通过热浴算法冷却改进量子机器学习
This work introduces an approach rooted in quantum thermodynamics to enhance sampling efficiency in quantum machine learning (QML).
背景与学术渊源
起源与学术渊源
本文所解决的问题源于量子信息处理(QIP)与数据科学的交叉领域,催生了量子机器学习(QML)这一分支。尽管QML在处理超越经典计算能力的数据分布方面展现出巨大潜力,但由于量子测量的概率性本质,它面临着固有的挑战。这种概率性意味着,在从量子态中提取信息(如可观测量期望值)时,QML算法的训练和推理阶段都容易受到“有限采样误差”的影响。
历史上,为缓解这些采样误差所做的尝试,例如改进量子幅度估计(QAE),提供了二次方的改进。然而,QAE协议需要多轮复杂类Grover操作,这在计算上非常密集,并严重限制了其在当前噪声中等规模量子(NISQ)设备上的可行性。此外,对于许多机器学习任务,特别是分类任务,QAE提供了“过量”的精度。通常情况下,仅确定测量统计量的符号(例如,分类分数是正还是负)就已足够,而无需精确知道其幅度。这一认识凸显了对更实用、更高效的采样减少技术的需求,这些技术应能超越QAE的二次方改进,同时与NISQ硬件的限制兼容。
促使作者开发这项工作的先前方法的根本限制或“痛点”是双重的。首先,QAE等现有方法对于在当前NISQ硬件上实际实现来说过于耗费资源且复杂(需要大量类Grover操作),使得实时应用成为不可能。其次,启发这项工作的传统算法冷却技术本质上是“单向的”。它们旨在增加预定基态(例如 $|0\rangle$)的布居数,需要预先了解期望输出的符号。然而,在监督式QML中,分类分数的符号(决定标签或梯度方向)正是我们旨在确定的未知量。先前冷却方法缺乏“双向”能力意味着它们不能直接应用于偏差方向最初未知的QML分类问题。本文通过引入一种新颖的、保持符号的、双向冷却方法,直接解决了这些限制。
直观领域术语
- 量子机器学习 (QML):想象一台常规计算机试图从数据中学习模式,就像一个学生在为考试学习一样。QML就像是给这位学生一个神奇的量子大脑,它能以全新的方式处理信息,使其能够更快地学习或发现普通学生可能忽略的模式,尤其是在处理非常复杂的数据时。
- 噪声中等规模量子 (NISQ) 设备:将NISQ设备想象成第一代电动汽车。它们具有革命性,并展现出令人难以置信的潜力,但它们的电池续航有限,有些不可靠,并且在需要充电或维修之前只能执行某些任务。它们尚未准备好进行长途旅行,但它们是实现全功能量子汽车的关键一步。
-
热浴算法冷却 (HBAC):想象一张杂乱的桌子,重要的文件与垃圾混在一起。HBAC就像一个一丝不苟的助手,分两步整理:首先,他们将所有重要文件堆成一堆,并将垃圾推到桌子的另一边(熵压缩)。其次,他们将垃圾从桌子上扔掉(热化/重置),使重要文件更加整洁和易于访问。这是一个关键的解决方案。
-
(量子比特的)极化:想象一下指南针的指针。如果它平衡得很好,它可能会指向任何方向(低极化)。如果它强烈地指向北方,它就具有高北方极化。对于量子比特(qubit),极化描述了它在特定状态(如“0”)上相对于另一个状态(如“1”)的偏好程度。高极化意味着从量子比特获得更清晰、更可靠的“是”或“否”答案。
- 熵压缩:考虑一群人随机散布在一个大厅里(高熵)。熵压缩就像一个聪明的活动组织者,在不移除任何人的情况下,将所有贵宾引导到一个指定且易于访问的区域,而其余的与会者则分散开来。大厅里的人数(信息)总量保持不变,但“重要”的部分现在更加集中和有序。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文所解决的核心问题是量子机器学习(QML)算法,特别是变分量子二元分类器(VQBC)中固有的有限采样误差。这种误差源于量子测量的概率性本质,这是QML训练和预测阶段的基础。
输入/当前状态:
在当前状态下,QML算法处理量子数据表示,其输出(例如,分类标签或梯度方向)被编码在目标量子比特的测量统计量Z极化 $\alpha(x, \theta)$ 的符号中。该极化源自单量子比特密度算符 $\rho_1(x, \theta) = \frac{I + \alpha(x, \theta)Z + \beta(x, \theta)X + \gamma(x, \theta)Y}{2}$,其中分类分数为 $q(x, \theta) = \alpha(x, \theta)$。为了估计该分数,需要进行有限次数的测量重复(shots),记为 $k$。这个有限的 $k$ 导致估计误差。为了稳健预测,估计的期望值 $\mu$ 必须满足 $|\mu - \langle M \rangle| < |\langle M \rangle|$,其中 $\langle M \rangle$ 是真实的期望值。对于训练,为了准确评估铰链损失梯度, $q(x_j, \theta)$ 的估计误差必须小于 $|q(x_j, \theta) - b|$。这些任务的误差概率上限如下,例如,对于预测:
$$ \text{Pr[error]} = \text{Pr}[|\mu - \langle M \rangle| \geq |\langle M \rangle|] \leq \frac{1 - \alpha^2(x, \theta^*)}{k\alpha^2(x, \theta^*)} $$
以及对于训练:
$$ \text{Pr[error]} = \frac{1 - \alpha^2(x_j, \theta)}{k(\alpha(x_j, \theta) - b)^2} $$
这些界限表明,为了保持低误差概率, $|\alpha(x, \theta)|$ 的幅度越小,所需的测量次数 $k$ 就越大。至关重要的是,在QML的背景下, $\alpha(x, \theta)$ 的符号并非先验已知,因为它代表了算法旨在确定的信息(标签或梯度方向)。
期望终点(输出/目标状态):
期望的终点是显著减少这些有限采样误差,从而最小化准确分类和梯度估计所需的测量重复次数 $k$。这是通过将目标量子比特的极化幅度 $|\alpha(x, \theta)|$ 增加到一个新的、增强的值 $|\alpha'(x, \theta)|$ 来实现的。关键要求是这种增强必须是双向的,意味着必须保持极化的符号,同时增加其幅度。单量子比特密度矩阵的目标变换是:
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{其中} \quad \begin{cases} \alpha' > \alpha & \text{如果 } \alpha > 0 \\ \alpha' < \alpha & \text{如果 } \alpha < 0 \end{cases} $$
这个过程应在不依赖于计算成本高昂的操作(如Grover迭代或量子相位估计)的情况下,提高训练和预测阶段的样本效率。
缺失的环节与困境:
确切的缺失环节是一种高效且保持符号的机制,用于在QML的背景下放大目标量子比特的极化幅度。先前的算法冷却技术,如热浴算法冷却(HBAC),是“单向的”;它们旨在增加预定基态(例如 $|0\rangle$)的布居数。这需要预先了解期望输出(即 $\alpha(x, \theta)$ 的符号),这正是QML分类中未知的精确信息。这造成了一个痛苦的困境:要使用常规冷却来提高准确性,就需要预先知道答案,这使得冷却过程对于分类来说毫无意义。本文试图通过开发一种新颖的“双向”冷却协议来弥合这一差距,该协议独立于初始极化符号工作。
约束与失效模式
QML采样效率增强的问题由于几个严峻的现实约束而变得异常困难:
1. 计算与硬件约束:
* NISQ设备限制: 解决方案必须与噪声中等规模量子(NISQ)设备兼容。这意味着要避免复杂的、深层的电路和操作,如Grover迭代或量子相位估计,因为这些操作由于量子比特数量有限、相干时间短和错误率高而不可行。
* 计算开销: 任何提出的方法都必须最小化与估计分类分数和梯度相关的计算开销。增加测量次数($k$)以减少误差是与计算成本的直接权衡。
* 量子比特资源限制: 当前硬件上可用的量子比特数量有限。该协议必须资源高效,最好通过回收量子比特来减少所需的总量子比特数量。
2. 数据驱动与算法约束:
* 未知极化符号(双向性要求): 如核心问题所示,目标量子比特极化 $\alpha(x, \theta)$ 的符号并非先验已知。这是一个基本约束,使得常规的、单向的算法冷却协议不适用。冷却机制必须对正极化和负极化都能正确运行,而无需预先知道是哪一种。
* 有限采样误差: 量子测量的固有概率性意味着任何基于有限次数测量的估计都将始终存在一定误差。目标是在实际限制内减少此误差,而不是完全消除它。
* 贫瘠高原: 虽然本文并未直接解决,但变分量子算法中的贫瘠高原问题(梯度随量子比特数量指数级衰减)是QML中一个已知的挑战。本文指出其方法是一种独立的机制,可以与现有的贫瘠高原缓解策略结合使用。
3. 物理噪声约束:
* 嘈杂的量子环境: 当前的量子硬件容易受到各种形式的噪声和退相干的影响。该协议必须对这些不完善之处具有鲁棒性。
* 特定噪声模型: 本文特别考虑了广义幅度阻尼(GAD)和去极化通道,它们是NISQ设备中主要的噪声机制。该协议的设计主要在对角态子空间内运行,必须确保对不影响对角元素的退相干噪声(例如,去相位、相位阻尼、控制相位波动)具有抵抗力。
失效模式:
如果未能满足这些约束,或问题未能得到充分解决,QML算法将面临几种失效模式:
* 不准确的分类: 高采样误差将导致不可靠的预测,估计的标签可能与真实标签不同。
* 无效的训练: 由于高采样误差导致的梯度估计不正确将阻碍优化过程,阻止模型收敛到最优解。
* 过高的资源消耗: 依赖于过多的测量次数或复杂的量子操作将使QML在当前和近期量子硬件上不切实际且不可扩展。
* 冷却的不可适用性: 如果冷却协议在不知道极化符号先验知识的情况下无法双向运行,则无法有效地将其集成到QML分类任务中,因为该符号是未知的输出。
* 对噪声的敏感性: 对NISQ设备噪声特性不鲁棒的协议将产生不一致且不可靠的结果,否定任何理论上的性能提升。本文专门在现实的NISQ噪声条件下(包括典型和最坏情况下的情况)测试其协议,以证明对真实硬件中发生的噪声的鲁棒性。
为什么选择这种方法
选择的必然性
量子机器学习(QML)算法,特别是分类任务,其核心挑战源于量子测量的概率性本质。训练和推理阶段都需要从概率分布中提取信息,这不可避免地引入了有限采样误差。这一限制直接影响了分类分数和梯度的可靠性,需要大量的重复(shots)才能获得准确的结果。
传统的最新(SOTA)量子方法,如量子幅度估计(QAE),被认为不足以解决这个特定问题。虽然QAE理论上提供了二次方采样误差的减少,但它依赖于复杂的类Grover操作[13,14],这使其在噪声中等规模量子(NISQ)设备[15,16]上基本不切实际且不可行。此外,QAE提供了过量的幅度估计,这对于分类任务来说通常是过度的。对于二元分类,只需要测量统计量(极化)的符号,而不需要其精确幅度。
作者意识到,关键需求是增加分类分数极化 $|\alpha(x, \theta)|$ 的幅度,以最小化所需的测量次数。然而,这种增加不能通过对单个测量量子比特进行简单的局部酉过程来实现,因为这种操作会改变其状态的纯度。这导致了对算法冷却技术的考虑。
作者认识到现有方法不足的时刻是,他们发现传统的算法冷却协议旨在增加预定基态的布居数,这根本不适合。在QML分类中, $\alpha(x, \theta)$ 的符号(决定类别标签或梯度方向)是先验未知的。因此,任何可行的解决方案必须是一个双向协议,能够动态地变换单量子比特密度矩阵以增加极化幅度,同时保持其未知符号,如变换所示:
$$ \frac{I + \alpha Z}{2} \rightarrow \frac{I + \alpha' Z}{2} \quad \text{其中} \quad \begin{cases} \alpha' > \alpha & \text{如果 } \alpha > 0 \\ \alpha' < \alpha & \text{如果 } \alpha < 0 \end{cases} $$
这种对保持符号的双向极化增强的要求,使得所提出的量子热力学冷却方法成为唯一可行的解决方案。
比较优势
这种将监督学习重塑为冷却过程的量子热力学方法,在性能指标之外提供了定性的优越性。其结构优势使其在几个关键方面远远优于先前的黄金标准:
-
降低计算开销: 该方法显著减少了估计分类分数和梯度所需的测量次数。通过增加目标量子比特的极化,只需更少的shots即可达到所需的精度,从而最小化了整体计算开销。这是优于需要大量采样的方法的直接优势。
-
缓解贫瘠高原: 与修改分类器结构或训练程序的策略不同,该方法作为减少有限采样误差的独立机制。无论系统是否表现出贫瘠高原,它都有效,贫瘠高原是变分量子算法中的一个常见挑战[8,30]。这提供了一个稳健的解决方案,而无需改变底层的QML模型。
-
资源效率和收敛速率: 双向量子冰箱(BQR)协议采用循环操作,其中增强的量子比特被提取,剩余的 $n-1$ 个量子比特被回收作为后续冷却轮的工作体。这种回收机制大大减少了准备多个增强量子比特所需的总量子比特资源(从 $n + m N_{rounds}$ 到 $\sim m N_{rounds} + 1$),并显著提高了冷却过程的收敛速率。
-
硬件可行性(k-局部BQR): k-局部BQR变体的引入是实际实现的关键结构优势。通过将压缩操作限制在k-局部邻域,该协议变得更加硬件友好,并且更容易在当前的NISQ设备上实现,同时仍然保留了更通用的BQR协议的核心性能优势。在某些配置中,k-局部BQR在误差概率降低方面甚至优于渐进边界熵压缩BQR。
-
噪声鲁棒性: 该协议的设计完全在对角态子空间内运行(重置、置换和条件交换保持对角性),使其布居动力学对小的随机波动本质上不敏感。至关重要的是,仅作用于量子相干性的噪声过程(例如,去相位、相位阻尼、控制相位波动)对结果没有可测量的影响,因为它们在整个演化过程中保持对角态不变。这种对退相干噪声的内在鲁棒性是NISQ兼容性的一个重要定性优势。
与约束的对齐
所选方法完美地符合QML中固有的严苛要求和约束,形成了“问题与解决方案的结合”:
-
有限采样误差: 本工作的主要动机是减少有限采样误差。BQR协议通过增加测量量子比特的极化幅度直接解决此问题,进而减少实现所需估计精度所需的测量次数。这是该方法旨在解决的核心问题。
-
NISQ设备兼容性: 该协议明确为NISQ设备设计。它避免了Grover迭代和量子相位估计等复杂操作,加上硬件友好的k-局部压缩酉算子的开发,使其在当前量子硬件上变得实用且高效。在现实NISQ噪声条件下的数值模拟进一步证明了其鲁棒性和适用性。
-
未知极化符号: QML分类的一个关键约束是分类分数(极化)的符号并非先验已知。常规算法冷却在此失败。所提出的“双向冷却”经过专门设计,无论初始符号如何,都能增强极化幅度,从而保持符号并实现无需先验知识的正确分类。
-
计算开销: 该方法通过显著减少准确分类分数和梯度所需的测量次数来直接最小化计算开销。量子比特的回收进一步优化了资源使用,使得整个过程比重复的独立测量更有效。
-
贫瘠高原: 该方法提供了一个独立的机制来减少采样误差,即使在存在贫瘠高原的情况下也很有益。它不需要改变变分电路结构或训练策略,因此可以补充现有的贫瘠高原缓解技术。
替代方案的拒绝
本文明确或隐含地拒绝了几种流行的方法,因为它们在解决特定问题约束方面存在根本性局限:
-
量子幅度估计(QAE): QAE被拒绝主要是因为其高资源成本和对NISQ设备的不切实际性。它需要多轮类Grover操作[13,14],这在当前量子硬件上要求极高[15,16]。此外,QAE提供的幅度估计通常对于分类任务来说是过度的,而分类任务只需要极化的符号。对于这个问题,其复杂性超过了其带来的好处。
-
常规算法冷却(AC)/热浴算法冷却(HBAC): 这些传统冷却技术被拒绝是因为它们是单向的,并且需要预先了解目标状态的偏差。常规AC协议旨在增加预定基态(例如 $|0\rangle$)的布居数。然而,在QML分类中,分类分数 $\alpha(x, \theta)$ 的符号(决定正确标签)是未知的。因此,一个假设已知偏差方向的单向冷却方法无法实现增强极化同时保持未知符号的目标。
-
单量子比特的局部酉过程: 作者指出,简单地对单个测量量子比特应用局部酉过程是不够的,因为这种操作无法改变量子比特状态的纯度[第三节]。为了增加极化,必须减少量子比特的熵,这需要与其他量子比特的相互作用和耗散过程,超出了单量子比特酉变换的范畴。
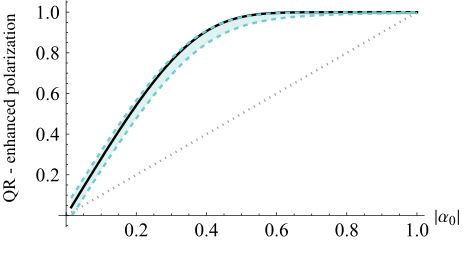 FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
FIG. 10. Enhanced polarization αQR of the quantum refrig- erator, with the progressive boundary entropy compression- bidirectional quantum refrigerator protocol operating with n = 5 qubits and Nrounds = 5 as a function of the initial polarization |α0|, under typical noise parameters representative of current noisy intermediate-scale quantum devices. The dotted straight line indicates the baseline initial polarization, while the solid black curve corresponds to the ideal noise-free enhancement. The green zone shows the expected polarization in the presence of typical noise channels—generalized amplitude damping and depolarizing noise
数学与逻辑机制
主方程
本文用于增强量子机器学习(QML)中采样效率的核心机制是双向量子冰箱(BQR)协议。特别是,渐进边界熵压缩BQR(PBEC-BQR)描述了一个循环过程。捕捉这个机制一个完整轮次的核心方程,展示了总量子态如何演化,由下式给出:
$$ \rho_T^{\text{QR round}}(\rho_T) := \text{Tr}_m[U_{\text{QR}}(n)\rho_T U_{\text{QR}}^\dagger(n)] \otimes \rho_a^{\otimes m} $$
这个方程,在论文的Eq. (19)中找到,描述了PBEC-BQR协议一个轮次后,n量子比特寄存器总量子态 $\rho_T$ 的变换。它包含了酉熵压缩和耗散热化步骤。
按项解剖
让我们剖析这个主方程的每个组成部分,以理解其数学定义、物理/逻辑作用以及所选数学运算的原理。
-
$\rho_T$:
- 数学定义: 这是BQR一个轮次之前,n量子比特寄存器的总量子态的密度矩阵。它是一个迹为一的正半定厄米算符。
- 物理/逻辑作用: $\rho_T$ 是量子冰箱单轮的输入状态。它包含所有n个量子比特的量子信息,包括极化要增强的目标量子比特、辅助熵重分布的辅助量子比特,以及将吸收熵的重置量子比特。它本质上是冷却循环的“工作流体”。
- 为何使用: 密度矩阵是量子力学中描述量子系统状态的标准形式,特别是当它处于混合态(纯态的统计集合)或与其他系统纠缠时。这对于模拟现实的量子系统,特别是那些与热浴相互作用的系统至关重要。
-
$\rho_T^{\text{QR round}}(\rho_T)$:
- 数学定义: 这是BQR协议一个完整轮次之后,n量子比特寄存器的总量子态的密度矩阵。它是变换的输出状态。
- 物理/逻辑作用: 这是量子冰箱执行一个冷却周期后更新的状态。该协议的目标是,在这个输出状态中,目标量子比特的极化幅度已增加,使其“更冷”或更偏置。然后,该状态作为下一个轮次的输入,进行循环操作。
- 为何使用: 这种表示法清楚地表明状态 $\rho_T$ 经过了由“QR round”操作定义的变换,产生了一个新状态。
-
$U_{\text{QR}}(n)$:
- 数学定义: 这是一个作用在n量子比特寄存器上的全局酉算符。对于PBEC-BQR,它由一系列局部酉操作 $U_{C_j}$ 组成,以楼梯状方式应用(例如,如Eq. (B7)所示,$U_{\text{QR}}(n) = U_{C_n} (I_2 \otimes U_{C_{n-1}}) \dots (I_2^{\otimes (n-3)} \otimes U_{C_3})$)。
- 物理/逻辑作用: 这个酉操作执行“熵压缩”步骤。它相干地将熵在整个n量子比特寄存器中重新分布,有效地从目标和辅助量子比特中提取熵,并将它们集中到重置量子比特中。这里的关键创新是其双向性质:它放大了目标量子比特极化($|\alpha|$)的幅度,同时保持了其原始符号,而无需预先了解该符号。这是核心的“冷却”作用。
- 为何使用: 酉操作是量子力学中的基本操作,代表了保持封闭系统总熵的可逆变换。通过精心设计这个酉算符,作者可以操纵系统内的熵分布,实现期望的极化增强。使用一系列局部酉算符使得该协议比单个复杂的全局酉算符更具实验可行性。
-
$U_{\text{QR}}^\dagger(n)$:
- 数学定义: 这是酉算符 $U_{\text{QR}}(n)$ 的厄米共轭(伴随)。
- 物理/逻辑作用: 在量子力学中,当一个酉算符 $U$ 作用于密度矩阵 $\rho$ 时,变换由 $U \rho U^\dagger$ 给出。伴随确保变换后的状态仍然是一个有效的密度矩阵(厄米、正半定且迹保持)。
- 为何使用: 这是将酉变换正确应用于密度矩阵的数学必要条件。
-
$\text{Tr}_m[\dots]$:
- 数学定义: 这表示对m个重置量子比特进行偏迹运算。如果总系统由两个子系统A和B组成,其状态为 $\rho_{AB}$,则 $\text{Tr}_B[\rho_{AB}]$ 得到子系统A的约化密度矩阵。
- 物理/逻辑作用: 这个操作代表了在熵吸收后,从系统中有效“移除”或“丢弃”m个重置量子比特。这是耗散步骤的第一部分,为热化准备系统。
- 为何使用: 偏迹是获得子系统约化状态的正确数学工具,当总系统处于混合态或纠缠态时。在这里,它允许我们关注目标和辅助量子比特的状态,有效地将它们与“热”的重置量子比特隔离开来。
-
$\otimes$:
- 数学定义: 这是张量积算符,用于组合独立子系统的量子态。
- 物理/逻辑作用: 这个算符将剩余 $n-m$ 个量子比特(在迹出旧重置量子比特后)的约化状态与m个新鲜的、热化的重置量子比特($\rho_a^{\otimes m}$)结合起来。这代表了“热化”或“重置”步骤,其中累积的熵被排出到热浴中,通过用“冷”的量子比特替换“热”的量子比特。
- 为何使用: 张量积用于此处,因为引入的新重置量子比特被假定为在热态 $\rho_a$ 中独立制备,因此它们的状态与剩余的 $n-m$ 个量子比特不相关。
-
$\rho_a^{\otimes m}$:
- 数学定义: 这表示m个相同量子比特的状态,每个量子比特都处于热浴态 $\rho_a$ 中。$\otimes m$ 表示m个 $\rho_a$ 副本的张量积。
- 物理/逻辑作用: 这些是引入系统以替换“热”重置量子比特的“新鲜”或“冷”量子比特。它们充当热浴,吸收在酉步骤中集中在重置量子比特中的熵,并有效地将它们重置到低熵状态。这种补充对于冰箱的循环操作至关重要,使其能够持续提取熵。
- 为何使用: 该项模拟了冷却循环的耗散部分,其中系统与外部环境(热浴)相互作用以排出熵。相同热浴量子比特的假设简化了该重置过程的建模。
分步流程
让我们追踪一个抽象数据点通过这个量子制冷机制一个轮次的精确生命周期,该数据点由其初始极化 $\alpha$ 表示。
- 初始状态制备: 一个抽象数据点,由其特征向量 $x$ 表征,被编码到量子态的极化 $\alpha$ 中。该状态,连同 $n-1$ 个其他量子比特(辅助和重置量子比特),构成了初始的n量子比特寄存器 $\rho_T$。为简单起见,假设目标量子比特是第一个,其余 $n-1$ 个量子比特处于某种初始状态,通常是热态。
- 熵压缩(酉步骤): 整个n量子比特寄存器 $\rho_T$ 受到精心设计的全局酉操作 $U_{\text{QR}}(n)$ 的作用。将其想象成一个量子排序机。该酉算符相干地在所有量子比特之间重新分布计算基态的布居数。其主要任务是从目标量子比特和辅助量子比特中提取熵,并将这种“热量”集中到一个特定的m个“重置”量子比特子集中。这里的魔力在于该酉算符是“双向的”:它不关心目标量子比特的初始极化 $\alpha$ 是正还是负。它只是放大其幅度,将 $\alpha$ 变为 $\alpha'$,使得 $|\alpha'| > |\alpha|$,同时保持 $\alpha$ 的原始符号。这使得目标量子比特“更冷”或更极化。
- 熵排出(偏迹): 在酉操作之后,m个重置量子比特,它们现在由于熵的集中而变得“更热”,被有效地隔离并从系统中移除。在数学上,我们对这m个量子比特进行偏迹运算 $\text{Tr}_m[\dots]$。这为剩余的 $n-m$ 个量子比特留下了一个约化量子态,其中包含增强的目标量子比特和辅助量子比特。此步骤为“冷”量子比特的补充做好了准备。
- 热化/重置(量子比特替换): 为了完成轮次并确保冰箱能够持续运行,引入了m个全新的、“冷”的量子比特,每个量子比特都处于热浴态 $\rho_a$ 中。这些新鲜的量子比特通过张量积($\otimes \rho_a^{\otimes m}$)与剩余的 $n-m$ 个量子比特结合。此操作通过将累积的熵排出到外部热浴(由新鲜量子比特表示)来有效地“重置”冰箱的容量。系统现在又回到了一个n量子比特寄存器,但目标量子比特的极化得到了增强。
- 为下一轮回收: 新形成的n量子比特状态成为BQR下一轮的输入 $\rho_T$。增强的目标量子比特可以被提取用于测量,或者该过程可以重复多轮($N_{\text{rounds}}$)以实现更大的极化增强。剩余的 $n-1$ 个量子比特(辅助和新鲜重置量子比特)被回收以制备后续的目标量子比特,从而使该协议资源高效。
这个迭代过程确保目标量子比特的极化得到逐步提升,使得分类信号更强、更可靠。
优化动力学
BQR机制通过直接解决有限采样误差的挑战来优化量子机器学习的性能,这些误差源于量子测量的概率性本质。它不是通过传统意义上调整模型参数来实现的,而是通过预处理量子态来增强分类分数信噪比。
- 损失景观和梯度可靠性: 在QML中,分类分数 $q(x, \theta) = \alpha(x, \theta)$ 是从有限次数测量中估计出来的。训练过程通常涉及最小化损失函数(例如,铰链损失),通过基于梯度 $\frac{dl}{d\theta}$(Eq. (8))迭代更新模型参数 $\theta$ 来实现。如果极化幅度 $|\alpha(x, \theta)|$ 很小,有限测量产生的统计波动很容易掩盖 $\alpha$ 的真实符号,导致错误的分类标签,或者更关键的是,错误的梯度更新方向。这使得“损失景观”实际上非常平坦或嘈杂,阻碍了有效的优化。
- 极化增强作为“信号放大”: BQR的核心“优化”是增加该极化的幅度,
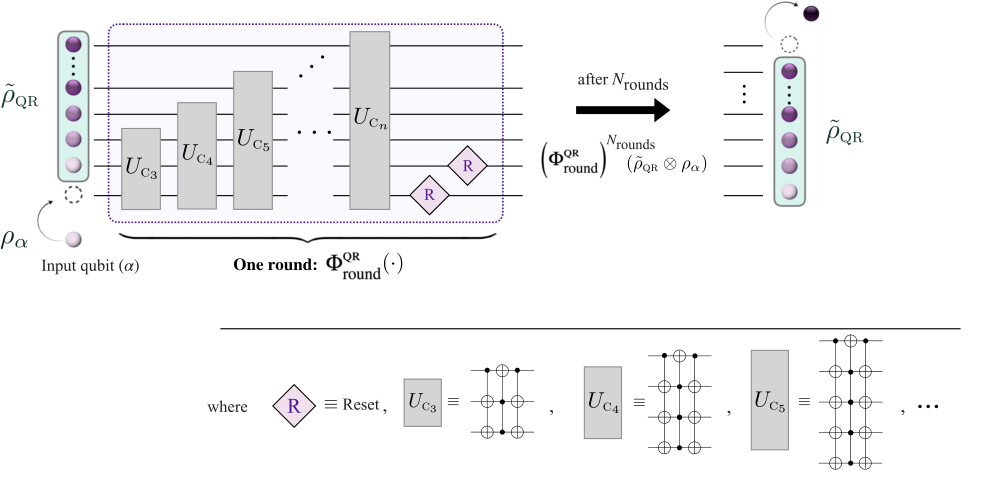 FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
FIG. 4. Bidirectional quantum refrigerator. Circuit diagram of the progressive boundary entropy compression-bidirectional quantum refrigerator protocol acting on an n-qubit register with m reset qubits (m = 2 shown). The unitary stage consists of a stairlike sequence of unitaries UC3, . . . , UCn, where each UCj performs a boundary entropy-compression step by swapping the states |0⟩|1⟩⊗(j −1) and |1⟩|0⟩⊗(j −1) on the last j qubits. After the unitary stage, the m reset qubits are refreshed, completing one round of the protocol. The protocol runs for Nrounds to prepare the target qubit; once prepared, the target qubit is extracted ready for the classification task, and the process restarts by recycling the remaining n −1 qubits to prepare subsequent target qubits
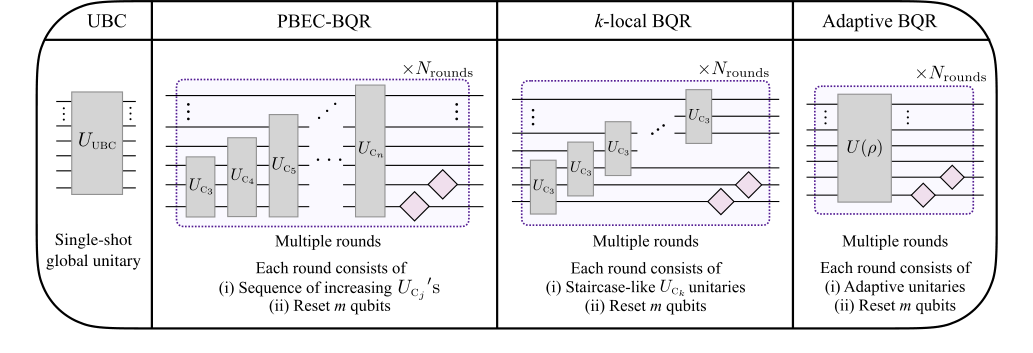 FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
FIG. 9. Schematic overview of the bidirectional cooling methods. From left to right, the figure illustrates: (i) the unitary bidirectional cooling protocol (Sec. V A), implemented as a single-shot global unitary; (ii) the progressive boundary entropy compression- bidirectional quantum refrigerator (Sec. VI A), whose unitary step consists of a sequence of increasing UCj operations (complete circuit shown in Fig. 4); (iii) the k-local bidirectional quantum refrigerator protocol (Sec. VI B), implemented via staircaselike k-local unitaries UCk acting on neighboring qubits (full circuit in Fig. 7); and (iv) the adaptive bidirectional quantum refrigerator, in which the unitary step may vary from one round to the next depending on the state of the system. In this work, this protocol is used only numerically to obtain optimal benchmarks for comparison with the explicit constructions above. All bidirectional quantum refrigerator variants operate in multiple rounds, each consisting of a unitary compression stage followed by a reset of m qubits
结果、局限性与结论
实验设计与基线
为了严格验证其数学声明,作者精心设计了一系列模拟实验,使用Qiskit和scikit-learn,重点关注其双向量子冰箱(BQR)协议的实际分类性能。核心目标是证明通过BQR增强测量量子比特的极化直接转化为分类准确性的切实改进,特别是通过缓解有限采样误差。
实验架构围绕一个保守的选择:三局部BQR协议(k=3),使用n=5个系统量子比特,m=2个重置量子比特,以及$N_{rounds}=2$个冷却轮次。选择这个特定配置是因为,如果连这个更实用的k-局部版本都能优于基线,那么完整的BQR协议(提供更强的冷却)预计会表现得更好。
与BQR无缝比较的基线模型是常规采样方法,它们不使用任何BQR增强。为了确保公平比较并隔离BQR旨在减少的有限采样误差的影响,基线方法被分配了成比例更多的测量次数。具体来说,如果BQR增强分类器使用 $k_{BQR}$ 次测量(例如,10或100次,以反映实际NISQ限制),则常规基线获得 $k_c = k_{BQR} \times m \times (N_{rounds} - 1) + n$ 次测量。对于 $k_{BQR}=10$,这意味着基线获得 $10 \times 2 \times (2-1) + 5 = 25$ 次测量。对于 $k_{BQR}=100$,基线获得 $100 \times 2 \times (2-1) + 5 = 205$ 次测量。这种缩放确保了两种方法消耗了相当的量子比特资源,使得任何观察到的性能差异都可以归因于BQR的效率,而不是仅仅更多的原始测量。
为了进一步将采样误差的影响与QML模型固有的表达能力或可训练性区分开来,简化了问题设置。实验假设可以直接访问最终量子态,形式为单量子比特约化密度矩阵,其Z极化直接编码了分类信号。这使得能够清晰地评估BQR如何通过更少的测量来提高预测的可靠性。
实验使用了各种数据集进行二元分类任务,包括合成数据集(均匀和高斯分布)以及几个真实世界数据集:Iris、Wine、手写数字(特别是2 vs 5)、Sonar和Pima Indians Diabetes。对于每个数据集,从每个类别中随机抽取50个数据点以创建平衡的任务,并重复整个采样和评估过程100次,以生成稳健的统计集合。
至关重要的是,作者还在现实的噪声中等规模量子(NISQ)条件下测试了这些协议。数值模拟包含了广义幅度阻尼(GAD)和去极化通道,它们分别模拟能量弛豫和随机门错误。考虑了两种噪声模式:“典型NISQ模式”具有中等噪声参数,以及“最坏情况模式”具有故意夸大的噪声强度,以对协议的鲁棒性进行压力测试。这种全面的实验设计旨在提供BQR有效性和实用性的无可辩驳的证据。
证据证明的内容
本文提供的证据明确证明,双向量子冰箱(BQR)协议,特别是三局部BQR,显著提高了量子机器学习中的采样效率并改善了分类准确性,即使在现实噪声条件下也是如此。将目标量子比特的极化幅度在保持其符号的同时增加的核心机制被证明在实践中有效,从而大大减少了准确分类所需的测量次数。
最令人信服的证据来自表I,它总结了所有测试数据集的分类准确性。在所有情况下,BQR增强的分类器始终优于常规采样基线。例如,在Uniform数据集上,使用 $k_{BQR}=10$ 次shots时,BQR达到了 $95.8\% \pm 1.8\%$ 的准确率,而基线(使用25次shots)仅达到 $93.1\% \pm 2.3\%$。当 $k_{BQR}$ 增加到100次shots(基线为205次shots)时,BQR达到了 $99.3\% \pm 0.7\%$ 的准确率,而基线为 $97.7\% \pm 1.3\%$。这种BQR性能优越的模式在所有合成和真实数据集上都得到了观察,包括Iris、Wine、手写数字、Sonar和Diabetes。Welch t检验严格证实了这些改进的统计显著性,其p值在所有情况下均小于0.05,表明观察到的增益并非偶然。
除了原始准确率之外,本文还提供了其底层机制成功的图形证据。图5和图6展示了在理想无噪声环境下,渐进边界熵压缩BQR(PBEC-BQR)的增强极化($\alpha_{PBEC}'$)和采样误差概率界限的降低因子($r_{PBEC}$)。这些图表明BQR显著增加了极化幅度并大幅降低了误差界限,尤其是在中等和高极化区域。这直接验证了熵减少导致统计估计改进的数学声明。
此外,BQR对噪声的鲁棒性(NISQ设备的关键问题)也得到了充分证明。图10显示,即使在典型的NISQ级别噪声下,BQR仍然实现了显著的极化增强,收敛到一个接近理想无噪声性能的稳态。图11通过显示典型NISQ噪声下的误差概率界限降低因子($r_{QR}$)来量化这一点。尽管幅度阻尼引入了一些不对称性(将极化驱动向一个方向),但总体降低因子仍然很大,证明该协议即使在不完美的量子硬件中也能有效地缓解采样误差。最后,图12提供了一个有力的证明,证明了该协议的韧性,显示即使在“最坏情况”噪声模式下——具有故意夸大的噪声强度——BQR在相当广泛的初始极化范围内仍然能有效降低有效误差概率。这些无可否认的证据证实了BQR的核心机制在实践中有效,为QML中增强的学习性能提供了一条基于物理且对噪声鲁棒的途径。
局限性与未来方向
尽管双向量子冰箱(BQR)协议为QML带来了显著的进步,但作者坦诚地承认了几项局限性,并提出了引人注目的未来研究方向。
一个显著的局限性是低极化区域的性能。无论是酉双向冷却(UBC)还是BQR协议,当初始极化 $\alpha$ 非常接近零时,它们都无法提供有意义的改进。虽然可以通过优化协议参数来扩大优势区域,但极低极化极限仍然是一个具有挑战性的领域。这表明对于某些类型的数据或模型状态,BQR的好处可能很小,这促使在这些情况下需要替代或补充策略。
另一个悬而未决的问题是PBEC-BQR协议的最优性。本文并未明确确定该特定冷却协议是否真正是减少有限采样误差的最优选择。如果不是,那么未来工作就有明确的方向来进一步完善该协议,可能带来更大的性能提升。
从资源角度来看,虽然BQR方案比单个全局酉UBC更实用,但它们仍然需要额外的量子比特来维持循环冷却轮次。与单次UBC相比,这增加了量子比特的开销。未来的工作可以探索最小化此开销的方法,或研究量子比特数量、电路深度和冷却性能之间的权衡。本文还指出,虽然作用于所有量子比特的单个全局酉算符可以实现最佳的极化增强,但这种操作在实现上并不可行。这凸显了量子计算中理论最优性与实验可行性之间持续存在的张力。
一个重要的未来发展领域在于扩展到量子核估计的应用。当前的方法主要辅助二元结果的符号估计,这对于估计核矩阵元素并不直接足够。将这些冷却技术应用于量子核的有限采样误差减少,带来了独特的挑战,因为需要估计的量更加复杂。解决这个问题将拓宽量子热力学见解在更广泛的QML应用中的影响。
展望未来,出现了几个令人兴奋的讨论主题:
- 利用相干性和非经典关联:本文提到研究系统和浴量子比特内的相干性和非经典关联如何用于提高冷却效率。这是一个引人入胜的方向,因为当前协议主要在对角子空间内运行,使其对去相位噪声具有鲁棒性,但可能留下了未开发的资源以供进一步增强。
- 贫瘠高原缓解:有必要对BQR如何缓解贫瘠高原效应进行详细的定量分析。作者建议,他们的技术可以作为一种独立的机制,与现有的贫瘠高原缓解策略结合使用。理解这种相互作用可能带来更鲁棒、更具可扩展性的QML算法。
- 数据重编码与BQR电路:数据重编码方法与BQR的联系开启了有趣的可能。构建数据重编码版本的BQR电路可以实现电路深度与量子比特开销之间的全面权衡分析,可能导致更资源高效的实现。
- 超越二元分类:虽然当前工作侧重于二元分类,但用于熵减少的热力学框架原则上可以扩展到其他QML任务,如回归或更复杂的多类问题。这需要仔细考虑“极化”和“符号”在这些情况下的泛化方式。
- 实验实现与硬件优化:在NISQ噪声下的数值模拟很有希望,但实际在各种量子硬件平台(超导、离子阱、中性原子)上的实验实现将是最终的验证。这还将为优化BQR电路以适应特定硬件架构和噪声特性提供宝贵的反馈。
- 冷却在QML中的理论基础:这项工作在量子热力学与QML之间建立了新颖的联系。对学习任务冷却的根本限制进行进一步的理论探索,以及与其他领域的潜在同构(如在典型章节顺序中所暗示的),可能会产生更深入的见解,并激发全新的算法范式。
这些多样的观点强调,BQR协议不仅是当前QML挑战的实际解决方案,也是跨学科研究的沃土,推动着量子信息科学和机器学习的边界。
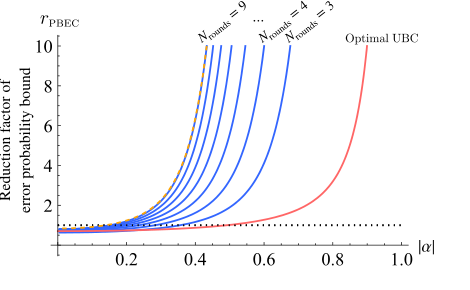 FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
FIG. 6. Reduction factor of the error-probability bound for the progressive boundary entropy compression-bidirectional quan- tum refrigerator with n = 5 qubits, shown in blue for different numbers of rounds as a function of the initial |α|. The pink line shows the performance of unitary bidirectional cooling, and the yellow dashed line corresponds to an adaptive bidirec- tional quantum refrigerator using optimal per-round compres- sions (shown here for Nrounds = 9). The progressive boundary entropy compression-bidirectional quantum refrigerator, despite using identical rounds, closely matches the adaptive scheme for n = 5, m = 2, and Nrounds = 9—whereas deviations from this number of rounds lead to a visible performance gap (not shown)
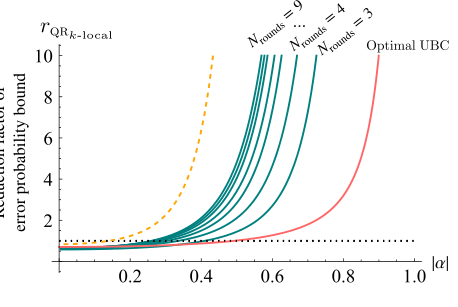 FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound
FIG. 8. Reduction factor of the error-probability bound for the three-local bidirectional quantum refrigerator with n = 5, shown in green for different numbers of rounds as a function of the ini- tial |α|. The pink line shows the improvement achieved through single-shot unitary bidirectional cooling on an n = 5 register, while the yellow dashed line indicates the upper bound obtained from simulations of the adaptive-round bidirectional quantum refrigerator with Nrounds = 9. Although the performance of the three-local bidirectional quantum refrigerator shows a noticeable gap relative to this upper bound—reflecting its reduced optimal- ity—it remains significantly more practical to implement while still achieving substantial reductions in the error-probability bound