MTSAM: 세그먼트 애니띵 모델을 위한 다중 작업 미세 조정
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has the potential to be a foundation model for multi-task learning.
배경 및 학문적 계보
기원 및 학술적 계보
본 논문에서 다루는 문제는 인공지능, 특히 컴퓨터 비전 분야에서 최근 등장한 대규모 파운데이션 모델의 놀라운 능력에서 비롯된다. 역사적으로 파운데이션 모델은 먼저 자연어 처리(NLP) 분야에서 인상적인 제로샷(zero-shot) 능력을 통해 혁신을 가져왔다. 이는 명시적으로 학습되지 않은 작업도 수행할 수 있음을 의미한다. 이러한 성공은 컴퓨터 비전 분야에서도 유사한 모델 개발을 촉발했다.
2023년 Kirillov 등이 소개한 Segment Anything Model (SAM)은 이미지 분할을 위한 대표적인 파운데이션 모델로 부상했다. SAM은 1,100만 개의 샘플로 구성된 방대한 데이터셋으로 학습된 후, 이미지 내의 거의 모든 객체를 분할할 수 있는 뛰어난 제로샷 성능을 입증했다. 이러한 획기적인 발전은 고품질 분할, 3D 재구성, 객체 추적, 의료 영상 처리, 개인화된 분할, 원격 감지 등 다양한 다운스트림 작업에 SAM을 적용하는 연구의 급증을 이끌었다.
그러나 이러한 이전 접근 방식의 근본적인 한계, 즉 "고충점(pain point)"은 SAM을 단일 작업 학습(single-task learning)에만 독점적으로 채택했다는 점이다. 이는 새로운 작업마다 SAM을 독립적으로 파인튜닝(fine-tuning)해야 했으며, 다중 작업 학습(multi-task learning, MTL)을 위한 통합 파운데이션 모델로서의 잠재력을 간과했음을 의미한다. 많은 실제 컴퓨터 비전 시나리오에서 여러 작업은 본질적으로 관련되어 있으며 종종 동시에 처리되어야 한다 (예: 장면 이해에서의 깊이 추정 및 표면 법선 추정). MTL에 대한 이전 연구는 공유된 지식이 전반적인 성능과 효율성을 향상시킬 수 있으므로, 작업을 함께 학습함으로써 이점을 얻을 수 있음을 일관되게 보여주었다.
본 논문은 SAM을 다중 작업 학습에 적용하는 데 있어 두 가지 핵심 과제를 구체적으로 식별한다.
1. 출력 차원 불일치: 원본 SAM은 일반적으로 고정된 수의 출력 채널(예: Figure 1a에 표시된 대로 동일한 채널 수를 갖는 세 가지 다른 수준)을 생성하도록 설계되었다. 그러나 다양한 다운스트림 작업은 다양한 차원의 출력을 요구한다 (예: 깊이 추정은 하나의 채널이 필요할 수 있고, 표면 법선 예측은 세 개의 채널이 필요할 수 있다). SAM의 아키텍처는 이러한 작업별 출력을 다른 채널 수로 생성하는 데 본질적으로 충분히 유연하지 않았다.
2. 동시 파인튜닝: SAM을 여러 다운스트림 작업에 동시에 적용하도록 효과적으로 파인튜닝하는 확립된 방법이 없었다. Low-Rank Adaptation (LoRA)과 같은 기존의 파라미터 효율적 파인튜닝(PEFT) 방법은 주로 단일 작업 적응을 위해 설계되었다. 다중 작업 설정에 적용될 때, 이러한 방법들은 작업 간의 공유 정보를 활용하는 데 어려움을 겪거나(각 작업에 자체 LoRA가 있는 LoRA-STL과 같은 경우) 공유 파라미터에 대한 작업 간 경쟁으로 인해 성능 불균형을 겪었다(LoRA-HPS와 같은 경우). SAM과 같은 대규모 파운데이션 모델에 대한 강력한 다중 작업 파인튜닝 전략의 부재는 상당한 장애물을 제시했다.
저자들은 이러한 정확한 한계를 해결하기 위해 본 논문을 작성했으며, SAM이 출력 차원 및 동시 파인튜닝 과제를 극복하고 다중 작업 학습을 위한 다목적 파운데이션 모델로 기능할 수 있도록 Multi-Task SAM (MTSAM) 프레임워크와 Tensorized low-Rank Adaptation (ToRA) 방법을 제안한다.
직관적인 도메인 용어
-
Segment Anything Model (SAM): 복잡하거나 익숙하지 않더라도 사진 속 어떤 객체든 완벽하게 윤곽을 그릴 수 있는 매우 숙련된 디지털 아티스트를 상상해 보라. SAM은 컴퓨터를 위한 그 아티스트와 같아서, 해당 객체를 정확히 본 적이 없더라도 이미지에서 객체를 놀라운 정밀도로 "잘라낼" 수 있다.
-
제로샷 능력(Zero-shot capability): 이는 많은 것에 대한 일반 원칙을 배운 매우 똑똑한 학생과 같다. 만약 그들에게 완전히 새로운 것을 보여준다면, 예를 들어 한 번도 접해보지 못한 희귀한 종류의 과일을 보여준다면, 그 과일에 대한 특정 훈련 없이도 광범위한 이해를 적용하여 그것이 무엇인지 또는 어떻게 분류해야 하는지에 대해 좋은 추측을 할 수 있다.
-
다중 작업 학습(Multi-Task Learning, MTL): 여러 관련 요리를 동시에 배우는 요리사를 생각해 보라. 아마도 메인 요리, 사이드 요리, 소스일 것이다. 함께 학습함으로써, 요리사는 각 요리를 개별적으로 학습하는 대신 전체 요리 과정을 더 효율적으로 만들고 최종 식사를 더 조화롭게 만드는 일반적인 기술이나 재료를 발견할 수 있다.
-
파라미터 효율적 파인튜닝(Parameter-Efficient Fine-Tuning, PEFT): 많은 종류의 자동차를 수리하는 방법을 아는 숙련된 전문가, 예를 들어 마스터 정비사를 고려해 보라. 새로운 자동차 모델이 출시되면, 정비사를 처음부터 다시 훈련시키는 대신, 해당 특정 모델에 대한 몇 가지 작고 구체적인 조정이나 새로운 도구만 가르치면 된다. 그의 방대한 기존 지식의 대부분은 그대로 유지되어 적응을 빠르고 효율적으로 만든다.
-
Low-Rank Adaptation (LoRA): 정비사 비유를 확장하면, LoRA는 마스터 정비사에게 각 새로운 자동차 모델에 대한 작고 전문화된 "치트 시트"를 제공하는 것과 같다. 이 시트에는 표준 절차에 대한 몇 가지 핵심 수정 사항만 포함되어 있어, 전체 자동차 엔지니어링을 다시 배울 필요 없이 기술을 조정할 수 있다. 이는 매우 적은 새로운 정보로 큰 변화를 만드는 영리한 방법이다.
표기법 테이블
| 표기법 | 설명 |
|---|---|
| $I$ | $3 \times H \times W$ (채널, 높이, 너비) 차원의 입력 이미지. |
| $H, W$ | 입력 이미지의 높이와 너비. |
| $F_I$ | SAM의 이미지 인코더에 의해 추출된 이미지 특징으로, $D \times \frac{H}{16} \times \frac{W}{16}$ 차원을 갖는다. |
| $D$ | 모델의 은닉 상태 차원. |
| $O$ | 원본 SAM의 최종 분할 마스크 출력으로, $3 \times \frac{H}{4} \times \frac{W}{4}$ 차원을 갖는다. |
| $T$ | 학습 중인 고유 작업의 총 개수. |
| $\Delta W$ | 단일 레이어에 대한 일반적인 업데이트 파라미터 행렬로, $d \times k$ 차원을 갖는다. |
| $W_0$ | 레이어의 사전 학습된 파라미터 행렬로, $d \times k$ 차원을 갖는다. |
| $A, B$ | LoRA에 사용되는 저랭크 행렬로, $B \in \mathbb{R}^{d \times r}$이고 $A \in \mathbb{R}^{r \times k}$이다. |
| $r$ | LoRA의 저랭크 행렬의 랭크로, $r \ll \min(d, k)$이다. |
| $\Delta \mathcal{W}$ | ToRA에 대한 업데이트 파라미터 텐서로, 모든 작업별 업데이트를 $d \times k \times T$ 텐서로 집계한다. |
| $G$ | ToRA의 Tucker 분해에서 핵심 텐서로, $p \times q \times v$ 차원을 갖는다. |
| $U_1, U_2, U_3$ | ToRA의 Tucker 분해에서 요인 행렬로, 각각 $d \times p$, $k \times q$, $T \times v$ 차원을 갖는다. |
| $p, q, v$ | ToRA의 요인 행렬 차원으로, 일반적으로 $d, k, T$보다 훨씬 작다. |
| $E_t$ | 특정 작업 $t$에 대한 학습 가능한 작업 임베딩으로, $N_t \times D$ 차원을 갖는다. |
| $N_t$ | 작업 $t$에 필요한 출력 채널 수. |
| $O_t$ | MTSAM이 작업 $t$에 대해 생성하는 출력 예측으로, $N_t \times \frac{H}{4} \times \frac{W}{4}$ 차원을 갖는다. |
| $\mathcal{L}_{MTL}$ | MTSAM이 최소화하려는 전체 다중 작업 학습 목적 함수. |
| $\lambda$ | 직교 정규화 항의 영향을 제어하는 하이퍼파라미터. |
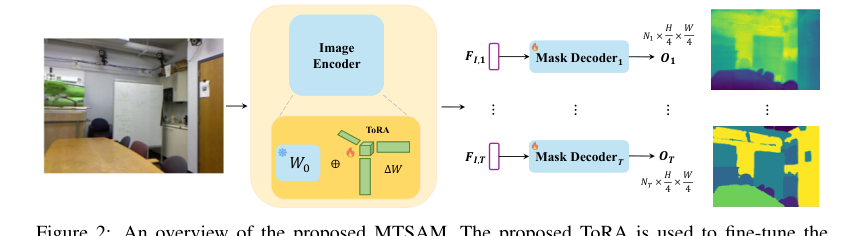 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
Segment Anything Model (SAM)은 제로샷 일반화 능력으로 유명한 이미지 분할을 위한 강력한 파운데이션 모델로 부상했다. 본 논문에서 다루는 핵심 문제는 SAM을 다중 작업 학습(MTL)을 위한 파운데이션 모델로 효과적으로 변환하는 방법이다.
입력/현재 상태:
시작점은 이미지 $I \in \mathbb{R}^{3 \times H \times W}$와 다양한 프롬프트(예: 점, 경계 상자 또는 마스크)를 입력으로 받는 원본 SAM이다. 이 모델의 아키텍처는 무거운 이미지 인코더, 프롬프트 인코더, 그리고 가벼운 마스크 디코더로 구성된다. 원본 SAM은 일반적으로 고정된 수의 출력 채널(예: 4페이지의 식 3에서 볼 수 있는 3채널, 2페이지의 그림 1a에서 설명된 것)을 가진 분할 마스크를 생성하도록 설계되었다.
목표 상태 (출력/목표):
목표 상태는 Multi-Task SAM (MTSAM)이라고 명명된 수정된 SAM으로, 다음을 수행할 수 있다:
1. 다양한 차원의 작업별 출력 생성: 예를 들어, 단일 입력으로부터 동시에 깊이 추정을 위한 1채널 출력, 의미론적 분할을 위한 13채널 출력, 표면 법선 추정을 위한 3채널 출력을 생성한다 (2페이지의 그림 1b).
2. 여러 다운스트림 작업에 동시에 적응하도록 미세 조정: 이 적응은 각 작업을 개별적으로 처리하는 대신, 전반적인 성능 향상을 위해 작업 간 공유 정보를 활용해야 한다.
누락된 연결 및 수학적 격차:
현재 상태와 목표 상태 사이의 정확한 누락된 연결 또는 수학적 격차는 두 가지로 요약된다:
1. 다양한 출력에 대한 아키텍처적 유연성 부족: 원본 SAM의 마스크 디코더는 아키텍처적으로 고정된 채널 수를 가진 출력을 생성하도록 제약되어 있어, 서로 다른 출력 차원을 요구하는 작업에는 부적합하다. 특정 작업에 따라 출력 채널을 동적으로 조정하는 내재된 메커니즘이 없다.
2. 비효율적인 다중 작업 미세 조정: 여러 작업을 동시에 수행하기 위해 SAM의 대규모 인코더를 미세 조정하고, 작업 공유 정보와 작업별 지식을 효과적으로 균형 잡는 강력하고 파라미터 효율적인 방법이 부재하다. LoRA와 같은 기존의 파라미터 효율적인 미세 조정(PEFT) 방법은 MTL에 무분별하게 적용될 때, 파라미터를 너무 광범위하게 공유하여(LoRA-HPS) 작업 경쟁으로 인한 성능 저하를 초래하거나, 너무 작업별적이어서(LoRA-STL) 유익한 작업 간 정보 공유를 활용하지 못하는 단순화된 접근 방식을 취한다.
딜레마:
이전 연구자들이 겪었던 핵심 딜레마는 대규모 파운데이션 모델의 다중 작업 학습에서 파라미터 효율성과 표현력/성능 사이의 고통스러운 절충점이다.
* SAM과 같은 무거운 모델을 여러 작업에 대해 전체 미세 조정하는 것은 계산적으로 불가능하며 파라미터 효율성이 떨어진다.
* 기존 PEFT 방법을 MTL에 무분별하게 적용하는 것은 딜레마를 제시한다:
* 하드 파라미터 공유 (LoRA-HPS): 이 접근 방식은 모든 작업에 대해 하나의 공유 LoRA 행렬을 사용하므로 파라미터 효율적이다. 그러나 이는 종종 "작업 간 경쟁으로 인해 모든 작업에서 성능이 불균형해지는" 결과를 초래한다 (4페이지). 작업별 미묘한 차이를 포착하는 데 어려움을 겪으며, 효율성을 위해 성능을 희생시킨다.
* 작업별 LoRA (LoRA-STL): 이 방법은 각 작업에 대해 별도의 LoRA 모듈을 학습시켜 작업별 적응과 잠재적으로 더 나은 개별 작업 성능을 가능하게 한다. 그러나 파라미터 수는 작업 수에 선형적으로 증가한다 ($O(Trd+Trk)$, 6페이지). 이는 많은 수의 작업에 대해 비효율적이다. 결정적으로, 이는 "여러 작업에 걸쳐 미세 조정하는 데 필요한 작업 간 공유 정보를 활용할 수 없다" (4페이지)는 점에서 MTL의 시너지 효과를 놓치게 된다.
과제는 파라미터 효율적이며(작업 수에 대한 파라미터의 부분 선형 성장) 작업 공유 일반 지식과 작업별 세부 사항을 동시에 포착할 수 있는 방법을 고안하여, 다중 작업 설정에서 기존 PEFT 전략의 한계를 극복하는 것이다.
제약 조건 및 실패 모드
SAM을 다중 작업 학습에 적응시키는 문제는 저자들이 직면했던 몇 가지 가혹하고 현실적인 장벽으로 인해 매우 어렵게 된다:
- 하드웨어 메모리 및 계산 한계: SAM의 이미지 인코더는 "무거운(heavyweight)" 것으로 설명된다 (3페이지). 이러한 대규모 모델을 여러 작업에 대해 동시에 미세 조정하는 것은 막대한 계산 자원과 메모리를 요구하며, 전체 미세 조정을 비현실적으로 만든다. 이러한 제약 조건은 파라미터 효율적인 방법의 사용을 필수적으로 만든다.
- 고정 출력 채널 제약: 원본 SAM의 마스크 디코더는 고정된 수의 채널(예: 분할을 위한 3개)을 가진 출력을 생성하도록 하드코딩되어 있다. 이러한 아키텍처적 경직성은 깊이 추정(1채널) 또는 다중 클래스 의미론적 분할(예: 13채널)과 같은 다양한 작업에 필요한 다양한 채널 수를 가진 출력을 직접 생성하는 것을 방해한다. 이는 극복해야 할 근본적인 아키텍처적 한계이다.
- 작업 공유 및 작업별 학습 균형 능력 부재: MTL에 적용될 때 이전 PEFT 방법들은 일반적인 작업 공유 특징 학습과 특정 작업 의존적 적응 학습 사이의 균형을 효과적으로 맞추는 데 실패한다. LoRA-HPS는 작업 경쟁으로 고통받는 반면, LoRA-STL은 작업 간 공유 정보를 활용할 수 없다 (4페이지). 이는 최적이 아닌 성능 또는 비효율적인 파라미터 사용으로 이어진다.
- 최적 근사를 위한 텐서 분해의 복잡성: 텐서 분해는 강력한 수학적 도구이지만, 특히 다중 작업 학습의 맥락에서 복잡한 목표에 대한 "최적의 근사"를 찾는 것은 본질적으로 어렵고 "항상 존재하지 않을 수 있다" (Kolda & Bader, 2009, 7페이지 인용). 이는 저랭크 텐서 적응의 이론적 최적성을 보장하는 데 잠재적인 어려움이 있음을 시사한다.
- 작업 간 데이터 이질성: 서로 다른 작업은 종종 고유한 데이터 분포, 의미론적 의미 및 출력 형식을 포함한다. 예를 들어, 깊이 추정과 의미론적 분할은 다른 유형의 Ground Truth와 평가 지표를 요구한다. 모델은 단일 작업의 성능을 저하시키지 않으면서 이러한 내재된 다양성을 처리할 만큼 충분히 견고해야 한다.
- 실시간 지연 요구 사항 부재 (암시적): 저자들이 어려움을 겪었던 제약 조건으로 명시적으로 언급되지는 않았지만, 파라미터 효율성의 목표와 ToRA가 "추론 중 추가 지연을 도입하지 않는다"는 진술 (6페이지)은 실용적인 응용에서 종종 중요한 효율적인 추론에 대한 암시적인 필요성을 시사한다. 모델의 복잡성이 추론 시간을 크게 증가시키지 않아야 한다.
이 접근 방식은 왜
선택의 필연성
Segment Anything Model (SAM)은 이미지 분할에 대한 놀라운 제로샷(zero-shot) 능력을 보여주는 강력한 파운데이션 모델로 등장했다. 그러나 다중 작업 학습(multi-task learning)에 직접 적용하는 과정에서 전통적인 "SOTA" 방법론, 심지어 원본 SAM 자체를 포함하여 처리하기 어려운 두 가지 근본적인 아키텍처적 난관에 직면했다. 이러한 비효율성에 대한 저자들의 인식은 다중 작업 학습의 핵심 요구 사항을 고려할 때 명확해졌다: (a) 다양한 채널 수를 가진 작업별 출력을 생성해야 할 필요성(예: 깊이 추정에는 1채널, 표면 법선 예측에는 3채널, 의미론적 분할에는 다중 채널), 그리고 (b) SAM을 여러 다운스트림 작업에 효율적으로 적응시키기 위해 동시에 미세 조정(fine-tuning)하는 과제.
원본 SAM은 설계상 분할 마스크를 서로 다른 수준에서 생성하지만, 결정적으로 이러한 모든 출력은 동일한 채널 수를 특징으로 한다. 깊이 추정이나 표면 법선 예측과 같은 작업이 다른 출력 구조를 요구할 때, 이 고정된 출력 차원은 심각한 제약이 된다. 논문에서는 명시적으로 "SAM이 근본적인 시각 모델로서 보여주는 엄청난 잠재력에도 불구하고, 프롬프트 기반 마스크 생성에 의존하는 것은 다양한 수의 출력 채널을 가진 다운스트림 작업에 대한 종단 간(end-to-end) 적응성을 달성하는 데 어려움을 제시한다"고 기술한다. 이것이 바로 저자들이 SAM의 고유한 아키텍처, 특히 프롬프트 인코더와 마스크 디코더가 다양한 다중 작업 출력에 충분히 유연하지 않다는 것을 인식한 순간이었다. 따라서 SAM의 직접적인 적용이나 기존의 단일 작업 미세 조정 방법은 진정한 다중 작업 파운데이션 모델에는 단순히 실행 불가능했다.
비교 우위
제안된 Multi-Task SAM (MTSAM) 프레임워크, 특히 Tensorized low-Rank Adaptation (ToRA) 방법은 파라미터 효율성과 정보 활용 측면에서 이전의 골드 스탠다드에 비해 압도적인 질적 및 구조적 우수성을 보여준다.
첫째, ToRA의 가장 중요한 구조적 이점은 파라미터 효율성에 있다. $T$개의 작업에 적용될 때, 하드 파라미터 공유(LoRA-HPS) 또는 작업별 LoRA(LoRA-STL)를 사용하는 전통적인 Low-Rank Adaptation (LoRA) 방법은 일반적으로 $O(Trd + Trk)$의 파라미터 복잡성을 보이며, 작업 수에 따라 선형적으로 증가한다. 이와 극명하게 대조적으로, ToRA는 모든 작업의 업데이트 파라미터 행렬을 단일 업데이트 파라미터 텐서 $\Delta W \in \mathbb{R}^{d \times k \times T}$로 집계하고 저랭크 텐서 분해(특히 Tucker 분해)를 적용한다. 이는 $O(dp + kq)$의 파라미터 복잡성을 초래하며, 여기서 $p, q, v \ll \min(d, k)$이고 $T$는 작업의 수이다. 이는 작업 수에 대한 학습 가능한 파라미터의 준선형(sublinear) 증가를 나타내며, 대규모 작업 수로 확장하는 데 있어 훨씬 더 효율적이다. 메모리 복잡성의 이러한 감소는 SAM과 같은 거대한 파운데이션 모델을 미세 조정하는 데 있어 게임 체인저이다.
둘째, ToRA는 작업 공유 정보와 작업별 정보를 효과적으로 포착함으로써 질적으로 대안을 능가한다. LoRA-HPS는 모든 작업에 대해 단일 $\Delta W$를 공유함으로써 작업 경쟁에 어려움을 겪으며 종종 불균형적인 성능으로 이어진다. 반면에 LoRA-STL은 각 작업에 대해 별도의 $\Delta W_t$를 학습하여 귀중한 작업 간 공유 정보를 완전히 무시한다. ToRA의 Tucker 분해 사용은 핵심 텐서 $G$와 요인 행렬 $U_1, U_2, U_3$가 작업 공유 정보의 주요 부분 공간 변동( $U_1$ 및 $U_2$를 통해)과 작업별 부분 공간 구조( $U_3$를 통해)를 명시적으로 모델링할 수 있도록 한다. 정보 공유 및 전문화에 대한 이러한 총체적인 접근 방식은 다양한 작업에 걸쳐 미세 조정 성능을 향상시키는 핵심 구조적 이점이다. Theorem 1의 이론적 분석은 ToRA가 더 우수한 표현력을 가지며 여러 LoRA보다 적은 파라미터로 동일한 가중치 업데이트를 달성할 수 있음을 증명함으로써 이를 더욱 뒷받침한다.
마지막으로, 질적 평가(예: Figure 5)는 ToRA로 미세 조정된 MTSAM이 특히 "모호하고 가느다란 객체"에 대해 더 정확한 결과를 생성함을 보여준다. 이는 ToRA가 공유 및 특정 정보를 분리하고 활용하는 능력이 시각적 장면에 대한 더 강력하고 미묘한 이해로 이어져, 다른 방법론이 세밀한 디테일이나 복잡한 객체 경계에서 어려움을 겪을 수 있는 어려운 시나리오에서 성능을 향상시킨다는 것을 시사한다.
제약 조건과의 정렬
선택된 MTSAM 프레임워크는 아키텍처 수정과 ToRA 미세 조정 방법을 통해 SAM을 다중 작업 학습에 적응시키는 데 있어 식별된 두 가지 주요 제약 조건과 완벽하게 일치한다.
-
제약 조건: 다양한 채널 수를 가진 작업별 출력 생성.
- 해결책의 속성: MTSAM은 SAM의 마스크 디코더를 근본적으로 변경하여 이를 해결한다. 원본 프롬프트 인코더를 제거하고 작업별 비마스크 임베딩(no-mask embeddings)과 전용 작업별 마스크 디코더를 도입한다. Figure 1 및 Figure 3에 설명된 바와 같이, 이 수정은 MTSAM이 SAM의 고정 채널 출력 대신 각 작업에 맞춤화된 차원($N_t \times H \times W$)의 출력을 생성할 수 있도록 한다. 예를 들어, 깊이에는 1채널, 표면 법선에는 3채널, 의미론적 분할에는 13채널을 출력하여 다양한 출력 구조에 대한 요구 사항을 직접적으로 충족시킨다. 학습 가능한 작업 임베딩 $E_t$의 도입은 디코더가 특정 작업에 따라 처리를 조정할 수 있도록 보장한다. 이는 문제의 출력 유연성 요구와 해결책의 모듈식, 작업 인식 디코더 설계 간의 직접적인 "결합"이다.
-
제약 조건: SAM을 여러 다운스트림 작업에 동시에 효율적으로 적응시키기 위한 미세 조정.
- 해결책의 속성: ToRA는 이 제약 조건의 핵심 혁신이다. SAM 인코더의 각 계층에 업데이트 파라미터 텐서를 주입하고 저랭크 텐서 분해를 사용하여 작업 공유 및 작업별 정보를 모두 포착한다. 이를 통해 모델은 여러 작업에서 동시에 학습하고 상호 의존성을 활용하는 동시에 작업별 적응을 허용할 수 있다. ToRA의 파라미터 효율성은 작업 수에 대한 준선형 파라미터 증가를 통해 SAM과 같은 무거운 파운데이션 모델을 과도한 계산 비용이나 메모리 사용량 없이 미세 조정하는 데 중요하다. 이러한 효율성은 동시 적응이 단순히 가능한 것이 아니라 실용적임을 보장하여 대규모 다중 작업 학습의 엄격한 요구 사항에 완벽하게 부합한다. 총 손실 함수($L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$)의 직교 정규화 항은 학습된 요인 행렬이 잘 동작하고 중복되지 않도록 하여 다중 작업 미세 조정 프로세스의 안정성과 효과에 기여한다.
대안의 기각
이 논문은 주로 기존의 파라미터 효율적 미세 조정(PEFT) 방법과 다중 작업 맥락에서 LoRA를 적용하는 다양한 전략에 초점을 맞춰 여러 대안적 접근 방식을 기각하는 명확한 이유를 제공한다.
-
전통적인 PEFT 방법(예: 어댑터 기반, 프롬프트 튜닝, 단일 작업용 기존 LoRA 변형): 저자들은 이러한 방법들이 "단일 작업 미세 조정에서 경쟁력 있는 성능과 높은 파라미터 효율성을 달성하지만," "여러 작업 간의 공유 정보를 고려하지 않기 때문에 다중 작업 학습 설정에는 적합하지 않다"고 명시적으로 언급한다. 이는 여러 작업을 동시에 학습하는 데서 발생하는 시너지 효과를 활용하거나 충돌을 관리할 수 없는 방법들에 대한 포괄적인 기각이다. 이러한 방법들의 설계는 본질적으로 한 번에 하나의 작업에 최적화되도록 되어 있으며, 이는 다중 작업 학습의 목표와 상반된다.
-
LoRA-HPS (하드 파라미터 공유): 이 접근 방식은 모든 작업에 대해 하나의 공유 LoRA 행렬($\Delta W$)을 사용하여 다중 작업 학습을 시도한다. 논문은 "작업 간 경쟁으로 인해 모든 작업에서 불균형적인 성능으로 이어질 수 있다"는 이유로 이를 기각한다. 작업들이 상충되는 기울기나 다른 학습 역학을 가질 때, 단일하고 차별화되지 않은 업데이트 행렬을 공유하도록 강제하면 일부 또는 모든 작업의 성능이 저하될 수 있다.
-
LoRA-STL (단일 작업 LoRA): 이 대안은 각 작업에 대해 별도의 LoRA 행렬($\Delta W_t$)을 학습하는 것을 포함한다. 논문은 "여러 작업에 걸쳐 미세 조정하는 데 필요한 작업 간 공유 정보를 활용할 수 없다"는 이유로 이를 기각한다. 이는 LoRA-HPS의 경쟁 문제를 피하지만, 관련 작업 간의 공유 지식과 공통 특징의 잠재적 이점을 활용하지 못하는데, 이는 다중 작업 학습의 핵심 원칙이다. 이로 인해 정보를 지능적으로 공유할 수 있는 접근 방식보다 효율성이 떨어지고 잠재적으로 성능이 낮아진다.
-
전체 미세 조정(Full Fine-Tuning): 다른 PEFT 방법과 같은 강력한 용어로 명시적으로 "기각"되지는 않았지만, 논문은 "파라미터 및 계산 효율성 문제"로 인해 SAM의 무거운 이미지 인코더의 전체 미세 조정을 암묵적으로 일축한다. Table 7은 이를 정량적으로 뒷받침하며, 전체 미세 조정은 MTSAM의 59.59 MB보다 훨씬 많은 1222.47 MB의 학습 가능한 파라미터를 요구하는 반면, 전반적인 성능 향상은 더 낮다(전체 미세 조정의 +14.57% 대비 MTSAM의 +23.93% $\Delta_b$). 이는 전체 미세 조정을 대규모 파운데이션 모델 및 효율성이 중요한 다중 작업 시나리오에 비실용적으로 만든다. 파라미터의 엄청난 규모는 계산 비용이 많이 들고 소규모 다중 작업 데이터셋에 과적합되기 쉽다.
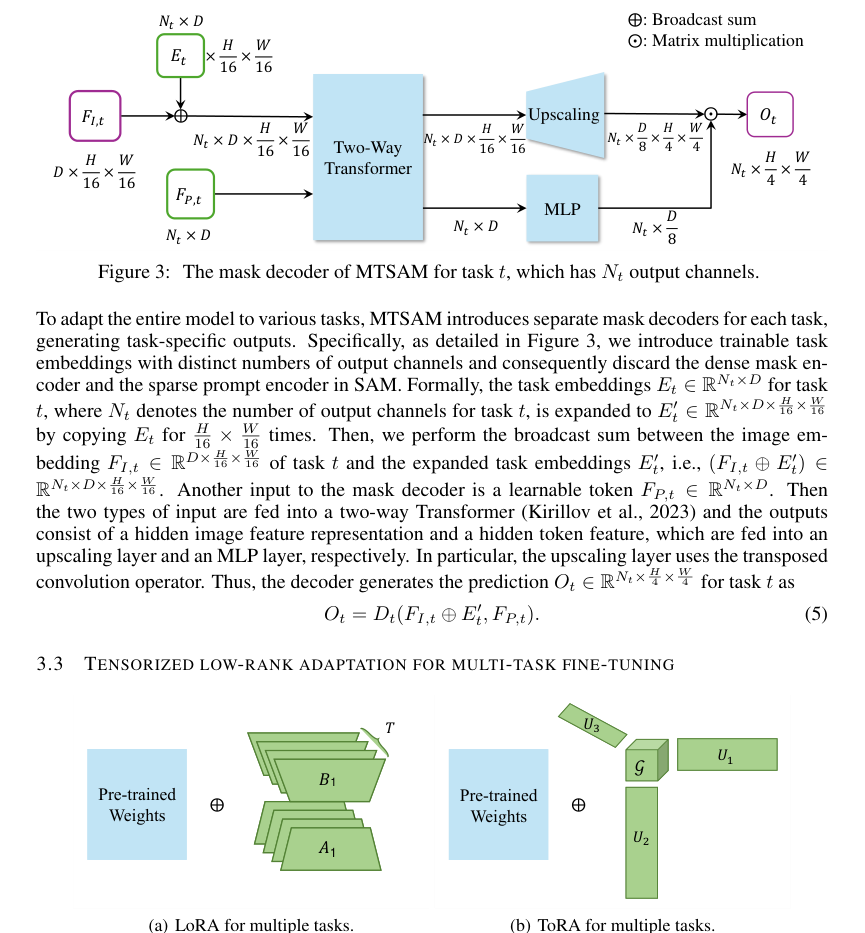 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
수학 및 논리 메커니즘
마스터 방정식
MTSAM 프레임워크의 학습 과정의 절대적인 핵심은 효율적이고 효과적인 파라미터 업데이트를 보장하기 위해 다중 작업 학습 손실과 정규화 항을 결합하는 전체 목적 함수이다. 이 마스터 방정식은 전체 훈련 과정을 안내한다:
$$ L_{total} = L_{MTL} + \lambda R(U_1, U_2, G) $$
이 방정식은 모델이 텐서 분해 및 정규화를 통해 파라미터 효율성을 유지하고 중복성을 방지하면서 동시에 여러 작업으로부터 어떻게 학습하는지를 요약한다.
항별 분석
마스터 방정식과 그 구성 요소를 분해하여 수학적 정의, 물리적/논리적 역할 및 저자의 설계 선택을 이해해 보자.
-
$L_{total}$: 이는 MTSAM 프레임워크가 훈련 중에 최소화하고자 하는 총 목적 함수이다. 이 함수의 역할은 모든 작업에 걸친 성능과 파라미터 업데이트의 효율성 및 구조적 무결성 간의 균형을 맞추는 것이다. 저자들은 다중 작업 손실과 정규화 항을 결합하기 위해 덧셈을 사용하는데, 이는 작업 오류를 최소화하고 잘 구조화된 저랭크 파라미터 공간을 유지하는 두 가지 별개의 목표이기 때문이다.
-
$L_{MTL}$: 이 항은 다중 작업 학습(MTL) 손실을 나타낸다. 이는 모든 개별 작업의 가중치 손실의 평균이다.
$$ L_{MTL} = \frac{1}{T} \sum_{i=1}^T w_i L_i $$- $T$: 이는 MTSAM 모델이 훈련 중인 총 고유 작업 수 (예: 의미론적 분할, 깊이 추정, 표면 법선 예측)이다. 이 함수의 역할은 개별 작업 손실의 합을 정규화하여 모든 작업에 대한 평균 손실을 제공하는 것이다. 전체 다중 작업 목표가 개별 작업 목표의 복합체이기 때문에 여기서는 합계를 사용한다.
- $w_i$: 이는 작업 $i$에 대한 손실 가중치이다. 이는 전체 다중 작업 목표에서 각 작업 손실의 상대적 중요성을 제어하는 하이퍼파라미터이다. 예를 들어, 더 중요하거나 더 어려운 작업은 더 높은 가중치를 받을 수 있다. 저자들은 각 작업의 총 손실 기여도를 조정하기 위해 곱셈을 사용하여 유연한 우선순위 지정을 가능하게 한다.
- $L_i$: 이는 해당 특정 작업의 모든 훈련 샘플에 대한 평균 손실로 계산된 작업 $i$에 대한 손실이다.
$$ L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j, f(x_j)) $$- $N_i$: 이는 작업 $i$에 대한 훈련 샘플 수를 나타낸다. 이 함수의 역할은 샘플에 대한 손실을 평균화하여 작업의 손실이 샘플 수에 의해 불균형적으로 영향을 받지 않도록 하는 것이다. 합계는 개별 샘플의 손실을 집계하고 $N_i$로 나누어 평균 손실을 제공한다.
- $l_i(\cdot, \cdot)$: 이는 작업 $i$에 대한 작업별 손실 함수이다. 이 함수의 수학적 정의는 작업 $i$의 특성 (예: 분할을 위한 교차 엔트로피, 깊이 추정을 위한 L1 손실, 표면 법선을 위한 코사인 유사도)에 따라 달라진다. 이 함수의 역할은 단일 샘플에 대한 모델의 예측과 Ground Truth 간의 불일치를 정량화하는 것이다.
- $y_j$: 이는 작업 $i$의 $j$-번째 훈련 샘플에 대한 Ground Truth 레이블이다. 이는 모델이 생성해야 하는 올바른 출력이다.
- $f(x_j)$: 이는 작업 $i$의 $j$-번째 훈련 샘플 $x_j$에 대한 MTSAM 모델의 예측을 나타낸다. 함수 $f(\cdot)$는 ToRA 수정 가중치를 통합하는 이미지 인코더와 작업별 마스크 디코더를 포함한 전체 MTSAM 아키텍처를 구현한다.
- $x_j$: 이는 예측 $f(x_j)$가 이루어지는 입력 훈련 샘플 (예: 이미지)이다.
-
$\lambda$: 이는 직교 정규화 항 $R(U_1, U_2, G)$의 영향을 제어하는 하이퍼파라미터이다. 이 함수의 역할은 작업별 오류 최소화와 ToRA 파라미터에 대한 원하는 저랭크, 직교 구조 강제화 간의 절충을 균형 맞추는 것이다. $\lambda$가 클수록 정규화에 더 중점을 둔다. 저자들은 정규화의 총 손실 기여도를 조정하기 위해 곱셈을 사용한다.
-
$R(U_1, U_2, G)$: 이는 직교 정규화 항이다. 이는 요인 행렬 $U_1, U_2$와 코어 텐서 $G$의 슬라이스가 직교하도록 장려하여 중복성을 줄이고 텐서 분해의 안정성을 향상시킨다.
$$ R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^v ||G(:,:,l)^T G(:,:,l) - I||_F^2 $$- $U_1$: 이는 차원 $d \times p$의 요인 행렬이다. 이는 업데이트 파라미터 텐서 $\Delta W$의 출력 특징 차원에 해당하는 작업 공유 정보의 주요 부분 공간 변이를 포착한다.
- $U_2$: 이는 차원 $k \times q$의 요인 행렬이다. 이는 업데이트 파라미터 텐서 $\Delta W$의 입력 특징 차원에 해당하는 작업 공유 정보의 주요 부분 공간 변이를 포착한다.
- $G$: 이는 차원 $p \times q \times v$의 코어 텐서이다. 이는 분해 후 업데이트 파라미터 텐서 $\Delta W$의 압축된 저랭크 표현을 나타낸다. 이는 공유 및 특정 정보의 "본질"을 담고 있다.
- $||\cdot||_F^2$: 이는 프로베니우스 노름 제곱을 나타낸다. 수학적으로 행렬 $A$에 대해 $||A||_F^2 = \sum_{i,j} |A_{i,j}|^2$이다. 여기서 이 함수의 역할은 직교성으로부터의 편차의 "크기" 또는 크기를 정량화하는 것이다. 제곱은 값이 음수가 아니도록 보장하고 더 큰 편차를 더 심하게 페널티를 부여한다.
- $I$: 이는 적절한 크기의 항등 행렬이다. $U^T U - I$와 같은 항에서 이 함수의 역할은 직교성의 목표 역할을 하는 것이다: 만약 $U^T U = I$이면, $U$는 직교 행렬이다.
- $U_1^T U_1 - I$: 이 항은 $U_1$의 직교성으로부터의 편차를 측정한다. 이의 프로베니우스 노름 제곱을 최소화하면 $U_1$이 직교 행렬에 가깝게 된다.
- $U_2^T U_2 - I$: $U_1$과 유사하게, 이 항은 $U_2$의 직교성으로부터의 편차를 측정한다.
- $G(:,:,l)^T G(:,:,l) - I$: 이 항은 코어 텐서 $G$의 $l$-번째 전면 슬라이스의 직교성으로부터의 편차를 측정한다. $G(:,:,l)$는 세 번째 모드(작업 축)를 $l$로 고정하여 형성된 행렬을 참조한다. 이는 코어 텐서 내에서 작업 차원을 따라 직교성을 보장한다. 합계 $\sum_{l=1}^v$는 코어 텐서의 모든 슬라이스에 걸쳐 이러한 직교성 페널티를 집계한다. 저자들은 이러한 개별 직교성 제약 조건을 결합하기 위해 덧셈을 사용하는데, 이는 각각 중복성 감소라는 전반적인 목표에 독립적으로 기여하기 때문이다.
$L_{MTL}$의 작동에 핵심적인 것은 모델의 가중치가 업데이트되는 방식을 정의하는 텐서화된 저랭크 적응(ToRA) 방법이다. ToRA는 Tucker 분해를 사용하여 업데이트 파라미터 텐서 $\Delta W$를 매개변수화한다:
$$ \Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3 $$
- $\Delta W$: 이는 차원 $d \times k \times T$의 업데이트 파라미터 텐서이다. 이는 모든 작업에 걸쳐 사전 훈련된 가중치의 집합적 변화를 나타낸다. 각 슬라이스 $\Delta W(:,:,t)$는 작업 $t$에 대한 업데이트 행렬이다. 이 함수의 역할은 사전 훈련된 모델을 여러 다운스트림 작업에 효율적으로 적응시키는 것이다. 저자들은 여러 작업에 대한 업데이트를 나타내기 위해 텐서를 선택했는데, 이는 작업 공유 및 작업별 정보를 다차원적으로 자연스럽게 포착하기 때문이다.
- $G$: 이는 코어 텐서 (위에서 정의됨)이며, 차원은 $p \times q \times v$이다. 이는 텐서의 가장 중요한 구성 요소를 담고 있으며, 압축된 표현 역할을 한다.
- $U_1$: 이는 모드 1(출력 특징 차원)에 대한 요인 행렬이며, 차원은 $d \times p$이다. 이는 코어 텐서를 첫 번째 모드를 따라 변환한다.
- $U_2$: 이는 모드 2(입력 특징 차원)에 대한 요인 행렬이며, 차원은 $k \times q$이다. 이는 코어 텐서를 두 번째 모드를 따라 변환한다.
- $U_3$: 이는 모드 3(작업 차원)에 대한 요인 행렬이며, 차원은 $T \times v$이다. 이는 코어 텐서를 세 번째 모드를 따라 변환하여 분해가 작업별 변이를 포착하도록 한다.
- $\times_n$: 이는 n-모드 곱을 나타낸다. 수학적으로 $A \times_n B$는 텐서 $A$를 행렬 $B$와 $n$-번째 모드를 따라 곱하는 것을 의미한다. 이 함수의 역할은 요인 행렬 $U_1, U_2, U_3$를 사용하여 코어 텐서 $G$를 전체 $\Delta W$ 텐서로 "펼치거나" 투영하는 것이다. 이 연산자는 텐서 분해에 기본이며, 코어 텐서와 여러 행렬로부터 고차 텐서를 재구성할 수 있게 한다.
마지막으로, 특정 작업 $t$에 대한 모델의 순방향 통과에 이러한 업데이트를 실제로 적용하는 것은 다음과 같다:
$$ h = W_0x + \Delta W(:,:,t)x $$
- $h$: 이는 ToRA 업데이트를 적용한 후 SAM 인코더의 레이어 출력이다.
- $W_0$: 이는 SAM 인코더의 레이어에 대한 원래 사전 훈련된 가중치 행렬이다. 이는 미세 조정 중에 고정된다.
- $\Delta W(:,:,t)$: 이는 작업 $t$에 대한 업데이트 행렬이며, 전체 $\Delta W$ 텐서의 $t$-번째 슬라이스이다. 이 함수의 역할은 사전 훈련된 가중치에 작업별 조정을 제공하는 것이다.
- $x$: 이는 SAM 인코더의 레이어에 대한 입력이다.
- 여기서 덧셈 연산자는 ToRA 업데이트가 사전 훈련된 가중치에 대한 가산적 수정임을 의미하며, 이는 LoRA와 같은 PEFT 방법에서 일반적인 관행이다.
단계별 흐름
특정 작업 $t$에 대해 단일 추상 데이터 포인트인 이미지 $x_j$가 MTSAM 프레임워크를 통해 여정을 시작한다고 상상해 보자.
-
이미지 인코딩 (고정된 기반): 여정은 SAM의 강력한 이미지 인코더 $E_1$에 입력 이미지 $x_j$가 들어가는 것으로 시작된다. 중요하게도, $E_1$의 파라미터는 고정된다. 이는 SAM의 사전 훈련 중에 학습된 기초 지식이 보존됨을 의미한다. 인코더는 이미지 특징 세트 $F_1$을 출력한다.
-
ToRA 주입 (적응형 레이어): $F_1$이 이미지 인코더 내의 셀프 어텐션 모듈을 통해 전파될 때, ToRA 메커니즘을 만난다. 각 레이어에 대해 원래 사전 훈련된 가중치 행렬 $W_0$를 직접 사용하는 대신, 해당 레이어의 입력 $x$는 적응된 가중치 행렬 $W'$로 처리된다. 이 $W'$는 효과적으로 $W_0 + \Delta W(:,:,t)$이다. $\Delta W(:,:,t)$ 구성 요소는 텐서 분해 $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$를 통해 코어 텐서 $G$와 요인 행렬 $U_1, U_2, U_3$를 사용하여 작업 $t$에 대해 동적으로 구성된다. 이는 각 작업 $t$에 대해 고유한 저랭크 업데이트가 고정된 가중치에 적용되어, 모델 파라미터의 대다수를 변경하지 않고도 작업별 요구 사항을 향해 모델의 동작을 미묘하게 조정함을 의미한다.
-
작업별 디코딩 (출력 생성): ToRA 적응형 이미지 특징은 이제 암묵적으로 작업 $t$에 맞게 조정되어 작업별 마스크 디코더 $D_t$로 공급된다. 이 디코더는 또한 훈련 가능한 작업 임베딩 $E_t$ (특징 차원에 맞게 확장됨)와 학습 가능한 토큰 $F_{P,t}$를 받는다. 작업 임베딩 $E_t$는 이미지 특징 $F_{1,t}$ ( $F_1$에서 파생되고 작업 $t$에 대해 추가로 처리될 수 있음)와 브로드캐스트-합산된다. 이러한 결합된 특징은 학습 가능한 토큰과 함께 양방향 트랜스포머, 업스케일링 레이어 및 MLP 레이어를 통과한다. 이 전체 과정은 작업 $t$에 대해 적절한 채널 수를 가진 작업별 출력 $O_t$ (예: 분할 마스크, 깊이 맵 또는 표면 법선)를 생성한다.
-
손실 계산 (성능 측정): 샘플 $x_j$에 대한 생성된 출력 $O_t$는 작업별 손실 함수 $l_t$를 사용하여 해당 Ground Truth 레이블 $y_j$와 비교된다. 이는 $l_t(y_j, f(x_j))$를 생성하며, 이는 이 특정 샘플에 대한 작업 $t$에 대해 모델이 얼마나 잘 수행했는지를 나타낸다.
-
다중 작업 집계 (전체 오류): 이 개별 샘플 손실 $l_t(y_j, f(x_j))$는 전체 작업 손실 $L_t$에 기여한다. 작업 $t$의 모든 샘플에 대해 손실이 평균화되어 $L_t$를 형성한다. 그런 다음 $L_t$는 $w_t$로 가중치가 부여되고 다른 모든 작업의 가중치 손실과 결합되어 총 다중 작업 학습 손실 $L_{MTL}$을 계산한다.
-
정규화 (구조적 무결성): 동시에, 훈련 가능한 ToRA 구성 요소 ($U_1, U_2, G$)의 현재 상태는 직교 정규화 항 $R(U_1, U_2, G)$와 비교하여 평가된다. 이 항은 이러한 행렬 및 코어 텐서 슬라이스의 직교성으로부터의 편차를 페널티한다.
-
총 목적 함수 (통합 목표): 마지막으로, $L_{MTL}$과 스케일링된 정규화 항 $\lambda R(U_1, U_2, G)$가 합산되어 $L_{total}$ 목적 함수를 형성한다. 이 단일 값은 모델이 최소화해야 하는 전반적인 "비용" 또는 오류를 나타낸다.
최적화 역학
MTSAM 프레임워크는 $L_{total}$ 목적 함수의 최소화를 통해 구동되는 반복적인 최적화 과정을 통해 파라미터를 학습하고 업데이트한다.
-
파라미터 초기화: 훈련 시작 시, 코어 텐서 $G$는 모두 0으로 초기화된다. 이는 초기에는 ToRA 업데이트 $\Delta W(:,:,t)$도 0이 되어, 모델이 처음에 고정된 사전 훈련된 가중치 $W_0$에만 의존함을 보장한다. 요인 행렬 $U_1, U_2, U_3$는 표준 가우시안 분포에서 무작위로 초기화된다. 이 무작위 초기화는 파라미터 공간 탐색을 위한 시작점을 제공한다.
-
기울기 계산: 각 훈련 반복 중에, 모든 작업에 걸쳐 데이터 배치에 대한 $L_{total}$을 계산한 후, Adam 옵티마이저를 사용하여 기울기를 계산한다. 기울기는 훈련 가능한 파라미터, 즉 요인 행렬 $U_1, U_2, U_3$, 코어 텐서 $G$, 그리고 이미지 인코더의 레이어 정규화 레이어 내의 스케일 및 편향 파라미터에 대해 계산된다. 중요하게도, 이미지 인코더의 원래 사전 훈련된 가중치 $W_0$는 고정되어, 이를 통해 기울기가 흐르지 않으므로 훈련 가능한 파라미터 수와 계산 비용이 크게 줄어든다.
-
손실 지형 형성: 손실 지형은 다중 작업 학습 손실 ($L_{MTL}$)과 직교 정규화 항 ($R$)의 상호 작용에 의해 형성된다.
- $L_{MTL}$은 모델이 모든 작업에 걸쳐 성능을 향상시키도록 유도한다. 정규화 없이는 이 지형이 복잡해져 작업 간의 상충되는 기울기 또는 과적합으로 이어질 수 있다.
- 정규화 항 $R$은 구조적 제약 역할을 한다. $U_1, U_2, G$의 비직교성을 페널티함으로써, 이는 업데이트 파라미터의 더 컴팩트하고 덜 중복적인 표현을 장려한다. 이는 더 부드러운 손실 지형으로 이어져 수렴을 돕고 모델이 고도로 상관되거나 중복된 특징을 학습하는 것을 방지하여 일반화를 개선할 수 있다. 저자들의 이론적 분석은 이러한 저랭크, 직교 구조가 ToRA가 LoRA에 비해 적은 파라미터로 더 우수한 표현력을 달성할 수 있도록 한다고 시사한다.
-
반복적 업데이트: Adam 옵티마이저는 계산된 기울기를 사용하여 훈련 가능한 파라미터 ($U_1, U_2, U_3, G$, 및 레이어 정규화 파라미터)를 반복적으로 업데이트한다. 업데이트는 $10^{-3}$의 초기 학습률을 사용하여 수행되며, 이는 0.05의 워밍업 비율을 가진 선형 학습률 스케줄러에 의해 조정된다. 과적합을 방지하기 위해 $10^{-6}$의 가중치 감쇠도 적용된다. 이러한 반복적 업데이트는 점진적으로 ToRA 구성 요소를 개선하여 작업 공유 및 작업별 정보를 모두 학습할 수 있도록 한다.
-
수렴: 훈련 과정은 정해진 에포크 수 (예: NYUv2의 경우 200) 동안 계속된다. 파라미터가 업데이트됨에 따라 $L_{total}$은 감소할 것으로 예상되며, 이는 모델이 원하는 저랭크 구조를 유지하면서 작업에 더 잘 수행하도록 학습하고 있음을 나타낸다. 목표는 $L_{total}$을 최소화하는 파라미터 세트로 수렴하여 다중 작업 성능 및 파라미터 효율성을 향상시키는 것이다. 추론 시, 각 작업 $t$에 대한 학습된 $\Delta W(:,:,t)$는 사전 계산되어 $W_0$에 추가되어 $W_t'$를 형성하므로 추가 지연이 없다. 이 영리한 설계는 미세 조정의 이점이 더 느린 예측 시간의 비용으로 오지 않도록 보장한다.
결과, 한계점 및 결론
실험 설계 및 베이스라인
제안된 Multi-Task SAM (MTSAM) 프레임워크와 그 핵심 구성 요소인 Tensorized low-Rank Adaptation (ToRA)을 엄격하게 검증하기 위해, 저자들은 세 가지 잘 확립된 벤치마크 데이터셋인 NYUv2, CityScapes, PASCAL-Context에 걸쳐 광범위한 실험을 수행하였다. 이 데이터셋들은 실내 장면(NYUv2)과 도시 실외 환경(CityScapes, PASCAL-Context)을 포괄하며 다양한 밀집 예측 작업을 포함하는, 다양한 컴퓨터 비전 시나리오를 대표한다.
실험 설정은 MTSAM의 다양한 출력 차원을 처리하고 여러 작업을 동시에 효율적으로 fine-tuning하는 능력에 대한 수학적 주장을 철저히 입증하도록 설계되었다. MTSAM이 비교된 "희생양"(베이스라인 모델)에는 전통적인 multi-task learning (MTL) 접근 방식과 더 최근의 parameter-efficient fine-tuning (PEFT) 방법들이 포괄적으로 포함되었다:
- CNN 기반 MTL 베이스라인: Single-Task Learning (STL), Hard-Parameter Sharing (HPS), Cross-Stitch, Multi-Task Attention Network (MTAN), NDDR-CNN. 이들은 다중 작업 학습을 위한 확립된 방법들을 나타내며, HPS는 $\Delta_b$ 지표에 대한 중요한 베이스라인 역할을 한다.
- Transformer 기반 MTL 베이스라인: VTAGML 및 SwinMTL은 최신 아키텍처를 반영한다.
- Cross-attention 기반 MTL: DenseMTL.
- LoRA 기반 PEFT 베이스라인: ToRA의 효과를 구체적으로 평가하기 위해, 저자들은 다중 작업 설정에서 LoRA를 직접 적용한 것과 비교하였다: LoRA-STL (작업별 LoRA), LoRA-HPS (공유 LoRA), MultiLoRA. Terra 및 HydraLoRA와 같은 다른 고급 LoRA 변형과 전체 모델의 완전한 fine-tuning과도 추가 비교가 이루어졌다.
데이터셋별로 평가된 작업은 다음과 같다:
* NYUv2: 13개 클래스 의미론적 분할, 깊이 추정, 표면 법선 예측.
* CityScapes: 7개 클래스 의미론적 분할, 깊이 추정.
* PASCAL-Context: 21개 클래스 의미론적 분할, 7개 클래스 인간 부위 분할, saliency 추정, 표면 법선 추정.
성능은 표준 지표 모음을 사용하여 정량화되었다:
* 의미론적 분할: Mean Intersection over Union (mIoU) 및 Pixel Accuracy (Pix Acc). 값이 높을수록 좋다.
* 깊이 추정: Absolute Error (Abs Err) 및 Relative Error (Rel Err). 값이 낮을수록 좋다.
* 표면 법선 예측: 각도 오차의 평균 및 중앙값 (낮을수록 좋음), 그리고 각도 오차가 11.25, 22.5, 30도 이내인 픽셀의 비율 (높을수록 좋음).
* 전반적인 성능: HPS 아키텍처 대비 각 작업의 평균 상대 개선을 나타내는 복합 지표인 $\Delta_b$. 값이 높을수록 더 나은 성능을 나타낸다.
* 매개변수 효율성: 메가바이트(MB) 단위의 학습 가능한 매개변수 수 (Params.). 값이 낮을수록 더 효율적이다.
구현 세부 사항에는 학습률 $10^{-3}$의 Adam 옵티마이저, warmup을 포함한 선형 학습률 스케줄러, 그리고 각 데이터셋에 맞게 조정된 ToRA ($p, q, v$)의 특정 rank 설정이 포함되었다. 하이퍼파라미터 $\lambda$로 제어되는 직교 정규화(Orthogonal regularization)도 적용되었다.
증거가 입증하는 바
실험 결과는 MTSAM, 특히 ToRA 구성 요소가 foundation 모델의 multi-task learning을 상당히 발전시킨다는 명확하고 부인할 수 없는 증거를 제공한다.
-
전반적인 우수성 및 매개변수 효율성: 세 가지 벤치마크 데이터셋(NYUv2, CityScapes, PASCAL-Context) 전반에 걸쳐, MTSAM은 $\Delta_b$ 지표로 측정된 평균 성능에서 일관되게 최고치를 달성했다(표 1, 2, 3). 예를 들어, NYUv2에서 MTSAM은 59.59 MB의 학습 가능한 매개변수만으로 +23.93%의 $\Delta_b$를 달성하여, 완전 fine-tuning (+14.57% 및 1222.47 MB) 및 다른 모든 베이스라인을 능가했다. 이는 MTSAM이 우수한 성능을 달성할 뿐만 아니라 놀라운 매개변수 효율성으로 이를 달성하여 저장 및 실제 응용에 상당한 이점을 제공함을 보여준다.
-
공유 및 특정 정보 활용에 대한 ToRA의 효과: ToRA와 LoRA 기반 방법(LoRA-HPS, LoRA-STL, MultiLoRA) 간의 비교는 중요하다. 단일 공유 LoRA 행렬을 사용하는 LoRA-HPS는 종종 작업 경쟁으로 어려움을 겪는다. 작업별 LoRA를 사용하는 LoRA-STL은 LoRA-HPS보다 더 나은 성능을 보여, 작업별 구성 요소의 중요성을 강조한다. 그러나 ToRA는 일관되게 LoRA-STL 및 LoRA-HPS보다 우수한 성능을 보인다(표 1, 2, 3, 7). 이 명확한 증거는 ToRA가 저랭크 텐서 분해를 통해 작업 공유 및 작업별 정보를 효과적으로 활용하여 전반적인 성능을 향상시킨다는 이론적 주장을 뒷받침한다. 질적 결과(그림 5-11)는 이를 더욱 강화하며, MTSAM과 ToRA가 다른 LoRA 변형에 비해 특히 어려운 "모호하고 가는 객체"에 대해 시각적으로 더 정확한 예측을 생성함을 보여준다.
-
아키텍처 수정의 영향:
- 작업 임베딩: ablation study(표 8)는 제안된 작업 임베딩이 서로 다른 작업에 대해 MLP 출력 차원을 단순히 수정하는 것보다 더 효과적임을 명확히 보여준다. 이 개선은 작업 임베딩과 이미지 특징 간의 상호 작용을 통해 작업별 지식의 더 나은 학습을 촉진하는 cross-attention 메커니즘에 기인한다.
- 직교 정규화: 직교 정규화에 대한 ablation study(표 5)는 그 긍정적인 영향을 보여준다. $G$, $U_1$, $U_2$에 대한 완전한 직교 정규화를 갖춘 MTSAM은 이를 사용하지 않는 변형보다 상당히 우수한 성능을 보여, 중복성을 줄여 다양한 작업에 걸쳐 성능을 향상시키는 데 효과적임을 입증한다.
-
하이퍼파라미터 설정에 대한 견고성: 하이퍼파라미터 $\lambda$(직교 정규화 가중치)에 대한 민감도 분석(표 6)은 MTSAM의 성능이 합리적인 범위(예: [0.5, 1.5]) 내에서 $\lambda$에 크게 민감하지 않음을 나타낸다. 이는 모델이 상대적으로 견고하고 튜닝하기 쉽다는 것을 시사하며, 이는 실용적인 이점이다.
한계 및 향후 방향
MTSAM은 특히 SAM과 같은 foundation 모델의 multi-task fine-tuning에서 인상적인 기능을 보여주지만, 본 논문은 여러 한계점을 강조하고 흥미로운 연구 방향을 제시한다.
한 가지 주목할 만한 한계는 매우 다른 데이터 분포에 걸친 zero-shot 일반화와 관련이 있다. 저자들은 NYUv2에서만 훈련된 후 CityScapes 데이터셋에서 zero-shot 깊이 추정을 수행하는 MTSAM의 능력을 탐구했다(그림 12). 보이지 않는 데이터를 처리하는 일부 능력을 보여주지만, 결과는 특히 원거리 객체에 대해 부정확성을 나타낸다. 이는 데이터셋 간의 내재적 차이에 기인한다: NYUv2는 실내 이미지를 포함하는 반면, CityScapes는 실외 도시 장면을 특징으로 하여 깊이 분포, 객체 유형, 해상도 및 심지어 ground truth 깊이 예측에 사용된 하드웨어에서도 불일치를 야기한다. 이는 MTSAM이 적응할 수 있지만, 큰 도메인 이동은 여전히 상당한 과제를 제기하며, zero-shot 전이성은 매우 다른 환경에 걸쳐 보편적으로 견고하지 않음을 시사한다.
앞으로, 본 논문의 결과는 추가 개발 및 발전을 위한 몇 가지 설득력 있는 논의 주제를 제시한다:
-
Zero-Shot Multi-Tasking을 위한 향상된 도메인 적응: 서로 다른 도메인에 걸친 zero-shot 전이에서의 관찰된 한계를 고려할 때, 중요한 미래 방향은 MTSAM 프레임워크에 보다 정교한 도메인 적응 기술을 직접 통합하는 것이다. 적대적 훈련, 도메인 일반화를 위한 메타 학습, 또는 더 고급 프롬프트 엔지니어링 전략을 ToRA와 결합하여 보이지 않는, out-of-domain 작업에서 성능을 향상시킬 수 있을까? 텐서 분해 내에서 도메인 격차를 명시적으로 모델링하고 완화하는 방법을 탐구하는 것은 유익한 영역이 될 수 있다.
-
동적 ToRA Rank 및 작업 가중치 할당: 현재 ToRA의 rank($p, q, v$)와 작업 손실 가중치($w_i$)는 고정된 하이퍼파라미터로 설정되어 있다. 향후 연구에서는 훈련 중에 이러한 매개변수를 조정하기 위한 동적 방법을 조사할 수 있다. 예를 들어, 일부 PEFT 방법이 동적으로 rank를 조정하는 방식과 유사하게, 적응 메커니즘이 각 작업 또는 레이어에 대한 최적의 rank를 학습할 수 있을까? 마찬가지로, 작업 불확실성 또는 기울기 충돌에 기반한 동적 작업 가중치 전략은 모델이 다양한 작업에 걸쳐 성능을 균형 잡고 최적화하는 능력을 더욱 향상시켜, 이 연구에서 사용된 고정 가중치를 넘어서는 것을 가능하게 할 수 있다.
-
다른 Foundation 모델 및 모달리티로 ToRA 확장: 본 논문은 이미지 분할 작업에 SAM에 초점을 맞춘다. 자연스러운 확장은 MTSAM 프레임워크와 ToRA를 다른 모달리티의 다른 대형 foundation 모델에 적용하는 것이다. 예를 들어, 대규모 언어 모델(LLM) 또는 비전과 언어를 통합하는 멀티모달 모델. 다양한 NLP 작업에 대한 LLM fine-tuning 또는 교차 모달 이해가 필요한 작업에 대한 멀티모달 모델 적응에 ToRA는 어떻게 수행될까? 이는 텐서화된 저랭크 적응의 일반화 가능성과 확장성에 대한 새로운 통찰력을 드러낼 수 있다.
-
표현력 및 일반화에 대한 이론적 심층 분석: Theorem 1은 매개변수 효율성 측면에서 여러 LoRA에 대한 ToRA의 우수성을 증명하지만, 복잡한 다중 작업, 다중 도메인 시나리오에서의 표현력 및 일반화 경계에 대한 더 깊은 이론적 분석은 가치가 있을 것이다. ToRA의 텐서 분해가 작업 공유 및 작업별 정보를 최적으로 포착하는 조건과 이것이 기본 작업 관련성과 어떻게 관련되는지를 형식적으로 특성화할 수 있을까? 이는 향후 다중 작업 PEFT 방법에 대한 보다 원칙적인 설계 선택으로 이어질 수 있다.
-
배포 및 추론에서의 효율성: 본 논문은 ToRA가 추론 중에 추가 지연 시간을 도입하지 않는다고 언급한다. 왜냐하면 업데이트된 매개변수 행렬은 사전 저장될 수 있기 때문이다. 그러나 작업 수가 증가함에 따라 작업별 업데이트 가중치($W_t = W_0 + \Delta W_t$)의 저장 공간은 여전히 상당할 수 있다. 향후 연구에서는 특히 리소스 제약 환경에서 MTSAM의 실용적인 유용성을 더욱 향상시키기 위해, 더 컴팩트한 저장 또는 추론 중 $\Delta W_t$의 실시간 재구성을 위한 전략을 탐구할 수 있다.
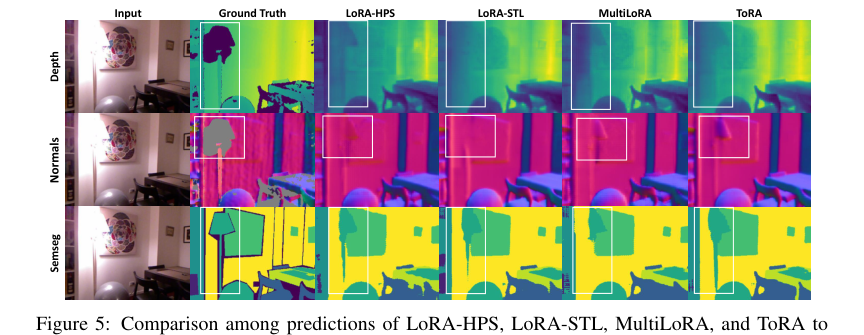 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
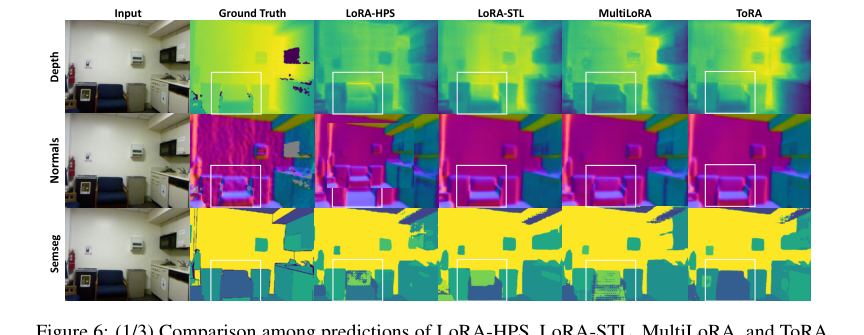 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
다른 필드와의 동형 사상
구조적 골격
본 논문은 파라미터 업데이트를 공유 및 작업별 저랭크 텐서 구성 요소로 분해함으로써 고용량 사전 학습 모델을 여러 다양한 작업에 효율적으로 적응시키는 메커니즘을 제시한다.