Rotated Runtime Smooth: Training-Free Activation Smoother for accurate INT4 inference
Large language models have demonstrated promising capabilities upon scaling up parameters.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the increasing scale and complexity of Large Language Models (LLMs). As these models grow, serving them for inference becomes incredibly expensive in terms of computational resources and memory usage. To mitigate these costs and improve latency, quantization methods have been widely adopted. Quantization essentially reduces the precision of the numbers (weights and activations) used in the model, for example, from high-precision floating-point numbers to low-bit integers like INT4 (4-bit integers).
However, a significant "pain point" emerged with low-bit quantization, particularly for INT4 weight-activation quantization: the presence of outliers in activations. These outliers are extreme values within the activation tensors that disproportionately stretch the overall range of values. When the entire range is compressed into a very limited number of bits (like 4 bits), these outliers consume most of the available "precision slots," leaving very few effective bits for the more common, "normal" values. This severely degrades the model's accuracy during inference.
Previous approaches attempted to tackle these outliers but faced fundamental limitations:
* Separating outliers: Early methods (e.g., Kim et al., 2023; Dettmers et al., 2022) tried to separate outliers from normal values into different matrices. The major drawback here was that these implementations were often not hardware-compatible, leading to high latency and failing to expedite inference.
* Offline smoothing and migration (SmoothQuant): SmoothQuant (Xiao et al., 2023) aimed to transfer outliers from activations to weights using channel-wise smoothing scales. While effective for higher-bit quantization (like A8W8), it failed for INT4 inference for several reasons:
* The smoothing scales were pre-computed offline using a calibration set, making them ineffective when encountering new, "unmatched" online activations.
* Outliers were not truly eliminated but merely partially migrated, still hindering low-bit quantization.
* SmoothQuant primarily addressed "channel-wise" outliers but struggled with "spike" outliers, which are not consistent across channels, leading to normal values being incorrectly pruned as "victims."
* Rotation-based methods (QuaRot): More recent work like QuaRot (Ashkboos et al., 2024) introduced rotation matrices to suppress outliers by spreading them internally. While promising for A4W4 quantization, rotation alone couldn't guarantee a perfectly smooth matrix and might still exhibit channel-wise outliers, leaving room for further improvement. The challenge remained to find a robust, accurate, and training-free scheme for INT4 inference that could handle both types of outliers effectively.
Intuitive Domain Terms
- Quantization: Imagine you have a very detailed color palette with millions of shades (like floating-point numbers). Quantization is like choosing to use only a much smaller set of colors, say 16 specific shades (like 4-bit integers), to represent all your images. The goal is to make the images much smaller and faster to process, while still making them look as good as possible.
- Outliers in Activations: Think of a group of people whose heights are mostly between 5 and 6 feet. But then you have a few giants who are 20 feet tall and a few tiny people who are 1 foot tall. If you try to create a height scale for everyone using only 10 marks, those extreme giants and tiny people will force the scale to cover a huge range (1 to 20 feet). This means the common 5-6 foot range gets very few marks, making it hard to tell the difference between someone who is 5'2" and 5'4". The "giants" and "tiny people" are the outliers, making it hard to accurately represent the "normal" heights.
- INT4 Inference: This is like doing calculations with very simple, rounded numbers (e.g., only numbers from -8 to 7, which is what 4-bit integers can represent) instead of very precise decimals. It's much faster and uses less mental effort (or computer memory/power) to calculate $5 \times 3$ than $5.123 \times 3.456$. The "INT4" part means using 4-bit integers, which is a very aggressive form of rounding to gain maximum speed and memory savings for LLMs.
- Perplexity: In the context of language models, perplexity is a measure of how "surprised" the model is by the next word in a sequence. Imagine you're trying to guess the next word in a sentence. If you're very confident and guess correctly, your "surprise" is low. If you're often wrong or unsure, your "surprise" is high. A lower perplexity score means the language model is less surprised, indicating it's better at predicting text and understands the language more accurately.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The fundamental problem addressed by this paper is the significant accuracy degradation in Large Language Models (LLMs) when attempting to perform inference using extremely low-bit weight-activation quantization, specifically INT4.
The Input/Current State is that LLMs, despite their impressive capabilities, are computationally and memory-intensive to serve due to their massive scale. Quantization, which reduces the precision of model parameters and activations (e.g., from FP32 to INT4), is a promising technique to mitigate these costs and improve inference latency. However, a critical impediment to the widespread adoption of INT4 weight-activation quantization is the presence of "outliers" in activation tensors. These outliers are extreme values that disproportionately stretch the quantization range, effectively compressing the dynamic range available for normal values and leading to substantial information loss and accuracy drops.
The Desired Endpoint (Output/Goal State) is to enable accurate and efficent INT4 weight-activation inference for LLMs. This means achieving the computational and memory benefits of INT4 quantization without incurring significant accuracy degradation. The paper aims to develop a "training-free activation smoother" that can robustly handle activation outliers, thereby allowing normal values to be quantized with sufficient precision, ultimately leading to state-of-the-art performance in INT4 inference across various LLM families.
The exact missing link or mathematical gap between the current state and the desired endpoint lies in finding a method to effectively "smooth" or normalize activation outliers such that the entire activation tensor can be quantized to INT4 with minimal information loss, all while being computationally inexpensive and training-free. Mathematically, if $X$ is an activation tensor and $\alpha$ is its scaling factor for quantization (e.g., $\alpha = \frac{\max(|X|)}{2^{N-1}-1}$ for N-bit quantization), outliers cause $\max(|X|)$ to be very large, making $\alpha$ large. This results in normal values being mapped to a very small range of integer values, leading to severe precision loss. The missing link is a transformation $f(X)$ such that $f(X)$ has a much smaller $\max(|f(X)|)$ than $\max(|X|)$, but $f(X)$ still accurately represents the original information, allowing for a smaller $\alpha'$ and thus more effective quantization of normal values. This transformation must also be compatible with the weight matrix $W$ to preserve the output $XW$.
The painful trade-off or dilemma that has trapped previous researchers is primarily the Accuracy vs. Efficiency vs. Robustness triangle:
1. Accuracy vs. Efficiency (Low-bit Quantization): Aggressive low-bit quantization (INT4) offers significant speedup and memory savings but is highly susceptible to activation outliers, leading to severe accuracy degradation. Preserving accuracy often requires higher bit-widths or complex outlier handling, which negates efficiency gains.
2. Outlier Handling vs. Hardware Compatibility/Latency: Existing methods to address outliers, such as separating outliers into different matrices (e.g., Kim et al., 2023; Dettmers et al., 2022) or migrating them to weights (e.g., SmoothQuant), often introduce hardware incompatibility, significant latency overhead, or make weight quantization difficult. This undermines the core goal of faster, more efficent inference.
3. Static vs. Dynamic Smoothing: Pre-computed smoothing scales (e.g., in SmoothQuant) are efficient but become "unmatched" with online activations, rendering them ineffective for real-world, dynamic inputs. Runtime smoothing is more robust but traditionally incurs unacceptable computational overhead.
4. Channel-wise vs. Spike Outliers: Outliers manifest in different forms: "channel-wise" (consistent across a channel) and "spike" (isolated, extreme values). Methods effective for one type (e.g., channel-wise smoothing) can exacerbate the "victim effect" for the other (e.g., spike outliers causing normal values to be pruned), leading to quantization error. A unified solution without new side effects is elusive.
Constraints & Failure Modes
The problem of accurate INT4 inference for LLMs is insanely difficult due to several harsh, realistic walls the authors hit:
- Extreme Sparsity/Magnitude of Activation Outliers: Activation outliers can be orders of magnitude larger than normal values (e.g., 1000x larger, as mentioned on page 14). This extreme magnitude stretches the quantization range so severely that normal values lose almost all their effective bits, leading to catastrophic accuracy loss.
- INT4 Precision Limits: Quantizing to INT4 means only 16 possible values ($2^4$) can represent the entire range of activations. This extremely limited precision leaves very little room for error or for accommodating outliers without significant information loss for the majority of values.
- Real-time Latency Requirements: LLM inference, especially the pre-filling stage, demands strict real-time latency. Any outlier smoothing or handling mechanism must introduce "negligble overhead" (page 2, page 9) to be practical. Complex operations that add significant computation time are unacceptable.
- Hardware Memory Limits: LLMs are massive, and memory bandwidth is often a bottleneck. Quantization aims to reduce memory footprint and movement. Solutions that require storing additional high-precision data or complex data structures for outliers can negate these benefits.
- Training-Free Requirement: The solution must be "training-free" and "plug-and-play" (Abstract, page 2). This means it cannot rely on extensive fine-tuning or calibration on large datasets, which is time-consuming and resource-intensive, especially for large models.
- Dynamic Input Distributions: The distribution of activations can vary significantly across different inputs and different layers of an LLM. Smoothing scales derived from a static calibration set are prone to being "unmatched" with online activations (page 3), leading to ineffective smoothing and accuracy degradation.
- "Victim" Effect: When smoothing scales are determined by extreme outliers, normal values, which are much smaller, can be effectively "pruned" or become "victims" (page 2, Figure 1c, page 3). This loss of precision for normal values is a critical failure mode, as it directly impacts the model's ability to represent nuanced information.
- Incompatibility with GEMM Kernels: Naive implementations of runtime smoothing, especially with inconsistent smoothing scales, cannot be easily integrated into highly optimized General Matrix Multiply (GEMM) kernels (page 4). This makes achieving hardware acceleration challenging, as custom kernels or complex block-wise computations would be required.
- Sub-smoothness after Rotation: While rotation-based methods (like QuaRot) can spread outliers, they do not guarantee a perfectly smooth matrix and may still exhibit "channel-wise outliers" or "sub-smoothness" (page 2, Figure 2c, page 4). This means rotation alone is insufficient to fully address the outlier problem for INT4 quantization.
- Outlier Migration Challenges: Previous approaches that migrate outliers from activations to weights (e.g., SmoothQuant) can make the weights difficult to quantify, especially for very low-bit schemes like A4W4 (page 1). This creates a new problem in the weight domain while trying to solve one in the activation domain.
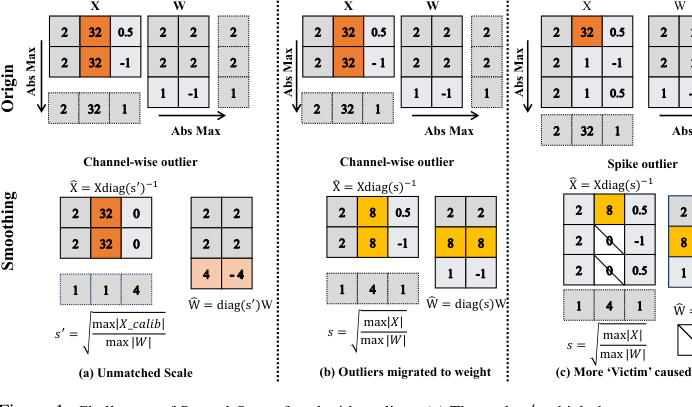 Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Why This Approach
The Inevitability of the Choice
The authors' journey toward Rotated Runtime Smooth (RRS) was driven by the fundamental limitations of existing quantization methods when applied to the challenging landscape of INT4 inference for large language models (LLMs). The "exact moment" of realization that traditional state-of-the-art (SOTA) methods were insufficient can be pinpointed to the persistent problem of activation outliers.
Traditional approaches, such as those that separate outliers and normal values into two distinct matrices (e.g., Kim et al., 2023; Dettmers et al., 2022), were found to suffer from high latency or significant accuracy degradation. Crucially, these methods often proved incompatible with hardware acceleration, failing to expedite inference as intended.
A more direct predecessor, SmoothQuant (Xiao et al., 2023), attempted to mitigate outliers by transferring them from activations to weights using channel-wise smoothing scales. However, for INT4 quantization, SmoothQuant faced three critical failures:
1. Unmatched Scales: The offline pre-computed smoothing scales, derived from a calibration set, frequently became mismatched with online activations, rendering them ineffective for smoothing.
2. Incomplete Outlier Elimination: Outlier channels were not fully eliminated but merely partially migrated to weights, which made low-bit quantization (specifically INT4) difficult.
3. Spike Outliers and "Victims": SmoothQuant primarily addressed channel-wise outliers but failed to account for "spike outliers" that are not consistently channel-wise. When these spike outliers were present, normal values were inadvertently pruned as "victims" during smoothing, leading to accuracy loss.
Even rotation-based methods like QuaRot (Ashkboos et al., 2024), while showing promise in spreading outliers, could not theoretically guarantee a uniformly smoother matrix. Rotated activations, particularly those with channel-wise outliers, could still exhibit "sub-smoothness" (as illustrated in Figure 2c), leaving room for further improvement. This collective failure of prior methods to robustly, accurately, and efficiently handle both channel-wise and spike outliers in a training-free manner for INT4 inference made the development of a new, comprehensive solution like RRS not just an option, but an inevitability.
Comparative Superiority
Rotated Runtime Smooth (RRS demonstrates qualitative superiority over previous methods primarily through its comprehensive and robust outlier handling, coupled with minimal computational overhead.
The structural advantage of RRS lies in its two-pronged approach:
1. Runtime Smooth (RS): This component directly addresses channel-wise outliers by dynamically computing smoothing scales at runtime. Unlike SmoothQuant, which relies on offline calibration and merges scales into weights, RS avoids the issues of unmatched scales and the difficulty of quantizing weights with migrated outliers. By obtaining smoothing scales in runtime and not merging them into weights, RS ensures that the smoothing is always relevant to the current input, making it more adaptive and accurate.
2. Rotation Operation: This is where RRS tackles spike outliers and enhances robustness. By rotating weights and activations (following QuaRot's principle), spike outliers are effectively spread across tokens. This spreading leads to more consistent smoothing scales across channels, which in turn prevents normal values from becoming "victims" during the channel-wise smoothing process. For activations with channel-wise outliers, rotation helps maintain consistency while also offering a chance to reduce the level of outliers.
This combined strategy provides a structural advantage that previous methods lacked. SmoothQuant, for instance, could not handle spike outliers effectively and suffered from calibration set mismatches. Pure rotation methods, while beneficial, did not guarantee sufficient smoothness on their own. RRS integrates the best aspects of both, ensuring that all types of outliers (channel-wise and spike) are addressed comprehensively.
Furthermore, RRS is designed to be a "plug-and-play" component, incurring negligible overhead for INT4 matrix multiplication. The paper explicitly states that the extra runtime scale multiplication in the fused GEMM kernel brings only "negligible overhead" compared to the A4W4 baseline. This is a significant qualitative advantage, as it achieves superior accuracy without sacrificing the critical latency benefits expected from low-bit quantization. It does not introduce high-dimensional noise, but rather mitigates the impact of outliers that act as a form of noise by stretching the quantization range.
Alignment with Constraints
The Rotated Runtime Smooth (RRS) method perfectly aligns with the stringent requirements for efficient LLM inference, particularly for INT4 quantization. The core constraints, implicitly defined by the problem of serving large LLMs, include:
1. INT4 Inference: The primary goal is to enable accurate inference at INT4 precision, which is crucial for reducing memory and computation costs. RRS is specifically designed as a "training-free activation smoother for accurate INT4 inference." Its entire mechanism, from handling channel-wise to spike outliers, is geared towards making activations amenable to 4-bit quantization without significant accuracy loss. The perplexity improvements on LLaMA and Qwen families under A4W4KV16 settings (e.g., LLaMA3-70B from 57.33 to 6.66) directly validate its effectiveness in achieving this.
2. Training-Free: A critical requirement for practical deployment is to avoid costly retraining or fine-tuning. RRS is explicitly "training-free," meaning it can be applied post-training without additional model optimization. This aligns perfectly with the need for a readily deployable solution that doesn't add to the already substantial training burden of LLMs.
3. Accuracy Preservation: Low-bit quantization often leads to accuracy degradation. RRS's comprehensive outlier mitigation strategy—combining runtime smoothing for channel-wise outliers and rotation for spike outliers—is designed to "comprehensively eliminate outliers" and "enhance the robustness," thereby preserving accuracy. The consistent outperformance over SOTA methods in perplexity and zero-shot QA tasks demonstrates this alignment.
4. Low Latency/Minimal Overhead: Quantization aims to reduce service costs and latency. RRS is engineered for efficiency, with its Runtime Smooth component incurring "minimal overhead compared to the original A4W4 pipeline." The kernel fusion for Runtime Smooth ensures that the process is integrated efficiently into the GEMM pipeline, adding "negligible overhead" compared to A4W4 Per-Channel quantization. This directly addresses the constraint of maintaining high throughput and low latency.
5. Robustness to Outliers: The problem statement highlights outliers as the main impediment. RRS's unique property of addressing both channel-wise and spike outliers, and preventing "victims" by ensuring consistent smoothing scales, makes it inherently robust to the diverse outlier patterns observed in LLM activations. This "marriage" between the problem's harsh outlier challenge and the solution's unique dual-outlier handling is central to its success.
Rejection of Alternatives
The paper provides clear reasoning for rejecting several alternative approaches, highlighting their shortcomings, especially in the context of INT4 inference for LLMs:
-
Traditional Outlier Separation (e.g., LLM.int8(), Kim et al., 2023; Dettmers et al., 2022): These methods, which either separate outliers into a higher-precision format (mixed INT8/FP16) or into separate matrices, were rejected due to "high latency or accuracy degradation" and often being "not hardware-compatible," thus failing to "expedite inference." LLM.int8() specifically "results in significant latency overhead and can even be slower than FP16 inference."
-
SmoothQuant (Xiao et al., 2023): While effective for A8W8 quantization, SmoothQuant was deemed insufficient for INT4 because its offline, calibration-set-dependent smoothing scales were "prone to being unmatched with online activations." Moreover, it only partially migrated outliers to weights rather than eliminating them, making low-bit quantization difficult, and crucially, it failed to address "spike outliers," leading to "victim" pruning.
-
Pure Rotation-Based Methods (e.g., QuaRot, Ashkboos et al., 2024): While rotation helps spread outliers, the paper notes that multiplying by a single rotation matrix "could not theoretically guarantee a smoother weight or activation." Activations, even after rotation, could remain "sub-smooth" with channel-wise outliers (Figure 2c), indicating that rotation alone was not a complete solution for comprehensive smoothing. QuaRot also requires "complex online Hadamard rotation," which RRS aims to simplify.
-
Training-Based Quantization (e.g., SpinQuant, Liu et al., 2024): The paper explicitly compares RRS with SpinQuant and rejects training-based approaches due to their prohibitive computational cost. SpinQuant's training process is "time-consuming, taking 1.5 hours for a 7B model on one A100 GPU and 12 hours for 70B models on eight A100 GPUs." Furthermore, the results showed that training-based methods "degrades WikiText-2 perplexity compared to the training-free method and still has room for improvement," making them less desirable in terms of both efficiency and final accuracy.
-
Other Reordering Techniques (e.g., RPTQ, Yuan et al., 2023; Atom, Zhao et al., 2024): While these methods rearrange channels to reduce variance or use mixed precision, they don't offer the comprehensive, training-free, and low-overhead solution for both channel-wise and spike outliers in INT4 that RRS provides. For instance, Atom integrates reorder with mixed INT4/INT8, which is not pure INT4.
The consistent theme in rejecting these alternatives is their inability to simultaneously meet the strict demands of INT4 inference: high accuracy, low latency, and a training-free, robust solution for all types of activation outliers.
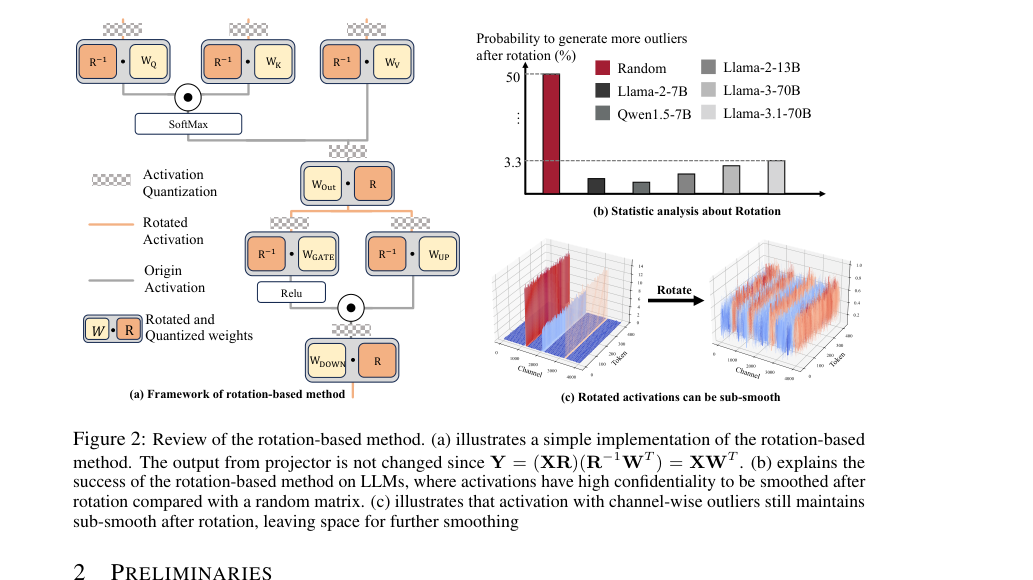 Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Mathematical & Logical Mechanism
The Master Equation
The core mathematical engine powering the Rotated Runtime Smooth (RRS) method combines a rotation operation with a runtime smoothing mechanism. Given an input activation matrix $X$ and a weight matrix $W$, the RRS process can be encapsulated by the following sequence of operations:
$$ X_{rot} = XR \\ W_{rot} = R^{-1}W \\ s_j = \max(|(X_{rot})_j|), \quad j = 1, \dots, K \\ X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1}) \\ W'_{quant} = \text{Quantize}(W_{rot}) \\ Y = \sum_{j=1}^{K} (X'_{quant})_j (W'_{quant})_j^T s_j $$
This set of equations describes how activations and weights are first rotated, then activations are smoothed using runtime-derived scales, both are quantized, and finally, a modified matrix multiplication produces the low-bit output.
Term-by-Term Autopsy
Let's dissect each component of the master equation to understand its mathematical definition, logical role, and the rationale behind its design.
-
$X$: This represents the input activation tensor to a linear layer.
1) Mathematical Definition: A floating-point matrix of dimensions $N \times K$, where $N$ is typically the batch size multiplied by the sequence length, and $K$ is the input channel dimension.
2) Physical/Logical Role: It carries the feature information from the previous layer, which needs to be processed by the current linear layer.
3) Why this form: It's the standard representation for a batch of input features. -
$W$: This is the weight matrix of the linear layer.
1) Mathematical Definition: A floating-point matrix of dimensions $M \times K$, where $M$ is the output dimension and $K$ is the input channel dimension.
2) Physical/Logical Role: Contains the learnable parameters that transform the input activations into output features.
3) Why this form: Standard representation for linear layer weights. -
$R$: This is the rotation matrix.
1) Mathematical Definition: An orthogonal matrix of size $K \times K$, meaning $RR^T = I$ (where $I$ is the identity matrix) and its determinant $\det(R) = 1$. The paper often refers to a Hadamard rotation matrix, where $R = \frac{1}{\sqrt{K}}[s_{i,j}]_{K \times K}$ with elements $s_{i,j} \in \{-1, +1\}$.
2) Physical/Logical Role: Its primary role is to linearly transform (rotate) the vector spaces of both activations and weights. This rotation is crucial for "spreading out" concentrated outliers within activations, making them less impactful on the quantization range. By rotating both $X$ and $W$ appropriately, the original output $XW^T$ is mathematically preserved as $(XR)(R^{-1}W^T)$.
3) Why multiplication: Matrix multiplication is the fundamental operation for applying linear transformations like rotations in vector spaces. -
$R^{-1}$: This is the inverse of the rotation matrix.
1) Mathematical Definition: Since $R$ is orthogonal, its inverse is simply its transpose, $R^T$. It is also a $K \times K$ matrix.
2) Physical/Logical Role: It rotates the weight matrix $W$ in a complementary way to $X$, ensuring that the overall transformation remains equivalent to the original full-precision operation.
3) Why multiplication: Similar to $R$, it's a linear transformation. -
$X_{rot} = XR$: The rotated activation tensor.
1) Mathematical Definition: The result of multiplying the input activation matrix $X$ by the rotation matrix $R$. It retains the shape $N \times K$.
2) Physical/Logical Role: These are the activations after their features have been linearly combined and redistributed across channels by the rotation. This step aims to mitigate channel-wise outliers by making their magnitudes less extreme or more uniformly distributed.
3) Why multiplication: It's the direct application of the rotation transformation. -
$W_{rot} = R^{-1}W$: The rotated weight matrix.
1) Mathematical Definition: The result of multiplying the weight matrix $W$ by the inverse rotation matrix $R^{-1}$. It retains the shape $M \times K$.
2) Physical/Logical Role: These are the weights after being rotated. This rotation is necessary to maintain the mathematical equivalence of the original matrix multiplication when combined with $X_{rot}$.
3) Why multiplication: Direct application of the inverse rotation. -
$s_j = \max(|(X_{rot})_j|)$: The runtime smoothing scale for the $j$-th channel.
1) Mathematical Definition: For each column $j$ of the rotated activation matrix $X_{rot}$ (denoted as $(X_{rot})_j$, which is an $N \times 1$ vector), this operation computes the maximum absolute value among all elements in that column. This yields a scalar $s_j$.
2) Physical/Logical Role: This scale dynamically captures the largest magnitude present in each channel of the rotated activations. It serves as a normalization factor to bring the values within that channel into a more manageable range for quantization. By using the maximum absolute value, it ensures that no values are clipped during the subsequent division, preserving information. This is a key part of the "Runtime Smooth" component, addressing channel-wise outliers.
3) Whymaxand absolute value:maxidentifies the extreme value that dictates the necessary scaling range. Absolute value ensures both positive and negative outliers are treated symmetrically. -
$\text{diag}(s)^{-1}$: The inverse diagonal matrix of smoothing scales.
1) Mathematical Definition: A $K \times K$ diagonal matrix where the $j$-th diagonal element is $1/s_j$.
2) Physical/Logical Role: This matrix facilitates the channel-wise scaling of $X_{rot}$ by allowing each column to be divided by its specific $s_j$.
3) Why diagonal matrix: It's an efficient way to represent element-wise column scaling as a matrix multiplication. -
$X_{rot}\text{diag}(s)^{-1}$: The smoothed rotated activations.
1) Mathematical Definition: Each column $(X_{rot})_j$ of the rotated activation matrix is element-wise divided by its corresponding scalar $s_j$. This results in an $N \times K$ matrix.
2) Physical/Logical Role: This operation normalizes the rotated activations channel-wise. By scaling values based on their channel's maximum magnitude, outliers are effectively "compressed" relative to normal values, making the entire channel's data fit better within a low-bit quantization range.
3) Why division: Division by the maximum absolute value scales the data, typically to a range like $[-1, 1]$, which is optimal for symmetric quantization schemes. -
$\text{Quantize}(\cdot)$: The quantization function.
1) Mathematical Definition: A function that maps a floating-point number to a low-bit integer representation. For example, for INT4, it might map a float $x$ to an integer $q$ such that $q = \text{round}(x \cdot \text{scale}) + \text{offset}$, wherescaleandoffsetare determined by the target bit-width and the range of values.
2) Physical/Logical Role: This is the core operation for reducing the precision of the numbers. It converts the high-precision floating-point values into discrete, low-bit integer values, which significantly reduces memory footprint and computational cost during inference.
3) Why this function: It's the standard method for converting continuous values to a finite set of discrete values, which is the essence of quantization. -
$X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1})$: The quantized smoothed rotated activations.
1) Mathematical Definition: The result of applying the $\text{Quantize}$ function to the smoothed rotated activation matrix. It is an $N \times K$ matrix of low-bit integers.
2) Physical/Logical Role: These are the input activations in their final low-bit, outlier-mitigated form, ready for efficient matrix multiplication. -
$W'_{quant} = \text{Quantize}(W_{rot})$: The quantized rotated weights.
1) Mathematical Definition: The result of applying the $\text{Quantize}$ function to the rotated weight matrix. It is an $M \times K$ matrix of low-bit integers.
2) Physical/Logical Role: These are the weights in their low-bit, outlier-mitigated form, ready for efficient matrix multiplication. -
$(X'_{quant})_j$: The $j$-th column of $X'_{quant}$.
1) Mathematical Definition: A column vector of shape $N \times 1$ containing low-bit integers.
2) Physical/Logical Role: Represents the quantized and smoothed activations for a specific input channel. -
$(W'_{quant})_j^T$: The $j$-th row of $W'_{quant}$ (transposed).
1) Mathematical Definition: A row vector of shape $1 \times M$ containing low-bit integers. (Note: Assuming $W'_{quant}$ is $M \times K$, then $(W'_{quant})_j$ is its $j$-th column, $M \times 1$. Thus, $(W'_{quant})_j^T$ is $1 \times M$. This aligns with the dimensions needed for an $N \times M$ outer product).
2) Physical/Logical Role: Represents the quantized weights corresponding to the contribution of the $j$-th input channel to all output channels. -
$\sum_{j=1}^{K} (\cdot)$: Summation over channels.
1) Mathematical Definition: This operator sums $K$ individual matrices, each of shape $N \times M$.
2) Physical/Logical Role: This summation combines the contributions from each input channel to form the final output matrix. Each term $(X'_{quant})_j (W'_{quant})_j^T s_j$ represents a scaled outer product. The scaling by $s_j$ here is a unique aspect of the paper's formulation, implying that the contribution of each channel's partial product to the final output is scaled by the original activation smoothing factor for that channel. This can be interpreted as a form of channel-wise dequantization or re-scaling applied to the partial products before summation, which is a departure from how scales are typically handled in standard quantized matrix multiplication (where scales are often applied uniformly to inputs or outputs, or absorbed into the quantized values). The paper's description in Section 4.5, "multiply the runtime scale on the dequantized result," suggests a slightly different order of operations for the final scaling, but the equation in Section 3.1 is the most explicit mathematical statement of the mechanism.
3) Why summation: Matrix multiplication is fundamentally a sum of outer products of column vectors from the first matrix and row vectors from the second. -
$Y$: The final output matrix.
1) Mathematical Definition: The resulting matrix of dimensions $N \times M$.
2) Physical/Logical Role: This is the low-bit approximation of the full-precision matrix multiplication $XW^T$, produced after rotation, smoothing, quantization, and the modified summation. It represents the processed features from the linear layer, ready for subsequent operations in the neural network.
Step-by-Step Flow
Imagine a single abstract data point, say $x_{token, feature\_in}$, representing a specific feature for a particular input token, and a weight $w_{feature\_out, feature\_in}$, which connects an input feature to an output feature. Let's trace their journey through the Rotated Runtime Smooth (RRS) mechanism:
-
Initial Entry: Our abstract data point $x_{token, feature\_in}$ enters the system as part of the floating-point activation matrix $X$. The weight $w_{feature\_out, feature\_in}$ is part of the floating-point weight matrix $W$.
-
Activation Rotation: The entire activation matrix $X$ is fed into a "rotation engine" where it's multiplied by the rotation matrix $R$. Our data point $x_{token, feature\_in}$ is now transformed. It's no longer isolated but contributes to and is influenced by other features in its channel, becoming a new value, $x'_{token, feature\_k}$, within the rotated activation matrix $X_{rot}$. This process aims to evenly distribute any extreme values (outliers) across the feature space.
-
Weight Rotation: Simultaneously, the weight matrix $W$ passes through a "counter-rotation engine" where it's multiplied by $R^{-1}$ (the inverse rotation matrix), yielding $W_{rot}$. This ensures that the overall mathematical integrity of the original operation is maintained, even after the input activations have been rotated.
-
Runtime Scale Discovery: For each column (representing a feature channel) of the rotated activation matrix $X_{rot}$, a "magnitude scanner" identifies the maximum absolute value. For the column containing $x'_{token, feature\_k}$, a specific scale $s_{feature\_k}$ is computed. This scale is dynamic, adapting to the current input's characteristics.
-
Activation Smoothing: The rotated activation matrix $X_{rot}$ then enters a "smoothing chamber." Here, each value in a column is divided by its corresponding channel's scale $s_j$. So, our $x'_{token, feature\_k}$ is scaled down to $x''_{token, feature\_k} = x'_{token, feature\_k} / s_{feature\_k}$. This operation effectively "squashes" the range of values within each channel, making outliers less dominant and preparing the data for efficient low-bit quantization.
-
Activation Quantization: The smoothed rotated activations ($X_{rot}\text{diag}(s)^{-1}$) are then fed into a "quantization unit." This unit converts each floating-point value, including our $x''_{token, feature\_k}$, into a low-bit integer, $q_{X,token,feature\_k}$. This is where the significant memory and computational savings begin.
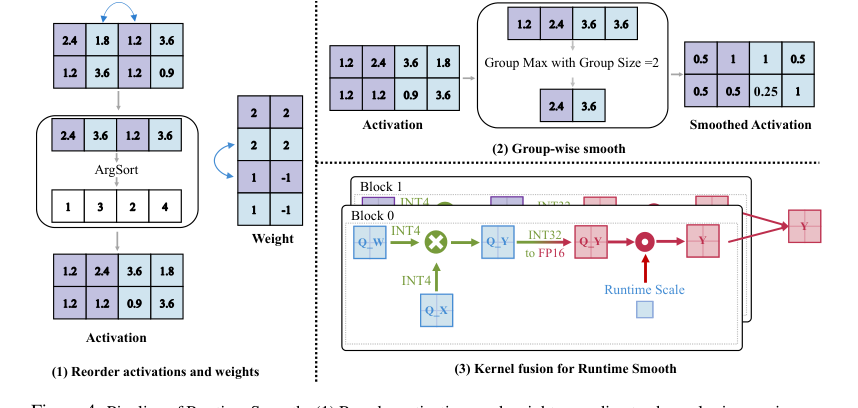 Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
-
Weight Quantization: In parallel, the rotated weight matrix $W_{rot}$ also passes through its own "quantization unit," converting its floating-point values (like $w'_{feature\_out, feature\_in}$) into low-bit integers, $q_{W,feature\_out,feature\_in}$.
-
Channel-wise Output Assembly: Now, the system begins to assemble the final output. For each feature channel $j$ (from $1$ to $K$):
- The $j$-th column of the quantized activations, $(X'_{quant})_j$, is extracted.
- The $j$-th row of the quantized weights (transposed), $(W'_{quant})_j^T$, is extracted.
- These two vectors are multiplied (an outer product) to form a partial output matrix. This matrix represents the contribution of only the $j$-th channel to the final result.
- Crucially, this partial output matrix is then scaled by the runtime smoothing factor $s_j$ that was calculated earlier for the $j$-th activation channel. This step re-introduces the magnitude information that was removed during activation smoothing, but now applied to the partial product.
-
Final Summation: All these $K$ scaled partial output matrices are then fed into a "summation unit," which adds them together element-wise. The result is the final output matrix $Y$, where each element $y_{token, feature\_out}$ is the sum of all scaled channel contributions. This completes the forward pass, delivering a low-bit, yet accurate, approximation of the original full-precision operation.
Optimization Dynamics
It's important to clarify that Rotated Runtime Smooth (RRS) is a training-free method. This means its "optimization dynamics" are not about iterative learning or gradient-based updates in the traditional sense. Instead, the mechanism is designed to optimize for quantization accuracy directly through its structural components.
-
Absence of Iterative Learning: Unlike methods that rely on backpropagation and gradient descent to update model parameters, RRS does not involve any such learning loop during its operation. The rotation matrix $R$ is either a fixed, pre-defined matrix (like a Hadamard matrix) or derived from an offline calibration process (as in related works), but it is not updated during inference. The smoothing scales $s_j$ are computed on-the-fly for each new input, making them adaptive but not "learned" over time.
-
No Loss Landscape Traversal: Since there's no training, the concept of navigating a "loss landscape" with gradients is not applicable to the RRS mechanism itself. The "optimization" is embedded in the design choices: how to rotate, how to smooth, and how to quantize to minimize the quantization error and preserve model performance. The effectiveness of these design choices is evaluated by metrics like perplexity or accuracy, which are observed outcomes rather than targets for direct gradient-based optimization within the mechanism.
-
Deterministic State Updates: The state of the RRS mechanism does not evolve iteratively. For every input, the process is a direct, deterministic sequence of transformations:
- Activations and weights are rotated using a fixed $R$.
- Smoothing scales are calculated based on the current input's rotated activations.
- Quantization is applied using fixed bit-widths and rounding rules.
- The final matrix multiplication (with the peculiar channel-wise scaling of partial products) is computed.
Each step is a direct computation, not an update based on previous states or errors.
-
Design-Driven "Convergence": The "convergence" of RRS is not an iterative process but rather a state achieved by its inherent design. The goal is to transform the activations and weights such that they are "smooth" enough (i.e., outliers are sufficiently mitigated) to allow for accurate low-bit (INT4) quantization. The paper demonstrates that this design effectively reduces quantization error, leading to improved perplexity and accuracy on various models. The "optimization" is therefore in the clever engineering of these transformations to achieve high-quality low-bit inference, rather than an iterative learning proces. The mechanism's robustness and performance gains are a testament to this design optimization, making it a highly efficent and plug-and-play solution. The negligible overhead further reinforces its practical utility.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate their mathematical claims, the authors conducted extensive experiments across a diverse set of mainstream Large Language Models (LLMs). These included various models from the LLaMA families (LLaMA2-13B, LLaMA2-70B, LLaMA3-8B, LLaMA3-70B, LLaMA3.1-8B, LLaMA3.1-70B), Qwen families (Qwen1.5-7B, Qwen1.5-14B), Mistral, and Mixtral. The evaluation focused on INT4 quantization, specifically using three schemes: A4W4KV4, A4W4KV16, and A4W16KV16, which denote 4-bit activation, 4-bit weight, and 4-bit KV cache quantization, respectively, with varying KV cache bit-widths.
For activation quantization, a per-channel symmetric scheme with a round-to-nearest (RTN) strategy was employed. KV cache quantization utilized a sub-channel symmetric scheme with a groupsize of 128, also with RTN. Weight quantization primarily used a per-channel symmetric scheme with GPTQ (Frantar et al., 2022), except for the baseline 'RTN' method. The calibration set for GPTQ consisted of 128 samples from WikiText-2, each with a sequence length of 2048.
The "victims" (baseline models/methods) against which the proposed Rotated Runtime Smooth (RRS) and its component, Runtime Smooth (RS), were compared included:
- RTN: A basic Round-to-Nearest quantization.
- SmoothQuant (Xiao et al., 2023): A prominent channel-wise smoothing method that migrates outliers offline.
- GPTQ (Frantar et al., 2022): A post-training weight quantization method.
- QuaRot (Ashkboos et al., 2024): A rotation-based method for outlier suppression.
- SpinQuant (Liu et al., 2024) and DuQuant (Lin et al., 2024a): Additional baselines for specific comparisons, including training-based methods.
The definitive evidence for their core mechanism's efficacy was gathered through several experimental architectures:
1. Perplexity on WikiText-2: This standard benchmark measures how well a language model predicts a sample of text, with lower perplexity indicating better performance.
2. Zero-shot Common Sense QA Benchmarks: Performance was assessed on tasks like ARC-e, ARC-c, BoolQ, and OBQA to evaluate the models' reasoning capabilities post-quantization.
3. Ablation Studies:
* A preliminary ablation (Figure 3) directly compared Runtime Smooth with SmoothQuant and an "Origin A4W4" baseline, demonstrating the necessity of runtime smoothing and the pitfalls of migrating outliers to weights.
* An ablation on the group size of the runtime smoothing scale (Table 4) explored the impact of this hyperparameter on accuracy.
4. Efficiency Evaluation: Using NVBench on an RTX 4070 Ti GPU, the authors measured the overhead of their fused GEMM kernel compared to Per-Channel A4W4 and Sub-Channel A4W4 baselines (Figure 6), proving the practical viability of their approach.
5. Statistical Outlier Analysis: Figure 9 provided a detailed statistical breakdown of outlier removal across different LLM components (QKV_Projector, Output_Projector, Up_Proj or Gate_Proj, Down_Projector) for various models, visually demonstrating how RRS effectively shifts activations into a smoother range compared to other methods.
What the Evidence Proves
The evidence presented in the paper provides compelling proof of the effectiveness of Rotated Runtime Smooth (RRS) and its constituent Runtime Smooth (RS) in enabling accurate INT4 inference for LLMs.
Firstly, the Runtime Smooth (RS) component, designed to eliminate channel-wise outliers, showed significant improvements. The preliminary ablation study (Figure 3) clearly demonstrated that simply applying a runtime smoothing scale was insufficient for A4W4 quantization. However, when RS was fully implemented, it made A4W4 feasible, leading to a dramatic perplexity improvement from 4e2 to 10.9 for LLaMA3-8B under the A4W16 setting. This was crucial in validating the core idea of adopting runtime scales without migrating outliers to weights, which was a key limitation of prior methods like SmoothQuant. In Table 1, RS consistantly outperformed SmoothQuant and RTN across various models and quantization schemes, for instance, reducing LLaMA2-70B perplexity from 1e2 (SmoothQuant) to 6.95 (RS) under the 16-4-16 scheme. Furthermore, under activation-only quantization (A4W16KV16), RS acheives a 40x improvement on LLaMA3-8B, underscoring its efficacy.
Secondly, the full Rotated Runtime Smooth (RRS) method, which combines rotation with runtime smoothing to address both channel-wise and spike outliers, delivered superior performance. Table 1, the main result table for WikiText-2 perplexity, shows RRS consistently outperforming all baselines, including RS, QuaRot, SmoothQuant, and RTN, across nearly all evaluated LLaMA, Qwen, and Mistral models. A particularly striking example is LLaMA3-70B, where RRS reduced perplexity from 57.33 to 6.66 under A4W4KV16, and from 49.76 to 6.87 under A4W4KV4. These are substantial improvements over the state-of-the-art QuaRot, which yielded 57.33 and 49.73 respectively for the same model and settings. This definitive evidence proves that RRS's combined mechanism effectively mitigates the impact of both types of outliers.
Beyond perplexity, RRS also demonstrated its strength on zero-shot common sense QA tasks (Table 2). Across various LLMs and quantization schemes, RRS consistently surpassed all baselines (GPTQ, SmoothQuant, RS, QuaRot) by approximately 3% in average accuracy improvement. For example, on LLaMA-3-8B with 4-4-16 quantization, RRS achieved an average accuracy of 58.0%, compared to QuaRot's 55.0%. This indicates that the improved activation smoothing translates to better performance on complex reasoning tasks.
The statistical analysis of outlier removal (Figure 9) provides direct visual evidence of RRS's mechanism at work. It shows that RRS leads to a significantly higher proportion of activations falling into the 'u < 4' (smoother) category across all LLM components (QKV_Projector, Output_Projector, Up_Proj or Gate_Proj, Down_Projector) and models, compared to original activations (X), rotated activations (R), or Runtime Smooth alone (RS). This directly validates RRS's ability to comprehensively eliminate both channel-wise and spike outliers.
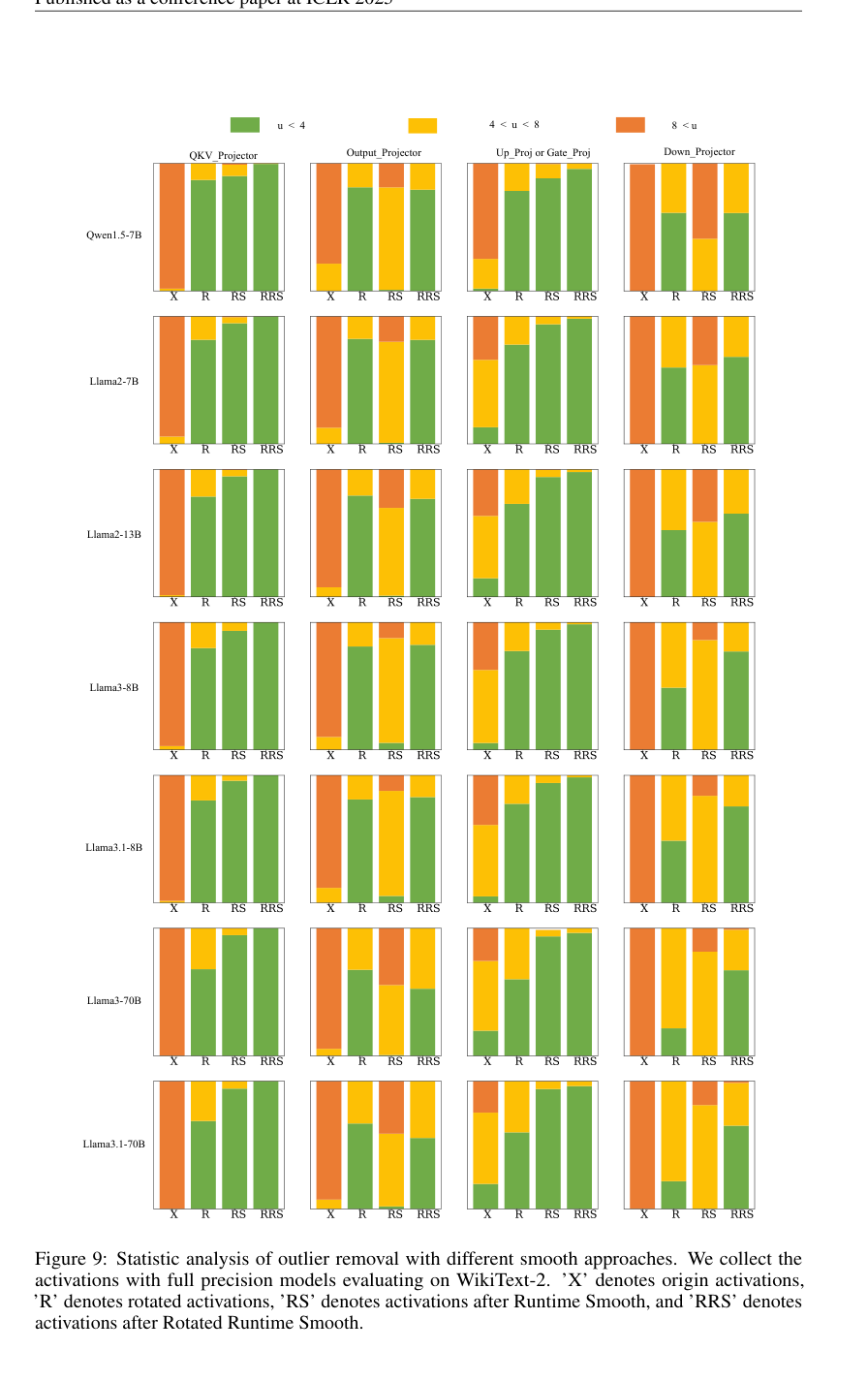 Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Finally, the efficiency evaluation (Figure 6 and Section 4.5) confirms that the RRS fused kernel introduces only negligible overhead compared to the A4W4 Per-Channel quantization baseline. This is a critical practical advantage, as it means the accuracy gains do not come at the cost of significant slowdowns, making RRS a truly plug-and-play solution for INT4 inference. The comparison with training-based methods (Table 3) further highlights RRS's strength, as it outperforms SpinQuant (a training-based method) in WikiText-2 perplexity without incurring the substantial training time costs.
Limitations & Future Directions
While Rotated Runtime Smooth (RRS) presents a significant advancement for training-free INT4 inference, the paper also implicitly and explicitly points to several limitations and opens doors for future research.
Current Limitations:
1. Incomplete Smoothing Guarantee from Rotation: The paper notes that "rotation cannot guarantee a smoother matrix, and a rotated matrix may still exhibit the shape of channel-wise outliers" (Section 1, Figure 2). This suggests that while rotation helps, it's not a perfect solution on its own, necessitating the Runtime Smooth component.
2. "Victim" Effect from Spike Outliers: The existence of spike outliers can still cause normal values to be pruned as "victims" after channel-wise smoothing (Section 1, Figure 1). Although RRS aims to mitigate this, the underlying challenge remains.
3. Group Size Sensitivity: The ablation study (Section 4.4, Table 4) indicates that while Runtime Smooth effectively minimizes the gap between A4W4 and full precision, "the accuracy deteriorates as the group size increases." This implies a trade-off and a potential sensitivity to the chosen group size, which might not be universally optimal.
4. Specific Outlier Scenarios: The paper mentions that "the case with only two outlier tokens is rare but could potentially trouble Rotated Runtime Smooth" (Section C.1). This highlights a specific, albeit uncommon, outlier pattern that RRS might struggle with, suggesting its robustness might not be absolute across all possible outlier distributions.
5. Model-Specific Outlier Sensitivity: The authors observe that "models have different sensitivities to outliers. Further suppressing the outliers can enhance robustness" (Section 4.2). This implies that while RRS is generalized, there might be model-specific outlier characteristics that could be further optimized.
6. Hardware Constraints on Group Size: For certain models like Qwen1.5-7B, the input activation size for Down_projector (11008) "does not support a group size of 512" (Section 4.4). This indicates practical limitations in applying the largest group sizes, which might otherwise offer certain benefits.
Future Directions & Discussion Topics:
- Adaptive and Dynamic Smoothing Strategies: Given the sensitivity to group size and varying outlier patterns, future work could explore adaptive smoothing strategies. Instead of a fixed group size or a universal rotation, can we dynamically adjust these parameters based on real-time activation statistics or model layer characteristics? This could involve lightweight, on-the-fly analysis to optimize smoothing for each specific input and layer, potentially leading to even greater accuracy and robustness.
- Theoretical Bounds and Guarantees for Outlier Suppression: The paper empirically demonstrates RRS's effectiveness. A deeper theoretical investigation into the mathematical properties of rotation and runtime smoothing could establish formal bounds on outlier suppression and its impact on quantization error. This could lead to a more principled design of future quantization methods with provable guarantees.
- Hybrid Training-Free and Training-Based Approaches: While RRS is training-free and outperforms some training-based methods, the concept of learned rotations (as in SpinQuant) still holds promise. Future research could investigate hybrid approaches that combine the efficiency of training-free methods like RRS with minimal, targeted training or fine-tuning steps to further refine the rotation or smoothing scales, potentially achieving even higher accuracy without the extensive training overhead of current training-based methods.
- Hardware-Software Co-design for Advanced Quantization: The negligible overhead of RRS is a significant advantage. To push this further, dedicated hardware accelerators or specialized instruction sets could be designed to natively support the reordering, group-wise maximum computation, and rotation operations central to RRS. This co-design approach could unlock unprecedented speedups and energy efficiency for INT4 inference.
- Generalization to Other Data Types and Model Architectures: RRS is validated for INT4 inference in LLMs. How well would these principles extend to other low-bit quantization schemes (e.g., INT2, binary) or different model architectures beyond transformers, such as vision models or multi-modal architectures? Investigating these broader applications could reveal new challenges and opportunities for adapting RRS.
- Robustness to Adversarial Attacks and Distribution Shifts: Quantized models can be more vulnerable to adversarial attacks or performance degradation under out-of-distribution data. Future work could explore how RRS, by making activations smoother and more consistent, might inherently improve the robustness of quantized LLMs against such challenges, or if specific modifications are needed to enhance this aspect.
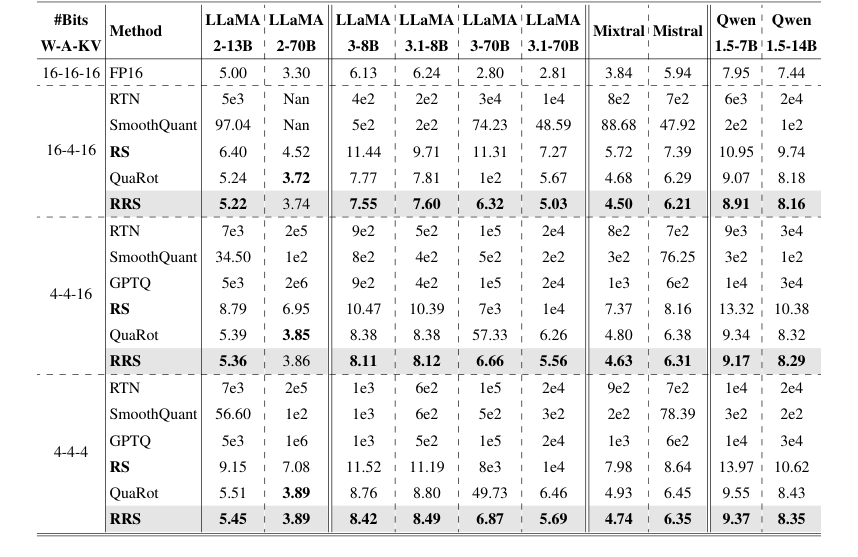 Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
 Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
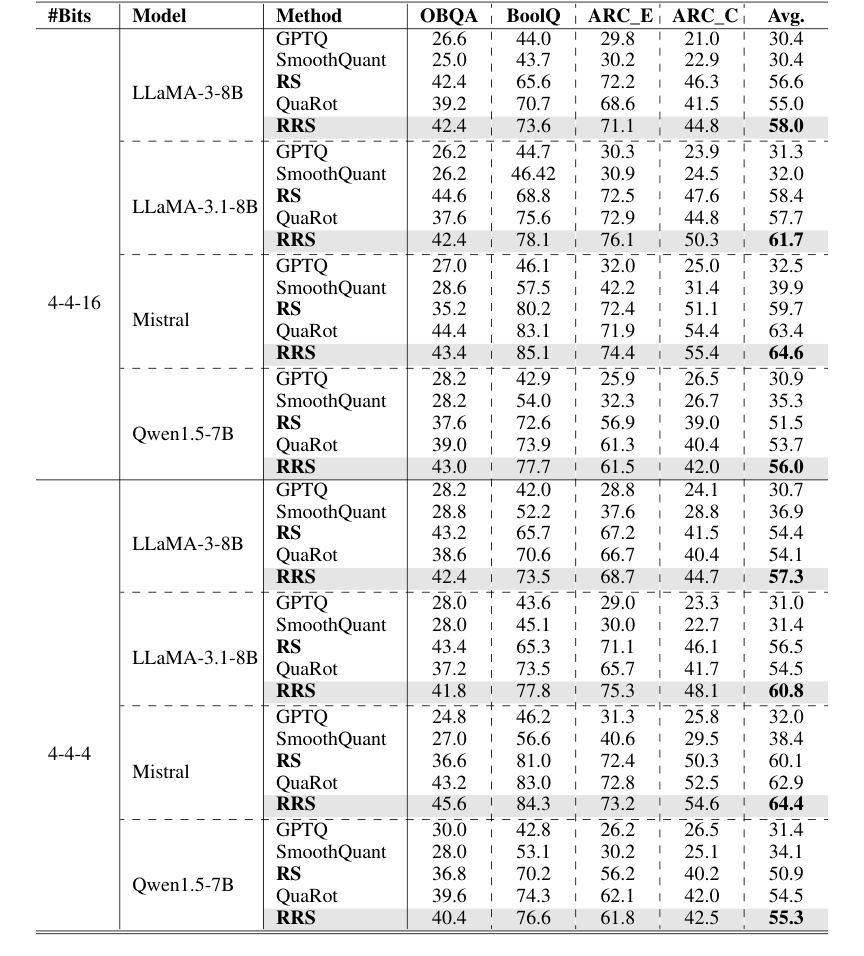 Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes