熱浴アルゴリズム冷却による量子機械学習の改善
This work introduces an approach rooted in quantum thermodynamics to enhance sampling efficiency in quantum machine learning (QML).
背景と学術的系譜
起源と学術的系譜
本論文で取り組む問題は、量子情報処理(QIP)とデータサイエンスの交差点から生じ、量子機械学習(QML)という分野を創出した。QMLは、古典的能力を超える複雑なデータ分布に対処する immense な可能性を秘めているが、量子測定の確率的性質に起因する固有の課題に直面している。この確率的性質は、QMLアルゴリズムの訓練段階と推論段階の両方が、量子状態からの情報(観測量の期待値など)を抽出する際に「有限サンプリング誤差」の影響を受けやすいことを意味する。
歴史的に、量子振幅推定(QAE)を適応させるなどのサンプリング誤差を軽減する試みは、二次的な改善を提供した。しかし、QAEプロトコルは、計算集約的であり、現在のノイズ中規模量子(NISQ)デバイスでの実現可能性を著しく制限する、複数の複雑なグローバー様操作を必要とする。さらに、多くの機械学習タスク、特に分類においては、QAEは「過剰な」レベルの精度を提供する。多くの場合、観測統計量の正確な大きさではなく、その符号(例えば、分類スコアが正か負か)を決定するだけで十分である。この認識は、QAEの二次的改善を上回り、NISQハードウェアの制限と互換性のある、より実用的で効率的なサンプリング削減技術の必要性を浮き彫りにした。
著者らが本研究を開発するに至った過去のアプローチの根本的な制限、すなわち「ペインポイント」は二重である。第一に、QAEのような既存の方法は、現在のNISQハードウェアでの実用的な実装にはリソースが多すぎ、複雑すぎる(多くのグローバー様操作を必要とする)ため、リアルタイムでの応用は不可能である。第二に、本研究の着想源となった従来のアルゴリズム冷却技術は、本質的に「一方向」である。これらは、所望の出力の符号に関する事前知識を必要とする、所定の基底状態(例えば、$|0\rangle$)の集団を増加させるように設計されている。しかし、教師ありQMLにおいては、分類ラベルまたは勾配方向を決定する分類スコアの符号は、まさに我々が決定しようとしている未知の量である。以前の冷却方法におけるこの「双方向」能力の欠如は、バイアス方向が初期には未知であるQML分類問題に直接適用できないことを意味した。本論文は、新しい、符号を保存する、双方向冷却アプローチを導入することにより、これらの制限に直接対処する。
直感的なドメイン用語
- 量子機械学習(QML): 通常のコンピュータが、試験勉強をする学生のように、データからパターンを学習しようとする様子を想像してください。QMLは、その学生に、情報を全く新しい方法で処理できる魔法のような量子脳を与えるようなもので、特に非常に複雑なデータに対して、学習をはるかに速くしたり、通常の学生が見落とす可能性のあるパターンを発見したりすることを可能にします。
- ノイズ中規模量子(NISQ)デバイス: NISQデバイスを、第一世代の電気自動車と考えてください。これらは革命的で、信じられないほどの可能性を示していますが、バッテリー寿命が限られており、やや信頼性が低く、再充電または修理が必要になる前に特定のタスクしか実行できません。まだ長距離旅行には適していませんが、完全に機能する量子車両への重要な一歩です。
-
熱浴アルゴリズム冷却(HBAC): 重要な書類がジャンクと混ざっている乱雑な机を想像してください。HBACは、2つのステップで整理する几帳面なアシスタントのようなものです。まず、重要な書類をすべて1つのきれいにまとまった山に集め、ジャンクを机の別の部分に押しやります(エントロピー圧縮)。次に、机からジャンクを捨てます(熱化/リセット)、重要な書類をはるかに整理され、アクセスしやすくします。これは重要な解決策です。
-
(量子ビットの)偏光: コンパスの針を想像してください。完全にバランスが取れていると、どこを指すかわかりません(低偏光)。北に強く引かれている場合、北に向かって高い偏光を持っています。量子ビット(qubit)の場合、偏光は、特定の状態(「0」など)を別の状態(「1」など)よりもどれだけ強く好むかを記述します。高い偏光は、量子ビットからより明確で信頼性の高い「はい」または「いいえ」の回答を意味します。
- エントロピー圧縮: 大きなホールにランダムに散らばった人々のグループ(高エントロピー)を考えてください。エントロピー圧縮は、誰も削除せずに、VIP全員を指定されたアクセスしやすいエリアに誘導し、残りの参加者は散らばったままにする、賢いイベントオーガナイザーのようなものです。ホールの総人数(情報)は同じですが、「重要な」部分はより集中され、秩序立っています。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題の定式化とジレンマ
本論文で取り組む中心的な問題は、特に変分量子二値分類器(VQBC)において、量子機械学習(QML)アルゴリズムに固有の有限サンプリング誤差である。この誤差は、QMLの訓練段階と予測段階の両方に不可欠な量子測定の確率的性質から生じる。
入力/現在の状態:
現在の状態では、QMLアルゴリズムは量子データ表現を処理し、その出力(例えば、分類ラベルまたは勾配方向)は、ターゲット量子ビットのZ偏光 $\alpha(x, \theta)$ として測定される統計量の符号にエンコードされる。この偏光は、単一量子ビット密度演算子 $\rho_1(x, \theta) = \frac{I + \alpha(x, \theta)Z + \beta(x, \theta)X + \gamma(x, \theta)Y}{2}$ から導出され、分類スコアは $q(x, \theta) = \alpha(x, \theta)$ である。このスコアを推定するために、有限回数の測定繰り返し(ショット)、$k$ で示される、が実行される。この有限の $k$ は推定誤差につながる。堅牢な予測のためには、推定期待値 $\mu$ は $|\mu - \langle M \rangle| < |\langle M \rangle|$ を満たす必要がある。ここで $\langle M \rangle$ は真の期待値である。訓練のためには、$q(x_j, \theta)$ の推定誤差は、ヒンジ損失勾配を正確に評価するために $|q(x_j, \theta) - b|$ より小さくなければならない。これらのタスクの誤差確率は、例えば予測の場合:
$$ \text{Pr[error]} = \text{Pr}[|\mu - \langle M \rangle| \geq |\langle M \rangle|] \leq \frac{1 - \alpha^2(x, \theta^*)}{k\alpha^2(x, \theta^*)} $$
および訓練の場合:
$$ \text{Pr[error]} = \frac{1 - \alpha^2(x_j, \theta)}{k(\alpha(x_j, \theta) - b)^2} $$
と上からバウンドされる。これらのバウンドは、$|\alpha(x, \theta)|$ の値が小さいほど、低い誤差確率を維持するためにはより多くのショット $k$ が必要であることを強調している。QMLの文脈では、$\alpha(x, \theta)$ の符号は事前に知られていないことが重要である。なぜなら、それはアルゴリズムが決定しようとしているまさにその情報(ラベルまたは勾配方向)を表すからである。
望ましい終点(出力/目標状態):
望ましい終点は、これらの有限サンプリング誤差を大幅に削減し、それによって正確な分類と勾配推定に必要な測定繰り返し数 $k$ を最小限に抑えることである。これは、ターゲット量子ビットの偏光の大きさ $|\alpha(x, \theta)|$ を、新しい、強化された値 $|\alpha'(x, \theta)|$ に増加させることによって達成される。重要な要件は、この強化が双方向でなければならないことである。すなわち、偏光の符号は維持されつつ、その大きさが増加しなければならない。単一量子ビット密度行列のターゲット変換は次のようになる:
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{with} \quad \begin{cases} \alpha' > \alpha & \text{if } \alpha > 0 \\ \alpha' < \alpha & \text{if } \alpha < 0 \end{cases} $$
このプロセスは、計算的に高価なグローバー反復や量子位相推定のような操作に依存することなく、訓練と予測の両方の段階でサンプル効率を向上させるべきである。
欠落しているリンクとジレンマ:
正確に欠落しているリンクは、QMLの文脈におけるターゲット量子ビットの偏光 magnitude を増幅するための効率的で符号を保存するメカニズムである。熱浴アルゴリズム冷却(HBAC)のような以前のアルゴリズム冷却技術は「一方向」である。これらは、所定の基底状態(例えば、$|0\rangle$)の集団を増加させるように設計されている。これは、望ましい出力(すなわち、$\alpha(x, \theta)$ の符号)の事前知識を必要とする。QML分類では、しかし、分類スコアの符号(ラベルまたは勾配方向を決定する)は、アルゴリズムが決定しようとしているまさに未知の情報である。この「双方向」能力の欠如は、以前の冷却方法では、初期バイアス方向が未知であるQML分類問題に直接適用できないことを意味した。本論文は、初期偏光の符号に関係なく機能する新しい「双方向」冷却プロトコルを開発することにより、これらの制限に直接対処する。
制約と失敗モード
QMLサンプリング効率の向上という問題は、いくつかの厳しい現実的な制約によって非常に困難になっている:
1. 計算およびハードウェアの制約:
* NISQデバイスの制限: ソリューションは、ノイズ中規模量子(NISQ)デバイスと互換性がなければならない。これは、量子ビット数、コヒーレンス時間、およびエラー率が限られているため、複雑で深い回路やグローバー反復や量子位相推定のような操作を避けることを意味する。
* 計算オーバーヘッド: 提案された方法は、分類スコアと勾配の推定に関連する計算オーバーヘッドを最小限に抑えなければならない。誤差を減らすために測定ショット数($k$)を増やすことは、計算コストとの直接的なトレードオフである。
* 量子ビットリソースの制限: 現在のハードウェアでは、利用可能な量子ビット数は限られている。プロトコルは、リソース効率的でなければならず、理想的には量子ビットをリサイクルして必要な総量子ビット数を削減しなければならない。
2. データ駆動型およびアルゴリズム的制約:
* 未知の偏光符号(双方向性の要件): コア問題で強調されているように、ターゲット量子ビットの偏光 $\alpha(x, \theta)$ の符号は事前に未知である。これは、従来の、一方向のアルゴリズム冷却プロトコルを不適切にする根本的な制約である。冷却メカニズムは、どちらがどちらであるかの事前知識なしに、正および負の初期偏光の両方に対して正しく動作しなければならない。
* 有限サンプリング誤差: 量子測定の固有の確率的性質は、有限回のショットに基づく任意の推定には常にいくらかの誤差があることを意味する。目標は、実用的な範囲内で、この誤差を削減することであり、完全に排除することではない。
* バレンプラトー: 本論文で直接解決されているわけではないが、変分量子アルゴリズムにおけるバレンプラトーの問題(量子ビット数とともに勾配が指数関数的に消失する)は、QMLにおける既知の課題である。本論文は、既存のバレンプラトー緩和戦略と組み合わせて使用できる独立したメカニズムであると述べている。
3. 物理的ノイズの制約:
* ノイズのある量子環境: 現在の量子ハードウェアは、さまざまな形態のノイズとデコヒーレンスの影響を受けやすい。プロトコルは、これらの不完全性に対して堅牢でなければならない。
* 特定のノイズモデル: 本論文は、NISQデバイスで支配的なノイズメカニズムである、一般化振幅減衰(GAD)およびデポラライジングチャネルを特に考慮している。対角状態のサブスペース内で主に動作するプロトコルの設計は、対角要素に影響を与えないコヒーレンス劣化ノイズ(例えば、デフェージング、位相減衰、制御位相変動)に対する耐性を確保しなければならない。
失敗モード:
これらの制約が満たされない場合、または問題が適切に解決されない場合、QMLアルゴリズムはいくつかの失敗モードに直面するだろう:
* 不正確な分類: 高いサンプリング誤差は、推定されたラベルが真のラベルと異なる信頼性の低い予測につながるだろう。
* 非効率的な訓練: 高いサンプリング誤差による不正確な勾配推定は、最適化プロセスを妨げ、モデルが最適な解に収束するのを防ぐだろう。
* 法外なリソース消費: 過度に多くの測定ショットまたは複雑な量子操作に依存することは、QMLを現在のおよび近い将来の量子ハードウェアでの実世界アプリケーションにとって非実用的でスケーラブルでないものにするだろう。
* 冷却の非適用性: 冷却プロトコルが偏光符号の事前知識なしに双方向で動作できない場合、それらはこの符号が未知の出力であるQML分類タスクに効果的に統合できないだろう。
* ノイズへの感受性: NISQデバイスのノイズ特性に対して堅牢でないプロトコルは、一貫性がなく信頼性の低い結果をもたらし、理論的なパフォーマンス上の利点を無効にするだろう。本論文は、実際のハードウェアで発生するノイズに対する堅牢性を示すために、現実的なNISQノイズ条件(典型的なおよび最悪の場合のレジームを含む)の下でプロトコルを特別にテストしている。
なぜこのアプローチなのか
選択の必然性
量子機械学習(QML)アルゴリズム、特に分類タスクにおける中心的な課題は、量子測定の確率的性質に起因する。訓練段階と推論段階の両方で確率分布から情報を抽出する必要があり、これは本質的に有限サンプリング誤差を導入する。この制限は、分類スコアと勾配の信頼性に直接影響を与え、正確な結果を得るためには相当数の繰り返し(ショット)を必要とする。
従来の最先端(SOTA)量子手法、例えば量子振幅推定(QAE)は、この特定の問題には不十分であると見なされた。QAEは理論的にはサンプリング誤差の二次的な削減を提供するが、複雑なグローバー様操作[13,14]への依存は、ノイズ中規模量子(NISQ)デバイス[15,16]にとってほとんど非現実的で実現不可能である。さらに、QAEは大きさの過度に正確な推定を提供するが、これは分類にはしばしば過剰である。二値分類の場合、測定された統計量(偏光)の符号のみが必要であり、その正確な大きさは必要ない。
著者らは、必要な測定回数を最小限に抑えるために、分類スコアの偏光の大きさ $|\alpha(x, \theta)|$ を増加させる必要があることを認識した。しかし、この増加は、単一測定量子ビットに対する単純な局所ユニタリプロセスでは達成できない。なぜなら、そのような操作はその状態の純度を変化させるからである。これにより、アルゴリズム冷却技術の検討につながった。
著者らが既存手法の不十分さを認識した正確な瞬間は、従来のアルゴリズム冷却プロトコルが、所定の基底状態の集団を増加させることを目的としているが、根本的に不適切であることに気づいたときであった。QML分類では、$\alpha(x, \theta)$ の符号(クラスラベルまたは勾配方向を決定する)は事前に未知である。したがって、実行可能な解決策は、未知の符号を保存しながら偏光 magnitude を増加させるために、単一量子ビット密度行列を動的に変換できる双方向プロトコルでなければならない。これは、変換によって表される:
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{with} \quad \begin{cases} \alpha' > \alpha & \text{if } \alpha > 0 \\ \alpha' < \alpha & \text{if } \alpha < 0 \end{cases} $$
符号を保存する双方向偏光増強のこの要件は、提案された量子熱力学的冷却アプローチを唯一実行可能な解決策にした。
比較優位性
教師あり学習を冷却プロセスとして再構築するこの量子熱力学的アプローチは、単なるパフォーマンス指標を超えた質的な優位性を提供する。その構造的利点は、いくつかの重要な側面で、以前のゴールドスタンダードを圧倒的に凌駕する:
-
計算オーバーヘッドの削減: この方法は、分類スコアと勾配を推定するために必要な測定回数を大幅に削減する。ターゲット量子ビットの偏光を増加させることにより、所望の精度を達成するために必要なショット数が少なくなり、全体的な計算オーバーヘッドが最小限に抑えられる。これは、広範なサンプリングを必要とする方法に対する直接的な利点である。
-
バレンプラトーの緩和: 分類器の構造や訓練手順を変更する戦略とは異なり、このアプローチは、有限サンプリング誤差を削減するための独立したメカニズムとして機能する。システムがバレンプラトーを示すかどうかにかかわらず効果的であり、変分量子アルゴリズムにおける一般的な課題である[8,30]。これは、基盤となるQMLモデルを変更することなく、堅牢なソリューションを提供する。
-
リソース効率と収束率: 双方向量子冷蔵庫(BQR)プロトコルは、強化された量子ビットが抽出され、残りの $n-1$ 量子ビットが後続の冷却ラウンドの作業本体としてリサイクルされるサイクル操作を採用している。このリサイクルメカニズムは、複数の強化された量子ビットを準備するために必要な総量子ビットリソース($n + m N_{rounds}$ から $\sim m N_{rounds} + 1$ へ)を大幅に削減し、冷却プロセスの収束率を大幅に向上させる。
-
ハードウェアの実現可能性(k-local BQR): k-local BQRバリアントの導入は、実用的な実装にとって重要な構造的利点である。圧縮操作をk-local近傍に制限することにより、プロトコルは現在のNISQデバイスで大幅にハードウェアフレンドリーで実装が容易になり、より一般的なBQRプロトコルのコアパフォーマンスメリットを維持しながら。一部の構成では、k-local BQRは、エラー確率削減において、Progressive Boundary Entropy Compression BQRよりも優れたパフォーマンスを発揮することさえある。
-
ノイズ耐性: 対角状態のサブスペース内(リセット、置換、条件付きスワップは対角性を維持する)で完全に動作するプロトコルの設計により、その集団ダイナミクスは小さな確率的変動に対して本質的に影響を受けない。特に、量子コヒーレンスのみに作用するノイズプロセス(例えば、デフェージング、位相減衰、制御位相変動)は、対角状態を進化全体で不変に保つため、測定可能な影響を与えない。コヒーレンス劣化ノイズに対するこの固有の堅牢性は、NISQ互換性にとって重要な質的利点である。
制約との整合性
選択された方法は、QMLに固有の厳しい要件と制約と完全に整合し、「問題と解決策の結婚」を形成する:
-
有限サンプリング誤差: この研究の主な動機は、有限サンプリング誤差を削減することである。BQRプロトコルは、測定量子ビットの偏光 magnitude を増加させることにより、これを直接解決する。これにより、所望の推定精度を達成するために必要な測定回数が削減される。これは、方法が解決するように設計されている中心的な問題である。
-
NISQデバイス互換性: プロトコルは、NISQデバイス向けに明示的に設計されている。グローバー反復や量子位相推定のような複雑な操作を回避することと、ハードウェアフレンドリーなk-local圧縮ユニタリの開発と組み合わせることで、現在の量子ハードウェアにとって実用的で効率的である。現実的なNISQノイズ条件下での数値シミュレーションは、その堅牢性と適合性をさらに実証している。
-
未知の偏光符号: QML分類の重要な制約は、分類スコア(偏光)の符号が事前に未知であることである。従来のアルゴリズム冷却はここで失敗する。提案された「双方向冷却」は、初期符号の事前知識なしに、偏光 magnitude を増強するように特別に設計されており、それによって符号を保存し、正しい分類を可能にする。
-
計算オーバーヘッド: この方法は、正確な分類スコアと勾配に必要な測定ショット数を大幅に削減することにより、計算オーバーヘッドを直接最小限に抑える。量子ビットのリサイクルはリソース使用率をさらに最適化し、プロセス全体を独立した繰り返し測定よりも効率的にする。
-
バレンプラトー: このアプローチは、サンプリング誤差を削減するための独立したメカニズムを提供し、バレンプラトーが存在する場合でも有益である。変分回路構造または訓練戦略を変更する必要はなく、既存のバレンプラトー緩和技術を補完する。
代替案の却下
本論文は、特定の問題制約に対処する上での根本的な制限のために、いくつかの人気のあるアプローチを明示的または暗黙的に却下している:
-
量子振幅推定(QAE): QAEは、主にその高リソースコストとNISQデバイスでの非現実性のために却下された。それは、現在の量子ハードウェア[15,16]で非常に要求の厳しい複数のグローバー様操作[13,14]の反復を必要とする。さらに、QAEは大きさの推定を提供するが、これは分類タスクにはしばしば過剰である。なぜなら、偏光の符号のみが必要であり、その正確な大きさは必要ないからである。その複雑さは、この特定の問題に対する利点を上回る。
-
従来のアルゴリズム冷却(AC)/熱浴アルゴリズム冷却(HBAC): これらの従来の冷却技術は、一方向であり、ターゲット状態のバイアスの事前知識を必要とするために却下された。従来のACプロトコルは、所定の基底状態(例えば、$|0\rangle$)の集団を増加させるように設計されている。しかし、QML分類では、分類スコア $\alpha(x, \theta)$ の符号(正しいラベルを決定する)は、測定前に未知である。したがって、既知のバイアス方向を仮定する一方向冷却方法は、未知の符号を保存しながら偏光を増強するという目標を達成できない。
-
単一量子ビット上の局所ユニタリプロセス: 著者らは、単一測定量子ビットに局所ユニタリプロセスを単純に適用することは不十分であると指摘した。なぜなら、そのような操作は量子ビットの状態の純度を変更できない[セクションIII]からである。偏光を増加させるには、量子ビットのエントロピーを削減する必要があり、これは他の量子ビットとの相互作用と散逸プロセスを必要とし、単一量子ビットユニタリ変換を超える。
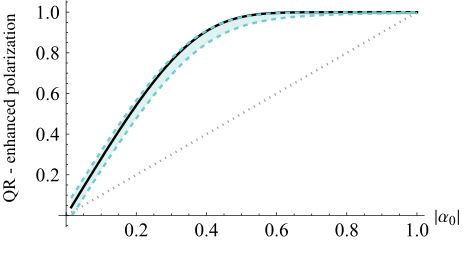 FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
数学的・論理的メカニズム
マスター方程式
量子機械学習(QML)におけるサンプリング効率の向上に関する本論文の中心的なメカニズムは、双方向量子冷蔵庫(BQR)プロトコルである。特に、Progressive Boundary Entropy Compression BQR(PBEC-BQR)は、サイクルプロセスを記述する。このメカニズムの1回の完全なラウンドを捉え、総量子状態がどのように進化するかを示す、絶対的なコア方程式は次のように与えられる:
$$ \rho_T^{\text{QR round}}(\rho_T) := \text{Tr}_m[U_{\text{QR}}(n)\rho_T U_{\text{QR}}^\dagger(n)] \otimes \rho_a^{\otimes m} $$
本論文の式(19)に見られるこの方程式は、PBEC-BQRプロトコルの1ラウンド後のn量子ビットレジスタの総量子状態 $\rho_T$ の変換を記述する。それは、ユニタリエントロピー圧縮と散逸熱化の両方のステップをカプセル化する。
項別解剖
このマスター方程式の各コンポーネントを分解して、その数学的定義、物理的/論理的役割、および選択された数学的操作の根拠を理解しよう。
-
$\rho_T$:
- 数学的定義: これは、BQRのラウンドの前のn量子ビットレジスタの総量子状態を表す密度行列である。それは、トレースが1である、正半定値エルミート演算子である。
- 物理的/論理的役割: $\rho_T$ は、量子冷蔵庫の1ラウンドの入力状態である。それは、偏光が増加されるターゲット量子ビット、エントロピー再分配を支援する補助量子ビット、およびエントロピーを吸収するリセット量子ビットを含む、すべてのn量子ビットの情報を含んでいる。それは本質的に、冷却サイクルの「作動流体」である。
- なぜ使用されるか: 密度行列は、量子系、特に混合状態(純粋状態の統計的アンサンブル)にある場合や、他のシステムとエンタングルしている場合に、量子力学における状態を記述するための標準的な形式主義である。これは、特に熱浴と相互作用する現実的な量子系をモデル化する上で重要である。
-
$\rho_T^{\text{QR round}}(\rho_T)$:
- 数学的定義: これは、BQRプロトコルの1ラウンドの後のn量子ビットレジスタの総量子状態を表す密度行列である。それは、変換の出力状態である。
- 物理的/論理的役割: これは、量子冷蔵庫が1サイクルの冷却を実行した後の、量子冷蔵庫の更新された状態である。プロトコルの目標は、この出力状態内で、ターゲット量子ビットの偏光 magnitude が増加し、それを「より冷たく」またはよりバイアスがかかった状態にすることである。この状態は、サイクル操作での次のラウンドの入力として機能する。
- なぜ使用されるか: この記法は、状態 $\rho_T$ が「QRラウンド」操作によって定義される変換を受け、新しい状態を生成することを示している。
-
$U_{\text{QR}}(n)$:
- 数学的定義: これは、n量子ビットレジスタに作用するグローバルユニタリ演算子である。PBEC-BQRの場合、それは、階段状に適用される局所ユニタリ演算子、$U_{C_j}$ のシーケンスで構成される(例えば、式(B7)に示すように、$U_{\text{QR}}(n) = U_{C_n} (I_2 \otimes U_{C_{n-1}}) \dots (I_2^{\otimes (n-3)} \otimes U_{C_3})$)。
- 物理的/論理的役割: このユニタリ操作は、「エントロピー圧縮」ステップを実行する。それは、ターゲット量子ビットと補助量子ビットからエントロピーを抽出し、それをリセット量子ビットに集中させることにより、レジスタ全体にわたってエントロピーをコヒーレントに再分配する。ここでの主な革新は、その双方向性である。ターゲット量子ビットの偏光 magnitude($|\alpha|$)を増幅するが、その元の符号を保存する。その符号を知る必要はない。これが「冷却」のコアアクションである。
- なぜ使用されるか: ユニタリ操作は、総エントロピーを保存する可逆変換を表す量子力学の基本である。このユニタリを慎重に設計することにより、著者らはシステム内のエントロピー分布を操作し、望ましい偏光増強を達成できる。局所ユニタリのシーケンスの使用は、単一の複雑なグローバルユニタリと比較して、プロトコルをより実験的に実現可能にする。
-
$U_{\text{QR}}^\dagger(n)$:
- 数学的定義: これは、ユニタリ演算子 $U_{\text{QR}}(n)$ のエルミート共役(随伴)である。
- 物理的/論理的役割: 量子力学では、ユニタリ演算子 $U$ が密度行列 $\rho$ に作用する場合、変換は $U \rho U^\dagger$ によって与えられる。随伴は、変換された状態が有効な密度行列(エルミート、正半定値、トレース保存)であり続けることを保証する。
- なぜ使用されるか: これは、密度行列にユニタリ変換を正しく適用するための数学的な必要条件である。
-
$\text{Tr}_m[\dots]$:
- 数学的定義: これは、m個のリセット量子ビットに対する部分トレース操作を示す。総システムが2つのサブシステム、AとBで構成され、その状態が $\rho_{AB}$ である場合、$\text{Tr}_B[\rho_{AB}]$ はサブシステムAの縮小密度行列を与える。
- 物理的/論理的役割: この操作は、エントロピーを吸収した後のm個のリセット量子ビットの「除去」または「破棄」を表す。これは、散逸ステップの最初の部分であり、システムを熱化のために準備する。
- なぜ使用されるか: 部分トレースは、総システムが混合状態またはエンタングル状態にある場合にサブシステムの縮小状態を取得するための正しい数学的ツールである。ここでは、ターゲット量子ビットと補助量子ビットの状態に焦点を当てることができ、それらを「熱い」リセット量子ビットから効果的に分離できる。
-
$\otimes$:
- 数学的定義: これはテンソル積演算子であり、独立したサブシステムの量子状態を結合するために使用される。
- 物理的/論理的役割: この演算子は、古いリセット量子ビットをトレースアウトした後の残りの $n-m$ 量子ビットの縮小状態と、m個の新鮮で熱化されたリセット量子ビット($\rho_a^{\otimes m}$)を組み合わせる。これは、「熱化」または「リセット」ステップを表し、蓄積されたエントロピーがリセット量子ビットを「冷たい」ものに交換することによって放出される。この補充は、冷蔵庫のサイクル操作にとって重要であり、エントロピーを継続的に抽出することを可能にする。
- なぜ使用されるか: 新しく導入されたリセット量子ビットは熱浴 $\rho_a$ で独立に準備されていると仮定されるため、この項は、システムが外部環境(熱浴)と相互作用してエントロピーを放出する散逸部分をモデル化する。同一の熱浴量子ビットの仮定は、このリセットプロセスのモデリングを単純化する。
-
$\rho_a^{\otimes m}$:
- 数学的定義: これは、m個の同一の量子ビットの状態を表し、各量子ビットは熱浴状態 $\rho_a$ で準備される。$\otimes m$ は、$\rho_a$ のm個のコピーのテンソル積を示す。
- 物理的/論理的役割: これらは、リセット量子ビットから吸収されたエントロピーを吸収し、それらを低エントロピー状態に効果的にリセットする「熱浴」として機能する、システムに導入される「新鮮な」または「冷たい」量子ビットである。この補充は、冷蔵庫のサイクル操作を完了するために不可欠であり、継続的なエントロピー抽出を可能にする。
- なぜ使用されるか: この項は、冷却サイクルの散逸部分をモデル化し、システムが外部環境(熱浴)と相互作用してエントロピーを放出する。同一の熱浴量子ビットの仮定は、このリセットプロセスのモデリングを単純化する。
ステップバイステップフロー
この量子冷蔵メカニズムの1ラウンドを通過する単一の抽象データポイントの正確なライフサイクルを追跡してみましょう。その初期偏光 $\alpha$ によって表されます。
- 初期状態準備: 特徴ベクトル $x$ によって特徴付けられる抽象データポイントは、量子状態の偏光 $\alpha$ にエンコードされる。この状態は、$n-1$ 個の他の量子ビット(補助およびリセット量子ビット)とともに、初期のn量子ビットレジスタ $\rho_T$ を形成する。単純化のために、ターゲット量子ビットが最初のもの、残りの $n-1$ 個の量子ビットが何らかの初期状態、しばしば熱状態に準備されていると想像してください。
- エントロピー圧縮(ユニタリステップ): n量子ビットレジスタ全体、$\rho_T$ は、慎重に設計されたグローバルユニタリ操作、$U_{\text{QR}}(n)$ を受ける。これを量子ソートマシンと考えてください。このユニタリは、すべての量子ビットにわたって計算基底状態の集団をコヒーレントにシャッフルする。その主な仕事は、ターゲット量子ビットと補助量子ビットからエントロピーを抽出し、この「熱」をm個の「リセット」量子ビットの特定のサブセットに集中させることである。ここでの魔法は、このユニタリが「双方向」であることである。ターゲット量子ビットの初期偏光 $\alpha$ が正か負かに関係なく、それは単にその magnitude を増幅し、$\alpha$ を $\alpha'$ に変換して $|\alpha'| > |\alpha|$ とし、同時に $\alpha$ の元の符号を保存する。これにより、ターゲット量子ビットは「より冷たく」またはより偏光される。
- エントロピー放出(部分トレース): ユニタリ操作の後、エントロピーが集中したために「より熱く」なったm個のリセット量子ビットは、効果的に分離され、システムから除去される。数学的には、これらのm個の量子ビットに対して部分トレース $\text{Tr}_m[\dots]$ を実行する。これにより、強化されたターゲット量子ビットと補助量子ビットを含む、残りの $n-m$ 個の量子ビットの縮小量子状態が得られる。このステップは、リセット量子ビットの補充のために冷蔵庫の容量をリセットする。
- 熱化/リセット(量子ビット交換): ラウンドを完了し、冷蔵庫が継続的に動作できるようにするために、各々が熱浴状態 $\rho_a$ で準備されたm個のブランドニュー、「冷たい」量子ビットが導入される。これらの新鮮な量子ビットは、テンソル積($\otimes \rho_a^{\otimes m}$)を介して残りの $n-m$ 個の量子ビットと組み合わされる。この操作は、蓄積されたエントロピーを外部熱浴(新鮮な量子ビットによって表される)に放出することによって、冷蔵庫の容量を効果的に「リセット」する。システムは再びn量子ビットレジスタに戻るが、偏光が増強されたターゲット量子ビットを持つ。
- 次のラウンドのためのリサイクル: 新しく形成されたn量子ビット状態は、BQRの次のラウンドの入力 $\rho_T$ となる。強化されたターゲット量子ビットは測定のために抽出されるか、またはプロセスはさらなる偏光増強を達成するために複数ラウンド($N_{\text{rounds}}$)で繰り返されることができる。残りの $n-1$ 個の量子ビット(補助および新鮮なリセット量子ビット)は、後続のターゲット量子ビットを準備するためにリサイクルされ、プロトコルをリソース効率的にする。
この反復プロセスにより、ターゲット量子ビットの偏光が段階的にブーストされ、分類信号がより強く、より信頼性の高いものになる。
最適化ダイナミクス
BQRメカニズムは、量子測定の確率的性質に起因する有限サンプリング誤差という課題に直接対処することにより、量子機械学習のパフォーマンスを最適化する。これは、モデルパラメータを伝統的な意味で調整するのではなく、分類スコアの信号対雑音比を強化するために量子状態を前処理することによって行われる。
- 損失ランドスケープと勾配の信頼性: QMLでは、分類スコア $q(x, \theta) = \alpha(x, \theta)$ は有限回の測定から推定される。訓練プロセスは通常、損失関数(例えば、ヒンジ損失)を、モデルパラメータ $\theta$ を(式(8))の勾配 $\frac{dl}{d\theta}$ に基づいて反復的に更新することによって最小化する。偏光 magnitude $|\alpha(x, \theta)|$ が小さい場合、有限測定からの統計的変動は、$\alpha$ の真の符号を容易に不明瞭にし、不正確な分類ラベル、または決定的に、誤った方向の勾配更新につながる。これにより、「損失ランドスケープ」が効果的に非常に平坦またはノイズが多くなり、効率的な最適化が妨げられる。
- 偏光増強としての「信号増幅」: BQRのコア「最適化」は、この偏光の magnitude を増加させることである。
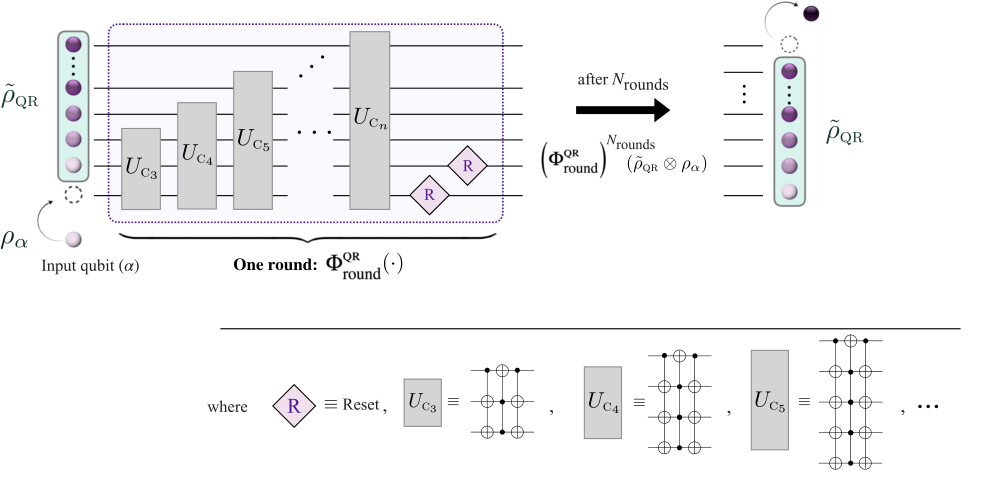 FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
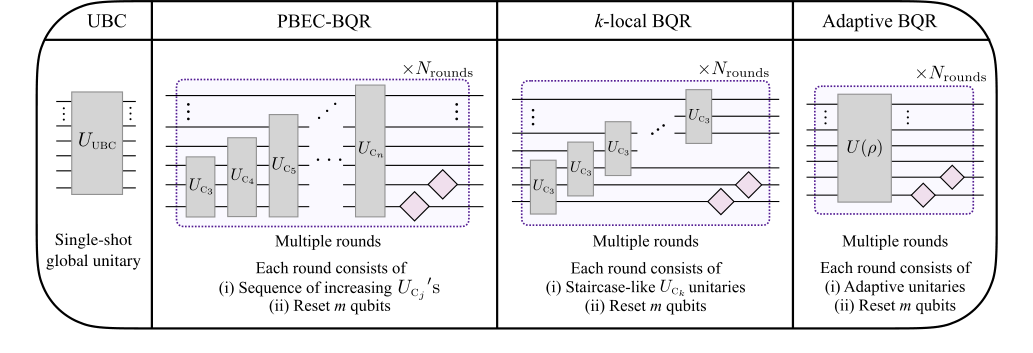 FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
結果、限界、および結論
実験設計とベースライン
数学的主張を厳密に検証するために、著者らは、双方向量子冷蔵庫(BQR)プロトコル、特に3-local BQRプロトコルの実用的な分類パフォーマンスに焦点を当て、Qiskitとscikit-learnを使用して一連のシミュレーション実験を綿密に設計した。コア目標は、BQRを介して測定量子ビットの偏光を強化することが、特に有限サンプリング誤差を緩和することにより、分類精度における具体的な改善に直接つながることを実証することであった。
実験アーキテクチャは、保守的な選択に焦点を当てた:$n=5$ システム量子ビット、$m=2$ リセット量子ビット、$N_{rounds}=2$ の冷却ラウンドで動作する3-local BQRプロトコル。この特定の構成は、このより実用的なk-localバージョンでさえベースラインを上回ることができれば、完全なBQRプロトコル(より強力な冷却を提供する)はさらにパフォーマンスが向上すると予想されるため選択された。
BQRに対して厳しくテストされた「犠牲者」またはベースラインモデルは、BQRを使用しない従来のサンプリング方法であった。有限サンプリング誤差(BQRが削減を目指すもの)の影響を分離するために、ベースライン方法には比例してより多くの測定ショットが割り当てられた。具体的には、BQR強化分類器が $k_{BQR}$ 測定ショット(例えば、現実的なNISQ制約を反映するために10または100ショット)を使用したとすると、従来のベースラインは $k_c = k_{BQR} \times m \times (N_{rounds} - 1) + n$ ショットを与えられた。$k_{BQR}=10$ の場合、これはベースラインが25ショットを受け取ったことを意味した。$k_{BQR}=100$ の場合、ベースラインは205ショットを受け取った。このスケーリングにより、両アプローチが同等の量子ビットリソースを消費することが保証され、観察されたパフォーマンスの違いは、単に多くの生の測定ではなく、BQRの効率に起因すると考えられた。
QMLモデルの固有の表現力や訓練可能性からサンプリング誤差の影響をさらに分離するために、問題設定は単純化された。実験では、そのZ偏光が直接分類信号をエンコードする単一量子ビット縮小密度行列の形式で最終量子状態への直接アクセスを仮定した。これにより、BQRがより少ない測定から予測の信頼性をどのように向上させるかを明確に評価できた。
実験では、合成データセット(一様およびガウス分布)およびいくつかの実世界データセット(Iris、Wine、手書き数字(特に2と5)、Sonar、Pima Indians Diabetes)を含む、二値分類タスク用の多様なデータセットが使用された。各データセットについて、クラスごとに50個のデータポイントがランダムにサンプリングされ、バランスの取れたタスクが作成され、このサンプリングと評価手順全体が100回繰り返され、堅牢な統計アンサンブルが生成された。
決定的に、著者らは現実的なノイズ中規模量子(NISQ)デバイスの条件下でもプロトコルをテストした。数値シミュレーションには、エネルギー緩和と確率的ゲートエラーをモデル化する、一般化振幅減衰(GAD)およびデポラライジングチャネルが組み込まれた。2つのノイズレジームが考慮された:「典型的なNISQレジーム」(中程度のノイズパラメータ)と「最悪の場合のレジーム」(プロトコルのストレステストのために意図的に誇張されたノイズ強度)。この包括的な実験設計は、BQRの効果と実用性の明白な証拠を提供することを目的とした。
証拠が証明すること
本論文で提示された証拠は、双方向量子冷蔵庫(BQR)プロトコル、特に3-local BQRが、現実的なノイズ条件下でも、量子機械学習におけるサンプリング効率を大幅に向上させ、分類精度を改善することを決定的に証明している。ターゲット量子ビットの偏光 magnitude を、その符号を維持しながら増加させるというコアメカニズムは、実際に機能することが示され、正確な分類に必要な測定回数を大幅に削減した。
最も説得力のある証拠は、すべてのテストされたデータセットにわたる分類精度をまとめた表Iから得られる。すべてのインスタンスで、BQR強化分類器は一貫して従来のサンプリングベースラインを上回った。例えば、一様データセットで $k_{BQR}=10$ ショットの場合、BQRは $95.8\% \pm 1.8\%$ の精度を達成したが、ベースライン(25ショット)は $93.1\% \pm 2.3\%$ しか達成できなかった。$k_{BQR}$ が100ショット(ベースラインは205ショット)に増加すると、BQRは $99.3\% \pm 0.7\%$ の精度を達成し、ベースラインの $97.7\% \pm 1.3\%$ と比較された。この優れたパフォーマンスのパターンは、Iris、Wine、手書き数字、Sonar、Diabetesを含むすべての合成および実世界データセットで観察された。これらの改善の統計的有意性は、ウェルチのt検定によって厳密に確認され、すべてのケースでp値が0.05未満となり、観察されたゲインが偶然によるものではないことを示した。
生の精度を超えて、本論文は根本的なメカニズムの成功を示すグラフィカルな証拠を提供する。図5と図6は、理想的なノイズフリー設定における、Progressive Boundary Entropy Compression BQR(PBEC-BQR)によって達成される強化された偏光($\alpha_{PBEC}'$)とサンプリング誤差確率バウンドの削減係数($r_{PBEC}$)を示している。これらの図は、BQRが偏光 magnitude を著しく増加させ、誤差バウンドを大幅に削減することを示しており、特に中間および高偏光レジームで顕著である。これは、エントロピー削減が統計的推定を改善するという数学的主張を直接検証する。
さらに、NISQデバイスにとって重要な懸念事項であるノイズに対するBQRの堅牢性は、徹底的に実証された。図10は、典型的なNISQレベルのノイズ下でも、BQRが依然として大幅な偏光増強を達成し、理想的なノイズフリーパフォーマンスに近い定常状態に収束することを示している。図11は、典型的なNISQノイズ下での誤差確率バウンドの削減係数($r_{QR}$)を示すことで、これを定量化している。振幅減衰によって導入されたいくらかの非対称性(偏光を一方向に駆動する)にもかかわらず、全体的な削減係数は依然として大きく、プロトコルが不完全な量子ハードウェアでもサンプリング誤差を効果的に緩和することを示している。最後に、図12は、プロトコルのロバスト性の強力な証拠を提供し、意図的に誇張されたノイズ強度を持つ「最悪の場合」のノイズレジーム下でも、BQRは理想的な場合とほぼ同じ初期偏光範囲にわたって誤差確率の削減を継続して生成することを示している。この明白な証拠は、BQRのコアメカニズムが実際に機能し、QMLにおける学習パフォーマンスの向上に向けた物理的に根拠があり、ノイズに強い経路を提供することを確認している。
限界と将来の方向性
双方向量子冷蔵庫(BQR)プロトコルはQMLにとって重要な進歩を提供するが、著者らは率直にいくつかの限界を認め、説得力のある将来の研究の方向性を提案している。
一つの注目すべき限界は、低偏光レジームにおけるパフォーマンスである。ユニタリ双方向冷却(UBC)およびBQRプロトコルの両方とも、初期偏光 $\alpha$ がゼロに非常に近い場合、意味のある改善を提供しない。利点の領域はプロトコルパラメータの最適化によって拡大できるが、極端な低偏光限界は依然として困難な領域である。これは、特定の種類のデータまたはモデル状態に対して、BQRの利点が最小限である可能性を示唆しており、そのようなシナリオでは代替または補完的な戦略の必要性を促している。
別の未解決の問題は、PBEC-BQRプロトコルの最適性に関するものである。本論文は、この特定の冷却プロトコルが有限サンプリング誤差の削減に真に最適であるとは断定していない。もしそうでない場合、パフォーマンスのさらなる向上につながる可能性のあるプロトコルの洗練のための明確な将来の作業の方向性が存在する。
リソースの観点からは、BQRスキームは単一のグローバルユニタリUBCよりも実用的であるが、サイクル冷却ラウンドを維持するために追加の量子ビットを必要とする。これは、シングルショットUBCと比較して量子ビットオーバーヘッドを増加させる。将来の研究では、このオーバーヘッドを最小限に抑える方法を模索するか、量子ビット数、回路深度、および冷却パフォーマンスの間のトレードオフを調査することが考えられる。本論文はまた、すべての量子ビットに対する単一のグローバルユニタリが最高の偏光増強を達成するであろうと述べているが、そのような操作は実装するのが現実的ではない。これは、理論的最適性と量子コンピューティングにおける実験的実現可能性の間の継続的な緊張を浮き彫りにしている。
将来の開発のための重要な領域は、量子カーネル推定への適用性の拡張である。現在の方法は主に二値結果の符号推定を支援するが、これはカーネル行列要素の推定には直接十分ではない。量子カーネルにおける有限サンプリング誤差を削減するためにこれらの冷却技術を適応させることは、推定される量がより複雑であるため、独自の課題を提示する。これを解決することは、量子熱力学の洞察のより広い範囲のQMLアプリケーションへの影響を広げるだろう。
将来に向けて、いくつかのエキサイティングな議論のトピックが現れる:
- コヒーレンスと非古典相関の活用: 本論文では、冷却効率を改善するために、システムおよび浴量子ビット内のコヒーレンスと非古典相関をどのように活用できるかを調査することに言及している。これは、現在のプロトコルが主に対角サブスペース内で動作し、デフェージングノイズに対して堅牢であるが、さらなる増強のための未開拓のリソースを残している可能性があるため、魅力的な方向性である。
- バレンプラトー緩和: BQRがバレンプラトー効果をどのように緩和するかについての詳細な定量的分析が求められる。著者らは、彼らの技術がバレンプラトー緩和のための既存の戦略と組み合わせて独立したメカニズムとして使用できることを示唆している。この相互作用を理解することは、より堅牢でスケーラブルなQMLアルゴリズムにつながる可能性がある。
- データ再アップロードとBQR回路: データ再アップロード技術とBQRメソッドの関係は、興味深い可能性を開く。BQR回路のデータ再アップロードバージョンを構築することで、回路深度と量子ビットオーバーヘッドの間の包括的なトレードオフ分析が可能になり、リソース効率的な実装につながる可能性がある。
- 二値分類を超えて: 現在の研究は二値分類に焦点を当てているが、エントロピー削減のための基盤となる熱力学的フレームワークは、回帰やより複雑な多クラス問題などの他のQMLタスクに潜在的に適応できる可能性がある。これには、「偏光」と「符号」がこれらの文脈でどのように一般化されるかを慎重に検討する必要がある。
- 実験的実現とハードウェア最適化: NISQノイズ下での数値シミュレーションは有望であるが、さまざまな量子ハードウェアプラットフォーム(超伝導、トラップドイオン、中性原子)での実際の実験的実現が究極の検証となるだろう。これは、特定のハードウェアアーキテクチャとノイズ特性のためにBQR回路を最適化するための貴重なフィードバックも提供するだろう。
- QMLのための冷却の理論的基盤: 本研究は、量子熱力学とQMLの間に新しい接続を確立する。学習タスクのための冷却の根本的な限界、および他の分野との潜在的な同型性(正準章順序で示唆されているように)に関するさらなる理論的探求は、より深い洞察をもたらし、全く新しいアルゴリズムパラダイムを刺激する可能性がある。
これらの多様な視点は、BQRプロトコルが現在のQMLの課題に対する実用的な解決策であるだけでなく、学際的な研究の肥沃な土壌であり、量子情報科学と機械学習の境界を押し広げていることを強調している。
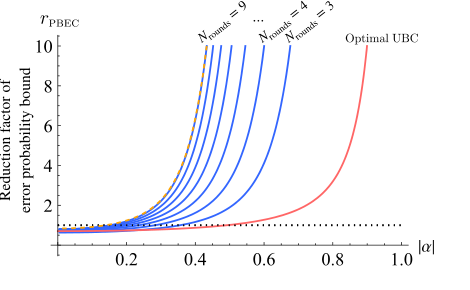 FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
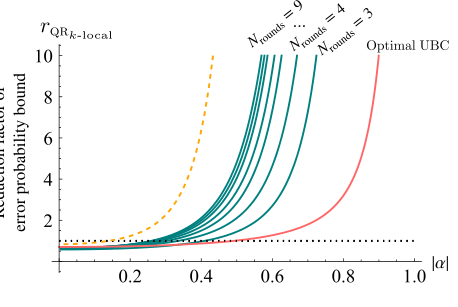 FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound
FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound
他の分野との同型性
構造的骨格
コアの数学的メカニズムは、エントロピーを体系的に圧縮し、過剰分を浴に放出することによって、二値値信号の magnitude を増幅するサイクルプロセスであり、信号の元の符号を保存する。