Измерение vBMD с использованием нескольких трубок и напряжения посредством двухканального балансировки частоты и асимметричного внимания к каналам
Чтобы понять точное происхождение проблемы, рассматриваемой в данной статье, необходимо обратиться к тому, как врачи диагностируют остеопороз.
Предыстория и академическая родословная
Чтобы понять точное происхождение проблемы, рассматриваемой в данной статье, необходимо обратиться к тому, как врачи диагностируют остеопороз. Золотым стандартом для оценки прочности костей является измерение объемной минеральной плотности костной ткани (vBMD). Исторически это делалось с помощью количественной компьютерной томографии (QCT), которая требовала размещения физического калибровочного объекта, известного как "фантом", под пациентом во время КТ-сканирования. В статье отмечается, что эти физические фантомы дороги, хотя, честно говоря, точную клиническую стоимость по одному лишь тексту я не могу полностью определить — но в медицинской визуализации специализированное калибровочное оборудование может легко стоить от 150 долларов и выше за сеанс, не говоря уже о хлопотах с частыми повторными калибровками.
Чтобы обойти это, в медицине были разработаны методы "без фантомов" (PL). Вместо внешнего объекта эти методы используют собственные внутренние ткани пациента (например, жир и мышцы) в качестве опорных точек для расчета плотности костной ткани. В последнее время для автоматизации этого процесса стали применяться глубокие нейронные сети (DNN).
Однако возникла серьезная "болевая точка" из-за сдвига в современной клинической практике. Для защиты пациентов от избыточного облучения больницы все чаще снижают напряжение трубки КТ-сканера со стандартных 120 кВп до 80 или 100 кВп. Фундаментальное ограничение предыдущих моделей DNN заключается в том, что они были жестко оптимизированы для сканирования при 120 кВп. При подаче изображений с более низким напряжением общая яркость и контрастность (ослабление КТ) резко меняются. Предыдущие модели, сильно полагающиеся на эти глобальные изменения интенсивности (низкочастотная информация), страдают от серьезного снижения производительности, производя ошибки оценки до $20 \text{ мг/см}^3$. Они полностью упускают тонкие, губчатые текстуры кости (высокочастотная информация), которые фактически остаются стабильными независимо от дозы облучения. Более того, традиционные методы разделения этих частот слишком вычислительно затратны, чтобы быть практически применимыми для 3D медицинских изображений.
Чтобы помочь вам интуитивно понять науку, вот несколько узкоспециализированных терминов, переведенных на обыденные понятия:
- Измерение vBMD без фантомов (PL): Представьте, что вы пытаетесь угадать вес яблока на фотографии. "Фантомный" метод требует наличия рядом со стандартным 1-фунтовым металлическим грузом для сравнения. Метод "без фантомов" похож на угадывание веса яблока, сравнивая его с размером тарелки, на которой оно лежит — используя то, что уже есть на снимке, вместо того, чтобы приносить внешний инструмент.
- Напряжение трубки (кВп): Думайте об этом как о яркости фонарика, используемого для фотографирования. Высокое напряжение (120 кВп) — это ослепительно яркий свет, который все четко показывает, но потребляет много энергии (излучения). Более низкое напряжение (80 кВп) — это более тусклый свет, который безопаснее для объекта, но делает полученное изображение другим, сбивая с толку старые компьютерные программы.
- Трабекулярная архитектура: Внутренняя структура кости не является сплошным камнем; она больше похожа на жесткую губку или соты. Этот термин относится к этой сложной, пористой сети внутри кости.
- Частотное разложение: Представьте, что вы слушаете симфонию. Этот процесс похож на использование аудиоэквалайзера для разделения глубоких, гулких басов (низкая частота: общая форма и расположение кости) от резких, четких звуков скрипок (высокая частота: тонкие, губчатые текстуры внутри кости).
Для решения этой проблемы авторы разработали легкую нейронную сеть с двумя ветвями, которая разделяет и балансирует эти частоты. Математически они извлекают высокочастотные детали без тяжелых вычислений и используют асимметричный механизм внимания к каналам для взвешивания важности каждой частотной полосы.
Вот как они математически интерпретируют и решают задачу частотной модуляции и слияния признаков:
Сначала они модулируют частотные признаки с помощью преобразования Фурье и механизма пространственного внимания:
$$ Y = \sum_{b \in B} \sigma(f(X_b; W_b)) \odot X_b $$
$$ X_b = \mathcal{F}^{-1}(M_b \odot \mathcal{F}(X)) $$
Позже они объединяют низко- и высокочастотные признаки для генерации весов внимания, гарантируя, что сеть фокусируется на наиболее критической информации:
$$ \widetilde{X} = upsample(X_L) + X_H $$
$$ A_H = \sigma(MLP(GMP(\widetilde{X}))) $$
$$ A_L = \sigma(MLP(GAP(\widetilde{X}))) $$
Наконец, они применяют эти веса внимания для разделения признаков обратно в их соответствующие домены:
$$ X = A_H \odot X_H + A_L \odot X_L $$
Ниже приведена таблица, организующая ключевые математические обозначения, необходимые для понимания их архитектуры:
| Обозначение | Описание |
|---|---|
| $X$ | Входная карта признаков, определенная в 3D пространстве как $X \in \mathbb{R}^{C,D,H,W}$ |
| $Y$ | Выходная карта признаков после частотной модуляции |
| $\mathcal{F}, \mathcal{F}^{-1}$ | Преобразование Фурье и его обратное |
| $M_b$ | Бинарная маска частоты, используемая для выделения определенных частотных полос |
| $W$ | Параметры свертки (веса) |
| $X_L, X_H$ | Разделенные низкочастотные и высокочастотные компоненты признаков |
| $Y_L, Y_H$ | Обработанные низкочастотные и высокочастотные признаки |
| $A_L, A_H$ | Карты внимания каналов для низких и высоких частот |
| $\widetilde{X}$ | Объединенная карта признаков перед повторным разделением |
| $AP(x)$ | Операция усредняющего пулинга с ядром $2 \times 2 \times 2$ |
| $upsample(x)$ | Операция апсемплинга ближайшего соседа |
| $\sigma$ | Сигмоидная функция активации |
| $\odot$ | Побитовое произведение Адамара (поэлементное умножение) |
Определение проблемы и ограничения
Представьте, что вы пытаетесь взвесить губку, но вместо того, чтобы положить ее на весы, вам приходится угадывать ее вес, просто глядя на фотографию. Теперь представьте, что освещение в комнате постоянно меняется — иногда оно яркое, иногда тусклое. Именно с такой проблемой сталкиваются врачи, пытаясь измерить плотность костной ткани по КТ-снимкам без использования физического калибровочного инструмента («фантома»).
Отправная точка и желаемая конечная точка
Входные данные (текущее состояние): Мы начинаем с трехмерных (3D) компьютерных томограмм (КТ) тел позвонков пациента. Эти снимки делаются при различных уровнях радиации, известных как напряжения трубки (обычно 80, 100 или 120 кВп).
Выходные данные (целевое состояние): Цель — получить высокоточное объемное измерение минеральной плотности костной ткани (vBMD), выраженное в $мг/см^3$.
Математический разрыв:
Традиционно врачи измеряют плотность костной ткани, ориентируясь на единицы Хаунсфилда (HU) — математическое представление того, насколько ткань блокирует рентгеновские лучи. Отсутствующее звено здесь заключается в том, что значения HU строго зависят от напряжения рентгеновской трубки. Если больница снижает напряжение, чтобы уменьшить лучевую нагрузку на пациента, значения HU той же самой кости значительно падают. Авторам необходимо было построить математический мост, который отображает сильно варьирующуюся, зависящую от напряжения трехмерную пространственную матрицу интенсивности $X \in \mathbb{R}^{C,D,H,W}$ в стабильное, абсолютное значение плотности, полностью независимое от настроек сканера.
Мучительная дилемма
В мире компьютерного зрения улучшение одного аспекта почти всегда нарушает другой. В контексте данной конкретной проблемы предыдущие исследователи оказались в ловушке жестокого компромисса между извлечением частотных характеристик и вычислительными затратами.
Чтобы понять это, мы должны разделить изображение на две «частоты»:
1. Низкочастотные признаки: Общие, макроскопические формы (например, общий контур позвоночника). Стандартные нейронные сети легко обучаются на них, и они помогают модели быстро локализовать кость. Однако они очень чувствительны к изменениям напряжения трубки.
2. Высокочастотные признаки: Мелкая, детализированная, похожая на губку микроархитектура кости (трабекулярная структура). Эти признаки чрезвычайно стабильны при различных напряжениях и являются истинными индикаторами остеопороза.
Вот дилемма: стандартные глубокие нейронные сети (DNN) естественным образом отдают приоритет низкочастотной информации. Если вы хотите заставить сеть обращать внимание на трехмерные текстуры высокой частоты, вам традиционно приходится использовать глубокие, сложные сети или тяжелые математические операции, такие как трехмерные вейвлет-преобразования. Но выполнение этого в трехмерном пространстве приводит к экспоненциальному росту требований к памяти и вычислительным ресурсам. В итоге вы получаете либо легковесную модель, которая дает сбой при изменении напряжения КТ в больнице, либо надежную модель, которая слишком громоздка и медленна для работы на стандартном клиническом оборудовании.
Жесткие стены и ограничения
Авторы столкнулись с несколькими жесткими, реалистичными ограничениями, которые делают эту проблему чрезвычайно сложной для решения:
- Стена клинического облучения: Существует масштабное глобальное стремление к снижению лучевой нагрузки на пациентов, что приводит к снижению напряжения сканирования со 120 кВп до 80 кВп. При более низких напряжениях глобальные измерения интенсивности становятся принципиально ненадежными. Модель должна адаптироваться к этим более темным снимкам с более низкой энергией, не теряя точности.
- Физическая разреженность заболевания: Остеопороз — это буквально исчезновение костной ткани. По мере прогрессирования заболевания трабекулярная кость становится чрезвычайно разреженной. Сеть вынуждена искать микроскопические текстурные признаки, которые активно исчезают.
- Трехмерное вычислительное узкое место: Медицинские изображения — это не плоские двумерные картинки, а массивные трехмерные объемы. Применение традиционного частотного разложения (например, многократных преобразований Фурье) по глубине, высоте и ширине требует огромного объема памяти. Авторам пришлось найти способ разделить частоты без сложных математических вычислений, вместо этого прибегнув к хитрому приему с использованием усредняющего пулинга для извлечения низких частот и вычитания этого из исходного изображения для получения высоких частот.
- Ловушка смешивания признаков: Если вы попытаетесь обрабатывать низкие и высокие частоты параллельно (двухканальная сеть), стандартные сверточные слои имеют тенденцию случайно смешивать информацию обратно. Авторам пришлось разработать строгий математический «привратник» — асимметричный механизм внимания к каналам — чтобы гарантировать, что высокочастотный канал обрабатывает только мелкие детали, а низкочастотный канал — только общие формы. Это математически определяется разделением карты признаков $X$ на низкочастотную ($X_L$) и высокочастотную ($X_H$) компоненты:
$$X = upsample(X_L) + X_H$$
Таким образом, авторам пришлось создать систему, которая могла бы видеть микроскопическую, исчезающую структуру кости в 3D, игнорировать меняющееся «освещение» рентгеновского аппарата и делать это при строгом ограничении вычислительных ресурсов.
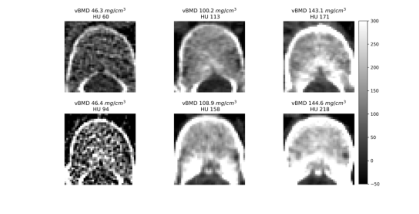 Figure 1. Intuitive comparison of features in vBMD measurement. The first row shows vertebral bodies with varying bone densities at 120 kVp. The second row shows corresponding vertebral bodies at non-120 kVp, where vBMD texture remains similar, but HU values within the VOI differ significantly. Low vBMD vertebral bodies exhibit both reduced HU values and a sparser trabecular structure in the measurement area
Figure 1. Intuitive comparison of features in vBMD measurement. The first row shows vertebral bodies with varying bone densities at 120 kVp. The second row shows corresponding vertebral bodies at non-120 kVp, where vBMD texture remains similar, but HU values within the VOI differ significantly. Low vBMD vertebral bodies exhibit both reduced HU values and a sparser trabecular structure in the measurement area
Почему этот подход
В тот самый момент, когда авторы осознали, что традиционные передовые (SOTA) методы — такие как стандартные 3D сверточные нейронные сети (CNN), Vision Transformers или диффузионные модели — принципиально недостаточны для данной задачи, произошло это при анализе физического поведения КТ-сканов при различных напряжениях трубки. Для снижения дозовой нагрузки современные клиники часто понижают напряжение рентгеновской трубки КТ со стандартных $120$ кВп до $100$ кВп или $80$ кВп. Однако это снижение напряжения кардинально изменяет глобальные значения единиц Хаунсфилда (HU) — стандартной меры радиоплотности. Стандартные CNN естественным образом отдают приоритет низкочастотной информации, которая соответствует общей форме и глобальной интенсивности изображения. Поскольку эти низкочастотные глобальные интенсивности очень чувствительны к изменениям напряжения, стандартная модель, обученная на данных при $120$ кВп, испытывает значительное снижение производительности при тестировании на данных при $80$ кВп, выдавая ошибки до $20$ $мг/см^3$.
Авторы пришли к ключевому осознанию: в то время как глобальная интенсивность смещается с изменением напряжения, высокочастотные признаки — в частности, тонкая, губчатая микроархитектура кости — остаются структурно стабильными. Следовательно, любая стандартная сеть, которая размывает высокочастотные текстурные детали в пользу макроскопических форм, обречена на провал. Им абсолютно необходимо было обрабатывать эти частотные домены раздельно.
Помимо простых метрик производительности, этот метод качественно превосходит существующие благодаря тому, как он справляется с огромной вычислительной нагрузкой 3D медицинской визуализации. Традиционные методы обработки в частотной области обычно полагаются на вычислительно интенсивные техники, такие как вейвлет-преобразования или сверточные ядра с несколькими масштабами, для разделения частот. При применении к массивным 3D объемным КТ-данным сложность по памяти резко возрастает, делая модели практически непригодными для использования в клинических условиях. Авторы добились значительного структурного преимущества, отказавшись от тяжелых математических преобразований на каждом слое. Вместо этого они ввели блестяще простой метод разделения: они извлекают низкочастотные компоненты ($X_L$) с помощью усредняющего пулинга для уменьшения масштаба карты признаков, а затем получают высокочастотные компоненты ($X_H$), просто вычисляя остаток между исходной картой признаков и увеличенной картой низкочастотных признаков. Математически это выражается следующим образом:
$$X_H = X - \text{upsample}(X_L)$$
Это элегантно обходит необходимость в сложной обработке сигналов. Более того, вместо многократного применения преобразований Фурье по всей сети, что создает огромные накладные расходы, они ограничивают модуляцию частоты мелкоуровневыми слоями, где извлечение локальных признаков наиболее критично.
Эта выбранная архитектура представляет собой идеальный "союз" между жесткими ограничениями задачи и уникальными свойствами решения. Ограничения диктуют, что модель должна обобщаться при различных напряжениях трубки КТ без опоры на внешние калибровочные фантомы, одновременно эффективно обрабатывая массивные 3D данные. Двухканальная архитектура идеально соответствует этому требованию. Разделяя сеть, модель использует более глубокий путь для понимания макроскопической анатомии позвонков (низкая частота) и более мелкий путь для захвата тонких трабекулярных структур (высокая частота). Для их объединения они используют асимметричный механизм внимания к каналам. Они применяют Global Max Pooling (GMP) для выделения резких, стабильных высокочастотных деталей и Global Average Pooling (GAP) для гладких низкочастотных данных:
$$A_H = \sigma(MLP(GMP(\tilde{X})))$$
$$A_L = \sigma(MLP(GAP(\tilde{X})))$$
Это гарантирует, что стабильные трабекулярные признаки активно направляют окончательное измерение объемной минеральной плотности костной ткани (vBMD), делая модель невероятно устойчивой к сдвигам интенсивности, вызванным напряжением.
Наконец, это объясняет, почему другие популярные подходы, такие как Generative Adversarial Networks (GANs) или Diffusion models, потерпели бы катастрофический провал здесь. Генеративные модели предназначены для синтеза или "галлюцинации" недостающих распределений данных. В количественной медицинской визуализации, где для диагностики остеопороза требуются точные физические измерения, "галлюцинация" структурных данных клинически опасна. Более того, эти модели известны своей тяжеловесностью. Авторы явно отмечают, что даже расширение стандартных 2D DNN до 3D требует "чрезмерных вычислительных ресурсов". Развертывание массивного Трансформера или многоэтапного диффузионного процесса для 3D объемных КТ-сканов было бы вычислительно парализующим и совершенно излишним для задачи регрессии, направленной на извлечение стабильных структурных текстур. Легковесная, балансирующая частоты двухканальная сеть была единственным жизнеспособным путем, удовлетворяющим как клиническому требованию абсолютной точности, так и инженерному требованию эффективности.
Математический и логический механизм
Чтобы понять суть данной статьи, необходимо сначала разобраться в физической проблеме, которую она решает. При измерении объемной минеральной плотности костной ткани (vBMD) с помощью КТ-сканирования врачи обычно используют определенное напряжение рентгеновской трубки, как правило, 120 кВп. Однако современные клиники переходят на более низкие напряжения (например, 80 или 100 кВп) для снижения лучевой нагрузки на пациентов. Проблема заключается в том, что снижение напряжения кардинально изменяет общую яркость и контрастность (единицы Хаунсфилда) КТ-изображения.
Если модель глубокого обучения запомнила общую яркость (низкочастотные данные) при 120 кВп, она будет совершенно неэффективна при 80 кВп. Однако тонкая, губчатая трабекулярная структура кости (высокочастотные данные) остается физически стабильной независимо от напряжения. Авторы разработали блестящую двухканальную нейронную сеть, которая разделяет изображение на низкие и высокие частоты, динамически взвешивает их важность и затем объединяет их обратно.
Вот основной математический механизм, который обеспечивает такую кросс-вольтажную обобщаемость.
$$ \widetilde{X}_{base} = upsample(X_L) + X_H $$
$$ A_H = \sigma(MLP(GMP(\widetilde{X}_{base}))) $$
$$ A_L = \sigma(MLP(GAP(\widetilde{X}_{base}))) $$
$$ \widetilde{X}_{coupled} = A_H \odot X_H + A_L \odot X_L $$
$$ Y_L = AP(\widetilde{X}_{coupled}) $$
$$ Y_H = \widetilde{X}_{coupled} - upsample(Y_L) $$
(Примечание: Авторы используют $\widetilde{X}$ для обозначения как начального объединенного состояния, так и состояния с примененным вниманием. Я добавил индексы 'base' и 'coupled' для более наглядного представления хронологической трансформации).
Разберем этот механизм по частям, чтобы понять, как он работает.
- $X_L$ и $X_H$: Это входные карты признаков для каналов низких и высоких частот. $X_L$ представляет макроскопическую, размытую форму кости (очень чувствительную к изменениям напряжения). $X_H$ представляет резкую, мелкозернистую трабекулярную сеть (стабильную при различных напряжениях).
- $upsample()$: Функция апсемплинга методом ближайшего соседа. Поскольку низкочастотные признаки часто подвергаются пулингу и понижению разрешения для экономии памяти, их необходимо растянуть до того же пространственного размера, что и высокочастотные признаки, прежде чем они смогут взаимодействовать.
- $+$ (Сложение): Почему сложение, а не конкатенация? Конкатенация удвоила бы потребление памяти. Сложение действует как физическое наложение — подобно наложению карты резкой текстуры непосредственно поверх размытой карты цвета в одном и том же математическом пространстве.
- $GMP()$ и $GAP()$: Global Max Pooling (глобальный максимальный пулинг) и Global Average Pooling (глобальный средний пулинг). Здесь вступает в игру физика кости. $GMP$ действует как радар для обнаружения самых резких, высокоинтенсивных пиков (идеально подходит для выделения структуры твердой трабекулярной кости). $GAP$ вычисляет общую энергию или среднюю плотность области.
- $MLP()$: Многослойный перцептрон (небольшая нейронная сеть). Он действует как "мозг", который анализирует статистические данные пулинга и определяет, какие конкретные каналы признаков действительно полезны для прогнозирования плотности костной ткани.
- $\sigma$ (Сигмоидальная функция): Эта функция сжимает выход MLP в диапазон от 0 до 1. Она действует как набор регуляторов яркости.
- $A_H$ и $A_L$: Полученные веса внимания для высоких и низких частот.
- $\odot$ (Поэлементное произведение): Поэлементное умножение. Почему здесь умножение, а не сложение? Потому что это механизм вентилирования (gating). Если определенный низкочастотный канал считается слишком искаженным из-за изменения напряжения, соответствующее значение $A_L$ может быть 0.1, что фактически приглушает этот канал. Если высокочастотный канал содержит жизненно важные структурные данные, его $A_H$ может быть 0.9, усиливая его.
- $AP()$: Средний пулинг с ядром $2 \times 2 \times 2$. Он действует как фильтр нижних частот, сглаживая объединенную мастер-карту признаков для извлечения уточненного низкочастотного выхода $Y_L$.
- $-$ (Вычитание): Почему вычитание для получения $Y_H$? Это элегантное использование остаточной логики. Высокая частота математически определяется как "все, что не является низкой частотой". Вычитая сглаженную основу ($upsample(Y_L)$) из объединенной мастер-карты ($\widetilde{X}_{coupled}$), сеть идеально выделяет четкие высокочастотные детали без необходимости использования сложных, вычислительно затратных преобразований Фурье на данном этапе.
Пошаговый процесс
Представьте трехмерный блок необработанных КТ-данных, поступающий на механизированную сборочную линию.
Сначала данные разделяются на два отдельных конвейера: один несет размытую, общую форму кости ($X_L$), а другой — резкую, губчатую текстуру кости ($X_H$). Размытая форма физически растягивается ($upsample$) до точного размера резкой текстуры, и они накладываются друг на друга, создавая составной блок ($\widetilde{X}_{base}$).
Затем этот составной блок проходит под двумя специализированными датчиками. Первый датчик ($GMP$) сканирует на предмет самых резких, экстремальных структурных пиков. Второй датчик ($GAP$) измеряет общую фоновую плотность. Эти показания подаются в центральный компьютер ($MLP$), который точно рассчитывает надежность каждого канала признаков.
Компьютер выдает два набора регуляторов ($A_H$ и $A_L$). Эти регуляторы применяются обратно к исходным конвейерам, приглушая нерелевантные или зашумленные каналы и усиливая высокорелевантные. Оптимизированные конвейеры затем объединяются в мастер-блок ($\widetilde{X}_{coupled}$).
Наконец, этот мастер-блок пропускается через машину для сглаживания ($AP$) для создания нового, уточненного, стабильного размытого изображения ($Y_L$). Чтобы получить уточненную резкую текстуру ($Y_H$), машина просто берет мастер-блок и "отрезает" от него размытое изображение ($-$). Два идеально сбалансированных, обновленных компонента затем перемещаются на следующий этап архитектуры.
Динамика оптимизации
Как этот механизм фактически обучается и сходится? Сеть обучается сквозным методом с использованием регрессионной функции потерь (например, Mean Absolute Error) по сравнению с эталонными измерениями, выполненными на фантомах при 120 кВп.
Поскольку архитектура в значительной степени полагается на сложение и вычитание, ландшафт функции потерь остается удивительно гладким. В исчислении локальная производная операции сложения или вычитания равна точно 1 (или -1). Это означает, что когда сеть допускает ошибку, сигнал градиента проходит обратно через уравнения $Y_H$ и $Y_L$ без деградации или затухания.
По мере прогресса обучения MLP получает непрерывную обратную связь. Если модель переоценивает плотность костной ткани из-за чрезмерной зависимости от низкочастотного канала, который был искусственно затемнен сканированием при 80 кВп, градиент сообщает MLP: "В следующий раз, когда вы увидите это конкретное отклонение, уменьшите яркость регулятора $A_L$". Со временем сеть учится динамически перераспределять свое внимание. Когда она обнаруживает сбивающие с толку глобальные сдвиги интенсивности при низковольтных сканированиях, она автоматически начинает больше полагаться на стабильные высокочастотные трабекулярные признаки.
Честно говоря, я не до конца уверен, какой именно оптимизатор (например, Adam, SGD) или расписание скорости обучения использовали авторы, поскольку эти детали гиперпараметров явно не указаны в предоставленном тексте. Однако сама структурная конструкция — в частности, остаточное разделение и асимметричное внимание — действует как естественный регуляризатор. Она предотвращает переобучение модели на абсолютных единицах Хаунсфилда любого конкретного напряжения трубки, заставляя ее вместо этого изучать лежащую в основе физическую реальность кости.
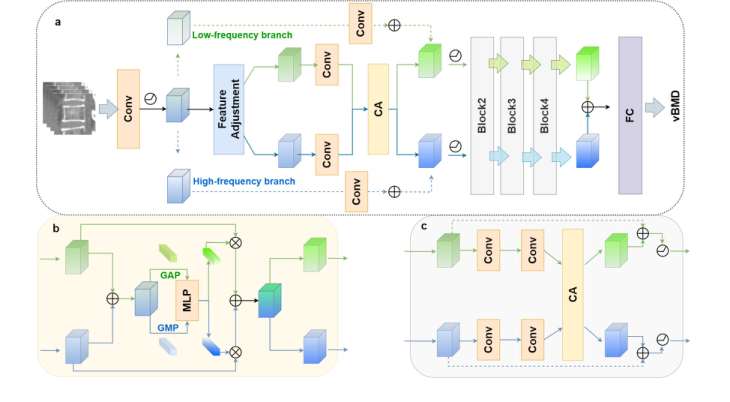 Figure 2. The proposed network. The proposed network adopts a dual-branch ar- chitecture consisting of four distinct modules (a). The first module is responsible for spatial reallocation of feature maps in the frequency domain. The following modules incorporate convolutional layers designed to perform coupling and re-decoupling oper- ations, guided by a channel attention mechanism (b and c). This design facilitates the effective fusion of frequency features, thereby enhancing the model’s ability to dynam- ically process both low- and high-frequency information.CA, channel attention; FC, fully connected
Figure 2. The proposed network. The proposed network adopts a dual-branch ar- chitecture consisting of four distinct modules (a). The first module is responsible for spatial reallocation of feature maps in the frequency domain. The following modules incorporate convolutional layers designed to perform coupling and re-decoupling oper- ations, guided by a channel attention mechanism (b and c). This design facilitates the effective fusion of frequency features, thereby enhancing the model’s ability to dynam- ically process both low- and high-frequency information.CA, channel attention; FC, fully connected
Результаты, ограничения и заключение
Представьте, что вы пытаетесь определить структурную целостность здания, но вам разрешено рассматривать только его фотографии. Чтобы усложнить задачу, некоторые фотографии сделаны при ярком дневном свете, а другие — в сумерках на дешевую камеру. Общий цвет и яркость здания резко меняются в зависимости от освещения, но мелкие трещины в бетоне — детали высокой частоты — остаются неизменными.
Именно с такой проблемой сталкиваются врачи при измерении объемной минеральной плотности костной ткани (vBMD) для диагностики остеопороза с использованием компьютерной томографии (КТ).
Исторически в больницах использовались физические калибровочные объекты, называемые «фантомами» (которые могут быть довольно дорогими, иногда увеличивая накладные расходы на процедуру на 150 долларов США или более), помещаемые под пациента во время сканирования для обеспечения эталонного значения плотности. Для снижения затрат были разработаны методы «без фантомов» (PL), использующие собственный жир и мышцы пациента в качестве эталонных точек. Однако возникло серьезное ограничение: современные клиники снижают дозу облучения при КТ-сканировании (снижая напряжение трубки со 120 кВп до 80 или 100 кВп) для защиты пациентов. Этот фундаментальный сдвиг изменяет единицы Хаунсфилда (значения интенсивности пикселей на КТ-скане). Традиционные модели ИИ, которые сильно полагаются на общую яркость «большой картины» (данные низкой частоты), полностью сбиваются с толку этим падением напряжения, что приводит к огромным ошибкам измерения.
Авторы данной статьи осознали нечто блестящее: хотя общая яркость кости меняется при более низком излучении, микроскопическая, губчатая текстура кости (трабекулярная структура) остается неизменной. Им нужен был ИИ, который мог бы игнорировать меняющееся освещение и сосредоточиться на трещинах в бетоне.
Математическое ядро: Разделение и модуляция реальности
Чтобы решить эту проблему, авторам пришлось преодолеть серьезное вычислительное ограничение. Извлечение трехмерных текстур высокой частоты обычно требует невероятно сложной математики, такой как вейвлет-преобразования на нескольких масштабах, которые могли бы вызвать сбой стандартных больничных компьютеров.
Вместо этого они разработали легкую двухканальную сеть, которая разделяет изображение на отдельные пути. Сначала они извлекают «размытые» данные низкой частоты ($X_L$) с помощью простой операции усредняющего пулинга. Затем они вычитают это размытое изображение из исходного, чтобы выделить «четкие» детали высокой частоты ($X_H$).
Чтобы гарантировать, что сеть с самого начала обращает внимание на эти четкие детали, не замедляя систему, они применяют модуляцию в частотной области с использованием преобразований Фурье ($\mathcal{F}$). Математически они выборочно усиливают высокочастотные признаки с помощью механизма пространственного внимания:
$$Y = \sum_{b \in B} \sigma(f(X_b; W_b)) \odot X_b$$
где частотные полосы выделяются с помощью:
$$X_b = \mathcal{F}^{-1}(M_b \odot \mathcal{F}(X))$$
Здесь $M_b$ — бинарная маска, фильтрующая частоты, а $\odot$ обозначает поэлементное произведение Адамара.
После модуляции признаков они направляются по двум различным сверточным ветвям:
$$Y_L = f(X_L; W_L) + X_L$$
$$Y_H = f(X_H; W_H) + X_H$$
Но истинный гений заключается в том, как они снова объединяют эти ветви. Они не просто смешивают их в конце. Они используют асимметричный механизм внимания к каналам. Для данных высокой частоты они используют Global Max Pooling (GMP), поскольку max pooling отлично подходит для обнаружения резких, изолированных пиков (например, края трабекулы кости). Для данных низкой частоты они используют Global Average Pooling (GAP) для захвата общего, гладкого анатомического строения.
Они вычисляют веса внимания ($A_H$ и $A_L$), чтобы определить важность каждого признака:
$$\widetilde{X} = upsample(X_L) + X_H$$
$$A_H = \sigma(MLP(GMP(\widetilde{X})))$$
$$A_L = \sigma(MLP(GAP(\widetilde{X})))$$
Наконец, они снова разделяют данные, применяя эти обученные веса, чтобы гарантировать, что сеть поддерживает идеальный баланс макроскопической анатомии и микроскопической текстуры:
$$X = A_H \odot X_H + A_L \odot X_L$$
Экспериментальная архитектура: Безжалостное доказательство
Авторы не просто бросили свою модель на чистый набор данных и заявили об увеличении точности на 5%. Они спроектировали эксперимент, призванный безжалостно проверить их математические утверждения в условиях хаотичной клинической среды.
Они собрали данные из двух совершенно независимых медицинских центров. Данные одного центра были использованы для обучения и внутреннего тестирования модели (1614 изображений), в то время как данные другого центра (2245 изображений) хранились в запертом хранилище в качестве «внешнего тестового набора». Это гарантирует, что ИИ не просто запомнил специфические особенности КТ-сканера одной больницы.
Жертвы:
Авторы противопоставили свое творение трем базовым методам:
1. Традиционный линейный регрессионный метод без фантомов (PL) (адаптированный с помощью математической формулы преобразования для попытки обработки данных с несколькими напряжениями).
2. ResNet-10 (стандартная, высокоуважаемая модель глубокого обучения).
3. OctResNet-10 (модель, специально разработанная для обработки пространственной избыточности).
Неоспоримое доказательство:
Окончательным доказательством того, что их основной механизм работал, стало не просто превосходство над базовыми методами на наборах данных 120 кВп и 100 кВп (достижение высоко превосходящей средней абсолютной ошибки в 5,990 $mg/cm^3$ на внутреннем и 7,175 $mg/cm^3$ на внешнем уровне). Настоящей уликой стало их исследование абляции.
Они систематически «лоботомировали» свою модель. Они отключили балансировку частот. Затем они отключили внимание к каналам. В каждом случае ошибки резко возрастали. Только когда одновременно работали разделение высоко/низкочастотных сигналов и асимметричные механизмы внимания GMP/GAP, модель достигала пиковой производительности. Это математически и эмпирически доказало правильность их гипотезы: необходимо изолировать и уникально взвешивать высокочастотные текстуры, чтобы выжить при вариациях напряжения трубки.
Честно говоря, я не до конца уверен в точной физической причине серьезной деградации изображения на уровне 80 кВп во внешнем наборе данных — авторы отмечают, что их модель показала худшие результаты, чем базовый метод, из-за «значительных различий в качестве изображения между центрами», что предполагает, что при чрезвычайно низком излучении высокочастотные трабекулярные данные могут быть просто разрушены квантовым шумом, прежде чем ИИ сможет их увидеть.
Темы для обсуждения для будущего развития
Исходя из глубоких последствий данной статьи, вот несколько направлений для будущих исследований и критического осмысления:
-
Порог разрушения информации:
При 80 кВп модель показала плохие результаты на внешних данных. Это поднимает захватывающий вопрос на стыке физики и ИИ: при какой точной дозе облучения высокочастотная трабекулярная структура переходит из состояния «скрыта, но восстановима» в состояние «физически разрушена из-за недостатка фотонов и квантового шума»? Можем ли мы математически определить абсолютный нижний предел излучения, необходимого для анализа плотности костной ткани с помощью ИИ? -
Разделение частот между модальностями:
Если разделение высокочастотных текстур от низкочастотного глобального освещения решает проблему напряжения КТ, может ли эта точная математическая структура быть перенесена на МРТ или УЗИ? Например, может ли эта двухканальная архитектура изолировать высокочастотные микроразрывы в связках на МРТ, игнорируя низкочастотные вариации, вызванные различными силами магнитного поля (1,5 Тл против 3 Тл)? -
Конец физических фантомов?
Экономические последствия здесь огромны. Если программное обеспечение сможет надежно динамически адаптироваться к напряжению любого сканера, используя внутренние тканевые ссылки и частотную модуляцию, потребуется ли нам когда-либо снова производить, отправлять и калибровать физические КТ-фантомы? Каковы нормативные и юридические препятствия для замены физического объекта истинности вероятностной нейронной сетью в сценариях диагностики, связанных с жизнью и смертью?
Изоморфизмы с другими полями
Для понимания данной статьи необходимо сначала рассмотреть, как врачи диагностируют остеопороз. Они измеряют объемную минеральную плотность костной ткани (vBMD) с помощью КТ-сканирования. Традиционно для этого требуется "фантом" — физический калибровочный объект, помещаемый под пациента во время сканирования, что является дорогостоящим и громоздким. Фантомные (PL) методы используют внутренние ткани самого пациента (например, жир и мышцы) в качестве эталонных точек.
Мотивация исходит из критического ограничения в современных больницах: вариативность доз облучения. Чтобы защитить пациентов от чрезмерного облучения, клиники все чаще используют более низкие напряжения трубки (например, 80 кВп или 100 кВп вместо стандартных 120 кВп). Проблема заключается в том, что снижение напряжения резко изменяет общую интенсивность пикселей (единицы Хаунсфилда, или HU) на КТ-изображении. Поскольку существующие модели глубокого обучения в значительной степени полагаются на эти низкочастотные глобальные интенсивности, их точность резко падает при снижении напряжения. Однако авторы заметили критическую биологическую лазейку: хотя общая яркость изменяется, высокочастотная текстура губчатой трабекулярной кости остается удивительно стабильной при различных напряжениях.
Для решения этой проблемы авторам потребовалось математически разделить нестабильные макроскопические данные и стабильные микроскопические данные. Вместо того чтобы подавать все изображение в стандартную нейронную сеть, они построили архитектуру с двумя ветвями для разделения частот.
Сначала они модулируют частотные признаки с помощью преобразования Фурье в сочетании с пространственным вниманием, чтобы избежать избыточных вычислительных затрат. Для входной карты признаков $X$ модулированный выход $Y$ определяется как:
$$ Y = \sum_{b \in B} \sigma(f(X_b; W_b)) \odot X_b $$
где частотные полосы извлекаются через $X_b = \mathcal{F}^{-1}(M_b \odot \mathcal{F}(X))$, причем $\mathcal{F}$ обозначает преобразование Фурье, а $M_b$ действует как бинарная маска частоты.
После разделения сигнала на низкочастотную ($X_L$) и высокочастотную ($X_H$) компоненты, они обрабатываются в параллельных ветвях. Истинный гений статьи заключается в том, как эти ветви снова объединяются. Авторы признали, что высокочастотные данные (четкие края костей) и низкочастотные данные (общая форма кости) требуют различных математических подходов. Они разработали асимметричный механизм внимания к каналам. Они применяют Global Max Pooling (GMP) для захвата резких пиков высокочастотных признаков и Global Average Pooling (GAP) для сглаживания и захвата низкочастотных признаков:
$$ A_H = \sigma(MLP(GMP(\tilde{X}))) $$
$$ A_L = \sigma(MLP(GAP(\tilde{X}))) $$
Эти веса внимания затем используются для динамического рекомбинирования разделенных сигналов:
$$ \tilde{X} = A_H \odot X_H + A_L \odot X_L $$
Это уравнение позволяет сети адаптивно полагаться на стабильную высокочастотную текстуру, когда низкочастотная глобальная интенсивность становится ненадежной из-за изменений напряжения.
По своей сути, структурный каркас этой работы представляет собой механизм, который изолирует сложный сигнал на нестабильные макроскопические базовые линии и стабильные микроскопические флуктуации, обрабатывает их параллельно и динамически рекомбинирует с использованием асимметричной функции взвешивания для извлечения инвариантной метрики в различных условиях окружающей среды.
Основываясь на этом каркасе, мы можем найти "зеркальные отражения" этой точной логики в совершенно разных областях науки и техники:
1) Количественные финансы: В алгоритмической торговле цены активов состоят из макроэкономических тенденций (низкочастотных, сильно чувствительных к внешним "напряжениям", таким как повышение процентных ставок) и микроструктурной динамики книги заявок (высокочастотных, представляющих стабильное, внутреннее торговое поведение). Извлечение истинной фундаментальной стоимости актива путем разделения общерыночного шума от внутренней микроволатильности является прямым отражением отделения глобальной интенсивности КТ от трабекулярной текстуры.
2) Сейсмология: При определении магнитуды землетрясения сейсмографы регистрируют низкочастотные поверхностные волны (которые сильно искажаются местным типом почвы, действующим как изменяющееся напряжение трубки КТ) и высокочастотные объемные волны (которые несут истинную, стабильную сигнатуру разрыва разлома). Сейсмологи постоянно борются за балансировку этих частот, чтобы найти инвариантную истину о землетрясении.
Что произойдет, если исследователь количественных финансов "украдет" точное уравнение асимметричного внимания из этой статьи завтра? Если они применят $$ \tilde{X} = A_H \odot X_H + A_L \odot X_L $$ к алгоритму высокочастотной торговли, они смогут использовать Global Max Pooling для агрессивного захвата абсолютных пиков аномалий книги заявок ("трабекулярные" сделки), в то время как Global Average Pooling будет использоваться для сглаживания волатильных макроэкономических настроений. Прорывом станет радикально надежный торговый бот, который сохранит свою предсказательную точность и прибыльность независимо от того, перейдет ли более широкий рынок внезапно в режим высокой или низкой волатильности — фактически делая алгоритм невосприимчивым к колебаниям "напряжения трубки" рынка.
В конечном итоге, эта архитектура доказывает, что независимо от того, измеряем ли мы плотность разрушающейся кости или скрытую стоимость колеблющегося финансового актива, математический поиск инвариантной истины опирается на ту же самую симфонию разделенных частот и адаптивного внимания, добавляя блестящий новый шаблон в Универсальную библиотеку структур.