Rotated Runtime Smooth: 训练无关的激活平滑器,用于精确的 INT4 推理
Large language models have demonstrated promising capabilities upon scaling up parameters.
背景与学术渊源
起源与学术渊源
本文所解决的问题源于大型语言模型(LLMs)日益增长的规模和复杂性。随着这些模型的不断发展,其推理服务的计算资源和内存消耗变得极其昂贵。为了降低这些成本并提高延迟,量化方法得到了广泛应用。量化本质上是降低模型中使用的数字(权重和激活)的精度,例如,从高精度浮点数降低到像 INT4(4位整数)这样的低比特整数。
然而,低比特量化,特别是 INT4 权重-激活量化,出现了一个显著的“痛点”:激活中的离群值。这些离群值是激活张量中的极端值,它们不成比例地拉伸了值的整体范围。当整个范围被压缩到非常有限的比特数(如 4 位)时,这些离群值会消耗掉大部分可用的“精度槽”,为更常见、更“正常”的值留下很少的有效比特。这严重损害了模型在推理过程中的准确性。
先前的方法试图解决这些离群值问题,但面临着根本性的限制:
* 分离离群值:早期的方法(例如,Kim 等人,2023;Dettmers 等人,2022)试图将离群值与正常值分离到不同的矩阵中。这里的主要缺点是这些实现通常不兼容硬件,导致高延迟,未能加速推理。
* 离线平滑与迁移(SmoothQuant):SmoothQuant(Xiao 等人,2023)旨在通过通道级平滑尺度将离群值从激活迁移到权重。虽然对于更高比特的量化(如 A8W8)有效,但由于几个原因,它在 INT4 推理中失败了:
* 平滑尺度是使用校准集离线预计算的,当遇到新的、不匹配的在线激活时,它们就无效了。
* 离群值并未真正消除,只是部分迁移,仍然阻碍了低比特量化。
* SmoothQuant 主要解决了“通道级”离群值,但难以处理“尖峰”离群值,这些离群值在不同通道之间不一致,导致正常值被错误地剪枝为“受害者”。
* 基于旋转的方法(QuaRot):最近的工作如 QuaRot(Ashkboos 等人,2024)引入了旋转矩阵,通过在内部分散离群值来抑制它们。虽然对于 A4W4 量化很有前景,但单独的旋转不能保证完美的平滑矩阵,并且可能仍然存在通道级离群值,留下了进一步改进的空间。挑战仍然是找到一种鲁棒、准确且无需训练的 INT4 推理方案,能够有效地处理这两种类型的离群值。
直观的领域术语
- 量化(Quantization):想象一下你有一个拥有数百万种色调的非常精细的调色板(如浮点数)。量化就像选择只使用一个非常小的颜色集,比如 16 种特定颜色(如 4 位整数),来表示你所有的图像。目标是使图像更小、处理速度更快,同时仍使其看起来尽可能好。
- 激活中的离群值(Outliers in Activations):想象一群人的身高大多在 5 到 6 英尺之间。但你有一些高达 20 英尺的巨人,也有一些只有 1 英尺高的小矮人。如果你试图只用 10 个标记来为所有人创建一个身高尺度,那些极端的巨人和小矮人将迫使尺度覆盖一个巨大的范围(1 到 20 英尺)。这意味着常见的 5-6 英尺范围内的标记非常少,使得很难区分身高 5'2" 和 5'4" 的人。“巨人”和“小矮人”就是离群值,使得准确表示“正常”身高变得困难。
- INT4 推理(INT4 Inference):这就像用非常简单、四舍五入的数字(例如,只有 -8 到 7 的数字,这是 4 位整数可以表示的)而不是非常精确的小数进行计算。计算 $5 \times 3$ 比计算 $5.123 \times 3.456$ 要快得多,也更省力(或计算机内存/功耗)。“INT4”部分意味着使用 4 位整数,这是一种非常激进的四舍五入形式,以获得 LLMs 的最大速度和内存节省。
- 困惑度(Perplexity):在语言模型的上下文中,困惑度是衡量模型对序列中下一个词的“惊讶”程度的度量。想象一下你正在尝试猜测句子中的下一个词。如果你非常有信心并且猜对了,你的“惊讶”程度就很低。如果你经常出错或不确定,你的“惊讶”程度就很高。较低的困惑度分数意味着语言模型不太惊讶,表明它在预测文本方面表现更好,并且更准确地理解语言。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决的根本问题是,在尝试使用极低比特的权重-激活量化,特别是 INT4 进行推理时,大型语言模型(LLMs)的准确性会显著下降。
输入/当前状态是,尽管 LLMs 具有令人印象深刻的能力,但由于其庞大的规模,服务它们进行推理在计算和内存方面非常密集。量化,即降低模型参数和激活的精度(例如,从 FP32 到 INT4),是一种有前景的技术,可以缓解这些成本并提高推理延迟。然而,INT4 权重-激活量化广泛采用的一个关键障碍是激活张量中存在“离群值”。这些离群值是极端值,不成比例地拉伸了量化范围,有效地压缩了正常值可用的动态范围,并导致大量信息丢失和准确性下降。
期望终点(输出/目标状态)是实现准确且高效的 LLMs INT4 权重-激活推理。这意味着在不产生显著准确性下降的情况下,实现 INT4 量化的计算和内存优势。本文旨在开发一种“无需训练的激活平滑器”,能够鲁棒地处理激活离群值,从而使正常值能够以足够的精度进行量化,最终在各种 LLM 系列的 INT4 推理中实现最先进的性能。
当前状态与目标状态之间的确切缺失环节或数学鸿沟在于找到一种有效“平滑”或归一化激活离群值的方法,使得整个激活张量能够以最小的信息丢失量化到 INT4,同时计算成本低廉且无需训练。从数学上讲,如果 $X$ 是一个激活张量,$\alpha$ 是其量化的缩放因子(例如,对于 N 位量化,$\alpha = \frac{\max(|X|)}{2^{N-1}-1}$),离群值会导致 $\max(|X|)$ 非常大,从而使 $\alpha$ 变大。这导致正常值被映射到一个非常小的整数值范围,从而导致严重的精度损失。缺失的环节是一个变换 $f(X)$,使得 $f(X)$ 的 $\max(|f(X)|)$ 比 $\max(|X|)$ 小得多,但 $f(X)$ 仍然准确地表示原始信息,从而允许使用更小的 $\alpha'$,从而更有效地量化正常值。此变换还必须与权重矩阵 $W$ 兼容,以保留输出 $XW$。
困扰先前研究人员的痛苦权衡或困境主要是准确性 vs. 效率 vs. 鲁棒性三角形:
1. 准确性 vs. 效率(低比特量化):激进的低比特量化(INT4)提供了显著的加速和内存节省,但极易受到激活离群值的影响,导致准确性严重下降。保持准确性通常需要更高的比特宽度或复杂的离群值处理,这会抵消效率的提升。
2. 离群值处理 vs. 硬件兼容性/延迟:现有的解决离群值问题的方法,例如将离群值分离到不同的矩阵(例如,Kim 等人,2023;Dettmers 等人,2022)或将它们迁移到权重(例如,SmoothQuant),通常会引入硬件不兼容、显著的延迟开销或使权重量化变得困难。这破坏了更快、更高效推理的核心目标。
3. 静态 vs. 动态平滑:预计算的平滑尺度(例如,在 SmoothQuant 中)很高效,但会与在线激活“不匹配”,使其对真实世界的动态输入无效。运行时平滑更鲁棒,但传统上会产生不可接受的计算开销。
4. 通道级 vs. 尖峰离群值:离群值表现为不同的形式:“通道级”(在通道内一致)和“尖峰”(孤立的极端值)。对一种类型有效的方法(例如,通道级平滑)可能会加剧另一种类型的“受害者效应”(例如,尖峰离群值导致正常值被剪枝),导致量化误差。一种不产生新副作用的统一解决方案仍然难以捉摸。
约束与失效模式
由于作者遇到的严峻的现实障碍,准确进行 LLMs INT4 推理的问题极其困难:
- 激活离群值的极端稀疏性/幅度:激活离群值的幅度可以比正常值大几个数量级(例如,大 1000 倍,如第 14 页所述)。这种极端的幅度如此严重地拉伸了量化范围,以至于正常值几乎失去了所有有效比特,导致灾难性的准确性损失。
- INT4 精度限制:量化到 INT4 意味着只有 16 种可能的离散值($2^4$)可以表示激活的整个范围。这种极其有限的精度几乎没有容错空间,也无法在不显著丢失大多数值信息的情况下容纳离群值。
- 实时延迟要求:LLM 推理,尤其是预填充阶段,要求严格的实时延迟。任何离群值平滑或处理机制都必须引入“可忽略的开销”(第 2 页,第 9 页)才能实用。增加显著计算时间的复杂操作是不可接受的。
- 硬件内存限制:LLMs 非常庞大,内存带宽通常是瓶颈。量化的目的是减少内存占用和移动。需要存储额外高精度数据或复杂离群值数据结构的解决方案可能会抵消这些好处。
- 无需训练的要求:解决方案必须是“无需训练”且“即插即用”的(摘要,第 2 页)。这意味着它不能依赖于大型数据集上的广泛微调或校准,这对于大型模型来说既耗时又耗资源。
- 动态输入分布:激活的分布在不同的输入和 LLM 的不同层之间可能存在显著差异。从静态校准集派生的平滑尺度容易与在线激活“不匹配”(第 3 页),导致平滑无效和准确性下降。
- “受害者”效应:当平滑尺度由极端离群值决定时,正常值(它们小得多)可能会被有效“剪枝”或成为“受害者”(第 2 页,图 1c,第 3 页)。正常值精度的这种损失是一个关键的失效模式,因为它直接影响模型表示细微信息的能力。
- 与 GEMM 内核的不兼容性:运行时平滑的朴素实现,尤其是在平滑尺度不一致的情况下,无法轻松集成到高度优化的通用矩阵乘法(GEMM)内核中(第 4 页)。这使得实现硬件加速具有挑战性,因为需要自定义内核或复杂的块状计算。
- 旋转后的亚平滑性:虽然基于旋转的方法(如 QuaRot)可以分散离群值,但它们不能保证完全平滑的矩阵,并且可能仍然表现出“通道级离群值”或“亚平滑性”(第 2 页,图 2c,第 4 页)。这意味着单独的旋转不足以完全解决 INT4 量化的离群值问题。
- 离群值迁移挑战:先前将离群值从激活迁移到权重的方法(例如,SmoothQuant)可能会使权重难以量化,特别是对于 A4W4 这样的极低比特方案(第 1 页)。这在解决激活域问题时,在权重域中产生了新问题。
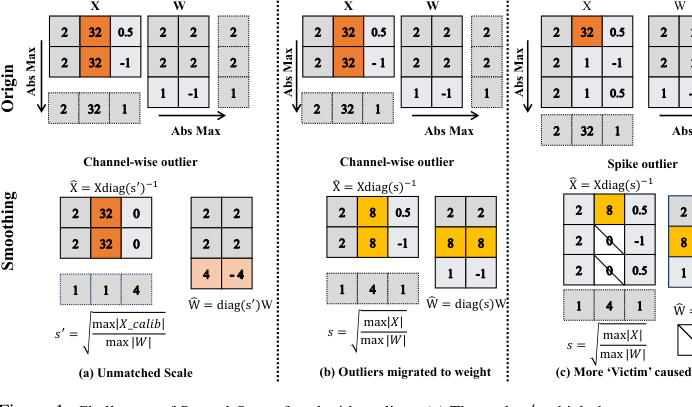 Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
为什么选择这种方法
选择的必然性
作者转向 Rotated Runtime Smooth (RRS) 的驱动力在于现有量化方法在应用于大型语言模型(LLMs)的 INT4 推理的挑战性环境中时所面临的根本性限制。“精确时刻”的认识是,传统的最新(SOTA)方法不足以解决激活离群值这一持续存在的问题。
传统方法,例如将离群值和正常值分离到两个不同的矩阵中(例如,Kim 等人,2023;Dettmers 等人,2022),被发现存在高延迟或显著的准确性下降。至关重要的是,这些方法通常与硬件加速不兼容,未能按预期加速推理。
一个更直接的前身是 SmoothQuant(Xiao 等人,2023),它试图通过使用通道级平滑尺度将离群值从激活迁移到权重来缓解离群值。然而,对于 INT4 量化,SmoothQuant 面临三个关键的失败:
1. 不匹配的尺度:从校准集派生的离线预计算平滑尺度,经常与在线激活不匹配,使其平滑效果无效。
2. 不完全的离群值消除:离群值通道并未完全消除,只是部分迁移到权重,这使得低比特量化(特别是 INT4)变得困难。
3. 尖峰离群值和“受害者”:SmoothQuant 主要解决了通道级离群值,但未能处理不一致地跨通道的“尖峰离群值”。当存在这些尖峰离群值时,正常值在平滑过程中被无意地剪枝为“受害者”,导致准确性下降。
即使是像 QuaRot(Ashkboos 等人,2024)这样的基于旋转的方法,虽然在分散离群值方面显示出前景,但理论上不能保证均匀平滑的矩阵。旋转后的激活,特别是那些具有通道级离群值的激活,仍然可能表现出“亚平滑性”(如图 2c 所示),留下了进一步改进的空间。这种先前方法未能以无需训练的方式鲁棒、准确且高效地处理 INT4 推理中通道级和尖峰离群值的集体失败,使得开发 RRS 这样一种新的、全面的解决方案不仅是一个选择,而且是必然的。
比较优势
Rotated Runtime Smooth (RRS) 主要通过其全面而鲁棒的离群值处理能力,以及极低的计算开销,在定性上优于先前的方法。
RRS 的结构优势在于其双管齐下的方法:
1. 运行时平滑(RS):该组件通过在运行时动态计算平滑尺度直接解决通道级离群值问题。与依赖离线校准并将尺度合并到权重的 SmoothQuant 不同,RS 避免了不匹配尺度和量化具有迁移离群值的权重的问题。通过在运行时获取平滑尺度并且不将其合并到权重中,RS 确保了平滑始终与当前输入相关,使其更具适应性和准确性。
2. 旋转操作:这是 RRS 处理尖峰离群值并增强鲁棒性的地方。通过旋转权重和激活(遵循 QuaRot 的原理),尖峰离群值被有效地分散到 token 中。这种分散导致通道之间更一致的平滑尺度,进而防止正常值在通道级平滑过程中成为“受害者”。对于具有通道级离群值的激活,旋转有助于保持一致性,同时也提供了降低离群值水平的机会。
这种组合策略提供了先前方法所缺乏的结构优势。例如,SmoothQuant 无法有效处理尖峰离群值,并且存在校准集不匹配的问题。纯粹的旋转方法虽然有益,但本身不能保证足够的平滑度。RRS 集成了两者的最佳方面,确保所有类型的离群值(通道级和尖峰)都得到全面解决。
此外,RRS 被设计为一个“即插即用”的组件,为 INT4 矩阵乘法带来了可忽略的开销。本文明确指出,在融合的 GEMM 内核中增加的运行时尺度乘法,与 A4W4 基线相比,仅带来“可忽略的开销”。这是一个显著的定性优势,因为它在不牺牲低比特量化所期望的关键延迟优势的情况下,实现了卓越的准确性。它没有引入高维噪声,而是通过拉伸量化范围的离群值的影响来缓解这些噪声。
与约束的对齐
Rotated Runtime Smooth (RRS) 方法完美地符合高效 LLM 推理的严格要求,特别是对于 INT4 量化。核心约束,由服务大型 LLMs 的问题隐含定义,包括:
1. INT4 推理:主要目标是以 INT4 精度实现准确推理,这对于降低内存和计算成本至关重要。RRS 被专门设计为“用于精确 INT4 推理的无需训练的激活平滑器”。其整个机制,从处理通道级到尖峰离群值,都旨在使激活能够进行 4 位量化,而不会显著降低准确性。在 A4W4KV16 设置下,LLaMA 和 Qwen 系列上的困惑度改进(例如,LLaMA3-70B 从 57.33 降至 6.66)直接验证了其在实现此目标方面的有效性。
2. 无需训练:实际部署的一个关键要求是避免昂贵的重新训练或微调。RRS 明确是“无需训练的”,这意味着它可以在训练后应用,而无需额外的模型优化。这完美地符合了不需要增加 LLMs 本已巨大的训练负担的可部署解决方案的需求。
3. 准确性保持:低比特量化通常会导致准确性下降。RRS 的全面离群值缓解策略——结合运行时平滑处理通道级离群值和旋转处理尖峰离群值——旨在“全面消除离群值”和“增强鲁棒性”,从而保持准确性。在困惑度和零样本 QA 任务上持续优于 SOTA 方法的性能证明了这种对齐。
4. 低延迟/最小开销:量化的目的是降低服务成本和延迟。RRS 的设计注重效率,其运行时平滑组件与原始 A4W4 流水线相比,开销极小。与 A4W4 每通道量化相比,运行时平滑的内核融合确保了该过程有效地集成到 GEMM 流水线中,增加了可忽略的开销。这直接解决了保持高吞吐量和低延迟的约束。
5. 对离群值的鲁棒性:问题陈述强调离群值是主要障碍。RRS 独特地解决了通道级和尖峰离群值两种类型,并通过确保一致的平滑尺度来防止“受害者”,使其本质上对 LLM 激活中观察到的各种离群值模式具有鲁棒性。这种“结合”——问题严峻的离群值挑战与解决方案独特的双离群值处理——是其成功的核心。
替代方案的拒绝
本文提供了清晰的理由来拒绝几种替代方法,突出了它们在 LLMs INT4 推理方面的不足:
-
传统离群值分离(例如,LLM.int8(),Kim 等人,2023;Dettmers 等人,2022):这些方法,无论是将离群值分离到更高精度格式(混合 INT8/FP16)还是分离到单独的矩阵中,都因“高延迟或准确性下降”以及通常“不兼容硬件”而被拒绝,因此未能“加速推理”。LLM.int8() 特别“导致显著的延迟开销,甚至可能比 FP16 推理慢。”
-
SmoothQuant(Xiao 等人,2023):虽然对于 A8W8 量化有效,但 SmoothQuant 对于 INT4 来说被认为不足,因为其离线、依赖校准集的平滑尺度“容易与在线激活不匹配”。此外,它只是部分地将离群值迁移到权重而不是消除它们,这使得低比特量化变得困难,并且至关重要的是,它未能处理“尖峰离群值”,导致“受害者”剪枝。
-
纯粹的基于旋转的方法(例如,QuaRot,Ashkboos 等人,2024):虽然旋转有助于分散离群值,但本文指出“乘以单个旋转矩阵在理论上不能保证更平滑的权重或激活”。即使旋转后,激活仍然可能表现出“亚平滑性”,带有通道级离群值(图 2c),表明单独的旋转不是解决全面平滑的完整方案。QuaRot 还需要“复杂的在线 Hadamard 旋转”,RRS 旨在简化这一点。
-
基于训练的量化(例如,SpinQuant,Liu 等人,2024):本文明确将 RRS 与 SpinQuant 进行比较,并因其高昂的计算成本而拒绝基于训练的方法。SpinQuant 的训练过程“耗时,对于一个 7B 模型在单个 A100 GPU 上需要 1.5 小时,对于八个 A100 GPU 上的 70B 模型需要 12 小时”。此外,结果表明基于训练的方法“导致 WikiText-2 困惑度比无需训练的方法下降,并且仍有改进空间”,使其在效率和最终准确性方面都更不可取。
-
其他重排序技术(例如,RPTQ,Yuan 等人,2023;Atom,Zhao 等人,2024):虽然这些方法重新排列通道以减少方差或使用混合精度,但它们没有为 RRS 提供的 INT4 中的通道级和尖峰离群值提供全面、无需训练且低开销的解决方案。例如,Atom 将重排序与混合 INT4/INT8 集成,这不是纯 INT4。
拒绝这些替代方案的共同主题是它们无法同时满足 INT4 推理的严格要求:高准确性、低延迟以及针对所有类型激活离群值的无需训练、鲁棒的解决方案。
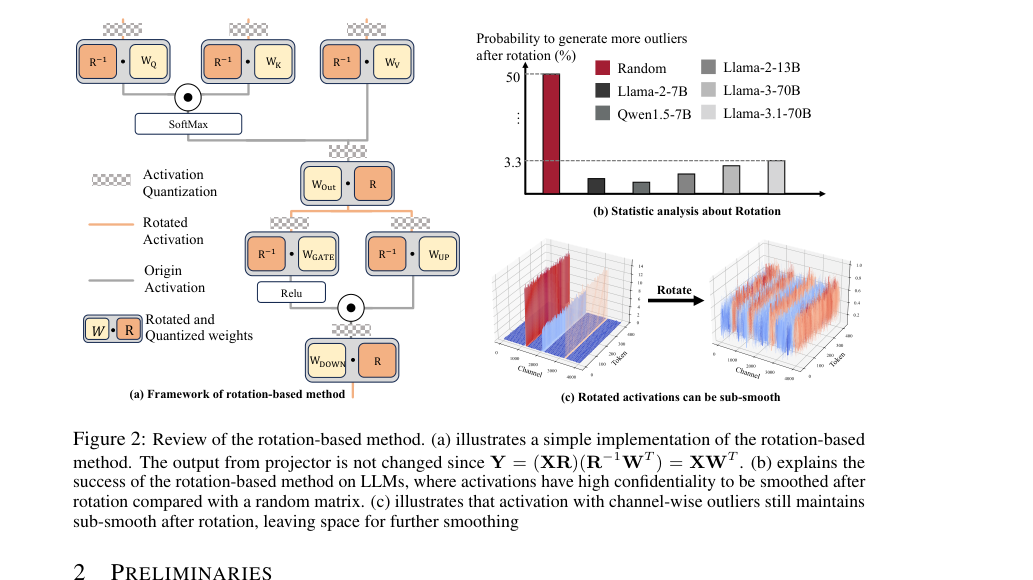 Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
数学与逻辑机制
主方程
驱动 Rotated Runtime Smooth (RRS) 方法的核心数学引擎结合了旋转操作和运行时平滑机制。给定一个激活矩阵 $X$ 和一个权重矩阵 $W$,RRS 过程可以通过以下一系列操作来概括:
$$ X_{rot} = XR \\ W_{rot} = R^{-1}W \\ s_j = \max(|(X_{rot})_j|), \quad j = 1, \dots, K \\ X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1}) \\ W'_{quant} = \text{Quantize}(W_{rot}) \\ Y = \sum_{j=1}^{K} (X'_{quant})_j (W'_{quant})_j^T s_j $$
这组方程描述了激活和权重如何首先被旋转,然后激活使用运行时派生的尺度进行平滑,两者都被量化,最后,修改后的矩阵乘法产生低比特输出。
逐项解剖
让我们剖析主方程的每个组成部分,以理解其数学定义、逻辑作用以及其设计背后的原理。
-
$X$:表示线性层的输入激活张量。
1) 数学定义:一个 $N \times K$ 的浮点矩阵,其中 $N$ 通常是批次大小乘以序列长度,而 $K$ 是输入通道维度。
2) 物理/逻辑作用:它承载来自前一层的特征信息,需要由当前线性层处理。
3) 为何采用此形式:它是输入批次的标准表示。 -
$W$:这是线性层的权重矩阵。
1) 数学定义:一个 $M \times K$ 的浮点矩阵,其中 $M$ 是输出维度,$K$ 是输入通道维度。
2) 物理/逻辑作用:包含将输入激活转换为输出特征的可学习参数。
3) 为何采用此形式:线性层权重的标准表示。 -
$R$:这是旋转矩阵。
1) 数学定义:一个 $K \times K$ 的正交矩阵,意味着 $RR^T = I$(其中 $I$ 是单位矩阵)且其行列式 $\det(R) = 1$。本文常指 Hadamard 旋转矩阵,其中 $R = \frac{1}{\sqrt{K}}[s_{i,j}]_{K \times K}$,元素 $s_{i,j} \in \{-1, +1\}$。
2) 物理/逻辑作用:其主要作用是线性变换(旋转)激活和权重的向量空间。这种旋转对于“分散”集中在激活中的离群值至关重要,使其对量化范围的影响减小。通过适当旋转 $X$ 和 $W$,原始输出 $XW^T$ 在数学上保持为 $(XR)(R^{-1}W^T)$。
3) 为何乘法:矩阵乘法是向量空间中应用线性变换(如旋转)的基本运算。 -
$R^{-1}$:这是旋转矩阵的逆。
1) 数学定义:由于 $R$ 是正交的,其逆就是其转置 $R^T$。它也是一个 $K \times K$ 矩阵。
2) 物理/逻辑作用:它以与 $X$ 互补的方式旋转权重矩阵 $W$,确保在与 $X_{rot}$ 结合时,整体变换保持与原始全精度运算等效。
3) 为何乘法:与 $R$ 类似,它是一种线性变换。 -
$X_{rot} = XR$:旋转后的激活张量。
1) 数学定义:输入激活矩阵 $X$ 与旋转矩阵 $R$ 相乘的结果。它保持 $N \times K$ 的形状。
2) 物理/逻辑作用:这些是经过旋转线性组合和重新分布到不同通道后的激活。此步骤旨在通过降低其幅度或使其分布更均匀来缓解通道级离群值。
3) 为何乘法:这是旋转变换的直接应用。 -
$W_{rot} = R^{-1}W$:旋转后的权重矩阵。
1) 数学定义:权重矩阵 $W$ 与逆旋转矩阵 $R^{-1}$ 相乘的结果。它保持 $M \times K$ 的形状。
2) 物理/逻辑作用:这些是经过旋转的权重。这种旋转是必需的,以在与 $X_{rot}$ 结合时保持原始矩阵乘法的数学等价性。
3) 为何乘法:逆旋转的直接应用。 -
$s_j = \max(|(X_{rot})_j|)$:第 $j$ 个通道的运行时平滑尺度。
1) 数学定义:对于旋转激活矩阵 $X_{rot}$ 的每一列 $j$(表示为 $(X_{rot})_j$,这是一个 $N \times 1$ 的向量),此操作计算该列中所有元素的最大绝对值。这产生一个标量 $s_j$。
2) 物理/逻辑作用:此尺度动态捕获旋转后激活的每个通道中存在的最大幅度。它作为归一化因子,将该通道内的值带入更易于管理的范围,以便进行量化。通过使用最大绝对值,它确保在后续除法过程中没有值被裁剪,从而保留信息。这是“运行时平滑”组件的关键部分,用于处理通道级离群值。
3) 为何取最大值和绝对值:max确定了决定所需缩放范围的极端值。绝对值确保正负离群值对称处理。 -
$\text{diag}(s)^{-1}$:平滑尺度逆对角矩阵。
1) 数学定义:一个 $K \times K$ 的对角矩阵,其中第 $j$ 个对角线元素是 $1/s_j$。
2) 物理/逻辑作用:该矩阵允许通过将每列除以其特定的 $s_j$ 来实现 $X_{rot}$ 的通道级缩放。
3) 为何对角矩阵:它是一种将元素级列缩放表示为矩阵乘法的有效方式。 -
$X_{rot}\text{diag}(s)^{-1}$:平滑后的旋转激活。
1) 数学定义:旋转激活矩阵的每一列 $(X_{rot})_j$ 被其对应的标量 $s_j$ 进行元素级除法。这产生一个 $N \times K$ 矩阵。
2) 物理/逻辑作用:此操作对旋转激活进行通道级归一化。通过根据通道的最大幅度缩放值,离群值相对于正常值被有效地“压缩”,使得整个通道的数据更好地适应低比特量化范围。
3) 为何除法:除以最大绝对值会缩放数据,通常缩放到 $[-1, 1]$ 的范围,这对于对称量化方案是最佳的。 -
$\text{Quantize}(\cdot)$:量化函数。
1) 数学定义:一个将浮点数映射到低比特整数表示的函数。例如,对于 INT4,它可能将浮点数 $x$ 映射到整数 $q$,其中 $q = \text{round}(x \cdot \text{scale}) + \text{offset}$,其中scale和offset由目标比特宽度和值范围确定。
2) 物理/逻辑作用:这是降低数字精度的核心操作。它将高精度浮点值转换为离散的低比特整数值,这在推理过程中显著减少了内存占用和计算成本。
3) 为何此函数:它是将连续值转换为有限离散值集合的标准方法,这是量化的本质。 -
$X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1})$:量化后的平滑旋转激活。
1) 数学定义:将 $\text{Quantize}$ 函数应用于平滑旋转激活矩阵的结果。它是一个 $N \times K$ 的低比特整数矩阵。
2) 物理/逻辑作用:这些是输入激活的最终低比特、离群值缓解形式,已准备好进行高效的矩阵乘法。 -
$W'_{quant} = \text{Quantize}(W_{rot})$:量化后的旋转权重。
1) 数学定义:将 $\text{Quantize}$ 函数应用于旋转权重矩阵的结果。它是一个 $M \times K$ 的低比特整数矩阵。
2) 物理/逻辑作用:这些是权重经过低比特、离群值缓解处理后的形式,已准备好进行高效的矩阵乘法。 -
$(X'_{quant})_j$:$X'_{quant}$ 的第 $j$ 列。
1) 数学定义:一个形状为 $N \times 1$ 的列向量,包含低比特整数。
2) 物理/逻辑作用:表示特定输入通道的量化和已平滑的激活。 -
$(W'_{quant})_j^T$:$W'_{quant}$ 的第 $j$ 行(转置)。
1) 数学定义:一个形状为 $1 \times M$ 的行向量,包含低比特整数。(注意:假设 $W'_{quant}$ 是 $M \times K$,则 $(W'_{quant})_j$ 是其第 $j$ 列,形状为 $M \times 1$。因此,$(W'_{quant})_j^T$ 是 $1 \times M$。这与 $N \times M$ 外积所需的维度一致)。
2) 物理/逻辑作用:表示对应于第 $j$ 个输入通道对所有输出通道贡献的量化权重。 -
$\sum_{j=1}^{K} (\cdot)$:按通道求和。
1) 数学定义:此运算符对 $K$ 个单独的矩阵求和,每个矩阵的形状为 $N \times M$。
2) 物理/逻辑作用:此求和将来自每个输入通道的贡献组合起来,形成最终的输出矩阵。每个项 $(X'_{quant})_j (W'_{quant})_j^T s_j$ 代表一个缩放后的外积。这里的 $s_j$ 缩放是本文公式的一个独特方面,意味着每个通道的局部乘积对最终输出的贡献被该通道的原始激活平滑因子缩放。这可以解释为在求和之前应用于局部乘积的某种形式的通道级反量化或重新缩放,这与标准量化矩阵乘法中尺度如何处理不同(通常尺度被均匀地应用于输入或输出,或被吸收到量化值中)。本文第 4.5 节“在反量化结果上乘以运行时尺度”的描述,暗示了最终缩放的运算顺序略有不同,但第 3.1 节的方程是机制最明确的数学陈述。
3) 为何求和:矩阵乘法本质上是第一个矩阵的列向量与第二个矩阵的行向量的外积之和。 -
$Y$:最终输出矩阵。
1) 数学定义:结果矩阵,尺寸为 $N \times M$。
2) 物理/逻辑作用:这是经过旋转、平滑、量化和修改求和后产生的低比特近似全精度矩阵乘法 $XW^T$。它代表了线性层处理后的特征,已准备好在神经网络中进行后续操作。
分步流程
想象一个单一的抽象数据点,例如 $x_{token, feature\_in}$,代表一个特定输入 token 的特定特征,以及一个权重 $w_{feature\_out, feature\_in}$,它将一个输入特征连接到一个输出特征。让我们追踪它们在 Rotated Runtime Smooth (RRS) 机制中的旅程:
-
初始进入:我们的抽象数据点 $x_{token, feature\_in}$ 作为浮点激活矩阵 $X$ 的一部分进入系统。权重 $w_{feature\_out, feature\_in}$ 是浮点权重矩阵 $W$ 的一部分。
-
激活旋转:整个激活矩阵 $X$ 被输入到一个“旋转引擎”,在那里它与旋转矩阵 $R$ 相乘。我们的数据点 $x_{token, feature\_in}$ 现在被转换了。它不再孤立,而是贡献于其通道中的其他特征并受其影响,成为旋转激活矩阵 $X_{rot}$ 中的一个新值 $x'_{token, feature\_k}$。此过程旨在将任何极端值(离群值)均匀地分布到特征空间中。
-
权重旋转:同时,权重矩阵 $W$ 通过一个“反旋转引擎”,在那里它与 $R^{-1}$(逆旋转矩阵)相乘,得到 $W_{rot}$。这确保了即使在输入激活被旋转后,原始运算的整体数学完整性仍然得以保持。
-
运行时尺度发现:对于旋转后激活矩阵 $X_{rot}$ 的每个通道(代表一个特征通道),一个“幅度扫描器”会识别出最大绝对值。对于包含 $x'_{token, feature\_k}$ 的列,会计算一个特定的尺度 $s_{feature\_k}$。这个尺度是动态的,会适应当前输入的特征。
-
激活平滑:旋转后的激活矩阵 $X_{rot}$ 然后进入一个“平滑室”。在这里,通道中的每个值都除以其对应的通道尺度 $s_j$。因此,$x'_{token, feature\_k}$ 被缩放为 $x''_{token, feature\_k} = x'_{token, feature\_k} / s_{feature\_k}$。此操作有效地“压缩”了每个通道内值的范围,使得离群值的影响减小,并为高效的低比特量化准备数据。
-
激活量化:平滑后的旋转激活 ($X_{rot}\text{diag}(s)^{-1}$) 然后被输入到一个“量化单元”。该单元将每个浮点值,包括我们的 $x''_{token, feature\_k}$,转换为一个低比特整数 $q_{X,token,feature\_k}$。这是显著的内存和计算节省开始的地方。
-
权重量化:同时,旋转后的权重矩阵 $W_{rot}$ 也通过其自己的“量化单元”,将其浮点值(如 $w'_{feature\_out, feature\_in}$)转换为低比特整数 $q_{W,feature\_out,feature\_in}$。
-
通道级输出组装:现在,系统开始组装最终输出。对于每个特征通道 $j$(从 $1$ 到 $K$):
- 提取量化激活的第 $j$ 列 $(X'_{quant})_j$。
- 提取量化权重的第 $j$ 行(转置)$(W'_{quant})_j^T$。
- 将这两个向量相乘(外积)以形成一个局部输出矩阵。该矩阵代表仅第 $j$ 个通道对最终结果的贡献。
- 至关重要的是,该局部输出矩阵随后乘以早期为第 $j$ 个激活通道计算的运行时平滑因子 $s_j$。此步骤重新引入了在激活平滑过程中移除的幅度信息,但现在应用于局部乘积。
-
最终求和:所有这些 $K$ 个缩放后的局部输出矩阵随后被输入到一个“求和单元”,该单元将它们逐元素相加。结果是最终输出矩阵 $Y$,其中每个元素 $y_{token, feature\_out}$ 是所有缩放后的通道贡献的总和。这完成了前向传播,提供了一个低比特但准确的全精度运算的近似值。
优化动态
需要澄清的是,Rotated Runtime Smooth (RRS) 是一种无需训练的方法。这意味着其“优化动态”不是关于传统的基于梯度的迭代学习或更新。相反,该机制旨在通过其结构组件直接优化量化精度。
-
无迭代学习:与依赖反向传播和梯度下降来更新模型参数的方法不同,RRS 在其操作过程中不涉及任何此类学习循环。旋转矩阵 $R$ 要么是一个固定的、预定义的矩阵(如 Hadamard 矩阵),要么是从离线校准过程派生的(如相关工作中),但它在推理过程中不会被更新。平滑尺度 $s_j$ 是为每个新输入即时计算的,使其具有适应性但不是“学习”的。
-
无损失景观遍历:由于没有训练,因此在 RRS 机制本身中,导航“损失景观”的梯度概念不适用。这种“优化”嵌入在设计选择中:如何旋转、如何平滑以及如何量化以最小化量化误差并保持模型性能。这些设计选择的有效性通过困惑度或准确性等指标来评估,这些指标是观察到的结果,而不是直接基于梯度的优化目标。
-
确定性状态更新:RRS 机制的状态不会迭代演变。对于每个输入,该过程是一个直接的、确定性的变换序列:
- 使用固定的 $R$ 旋转激活和权重。
- 根据当前输入的旋转激活计算平滑尺度。
- 使用固定的比特宽度和舍入规则应用量化。
- 计算最终矩阵乘法(带有特殊的局部乘积通道级缩放)。
每个步骤都是直接计算,而不是基于先前状态或错误的更新。
-
设计驱动的“收敛”:RRS 的“收敛”不是一个迭代过程,而是由其固有的设计达到的状态。目标是变换激活和权重,使其足够“平滑”(即,离群值得到充分缓解),以便能够进行准确的低比特(INT4)量化。本文证明了这种设计有效地减少了量化误差,从而在各种模型上提高了困惑度和准确性。因此,“优化”在于巧妙地设计这些变换以实现高质量的低比特推理,而不是迭代学习过程。该机制的鲁棒性和性能提升证明了这种设计优化,使其成为一种高效且即插即用的解决方案。可忽略的开销进一步增强了其实用性。
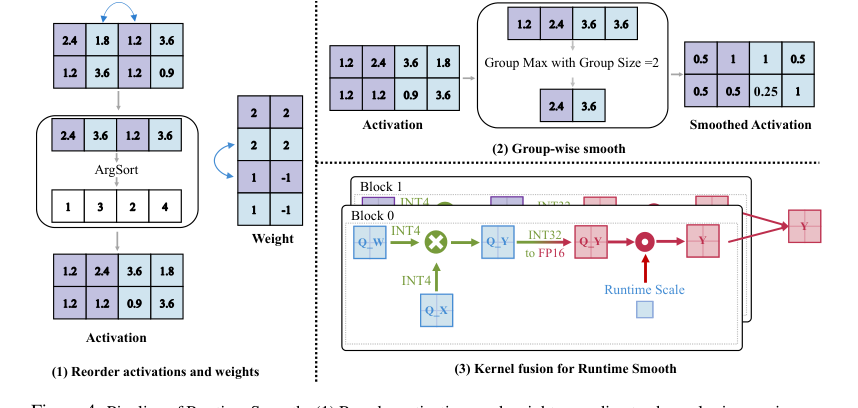 Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
结果、局限性与结论
实验设计与基线
为了严格验证其数学主张,作者在各种主流大型语言模型(LLMs)上进行了广泛的实验。这些模型包括 LLaMA 系列(LLaMA2-13B、LLaMA2-70B、LLaMA3-8B、LLaMA3-70B、LLaMA3.1-8B、LLaMA3.1-70B)、Qwen 系列(Qwen1.5-7B、Qwen1.5-14B)、Mistral 和 Mixtral 的各种模型。评估重点是 INT4 量化,特别是使用三种方案:A4W4KV4、A4W4KV16 和 A4W16KV16,它们分别表示 4 位激活、4 位权重和 4 位 KV 缓存量化,具有不同的 KV 缓存比特宽度。
对于激活量化,采用了具有四舍五入到最近(RTN)策略的每通道对称方案。KV 缓存量化使用了具有 128 组大小的子通道对称方案,也使用了 RTN。权重量化主要使用了 GPTQ(Frantar 等人,2022)的每通道对称方案,除了基线“RTN”方法。GPTQ 的校准集包含来自 WikiText-2 的 128 个样本,每个样本的序列长度为 2048。
与提出的 Rotated Runtime Smooth (RRS) 及其组成部分 Runtime Smooth (RS) 进行比较的“受害者”(基线模型/方法)包括:
- RTN:基本的四舍五入到最近量化。
- SmoothQuant(Xiao 等人,2023):一种著名的通道级平滑方法,它离线迁移离群值。
- GPTQ(Frantar 等人,2022):一种训练后权重量化方法。
- QuaRot(Ashkboos 等人,2024):一种用于离群值抑制的基于旋转的方法。
- SpinQuant(Liu 等人,2024)和 DuQuant(Lin 等人,2024a):用于特定比较的其他基线,包括基于训练的方法。
他们核心机制有效性的决定性证据是通过几种实验架构获得的:
1. WikiText-2 上的困惑度:这个标准基准衡量语言模型预测文本样本的程度,困惑度越低表示性能越好。
2. 零样本常识 QA 基准:在 ARC-e、ARC-c、BoolQ 和 OBQA 等任务上评估性能,以评估模型量化后的推理能力。
3. 消融研究:
* 初步消融(图 3)直接比较了 Runtime Smooth、SmoothQuant 和“原始 A4W4”基线,证明了运行时平滑的必要性以及将离群值迁移到权重的陷阱。
* 运行时平滑组大小的消融(表 4)探讨了该超参数对准确性的影响。
4. 效率评估:使用 NVBench 在 RTX 4070 Ti GPU 上,作者测量了其融合 GEMM 内核与每通道 A4W4 和子通道 A4W4 基线相比的开销(图 6),证明了其方法的实际可行性。
5. 统计离群值分析:图 9 提供了不同 LLM 组件(QKV_Projector、Output_Projector、Up_Proj 或 Gate_Proj、Down_Projector)在各种模型上离群值去除的详细统计细分,直观地展示了 RRS 与其他方法相比如何有效地将激活转移到更平滑的范围。
证据证明了什么
本文提供的证据有力地证明了 Rotated Runtime Smooth (RRS) 及其组成部分 Runtime Smooth (RS) 在实现 LLMs 精确 INT4 推理方面的有效性。
首先,旨在消除通道级离群值的运行时平滑(RS)组件显示出显著的改进。初步的消融研究(图 3)清楚地表明,仅应用运行时平滑尺度不足以进行 A4W4 量化。然而,当完全实现 RS 时,它使得 A4W4 可行,在 A4W16 设置下,LLaMA3-8B 的困惑度从 4e2 显著提高到 10.9。这对于验证在不将离群值迁移到权重的情况下采用运行时尺度的核心思想至关重要,而这正是 SmoothQuant 等先前方法的关键局限性。在表 1 中,RS 在各种模型和量化方案下持续优于 SmoothQuant 和 RTN,例如,在 16-4-16 方案下,将 LLaMA2-70B 的困惑度从 1e2(SmoothQuant)降低到 6.95(RS)。此外,在仅激活量化(A4W16KV16)下,RS 在 LLaMA3-8B 上实现了 40 倍的改进,这凸显了其有效性。
其次,旋转运行时平滑(RRS)的完整方法,它结合了旋转和运行时平滑来处理通道级和尖峰离群值,提供了卓越的性能。表 1,WikiText-2 困惑度的主要结果表,显示 RRS 在几乎所有评估的 LLaMA、Qwen 和 Mistral 模型上,持续优于包括 RS、QuaRot、SmoothQuant 和 RTN 在内的所有基线。一个特别引人注目的例子是 LLaMA3-70B,其中 RRS 在 A4W4KV16 下将困惑度从 57.33 降低到 6.66,在 A4W4KV4 下从 49.76 降低到 6.87。这些是与 SOTA 的 QuaRot 相比的显著改进,QuaRot 在相同模型和设置下分别产生了 57.33 和 49.73。这确凿的证据证明了 RRS 的组合机制有效地缓解了这两种类型离群值的影响。
除了困惑度之外,RRS 在零样本常识 QA 任务(表 2)上也展示了其优势。在各种 LLMs 和量化方案下,RRS 在平均准确性改进方面持续优于所有基线(GPTQ、SmoothQuant、RS、QuaRot)约 3%。例如,在具有 4-4-16 量化的 LLaMA-3-8B 上,RRS 实现了 58.0% 的平均准确性,而 QuaRot 为 55.0%。这表明激活平滑的改进转化为复杂推理任务上更好的性能。
离群值去除的统计分析(图 9)直接提供了 RRS 机制工作的可视化证据。它表明,与原始激活(X)、旋转激活(R)或单独的运行时平滑(RS)相比,RRS 在所有 LLM 组件(QKV_Projector、Output_Projector、Up_Proj 或 Gate_Proj、Down_Projector)和模型中,导致更高比例的激活落入“u < 4”(更平滑)类别。这直接验证了 RRS 全面消除通道级和尖峰离群值的能力。
最后,效率评估(图 6 和第 4.5 节)证实,RRS 融合内核与 A4W4 每通道量化基线相比,仅引入了可忽略的开销。这是一个关键的实际优势,因为它意味着准确性收益不会以显著减慢的速度为代价,这使得 RRS 成为 INT4 推理真正即插即用的解决方案。与基于训练的方法(表 3)的比较进一步凸显了 RRS 的优势,因为它在 WikiText-2 困惑度上优于 SpinQuant(一种基于训练的方法),而没有产生高昂的训练时间成本。
局限性与未来方向
尽管 Rotated Runtime Smooth (RRS) 为无需训练的 INT4 推理带来了显著的进步,但本文也隐含和明确地指出了几个局限性,并为未来的研究打开了大门。
当前局限性:
1. 旋转的平滑保证不完整:本文指出,“旋转不能保证更平滑的矩阵,并且旋转后的矩阵可能仍然表现出通道级离群值的形状”(第 1 节,图 2)。这表明虽然旋转有帮助,但它本身并不是一个完美的解决方案,需要运行时平滑组件。
2. 尖峰离群值的“受害者”效应:通道级平滑后,尖峰离群值仍然可能导致正常值被剪枝为“受害者”(第 1 节,图 1)。尽管 RRS 旨在缓解这种情况,但根本挑战仍然存在。
3. 组大小敏感性:消融研究(第 4.4 节,表 4)表明,虽然运行时平滑有效地最小化了 A4W4 和全精度之间的差距,“准确性随着组大小的增加而下降”。这暗示了权衡和对所选组大小的潜在敏感性,这可能不是普遍最优的。
4. 特定离群值场景:作者提到“只有两个离群值 token 的情况很少见,但可能会困扰 Rotated Runtime Smooth”(第 C.1 节)。这突出了一种特定但罕见的离群值模式,RRS 可能难以处理,这表明其鲁棒性可能不是绝对的。
5. 模型特定离群值敏感性:作者观察到“模型对离群值的敏感性不同。进一步抑制离群值可以增强鲁棒性”(第 4.2 节)。这表明尽管 RRS 是通用的,但可能存在模型特定的离群值特征,可以进一步优化。
6. 硬件约束的组大小:对于 Qwen1.5-7B 等某些模型,Down_projector 的输入激活大小(11008)“不支持 512 的组大小”(第 4.4 节)。这表明在应用最大的组大小时存在实际限制,而这些组大尺寸可能提供某些好处。
未来方向与讨论主题:
- 自适应和动态平滑策略:考虑到对组大小和不同离群值模式的敏感性,未来的工作可以探索自适应平滑策略。而不是固定的组大小或通用的旋转,我们能否根据实时的激活统计数据或模型层特征动态调整这些参数?这可能涉及轻量级的即时分析,为每个特定输入和层优化平滑,从而可能带来更高的准确性和鲁棒性。
- 离群值抑制的理论界限和保证:本文实证证明了 RRS 的有效性。对旋转和运行时平滑的数学性质进行更深入的理论研究,可以为离群值抑制及其对量化误差的影响建立正式的界限。这可能导致未来量化方法以可证明的保证进行更原则性的设计。
- 混合无需训练和基于训练的方法:尽管 RRS 无需训练且优于某些基于训练的方法,但学习旋转的概念(如 SpinQuant 中)仍然有前景。未来的研究可以探索混合方法,将 RRS 等无需训练方法的效率与最小的、有针对性的训练或微调步骤相结合,以进一步完善旋转或平滑尺度,可能在不产生当前基于训练方法的大量训练开销的情况下实现更高的准确性。
- 面向高级量化的软硬件协同设计:RRS 的可忽略开销是一个显著优势。为了进一步推动这一点,可以设计专用的硬件加速器或专用指令集来原生支持 RRS 的核心重排序、分组最大值计算和旋转操作。这种协同设计方法可以为 INT4 推理带来前所未有的加速和能效。
- 泛化到其他数据类型和模型架构:RRS 已在 LLMs 的 INT4 推理方面得到验证。这些原理在多大程度上可以推广到其他低比特量化方案(例如,INT2、二值化)或其他模型架构(如视觉模型或多模态架构)?探索这些更广泛的应用可能会揭示适应 RRS 的新挑战和机遇。
- 对对抗性攻击和分布偏移的鲁棒性:量化模型可能更容易受到对抗性攻击或在分布外数据下的性能下降。未来的工作可以探讨 RRS 如何通过使激活更平滑、更一致,从而可能提高量化 LLMs 对抗这些挑战的鲁棒性,或者是否需要进行特定修改来增强这一方面。
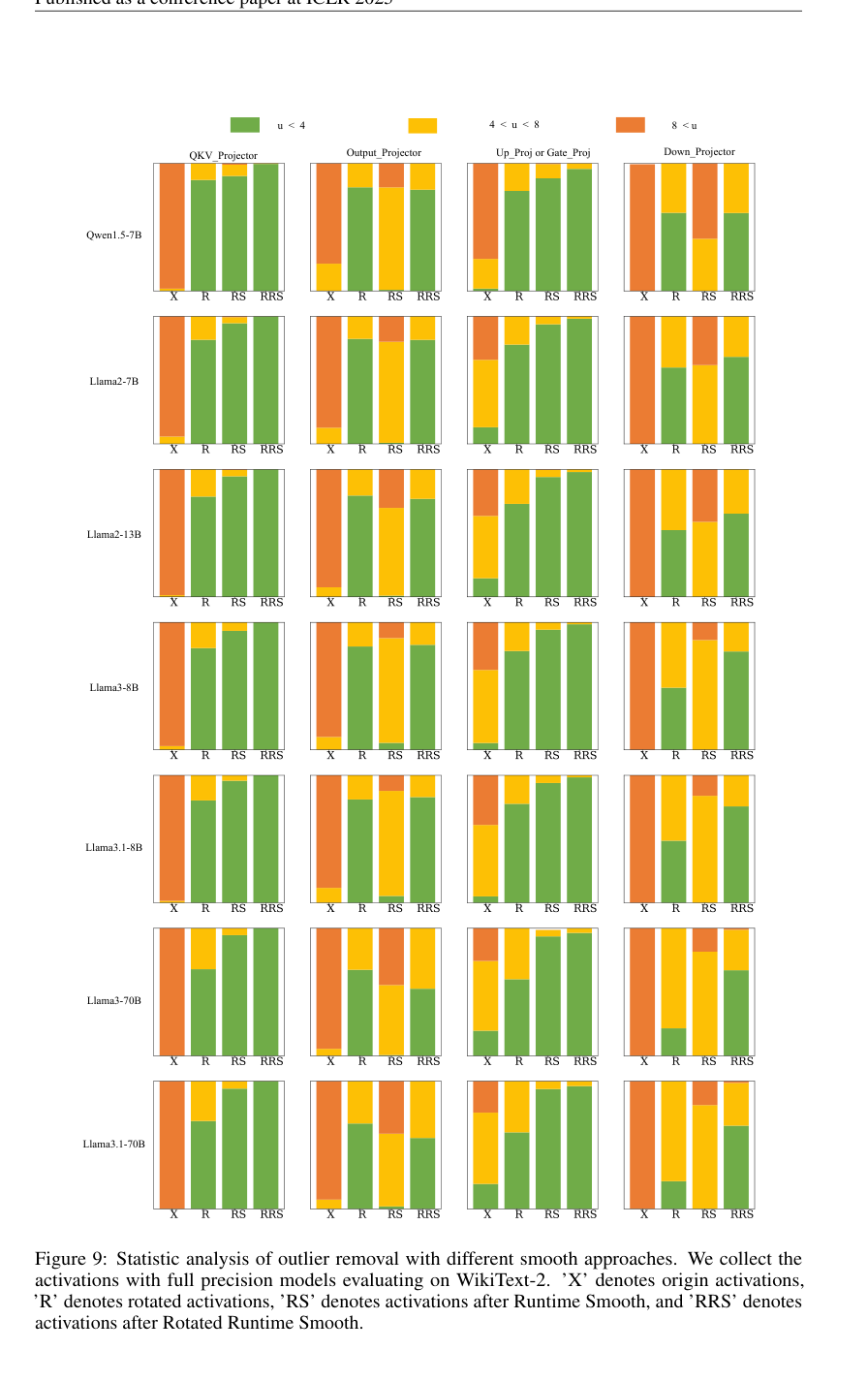 Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
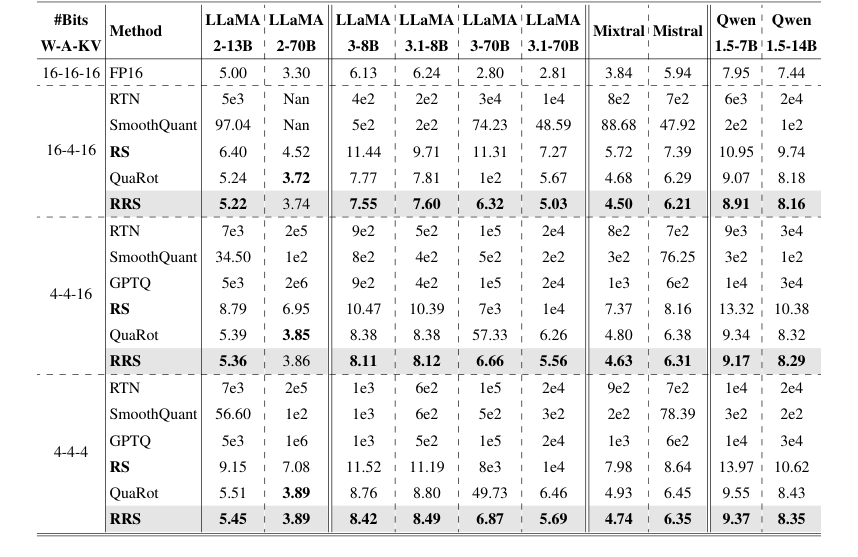 Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
 Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
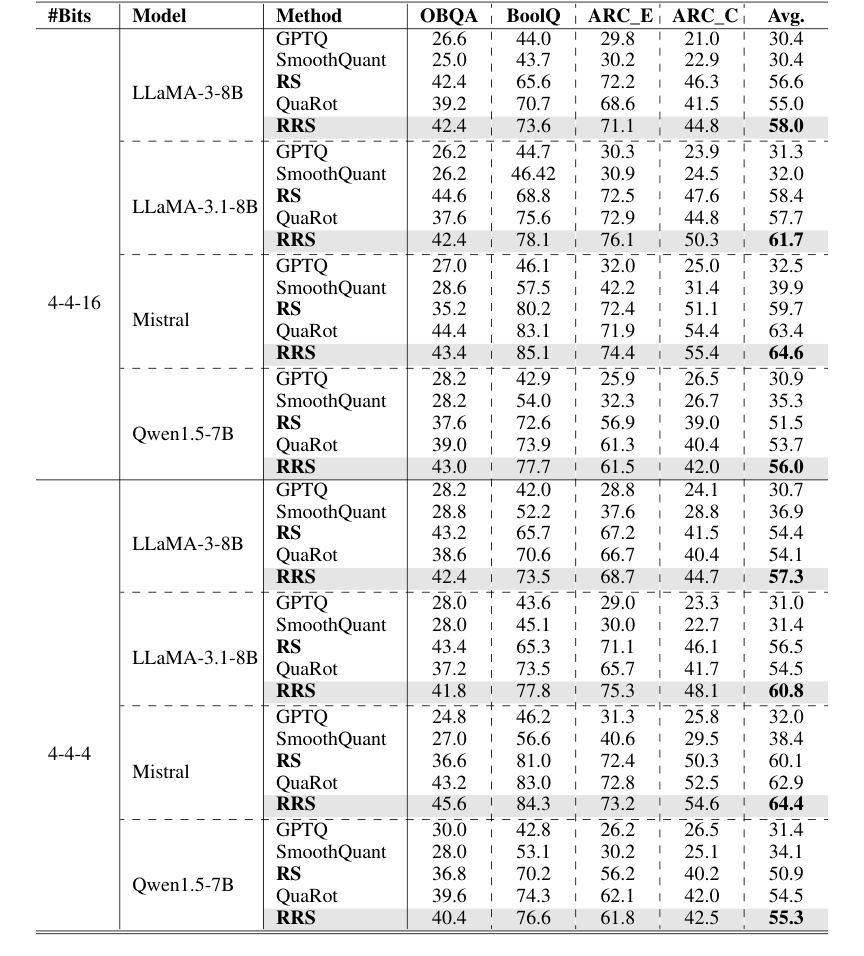 Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
与其他领域的同构性
结构骨架
本文的核心机制是一种方法,它通过动态缩放和正交旋转其组件来转换高维数据,以减少极端值的影响,从而实现更高效的低精度表示。