MTSAM: Multi-Task Fine-Tuning for Segment Anything Model
MTSAM: Multi-Task Fine-Tuning for Segment Anything Model
背景と学術的系譜
起源と学術的系譜
本稿で取り組む問題は、人工知能、特にコンピュータビジョン分野における大規模基盤モデルの最近の出現とその驚異的な能力に端を発する。歴史的に、基盤モデルはまず自然言語処理(NLP)分野に革命をもたらし、明示的に学習されていないタスクを実行できる驚異的なゼロショット能力を発揮した。この成功は、コンピュータビジョン分野でも同様のモデルの開発を触発した。
2023年にKirillovらによって導入されたSegment Anything Model (SAM)は、画像セグメンテーションのための著名な基盤モデルとして際立っている。SAMは、1100万サンプルの大規模データセットで学習された後、画像内の事実上あらゆるオブジェクトをセグメンテーションできる、卓越したゼロショット性能を示した。このブレークスルーは、高品質セグメンテーション、3D再構成、オブジェクトトラッキング、医療画像処理、パーソナライズドセグメンテーション、リモートセンシングなど、様々な下流タスクへのSAMの応用を探求する研究の急増につながった。
しかし、これらの先行アプローチの根本的な限界、あるいは「ペインポイント」は、それらがSAMを単一タスク学習にのみ採用していたことである。これは、新しいタスクごとにSAMを個別にファインチューニングし、マルチタスク学習(MTL)のための統一基盤モデルとしての可能性を見過ごしていたことを意味する。多くの現実世界のコンピュータビジョンシナリオでは、複数のタスクは本質的に関連しており、しばしば同時に(例えば、シーン理解における深度推定と法線推定)対処する必要がある。MTLにおける先行研究は、共有知識が全体的なパフォーマンスと効率を向上させることができるため、タスクが一緒に学習されることから利益を得られることを一貫して示してきた。
本稿では、SAMをマルチタスク学習に適応させる上で、特に2つの中心的な課題を特定する。
1. 出力次元の不一致: 元のSAMはセグメンテーションマスクを生成するように設計されており、通常は固定数の出力チャネル(例えば、図1aに示すように、すべて同じチャネル数を持つ3つの異なるレベル)を持つ。しかし、異なる下流タスクは異なる次元の出力を必要とする(例えば、深度推定は1チャネルを必要とするかもしれないが、法線推定は3チャネルを必要とする)。SAMのアーキテクチャは、これらのタスク固有の出力を異なるチャネル数で生成するのに十分な柔軟性を備えていなかった。
2. 同時ファインチューニング: SAMを複数の下流タスクに同時に適応させる効果的なファインチューニング方法は確立されていなかった。Low-Rank Adaptation (LoRA)のような既存のパラメータ効率的ファインチューニング(PEFT)手法は、主に単一タスク適応のために設計されていた。マルチタスク設定に適用された場合、これらの手法は、タスク間の共有情報を活用するのに苦労するか(各タスクに独自のLoRAを持つLoRA-STLなど)、共有パラメータを巡るタスク間の競争によるパフォーマンスの不均衡に悩まされるか(LoRA-HPSなど)であった。SAMのような大規模基盤モデルのための堅牢なマルチタスクファインチューニング戦略の欠如は、大きな障害となった。
著者らは、これらの正確な限界に対処するために本稿を執筆し、Multi-Task SAM (MTSAM)フレームワークとTensorized low-Rank Adaptation (ToRA)手法を提案し、SAMが出力次元と同時ファインチューニングの課題を克服し、マルチタスク学習のための汎用的な基盤モデルとして機能できるようにする。
直感的なドメイン用語
-
Segment Anything Model (SAM): 写真の中の、どんなに複雑で馴染みのないオブジェクトでも、完璧に輪郭を描くことができる非常に熟練したデジタルアーティストを想像してほしい。SAMはコンピュータにとってそのようなアーティストのようなもので、その正確なオブジェクトを見たことがなくても、画像からオブジェクトを信じられないほどの精度で「切り出す」ことができる。
-
ゼロショット能力: これは、多くの物事に関する一般的な原則を学んだ非常に賢い学生のようなものである。彼らに全く新しいもの、例えば珍しい種類の果物を見せても、その果物について特別に訓練されていなくても、彼らの広範な理解を適用するだけで、それが何であるか、あるいはどのように分類されるかについて良い推測をすることができる。
-
マルチタスク学習 (MTL): いくつかの関連する料理を同時に調理することを学ぶシェフを考えてほしい。例えば、メインコース、サイドディッシュ、ソースなどだ。それらを一緒に学ぶことで、シェフは、各料理を個別に学ぶのではなく、全体的な調理プロセスをより効率的にし、最終的な食事をより調和させる共通のテクニックや食材を発見するかもしれない。
-
パラメータ効率的ファインチューニング (PEFT): 多くの種類の車を修理する方法を知っている熟練した専門家、例えばマスターメカニックを想像してほしい。新しい車種が登場した場合、メカニックをゼロから再訓練するのではなく、その特定のモデルのためにいくつかの小さな、具体的な調整や新しいツールを教えるだけだ。彼らの広範な既存知識のほとんどはそのまま残され、適応は迅速かつ効率的になる。
-
Low-Rank Adaptation (LoRA): メカニックの例をさらに発展させると、LoRAはマスターメカニックに新しい車種ごとに小さな、専門的な「チートシート」を与えるようなものである。このシートには、標準的な手順に対する数少ない重要な変更のみが含まれており、メカニックは車のエンジニアリング全体を再学習することなく、スキルを適応させることができる。これは、非常に少ない新しい情報で大きな変更を加えるための巧妙な方法である。
記法表
| 記法 | 説明 |
|---|---|
| $I$ | 入力画像、次元は $3 \times H \times W$(チャネル、高さ、幅)。 |
| $H, W$ | 入力画像の高さと幅。 |
| $F_I$ | SAMの画像エンコーダーによって抽出された画像特徴、次元は $D \times \frac{H}{16} \times \frac{W}{16}$。 |
| $D$ | モデルにおける隠れ状態の次元。 |
| $O$ | 元のSAMからの最終セグメンテーションマスク出力、次元は $3 \times \frac{H}{4} \times \frac{W}{4}$。 |
| $T$ | 学習されている異なるタスクの総数。 |
| $\Delta W$ | 単一レイヤーの一般的な更新パラメータ行列、次元は $d \times k$。 |
| $W_0$ | レイヤーの事前学習済みパラメータ行列、次元は $d \times k$。 |
| $A, B$ | LoRAで使用される低ランク行列、ここで $B \in \mathbb{R}^{d \times r}$ かつ $A \in \mathbb{R}^{r \times k}$。 |
| $r$ | LoRAにおける低ランク行列のランク、ここで $r \ll \min(d, k)$。 |
| $\Delta \mathcal{W}$ | ToRAの更新パラメータテンソル、すべてのタスク固有の更新を $d \times k \times T$ テンソルに集約したもの。 |
| $G$ | ToRAのタッカー分解におけるコアテンソル、次元は $p \times q \times v$。 |
| $U_1, U_2, U_3$ | ToRAのタッカー分解における因子行列、次元はそれぞれ $d \times p$, $k \times q$, $T \times v$。 |
| $p, q, v$ | ToRAの因子行列の次元、通常は $d, k, T$ より小さい。 |
| $E_t$ | 特定のタスク $t$ のための学習可能なタスク埋め込み、次元は $N_t \times D$。 |
| $N_t$ | タスク $t$ に必要な出力チャネル数。 |
| $O_t$ | MTSAMがタスク $t$ に対して生成する出力予測、次元は $N_t \times \frac{H}{4} \times \frac{W}{4}$。 |
| $\mathcal{L}_{MTL}$ | MTSAMが最小化を目指す全体的なマルチタスク学習目的関数。 |
| $\lambda$ | 直交正則化項の影響を制御するハイパーパラメータ。 |
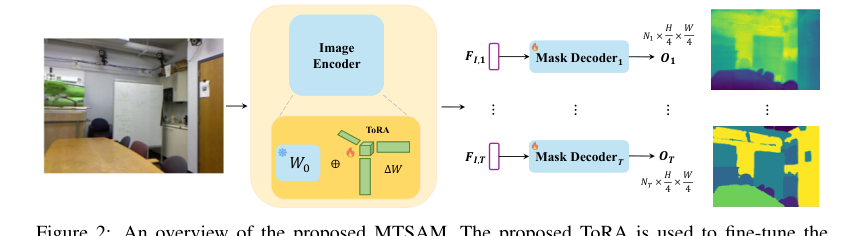 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
問題定義と制約
中心的な問題定式化とジレンマ
Segment Anything Model (SAM)は、ゼロショット汎化能力で知られる、画像セグメンテーションのための強力な基盤モデルとして登場した。本稿が取り組む中心的な問題は、SAMをマルチタスク学習(MTL)のための基盤モデルに効果的に変換する方法である。
入力/現在の状態:
出発点は元のSAMであり、画像 $I \in \mathbb{R}^{3 \times H \times W}$ と様々なプロンプト(点、バウンディングボックス、マスクなど)を入力として受け取る。そのアーキテクチャは、ヘビー級の画像エンコーダー、プロンプトエンコーダー、軽量マスクデコーダーから構成される。元のSAMはセグメンテーションマスクを生成するように設計されており、通常は固定数の出力チャネル(例えば、図1aのページ2に示すように、式3のページ4の $O \in \mathbb{R}^{3 \times H \times W}$ で見られるように3チャネル)を持つ。
望ましい終点(出力/目標状態):
望ましい終点は、Multi-Task SAM (MTSAM)と名付けられた変更されたSAMであり、以下のことが可能である。
1. 異なる次元を持つタスク固有の出力を生成する: 例えば、深度推定のために1チャネルの出力、意味セグメンテーションのために13チャネルの出力、法線推定のために3チャネルの出力を、すべて単一の入力から同時に生成する(図1b、ページ2)。
2. 複数の下流タスクに同時に適応するようにファインチューニングされる: この適応は、各タスクを個別に扱うのではなく、タスク間の共有情報を活用して全体的なパフォーマンスを向上させるべきである。
欠落しているリンクと数学的ギャップ:
現在と望ましい状態との間の正確な欠落リンクまたは数学的ギャップは、2つの側面からなる。
1. 多様な出力に対するアーキテクチャの柔軟性の欠如: 元のSAMのマスクデコーダーは、固定チャネル数の出力を生成するようにアーキテクチャ的に制約されており、異なる出力次元を必要とするタスク(深度推定や意味セグメンテーションなど)には不向きである。特定のタスクに基づいて出力チャネルを動的に調整するメカニズムは本質的に存在しない。
2. 非効率的なマルチタスクファインチューニング: SAMのような大規模エンコーダーを複数のタスクに同時にファインチューニングし、タスク共有知識とタスク固有知識のバランスを効果的に取るための、堅牢でパラメータ効率的な方法が欠如している。既存のPEFT手法(LoRAなど)をMTLに単純に適用すると、パラメータを広範に共有しすぎる(LoRA-HPS)とタスク間の競争によるパフォーマンスの低下を招くか、タスク固有のLoRA(LoRA-STL)ではタスク間の共有情報を活用できないというジレンマに陥る。
ジレンマ:
過去の研究者を閉じ込めてきた中心的なジレンマは、大規模基盤モデルのマルチタスク学習におけるパラメータ効率と表現力/パフォーマンスの間の痛みを伴うトレードオフである。
* SAMのようなヘビー級モデルを複数のタスクにフルファインチューニングすることは、計算上不可能であり、パラメータ効率が悪い。
* 既存のPEFT手法をMTLに単純に適用することはジレンマをもたらす。
* ハードパラメータ共有(LoRA-HPS): このアプローチは、すべてのタスクに1つの共有LoRA行列を使用するため、パラメータ効率が良い。しかし、それはしばしば「共有LoRAを巡るタスク間の競争により、すべてのタスクでパフォーマンスが不均衡になる」(ページ4)という結果を招く。タスク固有のニュアンスを捉えるのに苦労し、効率のためにパフォーマンスを犠牲にする。
* タスク固有LoRA(LoRA-STL): この手法は、タスクごとに個別のLoRAモジュールをトレーニングし、タスク固有の適応を可能にし、個々のタスクパフォーマンスを向上させる可能性がある。しかし、そのパラメータ数はタスク数に線形に増加する($O(Trd+Trk)$、ページ6)ため、タスク数が多い場合には効率が悪くなる。特に、「複数のタスクにわたるファインチューニングに必要なタスク間共有情報を活用できない」(ページ4)ため、MTLの相乗効果を見逃すことになる。
課題は、パラメータ効率が良く(タスク数に対するパラメータの線形未満の増加)、タスク共有の一般的な知識とタスク固有の詳細の両方を同時に捉えることができる方法を考案することであり、それによってマルチタスク設定における既存のPEFT戦略の限界を克服することである。
制約と失敗モード
SAMをマルチタスク学習に適応させる問題は、著者らが直面したいくつかの厳しい現実的な壁によって非常に困難になっている。
- ハードウェアメモリと計算リミット: SAMの画像エンコーダーは「ヘビー級」(ページ3)と説明されている。このような大規模モデルを複数のタスクに同時にファインチューニングするには、莫大な計算リソースとメモリが必要となり、フルファインチューニングは非現実的になる。この制約により、パラメータ効率的な手法の使用が不可欠となる。
- 固定出力チャネル制約: 元のSAMのマスクデコーダーは、固定数のチャネル(例えば、セグメンテーションのために3つ)を出力するようにハードワイヤードされている。このアーキテクチャ上の剛性は、深度推定(1チャネル)やマルチクラス意味セグメンテーション(例えば、13チャネル)のような多様なタスクに必要な異なるチャネル数の出力を直接生成することを妨げる。これは克服されるべき根本的なアーキテクチャ上の限界である。
- タスク共有学習とタスク固有学習のバランスを取れないこと: 既存のPEFT手法をMTLに適用した場合、一般的なタスク共有特徴と特定のタスク依存適応の学習のバランスを効果的に取ることができない。LoRA-HPSはタスク競争に悩まされ、LoRA-STLはタスク間共有情報を活用できない(ページ4)。これにより、パフォーマンスが最適化されないか、パラメータ使用が非効率になる。
- 最適な近似のためのテンソル分解の複雑さ: テンソル分解は強力な数学的ツールであるが、「最良の近似」を複雑な目的、特にマルチタスク学習の文脈で見つけることは本質的に困難であり、「常に存在するとは限らない」(Kolda & Bader, 2009、ページ7で引用)。これは、低ランクテンソル適応の理論的な最適性を保証する可能性のある困難を示唆している。
- タスク間のデータの異質性: 異なるタスクは、しばしば異なるデータ分布、意味論的意味、および出力形式を伴う。例えば、深度推定と意味セグメンテーションは、異なる種類のグラウンドトゥルースと評価指標を必要とする。モデルは、単一タスクのパフォーマンスを損なうことなく、この固有の多様性を処理するのに十分な堅牢性を持つ必要がある。
- リアルタイムレイテンシ要件の欠如(暗黙的): 明示的に著者らが苦労した「制約」として述べられていないが、パラメータ効率の目標と、ToRAが「推論中に追加のレイテンシを導入しない」(ページ6)という記述は、実際的なアプリケーションでしばしば重要な効率的な推論の暗黙的な必要性を示唆している。モデルの複雑さは推論時間を大幅に増加させるべきではない。
なぜこのアプローチなのか
選択の必然性
Segment Anything Model (SAM)は、画像セグメンテーションのための驚異的なゼロショット能力を示す、強力な基盤モデルとして登場した。しかし、マルチタスク学習への直接的な応用は、従来の「SOTA」手法、元のSAM自体を含む、対応するのが困難な2つの根本的なアーキテクチャ上のハードルを提示した。これらの不十分さの著者らの認識は、マルチタスク学習のコア要件を考慮したときに明らかになった。(a)異なるチャネル数を持つタスク固有の出力を生成する必要性(例:深度推定のための1チャネル、法線推定のための3チャネル、意味セグメンテーションのための複数チャネル)、および(b)SAMを複数の下流タスクに効率的に同時にファインチューニングする課題である。
元のSAMは、設計上、異なるレベルでセグメンテーションマスクを生成するが、決定的に、これらのすべての出力は同じチャネル数を持つ。この固定出力次元は、深度推定や法線推定のようなタスクが異なる出力構造を必要とする場合に、深刻な制約となる。本稿では、「SAMが基本的な視覚モデルとして示した計り知れない可能性にもかかわらず、プロンプト誘導型のマスク生成への依存は、出力チャネル数が異なる下流タスクへのエンドツーエンドの適応性を達成する上で課題を提示する」と明確に述べている。これは、SAMの固有のアーキテクチャ、特にそのプロンプトエンコーダーとマスクデコーダーが多様なマルチタスク出力に対して十分に柔軟ではなかったことを著者らが認識したまさにその瞬間であった。したがって、SAMまたは既存の単一タスクファインチューニング手法の直接的な応用は、真のマルチタスク基盤モデルにとっては単に実行可能ではなかった。
比較優位性
提案されたMulti-Task SAM (MTSAM)フレームワーク、特にそのTensorized low-Rank Adaptation (ToRA)手法は、特にパラメータ効率と情報活用において、以前のゴールドスタンダードに対して圧倒的な定性的および構造的優位性を示す。
第一に、ToRAの最も重要な構造的利点は、そのパラメータ効率にある。$T$個のタスクに適用された場合、従来のLow-Rank Adaptation (LoRA)手法は、ハードパラメータ共有(LoRA-HPS)またはタスク固有LoRA(LoRA-STL)のいずれを使用しても、通常$O(Trd + Trk)$という、タスク数に線形に増加するパラメータ複雑性を示す。対照的に、ToRAはすべてのタスクの更新パラメータ行列を単一の更新パラメータテンソル $\Delta W \in \mathbb{R}^{d \times k \times T}$ に集約し、低ランクテンソル分解(特にタッカー分解)を適用する。これにより、パラメータ複雑性は$O(dp + kq)$となり、ここで $p, q, v \ll \min(d, k)$ かつ $T$ はタスク数である。これは、タスク数に対する学習可能パラメータのサブ線形増加を表しており、多数のタスクへのスケーリングにおいて劇的に効率的である。このメモリ複雑性の削減は、SAMのような巨大な基盤モデルのファインチューニングにとってゲームチェンジャーである。
第二に、ToRAは、タスク共有情報とタスク固有情報の両方を効果的に捉えることで、代替手法を質的に凌駕する。LoRA-HPSは、単一の $\Delta W$ をすべてのタスクで共有することにより、タスク競争に苦労し、しばしばパフォーマンスの不均衡を招く。一方、LoRA-STLは、タスクごとに個別の $\Delta W_t$ をトレーニングするが、貴重なタスク間共有情報を完全に無視する。ToRAのタッカー分解の使用は、コアテンソル $G$ と因子行列 $U_1, U_2, U_3$ が、タスク共有情報の主要なサブスペース変動($U_1$と$U_2$を通じて)とタスク固有のサブスペース構造($U_3$を通じて)の両方を明示的にモデル化することを可能にする。情報共有と専門化に対するこの全体的なアプローチは、多様なタスクにわたるファインチューニングパフォーマンスを向上させる主要な構造的利点である。定理1における理論的分析は、これをさらに裏付けており、ToRAは複数のLoRAと比較して、より少ないパラメータで同じ重み更新を達成できる、より優れた表現力を持つことを証明している。
最後に、定性的な評価(例えば、図5)は、ToRAでファインチューニングされたMTSAMが、特に「曖昧で細いオブジェクト」に対して、より正確な結果を生成することを示している。これは、ToRAが共有情報と固有情報を分離して活用する能力が、視覚シーンのより堅牢でニュアンスのある理解につながり、他の手法が細かい詳細や複雑なオブジェクト境界で苦労する可能性のある困難なシナリオでパフォーマンスを向上させることを示唆している。
制約との整合性
選択されたMTSAMフレームワークは、そのアーキテクチャ変更とToRAファインチューニング手法により、SAMをマルチタスク学習に適応させるために特定された2つの主要な制約に完全に適合している。
-
制約:異なるチャネル数を持つタスク固有の出力を生成すること。
- ソリューションの特性: MTSAMは、SAMのマスクデコーダーを根本的に変更することで、これを解決する。元のプロンプトエンコーダーを削除し、タスク固有のノーマスク埋め込みと専用のタスク固有マスクデコーダーを導入する。図1と図3に示すように、この変更により、MTSAMはSAMの固定チャネル出力ではなく、各タスク($N_t \times H \times W$)に合わせた次元の出力を生成できるようになる。例えば、深度用に1チャネル、法線用に3チャネル、意味セグメンテーション用に13チャネルを出力できる。学習可能なタスク埋め込み$E_t$の導入は、デコーダーがタスク自体に基づいて処理を適応させることができることをさらに保証する。これは、出力柔軟性に対する問題の必要性と、ソリューションのモジュラーでタスクを意識したデコーダー設計との直接的な「結婚」である。
-
制約:SAMを複数の下流タスクに同時に、かつ効率的に適応させるためにファインチューニングすること。
- ソリューションの特性: ToRAは、この制約に対する中心的なイノベーションである。各レイヤーのSAMエンコーダーに更新パラメータテンソルを挿入し、低ランクテンソル分解を使用してタスク共有情報とタスク固有情報の両方を捉える。これにより、モデルはタスク間の相互依存関係を活用しながら、複数のタスクから同時に学習することができ、同時にタスク固有の適応も可能になる。ToRAのパラメータ効率は、タスク数に対するパラメータのサブ線形増加により、計算コストやメモリフットプリントを許容できないレベルにすることなく、SAMのようなヘビー級基盤モデルのファインチューニングに不可欠である。この効率性は、同時適応が単に可能であるだけでなく、実践的であることを保証し、大規模マルチタスク学習の厳しい要件に最適である。全体の損失関数($L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$)における直交正則化項は、学習された因子行列が適切に振る舞い、冗長でないことを保証し、マルチタスクファインチューニングプロセスの安定性と有効性に貢献する。
代替案の却下
本稿では、主に既存のパラメータ効率的ファインチューニング(PEFT)手法と、マルチタスク設定でLoRAを適用するための異なる戦略に焦点を当て、いくつかの代替アプローチを却下する明確な理由を提供している。
-
従来のPEFT手法(例:アダプターベース、プロンプトチューニング、単一タスク用の既存のLoRAバリアント): 著者らは、これらの手法が「単一タスクファインチューニングにおいて競争力のあるパフォーマンスと高いパラメータ効率を達成する」と明記しているが、「複数のタスク間の共有情報を考慮しないため、マルチタスク学習設定には適さない」としている。これは、同時に複数のタスクを学習することから生じる相乗効果や競合を本質的に活用できない手法の包括的な却下である。それらの設計は、根本的に一度に1つのタスクを最適化するように設定されており、マルチタスク学習の目標とは相反する。
-
LoRA-HPS(ハードパラメータ共有): このアプローチは、すべてのタスクに1つの共有LoRA行列($\Delta W$)を使用してマルチタスク学習を試みる。本稿では、これが「共有LoRAを巡るタスク間の競争により、すべてのタスクでパフォーマンスが不均衡になる可能性がある」ため、これを却下する。タスクに相反する勾配や異なる学習ダイナミクスがある場合、それらを単一の区別されていない更新行列で共有することを強制すると、一部またはすべてのタスクのパフォーマンスが低下する可能性がある。
-
LoRA-STL(シングルタスクLoRA): この代替案は、タスクごとに個別のLoRA行列($\Delta W_t$)をトレーニングすることを含む。本稿では、これが「複数のタスクにわたるファインチューニングに必要なタスク間共有情報を活用できない」ため、これを却下する。LoRA-HPSの競争問題を回避する一方で、マルチタスク学習の核心である関連タスク間の共有知識と共通特徴の潜在的な利点を活用できない。これにより、情報をインテリジェントに共有できるアプローチよりも効率が悪く、パフォーマンスも低下する可能性がある。
-
フルファインチューニング: 他のPEFT手法ほど強く「却下」されているわけではないが、本稿では、SAMのヘビー級画像エンコーダーのフルファインチューニングを、「パラメータと計算効率の懸念」から暗黙的に却下している。表7は、フルファインチューニングが1222.47 MBという膨大な学習可能パラメータを必要とする一方、MTSAMの59.59 MBよりも大幅に多いが、全体的なパフォーマンス向上(フルファインチューニングで+14.57%、MTSAMで+23.93%)は低いことを定量的に裏付けている。これにより、フルファインチューニングは大規模基盤モデルや効率が最重要視されるマルチタスクシナリオには非現実的となる。パラメータの規模が大きいため、計算コストが高く、小規模なマルチタスクデータセットでの過学習を招きやすい。
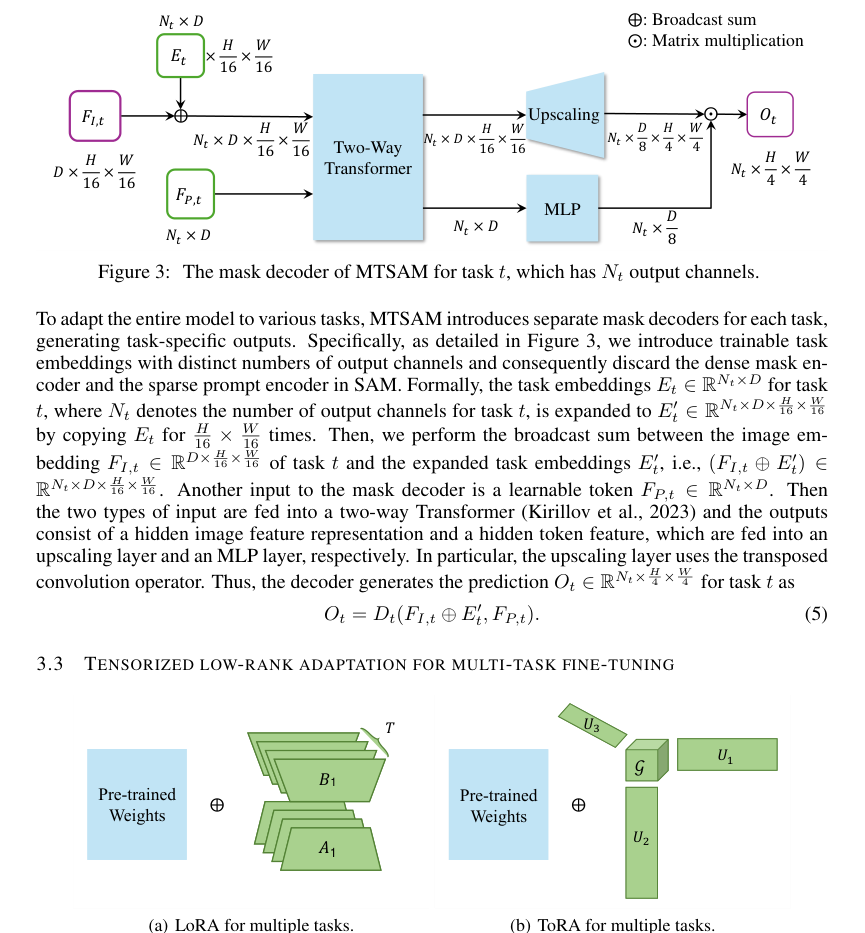 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
数学的・論理的メカニズム
マスター方程式
MTSAMフレームワークの学習プロセスの絶対的な核心は、マルチタスク学習損失と、効率的で効果的なパラメータ更新を保証するための正則化項を組み合わせた全体的な目的関数である。このマスター方程式は、トレーニングプロセス全体を導く。
$$ L_{total} = L_{MTL} + \lambda R(U_1, U_2, G) $$
この方程式は、モデルが複数のタスクから同時に学習し、同時にパラメータ効率を維持し、テンソル分解と正則化を通じて冗長性を防ぐ方法を包括している。
項ごとの解剖
マスター方程式とその構成要素を詳細に分析し、それらの数学的定義、物理的/論理的役割、および著者らの設計選択を理解しよう。
-
$L_{total}$: これは、MTSAMフレームワークがトレーニング中に最小化を目指す合計目的関数である。その役割は、すべてのタスクにおけるパフォーマンスと、パラメータ更新の効率性と構造的整合性のバランスを取ることである。著者らは、これらが同時に最適化されるべき2つの異なる目的であるため、マルチタスク損失と正則化項を結合するために加算を使用している。タスクエラーの最小化と、低ランクで構造化されたパラメータ空間の維持である。
-
$L_{MTL}$: この項は、マルチタスク学習(MTL)損失を表す。これは、すべての個々のタスクからの重み付けされた損失の平均である。
$$ L_{MTL} = \frac{1}{T} \sum_{i=1}^T w_i L_i $$- $T$: これは、MTSAMモデルがトレーニングされている異なるタスクの総数(例:意味セグメンテーション、深度推定、法線推定)である。その役割は、個々のタスク損失の合計を正規化し、すべてのタスクにわたる平均損失を提供することである。全体的なマルチタスク目的は個々のタスク目的の複合体であるため、合計が使用される。
- $w_i$: これは、タスク $i$ の損失重みである。それは、全体的なマルチタスク目的における各タスクの損失の相対的な重要性を制御するハイパーパラメータである。例えば、より重要または困難と見なされるタスクには、より高い重みが与えられる可能性がある。著者らは、各タスクの損失への寄与をスケーリングするために乗算を使用し、柔軟な優先順位付けを可能にする。
- $L_i$: これは、タスク $i$ の損失であり、その特定のタスクのすべてのトレーニングサンプルにわたる平均損失として計算される。
$$ L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j, f(x_j)) $$- $N_i$: これは、タスク $i$ のトレーニングサンプルの数を示す。その役割は、損失をサンプルにわたって平均化し、タスクの損失がそのサンプル数によって不均衡に影響されないようにすることである。合計は個々のサンプルの損失を収集し、$N_i$ で割ることで平均損失を提供する。
- $l_i(\cdot, \cdot)$: これは、タスク $i$ のタスク固有損失関数である。その数学的定義は、タスク $i$ の性質に依存する(例:セグメンテーションのクロスエントロピー、深度推定のL1損失、法線推定のコサイン類似度)。その役割は、モデルの予測とグラウンドトゥルースとの間の不一致を単一サンプルに対して定量化することである。
- $y_j$: これは、タスク $i$ の$j$番目のトレーニングサンプルのグラウンドトゥルースラベルである。モデルが生成すべき正しい出力を表す。
- $f(x_j)$: これは、タスク $i$ の$j$番目のトレーニングサンプル $x_j$ に対するMTSAMモデルの予測を表す。関数$f(\cdot)$は、画像エンコーダーとToRAで変更された重みを含むタスク固有マスクデコーダーを含む、MTSAMアーキテクチャ全体を具体化する。
- $x_j$: これは、予測$f(x_j)$が生成される入力トレーニングサンプル(例:画像)である。
-
$\lambda$: これは、直交正則化項 $R(U_1, U_2, G)$ の影響を制御するハイパーパラメータである。その役割は、タスク固有のエラーの最小化と、ToRAパラメータの望ましい低ランクで直交構造の維持との間のトレードオフをバランスさせることである。より大きな $\lambda$ は、正則化に重点を置く。著者らは、正則化の合計損失への寄与をスケーリングするために乗算を使用している。
-
$R(U_1, U_2, G)$: これは、直交正則化項である。これは、因子行列 $U_1, U_2$ およびコアテンソル $G$ のスライスが直交するように奨励し、冗長性を削減し、テンソル分解の安定性を向上させる。
$$ R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^v ||G(:,:,l)^T G(:,:,l) - I||_F^2 $$- $U_1$: これは、次元 $d \times p$ の因子行列である。これは、更新パラメータテンソル $\Delta W$ の出力特徴次元に対応する、タスク共有情報の主要なサブスペース変動を捉える。
- $U_2$: これは、次元 $k \times q$ の因子行列である。これは、更新パラメータテンソル $\Delta W$ の入力特徴次元に対応する、タスク共有情報の主要なサブスペース変動を捉える。
- $G$: これは、次元 $p \times q \times v$ のコアテンソルである。これは、テンソル $\Delta W$ の圧縮された低ランク表現であり、分解後の「エッセンス」を保持する。
- $||\cdot||_F^2$: これは、フロベニウスノルム二乗を示す。数学的には、行列 $A$ に対して、$||A||_F^2 = \sum_{i,j} |A_{i,j}|^2$ である。ここでは、直交性からの逸脱の「サイズ」または大きさを定量化する役割を果たす。二乗することで値が非負になり、より大きな逸脱により重くペナルティを課す。
- $I$: これは、適切なサイズの単位行列である。 $U^T U - I$ のような項におけるその役割は、直交性のターゲットとして機能することである。もし $U^T U = I$ ならば、$U$ は直交である。
- $U_1^T U_1 - I$: この項は、$U_1$ の直交性からの逸脱を測定する。そのフロベニウスノルム二乗を最小化することで、$U_1$ を直交行列に近づける。
- $U_2^T U_2 - I$: $U_1$ と同様に、この項は、$U_2$ の直交性からの逸脱を測定する。
- $G(:,:,l)^T G(:,:,l) - I$: この項は、コアテンソル $G$ の$l$番目の正面スライスの直交性からの逸脱を測定する。$G(:,:,l)$ は、第3モード(タスク軸)を $l$ に固定して形成される行列を指す。これは、コアテンソル内のタスク次元に沿った直交性を保証する。合計 $\sum_{l=1}^v$ は、冗長性を削減するという全体的な目標に各直交性制約が独立に寄与するため、コアテンソルのすべてのスライスにわたるこれらの直交性制約を集約する。著者らは、これらの個々の直交性制約を結合するために加算を使用している。
$L_{MTL}$ の操作の中心は、モデルの重みが更新される方法を定義するTensorized low-Rank Adaptation (ToRA)手法である。ToRAはタッカー分解を使用して更新パラメータテンソル $\Delta W$ をパラメータ化する。
$$ \Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3 $$
- $\Delta W$: これは、次元 $d \times k \times T$ の更新パラメータテンソルである。これは、すべてのタスクにわたる事前学習済み重みへの集合的な変更を表す。各スライス $\Delta W(:,:,t)$ は、タスク $t$ の更新行列である。その役割は、事前学習済みモデルを複数の下流タスクに効率的に適応させることである。著者らは、テンソルがタスク共有情報とタスク固有情報の多次元的な性質を自然に捉えるため、複数のタスクの更新を表すためにテンソルを選択した。
- $G$: これは、次元 $p \times q \times v$ のコアテンソル(上記で定義)である。これはテンソルの最も重要な成分を保持し、圧縮された表現として機能する。
- $U_1$: これは、次元 $d \times p$ のモード1(出力特徴次元)の因子行列である。これは、コアテンソルをその第1モードに沿って変換する。
- $U_2$: これは、次元 $k \times q$ のモード2(入力特徴次元)の因子行列である。これは、コアテンソルをその第2モードに沿って変換する。
- $U_3$: これは、次元 $T \times v$ のモード3(タスク次元)の因子行列である。これは、コアテンソルをその第3モードに沿って変換し、分解がタスク固有のバリエーションを捉えることを可能にする。
- $\times_n$: これは、n-モード積を示す。数学的には、$A \times_n B$ は、テンソル $A$ を行列 $B$ とその $n$ 番目のモードに沿って乗算することを意味する。その役割は、因子行列 $U_1, U_2, U_3$ を使用してコアテンソル $G$ から完全な $\Delta W$ テンソルを再構築することを可能にする、テンソル分解の「展開」または投影である。この演算子はテンソル分解の基本であり、高次テンソルをコアテンソルといくつかの行列から再構築することを可能にする。
最後に、特定のタスク $t$ に対するこれらの更新のモデルのフォワードパスへの実際の適用は次のとおりである。
$$ h = W_0x + \Delta W(:,:,t)x $$
- $h$: これは、ToRA更新を適用した後のSAMエンコーダーのレイヤーの出力である。
- $W_0$: これは、SAMエンコーダーのレイヤーの元の事前学習済み重み行列である。ファインチューニング中は凍結されたままである。
- $\Delta W(:,:,t)$: これは、完全な $\Delta W$ テンソルの $t$ 番目のスライスである、タスク $t$ の更新行列である。その役割は、事前学習済み重みにタスク固有の調整を提供することである。
- $x$: これは、SAMエンコーダーのレイヤーへの入力である。
加算演算子は、ToRA更新が事前学習済み重みへの加算的な変更であることを示している。これは、LoRAのようなPEFT手法で一般的な慣習である。
ステップバイステップフロー
単一の抽象的なデータポイント、画像 $x_j$ が、特定のタスク $t$ のためにMTSAMフレームワークを旅する様子を想像してみよう。
-
画像エンコーディング(凍結された基盤): 旅は、SAMのヘビー級画像エンコーダー $E_1$ に入力画像 $x_j$ が入ることから始まる。決定的に、$E_1$ のパラメータは凍結されている。これは、SAMの事前学習中に学習された基盤知識が保存されていることを意味する。エンコーダーは画像特徴のセット、$F_1$ を出力する。
-
ToRA注入(適応レイヤー): $F_1$ が画像エンコーダー内の自己注意モジュールを伝播するにつれて、ToRAメカニズムに遭遇する。各レイヤーでは、元の事前学習済み重み行列 $W_0$ を直接使用するのではなく、そのレイヤーへの入力 $x$ は適応された重み行列 $W'$ によって処理される。この $W'$ は効果的に $W_0 + \Delta W(:,:,t)$ である。 $\Delta W(:,:,t)$ 成分は、テンソル分解 $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$ を使用して、タスク $t$ のために動的に構築される。これは、各タスク $t$ について、凍結された重みにユニークな低ランク更新が適用され、パラメータの大部分を変更することなく、モデルの動作をタスク固有の要件に微妙に誘導することを意味する。
-
タスク固有デコーディング(出力生成): ToRAで適応された画像特徴は、タスク $t$ に暗黙的に適合するように調整され、その後、タスク固有のマスクデコーダー $D_t$ に供給される。このデコーダーには、学習可能なタスク埋め込み $E_t$(特徴次元に一致するように拡張される)と学習可能なトークン $F_{P,t}$ も与えられる。タスク埋め込み $E_t$ は、タスク埋め込みと画像特徴 $F_{1,t}$($F_1$ から派生し、タスク $t$ のためにさらに処理される可能性がある)とブロードキャスト和される。これらの結合された特徴は、学習可能なトークンとともに、双方向トランスフォーマー、アップサンプリングレイヤー、およびMLPレイヤーを通過する。このプロセス全体により、タスク $t$ に適切なチャネル数を持つタスク固有の出力 $O_t$(例:セグメンテーションマスク、深度マップ、または法線)が生成される。
-
損失計算(パフォーマンス測定): サンプル $x_j$ に対して生成された出力 $O_t$ は、タスク固有損失関数 $l_t$ を使用して、対応するグラウンドトゥルースラベル $y_j$ と比較される。これにより、$l_t(y_j, f(x_j))$ が得られる。これは、この特定のサンプルでタスク $t$ に対してモデルがどれだけうまくパフォーマンスを発揮したかの尺度である。
-
マルチタスク集約(集合誤差): サンプル損失 $l_t(y_j, f(x_j))$ は、タスク損失 $L_t$ に寄与する。タスク $t$ のすべてのサンプルの損失は平均化されて $L_t$ を形成する。次に、$L_t$ は $w_t$ で重み付けされ、他のすべてのタスクからの重み付けされた損失と組み合わされて、合計マルチタスク学習損失 $L_{MTL}$ が計算される。
-
正則化(構造的整合性): 同時に、学習可能なToRAコンポーネント($U_1, U_2, G$)の現在の状態は、直交正則化項 $R(U_1, U_2, G)$ に対して評価される。この項は、これらの行列とコアテンソルスライスの直交性からの逸脱をペナルティする。
-
合計目的(統一目標): 最後に、$L_{MTL}$ とスケーリングされた正則化項 $\lambda R(U_1, U_2, G)$ が合計されて、$L_{total}$ 目的関数が形成される。この単一の値は、モデルが最小化する必要がある全体的な「コスト」またはエラーを表す。
最適化ダイナミクス
MTSAMフレームワークは、$L_{total}$ 目的関数の最小化によって駆動される反復最適化プロセスを通じて、パラメータを学習および更新する。
-
パラメータ初期化: トレーニング開始時、コアテンソル $G$ はすべてゼロに初期化される。これにより、当初はToRA更新 $\Delta W(:,:,t)$ もゼロとなり、モデルは当初凍結された事前学習済み重み $W_0$ のみに依存することになる。因子行列 $U_1, U_2, U_3$ は、標準ガウス分布からランダムに初期化される。このランダム初期化は、パラメータ空間を探索するための開始点を提供する。
-
勾配計算: 各トレーニングイテレーションで、すべてのタスクにわたるデータバッチに対する $L_{total}$ を計算した後、Adamオプティマイザが勾配を計算するために使用される。勾配は、学習可能なパラメータ:因子行列 $U_1, U_2, U_3$、コアテンソル $G$、および画像エンコーダーのレイヤー正規化レイヤー内のスケールとバイアスパラメータに対して計算される。決定的に、画像エンコーダーの元の事前学習済み重み $W_0$ は凍結されており、勾配はそれらを通過しないため、学習可能パラメータの数と計算コストが大幅に削減される。
-
損失ランドスケープの形成: 損失ランドスケープは、マルチタスク学習損失($L_{MTL}$)と直交正則化項($R$)の相互作用によって形成される。
- $L_{MTL}$ は、モデルがすべてのタスクでパフォーマンスを向上させるように駆動する。正則化がない場合、このランドスケープは複雑になり、タスク間の相反する勾配や過学習を招く可能性がある。
- 正則化項 $R$ は構造的制約として機能する。 $U_1, U_2, G$ の非直交性をペナルティすることで、更新パラメータのよりコンパクトで冗長性の低い表現を促進する。これは、より滑らかな損失ランドスケープにつながり、収束を助け、モデルが高度に関連付けられたまたは冗長な特徴を学習するのを防ぐことで汎化を改善する可能性がある。著者らの理論的分析は、この低ランクで直交な構造により、ToRAはLoRAと比較して、より少ないパラメータで優れた表現力を達成できることを示唆している。
-
反復更新: Adamオプティマイザは、計算された勾配を使用して、学習可能なパラメータ($U_1, U_2, U_3, G$、およびレイヤー正規化パラメータ)を反復的に更新する。更新は、初期学習率 $10^{-3}$ を使用して実行され、その後、0.05のウォームアップ率を持つ線形学習率スケジューラによって調整される。過学習を防ぐために、重み減衰 $10^{-6}$ も適用される。これらの反復更新は、ToRAコンポーネントを徐々に洗練させ、タスク共有情報とタスク固有情報の両方を学習できるようにする。
-
収束: トレーニングプロセスは、指定されたエポック数(例:NYUv2の場合は200)まで続く。パラメータが更新されるにつれて、$L_{total}$ は減少し、モデルが望ましい低ランク構造を維持しながらタスクでより良くパフォーマンスを発揮するように学習していることを示すことが期待される。目標は、$L_{total}$ を最小化するパラメータセットに収束させることであり、マルチタスクパフォーマンスとパラメータ効率の向上につながる。推論中、各タスク $t$ のために学習された $\Delta W(:,:,t)$ は事前に計算され、$W_0$ に追加されて $W_t'$ が形成されるため、追加のレイテンシは導入されない。この巧妙な設計により、ファインチューニングの利点が予測時間の遅延というコストなしに得られることが保証される。
結果、限界、結論
実験設計とベースライン
提案されたMulti-Task SAM (MTSAM)フレームワークとそのコアコンポーネントであるTensorized low-Rank Adaptation (ToRA)を厳密に検証するために、著者らは3つの確立されたベンチマークデータセット:NYUv2、CityScapes、およびPASCAL-Contextで広範な実験を実施した。これらのデータセットは、屋内のシーン(NYUv2)と都市部の屋外環境(CityScapes、PASCAL-Context)を網羅し、多様なコンピュータビジョンシナリオを表し、様々な密な予測タスクを伴う。
実験設定は、MTSAMが異なる出力次元を処理し、複数のタスクを効率的にファインチューニングする能力に関するMTSAMの数学的主張を、徹底的に証明するように設計された。MTSAMと比較された「犠牲者」(ベースラインモデル)は、従来のマルチタスク学習(MTL)アプローチとより最近のパラメータ効率的ファインチューニング(PEFT)手法の両方を含む、包括的な配列であった。
- CNNベースMTLベースライン: 単一タスク学習(STL)、ハードパラメータ共有(HPS)、クロスステッチ、マルチタスクアテンションネットワーク(MTAN)、NDDR-CNN。これらはマルチタスク学習のための確立された手法を表しており、HPSは $\Delta_b$ メトリックの重要なベースラインとして機能する。
- TransformerベースMTLベースライン: VTAGMLとSwinMTLは、現代的なアーキテクチャを反映している。
- クロスアテンションベースMTL: DenseMTL。
- LoRAベースPEFTベースライン: ToRAの効果を評価するために、著者らはマルチタスク設定でLoRAを直接適用したものと比較した:LoRA-STL(タスク固有LoRA)、LoRA-HPS(共有LoRA)、およびMultiLoRA。さらに、TerraやHydraLoRAのような他の高度なLoRAバリアント、およびモデル全体のファインチューニングとの比較も行われた。
評価されたタスクはデータセットによって異なった。
* NYUv2: 13クラス意味セグメンテーション、深度推定、法線推定。
* CityScapes: 7クラス意味セグメンテーション、深度推定。
* PASCAL-Context: 21クラス意味セグメンテーション、7クラス人間部位セグメンテーション、サリエンシー推定、法線推定。
パフォーマンスは、標準的なメトリックのスイートを使用して定量化された。
* 意味セグメンテーション: 平均IoU(mIoU)とピクセル精度(Pix Acc)、値が高いほど良い。
* 深度推定: 絶対誤差(Abs Err)と相対誤差(Rel Err)、値が低いほど良い。
* 法線推定: 角誤差の平均および中央値(低いほど良い)、および角度誤差が11.25、22.5、30度以内にあるピクセルの割合(高いほど良い)。
* 全体的なパフォーマンス: HPSアーキテクチャに対する各タスクの平均相対改善を表す複合メトリック、$\Delta_b$、値が高いほどパフォーマンスが良いことを示す。
* パラメータ効率: 学習可能パラメータ数(Params.)、メガバイト(MB)単位、値が低いほど効率的。
実装の詳細には、Adamオプティマイザを学習率 $10^{-3}$、ウォームアップ付き線形学習率スケジューラ、および各データセットに合わせたToRAの特定のランク設定($p, q, v$)で使用することが含まれた。ハイパーパラメータ $\lambda$ で制御される直交正則化も適用された。
証拠が証明すること
実験結果は、MTSAM、特にそのToRAコンポーネントが、基盤モデルのマルチタスク学習を大幅に進歩させるという、決定的で否定できない証拠を提供する。
-
全体的な優位性とパラメータ効率: 3つのベンチマークデータセット(NYUv2、CityScapes、PASCAL-Context)すべてにおいて、MTSAMは $\Delta_b$ メトリックで測定された平均パフォーマンスで一貫して最高を達成した(表1、2、3)。例えば、NYUv2では、MTSAMはわずか59.59 MBの学習可能パラメータで +23.93% の $\Delta_b$ を達成し、フルファインチューニング(1222.47 MBで+14.57%)および他のすべてのベースラインを上回った。これは、MTSAMが優れたパフォーマンスを達成するだけでなく、驚異的なパラメータ効率でそれを達成し、ストレージと実用的なアプリケーションにおいて大幅な利点を提供することを示している。
-
共有情報と固有情報の活用におけるToRAの効果: ToRAとLoRAベースの手法(LoRA-HPS、LoRA-STL、MultiLoRA)との比較は重要である。単一の共有LoRA行列を使用するLoRA-HPSは、タスク競争にしばしば悩まされる。タスク固有のLoRAを使用するLoRA-STLは、LoRA-HPSよりもパフォーマンスが良い。これは、タスク固有コンポーネントの重要性を強調している。しかし、ToRAはLoRA-STLとLoRA-HPSの両方を一貫して上回っている(表1、2、3、7)。この確固たる証拠は、ToRAが低ランクテンソル分解を通じてタスク共有情報とタスク固有情報の両方を効果的に活用するという理論的主張を裏付けており、全体的なパフォーマンスの向上につながっている。定性的な結果(図5-11)はこれをさらに強化し、ToRAを持つMTSAMが、他のLoRAバリアントと比較して、特に「曖昧で細いオブジェクト」に対して、視覚的に正確な予測を生成することを示している。
-
アーキテクチャ変更の影響:
- タスク埋め込み: 削除研究(表8)は、提案されたタスク埋め込みが、異なるタスクのためにMLP出力次元を変更するよりも効果的であることを明確に示している。この改善は、クロスアテンションメカニズムに起因しており、タスク埋め込みと画像特徴との相互作用を通じて、タスク固有知識のより良い学習を促進する。
- 直交正則化: 直交正則化に関する削除研究(表5)は、その肯定的な影響を示している。完全な直交正則化を持つMTSAM($G$、$U_1$、$U_2$ に対して)は、それを持たないバリアントを大幅に上回り、冗長性を削減することで様々なタスクにおけるパフォーマンスを向上させるその有効性を証明している。
-
ハイパーパラメータ設定に対する堅牢性: ハイパーパラメータ $\lambda$(直交正則化重み)に関する感度分析(表6)は、MTSAMのパフォーマンスが合理的な範囲(例:[0.5, 1.5])では $\lambda$ にそれほど敏感ではないことを示唆している。これは、モデルが比較的堅牢でチューニングが容易であることを示しており、実用的な利点である。
限界と将来の方向性
MTSAMは、特にSAMのような基盤モデルのマルチタスクファインチューニングにおいて、印象的な能力を示すが、本稿ではいくつかの限界を強調し、将来の研究のためのエキサイティングな方向性も開いている。
- 大幅に異なるデータ分布を横断するゼロショット汎化: 著者らは、NYUv2のみでトレーニングされた後、CityScapesデータセットでゼロショット深度推定を実行するMTSAMの能力を調査した(図12)。未知のデータに対処する能力を示すものの、特に遠方のオブジェクトに対しては不正確さが見られる。これは、NYUv2が屋内画像で構成されているのに対し、CityScapesは屋外の都市シーンを特徴とするというデータセット間の固有の違いに起因しており、深度分布、オブジェクトタイプ、解像度、さらには深度推定のグラウンドトゥルースに使用されたハードウェアの違いにつながる。これは、MTSAMが適応できる一方で、大きなドメインシフトは依然として重大な課題であり、そのゼロショット転移性は、大きく異なる環境全体で普遍的に堅牢ではないことを示唆している。
将来に向けて、本稿での発見は、さらなる開発と進化のためのいくつかの説得力のある議論トピックを提示している。
-
ゼロショットマルチタスクのためのドメイン適応の強化: 異なるドメインを横断するゼロショット転移における観察された限界を考慮すると、重要な将来の方向性は、より洗練されたドメイン適応技術をMTSAMフレームワークに直接統合することである。敵対的トレーニング、ドメイン汎化のためのメタ学習、またはより高度なプロンプトエンジニアリング戦略をToRAと組み合わせることで、未知の、ドメイン外のタスクでのパフォーマンスを向上させることができるだろうか?テンソル分解内でドメインギャップを明示的にモデル化し、軽減する方法を探ることは、有望な領域となる可能性がある。
-
動的なToRAランクとタスク重み割り当て: 現在、ToRAのランク($p, q, v$)とタスク損失重み($w_i$)は固定ハイパーパラメータとして設定されている。将来の研究では、これらのパラメータをトレーニング中に調整するための動的な方法を調査する可能性がある。例えば、一部のPEFT手法がランクを動的に調整するのと同様に、適応メカニズムが各タスクまたはレイヤーに最適なランクを学習できるだろうか?同様に、タスクの不確実性や勾配の競合に基づいた動的なタスク重み付け戦略は、モデルが多様なタスクにわたるパフォーマンスのバランスを取り、最適化する能力をさらに向上させ、固定重みを超えて進む可能性がある。
-
他の基盤モデルやモダリティへのToRAの拡張: 本稿は、画像セグメンテーションタスクのためのSAMに焦点を当てている。自然な拡張は、MTSAMフレームワークとToRAを、言語モデル(LLM)や、視覚と言語を統合するマルチモーダルモデルのような、異なるモダリティの他の大規模基盤モデルに適用することである。ToRAは、LLMを様々なNLPタスクにファインチューニングしたり、クロスモーダル理解を必要とするタスクにマルチモーダルモデルを適応させたりする際に、どのようにパフォーマンスを発揮するだろうか?これは、テンソル化低ランク適応の一般化可能性とスケーラビリティに関する新しい洞察を明らかにする可能性がある。
-
表現力と汎化に関する理論的深掘り: 定理1は、パラメータ効率の点でToRAが複数のLoRAよりも優れていることを証明しているが、複雑なマルチタスク、マルチドメインシナリオにおけるその表現力と汎化限界のより深い理論的分析は価値があるだろう。ToRAのテンソル分解がタスク共有情報とタスク固有情報を最適に捉える条件を形式的に特徴づけることができ、それが基盤となるタスク関連性とどのように関連するか?これは、将来のマルチタスクPEFT手法のより原則的な設計選択につながる可能性がある。
-
デプロイメントと推論における効率: 本稿では、ToRAが推論中に追加のレイテンシを導入しないと述べている。これは、タスク固有の更新重み($W_t = W_0 + \Delta W_t$)の保存が、タスク数が増加するにつれて依然として相当なものになる可能性があるためである。将来の研究では、特にリソースが制約された環境で、MTSAMの実用的な有用性をさらに高めるために、タスク固有の更新重みのためのよりコンパクトな保存またはオンザフライ再構築戦略を模索する可能性がある。
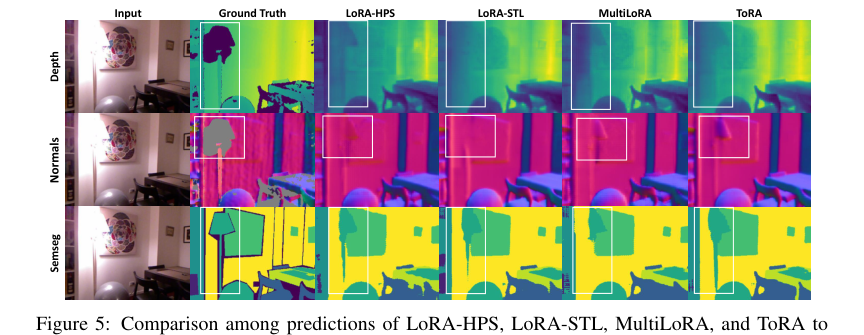 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
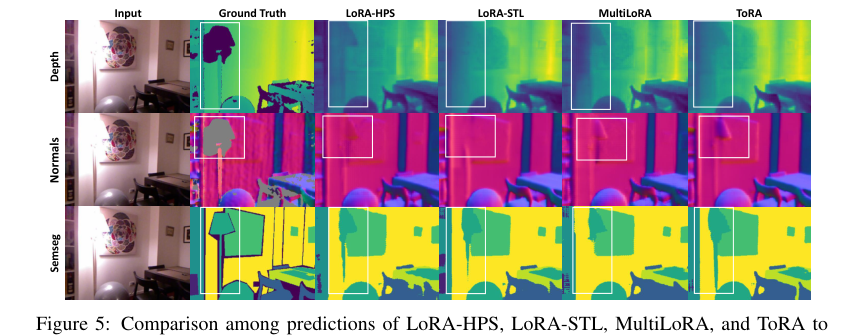 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
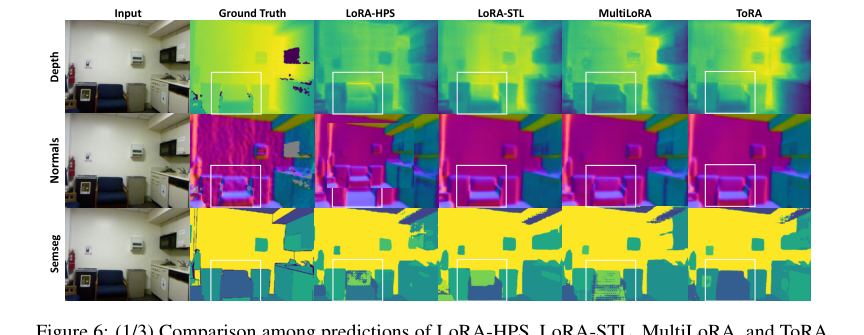 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset