QKAN: 量子コルモゴロフ・アーノルド・ネットワークと機械学習および多変数状態準備への応用
We introduce quantum Kolmogorov-Arnold networks (QKAN), a quantum algorithmic framework inspired by the recently proposed Kolmogorov-Arnold Networks (KAN).
背景と学術的系譜
起源と学術的系譜
本論文で取り組む問題、すなわち量子コルモゴロフ・アーノルド・ネットワーク(QKAN)の開発は、古典ニューラルネットワークと量子コンピューティングの交差点に正確に位置し、最近提案された古典コルモゴロフ・アーノルド・ネットワーク(KAN)[5]に触発されています。その学術的文脈は、1950年代の基本的な数学的結果であるコルモゴロフ・アーノルド表現定理(KART)[1-4]に始まります。KARTは、任意の連続多変数関数(複数の入力変数を持つ関数)は、有限個の一変数関数(単一の入力変数を持つ関数)の合成と和に分解できると述べています。この定理は、複雑な関数がより単純な構成要素を用いてどのように表現できるかを理解するための理論的基盤を提供しました。
しかし、KARTの直接的な実用的な応用、特にニューラルネットワークにおける応用は、その内部関数と外部関数が非常に非滑らかになる可能性があり、正確かつ堅牢な近似が困難であるため、限定的でした[5]。この「痛点」は、KARTが理論的には強力であるにもかかわらず、効果的なニューラルネットワークアーキテクチャに直接変換できなかったことを意味します。
この状況は、Liuら[5]によるコルモゴロフ・アーノルド・ネットワーク(KAN)の最近の導入によって変化しました。KANはKARTの合成構造を一般化し、KARTが保証する2層とは異なり、任意の数の層を許容します。古典KANはKARTの普遍的表現特性を継承していませんが、特に科学分野において、解釈可能性の向上と小規模タスクでの精度の向上を提供することで、特定の応用において有望であることが示されています。また、ターゲット関数内のモジュラ構造を明らかにすることによって、新しい物理法則の発見を助ける可能性もあります[10]。
本論文の著者らは、古典KANの可能性に動機づけられ、量子版であるQKANを導入しようとしました。本論文を書くに至った、以前の量子アプローチの根本的な限界は、量子機械学習モデルの性質に起因します。変分量子アルゴリズム(VQA)[34-39]のような既存の量子学習モデルは、量子回路内のパラメータを最適化することに依存することがよくあります。対照的に、QKANは異なるパラダイムを提供します。ブロックエンコードされた行列の固有値を「ニューロン」として扱い、量子特異値変換(QSVT)を使用してネットワークの「エッジ」にパラメータ化された活性化関数を適用します。このアプローチは、KANの合成構造を量子設定で活用することを目的としており、特に効率的な入力のブロックエンコーディングが利用可能な場合、特定のタスクで効率性の利点を提供する可能性があります。しかし、QKANも独自の制約に直面しています。QSVTを使用して層を再帰的に合成すると、回路の深さに指数関数的なオーバーヘッドが生じます。これは、QKANが自然に浅いアーキテクチャに限定されることを意味します。
直感的なドメイン用語
-
コルモゴロフ・アーノルド表現定理(KART): 多くの材料と手順を持つ非常に複雑なレシピがあると想像してください。KARTは、レシピがどれほど複雑であっても、それらを組み合わせて単一材料のミニレシピに分解できることを示す数学的証明のようなものです。それは、複雑さを管理可能な単一変数部分に単純化することです。
-
ブロックエンコーディング: 安全に送信したい秘密のメッセージ(行列またはベクトル)を考えてください。ブロックエンコーディングは、この秘密のメッセージを、一見普通の非常に大きなドキュメント(ユニタリ量子操作)に埋め込むようなものです。より大きなドキュメントは無害に見えますが、その特定のブロックに秘密のメッセージが縮小されて含まれています。量子コンピュータは、このより大きなドキュメントを操作して、秘密のメッセージを直接「読み取る」ことなく効果的に処理できます。
-
量子特異値変換(QSVT): 写真編集アプリで、特定の効果(明るさやコントラストの変更など)を適用したいが、画像内の特定の色のパターンにのみ適用したいと考えていると想像してください。QSVTは、非常に正確なデジタルフィルターとして機能する強力な量子技術です。ブロックエンコードされた行列でエンコードされた情報の「強度」または「重要度」(特異値)に、ほぼ任意の望ましい数学関数(多項式など)を適用でき、非常に特定で複雑な変換を可能にします。
-
多変数状態準備: 各音符の大きさが複数の要因(温度、湿度、時刻など)を含む複雑な数学的公式によって正確に決定されるユニークな音楽コードを作成したいと想像してください。量子コンピューティングにおける多変数状態準備は、各可能な結果(ビットの各組み合わせ)の「大きさ」または「振幅」が、複数の入力変数を持つ複雑な関数の値に一致するように設定された量子状態(量子ビットのコレクション)を作成することです。それは、複雑な値の風景を直接量子領域にエンコードするようなものです。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題定式化とジレンマ
本論文は、古典コルモゴロフ・アーノルド・ネットワーク(KAN)に触発された量子アルゴリズムフレームワークとして、量子コルモゴロフ・アーノルド・ネットワーク(QKAN)を導入します。コアの問題は、機械学習および多変数状態準備への応用のため、KANの効率的な量子実装を開発することです。
入力/現在の状態:
QKANの出発点は、$N$次元実数ベクトル $\vec{x} \in [-1,1]^N$ のブロックエンコーディングです。これは、ベクトルの成分がユニタリ行列 $U_x$ の対角成分にエンコードされていることを意味し、$|| \langle 0|_a U_x |0\rangle_a - \text{diag}(x_1, \dots, x_N) || \le \epsilon_x$ となります。量子機械学習では、この入力は量子状態の振幅または行列の対角成分である可能性があります。多変数状態準備では、入力は通常、ベクトル化された $D$次元グリッドの点であり、これも対角ブロックエンコーディングとして提供されます。
出力/目標状態:
目的のエンドポイントは、応用によって異なります。
* 量子学習モデルとして: 目標は、$K$次元出力ベクトル $\Phi(\vec{x}) \in [-1,1]^K$ の対角ブロックエンコーディングを生成することです。この出力ベクトルの成分、$\Phi(\vec{x})_q = \frac{1}{N} \sum_{p=1}^N \phi_{pq}(x_p)$ (ここで $\phi_{pq}$ は一変数活性化関数)は、加法 $\delta$ 精度で古典的に推定される必要があります。
* 多変数量子状態準備プロトコルとして: 目標は、その振幅が入力の多変数関数(例えば、正規グリッド上の $D$次元ガウス分布)に対応する量子状態 $|\psi\rangle$ を準備することです。これは、一様重ね合わせに最終ブロックエンコーディングを適用し、その後振幅増幅を使用することによって達成されます。
欠落しているリンク/数学的ギャップ:
本論文が橋渡ししようとしている根本的なギャップは、古典KANの合成構造を量子コンピューティングパラダイムに効率的かつ正確に翻訳することです。古典KANは、複雑な多変数関数を、一変数関数の合成と和に分解します。課題は、これらの非線形一変数関数とその和を量子演算、特にブロックエンコードされたデータに対する量子特異値変換(QSVT)を活用して実現することであり、同時にユニタリ性や誤差伝播などの固有の量子制約を克服することです。本論文は、潜在的な量子加速でこれらの演算を実行できる具体的な量子アーキテクチャを提供することを目指しています。
ジレンマと痛みを伴うトレードオフ:
量子機械学習および状態準備における同様の問題を解決しようとした以前の研究者は、いくつかの痛みを伴うトレードオフに直面しました。
* 量子加速 vs. 古典読み出し: 量子アルゴリズムは指数関数的に大きなデータ構造(ブロックエンコーディングなど)を効率的に処理できますが、完全な出力を古典的に抽出することは、いかなる量子優位性も無効にする可能性があります。QKANの場合、量子加速の達成は、古典的な後処理コストがサブ指数関数的に留まることに依存します。これは、出力次元 $K$ が $O(\text{polylog}(N))$ に制限される必要があることを意味します。指数関数的な数の値を推定すること自体に指数関数的な時間がかかるためです。
* 浅い vs. 深いアーキテクチャ: QKANは「幅広く浅い」ように設計されています。効率的なブロックエンコーディングが利用可能な場合、それらは多対数コストで指数関数的に広い層を実現できます。これは古典ニューラルネットワークでは到達不可能な領域です。しかし、複数の層を合成するための再帰的なQSVTベースの構築は、回路の深さに指数関数的なオーバーヘッドをもたらします。これにより、QKANは計算上の実現可能性を維持するために、通常 $L=O(1)$ 層に限定される浅いものになります。
* 精度 vs. クエリ複雑性: 量子学習モデルにおける出力推定では、より高い精度(小さい $\delta$)を達成するには、制御された対角ブロックエンコーディングへのより多くのクエリが必要です。具体的には、加法 $\delta$ 近似には $O(d^2/\delta)$ クエリが必要です。乗法誤差が必要な場合、クエリ数は $O(d^2/(\delta|a_q|))$ に増加します。これは、振幅 $a_q$ が指数関数的に減衰しない場合にのみ、潜在的な量子加速が維持されることを意味します。これは、望ましい精度と必要な計算リソース(クエリ)との間のトレードオフを示しています。
制約と失敗モード
QKANの実装という問題は、いくつかの厳しい現実的な壁によって非常に困難になっています。
- ユニタリ性制約: 量子力学は、すべての操作がユニタリでなければならないと規定しています。これは、すべてのベクトル要素(入力、出力、重み)がブロックエンコーディングとしてエンコードされたときに1以下の大きさでなければならないという厳格な制約を課します。これは基本的な物理的制約であり、データの慎重な正規化とスケーリングが必要です。
- 入力の効率的なブロックエンコーディング: QKANのゲート複雑性は、$N$次元入力ベクトルの初期ブロックエンコーディングの構築コストに線形にスケールします。QKANが量子加速を提供するためには、入力は $O(\text{polylog}(N))$ 時間で準備できる効率的なブロックエンコーディングを許容しなければなりません。入力エンコーディング自体に $O(N)$ ゲートが必要な場合、古典アルゴリズムに対する量子優位性は失われます。これは重要なデータ駆動型制約です。
- 再帰的な誤差伝播: 入力と重みのブロックエンコーディングの不完全さは蓄積します。多層QKANでは、これらの誤差は後続の各層で再帰的に伝播し、最終出力ブロックエンコーディングで誤差が増幅されます。これにより、深いQKANの高精度達成が非常に困難になり、実用的な深さが制限されます。
- 深いアーキテクチャのための指数関数的な回路深さ: QKANの構築の再帰的な性質、すなわちある層の出力ブロックエンコーディングが次の層の入力となることは、層数 $L$ に対する回路深さの指数関数的な依存性をもたらします。この計算上の制約は、理論的な深いネットワークの利点にもかかわらず、QKANを浅いアーキテクチャ($L=O(1)$)に厳しく制限します。
- 補助量子ビットの制限: QKAN構築に必要な補助量子ビットの総数は、層数 $L$ に線形に増加します。指数関数的なスケーリングではありませんが、これは現在のおよび近未来の量子デバイスのハードウェアメモリ制限となる可能性があります。
- 多項式近似の限界: 非線形変換の適用における中心的なメカニズムであるQSVTは、ターゲット関数の多項式近似に依存します。すべての関数が低次の多項式によって効率的に近似できるわけではなく、これは特定のタスクに対するQKANの表現力と精度を制限します。例えば、ガウス状態準備のための指数関数を近似するには、十分な高い多項式次数が必要であり、全体的な精度に影響します。
- 実数値制限: 現在の研究は、明示的に実数値入力、出力、および重みに範囲を限定しています。複素数への一般化は可能ですが、将来の研究のために残されており、モデルの適用可能性における現在の制限を示しています。
- 勾配推定のコスト: パラメータシフト規則を使用してQKANをトレーニングして解析勾配を取得することは、計算コストが高くなります。コストは、単層QKANの場合は $O(d)$ クエリ、 $L$ 層QKANの場合は $O(d^2L)$ クエリにスケールします。ここで、$d$ はチェビシェフ多項式の最大次数です。層数に対するこの指数関数的なスケーリングは、深いQKANのトレーニングを信じられないほど困難でリソース集約的にします。
なぜこのアプローチなのか
選択の必然性
量子コルモゴロフ・アーノルド・ネットワーク(QKAN)の採用は、単なる選択ではなく、多変数関数近似および量子領域における状態準備の固有の要求によって駆動される必然的な必要性でした。著者らが従来の「最先端」(SOTA)手法が不十分であると認識したことは、いくつかの重要な観察から生じました。
第一に、古典コルモゴロフ・アーノルド・ネットワーク(KAN)は、特にシンボリック関数を扱う科学的応用において、解釈可能性と精度の点で、従来の多層パーセプトロン(MLP)よりも質的な利点をすでに実証していました。これらの利点を量子コンピューティングに翻訳するには、量子ネイティブなアプローチが不可欠でした。パラメータ化された量子回路を採用する変分量子アルゴリズム(VQA)や、CNNおよびTransformerの量子バージョンなどの標準的な量子機械学習モデルは、通常、KANの合成構造を本質的に捉えない異なるアーキテクチャ原則に依存しています。
決定的な「アハ!」の瞬間は、量子フレームワーク内でKANの中心的な非線形活性化関数を実装し、量子加速を維持する方法を検討したときに起こった可能性が高いです。量子状態での古典的な非線形性の直接シミュレーションは、一般的に非効率的です。量子特異値変換(QSVT)は、ブロックエンコードされた行列の特異値に多項式変換を適用するための強力で汎用的なメタアルゴリズムを提供する、唯一の実行可能な解決策として浮上しました。この機能は、KANの一変数活性化関数を量子設定で実現するためにまさに必要なものです。QSVTなしでは、量子データ(ブロックエンコーディングとして表される)でそのような非線形性を効率的に実装することは、実行不可能になるか、潜在的な量子優位性を無効にするでしょう。論文では、QKANが「ブロックエンコードされた行列の固有値をニューロンとして扱い、チェビシェフ多項式またはQSVTを使用して効率的に実現できる他の基底関数の線形結合を使用して、ネットワークエッジにパラメータ化された活性化関数を適用する」と明確に述べており、QSVTをコアエンベダーとして強調しています。
比較優位性
QKANは、特定の問題クラスに対して以前のゴールドスタンダードよりも質的に優れた構造的利点を圧倒的に示しています。最も重要な利点は、「幅広く浅い」アーキテクチャにあります。QKAN層を再帰的に合成すると深さに指数関数的なオーバーヘッドが生じ、アーキテクチャが浅い構成($L = O(1)$)に限定されますが、この浅い深さは、効率的なブロックエンコーディングが利用可能な場合、多対数コストで指数関数的に広い層を実現できる能力によって驚くほど補償されます。この領域は、$N$次元状態を処理するために $O(N)$ の実行時間を必要とする古典ニューラルネットワークでは根本的に到達不可能です。
例えば、QKANは、ターゲット関数が効率的な多項式近似を持つと仮定すると、$O(\text{polylog}(N))$ 時間で多変数関数の計算を実行することにより、$N$次元量子状態を処理できます。これは、同じ操作に対する古典的な $O(N)$ 実行時間に対して、実質的な量子加速を提供します。この効率性は、ブロックエンコーディングとQSVTへのQKANの依存性から生じます。これにより、指数関数的に大きなユニタリ演算子を効率的に操作できます。
さらに、QKANは古典KANの解釈可能性の利点を継承しています。個々の活性化関数を検査し、ゼロ関数に似たものを削除する能力により、スパースな合成構造や新しい物理法則の発見の可能性が得られます。これは、ブラックボックスディープラーニングモデルではしばしば欠けている質的な利点です。QSVTフレームワークの汎用性により、QKANはチェビシェフ多項式に限定されず、さまざまな応用に合わせて調整された柔軟性を提供する、さまざまな基底関数を実装できます。論文では、高次元ノイズの処理や $O(N^2)$ から $O(N)$ へのメモリ複雑性の削減における利点を明示的に詳述していませんが、ブロックエンコーディングアプローチは本質的に情報を圧縮し、広い層に対する多対数スケーリングは大きな入力に対して非常に効率的なリソース使用を意味します。
制約との整合性
選択されたQKANメソッドは、量子コンピューティングの固有の制約と問題定義との完璧な「結婚」を示しています。
-
効率的な入力エンコーディング: 量子アルゴリズムが加速を達成するための主要な制約は、入力データの効率的な準備またはエンコーディングです。QKANは、入力ベクトルのブロックエンコーディングを操作することにより、これに完全に適合します。そのゲート複雑性は、これらのブロックエンコーディングの構築コストに線形にスケールします。これは、本質的に量子的な入力(例えば、量子状態の振幅またはハミルトニアンのブロックエンコーディング)の場合、$O(\text{polylog}(N))$ と効率的になる可能性があります。これにより、入力ボトルネックが量子優位性を無効にしないことが保証されます。
-
ユニタリ性と制限された値: 量子コンピューティングは厳密にユニタリな操作を必要とします。QKANの設計は、QSVTに基づき、これを本質的に尊重しています。ブロックエンコーディング表現自体は、ベクトルがユニタリ行列内にエンコードされ、これらのベクトルの要素の大きさが1以下に制限されていることを保証し、量子状態の振幅制約を満たします。
-
浅い深さの要件: QSVTを使用したQKAN層の再帰的な構築は、各追加層で回路深さに指数関数的なオーバーヘッドをもたらします。この制約は、QKANを自然に浅いアーキテクチャ($L=O(1)$)にします。これは制限ではなく、この制約がQKANのニッチを「幅広く浅い」モデルとして定義し、指数関数的な幅が限られた深さを補償し、ソリューションのプロパティをこの厳しい要件に適合させています。
-
実数値操作: 本論文は、入力、出力、および重みに対して実数値を扱う範囲を明示的に限定しています。チェビシェフ多項式とブロックエンコーディングフレームワークを使用したQKANの構築は、実数値関数を処理するのに適していますが、複素数への一般化は将来の研究として注目されています。
代替案の却下
本論文は、QKANの独自のアーキテクチャ的および機能的な違いを強調することにより、他の一般的な量子機械学習アプローチの却下を暗示しています。
まず、QKANは、しばしばヒューリスティックであり、パラメータ化された量子回路のパラメータの最適化に依存する「変分アーキテクチャ」(VQA)から逸脱しています。VQAは近未来の量子デバイスに適していますが、QKANは「より強力な量子線形代数ツールセットに足を踏み入れ」、正確な構築によるフォールトトレラント量子加速に焦点を当てていることを示唆しています。特に多変数量子状態を効率的に準備したり、合成構造を持つ関数を近似したりするという特定の目的のために、QKANのQSVTベースのアプローチは、量子優位性へのより直接的で潜在的に堅牢なパスを提供します。
第二に、古典KANに触発されたQKANの合成構造は、量子MLPの固定された密な層や、量子CNNまたはTransformerの特定の帰納的バイアスとは根本的に異なります。これらの代替アーキテクチャは、関数を単変数関数の合成と和として表現するKANの能力を自然に捉えられない可能性があり、また同じ解釈可能性の利点を提供しない可能性があります。本論文が「以前のアーキテクチャとは対照的に」と述べていることは、この区別を強調しています。
例えば、量子GANや量子拡散モデルがなぜ失敗するのかを本論文が明示的に詳述していなくても、ブロックエンコードされた入力に対して多対数コストで指数関数的に広い層を実現するQKANの能力と、科学的発見のための解釈可能性は、これらの特定の利点が最も重要である問題領域を指しています。他の方法では、同じ量子加速、ブロックエンコードされたデータの効率的な処理、および固有の解釈可能性の組み合わせを提供しない可能性があります。
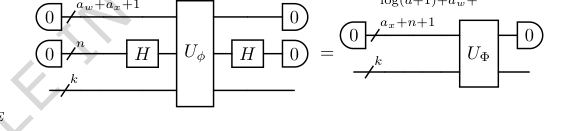 FIG. 9. Step 5. Sum the individual activation functions over N input nodes for each output node, creating the desired diagonal block-encoding UΦ of the K-dimensional output vector Φ(⃗x). This is achieved by sandwiching the block-encoding from Step 4 with two n-qubit Hadamard gates. The dimension reduction occurs as the n qubits originally used for input block-encoding are moved to the auxiliary register
FIG. 9. Step 5. Sum the individual activation functions over N input nodes for each output node, creating the desired diagonal block-encoding UΦ of the K-dimensional output vector Φ(⃗x). This is achieved by sandwiching the block-encoding from Step 4 with two n-qubit Hadamard gates. The dimension reduction occurs as the n qubits originally used for input block-encoding are moved to the auxiliary register
数学的・論理的メカニズム
マスター方程式
量子コルモゴロフ・アーノルド・ネットワーク(QKAN)層、特にCHEB-QKANバリアントのコアとなる数学的エンジンは、入力ベクトル $\vec{x}$ を出力ベクトル $\Phi(\vec{x})$ に変換する方法にカプセル化されています。この変換は、一変数活性化関数の合成として表される$K$次元ベクトルの対角ブロックエンコーディングとして表現されます。活性化関数自体は、チェビシェフ多項式の線形結合として定義されます。
単一のQKAN層の出力は次のように与えられます。
$$ \Phi(\vec{x}) = \text{diag}\left( \frac{1}{N} \sum_{p=1}^N \phi_{p1}(x_p), \dots, \frac{1}{N} \sum_{p=1}^N \phi_{pK}(x_p) \right)^T $$
ここで、各一変数活性化関数 $\phi_{pq}(x)$ は、チェビシェフ多項式の線形結合として定義されます。
$$ \phi_{pq}(x) = \frac{1}{d+1} \sum_{r=0}^d w_{pq}^{(r)} T_r(x) $$
項ごとの解剖
これらの数式を分解して、各コンポーネントの役割と数学的定義を理解しましょう。
- $\Phi(\vec{x})$: これは単一のQKAN層の出力を表します。
- 数学的定義: 集約され変換された入力特徴の$K$次元ベクトルです。量子コンテキストでは、対角行列としてブロックエンコードされており、その成分はより大きなユニタリ演算子の対角線上に現れます。
- 物理的/論理的役割: これは、QKAN層が生成する「処理された情報」です。古典的なニューラルネットワークの層の出力に類似していますが、量子互換形式です。
- $\text{diag}(\dots)^T$: これはベクトルから対角行列を構築する演算子です。
- 数学的定義: ベクトル $\vec{v} = (v_1, \dots, v_K)$ が与えられた場合、$\text{diag}(\vec{v})$ は $v_1, \dots, v_K$ を主対角線に持つ $K \times K$ 対角行列を作成します。転置 $T$ は、入力ベクトルが概念的に列ベクトルであることを示します。
- 物理的/論理的役割: QKANでは、ベクトルは対角ブロックエンコーディングとして表現されます。この操作は、層の出力が対角ブロックエンコーディングであることを明確に示しており、これは後続のQKAN層への入力としての再帰的な使用に不可欠です。
- $N$: 入力ベクトル $\vec{x}$ の次元。
- 数学的定義: 通常は2のべき乗である整数、$N=2^n$、ここで $n$ は入力をエンコードするために使用される量子ビットの数です。
- 物理的/論理的役割: 古典KANの類推における入力特徴または「ノード」の数を表します。$N$ による除算は、和の正規化係数として機能し、出力が有界範囲内に留まることを保証します。これはブロックエンコーディングにとって重要です。
- $K$: 出力ベクトル $\Phi(\vec{x})$ の次元。
- 数学的定義: 通常は2のべき乗である整数、$K=2^k$、ここで $k$ は出力エンコーディング用の量子ビットの数です。
- 物理的/論理的役割: 古典KANの類推における出力特徴または「ノード」の数を表します。
- $\sum_{p=1}^N$: 入力ノードの合計。
- 数学的定義: この演算子は、$p$ が1から$N$までの各 $\phi_{pq}(x_p)$ の値を合計します。
- 物理的/論理的役割: これは基本的な集約ステップです。各出力ノード $q$ について、すべての入力ノード $p$ からの変換された情報を組み合わせます。この合計は、コルモゴロフ・アーノルド表現定理のユニ変数関数の結合の原則の直接的な翻訳です。ここでの乗算ではなく加算の選択は、KANアーキテクチャの本質であり、関数を合成の合計としてモデル化し、出力層で特徴の線形結合を提供します。
- $\phi_{pq}(x_p)$: 一変数活性化関数。
- 数学的定義: 単一の実数入力 $x_p \in [-1,1]$ を受け取り、実数出力にマッピングする関数です。入力ノード $p$ と出力ノード $q$ の各ペアに対して一意に定義されます。
- 物理的/論理的役割: これらはネットワークの「エッジ」であり、個々の入力成分に非線形変換を適用します。これらはQKANのコアとなる学習可能な要素であり、非線形性を導入し、複雑な関係を学習する責任があります。
- $x_p$: 入力ベクトル $\vec{x}$ の $p$ 番目の成分。
- 数学的定義: 単一の入力特徴を表す実数、$x_p \in [-1,1]$。
- 物理的/論理的役割: これは、QKAN層に入る生の入力データポイントです。
- $d$: 使用されるチェビシェフ多項式の最大次数。
- 数学的定義: 非負整数。
- 物理的/論理的役割: このパラメータは、活性化関数 $\phi_{pq}(x)$ の複雑さと表現力を制御します。$d$ が大きいほど、より複雑な非線形変換が可能になります。
- $\frac{1}{d+1} \sum_{r=0}^d$: チェビシェフ多項式次数に対する正規化された合計。
- 数学的定義: これは $d+1$ 個のチェビシェフ多項式の線形結合であり、$1/(d+1)$ で正規化されています。
- 物理的/論理的役割: これは異なる基底関数を組み合わせて、全体的な活性化関数 $\phi_{pq}(x)$ を構築します。正規化は、関数出力を有界に保つのに役立ちます。合計(線形結合)の使用は、係数 $w_{pq}^{(r)}$ を調整することによって、さまざまな関数の柔軟な近似を可能にします。
- $w_{pq}^{(r)}$: 重み係数。
- 数学的定義: 実数、$w_{pq}^{(r)} \in [-1,1]$。
- 物理的/論理的役割: これらはQKANの学習可能なパラメータです。これらは、各チェビシェフ多項式 $T_r(x)$ が活性化関数 $\phi_{pq}(x)$ に寄与する度合いを決定し、実質的に非線形性を形成します。
- $T_r(x)$: 第一種チェビシェフ多項式の $r$ 番目。
- 数学的定義: $T_r(x) = \cos(r \arccos(x))$、$x \in [-1,1]$ で定義されます。
- 物理的/論理的役割: これらの多項式は、活性化関数の基底関数として機能します。これらは、量子特異値変換(QSVT)を使用して量子コンピュータ上で効率的に実装できるため、量子フレームワークに自然に適合します。
ステップバイステップフロー
単一の抽象データポイント、例えば $x_p$ がQKAN層を通過し、入力成分から最終出力ベクトルの一部に変換される様子を想像してください。このプロセスは量子組立ラインのようです。
- 入力ブロックエンコーディング: まず、$N$次元の入力ベクトル全体 $\vec{x} = (x_1, \dots, x_N)$ が対角ブロックエンコーディング $U_x$ として提示されます。これは、各 $x_p$ がより大きなユニタリ行列内の対角要素としてエンコードされていることを意味します。これが、量子工場に入る生材料です。
- 拡張と複製: 次に、入力ブロックエンコーディング $U_x$ は、$k = \log_2 K$ 個の補助量子ビットを追加することによって「拡張」されます。概念的には、このステップは各入力成分 $x_p$ を $K$ 個の異なる「チャネル」に複製し、各チャネルは出力ノード $q$ 用です。これにより、各入力がすべての出力に影響を与えることが保証されます。
- チェビシェフ多項式変換: 各複製された $x_p$ と各多項式次数 $r$ ($0$ から $d$ まで) について、量子特異値変換(QSVT)が適用されます。これは、ブロックエンコードされた形式で、$T_r(x_p)$ をすべての $p$ と $r$ について効果的に計算します。これは、生材料を、それに異なる数学関数(チェビシェフ多項式)を適用する特殊な機械に送るようなものです。
- 重み付きスケーリング: 次に、各ブロックエンコードされた $T_r(x_p)$ が対応する重み係数 $w_{pq}^{(r)}$ で乗算されます。これらの重みも対角ブロックエンコーディングとして提供されます。この乗算は、量子線形代数サブルーチンを使用して実行されます。このステップは、学習されたパラメータに従って変換された特徴をスケーリングします。これは、各信号の強度を調整するようなものです。
- 基底関数結合(LCU): 特定の入力-出力ペア $(p,q)$ について、すべての重み付きチェビシェフ多項式 $w_{pq}^{(r)} T_r(x_p)$ ($r=0, \dots, d$ について) が線形に結合されます。これは、制御量子ビットの等しい重ね合わせを準備し、重み付きブロックエンコーディングを適用することを含む線形結合ユニタリ(LCU)手順を使用して達成されます。この機械は、各出力ノード $q$ のためのすべての入力ノードからの寄与を収集し、出力ベクトル $\Phi(\vec{x})$ の $q$ 番目の成分を生成します。その後、入力量子ビットは補助レジスタに吸収され、全体的な次元が削減されます。
- 入力ノード集約(アダマール和): 最後に、各出力ノード $q$ について、値 $\phi_{pq}(x_p)$ ($p=1, \dots, N$ について) が合計されます。これは、$\phi_{pq}(x_p)$ のブロックエンコーディングを、入力量子ビット上のアダマールゲートで挟むことによって行われます。この操作は、各特定の出力ノード $q$ について、すべての入力ノードからの寄与を効果的に平均化し、出力ベクトル $\Phi(\vec{x})$ の $q$ 番目の成分を生成します。その後、入力量子ビットは補助レジスタに吸収され、全体的な次元が削減されます。
- 出力ブロックエンコーディング: これらの操作の結果は、$K$次元出力ベクトル $\Phi(\vec{x})$ の対角ブロックエンコーディングです。この最終的な製品は、別のQKAN層にフィードされるか、古典的な出力のために測定される準備ができています。
最適化ダイナミクス
QKANメカニズムは、学習可能なパラメータである重み係数 $w_{pq}^{(r)}$ を調整して、定義済みのコスト関数を最小化することによって学習します。この学習プロセスには、いくつかの主要なダイナミクスが含まれます。
-
重みのパラメータ化: 重み $w_{pq}^{(r)}$ は直接的な古典的な数値ではなく、対角ブロックエンコーディング $U_{w^{(r)}}$ にエンコードされます。論文では、このパラメータ化のための2つの主要な方法を概説しています。
- 振幅エンコーディング: 重みは、パラメータ化された量子状態 $|w(\theta)\rangle = U(\theta)|0\rangle$ の実数振幅から導出できます。ここで、$U(\theta)$ は、ゲート角度 $\theta$ が実際の学習可能なパラメータであるパラメータ化量子回路(PQC)です。この方法は、重みに $L_2$ 正規化制約を自然に課し、正則化の一形態として機能します。
- アダマール積エンコーディング: 代わりに、パラメータ化されたユニタリ $U(\theta)$ をチェビシェフ多項式ブロックエンコーディングとアダマール積を介して組み合わせることができます。このアプローチは、より大きな表現力を持つと推測されており、$L_\infty$ ノルム制約を重みに許容します。
パラメータ化方法の選択は、学習可能な関数の空間とモデルの正則化特性を形成します。
-
損失関数とランドスケープ: QKANは量子学習モデルとして設計されており、コスト関数が存在することを意味します。このコスト関数は、QKANの出力とターゲット値との間の乖離を定量化します(例えば、回帰または分類のため)。「損失ランドスケープ」は、パラメータ $\theta$ の空間全体にわたるこのコスト関数の表面によって定義されます。論文では損失関数を明示的に詳述していませんが、通常は抽出された出力振幅の関数になります。基底関数(チェビシェフ多項式)とパラメータ化方法の選択は、このランドスケープの滑らかさと複雑さに影響します。
-
勾配計算: 損失ランドスケープをナビゲートし、その最小値を見つけるために、モデルはパラメータ $\theta$ に関する損失の勾配を計算する必要があります。
- 解析勾配: 論文では、変分量子アルゴリズムで一般的な技術であるパラメータシフト規則を使用して解析勾配を計算することを提案しています。QKANの再帰的かつ合成的な構築(QSVT、LCU、ブロックエンコーディング積を含む)のため、同じPQCパラメータ $\theta$ が回路のさまざまな部分で再利用されます。これは、個々のサブ項からの寄与を合計することによって勾配が得られることを意味します。しかし、このアプローチは、単層QKANの場合は $O(d)$ クエリ、 $L$ 層QKANの場合は指数関数的に $O(d^2L)$ クエリにスケールし、これはかなりの計算コストです。
- 勾配推定: 解析勾配の高いコストを回避するために、著者らは有限差分法や同時摂動確率近似(SPSA)などの勾配推定技術の使用を提案しています。SPSAは、計算コストがパラメータ数にほとんど依存しないため、特に学習可能なパラメータが多いモデルの場合、勾配を推定するより効率的な方法として特に魅力的です。
-
パラメータ更新と収束: 勾配(またはその推定値)が得られると、勾配降下法やAdamなどの古典的な最適化アルゴリズムが使用され、パラメータ $\theta$ が反復的に更新されます。これらのオプティマイザは、損失関数を減少させる方向にパラメータを調整します。量子フィッシャー情報行列を計算することを含む量子自然勾配法も、潜在的に高速な収束のために使用できます。ガウス状態準備の数値例は、$L_2$誤差が多項式次数 $d$ とともに指数関数的に減少することを示しており、関数近似の良好な収束挙動を示しています。しかし、層数 $L$ に対するクエリ複雑性の指数関数的なスケーリングは、QKANが浅いアーキテクチャに最も適していることを意味し、これは非常に複雑な深い関数を学習する能力に影響を与える可能性があります。
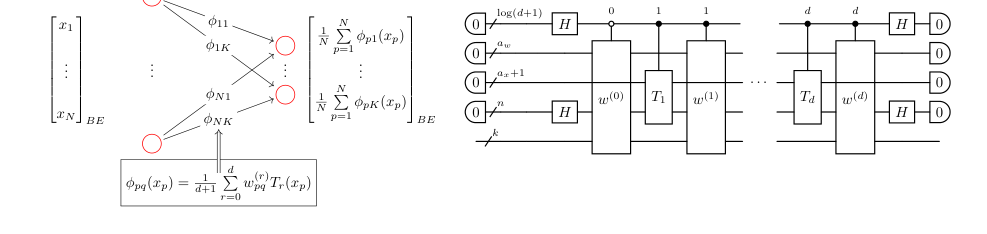 FIG. 1. Construction of a CHEB-QKAN layer with the corresponding quantum circuit. The input to the QKAN model is a diagonal block-encoding of an N-dimensional real vector ⃗x. The CHEB-QKAN layer applies univariate activation functions ϕpq to each input component xp, where p ∈[N] indexes input nodes and q ∈[K] indexes output nodes. The output vector is computed as a sum over activated input nodes. This operation yields a block-encoded real K-dimensional output vector. The quantum circuit implementation requires 1 + log2(d + 1) qubits for the construction and linear combination of weighted Chebyshev polynomials, aw + ax qubits for the block-encodings of input and weights, n = log2 N qubits for input vector encoding, and k = log2 K qubits for output. The circuit consists of a series of multi-controlled block-encodings of Chebyshev polynomials, interspersed with diagonal block- encodings of the corresponding real weights. The entire circuit represents a block-encoding of the K-dimensional vector corresponding to the CHEB-QKAN layer, with auxiliary qubits initialized and measured in the |0⟩state
FIG. 1. Construction of a CHEB-QKAN layer with the corresponding quantum circuit. The input to the QKAN model is a diagonal block-encoding of an N-dimensional real vector ⃗x. The CHEB-QKAN layer applies univariate activation functions ϕpq to each input component xp, where p ∈[N] indexes input nodes and q ∈[K] indexes output nodes. The output vector is computed as a sum over activated input nodes. This operation yields a block-encoded real K-dimensional output vector. The quantum circuit implementation requires 1 + log2(d + 1) qubits for the construction and linear combination of weighted Chebyshev polynomials, aw + ax qubits for the block-encodings of input and weights, n = log2 N qubits for input vector encoding, and k = log2 K qubits for output. The circuit consists of a series of multi-controlled block-encodings of Chebyshev polynomials, interspersed with diagonal block- encodings of the corresponding real weights. The entire circuit represents a block-encoding of the K-dimensional vector corresponding to the CHEB-QKAN layer, with auxiliary qubits initialized and measured in the |0⟩state
結果、限界、結論
実験設計とベースライン
量子コルモゴロフ・アーノルド・ネットワーク(QKAN)アーキテクチャを厳密に検証するために、著者らは特定の、しかし説明的な応用、すなわち多変数量子状態準備に焦点を当てました。実験設計は、競合する量子モデルを直接ベンチマークで打ち負かすように設定されたものではなく、QKANのコア合成メカニズム、すなわち量子特異値変換(QSVT)を活用したものが、複雑な多変数関数を正確に実現できることを決定的な証拠を提供することを目的としていました。この文脈での「犠牲者」は、QKANが近似しようとした理想的なターゲット関数自体、すなわち$D$次元ガウス分布でした。
実験では、パラメータ $\beta=6$ を選択して、$32 \times 32$ グリッド上で2Dガウス量子状態を準備することに特に焦点を当てました。このセットアップにより、QKANのパフォーマンスを明確に数値的に示すことができました。アーキテクチャは2層QKANを採用しました。最初の層は、各グリッドポイントに対して関数 $x^2 + y^2 - 1$ を正確に計算するように設計されており、シフトされた半径の二乗を効果的にエンコードしました。2番目の層は、さまざまな次数のチェビシェフ多項式を使用して、指数関数的減衰関数 $e^{-\beta(x+1)}$ の多項式近似を適用しました。この2層構造は、ある層の出力($x^2 + y^2 - 1$ のブロックエンコーディング)が次の層の入力として機能するという、QKANの合成原則の直接的なインスタンス化でした。実験は、QKANメカニズムが入力グリッドポイントを層を通して変換し、望ましいガウス分布に密接に対応する振幅を生成できるという数学的主張が、具体的で正確な量子状態に変換できることを証明するように設計されました。
証拠が証明すること
数値例は、多変数量子状態準備におけるQKANアーキテクチャの有効性に関する説得力のある証拠を提供します。主な発見は図10に示されています。
-
多項式近似精度(図10a): 論文ではまず、区間 $[-1,1]$ 上で次数3のチェビシェフ多項式 $P_3(x)$ を使用して、非線形指数関数 $e^{-\beta(x+1)}$ を近似する精度を示しています。これは、これらの多項式近似がQKAN内の活性化関数の基礎を形成し、QSVTを通じて実現されるため重要です。プロットは、指定された範囲内でターゲット関数とその多項式近似との間に密接な適合性を示しており、これらの非線形性を実装する可能性を確認しています。
-
絶対振幅誤差(図10b): 次数3の多項式 $P_3(x)$ を使用して準備された正規化された2Dガウス状態の、$32 \times 32$ グリッド全体にわたる絶対振幅誤差 $| \psi_{\text{exp}}(i,j) - \psi_{\text{QKAN}}(i,j) |$ が視覚的に提示されています。このヒートマップのようなプロットは、QKANで準備された状態が理想的なガウス状態にどれだけよく一致するかを直接的かつ否定できない視覚的な証拠を提供します。誤差は一般的に低く、中心付近で最大の不一致が見られます。これは、誤差がその領域で最大であった多項式近似自体の挙動と一致しています。この厳密な証拠は、QKANメカニズムが入力グリッドポイントを層を通して正確に変換し、望ましいガウス分布に対応する振幅を生成することを示しています。
-
指数関数的な誤差減衰(図10c): おそらく最も決定的な証拠は、多項式次数 $d$ の関数としての $L_2$ 誤差、$|| \psi_{\text{exp}} - \psi_{\text{QKAN}} ||_2$ です。プロットは、多項式次数が増加するにつれて、経験的誤差が指数関数的に減衰することを示しています。この指数関数的な改善は、誤差が機械精度、約 $10^{-14}-10^{-15}$ で飽和するまで続きます。これは $d=20$ の場合です。この結果は、理論的限界と、活性化関数の複雑さを増やすことによって高精度の近似を達成するQKANの能力の強力な検証です。これは、QSVTを介した非線形変換のための多項式近似の使用というコアメカニズムが意図したとおりに機能し、制御可能で高精度の状態準備を可能にすることを厳密に証明しています。経験的誤差と理論的限界との一致は、主張をさらに強固なものにします。
要するに、この証拠は、QKANがその合成ブロックエンコーディング構造とQSVT対応の非線形活性化を通じて、複雑な多変数量子状態を正確に準備できることを証明しており、量子機械学習および状態準備のための強力な新しいパラダイムを示しています。
限界と将来の方向性
QKANは有望な新しい方向性を示していますが、論文ではいくつかの限界を率直に議論し、将来の研究のための豊かな景観を開いています。
現在の限界:
-
継承されたKANの限界: QKANは、古典的な対応物からいくつかの注意点を継承しています。コルモゴロフ・アーノルド表現定理(KART)は2層分解を保証しますが、古典KAN、ひいてはQKANは、KARTの普遍的表現特性を必ずしも継承していません。これは、特にKANの設計に適した合成構造を欠いている場合、深いQKANが任意の所与の多変数関数を表現できる保証がないことを意味します。KANの完全な可能性は、特にシンボリック回帰に関して、古典的であっても、依然として活発な研究分野です。
-
浅いアーキテクチャ制約: 多層QKANの重要な限界は、層数に対するクエリ複雑性の指数関数的なスケーリングです。再帰的なQSVTベースの構築は、前の層からのすべての出力ブロックエンコーディングが次の層の基本的な構成要素になることを意味し、回路深さに指数関数的なオーバーヘッドをもたらします。これは根本的にQKANを「浅いが幅広く」アーキテクチャに制限し、つまり $L = O(1)$ 層を意味します。浅い深さは指数関数的に広い層で補償できますが、効率的なブロックエンコーディングが利用可能な場合、この制約は非常に深い学習タスクにとって実用的なハードルです。
-
多項式近似の範囲: 量子コンピュータは多項式を表現することに優れていますが、すべての関数が多項式によって効率的に近似できるわけではありません。これは、QKANの活性化関数の基底関数の選択が重要であることを意味します。QSVTは汎用的ですが、依然として多項式近似に依存しており、任意の関数を直接近似するスプラインなどよりも強力ではない可能性があります。符号関数のような関数を近似する精度も、パラメータがゼロに近い場合、制限される可能性があります。
-
実数値制限: 簡単にするために、現在の作業は、入力、出力、および重みに対して実数値を扱う範囲に限定されています。複素数への一般化は可能ですが、実部と虚部を別々に扱うことによって、複雑さが追加され、将来の研究のために残されています。
将来の方向性と議論トピック:
-
強化されたパラメータ化とトレーニング戦略:
- 重みパラメータ化を超えて: 論文では、重みベクトルだけでなく、QKANの他のステップをパラメータ化することを示唆しています。例えば、線形結合ユニタリ(LCU)ステップでは、固定アダマール変換の代わりに、状態準備ペアとして使用されるユニタリをパラメータ化できます。これにより、さまざまな次数のチェビシェフ多項式のグローバル重みに対するよりきめ細かな制御が可能になり、表現力が増す可能性があります。
- 適応的基底関数選択: 現在、チェビシェフ多項式はQSVTのために自然な選択です。しかし、QSVTフレームワークは任意の有界多項式の実装を可能にします。興味深い方向性は、基底関数の選択自体を学習プロセスの一部にすることであり、固定の選択に依存するのではなく、特定のタスクに最適な基底セットを発見する可能性があります。
- 反復的なモデル洗練: トレーニング戦略には、高次チェビシェフ多項式を合計に反復的に追加し、それらのグローバル重みを最適化することが含まれる場合があります。最適化された重みを検査することにより、必要な多項式の数を決定できます。例えば、新しく追加された多項式の重みが消滅した場合などです。これにより、より解釈可能で効率的なモデルが得られる可能性があります。
-
直接的な量子入力のためのQKANの探索:
- 量子位相分類: QKANは、古典的に解析が困難な量子状態のような直接的な量子入力に適している可能性があるとして提案されています。例えば、位相分類タスクでは、未知の量子位相に対応する状態を効率的に準備できる場合、QKANは古典モデルよりも優れたパフォーマンスを発揮する可能性があります。これは、多変数関数の計算を助け、物理システムにおける新しい順序パラメータの発見に役立つ可能性があります。これは、QKANの量子性が明確な利点を提供する説得力のある応用です。
-
一般化と表現力:
- 複素数値QKAN: QKANを複素数を扱うように拡張すると、より幅広い量子問題とデータ型への適用が大幅に広がります。
- 代替基底関数: チェビシェフ多項式は効率的ですが、QSVTによって効率的に近似できる他の基底関数(例えば、Bスプライン、ウェーブレット、フーリエ展開)を探索すると、さまざまな種類の関数に対するQKANの表現力が向上する可能性があります。論文では、Bスプラインは、LCUを使用して区分的セクションを分離することによって実装できると述べており、これは複雑ですが潜在的に有望な道です。
-
高度な状態準備技術:
- 多変数重要度サンプリング: 論文では、重要度サンプリングによる多変数版の指数関数的改善の達成は、多変数設定における課題のため、未解決の問題であると指摘しています。これを克服することは、非常に複雑で非一様な多変数状態を準備するためのQKANの有用性を大幅に向上させるでしょう。
-
解釈可能性と科学的発見:
- 古典KANの解釈可能性の利点、すなわち個々の活性化関数を検査して削除できることは、重要な強みです。これがQKANにどのように翻訳されるか、特に量子データからスパースな合成構造を特定したり、新しい物理法則を発見したりする点について、さらに研究することは魅力的な見通しです。訓練された重み分布からサンプリングする能力は、プルーニングとモデル圧縮への道を提供します。
これらの議論のポイントは、QKANが単なる理論的構築ではなく、特に古典的な方法では解決不可能な問題に対する量子コンピューティングの固有の能力を活用する上で、進化の大きな可能性を秘めた基盤フレームワークであることを強調しています。その可能性を完全に実現する旅には、これらの限界に対処し、これらの将来の方向性を創造的に探求することが含まれます。
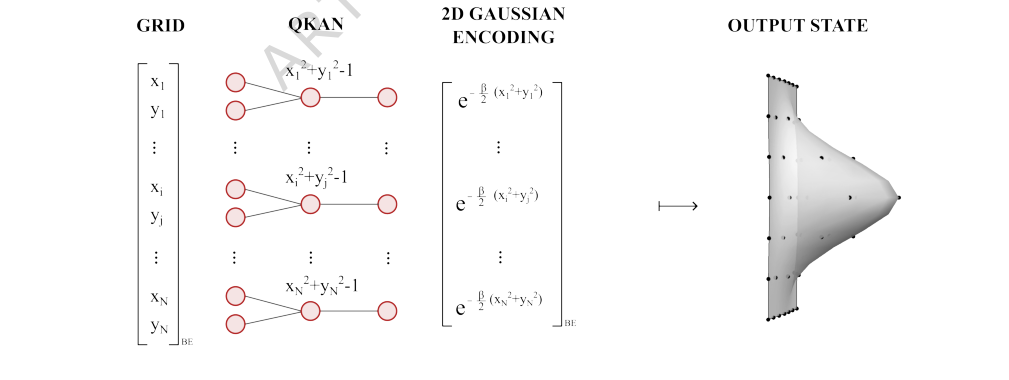 FIG. 4. Example: 2D Gaussian state preparation via QKAN. Starting from a vectorized 2D grid of points {(xi, yi)} encoded as a diagonal block-encoding (left), the first QKAN layer applies Chebyshev polynomial T2 and sums over the two dimensions, computing 1
FIG. 4. Example: 2D Gaussian state preparation via QKAN. Starting from a vectorized 2D grid of points {(xi, yi)} encoded as a diagonal block-encoding (left), the first QKAN layer applies Chebyshev polynomial T2 and sums over the two dimensions, computing 1
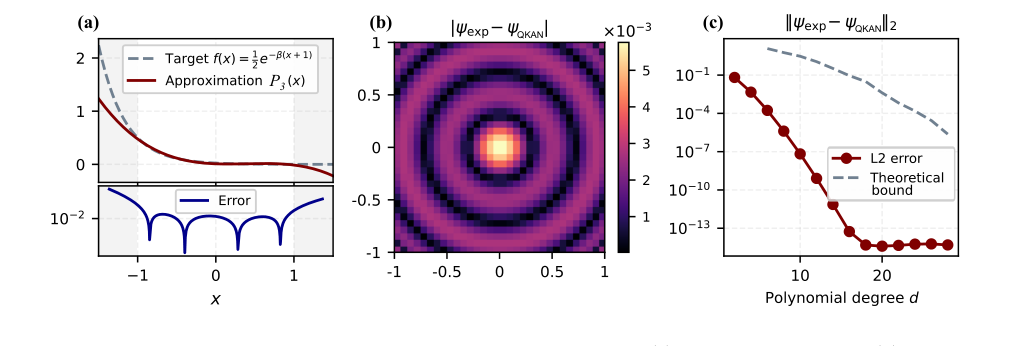 FIG. 10. Numerical illustration of Gaussian state preparation via QKAN. (a) Degree-3 polynomial P3(x) approxi- mating 1
FIG. 10. Numerical illustration of Gaussian state preparation via QKAN. (a) Degree-3 polynomial P3(x) approxi- mating 1