MTSAM: Multi-Task Fine-Tuning for Segment Anything Model
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has the potential to be a foundation model for multi-task learning.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the recent emergence and remarkable capabilities of large foundation models in artificial intelligence, particularly in computer vision. Historically, foundation models first revolutionized natural language processing (NLP) with their impressive zero-shot abilities, meaning they could perform tasks they weren't explicitly trained on. This success inspired the development of similar models in computer vision.
The Segment Anything Model (SAM), introduced in 2023 by Kirillov et al., stands out as a prominent foundation model for image segmentation. SAM demonstrated exceptional zero-shot performance, capable of segmenting virtually any object in an image after being trained on a massive dataset of 11 million samples. This breakthrough led to a surge of research exploring SAM's application to various downstream tasks, such as high-quality segmentation, 3D reconstruction, object tracking, medical image processing, personalized segmentation, and remote sensing.
However, a fundamental limitation, or "pain point," of these previous approaches was that they exclusively adopted SAM for single-task learning. This meant that for each new task, SAM was fine-tuned independently, overlooking its potential as a unified foundation model for multi-task learning (MTL). In many real-world computer vision scenarios, multiple tasks are inherently related and often need to be addressed simultaneously (e.g., depth estimation and surface normal estimation in scene understanding). Prior research in MTL has consistently shown that tasks can benefit from being learned together, as shared knowledge can improve overall performance and efficiency.
This paper specifically identifies two core challenges in adapting SAM for multi-task learning:
1. Output Dimensionality Mismatch: The original SAM is designed to produce segmentation masks, typically with a fixed number of output channels (e.g., three distinct levels, all with identical channel numbers, as shown in Figure 1a). However, different downstream tasks require outputs with varying dimensions (e.g., depth estimation might need one channel, while surface normal prediction requires three). SAM's architecture was not inherently flexible enough to generate these task-specific outputs with different channel numbers.
2. Simultaneous Fine-Tuning: There was no established method to effectively fine-tune SAM to adapt to multiple downstream tasks simultaneously. Existing parameter-efficient fine-tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), were primarily designed for single-task adaptation. When applied to multi-task settings, these methods either struggled to leverage shared information between tasks (like LoRA-STL, where each task has its own LoRA) or suffered from performance imbalances due to competition among tasks for shared parameters (like LoRA-HPS). This lack of a robust multi-task fine-tuning strategy for large foundation models like SAM presented a significant hurdle.
The authors wrote this paper to address these precise limitations, proposing the Multi-Task SAM (MTSAM) framework and the Tensorized low-Rank Adaptation (ToRA) method to enable SAM to function as a versatile foundation model for multi-task learning, overcoming the output dimensionality and simultaneous fine-tuning challenges.
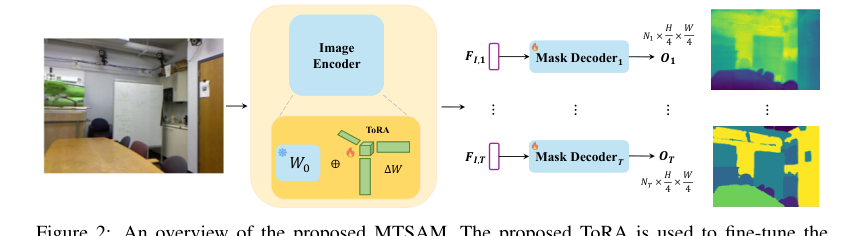 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Intuitive Domain Terms
-
Segment Anything Model (SAM): Imagine a highly skilled digital artist who can perfectly outline any object in a photograph, no matter how complex or unfamiliar it is. SAM is like that artist, but for computers, able to "cut out" objects from images with incredible precision, even if it's never seen that exact object before.
-
Zero-shot capability: This is like a very smart student who has learned general principles about many things. If you show them something entirely new, say a rare type of fruit they've never encountered, they can still make a good guess about what it is or how to categorize it, simply by applying their broad understanding, without needing specific training on that fruit.
-
Multi-Task Learning (MTL): Think of a chef who learns to cook several related dishes at once – perhaps a main course, a side dish, and a sauce. By learning them together, the chef might discover common techniques or ingredients that make the overall cooking process more efficient and the final meal more harmonious, rather than learning each dish in isolation.
-
Parameter-Efficient Fine-Tuning (PEFT): Consider a highly trained expert, like a master mechanic, who knows how to fix many types of cars. If a new car model comes out, instead of retraining the mechanic from scratch, you just teach them a few small, specific adjustments or new tools for that particular model. Most of their vast existing knowledge remains untouched, making the adaptation quick and efficient.
-
Low-Rank Adaptation (LoRA): Building on the mechanic analogy, LoRA is like giving the master mechanic a small, specialized "cheat sheet" for each new car model. This sheet contains only a few key modifications to their standard procedures, allowing them to adapt their skills without having to relearn the entire car's engineering. It's a clever way to make big changes with very little new information.
Notation Table
| Notation | Description |
|---|---|
| $I$ | Input image with dimensions $3 \times H \times W$ (channels, height, width). |
| $H, W$ | Height and width of the input image. |
| $F_I$ | Image features extracted by SAM's image encoder, with dimensions $D \times \frac{H}{16} \times \frac{W}{16}$. |
| $D$ | Dimension of the hidden state in the model. |
| $O$ | Final segmentation mask output from the original SAM, with dimensions $3 \times \frac{H}{4} \times \frac{W}{4}$. |
| $T$ | Total number of distinct tasks being learned. |
| $\Delta W$ | A general update parameter matrix for a single layer, with dimensions $d \times k$. |
| $W_0$ | The pre-trained parameter matrix of a layer, with dimensions $d \times k$. |
| $A, B$ | Low-rank matrices used in LoRA, where $B \in \mathbb{R}^{d \times r}$ and $A \in \mathbb{R}^{r \times k}$. |
| $r$ | The rank of the low-rank matrices in LoRA, where $r \ll \min(d, k)$. |
| $\Delta \mathcal{W}$ | The update parameter tensor for ToRA, aggregating all task-specific updates into a $d \times k \times T$ tensor. |
| $G$ | The core tensor in the Tucker decomposition for ToRA, with dimensions $p \times q \times v$. |
| $U_1, U_2, U_3$ | Factor matrices in the Tucker decomposition for ToRA, with dimensions $d \times p$, $k \times q$, and $T \times v$ respectively. |
| $p, q, v$ | Dimensions of the factor matrices for ToRA, typically much smaller than $d, k, T$. |
| $E_t$ | Trainable task embedding for a specific task $t$, with dimensions $N_t \times D$. |
| $N_t$ | The number of output channels required for task $t$. |
| $O_t$ | The output prediction generated by MTSAM for task $t$, with dimensions $N_t \times \frac{H}{4} \times \frac{W}{4}$. |
| $\mathcal{L}_{MTL}$ | The overall multi-task learning objective function, which MTSAM aims to minimize. |
| $\lambda$ | A hyper-parameter that controls the impact of the orthogonal regularization term. |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The Segment Anything Model (SAM) has emerged as a powerful foundation model for image segmentation, renowned for its zero-shot generalization capabilities. The core problem this paper addresses is how to effectively transform SAM into a foundation model for multi-task learning (MTL).
Input/Current State:
The starting point is the original SAM, which takes an image $I \in \mathbb{R}^{3 \times H \times W}$ and various prompts (e.g., points, bounding boxes, or masks) as input. Its architecture comprises a heavyweight image encoder, a prompt encoder, and a lightweight mask decoder. The original SAM is designed to produce segmentation masks, typically with a fixed number of output channels (e.g., 3 channels, as seen in $O \in \mathbb{R}^{3 \times H \times W}$ in Equation 3 on page 4, and illustrated in Figure 1a on page 2).
Desired Endpoint (Output/Goal State):
The desired endpoint is a modified SAM, termed Multi-Task SAM (MTSAM), that can:
1. Generate task-specific outputs with varying dimensions: For instance, producing a 1-channel output for depth estimation, a 13-channel output for semantic segmentation, and a 3-channel output for surface normal estimation, all simultaneously from a single input (Figure 1b, page 2).
2. Be fine-tuned to adapt to multiple downstream tasks concurrently: This adaptation should leverage shared information across tasks to improve overall performance, rather than treating each task in isolation.
Missing Link & Mathematical Gap:
The exact missing links or mathematical gaps between the current and desired states are two-fold:
1. Architectural Inflexibility for Diverse Outputs: The original SAM's mask decoder is architecturally constrained to produce outputs with a fixed channel count, making it unsuitable for tasks requiring different output dimensions. There is no inherent mechanism to dynamically adjust the output channels based on the specific task.
2. Inefficient Multi-Task Fine-Tuning: A robust and parameter-efficient method to fine-tune SAM's large encoder for multiple tasks simultaneously, while effectively balancing task-shared and task-specific knowledge, is absent. Existing parameter-efficient fine-tuning (PEFT) methods like LoRA, when naively applied to MTL, either oversimplify by sharing parameters too broadly (LoRA-HPS), leading to performance compromises due to task competition, or are too task-specific (LoRA-STL), failing to harness beneficial inter-task information sharing.
The Dilemma:
The central dilemma that has trapped previous researchers is the painful trade-off between parameter efficiency and expressive power/performance in multi-task learning for large foundation models.
* Full fine-tuning of a heavyweight model like SAM for multiple tasks is computationally prohibitive and parameter-inefficient.
* Naively applying existing PEFT methods to MTL presents a dilemma:
* Hard Parameter Sharing (LoRA-HPS): This approach is parameter-efficient as it uses one shared LoRA matrix for all tasks. However, it often leads to "imbalanced performance on all the tasks due to the competition among tasks for the shared LoRA" (page 4). It struggles to capture task-specific nuances, effectively sacrificing performance for efficiency.
* Task-Specific LoRA (LoRA-STL): This method trains a separate LoRA module for each task, allowing for task-specific adaptation and potentially better individual task performance. However, its parameter count grows linearly with the number of tasks ($O(Trd+Trk)$, page 6), making it less efficient for a large number of tasks. Crucially, it "cannot harness the inter-task shared information necessary for fine-tuning across multiple tasks" (page 4), thus missing out on the synergistic benefits of MTL.
The challenge is to devise a method that is both parameter-efficient (sublinear growth in parameters with tasks) and capable of simultaneously capturing both task-shared general knowledge and task-specific details, thereby overcoming the limitations of existing PEFT strategies in a multi-task setting.
Constraints & Failure Modes
The problem of adapting SAM for multi-task learning is made insanely difficult by several harsh, realistic walls the authors hit:
- Hardware Memory and Computational Limits: SAM's image encoder is described as "heavyweight" (page 3). Fine-tuning such a large model for multiple tasks simultaneously would demand immense computational resources and memory, making full fine-tuning impractical. This constraint necessitates the use of parameter-efficient methods.
- Fixed Output Channel Constraint: The original SAM's mask decoder is hardwired to produce outputs with a fixed number of channels (e.g., 3 for segmentation). This architectural rigidity prevents it from directly generating outputs with varying channel numbers required by diverse tasks like depth estimation (1 channel) or multi-class semantic segmentation (e.g., 13 channels). This is a fundamental architectural limitation that needs to be overcome.
- Inability to Balance Task-Shared and Task-Specific Learning: Previous PEFT methods, when applied to MTL, fail to effectively balance the learning of general, task-shared features with specific, task-dependent adaptations. LoRA-HPS suffers from task competition, while LoRA-STL cannot leverage inter-task shared information (page 4). This leads to suboptimal performance or inefficient parameter usage.
- Complexity of Tensor Decomposition for Optimal Approximation: While tensor decomposition is a powerful mathematical tool, finding the "best approximation" for complex objectives, especially in the context of multi-task learning, is inherently challenging and "may not always exist" (Kolda & Bader, 2009, cited on page 7). This implies a potential difficulty in guaranteeing the theoretical optimality of the low-rank tensor adaptation.
- Data Heterogeneity Across Tasks: Different tasks often involve distinct data distributions, semantic meanings, and output formats. For example, depth estimation and semantic segmentation require different types of ground truth and evaluation metrics. The model must be robust enough to handle this inherent diversity without compromising performance on any single task.
- Lack of Real-time Latency Requirements (Implicit): While not explicitly stated as a constraint the authors struggled with, the goal of parameter efficiency and the statement that ToRA introduces "no additional latency introduced during inference" (page 6) suggest an implicit need for efficient inference, which is often critical in practical applications. The complexity of the model should not significantly increase inference time.
Why This Approach
The Inevitability of the Choice
The Segment Anything Model (SAM) emerged as a powerful foundation model, showcasing remarkable zero-shot capabilities for image segmentation. However, its direct application to multi-task learning presented two fundamental architectural hurdles that traditional "SOTA" methods, including the original SAM itself, were ill-equipped to handle. The authors' realization of these insufficiencies became evident when considering the core requirements of multi-task learning: (a) the need to generate task-specific outputs with varying channel numbers (e.g., 1 channel for depth estimation, 3 for surface normal prediction, and multiple for semantic segmentation), and (b) the challenge of simultaneously fine-tuning SAM to adapt to multiple downstream tasks efficiently.
The original SAM, by design, generates segmentation masks at distinct levels, but crucially, all these outputs feature an identical number of channels. This fixed output dimension is a severe limitation when tasks like depth estimation or surface normal prediction require different output structures. The paper explicitly states, "Despite the tremendous potential exhibited by SAM as a fundamental visual model, its reliance on prompt-guided mask generation presents challenges in achieving end-to-end adaptability to downstream tasks with varying numbers of output channels." This was the exact moment the authors recognized that SAM's inherent architecture, particularly its prompt encoder and mask decoder, was not flexible enough for diverse multi-task outputs. Therefore, a direct application of SAM or existing single-task fine-tuning methods was simply not viable for a truly multi-task foundation model.
Comparative Superiority
The proposed Multi-Task SAM (MTSAM) framework, particularly its Tensorized low-Rank Adaptation (ToRA) method, demonstrates overwhelming qualitative and structural superiority over previous gold standards, especially in parameter efficiency and information leveraging.
Firstly, ToRA's most significant structural advantage lies in its parameter efficiency. When applied to $T$ tasks, traditional Low-Rank Adaptation (LoRA) methods, whether using hard parameter sharing (LoRA-HPS) or task-specific LoRAs (LoRA-STL), exhibit a parameter complexity that grows linearly with the number of tasks, typically $O(Trd + Trk)$. In stark contrast, ToRA aggregates the update parameter matrices of all tasks into a single update parameter tensor $\Delta W \in \mathbb{R}^{d \times k \times T}$ and applies low-rank tensor decomposition (specifically, Tucker decomposition). This results in a parameter complexity of $O(dp + kq)$, where $p, q, v \ll \min(d, k)$ and $T$ is the number of tasks. This represents a sublinear growth in learnable parameters with respect to the number of tasks, making it dramatically more efficient for scaling to a large number of tasks. This reduction in memory complexity is a game-changer for fine-tuning massive foundation models like SAM.
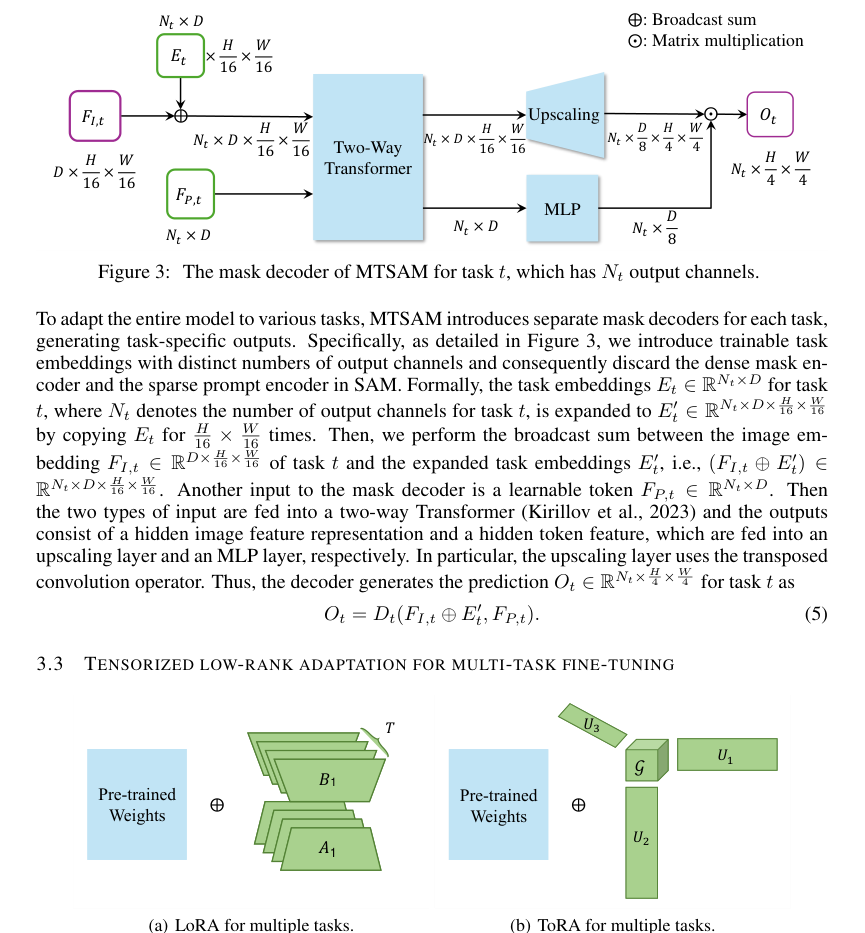 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Secondly, ToRA qualitatively surpasses alternatives by effectively capturing both task-shared and task-specific information. LoRA-HPS, by sharing a single $\Delta W$ across all tasks, struggles with task competition and often leads to imbalanced performance. LoRA-STL, on the other hand, trains separate $\Delta W_t$ for each task, completely neglecting the valuable inter-task shared information. ToRA's use of Tucker decomposition allows the core tensor $G$ and factor matrices $U_1, U_2, U_3$ to explicitly model both the main subspace variation of task-shared information (through $U_1$ and $U_2$) and the task-specific subspace structure (through $U_3$). This holistic approach to information sharing and specialization is a key structural advantage that enhances fine-tuning performance across diverse tasks. The theoretical analysis in Theorem 1 further substantiates this, proving that ToRA possesses superior expressive power and can achieve the same weight updates with fewer parameters compared to multiple LoRAs.
Finally, qualitative evaluations (e.g., Figure 5) show that MTSAM fine-tuned with ToRA generates more accurate results, particularly for "vague and slender objects." This suggests that ToRA's ability to disentangle and leverage shared and specific information leads to a more robust and nuanced understanding of visual scenes, improving performance in challenging scenarios where other methods might struggle with fine-grained details or complex object boundaries.
Alignment with Constraints
The chosen MTSAM framework, with its architectural modifications and the ToRA fine-tuning method, perfectly aligns with the two primary constraints identified for adapting SAM to multi-task learning.
-
Constraint: Generating task-specific outputs with varying channel numbers.
- Solution's Property: MTSAM addresses this by fundamentally altering SAM's mask decoder. It removes the original prompt encoder and introduces task-specific no-mask embeddings and dedicated task-specific mask decoders. As illustrated in Figure 1 and Figure 3, this modification enables MTSAM to produce outputs with dimensions tailored to each task ($N_t \times H \times W$), rather than SAM's fixed channel outputs. For instance, it can output 1 channel for depth, 3 for surface normal, or 13 for semantic segmentation, directly satisfying the requirement for diverse output structures. The introduction of trainable task embeddings $E_t$ further ensures that the decoder can adapt its processing based on the specific task at hand. This is a direct "marriage" between the problem's need for output flexibility and the solution's modular, task-aware decoder design.
-
Constraint: Fine-tuning SAM to adapt multiple downstream tasks simultaneously and efficiently.
- Solution's Property: ToRA is the core innovation for this constraint. It injects an update parameter tensor into each layer of the SAM encoder and employs low-rank tensor decomposition to capture both task-shared and task-specific information. This allows the model to learn from multiple tasks concurrently, leveraging their interdependencies while also allowing for task-specific adaptations. The parameter efficiency of ToRA, with its sublinear growth in parameters relative to the number of tasks, is crucial for fine-tuning a heavyweight foundation model like SAM without prohibitive computational costs or memory footprints. This efficiency ensures that simultaneous adaptation is not only possible but also practical, making it a perfect fit for the harsh requirements of large-scale multi-task learning. The orthogonal regularization term in the total loss function ($L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$) further ensures that the learned factor matrices are well-behaved and non-redundant, contributing to the stability and effectiveness of the multi-task fine-tuning process.
Rejection of Alternatives
The paper provides clear reasoning for rejecting several alternative approaches, primarily focusing on existing Parameter-Efficient Fine-Tuning (PEFT) methods and different strategies for applying LoRA in a multi-task context.
-
Traditional PEFT Methods (e.g., Adapter-based, Prompt Tuning, existing LoRA variants for single-task): The authors explicitly state that while these methods "achieve competitive performance and high parameter efficiency in single-task fine-tuning," they are "not suitable for multi-task learning settings, since they do not consider shared information between multiple tasks." This is a blanket rejection of methods that cannot inherently leverage the synergies or manage the conflicts arising from learning multiple tasks simultaneously. Their design is fundamentally geared towards optimizing for one task at a time, which is antithetical to the goal of multi-task learning.
-
LoRA-HPS (Hard Parameter Sharing): This approach attempts multi-task learning by using one shared LoRA matrix ($\Delta W$) for all tasks. The paper rejects this because it "may lead to imbalanced performance on all the tasks due to the competition among tasks for the shared LoRA." When tasks have conflicting gradients or different learning dynamics, forcing them to share a single, undifferentiated update matrix can degrade performance on some or all tasks.
-
LoRA-STL (Single-Task LoRA): This alternative involves training a separate LoRA matrix ($\Delta W_t$) for each task. The paper rejects this because it "cannot harness the inter-task shared information necessary for fine-tuning across multiple tasks." While it avoids the competition issue of LoRA-HPS, it fails to exploit the potential benefits of shared knowledge and common features across related tasks, which is a core tenet of multi-task learning. This makes it less efficient and potentially less performant than an approach that can intelligently share information.
-
Full Fine-Tuning: Although not explicitly "rejected" in the same strong terms as other PEFT methods, the paper implicitly dismisses full fine-tuning of SAM's heavyweight image encoder due to "parameter and computational efficiency concerns." Table 7 quantitatively supports this rejection, showing that full fine-tuning requires a massive 1222.47 MB of trainable parameters, significantly more than MTSAM's 59.59 MB, while yielding a lower overall performance improvement ($\Delta_b$ of +14.57% for full fine-tuning versus +23.93% for MTSAM). This makes full fine-tuning impractical for large foundation models and multi-task scenarios where efficiency is paramount. The sheer scale of parameters makes it computationally expensive and prone to overfitting on smaller multi-task datasets.
Mathematical & Logical Mechanism
The Master Equation
The absolute core of the MTSAM framework's learning process is its overall objective function, which combines a multi-task learning loss with a regularization term to ensure efficient and effective parameter updates. This master equation guides the entire training process:
$$ L_{total} = L_{MTL} + \lambda R(U_1, U_2, G) $$
This equation encapsulates how the model learns from multiple tasks simultaneously while maintaining parameter efficiency and preventing redundancy through tensor decomposition and regularization.
Term-by-Term Autopsy
Let's dissect the master equation and its components to understand their mathematical definitions, physical/logical roles, and the authors' design choices.
-
$L_{total}$: This is the total objective function that the MTSAM framework aims to minimize during training. Its role is to balance the performance across all tasks with the efficiency and structural integrity of the parameter updates. The authors use addition to combine the multi-task loss and the regularization term because these are two distinct objectives that need to be optimized concurrently: minimizing task error and maintaining a well-structured, low-rank parameter space.
-
$L_{MTL}$: This term represents the Multi-Task Learning (MTL) loss. It's an average of the weighted losses from all individual tasks.
$$ L_{MTL} = \frac{1}{T} \sum_{i=1}^T w_i L_i $$- $T$: This is the total number of distinct tasks the MTSAM model is being trained on (e.g., semantic segmentation, depth estimation, surface normal prediction). Its role is to normalize the sum of individual task losses, providing an average loss across all tasks. The summation is used here because the overall multi-task objective is a composite of individual task objectives.
- $w_i$: This is the loss weight for task $i$. It's a hyper-parameter that controls the relative importance of each task's loss in the overall multi-task objective. For instance, a task deemed more critical or harder might receive a higher weight. The authors use multiplication to scale each task's contribution to the total loss, allowing for flexible prioritization.
- $L_i$: This is the loss for task $i$, calculated as the average loss over all training samples for that specific task.
$$ L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j, f(x_j)) $$- $N_i$: This denotes the number of training samples for task $i$. Its role is to average the loss over the samples, ensuring that the loss for a task is not disproportionately influenced by the number of samples it has. The summation aggregates losses from individual samples, and division by $N_i$ provides the mean loss.
- $l_i(\cdot, \cdot)$: This is the task-specific loss function for task $i$. Its mathematical definition depends on the nature of task $i$ (e.g., cross-entropy for segmentation, L1 loss for depth estimation, cosine similarity for surface normals). Its role is to quantify the discrepancy between the model's prediction and the ground truth for a single sample.
- $y_j$: This is the ground truth label for the $j$-th training sample of task $i$. It represents the correct output the model should produce.
- $f(x_j)$: This represents the MTSAM model's prediction for the $j$-th training sample $x_j$ of task $i$. The function $f(\cdot)$ embodies the entire MTSAM architecture, including the image encoder and the task-specific mask decoder, which incorporates the ToRA-modified weights.
- $x_j$: This is the input training sample (e.g., an image) for which the prediction $f(x_j)$ is made.
-
$\lambda$: This is a hyper-parameter that controls the impact of the orthogonal regularization term $R(U_1, U_2, G)$. Its role is to balance the trade-off between minimizing task-specific errors and enforcing the desired low-rank, orthogonal structure on the ToRA parameters. A larger $\lambda$ places more emphasis on regularization. The authors use multiplication to scale the regularization's contribution to the total loss.
-
$R(U_1, U_2, G)$: This is the orthogonal regularization term. It encourages the factor matrices $U_1, U_2$ and slices of the core tensor $G$ to be orthogonal, which helps reduce redundancy and improve the stability of the tensor decomposition.
$$ R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^v ||G(:,:,l)^T G(:,:,l) - I||_F^2 $$- $U_1$: This is a factor matrix of dimensions $d \times p$. It captures the main subspace variation of task-shared information corresponding to the output feature dimension of the update parameter tensor $\Delta W$.
- $U_2$: This is a factor matrix of dimensions $k \times q$. It captures the main subspace variation of task-shared information corresponding to the input feature dimension of the update parameter tensor $\Delta W$.
- $G$: This is the core tensor of dimensions $p \times q \times v$. It represents the compressed, low-rank representation of the update parameter tensor $\Delta W$ after decomposition. It holds the "essence" of the shared and specific information.
- $||\cdot||_F^2$: This denotes the Frobenius norm squared. Mathematically, for a matrix $A$, $||A||_F^2 = \sum_{i,j} |A_{i,j}|^2$. Its role here is to quantify the "size" or magnitude of the deviation from orthogonality. Squaring ensures the value is non-negative and penalizes larger deviations more heavily.
- $I$: This is the identity matrix of appropriate size. Its role in terms like $U^T U - I$ is to serve as the target for orthogonality: if $U^T U = I$, then $U$ is orthogonal.
- $U_1^T U_1 - I$: This term measures the deviation of $U_1$ from orthogonality. Minimizing its Frobenius norm squared forces $U_1$ to be close to an orthogonal matrix.
- $U_2^T U_2 - I$: Similar to $U_1$, this term measures the deviation of $U_2$ from orthogonality.
- $G(:,:,l)^T G(:,:,l) - I$: This term measures the deviation of the $l$-th frontal slice of the core tensor $G$ from orthogonality. $G(:,:,l)$ refers to the matrix formed by fixing the third mode (task axis) to $l$. This ensures orthogonality along the task dimension within the core tensor. The summation $\sum_{l=1}^v$ aggregates these orthogonality penalties across all slices of the core tensor. The authors use addition to combine these individual orthogonality constraints, as each contributes independently to the overall goal of reducing redundancy.
Central to $L_{MTL}$'s operation is the Tensorized low-Rank Adaptation (ToRA) method, which defines how the model's weights are updated. ToRA parameterizes the update parameter tensor $\Delta W$ using Tucker decomposition:
$$ \Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3 $$
- $\Delta W$: This is the update parameter tensor of dimensions $d \times k \times T$. It represents the collective changes to the pre-trained weights across all tasks. Each slice $\Delta W(:,:,t)$ is the update matrix for task $t$. Its role is to adapt the frozen pre-trained model to multiple downstream tasks efficiently. The authors chose a tensor to represent updates for multiple tasks because it naturally captures the multi-dimensional nature of task-shared and task-specific information.
- $G$: This is the core tensor (as defined above), with dimensions $p \times q \times v$. It holds the most significant components of the tensor, acting as a compressed representation.
- $U_1$: This is the factor matrix for mode 1 (output feature dimension), with dimensions $d \times p$. It transforms the core tensor along its first mode.
- $U_2$: This is the factor matrix for mode 2 (input feature dimension), with dimensions $k \times q$. It transforms the core tensor along its second mode.
- $U_3$: This is the factor matrix for mode 3 (task dimension), with dimensions $T \times v$. It transforms the core tensor along its third mode, allowing the decomposition to capture task-specific variations.
- $\times_n$: This denotes the n-mode product. Mathematically, $A \times_n B$ means multiplying tensor $A$ by matrix $B$ along its $n$-th mode. Its role is to "unfold" or project the core tensor $G$ back into the full $\Delta W$ tensor using the factor matrices $U_1, U_2, U_3$. This operator is fundamental to tensor decomposition, allowing the reconstruction of a higher-order tensor from a core tensor and several matrices.
Finally, the actual application of these updates to the model's forward pass for a given task $t$ is:
$$ h = W_0x + \Delta W(:,:,t)x $$
- $h$: This is the output of a layer in the SAM encoder after applying the ToRA update.
- $W_0$: This is the original pre-trained weight matrix of a layer in the SAM encoder. It is kept frozen during fine-tuning.
- $\Delta W(:,:,t)$: This is the update matrix for task $t$, which is the $t$-th slice of the full $\Delta W$ tensor. Its role is to provide task-specific adjustments to the pre-trained weights.
- $x$: This is the input to the layer in the SAM encoder.
- The addition operator here signifies that the ToRA update is an additive modification to the pre-trained weights, a common practice in PEFT methods like LoRA.
Step-by-Step Flow
Imagine a single abstract data point, an image $x_j$, embarking on a journey through the MTSAM framework for a specific task $t$.
-
Image Encoding (Frozen Foundation): The journey begins with the input image $x_j$ entering the heavyweight image encoder $E_1$ of SAM. Crucially, the parameters of $E_1$ are frozen. This means the foundational knowledge learned during SAM's pre-training is preserved. The encoder outputs a set of image features, $F_1$.
-
ToRA Injection (Adaptive Layer): As $F_1$ propagates through the self-attention modules within the image encoder, it encounters the ToRA mechanism. For each layer, instead of directly using the original pre-trained weight matrix $W_0$, the input $x$ to that layer is processed by an adapted weight matrix $W'$. This $W'$ is effectively $W_0 + \Delta W(:,:,t)$. The $\Delta W(:,:,t)$ component is dynamically constructed for task $t$ using the core tensor $G$ and factor matrices $U_1, U_2, U_3$ via the tensor decomposition $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$. This means that for each task $t$, a unique, low-rank update is applied to the frozen weights, subtly steering the model's behavior towards task-specific requirements without altering the vast majority of its parameters.
-
Task-Specific Decoding (Output Generation): The ToRA-adapted image features, now implicitly tailored for task $t$, are then fed into a task-specific mask decoder $D_t$. This decoder is also given a trainable task embedding $E_t$ (expanded to match feature dimensions) and a learnable token $F_{P,t}$. The task embedding $E_t$ is broadcast-summed with the image features $F_{1,t}$ (which are derived from $F_1$ and potentially further processed for task $t$). These combined features, along with the learnable token, pass through a two-way Transformer, an upscaling layer, and an MLP layer. This entire process generates the task-specific output $O_t$ (e.g., a segmentation mask, a depth map, or surface normals) with the appropriate number of channels for task $t$.
-
Loss Calculation (Performance Measurement): The generated output $O_t$ for sample $x_j$ is then compared against its corresponding ground truth label $y_j$ using the task-specific loss function $l_t$. This yields $l_t(y_j, f(x_j))$, a measure of how well the model performed on this specific sample for task $t$.
-
Multi-Task Aggregation (Collective Error): This individual sample loss $l_t(y_j, f(x_j))$ contributes to the overall task loss $L_t$. For all samples of task $t$, their losses are averaged to form $L_t$. Then, $L_t$ is weighted by $w_t$ and combined with the weighted losses from all other tasks to compute the total multi-task learning loss $L_{MTL}$.
-
Regularization (Structural Integrity): Simultaneously, the current states of the trainable ToRA components ($U_1, U_2, G$) are evaluated against the orthogonal regularization term $R(U_1, U_2, G)$. This term penalizes deviations from orthogonality in these matrices and core tensor slices.
-
Total Objective (Unified Goal): Finally, $L_{MTL}$ and the scaled regularization term $\lambda R(U_1, U_2, G)$ are summed to form the $L_{total}$ objective function. This single value represents the overall "cost" or error that the model needs to minimize.
Optimization Dynamics
The MTSAM framework learns and updates its parameters through an iterative optimization process driven by the minimization of the $L_{total}$ objective function.
-
Parameter Initialization: At the start of training, the core tensor $G$ is initialized to all zeros. This ensures that initially, the ToRA updates $\Delta W(:,:,t)$ are also zero, meaning the model starts by relying solely on the frozen pre-trained weights $W_0$. The factor matrices $U_1, U_2, U_3$ are randomly initialized from a standard Gaussian distribution. This random initialization provides a starting point for exploring the parameter space.
-
Gradient Computation: During each training iteration, after computing $L_{total}$ for a batch of data across all tasks, the Adam optimizer is employed to calculate gradients. The gradients are computed with respect to the trainable parameters: the factor matrices $U_1, U_2, U_3$, the core tensor $G$, and the scale and bias parameters within the layer normalization layers of the image encoder. Crucially, the original pre-trained weights $W_0$ of the image encoder are frozen, meaning no gradients flow through them, significantly reducing the number of trainable parameters and computational cost.
-
Loss Landscape Shaping: The loss landscape is shaped by the interplay of the multi-task learning loss ($L_{MTL}$) and the orthogonal regularization term ($R$).
- $L_{MTL}$ drives the model to improve performance across all tasks. Without regularization, this landscape could be complex, potentially leading to conflicting gradients between tasks or overfitting.
- The regularization term $R$ acts as a structural constraint. By penalizing non-orthogonality in $U_1, U_2, G$, it encourages a more compact, less redundant representation of the update parameters. This can lead to a smoother loss landscape, potentially aiding convergence and improving generalization by preventing the model from learning highly correlated or redundant features. The authors' theoretical analysis suggests that this low-rank, orthogonal structure allows ToRA to achieve superior expressive power with fewer parameters compared to LoRA.
-
Iterative Updates: The Adam optimizer uses the computed gradients to iteratively update the trainable parameters ($U_1, U_2, U_3, G$, and layer norm parameters). The updates are performed using an initial learning rate of $10^{-3}$, which is then adjusted by a linear learning rate scheduler with a warmup rate of 0.05. A weight decay of $10^{-6}$ is also applied to prevent overfitting. These iterative updates gradually refine the ToRA components, allowing them to learn both task-shared and task-specific information.
-
Convergence: The training process continues for a set number of epochs (e.g., 200 for NYUv2). As the parameters are updated, $L_{total}$ is expected to decrease, indicating that the model is learning to perform better on the tasks while maintaining the desired low-rank structure. The goal is to converge to a set of parameters that minimizes $L_{total}$, leading to improved multi-task performance and parameter efficiency. During inference, the learned $\Delta W(:,:,t)$ for each task $t$ is pre-computed and added to $W_0$ to form $W_t'$, so there is no additional latency. This clever design ensures that the benefits of fine-tuning don't come at the cost of slower prediction times.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate the proposed Multi-Task SAM (MTSAM) framework and its core component, Tensorized low-Rank Adaptation (ToRA), the authors conducted extensive experiments across three well-established benchmark datasets: NYUv2, CityScapes, and PASCAL-Context. These datasets represent diverse computer vision scenarios, encompassing indoor scenes (NYUv2) and urban outdoor environments (CityScapes, PASCAL-Context), and involve a variety of dense prediction tasks.
The experimental setup was designed to ruthlessly prove MTSAM's mathematical claims regarding its ability to handle varying output dimensions and efficiently fine-tune for multiple tasks simultaneously. The "victims" (baseline models) against which MTSAM was pitted included a comprehensive array of both traditional multi-task learning (MTL) approaches and more recent parameter-efficient fine-tuning (PEFT) methods:
- CNN-based MTL Baselines: Single-Task Learning (STL), Hard-Parameter Sharing (HPS), Cross-Stitch, Multi-Task Attention Network (MTAN), and NDDR-CNN. These represent established methods for multi-task learning, with HPS serving as a crucial baseline for the $\Delta_b$ metric.
- Transformer-based MTL Baselines: VTAGML and SwinMTL, reflecting contemporary architectures.
- Cross-attention-based MTL: DenseMTL.
- LoRA-based PEFT Baselines: To specifically evaluate ToRA's effectiveness, the authors compared it against direct applications of LoRA in multi-task settings: LoRA-STL (task-specific LoRA), LoRA-HPS (shared LoRA), and MultiLoRA. Further comparisons were made against other advanced LoRA variants like Terra and HydraLoRA, as well as full fine-tuning of the entire model.
The tasks evaluated varied by dataset:
* NYUv2: 13-class semantic segmentation, depth estimation, and surface normal prediction.
* CityScapes: 7-class semantic segmentation and depth estimation.
* PASCAL-Context: 21-class semantic segmentation, 7-class human parts segmentation, saliency estimation, and surface normal estimation.
Performance was quantified using a suite of standard metrics:
* Semantic Segmentation: Mean Intersection over Union (mIoU) and Pixel Accuracy (Pix Acc), where higher values are better.
* Depth Estimation: Absolute Error (Abs Err) and Relative Error (Rel Err), where lower values are better.
* Surface Normal Prediction: Mean and Median of angular error (lower is better), and the percentage of pixels whose angular error is within 11.25, 22.5, and 30 degrees (higher is better).
* Overall Performance: A composite metric, $\Delta_b$, representing the average relative improvement of each task over the HPS architecture, with higher values indicating better performance.
* Parameter Efficiency: The number of trainable parameters (Params.) in megabytes (MB), with lower values being more efficient.
The implementation details included using the Adam optimizer with a learning rate of $10^{-3}$, a linear learning rate scheduler with warmup, and specific rank settings for ToRA ($p, q, v$) tailored to each dataset. Orthogonal regularization, controlled by a hyper-parameter $\lambda$, was also applied.
What the Evidence Proves
The experimental results provide definitive, undeniable evidence that MTSAM, particularly with its ToRA component, significantly advances multi-task learning with foundation models.
-
Overall Superiority and Parameter Efficay: Across all three benchmark datasets (NYUv2, CityScapes, and PASCAL-Context), MTSAM consistently achieved the best average performance as measured by the $\Delta_b$ metric (Tables 1, 2, 3). For instance, on NYUv2, MTSAM yielded a $\Delta_b$ of +23.93% with only 59.59 MB of trainable parameters, outperforming full fine-tuning (+14.57% with 1222.47 MB) and all other baselines. This demonstrates that MTSAM not only achieves superior performance but also does so with remarkable parameter efficiency, offering significant advantages in storage and practical application.
-
ToRA's Effectiveness in Leveraging Shared and Specific Information: The comparison between ToRA and LoRA-based methods (LoRA-HPS, LoRA-STL, MultiLoRA) is crucial. LoRA-HPS, which uses a single shared LoRA matrix, often suffers from task competition. LoRA-STL, which uses task-specific LoRAs, performs better than LoRA-HPS, highlighting the importance of task-specific components. However, ToRA consistently outperforms both LoRA-STL and LoRA-HPS (Tables 1, 2, 3, 7). This hard evidence substantiates the theoretical claim that ToRA effectively leverages both task-shared and task-specific information through its low-rank tensor decomposition, leading to improved overall performance. The qualitative results (Figures 5-11) further reinforce this, showing MTSAM with ToRA producing visibly more accurate predictions, especially for challenging "vague and slender objects," compared to other LoRA variants.
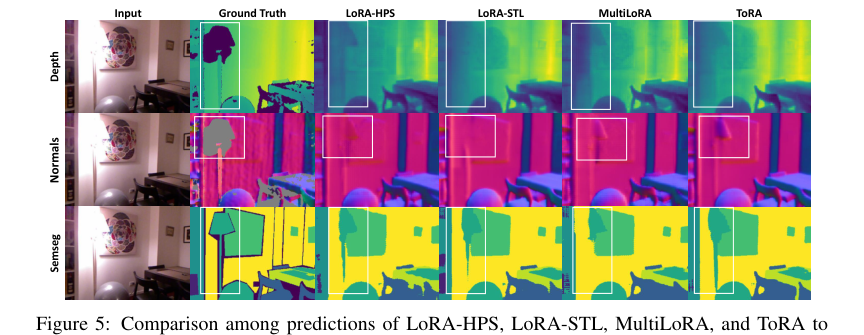 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
-
Impact of Architectural Modifications:
- Task Embeddings: An ablation study (Table 8) clearly shows that the proposed task embeddings are more effective than simply modifying the MLP output dimensions for different tasks. This improvement is attributed to the cross-attention mechanism, which facilitates better learning of task-specific knowledge through interaction between task embeddings and image features.
- Orthogonal Regularization: The ablation study on orthogonal regularization (Table 5) demonstrates its positive impact. MTSAM with full orthogonal regularization on $G$, $U_1$, and $U_2$ significantly outperforms variants without it, proving its effectiveness in improving performance across various tasks by reducing redundancy.
-
Robustness to Hyper-parameter Settings: The sensitivity analysis regarding the hyper-parameter $\lambda$ (orthogonal regularization weight) in Table 6 indicates that MTSAM's performance is not highly sensitive to $\lambda$ within a reasonable range (e.g., [0.5, 1.5]). This suggests that the model is relatively robust and easier to tune, which is a practical advantage.
Limitations & Future Directions
While MTSAM demonstrates impressive capabilities, particularly in multi-task fine-tuning of foundation models like SAM, the paper also highlights several limitations and opens up exciting avenues for future research.
One notable limitation pertains to zero-shot generalization across significantly different data distributions. The authors explored MTSAM's ability to perform zero-shot depth estimation on the CityScapes dataset after being trained solely on NYUv2 (Figure 12). While it shows some capacity to handle unseen data, the results indicate inaccuracies, particulary for distant objects. This is attributed to the inherent differences between the datasets: NYUv2 consists of indoor images, while CityScapes features outdoor urban scenes, leading to discrepancies in depth distribution, object types, resolution, and even the hardware used for ground-truth depth predictions. This suggests that while MTSAM can adapt, large domain shifts still pose a significant challenge, and its zero-shot transferability is not universally robust across vastly dissimilar environments.
Looking ahead, the findings in this paper present several compelling discussion topics for further development and evolution:
-
Enhanced Domain Adaptation for Zero-Shot Multi-Tasking: Given the observed limitations in zero-shot transfer across disparate domains, a critical future direction is to integrate more sophisticated domain adaptation techniques directly into the MTSAM framework. Could adversarial training, meta-learning for domain generalization, or more advanced prompt engineering strategies be combined with ToRA to improve performance on unseen, out-of-domain tasks? Exploring how to explicitly model and mitigate domain gaps within the tensor decomposition could be a fruitful area.
-
Dynamic ToRA Rank and Task Weight Allocation: Currently, ToRA's ranks ($p, q, v$) and task loss weights ($w_i$) are set as fixed hyper-parameters. Future work could investigate dynamic methods for adjusting these parameters during training. For instance, could an adaptive mechanism learn optimal ranks for each task or layer, similar to how some PEFT methods dynamically adjust ranks? Similarly, dynamic task weighting strategies, perhaps based on task uncertainty or gradient conflicts, could further enhance the model's ability to balance and optimize performance across diverse tasks, moving beyond the fixed weights used in this study.
-
Extending ToRA to Other Foundation Models and Modalities: The paper focuses on SAM for image segmentation tasks. A natural extension is to apply the MTSAM framework and ToRA to other large foundation models in different modalities, such as large language models (LLMs) or multi-modal models that integrate vision and language. How would ToRA perform in fine-tuning LLMs for various NLP tasks, or in adapting multi-modal models for tasks requiring cross-modal understanding? This could reveal new insights into the generalizability and scalability of tensorized low-rank adaptation.
-
Theoretical Deep Dive into Expressive Power and Generalization: While Theorem 1 proves ToRA's superiority over multiple LoRAs in terms of parameter efficiency, a deeper theoretical analysis of its expressive power and generalization bounds in complex multi-task, multi-domain scenarios would be valuable. Can we formally characterize the conditions under which ToRA's tensor decomposition optimally captures task-shared and task-specific information, and how this relates to the underlying task relatedness? This could lead to more principled design choices for future multi-task PEFT methods.
-
Efficiency in Deployment and Inference: The paper mentions that ToRA introduces no additional latency during inference, as the updated parameter matrix can be pre-stored. However, as the number of tasks grows, the storage of task-specific updated weights ($W_t = W_0 + \Delta W_t$) could still become substantial. Future work could explore strategies for even more compact storage or on-the-fly reconstruction of $\Delta W_t$ during inference, especially in resource-constrained environments, to further enhance the practical utility of MTSAM.
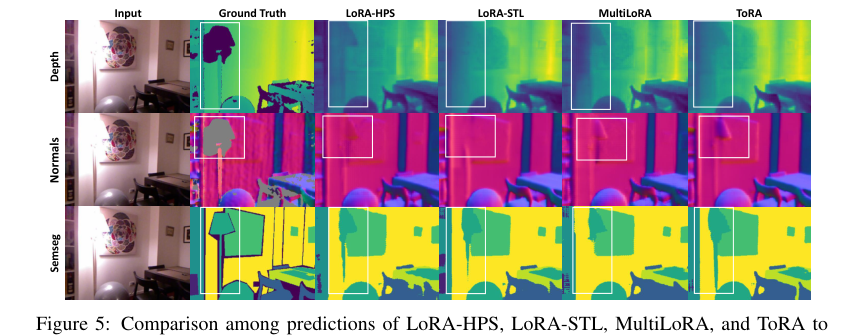 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
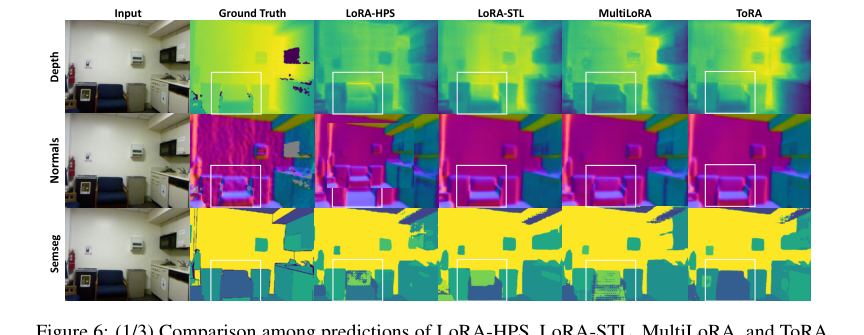 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset