MTSAM: Многозадачное дообучение модели Segment Anything Model
Проблема, рассматриваемая в данной статье, проистекает из недавнего появления и выдающихся возможностей больших фундаментальных моделей в области искусственного интеллекта, особенно в компьютерном зрении.
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, проистекает из недавнего появления и выдающихся возможностей больших фундаментальных моделей в области искусственного интеллекта, особенно в компьютерном зрении. Исторически фундаментальные модели впервые произвели революцию в обработке естественного языка (NLP) благодаря своим впечатляющим способностям zero-shot, то есть они могли выполнять задачи, на которых они явно не обучались. Этот успех вдохновил на разработку аналогичных моделей в компьютерном зрении.
Segment Anything Model (SAM), представленная в 2023 году Кирилловым и др., выделяется как выдающаяся фундаментальная модель для сегментации изображений. SAM продемонстрировала исключительную производительность zero-shot, способную сегментировать практически любой объект на изображении после обучения на массивном наборе данных из 11 миллионов образцов. Этот прорыв привел к всплеску исследований, изучающих применение SAM в различных последующих задачах, таких как высококачественная сегментация, 3D-реконструкция, отслеживание объектов, обработка медицинских изображений, персонализированная сегментация и дистанционное зондирование.
Однако фундаментальным ограничением или "болевой точкой" этих предыдущих подходов было то, что они исключительно использовали SAM для обучения одной задаче. Это означало, что для каждой новой задачи SAM дообучалась независимо, игнорируя ее потенциал как унифицированной фундаментальной модели для многозадачного обучения (MTL). Во многих сценариях компьютерного зрения реального мира несколько задач по своей природе связаны и часто требуют одновременного решения (например, оценка глубины и оценка нормалей поверхности при понимании сцены). Предшествующие исследования в области MTL последовательно показывали, что задачи могут выиграть от совместного обучения, поскольку общие знания могут улучшить общую производительность и эффективность.
Данная статья конкретно выявляет две основные проблемы при адаптации SAM для многозадачного обучения:
1. Несоответствие размерности выходных данных: Исходная SAM разработана для генерации масок сегментации, обычно с фиксированным количеством выходных каналов (например, три различных уровня, все с одинаковым количеством каналов, как показано на Рисунке 1а). Однако различные последующие задачи требуют выходов с разными размерностями (например, оценка глубины может потребовать один канал, в то время как предсказание нормалей поверхности требует три). Архитектура SAM не была изначально достаточно гибкой для генерации этих специфичных для задач выходов с разным количеством каналов.
2. Одновременное дообучение: Не существовало установленного метода для эффективного дообучения SAM для одновременной адаптации к нескольким последующим задачам. Существующие методы параметрически эффективного дообучения (PEFT), такие как Low-Rank Adaptation (LoRA), были в первую очередь разработаны для адаптации к одной задаче. При применении к многозадачным настройкам эти методы либо испытывали трудности с использованием общей информации между задачами (как LoRA-STL, где каждая задача имеет свою собственную LoRA), либо страдали от дисбаланса производительности из-за конкуренции между задачами за общие параметры (как LoRA-HPS). Отсутствие надежной стратегии многозадачного дообучения для больших фундаментальных моделей, таких как SAM, представляло собой значительное препятствие.
Авторы написали эту статью, чтобы устранить эти точные ограничения, предлагая фреймворк Multi-Task SAM (MTSAM) и метод Tensorized low-Rank Adaptation (ToRA) для того, чтобы SAM могла функционировать как универсальная фундаментальная модель для многозадачного обучения, преодолевая проблемы несоответствия размерности выходных данных и одновременного дообучения.
Интуитивные термины предметной области
-
Segment Anything Model (SAM): Представьте себе высококвалифицированного цифрового художника, который может идеально обвести любой объект на фотографии, независимо от того, насколько он сложен или незнаком. SAM похожа на этого художника, но для компьютеров, способная с невероятной точностью "вырезать" объекты из изображений, даже если она никогда не видела именно этот объект раньше.
-
Возможность zero-shot: Это похоже на очень умного студента, который изучил общие принципы многих вещей. Если вы покажете ему что-то совершенно новое, скажем, редкий вид фруктов, с которым он никогда не сталкивался, он все равно сможет хорошо угадать, что это такое или как это категоризировать, просто применяя свое широкое понимание, без необходимости специального обучения на этом фрукте.
-
Многозадачное обучение (MTL): Подумайте о шеф-поваре, который учится готовить несколько связанных блюд одновременно – возможно, основное блюдо, гарнир и соус. Обучаясь им вместе, повар может обнаружить общие техники или ингредиенты, которые делают весь процесс приготовления более эффективным, а конечное блюдо – более гармоничным, вместо того чтобы изучать каждое блюдо изолированно.
-
Параметрически эффективное дообучение (PEFT): Представьте себе высококвалифицированного эксперта, такого как мастер-механик, который знает, как ремонтировать многие типы автомобилей. Если выходит новая модель автомобиля, вместо того чтобы переобучать механика с нуля, вы просто обучаете его нескольким небольшим, специфическим настройкам или новым инструментам для этой конкретной модели. Большая часть его обширных существующих знаний остается нетронутой, что делает адаптацию быстрой и эффективной.
-
Low-Rank Adaptation (LoRA): Продолжая аналогию с механиком, LoRA похожа на предоставление мастеру-механику небольшой, специализированной "шпаргалки" для каждой новой модели автомобиля. Эта шпаргалка содержит лишь несколько ключевых модификаций его стандартных процедур, позволяющих ему адаптировать свои навыки без необходимости переучивать всю инженерию автомобиля. Это умный способ внести большие изменения при очень малом количестве новой информации.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $I$ | Входное изображение с размерами $3 \times H \times W$ (каналы, высота, ширина). |
| $H, W$ | Высота и ширина входного изображения. |
| $F_I$ | Признаки изображения, извлеченные энкодером изображений SAM, с размерами $D \times \frac{H}{16} \times \frac{W}{16}$. |
| $D$ | Размер скрытого состояния в модели. |
| $O$ | Финальная маска сегментации, выход исходной SAM, с размерами $3 \times \frac{H}{4} \times \frac{W}{4}$. |
| $T$ | Общее количество различных обучаемых задач. |
| $\Delta W$ | Общая матрица параметров обновления для одного слоя, с размерами $d \times k$. |
| $W_0$ | Матрица предварительно обученных параметров слоя, с размерами $d \times k$. |
| $A, B$ | Матрицы низкого ранга, используемые в LoRA, где $B \in \mathbb{R}^{d \times r}$ и $A \in \mathbb{R}^{r \times k}$. |
| $r$ | Ранг матриц низкого ранга в LoRA, где $r \ll \min(d, k)$. |
| $\Delta \mathcal{W}$ | Тензор параметров обновления для ToRA, агрегирующий все специфичные для задач обновления в тензор $d \times k \times T$. |
| $G$ | Основной тензор в разложении Таккера для ToRA, с размерами $p \times q \times v$. |
| $U_1, U_2, U_3$ | Факторные матрицы в разложении Таккера для ToRA, с размерами $d \times p$, $k \times q$ и $T \times v$ соответственно. |
| $p, q, v$ | Размеры факторных матриц для ToRA, обычно намного меньше $d, k, T$. |
| $E_t$ | Обучаемое векторное представление задачи для конкретной задачи $t$, с размерами $N_t \times D$. |
| $N_t$ | Количество выходных каналов, необходимых для задачи $t$. |
| $O_t$ | Предсказанный выход, сгенерированный MTSAM для задачи $t$, с размерами $N_t \times \frac{H}{4} \times \frac{W}{4}$. |
| $\mathcal{L}_{MTL}$ | Общая целевая функция многозадачного обучения, которую MTSAM стремится минимизировать. |
| $\lambda$ | Гиперпараметр, контролирующий влияние члена ортогональной регуляризации. |
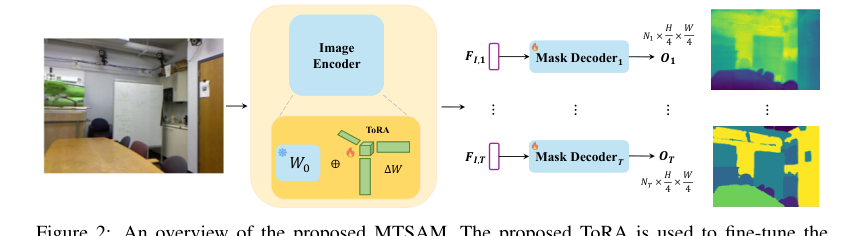 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Segment Anything Model (SAM) стала мощной фундаментальной моделью для сегментации изображений, известной своими возможностями обобщения zero-shot. Основная проблема, которую решает данная статья, заключается в том, как эффективно преобразовать SAM в фундаментальную модель для многозадачного обучения (MTL).
Входные данные / Текущее состояние:
Отправной точкой является оригинальная SAM, которая принимает на вход изображение $I \in \mathbb{R}^{3 \times H \times W}$ и различные подсказки (например, точки, ограничивающие рамки или маски). Ее архитектура состоит из тяжелого энкодера изображений, энкодера подсказок и легкого декодера масок. Оригинальная SAM разработана для генерации масок сегментации, обычно с фиксированным количеством выходных каналов (например, 3 канала, как показано в $O \in \mathbb{R}^{3 \times H \times W}$ в Уравнении 3 на странице 4 и проиллюстрировано на Рисунке 1а на странице 2).
Желаемый конечный результат (выходные данные / цель):
Желаемый конечный результат — модифицированная SAM, названная Multi-Task SAM (MTSAM), которая может:
1. Генерировать специфичные для задач выходы с различными размерностями: Например, генерировать выход с 1 каналом для оценки глубины, выход с 13 каналами для семантической сегментации и выход с 3 каналами для предсказания нормалей поверхности, все одновременно из одного входа (Рисунок 1b, страница 2).
2. Дообучаться для одновременной адаптации к нескольким последующим задачам: Эта адаптация должна использовать общую информацию между задачами для улучшения общей производительности, а не рассматривать каждую задачу изолированно.
Отсутствующее звено и математический пробел:
Точные отсутствующие звенья или математические пробелы между текущим и желаемым состояниями двояки:
1. Архитектурная негибкость для разнообразных выходов: Декодер масок оригинальной SAM архитектурно ограничен в генерации выходов с фиксированным количеством каналов, что делает его непригодным для задач, требующих разных размерностей выходов. В нем нет встроенного механизма для динамической корректировки выходных каналов в зависимости от конкретной задачи.
2. Неэффективное многозадачное дообучение: Отсутствует надежный и параметрически эффективный метод дообучения тяжелого энкодера SAM для нескольких задач одновременно, при этом эффективно балансируя общие для задач и специфичные для задач знания. Существующие методы параметрически эффективного дообучения (PEFT), такие как LoRA, при наивном применении к MTL либо чрезмерно упрощают, разделяя параметры слишком широко (LoRA-HPS), что приводит к компромиссам в производительности из-за конкуренции задач за общие параметры, либо являются слишком специфичными для задач (LoRA-STL), не используя выгодный обмен информацией между задачами.
Дилемма:
Центральная дилемма, в которой оказались предыдущие исследователи, — это болезненный компромисс между параметрической эффективностью и выразительной мощностью/производительностью в многозадачном обучении для больших фундаментальных моделей.
* Полное дообучение тяжеловесной модели, такой как SAM, для нескольких задач является вычислительно непомерным и параметрически неэффективным.
* Наивное применение существующих методов PEFT к MTL представляет дилемму:
* Жесткое разделение параметров (LoRA-HPS): Этот подход параметрически эффективен, поскольку использует одну общую матрицу LoRA для всех задач. Однако он часто приводит к "несбалансированной производительности по всем задачам из-за конкуренции между задачами за общую LoRA" (стр. 4). Он испытывает трудности с улавливанием специфичных для задач нюансов, фактически жертвуя производительностью ради эффективности.
* LoRA, специфичная для задач (LoRA-STL): Этот метод обучает отдельный модуль LoRA для каждой задачи, позволяя адаптацию, специфичную для задач, и потенциально лучшую производительность по отдельным задачам. Однако количество его параметров растет линейно с количеством задач ($O(Trd+Trk)$, стр. 6), что делает его менее эффективным для большого количества задач. Важно отметить, что он "не может использовать необходимую для дообучения по нескольким задачам информацию, общую для задач" (стр. 4), таким образом, упуская синергетические преимущества MTL.
Задача состоит в том, чтобы разработать метод, который является одновременно параметрически эффективным (сублинейный рост параметров с задачами) и способным одновременно улавливать как общие для задач знания, так и специфичные для задач детали, тем самым преодолевая ограничения существующих стратегий PEFT в многозадачной настройке.
Ограничения и режимы отказа
Проблема адаптации SAM для многозадачного обучения делает ее чрезвычайно сложной из-за нескольких суровых, реалистичных стен, с которыми столкнулись авторы:
- Ограничения аппаратной памяти и вычислительных ресурсов: Энкодер изображений SAM описывается как "тяжеловесный" (стр. 3). Одновременное дообучение такой большой модели для нескольких задач потребует огромных вычислительных ресурсов и памяти, что делает полное дообучение непрактичным. Это ограничение требует использования параметрически эффективных методов.
- Ограничение фиксированного количества выходных каналов: Декодер масок оригинальной SAM жестко запрограммирован на генерацию выходов с фиксированным количеством каналов (например, 3 для сегментации). Эта архитектурная жесткость не позволяет ему напрямую генерировать выходы с разным количеством каналов, требуемым различными задачами, такими как оценка глубины (1 канал) или семантическая сегментация с несколькими классами (например, 13 каналов). Это фундаментальное архитектурное ограничение, которое необходимо преодолеть.
- Неспособность сбалансировать обучение общих и специфичных для задач знаний: Предыдущие методы PEFT при применении к MTL не могут эффективно сбалансировать обучение общих, общих для задач признаков со специфичными, зависящими от задач адаптациями. LoRA-HPS страдает от конкуренции задач, в то время как LoRA-STL не может использовать информацию, общую для задач (стр. 4). Это приводит к субоптимальной производительности или неэффективному использованию параметров.
- Сложность тензорного разложения для оптимальной аппроксимации: Хотя тензорное разложение является мощным математическим инструментом, нахождение "наилучшей аппроксимации" для сложных целей, особенно в контексте многозадачного обучения, inherently сложно и "может не всегда существовать" (Kolda & Bader, 2009, цитируется на стр. 7). Это подразумевает потенциальную трудность в гарантировании теоретической оптимальности адаптации тензора низкого ранга.
- Гетерогенность данных между задачами: Различные задачи часто включают различные распределения данных, семантические значения и форматы вывода. Например, оценка глубины и семантическая сегментация требуют различных типов истинных значений и метрик оценки. Модель должна быть достаточно устойчивой, чтобы обрабатывать это присущее разнообразие без ущерба для производительности по любой отдельной задаче.
- Отсутствие требований к задержке в реальном времени (неявное): Хотя это явно не указано как ограничение, с которым столкнулись авторы, цель параметрической эффективности и утверждение о том, что ToRA не вводит "дополнительной задержки во время инференса" (стр. 6), предполагают неявную потребность в эффективном инференсе, что часто критически важно в практических приложениях. Сложность модели не должна значительно увеличивать время инференса.
Почему такой подход
Неизбежность выбора
Segment Anything Model (SAM) стала мощной фундаментальной моделью, демонстрирующей выдающиеся возможности zero-shot для сегментации изображений. Однако ее прямое применение к многозадачному обучению представило два фундаментальных архитектурных препятствия, с которыми традиционные методы "SOTA", включая саму оригинальную SAM, были плохо приспособлены справляться. Осознание авторами этих недостатков стало очевидным при рассмотрении основных требований многозадачного обучения: (a) необходимость генерации специфичных для задач выходов с различными количествами каналов (например, 1 канал для оценки глубины, 3 для предсказания нормалей поверхности и несколько для семантической сегментации) и (b) сложность одновременного дообучения SAM для эффективной адаптации к нескольким последующим задачам.
Оригинальная SAM по своей конструкции генерирует маски сегментации на различных уровнях, но, что важно, все эти выходы имеют одинаковое количество каналов. Эта фиксированная размерность выходных данных является серьезным ограничением, когда задачи, такие как оценка глубины или предсказание нормалей поверхности, требуют различных структур вывода. В статье прямо указано: "Несмотря на огромный потенциал SAM как фундаментальной визуальной модели, ее зависимость от генерации масок, управляемой подсказками, создает проблемы для достижения сквозной адаптивности к последующим задачам с различным количеством выходных каналов". Именно в этот момент авторы осознали, что присущая SAM архитектура, особенно ее энкодер подсказок и декодер масок, не была достаточно гибкой для разнообразных многозадачных выходов. Следовательно, прямое применение SAM или существующих методов дообучения для одной задачи просто не было жизнеспособным для истинно многозадачной фундаментальной модели.
Сравнительное превосходство
Предлагаемый фреймворк Multi-Task SAM (MTSAM), особенно его метод Tensorized low-Rank Adaptation (ToRA), демонстрирует подавляющее качественное и структурное превосходство над предыдущими золотыми стандартами, особенно в параметрической эффективности и использовании информации.
Во-первых, самое значительное структурное преимущество ToRA заключается в его параметрической эффективности. При применении к $T$ задачам традиционные методы Low-Rank Adaptation (LoRA), будь то с жестким разделением параметров (LoRA-HPS) или с LoRA, специфичными для задач (LoRA-STL), демонстрируют сложность параметров, которая растет линейно с количеством задач, обычно $O(Trd + Trk)$. В отличие от этого, ToRA агрегирует матрицы параметров обновления всех задач в один тензор параметров обновления $\Delta W \in \mathbb{R}^{d \times k \times T}$ и применяет низкоранговое тензорное разложение (в частности, разложение Таккера). Это приводит к сложности параметров $O(dp + kq)$, где $p, q, v \ll \min(d, k)$ и $T$ — количество задач. Это представляет собой сублинейный рост обучаемых параметров по отношению к количеству задач, что делает его значительно более эффективным для масштабирования к большому количеству задач. Это сокращение сложности памяти является революционным для дообучения массивных фундаментальных моделей, таких как SAM.
Во-вторых, ToRA качественно превосходит альтернативы, эффективно улавливая как общие для задач, так и специфичные для задач знания. LoRA-HPS, разделяя одну $\Delta W$ между всеми задачами, испытывает трудности с конкуренцией задач и часто приводит к несбалансированной производительности. LoRA-STL, напротив, обучает отдельные $\Delta W_t$ для каждой задачи, полностью игнорируя ценную информацию, общую для задач. Разложение Таккера в ToRA позволяет основному тензору $G$ и факторным матрицам $U_1, U_2, U_3$ явно моделировать как основное пространственное изменение общих для задач знаний (через $U_1$ и $U_2$), так и специфичную для задач структуру пространства (через $U_3$). Этот целостный подход к обмену информацией и специализации является ключевым структурным преимуществом, которое повышает производительность дообучения на разнообразных задачах. Теоретический анализ в Теореме 1 далее подтверждает это, доказывая, что ToRA обладает превосходной выразительной мощностью и может достигать тех же обновлений весов с меньшим количеством параметров по сравнению с несколькими LoRA.
Наконец, качественные оценки (например, Рисунок 5) показывают, что MTSAM, дообученный с помощью ToRA, генерирует более точные результаты, особенно для "нечетких и тонких объектов". Это предполагает, что способность ToRA разделять и использовать общую и специфичную информацию приводит к более надежному и тонкому пониманию визуальных сцен, улучшая производительность в сложных сценариях, где другие методы могут испытывать трудности с мелкими деталями или сложными границами объектов.
Соответствие ограничениям
Выбранный фреймворк MTSAM с его архитектурными модификациями и методом дообучения ToRA идеально соответствует двум основным ограничениям, выявленным при адаптации SAM для многозадачного обучения.
-
Ограничение: Генерация специфичных для задач выходов с различными количествами каналов.
- Свойство решения: MTSAM решает эту проблему, фундаментально изменяя декодер масок SAM. Он удаляет исходный энкодер подсказок и вводит специфичные для задач векторные представления без масок и выделенные декодеры масок, специфичные для задач. Как показано на Рисунке 1 и Рисунке 3, эта модификация позволяет MTSAM генерировать выходы с размерностями, адаптированными для каждой задачи ($N_t \times H \times W$), а не с фиксированными выходными данными SAM. Например, он может выводить 1 канал для глубины, 3 для нормалей поверхности или 13 для семантической сегментации, напрямую удовлетворяя требование к разнообразным структурам вывода. Введение обучаемых векторных представлений задач $E_t$ далее гарантирует, что декодер может адаптировать свою обработку в зависимости от конкретной задачи. Это прямое "слияние" потребности проблемы в гибкости вывода и модульной, ориентированной на задачи конструкции решения.
-
Ограничение: Дообучение SAM для одновременной и эффективной адаптации к нескольким последующим задачам.
- Свойство решения: ToRA является ключевым нововведением для этого ограничения. Он вводит тензор параметров обновления в каждый слой энкодера SAM и использует низкоранговое тензорное разложение для захвата как общих для задач, так и специфичных для задач знаний. Это позволяет модели учиться на нескольких задачах одновременно, используя их взаимозависимости, одновременно допуская специфичные для задач адаптации. Параметрическая эффективность ToRA с его сублинейным ростом параметров по отношению к количеству задач имеет решающее значение для дообучения тяжеловесной фундаментальной модели, такой как SAM, без непомерных вычислительных затрат или требований к памяти. Эта эффективность гарантирует, что одновременная адаптация не только возможна, но и практична, что делает ее идеальным решением для суровых требований крупномасштабного многозадачного обучения. Ортогональный член регуляризации в общей целевой функции ($L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$) далее гарантирует, что обучаемые факторные матрицы хорошо себя ведут и не избыточны, способствуя стабильности и эффективности процесса многозадачного дообучения.
Отклонение альтернатив
Статья предоставляет четкое обоснование для отклонения нескольких альтернативных подходов, в первую очередь фокусируясь на существующих методах параметрически эффективного дообучения (PEFT) и различных стратегиях применения LoRA в многозадачном контексте.
-
Традиционные методы PEFT (например, на основе адаптеров, промпт-тюнинг, существующие варианты LoRA для одной задачи): Авторы явно заявляют, что, хотя эти методы "достигают конкурентоспособной производительности и высокой параметрической эффективности при дообучении одной задачи", они "не подходят для многозадачных сценариев, поскольку они не учитывают общую информацию между несколькими задачами". Это является полным отклонением методов, которые не могут изначально использовать синергию или управлять конфликтами, возникающими при обучении нескольких задач одновременно. Их конструкция принципиально ориентирована на оптимизацию одной задачи за раз, что противоречит цели многозадачного обучения.
-
LoRA-HPS (жесткое разделение параметров): Этот подход пытается многозадачное обучение, используя одну общую матрицу LoRA ($\Delta W$) для всех задач. Статья отклоняет его, поскольку он "может привести к несбалансированной производительности по всем задачам из-за конкуренции между задачами за общую LoRA". Когда задачи имеют конфликтующие градиенты или различную динамику обучения, принуждение их к разделению одной, недифференцированной матрицы обновления может снизить производительность по некоторым или всем задачам.
-
LoRA-STL (LoRA для одной задачи): Эта альтернатива включает обучение отдельной матрицы LoRA ($\Delta W_t$) для каждой задачи. Статья отклоняет ее, поскольку она "не может использовать информацию, общую для задач, необходимую для дообучения по нескольким задачам". Хотя это позволяет избежать проблемы конкуренции LoRA-HPS, она не использует потенциальные преимущества общих знаний и общих признаков между связанными задачами, что является основным принципом многозадачного обучения. Это делает ее менее эффективной и потенциально менее производительной, чем подход, который может разумно обмениваться информацией.
-
Полное дообучение: Хотя и не "отклоняется" в тех же сильных терминах, что и другие методы PEFT, статья косвенно отвергает полное дообучение тяжеловесного энкодера изображений SAM из-за "проблем параметрической и вычислительной эффективности". Таблица 7 количественно подтверждает это отклонение, показывая, что полное дообучение требует массивных 1222,47 МБ обучаемых параметров, значительно больше, чем 59,59 МБ у MTSAM, при этом давая более низкое общее улучшение производительности ($\Delta_b$ +14,57% для полного дообучения против +23,93% для MTSAM). Это делает полное дообучение непрактичным для больших фундаментальных моделей и многозадачных сценариев, где эффективность имеет первостепенное значение. Огромный масштаб параметров делает его вычислительно дорогим и склонным к переобучению на меньших многозадачных наборах данных.
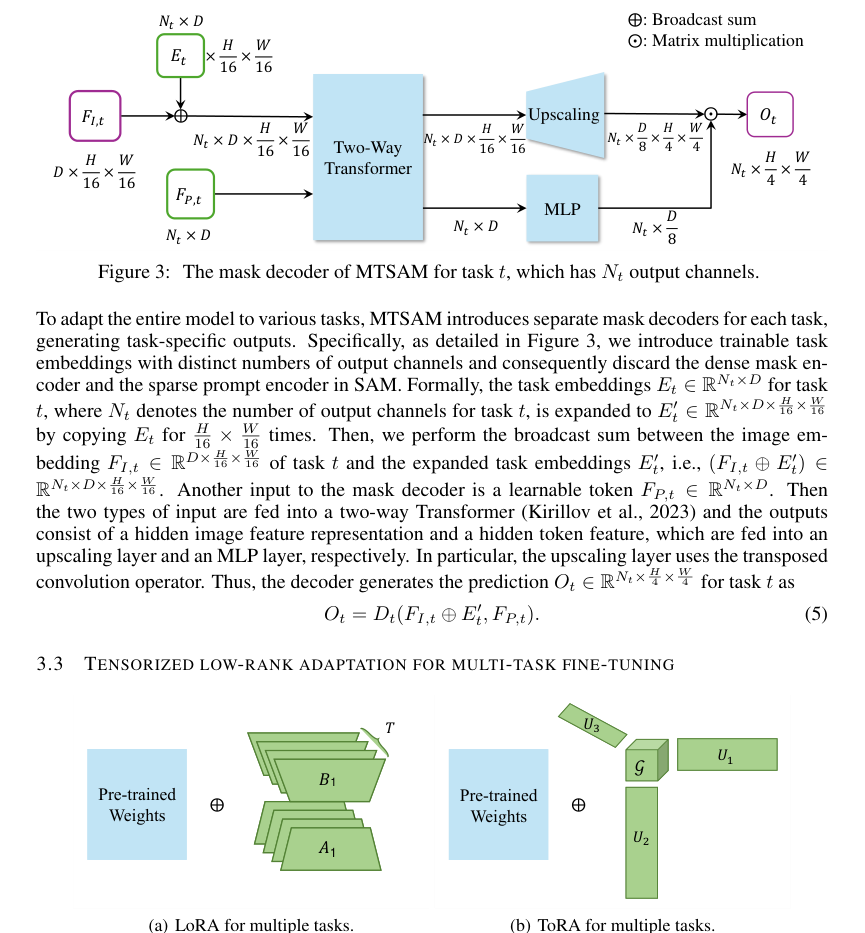 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Математический и логический механизм
Мастер-уравнение
Абсолютным ядром процесса обучения фреймворка MTSAM является его общая целевая функция, которая объединяет функцию потерь многозадачного обучения с членом регуляризации для обеспечения эффективного и результативного обновления параметров. Это мастер-уравнение управляет всем процессом обучения:
$$ L_{total} = L_{MTL} + \lambda R(U_1, U_2, G) $$
Это уравнение охватывает то, как модель учится на нескольких задачах одновременно, сохраняя при этом параметрическую эффективность и предотвращая избыточность посредством тензорного разложения и регуляризации.
Потерминальный разбор
Давайте разберем мастер-уравнение и его компоненты, чтобы понять их математические определения, физическую/логическую роль и выбор авторов.
-
$L_{total}$: Это общая целевая функция, которую фреймворк MTSAM стремится минимизировать во время обучения. Ее роль заключается в балансировке производительности по всем задачам с эффективностью и структурной целостностью обновлений параметров. Авторы используют сложение для объединения многозадачной потери и члена регуляризации, поскольку это две различные цели, которые необходимо оптимизировать одновременно: минимизация ошибки задачи и поддержание хорошо структурированного, низкорангового пространства параметров.
-
$L_{MTL}$: Этот член представляет собой функцию потерь многозадачного обучения (MTL). Это среднее взвешенных потерь от всех отдельных задач.
$$ L_{MTL} = \frac{1}{T} \sum_{i=1}^T w_i L_i $$- $T$: Это общее количество различных задач, на которых обучается модель MTSAM (например, семантическая сегментация, оценка глубины, предсказание нормалей поверхности). Ее роль заключается в нормализации суммы индивидуальных потерь задач, обеспечивая среднюю потерю по всем задачам. Суммирование используется здесь, поскольку общая многозадачная цель является композицией индивидуальных целей задач.
- $w_i$: Это вес потери для задачи $i$. Это гиперпараметр, который контролирует относительную важность потери каждой задачи в общей многозадачной цели. Например, задача, считающаяся более критичной или более сложной, может получить более высокий вес. Авторы используют умножение для масштабирования вклада каждой задачи в общую потерю, позволяя гибко приоритизировать.
- $L_i$: Это потеря для задачи $i$, рассчитанная как средняя потеря по всем обучающим выборкам для этой конкретной задачи.
$$ L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j, f(x_j)) $$- $N_i$: Это обозначает количество обучающих выборок для задачи $i$. Ее роль заключается в усреднении потери по выборкам, гарантируя, что потеря задачи не будет непропорционально влиять на количество выборок, которое она имеет. Суммирование агрегирует потери от отдельных выборок, а деление на $N_i$ дает среднюю потерю.
- $l_i(\cdot, \cdot)$: Это функция потерь, специфичная для задачи $i$. Ее математическое определение зависит от природы задачи $i$ (например, перекрестная энтропия для сегментации, L1-потеря для оценки глубины, косинусное сходство для нормалей поверхности). Ее роль заключается в количественной оценке расхождения между предсказанием модели и истинным значением для одной выборки.
- $y_j$: Это истинное значение (ground truth) для $j$-й обучающей выборки задачи $i$. Оно представляет собой правильный выход, который должна произвести модель.
- $f(x_j)$: Это представляет собой предсказание модели MTSAM для $j$-й обучающей выборки $x_j$ задачи $i$. Функция $f(\cdot)$ воплощает всю архитектуру MTSAM, включая энкодер изображений и декодер масок, специфичный для задач, который включает веса, модифицированные ToRA.
- $x_j$: Это входная обучающая выборка (например, изображение), для которой делается предсказание $f(x_j)$.
-
$\lambda$: Это гиперпараметр, который контролирует влияние члена ортогональной регуляризации $R(U_1, U_2, G)$. Его роль заключается в балансировке компромисса между минимизацией ошибок, специфичных для задач, и обеспечением желаемой низкоранговой, ортогональной структуры параметров ToRA. Большее $\lambda$ придает больший акцент на регуляризацию. Авторы используют умножение для масштабирования вклада регуляризации в общую потерю.
-
$R(U_1, U_2, G)$: Это член ортогональной регуляризации. Он поощряет факторные матрицы $U_1, U_2$ и срезы основного тензора $G$ быть ортогональными, что помогает уменьшить избыточность и повысить стабильность тензорного разложения.
$$ R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^v ||G(:,:,l)^T G(:,:,l) - I||_F^2 $$- $U_1$: Это факторная матрица размером $d \times p$. Она захватывает основное пространственное изменение общих для задач знаний, соответствующее размерности выходных признаков тензора параметров обновления $\Delta W$.
- $U_2$: Это факторная матрица размером $k \times q$. Она захватывает основное пространственное изменение общих для задач знаний, соответствующее размерности входных признаков тензора параметров обновления $\Delta W$.
- $G$: Это основной тензор размером $p \times q \times v$. Он содержит наиболее значимые компоненты тензора, действуя как сжатое представление.
- $||\cdot||_F^2$: Это обозначает квадрат нормы Фробениуса. Математически, для матрицы $A$, $||A||_F^2 = \sum_{i,j} |A_{i,j}|^2$. Его роль здесь заключается в количественной оценке "размера" или величины отклонения от ортогональности. Квадрирование гарантирует, что значение будет неотрицательным и будет сильнее штрафовать большие отклонения.
- $I$: Это единичная матрица соответствующего размера. Ее роль в членах типа $U^T U - I$ заключается в том, чтобы служить целью ортогональности: если $U^T U = I$, то $U$ ортогональна.
- $U_1^T U_1 - I$: Этот член измеряет отклонение $U_1$ от ортогональности. Минимизация его квадрата нормы Фробениуса заставляет $U_1$ быть близкой к ортогональной матрице.
- $U_2^T U_2 - I$: Аналогично $U_1$, этот член измеряет отклонение $U_2$ от ортогональности.
- $G(:,:,l)^T G(:,:,l) - I$: Этот член измеряет отклонение $l$-го фронтального среза основного тензора $G$ от ортогональности. $G(:,:,l)$ обозначает матрицу, образованную фиксацией третьего режима (ось задач) на $l$. Это обеспечивает ортогональность вдоль оси задач в основном тензоре. Суммирование $\sum_{l=1}^v$ агрегирует эти штрафы за ортогональность по всем срезам основного тензора. Авторы используют сложение для объединения этих индивидуальных ограничений ортогональности, поскольку каждый из них независимо вносит вклад в общую цель уменьшения избыточности.
Центральным элементом $L_{MTL}$ является метод Tensorized low-Rank Adaptation (ToRA), который определяет, как обновляются веса модели. ToRA параметризует тензор параметров обновления $\Delta W$ с помощью разложения Таккера:
$$ \Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3 $$
- $\Delta W$: Это тензор параметров обновления размером $d \times k \times T$. Он представляет собой совокупные изменения предварительно обученных весов по всем задачам. Каждый срез $\Delta W(:,:,t)$ является матрицей обновления для задачи $t$. Его роль заключается в эффективной адаптации замороженной предварительно обученной модели к нескольким последующим задачам. Авторы выбрали тензор для представления обновлений для нескольких задач, поскольку он естественно захватывает многомерную природу общих для задач и специфичных для задач знаний.
- $G$: Это основной тензор (как определено выше), размером $p \times q \times v$. Он содержит наиболее значимые компоненты тензора, действуя как сжатое представление.
- $U_1$: Это факторная матрица для режима 1 (размерность выходных признаков), размером $d \times p$. Она преобразует основной тензор вдоль его первого режима.
- $U_2$: Это факторная матрица для режима 2 (размерность входных признаков), размером $k \times q$. Она преобразует основной тензор вдоль его второго режима.
- $U_3$: Это факторная матрица для режима 3 (ось задач), размером $T \times v$. Она преобразует основной тензор вдоль его третьего режима, позволяя разложению захватывать специфичные для задач вариации.
- $\times_n$: Это обозначает n-кратное произведение. Математически, $A \times_n B$ означает умножение тензора $A$ на матрицу $B$ вдоль его $n$-го режима. Его роль заключается в "развертывании" или проецировании основного тензора $G$ обратно в полный тензор $\Delta W$ с использованием факторных матриц $U_1, U_2, U_3$. Этот оператор является фундаментальным для тензорного разложения, позволяя восстановить тензор более высокого порядка из основного тензора и нескольких матриц.
Наконец, фактическое применение этих обновлений к прямому проходу модели для данной задачи $t$ выглядит следующим образом:
$$ h = W_0x + \Delta W(:,:,t)x $$
- $h$: Это выход слоя в энкодере SAM после применения обновления ToRA.
- $W_0$: Это исходная предварительно обученная матрица весов слоя в энкодере SAM. Она остается замороженной во время дообучения.
- $\Delta W(:,:,t)$: Это матрица обновления для задачи $t$, которая является $t$-м срезом полного тензора $\Delta W$. Ее роль заключается в обеспечении специфичных для задач корректировок предварительно обученных весов.
- $x$: Это вход в слой в энкодере SAM.
- Оператор сложения здесь означает, что обновление ToRA является аддитивной модификацией предварительно обученных весов, что является обычной практикой в методах PEFT, таких как LoRA.
Пошаговый поток
Представьте, что одна абстрактная точка данных, изображение $x_j$, отправляется в путешествие через фреймворк MTSAM для конкретной задачи $t$.
-
Кодирование изображения (Замороженный фундамент): Путешествие начинается с входного изображения $x_j$, поступающего в тяжелый энкодер изображений $E_1$ модели SAM. Важно отметить, что параметры $E_1$ заморожены. Это означает, что фундаментальные знания, полученные во время предварительного обучения SAM, сохраняются. Энкодер выдает набор признаков изображения $F_1$.
-
Внедрение ToRA (Адаптивный слой): Когда $F_1$ распространяется через модули самовнимания в энкодере изображений, он сталкивается с механизмом ToRA. Для каждого слоя вместо прямого использования исходной предварительно обученной матрицы весов $W_0$ вход $x$ в этот слой обрабатывается адаптированной матрицей весов $W'$. Эта $W'$ фактически равна $W_0 + \Delta W(:,:,t)$. Компонент $\Delta W(:,:,t)$ динамически конструируется для задачи $t$ с использованием основного тензора $G$ и факторных матриц $U_1, U_2, U_3$ посредством тензорного разложения $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$. Это означает, что для каждой задачи $t$ применяется уникальное низкоранговое обновление к замороженным весам, тонко направляя поведение модели к специфичным для задач требованиям, не изменяя подавляющее большинство ее параметров.
-
Декодирование, специфичное для задач (Генерация выхода): Адаптированные с помощью ToRA признаки изображения, теперь неявно настроенные для задачи $t$, затем подаются в декодер масок, специфичный для задач, $D_t$. Этому декодеру также передается обучаемое векторное представление задачи $E_t$ (расширенное для соответствия размерностям признаков) и обучаемый токен $F_{P,t}$. Векторное представление задачи $E_t$ транслируется (broadcast-summed) с признаками изображения $F_{1,t}$ (которые получены из $F_1$ и, возможно, далее обработаны для задачи $t$). Эти объединенные признаки вместе с обучаемым токеном проходят через двусторонний трансформер, слой масштабирования и слой MLP. Весь этот процесс генерирует выход $O_t$, специфичный для задач (например, маску сегментации, карту глубины или нормали поверхности), с соответствующим количеством каналов для задачи $t$.
-
Расчет потерь (Измерение производительности): Сгенерированный выход $O_t$ для выборки $x_j$ затем сравнивается с соответствующим истинным значением $y_j$ с использованием функции потерь $l_t$, специфичной для задач. Это дает $l_t(y_j, f(x_j))$, меру того, насколько хорошо модель справилась с этой конкретной выборкой для задачи $t$.
-
Агрегация многозадачных данных (Коллективная ошибка): Эта потеря на отдельной выборке $l_t(y_j, f(x_j))$ вносит вклад в общую потерю задачи $L_t$. Для всех выборок задачи $t$ их потери усредняются для формирования $L_t$. Затем $L_t$ взвешивается на $w_t$ и объединяется со взвешенными потерями от всех других задач для вычисления общей многозадачной потери $L_{MTL}$.
-
Регуляризация (Структурная целостность): Одновременно текущие состояния обучаемых компонентов ToRA ($U_1, U_2, G$) оцениваются по отношению к члену ортогональной регуляризации $R(U_1, U_2, G)$. Этот член штрафует отклонения от ортогональности в этих матрицах и срезах основного тензора.
-
Общая цель (Единая цель): Наконец, $L_{MTL}$ и масштабированный член регуляризации $\lambda R(U_1, U_2, G)$ суммируются для формирования целевой функции $L_{total}$. Это единое значение представляет собой общую "стоимость" или ошибку, которую модель должна минимизировать.
Динамика оптимизации
Фреймворк MTSAM обучается и обновляет свои параметры посредством итеративного процесса оптимизации, движимого минимизацией целевой функции $L_{total}$.
-
Инициализация параметров: В начале обучения основной тензор $G$ инициализируется нулями. Это гарантирует, что изначально обновления ToRA $\Delta W(:,:,t)$ также равны нулю, что означает, что модель изначально полагается исключительно на замороженные предварительно обученные веса $W_0$. Факторные матрицы $U_1, U_2, U_3$ инициализируются случайным образом из стандартного нормального распределения. Эта случайная инициализация обеспечивает отправную точку для исследования пространства параметров.
-
Вычисление градиентов: Во время каждой итерации обучения, после вычисления $L_{total}$ для пакета данных по всем задачам, используется оптимизатор Adam для вычисления градиентов. Градиенты вычисляются относительно обучаемых параметров: факторных матриц $U_1, U_2, U_3$, основного тензора $G$, а также параметров масштабирования и смещения в слоях нормализации энкодера изображений. Важно отметить, что исходные предварительно обученные веса $W_0$ энкодера изображений заморожены, что означает, что градиенты через них не проходят, значительно сокращая количество обучаемых параметров и вычислительные затраты.
-
Формирование ландшафта потерь: Ландшафт потерь формируется за счет взаимодействия многозадачной функции потерь ($L_{MTL}$) и члена ортогональной регуляризации ($R$).
- $L_{MTL}$ побуждает модель улучшать производительность по всем задачам. Без регуляризации этот ландшафт может быть сложным, потенциально приводя к конфликтующим градиентам между задачами или переобучению.
- Член регуляризации $R$ действует как структурное ограничение. Штрафуя неортогональность в $U_1, U_2, G$, он поощряет более компактное, менее избыточное представление параметров обновления. Это может привести к более гладкому ландшафту потерь, потенциально способствуя сходимости и улучшая обобщение, предотвращая обучение модели сильно коррелированных или избыточных признаков. Теоретический анализ авторов предполагает, что эта низкоранговая, ортогональная структура позволяет ToRA достигать превосходной выразительной мощности при меньшем количестве параметров по сравнению с LoRA.
-
Итеративные обновления: Оптимизатор Adam использует вычисленные градиенты для итеративного обновления обучаемых параметров ($U_1, U_2, U_3, G$ и параметры нормализации слоев). Обновления выполняются с использованием начальной скорости обучения $10^{-3}$, которая затем корректируется линейным планировщиком скорости обучения с фазой разогрева 0,05. Также применяется затухание весов $10^{-6}$ для предотвращения переобучения. Эти итеративные обновления постепенно уточняют компоненты ToRA, позволяя им изучать как общие для задач, так и специфичные для задач знания.
-
Сходимость: Процесс обучения продолжается в течение заданного количества эпох (например, 200 для NYUv2). По мере обновления параметров $L_{total}$ ожидается, что он будет уменьшаться, что указывает на то, что модель учится лучше выполнять задачи, сохраняя при этом желаемую низкоранговую структуру. Цель состоит в том, чтобы сойтись к набору параметров, который минимизирует $L_{total}$, что приведет к улучшенной многозадачной производительности и параметрической эффективности. Во время инференса выученные $\Delta W(:,:,t)$ для каждой задачи $t$ предварительно вычисляются и добавляются к $W_0$ для формирования $W_t'$, поэтому дополнительная задержка отсутствует. Эта умная конструкция гарантирует, что преимущества дообучения не достигаются за счет более медленного времени предсказания.
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгого подтверждения предлагаемого фреймворка Multi-Task SAM (MTSAM) и его основного компонента Tensorized low-Rank Adaptation (ToRA) авторы провели обширные эксперименты на трех общепризнанных эталонных наборах данных: NYUv2, CityScapes и PASCAL-Context. Эти наборы данных представляют собой разнообразные сценарии компьютерного зрения, охватывающие внутренние сцены (NYUv2) и городские открытые пространства (CityScapes, PASCAL-Context), и включают в себя различные задачи плотного предсказания.
Экспериментальная установка была разработана для безжалостного доказательства математических утверждений MTSAM относительно его способности обрабатывать различные выходные размерности и эффективно дообучаться для нескольких задач одновременно. "Жертвами" (базовыми моделями), против которых был противопоставлен MTSAM, были всесторонний набор как традиционных методов многозадачного обучения (MTL), так и более современных методов параметрически эффективного дообучения (PEFT):
- Базовые модели MTL на основе CNN: Обучение одной задаче (STL), Жесткое разделение параметров (HPS), Cross-Stitch, Multi-Task Attention Network (MTAN) и NDDR-CNN. Это представляют собой установленные методы для многозадачного обучения, причем HPS служит важной базовой моделью для метрики $\Delta_b$.
- Базовые модели MTL на основе трансформеров: VTAGML и SwinMTL, отражающие современные архитектуры.
- MTL на основе перекрестного внимания: DenseMTL.
- Базовые модели PEFT на основе LoRA: Чтобы конкретно оценить эффективность ToRA, авторы сравнили ее с прямыми применениями LoRA в многозадачных сценариях: LoRA-STL (LoRA, специфичная для задач), LoRA-HPS (общая LoRA) и MultiLoRA. Были проведены дальнейшие сравнения с другими передовыми вариантами LoRA, такими как Terra и HydraLoRA, а также с полным дообучением всей модели.
Оцениваемые задачи различались в зависимости от набора данных:
* NYUv2: Семантическая сегментация 13 классов, оценка глубины и предсказание нормалей поверхности.
* CityScapes: Семантическая сегментация 7 классов и оценка глубины.
* PASCAL-Context: Семантическая сегментация 21 класса, сегментация частей тела человека 7 классов, оценка saliency и предсказание нормалей поверхности.
Производительность была количественно оценена с помощью набора стандартных метрик:
* Семантическая сегментация: Среднее пересечение над объединением (mIoU) и точность пикселей (Pix Acc), где более высокие значения лучше.
* Оценка глубины: Абсолютная ошибка (Abs Err) и относительная ошибка (Rel Err), где более низкие значения лучше.
* Предсказание нормалей поверхности: Средняя и медианная угловая ошибка (чем ниже, тем лучше), и процент пикселей, чья угловая ошибка находится в пределах 11,25, 22,5 и 30 градусов (чем выше, тем лучше).
* Общая производительность: Составная метрика, $\Delta_b$, представляющая среднее относительное улучшение каждой задачи по сравнению с архитектурой HPS, причем более высокие значения указывают на лучшую производительность.
* Параметрическая эффективность: Количество обучаемых параметров (Params.) в мегабайтах (MB), причем более низкие значения более эффективны.
Детали реализации включали использование оптимизатора Adam со скоростью обучения $10^{-3}$, линейным планировщиком скорости обучения с разогревом и специфическими настройками ранга для ToRA ($p, q, v$), адаптированными для каждого набора данных. Также применялась ортогональная регуляризация, контролируемая гиперпараметром $\lambda$.
Что доказывают свидетельства
Экспериментальные результаты предоставляют окончательные, неоспоримые доказательства того, что MTSAM, особенно с его компонентом ToRA, значительно продвигает многозадачное обучение с фундаментальными моделями.
-
Общее превосходство и параметрическая эффективность: На всех трех эталонных наборах данных (NYUv2, CityScapes и PASCAL-Context) MTSAM последовательно достигал лучшей средней производительности, измеряемой метрикой $\Delta_b$ (Таблицы 1, 2, 3). Например, на NYUv2 MTSAM дал $\Delta_b$ +23,93% всего с 59,59 МБ обучаемых параметров, превзойдя полное дообучение (+14,57% со 1222,47 МБ) и все другие базовые модели. Это демонстрирует, что MTSAM не только достигает превосходной производительности, но и делает это с замечательной параметрической эффективностью, предлагая значительные преимущества в хранении и практическом применении.
-
Эффективность ToRA в использовании общих и специфичных знаний: Сравнение между ToRA и методами на основе LoRA (LoRA-HPS, LoRA-STL, MultiLoRA) имеет решающее значение. LoRA-HPS, использующая одну общую матрицу LoRA, часто страдает от конкуренции задач. LoRA-STL, использующая LoRA, специфичные для задач, работает лучше, чем LoRA-HPS, подчеркивая важность специфичных для задач компонентов. Однако ToRA последовательно превосходит как LoRA-STL, так и LoRA-HPS (Таблицы 1, 2, 3, 7). Эти жесткие доказательства подтверждают теоретическое утверждение о том, что ToRA эффективно использует как общие для задач, так и специфичные для задач знания посредством своего низкорангового тензорного разложения, что приводит к улучшенной общей производительности. Качественные результаты (Рисунки 5-11) далее подтверждают это, показывая, что MTSAM с ToRA генерирует заметно более точные предсказания, особенно для сложных "нечетких и тонких объектов", по сравнению с другими вариантами LoRA.
-
Влияние архитектурных модификаций:
- Векторные представления задач: Исследование абляции (Таблица 8) ясно показывает, что предлагаемые векторные представления задач более эффективны, чем простое изменение выходных размерностей MLP для различных задач. Это улучшение приписывается механизму перекрестного внимания, который облегчает лучшее изучение специфичных для задач знаний посредством взаимодействия между векторными представлениями задач и признаками изображений.
- Ортогональная регуляризация: Исследование абляции по ортогональной регуляризации (Таблица 5) демонстрирует ее положительное влияние. MTSAM с полной ортогональной регуляризацией на $G$, $U_1$ и $U_2$ значительно превосходит варианты без нее, доказывая ее эффективность в улучшении производительности по различным задачам за счет уменьшения избыточности.
-
Устойчивость к настройкам гиперпараметров: Анализ чувствительности к гиперпараметру $\lambda$ (вес ортогональной регуляризации) в Таблице 6 указывает на то, что производительность MTSAM не сильно зависит от $\lambda$ в разумном диапазоне (например, [0,5, 1,5]). Это предполагает, что модель относительно устойчива и ее легче настраивать, что является практическим преимуществом.
Ограничения и будущие направления
Хотя MTSAM демонстрирует впечатляющие возможности, особенно в многозадачном дообучении фундаментальных моделей, таких как SAM, статья также освещает несколько ограничений и открывает захватывающие возможности для будущих исследований.
Одно заметное ограничение касается обобщения zero-shot на значительно отличающиеся распределения данных. Авторы исследовали способность MTSAM выполнять оценку глубины zero-shot на наборе данных CityScapes после обучения исключительно на NYUv2 (Рисунок 12). Хотя он демонстрирует некоторую способность обрабатывать невиданные данные, результаты указывают на неточности, особенно для удаленных объектов. Это связано с присущими различиями между наборами данных: NYUv2 состоит из внутренних изображений, в то время как CityScapes содержит городские открытые сцены, что приводит к расхождениям в распределении глубины, типах объектов, разрешении и даже оборудовании, используемом для предсказания истинных значений глубины. Это предполагает, что, хотя MTSAM может адаптироваться, большие сдвиги домена по-прежнему представляют собой значительную проблему, и его переносимость zero-shot не является универсально надежной для совершенно разных сред.
Заглядывая вперед, результаты данной статьи представляют несколько убедительных тем для обсуждения для дальнейшего развития и эволюции:
-
Улучшенная адаптация домена для многозадачного zero-shot: Учитывая наблюдаемые ограничения в передаче zero-shot между различными доменами, критическим будущим направлением является интеграция более сложных методов адаптации домена непосредственно во фреймворк MTSAM. Могут ли быть объединены стратегии состязательного обучения, метаобучения для обобщения домена или более продвинутого конструирования промптов с ToRA для улучшения производительности на невиданных, внедоменных задачах? Исследование того, как явно моделировать и смягчать пробелы в доменах в рамках тензорного разложения, может стать плодотворной областью.
-
Динамический ранг ToRA и распределение весов задач: В настоящее время ранги ToRA ($p, q, v$) и веса потерь задач ($w_i$) устанавливаются как фиксированные гиперпараметры. Будущая работа может исследовать динамические методы корректировки этих параметров во время обучения. Например, может ли адаптивный механизм изучать оптимальные ранги для каждой задачи или слоя, аналогично тому, как некоторые методы PEFT динамически корректируют ранги? Аналогично, динамические стратегии взвешивания задач, возможно, основанные на неопределенности задачи или конфликтах градиентов, могли бы далее повысить способность модели балансировать и оптимизировать производительность на разнообразных задачах, выходя за рамки фиксированных весов, используемых в этом исследовании.
-
Расширение ToRA на другие фундаментальные модели и модальности: Статья фокусируется на SAM для задач сегментации изображений. Естественным расширением является применение фреймворка MTSAM и ToRA к другим большим фундаментальным моделям в различных модальностях, таким как большие языковые модели (LLM) или мультимодальные модели, интегрирующие зрение и язык. Как ToRA покажет себя при дообучении LLM для различных NLP-задач или при адаптации мультимодальных моделей для задач, требующих межмодального понимания? Это может выявить новые идеи о обобщаемости и масштабируемости тензорной низкоранговой адаптации.
-
Теоретическое углубление в выразительную мощность и обобщение: Хотя Теорема 1 доказывает превосходство ToRA над несколькими LoRA с точки зрения параметрической эффективности, более глубокий теоретический анализ его выразительной мощности и границ обобщения в сложных многозадачных, многодоменных сценариях был бы ценным. Можем ли мы формально охарактеризовать условия, при которых тензорное разложение ToRA оптимально захватывает общие для задач и специфичные для задач знания, и как это связано с лежащей в основе связностью задач? Это могло бы привести к более принципиальным выборам дизайна для будущих методов PEFT для многозадачного обучения.
-
Эффективность в развертывании и инференсе: В статье упоминается, что ToRA не вводит дополнительной задержки во время инференса, поскольку обновленная матрица параметров может быть предварительно сохранена. Однако, поскольку количество задач растет, хранение специфичных для задач обновленных весов ($W_t = W_0 + \Delta W_t$) все еще может стать существенным. Будущая работа может исследовать стратегии для еще более компактного хранения или реконструкции $\Delta W_t$ "на лету" во время инференса, особенно в условиях ограниченных ресурсов, для дальнейшего повышения практической полезности MTSAM.
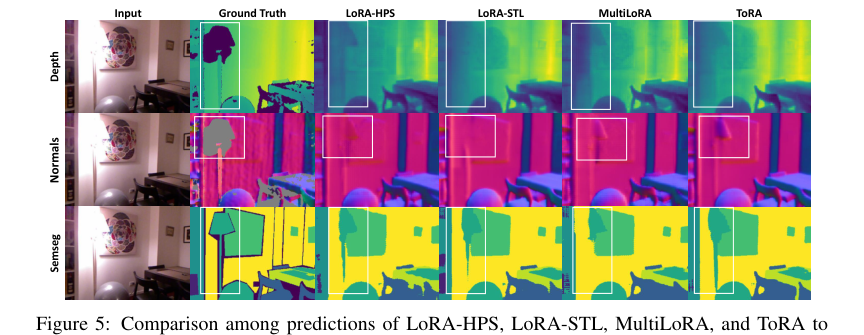 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
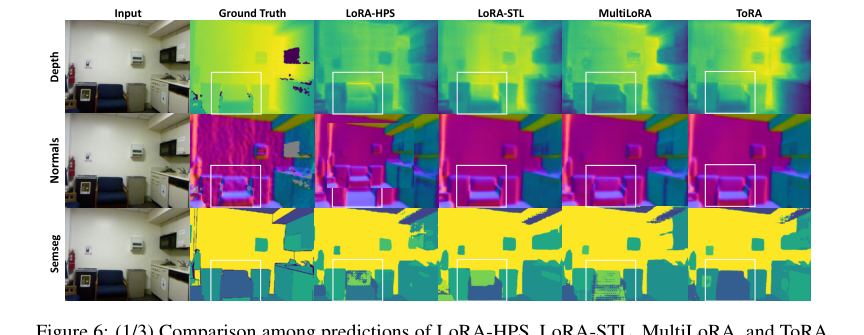 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset