QKAN: 양자 콜모고로프-아르놀트 신경망과 기계 학습 및 다변수 상태 준비에서의 응용
We introduce quantum Kolmogorov-Arnold networks (QKAN), a quantum algorithmic framework inspired by the recently proposed Kolmogorov-Arnold Networks (KAN).
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 양자 콜모고로프-아르놀트 신경망(QKAN) 개발 문제는 최근 제안된 고전 콜모고로프-아르놀트 신경망(KAN) [5]에서 영감을 받아, 고전 신경망과 양자 컴퓨팅의 교차점에서 정확히 기원한다. 역사적 맥락은 1950년대의 근본적인 수학적 결과인 콜모고로프-아르놀트 표현 정리(KART) [1-4]에서 시작된다. KART는 임의의 연속적인 다변수 함수(여러 입력 변수를 가진 함수)가 유한 개의 단변수 함수(하나의 입력 변수만 가진 함수)의 합성 및 합으로 분해될 수 있다고 명시한다. 이 정리는 복잡한 함수가 어떻게 더 간단한 구성 요소들을 사용하여 표현될 수 있는지 이해하는 이론적 기반을 제공했다.
그러나 KART의 직접적인 실제 적용, 특히 신경망에서의 적용은 이론적으로 보장된 내부 및 외부 함수가 매우 비매끄러울 수 있어 정확하고 강건하게 근사하기 어렵다는 한계 때문에 제한적이었다 [5]. 이러한 "고충점"은 KART가 이론적으로는 강력하지만 효과적인 신경망 아키텍처로 직접 변환하기 어렵다는 것을 의미했다.
이러한 상황은 Liu 등이 제안한 콜모고로프-아르놀트 신경망(KAN) [5]의 최근 도입으로 변화했다. KAN은 KART의 합성 구조를 일반화하여, KART가 보장하는 두 개의 계층과는 달리 임의의 수의 계층을 허용한다. 고전 KAN은 KART의 보편적 표현 속성을 상속하지는 않지만, 특히 과학 분야에서 특정 응용에서 해석 가능성을 높이고 소규모 작업에서 정확도를 향상시키는 등 유망한 결과를 보여주었다. 또한 대상 함수에서 모듈식 구조를 드러냄으로써 새로운 물리 법칙 발견에 기여할 가능성도 있다 [10].
본 논문의 저자들은 고전 KAN의 잠재력에 동기를 부여받아 양자 버전을 제안하고자 하였으며, 그것이 바로 QKAN이다. 본 논문을 작성하게 된 저자들을 강요한 기존의 양자 접근 방식의 근본적인 한계는 양자 기계 학습 모델의 본질에서 비롯된다. 변분 양자 알고리즘(VQA) [34-39]과 같은 기존 양자 학습 모델은 종종 양자 회로의 매개변수를 최적화하는 데 의존한다. 반면 QKAN은 다른 패러다임을 제공한다. 즉, 블록 인코딩된 행렬의 고유값을 "뉴런"으로 취급하고 양자 특이값 변환(QSVT)을 사용하여 네트워크의 "에지"에 매개변수화된 활성화 함수를 적용한다. 이 접근 방식은 KAN의 합성 구조를 양자 설정에서 활용하여, 특히 입력의 효율적인 블록 인코딩이 가능한 경우 특정 작업에서 효율성 이점을 제공하는 것을 목표로 한다. 그러나 QKAN 역시 자체적인 제약에 직면한다. QSVT를 사용하여 계층을 재귀적으로 합성하면 회로 깊이에 지수적인 오버헤드가 발생하므로, QKAN은 자연스럽게 얕은 아키텍처로 제한된다.
직관적인 도메인 용어
-
콜모고로프-아르놀트 표현 정리(KART): 여러 재료와 단계가 포함된 매우 복잡한 레시피가 있다고 상상해 보라. KART는 아무리 복잡한 레시피라도, 그것을 결합하는 훨씬 더 간단하고 단일 재료로 구성된 미니 레시피들의 연속으로 항상 분해할 수 있다는 수학적 증명과 같다. 복잡성을 관리 가능한 단일 변수 부분으로 단순화하는 것에 관한 것이다.
-
블록 인코딩(Block-encoding): 안전하게 보내고 싶은 비밀 메시지(행렬 또는 벡터)를 생각해 보라. 블록 인코딩은 이 비밀 메시지를 훨씬 더 크고 겉보기에는 평범한 문서(유니터리 양자 연산)에 내장하는 것과 같다. 더 큰 문서는 무해해 보이지만, 그 안의 특정 부분, 즉 "블록"이 축소된 비밀 메시지를 포함한다. 양자 컴퓨터는 이 더 큰 문서를 조작하여 비밀 메시지를 직접 "읽지 않고" 효과적으로 처리할 수 있다.
-
양자 특이값 변환(Quantum Singular Value Transformation, QSVT): 사진 편집 앱에서 특정 효과, 예를 들어 밝기나 대비를 변경하고 싶지만, 특정 색상이나 패턴에만 적용하고 싶다고 상상해 보라. QSVT는 매우 정밀한 디지털 필터 역할을 하는 강력한 양자 기술이다. 블록 인코딩된 행렬에 인코딩된 정보의 "강도" 또는 "중요도"(특이값)에 거의 모든 원하는 수학적 함수(다항식 등)를 적용할 수 있어 매우 특정적이고 복잡한 변환이 가능하다.
-
다변수 상태 준비(Multivariate State Preparation): 여러 요인(온도, 습도, 시간 등)에 의해 복잡한 수학 공식으로 각 음의 크기가 정확하게 결정되는 독특한 음악 코드를 만들고 싶다고 상상해 보라. 양자 컴퓨팅에서의 다변수 상태 준비는 여러 입력 변수를 가진 복잡한 함수의 값을 일치시키도록 "볼륨" 또는 "진폭"이 설정된 양자 상태(양자 비트의 모음)를 생성하는 것이다. 이는 복잡한 값의 지형을 양자 영역으로 직접 인코딩하는 것과 같다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문은 고전 콜모고로프-아르놀트 신경망(KAN)에서 영감을 받은 양자 알고리즘 프레임워크인 양자 콜모고로프-아르놀트 신경망(QKAN)을 소개한다. 핵심 문제는 기계 학습 및 다변수 상태 준비 응용을 위한 KAN의 효율적인 양자 구현을 개발하는 것이다.
입력/현재 상태:
QKAN의 시작점은 $N$차원 실수 벡터 $\vec{x} \in [-1,1]^N$의 블록 인코딩이다. 이는 벡터의 구성 요소가 유니터리 행렬 $U_x$의 대각 항목에 인코딩됨을 의미하며, $|| \langle 0|_a U_x |0\rangle_a - \text{diag}(x_1, \dots, x_N) || \le \epsilon_x$를 만족한다. 양자 기계 학습의 경우, 이 입력은 양자 상태의 진폭 또는 행렬의 대각 항목일 수 있다. 다변수 상태 준비의 경우, 입력은 일반적으로 벡터화된 $D$차원 격자점이며, 역시 대각 블록 인코딩으로 제공된다.
출력/목표 상태:
원하는 최종 상태는 응용에 따라 달라진다.
* 양자 학습 모델로서: 목표는 $K$차원 출력 벡터 $\Phi(\vec{x}) \in [-1,1]^K$의 대각 블록 인코딩을 생성하는 것이다. 이 출력 벡터의 항목, $\Phi(\vec{x})_q = \frac{1}{N} \sum_{p=1}^N \phi_{pq}(x_p)$ (여기서 $\phi_{pq}$는 단변수 활성화 함수)는 덧셈 $\delta$-정밀도로 고전적으로 추정되어야 한다.
* 다변수 양자 상태 준비 프로토콜로서: 목표는 입력의 다변수 함수, 예를 들어 정규 제곱 격자상의 $D$차원 가우시안 분포에 해당하는 진폭을 가진 양자 상태 $|\psi\rangle$를 준비하는 것이다. 이는 균일한 중첩에 최종 블록 인코딩을 적용한 후 진폭 증폭을 사용하여 달성된다.
누락된 연결/수학적 간극:
본 논문이 해결하고자 하는 근본적인 간극은 고전 KAN의 합성 구조를 양자 컴퓨팅 패러다임으로 효율적이고 정확하게 변환하는 것이다. 고전 KAN은 복잡한 다변수 함수를 단변수 함수의 합성 및 합으로 분해한다. 과제는 이러한 비선형 단변수 함수와 그 합을 양자 연산을 사용하여 실현하는 것이며, 특히 블록 인코딩된 데이터를 사용한 양자 특이값 변환(QSVT)을 활용하면서 유니터리성 및 오류 전파와 같은 고유한 양자 제약을 극복하는 것이다. 본 논문은 잠재적인 양자 속도를 제공하는 이러한 연산을 수행할 수 있는 구체적인 양자 아키텍처를 제공하는 것을 목표로 한다.
딜레마 및 고통스러운 절충:
양자 기계 학습 및 상태 준비와 유사한 문제를 해결하려 했던 이전 연구자들은 여러 고통스러운 절충에 직면했다.
* 양자 속도 향상 대 고전 판독: 양자 알고리즘은 지수적으로 큰 데이터 구조(블록 인코딩 등)를 효율적으로 처리할 수 있지만, 전체 출력을 고전적으로 추출하는 것은 양자 이점을 상쇄할 수 있다. QKAN의 경우, 양자 속도 향상을 달성하는 것은 고전 후처리 비용이 지수적이지 않은 경우에 달려 있다. 이는 지수적으로 많은 값을 추정하는 데에도 지수적인 시간이 소요되므로 출력 차원 $K$가 $O(\text{polylog}(N))$으로 제한되어야 함을 의미한다.
* 얕은 대 깊은 아키텍처: QKAN은 "넓고 얕은" 아키텍처로 설계되었다. 효율적인 블록 인코딩이 가능한 경우, 고전 신경망에서는 접근할 수 없는 영역에서 다항 로그 비용으로 지수적으로 넓은 계층을 실현할 수 있다. 그러나 여러 계층을 합성하기 위한 재귀적 QSVT 기반 구성은 회로 깊이에 지수적인 오버헤드를 발생시킨다. 이는 계산상 실현 가능성을 유지하기 위해 QKAN을 일반적으로 $L=O(1)$ 계층으로 제한된 얕은 아키텍처로 강제한다.
* 정밀도 대 쿼리 복잡성: 양자 학습 모델의 출력 추정을 위해 더 높은 정밀도(더 작은 $\delta$)를 달성하려면 제어된 대각 블록 인코딩에 대한 더 많은 쿼리가 필요하다. 구체적으로, 덧셈 $\delta$ 근사는 $O(d^2/\delta)$ 쿼리가 필요하다. 곱셈 오차가 필요한 경우 쿼리 수는 $O(d^2/(\delta|a_q|))$로 증가하므로, 진폭 $a_q$가 지수적으로 감소하지 않는 경우에만 잠재적인 양자 속도 향상이 유지된다. 이는 원하는 정확도와 필요한 계산 리소스(쿼리) 간의 절충을 제시한다.
제약 조건 및 실패 모드
QKAN을 구현하는 문제는 다음과 같은 여러 가혹하고 현실적인 장벽으로 인해 매우 어렵다.
- 유니터리 제약: 양자 역학은 모든 연산이 유니터리여야 한다고 규정한다. 이는 모든 벡터 요소(입력, 출력, 가중치)가 블록 인코딩으로 인코딩될 때 크기가 1로 제한되어야 한다는 엄격한 제약을 부과한다. 이는 데이터의 신중한 정규화 및 스케일링을 요구하는 근본적인 물리적 제약이다.
- 입력의 효율적인 블록 인코딩: QKAN의 게이트 복잡성은 $N$차원 입력 벡터의 초기 블록 인코딩을 구성하는 비용에 선형적으로 비례한다. QKAN이 양자 속도 향상을 제공하려면 입력이 $O(\text{polylog}(N))$ 시간에 준비될 수 있는 효율적인 블록 인코딩을 허용해야 한다. 입력 인코딩 자체가 $O(N)$ 게이트를 요구하는 경우, 고전 알고리즘에 대한 양자 이점은 사라진다. 이는 상당한 데이터 중심 제약이다.
- 재귀적 오류 전파: 입력 및 가중치의 블록 인코딩의 불완전성은 누적된다. 다층 QKAN에서 이러한 오류는 각 후속 계층마다 재귀적으로 전파되어 최종 출력 블록 인코딩에서 오류가 증폭된다. 이는 깊은 QKAN에 대한 높은 정밀도를 달성하는 것을 극도로 어렵게 만들고 실용적인 깊이를 제한한다.
- 깊은 아키텍처에 대한 지수적 회로 깊이: 한 계층의 출력 블록 인코딩이 다음 계층의 입력 역할을 하는 QKAN의 재귀적 구성은 계층 수 $L$에 대한 회로 깊이의 지수적 의존성을 초래한다. 이러한 계산 제약은 QKAN을 얕은 아키텍처($L=O(1)$)로 심각하게 제한하며, 깊은 네트워크의 이론적 이점에도 불구하고 그렇다.
- 보조 큐비트 제한: QKAN 구성에 필요한 총 보조 큐비트 수는 계층 수 $L$에 선형적으로 증가한다. 지수적 스케일링은 아니지만, 현재 및 근미래 양자 장치에 대한 하드웨어 메모리 제한이 될 수 있다.
- 다항식 근사 제한: 비선형 변환 적용의 핵심 메커니즘인 QSVT는 대상 함수의 다항식 근사에 의존한다. 모든 함수를 낮은 차수의 다항식으로 효율적으로 근사할 수 있는 것은 아니므로, 특정 작업에 대한 QKAN의 표현력과 정확도가 제한된다. 예를 들어, 가우시안 상태 준비를 위한 지수 함수 근사는 충분히 높은 다항식 차수를 요구하며, 이는 전체 정확도에 영향을 미친다.
- 실수 제한: 현재 작업은 명시적으로 실수 입력, 출력 및 가중치로 범위를 제한한다. 복소수로의 일반화는 가능하지만, 향후 작업으로 남겨두어 모델 적용 가능성의 현재 한계를 나타낸다.
- 기울기 추정 비용: 매개변수 이동 규칙을 사용하여 QKAN을 훈련하여 해석적 기울기를 얻는 것은 계산 비용이 많이 든다. 비용은 단일 계층 QKAN의 경우 $O(d)$ 쿼리, $L$ 계층 QKAN의 경우 $O(d^2L)$로 확장되며, 여기서 $d$는 체비쇼프 다항식의 최대 차수이다. 계층에 대한 이러한 지수적 스케일링은 깊은 QKAN을 훈련하는 것을 극도로 어렵고 리소스 집약적으로 만든다.
왜 이 접근 방식인가
선택의 불가피성
양자 콜모고로프-아르놀트 신경망(QKAN)의 채택은 단순히 선택이 아니라, 양자 영역에서 다변수 함수 근사 및 상태 준비의 고유한 요구 사항에 의해 주도된 본질적인 필요성이었다. 저자들이 기존의 "최첨단"(SOTA) 방법이 불충분하다는 것을 깨달은 것은 몇 가지 주요 관찰에서 비롯되었다.
첫째, 고전 콜모고로프-아르놀트 신경망(KAN)은 이미 해석 가능성과 특정 작업(특히 기호 함수를 포함하는 과학 응용)에서의 정확도 측면에서 기존의 다층 퍼셉트론(MLP)에 비해 질적인 이점을 입증했다. 이러한 이점을 양자 컴퓨팅으로 이전하려면 양자 네이티브 접근 방식이 필수적이었다. 매개변수화된 양자 회로를 사용하는 변분 양자 알고리즘(VQA) 또는 CNN 및 트랜스포머의 양자 버전과 같은 표준 양자 기계 학습 모델은 일반적으로 KAN의 합성 구조를 본질적으로 포착하지 않는 다른 아키텍처 원리에 의존한다.
결정적인 "아하!" 순간은 양자 프레임워크 내에서 KAN의 핵심인 비선형 활성화 함수를 양자 속도 향상을 유지하면서 구현하는 방법을 고려할 때 발생했을 가능성이 높다. 양자 상태에서 고전적인 비선형성을 직접 시뮬레이션하는 것은 일반적으로 비효율적이다. 양자 특이값 변환(QSVT)은 블록 인코딩된 행렬의 특이값에 다항식 변환을 적용하는 강력하고 다재다능한 메타 알고리즘을 제공하기 때문에 유일하게 실행 가능한 해결책으로 부상했다. 이 기능은 KAN의 단변수 활성화 함수를 양자 설정에서 실현하는 데 정확히 필요한 것이다. QSVT 없이는 양자 데이터(블록 인코딩으로 표현됨)에서 이러한 비선형성을 효율적으로 구현하는 것은 불가능하거나 잠재적인 양자 이점을 무효화할 것이다. 본 논문은 QKAN이 "블록 인코딩된 행렬의 고유값을 뉴런으로 취급하고 체비쇼프 다항식 또는 QSVT를 사용하여 효율적으로 실현할 수 있는 다른 기저 함수들의 선형 조합을 통해 네트워크 에지에 매개변수화된 활성화 함수를 적용한다"고 명시적으로 언급하며, QSVT를 핵심 가능하게 하는 요소로 강조한다.
비교 우위
QKAN은 특정 문제 클래스에 대한 이전의 황금 표준에 비해 질적으로 우수한 구조적 이점을 압도적으로 보여준다. 가장 중요한 이점은 "넓고 얕은" 아키텍처에 있다. QKAN 계층을 재귀적으로 합성하면 깊이에 지수적인 오버헤드가 발생하여 아키텍처를 얕은 구성($L = O(1)$)으로 제한하지만, 이 얕은 깊이는 효율적인 블록 인코딩이 가능한 경우 다항 로그 비용으로 지수적으로 넓은 계층을 실현할 수 있는 능력으로 놀랍게 보상된다. 이 영역은 $N$차원 상태를 처리하기 위해 $O(N)$ 런타임이 필요한 고전 신경망에서는 근본적으로 접근할 수 없다.
예를 들어, QKAN은 대상 함수가 효율적인 다항식 근사를 가지고 있다고 가정할 때, $O(\text{polylog}(N))$ 시간 내에 다변수 함수를 계산하여 $N$차원 양자 상태를 처리할 수 있다. 이는 동일한 연산에 대한 고전 $O(N)$ 런타임에 비해 상당한 양자 속도 향상을 제공한다. 이러한 효율성은 블록 인코딩과 QSVT에 의존하는 QKAN에서 비롯되며, 이는 지수적으로 큰 유니터리 연산자를 효율적으로 조작할 수 있게 한다.
또한, QKAN은 고전 KAN의 해석 가능성 이점을 상속한다. 개별 활성화 함수를 검사하고 0 함수와 유사한 함수를 가지치기하는 능력은 잠재적인 희소 합성 구조 발견 및 새로운 물리 법칙 발견을 가능하게 하며, 이는 블랙박스 딥러닝 모델에서 종종 부족한 질적인 이점이다. QSVT 프레임워크의 다재다능함은 QKAN이 체비쇼프 다항식에 국한되지 않고 다양한 응용에 맞게 조정된 유연성을 제공하는 광범위한 기저 함수를 구현할 수 있음을 의미한다. 본 논문은 고차원 노이즈 처리 또는 $O(N^2)$에서 $O(N)$으로의 메모리 복잡성 감소에 대한 이점을 명시적으로 자세히 설명하지는 않지만, 블록 인코딩 접근 방식은 본질적으로 정보를 압축하며, 넓은 계층에 대한 다항 로그 스케일링은 대규모 입력에 대해 매우 효율적인 리소스 사용을 의미한다.
제약 조건과의 정렬
선택된 QKAN 방법은 양자 컴퓨팅의 고유한 제약 조건 및 문제 정의와 완벽하게 "결혼"한다.
-
효율적인 입력 인코딩: 양자 알고리즘이 속도 향상을 달성하기 위한 주요 제약 조건은 입력 데이터를 효율적으로 준비하거나 인코딩하는 것이다. QKAN은 입력 벡터의 블록 인코딩을 사용하여 작동함으로써 완벽하게 정렬된다. 게이트 복잡성은 이러한 블록 인코딩을 구성하는 비용에 선형적으로 비례하며, 본질적으로 양자 입력(예: 양자 상태의 진폭 또는 해밀토니안의 블록 인코딩)의 경우 $O(\text{polylog}(N))$만큼 효율적일 수 있다. 이는 입력 병목 현상이 양자 이점을 무효화하지 않도록 보장한다.
-
유니터리성 및 제한된 값: 양자 컴퓨팅은 연산이 유니터리여야 한다고 엄격하게 요구한다. QKAN의 설계는 QSVT를 기반으로 하며 본질적으로 이를 존중한다. 블록 인코딩 표현 자체는 벡터가 유니터리 행렬 내에 인코딩되고 이러한 벡터의 요소는 크기가 1로 제한되어 양자 상태의 진폭 제약을 만족함을 보장한다.
-
얕은 깊이 요구 사항: QSVT를 사용한 QKAN 계층의 재귀적 구성은 각 추가 계층에 따라 회로 깊이에 지수적인 오버헤드를 초래한다. 이 제약은 자연스럽게 QKAN을 얕은 아키텍처($L=O(1)$)로 강제한다. 이는 제약이라기보다는 QKAN의 "넓고 얕은" 모델로서의 틈새를 정의하며, 여기서 지수적 너비는 제한된 깊이를 보상하여 솔루션의 속성을 이 가혹한 요구 사항과 일치시킨다.
-
실수 연산: 본 논문은 명시적으로 입력, 출력 및 가중치에 대해 실수 값으로 논의를 제한한다. 복소수로의 일반화는 가능하지만, 미래 작업으로 남겨두고 있으며, QKAN의 구성은 실수 함수를 처리하는 데 적합하다.
대안의 거부
본 논문은 QKAN의 고유한 아키텍처 및 기능적 차이점을 강조함으로써 다른 인기 있는 양자 기계 학습 접근 방식을 거부함을 암시한다.
첫째, QKAN은 종종 휴리스틱이며 매개변수화된 양자 회로의 매개변수를 최적화하는 데 의존하는 "변분 아키텍처"(VQA)와 다르다. VQA는 근미래 양자 장치에 적합하지만, QKAN은 "더 강력한 양자 선형 대수 도구 세트"로 진입하여 정확한 구성을 통한 내결함성 양자 속도 향상에 초점을 맞추고 있음을 시사한다. 특히 다변수 양자 상태를 효율적으로 준비하거나 합성 구조를 가진 함수를 근사하는 문제에 대해 QKAN의 QSVT 기반 접근 방식은 양자 이점을 향한 더 직접적이고 잠재적으로 더 강력한 경로를 제공한다.
둘째, 고전 KAN에서 영감을 받은 QKAN의 합성 구조는 양자 MLP의 고정된 밀집 계층 또는 양자 CNN 또는 트랜스포머의 특정 귀납적 편향과 근본적으로 다르다. 이러한 대안 아키텍처는 KAN의 함수를 단변수 함수의 합성 및 합으로 표현하는 능력과 같은 것을 자연스럽게 포착하지 못할 수 있으며, 동일한 해석 가능성 이점을 제공하지도 않을 것이다. 본 논문의 "이전 아키텍처와는 반대로"라는 진술은 이러한 구분을 강조한다.
본 논문은 예를 들어 양자 GAN 또는 양자 확산 모델이 왜 실패할지를 명시적으로 자세히 설명하지는 않지만, 블록 인코딩된 입력에 대해 다항 로그 비용으로 지수적으로 넓은 계층을 달성하는 QKAN의 능력과 과학적 발견을 위한 해석 가능성에 대한 강조는 이러한 특정 이점이 가장 중요한 문제 영역을 가리킨다. 다른 방법은 특정 함수 구조에 대한 양자 속도 향상, 블록 인코딩된 데이터의 효율적인 처리 및 고유한 해석 가능성의 동일한 조합을 제공하지 않을 수 있다.
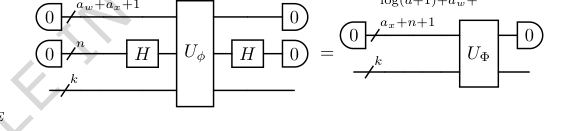 FIG. 9. Step 5. Sum the individual activation functions over N input nodes for each output node, creating the desired diagonal block-encoding UΦ of the K-dimensional output vector Φ(⃗x). This is achieved by sandwiching the block-encoding from Step 4 with two n-qubit Hadamard gates. The dimension reduction occurs as the n qubits originally used for input block-encoding are moved to the auxiliary register
FIG. 9. Step 5. Sum the individual activation functions over N input nodes for each output node, creating the desired diagonal block-encoding UΦ of the K-dimensional output vector Φ(⃗x). This is achieved by sandwiching the block-encoding from Step 4 with two n-qubit Hadamard gates. The dimension reduction occurs as the n qubits originally used for input block-encoding are moved to the auxiliary register
수학적 및 논리적 메커니즘
마스터 방정식
양자 콜모고로프-아르놀트 신경망(QKAN) 계층, 특히 CHEB-QKAN 변형의 핵심 수학적 엔진은 입력 벡터 $\vec{x}$를 $\Phi(\vec{x})$ 출력 벡터로 변환하는 방식에 의해 요약된다. 이 변환은 블록 인코딩된 $K$차원 벡터의 대각 블록 인코딩으로 표현되며, 각 구성 요소는 단변수 활성화 함수의 합이다. 활성화 함수 자체는 체비쇼프 다항식의 선형 조합으로 정의된다.
단일 QKAN 계층의 출력은 다음과 같이 주어진다.
$$ \Phi(\vec{x}) = \text{diag}\left( \frac{1}{N} \sum_{p=1}^N \phi_{p1}(x_p), \dots, \frac{1}{N} \sum_{p=1}^N \phi_{pK}(x_p) \right)^T $$
여기서 각 단변수 활성화 함수 $\phi_{pq}(x)$는 첫 번째 종류의 체비쇼프 다항식의 선형 조합으로 정의된다.
$$ \phi_{pq}(x) = \frac{1}{d+1} \sum_{r=0}^d w_{pq}^{(r)} T_r(x) $$
항별 분석
이 방정식들을 해부하여 각 구성 요소의 역할과 수학적 정의를 이해해 보자.
- $\Phi(\vec{x})$: 이는 단일 QKAN 계층의 출력을 나타낸다.
- 수학적 정의: 각 구성 요소가 단변수 활성화 함수의 합으로 이루어진 $K$차원 출력 벡터이다. 양자 맥락에서는 대각 행렬로 블록 인코딩된다.
- 물리적/논리적 역할: 이는 QKAN 계층이 생성하는 "처리된 정보"이다. 고전 신경망 계층의 출력과 유사하지만 양자 호환 형식이라는 점에서 유사하다.
- $\text{diag}(\dots)^T$: 이 연산자는 벡터로부터 대각 행렬을 구성한다.
- 수학적 정의: 벡터 $\vec{v} = (v_1, \dots, v_K)$가 주어졌을 때, $\text{diag}(\vec{v})$는 $v_1, \dots, v_K$를 주 대각선에 갖는 $K \times K$ 대각 행렬을 생성한다. 전치 $T$는 입력 벡터가 개념적으로 열 벡터임을 나타낸다.
- 물리적/논리적 역할: QKAN에서는 벡터가 대각 블록 인코딩으로 표현된다. 이 연산자는 계층의 출력이 대각 블록 인코딩임을 명시적으로 나타내며, 이는 후속 QKAN 계층의 입력으로 재귀적으로 사용하는 데 중요하다.
- $N$: 입력 벡터 $\vec{x}$의 차원이다.
- 수학적 정의: 일반적으로 2의 거듭제곱인 정수, $N=2^n$, 여기서 $n$은 입력을 인코딩하는 데 사용되는 큐비트 수이다.
- 물리적/논리적 역할: 고전 KAN 비유에서 입력 특징 또는 "노드"의 수를 나타낸다. $N$으로 나누는 것은 합에 대한 정규화 계수로 작용하여 출력이 블록 인코딩에 중요한 범위 내에 유지되도록 한다.
- $K$: 출력 벡터 $\Phi(\vec{x})$의 차원이다.
- 수학적 정의: 일반적으로 2의 거듭제곱인 정수, $K=2^k$, 여기서 $k$는 출력 인코딩을 위한 큐비트 수이다.
- 물리적/논리적 역할: 고전 KAN 비유에서 출력 특징 또는 "노드"의 수를 나타낸다.
- $\sum_{p=1}^N$: 입력 노드에 대한 합계이다.
- 수학적 정의: 이 연산자는 각 $p$에 대해 $1$부터 $N$까지 $\phi_{pq}(x_p)$의 값을 합산한다.
- 물리적/논리적 역할: 이는 근본적인 집계 단계이다. 각 출력 노드 $q$에 대해 모든 입력 노드 $p$로부터의 변환된 정보를 결합한다. 이 합계는 콜모고로프-아르놀트 표현 정리의 단변수 함수 결합 원리를 직접적으로 번역한 것이다. 곱셈 대신 덧셈을 선택하는 것은 KAN 아키텍처에 내재되어 있으며, 이는 출력 계층에서 특징의 선형 조합을 모델링하여 복잡한 다변수 함수를 표현한다.
- $\phi_{pq}(x_p)$: 단변수 활성화 함수이다.
- 수학적 정의: 단일 실수 입력 $x_p \in [-1,1]$을 받아 실수 출력으로 매핑하는 함수이다. 입력 노드 $p$와 출력 노드 $q$의 각 쌍에 대해 고유하게 정의된다.
- 물리적/논리적 역할: 이들은 네트워크의 "에지"이며, 개별 입력 구성 요소에 비선형 변환을 적용한다. 이들은 QKAN의 핵심 학습 가능한 요소로, 비선형성을 도입하고 복잡한 관계를 학습하는 데 책임이 있다.
- $x_p$: 입력 벡터 $\vec{x}$의 $p$-번째 구성 요소이다.
- 수학적 정의: 단일 입력 특징을 나타내는 실수, $x_p \in [-1,1]$이다.
- 물리적/논리적 역할: QKAN 계층으로 들어가는 원시 입력 데이터 포인트이다.
- $d$: 사용된 체비쇼프 다항식의 최대 차수이다.
- 수학적 정의: 음이 아닌 정수이다.
- 물리적/논리적 역할: 이 매개변수는 활성화 함수 $\phi_{pq}(x)$의 복잡성과 표현력을 제어한다. 더 높은 $d$는 더 복잡한 비선형 변환을 허용한다.
- $\frac{1}{d+1} \sum_{r=0}^d$: 체비쇼프 다항식 차수에 대한 정규화된 합계이다.
- 수학적 정의: 이는 $1/(d+1)$로 정규화된 $d+1$개의 체비쇼프 다항식의 선형 조합이다.
- 물리적/논리적 역할: 이는 다른 기저 함수를 결합하여 전체 활성화 함수 $\phi_{pq}(x)$를 구성한다. 정규화는 함수 출력을 제한된 범위 내로 유지하는 데 도움이 된다. 합계(선형 조합)의 사용은 계수를 조정하여 다양한 함수를 유연하게 근사할 수 있게 한다.
- $w_{pq}^{(r)}$: 가중치 계수이다.
- 수학적 정의: 실수, $w_{pq}^{(r)} \in [-1,1]$이다.
- 물리적/논리적 역할: 이들은 QKAN의 학습 가능한 매개변수이다. 이들은 각 체비쇼프 다항식 $T_r(x)$가 활성화 함수 $\phi_{pq}(x)$에 기여하는 정도를 결정하며, 효과적으로 비선형성을 형성한다.
- $T_r(x)$: 첫 번째 종류의 $r$-번째 체비쇼프 다항식이다.
- 수학적 정의: $T_r(x) = \cos(r \arccos(x))$, $x \in [-1,1]$에 대해 정의된다.
- 물리적/논리적 역할: 이 다항식은 활성화 함수의 기저 함수 역할을 한다. 양자 컴퓨터에서 양자 특이값 변환(QSVT)을 사용하여 효율적으로 구현할 수 있기 때문에 선택되었으며, 이는 양자 프레임워크에 자연스럽게 적합하다.
단계별 흐름
단일 추상 데이터 포인트, 예를 들어 $x_p$가 QKAN 계층을 통과하면서 입력 구성 요소에서 최종 출력 벡터의 일부로 변환되는 과정을 상상해 보라. 이 과정은 양자 조립 라인과 같다.
- 입력 블록 인코딩: 먼저, 전체 $N$차원 입력 벡터 $\vec{x} = (x_1, \dots, x_N)$가 대각 블록 인코딩 $U_x$로 제공된다. 이는 각 $x_p$가 더 큰 유니터리 행렬 내의 대각 요소로 인코딩됨을 의미한다. 이것이 양자 공장에 들어가는 원자재이다.
- 확장 및 복제: 입력 블록 인코딩 $U_x$는 $k = \log_2 K$개의 보조 큐비트를 추가하여 "확장"된다. 개념적으로, 이 단계는 각 입력 구성 요소 $x_p$를 $K$개의 다른 "채널"로 복제하며, 각 채널은 하나의 출력 노드 $q$에 해당한다. 이는 각 입력이 모든 출력에 영향을 미칠 수 있도록 보장한다.
- 체비쇼프 다항식 변환: 복제된 각 $x_p$와 모든 다항식 차수 $r$ (0부터 $d$까지)에 대해 양자 특이값 변환(QSVT)이 적용된다. 이는 블록 인코딩된 형태로 $T_r(x_p)$를 모든 $p$와 $r$에 대해 효과적으로 계산한다. 이는 원자재를 다양한 수학적 함수(체비쇼프 다항식)를 적용하는 특수 기계로 보내는 것과 같다.
- 가중치 스케일링: 다음으로, 각 블록 인코딩된 $T_r(x_p)$는 해당 가중치 계수 $w_{pq}^{(r)}$를 곱한다. 이러한 가중치도 대각 블록 인코딩으로 제공된다. 이 곱셈은 양자 선형 대수 하위 루틴을 사용하여 수행된다. 이 단계는 학습된 매개변수에 따라 변환된 특징을 스케일링하며, 각 신호의 강도를 조정하는 것과 같다.
- 기저 함수 결합 (LCU): 특정 입력-출력 쌍 $(p,q)$에 대해, 모든 가중치 체비쇼프 다항식 $w_{pq}^{(r)} T_r(x_p)$ ( $r=0, \dots, d$에 대해)이 선형적으로 결합된다. 이는 제어 큐비트의 균일한 중첩을 준비하고 가중치 블록 인코딩을 적용하는 선형 유니터리 조합(LCU) 절차를 사용하여 달성된다. 이 기계는 개별 다항식 기여를 집계하여 출력 벡터 $\Phi(\vec{x})$의 $q$-번째 구성 요소를 형성하는 전체 비선형 활성화 함수 $\phi_{pq}(x_p)$를 형성한다. 그런 다음 입력 큐비트는 보조 레지스터로 흡수되어 전체 차원을 줄인다.
- 입력 노드 집계 (하드마드 합계): 마지막으로, 각 출력 노드 $q$에 대해 값 $\phi_{pq}(x_p)$ ( $p=1, \dots, N$에 대해)이 합산된다. 이는 $\phi_{pq}(x_p)$ 값의 블록 인코딩을 "입력" 큐비트의 하드마드 게이트로 샌드위치하여 수행된다. 이 연산은 각 특정 출력 노드 $q$에 대한 모든 입력 노드의 기여를 효과적으로 평균화하여 출력 벡터 $\Phi(\vec{x})$의 $q$-번째 구성 요소를 생성한다. 그런 다음 입력 큐비트는 보조 레지스터로 흡수되어 전체 차원을 줄인다.
- 출력 블록 인코딩: 이러한 연산의 결과는 $K$차원 출력 벡터 $\Phi(\vec{x})$의 대각 블록 인코딩이다. 이 최종 결과는 다른 QKAN 계층으로 공급되거나 고전적 출력을 위해 측정될 준비가 된다.
최적화 역학
QKAN 메커니즘은 학습 가능한 매개변수인 가중치 계수 $w_{pq}^{(r)}$를 조정하여 미리 정의된 비용 함수를 최소화함으로써 학습한다. 이 학습 과정은 몇 가지 주요 역학을 포함한다.
-
가중치 매개변수화: 가중치 $w_{pq}^{(r)}$는 직접적인 고전 숫자가 아니라 대각 블록 인코딩 $U_{w^{(r)}}$로 인코딩된다. 본 논문은 이 매개변수화에 대해 두 가지 주요 방법을 제시한다.
- 진폭 인코딩: 가중치는 매개변수화된 양자 상태 $|w(\theta)\rangle = U(\theta)|0\rangle$의 실수 진폭에서 파생될 수 있다. 여기서 $U(\theta)$는 게이트 각도 $\theta$가 실제 학습 가능한 매개변수인 매개변수화된 양자 회로(PQC)이다. 이 방법은 가중치에 대한 $L_2$ 정규화 제약을 자연스럽게 부과하며, 이는 일종의 정규화 역할을 한다.
- 하드마드 곱 인코딩: 대안으로, 매개변수화된 유니터리 $U(\theta)$를 체비쇼프 다항식 블록 인코딩과 하드마드 곱을 통해 결합할 수 있다. 이 접근 방식은 더 큰 표현력을 제공할 것으로 추정되며, 가중치에 대한 $L_\infty$ 노름 제약을 허용한다.
매개변수화 방법의 선택은 학습 가능한 함수의 공간과 모델의 정규화 속성을 형성한다.
-
손실 함수 및 풍경: QKAN은 양자 학습 모델로 설계되었으므로, QKAN의 출력과 대상 값 간의 불일치를 정량화하는 비용 함수(예: 회귀 또는 분류)의 존재를 의미한다. "손실 풍경"은 매개변수 $\theta$의 공간에 걸쳐 이 비용 함수로 정의된 표면이다. 본 논문은 손실 함수를 명시적으로 자세히 설명하지는 않지만, 일반적으로 추출된 출력 진폭의 함수일 것이다. 기저 함수(체비쇼프 다항식) 및 매개변수화 방법의 선택은 이러한 풍경의 부드러움과 복잡성에 영향을 미친다.
-
기울기 계산: 손실 풍경을 탐색하고 최소값을 찾기 위해 모델은 매개변수 $\theta$에 대한 손실의 기울기를 계산해야 한다.
- 해석적 기울기: 본 논문은 변분 양자 알고리즘에서 흔히 사용되는 매개변수 이동 규칙을 사용하여 해석적 기울기를 계산할 것을 제안한다. QKAN의 재귀적 및 합성적 구성(QSVT, LCU 및 블록 인코딩 곱셈 포함)으로 인해 동일한 PQC 매개변수 $\theta$가 회로의 다른 부분에 걸쳐 재사용된다. 이는 개별 하위 항의 기여를 합산하여 기울기를 얻을 수 있음을 의미한다. 그러나 이 접근 방식은 단일 계층 QKAN의 경우 $O(d)$ 쿼리, $L$ 계층 QKAN의 경우 지수적으로 $O(d^2L)$로 확장되며, 이는 상당한 계산 비용이다.
- 기울기 추정: 해석적 기울기의 높은 비용을 피하기 위해 저자들은 유한 차분 방법 또는 동시 섭동 확률 근사(SPSA)와 같은 기울기 추정 기법을 사용할 것을 제안한다. SPSA는 매개변수 수에 관계없이 계산 비용이 거의 독립적이므로, 특히 학습 가능한 매개변수가 많은 모델의 경우 기울기를 추정하는 더 효율적인 방법을 제공하므로 특히 매력적이다.
-
매개변수 업데이트 및 수렴: 기울기(또는 그 추정치)가 얻어지면, 기울기 하강 또는 Adam과 같은 고전 최적화 알고리즘을 사용하여 매개변수 $\theta$를 반복적으로 업데이트한다. 이러한 최적화기는 손실 함수를 줄이는 방향으로 매개변수를 조정한다. 양자 자연 기울기 방법도 잠재적으로 더 빠른 수렴을 위해 사용될 수 있으며, 이는 양자 Fisher 정보 행렬을 계산하는 것을 포함한다. 반복적인 업데이트는 모델이 만족스러운 최소값으로 수렴할 때까지 계속된다. 가우시안 상태 준비의 수치적 예시는 $L_2$ 오차가 다항식 차수 $d$에 따라 지수적으로 감소함을 보여주며, 이는 함수 근사에 대한 좋은 수렴 동작을 나타낸다. 그러나 계층 수 $L$에 대한 쿼리 복잡성의 지수적 스케일링은 QKAN이 얕은 아키텍처에 가장 적합함을 의미하며, 이는 매우 복잡한 깊은 함수를 학습하는 능력에 영향을 미칠 수 있다.
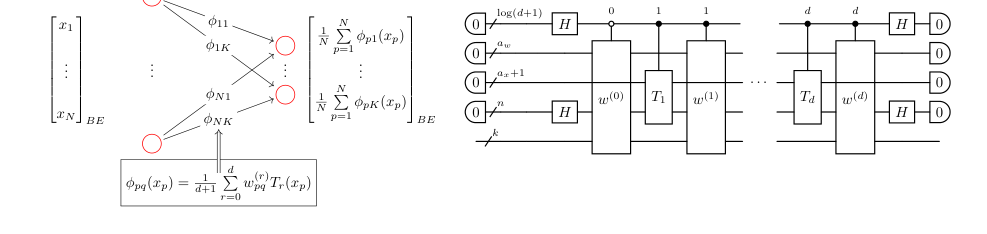 FIG. 1. Construction of a CHEB-QKAN layer with the corresponding quantum circuit. The input to the QKAN model is a diagonal block-encoding of an N-dimensional real vector ⃗x. The CHEB-QKAN layer applies univariate activation functions ϕpq to each input component xp, where p ∈[N] indexes input nodes and q ∈[K] indexes output nodes. The output vector is computed as a sum over activated input nodes. This operation yields a block-encoded real K-dimensional output vector. The quantum circuit implementation requires 1 + log2(d + 1) qubits for the construction and linear combination of weighted Chebyshev polynomials, aw + ax qubits for the block-encodings of input and weights, n = log2 N qubits for input vector encoding, and k = log2 K qubits for output. The circuit consists of a series of multi-controlled block-encodings of Chebyshev polynomials, interspersed with diagonal block- encodings of the corresponding real weights. The entire circuit represents a block-encoding of the K-dimensional vector corresponding to the CHEB-QKAN layer, with auxiliary qubits initialized and measured in the |0⟩state
FIG. 1. Construction of a CHEB-QKAN layer with the corresponding quantum circuit. The input to the QKAN model is a diagonal block-encoding of an N-dimensional real vector ⃗x. The CHEB-QKAN layer applies univariate activation functions ϕpq to each input component xp, where p ∈[N] indexes input nodes and q ∈[K] indexes output nodes. The output vector is computed as a sum over activated input nodes. This operation yields a block-encoded real K-dimensional output vector. The quantum circuit implementation requires 1 + log2(d + 1) qubits for the construction and linear combination of weighted Chebyshev polynomials, aw + ax qubits for the block-encodings of input and weights, n = log2 N qubits for input vector encoding, and k = log2 K qubits for output. The circuit consists of a series of multi-controlled block-encodings of Chebyshev polynomials, interspersed with diagonal block- encodings of the corresponding real weights. The entire circuit represents a block-encoding of the K-dimensional vector corresponding to the CHEB-QKAN layer, with auxiliary qubits initialized and measured in the |0⟩state
결과, 제약 조건 및 결론
실험 설계 및 기준선
양자 콜모고로프-아르놀트 신경망(QKAN) 아키텍처를 엄격하게 검증하기 위해 저자들은 특정하지만 설명적인 응용인 다변수 양자 상태 준비에 초점을 맞췄다. 실험 설계는 경쟁 양자 모델을 정면으로 벤치마킹하도록 설정된 것이 아니라, QKAN의 핵심 합성 메커니즘, 즉 양자 특이값 변환(QSVT)을 활용하는 것이 복잡한 다변수 함수를 정확하게 실현할 수 있다는 것을 결정적인 증거를 제공하도록 설계되었다. 이 맥락에서 "희생자"는 이상적인 대상 함수 자체, 즉 QKAN이 높은 충실도로 근사하고자 했던 $D$차원 가우시안 분포였다.
실험은 특히 $n=5$ 큐비트/차원, $\beta=6$ 매개변수를 사용하여 $32 \times 32$ 격자에서 2D 가우시안 양자 상태를 준비하는 데 초점을 맞췄다. 이 설정은 QKAN 성능에 대한 명확한 수치적 예시를 허용했다. 아키텍처는 두 계층 QKAN을 사용했다. 첫 번째 계층은 각 격자점에 대해 함수 $x^2 + y^2 - 1$을 정확하게 계산하도록 설계되어, 이동된 제곱 반경을 인코딩했다. 두 번째 계층은 다양한 차수의 체비쇼프 다항식을 사용하여 지수 감쇠 함수 $e^{-\beta(x+1)}$의 다항식 근사를 적용했다. 이 두 계층 구조는 한 계층의 출력( $x^2 + y^2 - 1$의 블록 인코딩)이 다음 계층의 입력으로 사용되는 QKAN의 합성 원리를 직접적으로 구현한 것이다. 실험은 QKAN 메커니즘이 블록 인코딩 및 QSVT를 통해 비선형 변환을 적용하고 계층을 합성할 수 있다는 수학적 주장이 구체적이고 정확한 양자 상태로 번역될 수 있음을 입증하도록 설계되었다.
증거가 입증하는 것
수치적 예시는 다변수 양자 상태 준비에서 QKAN 아키텍처의 효능에 대한 설득력 있는 증거를 제공한다. 주요 결과는 그림 10에 제시되어 있다.
-
다항식 근사 정확도 (그림 10a): 본 논문은 먼저 $[-1,1]$ 구간에서 3차 체비쇼프 다항식 $P_3(x)$를 사용하여 비선형 지수 함수 $e^{-\beta(x+1)}$의 근사 정확도를 보여준다. 이는 QSVT를 통해 실현되는 QKAN 내 활성화 함수의 기초를 형성하는 다항식 근사의 타당성을 확인하는 데 중요하다. 플롯은 지정된 범위 내에서 대상 함수와 그 다항식 근사 간의 근접성을 명확하게 보여주며, 이러한 비선형성을 구현하는 것이 가능함을 확인한다.
-
절대 진폭 오차 (그림 10b): 3차 다항식 $P_3(x)$를 사용하여 준비된 정규화된 2D 가우시안 상태에 대한 $32 \times 32$ 격자 전체의 절대 진폭 오차, $| \psi_{\text{exp}}(i,j) - \psi_{\text{QKAN}}(i,j) |$가 시각적으로 제시된다. 이 히트맵과 같은 플롯은 QKAN으로 준비된 상태가 이상적인 가우시안 상태와 얼마나 잘 일치하는지에 대한 직접적이고 부인할 수 없는 시각적 증거를 제공한다. 오차는 일반적으로 낮으며, 분포의 중심 근처에서 가장 큰 불일치가 관찰된다. 이는 근사 오차가 해당 영역에서 최대였던 다항식 근사 자체의 동작과 일치한다. 이 엄격한 증거는 QKAN 메커니즘이 입력 격자점을 계층을 통해 성공적으로 변환하여 원하는 가우시안 분포에 가깝게 해당하는 진폭을 생성함을 보여준다.
-
지수적 오차 감소 (그림 10c): 아마도 가장 결정적인 증거는 다항식 차수 $d$의 함수로서의 $L_2$-오차, $|| \psi_{\text{exp}} - \psi_{\text{QKAN}} ||_2$일 것이다. 플롯은 다항식 차수가 증가함에 따라 경험적 오차가 지수적으로 감소함을 보여준다. 이 지수적 개선은 오차가 기계 정밀도, 약 $10^{-14}-10^{-15}$에서 $d=20$으로 포화될 때까지 계속된다. 이 결과는 이론적 경계를 검증하고 QKAN이 활성화 함수의 복잡성을 증가시킴으로써 높은 충실도 근사를 달성할 수 있음을 강력하게 입증한다. 이는 QSVT를 통한 비선형 변환을 위해 다항식 근사를 사용하는 핵심 메커니즘이 의도한 대로 작동하여 제어 가능하고 높은 정밀도의 상태 준비를 가능하게 함을 무자비하게 증명한다. 경험적 오차와 이론적 경계 간의 일치는 주장을 더욱 공고히 한다.
본질적으로, 증거는 QKAN이 블록 인코딩 구조와 QSVT 지원 비선형 활성화를 통한 합성 방식을 통해 복잡한 다변수 양자 상태를 정확하게 준비할 수 있으며, 이는 양자 기계 학습 및 상태 준비를 위한 강력한 새로운 패러다임을 보여준다는 것을 입증한다.
제약 조건 및 향후 방향
QKAN은 유망한 새로운 방향을 제시하지만, 본 논문은 솔직하게 여러 제약 조건을 논의하고 풍부한 미래 연구 환경을 열어준다.
현재 제약 조건:
-
상속된 KAN 제약: QKAN은 고전적 대응물로부터 일부 주의 사항을 상속한다. 콜모고로프-아르놀트 표현 정리(KART)는 두 계층 분해를 보장하지만, 고전 KAN 및 QKAN은 KART의 보편적 표현 속성을 반드시 상속하지는 않는다. 이는 깊은 QKAN이 QKAN 설계에 적합한 합성 구조가 부족한 경우, 특히 임의의 다변수 함수를 표현할 수 없음을 의미한다. KAN의 전체 잠재력은 상징적 회귀와 관련하여 여전히 활발한 연구 분야이다.
-
얕은 아키텍처 제약: 다층 QKAN의 중요한 제약은 계층 수에 대한 쿼리 복잡성의 지수적 스케일링이다. 재귀적 QSVT 기반 구성은 이전 계층의 모든 출력 블록 인코딩이 다음 계층의 기본 빌딩 블록이 됨을 의미하며, 회로 깊이에 지수적인 오버헤드를 초래한다. 이는 QKAN을 본질적으로 "얕고 넓은" 아키텍처로 제한하며, 즉 $L = O(1)$ 계층이다. 얕은 깊이는 효율적인 블록 인코딩이 가능한 경우 지수적으로 넓은 계층으로 보상될 수 있지만, 이 제약은 매우 깊은 학습 작업에 대한 실질적인 장애물이다.
-
다항식 근사 범위: 양자 컴퓨터는 다항식을 표현하는 데 뛰어나지만, 모든 함수를 다항식으로 효율적으로 근사할 수 있는 것은 아니다. 따라서 QKAN 활성화 함수의 기저 함수 선택이 중요하다. QSVT는 다재다능하지만, 여전히 다항식 근사에 의존하며, 이는 임의의 함수를 직접 근사하는 데 있어 스플라인과 같은 것보다 덜 강력할 수 있다. 예를 들어, 매개변수가 0에 가까울 때 정규화에 필요할 수 있는 부호 함수를 근사하는 정확도는 제한될 수 있다.
-
실수 제한: 단순화를 위해 현재 작업은 입력, 출력 및 가중치에 대해 실수 값으로 논의를 제한한다. 복소수로의 일반화는 가능하지만, 실수부와 허수부를 별도로 처리함으로써 복잡성을 더하며 향후 작업으로 남겨둔다.
향후 방향 및 토론 주제:
-
향상된 매개변수화 및 훈련 전략:
- 가중치 매개변수화 너머: 본 논문은 가중치 벡터뿐만 아니라 QKAN의 다른 단계도 매개변수화할 것을 제안한다. 예를 들어, 선형 유니터리 조합(LCU) 단계에서 고정된 하드마드 변환 대신, 상태 준비 쌍으로 사용되는 유니터리를 매개변수화할 수 있다. 이는 체비쇼프 다항식의 다른 차수에 대한 전역 가중치를 보다 세밀하게 제어할 수 있게 하여 표현력을 높일 수 있다.
- 적응형 기저 함수 선택: 현재 체비쇼프 다항식은 QSVT로 인해 자연스러운 선택이다. 그러나 QSVT 프레임워크는 모든 유계 다항식을 구현할 수 있다. 흥미로운 방향은 QSVT의 각도 자체를 학습 가능한 매개변수로 만드는 것이다. 이를 통해 고정된 선택에 의존하는 대신 특정 문제에 대한 최적의 기저 집합을 발견함으로써 기저 함수 선택을 학습 과정의 일부로 만들 수 있다.
- 반복적 모델 개선: 훈련 전략은 더 높은 차수의 체비쇼프 다항식을 합에 반복적으로 추가하고 전역 가중치를 최적화하는 것을 포함할 수 있다. 최적화된 가중치를 검사함으로써, 예를 들어 새로 추가된 다항식의 가중치가 사라지는 경우 필요한 다항식 수를 결정할 수 있다. 이는 더 해석 가능하고 효율적인 모델로 이어질 수 있다.
-
직접 양자 입력에 대한 QKAN 탐색:
- 양자 위상 분류: QKAN은 고전적으로 다루기 어려운 분석이 필요한 양자 상태와 같은 직접 양자 입력에 잠재적으로 적합한 것으로 제안된다. 예를 들어, 위상 분류 작업에서, 알려지지 않은 양자 위상에 해당하는 상태를 효율적으로 준비할 수 있다면, QKAN은 지도 학습 방식으로 훈련되어 위상을 분류할 수 있다. 이는 상태의 진폭에 대한 다변수 함수를 계산하고 물리 시스템에서 새로운 순서 매개변수 발견에 기여할 수 있다. 이는 QKAN의 양자 특성이 뚜렷한 이점을 제공하는 매력적인 응용이다.
-
일반화 및 표현력:
- 복소수 QKAN: QKAN을 복소수를 처리하도록 확장하면 적용 범위를 훨씬 더 넓은 범위의 양자 문제 및 데이터 유형으로 확장할 수 있다.
- 대체 기저 함수: 체비쇼프 다항식은 효율적이지만, QSVT를 통해 다항식으로 효율적으로 근사할 수 있는 다른 기저 함수(예: B-스플라인, 웨이블릿, 푸리에 전개)를 탐색하면 다양한 유형의 함수에 대한 QKAN의 표현력을 향상시킬 수 있다. 본 논문은 B-스플라인이 조각별 섹션을 분리하고 LCU를 사용하여 구현될 수 있다고 언급하며, 이는 복잡하지만 잠재적으로 유익한 경로이다.
-
고급 상태 준비 기법:
- 다변수 중요도 샘플링: 본 논문은 중요도 샘플링을 통한 다변수 버전의 지수적 개선 달성이 다변수 설정의 어려움으로 인해 열린 문제로 남아 있다고 언급한다 [59]. 이를 극복하면 매우 복잡하고 비균일한 다변수 상태를 준비하는 데 QKAN의 유용성이 크게 향상될 것이다.
-
해석 가능성 및 과학적 발견:
- 고전 KAN의 해석 가능성 이점, 즉 개별 활성화 함수를 검사하고 가지치기할 수 있다는 것은 주요 강점이다. 이러한 해석 가능성이 QKAN으로 어떻게 변환되는지, 특히 희소 합성 구조를 식별하거나 양자 데이터에서 새로운 물리 법칙을 발견하는 데 있어 추가 연구는 흥미로운 전망이다. 훈련된 가중치 분포에서 샘플링하는 능력은 가지치기 및 모델 압축 경로를 제공한다.
이러한 토론 포인트는 QKAN이 단순한 이론적 구성이 아니라, 특히 고전적인 방법으로는 해결할 수 없는 문제에 대한 양자 컴퓨팅의 고유한 기능을 활용하는 데 있어 상당한 진화 잠재력을 가진 기초 프레임워크임을 강조한다. 잠재력을 완전히 실현하기 위한 여정은 이러한 제약 조건을 해결하고 이러한 미래 방향을 창의적으로 탐색하는 것을 포함할 것이다.
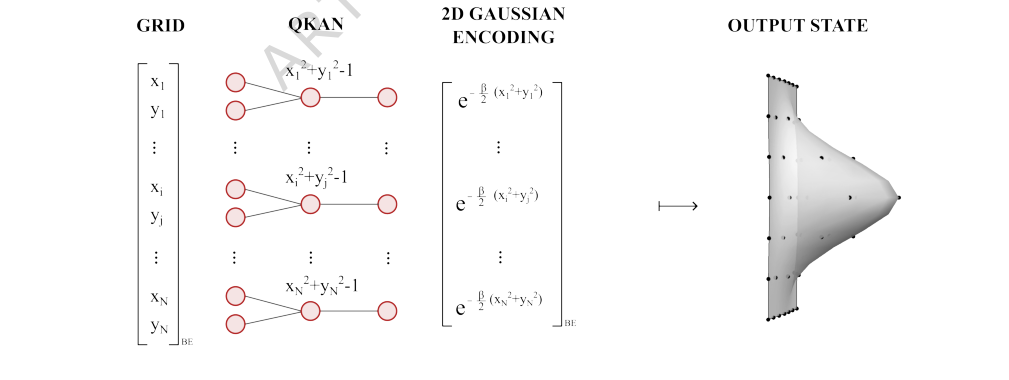 FIG. 4. Example: 2D Gaussian state preparation via QKAN. Starting from a vectorized 2D grid of points {(xi, yi)} encoded as a diagonal block-encoding (left), the first QKAN layer applies Chebyshev polynomial T2 and sums over the two dimensions, computing 1
FIG. 4. Example: 2D Gaussian state preparation via QKAN. Starting from a vectorized 2D grid of points {(xi, yi)} encoded as a diagonal block-encoding (left), the first QKAN layer applies Chebyshev polynomial T2 and sums over the two dimensions, computing 1
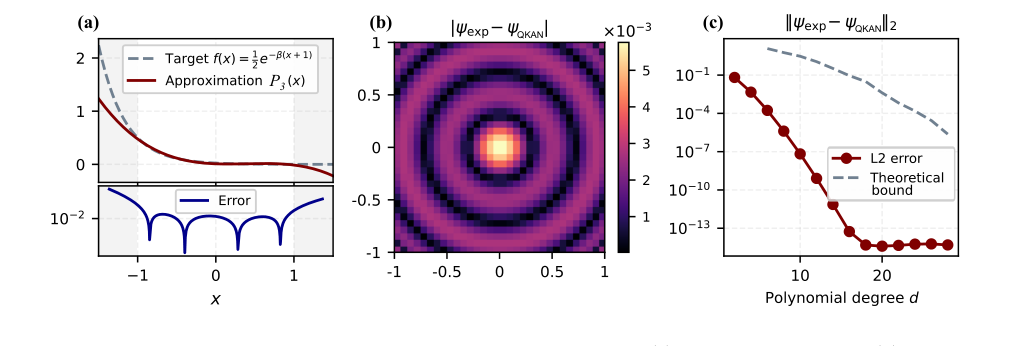 FIG. 10. Numerical illustration of Gaussian state preparation via QKAN. (a) Degree-3 polynomial P3(x) approxi- mating 1
FIG. 10. Numerical illustration of Gaussian state preparation via QKAN. (a) Degree-3 polynomial P3(x) approxi- mating 1