에 알려지지 않은 QML 분류 문제에 직접 적용할 수 없음을 의미했다. 본 논문은 새롭고, 부호 보존적이며, 양방향 냉각 접근 방식을 도입함으로써 이러한 한계를 직접적으로 해결한다.
직관적인 도메인 용어
- 양자 기계 학습 (QML): 일반 컴퓨터가 시험 공부를 하는 학생처럼 데이터에서 패턴을 학습하려고 하는 것을 상상해 보라. QML은 그 학생에게 완전히 새로운 방식으로 정보를 처리할 수 있는 마법의 양자 두뇌를 주는 것과 같다. 이를 통해 학생은 훨씬 더 빨리 학습하거나 일반 학생이 놓칠 수 있는 패턴을 발견할 수 있으며, 특히 매우 복잡한 데이터의 경우 더욱 그렇다.
- 잡음 중간 규모 양자 (NISQ) 장치: NISQ 장치를 1세대 전기 자동차라고 생각하라. 혁신적이고 엄청난 잠재력을 보여주지만, 배터리 수명이 제한적이고 다소 신뢰할 수 없으며, 충전하거나 수리하기 전에 특정 작업만 수행할 수 있다. 아직 장거리 여행에는 적합하지 않지만, 완전한 기능을 갖춘 양자 차량으로 가는 중요한 단계이다.
-
열-욕조 알고리즘 냉각 (HBAC): 중요한 문서가 쓰레기와 섞여 있는 어수선한 책상을 상상해 보라. HBAC는 꼼꼼한 조수와 같아서 두 단계로 정리한다. 첫째, 중요한 문서를 모두 한 묶음으로 모아 쓰레기를 책상의 다른 부분으로 밀어낸다(엔트로피 압축). 둘째, 책상에서 쓰레기를 버린다(열화/재설정). 그러면 중요한 문서가 훨씬 더 체계적이고 접근하기 쉬워진다. 이것은 핵심 해결책이다.
-
큐비트의 분극 (Polarization): 나침반 바늘을 상상해 보라. 완벽하게 균형 잡혀 있다면 어디든 가리킬 수 있다(낮은 분극). 북쪽으로 강하게 끌린다면 북쪽으로 높은 분극을 가진다. 양자 비트(큐비트)의 경우, 분극은 특정 상태(예: '0')를 다른 상태(예: '1')보다 얼마나 강하게 선호하는지를 설명한다. 높은 분극은 큐비트로부터 훨씬 더 명확하고 신뢰할 수 있는 '예' 또는 '아니오' 답변을 의미한다.
- 엔트로피 압축: 넓은 홀에 무작위로 흩어져 있는 사람들의 그룹(높은 엔트로피)을 고려해 보라. 엔트로피 압축은 아무도 제거하지 않고 VIP를 모두 지정된 접근하기 쉬운 영역으로 안내하는 영리한 이벤트 주최자와 같다. 나머지 참석자는 흩어져 있다. 홀에 있는 사람(정보)의 총 수는 동일하지만, "중요한" 부분은 이제 훨씬 더 집중되고 질서 정연하다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 양자 기계 학습(QML) 알고리즘, 특히 변분 양자 이진 분류기(VQBC)에서 발생하는 내재적인 유한 샘플링 오류이다. 이 오류는 QML의 훈련 및 예측 단계 모두에 근본적인 양자 측정의 확률적 특성에서 발생한다.
입력/현재 상태:
현재 상태에서 QML 알고리즘은 양자 데이터 표현을 처리하며, 그 출력(예: 분류 레이블 또는 기울기 방향)은 측정된 통계량, 특히 대상 큐비트의 Z-분극 $\alpha(x, \theta)$의 부호에 인코딩된다. 이 분극은 단일 큐비트 밀도 연산자 $\rho_1(x, \theta) = \frac{I + \alpha(x, \theta)Z + \beta(x, \theta)X + \gamma(x, \theta)Y}{2}$에서 파생되며, 여기서 분류 점수는 $q(x, \theta) = \alpha(x, \theta)$이다. 이 점수를 추정하기 위해 유한 횟수의 측정 반복(샷), $k$로 표시되는 횟수가 수행된다. 이 유한 $k$는 추정 오류를 초래한다. 강력한 예측을 위해 추정된 기댓값 $\mu$는 $|\mu - \langle M \rangle| < |\langle M \rangle|$를 만족해야 하며, 여기서 $\langle M \rangle$은 실제 기댓값이다. 훈련을 위해서는 $q(x_j, \theta)$에 대한 추정 오류가 힌지 손실 기울기를 정확하게 평가하기 위해 $|q(x_j, \theta) - b|$보다 작아야 한다. 이러한 작업에 대한 오류 확률은 예를 들어 예측의 경우 다음과 같이 위에서 제한된다.
$$ \text{Pr[error]} = \text{Pr}[|\mu - \langle M \rangle| \geq |\langle M \rangle|] \leq \frac{1 - \alpha^2(x, \theta^*)}{k\alpha^2(x, \theta^*)} $$
그리고 훈련의 경우:
$$ \text{Pr[error]} = \frac{1 - \alpha^2(x_j, \theta)}{k(\alpha(x_j, \theta) - b)^2} $$
이러한 경계는 $|\alpha(x, \theta)|$의 크기가 작을수록 낮은 오류 확률을 유지하기 위해 더 많은 샷 $k$가 필요함을 강조한다. 결정적으로, QML 맥락에서 $\alpha(x, \theta)$의 부호는 알고리즘이 결정하고자 하는 정보(레이블 또는 기울기 방향)를 나타내기 때문에 사전에 알려지지 않는다.
원하는 종점 (출력/목표 상태):
원하는 종점은 이러한 유한 샘플링 오류를 크게 줄여 정확한 분류 및 기울기 추정에 필요한 측정 반복 횟수 $k$를 최소화하는 것이다. 이는 대상 큐비트의 분극 크기 $|\alpha(x, \theta)|$를 새로운, 향상된 값 $|\alpha'(x, \theta)|$로 증가시킴으로써 달성된다. 핵심 요구 사항은 이 향상이 양방향이어야 한다는 것이다. 즉, 분극의 부호는 유지되면서 크기가 증가해야 한다. 단일 큐비트 밀도 행렬에 대한 목표 변환은 다음과 같다.
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{with} \quad \begin{cases} \alpha' > \alpha & \text{if } \alpha > 0 \\ \alpha' < \alpha & \text{if } \alpha < 0 \end{cases} $$
이 과정은 계산적으로 비용이 많이 드는 그로버 반복 또는 양자 위상 추정과 같은 연산에 의존하지 않고 훈련 및 예측 단계 모두에서 샘플 효율성을 향상시켜야 한다.
누락된 연결고리 및 딜레마:
정확히 누락된 연결고리는 QML 맥락에서 대상 큐비트의 분극 크기를 증폭하는 효율적이고 부호 보존적인 메커니즘이다. 열-욕조 알고리즘 냉각(HBAC)과 같은 이전 알고리즘 냉각 기술은 "단방향"이다. 이는 미리 결정된 기저 상태(예: $|0\rangle$)의 모집단을 증가시키도록 설계되었다. 이는 원하는 출력(즉, $\alpha(x, \theta)$의 부호)을 사전에 알아야 한다. 그러나 QML 분류에서는 이 부호가 알고리즘이 결정하고자 하는 정확히 알려지지 않은 정보이다. 이는 고통스러운 딜레마를 야기한다. 기존 냉각을 사용하여 정확도를 높이려면 미리 답을 알아야 하는데, 이는 분류에 대한 냉각 과정을 무의미하게 만든다. 본 논문은 초기 분극의 부호에 관계없이 작동하는 새로운 "양방향" 냉각 프로토콜을 개발함으로써 이 간극을 메우려고 시도한다.
제약 조건 및 실패 모드
QML 샘플링 효율성 향상 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵게 만들어진다.
1. 계산 및 하드웨어 제약 조건:
* NISQ 장치 제한: 솔루션은 잡음 중간 규모 양자(NISQ) 장치와 호환되어야 한다. 이는 제한된 큐비트 수, 짧은 코히어런스 시간 및 높은 오류율로 인해 비현실적인 복잡하고 깊은 회로 및 그로버 반복 또는 양자 위상 추정과 같은 연산을 피해야 함을 의미한다.
* 계산 오버헤드: 제안된 방법은 분류 점수 및 기울기 추정과 관련된 계산 오버헤드를 최소화해야 한다. 오류를 줄이기 위해 측정 샷 수($k$)를 늘리는 것은 계산 비용과의 직접적인 절충이다.
* 큐비트 자원 제한: 현재 하드웨어에서는 사용 가능한 큐비트 수가 제한적이다. 프로토콜은 이상적으로 큐비트를 재활용하여 필요한 총 큐비트 수를 줄임으로써 리소스 효율적이어야 한다.
2. 데이터 기반 및 알고리즘 제약 조건:
* 알 수 없는 분극 부호 (양방향 요구 사항): 핵심 문제에서 강조했듯이, 대상 큐비트 분극 $\alpha(x, \theta)$의 부호는 사전에 알려지지 않는다. 이는 기존의 단방향 알고리즘 냉각 프로토콜을 부적합하게 만드는 근본적인 제약 조건이다. 냉각 메커니즘은 어느 것이 어느 것인지 사전에 알 필요 없이 초기 분극이 양수이든 음수이든 올바르게 작동해야 한다.
* 유한 샘플링 오류: 양자 측정의 본질적인 확률적 특성은 유한 샷을 기반으로 한 모든 추정에는 항상 어느 정도의 오류가 있음을 의미한다. 목표는 실용적인 한계 내에서 이 오류를 완전히 제거하는 것이 아니라 줄이는 것이다.
* 황무지 고원: 본 논문에서 직접 해결되지는 않았지만, 변분 양자 알고리즘의 황무지 고원 문제(큐비트 수가 증가함에 따라 기울기가 지수적으로 사라지는 곳)는 QML에서 알려진 과제이다. 본 논문은 기존 황무지 고원 완화 전략과 함께 사용할 수 있는 독립적인 메커니즘이라고 언급한다.
3. 물리적 잡음 제약 조건:
* 잡음이 있는 양자 환경: 현재 양자 하드웨어는 다양한 형태의 잡음 및 결맞음 상실에 취약하다. 프로토콜은 이러한 불완전성에 대해 견고해야 한다.
* 특정 잡음 모델: 본 논문은 NISQ 장치에서 지배적인 잡음 메커니즘인 일반화된 진폭 감쇠(GAD) 및 탈분극 채널을 구체적으로 고려한다. 주로 대각선 상태의 부분 공간에서 작동하는 프로토콜의 설계는 대각선 요소에 영향을 미치지 않는 코히어런스 저하 잡음(예: 위상 소멸, 위상 감쇠, 제어-위상 변동)에 대한 복원력을 보장해야 한다.
실패 모드:
이러한 제약 조건이 충족되지 않거나 문제가 적절하게 해결되지 않으면 QML 알고리즘은 여러 실패 모드에 직면하게 된다.
* 부정확한 분류: 높은 샘플링 오류는 추정된 레이블이 실제 레이블과 다를 수 있는 신뢰할 수 없는 예측으로 이어진다.
* 비효율적인 훈련: 높은 샘플링 오류로 인한 잘못된 기울기 추정은 최적화 프로세스를 방해하여 모델이 최적의 솔루션으로 수렴하는 것을 방지한다.
* 금지된 자원 소비: 과도하게 많은 수의 측정 샷 또는 복잡한 양자 연산에 의존하는 것은 QML을 현재 및 가까운 미래의 양자 하드웨어에서 실제 응용 프로그램에 대해 비실용적이고 확장 불가능하게 만든다.
* 냉각의 비적용성: 냉각 프로토콜이 분극 부호를 사전에 알 필요 없이 양방향으로 작동할 수 없다면, 이 부호가 알려지지 않은 출력인 QML 분류 작업에 효과적으로 통합될 수 없다.
* 잡음에 대한 취약성: NISQ 장치의 잡음 특성에 견고하지 않은 프로토콜은 이론적인 성능 이점을 무효화하는 일관성 없고 신뢰할 수 없는 결과를 산출할 것이다. 본 논문은 실제 하드웨어에서 발생하는 잡음에 대한 견고성을 입증하기 위해 현실적인 NISQ 잡음 조건, 일반적인 경우와 최악의 경우를 포함하여 프로토콜을 구체적으로 테스트한다.
왜 이 접근 방식인가
선택의 불가피성
양자 기계 학습(QML) 알고리즘, 특히 분류 작업의 핵심 과제는 양자 측정의 확률적 특성에서 비롯된다. 훈련 및 추론 단계 모두 확률 분포에서 정보를 추출해야 하며, 이는 본질적으로 유한 샘플링 오류를 도입한다. 이 제약 조건은 분류 점수 및 기울기의 신뢰성에 직접적인 영향을 미치며, 정확한 결과를 얻기 위해 상당한 수의 반복(샷)을 요구한다.
기존의 최첨단(SOTA) 양자 방법인 양자 진폭 추정(QAE)은 이 특정 문제에 대해 불충분하다고 간주되었다. QAE는 이론적으로 샘플링 오류를 이차적으로 감소시키지만, 복잡한 그로버 유사 연산 [13,14]에 의존하기 때문에 잡음 중간 규모 양자(NISQ) 장치 [15,16]에 대해 대부분 비실용적이고 실현 불가능하다. 더욱이, QAE는 크기에 대한 과도하게 정확한 추정을 제공하며, 이는 분류에 종종 과도하다. 이진 분류의 경우, 측정된 통계량(분극)의 부호만 필요하며, 그 정확한 크기는 필요하지 않다.
저자들은 필요한 측정 횟수를 최소화하기 위해 분극 크기 $|\alpha(x, \theta)|$를 증가시키는 것이 비판적으로 필요하다는 것을 깨달았다. 그러나 이는 측정된 단일 큐비트에 대한 국소적으로 유니터리한 프로세스로는 달성할 수 없었다. 그러한 연산은 그 상태의 순수성을 변경할 것이기 때문이다. 이로 인해 알고리즘 냉각 기술을 고려하게 되었다.
저자들이 기존 방법의 불충분성을 인식한 정확한 순간은, 미리 결정된 기저 상태의 모집단을 증가시키는 것을 목표로 하는 기존 알고리즘 냉각 프로토콜이 근본적으로 부적합하다는 것을 깨달았을 때였다. QML 분류에서 $\alpha(x, \theta)$의 부호(클래스 레이블 또는 기울기 방향을 결정하는)는 사전에 알려지지 않는다. 따라서 실행 가능한 솔루션은 분극 크기를 증가시키면서 알려지지 않은 부호를 보존하는 단일 큐비트 밀도 행렬을 동적으로 변환할 수 있는 양방향 프로토콜이어야 하며, 이는 다음과 같은 변환으로 표현된다.
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{with} \quad \begin{cases} \alpha' > \alpha & \text{if } \alpha > 0 \\ \alpha' < \alpha & \text{if } \alpha < 0 \end{cases} $$
부호 보존적이고 양방향인 분극 향상에 대한 이러한 요구 사항은 제안된 양자 열역학적 냉각 접근 방식을 유일하게 실행 가능한 솔루션으로 만들었다.
비교 우위
지도 학습을 냉각 프로세스로 재구성하는 이 양자 열역학적 접근 방식은 단순한 성능 지표를 넘어 질적인 우수성을 제공한다. 구조적 장점으로 인해 여러 핵심 측면에서 이전의 황금 표준보다 압도적으로 우수하다.
-
계산 오버헤드 감소: 이 방법은 분류 점수 및 기울기를 추정하는 데 필요한 측정 횟수를 크게 줄인다. 대상 큐비트의 분극을 증가시킴으로써 원하는 정밀도를 달성하는 데 더 적은 샷이 필요하며, 따라서 전반적인 계산 오버헤드를 최소화한다. 이는 광범위한 샘플링을 요구하는 방법보다 직접적인 이점이다.
-
황무지 고원 완화: 분류기 구조나 훈련 절차를 수정하는 전략과 달리, 이 접근 방식은 유한 샘플링 오류를 줄이기 위한 독립적인 메커니즘으로 작용한다. 시스템이 황무지 고원을 나타내는지 여부에 관계없이 효과적이며, 이는 변분 양자 알고리즘 [8,30]에서 흔히 발생하는 과제이다. 이는 기본 QML 모델을 변경하지 않고도 강력한 솔루션을 제공한다.
-
리소스 효율성 및 수렴 속도: 양방향 양자 냉장고(BQR) 프로토콜은 향상된 큐비트가 추출되고 나머지 $n-1$개의 큐비트가 후속 냉각 라운드의 작동 본체로 재활용되는 순환 작업을 사용한다. 이 재활용 메커니즘은 여러 개의 향상된 큐비트를 준비하는 데 필요한 총 큐비트 리소스($n + m N_{rounds}$에서 $\sim m N_{rounds} + 1$로)를 상당히 줄이고 냉각 프로세스의 수렴 속도를 크게 향상시킨다.
-
하드웨어 실현 가능성 (k-local BQR): k-local BQR 변형의 도입은 실용적인 구현을 위한 중요한 구조적 이점이다. k-local 영역으로 압축 연산을 제한함으로써 프로토콜은 현재 NISQ 장치에서 훨씬 더 하드웨어 친화적이고 구현하기 쉬워지면서도 일반 BQR 프로토콜의 핵심 성능 이점을 유지한다. 일부 구성에서는 k-local BQR이 진행 경계 엔트로피 압축 BQR보다 오류 확률 감소에서 더 나은 성능을 보일 수도 있다.
-
잡음 복원력: 주로 대각선 상태의 부분 공간에서 작동하는 프로토콜의 설계(재설정, 순열 및 조건부 스왑은 대각선 유지)는 모집단 역학을 작은 확률적 변동에 본질적으로 둔감하게 만든다. 결정적으로, 양자 코히어런스에만 작용하는 잡음 프로세스(예: 위상 소멸, 위상 감쇠, 제어-위상 변동)는 대각선 상태를 진화 내내 불변으로 유지하기 때문에 측정 가능한 영향을 미치지 않는다. 코히어런스 저하 잡음에 대한 이러한 고유한 복원력은 NISQ 호환성에 대한 중요한 질적 이점이다.
제약 조건과의 정렬
선택된 방법은 QML에 내재된 가혹한 요구 사항 및 제약 조건과 완벽하게 일치하며, 문제와 솔루션 간의 "결혼"을 형성한다.
-
유한 샘플링 오류: 이 연구의 주요 동기는 유한 샘플링 오류를 줄이는 것이다. BQR 프로토콜은 대상 큐비트의 분극 크기를 증가시킴으로써 이를 직접적으로 해결하며, 이는 결과적으로 원하는 추정 정밀도를 달성하는 데 필요한 측정 횟수를 줄인다. 이것이 해결하도록 설계된 핵심 문제이다.
-
NISQ 장치 호환성: 프로토콜은 명시적으로 NISQ 장치를 위해 설계되었다. 그로버 반복 및 양자 위상 추정과 같은 복잡한 연산을 피하고 하드웨어 친화적인 k-local 압축 유니터리를 개발하는 것과 결합하여 현재 양자 하드웨어에 대해 실용적이고 효율적이다. 현실적인 NISQ 잡음 조건에서의 수치 시뮬레이션은 또한 그 견고성과 적합성을 입증한다.
-
알 수 없는 분극 부호: QML 분류의 중요한 제약 조건은 분류 점수(분극)의 부호가 사전에 알려지지 않는다는 것이다. 기존의 알고리즘 냉각은 여기서 실패한다. 제안된 "양방향 냉각"은 초기 부호에 관계없이 분극 크기를 향상시키도록 특별히 설계되었으므로, 부호를 보존하고 사전 지식 없이 올바른 분류를 가능하게 한다.
-
계산 오버헤드: 이 방법은 정확한 분류 점수 및 기울기에 필요한 측정 샷 수를 크게 줄임으로써 계산 오버헤드를 직접적으로 최소화한다. 큐비트 재활용은 또한 리소스 사용을 최적화하여 전체 프로세스를 반복적이고 독립적인 측정보다 더 효율적으로 만든다.
-
황무지 고원: 이 접근 방식은 황무지 고원이 있는 경우에도 유익한 샘플링 오류를 줄이기 위한 독립적인 메커니즘을 제공한다. 이는 변분 회로 구조나 훈련 전략을 변경할 필요가 없으므로 기존 황무지 고원 완화 기술을 보완한다.
대안의 거부
본 논문은 근본적인 한계로 인해 몇 가지 인기 있는 접근 방식을 명시적으로 또는 암묵적으로 거부한다.
-
양자 진폭 추정 (QAE): QAE는 주로 높은 리소스 비용과 NISQ 장치에 대한 비실용성 때문에 거부되었다. 이는 그로버 유사 연산 [13,14]의 여러 라운드를 요구하며, 이는 현재 양자 하드웨어 [15,16]에서 악명 높게 까다롭다. 또한, QAE는 종종 분류 작업에 과도한 크기 추정을 제공하며, 여기서 분극의 부호만 필요하다. 그 복잡성은 이 특정 문제에 대한 이점을 능가한다.
-
기존 알고리즘 냉각 (AC) / 열-욕조 알고리즘 냉각 (HBAC): 이러한 전통적인 냉각 기술은 단방향이며 대상 상태의 편향에 대한 사전 지식이 필요하기 때문에 거부되었다. 기존 AC 프로토콜은 미리 결정된 기저 상태(예: $|0\rangle$)의 모집단을 증가시키도록 설계되었다. 그러나 QML 분류에서는 분류 점수 $\alpha(x, \theta)$의 부호(올바른 레이블을 결정하는)가 측정 전에 알려지지 않는다. 따라서 알려진 편향 방향을 가정하는 단방향 냉각 방법은 알려지지 않은 부호를 보존하면서 분극을 향상시키는 목표를 달성할 수 없다.
-
단일 큐비트에 대한 국소적으로 유니터리한 프로세스: 저자들은 단일 큐비트에 국소적으로 유니터리한 프로세스를 단순히 적용하는 것은 그러한 연산이 큐비트 상태의 순수성을 변경할 수 없기 때문에 불충분할 것이라고 언급했다 [III절]. 분극을 증가시키려면 큐비트의 엔트로피를 줄여야 하며, 이는 다른 큐비트와의 상호 작용 및 소산 프로세스를 필요로 하며, 단일 큐비트 유니터리 변환을 넘어선다.
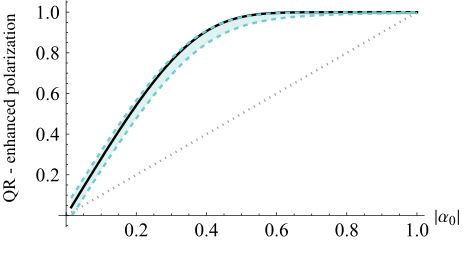 FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 핵심 메커니즘은 양자 기계 학습(QML)에서 샘플링 효율성을 향상시키는 양방향 양자 냉장고(BQR) 프로토콜이다. 특히, 진행 경계 엔트로피 압축 BQR(PBEC-BQR)은 순환 프로세스를 설명한다. 이 메커니즘의 한 번의 전체 라운드를 포착하는 절대적인 핵심 방정식은 다음과 같다.
$$ \rho_T^{\text{QR round}}(\rho_T) := \text{Tr}_m[U_{\text{QR}}(n)\rho_T U_{\text{QR}}^\dagger(n)] \otimes \rho_a^{\otimes m} $$
논문에서 Eq. (19)로 찾을 수 있는 이 방정식은 PBEC-BQR 프로토콜의 한 라운드 후 $n$-큐비트 레지스터의 총 양자 상태 $\rho_T$의 변환을 설명한다. 이는 유니터리 엔트로피 압축 및 소산 열화 단계를 모두 포함한다.
용어별 분석
이 마스터 방정식의 각 구성 요소를 분해하여 수학적 정의, 물리적/논리적 역할 및 선택된 수학적 연산의 근거를 이해해 보자.
-
$\rho_T$:
- 수학적 정의: BQR 라운드 전에 $n$-큐비트 레지스터의 총 양자 상태를 나타내는 밀도 행렬이다. 이는 1의 추적을 갖는 양의 준정부호 에르미트 연산자이다.
- 물리적/논리적 역할: $\rho_T$는 양자 냉장고의 단일 라운드에 대한 입력 상태이다. 이는 분극이 향상될 대상 큐비트, 엔트로피 재분배를 돕는 보조 큐비트, 그리고 엔트로피를 흡수할 재설정 큐비트를 포함한 모든 $n$ 큐비트의 양자 정보를 포함한다. 이는 냉각 사이클의 "작동 유체"이다.
- 사용 이유: 밀도 행렬은 양자 시스템의 상태, 특히 혼합 상태(순수 상태의 통계적 앙상블)이거나 다른 시스템과 얽혀 있을 때를 설명하는 양자 역학의 표준 형식이다. 이는 특히 열 욕조와 상호 작용하는 실제 양자 시스템을 모델링하는 데 중요하다.
-
$\rho_T^{\text{QR round}}(\rho_T)$:
- 수학적 정의: BQR의 한 라운드 후 $n$-큐비트 레지스터의 총 양자 상태를 나타내는 밀도 행렬이다. 이는 변환의 출력 상태이다.
- 물리적/논리적 역할: 이는 양자 냉장고가 한 번의 냉각 주기를 수행한 후의 업데이트된 상태이다. 프로토콜의 목표는 이 출력 상태 내에서 대상 큐비트의 분극 크기가 증가하여 "더 차갑게" 또는 더 편향되도록 하는 것이다. 이 상태는 순환 작업에서 다음 라운드의 입력 역할을 한다.
- 사용 이유: 이 표기법은 상태 $\rho_T$가 "QR 라운드" 연산으로 정의된 변환을 거쳐 새로운 상태를 생성함을 명확하게 나타낸다.
-
$U_{\text{QR}}(n)$:
- 수학적 정의: $n$-큐비트 레지스터에 작용하는 전역 유니터리 연산자이다. PBEC-BQR의 경우, 이는 계단식으로 적용되는 국소 유니터리 연산 $U_{C_j}$의 시퀀스로 구성된다 (예: Eq. (B7)에 표시된 대로 $U_{\text{QR}}(n) = U_{C_n} (I_2 \otimes U_{C_{n-1}}) \dots (I_2^{\otimes (n-3)} \otimes U_{C_3})$).
- 물리적/논리적 역할: 이 유니터리 연산은 "엔트로피 압축" 단계를 수행한다. 이는 전체 $n$-큐비트 레지스터에 걸쳐 엔트로피를 일관되게 재분배하여, 대상 및 보조 큐비트로부터 엔트로피를 효과적으로 추출하고 이를 재설정 큐비트로 집중시킨다. 여기서의 핵심 혁신은 양방향 특성이다. 이는 대상 큐비트의 분극 크기($|\alpha|$)를 증폭하면서도 원래 부호를 보존하며, 해당 부호에 대한 사전 지식을 요구하지 않는다. 이것이 핵심 "냉각" 작용이다.
- 사용 이유: 유니터리 연산은 양자 역학에서 시스템의 총 엔트로피를 보존하는 가역 변환을 나타내므로 기본적이다. 이 유니터리를 신중하게 설계함으로써 저자들은 엔트로피 분포를 조작하여 원하는 분극 향상을 달성할 수 있다. 국소 유니터리 시퀀스의 사용은 단일 복잡한 전역 유니터리보다 프로토콜을 실험적으로 더 실현 가능하게 만든다.
-
$U_{\text{QR}}^\dagger(n)$:
- 수학적 정의: 유니터리 연산자 $U_{\text{QR}}(n)$의 에르미트 켤레(켤레)이다.
- 물리적/논리적 역할: 양자 역학에서 유니터리 연산자 $U$가 밀도 행렬 $\rho$에 작용할 때, 변환은 $U \rho U^\dagger$로 주어진다. 켤레는 변환된 상태가 유효한 밀도 행렬(에르미트, 양의 준정부호, 추적 보존)로 유지되도록 보장한다.
- 사용 이유: 이는 밀도 행렬에 유니터리 변환을 올바르게 적용하기 위한 수학적 필수 사항이다.
-
$\text{Tr}_m[\dots]$:
- 수학적 정의: $m$개의 재설정 큐비트에 대한 부분 추적 연산을 나타낸다. 총 시스템이 두 부분, $A$와 $B$로 구성되고 그 상태가 $\rho_{AB}$이면, $\text{Tr}_B[\rho_{AB}]$는 부분 시스템 $A$의 축소 밀도 행렬을 제공한다.
- 물리적/논리적 역할: 이 연산은 대상 및 보조 큐비트로부터 엔트로피를 흡수한 후 시스템에서 $m$개의 재설정 큐비트를 효과적으로 "제거" 또는 "폐기"하는 것을 나타낸다. 이는 소산 단계의 첫 번째 부분으로, 시스템을 열화 단계를 위한 준비 상태로 만든다.
- 사용 이유: 부분 추적은 총 시스템이 혼합 또는 얽힌 상태일 때 부분 시스템의 축소 상태를 얻는 올바른 수학적 도구이다. 여기서 이를 통해 우리는 대상 및 보조 큐비트의 상태에 집중할 수 있으며, "뜨거운" 재설정 큐비트로부터 효과적으로 분리할 수 있다.
-
$\otimes$:
- 수학적 정의: 독립적인 부분 시스템의 양자 상태를 결합하는 데 사용되는 텐서 곱 연산자이다.
- 물리적/논리적 역할: 이 연산자는 이전 재설정 큐비트를 추적한 후 남은 $n-m$개의 큐비트의 축소 상태와 $m$개의 신선하고 열화된 재설정 큐비트($\rho_a^{\otimes m}$)를 결합한다. 이는 "열화" 또는 "재설정" 단계를 나타내며, 여기서 축적된 엔트로피는 "차가운" 재설정 큐비트를 대체함으로써 열 욕조로 배출된다.
- 사용 이유: 텐서 곱은 새로 도입된 재설정 큐비트가 열 상태 $\rho_a$에서 독립적으로 준비되었다고 가정하고, 따라서 그 상태는 나머지 $n-m$개의 큐비트와 상관이 없기 때문에 사용된다.
-
$\rho_a^{\otimes m}$:
- 수학적 정의: 각각 열 욕조 상태 $\rho_a$로 준비된 $m$개의 동일한 큐비트의 상태를 나타낸다. $\otimes m$은 $\rho_a$의 $m$개 복사본의 텐서 곱을 나타낸다.
- 물리적/논리적 역할: 이들은 시스템에 도입되어 "뜨거운" 재설정 큐비트를 대체하는 "신선한" 또는 "차가운" 큐비트이다. 이들은 재설정 큐비트에 집중된 엔트로피를 흡수하여 효과적으로 재설정하는 열 욕조 역할을 한다. 이 보충은 냉장고의 순환 작동을 가능하게 하여 엔트로피를 지속적으로 추출할 수 있도록 하는 데 중요하다.
- 사용 이유: 이 항은 시스템이 외부 환경(열 욕조)과 상호 작용하여 엔트로피를 배출하는 냉각 사이클의 소산 부분을 모델링한다. 동일한 열 욕조 큐비트에 대한 가정은 이 재설정 프로세스의 모델링을 단순화한다.
단계별 흐름
이 양자 냉각 메커니즘의 한 라운드를 통과하는 초기 분극 $\alpha$로 표현되는 단일 추상 데이터 포인트의 정확한 수명 주기를 추적해 보자.
- 초기 상태 준비: 특징 벡터 $x$로 특징지어지는 추상 데이터 포인트는 양자 상태의 분극 $\alpha$로 인코딩된다. 이 상태는 $n-1$개의 다른 큐비트(보조 및 재설정 큐비트)와 함께 초기 $n$-큐비트 레지스터 $\rho_T$를 형성한다. 단순화를 위해 대상 큐비트가 첫 번째 큐비트이고 나머지 $n-1$개의 큐비트는 종종 열 상태로 준비된다고 가정하자.
- 엔트로피 압축 (유니터리 단계): 전체 $n$-큐비트 레지스터 $\rho_T$는 신중하게 설계된 전역 유니터리 연산 $U_{\text{QR}}(n)$을 받는다. 이를 양자 정렬 기계라고 생각하라. 이 유니터리는 모든 큐비트에 걸쳐 계산 기저 상태의 모집단을 일관되게 섞는다. 주요 작업은 대상 큐비트와 보조 큐비트로부터 엔트로피를 추출하여 이 "열"을 $m$개의 "재설정" 큐비트의 특정 부분 집합으로 집중시키는 것이다. 여기서의 마법은 이 유니터리가 "양방향"이라는 것이다. 대상 큐비트의 초기 분극 $\alpha$가 양수인지 음수인지 신경 쓰지 않는다. 단순히 크기를 증폭하여 $\alpha$를 $|\alpha'| > |\alpha|$인 $\alpha'$로 변환하면서 원래 $\alpha$의 부호를 보존한다. 이는 대상 큐비트를 "더 차갑게" 또는 더 분극되게 만든다.
- 엔트로피 배출 (부분 추적): 유니터리 연산 후, "더 뜨거워진" 재설정 큐비트 $m$개는 효과적으로 분리되어 시스템에서 제거된다. 수학적으로, 이 $m$개의 큐비트에 대한 부분 추적 $\text{Tr}_m[\dots]$을 수행한다. 이는 나머지 $n-m$개의 큐비트에 대한 축소된 양자 상태를 남기며, 여기에는 향상된 대상 큐비트와 보조 큐비트가 포함된다. 이 단계는 "차가운" 큐비트를 보충하기 위해 시스템을 준비한다.
- 열화/재설정 (큐비트 교체): 냉장고가 지속적으로 작동할 수 있도록 라운드를 완료하기 위해, 각각 열 욕조 상태 $\rho_a$로 준비된 $m$개의 새롭고 "차가운" 큐비트가 도입된다. 이 신선한 큐비트는 텐서 곱($\otimes \rho_a^{\otimes m}$)을 통해 나머지 $n-m$개의 큐비트와 결합된다. 이 작업은 축적된 엔트로피를 외부 열 욕조(신선한 큐비트로 표현됨)로 배출함으로써 냉장고의 용량을 효과적으로 "재설정"한다. 시스템은 이제 $n$-큐비트 레지스터로 돌아왔지만, 향상된 분극을 가진 대상 큐비트가 있다.
- 다음 라운드를 위한 재활용: 새로 형성된 $n$-큐비트 상태는 BQR의 다음 라운드에 대한 입력 $\rho_T$가 된다. 향상된 대상 큐비트는 측정용으로 추출될 수 있거나, 더 큰 분극 향상을 달성하기 위해 여러 라운드($N_{\text{rounds}}$) 동안 프로세스를 반복할 수 있다. 나머지 $n-1$개의 큐비트(보조 및 신선한 재설정 큐비트)는 후속 대상 큐비트를 준비하기 위해 재활용되어 프로토콜을 리소스 효율적으로 만든다.
이 반복적인 프로세스는 대상 큐비트의 분극이 점진적으로 향상되도록 보장하여 분류 신호를 더 강력하고 신뢰할 수 있게 만든다.
최적화 역학
BQR 메커니즘은 양자 측정의 확률적 특성에서 발생하는 유한 샘플링 오류라는 과제를 직접적으로 해결함으로써 양자 기계 학습의 성능을 최적화한다. 이는 전통적인 의미에서 모델 매개변수를 조정하는 것이 아니라, 분류 점수의 신호 대 잡음비를 향상시키기 위해 양자 상태를 사전 처리함으로써 이를 수행한다.
- 손실 지형 및 기울기 신뢰성: QML에서 분류 점수 $q(x, \theta) = \alpha(x, \theta)$는 유한 횟수의 측정에서 추정된다. 훈련 프로세스는 일반적으로 (8)식에 따라 잘못된 기울기 $\frac{dl}{d\theta}$를 기반으로 모델 매개변수 $\theta$를 반복적으로 업데이트하여 손실 함수(예: 힌지 손실)를 최소화한다. 분극의 크기 $|\alpha(x, \theta)|$가 작으면, 유한 측정으로 인한 통계적 변동은 $\alpha$의 실제 부호를 쉽게 가릴 수 있으며, 이는 잘못된 분류 레이블 또는 결정적으로 잘못된 기울기 업데이트로 이어진다. 이는 "손실 지형"을 효과적으로 매우 평평하거나 잡음이 많게 만들어 효율적인 최적화를 방해한다.
- 분극 향상을 "신호 증폭"으로: BQR의 핵심 "최적화"는 이 분극의 크기를 증가시키는 것이다.
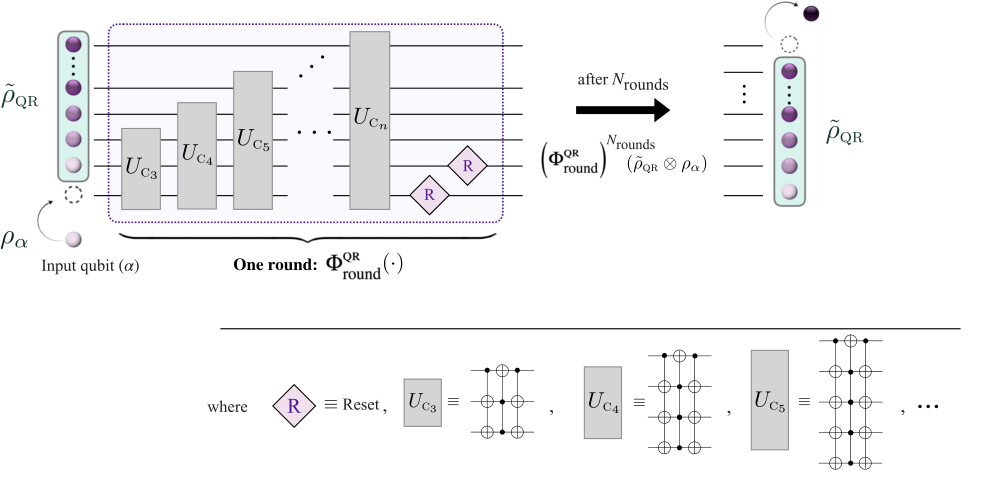 FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
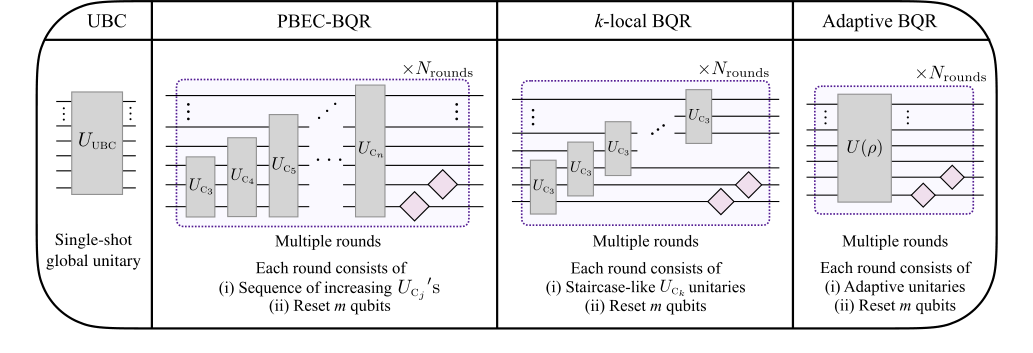 FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
결과, 한계 및 결론
실험 설계 및 기준선
수학적 주장을 엄격하게 검증하기 위해, 저자들은 Qiskit과 scikit-learn을 사용하여 양방향 양자 냉장고(BQR) 프로토콜의 실제 분류 성능에 초점을 맞춰 시뮬레이션된 일련의 실험을 세심하게 설계했다. 핵심 목표는 BQR을 통한 측정 큐비트의 분극 향상이 특히 유한 샘플링 오류를 완화함으로써 양자 기계 학습에서 분류 정확도의 실질적인 개선으로 직접 이어진다는 것을 입증하는 것이었다.
실험 아키텍처는 보수적인 선택에 중점을 두었다. 즉, $n=5$개의 시스템 큐비트, $m=2$개의 재설정 큐비트, $N_{rounds}=2$번의 냉각 라운드를 사용하는 3-local BQR 프로토콜이었다. 이 특정 구성은 더 실용적인 k-local 버전조차 기준선을 능가할 수 있다면, 완전한 BQR 프로토콜(더 강력한 냉각 제공)이 더 나은 성능을 보일 것으로 예상되었기 때문에 선택되었다.
BQR과 철저하게 테스트된 "희생자" 또는 기준선 모델은 BQR을 사용하지 않는 기존 샘플링 방법이었다. 유한 샘플링 오류(BQR이 줄이려는 것)의 영향을 분리하기 위해, 기준선 방법에는 비례적으로 더 많은 측정 샷이 할당되었다. 구체적으로, BQR 강화 분류기가 $k_{BQR}$ 측정 샷(예: 현실적인 NISQ 제약 조건을 반영하기 위해 10 또는 100 샷)을 사용했다면, 기존 기준선에는 $k_c = k_{BQR} \times m \times (N_{rounds} - 1) + n$ 샷이 주어졌다. $k_{BQR}=10$의 경우, 이는 기준선이 25 샷을 받는다는 것을 의미했다. $k_{BQR}=100$의 경우, 기준선은 205 샷을 받았다. 이 스케일링은 두 접근 방식 모두 유사한 큐비트 리소스를 소비하도록 보장하여, 관찰된 성능 차이가 단순히 더 많은 원시 측정보다는 BQR의 효율성에 기인하도록 했다.
QML 모델의 고유한 표현력 또는 훈련 가능성에서 샘플링 오류의 영향을 더욱 분리하기 위해 문제 설정이 단순화되었다. 실험은 단일 큐비트 축소 밀도 행렬의 형태로 최종 양자 상태에 직접 접근할 수 있다고 가정했으며, 여기서 Z-분극은 분류 신호를 직접 인코딩했다. 이를 통해 BQR이 더 적은 측정으로 예측의 신뢰성을 어떻게 향상시키는지 명확하게 평가할 수 있었다.
실험은 합성 데이터셋(균일 및 가우시안 분포) 및 여러 실제 데이터셋(Iris, Wine, 필기 숫자(특히 2 대 5), Sonar 및 Pima Indians Diabetes)을 포함한 이진 분류 작업을 위한 다양한 데이터셋을 사용했다. 각 데이터셋에 대해 각 클래스에서 50개의 데이터 포인트를 무작위로 샘플링하여 균형 잡힌 작업을 생성했으며, 이 전체 샘플링 및 평가 절차를 100번 반복하여 강력한 통계 앙상블을 생성했다.
결정적으로, 저자들은 현실적인 잡음 중간 규모 양자(NISQ) 장치 조건에서도 프로토콜을 테스트했다. 수치 시뮬레이션은 에너지 완화 및 확률적 게이트 오류를 모델링하는 일반화된 진폭 감쇠(GAD) 및 탈분극 채널을 통합했다. 두 가지 잡음 체제가 고려되었다. 즉, 적당한 잡음 매개변수를 가진 "일반적인 NISQ 체제"와 프로토콜의 견고성을 테스트하기 위해 의도적으로 과장된 잡음 강도를 가진 "최악의 경우 체제"이다. 이 포괄적인 실험 설계는 BQR의 효능과 실용성에 대한 부인할 수 없는 증거를 제공하는 것을 목표로 했다.
증거가 증명하는 것
본 논문에서 제시된 증거는 양방향 양자 냉장고(BQR) 프로토콜, 특히 3-local BQR이 현실적인 잡음 조건에서도 양자 기계 학습에서 샘플링 효율성을 크게 향상시키고 분류 정확도를 개선한다는 것을 확실하게 증명한다. 대상 큐비트의 분극 크기를 부호를 보존하면서 증가시키는 핵심 메커니즘은 실제로 작동하여 정확한 분류에 필요한 측정 횟수를 실질적으로 줄이는 것으로 나타났다.
가장 설득력 있는 증거는 모든 테스트된 데이터셋에 걸친 분류 정확도를 요약하는 표 I에서 나온다. 모든 경우에 BQR 강화 분류기는 기존 샘플링 기준선보다 일관되게 우수한 성능을 보였다. 예를 들어, $k_{BQR}=10$ 샷에서 균일 데이터셋의 경우, BQR은 $95.8\% \pm 1.8\%$의 정확도를 달성한 반면, 기준선(25 샷)은 $93.1\% \pm 2.3\%$에 불과했다. $k_{BQR}$이 100 샷(기준선 205 샷)으로 증가했을 때, BQR은 $99.3\% \pm 0.7\%$의 정확도를 달성했으며, 이는 기준선의 $97.7\% \pm 1.3\%$와 비교된다. 이러한 우수한 성능 패턴은 모든 합성 및 실제 데이터셋, 즉 Iris, Wine, 필기 숫자, Sonar 및 Diabetes에서 관찰되었다. 이러한 개선의 통계적 유의성은 Welch의 t-검정을 통해 엄격하게 확인되었으며, 이는 관찰된 이득이 무작위로 발생한 것이 아님을 나타내는 0.05 미만의 p-값을 산출했다.
단순 정확도 외에도, 본 논문은 기본 메커니즘의 성공을 보여주는 그래픽 증거를 제공한다. 그림 5와 6은 이상적인 잡음 없는 설정에서 진행 경계 엔트로피 압축 BQR(PBEC-BQR)에 의해 달성된 향상된 분극($\alpha_{PBEC}'$)과 샘플링 오류-확률 경계의 감소 계수($r_{PBEC}$)를 보여준다. 이 그림들은 BQR이 분극 크기를 현저하게 증가시키고 오류 경계를 상당히 감소시킨다는 것을 보여주며, 특히 중간 및 높은 분극 영역에서 그렇다. 이는 엔트로피 감소가 통계적 추정을 개선한다는 수학적 주장을 직접적으로 검증한다.
더욱이, NISQ 장치에 대한 중요한 관심사인 BQR의 잡음에 대한 견고성은 철저하게 입증되었다. 그림 10은 일반적인 NISQ 수준 잡음 하에서도 BQR이 여전히 상당한 분극 향상을 달성하여 이상적인 잡음 없는 성능에 가까운 정상 상태로 수렴한다는 것을 보여준다. 그림 11은 일반적인 NISQ 잡음 하에서 오류-확률 경계의 감소 계수($r_{QR}$)를 정량화하여 이를 보여준다. 진폭 감쇠에 의해 도입된 일부 비대칭성에도 불구하고(이는 분극을 한 방향으로 구동함), 전반적인 감소 계수는 상당하게 유지되어 프로토콜이 불완전한 양자 하드웨어에서도 샘플링 오류를 효과적으로 완화한다는 것을 증명한다. 마지막으로, 그림 12는 "최악의 경우" 잡음 체제, 즉 의도적으로 과장된 잡음 강도 하에서도 BQR이 이상적인 경우와 거의 동일한 초기 분극 범위에 걸쳐 오류 확률의 감소를 계속 산출한다는 것을 보여주며, 프로토콜의 복원력에 대한 강력한 증거를 제공한다. 이 부인할 수 없는 증거는 BQR의 핵심 메커니즘이 실제로 작동하여 QML에서 향상된 학습 성능을 위한 물리적으로 근거 있고 잡음 복원력 있는 경로를 제공한다는 것을 확인한다.
한계 및 향후 방향
양방향 양자 냉장고(BQR) 프로토콜은 QML에 대한 상당한 발전을 제시하지만, 저자들은 몇 가지 한계를 솔직하게 인정하고 미래 연구를 위한 설득력 있는 방향을 제안한다.
한 가지 주목할 만한 한계는 저분극 영역에서의 성능이다. 유니터리 양방향 냉각(UBC) 및 BQR 프로토콜 모두 초기 분극 $\alpha$가 0에 매우 가까울 때 의미 있는 개선을 제공하지 않는다. 장점 영역은 프로토콜 매개변수를 최적화하여 확장할 수 있지만, 극단적인 저분극 한계는 여전히 어려운 영역이다. 이는 이러한 시나리오에서 BQR의 이점이 최소화될 수 있음을 시사하며, 이러한 경우에 대한 대체 또는 보완 전략의 필요성을 촉구한다.
또 다른 열린 질문은 PBEC-BQR 프로토콜의 최적성에 관한 것이다. 본 논문은 이 특정 냉각 프로토콜이 유한 샘플링 오류를 줄이는 데 진정으로 최적인지 여부를 확실하게 확립하지 않는다. 만약 그렇지 않다면, 프로토콜을 더욱 개선하여 잠재적으로 더 큰 성능 향상을 가져올 수 있는 미래 작업을 위한 명확한 방향이 있다.
리소스 관점에서 볼 때, BQR 체제는 단일 전역 유니터리 UBC보다 더 실용적이지만, 냉각의 순환 라운드를 유지하기 위해 여전히 추가 큐비트가 필요하다. 이는 단일 샷 UBC에 비해 큐비트 오버헤드를 증가시킨다. 향후 연구는 이 오버헤드를 최소화하는 방법을 탐색하거나 큐비트 수, 회로 깊이 및 냉각 성능 간의 절충을 조사할 수 있다. 본 논문은 또한 모든 큐비트에 대한 단일 전역 유니터리가 최상의 분극 향상을 달성할 것이라고 언급하지만, 그러한 연산은 구현하기에 실용적이지 않다. 이는 이론적 최적성과 양자 컴퓨팅의 실험적 실현 가능성 간의 지속적인 긴장을 강조한다.
미래 개발의 중요한 영역은 양자 커널 추정으로의 적용 확장이다. 현재 방법은 주로 이진 결과에 대한 부호 추정을 지원하며, 이는 커널 행렬 요소를 추정하는 데 직접적으로 충분하지 않다. 이러한 냉각 기술을 양자 커널의 유한 샘플링 오류를 줄이기 위해 적용하는 것은 추정하려는 양이 더 복잡하기 때문에 고유한 과제를 제시한다. 이를 해결하면 QML 응용 프로그램의 더 넓은 스펙트럼에 걸쳐 양자 열역학적 통찰력의 영향을 확대할 것이다.
미래를 내다볼 때, 몇 가지 흥미로운 논의 주제가 떠오른다.
- 코히어런스 및 비고전적 상관 관계 활용: 본 논문은 시스템 및 욕조 큐비트 내의 코히어런스 및 비고전적 상관 관계가 냉각 효율성을 개선하기 위해 어떻게 활용될 수 있는지 조사한다고 언급한다. 현재 프로토콜은 주로 대각선 부분 공간에서 작동하므로 위상 소멸 잡음에 대해 견고하지만 잠재적으로 추가 향상을 위한 미개척 리소스를 남겨두기 때문에 이는 흥미로운 방향이다.
- 황무지 고원 완화: BQR이 황무지 고원 효과를 어떻게 완화하는지에 대한 상세한 정량적 분석이 필요하다. 저자들은 그들의 기술이 기존의 황무지 고원 완화 전략과 함께 독립적인 메커니즘으로 사용될 수 있다고 제안한다. 이 상호 작용을 이해하면 더 강력하고 확장 가능한 QML 알고리즘을 얻을 수 있다.
- 데이터 재업로드 및 BQR 회로: BQR 방법과 데이터 재업로드 기술 간의 연결은 흥미로운 가능성을 열어준다. BQR 회로의 데이터 재업로드 버전을 구성하면 회로 깊이와 큐비트 오버헤드 간의 포괄적인 절충 분석이 가능해져 잠재적으로 더 리소스 효율적인 구현으로 이어질 수 있다.
- 이진 분류를 넘어서: 현재 작업은 이진 분류에 초점을 맞추고 있지만, 엔트로피 감소를 위한 기본 열역학적 프레임워크는 잠재적으로 회귀 또는 더 복잡한 다중 클래스 문제와 같은 다른 QML 작업에 적용될 수 있다. 이를 위해서는 "분극" 및 "부호"가 이러한 맥락에서 어떻게 일반화되는지에 대한 신중한 고려가 필요할 것이다.
- 실험적 구현 및 하드웨어 최적화: NISQ 잡음 하에서의 수치 시뮬레이션은 유망하지만, 다양한 양자 하드웨어 플랫폼(초전도, 이온 트랩, 중성 원자)에서의 실제 실험적 구현이 궁극적인 검증이 될 것이다. 이는 또한 특정 하드웨어 아키텍처 및 잡음 특성에 대한 BQR 회로를 최적화하기 위한 귀중한 피드백을 제공할 것이다.
- QML을 위한 냉각의 이론적 기초: 이 작업은 양자 열역학 및 QML 간의 새로운 연결을 확립한다. 학습 작업에 대한 냉각의 근본적인 한계, 그리고 다른 분야와의 잠재적인 동형성(정규 장 순서에서 암시된 대로)에 대한 추가 이론적 탐구는 더 깊은 통찰력을 제공하고 완전히 새로운 알고리즘 패러다임을 영감을 줄 수 있다.
이러한 다양한 관점은 BQR 프로토콜이 현재 QML 과제에 대한 실용적인 솔루션일 뿐만 아니라, 양자 정보 과학 및 기계 학습의 경계를 넓히는 학제 간 연구의 비옥한 토대임을 강조한다.
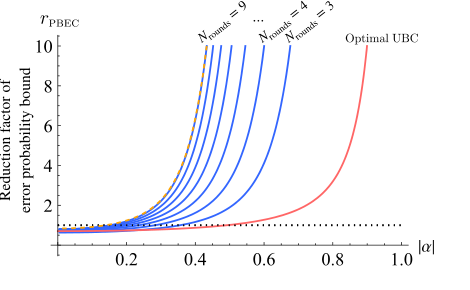 FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
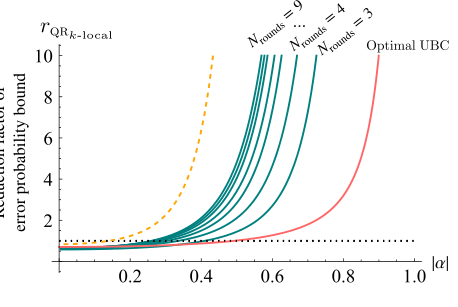 FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound
FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound