Rotated Runtime Smooth: Обучающе-свободный сглаживатель активаций для точного INT4-инференса
Проблема, рассматриваемая в данной статье, проистекает из растущего масштаба и сложности больших языковых моделей (LLM).
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, проистекает из растущего масштаба и сложности больших языковых моделей (LLM). По мере роста этих моделей их обслуживание для инференса становится чрезвычайно дорогим с точки зрения вычислительных ресурсов и использования памяти. Для снижения этих затрат и улучшения задержки широко применяются методы квантования. Квантование по сути снижает точность чисел (весов и активаций), используемых в модели, например, с высокоточных чисел с плавающей запятой до целочисленных значений с низким количеством бит, таких как INT4 (4-битные целые числа).
Однако при низкобитном квантовании, особенно при квантовании весов-активаций INT4, возникла значительная "болевая точка": наличие выбросов в активациях. Эти выбросы представляют собой экстремальные значения в тензорах активаций, которые непропорционально растягивают общий диапазон значений. Когда весь диапазон сжимается в очень ограниченное количество бит (например, 4 бита), эти выбросы потребляют большую часть доступных "слотов точности", оставляя очень мало эффективных бит для более распространенных, "нормальных" значений. Это существенно снижает точность модели во время инференса.
Предыдущие подходы пытались справиться с этими выбросами, но столкнулись с фундаментальными ограничениями:
* Разделение выбросов: Ранние методы (например, Kim et al., 2023; Dettmers et al., 2022) пытались разделить выбросы от нормальных значений на разные матрицы. Основным недостатком здесь было то, что эти реализации часто не были совместимы с аппаратным обеспечением, что приводило к высокой задержке и не ускоряло инференс.
* Офлайн-сглаживание и миграция (SmoothQuant): SmoothQuant (Xiao et al., 2023) стремился перенести выбросы из активаций в веса с помощью канально-ориентированных масштабов сглаживания. Хотя это было эффективно для квантования с более высоким количеством бит (например, A8W8), оно не сработало для INT4-инференса по нескольким причинам:
* Масштабы сглаживания предварительно вычислялись офлайн с использованием калибровочного набора, что делало их неэффективными при столкновении с новыми, "несоответствующими" онлайн-активациями.
* Выбросы на самом деле не устранялись, а лишь частично мигрировали, по-прежнему препятствуя низкобитному квантованию.
* SmoothQuant в основном решал "канально-ориентированные" выбросы, но испытывал трудности с "пиковыми" выбросами, которые не являются постоянными по всем каналам, что приводило к неправильному отсечению нормальных значений как "жертв".
* Методы на основе вращения (QuaRot): Более поздние работы, такие как QuaRot (Ashkboos et al., 2024), представили матрицы вращения для подавления выбросов путем их внутреннего распределения. Хотя это было многообещающе для квантования A4W4, само по себе вращение не могло гарантировать идеально гладкую матрицу и все еще могло проявлять канально-ориентированные выбросы, оставляя пространство для дальнейших улучшений. Задача оставалась в поиске надежной, точной и не требующей обучения схемы для INT4-инференса, которая могла бы эффективно обрабатывать оба типа выбросов.
Интуитивные термины предметной области
- Квантование: Представьте, что у вас есть очень детализированная палитра цветов с миллионами оттенков (как числа с плавающей запятой). Квантование похоже на выбор использования гораздо меньшего набора цветов, скажем, 16 конкретных оттенков (как 4-битные целые числа), для представления всех ваших изображений. Цель состоит в том, чтобы сделать изображения намного меньше и быстрее в обработке, при этом делая их максимально качественными.
- Выбросы в активациях: Подумайте о группе людей, чей рост в основном составляет от 5 до 6 футов. Но затем у вас есть несколько гигантов ростом 20 футов и несколько крошечных людей ростом 1 фут. Если вы попытаетесь создать шкалу роста для всех, используя всего 10 отметок, эти крайние гиганты и крошечные люди заставят шкалу охватить огромный диапазон (от 1 до 20 футов). Это означает, что обычный диапазон 5-6 футов получит очень мало отметок, что затруднит различение между человеком ростом 5'2" и 5'4". "Гиганты" и "крошечные люди" — это выбросы, затрудняющие точное представление "нормального" роста.
- INT4-инференс: Это похоже на выполнение расчетов с очень простыми, округленными числами (например, только числами от -8 до 7, что могут представлять 4-битные целые числа) вместо очень точных десятичных дробей. Это намного быстрее и требует меньше умственных усилий (или памяти/мощности компьютера) для расчета $5 \times 3$, чем $5.123 \times 3.456$. Часть "INT4" означает использование 4-битных целых чисел, что является очень агрессивной формой округления для достижения максимальной скорости и экономии памяти для LLM.
- Перплексия: В контексте языковых моделей перплексия — это мера того, насколько "удивлена" модель следующим словом в последовательности. Представьте, что вы пытаетесь угадать следующее слово в предложении. Если вы очень уверены и угадываете правильно, ваше "удивление" низкое. Если вы часто ошибаетесь или не уверены, ваше "удивление" высокое. Более низкий показатель перплексии означает, что языковая модель менее удивлена, что указывает на ее лучшую способность предсказывать текст и более точное понимание языка.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Фундаментальная проблема, рассматриваемая в данной статье, заключается в значительном снижении точности больших языковых моделей (LLM) при попытке выполнения инференса с использованием квантования весов-активаций с очень низким количеством бит, в частности INT4.
Входное/текущее состояние: LLM, несмотря на свои впечатляющие возможности, требуют значительных вычислительных ресурсов и памяти для обслуживания из-за их огромного масштаба. Квантование, которое снижает точность параметров модели и активаций (например, с FP32 до INT4), является перспективным методом для снижения этих затрат и улучшения задержки инференса. Однако критическим препятствием для широкого внедрения квантования весов-активаций INT4 является наличие "выбросов" в тензорах активаций. Эти выбросы представляют собой экстремальные значения, которые непропорционально растягивают диапазон квантования, фактически сжимая динамический диапазон, доступный для нормальных значений, и приводя к существенной потере информации и падению точности.
Желаемый конечный пункт (выходное/целевое состояние): Обеспечение точного и эффективного INT4-инференса весов-активаций для LLM. Это означает достижение вычислительных и ресурсных преимуществ квантования INT4 без существенного снижения точности. Статья направлена на разработку "обучающе-свободного сглаживателя активаций", который может надежно обрабатывать выбросы активаций, тем самым позволяя нормальным значениям квантоваться с достаточной точностью, что в конечном итоге приведет к состоянию современной производительности в INT4-инференсе для различных семейств LLM.
Точное недостающее звено или математический пробел между текущим состоянием и желаемым конечным пунктом заключается в поиске метода для эффективного "сглаживания" или нормализации выбросов активаций таким образом, чтобы весь тензор активаций мог быть квантован до INT4 с минимальной потерей информации, при этом будучи вычислительно недорогим и не требующим обучения. Математически, если $X$ — тензор активаций, а $\alpha$ — его масштабный коэффициент для квантования (например, $\alpha = \frac{\max(|X|)}{2^{N-1}-1}$ для N-битного квантования), выбросы вызывают очень большое значение $\max(|X|)$, что приводит к большому $\alpha$. Это приводит к тому, что нормальные значения отображаются в очень малый диапазон целочисленных значений, что приводит к серьезной потере точности. Недостающее звено — это преобразование $f(X)$ такое, что $f(X)$ имеет гораздо меньшее $\max(|f(X)|)$, чем $\max(|X|)$, но $f(X)$ все еще точно представляет исходную информацию, позволяя использовать меньший $\alpha'$ и, следовательно, более эффективное квантование нормальных значений. Это преобразование также должно быть совместимо с матрицей весов $W$ для сохранения выходного значения $XW$.
Болезненный компромисс или дилемма, которая поставила в тупик предыдущих исследователей, — это в первую очередь треугольник Точность против Эффективности против Надежности:
1. Точность против Эффективности (Низкобитное квантование): Агрессивное низкобитное квантование (INT4) обеспечивает значительное ускорение и экономию памяти, но очень чувствительно к выбросам активаций, что приводит к серьезному снижению точности. Сохранение точности часто требует более высоких битовых ширин или сложной обработки выбросов, что сводит на нет преимущества эффективности.
2. Обработка выбросов против совместимости с аппаратным обеспечением/задержки: Существующие методы решения проблем выбросов, такие как разделение выбросов на разные матрицы (например, Kim et al., 2023; Dettmers et al., 2022) или их миграция в веса (например, SmoothQuant), часто приводят к несовместимости с аппаратным обеспечением, значительному накладному расходу на задержку или затрудняют квантование весов. Это подрывает основную цель более быстрого и эффективного инференса.
3. Статическое против динамического сглаживания: Предварительно вычисленные масштабы сглаживания (например, в SmoothQuant) эффективны, но становятся "несоответствующими" онлайн-активациям, делая их неэффективными для реальных, динамических входных данных. Сглаживание во время выполнения более надежно, но традиционно влечет за собой неприемлемые вычислительные накладные расходы.
4. Канально-ориентированные против пиковых выбросов: Выбросы проявляются в различных формах: "канально-ориентированные" (постоянные по всему каналу) и "пиковые" (изолированные, экстремальные значения). Методы, эффективные для одного типа (например, канально-ориентированное сглаживание), могут усугубить "эффект жертвы" для другого (например, пиковые выбросы, приводящие к отсечению нормальных значений), что приводит к ошибке квантования. Единое решение без новых побочных эффектов неуловимо.
Ограничения и режимы отказа
Проблема точного INT4-инференса для LLM чрезвычайно сложна из-за нескольких суровых, реалистичных стен, с которыми столкнулись авторы:
- Экстремальная разреженность/величина выбросов активаций: Выбросы активаций могут быть на порядки больше нормальных значений (например, в 1000 раз больше, как указано на странице 14). Эта экстремальная величина настолько сильно растягивает диапазон квантования, что нормальные значения теряют почти все свои эффективные биты, что приводит к катастрофической потере точности.
- Ограничения точности INT4: Квантование до INT4 означает, что только 16 возможных значений ($2^4$) могут представлять весь диапазон активаций. Эта чрезвычайно ограниченная точность оставляет очень мало места для ошибок или для учета выбросов без существенной потери информации для большинства значений.
- Требования к задержке в реальном времени: Инференс LLM, особенно этап предварительного заполнения, требует строгой задержки в реальном времени. Любой механизм сглаживания или обработки выбросов должен вносить "пренебрежимо малые накладные расходы" (стр. 2, стр. 9), чтобы быть практичным. Сложные операции, добавляющие значительное время вычислений, неприемлемы.
- Ограничения памяти аппаратного обеспечения: LLM огромны, и пропускная способность памяти часто является узким местом. Квантование направлено на снижение потребления памяти и перемещения данных. Решения, требующие хранения дополнительных данных с высокой точностью или сложных структур данных для выбросов, могут свести на нет эти преимущества.
- Требование отсутствия обучения: Решение должно быть "обучающе-свободным" и "подключаемым" (Abstract, стр. 2). Это означает, что оно не может полагаться на обширную дообучение или калибровку на больших наборах данных, что является трудоемким и ресурсоемким, особенно для больших моделей.
- Динамические распределения входных данных: Распределение активаций может значительно варьироваться в зависимости от входных данных и различных слоев LLM. Масштабы сглаживания, полученные из статического калибровочного набора, склонны быть "несоответствующими" онлайн-активациям (стр. 3), что приводит к неэффективному сглаживанию и снижению точности.
- Эффект "жертвы": Когда масштабы сглаживания определяются экстремальными выбросами, нормальные значения, которые намного меньше, могут быть фактически "отсечены" или стать "жертвами" (стр. 2, рис. 1c, стр. 3). Эта потеря точности для нормальных значений является критическим режимом отказа, поскольку она напрямую влияет на способность модели представлять нюансированную информацию.
- Несовместимость с GEMM-ядрами: Наивные реализации сглаживания во время выполнения, особенно с непоследовательными масштабами сглаживания, не могут быть легко интегрированы в высокооптимизированные ядра General Matrix Multiply (GEMM) (стр. 4). Это затрудняет достижение аппаратного ускорения, поскольку потребуются пользовательские ядра или сложные блочные вычисления.
- Суб-гладкость после вращения: Хотя методы на основе вращения (например, QuaRot) могут распределять выбросы, они не гарантируют идеально гладкую матрицу и все еще могут проявлять "канально-ориентированные выбросы" или "суб-гладкость" (стр. 2, рис. 2c, стр. 4). Это означает, что само по себе вращение недостаточно для полного решения проблемы выбросов для квантования INT4.
- Проблемы миграции выбросов: Предыдущие подходы, которые мигрируют выбросы из активаций в веса (например, SmoothQuant), могут затруднить квантование весов, особенно для схем с очень низким количеством бит, таких как A4W4 (стр. 1). Это создает новую проблему в домене весов при попытке решить проблему в домене активаций.
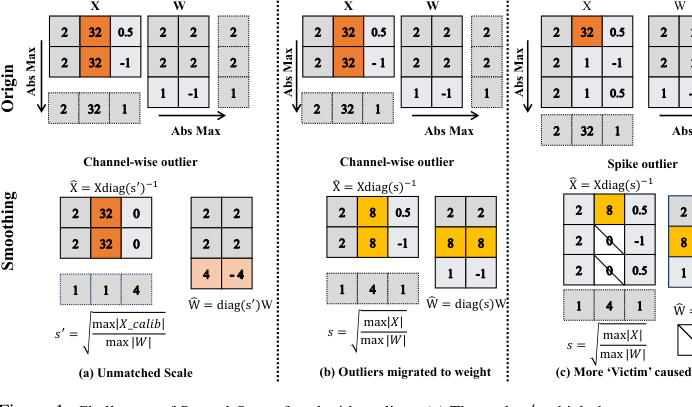 Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Почему такой подход
Неизбежность выбора
Путь авторов к Rotated Runtime Smooth (RRS) был обусловлен фундаментальными ограничениями существующих методов квантования при их применении к сложной области INT4-инференса для больших языковых моделей (LLM). "Точный момент" осознания того, что традиционные современные (SOTA) методы недостаточны, можно pinpoint к постоянной проблеме выбросов активаций.
Традиционные подходы, такие как те, которые разделяют выбросы и нормальные значения на две отдельные матрицы (например, Kim et al., 2023; Dettmers et al., 2022), оказались страдающими от высокой задержки или значительного снижения точности. Критически важно, что эти методы часто оказывались несовместимыми с аппаратным ускорением, не ускоряя инференс, как предполагалось.
Более прямой предшественник, SmoothQuant (Xiao et al., 2023), пытался смягчить выбросы, перенося их из активаций в веса с помощью канально-ориентированных масштабов сглаживания. Однако для квантования INT4 SmoothQuant столкнулся с тремя критическими сбоями:
1. Несоответствующие масштабы: Предварительно вычисленные офлайн масштабы сглаживания, полученные из калибровочного набора, часто становились несоответствующими онлайн-активациям, делая их неэффективными для сглаживания.
2. Неполное устранение выбросов: Каналы выбросов не были полностью устранены, а лишь частично мигрировали в веса, что затрудняло низкобитное квантование (в частности, INT4).
3. Пиковые выбросы и "жертвы": SmoothQuant в основном решал канально-ориентированные выбросы, но не учитывал "пиковые выбросы", которые не являются постоянно канально-ориентированными. Когда присутствовали эти пиковые выбросы, нормальные значения непреднамеренно отсекались как "жертвы" во время сглаживания, что приводило к потере точности.
Даже методы на основе вращения, такие как QuaRot (Ashkboos et al., 2024), хотя и показали многообещающие результаты в распределении выбросов, теоретически не могли гарантировать равномерно более гладкую матрицу. Вращенные активации, особенно те, которые имели канально-ориентированные выбросы, все еще могли проявлять "суб-гладкость" (как показано на рис. 2c), оставляя пространство для дальнейших улучшений. Этот коллективный провал предыдущих методов надежно, точно и эффективно обрабатывать как канально-ориентированные, так и пиковые выбросы в режиме, не требующем обучения, для INT4-инференса сделал разработку нового, комплексного решения, такого как RRS, не просто вариантом, а неизбежностью.
Сравнительное превосходство
Rotated Runtime Smooth (RRS) демонстрирует качественное превосходство над предыдущими методами, в первую очередь благодаря своему комплексному и надежному управлению выбросами в сочетании с минимальными вычислительными накладными расходами.
Структурное преимущество RRS заключается в его двухстороннем подходе:
1. Runtime Smooth (RS): Этот компонент напрямую решает проблему канально-ориентированных выбросов путем динамического вычисления масштабов сглаживания во время выполнения. В отличие от SmoothQuant, который полагается на офлайн-калибровку и объединяет масштабы с весами, RS избегает проблем несоответствующих масштабов и сложности квантования весов с мигрированными выбросами. Получая масштабы сглаживания во время выполнения и не объединяя их с весами, RS гарантирует, что сглаживание всегда актуально для текущего входного сигнала, делая его более адаптивным и точным.
2. Операция вращения: Здесь RRS решает проблему пиковых выбросов и повышает надежность. Вращая веса и активации (следуя принципу QuaRot), пиковые выбросы эффективно распределяются по токенам. Это распределение приводит к более последовательным масштабам сглаживания по каналам, что, в свою очередь, предотвращает превращение нормальных значений в "жертвы" во время канально-ориентированного процесса сглаживания. Для активаций с канально-ориентированными выбросами вращение помогает поддерживать согласованность, одновременно предлагая возможность снизить уровень выбросов.
Эта комбинированная стратегия обеспечивает структурное преимущество, которого не хватало предыдущим методам. Например, SmoothQuant не мог эффективно обрабатывать пиковые выбросы и страдал от несоответствия калибровочного набора. Чистые методы вращения, хотя и полезны, сами по себе не гарантировали достаточной гладкости. RRS интегрирует лучшие аспекты обоих, гарантируя, что все типы выбросов (канально-ориентированные и пиковые) обрабатываются комплексно.
Более того, RRS разработан как "подключаемый" компонент, вносящий пренебрежимо малые накладные расходы для INT4-умножения матриц. В статье прямо указано, что дополнительное умножение масштаба во время выполнения в объединенном GEMM-ядре приносит лишь "пренебрежимо малые накладные расходы" по сравнению с базовым A4W4. Это значительное качественное преимущество, поскольку оно обеспечивает превосходную точность без ущерба для критических преимуществ задержки, ожидаемых от низкобитного квантования. Он не вносит высокоразмерный шум, а скорее смягчает влияние выбросов, которые действуют как форма шума, растягивая диапазон квантования.
Соответствие ограничениям
Метод Rotated Runtime Smooth (RRS) идеально соответствует строгим требованиям эффективного инференса LLM, особенно для квантования INT4. Основные ограничения, неявно определенные проблемой обслуживания больших LLM, включают:
1. INT4-инференс: Основная цель — обеспечить точный инференс на уровне INT4, что имеет решающее значение для снижения затрат на память и вычисления. RRS специально разработан как "обучающе-свободный сглаживатель активаций для точного INT4-инференса". Весь его механизм, от обработки канально-ориентированных до пиковых выбросов, направлен на то, чтобы сделать активации пригодными для 4-битного квантования без существенного снижения точности. Улучшения перплексии на семействах LLaMA и Qwen в настройках A4W4KV16 (например, LLaMA3-70B с 57.33 до 6.66) напрямую подтверждают его эффективность в достижении этого.
2. Отсутствие обучения: Критическое требование для практического развертывания — избежать дорогостоящего переобучения или дообучения. RRS явно "не требует обучения", что означает, что его можно применять после обучения без дополнительной оптимизации модели. Это идеально соответствует необходимости в готовом к развертыванию решении, которое не увеличивает уже существенную нагрузку на обучение LLM.
3. Сохранение точности: Низкобитное квантование часто приводит к снижению точности. Комплексная стратегия смягчения выбросов RRS — сочетание сглаживания во время выполнения для канально-ориентированных выбросов и вращения для пиковых выбросов — предназначена для "комплексного устранения выбросов" и "повышения надежности", тем самым сохраняя точность. Последовательное превосходство над современными методами по перплексии и задачам zero-shot QA демонстрирует это соответствие.
4. Низкая задержка/минимальные накладные расходы: Квантование направлено на снижение затрат на обслуживание и задержки. RRS разработан для эффективности, при этом компонент Runtime Smooth вносит "минимальные накладные расходы по сравнению с исходным конвейером A4W4". Объединение ядер для Runtime Smooth гарантирует, что процесс эффективно интегрирован в конвейер GEMM, добавляя "пренебрежимо малые накладные расходы" по сравнению с A4W4 Per-Channel квантованием. Это напрямую решает проблему поддержания высокой пропускной способности и низкой задержки.
5. Надежность к выбросам: Постановка задачи подчеркивает выбросы как основное препятствие. Уникальное свойство RRS — обработка как канально-ориентированных, так и пиковых выбросов, и предотвращение "жертв" путем обеспечения последовательных масштабов сглаживания — делает его по своей сути надежным к разнообразным паттернам выбросов, наблюдаемым в активациях LLM. Этот "брак" между суровой проблемой выбросов и уникальной двойной обработкой выбросов решения является центральным для его успеха.
Отклонение альтернатив
В статье представлены четкие обоснования для отклонения нескольких альтернативных подходов, подчеркивая их недостатки, особенно в контексте INT4-инференса для LLM:
-
Традиционное разделение выбросов (например, LLM.int8(), Kim et al., 2023; Dettmers et al., 2022): Эти методы, которые либо разделяют выбросы в формат с более высокой точностью (смешанный INT8/FP16), либо на отдельные матрицы, были отклонены из-за "высокой задержки или снижения точности" и часто "несовместимости с аппаратным обеспечением", таким образом, не "ускоряя инференс". LLM.int8() конкретно "приводит к значительному накладному расходу на задержку и может быть даже медленнее, чем FP16-инференс".
-
SmoothQuant (Xiao et al., 2023): Хотя и эффективен для квантования A8W8, SmoothQuant был признан недостаточным для INT4, поскольку его офлайн-масштабы сглаживания, зависящие от калибровочного набора, были "склонны быть несоответствующими онлайн-активациям". Более того, он лишь частично мигрировал выбросы в веса, а не устранял их, что затрудняло низкобитное квантование, и, что критически важно, он не справлялся с "пиковыми выбросами", что приводило к отсечению "жертв".
-
Чистые методы на основе вращения (например, QuaRot, Ashkboos et al., 2024): Хотя вращение помогает распределять выбросы, в статье отмечается, что умножение на одну матрицу вращения "теоретически не могло гарантировать более гладкий вес или активацию". Активации, даже после вращения, могли оставаться "суб-гладкими" с канально-ориентированными выбросами (рис. 2c), что указывает на то, что само по себе вращение не было полным решением для комплексного сглаживания. QuaRot также требует "сложного онлайн-вращения Адамара", которое RRS стремится упростить.
-
Квантование на основе обучения (например, SpinQuant, Liu et al., 2024): В статье прямо сравнивается RRS со SpinQuant и отклоняются подходы на основе обучения из-за их непомерной вычислительной стоимости. Процесс обучения SpinQuant "трудоемкий, занимает 1,5 часа для модели 7B на одном GPU A100 и 12 часов для моделей 70B на восьми GPU A100". Кроме того, результаты показали, что методы на основе обучения "снижают перплексию WikiText-2 по сравнению с методом, не требующим обучения, и все еще имеют возможности для улучшения", что делает их менее желательными как с точки зрения эффективности, так и конечной точности.
-
Другие методы переупорядочивания (например, RPTQ, Yuan et al., 2023; Atom, Zhao et al., 2024): Хотя эти методы переупорядочивают каналы для уменьшения дисперсии или используют смешанную точность, они не предлагают комплексного, не требующего обучения и низкозатратного решения для обоих канально-ориентированных и пиковых выбросов в INT4, которое предоставляет RRS. Например, Atom интегрирует переупорядочивание со смешанным INT4/INT8, что не является чистым INT4.
Последовательная тема в отклонении этих альтернатив заключается в их неспособности одновременно удовлетворить строгие требования INT4-инференса: высокая точность, низкая задержка и надежное решение, не требующее обучения, для всех типов выбросов активаций.
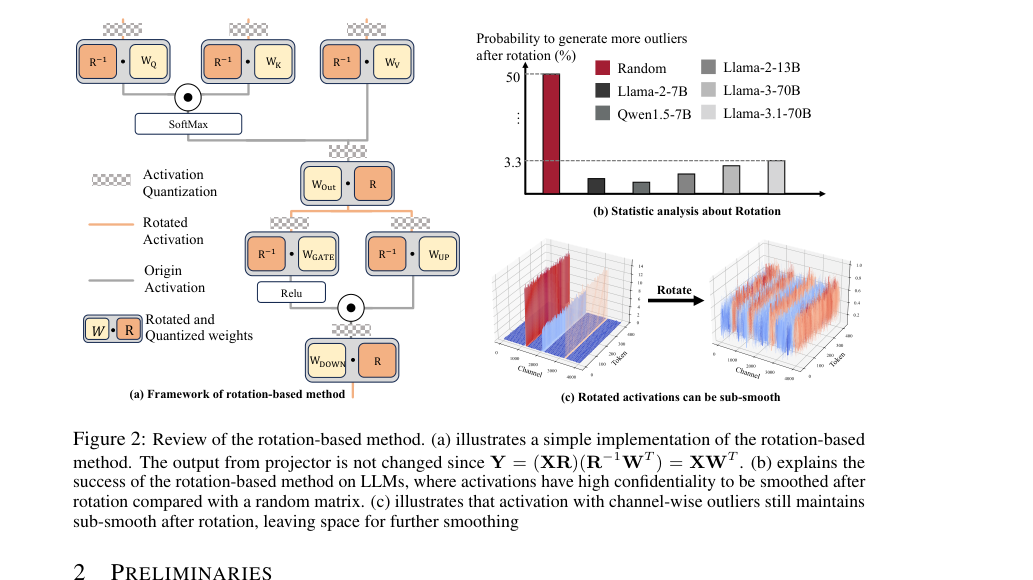 Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Математический и логический механизм
Основное уравнение
Основной математический движок, лежащий в основе метода Rotated Runtime Smooth (RRS), сочетает операцию вращения с механизмом сглаживания во время выполнения. Учитывая входную матрицу активаций $X$ и матрицу весов $W$, процесс RRS может быть инкапсулирован следующей последовательностью операций:
$$ X_{rot} = XR \\ W_{rot} = R^{-1}W \\ s_j = \max(|(X_{rot})_j|), \quad j = 1, \dots, K \\ X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1}) \\ W'_{quant} = \text{Quantize}(W_{rot}) \\ Y = \sum_{j=1}^{K} (X'_{quant})_j (W'_{quant})_j^T s_j $$
Этот набор уравнений описывает, как активации и веса сначала вращаются, затем активации сглаживаются с использованием масштабов, полученных во время выполнения, оба квантуются, и, наконец, модифицированное умножение матриц дает низкобитный выход.
Поэлементный разбор
Давайте разберем каждый компонент основного уравнения, чтобы понять его математическое определение, логическую роль и обоснование его дизайна.
-
$X$: Представляет тензор активаций, поступающий в линейный слой.
1) Математическое определение: Матрица с плавающей запятой размером $N \times K$, где $N$ обычно представляет собой размер пакета, умноженный на длину последовательности, а $K$ — размер входного канала.
2) Физическая/логическая роль: Он несет информацию о признаках из предыдущего слоя, которая должна быть обработана текущим линейным слоем.
3) Почему такая форма: Это стандартное представление для пакета входных признаков. -
$W$: Это матрица весов линейного слоя.
1) Математическое определение: Матрица с плавающей запятой размером $M \times K$, где $M$ — выходной размер, а $K$ — размер входного канала.
2) Физическая/логическая роль: Содержит обучаемые параметры, которые преобразуют входные активации в выходные признаки.
3) Почему такая форма: Стандартное представление для весов линейного слоя. -
$R$: Это матрица вращения.
1) Математическое определение: Ортогональная матрица размера $K \times K$, означающая $RR^T = I$ (где $I$ — единичная матрица) и ее определитель $\det(R) = 1$. В статье часто упоминается матрица вращения Адамара, где $R = \frac{1}{\sqrt{K}}[s_{i,j}]_{K \times K}$ с элементами $s_{i,j} \in \{-1, +1\}$.
2) Физическая/логическая роль: Ее основная роль заключается в линейном преобразовании (вращении) векторных пространств как активаций, так и весов. Это вращение имеет решающее значение для "распределения" сконцентрированных выбросов внутри активаций, делая их менее влиятельными на диапазон квантования. Вращая как $X$, так и $W$ соответствующим образом, исходный выход $XW^T$ математически сохраняется как $(XR)(R^{-1}W^T)$.
3) Почему умножение: Умножение матриц — это фундаментальная операция для применения линейных преобразований, таких как вращения, в векторных пространствах. -
$R^{-1}$: Это обратная матрица вращения.
1) Математическое определение: Поскольку $R$ ортогональна, ее обратная матрица — это просто ее транспонированная матрица, $R^T$. Это также матрица $K \times K$.
2) Физическая/логическая роль: Она вращает матрицу весов $W$ комплементарным образом к $X$, гарантируя, что общее преобразование остается эквивалентным исходной операции с полной точностью.
3) Почему умножение: Аналогично $R$, это линейное преобразование. -
$X_{rot} = XR$: Вращенный тензор активаций.
1) Математическое определение: Результат умножения входной матрицы активаций $X$ на матрицу вращения $R$. Она сохраняет размер $N \times K$.
2) Физическая/логическая роль: Это активации после того, как их признаки были линейно объединены и перераспределены по каналам путем вращения. Этот шаг направлен на смягчение канально-ориентированных выбросов, делая их величины менее экстремальными или более равномерно распределенными.
3) Почему умножение: Это прямое применение преобразования вращения. -
$W_{rot} = R^{-1}W$: Вращенная матрица весов.
1) Математическое определение: Результат умножения матрицы весов $W$ на обратную матрицу вращения $R^{-1}$. Она сохраняет размер $M \times K$.
2) Физическая/логическая роль: Это веса после вращения. Это вращение необходимо для сохранения математической эквивалентности исходного умножения матриц при сочетании с $X_{rot}$.
3) Почему умножение: Прямое применение обратного вращения. -
$s_j = \max(|(X_{rot})_j|)$: Масштаб сглаживания во время выполнения для $j$-го канала.
1) Математическое определение: Для каждого столбца $j$ вращенной матрицы активаций $X_{rot}$ (обозначаемого как $(X_{rot})_j$, что является вектором $N \times 1$), эта операция вычисляет максимальное абсолютное значение среди всех элементов в этом столбце. Это дает скаляр $s_j$.
2) Физическая/логическая роль: Этот масштаб динамически захватывает максимальную величину, присутствующую в каждом канале вращенных активаций. Он служит нормализующим множителем для приведения значений в этом канале в более управляемый диапазон для квантования. Используя максимальное абсолютное значение, он гарантирует, что никакие значения не будут обрезаны во время последующего деления, сохраняя информацию. Это ключевая часть компонента "Runtime Smooth", решающего проблему канально-ориентированных выбросов.
3) Почемуmaxи абсолютное значение:maxопределяет экстремальное значение, которое диктует необходимый диапазон масштабирования. Абсолютное значение гарантирует, что как положительные, так и отрицательные выбросы обрабатываются симметрично. -
$\text{diag}(s)^{-1}$: Обратная диагональная матрица масштабов сглаживания.
1) Математическое определение: Диагональная матрица $K \times K$, где $j$-й диагональный элемент равен $1/s_j$.
2) Физическая/логическая роль: Эта матрица облегчает канально-ориентированное масштабирование $X_{rot}$, позволяя каждому столбцу делиться на соответствующий скаляр $s_j$.
3) Почему диагональная матрица: Это эффективный способ представления поэлементного масштабирования столбцов в виде умножения матриц. -
$X_{rot}\text{diag}(s)^{-1}$: Сглаженные вращенные активации.
1) Математическое определение: Каждый столбец $(X_{rot})_j$ вращенной матрицы активаций поэлементно делится на соответствующий скаляр $s_j$. Это дает матрицу $N \times K$.
2) Физическая/логическая роль: Эта операция нормализует вращенные активации по каналам. Масштабируя значения на основе максимальной величины их канала, выбросы эффективно "сжимаются" по сравнению с нормальными значениями, делая данные всего канала лучше подходящими для диапазона низкобитного квантования.
3) Почему деление: Деление на максимальное абсолютное значение масштабирует данные, обычно до диапазона, такого как $[-1, 1]$, который оптимален для схем симметричного квантования. -
$\text{Quantize}(\cdot)$: Функция квантования.
1) Математическое определение: Функция, которая отображает число с плавающей запятой в целочисленное представление с низким количеством бит. Например, для INT4 она может отображать число с плавающей запятой $x$ в целое число $q$ такое, что $q = \text{round}(x \cdot \text{scale}) + \text{offset}$, гдеscaleиoffsetопределяются целевой битовой шириной и диапазоном значений.
2) Физическая/логическая роль: Это основная операция для снижения точности чисел. Она преобразует значения с высокой точностью с плавающей запятой в дискретные целочисленные значения с низким количеством бит, что значительно снижает потребление памяти и вычислительные затраты во время инференса.
3) Почему такая функция: Это стандартный метод преобразования непрерывных значений в конечное множество дискретных значений, что является сутью квантования. -
$X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1})$: Квантованные сглаженные вращенные активации.
1) Математическое определение: Результат применения функции $\text{Quantize}$ к сглаженной вращенной матрице активаций. Это матрица $N \times K$ целочисленных значений с низким количеством бит.
2) Физическая/логическая роль: Это входные активации в их окончательной низкобитной форме с уменьшенными выбросами, готовые для эффективного умножения матриц. -
$W'_{quant} = \text{Quantize}(W_{rot})$: Квантованные вращенные веса.
1) Математическое определение: Результат применения функции $\text{Quantize}$ к вращенной матрице весов. Это матрица $M \times K$ целочисленных значений с низким количеством бит.
2) Физическая/логическая роль: Это веса в их низкобитной форме с уменьшенными выбросами, готовые для эффективного умножения матриц. -
$(X'_{quant})_j$: $j$-й столбец $X'_{quant}$.
1) Математическое определение: Вектор-столбец размера $N \times 1$, содержащий целочисленные значения с низким количеством бит.
2) Физическая/логическая роль: Представляет собой квантованные и сглаженные активации для конкретного входного канала. -
$(W'_{quant})_j^T$: $j$-я строка $W'_{quant}$ (транспонированная).
1) Математическое определение: Вектор-строка размера $1 \times M$, содержащий целочисленные значения с низким количеством бит. (Примечание: предполагая, что $W'_{quant}$ имеет размер $M \times K$, тогда $(W'_{quant})_j$ — это ее $j$-й столбец, $M \times 1$. Следовательно, $(W'_{quant})_j^T$ имеет размер $1 \times M$. Это соответствует размерностям, необходимым для внешнего произведения $N \times M$).
2) Физическая/логическая роль: Представляет собой квантованные веса, соответствующие вкладу $j$-го входного канала во все выходные каналы. -
$\sum_{j=1}^{K} (\cdot)$: Суммирование по каналам.
1) Математическое определение: Этот оператор суммирует $K$ отдельных матриц размера $N \times M$.
2) Физическая/логическая роль: Это суммирование объединяет вклады от каждого входного канала для формирования окончательной выходной матрицы. Каждый член $(X'_{quant})_j (W'_{quant})_j^T s_j$ представляет собой масштабированное внешнее произведение. Масштабирование на $s_j$ здесь является уникальным аспектом формулировки статьи, подразумевая, что вклад частичного произведения каждого канала в окончательный выход масштабируется на фактор сглаживания активаций, рассчитанный для этого канала. Это можно интерпретировать как форму канально-ориентированного деквантования или перемасштабирования, применяемого к частичным произведениям перед суммированием, что отличается от того, как масштабы обычно обрабатываются в стандартном квантованном умножении матриц (где масштабы часто применяются равномерно к входам или выходам, или поглощаются в квантованные значения). Описание в статье в разделе 4.5, "умножить масштаб времени выполнения на деквантованном результате", предполагает несколько иной порядок операций для окончательного масштабирования, но уравнение в разделе 3.1 является наиболее явным математическим выражением механизма.
3) Почему суммирование: Умножение матриц по сути является суммой внешних произведений векторов-столбцов из первой матрицы и векторов-строк из второй. -
$Y$: Окончательная выходная матрица.
1) Математическое определение: Результирующая матрица размером $N \times M$.
2) Физическая/логическая роль: Это низкобитное приближение умножения матриц с полной точностью $XW^T$, полученное после вращения, сглаживания, квантования и модифицированного суммирования. Оно представляет собой обработанные признаки из линейного слоя, готовые для последующих операций в нейронной сети.
Пошаговый поток
Представьте себе одну абстрактную точку данных, скажем, $x_{token, feature\_in}$, представляющую конкретный признак для данного входного токена, и вес $w_{feature\_out, feature\_in}$, который связывает входной признак с выходным признаком. Давайте проследим их путь через механизм Rotated Runtime Smooth (RRS):
-
Первоначальный вход: Наша абстрактная точка данных $x_{token, feature\_in}$ поступает в систему как часть матрицы активаций с плавающей запятой $X$. Вес $w_{feature\_out, feature\_in}$ является частью матрицы весов с плавающей запятой $W$.
-
Вращение активаций: Вся матрица активаций $X$ подается в "движок вращения", где она умножается на матрицу вращения $R$. Наша точка данных $x_{token, feature\_in}$ теперь трансформируется. Она больше не изолирована, а вносит вклад в другие признаки в своем канале и подвергается их влиянию, становясь новым значением, $x'_{token, feature\_k}$, в пределах вращенной матрицы активаций $X_{rot}$. Этот процесс направлен на равномерное распределение любых экстремальных значений (выбросов) по пространству признаков.
-
Вращение весов: Одновременно матрица весов $W$ проходит через "движок контрвращения", где она умножается на $R^{-1}$ (обратную матрицу вращения), давая $W_{rot}$. Это гарантирует, что общая математическая целостность исходной операции сохраняется, даже после вращения входных активаций.
-
Обнаружение масштаба во время выполнения: Для каждого столбца (представляющего канал признаков) вращенной матрицы активаций $X_{rot}$ "сканер величины" определяет максимальное абсолютное значение. Для столбца, содержащего $x'_{token, feature\_k}$, вычисляется конкретный масштаб $s_{feature\_k}$. Этот масштаб является динамическим, адаптируясь к характеристикам текущего входного сигнала.
-
Сглаживание активаций: Вращенная матрица активаций $X_{rot}$ затем поступает в "камеру сглаживания". Здесь каждое значение в столбце делится на соответствующий масштаб канала $s_j$. Таким образом, $x'_{token, feature\_k}$ масштабируется до $x''_{token, feature\_k} = x'_{token, feature\_k} / s_{feature\_k}$. Эта операция эффективно "сжимает" диапазон значений в каждом канале, делая выбросы менее доминирующими и подготавливая данные для эффективного низкобитного квантования.
-
Квантование активаций: Сглаженные вращенные активации ($X_{rot}\text{diag}(s)^{-1}$) затем подаются в "блок квантования". Этот блок преобразует каждое значение с плавающей запятой, включая наш $x''_{token, feature\_k}$, в низкобитное целое число, $q_{X,token,feature\_k}$. Именно здесь начинаются значительная экономия памяти и вычислительных затрат.
-
Квантование весов: Параллельно вращенная матрица весов $W_{rot}$ также проходит через свой собственный "блок квантования", преобразуя свои значения с плавающей запятой (например, $w'_{feature\_out, feature\_in}$) в низкобитные целые числа, $q_{W,feature\_out,feature\_in}$.
-
Сборка выходных данных по каналам: Теперь система начинает собирать окончательный выход. Для каждого канала признаков $j$ (от $1$ до $K$):
- Извлекается $j$-й столбец квантованных активаций, $(X'_{quant})_j$.
- Извлекается $j$-я строка квантованных весов (транспонированная), $(W'_{quant})_j^T$.
- Эти два вектора умножаются (внешнее произведение) для формирования частичной выходной матрицы. Эта матрица представляет вклад только $j$-го канала в окончательный результат.
- Критически важно, что эта частичная выходная матрица затем масштабируется на фактор сглаживания во время выполнения $s_j$, который был рассчитан ранее для $j$-го канала активаций. Этот шаг повторно вводит информацию о величине, которая была удалена во время сглаживания активаций, но теперь применяется к частичному произведению.
-
Окончательное суммирование: Все эти $K$ масштабированных частичных выходных матриц затем подаются в "блок суммирования", который поэлементно складывает их. Результатом является окончательная выходная матрица $Y$, где каждый элемент $y_{token, feature\_out}$ является суммой всех масштабированных вкладов каналов. Это завершает прямой проход, выдавая низкобитное, но точное приближение исходной операции с полной точностью.
Динамика оптимизации
Важно уточнить, что Rotated Runtime Smooth (RRS) является обучающе-свободным методом. Это означает, что его "динамика оптимизации" не связана с итеративным обучением или обновлениями на основе градиентов в традиционном смысле. Вместо этого механизм разработан для прямой оптимизации точности квантования через свои структурные компоненты.
-
Отсутствие итеративного обучения: В отличие от методов, которые полагаются на обратное распространение ошибки и градиентный спуск для обновления параметров модели, RRS не включает такого цикла обучения во время своей работы. Матрица вращения $R$ либо является фиксированной, предопределенной матрицей (например, матрицей Адамара), либо получается из офлайн-калибровки (как в связанных работах), но она не обновляется во время инференса. Масштабы сглаживания $s_j$ вычисляются "на лету" для каждого нового входного сигнала, что делает их адаптивными, но не "изучаемыми" с течением времени.
-
Отсутствие перемещения по ландшафту потерь: Поскольку обучение отсутствует, концепция перемещения по "ландшафту потерь" с помощью градиентов не применима к самому механизму RRS. "Оптимизация" встроена в выбор дизайна: как вращать, как сглаживать и как квантовать, чтобы минимизировать ошибку квантования и сохранить производительность модели. Эффективность этих проектных решений оценивается по таким метрикам, как перплексия или точность, которые являются наблюдаемыми результатами, а не целями для прямой оптимизации на основе градиентов в рамках механизма.
-
Детерминированные обновления состояния: Состояние механизма RRS не эволюционирует итеративно. Для каждого входного сигнала процесс представляет собой прямой, детерминированный ряд преобразований:
- Активации и веса вращаются с использованием фиксированного $R$.
- Масштабы сглаживания вычисляются на основе вращенных активаций текущего входного сигнала.
- Применяется квантование с использованием фиксированных битовых ширин и правил округления.
- Вычисляется окончательное умножение матриц (с особым масштабированием частичных произведений по каналам).
Каждый шаг является прямым вычислением, а не обновлением на основе предыдущих состояний или ошибок.
-
"Сходимость" на основе дизайна: "Сходимость" RRS — это не итеративный процесс, а скорее состояние, достигаемое благодаря его внутреннему дизайну. Цель состоит в том, чтобы преобразовать активации и веса таким образом, чтобы они были "достаточно гладкими" (т.е. выбросы были достаточно смягчены), чтобы обеспечить точное низкобитное (INT4) квантование. Статья демонстрирует, что этот дизайн эффективно снижает ошибку квантования, что приводит к улучшению перплексии и точности на различных моделях. Таким образом, "оптимизация" заключается в умной инженерии этих преобразований для достижения высококачественного низкобитного инференса, а не в итеративном процессе обучения. Надежность механизма и прирост производительности являются свидетельством этой оптимизации дизайна, что делает его высокоэффективным и подключаемым решением. Пренебрежимо малые накладные расходы дополнительно подчеркивают его практическую полезность.
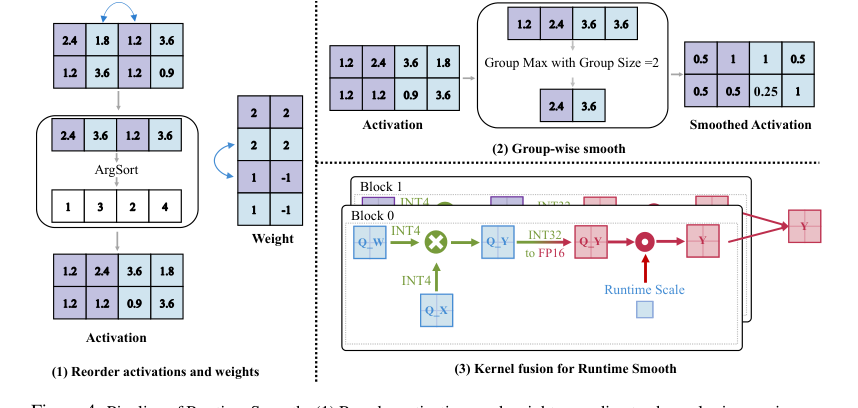 Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые линии
Для строгого подтверждения своих математических утверждений авторы провели обширные эксперименты на разнообразном наборе основных больших языковых моделей (LLM). К ним относились различные модели из семейств LLaMA (LLaMA2-13B, LLaMA2-70B, LLaMA3-8B, LLaMA3-70B, LLaMA3.1-8B, LLaMA3.1-70B), Qwen (Qwen1.5-7B, Qwen1.5-14B), Mistral и Mixtral. Оценка была сосредоточена на INT4-квантовании, в частности, с использованием трех схем: A4W4KV4, A4W4KV16 и A4W16KV16, которые обозначают 4-битное квантование активаций, 4-битное квантование весов и 4-битное квантование KV-кэша соответственно, с различными битовыми ширинами KV-кэша.
Для квантования активаций использовалась симметричная схема на канал с стратегией округления до ближайшего (RTN). Квантование KV-кэша использовало симметричную схему подканала с размером группы 128, также с RTN. Квантование весов в основном использовало симметричную схему на канал с GPTQ (Frantar et al., 2022), за исключением базового метода 'RTN'. Калибровочный набор для GPTQ состоял из 128 образцов из WikiText-2, каждый с длиной последовательности 2048.
"Жертвами" (базовыми моделями/методами), с которыми сравнивались предлагаемый Rotated Runtime Smooth (RRS) и его компонент Runtime Smooth (RS), были:
- RTN: Базовое квантование Round-to-Nearest.
- SmoothQuant (Xiao et al., 2023): Известный метод канально-ориентированного сглаживания, который мигрирует выбросы офлайн.
- GPTQ (Frantar et al., 2022): Метод квантования весов после обучения.
- QuaRot (Ashkboos et al., 2024): Метод на основе вращения для подавления выбросов.
- SpinQuant (Liu et al., 2024) и DuQuant (Lin et al., 2024a): Дополнительные базовые линии для конкретных сравнений, включая методы, требующие обучения.
Окончательные доказательства эффективности их основного механизма были собраны с помощью нескольких экспериментальных архитектур:
1. Перплексия на WikiText-2: Этот стандартный бенчмарк измеряет, насколько хорошо языковая модель предсказывает образец текста, причем более низкая перплексия указывает на лучшую производительность.
2. Zero-shot Common Sense QA Benchmarks: Производительность оценивалась на задачах, таких как ARC-e, ARC-c, BoolQ и OBQA, для оценки рассуждающих способностей моделей после квантования.
3. Абляционные исследования:
* Предварительное абляционное исследование (рис. 3) напрямую сравнивало Runtime Smooth с SmoothQuant и базовой линией "Origin A4W4", демонстрируя необходимость сглаживания во время выполнения и подводные камни миграции выбросов в веса.
* Абляционное исследование по размеру группы масштаба сглаживания во время выполнения (табл. 4) исследовало влияние этого гиперпараметра на точность.
4. Оценка эффективности: Используя NVBench на GPU RTX 4070 Ti, авторы измерили накладные расходы их объединенного GEMM-ядра по сравнению с базовыми линиями Per-Channel A4W4 и Sub-Channel A4W4 (рис. 6), доказав практическую жизнеспособность их подхода.
5. Статистический анализ выбросов: Рисунок 9 предоставил подробный статистический анализ удаления выбросов в различных компонентах LLM (QKV_Projector, Output_Projector, Up_Proj или Gate_Proj, Down_Projector) для различных моделей, визуально демонстрируя, как RRS эффективно перемещает активации в более гладкий диапазон по сравнению с другими методами.
Что доказывают доказательства
Представленные в статье доказательства убедительно подтверждают эффективность Rotated Runtime Smooth (RRS) и его составляющей Runtime Smooth (RS) в обеспечении точного INT4-инференса для LLM.
Во-первых, компонент Runtime Smooth (RS), разработанный для устранения канально-ориентированных выбросов, показал значительные улучшения. Предварительное абляционное исследование (рис. 3) ясно продемонстрировало, что простое применение масштаба сглаживания во время выполнения было недостаточным для квантования A4W4. Однако, когда RS был полностью реализован, он сделал A4W4 осуществимым, приведя к драматическому улучшению перплексии с 4e2 до 10.9 для LLaMA3-8B в настройке A4W16. Это было критически важно для подтверждения основной идеи использования масштабов во время выполнения без миграции выбросов в веса, что было ключевым ограничением предыдущих методов, таких как SmoothQuant. В Таблице 1 RS последовательно превосходил SmoothQuant и RTN на различных моделях и схемах квантования, например, снизив перплексию LLaMA2-70B с 1e2 (SmoothQuant) до 6.95 (RS) в схеме 16-4-16. Более того, при квантовании только активаций (A4W16KV16), RS достиг 40-кратного улучшения на LLaMA3-8B, подчеркивая его эффективность.
Во-вторых, полный метод Rotated Runtime Smooth (RRS), который сочетает вращение с сглаживанием во время выполнения для решения проблем как канально-ориентированных, так и пиковых выбросов, продемонстрировал превосходную производительность. Таблица 1, основная таблица результатов для перплексии WikiText-2, показывает, что RRS последовательно превосходит все базовые линии, включая RS, QuaRot, SmoothQuant и RTN, почти на всех оцененных моделях LLaMA, Qwen и Mistral. Особенно поразительным примером является LLaMA3-70B, где RRS снизил перплексию с 57.33 до 6.66 в настройке A4W4KV16 и с 49.76 до 6.87 в настройке A4W4KV4. Эти существенные улучшения по сравнению с современным QuaRot, который дал 57.33 и 49.73 соответственно для той же модели и настроек. Эти окончательные доказательства подтверждают, что комбинированный механизм RRS эффективно смягчает влияние обоих типов выбросов.
Помимо перплексии, RRS также продемонстрировал свою силу в задачах zero-shot common sense QA (Таблица 2). На различных LLM и схемах квантования RRS последовательно превосходил все базовые линии (GPTQ, SmoothQuant, RS, QuaRot) примерно на 3% в среднем улучшении точности. Например, на LLaMA-3-8B с 4-4-16 квантованием RRS достиг средней точности 58.0%, по сравнению с 55.0% у QuaRot. Это указывает на то, что улучшенное сглаживание активаций приводит к лучшей производительности в задачах сложного рассуждения.
Статистический анализ удаления выбросов (рис. 9) предоставляет прямые визуальные доказательства работы механизма RRS. Он показывает, что RRS приводит к значительно большей доле активаций, попадающих в категорию 'u < 4' (более гладкие), во всех компонентах LLM (QKV_Projector, Output_Projector, Up_Proj или Gate_Proj, Down_Projector) и моделях по сравнению с исходными активациями (X), вращенными активациями (R) или только Runtime Smooth (RS). Это напрямую подтверждает способность RRS комплексно устранять как канально-ориентированные, так и пиковые выбросы.
Наконец, оценка эффективности (рис. 6 и раздел 4.5) подтверждает, что объединенное ядро RRS вносит лишь пренебрежимо малые накладные расходы по сравнению с базовой линией A4W4 Per-Channel квантования. Это критическое практическое преимущество, поскольку оно означает, что прирост точности не достигается ценой значительного замедления, что делает RRS поистине подключаемым решением для INT4-инференса. Сравнение с методами, требующими обучения (Таблица 3), далее подчеркивает силу RRS, поскольку он превосходит SpinQuant (метод, требующий обучения) по перплексии WikiText-2, не неся при этом значительных затрат времени на обучение.
Ограничения и будущие направления
Хотя Rotated Runtime Smooth (RRS) представляет собой значительный прогресс в области обучающе-свободного INT4-инференса, статья также явно и неявно указывает на несколько ограничений и открывает двери для будущих исследований.
Текущие ограничения:
1. Неполная гарантия сглаживания от вращения: В статье отмечается, что "вращение не может гарантировать более гладкую матрицу, и вращенная матрица все еще может проявлять форму канально-ориентированных выбросов" (Раздел 1, Рисунок 2). Это предполагает, что, хотя вращение помогает, оно само по себе не является идеальным решением, что требует компонента Runtime Smooth.
2. Эффект "жертвы" от пиковых выбросов: Наличие пиковых выбросов все еще может приводить к отсечению нормальных значений как "жертв" после канально-ориентированного сглаживания (Раздел 1, Рисунок 1). Хотя RRS стремится смягчить это, основная проблема остается.
3. Чувствительность к размеру группы: Абляционное исследование (Раздел 4.4, Таблица 4) указывает на то, что, хотя Runtime Smooth эффективно минимизирует разрыв между A4W4 и полной точностью, "точность ухудшается по мере увеличения размера группы". Это подразумевает компромисс и потенциальную чувствительность к выбранному размеру группы, который может быть не универсально оптимальным.
4. Сценарии специфических выбросов: Авторы отмечают, что "случай только с двумя выбросами токенов редок, но потенциально может затруднить работу Rotated Runtime Smooth" (Раздел C.1). Это указывает на специфический, хотя и редкий, паттерн выбросов, с которым RRS может испытывать трудности, предполагая, что его надежность может быть не абсолютной для всех возможных распределений выбросов.
5. Чувствительность выбросов к конкретным моделям: Авторы отмечают, что "модели имеют разную чувствительность к выбросам. Дальнейшее подавление выбросов может повысить надежность" (Раздел 4.2). Это подразумевает, что, хотя RRS является обобщенным, могут существовать специфические для модели характеристики выбросов, которые можно было бы дополнительно оптимизировать.
6. Ограничения аппаратного обеспечения по размеру группы: Для некоторых моделей, таких как Qwen1.5-7B, размер входной активации для Down_projector (11008) "не поддерживает размер группы 512" (Раздел 4.4). Это указывает на практические ограничения в применении самых больших размеров групп, которые в противном случае могли бы предложить определенные преимущества.
Будущие направления и темы для обсуждения:
- Адаптивные и динамические стратегии сглаживания: Учитывая чувствительность к размеру группы и различные паттерны выбросов, будущие работы могли бы исследовать адаптивные стратегии сглаживания. Вместо фиксированного размера группы или универсального вращения, можем ли мы динамически настраивать эти параметры на основе статистики активаций в реальном времени или характеристик слоя модели? Это может включать легкий анализ "на лету" для оптимизации сглаживания для каждого конкретного входного сигнала и слоя, что потенциально приведет к еще большей точности и надежности.
- Теоретические границы и гарантии подавления выбросов: В статье эмпирически демонстрируется эффективность RRS. Более глубокое теоретическое исследование математических свойств вращения и сглаживания во время выполнения могло бы установить формальные границы подавления выбросов и его влияния на ошибку квантования. Это могло бы привести к более принципиальному дизайну будущих методов квантования с доказуемыми гарантиями.
- Гибридные обучающе-свободные и обучающие подходы: Хотя RRS не требует обучения и превосходит некоторые методы, требующие обучения, концепция изученных вращений (как в SpinQuant) по-прежнему остается многообещающей. Будущие исследования могли бы изучить гибридные подходы, которые сочетают эффективность не требующих обучения методов, таких как RRS, с минимальными, целенаправленными шагами обучения или дообучения для дальнейшей доработки вращений или масштабов сглаживания, потенциально достигая еще более высокой точности без обширных затрат на обучение современных методов, требующих обучения.
- Совместное проектирование аппаратного и программного обеспечения для продвинутого квантования: Пренебрежимо малые накладные расходы RRS являются значительным преимуществом. Чтобы продвинуться дальше, можно было бы разработать специализированные аппаратные ускорители или наборы инструкций для нативной поддержки операций переупорядочивания, вычисления группового максимума и вращения, центральных для RRS. Этот подход совместного проектирования мог бы обеспечить беспрецедентное ускорение и энергоэффективность для INT4-инференса.
- Обобщение на другие типы данных и архитектуры моделей: RRS валидирован для INT4-инференса в LLM. Насколько хорошо эти принципы распространяются на другие низкобитные схемы квантования (например, INT2, бинарные) или на другие архитектуры моделей, помимо трансформеров, такие как модели компьютерного зрения или мультимодальные архитектуры? Исследование этих более широких применений могло бы выявить новые проблемы и возможности для адаптации RRS.
- Надежность к состязательным атакам и сдвигам распределения: Квантованные модели могут быть более уязвимы к состязательным атакам или снижению производительности при работе с данными вне распределения. Будущие работы могли бы исследовать, как RRS, делая активации более гладкими и последовательными, может по своей сути улучшить надежность квантованных LLM против таких проблем, или требуются ли специфические модификации для усиления этого аспекта.
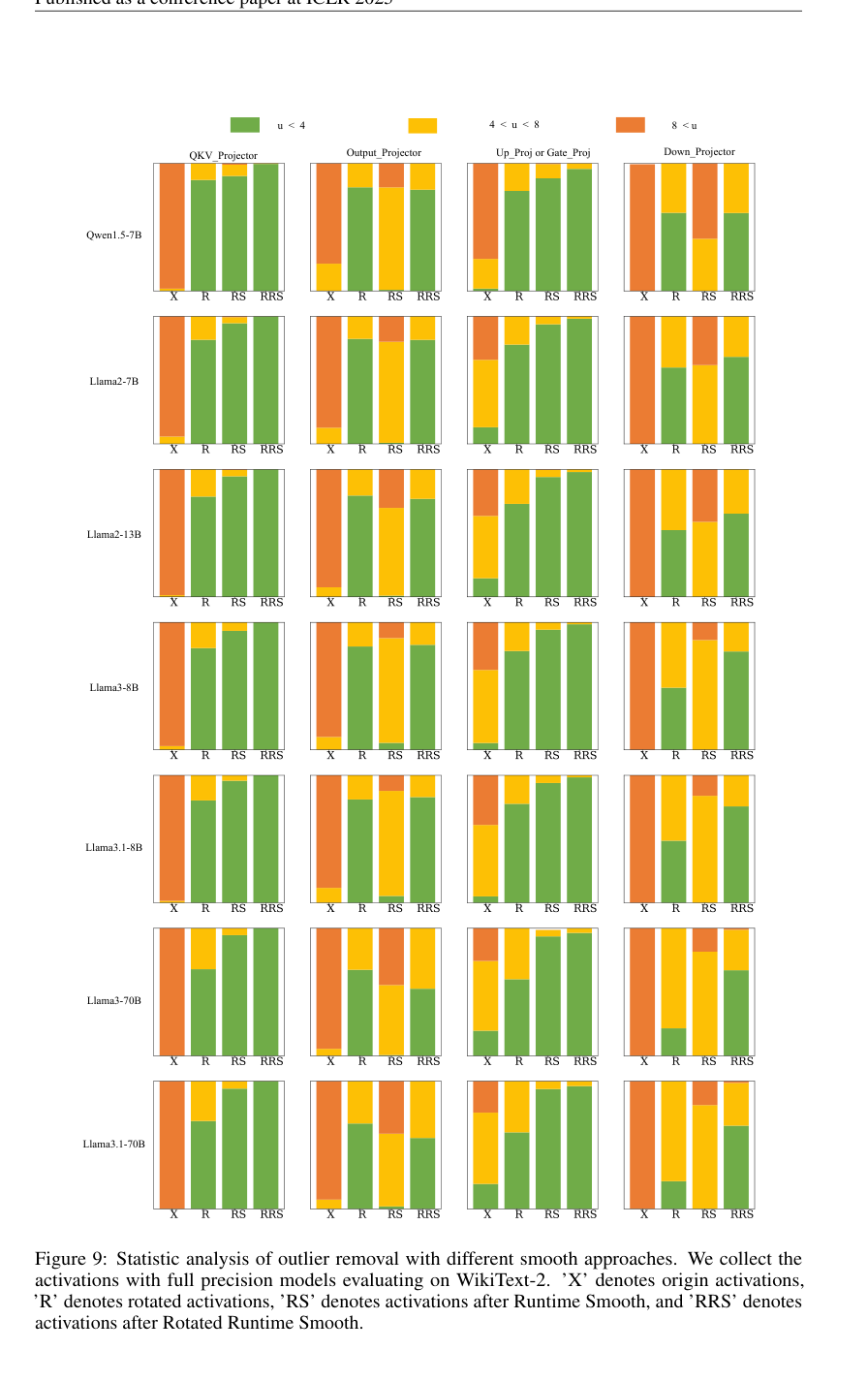 Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
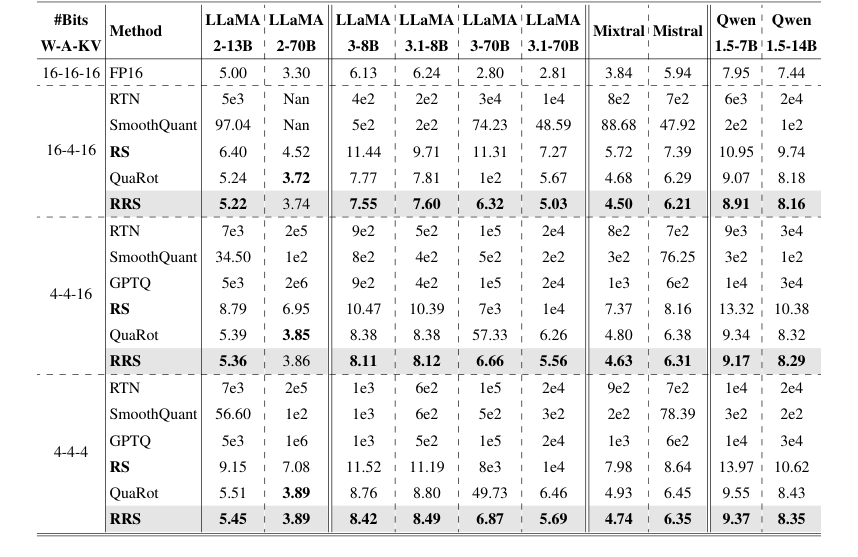 Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
 Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
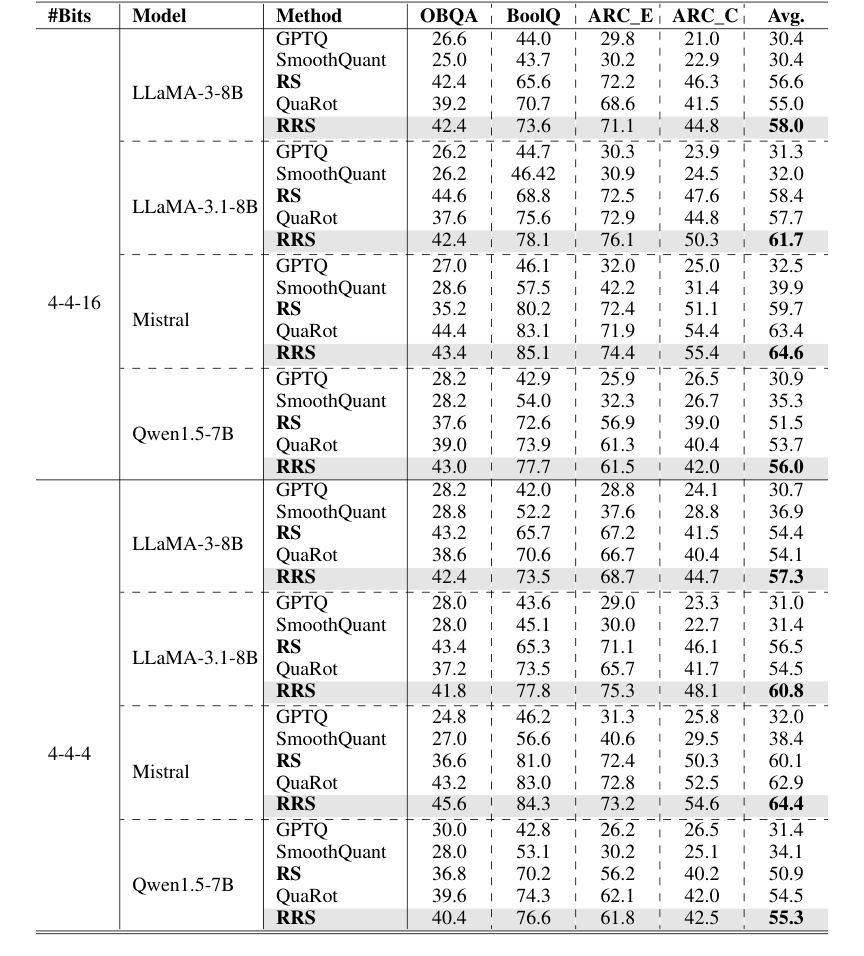 Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes