MTSAM: मल्टी-टास्क फाइन-ट्यूनिंग फॉर सेगमेंट एनीथिंग मॉडल
इस पत्र में संबोधित समस्या कृत्रिम बुद्धिमत्ता, विशेष रूप से कंप्यूटर विज़न में बड़े फाउंडेशन मॉडल के हालिया उद्भव और उल्लेखनीय क्षमताओं से उत्पन्न होती है। ऐतिहासिक रूप से, फाउंडेशन मॉडल ने अपनी प्रभावशाली ज़ीरो-शॉट...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या कृत्रिम बुद्धिमत्ता, विशेष रूप से कंप्यूटर विज़न में बड़े फाउंडेशन मॉडल के हालिया उद्भव और उल्लेखनीय क्षमताओं से उत्पन्न होती है। ऐतिहासिक रूप से, फाउंडेशन मॉडल ने अपनी प्रभावशाली ज़ीरो-शॉट क्षमताओं के साथ प्राकृतिक भाषा प्रसंस्करण (NLP) में क्रांति ला दी, जिसका अर्थ है कि वे ऐसे कार्य कर सकते थे जिन पर उन्हें स्पष्ट रूप से प्रशिक्षित नहीं किया गया था। इस सफलता ने कंप्यूटर विज़न में समान मॉडल के विकास को प्रेरित किया।
सेगमेंट एनीथिंग मॉडल (SAM), जिसे 2023 में किरिलोव एट अल. द्वारा प्रस्तुत किया गया था, छवि विभाजन के लिए एक प्रमुख फाउंडेशन मॉडल के रूप में खड़ा है। SAM ने असाधारण ज़ीरो-शॉट प्रदर्शन का प्रदर्शन किया, जो 11 मिलियन नमूनों के एक विशाल डेटासेट पर प्रशिक्षित होने के बाद छवि में लगभग किसी भी वस्तु को विभाजित करने में सक्षम था। इस सफलता ने उच्च-गुणवत्ता वाले विभाजन, 3डी पुनर्निर्माण, वस्तु ट्रैकिंग, चिकित्सा छवि प्रसंस्करण, व्यक्तिगत विभाजन और रिमोट सेंसिंग जैसे विभिन्न डाउनस्ट्रीम कार्यों के लिए SAM के अनुप्रयोग की खोज करने वाले शोध में वृद्धि की।
हालांकि, इन पिछले दृष्टिकोणों की एक मौलिक सीमा, या "दर्द बिंदु," यह थी कि उन्होंने विशेष रूप से सिंगल-टास्क लर्निंग के लिए SAM को अपनाया था। इसका मतलब था कि प्रत्येक नए कार्य के लिए, SAM को स्वतंत्र रूप से फाइन-ट्यून किया गया था, मल्टी-टास्क लर्निंग (MTL) के लिए एक एकीकृत फाउंडेशन मॉडल के रूप में इसकी क्षमता को अनदेखा किया गया था। कई वास्तविक दुनिया के कंप्यूटर विज़न परिदृश्यों में, कई कार्य स्वाभाविक रूप से संबंधित होते हैं और अक्सर एक साथ संबोधित करने की आवश्यकता होती है (जैसे, दृश्य समझ में गहराई का अनुमान और सतह सामान्य अनुमान)। MTL में पूर्व शोध ने लगातार दिखाया है कि कार्यों को एक साथ सीखने से लाभ हो सकता है, क्योंकि साझा ज्ञान समग्र प्रदर्शन और दक्षता में सुधार कर सकता है।
यह पत्र विशेष रूप से मल्टी-टास्क लर्निंग के लिए SAM को अनुकूलित करने में दो मुख्य चुनौतियों की पहचान करता है:
1. आउटपुट डायमेंशनलिटी मिसमैच: मूल SAM को विभाजन मास्क उत्पन्न करने के लिए डिज़ाइन किया गया है, आमतौर पर आउटपुट चैनलों की एक निश्चित संख्या के साथ (जैसे, तीन अलग-अलग स्तर, सभी समान चैनल संख्याओं के साथ, जैसा कि चित्र 1a में दिखाया गया है)। हालांकि, विभिन्न डाउनस्ट्रीम कार्यों के लिए विभिन्न आयामों वाले आउटपुट की आवश्यकता होती है (जैसे, गहराई अनुमान के लिए एक चैनल की आवश्यकता हो सकती है, जबकि सतह सामान्य भविष्यवाणी के लिए तीन की आवश्यकता होती है)। SAM की वास्तुकला विभिन्न चैनल संख्याओं के साथ इन कार्य-विशिष्ट आउटपुट उत्पन्न करने के लिए स्वाभाविक रूप से पर्याप्त लचीली नहीं थी।
2. सिमल्टेनियस फाइन-ट्यूनिंग: SAM को एक साथ कई डाउनस्ट्रीम कार्यों के अनुकूल बनाने के लिए प्रभावी ढंग से फाइन-ट्यून करने के लिए कोई स्थापित विधि नहीं थी। मौजूदा पैरामीटर-कुशल फाइन-ट्यूनिंग (PEFT) विधियाँ, जैसे कि लो-रैंक एडैप्टेशन (LoRA), मुख्य रूप से सिंगल-टास्क एडैप्टेशन के लिए डिज़ाइन की गई थीं। जब मल्टी-टास्क सेटिंग्स पर लागू किया जाता है, तो ये विधियाँ या तो कार्यों के बीच साझा जानकारी का लाभ उठाने में संघर्ष करती हैं (जैसे LoRA-STL, जहां प्रत्येक कार्य का अपना LoRA होता है) या साझा मापदंडों के लिए कार्यों के बीच प्रतिस्पर्धा के कारण प्रदर्शन असंतुलन से पीड़ित होती हैं (जैसे LoRA-HPS)। SAM जैसे बड़े फाउंडेशन मॉडल के लिए एक मजबूत मल्टी-टास्क फाइन-ट्यूनिंग रणनीति की यह कमी एक महत्वपूर्ण बाधा प्रस्तुत करती है।
लेखकों ने इन सटीक सीमाओं को दूर करने के लिए यह पत्र लिखा है, मल्टी-टास्क SAM (MTSAM) फ्रेमवर्क और टेंपोराइज़्ड लो-रैंक एडैप्टेशन (ToRA) विधि का प्रस्ताव दिया है ताकि SAM को मल्टी-टास्क लर्निंग के लिए एक बहुमुखी फाउंडेशन मॉडल के रूप में कार्य करने में सक्षम बनाया जा सके, आउटपुट डायमेंशनलिटी और सिमल्टेनियस फाइन-ट्यूनिंग चुनौतियों को दूर किया जा सके।
सहज डोमेन शब्द
-
सेगमेंट एनीथिंग मॉडल (SAM): एक अत्यधिक कुशल डिजिटल कलाकार की कल्पना करें जो किसी भी वस्तु की एक तस्वीर में किसी भी वस्तु की पूरी तरह से रूपरेखा तैयार कर सकता है, चाहे वह कितनी भी जटिल या अपरिचित क्यों न हो। SAM उस कलाकार की तरह है, लेकिन कंप्यूटर के लिए, जो अविश्वसनीय सटीकता के साथ छवियों से वस्तुओं को "काट" सकता है, भले ही उसने उस सटीक वस्तु को पहले कभी न देखा हो।
-
ज़ीरो-शॉट क्षमता: यह एक बहुत ही स्मार्ट छात्र की तरह है जिसने कई चीजों के बारे में सामान्य सिद्धांत सीखे हैं। यदि आप उन्हें कुछ पूरी तरह से नया दिखाते हैं, जैसे कि एक दुर्लभ प्रकार का फल जिसे उन्होंने कभी नहीं देखा है, तो वे अभी भी यह अनुमान लगा सकते हैं कि यह क्या है या इसे कैसे वर्गीकृत किया जाए, केवल अपनी व्यापक समझ को लागू करके, उस फल पर विशिष्ट प्रशिक्षण की आवश्यकता के बिना।
-
मल्टी-टास्क लर्निंग (MTL): एक शेफ के बारे में सोचें जो एक साथ कई संबंधित व्यंजन बनाना सीखता है - शायद एक मुख्य व्यंजन, एक साइड डिश और एक सॉस। उन्हें एक साथ सीखने से, शेफ सामान्य तकनीकों या सामग्री की खोज कर सकता है जो समग्र खाना पकाने की प्रक्रिया को अधिक कुशल बनाती है और अंतिम भोजन को अधिक सामंजस्यपूर्ण बनाती है, बजाय इसके कि प्रत्येक व्यंजन को अलग-अलग सीखा जाए।
-
पैरामीटर-कुशल फाइन-ट्यूनिंग (PEFT): एक उच्च प्रशिक्षित विशेषज्ञ पर विचार करें, जैसे कि एक मास्टर मैकेनिक, जो कई प्रकार की कारों को ठीक करना जानता है। यदि एक नई कार मॉडल आती है, तो मैकेनिक को खरोंच से फिर से प्रशिक्षित करने के बजाय, आप बस उस विशेष मॉडल के लिए कुछ छोटे, विशिष्ट समायोजन या नए उपकरण सिखाते हैं। उनके विशाल मौजूदा ज्ञान का अधिकांश हिस्सा अछूता रहता है, जिससे अनुकूलन त्वरित और कुशल हो जाता है।
-
लो-रैंक एडैप्टेशन (LoRA): मैकेनिक सादृश्य पर निर्माण करते हुए, LoRA मास्टर मैकेनिक को प्रत्येक नई कार मॉडल के लिए एक छोटी, विशेष "चीट शीट" देने जैसा है। इस शीट में उनकी मानक प्रक्रियाओं में केवल कुछ प्रमुख संशोधन होते हैं, जिससे उन्हें पूरी कार के इंजीनियरिंग को फिर से सीखने के बिना अपने कौशल को अनुकूलित करने की अनुमति मिलती है। यह बहुत कम नई जानकारी के साथ बड़े बदलाव करने का एक चतुर तरीका है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $I$ | इनपुट छवि आयाम $3 \times H \times W$ (चैनल, ऊंचाई, चौड़ाई) के साथ। |
| $H, W$ | इनपुट छवि की ऊंचाई और चौड़ाई। |
| $F_I$ | SAM के छवि एन्कोडर द्वारा निकाली गई छवि सुविधाएँ, आयाम $D \times \frac{H}{16} \times \frac{W}{16}$ के साथ। |
| $D$ | मॉडल में छिपी हुई स्थिति का आयाम। |
| $O$ | मूल SAM से अंतिम विभाजन मास्क आउटपुट, आयाम $3 \times \frac{H}{4} \times \frac{W}{4}$ के साथ। |
| $T$ | सीखे जा रहे कुल विशिष्ट कार्यों की संख्या। |
| $\Delta W$ | एक एकल परत के लिए एक सामान्य अद्यतन पैरामीटर मैट्रिक्स, आयाम $d \times k$ के साथ। |
| $W_0$ | एक परत का पूर्व-प्रशिक्षित पैरामीटर मैट्रिक्स, आयाम $d \times k$ के साथ। |
| $A, B$ | LoRA में उपयोग किए जाने वाले निम्न-रैंक मैट्रिक्स, जहां $B \in \mathbb{R}^{d \times r}$ और $A \in \mathbb{R}^{r \times k}$। |
| $r$ | LoRA में निम्न-रैंक मैट्रिक्स का रैंक, जहां $r \ll \min(d, k)$। |
| $\Delta \mathcal{W}$ | ToRA के लिए अद्यतन पैरामीटर टेंसर, सभी कार्य-विशिष्ट अद्यतनों को $d \times k \times T$ टेंसर में एकत्रित करता है। |
| $G$ | ToRA के लिए टकर अपघटन में मुख्य टेंसर, आयाम $p \times q \times v$ के साथ। |
| $U_1, U_2, U_3$ | ToRA के लिए टकर अपघटन में कारक मैट्रिक्स, आयाम $d \times p$, $k \times q$, और $T \times v$ क्रमशः के साथ। |
| $p, q, v$ | ToRA के लिए कारक मैट्रिक्स के आयाम, आमतौर पर $d, k, T$ से बहुत छोटे होते हैं। |
| $E_t$ | एक विशिष्ट कार्य $t$ के लिए प्रशिक्षण योग्य कार्य एम्बेडिंग, आयाम $N_t \times D$ के साथ। |
| $N_t$ | कार्य $t$ के लिए आवश्यक आउटपुट चैनलों की संख्या। |
| $O_t$ | MTSAM द्वारा कार्य $t$ के लिए उत्पन्न आउटपुट भविष्यवाणी, आयाम $N_t \times \frac{H}{4} \times \frac{W}{4}$ के साथ। |
| $\mathcal{L}_{MTL}$ | समग्र मल्टी-टास्क लर्निंग उद्देश्य फ़ंक्शन, जिसे MTSAM कम करने का लक्ष्य रखता है। |
| $\lambda$ | एक हाइपर-पैरामीटर जो ऑर्थोगोनल रेगुलराइज़ेशन टर्म के प्रभाव को नियंत्रित करता है। |
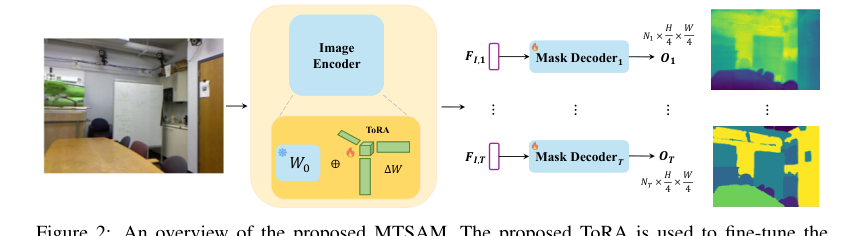 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
सेगमेंट एनीथिंग मॉडल (SAM) छवि विभाजन के लिए एक शक्तिशाली फाउंडेशन मॉडल के रूप में उभरा है, जो अपनी ज़ीरो-शॉट सामान्यीकरण क्षमताओं के लिए प्रसिद्ध है। इस पत्र में संबोधित मुख्य समस्या यह है कि SAM को मल्टी-टास्क लर्निंग (MTL) के लिए फाउंडेशन मॉडल में प्रभावी ढंग से कैसे परिवर्तित किया जाए।
इनपुट/वर्तमान स्थिति:
शुरुआती बिंदु मूल SAM है, जो इनपुट के रूप में एक छवि $I \in \mathbb{R}^{3 \times H \times W}$ और विभिन्न संकेतों (जैसे, बिंदु, बाउंडिंग बॉक्स, या मास्क) को लेता है। इसकी वास्तुकला में एक भारी छवि एन्कोडर, एक संकेत एन्कोडर और एक हल्का मास्क डिकोडर शामिल है। मूल SAM को विभाजन मास्क उत्पन्न करने के लिए डिज़ाइन किया गया है, आमतौर पर आउटपुट चैनलों की एक निश्चित संख्या के साथ (जैसे, 3 चैनल, जैसा कि समीकरण 3, पृष्ठ 4 पर $O \in \mathbb{R}^{3 \times H \times W}$ में देखा गया है, और चित्र 1a, पृष्ठ 2 पर चित्रित किया गया है)।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
वांछित अंतिम बिंदु एक संशोधित SAM है, जिसे मल्टी-टास्क SAM (MTSAM) कहा जाता है, जो निम्न में सक्षम हो सकता है:
1. विभिन्न आयामों वाले कार्य-विशिष्ट आउटपुट उत्पन्न करें: उदाहरण के लिए, गहराई अनुमान के लिए 1-चैनल आउटपुट, सिमेंटिक विभाजन के लिए 13-चैनल आउटपुट, और सतह सामान्य भविष्यवाणी के लिए 3-चैनल आउटपुट, सभी एक ही इनपुट से एक साथ (चित्र 1b, पृष्ठ 2)।
2. कई डाउनस्ट्रीम कार्यों के लिए समवर्ती रूप से अनुकूलित करने के लिए फाइन-ट्यून किया जाए: इस अनुकूलन को समग्र प्रदर्शन को बेहतर बनाने के लिए कार्यों के बीच साझा जानकारी का लाभ उठाना चाहिए, बजाय इसके कि प्रत्येक कार्य को अलग-अलग माना जाए।
लुप्त कड़ी और गणितीय अंतर:
वर्तमान और वांछित राज्यों के बीच सटीक लुप्त कड़ियाँ या गणितीय अंतर दो-गुना हैं:
1. विविध आउटपुट के लिए वास्तुकलात्मक अनम्यता: मूल SAM का मास्क डिकोडर निश्चित चैनल गणना वाले आउटपुट उत्पन्न करने के लिए वास्तुकलात्मक रूप से बाधित है, जिससे यह विभिन्न आउटपुट आयामों की आवश्यकता वाले कार्यों के लिए अनुपयुक्त हो जाता है। विशिष्ट कार्य के आधार पर आउटपुट चैनलों को गतिशील रूप से समायोजित करने के लिए कोई अंतर्निहित तंत्र नहीं है।
2. अक्षम मल्टी-टास्क फाइन-ट्यूनिंग: कई कार्यों के लिए SAM के भारी एन्कोडर को एक साथ फाइन-ट्यून करने के लिए एक मजबूत और पैरामीटर-कुशल विधि, जबकि प्रभावी ढंग से कार्य-साझा और कार्य-विशिष्ट ज्ञान को संतुलित करना, अनुपस्थित है। मौजूदा पैरामीटर-कुशल फाइन-ट्यूनिंग (PEFT) विधियाँ जैसे LoRA, जब MTL पर भोलेपन से लागू की जाती हैं, या तो बहुत व्यापक रूप से मापदंडों को साझा करके अतिसरलीकरण करती हैं (LoRA-HPS), जिससे कार्य प्रतिस्पर्धा के कारण प्रदर्शन से समझौता होता है, या बहुत कार्य-विशिष्ट होती हैं (LoRA-STL), अंतर-कार्य सूचना साझाकरण का लाभ उठाने में विफल रहती हैं।
दुविधा:
केंद्रीय दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह बड़े फाउंडेशन मॉडल के लिए मल्टी-टास्क लर्निंग में पैरामीटर दक्षता और अभिव्यंजक शक्ति/प्रदर्शन के बीच दर्दनाक ट्रेड-ऑफ है।
* SAM जैसे भारी मॉडल को कई कार्यों के लिए पूर्ण फाइन-ट्यूनिंग कम्प्यूटेशनल रूप से निषेधात्मक और पैरामीटर-अक्षम है।
* MTL पर मौजूदा PEFT विधियों को भोलेपन से लागू करने से एक दुविधा उत्पन्न होती है:
* हार्ड पैरामीटर शेयरिंग (LoRA-HPS): यह दृष्टिकोण पैरामीटर-कुशल है क्योंकि यह सभी कार्यों के लिए एक साझा LoRA मैट्रिक्स का उपयोग करता है। हालांकि, यह अक्सर "साझा LoRA के लिए कार्यों के बीच प्रतिस्पर्धा के कारण सभी कार्यों पर असंतुलित प्रदर्शन की ओर ले जाता है" (पृष्ठ 4)। यह कार्य-विशिष्ट बारीकियों को पकड़ने के लिए संघर्ष करता है, प्रभावी रूप से दक्षता के लिए प्रदर्शन का त्याग करता है।
* टास्क-विशिष्ट LoRA (LoRA-STL): यह विधि प्रत्येक कार्य के लिए एक अलग LoRA मॉड्यूल को प्रशिक्षित करती है, जिससे कार्य-विशिष्ट अनुकूलन और संभावित रूप से बेहतर व्यक्तिगत कार्य प्रदर्शन की अनुमति मिलती है। हालांकि, इसके पैरामीटर की संख्या कार्यों की संख्या के साथ रैखिक रूप से बढ़ती है ($O(Trd+Trk)$, पृष्ठ 6), जिससे यह बड़ी संख्या में कार्यों के लिए कम कुशल हो जाता है। महत्वपूर्ण रूप से, यह "कई कार्यों में फाइन-ट्यूनिंग के लिए आवश्यक अंतर-कार्य साझा जानकारी का लाभ नहीं उठा सकता है" (पृष्ठ 4), इस प्रकार MTL के सहक्रियात्मक लाभों से चूक जाता है।
चुनौती एक ऐसी विधि तैयार करना है जो पैरामीटर-कुशल (पैरामीटर के साथ सबलाइनियर वृद्धि) दोनों हो और कार्य-साझा सामान्य ज्ञान और कार्य-विशिष्ट विवरण दोनों को एक साथ पकड़ने में सक्षम हो, इस प्रकार मल्टी-टास्क सेटिंग में मौजूदा PEFT रणनीतियों की सीमाओं को दूर किया जा सके।
बाधाएँ और विफलता मोड
मल्टी-टास्क लर्निंग के लिए SAM को अनुकूलित करने की समस्या को कई कठोर, यथार्थवादी दीवारों से बेहद मुश्किल बना दिया गया है जिनसे लेखकों को सामना करना पड़ा:
- हार्डवेयर मेमोरी और कम्प्यूटेशनल सीमाएँ: SAM का छवि एन्कोडर "भारी" (पृष्ठ 3) के रूप में वर्णित है। ऐसे बड़े मॉडल को कई कार्यों के लिए एक साथ फाइन-ट्यून करने के लिए अत्यधिक कम्प्यूटेशनल संसाधनों और मेमोरी की आवश्यकता होगी, जिससे पूर्ण फाइन-ट्यूनिंग अव्यावहारिक हो जाएगी। यह बाधा पैरामीटर-कुशल विधियों के उपयोग को अनिवार्य करती है।
- निश्चित आउटपुट चैनल बाधा: मूल SAM का मास्क डिकोडर निश्चित संख्या में चैनलों (जैसे, 3 विभाजन के लिए) के साथ आउटपुट उत्पन्न करने के लिए हार्ड-वायर्ड है। यह वास्तुकलात्मक कठोरता इसे गहराई अनुमान (1 चैनल) या बहु-वर्ग सिमेंटिक विभाजन (जैसे, 13 चैनल) जैसे विभिन्न कार्यों के लिए आवश्यक विभिन्न चैनल संख्याओं वाले आउटपुट को सीधे उत्पन्न करने से रोकती है। यह एक मौलिक वास्तुकलात्मक सीमा है जिसे दूर करने की आवश्यकता है।
- कार्य-साझा और कार्य-विशिष्ट सीखने को संतुलित करने में असमर्थता: पिछले PEFT विधियाँ, जब MTL पर लागू की जाती हैं, तो सामान्य, कार्य-साझा सुविधाओं और विशिष्ट, कार्य-निर्भर अनुकूलन सीखने को प्रभावी ढंग से संतुलित करने में विफल रहती हैं। LoRA-HPS कार्य प्रतिस्पर्धा से पीड़ित है, जबकि LoRA-STL अंतर-कार्य साझा जानकारी का लाभ नहीं उठा सकता है (पृष्ठ 4)। इससे उप-इष्टतम प्रदर्शन या अक्षम पैरामीटर उपयोग होता है।
- इष्टतम सन्निकटन के लिए टेंसर अपघटन की जटिलता: जबकि टेंसर अपघटन एक शक्तिशाली गणितीय उपकरण है, जटिल उद्देश्यों के लिए "सर्वश्रेष्ठ सन्निकटन" खोजना, विशेष रूप से मल्टी-टास्क लर्निंग के संदर्भ में, स्वाभाविक रूप से चुनौतीपूर्ण है और "हमेशा मौजूद नहीं हो सकता है" (कोल्डा और बेडर, 2009, पृष्ठ 7 पर उद्धृत)। यह निम्न-रैंक टेंसर अनुकूलन की सैद्धांतिक इष्टतमता की गारंटी की संभावित कठिनाई का अर्थ है।
- कार्यों में डेटा विषमता: विभिन्न कार्यों में अक्सर अलग-अलग डेटा वितरण, सिमेंटिक अर्थ और आउटपुट प्रारूप शामिल होते हैं। उदाहरण के लिए, गहराई अनुमान और सिमेंटिक विभाजन के लिए विभिन्न प्रकार के ग्राउंड ट्रुथ और मूल्यांकन मेट्रिक्स की आवश्यकता होती है। मॉडल को किसी भी एकल कार्य पर प्रदर्शन से समझौता किए बिना इस अंतर्निहित विविधता को संभालने के लिए पर्याप्त मजबूत होना चाहिए।
- वास्तविक समय विलंबता आवश्यकताओं की कमी (अव्यक्त): हालांकि स्पष्ट रूप से लेखकों द्वारा संघर्ष की गई बाधा के रूप में नहीं कहा गया है, पैरामीटर दक्षता का लक्ष्य और यह कथन कि ToRA "अनुमान के दौरान कोई अतिरिक्त विलंबता पेश नहीं करता है" (पृष्ठ 6) कुशल अनुमान की एक अव्यक्त आवश्यकता का सुझाव देता है, जो व्यावहारिक अनुप्रयोगों में अक्सर महत्वपूर्ण होता है। मॉडल की जटिलता को अनुमान समय को महत्वपूर्ण रूप से नहीं बढ़ाना चाहिए।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
सेगमेंट एनीथिंग मॉडल (SAM) एक शक्तिशाली फाउंडेशन मॉडल के रूप में उभरा, जिसने छवि विभाजन के लिए उल्लेखनीय ज़ीरो-शॉट क्षमताओं का प्रदर्शन किया। हालांकि, मल्टी-टास्क लर्निंग के लिए इसका सीधा अनुप्रयोग दो मौलिक वास्तुकलात्मक बाधाएं प्रस्तुत करता है जिनसे पारंपरिक "SOTA" विधियाँ, जिनमें मूल SAM स्वयं शामिल है, निपटने के लिए सुसज्जित नहीं थीं। इन अपर्याप्तताओं की लेखकों की अहसास तब स्पष्ट हो गई जब मल्टी-टास्क लर्निंग की मुख्य आवश्यकताओं पर विचार किया गया: (ए) विभिन्न चैनल संख्याओं वाले कार्य-विशिष्ट आउटपुट उत्पन्न करने की आवश्यकता (जैसे, गहराई अनुमान के लिए 1 चैनल, सतह सामान्य भविष्यवाणी के लिए 3, और सिमेंटिक विभाजन के लिए कई), और (बी) SAM को कुशलतापूर्वक कई डाउनस्ट्रीम कार्यों के लिए एक साथ फाइन-ट्यून करने की चुनौती।
मूल SAM, डिजाइन द्वारा, विभिन्न स्तरों पर विभाजन मास्क उत्पन्न करता है, लेकिन महत्वपूर्ण रूप से, इन सभी आउटपुट में समान चैनलों की संख्या होती है। यह निश्चित आउटपुट आयाम गहराई अनुमान या सतह सामान्य भविष्यवाणी जैसे कार्यों के लिए अलग-अलग आउटपुट संरचनाओं की आवश्यकता होने पर एक गंभीर सीमा है। पत्र स्पष्ट रूप से कहता है, "एक मौलिक दृश्य मॉडल के रूप में SAM द्वारा प्रदर्शित जबरदस्त क्षमता के बावजूद, संकेत-निर्देशित मास्क पीढ़ी पर इसकी निर्भरता विभिन्न आउटपुट चैनलों की संख्या वाले डाउनस्ट्रीम कार्यों के लिए एंड-टू-एंड अनुकूलनशीलता प्राप्त करने में चुनौतियां प्रस्तुत करती है।" यह वह सटीक क्षण था जब लेखकों ने महसूस किया कि SAM की अंतर्निहित वास्तुकला, विशेष रूप से इसका संकेत एन्कोडर और मास्क डिकोडर, विविध मल्टी-टास्क आउटपुट के लिए पर्याप्त लचीला नहीं था। इसलिए, SAM या मौजूदा सिंगल-टास्क फाइन-ट्यूनिंग विधियों का सीधा अनुप्रयोग वास्तव में मल्टी-टास्क फाउंडेशन मॉडल के लिए बस व्यवहार्य नहीं था।
तुलनात्मक श्रेष्ठता
प्रस्तावित मल्टी-टास्क SAM (MTSAM) फ्रेमवर्क, विशेष रूप से इसकी टेंपोराइज़्ड लो-रैंक एडैप्टेशन (ToRA) विधि, पैरामीटर दक्षता और सूचना लाभ में, विशेष रूप से पिछले स्वर्ण मानकों पर भारी गुणात्मक और संरचनात्मक श्रेष्ठता प्रदर्शित करता है।
सबसे पहले, ToRA का सबसे महत्वपूर्ण संरचनात्मक लाभ इसकी पैरामीटर दक्षता में निहित है। जब $T$ कार्यों पर लागू किया जाता है, तो पारंपरिक लो-रैंक एडैप्टेशन (LoRA) विधियाँ, चाहे हार्ड पैरामीटर शेयरिंग (LoRA-HPS) का उपयोग करें या टास्क-विशिष्ट LoRAs (LoRA-STL), पैरामीटर जटिलता प्रदर्शित करती हैं जो कार्यों की संख्या के साथ रैखिक रूप से बढ़ती है, आमतौर पर $O(Trd + Trk)$। इसके विपरीत, ToRA सभी कार्यों के अपडेट पैरामीटर मैट्रिक्स को एक एकल अपडेट पैरामीटर टेंसर $\Delta W \in \mathbb{R}^{d \times k \times T}$ में एकत्रित करता है और निम्न-रैंक टेंसर अपघटन (विशेष रूप से, टकर अपघटन) लागू करता है। इसके परिणामस्वरूप पैरामीटर जटिलता $O(dp + kq)$ होती है, जहां $p, q, v \ll \min(d, k)$ और $T$ कार्यों की संख्या है। यह कार्यों की संख्या के संबंध में सीखने योग्य मापदंडों में सबलाइनियर वृद्धि का प्रतिनिधित्व करता है, जिससे यह बड़ी संख्या में कार्यों के लिए स्केलिंग के लिए नाटकीय रूप से अधिक कुशल हो जाता है। मेमोरी जटिलता में यह कमी बड़े फाउंडेशन मॉडल जैसे SAM को फाइन-ट्यून करने के लिए एक गेम-चेंजर है।
दूसरे, ToRA प्रभावी ढंग से कार्य-साझा और कार्य-विशिष्ट दोनों जानकारी को कैप्चर करके गुणात्मक रूप से विकल्पों से बेहतर प्रदर्शन करता है। LoRA-HPS, एक एकल साझा $\Delta W$ को सभी कार्यों में साझा करके, कार्य प्रतिस्पर्धा से संघर्ष करता है और अक्सर असंतुलित प्रदर्शन की ओर ले जाता है। LoRA-STL, इसके विपरीत, प्रत्येक कार्य के लिए अलग $\Delta W_t$ को प्रशिक्षित करता है, मूल्यवान अंतर-कार्य साझा जानकारी को पूरी तरह से उपेक्षित करता है। टकर अपघटन का ToRA का उपयोग मुख्य टेंसर $G$ और कारक मैट्रिक्स $U_1, U_2, U_3$ को कार्य-साझा जानकारी के मुख्य उप-स्थान भिन्नता ( $U_1$ और $U_2$ के माध्यम से) और कार्य-विशिष्ट उप-स्थान संरचना ( $U_3$ के माध्यम से) दोनों को स्पष्ट रूप से मॉडल करने की अनुमति देता है। सूचना साझाकरण और विशेषज्ञता के इस समग्र दृष्टिकोण एक प्रमुख संरचनात्मक लाभ है जो विविध कार्यों में फाइन-ट्यूनिंग प्रदर्शन को बढ़ाता है। प्रमेय 1 में सैद्धांतिक विश्लेषण इसे और अधिक पुष्ट करता है, यह साबित करता है कि ToRA में बेहतर अभिव्यंजक शक्ति है और यह कई LoRAs की तुलना में कम मापदंडों के साथ समान वजन अद्यतन प्राप्त कर सकता है।
अंत में, गुणात्मक मूल्यांकन (जैसे, चित्र 5) से पता चलता है कि ToRA के साथ फाइन-ट्यून किया गया MTSAM अधिक सटीक परिणाम उत्पन्न करता है, विशेष रूप से "अस्पष्ट और पतली वस्तुओं" के लिए। यह बताता है कि साझा और विशिष्ट जानकारी को अलग करने और उसका लाभ उठाने की ToRA की क्षमता दृश्य दृश्यों की अधिक मजबूत और सूक्ष्म समझ की ओर ले जाती है, जिससे चुनौतीपूर्ण परिदृश्यों में प्रदर्शन में सुधार होता है जहां अन्य विधियां बारीक विवरण या जटिल वस्तु सीमाओं के साथ संघर्ष कर सकती हैं।
बाधाओं के साथ संरेखण
चुना गया MTSAM फ्रेमवर्क, अपनी वास्तुकलात्मक संशोधनों और ToRA फाइन-ट्यूनिंग विधि के साथ, SAM को मल्टी-टास्क लर्निंग के लिए अनुकूलित करने के लिए पहचानी गई दो प्राथमिक बाधाओं के साथ पूरी तरह से संरेखित होता है।
-
बाधा: विभिन्न चैनल संख्याओं वाले कार्य-विशिष्ट आउटपुट उत्पन्न करना।
- समाधान की संपत्ति: MTSAM SAM के मास्क डिकोडर को मौलिक रूप से बदलकर इसे संबोधित करता है। यह मूल संकेत एन्कोडर को हटा देता है और कार्य-विशिष्ट नो-मास्क एम्बेडिंग और समर्पित कार्य-विशिष्ट मास्क डिकोडर पेश करता है। जैसा कि चित्र 1 और चित्र 3 में दर्शाया गया है, यह संशोधन MTSAM को SAM के निश्चित चैनल आउटपुट के बजाय, प्रत्येक कार्य ($N_t \times H \times W$) के लिए अनुकूलित आयामों वाले आउटपुट उत्पन्न करने में सक्षम बनाता है। उदाहरण के लिए, यह गहराई के लिए 1 चैनल, सतह सामान्य के लिए 3, या सिमेंटिक विभाजन के लिए 13 आउटपुट कर सकता है, सीधे विविध आउटपुट संरचनाओं के लिए आवश्यकता को पूरा करता है। प्रशिक्षण योग्य कार्य एम्बेडिंग $E_t$ का परिचय यह सुनिश्चित करता है कि डिकोडर विशिष्ट कार्य के आधार पर अपनी प्रसंस्करण को अनुकूलित कर सके। यह आउटपुट लचीलेपन की समस्या की आवश्यकता और समाधान के मॉड्यूलर, कार्य-जागरूक डिकोडर डिजाइन के बीच एक सीधा "विवाह" है।
-
बाधा: SAM को कई डाउनस्ट्रीम कार्यों के लिए समवर्ती और कुशलतापूर्वक अनुकूलित करने के लिए फाइन-ट्यून करना।
- समाधान की संपत्ति: ToRA इस बाधा के लिए मुख्य नवाचार है। यह SAM एन्कोडर की प्रत्येक परत में एक अद्यतन पैरामीटर टेंसर डालता है और कार्य-साझा और कार्य-विशिष्ट दोनों जानकारी को कैप्चर करने के लिए निम्न-रैंक टेंसर अपघटन का उपयोग करता है। यह मॉडल को कार्य-विशिष्ट अनुकूलन की अनुमति देते हुए, उनकी अंतर्निर्भरता का लाभ उठाते हुए, कई कार्यों से समवर्ती रूप से सीखने की अनुमति देता है। ToRA की पैरामीटर दक्षता, कार्यों की संख्या के संबंध में इसके सबलाइनियर वृद्धि के साथ, SAM जैसे भारी फाउंडेशन मॉडल को निषेधात्मक कम्प्यूटेशनल लागतों या मेमोरी फुटप्रिंट के बिना फाइन-ट्यून करने के लिए महत्वपूर्ण है। यह दक्षता सुनिश्चित करती है कि समवर्ती अनुकूलन न केवल संभव है बल्कि व्यावहारिक भी है, जो इसे बड़े पैमाने पर मल्टी-टास्क लर्निंग की कठोर आवश्यकताओं के लिए एक आदर्श फिट बनाता है। कुल हानि फ़ंक्शन ($L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$) में ऑर्थोगोनल रेगुलराइज़ेशन टर्म का परिचय यह भी सुनिश्चित करता है कि सीखे गए कारक मैट्रिक्स अच्छी तरह से व्यवहार करते हैं और अनावश्यक नहीं हैं, जो मल्टी-टास्क फाइन-ट्यूनिंग प्रक्रिया की स्थिरता और प्रभावशीलता में योगदान करते हैं।
विकल्पों का अस्वीकरण
पत्र ने विभिन्न वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान किया है, मुख्य रूप से मौजूदा पैरामीटर-कुशल फाइन-ट्यूनिंग (PEFT) विधियों और मल्टी-टास्क संदर्भ में LoRA लागू करने की विभिन्न रणनीतियों पर ध्यान केंद्रित किया है।
-
पारंपरिक PEFT विधियाँ (जैसे, एडेप्टर-आधारित, प्रॉम्प्ट ट्यूनिंग, सिंगल-टास्क के लिए मौजूदा LoRA वेरिएंट): लेखकों ने स्पष्ट रूप से कहा है कि जबकि ये विधियाँ "सिंगल-टास्क फाइन-ट्यूनिंग में प्रतिस्पर्धी प्रदर्शन और उच्च पैरामीटर दक्षता प्राप्त करती हैं," वे "मल्टी-टास्क लर्निंग सेटिंग्स के लिए उपयुक्त नहीं हैं, क्योंकि वे कई कार्यों के बीच साझा जानकारी पर विचार नहीं करती हैं।" यह उन विधियों का एक कंबल अस्वीकरण है जो स्वाभाविक रूप से एक साथ कई कार्यों को सीखने से उत्पन्न होने वाले सहक्रियाओं का लाभ उठाने या संघर्षों का प्रबंधन करने में असमर्थ हैं। उनका डिज़ाइन मौलिक रूप से एक समय में एक कार्य के लिए अनुकूलन के लिए तैयार किया गया है, जो मल्टी-टास्क लर्निंग के लक्ष्य के विपरीत है।
-
LoRA-HPS (हार्ड पैरामीटर शेयरिंग): यह दृष्टिकोण सभी कार्यों के लिए एक साझा LoRA मैट्रिक्स ($\Delta W$) का उपयोग करके मल्टी-टास्क लर्निंग का प्रयास करता है। पत्र इसे अस्वीकार करता है क्योंकि यह "साझा LoRA के लिए कार्यों के बीच प्रतिस्पर्धा के कारण सभी कार्यों पर असंतुलित प्रदर्शन की ओर ले जा सकता है।" जब कार्यों में विरोधी ग्रेडिएंट या अलग-अलग सीखने की गतिशीलता होती है, तो उन्हें एक एकल, अविभेदित अद्यतन मैट्रिक्स साझा करने के लिए मजबूर करने से कुछ या सभी कार्यों पर प्रदर्शन खराब हो सकता है।
-
LoRA-STL (सिंगल-टास्क LoRA): इस विकल्प में प्रत्येक कार्य के लिए एक अलग LoRA मैट्रिक्स ($\Delta W_t$) को प्रशिक्षित करना शामिल है। पत्र इसे अस्वीकार करता है क्योंकि यह "कई कार्यों में फाइन-ट्यूनिंग के लिए आवश्यक अंतर-कार्य साझा जानकारी का लाभ नहीं उठा सकता है।" जबकि यह LoRA-HPS की प्रतिस्पर्धा समस्या से बचता है, यह संबंधित कार्यों में साझा ज्ञान और सामान्य सुविधाओं के संभावित लाभों का फायदा उठाने में विफल रहता है, जो मल्टी-टास्क लर्निंग के मूल सिद्धांतों में से एक है। यह इसे कुशल बनाता है और संभावित रूप से सूचना को बुद्धिमानी से साझा करने में सक्षम दृष्टिकोण की तुलना में कम प्रदर्शनकारी होता है।
-
पूर्ण फाइन-ट्यूनिंग: हालांकि अन्य PEFT विधियों के रूप में स्पष्ट रूप से "अस्वीकृत" नहीं है, पत्र स्पष्ट रूप से SAM के भारी छवि एन्कोडर की पूर्ण फाइन-ट्यूनिंग को "पैरामीटर और कम्प्यूटेशनल दक्षता चिंताओं" के कारण खारिज कर देता है। तालिका 7 मात्रात्मक रूप से इस अस्वीकृति का समर्थन करती है, यह दिखाते हुए कि पूर्ण फाइन-ट्यूनिंग के लिए MTSAM के 59.59 MB की तुलना में बहुत अधिक 1222.47 MB प्रशिक्षित मापदंडों की आवश्यकता होती है, जबकि समग्र प्रदर्शन सुधार ($\Delta_b$ पूर्ण फाइन-ट्यूनिंग के लिए +14.57% बनाम MTSAM के लिए +23.93%) कम होता है। यह पूर्ण फाइन-ट्यूनिंग को बड़े फाउंडेशन मॉडल और मल्टी-टास्क परिदृश्यों के लिए अव्यावहारिक बनाता है जहां दक्षता सर्वोपरि है। मापदंडों का भारी पैमाना इसे कम्प्यूटेशनल रूप से महंगा बनाता है और मल्टी-टास्क डेटासेट पर ओवरफिटिंग की संभावना होती है।
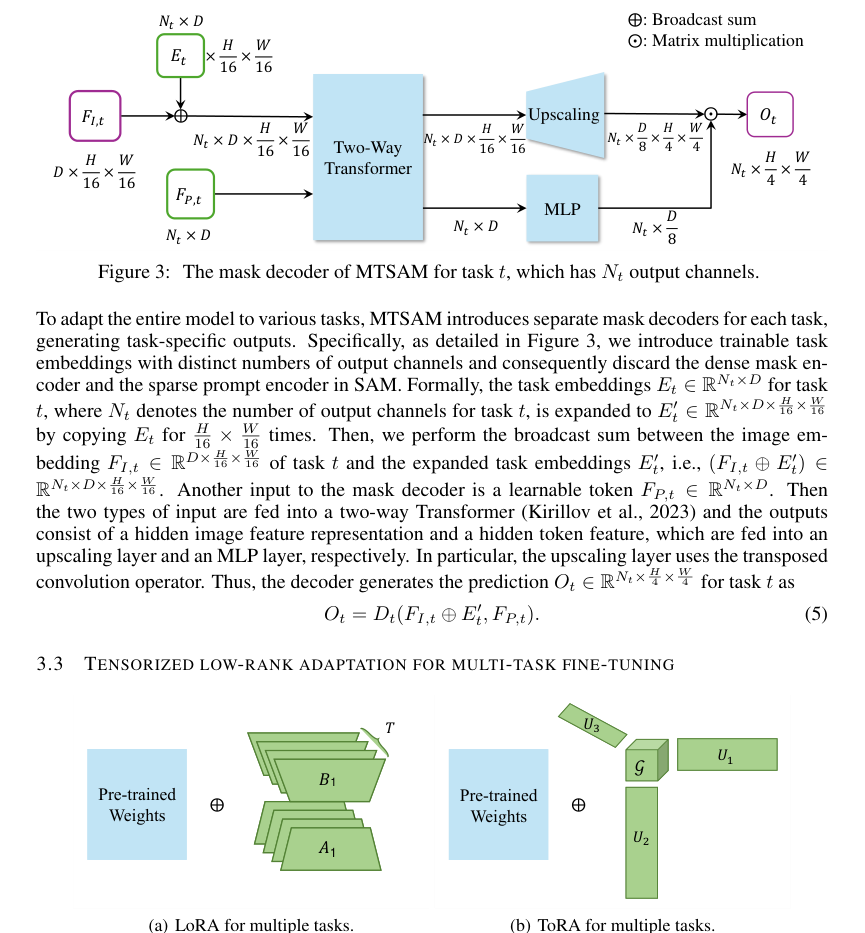 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
गणितीय और तार्किक तंत्र
मास्टर समीकरण
MTSAM फ्रेमवर्क की सीखने की प्रक्रिया का पूर्ण मूल इसके समग्र उद्देश्य फ़ंक्शन में निहित है, जो मल्टी-टास्क लर्निंग लॉस को एक रेगुलराइज़ेशन टर्म के साथ जोड़ता है ताकि कुशल और प्रभावी पैरामीटर अपडेट सुनिश्चित किया जा सके। यह मास्टर समीकरण पूरी प्रशिक्षण प्रक्रिया का मार्गदर्शन करता है:
$$ L_{total} = L_{MTL} + \lambda R(U_1, U_2, G) $$
यह समीकरण समाहित करता है कि मॉडल एक साथ कई कार्यों से कैसे सीखता है, जबकि टेंसर अपघटन और रेगुलराइज़ेशन के माध्यम से पैरामीटर दक्षता और अतिरेक को बनाए रखता है।
पद-दर-पद विच्छेदन
आइए मास्टर समीकरण और इसके घटकों को उनके गणितीय परिभाषाओं, भौतिक/तार्किक भूमिकाओं और लेखकों के डिजाइन विकल्पों को समझने के लिए विच्छेदित करें।
-
$L_{total}$: यह कुल उद्देश्य फ़ंक्शन है जिसे MTSAM फ्रेमवर्क प्रशिक्षण के दौरान कम करने का लक्ष्य रखता है। इसकी भूमिका सभी कार्यों में प्रदर्शन को पैरामीटर दक्षता और टेंसर अपडेट की संरचनात्मक अखंडता के साथ संतुलित करना है। लेखक इन दो अलग-अलग उद्देश्यों को संयोजित करने के लिए जोड़ का उपयोग करते हैं जिन्हें समवर्ती रूप से अनुकूलित करने की आवश्यकता होती है: कार्य त्रुटि को कम करना और एक अच्छी तरह से संरचित, निम्न-रैंक पैरामीटर स्थान बनाए रखना।
-
$L_{MTL}$: यह शब्द मल्टी-टास्क लर्निंग (MTL) लॉस का प्रतिनिधित्व करता है। यह सभी व्यक्तिगत कार्यों से भारित हानियों का औसत है।
$$ L_{MTL} = \frac{1}{T} \sum_{i=1}^T w_i L_i $$- $T$: यह सीखे जा रहे कुल विशिष्ट कार्यों की संख्या है (जैसे, सिमेंटिक विभाजन, गहराई अनुमान, सतह सामान्य भविष्यवाणी)। इसकी भूमिका समग्र मल्टी-टास्क उद्देश्य में प्रत्येक कार्य के योगदान को नियंत्रित करने के लिए एक हाइपर-पैरामीटर है। उदाहरण के लिए, अधिक महत्वपूर्ण या कठिन माने जाने वाले कार्य को उच्च भार प्राप्त हो सकता है। लेखक कुल हानि में प्रत्येक कार्य के योगदान को स्केल करने के लिए गुणन का उपयोग करते हैं, जिससे लचीली प्राथमिकता की अनुमति मिलती है।
- $w_i$: यह कार्य $i$ के लिए हानि भार है। यह एक हाइपर-पैरामीटर है जो समग्र मल्टी-टास्क उद्देश्य में प्रत्येक कार्य की हानि के सापेक्ष महत्व को नियंत्रित करता है। उदाहरण के लिए, अधिक महत्वपूर्ण या कठिन माने जाने वाले कार्य को उच्च भार प्राप्त हो सकता है। लेखक कुल हानि में प्रत्येक कार्य के योगदान को स्केल करने के लिए गुणन का उपयोग करते हैं, जिससे लचीली प्राथमिकता की अनुमति मिलती है।
- $L_i$: यह कार्य $i$ के लिए हानि है, जिसे उस विशिष्ट कार्य के लिए सभी प्रशिक्षण नमूनों पर औसत हानि के रूप में गणना की जाती है।
$$ L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j, f(x_j)) $$- $N_i$: यह कार्य $i$ के लिए प्रशिक्षण नमूनों की संख्या को दर्शाता है। इसकी भूमिका नमूनों पर हानि को औसत करना है, यह सुनिश्चित करना कि किसी कार्य के लिए हानि उस पर नमूनों की संख्या से असमान रूप से प्रभावित न हो। योग व्यक्तिगत नमूनों से हानियों को एकत्रित करता है, और $N_i$ से विभाजन माध्य हानि प्रदान करता है।
- $l_i(\cdot, \cdot)$: यह कार्य $i$ के लिए कार्य-विशिष्ट हानि फ़ंक्शन है। इसकी गणितीय परिभाषा कार्य $i$ की प्रकृति पर निर्भर करती है (जैसे, विभाजन के लिए क्रॉस-एंट्रॉपी, गहराई अनुमान के लिए L1 हानि, सतह सामान्य के लिए कोसाइन समानता)। इसकी भूमिका मॉडल की भविष्यवाणी और एकल नमूने के लिए ग्राउंड ट्रुथ के बीच विसंगति को मापना है।
- $y_j$: यह कार्य $i$ के $j$-वें प्रशिक्षण नमूने के लिए ग्राउंड ट्रुथ लेबल है। यह सही आउटपुट का प्रतिनिधित्व करता है जिसे मॉडल को उत्पन्न करना चाहिए।
- $f(x_j)$: यह कार्य $i$ के लिए नमूना $x_j$ के लिए MTSAM मॉडल की भविष्यवाणी का प्रतिनिधित्व करता है। फ़ंक्शन $f(\cdot)$ संपूर्ण MTSAM वास्तुकला को समाहित करता है, जिसमें छवि एन्कोडर और कार्य-विशिष्ट मास्क डिकोडर शामिल हैं, जो ToRA-संशोधित भार को शामिल करता है।
- $x_j$: यह इनपुट प्रशिक्षण नमूना (जैसे, एक छवि) है जिसके लिए भविष्यवाणी $f(x_j)$ की जाती है।
-
$\lambda$: यह एक हाइपर-पैरामीटर है जो ऑर्थोगोनल रेगुलराइज़ेशन टर्म $R(U_1, U_2, G)$ के प्रभाव को नियंत्रित करता है। इसकी भूमिका कार्य-विशिष्ट त्रुटियों को कम करने और ToRA मापदंडों पर वांछित निम्न-रैंक, ऑर्थोगोनल संरचना को लागू करने के बीच ट्रेड-ऑफ को संतुलित करना है। एक बड़ा $\lambda$ रेगुलराइज़ेशन पर अधिक जोर देता है। लेखक कुल हानि में रेगुलराइज़ेशन के योगदान को स्केल करने के लिए गुणन का उपयोग करते हैं।
-
$R(U_1, U_2, G)$: यह ऑर्थोगोनल रेगुलराइज़ेशन टर्म है। यह कारक मैट्रिक्स $U_1, U_2$ और कोर टेंसर $G$ के स्लाइस को ऑर्थोगोनल को प्रोत्साहित करता है, जो अतिरेक को कम करने और टेंसर अपघटन की स्थिरता में सुधार करने में मदद करता है।
$$ R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^v ||G(:,:,l)^T G(:,:,l) - I||_F^2 $$- $U_1$: यह $d \times p$ आयामों का एक कारक मैट्रिक्स है। यह अद्यतन पैरामीटर टेंसर $\Delta W$ के आउटपुट सुविधा आयाम से संबंधित कार्य-साझा जानकारी के मुख्य उप-स्थान भिन्नता को कैप्चर करता है।
- $U_2$: यह $k \times q$ आयामों का एक कारक मैट्रिक्स है। यह अद्यतन पैरामीटर टेंसर $\Delta W$ के इनपुट सुविधा आयाम से संबंधित कार्य-साझा जानकारी के मुख्य उप-स्थान भिन्नता को कैप्चर करता है।
- $G$: यह $p \times q \times v$ आयामों का कोर टेंसर है। यह अपघटन के बाद अद्यतन पैरामीटर टेंसर $\Delta W$ के संपीड़ित, निम्न-रैंक प्रतिनिधित्व को रखता है। यह साझा और विशिष्ट जानकारी का "सार" रखता है।
- $||\cdot||_F^2$: यह फ्रॉबेनियस नॉर्म स्क्वायर को दर्शाता है। गणितीय रूप से, एक मैट्रिक्स $A$ के लिए, $||A||_F^2 = \sum_{i,j} |A_{i,j}|^2$। यहां इसकी भूमिका ऑर्थोगोनैलिटी से विचलन के "आकार" या परिमाण को मापना है। वर्ग मान को गैर-नकारात्मक बनाता है और बड़े विचलन को अधिक भारी दंडित करता है।
- $I$: यह उपयुक्त आकार का पहचान मैट्रिक्स है। $U^T U - I$ जैसे शब्दों में इसकी भूमिका ऑर्थोगोनैलिटी के लक्ष्य के रूप में कार्य करना है: यदि $U^T U = I$, तो $U$ ऑर्थोगोनल है।
- $U_1^T U_1 - I$: यह शब्द $U_1$ के ऑर्थोगोनैलिटी से विचलन को मापता है। इसके फ्रॉबेनियस नॉर्म स्क्वायर को कम करने से $U_1$ एक ऑर्थोगोनल मैट्रिक्स के करीब हो जाता है।
- $U_2^T U_2 - I$: $U_1$ के समान, यह शब्द $U_2$ के ऑर्थोगोनैलिटी से विचलन को मापता है।
- $G(:,:,l)^T G(:,:,l) - I$: यह शब्द कोर टेंसर $G$ के $l$-वें फ्रंटल स्लाइस के ऑर्थोगोनैलिटी से विचलन को मापता है। $G(:,:,l)$ तीसरे मोड (कार्य अक्ष) को $l$ पर ठीक करके गठित मैट्रिक्स को संदर्भित करता है। यह कोर टेंसर के भीतर कार्य आयाम के साथ ऑर्थोगोनैलिटी सुनिश्चित करता है। योग $\sum_{l=1}^v$ कोर टेंसर के सभी स्लाइस में इन ऑर्थोगोनैलिटी दंडों को एकत्रित करता है। लेखक इन व्यक्तिगत ऑर्थोगोनैलिटी बाधाओं को संयोजित करने के लिए जोड़ का उपयोग करते हैं, क्योंकि प्रत्येक स्वतंत्र रूप से अतिरेक को कम करने के समग्र लक्ष्य में योगदान देता है।
$L_{MTL}$ के संचालन के केंद्र में टेंपोराइज़्ड लो-रैंक एडैप्टेशन (ToRA) विधि है, जो परिभाषित करती है कि मॉडल के भार को कैसे अद्यतन किया जाता है। ToRA टकर अपघटन का उपयोग करके अद्यतन पैरामीटर टेंसर $\Delta W$ को पैरामीटराइज़ करता है:
$$ \Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3 $$
- $\Delta W$: यह $d \times k \times T$ आयामों का अद्यतन पैरामीटर टेंसर है। यह सभी कार्यों में पूर्व-प्रशिक्षित भारों में सामूहिक परिवर्तनों का प्रतिनिधित्व करता है। प्रत्येक स्लाइस $\Delta W(:,:,t)$ कार्य $t$ के लिए अद्यतन मैट्रिक्स है। इसकी भूमिका कुशल रूप से कई डाउनस्ट्रीम कार्यों के लिए पूर्व-प्रशिक्षित मॉडल को अनुकूलित करना है। लेखकों ने कई कार्यों के लिए अपडेट का प्रतिनिधित्व करने के लिए एक टेंसर चुना क्योंकि यह स्वाभाविक रूप से कार्य-साझा और कार्य-विशिष्ट जानकारी की बहु-आयामी प्रकृति को कैप्चर करता है।
- $G$: यह कोर टेंसर (ऊपर परिभाषित) है, जिसमें $p \times q \times v$ आयाम हैं। यह टेंसर के सबसे महत्वपूर्ण घटकों को रखता है, एक संपीड़ित प्रतिनिधित्व के रूप में कार्य करता है।
- $U_1$: यह मोड 1 (आउटपुट सुविधा आयाम) के लिए कारक मैट्रिक्स है, जिसमें $d \times p$ आयाम हैं। यह कोर टेंसर को इसके पहले मोड के साथ रूपांतरित करता है।
- $U_2$: यह मोड 2 (इनपुट सुविधा आयाम) के लिए कारक मैट्रिक्स है, जिसमें $k \times q$ आयाम हैं। यह कोर टेंसर को इसके दूसरे मोड के साथ रूपांतरित करता है।
- $U_3$: यह मोड 3 (कार्य आयाम) के लिए कारक मैट्रिक्स है, जिसमें $T \times v$ आयाम हैं। यह कोर टेंसर को इसके तीसरे मोड के साथ रूपांतरित करता है, जिससे अपघटन कार्य-विशिष्ट भिन्नताओं को कैप्चर कर सकता है।
- $\times_n$: यह n-मोड उत्पाद को दर्शाता है। गणितीय रूप से, $A \times_n B$ का अर्थ है टेंसर $A$ को मैट्रिक्स $B$ के साथ इसके $n$-वें मोड के साथ गुणा करना। इसकी भूमिका कारक मैट्रिक्स $U_1, U_2, U_3$ का उपयोग करके कोर टेंसर $G$ से पूर्ण $\Delta W$ टेंसर में "अनफोल्ड" या प्रोजेक्ट करना है। यह ऑपरेटर टेंसर अपघटन के लिए मौलिक है, जो एक कोर टेंसर और कई मैट्रिक्स से एक उच्च-क्रम टेंसर के पुनर्निर्माण की अनुमति देता है।
अंत में, किसी दिए गए कार्य $t$ के लिए मॉडल के फॉरवर्ड पास पर इन अपडेट का वास्तविक अनुप्रयोग है:
$$ h = W_0x + \Delta W(:,:,t)x $$
- $h$: यह SAM एन्कोडर में एक परत का आउटपुट है जो ToRA अद्यतन लागू करने के बाद होता है।
- $W_0$: यह SAM एन्कोडर में एक परत का मूल पूर्व-प्रशिक्षित वजन मैट्रिक्स है। इसे फाइन-ट्यूनिंग के दौरान जमे हुए रखा जाता है।
- $\Delta W(:,:,t)$: यह कार्य $t$ के लिए अद्यतन मैट्रिक्स है, जो पूर्ण $\Delta W$ टेंसर का $t$-वां स्लाइस है। इसकी भूमिका पूर्व-प्रशिक्षित भारों में कार्य-विशिष्ट समायोजन प्रदान करना है।
- $x$: यह SAM एन्कोडर में परत का इनपुट है।
- यहां जोड़ ऑपरेटर यह दर्शाता है कि ToRA अद्यतन पूर्व-प्रशिक्षित भारों में एक योगात्मक संशोधन है, जो LoRA जैसी PEFT विधियों में एक सामान्य अभ्यास है।
चरण-दर-चरण प्रवाह
एक विशिष्ट डेटा बिंदु, एक छवि $x_j$ की कल्पना करें, जो एक विशिष्ट कार्य $t$ के लिए MTSAM फ्रेमवर्क के माध्यम से यात्रा शुरू करती है।
-
छवि एन्कोडिंग (जमा हुआ फाउंडेशन): यात्रा इनपुट छवि $x_j$ के SAM के भारी छवि एन्कोडर $E_1$ में प्रवेश करने के साथ शुरू होती है। महत्वपूर्ण रूप से, $E_1$ के पैरामीटर जमे हुए हैं। इसका मतलब है कि SAM के पूर्व-प्रशिक्षण के दौरान सीखी गई मूलभूत जानकारी संरक्षित है। एन्कोडर छवि सुविधाओं का एक सेट, $F_1$ आउटपुट करता है।
-
ToRA इंजेक्शन (अनुकूली परत): जैसे ही $F_1$ छवि एन्कोडर के भीतर स्व-ध्यान मॉड्यूल के माध्यम से प्रचारित होता है, यह ToRA तंत्र का सामना करता है। प्रत्येक परत के लिए, मूल पूर्व-प्रशिक्षित वजन मैट्रिक्स $W_0$ का सीधे उपयोग करने के बजाय, उस परत के इनपुट $x$ को एक अनुकूलित वजन मैट्रिक्स $W'$ द्वारा संसाधित किया जाता है। यह $W'$ प्रभावी रूप से $W_0 + \Delta W(:,:,t)$ है। $\Delta W(:,:,t)$ घटक टेंसर अपघटन $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$ का उपयोग करके कोर टेंसर $G$ और कारक मैट्रिक्स $U_1, U_2, U_3$ का उपयोग करके कार्य $t$ के लिए गतिशील रूप से निर्मित होता है। इसका मतलब है कि प्रत्येक कार्य $t$ के लिए, जमे हुए भारों में एक अद्वितीय, निम्न-रैंक अद्यतन लागू किया जाता है, जो मॉडल के व्यवहार को कार्य-विशिष्ट आवश्यकताओं की ओर सूक्ष्म रूप से निर्देशित करता है, बिना इसके विशाल बहुमत मापदंडों को बदले।
-
कार्य-विशिष्ट डिकोडिंग (आउटपुट जनरेशन): ToRA-अनुकूलित छवि सुविधाएँ, अब कार्य $t$ के लिए अंतर्निहित रूप से तैयार की गई हैं, फिर एक कार्य-विशिष्ट मास्क डिकोडर $D_t$ में फीड की जाती हैं। इस डिकोडर को एक प्रशिक्षण योग्य कार्य एम्बेडिंग $E_t$ (सुविधा आयामों से मेल खाने के लिए विस्तारित) और एक सीखने योग्य टोकन $F_{P,t}$ भी दिया जाता है। कार्य एम्बेडिंग $E_t$ को छवि सुविधाओं $F_{1,t}$ (जो $F_1$ से प्राप्त होते हैं और कार्य $t$ के लिए आगे संसाधित हो सकते हैं) के साथ ब्रॉडकास्ट-सम किया जाता है। इन संयुक्त सुविधाओं, सीखने योग्य टोकन के साथ, एक दो-तरफा ट्रांसफार्मर, एक अपस्केलिंग परत और एक एमएलपी परत से गुजरती हैं। यह पूरी प्रक्रिया कार्य $t$ के लिए उपयुक्त संख्या में चैनलों के साथ कार्य-विशिष्ट आउटपुट $O_t$ (जैसे, एक विभाजन मास्क, एक गहराई मानचित्र, या सतह सामान्य) उत्पन्न करती है।
-
हानि गणना (प्रदर्शन माप): नमूना $x_j$ के लिए उत्पन्न आउटपुट $O_t$ की तुलना कार्य-विशिष्ट हानि फ़ंक्शन $l_t$ का उपयोग करके इसके संगत ग्राउंड ट्रुथ लेबल $y_j$ से की जाती है। यह $l_t(y_j, f(x_j))$ उत्पन्न करता है, जो इस विशिष्ट नमूने पर कार्य $t$ के लिए मॉडल के प्रदर्शन को मापता है।
-
मल्टी-टास्क एकत्रीकरण (सामूहिक त्रुटि): यह व्यक्तिगत नमूना हानि $l_t(y_j, f(x_j))$ समग्र कार्य हानि $L_t$ में योगदान करती है। कार्य $t$ के सभी नमूनों के लिए, उनकी हानियों को $L_t$ बनाने के लिए औसत किया जाता है। फिर, $L_t$ को $w_t$ से भारित किया जाता है और कुल मल्टी-टास्क लर्निंग लॉस $L_{MTL}$ बनाने के लिए सभी अन्य कार्यों से भारित हानियों के साथ जोड़ा जाता है।
-
रेगुलराइज़ेशन (संरचनात्मक अखंडता): साथ ही, प्रशिक्षण योग्य ToRA घटकों ($U_1, U_2, G$) की वर्तमान स्थिति का मूल्यांकन ऑर्थोगोनल रेगुलराइज़ेशन टर्म $R(U_1, U_2, G)$ के विरुद्ध किया जाता है। यह शब्द इन मैट्रिक्स और कोर टेंसर स्लाइस में ऑर्थोगोनैलिटी से विचलन को दंडित करता है।
-
कुल उद्देश्य (एकीकृत लक्ष्य): अंत में, $L_{MTL}$ और स्केल किए गए रेगुलराइज़ेशन टर्म $\lambda R(U_1, U_2, G)$ को $L_{total}$ उद्देश्य फ़ंक्शन बनाने के लिए जोड़ा जाता है। यह एकल मान समग्र "लागत" या त्रुटि का प्रतिनिधित्व करता है जिसे मॉडल को कम करने की आवश्यकता है।
अनुकूलन गतिशीलता
MTSAM फ्रेमवर्क $L_{total}$ उद्देश्य फ़ंक्शन के न्यूनीकरण द्वारा संचालित एक पुनरावृत्ति अनुकूलन प्रक्रिया के माध्यम से अपने मापदंडों को सीखता और अद्यतन करता है।
-
पैरामीटर आरंभीकरण: प्रशिक्षण की शुरुआत में, कोर टेंसर $G$ को शून्य पर इनिशियलाइज़ किया जाता है। यह सुनिश्चित करता है कि प्रारंभ में, ToRA अपडेट $\Delta W(:,:,t)$ भी शून्य हैं, जिसका अर्थ है कि मॉडल प्रारंभ में केवल जमे हुए पूर्व-प्रशिक्षित भार $W_0$ पर निर्भर करता है। कारक मैट्रिक्स $U_1, U_2, U_3$ को एक मानक गॉसियन वितरण से यादृच्छिक रूप से इनिशियलाइज़ किया जाता है। यह यादृच्छिक आरंभीकरण पैरामीटर स्थान का पता लगाने के लिए एक प्रारंभिक बिंदु प्रदान करता है।
-
ग्रेडिएंट गणना: प्रत्येक प्रशिक्षण पुनरावृत्ति के दौरान, सभी कार्यों में डेटा के एक बैच के लिए $L_{total}$ की गणना करने के बाद, एडम ऑप्टिमाइज़र का उपयोग ग्रेडिएंट की गणना के लिए किया जाता है। ग्रेडिएंट प्रशिक्षण योग्य मापदंडों के संबंध में गणना की जाती है: कारक मैट्रिक्स $U_1, U_2, U_3$, कोर टेंसर $G$, और छवि एन्कोडर में परत सामान्यीकरण परतों के भीतर स्केल और पूर्वाग्रह पैरामीटर। महत्वपूर्ण रूप से, छवि एन्कोडर के मूल पूर्व-प्रशिक्षित भार $W_0$ जमे हुए हैं, जिसका अर्थ है कि उनके माध्यम से कोई ग्रेडिएंट प्रवाहित नहीं होता है, जिससे प्रशिक्षित मापदंडों की संख्या और कम्प्यूटेशनल लागत काफी कम हो जाती है।
-
हानि परिदृश्य आकार देना: हानि परिदृश्य को मल्टी-टास्क लर्निंग लॉस ($L_{MTL}$) और ऑर्थोगोनल रेगुलराइज़ेशन टर्म ($R$) के परस्पर क्रिया द्वारा आकार दिया जाता है।
- $L_{MTL}$ मॉडल को सभी कार्यों में प्रदर्शन में सुधार करने के लिए प्रेरित करता है। रेगुलराइज़ेशन के बिना, यह परिदृश्य जटिल हो सकता है, जिससे कार्यों के बीच विरोधी ग्रेडिएंट या ओवरफिटिंग हो सकती है।
- रेगुलराइज़ेशन टर्म $R$ एक संरचनात्मक बाधा के रूप में कार्य करता है। $U_1, U_2, G$ में गैर-ऑर्थोगोनैलिटी को दंडित करके, यह एक अधिक कॉम्पैक्ट, कम अनावश्यक अद्यतन पैरामीटर प्रतिनिधित्व को प्रोत्साहित करता है। यह एक चिकनी हानि परिदृश्य की ओर ले जा सकता है, संभावित रूप से अभिसरण में सहायता करता है और अतिरेक सुविधाओं को सीखने से रोककर सामान्यीकरण में सुधार करता है। लेखकों के सैद्धांतिक विश्लेषण से पता चलता है कि यह निम्न-रैंक, ऑर्थोगोनल संरचना ToRA को LoRA की तुलना में कम मापदंडों के साथ बेहतर अभिव्यंजक शक्ति प्राप्त करने की अनुमति देती है।
-
पुनरावृत्ति अद्यतन: एडम ऑप्टिमाइज़र गणना किए गए ग्रेडिएंट का उपयोग करके प्रशिक्षण योग्य मापदंडों ($U_1, U_2, U_3, G$, और परत सामान्यीकरण पैरामीटर) को पुनरावृत्ति से अद्यतन करता है। अद्यतन $10^{-3}$ की प्रारंभिक सीखने की दर का उपयोग करके किए जाते हैं, जिसे 0.05 की वार्मअप दर के साथ एक रैखिक सीखने की दर शेड्यूलर द्वारा समायोजित किया जाता है। ओवरफिटिंग को रोकने के लिए $10^{-6}$ का वजन क्षय भी लागू किया जाता है। ये पुनरावृत्ति अद्यतन धीरे-धीरे ToRA घटकों को परिष्कृत करते हैं, जिससे उन्हें कार्य-साझा और कार्य-विशिष्ट दोनों जानकारी सीखने की अनुमति मिलती है।
-
अभिसरण: प्रशिक्षण प्रक्रिया एक निश्चित संख्या में युगों (जैसे, NYUv2 के लिए 200) के लिए जारी रहती है। जैसे-जैसे मापदंडों को अद्यतन किया जाता है, $L_{total}$ के घटने की उम्मीद है, यह दर्शाता है कि मॉडल वांछित निम्न-रैंक संरचना को बनाए रखते हुए कार्यों पर बेहतर प्रदर्शन करना सीख रहा है। लक्ष्य मापदंडों के एक सेट पर अभिसरण करना है जो $L_{total}$ को कम करता है, जिससे मल्टी-टास्क प्रदर्शन और पैरामीटर दक्षता में सुधार होता है। अनुमान के दौरान, प्रत्येक कार्य $t$ के लिए सीखे गए $\Delta W(:,:,t)$ को पूर्व-गणना की जाती है और $W_t'$ बनाने के लिए $W_0$ में जोड़ा जाता है, इसलिए कोई अतिरिक्त विलंबता नहीं होती है। यह चतुर डिजाइन सुनिश्चित करता है कि फाइन-ट्यूनिंग के लाभ धीमी भविष्यवाणी समय की कीमत पर नहीं आते हैं।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
प्रस्तावित मल्टी-टास्क SAM (MTSAM) फ्रेमवर्क और इसके मुख्य घटक, टेंपोराइज़्ड लो-रैंक एडैप्टेशन (ToRA) को कठोरता से मान्य करने के लिए, लेखकों ने तीन अच्छी तरह से स्थापित बेंचमार्क डेटासेट: NYUv2, CityScapes और PASCAL-Context पर व्यापक प्रयोग किए। ये डेटासेट विविध कंप्यूटर विज़न परिदृश्यों का प्रतिनिधित्व करते हैं, जिनमें इनडोर दृश्य (NYUv2) और शहरी बाहरी वातावरण (CityScapes, PASCAL-Context) शामिल हैं, और विभिन्न प्रकार के सघन भविष्यवाणी कार्य शामिल हैं।
प्रयोगात्मक सेटअप को MTSAM के गणितीय दावों को निर्विवाद रूप से साबित करने के लिए डिज़ाइन किया गया था, जो विभिन्न आउटपुट आयामों को संभालने और कई कार्यों के लिए कुशलतापूर्वक फाइन-ट्यून करने की इसकी क्षमता के संबंध में था। जिन "पीड़ितों" (बेसलाइन मॉडल) के खिलाफ MTSAM को खड़ा किया गया था, उनमें पारंपरिक मल्टी-टास्क लर्निंग (MTL) दृष्टिकोण और अधिक हालिया पैरामीटर-कुशल फाइन-ट्यूनिंग (PEFT) विधियों की एक व्यापक श्रृंखला शामिल थी:
- CNN-आधारित MTL बेसलाइन: सिंगल-टास्क लर्निंग (STL), हार्ड-पैरामीटर शेयरिंग (HPS), क्रॉस-स्टिच, मल्टी-टास्क अटेंशन नेटवर्क (MTAN), और NDDR-CNN। ये मल्टी-टास्क लर्निंग के लिए स्थापित विधियों का प्रतिनिधित्व करते हैं, जिसमें HPS $\Delta_b$ मीट्रिक के लिए एक महत्वपूर्ण बेसलाइन के रूप में कार्य करता है।
- ट्रांसफार्मर-आधारित MTL बेसलाइन: VTAGML और SwinMTL, समकालीन वास्तुकला को दर्शाते हैं।
- क्रॉस-अटेंशन-आधारित MTL: DenseMTL।
- LoRA-आधारित PEFT बेसलाइन: ToRA की प्रभावशीलता का विशेष रूप से मूल्यांकन करने के लिए, लेखकों ने इसकी तुलना मल्टी-टास्क सेटिंग्स में LoRA के प्रत्यक्ष अनुप्रयोगों से की: LoRA-STL (टास्क-विशिष्ट LoRA), LoRA-HPS (साझा LoRA), और MultiLoRA। टेरा और हाइड्राLoRA जैसे अन्य उन्नत LoRA वेरिएंट के साथ-साथ पूरे मॉडल की पूर्ण फाइन-ट्यूनिंग से भी तुलना की गई।
मूल्यांकित कार्य डेटासेट के अनुसार भिन्न थे:
* NYUv2: 13-वर्ग सिमेंटिक विभाजन, गहराई अनुमान, और सतह सामान्य भविष्यवाणी।
* CityScapes: 7-वर्ग सिमेंटिक विभाजन और गहराई अनुमान।
* PASCAL-Context: 21-वर्ग सिमेंटिक विभाजन, 7-वर्ग मानव भागों का विभाजन, लपट अनुमान, और सतह सामान्य भविष्यवाणी।
प्रदर्शन को मानक मेट्रिक्स के एक सूट का उपयोग करके मापा गया था:
* सिमेंटिक विभाजन: मीन इंटरसेक्शन ओवर यूनियन (mIoU) और पिक्सेल एक्यूरेसी (Pix Acc), जहां उच्च मान बेहतर होते हैं।
* गहराई अनुमान: निरपेक्ष त्रुटि (Abs Err) और सापेक्ष त्रुटि (Rel Err), जहां निम्न मान बेहतर होते हैं।
* सतह सामान्य भविष्यवाणी: कोणीय त्रुटि के माध्य और मध्यिका (कम बेहतर है), और उन पिक्सेल का प्रतिशत जिनकी कोणीय त्रुटि 11.25, 22.5, और 30 डिग्री के भीतर है (उच्च बेहतर है)।
* समग्र प्रदर्शन: एक समग्र मीट्रिक, $\Delta_b$, जो प्रत्येक कार्य के लिए HPS वास्तुकला पर औसत सापेक्ष सुधार का प्रतिनिधित्व करता है, उच्च मान बेहतर प्रदर्शन का संकेत देते हैं।
* पैरामीटर दक्षता: प्रशिक्षित मापदंडों की संख्या (Params.) मेगाबाइट (MB) में, निम्न मान अधिक कुशल होते हैं।
कार्यान्वयन विवरण में एडम ऑप्टिमाइज़र का उपयोग $10^{-3}$ की सीखने की दर के साथ, वार्मअप के साथ एक रैखिक सीखने की दर शेड्यूलर, और प्रत्येक डेटासेट के लिए अनुकूलित ToRA ($p, q, v$) के लिए विशिष्ट रैंक सेटिंग्स शामिल हैं। ऑर्थोगोनल रेगुलराइज़ेशन, एक हाइपर-पैरामीटर $\lambda$ द्वारा नियंत्रित, भी लागू किया गया था।
साक्ष्य क्या साबित करता है
प्रयोगात्मक परिणाम निश्चित, निर्विवाद प्रमाण प्रदान करते हैं कि MTSAM, विशेष रूप से इसके ToRA घटक के साथ, फाउंडेशन मॉडल के मल्टी-टास्क लर्निंग को महत्वपूर्ण रूप से आगे बढ़ाता है।
-
समग्र श्रेष्ठता और पैरामीटर दक्षता: सभी तीन बेंचमार्क डेटासेट (NYUv2, CityScapes, और PASCAL-Context) में, MTSAM ने लगातार $\Delta_b$ मीट्रिक (तालिका 1, 2, 3) द्वारा मापे गए सर्वश्रेष्ठ औसत प्रदर्शन प्राप्त किया। उदाहरण के लिए, NYUv2 पर, MTSAM ने केवल 59.59 MB प्रशिक्षित मापदंडों के साथ +23.93% का $\Delta_b$ उत्पन्न किया, पूर्ण फाइन-ट्यूनिंग (+14.57% 1222.47 MB के साथ) और अन्य सभी बेसलाइन को पार कर गया। यह प्रदर्शित करता है कि MTSAM न केवल बेहतर प्रदर्शन प्राप्त करता है, बल्कि यह उल्लेखनीय पैरामीटर दक्षता के साथ भी करता है, जिससे भंडारण और व्यावहारिक अनुप्रयोग में महत्वपूर्ण लाभ मिलते हैं।
-
साझा और विशिष्ट जानकारी का लाभ उठाने में ToRA की प्रभावशीलता: ToRA और LoRA-आधारित विधियों (LoRA-HPS, LoRA-STL, MultiLoRA) के बीच तुलना महत्वपूर्ण है। LoRA-HPS, जो एक एकल साझा LoRA मैट्रिक्स का उपयोग करता है, अक्सर कार्य प्रतिस्पर्धा से पीड़ित होता है। LoRA-STL, जो कार्य-विशिष्ट LoRAs का उपयोग करता है, LoRA-HPS से बेहतर प्रदर्शन करता है, कार्य-विशिष्ट घटकों के महत्व को उजागर करता है। हालांकि, ToRA लगातार दोनों LoRA-STL और LoRA-HPS (तालिका 1, 2, 3, 7) से बेहतर प्रदर्शन करता है। यह कठोर साक्ष्य इस सैद्धांतिक दावे को पुष्ट करता है कि ToRA अपने निम्न-रैंक टेंसर अपघटन के माध्यम से कार्य-साझा और कार्य-विशिष्ट दोनों जानकारी का प्रभावी ढंग से लाभ उठाता है, जिससे समग्र प्रदर्शन में सुधार होता है। गुणात्मक परिणाम (चित्र 5-11) इसे और मजबूत करते हैं, जिसमें MTSAM ToRA के साथ स्पष्ट रूप से अधिक सटीक भविष्यवाणियां उत्पन्न करता है, विशेष रूप से चुनौतीपूर्ण "अस्पष्ट और पतली वस्तुओं" के लिए, अन्य LoRA वेरिएंट की तुलना में।
-
वास्तुकलात्मक संशोधनों का प्रभाव:
- कार्य एम्बेडिंग: एक एब्लेशन अध्ययन (तालिका 8) स्पष्ट रूप से दिखाता है कि प्रस्तावित कार्य एम्बेडिंग विभिन्न कार्यों के लिए एमएलपी आउटपुट आयामों को संशोधित करने की तुलना में अधिक प्रभावी हैं। इस सुधार का श्रेय क्रॉस-अटेंशन तंत्र को दिया जाता है, जो कार्य एम्बेडिंग और छवि सुविधाओं के बीच बातचीत के माध्यम से बेहतर कार्य-विशिष्ट ज्ञान सीखने की सुविधा प्रदान करता है।
- ऑर्थोगोनल रेगुलराइज़ेशन: ऑर्थोगोनल रेगुलराइज़ेशन (तालिका 5) पर एब्लेशन अध्ययन इसके सकारात्मक प्रभाव को प्रदर्शित करता है। पूर्ण ऑर्थोगोनल रेगुलराइज़ेशन के साथ MTSAM $G$, $U_1$, और $U_2$ पर विभिन्न वेरिएंट की तुलना में काफी बेहतर प्रदर्शन करता है, जो अतिरेक को कम करके विभिन्न कार्यों में प्रदर्शन में सुधार करने में इसकी प्रभावशीलता को साबित करता है।
-
हाइपर-पैरामीटर सेटिंग्स के प्रति मजबूती: हाइपर-पैरामीटर $\lambda$ (ऑर्थोगोनल रेगुलराइज़ेशन भार) के संबंध में संवेदनशीलता विश्लेषण (तालिका 6) इंगित करता है कि MTSAM का प्रदर्शन एक उचित सीमा (जैसे, [0.5, 1.5]) के भीतर $\lambda$ के प्रति अत्यधिक संवेदनशील नहीं है। यह बताता है कि मॉडल अपेक्षाकृत मजबूत है और ट्यून करने में आसान है, जो एक व्यावहारिक लाभ है।
सीमाएँ और भविष्य की दिशाएँ
जबकि MTSAM प्रभावशाली क्षमताएं प्रदर्शित करता है, विशेष रूप से SAM जैसे फाउंडेशन मॉडल के मल्टी-टास्क फाइन-ट्यूनिंग में, पत्र कई सीमाओं को भी उजागर करता है और भविष्य के शोध के लिए रोमांचक रास्ते खोलता है।
एक उल्लेखनीय सीमा काफी भिन्न डेटा वितरणों में ज़ीरो-शॉट सामान्यीकरण से संबंधित है। लेखकों ने केवल NYUv2 पर प्रशिक्षित होने के बाद CityScapes डेटासेट पर ज़ीरो-शॉट गहराई अनुमान करने के लिए MTSAM की क्षमता का पता लगाया (चित्र 12)। जबकि यह कुछ हद तक अनसीन डेटा को संभालने की क्षमता दिखाता है, परिणाम विशेष रूप से दूर की वस्तुओं के लिए सटीकता में कमी का संकेत देते हैं। इसका श्रेय डेटासेट के बीच अंतर्निहित अंतरों को दिया जाता है: NYUv2 में इनडोर छवियां शामिल हैं, जबकि CityScapes में बाहरी शहरी दृश्य शामिल हैं, जिससे गहराई वितरण, वस्तु प्रकार, रिज़ॉल्यूशन और यहां तक कि ग्राउंड-ट्रुथ गहराई भविष्यवाणियों के लिए उपयोग किए जाने वाले हार्डवेयर में विसंगतियां होती हैं। यह बताता है कि जबकि MTSAM अनुकूलित हो सकता है, बड़े डोमेन शिफ्ट अभी भी एक महत्वपूर्ण चुनौती पेश करते हैं, और इसकी ज़ीरो-शॉट हस्तांतरणीयता विशाल भिन्न वातावरणों में सार्वभौमिक रूप से मजबूत नहीं है।
आगे देखते हुए, इस पत्र के निष्कर्ष आगे के विकास और विकास के लिए कई सम्मोहक चर्चा विषयों को प्रस्तुत करते हैं:
-
ज़ीरो-शॉट मल्टी-टास्किंग के लिए उन्नत डोमेन अनुकूलन: विभिन्न डोमेन में ज़ीरो-शॉट ट्रांसफर में देखी गई सीमाओं को देखते हुए, एक महत्वपूर्ण भविष्य की दिशा MTSAM फ्रेमवर्क में अधिक परिष्कृत डोमेन अनुकूलन तकनीकों को सीधे एकीकृत करना है। क्या एडवरसैरियल ट्रेनिंग, डोमेन सामान्यीकरण के लिए मेटा-लर्निंग, या अधिक उन्नत प्रॉम्प्ट इंजीनियरिंग रणनीतियों को अंतर-कार्य साझा और विशिष्ट जानकारी को बेहतर ढंग से पकड़ने के लिए ToRA के साथ जोड़ा जा सकता है? टेंसर अपघटन के भीतर डोमेन अंतराल को स्पष्ट रूप से मॉडल करने और कम करने के तरीके की खोज एक फलदायी क्षेत्र हो सकती है।
-
गतिशील ToRA रैंक और कार्य भार आवंटन: वर्तमान में, ToRA के रैंक ($p, q, v$) और कार्य हानि भार ($w_i$) को निश्चित हाइपर-पैरामीटर के रूप में सेट किया गया है। भविष्य के काम इन मापदंडों को प्रशिक्षण के दौरान समायोजित करने के लिए गतिशील तरीकों की जांच कर सकते हैं। उदाहरण के लिए, क्या एक अनुकूली तंत्र प्रत्येक कार्य या परत के लिए इष्टतम रैंक सीख सकता है, कुछ PEFT विधियों के समान गतिशील रूप से रैंक को समायोजित करता है? इसी तरह, कार्य अनिश्चितता या ग्रेडिएंट संघर्षों के आधार पर, संभावित रूप से गतिशील कार्य भार रणनीतियाँ, विविध कार्यों में मॉडल के प्रदर्शन को संतुलित करने और अनुकूलित करने की क्षमता को और बढ़ा सकती हैं, जो इस अध्ययन में उपयोग किए जाने वाले निश्चित भारों से परे जा रही हैं।
-
अन्य फाउंडेशन मॉडल और तौर-तरीकों तक ToRA का विस्तार: यह पत्र छवि विभाजन कार्यों के लिए SAM पर केंद्रित है। एक प्राकृतिक विस्तार MTSAM फ्रेमवर्क और ToRA को विभिन्न तौर-तरीकों में अन्य बड़े फाउंडेशन मॉडल पर लागू करना है, जैसे बड़े भाषा मॉडल (LLMs) या मल्टी-मोडल मॉडल जो विज़न और भाषा को एकीकृत करते हैं। विभिन्न NLP कार्यों के लिए LLMs को फाइन-ट्यून करने में ToRA कैसा प्रदर्शन करेगा, या क्रॉस-मोडल समझ की आवश्यकता वाले कार्यों के लिए मल्टी-मोडल मॉडल को अनुकूलित करने में? यह टेंपोराइज़्ड लो-रैंक एडैप्टेशन की सामान्यता और स्केलेबिलिटी में नई अंतर्दृष्टि प्रकट कर सकता है।
-
अभिव्यंजक शक्ति और सामान्यीकरण में सैद्धांतिक गहराई: जबकि प्रमेय 1 पैरामीटर दक्षता के मामले में कई LoRAs पर ToRA की श्रेष्ठता को साबित करता है, जटिल मल्टी-टास्क, मल्टी-डोमेन परिदृश्यों में इसकी अभिव्यंजक शक्ति और सामान्यीकरण सीमाओं का गहरा सैद्धांतिक विश्लेषण मूल्यवान होगा। क्या हम औपचारिक रूप से उन स्थितियों को चिह्नित कर सकते हैं जिनके तहत ToRA का टेंसर अपघटन कार्य-साझा और कार्य-विशिष्ट जानकारी को इष्टतम रूप से कैप्चर करता है, और यह अंतर्निहित कार्य संबंध से कैसे संबंधित है? इससे भविष्य के मल्टी-टास्क PEFT विधियों के लिए अधिक सैद्धांतिक डिजाइन विकल्प हो सकते हैं।
-
परिनियोजन और अनुमान में दक्षता: पत्र में उल्लेख किया गया है कि ToRA अनुमान के दौरान कोई अतिरिक्त विलंबता पेश नहीं करता है, क्योंकि अद्यतन पैरामीटर मैट्रिक्स को पूर्व-संग्रहीत किया जा सकता है। हालांकि, जैसे-जैसे कार्यों की संख्या बढ़ती है, कार्य-विशिष्ट अद्यतन भारों ($W_t = W_0 + \Delta W_t$) का भंडारण अभी भी काफी हो सकता है। भविष्य के काम में संसाधन-बाधित वातावरण में, विशेष रूप से, MTSAM की व्यावहारिक उपयोगिता को और बढ़ाने के लिए, और भी कॉम्पैक्ट भंडारण या अनुमान के दौरान $\Delta W_t$ के ऑन-द-फ्लाई पुनर्निर्माण के लिए रणनीतियों का पता लगाया जा सकता है।
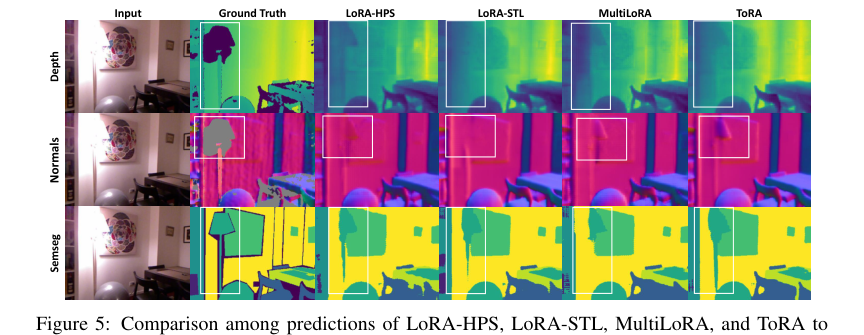 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
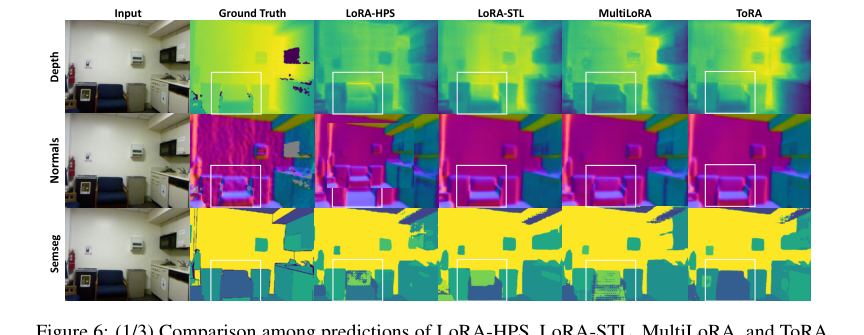 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset