MTSAM:面向分割任意模型的任务微调
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has the potential to be a foundation model for multi-task learning.
背景与学术渊源
起源与学术谱系
本文所解决的问题源于人工智能领域,特别是在计算机视觉领域,大型基础模型(foundation models)的最新涌现及其卓越能力。历史上,基础模型首先以其令人印象深刻的零样本(zero-shot)能力革新了自然语言处理(NLP)。零样本能力意味着模型能够执行它们未被明确训练过的任务。这种成功激发了在计算机视觉领域开发类似模型的灵感。
分割任意模型(Segment Anything Model, SAM)由 Kirillov 等人于 2023 年提出,是图像分割领域一个杰出的基础模型。SAM 在海量的 1100 万个样本数据集上进行训练后,展现了卓越的零样本性能,能够分割图像中的几乎任何物体。这一突破促使了大量研究探索 SAM 在各种下游任务中的应用,例如高质量分割、三维重建、物体跟踪、医学图像处理、个性化分割和遥感。
然而,这些先前方法的根本性局限性或“痛点”在于,它们仅将 SAM 用于单任务学习。这意味着对于每个新任务,SAM 都需要独立进行微调,而忽略了其作为多任务学习(MTL)统一基础模型的潜力。在许多现实世界的计算机视觉场景中,多个任务本质上是相关的,并且通常需要同时解决(例如,场景理解中的深度估计和表面法线估计)。MTL 的先前研究一贯表明,任务可以通过共同学习而受益,因为共享的知识可以提高整体性能和效率。
本文具体指出了将 SAM 适配于多任务学习的两个核心挑战:
1. 输出维度不匹配(Output Dimensionality Mismatch):原始 SAM 被设计用于生成分割掩码,通常具有固定的输出通道数(例如,如图 1a 所示,有三个不同的级别,但通道数相同)。然而,不同的下游任务需要不同维度的输出(例如,深度估计可能需要一个通道,而表面法线预测需要三个)。SAM 的架构本身不够灵活,无法生成具有不同通道数的特定任务输出。
2. 同步微调(Simultaneous Fine-Tuning):目前尚无成熟的方法可以有效地微调 SAM 以同时适应多个下游任务。现有的参数高效微调(PEFT)方法,如低秩自适应(Low-Rank Adaptation, LoRA),主要设计用于单任务自适应。当应用于多任务场景时,这些方法要么难以利用任务间的共享信息(如 LoRA-STL,其中每个任务都有自己的 LoRA),要么因任务竞争共享参数而导致性能不平衡(如 LoRA-HPS)。缺乏针对 SAM 等大型基础模型的稳健多任务微调策略,构成了重大障碍。
作者撰写本文旨在解决这些精确的局限性,提出了多任务 SAM(MTSAM)框架和张量化低秩自适应(ToRA)方法,使 SAM 能够作为多任务学习的多功能基础模型,克服输出维度和同步微调的挑战。
直观的领域术语
-
分割任意模型(Segment Anything Model, SAM):想象一位技艺精湛的数字艺术家,能够完美地勾勒出照片中任何物体的轮廓,无论其多么复杂或陌生。SAM 就像这位艺术家,但对于计算机而言,它能够以惊人的精度从图像中“抠出”物体,即使它从未见过该特定物体。
-
零样本能力(Zero-shot capability):这就像一个非常聪明的学生,他学习了许多事物的普遍原理。如果你给他看一些全新的东西,比如一种他从未见过的稀有水果,他仍然可以根据自己广泛的理解,而无需对该水果进行特定训练,就能很好地猜测它是什么或如何分类。
-
多任务学习(Multi-Task Learning, MTL):想象一位厨师同时学习烹饪几道相关的菜肴——可能是一道主菜、一道配菜和一个酱汁。通过一起学习,厨师可能会发现共同的技术或食材,从而使整体烹饪过程更有效率,最终的餐点也更和谐,而不是孤立地学习每道菜。
-
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT):考虑一位训练有素的专家,比如一位大师级汽车修理工,他知道如何修理多种类型的汽车。如果出现一款新车型,你不需要从头开始重新培训这位修理工,只需教他针对该特定车型进行一些小的、特定的调整或使用新工具。他绝大部分的丰富知识仍然保持不变,使得适应过程快速而高效。
-
低秩自适应(Low-Rank Adaptation, LoRA):基于修理工的比喻,LoRA 就像是为每款新车型给这位大师级修理工提供一份小巧的、专门的“秘籍”。这份秘籍只包含对他们标准程序的少数关键修改,使他们能够调整技能,而无需重新学习整辆车的工程原理。这是一种用很少的新信息就能进行重大改变的巧妙方法。
符号表
| 符号 | 描述 |
|---|---|
| $I$ | 输入图像,尺寸为 $3 \times H \times W$(通道、高度、宽度)。 |
| $H, W$ | 输入图像的高度和宽度。 |
| $F_I$ | SAM 图像编码器提取的图像特征,尺寸为 $D \times \frac{H}{16} \times \frac{W}{16}$。 |
| $D$ | 模型中隐藏状态的维度。 |
| $O$ | 原始 SAM 的最终分割掩码输出,尺寸为 $3 \times \frac{H}{4} \times \frac{W}{4}$。 |
| $T$ | 正在学习的总不同任务数。 |
| $\Delta W$ | 单个层的通用更新参数矩阵,尺寸为 $d \times k$。 |
| $W_0$ | 层的预训练参数矩阵,尺寸为 $d \times k$。 |
| $A, B$ | LoRA 中使用的低秩矩阵,其中 $B \in \mathbb{R}^{d \times r}$ 且 $A \in \mathbb{R}^{r \times k}$。 |
| $r$ | LoRA 中低秩矩阵的秩,其中 $r \ll \min(d, k)$。 |
| $\Delta \mathcal{W}$ | ToRA 的更新参数张量,将所有特定任务的更新汇总为一个 $d \times k \times T$ 的张量。 |
| $G$ | ToRA 的 Tucker 分解中的核心张量,尺寸为 $p \times q \times v$。 |
| $U_1, U_2, U_3$ | ToRA 的 Tucker 分解中的因子矩阵,尺寸分别为 $d \times p$、$k \times q$ 和 $T \times v$。 |
| $p, q, v$ | ToRA 因子矩阵的维度,通常远小于 $d, k, T$。 |
| $E_t$ | 特定任务 $t$ 的可训练任务嵌入,尺寸为 $N_t \times D$。 |
| $N_t$ | 任务 $t$ 所需的输出通道数。 |
| $O_t$ | MTSAM 为任务 $t$ 生成的输出预测,尺寸为 $N_t \times \frac{H}{4} \times \frac{W}{4}$。 |
| $\mathcal{L}_{MTL}$ | 整体多任务学习目标函数,MTSAM 旨在最小化该函数。 |
| $\lambda$ | 控制正交正则化项影响的超参数。 |
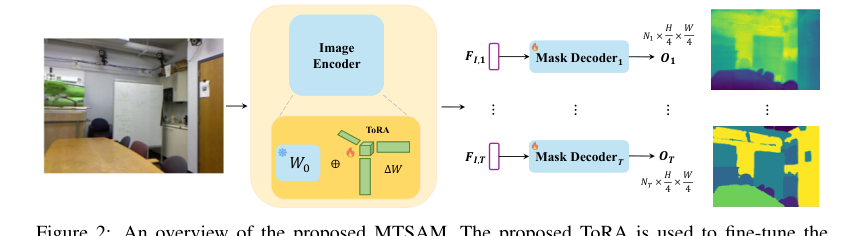 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
问题定义与约束
核心问题表述与困境
分割任意模型(SAM)已成为图像分割领域强大的基础模型,以其零样本泛化能力而闻名。本文要解决的核心问题是如何有效地将 SAM 转化为多任务学习(MTL)的基础模型。
输入/当前状态:
起点是原始 SAM,它接收图像 $I \in \mathbb{R}^{3 \times H \times W}$ 和各种提示(例如点、边界框或掩码)作为输入。其架构包括一个重量级的图像编码器、一个提示编码器和一个轻量级的掩码解码器。原始 SAM 被设计用于生成分割掩码,通常具有固定的输出通道数(例如,在第 4 页的公式 3 中看到的 3 个通道,以及第 2 页图 1a 中所示)。
期望终点(输出/目标状态):
期望的终点是一个修改后的 SAM,称为多任务 SAM(MTSAM),它能够:
1. 生成具有不同维度的特定任务输出:例如,从单个输入同时生成用于深度估计的 1 通道输出、用于语义分割的 13 通道输出以及用于表面法线预测的 3 通道输出(图 1b,第 2 页)。
2. 通过微调同时适应多个下游任务:这种适应应利用任务间的共享信息来提高整体性能,而不是孤立地处理每个任务。
缺失环节与数学鸿沟:
当前状态与期望状态之间的确切缺失环节或数学鸿沟是双重的:
1. 用于多样化输出的架构不灵活性:原始 SAM 的掩码解码器在架构上受限于生成固定通道数的输出,这使其不适用于需要不同输出维度的任务。没有固有的机制可以根据特定任务动态调整输出通道数。
2. 低效的多任务微调:缺乏一种稳健且参数高效的方法来同时微调 SAM 的大型编码器以适应多个任务,同时有效地平衡任务共享和任务特定的知识。现有的参数高效微调(PEFT)方法(如 LoRA)在应用于 MTL 时,要么过于简化,共享参数过于广泛(LoRA-HPS),导致因任务竞争共享参数而产生性能妥协,要么过于任务特定(LoRA-STL),未能利用有益的任务间信息共享。
困境:
困扰先前研究人员的核心困境是大型基础模型在多任务学习中参数效率与表达能力/性能之间的痛苦权衡。
* 对 SAM 这样的重量级模型进行多任务的完全微调在计算上是不可行的,并且参数效率低下。
* 将现有的 PEFT 方法 naively 应用于 MTL 会带来一个困境:
* 硬参数共享(LoRA-HPS):这种方法是参数高效的,因为它为所有任务使用一个共享的 LoRA 矩阵。然而,它常常导致“由于任务竞争共享 LoRA 而在所有任务上表现不平衡”(第 4 页)。它难以捕捉任务特定的细微差别,实际上是以牺牲性能为代价换取效率。
* 任务特定 LoRA(LoRA-STL):这种方法为每个任务训练一个单独的 LoRA 模块,允许任务特定的适应,并可能获得更好的单个任务性能。然而,其参数数量随任务数量线性增长($O(Trd+Trk)$,第 6 页),对于大量任务来说效率较低。至关重要的是,它“无法利用跨多个任务进行微调所需的任务间共享信息”(第 4 页),因此错失了 MTL 的协同效益。
挑战在于设计一种方法,既参数高效(参数随任务数量亚线性增长),又能同时捕捉任务共享的通用知识和任务特定的细节,从而克服现有 PEFT 策略在多任务设置中的局限性。
约束与失败模式
将 SAM 适配于多任务学习的问题因作者遇到的几个严峻的现实壁垒而变得异常困难:
- 硬件内存和计算限制:SAM 的图像编码器被描述为“重量级”(第 3 页)。同时微调如此庞大的模型以适应多个任务将需要巨大的计算资源和内存,使得完全微调不切实际。此约束要求使用参数高效的方法。
- 固定输出通道约束:原始 SAM 的掩码解码器被硬编码为生成固定数量通道的输出(例如,3 个用于分割)。这种架构上的僵化阻止了它直接生成不同任务所需的具有不同通道数的输出,如深度估计(1 通道)或多类语义分割(例如,13 通道)。这是一个需要克服的基本架构限制。
- 无法平衡任务共享和任务特定学习:先前的 PEFT 方法在应用于 MTL 时,未能有效平衡通用、任务共享特征的学习与特定、任务依赖的适应。LoRA-HPS 受制于任务竞争,而 LoRA-STL 无法利用任务间共享信息(第 4 页)。这导致次优性能或低效的参数使用。
- 最优近似的张量分解复杂性:虽然张量分解是一种强大的数学工具,但在多任务学习的背景下,找到复杂目标的“最佳近似”本身就极具挑战性,并且“可能并不总是存在”(Kolda & Bader, 2009,引用自第 7 页)。这暗示了保证低秩张量自适应理论最优性的潜在困难。
- 任务间数据异质性:不同任务通常涉及不同的数据分布、语义含义和输出格式。例如,深度估计和语义分割需要不同的地面真实数据和评估指标。模型必须足够鲁棒,能够处理这种固有的多样性而不损害任何单个任务的性能。
- 无实时延迟要求(隐含):虽然本文没有明确将其列为作者遇到的约束,但参数效率的目标以及“推理过程中不引入额外延迟”(第 6 页)的声明暗示了对高效推理的隐含需求,这在实际应用中通常至关重要。模型的复杂性不应显著增加推理时间。
为什么选择此方法
选择的必然性
分割任意模型(SAM)作为强大的基础模型出现,展示了卓越的图像分割零样本能力。然而,其直接应用于多任务学习遇到了两个根本性的架构障碍,而传统的“SOTA”方法,包括原始 SAM 本身,都难以应对。当考虑多任务学习的核心需求时,作者对这些不足的认识变得清晰:(a) 需要生成具有不同通道数的特定任务输出(例如,深度估计为 1 通道,表面法线预测为 3 通道,语义分割为多个通道),以及 (b) 同时高效地微调 SAM 以适应多个下游任务的挑战。
原始 SAM 按设计会生成不同级别的分割掩码,但关键在于,所有这些输出都具有相同的通道数。当深度估计或表面法线预测等任务需要不同输出结构时,这种固定的输出维度是一个严重的限制。本文明确指出,“尽管 SAM 作为基础视觉模型展现出巨大的潜力,但其依赖于提示引导的掩码生成,在实现端到端适应具有不同输出通道数的下游任务方面存在挑战。”这正是作者认识到 SAM 的固有架构,特别是其提示编码器和掩码解码器,对于多样化的多任务输出不够灵活的时刻。因此,直接应用 SAM 或现有的单任务微调方法对于真正多任务的基础模型来说是不可行的。
相对优势
提出的多任务 SAM(MTSAM)框架,特别是其张量化低秩自适应(ToRA)方法,在参数效率和信息利用方面,相对于之前的黄金标准,展现出压倒性的定性和结构优势。
首先,ToRA 最显著的结构优势在于其参数效率。当应用于 $T$ 个任务时,传统的低秩自适应(LoRA)方法,无论是使用硬参数共享(LoRA-HPS)还是任务特定 LoRA(LoRA-STL),都表现出参数复杂度随任务数量线性增长,通常为 $O(Trd + Trk)$。相比之下,ToRA 将所有任务的更新参数矩阵汇总到一个更新参数张量 $\Delta W \in \mathbb{R}^{d \times k \times T}$ 中,并应用低秩张量分解(特别是 Tucker 分解)。这导致参数复杂度为 $O(dp + kq)$,其中 $p, q, v \ll \min(d, k)$ 且 $T$ 是任务数量。这代表了可学习参数相对于任务数量的亚线性增长,使其在扩展到大量任务时具有显著的效率优势。内存复杂度的降低对于微调 SAM 这样的大型基础模型来说是革命性的。
其次,ToRA 在定性上超越了其他方法,因为它能有效地捕捉任务共享和任务特定的信息。LoRA-HPS 通过在所有任务之间共享一个 $\Delta W$,难以处理任务竞争,常常导致性能不平衡。LoRA-STL 则为每个任务训练单独的 $\Delta W_t$,完全忽略了宝贵的任务间共享信息。ToRA 使用 Tucker 分解,允许核心张量 $G$ 和因子矩阵 $U_1, U_2, U_3$ 显式地建模任务共享信息的主要子空间变化(通过 $U_1$ 和 $U_2$)以及任务特定的子空间结构(通过 $U_3$)。这种对信息共享和专业化的整体方法是增强跨不同任务的微调性能的关键结构优势。定理 1 中的理论分析进一步证实了这一点,证明了 ToRA 具有更强的表达能力,并且与多个 LoRA 相比,可以用更少的参数实现相同的权重更新。
最后,定性评估(例如图 5)表明,使用 ToRA 微调的 MTSAM 生成的结果更准确,尤其是在“模糊和细长的物体”方面。这表明 ToRA 分离和利用共享及特定信息的能力导致对视觉场景更鲁棒和细致的理解,在其他方法可能难以处理精细细节或复杂物体边界的挑战性场景中提高了性能。
与约束的对齐
选择的 MTSAM 框架,通过其架构修改和 ToRA 微调方法,完美地符合了将 SAM 适配于多任务学习所识别的两个主要约束。
-
约束:生成具有不同通道数的特定任务输出。
- 解决方案的特性:MTSAM 通过根本性地改变 SAM 的掩码解码器来解决此问题。它移除了原始的提示编码器,并引入了特定任务的无掩码嵌入和专用的特定任务掩码解码器。如图 1 和图 3 所示,此修改使 MTSAM 能够生成为每个任务量身定制的输出($N_t \times H \times W$ 尺寸),而不是 SAM 的固定通道输出。例如,它可以为深度输出 1 通道,为表面法线输出 3 通道,或为语义分割输出 13 通道,直接满足了多样化输出结构的需求。引入可训练的任务嵌入 $E_t$ 进一步确保解码器可以根据手头的特定任务调整其处理。这是问题对输出灵活性的需求与解决方案的模块化、任务感知解码器设计之间的直接“结合”。
-
约束:同时高效地微调 SAM 以适应多个下游任务。
- 解决方案的特性:ToRA 是此约束的核心创新。它将更新参数张量注入 SAM 编码器的每个层,并采用低秩张量分解来捕捉任务共享和任务特定的信息。这使得模型能够同时从多个任务中学习,利用它们之间的相互依赖性,同时也允许任务特定的适应。ToRA 的参数效率,其参数相对于任务数量的亚线性增长,对于在没有高昂计算成本或内存占用的情况下微调 SAM 这样的重量级基础模型至关重要。这种效率确保了同步适应不仅是可能的,而且是实用的,使其完美契合大规模多任务学习的严苛要求。整体损失函数中的正交正则化项($L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$)进一步确保了学习到的因子矩阵是良好行为且无冗余的,有助于多任务微调过程的稳定性和有效性。
替代方案的拒绝
本文提供了明确的理由来拒绝几种替代方法,主要侧重于现有的参数高效微调(PEFT)方法以及在多任务环境中应用 LoRA 的不同策略。
-
传统 PEFT 方法(例如,基于 Adapter 的、Prompt Tuning、现有的单任务 LoRA 变体):作者明确指出,虽然这些方法“在单任务微调中实现了具有竞争力的性能和高参数效率”,但它们“不适用于多任务学习场景,因为它们不考虑多个任务之间的共享信息。” 这是对无法内在利用协同效应或管理同时学习多个任务所产生的冲突的方法的全面拒绝。它们的设计根本上是为了优化一个任务而设计的,这与多任务学习的目标背道而驰。
-
LoRA-HPS(硬参数共享):该方法试图通过为所有任务使用一个共享的 LoRA 矩阵($\Delta W$)来实现多任务学习。本文拒绝了这种方法,因为它“可能由于任务竞争共享 LoRA 而在所有任务上表现不平衡。” 当任务具有冲突的梯度或不同的学习动态时,强迫它们共享一个单一的、无差别的更新矩阵可能会降低某些或所有任务的性能。
-
LoRA-STL(单任务 LoRA):这种替代方法为每个任务训练一个单独的 LoRA 矩阵($\Delta W_t$)。本文拒绝了这种方法,因为它“无法利用跨多个任务进行微调所需的任务间共享信息。” 虽然它避免了 LoRA-HPS 的竞争问题,但它未能利用跨相关任务的共享知识和共同特征的潜在好处,而这正是多任务学习的核心原则。这使得它比能够智能共享信息的模型效率更低,性能也可能更差。
-
完全微调:尽管没有像其他 PEFT 方法那样被强烈“拒绝”,但本文因“参数和计算效率方面的考虑”而隐含地否定了对 SAM 重量级图像编码器的完全微调。表 7 定量地支持了这一拒绝,显示完全微调需要大量的 1222.47 MB 可训练参数,远高于 MTSAM 的 59.59 MB,同时整体性能提升较低(完全微调的 $\Delta_b$ 为 +14.57%,而 MTSAM 为 +23.93%)。这使得完全微调对于大型基础模型和效率至关重要的多任务场景来说不切实际。巨大的参数量使其计算成本高昂,并且容易在较小的多任务数据集上过拟合。
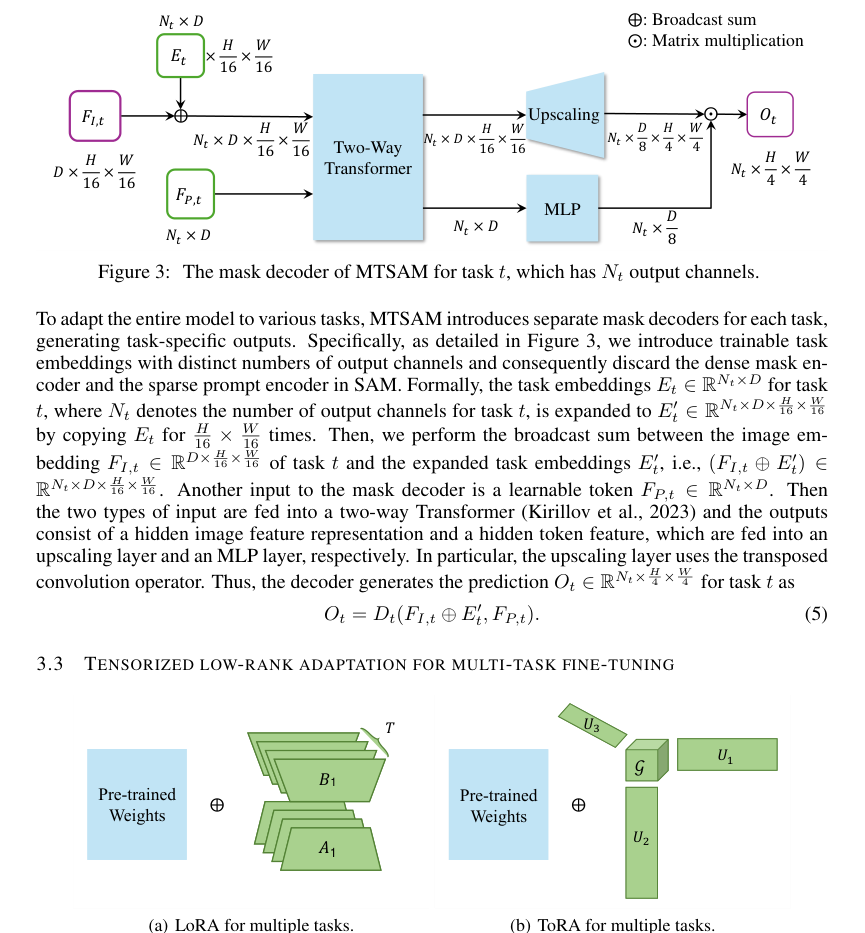 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
数学与逻辑机制
核心方程
MTSAM 框架学习过程的绝对核心是其整体目标函数,它将多任务学习损失与正则化项相结合,以确保高效且有效的参数更新。这个核心方程指导了整个训练过程:
$$ L_{total} = L_{MTL} + \lambda R(U_1, U_2, G) $$
该方程概括了模型如何同时从多个任务中学习,同时保持参数效率并通过张量分解和正则化来防止冗余。
项的逐一剖析
让我们剖析核心方程及其组成部分,以理解它们的数学定义、物理/逻辑作用以及作者的设计选择。
-
$L_{total}$:这是 MTSAM 框架在训练期间旨在最小化的总目标函数。它的作用是在所有任务的性能与参数更新的效率和结构完整性之间取得平衡。作者使用加法来组合多任务损失和正则化项,因为这是需要同时优化的两个独立目标:最小化任务误差和维护结构良好、低秩的参数空间。
-
$L_{MTL}$:这一项代表多任务学习(MTL)损失。它是所有个体任务加权损失的平均值。
$$ L_{MTL} = \frac{1}{T} \sum_{i=1}^T w_i L_i $$- $T$:这是 MTSAM 模型正在训练的总不同任务数(例如,语义分割、深度估计、表面法线预测)。它的作用是归一化个体任务损失的总和,提供跨所有任务的平均损失。这里使用求和是因为整体多任务目标是各个任务目标的复合。
- $w_i$:这是任务 $i$ 的损失权重。它是一个超参数,控制每个任务损失在整体多任务目标中的相对重要性。例如,一个被认为更关键或更难的任务可能会获得更高的权重。作者使用乘法来缩放每个任务对总损失的贡献,从而实现灵活的优先级排序。
- $L_i$:这是任务 $i$ 的损失,计算为该特定任务所有训练样本的平均损失。
$$ L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j, f(x_j)) $$- $N_i$:这表示任务 $i$ 的训练样本数。它的作用是平均样本损失,确保任务的损失不会因其样本数量而产生不成比例的影响。求和聚合了来自个体样本的损失,除以 $N_i$ 得到平均损失。
- $l_i(\cdot, \cdot)$:这是任务 $i$ 的特定损失函数。其数学定义取决于任务 $i$ 的性质(例如,分割的交叉熵,深度估计的 L1 损失,表面法线的余弦相似度)。它的作用是量化模型预测与单个样本的地面真实值之间的差异。
- $y_j$:这是任务 $i$ 的第 $j$ 个训练样本的地面真实标签。它代表模型应该产生的正确输出。
- $f(x_j)$:这代表任务 $i$ 的第 $j$ 个训练样本 $x_j$ 的MTSAM 模型预测。函数 $f(\cdot)$ 体现了整个 MTSAM 架构,包括图像编码器和特定任务的掩码解码器,后者包含了经过 ToRA 修改的权重。
- $x_j$:这是输入训练样本(例如,图像),用于进行预测 $f(x_j)$。
-
$\lambda$:这是一个超参数,控制正交正则化项 $R(U_1, U_2, G)$ 的影响。它的作用是平衡最小化任务特定误差与强制执行 ToRA 参数所需的低秩、正交结构之间的权衡。较大的 $\lambda$ 会更强调正则化。作者使用乘法来缩放正则化对总损失的贡献。
-
$R(U_1, U_2, G)$:这是正交正则化项。它鼓励因子矩阵 $U_1, U_2$ 和核心张量 $G$ 的切片是正交的,这有助于减少冗余并提高张量分解的稳定性。
$$ R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^v ||G(:,:,l)^T G(:,:,l) - I||_F^2 $$- $U_1$:这是一个维度为 $d \times p$ 的因子矩阵。它捕捉了与更新参数张量 $\Delta W$ 的输出特征维度相对应的任务共享信息的主要子空间变化。
- $U_2$:这是一个维度为 $k \times q$ 的因子矩阵。它捕捉了与更新参数张量 $\Delta W$ 的输入特征维度相对应的任务共享信息的主要子空间变化。
- $G$:这是维度为 $p \times q \times v$ 的核心张量。它代表了张量 $\Delta W$ 经过分解后的压缩低秩表示。它包含了共享和特定信息的“本质”。
- $||\cdot||_F^2$:这表示 Frobenius 范数平方。数学上,对于矩阵 $A$, $||A||_F^2 = \sum_{i,j} |A_{i,j}|^2$。它的作用是量化偏离正交性的“大小”或幅度。平方确保值非负,并更重地惩罚较大的偏差。
- $I$:这是适当大小的单位矩阵。在 $U^T U - I$ 等项中,它的作用是作为正交性的目标:如果 $U^T U = I$,则 $U$ 是正交的。
- $U_1^T U_1 - I$:这一项衡量了$U_1$ 偏离正交性的程度。最小化其 Frobenius 范数平方迫使 $U_1$ 接近正交矩阵。
- $U_2^T U_2 - I$:与 $U_1$ 类似,这一项衡量了$U_2$ 偏离正交性的程度。
- $G(:,:,l)^T G(:,:,l) - I$:这一项衡量了核心张量 $G$ 的第 $l$ 个正面切片偏离正交性的程度。$G(:,:,l)$ 指的是通过固定第三个模式(任务轴)为 $l$ 而形成的矩阵。这确保了核心张量在任务维度上的正交性。求和 $\sum_{l=1}^v$ 将这些正交性约束聚合到核心张量的所有切片上。作者使用加法来组合这些个体正交性约束,因为每个约束都独立地为减少冗余的总体目标做出贡献。
$L_{MTL}$ 操作的核心是张量化低秩自适应(ToRA)方法,它定义了模型权重的更新方式。ToRA 使用 Tucker 分解来参数化更新参数张量 $\Delta W$:
$$ \Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3 $$
- $\Delta W$:这是维度为 $d \times k \times T$ 的更新参数张量。它代表了所有任务的预训练权重变化的集合。每个切片 $\Delta W(:,:,t)$ 是任务 $t$ 的更新矩阵。它的作用是高效地将冻结的预训练模型适配到多个下游任务。作者选择张量来表示多个任务的更新,因为它自然地捕捉了任务共享和任务特定信息的多维性质。
- $G$:这是核心张量(如上定义),维度为 $p \times q \times v$。它包含了张量最重要的组成部分,充当压缩表示。
- $U_1$:这是模式 1(输出特征维度)的因子矩阵,维度为 $d \times p$。它沿着第一个模式变换核心张量。
- $U_2$:这是模式 2(输入特征维度)的因子矩阵,维度为 $k \times q$。它沿着第二个模式变换核心张量。
- $U_3$:这是模式 3(任务维度)的因子矩阵,维度为 $T \times v$。它沿着第三个模式变换核心张量,允许分解捕捉任务特定的变化。
- $\times_n$:这表示n-模式乘积。数学上,$A \times_n B$ 表示张量 $A$ 沿其 $n$ 模式与矩阵 $B$ 相乘。它的作用是使用因子矩阵 $U_1, U_2, U_3$ 将核心张量 $G$ “展开”或投影回完整的 $\Delta W$ 张量。此运算符是张量分解的基础,允许从核心张量和几个矩阵中重构高阶张量。
最后,对于给定任务 $t$,这些更新在模型前向传播中的实际应用是:
$$ h = W_0x + \Delta W(:,:,t)x $$
- $h$:这是 SAM 编码器中应用 ToRA 更新后层的输出。
- $W_0$:这是 SAM 编码器中层的原始预训练权重矩阵。在微调期间保持冻结。
- $\Delta W(:,:,t)$:这是任务 $t$ 的更新矩阵,它是完整 $\Delta W$ 张量的第 $t$ 个切片。它的作用是为预训练权重提供特定任务的调整。
- $x$:这是 SAM 编码器中层的输入。
- 这里的加法运算符表示 ToRA 更新是预训练权重的加性修改,这是像 LoRA 这样的 PEFT 方法中的常见做法。
分步流程
想象一个单一的抽象数据点,一张图像 $x_j$,它将踏上 MTSAM 框架为特定任务 $t$ 进行处理的旅程。
-
图像编码(冻结基础):旅程始于输入图像 $x_j$ 进入 SAM 的重量级图像编码器 $E_1$。关键在于,$E_1$ 的参数是冻结的。这意味着 SAM 预训练期间学到的基础知识得以保留。编码器输出一组图像特征 $F_1$。
-
ToRA 注入(自适应层):当 $F_1$ 在图像编码器内的自注意力模块中传播时,它会遇到 ToRA 机制。对于每一层,不是直接使用原始预训练权重矩阵 $W_0$,而是通过一个自适应权重矩阵 $W'$ 来处理该层的输入 $x$。这个 $W'$ 有效地是 $W_0 + \Delta W(:,:,t)$。$\Delta W(:,:,t)$ 组件是使用核心张量 $G$ 和因子矩阵 $U_1, U_2, U_3$ 通过张量分解 $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$ 为任务 $t$ 动态构建的。这意味着对于每个任务 $t$,都会对冻结的权重应用一个独特的、低秩的更新,从而在不改变其绝大多数参数的情况下,巧妙地引导模型的行为以满足特定任务的要求。
-
特定任务解码(输出生成):经过 ToRA 自适应的图像特征(现在已隐式地针对任务 $t$ 进行定制)随后被馈送到特定任务的掩码解码器 $D_t$。该解码器还接收一个可训练的任务嵌入 $E_t$(扩展以匹配特征维度)和一个可学习的 token $F_{P,t}$。任务嵌入 $E_t$ 与图像特征 $F_{1,t}$(从 $F_1$ 导出并可能针对任务 $t$ 进一步处理)进行广播求和。这些组合特征以及可学习的 token,通过一个双向 Transformer、一个上采样层和一个 MLP 层。整个过程生成具有适合任务 $t$ 的适当通道数的特定任务输出 $O_t$(例如,分割掩码、深度图或表面法线)。
-
损失计算(性能衡量):为任务 $t$ 生成的样本 $x_j$ 的输出 $O_t$ 然后使用特定任务的损失函数 $l_t$ 与其对应的地面真实标签 $y_j$ 进行比较。这将产生 $l_t(y_j, f(x_j))$,这是模型在该特定样本上针对任务 $t$ 表现的衡量标准。
-
多任务聚合(集体误差):这个个体样本损失 $l_t(y_j, f(x_j))$ 贡献到总任务损失 $L_t$ 中。对于任务 $t$ 的所有样本,它们的损失被平均以形成 $L_t$。然后,将 $L_t$ 按权重 $w_t$ 加权,并与其他所有任务的加权损失合并,以计算总多任务学习损失 $L_{MTL}$。
-
正则化(结构完整性):同时,可训练的 ToRA 组件($U_1, U_2, G$)的当前状态会根据正交正则化项 $R(U_1, U_2, G)$ 进行评估。该项惩罚了这些矩阵和核心张量切片偏离正交性的情况。
-
总目标(统一目标):最后,$L_{MTL}$ 和缩放后的正则化项 $\lambda R(U_1, U_2, G)$ 相加形成 $L_{total}$ 目标函数。这个单一值代表了模型需要最小化的总体“成本”或误差。
优化动力学
MTSAM 框架通过由最小化 $L_{total}$ 目标函数驱动的迭代优化过程来学习和更新其参数。
-
参数初始化:在训练开始时,核心张量 $G$ 被初始化为全零。这确保了最初,ToRA 更新 $\Delta W(:,:,t)$ 也为零,这意味着模型最初仅依赖于冻结的预训练权重 $W_0$。因子矩阵 $U_1, U_2, U_3$ 从标准高斯分布中随机初始化。这种随机初始化为探索参数空间提供了一个起点。
-
梯度计算:在每个训练迭代中,在计算了所有任务批次数据的 $L_{total}$ 后,采用Adam 优化器来计算梯度。梯度是相对于可训练参数计算的:因子矩阵 $U_1, U_2, U_3$、核心张量 $G$ 以及图像编码器层归一化层中的缩放和偏置参数。至关重要的是,图像编码器的原始预训练权重 $W_0$ 是冻结的,这意味着没有梯度流经它们,从而显著减少了可训练参数的数量和计算成本。
-
损失景观塑造:损失景观由多任务学习损失($L_{MTL}$)和正交正则化项($R$)之间的相互作用塑造。
- $L_{MTL}$ 驱动模型提高所有任务的性能。没有正则化,这个景观可能很复杂,可能导致任务之间出现冲突的梯度或过拟合。
- 正则化项 $R$ 充当结构约束。通过惩罚 $U_1, U_2, G$ 中的非正交性,它鼓励更新参数更紧凑、冗余度更低。这可能导致更平滑的损失景观,可能通过防止模型学习高度相关或冗余的特征来辅助收敛并提高泛化能力。作者的理论分析表明,这种低秩、正交结构使得 ToRA 能够以比 LoRA 更少的参数实现卓越的表达能力。
-
迭代更新:Adam 优化器使用计算出的梯度来迭代更新可训练参数($U_1, U_2, U_3, G$ 和层归一化参数)。更新使用初始学习率 $10^{-3}$ 进行,然后由具有 0.05 预热率的线性学习率调度器进行调整。还应用了 $10^{-6}$ 的权重衰减以防止过拟合。这些迭代更新逐渐精炼 ToRA 组件,使其能够学习任务共享和任务特定的信息。
-
收敛:训练过程持续预设的 epoch 数(例如,NYUv2 为 200)。随着参数的更新,$L_{total}$ 预计会下降,表明模型正在学习在执行任务的同时保持所需的低秩结构。目标是收敛到一组最小化 $L_{total}$ 的参数,从而提高多任务性能和参数效率。在推理过程中,每个任务 $t$ 的学习到的 $\Delta W(:,:,t)$ 会被预先计算并添加到 $W_0$ 中形成 $W_t'$,因此没有额外的延迟。这种巧妙的设计确保了微调的好处不会以更慢的预测时间为代价。
结果、局限性与结论
实验设计与基线
为了严格验证提出的多任务 SAM(MTSAM)框架及其核心组件张量化低秩自适应(ToRA),作者在三个公认的基准数据集上进行了广泛的实验:NYUv2、CityScapes 和 PASCAL-Context。这些数据集代表了多样化的计算机视觉场景,包括室内场景(NYUv2)和城市户外环境(CityScapes, PASCAL-Context),并涉及多种密集预测任务。
实验设置旨在无情地证明 MTSAM 在处理不同输出维度和高效微调以同时适应多个任务方面的数学声明。与 MTSAM 对比的“受害者”(基线模型)包括一系列传统的多任务学习(MTL)方法和更近期的参数高效微调(PEFT)方法:
- 基于 CNN 的 MTL 基线:单任务学习(STL)、硬参数共享(HPS)、Cross-Stitch、多任务注意力网络(MTAN)和 NDDR-CNN。这些代表了多任务学习的成熟方法,其中 HPS 为 $\Delta_b$ 指标提供了关键基线。
- 基于 Transformer 的 MTL 基线:VTAGML 和 SwinMTL,反映了当代架构。
- 交叉注意力基线 MTL:DenseMTL。
- 基于 LoRA 的 PEFT 基线:为了专门评估 ToRA 的有效性,作者将其与在多任务环境中直接应用 LoRA 的方法进行了比较:LoRA-STL(任务特定 LoRA)、LoRA-HPS(共享 LoRA)和 MultiLoRA。还与其他先进的 LoRA 变体(如 Terra 和 HydraLoRA)以及整个模型的完全微调进行了比较。
评估的任务因数据集而异:
* NYUv2:13 类语义分割、深度估计和表面法线预测。
* CityScapes:7 类语义分割和深度估计。
* PASCAL-Context:21 类语义分割、7 类人体部位分割、显著性估计和表面法线估计。
性能使用一套标准指标进行量化:
* 语义分割:平均交并比(mIoU)和像素准确率(Pix Acc),值越高越好。
* 深度估计:绝对误差(Abs Err)和相对误差(Rel Err),值越低越好。
* 表面法线预测:角度误差的平均值和中值(越低越好),以及角度误差在 11.25、22.5 和 30 度以内的像素百分比(越高越好)。
* 整体性能:复合指标 $\Delta_b$,表示每个任务相对于 HPS 架构的平均相对改进,值越高表示性能越好。
* 参数效率:可训练参数的数量(Params.),以兆字节(MB)为单位,值越低越高效。
实现细节包括使用 Adam 优化器,学习率为 $10^{-3}$,线性学习率调度器带预热,以及针对每个数据集定制的 ToRA 特定秩设置($p, q, v$)。还应用了由超参数 $\lambda$ 控制的正交正则化。
证据证明了什么
实验结果提供了确凿、不可否认的证据,表明 MTSAM,特别是其 ToRA 组件,显著推进了基础模型的多任务学习。
-
整体优越性和参数效率:在所有三个基准数据集(NYUv2、CityScapes 和 PASCAL-Context)上,MTSAM 在 $\Delta_b$ 指标的衡量下始终实现了最佳平均性能(表 1、2、3)。例如,在 NYUv2 上,MTSAM 以仅 59.59 MB 的可训练参数实现了 +23.93% 的 $\Delta_b$,优于完全微调(1222.47 MB 参数,+14.57%)和所有其他基线。这表明 MTSAM 不仅实现了卓越的性能,而且还以卓越的参数效率实现,在存储和实际应用方面提供了显著优势。
-
ToRA 在利用共享和特定信息方面的有效性:ToRA 与基于 LoRA 的方法(LoRA-HPS、LoRA-STL、MultiLoRA)之间的比较至关重要。使用单个共享 LoRA 矩阵的 LoRA-HPS 通常受制于任务竞争。LoRA-STL 使用任务特定 LoRA,其性能优于 LoRA-HPS,突显了任务特定组件的重要性。然而,ToRA 一贯优于 LoRA-STL 和 LoRA-HPS(表 1、2、3、7)。这些确凿的证据证实了 ToRA 通过其低秩张量分解有效利用任务共享和任务特定信息从而提高整体性能的理论主张。定性结果(图 5-11)进一步强化了这一点,显示使用 ToRA 的 MTSAM 生成了明显更准确的预测,尤其是在挑战性的“模糊和细长的物体”方面,与其他 LoRA 变体相比。
-
架构修改的影响:
- 任务嵌入:消融研究(表 8)清楚地表明,提出的任务嵌入比仅修改 MLP 输出维度以适应不同任务更有效。这种改进归因于交叉注意力机制,该机制通过任务嵌入和图像特征之间的交互促进了更好的任务特定知识学习。
- 正交正则化:关于正交正则化的消融研究(表 5)证明了其积极影响。完全对 $G$、$U_1$ 和 $U_2$ 进行正交正则化的 MTSAM,其性能显著优于没有正则化的变体,证明了其通过减少冗余来提高各种任务性能的有效性。
-
对超参数设置的鲁棒性:关于超参数 $\lambda$(正交正则化权重)的敏感性分析(表 6)表明,MTSAM 的性能在合理范围内(例如 [0.5, 1.5])对 $\lambda$ 不太敏感。这表明模型相对鲁棒且易于调整,这是一个实际优势。
局限性与未来方向
尽管 MTSAM 展现了令人印象深刻的能力,特别是在 SAM 等基础模型的多任务微调方面,但本文也强调了几项局限性,并为未来的研究开辟了令人兴奋的途径。
一个显著的局限性与跨显著不同数据分布的零样本泛化有关。作者探讨了 MTSAM 在仅在 NYUv2 上训练后,在 CityScapes 数据集上进行零样本深度估计的能力(图 12)。虽然它显示出处理未见数据的某些能力,但结果表明存在不准确之处,尤其是在远距离物体方面。这归因于数据集之间的固有差异:NYUv2 由室内图像组成,而 CityScapes 包含城市户外场景,导致深度分布、物体类型、分辨率甚至用于地面真实深度预测的硬件存在差异。这表明,虽然 MTSAM 可以适应,但大的领域偏移仍然构成重大挑战,并且其零样本可迁移性在截然不同的环境中并非普遍鲁棒。
展望未来,本文的研究结果为进一步发展和演变提供了几个引人注目的讨论主题:
-
增强的领域自适应以实现零样本多任务处理:鉴于在跨不同领域的零样本迁移方面观察到的局限性,一个关键的未来方向是将更复杂的领域自适应技术直接集成到 MTSAM 框架中。能否将对抗性训练、用于领域泛化的元学习或更高级的提示工程策略与 ToRA 相结合,以提高在未见、域外任务上的性能?探索如何在张量分解中显式建模和减轻领域差距可能是一个有益的领域。
-
动态 ToRA秩和任务权重分配:目前,ToRA 的秩($p, q, v$)和任务损失权重($w_i$)被设置为固定超参数。未来的工作可以研究动态调整这些参数的动态方法。例如,能否像某些 PEFT 方法动态调整秩一样,自适应机制能否学习每个任务或层的最佳秩?同样,动态任务加权策略,可能基于任务不确定性或梯度冲突,可以进一步增强模型在不同任务之间平衡和优化性能的能力,超越本研究中使用的固定权重。
-
将 ToRA 扩展到其他基础模型和模态:本文侧重于 SAM 在图像分割任务中的应用。一个自然的扩展是将 MTSAM 框架和 ToRA 应用于其他模态中的大型基础模型,例如大型语言模型(LLM)或整合视觉和语言的多模态模型。ToRA 在将 LLM 微调用于各种 NLP 任务,或在将多模态模型适配于需要跨模态理解的任务时表现如何?这可能会揭示关于张量化低秩自适应的通用性和可扩展性的新见解。
-
对表达能力和泛化能力的理论深入研究:虽然定理 1 证明了 ToRA 在参数效率方面优于多个 LoRA,但在复杂的多任务、多领域场景中对其表达能力和泛化界限进行更深入的理论分析将是有价值的。我们能否正式描述 ToRA 的张量分解最优地捕捉任务共享和任务特定信息的条件,以及这与底层任务相关性的关系?这可能导致对未来多任务 PEFT 方法更具原则性的设计选择。
-
部署和推理的效率:本文提到 ToRA 在推理过程中不引入额外延迟,因为可以预先存储更新的参数矩阵。然而,随着任务数量的增加,特定任务更新权重($W_t = W_0 + \Delta W_t$)的存储量仍然可能变得相当可观。未来的工作可以探索在资源受限的环境中,用于更紧凑存储或推理过程中动态重构 $\Delta W_t$ 的策略,以进一步提高 MTSAM 的实际效用。
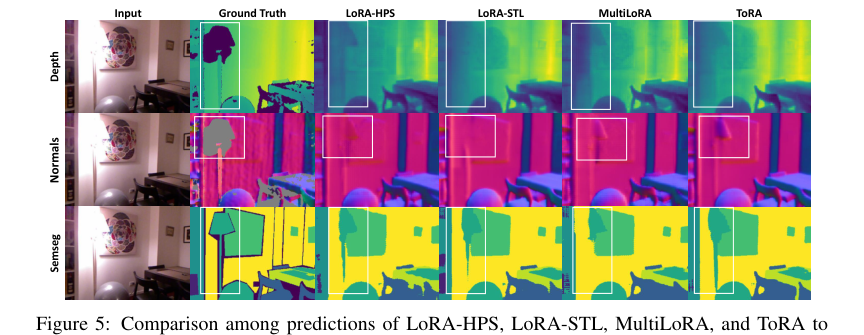 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
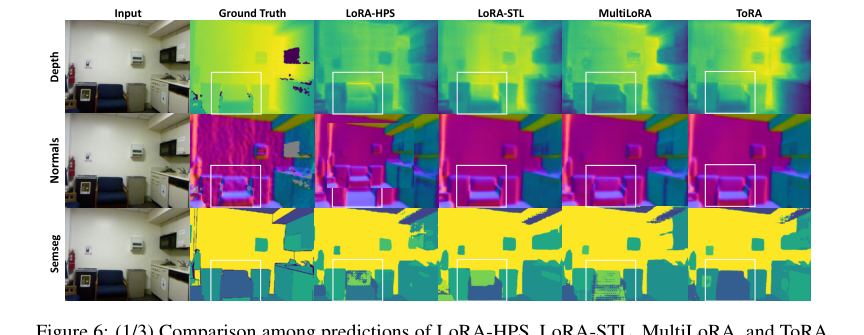 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
与其他领域的同构性
结构骨架
本文提出了一种机制,通过将参数更新分解为共享和特定任务的低秩张量组件,来高效地将高容量预训练模型适配到多个不同的任务。