多管电压vBMD测量:双分支频率平衡与非对称通道注意力
Phantom-less volumetric bone mineral density (vBMD) measurement using computed tomography (CT) presents a cost-effective alternative to conventional phantom-based approaches, yet faces accuracy challenges across...
背景与学术传承
要理解本文所解决问题的精确根源,我们必须审视医生诊断骨质疏松症的方式。评估骨强度的金标准是测量容积骨密度 (vBMD)。历史上,这通过定量计算机断层扫描 (QCT) 来实现,该方法需要在 CT 扫描过程中将一个称为“模型”(phantom) 的物理校准物体放置在患者下方。文章指出,这些物理模型价格昂贵,尽管坦白说,仅凭文本我并不完全确定确切的临床价格——但在医学影像领域,专业的校准硬件每次扫描的费用很容易超过 150 美元,甚至更高,更不用说频繁重新校准的麻烦了。
为了规避这一点,医学领域开发了“无模型”(phantom-less, PL) 方法。这些方法不使用外部物体,而是利用患者自身的内部组织(如脂肪和肌肉)作为参考点来计算骨密度。最近,深度神经网络 (DNN) 已被用于自动化这一过程。
然而,由于现代临床实践的转变,出现了一个巨大的“痛点”。为了保护患者免受过量辐射,医院正日益将 CT 扫描仪的管电压从标准的 120 kVp 降低到 80 或 100 kVp。先前 DNN 模型的根本局限在于它们是为 120 kVp 扫描进行严格优化的。当输入较低电压的图像时,整体亮度和对比度(CT 衰减)会发生剧烈变化。先前模型严重依赖这些全局强度变化(低频信息),导致性能严重下降,估计误差高达 $20 \text{ mg/cm}^3$。它们完全忽略了骨骼精细的海绵状纹理(高频信息),而这些纹理实际上无论辐射剂量如何都保持稳定。此外,传统的频率分离方法计算量过大,对于 3D 医学图像来说并不实用。
为了帮助您直观地理解其中的科学原理,这里将几个高度专业的领域术语翻译成日常概念:
- 无模型 (PL) vBMD 测量: 想象一下试图通过一张照片来猜测一个苹果的重量。一个“模型”方法需要一个标准的 1 磅金属砝码放在苹果旁边进行比较。而“无模型”方法则类似于通过将苹果与它所放置的盘子大小进行比较来猜测其重量——即使用照片中已有的参照物,而不是引入外部工具。
- 管电压 (kVp): 可以将其视为拍摄照片时使用的手电筒的亮度。高电压 (120 kVp) 是一种耀眼的光线,可以清晰地显示一切,但会消耗大量能量(辐射)。较低的电压 (80 kVp) 是一种较暗的光线,对拍摄对象更安全,但会导致生成的图像看起来不同,从而使旧的计算机程序感到困惑。
- 小梁骨结构: 骨骼的内部结构并非实心岩石;它更像是一个坚固的海绵或蜂窝状结构。这个术语指的是骨骼内部这种错综复杂、多孔的网络。
- 频率分解: 想象一下聆听一场交响乐。这个过程就像使用音频均衡器将深沉、浑厚的低音(低频:骨骼的整体形状和位置)与小提琴清脆的声音(高频:骨骼内部精细、海绵状的纹理)分离开来。
为了解决这个问题,作者设计了一个轻量级的双分支神经网络,用于分离和平衡这些频率。在数学上,他们提取高频细节而不进行繁重的计算,并使用非对称通道注意力机制来权衡每个频带的重要性。
以下是他们如何通过数学方法解释和解决频率调制与特征融合问题的:
首先,他们使用傅里叶变换和空间注意力机制来调制频率特征:
$$ Y = \sum_{b \in B} \sigma(f(X_b; W_b)) \odot X_b $$
$$ X_b = \mathcal{F}^{-1}(M_b \odot \mathcal{F}(X)) $$
之后,他们融合低频和高频特征以生成注意力权重,确保网络专注于最关键的信息:
$$ \widetilde{X} = upsample(X_L) + X_H $$
$$ A_H = \sigma(MLP(GMP(\widetilde{X}))) $$
$$ A_L = \sigma(MLP(GAP(\widetilde{X}))) $$
最后,他们应用这些注意力权重将特征解耦回各自的域:
$$ X = A_H \odot X_H + A_L \odot X_L $$
下表整理了理解其架构所需的关键数学符号:
| 符号 | 描述 |
|---|---|
| $X$ | 输入特征图,在 3D 空间中定义为 $X \in \mathbb{R}^{C,D,H,W}$ |
| $Y$ | 频率调制后的输出特征图 |
| $\mathcal{F}, \mathcal{F}^{-1}$ | 傅里叶变换及其逆变换 |
| $M_b$ | 用于分离特定频带的二元频率掩码 |
| $W$ | 卷积参数(权重) |
| $X_L, X_H$ | 解耦的低频和高频特征分量 |
| $Y_L, Y_H$ | 处理后的低频和高频特征 |
| $A_L, A_H$ | 低频和高频的通道注意力图 |
| $\widetilde{X}$ | 重分裂前的融合特征图 |
| $AP(x)$ | 使用 $2 \times 2 \times 2$ 核的平均池化操作 |
| $upsample(x)$ | 最近邻上采样操作 |
| $\sigma$ | Sigmoid 激活函数 |
| $\odot$ | Hadamard 乘积(逐元素乘法) |
问题定义与约束
想象一下,您试图称量一块海绵,但不是将其放在秤上,而是只能通过查看其照片来猜测其重量。现在,想象一下房间的光线不断变化——有时明亮,有时昏暗。这正是医生在不使用物理校准工具(“模型”)的情况下,仅凭 CT 扫描测量骨密度所面临的挑战。
起点与终点
输入(当前状态): 我们从患者椎体的三维计算机断层扫描(CT)图像开始。这些扫描以不同的辐射水平进行,称为管电压(通常为 80、100 或 120 kVp)。
输出(目标状态): 目标是输出高精度的体积骨矿物质密度(vBMD)测量值,单位为 $mg/cm^3$。
数学鸿沟:
传统上,医生通过查看 Hounsfield Unit (HU) 来测量骨密度,HU 是组织阻挡 X 射线的程度的数学表示。这里缺失的环节是 HU 值严格依赖于 X 射线管电压。如果医院降低电压以减少患者的辐射暴露,同一块骨头的 HU 值会显著下降。作者需要构建一个数学桥梁,将高度可变、依赖于电压的三维空间强度矩阵 $X \in \mathbb{R}^{C,D,H,W}$ 映射到一个稳定、绝对的密度值,该值完全独立于扫描仪的设置。
痛苦的困境
在计算机视觉领域,改进一个方面几乎总会破坏另一个方面。对于这个问题,之前的研究人员一直陷入频率提取与计算成本之间残酷的权衡。
为了理解这一点,我们需要将图像分解为两个“频率”:
1. 低频特征: 宽泛的、宏观的形状(如脊柱的整体轮廓)。这些特征易于标准神经网络学习,并帮助模型快速定位骨骼。然而,它们对管电压变化高度敏感。
2. 高频特征: 骨骼微观结构中微小、精细的、海绵状的纹理(小梁结构)。这些特征在不同电压下非常稳定,是骨质疏松症的真正指标。
困境在于:标准深度神经网络(DNN)自然会优先处理低频信息。如果您想迫使网络关注高频三维纹理,传统上需要使用深度、复杂的网络或繁重的数学运算,如三维小波变换。但在三维空间中这样做会导致内存和处理需求呈指数级爆炸。您要么得到一个在医院更改 CT 电压时失效的轻量级模型,要么得到一个过于庞大、运行缓慢而无法在标准临床硬件上运行的鲁棒模型。
严峻的现实与限制
作者遇到了几个严峻的现实障碍,使得这个问题极其难以解决:
- 临床辐射限制: 全球范围内都在大力推动降低患者的辐射暴露,将扫描电压从 120 kVp 降至 80 kVp。在这些较低的电压下,全局强度测量变得根本不可靠。模型必须适应这些更暗、能量更低的扫描,同时不损失精度。
- 疾病的物理稀疏性: 骨质疏松症字面意思就是骨骼的消失。随着疾病的进展,小梁骨变得极其稀疏。网络被迫寻找正在积极消失的微观纹理特征。
- 三维计算瓶颈: 医学图像不是平面的二维图片;它们是巨大的三维体。在深度、高度和宽度上应用传统频率分解(如重复傅里叶变换)需要巨大的内存。作者必须找到一种方法,在不进行繁重数学运算的情况下解耦频率,而是采用一种巧妙的技巧,使用平均池化来提取低频,然后从原始图像中减去它来找到高频。
- 特征混合陷阱: 如果尝试并行处理低频和高频(双分支网络),标准卷积层往往会意外地将信息混合在一起。作者不得不设计一个严格的数学守门员——一种不对称的通道注意力机制——以确保高频分支只关注细节,低频分支只关注宏观形状。这在数学上通过将特征图 $X$ 分解为其低频 ($X_L$) 和高频 ($X_H$) 分量来定义:
$$X = upsample(X_L) + X_H$$
简而言之,作者必须构建一个系统,能够观察骨骼在三维空间中的微观、正在消失的结构,忽略 X 射线机的“光照”变化,并且这一切都必须在严格的计算预算内完成。
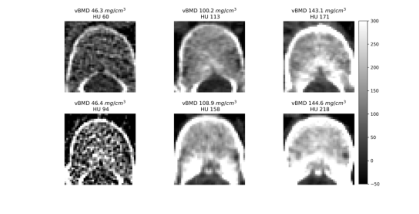 Figure 1. Intuitive comparison of features in vBMD measurement. The first row shows vertebral bodies with varying bone densities at 120 kVp. The second row shows corresponding vertebral bodies at non-120 kVp, where vBMD texture remains similar, but HU values within the VOI differ significantly. Low vBMD vertebral bodies exhibit both reduced HU values and a sparser trabecular structure in the measurement area
Figure 1. Intuitive comparison of features in vBMD measurement. The first row shows vertebral bodies with varying bone densities at 120 kVp. The second row shows corresponding vertebral bodies at non-120 kVp, where vBMD texture remains similar, but HU values within the VOI differ significantly. Low vBMD vertebral bodies exhibit both reduced HU values and a sparser trabecular structure in the measurement area
为何选择此方法
作者们意识到传统最先进 (SOTA) 方法——例如标准的 3D 卷积神经网络 (CNNs)、Vision Transformers 或 Diffusion 模型——在根本上不足以解决当前问题,其确切时刻发生在他们分析 CT 扫描在不同管电压下的物理行为时。为了减少辐射暴露,现代诊所通常将 CT 管电压从标准的 $120$ kVp 降低到 $100$ kVp 或 $80$ kVp。然而,电压的下降会剧烈改变全局 Hounsfield Unit (HU) 值(放射密度的标准测量单位)。标准的 CNNs 自然会优先处理低频信息,这对应于图像的整体形状和全局强度。由于这些低频全局强度对电压变化高度敏感,一个在 $120$ kVp 数据上训练的标准模型在测试 $80$ kVp 数据时会经历严重的性能下降,产生高达 $20$ $mg/cm^3$ 的误差。
作者们有一个关键的认识:虽然全局强度随电压变化,但高频特征——特别是骨骼精细、海绵状的骨小梁微观结构——在结构上保持稳定。因此,任何为了宏观形状而模糊高频纹理细节的标准网络注定会失败。他们必须分别处理这些频率域。
除了简单的性能指标,这种方法在处理 3D 医学影像巨大的计算负担方面也具有定性优势。传统的频域方法通常依赖于计算密集型技术,如小波变换或多尺度卷积核来分离频率。如果应用于海量的 3D 体积 CT 数据,内存复杂度将急剧上升,使得模型在临床环境中几乎无法使用。作者们通过在每一层放弃繁重的数学变换,实现了巨大的结构优势。取而代之的是,他们引入了一种巧妙的解耦方法:他们使用平均池化来下采样特征图,从而提取低频分量 ($X_L$),然后通过计算原始特征图与上采样低频图之间的残差来推导出高频分量 ($X_H$)。数学上,这表示为:
$$X_H = X - \text{upsample}(X_L)$$
这优雅地绕过了对繁重信号处理的需求。此外,他们没有在整个网络中反复应用傅里叶变换(这会产生巨大的开销),而是将频率调制限制在局部特征提取最关键的浅层。
这种选择的架构代表了问题严苛的约束条件与解决方案独特属性之间的完美“结合”。约束条件要求模型必须在不依赖外部校准体模的情况下,在变化的 CT 管电压之间进行泛化,同时高效地处理沉重的 3D 数据。双分支架构完美地契合了这一点。通过分割网络,模型使用一个更深层的通路来理解宏观的椎体解剖结构(低频),以及一个更浅层的通路来捕捉精细的骨小梁结构(高频)。为了融合它们,他们利用了一种非对称的通道注意力机制。他们应用全局最大池化 (GMP) 来突出清晰、稳定的高频细节,并应用全局平均池化 (GAP) 来处理平滑的低频数据:
$$A_H = \sigma(MLP(GMP(\tilde{X})))$$
$$A_L = \sigma(MLP(GAP(\tilde{X})))$$
这确保了稳定的骨小梁特征能够主动引导最终的体积骨矿物质密度 (vBMD) 测量,使得模型对电压引起的强度变化具有极强的鲁棒性。
最后,这解释了为什么其他流行的方法,如生成对抗网络 (GANs) 或 Diffusion 模型,在这里会灾难性地失败。生成模型旨在合成或“幻觉”缺失的数据分布。在定量医学影像中,需要精确的物理测量来诊断骨质疏松症,幻觉结构数据在临床上是危险的。此外,这些模型以其庞大而闻名。作者们明确指出,即使将标准的 2D DNNs 扩展到 3D 也需要“过度的计算资源”。为 3D 体积 CT 扫描部署一个庞大的 Transformer 或多步 Diffusion 过程,对于旨在提取稳定结构纹理的回归任务来说,在计算上是瘫痪的,而且完全不必要。轻量级的、频率平衡的双分支网络是唯一满足临床对绝对精度要求和工程对效率要求的可行途径。
数学与逻辑机制
为了理解本文的核心,我们首先需要理解它所解决的物理问题。当医生使用 CT 扫描测量骨密度 (vBMD) 时,他们通常依赖于特定的 X 射线管电压,通常为 120 kVp。然而,为了降低患者的辐射暴露,现代诊所正转向较低的电压(如 80 或 100 kVp)。问题在于:降低电压会急剧改变 CT 图像的整体亮度和对比度(Hounsfield Units)。
如果一个深度学习模型记住了 120 kVp 下的整体亮度(低频数据),那么在 80 kVp 下它将惨败。然而,骨骼精细的海绵状小梁结构(高频数据)无论电压如何,在物理上都是稳定的。作者设计了一个巧妙的双分支神经网络,将图像分割为低频和高频,动态地权衡它们的重要性,然后将它们融合在一起。
这是实现跨电压泛化的绝对核心数学引擎。
$$ \widetilde{X}_{base} = upsample(X_L) + X_H $$
$$ A_H = \sigma(MLP(GMP(\widetilde{X}_{base}))) $$
$$ A_L = \sigma(MLP(GAP(\widetilde{X}_{base}))) $$
$$ \widetilde{X}_{coupled} = A_H \odot X_H + A_L \odot X_L $$
$$ Y_L = AP(\widetilde{X}_{coupled}) $$
$$ Y_H = \widetilde{X}_{coupled} - upsample(Y_L) $$
(注:作者使用 $\widetilde{X}$ 来表示初始融合状态和注意力耦合状态。我添加了下标 'base' 和 'coupled' 以使时间转换更清晰。)
让我们逐一解析这个引擎,看看它是如何工作的。
- $X_L$ 和 $X_H$: 这是低频和高频分支的输入特征图。$X_L$ 代表骨骼的宏观、模糊形状(对电压变化高度敏感)。$X_H$ 代表清晰、精细的小梁网格(在不同电压下稳定)。
- $upsample()$: 一个最近邻上采样函数。由于低频特征通常会被池化和下采样以节省内存,因此在它们能够交互之前,必须将它们拉伸到与高频特征相同的空间维度。
- $+$ (加法): 为什么选择加法而不是拼接?拼接会将内存占用翻倍。加法充当物理叠加——就像在同一数学空间中将清晰的纹理图直接叠加在模糊的彩色图之上一样。
- $GMP()$ 和 $GAP()$: 全局最大池化 (Global Max Pooling) 和全局平均池化 (Global Average Pooling)。这是骨骼物理特性发挥作用的地方。$GMP$ 充当绝对最锐利、最高强度峰值的雷达(非常适合分离坚硬的小梁骨结构)。$GAP$ 计算该区域的整体环境能量或平均密度。
- $MLP()$: 多层感知机(一个小型神经网络)。它充当“大脑”,查看池化统计数据并决定哪些特定的特征通道实际上对于预测骨密度有用。
- $\sigma$ (Sigmoid 函数): 将 MLP 的输出压缩到 0 到 1 之间的范围。它充当一组调光器。
- $A_H$ 和 $A_L$: 高频和低频的最终注意力权重。
- $\odot$ (Hadamard 乘积): 逐元素乘法。为什么在这里使用乘法而不是加法?因为这是一个门控机制。如果某个低频通道被认为是由于电压变化而严重损坏的,其对应的 $A_L$ 值可能为 0.1,从而有效地抑制该通道。如果某个高频通道包含至关重要的结构数据,其 $A_H$ 值可能为 0.9,从而放大它。
- $AP()$: 使用 $2 \times 2 \times 2$ 核的平均池化。它充当低通滤波器,平滑新耦合的主特征图,以提取精炼的低频输出 $Y_L$。
- $-$ (减法): 为什么用减法来获得 $Y_H$?这是残差逻辑的一个绝妙应用。高频在数学上被定义为“非低频的一切”。通过从主耦合图($\widetilde{X}_{coupled}$)中减去平滑后的基值($upsample(Y_L)$),网络在无需在此阶段进行复杂、计算量大的傅里叶变换的情况下,完美地分离出清晰的高频细节。
分步流程
想象一个 3D 的原始 CT 数据块进入一个机械装配线。
首先,数据被分成两条独立的传送带:一条传送模糊的整体骨骼形状($X_L$),另一条传送清晰的海绵状骨骼纹理($X_H$)。模糊的形状被物理拉伸($upsample$)以匹配清晰纹理的精确尺寸,然后两者堆叠在一起创建一个复合块($\widetilde{X}_{base}$)。
接下来,这个复合块经过两个专用传感器。第一个传感器($GMP$)扫描最锐利、最极端的结构峰值。第二个传感器($GAP$)测量整体环境密度。这些读数被输入中央计算机($MLP$),该计算机精确计算每个特征通道的可靠性。
计算机输出两组旋钮($A_H$ 和 $A_L$)。这些旋钮被应用回原始传送带,调暗不相关或有噪声的通道,并增强高度相关的通道。然后,优化后的传送带合并成一个主耦合块($\widetilde{X}_{coupled}$)。
最后,这个主块通过一个平滑机($AP$)进行处理,以创建一个新精炼的、稳定的模糊形状($Y_L$)。为了获得精炼的锐利纹理($Y_H$),机器只需从主块中切除模糊形状($-$)。然后,这两个完美平衡、更新的组件会移至架构的下一阶段。
优化动态
这个机制实际上是如何学习和收敛的?该网络使用回归损失(如平均绝对误差)与在 120 kVp 下采集的金标准、基于模体的测量值进行端到端训练。
由于该架构在很大程度上依赖于加法和减法,因此损失景观异常平滑。在微积分中,加法或减法运算的局部导数恰好是 1(或 -1)。这意味着当网络出错时,梯度信号会通过 $Y_H$ 和 $Y_L$ 方程向后流动,而不会发生降级或消失。
随着训练的进行,$MLP$ 会收到持续的反馈。如果模型因为过度依赖 80 kVp 扫描人为变暗的低频通道而高估了骨密度,梯度会告诉 $MLP$:“下次看到这种特定的变化时,调低 $A_L$ 调光器的亮度。” 随着时间的推移,网络学会动态地转移其注意力。当它检测到低电压扫描中令人困惑的全局强度变化时,它会自动更多地依赖于稳定、高频的小梁特征。
老实说,我并不完全确定作者使用了哪种具体的优化器(例如 Adam、SGD)或学习率调度器,因为这些超参数细节在提供的文本中没有明确列出。然而,其结构设计本身——特别是残差解耦和非对称注意力——充当了自然的正则化器。它阻止模型过拟合任何单一 X 射线管电压的绝对 Hounsfield Units,迫使其学习骨骼的潜在物理现实。
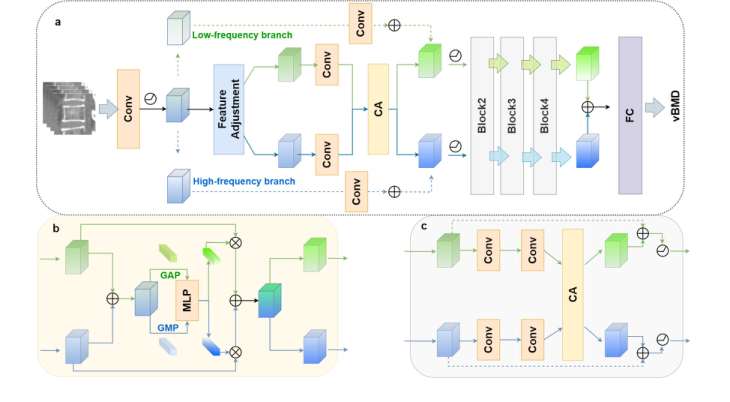 Figure 2. The proposed network. The proposed network adopts a dual-branch ar- chitecture consisting of four distinct modules (a). The first module is responsible for spatial reallocation of feature maps in the frequency domain. The following modules incorporate convolutional layers designed to perform coupling and re-decoupling oper- ations, guided by a channel attention mechanism (b and c). This design facilitates the effective fusion of frequency features, thereby enhancing the model’s ability to dynam- ically process both low- and high-frequency information.CA, channel attention; FC, fully connected
Figure 2. The proposed network. The proposed network adopts a dual-branch ar- chitecture consisting of four distinct modules (a). The first module is responsible for spatial reallocation of feature maps in the frequency domain. The following modules incorporate convolutional layers designed to perform coupling and re-decoupling oper- ations, guided by a channel attention mechanism (b and c). This design facilitates the effective fusion of frequency features, thereby enhancing the model’s ability to dynam- ically process both low- and high-frequency information.CA, channel attention; FC, fully connected
结果、局限性与结论
想象一下,你试图确定一座建筑的结构完整性,但你只能查看它的照片。为了增加难度,有些照片是在明亮的日光下拍摄的,而另一些则是在黄昏时用廉价相机拍摄的。建筑物的整体颜色和亮度会根据光照条件发生剧烈变化,但混凝土中的细小裂缝——高频细节——却保持一致。
这正是医生在测量体积骨矿密度 (vBMD) 以使用计算机断层扫描 (CT) 诊断骨质疏松症时面临的问题。
历史上,医院会使用一种称为“模型体”(phantoms) 的物理校准物体(成本可能相当高昂,有时会使手术费用增加相当于 150 美元或更多)放置在患者下方进行扫描,以提供基线密度参考。为了降低成本,人们开发了“无模型体”(phantom-less, PL) 方法,利用患者自身的脂肪和肌肉作为参考点。然而,一个巨大的限制出现了:为了保护患者,现代诊所正在降低 CT 扫描的辐射剂量(将管电压从 120 kVp 降至 80 或 100 kVp)。这一根本性转变改变了 Hounsfield 单位(CT 扫描中的像素强度值)。传统的 AI 模型严重依赖“大局观”的整体亮度(低频数据),在这种电压下降时会完全感到困惑,导致测量误差巨大。
本文的作者们意识到了一件绝妙的事情:虽然骨骼的整体亮度会随着辐射降低而变化,但骨骼微观的、海绵状的纹理(小梁结构)却不会。他们需要一种 AI,能够忽略不断变化的光照,专注于混凝土中的裂缝。
数学核心:解耦与调制现实
为了解决这个问题,作者们不得不克服一个严峻的计算限制。提取高频 3D 纹理通常需要极其复杂的数学运算,例如多尺度小波变换,这会使标准的医院计算机崩溃。
取而代之的是,他们设计了一个轻量级的双分支网络,将图像分割成独立的通道。首先,他们使用简单的平均池化操作提取低频“模糊”数据 ($X_L$)。然后,他们从原始图像中减去这个模糊图像,以分离出高频“清晰”细节 ($X_H$)。
为了确保网络在早期就关注这些清晰细节,而不会拖慢系统速度,他们使用傅里叶变换 ($\mathcal{F}$) 应用了频域调制。在数学上,他们使用空间注意力机制选择性地增强高频特征:
$$Y = \sum_{b \in B} \sigma(f(X_b; W_b)) \odot X_b$$
其中频带通过以下方式分离:
$$X_b = \mathcal{F}^{-1}(M_b \odot \mathcal{F}(X))$$
这里,$M_b$ 是一个二元掩码,用于过滤频率,而 $\odot$ 表示 Hadamard(逐元素)乘积。
一旦特征被调制,它们就会被送入两个不同的卷积分支:
$$Y_L = f(X_L; W_L) + X_L$$
$$Y_H = f(X_H; W_H) + X_H$$
但真正的天才在于它们如何将这两个分支重新融合。它们不是简单地在最后将它们混合在一起。它们使用了一种不对称的通道注意力机制。对于高频数据,它们使用全局最大池化 (GMP),因为最大池化在检测尖锐、孤立的峰值(如骨小梁的边缘)方面非常出色。对于低频数据,它们使用全局平均池化 (GAP) 来捕捉一般的、平滑的解剖结构。
它们计算注意力权重 ($A_H$ 和 $A_L$) 来决定每个特征的重要性:
$$\widetilde{X} = upsample(X_L) + X_H$$
$$A_H = \sigma(MLP(GMP(\widetilde{X})))$$
$$A_L = \sigma(MLP(GAP(\widetilde{X})))$$
最后,它们重新分割数据,应用这些学习到的权重,以确保网络在宏观解剖和微观纹理之间保持完美的平衡:
$$X = A_H \odot X_H + A_L \odot X_L$$
实验架构:严酷的证明
作者们并没有仅仅将他们的模型应用于干净的数据集并声称准确率提高了 5%。他们设计了一个实验,旨在严酷地检验他们的数学声明与临床环境的混乱现实。
他们收集了来自两个完全独立医疗中心的数据。一个中心的数据用于训练和内部测试模型(1,614 张图像),而另一个中心的数据(2,245 张图像)则被锁在保险库中作为“外部测试集”。这确保了 AI 没有仅仅记住一个医院 CT 扫描仪的特定怪癖。
受害者:
作者们将他们的创作与三个基线进行了比较:
1. 一种传统的无模型体 (PL) 线性回归方法(通过数学转换公式进行调整,以尝试处理多电压数据)。
2. ResNet-10(一个标准、备受推崇的深度学习模型)。
3. OctResNet-10(一个专门设计用于处理空间冗余的模型)。
无可辩驳的证据:
证明其核心机制有效性的决定性证据不仅仅在于在 120 kVp 和 100 kVp 数据集上击败了这些基线(在内部取得了 5.990 $mg/cm^3$ 的卓越平均绝对误差,在外部取得了 7.175 $mg/cm^3$)。真正的“铁证”是他们的消融研究。
他们系统地“解剖”了自己的模型。他们关闭了频率平衡。然后他们关闭了通道注意力。在每种情况下,误差率都飙升。只有当高/低频解耦和不对称的 GMP/GAP 注意力机制协同工作时,模型才达到了其巅峰性能。这在数学上和经验上都证明了他们的假设是正确的:你必须分离并独特地加权高频纹理才能在管电压变化中生存下来。
说实话,我并不完全确定导致外部数据集在 80 kVp 水平上出现严重图像退化的确切物理机制——作者们指出,由于“中心之间显著的图像质量差异”,他们的模型在该数据集上的表现不如基线,这表明在极低的辐射剂量下,高频小梁数据可能在 AI 能够看到它之前就被量子噪声所破坏。
未来演进的讨论话题
基于本文的深远影响,以下是未来探索和批判性思考的几个方向:
-
信息破坏的阈值:
在 80 kVp 时,模型在外部数据上表现不佳。这引发了一个有趣的物理学与人工智能交叉的问题:在什么确切的辐射剂量下,高频小梁结构会从“隐藏但可恢复”转变为“因光子饥饿和量子噪声而物理损坏”?我们能否在数学上定义 AI 驱动的骨密度分析所需的绝对最低辐射剂量? -
跨模态频率解耦:
如果将高频纹理与低频全局照明分离可以解决 CT 电压问题,那么这种精确的数学框架是否可以移植到 MRI 或超声波?例如,这种双分支架构是否可以隔离 MRI 上韧带的高频微撕裂,而忽略由不同磁场强度(1.5T vs 3T)引起的低频变化? -
物理模型体的终结?
这里的经济影响是巨大的。如果软件能够利用内部组织参考和频率调制可靠地动态适应任何扫描仪的电压,我们是否还需要再次制造、运输和校准物理 CT 模型体?在生死攸关的诊断场景中,用概率神经网络取代物理地面真值对象,会带来哪些监管和法律障碍?
与其他域的同构
要理解本文,我们首先需要了解医生如何诊断骨质疏松症。他们通过 CT 扫描测量骨密度 (vBMD)。传统上,这需要一个“体模”——一个在扫描时放置在患者下方的物理校准物体,这既昂贵又笨重。无体模 (Phantom-less, PL) 方法则使用患者自身的内部组织(如脂肪和肌肉)作为参考点。
其动机源于现代医院的一个关键限制:变化的辐射剂量。为了避免患者受到过量辐射,诊所越来越多地使用较低的管电压(例如 80 kVp 或 100 kVp,而非标准的 120 kVp)。问题在于,降低管电压会急剧改变 CT 图像的全局像素强度(Hounsfield Units, HU)。由于现有的深度学习模型严重依赖这些低频全局强度,当管电压下降时,它们的准确性会急剧下降。然而,作者注意到一个关键的生物学漏洞:虽然整体亮度会发生变化,但海绵状骨小梁的高频纹理在不同管电压下却能保持惊人地稳定。
为了解决这个问题,作者需要将易变的宏观数据与稳定的微观数据进行数学解耦。他们没有将整个图像输入标准神经网络,而是构建了一个双分支架构来分离频率。
首先,他们使用傅里叶变换结合空间注意力来调制频率特征,以避免冗余的计算开销。对于输入特征图 $X$,调制后的输出 $Y$ 定义为:
$$ Y = \sum_{b \in B} \sigma(f(X_b; W_b)) \odot X_b $$
其中频率带通过 $X_b = \mathcal{F}^{-1}(M_b \odot \mathcal{F}(X))$ 提取,$\mathcal{F}$ 表示傅里叶变换,而 $M_b$ 作为二元频率掩码。
一旦信号被分成低频 ($X_L$) 和高频 ($X_H$) 成分,它们就会在并行分支中进行处理。本文的真正巧妙之处在于这些分支如何重新融合。作者认识到高频数据(锐利的骨骼边缘)和低频数据(整体骨骼形状)需要不同的数学视角。他们设计了一种不对称的通道注意力机制。他们应用全局最大池化 (Global Max Pooling, GMP) 来捕捉高频特征的尖峰,并应用全局平均池化 (Global Average Pooling, GAP) 来平滑并捕捉低频特征:
$$ A_H = \sigma(MLP(GMP(\tilde{X}))) $$
$$ A_L = \sigma(MLP(GAP(\tilde{X}))) $$
然后,这些注意力权重被用于动态地重新组合解耦的信号:
$$ \tilde{X} = A_H \odot X_H + A_L \odot X_L $$
这个方程允许网络在低频全局强度因管电压变化而变得不可靠时,自适应地信任稳定的高频纹理。
其核心在于,这项工作结构化的骨架是一种机制,它将复杂信号分解为易变的宏观基线和稳定的微观波动,并行处理它们,并使用不对称加权函数动态地重新组合它们,以提取跨越不同环境条件的不变度量。
基于这个骨架,我们可以在完全不同的科学和工程领域找到这种精确逻辑的“镜像”:
1) 量化金融:在算法交易中,资产价格由宏观经济趋势(低频,对利率上升等外部“电压”高度敏感)和微观结构订单簿动态(高频,代表稳定的内在交易行为)组成。通过将市场范围内的噪音与内在的微观波动分离来提取资产的真实基本价值,与分离 CT 全局强度和骨小梁纹理直接对应。
2) 地震学:在检测地震震级时,地震仪记录低频面波(这些面波会受到当地土壤类型的大量扭曲,类似于变化的 CT 管电压)和高频体波(这些体波携带了断层线破裂的真实、稳定的特征)。地震学家一直在努力平衡这些频率,以找到地震的不变真相。
如果一位量化金融研究员明天“窃取”了本文精确的不对称注意力方程会怎样?如果他们将 $$ \tilde{X} = A_H \odot X_H + A_L \odot X_L $$ 应用于高频交易算法,他们就可以利用全局最大池化来积极捕捉订单簿异常的绝对峰值(“骨小梁”交易),同时利用全局平均池化来平滑波动的宏观经济情绪。这将带来突破性的、高度鲁棒的交易机器人,无论整体市场突然进入高波动率还是低波动率区间,都能保持其预测准确性和盈利能力——有效地使算法对市场“管电压”波动免疫。
最终,这种架构证明了,无论我们是在测量衰退骨骼的密度,还是在衡量波动性金融资产的隐藏价值,对不变真相的数学追求都依赖于完全相同的解耦频率和自适应注意力的协同作用,为通用结构库增添了一个出色的新蓝图。