Rotated Runtime Smooth: accurate INT4推論のためのトレーニングフリー活性化スムーザー
Large language models have demonstrated promising capabilities upon scaling up parameters.
背景と学術的系譜
起源と学術的系譜
本稿で取り上げる問題は、大規模言語モデル(LLM)の規模と複雑性の増大に端を発する。これらのモデルが成長するにつれて、推論のためのサービングは計算リソースとメモリ使用量の点で非常に高価になる。これらのコストを軽減し、レイテンシを改善するために、量子化手法が広く採用されている。量子化は、モデルで使用される数値(重みと活性化)の精度を、例えば高精度浮動小数点数からINT4(4ビット整数)のような低ビット整数に削減することである。
しかし、低ビット量子化、特にINT4の重み-活性化量子化において、活性化における外れ値の存在が大きな「ペインポイント」として現れた。これらの外れ値は、活性化テンソル内の極端な値であり、値の全体的な範囲を不均衡に引き伸ばす。全体の範囲が非常に限られたビット数(4ビットなど)に圧縮されると、これらの外れ値は利用可能な「精度スロット」のほとんどを消費し、より一般的で「通常の」値には効果的なビットがほとんど残らなくなる。これは、推論中のモデルの精度を著しく低下させる。
以前のアプローチはこれらの外れ値を処理しようとしたが、根本的な限界に直面していた。
* 外れ値の分離: 初期の手法(例:Kim et al., 2023; Dettmers et al., 2022)は、外れ値と通常の値を異なる行列に分離しようとした。ここでの主な欠点は、これらの実装がハードウェア互換性がないことが多く、高いレイテンシにつながり、推論の高速化に失敗したことである。
* オフラインスムージングと移行(SmoothQuant): SmoothQuant(Xiao et al., 2023)は、チャネルごとのスムージングスケールを使用して、活性化から重みへの外れ値の移行を目的とした。これは高ビット量子化(A8W8など)には効果的であったが、いくつかの理由でINT4推論には失敗した。
* スムージングスケールはキャリブレーションセットを使用してオフラインで事前に計算されたため、新しい、「一致しない」オンライン活性化に遭遇した場合に効果がなかった。
* 外れ値は実際には排除されず、部分的に移行されただけで、低ビット量子化を依然として妨げていた。
* SmoothQuantは主に「チャネルごとの」外れ値に対処したが、チャネル全体で一貫性のない「スパイク」外れ値には苦労し、通常の値を「犠牲者」として誤って削除してしまう結果となった。
* 回転ベースの手法(QuaRot): QuaRot(Ashkboos et al., 2024)のようなより最近の研究は、外れ値を内部に広げることで抑制するために回転行列を導入した。A4W4量子化には有望であったが、回転だけでは完全にスムーズな行列を保証できず、チャネルごとの外れ値を示す可能性があり、さらなる改善の余地を残していた。課題は、両方のタイプ外れ値を効果的に処理できる、INT4推論のための堅牢で正確、かつトレーニングフリーのスキームを見つけることであった。
直感的なドメイン用語
- 量子化 (Quantization): 何百万もの色合いを持つ非常に詳細なカラーパレット(浮動小数点数のような)を持っていると想像してください。量子化とは、すべての画像を表現するために、例えば16種類の特定の色合い(4ビット整数のような)という、はるかに小さい色のセットを選択することです。目標は、画像を可能な限り良く見せながら、画像をはるかに小さく、処理を速くすることです。
- 活性化における外れ値 (Outliers in Activations): 身長が主に5〜6フィートの間にある人々のグループを考えてみてください。しかし、20フィートの巨人と1フィートの小人が数人います。10個のマークだけを使って全員の身長スケールを作成しようとすると、その極端な巨人や小人はスケールを巨大な範囲(1〜20フィート)に広げることになります。これは、一般的な5〜6フィートの範囲にマークが非常に少なくなり、5フィート2インチの人と5フィート4インチの人の違いを区別するのが難しくなることを意味します。「巨人」や「小人」が外れ値であり、「通常の」身長を正確に表現するのが難しくなります。
- INT4推論 (INT4 Inference): これは、非常に正確な小数(5.123 x 3.456)ではなく、非常に単純で丸められた数値(例えば、4ビット整数で表現できる-8から7までの数値のみ)で計算を行うようなものです。LLMの最大の速度とメモリ節約を得るために、非常に積極的な丸め形式である「INT4」は、4ビット整数を使用することを意味します。
- パープレキシティ (Perplexity): 言語モデルの文脈では、パープレキシティは、モデルがシーケンス内の次の単語にどれだけ「驚くか」の尺度です。文章の次の単語を推測しようとしていると想像してください。あなたが非常に自信を持って正しく推測した場合、あなたの「驚き」は低いです。あなたがしばしば間違ったり不確かだったりする場合、「驚き」は高いです。パープレキシティスコアが低いほど、言語モデルは驚きが少なく、テキストをより正確に予測し、言語をより正確に理解していることを示します。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
中核問題定式化とジレンマ
本稿で取り上げる根本的な問題は、特にINT4において、非常に低ビットの重み-活性化量子化を実行しようとする際に、大規模言語モデル(LLM)の精度が著しく低下することである。
入力/現在の状態は、LLMがその印象的な能力にもかかわらず、その巨大な規模のためにサービングが計算上およびメモリ上非常に高価であるということである。モデルパラメータと活性化の精度を(例えばFP32からINT4に)削減する量子化は、これらのコストを軽減し、推論レイテンシを改善するための有望な技術である。しかし、INT4重み-活性化量子化の広範な採用に対する重要な障害は、活性化テンソルにおける「外れ値」の存在である。これらの外れ値は、量子化範囲を不均衡に引き伸ばす極端な値であり、通常の値に利用可能な動的範囲を効果的に圧縮し、実質的な情報損失と精度低下につながる。
望ましい終点(出力/目標状態)は、LLMのための正確で効率的なINT4重み-活性化推論を可能にすることである。これは、実質的な精度低下を招くことなく、INT4量子化の計算上およびメモリ上の利点を達成することを意味する。本稿は、「トレーニングフリー活性化スムーザー」を開発することを目的としており、これは活性化外れ値を堅牢に処理できるため、通常の値を十分な精度で量子化でき、最終的に様々なLLMファミリーにわたるINT4推論で最先端のパフォーマンスにつながる。
現在の状態と望ましい終点の間の正確な欠落リンクまたは数学的ギャップは、活性化テンソル全体を最小限の情報損失でINT4に量子化できるように、活性化外れ値を効果的に「平滑化」または正規化する方法を見つけることにある。これはすべて計算コストが低く、トレーニングフリーである必要がある。数学的には、$X$が活性化テンソルであり、$\alpha$が量子化のスケーリング係数(例えば、Nビット量子化の場合、$\alpha = \frac{\max(|X|)}{2^{N-1}-1}$)である場合、外れ値は$\max(|X|)$を非常に大きくし、$\alpha$を大きくする。これにより、通常の値は非常に小さな整数値の範囲にマッピングされ、深刻な精度損失につながる。欠落リンクは、$f(X)$が$\max(|X|)$よりもはるかに小さい$\max(|f(X)|)$を持つような変換$f(X)$であり、かつ$f(X)$が元の情報を正確に表現し、より小さな$\alpha'$を可能にし、それによって通常の値のより効果的な量子化を可能にすることである。この変換は、出力$XW$を維持するために、重み行列$W$とも互換性がある必要がある。
以前の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、主に精度 vs. 効率 vs. 堅牢性の三角形である。
1. 精度 vs. 効率(低ビット量子化): 積極的な低ビット量子化(INT4)は大幅な高速化とメモリ節約を提供するが、活性化外れ値に非常に敏感であり、深刻な精度低下につながる。精度を維持するには、しばしばより高いビット幅または複雑な外れ値処理が必要となり、効率の利点を無効にする。
2. 外れ値処理 vs. ハードウェア互換性/レイテンシ: 外れ値を分離する(例:Kim et al., 2023; Dettmers et al., 2022)または重みに移行する(例:SmoothQuant)既存の手法は、しばしばハードウェア互換性の問題、大幅なレイテンシオーバーヘッドを導入するか、重み量子化を困難にする。これは、より高速で効率的な推論という中核目標を損なう。
3. 静的 vs. 動的スムージング: 事前に計算されたスムージングスケール(例:SmoothQuant)は効率的だが、オンライン活性化と「一致しなくなり」、動的な入力に対して効果がなくなる。実行時スムージングはより堅牢であるが、伝統的に許容できない計算オーバーヘッドを発生させる。
4. チャネルごとの外れ値 vs. スパイク外れ値: 外れ値は異なる形式で現れる:「チャネルごとの」(チャネル全体で一貫性がある)と「スパイク」(孤立した極端な値)。一方のタイプに効果的な手法(例:チャネルごとのスムージング)は、もう一方のタイプ(例:スパイク外れ値が通常の値を削除させる)に対して「犠牲者効果」を悪化させる可能性があり、量子化エラーにつながる。新しい副作用のない統一されたソリューションは、まだ見つかっていない。
制約と失敗モード
LLMのための正確なINT4推論の問題は、著者らが直面するいくつかの厳しい現実的な壁のために非常に困難である。
- 活性化外れ値の極端な疎性/大きさ: 活性化外れ値は、通常の値よりも桁違いに大きい場合がある(例:14ページで言及されているように1000倍大きい)。この極端な大きさは量子化範囲を非常に厳しく引き伸ばし、通常の値が効果的なビットをほとんどすべて失い、壊滅的な精度損失につながる。
- INT4精度限界: INT4への量子化は、活性化の全体範囲を表現するために16個の値($2^4$)しか使用できないことを意味する。この極端に制限された精度は、実質的な情報損失なしに、外れ値を収容するための誤差の余地をほとんど残さない。
- リアルタイムレイテンシ要件: LLM推論、特にプリフィル段階は、厳格なリアルタイムレイテンシを要求する。あらゆる外れ値スムージングまたは処理メカニズムは、実用的であるためには「無視できるオーバーヘッド」(2ページ、9ページ)を導入する必要がある。大幅な計算時間を追加する複雑な操作は許容できない。
- ハードウェアメモリ制限: LLMは巨大であり、メモリ帯域幅がボトルネックとなることが多い。量子化は、メモリフットプリントと移動を削減することを目的としている。高精度データや外れ値のための複雑なデータ構造の保存を必要とするソリューションは、これらの利点を無効にする可能性がある。
- トレーニングフリー要件: ソリューションは「トレーニングフリー」かつ「プラグアンドプレイ」(Abstract、2ページ)である必要がある。これは、大規模モデルの場合、特に時間とリソースを大量に消費する、大規模データセットでの広範なファインチューニングやキャリブレーションに依存できないことを意味する。
- 動的入力分布: 活性化の分布は、異なる入力やLLMの異なる層間で大きく変化する可能性がある。静的なキャリブレーションセットから導出されたスムージングスケールは、「オンライン活性化と一致しない」(3ページ)傾向があり、効果のないスムージングと精度低下につながる。
- 「犠牲者」効果: スムージングスケールが極端な外れ値によって決定されると、はるかに小さい通常の値が効果的に「削除」されたり、「犠牲者」(2ページ、図1c、3ページ)になったりする可能性がある。通常の値のこの精度損失は、微妙な情報を表現するモデルの能力に直接影響するため、重要な失敗モードである。
- GEMMカーネルとの非互換性: 実行時スムージングの単純な実装、特に一貫性のないスムージングスケールでは、高度に最適化された汎用行列乗算(GEMM)カーネル(4ページ)に容易に統合できない。カスタムカーネルまたは複雑なブロックごとの計算が必要になるため、ハードウェアアクセラレーションの達成が困難になる。
- 回転後のサブスムージング: 回転ベースの手法(QuaRotなど)は外れ値を広げるのに役立つが、完全にスムーズな行列を保証できず、「チャネルごとの外れ値」または「サブスムージング」(2ページ、図2c、4ページ)を示す可能性がある。これは、回転だけではINT4量子化の外れ値問題を完全に解決するには不十分であることを意味する。
- 外れ値移行の課題: 活性化から重みへの外れ値を移行する以前の手法(例:SmoothQuant)は、特にA4W4のような非常に低ビットのスキーム(1ページ)では、重みの量子化を困難にする可能性がある。これは、活性化ドメインで問題を解決しようとする際に、重みドメインで新しい問題を作成する。
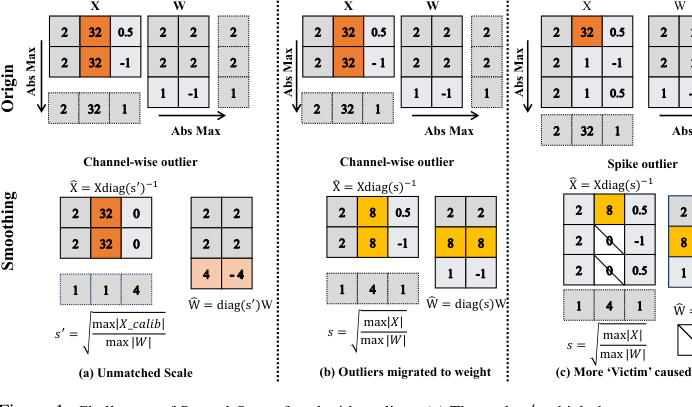 Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
なぜこのアプローチなのか
選択の必然性
著者らがRotated Runtime Smooth (RRS) に至ったのは、大規模言語モデル(LLM)のINT4推論という困難な状況に適用された既存の量子化手法の根本的な限界に駆動された。従来の最先端(SOTA)手法が不十分であるという認識の「正確な瞬間」は、活性化外れ値という持続的な問題に特定できる。
外れ値と通常の値を2つの別個の行列に分離するような従来の(例:Kim et al., 2023; Dettmers et al., 2022)アプローチは、高いレイテンシまたは実質的な精度低下に苦しむことが判明した。特に重要なのは、これらの手法がハードウェアアクセラレーションと互換性がないことが多く、意図したとおりに推論を高速化できなかったことである。
より直接的な前身であるSmoothQuant(Xiao et al., 2023)は、チャネルごとのスムージングスケールを使用して活性化から重みへの外れ値を移行することで、外れ値を軽減しようとした。しかし、INT4量子化では、SmoothQuantは3つの重要な失敗に直面した。
1. 一致しないスケール: キャリブレーションセットから導出されたオフラインで事前に計算されたスムージングスケールは、オンライン活性化と一致しないことが頻繁にあり、スムージングに効果がなかった。
2. 不完全な外れ値除去: 外れ値チャネルは完全に排除されず、部分的に重みに移行されただけで、低ビット量子化(特にINT4)を困難にした。
3. スパイク外れ値と「犠牲者」: SmoothQuantは主にチャネルごとの外れ値に対処したが、チャネルごとに一貫性のない「スパイク外れ値」を考慮できなかった。これらのスパイク外れ値が存在する場合、通常の値をスムージング中に意図せず「犠牲者」として削除してしまい、精度低下につながった。
QuaRot(Ashkboos et al., 2024)のような回転ベースの手法でさえ、外れ値を広げるのに有望であったが、理論的に均一にスムーズな行列を保証することはできなかった。回転された活性化、特にチャネルごとの外れ値を持つものは、依然として「サブスムージング」(図2cに示すように)を示す可能性があり、改善の余地を残していた。この、チャネルごとの外れ値とスパイク外れ値の両方を、INT4推論のためにトレーニングフリーで効率的かつ堅牢に処理するという、以前の手法の集団的な失敗は、RRSのような新しい包括的なソリューションの開発を、単なる選択肢ではなく、必然的なものにした。
比較優位性
Rotated Runtime Smooth (RRS) は、その包括的で堅牢な外れ値処理と、最小限の計算オーバーヘッドにより、以前の手法に対して質的な優位性を示している。
RRSの構造的利点は、その二重アプローチにある。
1. 実行時スムージング (RS): このコンポーネントは、実行時に動的にスムージングスケールを計算することにより、チャネルごとの外れ値を直接処理する。オフラインキャリブレーションに依存し、スケールを重みにマージするSmoothQuantとは異なり、RSは一致しないスケールの問題や、移行された外れ値を持つ重みの量子化の困難さを回避する。実行時にスムージングスケールを取得し、重みにマージしないことで、RSはスムージングが常に現在の入力に関連していることを保証し、より適応的で正確にする。
2. 回転操作: ここでRRSはスパイク外れ値に対処し、堅牢性を向上させる。重みと活性化を回転させること(QuaRotの原則に従って)により、スパイク外れ値は効果的にトークン全体に広がる。この広がりは、チャネル全体でより一貫したスムージングスケールにつながり、その結果、チャネルごとのスムージングプロセス中に通常の値が「犠牲者」になるのを防ぐ。チャネルごとの外れ値を持つ活性化の場合、回転は一貫性を維持するのに役立つと同時に、外れ値のレベルを減らす機会も提供する。
この組み合わせ戦略は、以前の手法が欠いていた構造的利点を提供する。例えば、SmoothQuantはスパイク外れ値を効果的に処理できず、キャリブレーションセットの不一致に苦しんだ。純粋な回転手法は有益であったが、それ自体では十分なスムージングを保証できなかった。RRSは両方の最良の側面を統合し、すべてのタイプ外れ値(チャネルごとのおよびスパイク)が包括的に対処されることを保証する。
さらに、RRSは「プラグアンドプレイ」コンポーネントとして設計されており、INT4行列乗算に対して無視できるオーバーヘッドしか発生しない。本稿では、融合されたGEMMカーネルにおける追加の実行時スケール乗算が、A4W4ベースラインと比較して「無視できるオーバーヘッド」しか発生しないと明示的に述べている。これは、優れた精度を低ビット量子化に期待される重要なレイテンシの利点を犠牲にすることなく達成するため、実用的な大きな利点である。高次元ノイズを導入するのではなく、量子化範囲を広げるノイズの一種として機能する外れ値の影響を軽減する。
制約との整合性
Rotated Runtime Smooth (RRS) メソッドは、特にINT4量子化における効率的なLLM推論の厳格な要件と完全に整合している。大規模LLMのサービングという問題によって暗黙的に定義される中核的な制約は、以下の通りである。
1. INT4推論: 主な目標は、INT4精度で正確な推論を可能にすることであり、これはメモリと計算コストの削減に不可欠である。RRSは、正確なINT4推論のための「トレーニングフリー活性化スムーザー」として特別に設計されている。チャネルごとの外れ値からスパイク外れ値までの処理から、そのメカニズム全体が、実質的な精度低下なしに、活性化を4ビット量子化に適したものにすることを目指している。LLaMAおよびQwenファミリーにおけるA4W4KV16設定でのパープレキシティの改善(例:LLaMA3-70Bが57.33から6.66に)は、この目標を達成する上での有効性を直接検証している。
2. トレーニングフリー: 実用的な展開における重要な要件は、コストのかかる再トレーニングまたはファインチューニングを回避することである。RRSは明確に「トレーニングフリー」であり、追加のモデル最適化なしに、トレーニング後に適用できることを意味する。これは、LLMのすでに相当なトレーニング負担を増加させない、すぐに展開可能なソリューションの必要性と完全に一致する。
3. 精度維持: 低ビット量子化はしばしば精度低下につながる。RRSの包括的な外れ値軽減戦略—チャネルごとの外れ値のための実行時スムージングとスパイク外れ値のための回転の組み合わせ—は、「外れ値を包括的に排除」し、「堅牢性を向上」させるように設計されており、それによって精度を維持する。パープレキシティとゼロショットQAタスクにおけるSOTA手法を上回る一貫したパフォーマンスは、この整合性を示している。
4. 低レイテンシ/最小限のオーバーヘッド: 量子化は、サービスコストとレイテンシを削減することを目的としている。RRSは効率のために設計されており、その実行時スムージングコンポーネントは、A4W4実行時量子化ベースラインと比較して「最小限のオーバーヘッド」しか発生しない。実行時スムージングのためのカーネル融合は、プロセスがGEMMパイプラインに効率的に統合され、A4W4チャネルごと量子化と比較して「無視できるオーバーヘッド」しか追加しないことを保証する。これは、高スループットと低レイテンシを維持するという制約に直接対処する。
5. 外れ値に対する堅牢性: 問題ステートメントは、外れ値を主な障害として強調している。RRSのユニークな特性である、チャネルごとの外れ値とスパイク外れ値の両方に対処し、「犠牲者」を防ぐ(スムージングスケールの一貫性を保証することによって)ことは、LLM活性化で見られる多様な外れ値パターンに対して本質的に堅牢である。この「問題の厳しい外れ値チャレンジ」と「ソリューションのユニークなデュアル外れ値処理」の「結婚」は、その成功の中心である。
代替案の却下
本稿は、特にLLMのINT4推論の文脈で、それらの欠点を強調し、いくつかの代替アプローチを却下する明確な理由を提供している。
-
従来の С外れ値分離 (例:LLM.int8(), Kim et al., 2023; Dettmers et al., 2022): これらは、外れ値を高精度フォーマット(混合INT8/FP16)または別個の行列に分離する手法は、「高いレイテンシまたは精度低下」に苦しみ、しばしば「ハードウェア互換性がない」ため、「推論を高速化できなかった」ために却下された。LLM.int8()は特に「実質的なレイテンシオーバーヘッドをもたらし、FP16推論よりも遅くなることさえある」。
-
SmoothQuant (Xiao et al., 2023): A8W8量子化には効果的であったが、SmoothQuantはINT4には不十分と見なされた。なぜなら、オフラインでキャリブレーションセットに依存するスムージングスケールは、「オンライン活性化と一致しない」傾向があったからである。さらに、外れ値を重みに部分的に移行するだけで、低ビット量子化(A4W4)を困難にし、特に重要なのは、「スパイク外れ値」に対処できず、「犠牲者」の削除につながったことである。
-
純粋な回転ベースの手法 (例:QuaRot, Ashkboos et al., 2024): 回転は外れ値を広げるのに役立つが、本稿は「単一の回転行列による乗算は、理論的にスムーズな重みまたは活性化を保証できなかった」と指摘している。回転後の活性化でさえ、「サブスムージング」(図2c)を示す可能性があり、回転だけでは完全な解決策ではないことを示唆している。QuaRotはまた、「複雑なオンラインアダマール回転」を必要とし、RRSはそれを簡素化することを目指している。
-
トレーニングベースの量子化 (例:SpinQuant, Liu et al., 2024): 本稿はRRSとSpinQuantを明確に比較し、その法外な計算コストのためにトレーニングベースのアプローチを却下している。SpinQuantのトレーニングプロセスは「時間のかかるもので、7Bモデルで1つのA100 GPUで1.5時間、70Bモデルで8つのA100 GPUで12時間かかる」。さらに、結果はトレーニングベースの手法が「トレーニングフリー手法と比較してWikiText-2パープレキシティを低下させ、まだ改善の余地がある」ことを示したため、効率と最終精度の両方の点で望ましくない。
-
その他の再順序付け手法 (例:RPTQ, Yuan et al., 2023; Atom, Zhao et al., 2024): これらの手法は分散を減らすためにチャネルを再順序付けしたり、混合精度を使用したりするが、RRSが提供するチャネルごとの外れ値とスパイク外れ値の両方に対する包括的でトレーニングフリーで低オーバーヘッドのソリューションを提供しない。例えば、Atomは再順序付けと混合INT4/INT8を統合しており、純粋なINT4ではない。
これらの代替案を却下する一貫したテーマは、INT4推論の厳格な要求—高精度、低レイテンシ、およびすべてのタイプ外れ値に対するトレーニングフリーで堅牢なソリューション—を同時に満たすことができないことである。
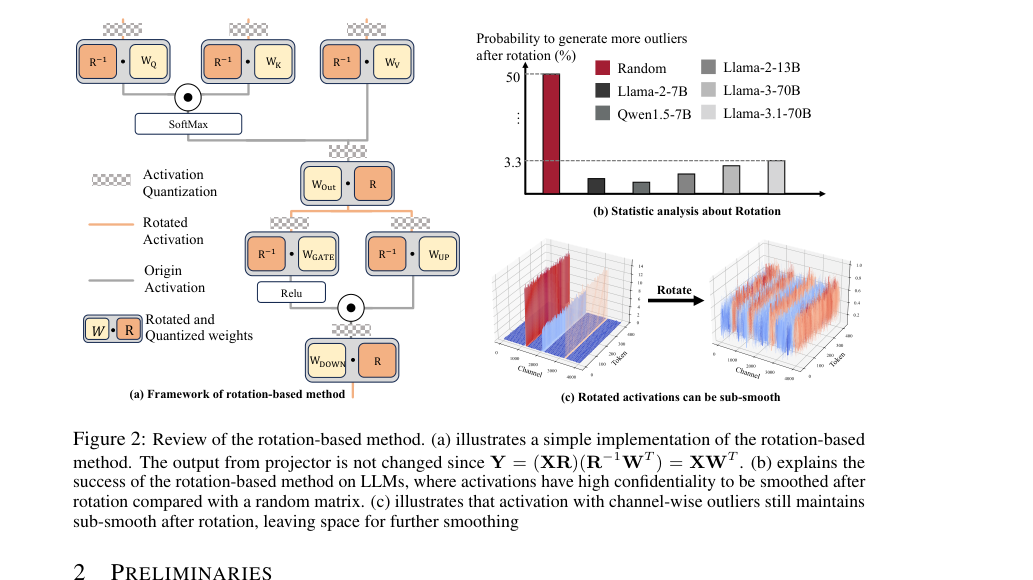 Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
数学的・論理的メカニズム
マスター方程式
Rotated Runtime Smooth (RRS) メソッドを支える中核的な数学的エンジンは、回転操作と実行時スムージングメカニズムを組み合わせたものである。入力活性化行列$X$と重み行列$W$が与えられた場合、RRSプロセスは以下の操作シーケンスでカプセル化できる。
$$ X_{rot} = XR \\ W_{rot} = R^{-1}W \\ s_j = \max(|(X_{rot})_j|), \quad j = 1, \dots, K \\ X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1}) \\ W'_{quant} = \text{Quantize}(W_{rot}) \\ Y = \sum_{j=1}^{K} (X'_{quant})_j (W'_{quant})_j^T s_j $$
この方程式のセットは、活性化と重みが最初に回転され、次に活性化が実行時導出スケールを使用してスムージングされ、両方が量子化され、最後に修正された行列乗算が低ビット出力を生成する方法を記述している。
用語ごとの解剖
マスター方程式の各コンポーネントを分解して、その数学的定義、論理的役割、および設計の根拠を理解しよう。
-
$X$: 線形層への入力活性化テンソルを表す。
1) 数学的定義: $N \times K$の次元を持つ浮動小数点行列。ここで、$N$は通常、バッチサイズにシーケンス長を掛けたものであり、$K$は入力チャネル次元である。
2) 物理的/論理的役割: 次の層からの特徴情報を含み、現在の線形層によって処理される必要がある。
3) この形式である理由: 入力特徴のバッチの標準的な表現である。 -
$W$: 線形層の重み行列である。
1) 数学的定義: $M \times K$の次元を持つ浮動小数点行列。ここで、$M$は出力次元、$K$は入力チャネル次元である。
2) 物理的/論理的役割: 入力活性化を入力特徴に変換する学習可能なパラメータを含む。
3) この形式である理由: 線形層の重みの標準的な表現である。 -
$R$: 回転行列である。
1) 数学的定義: $K \times K$の直交行列。つまり、$RR^T = I$(ここで$I$は単位行列)であり、その行列式$\det(R) = 1$である。本稿ではしばしばアダマール回転行列に言及しており、$R = \frac{1}{\sqrt{K}}[s_{i,j}]_{K \times K}$で、要素$s_{i,j} \in \{-1, +1\}$である。
2) 物理的/論理的役割: 活性化と重みの両方のベクトル空間を線形変換(回転)する主要な役割を果たす。この回転は、活性化内に集中した外れ値を「広げる」ために重要であり、量子化範囲への影響を少なくする。$X$と$W$の両方を適切に回転させることにより、元の出力$XW^T$は数学的に$(XR)(R^{-1}W^T)$として維持される。
3) 乗算である理由: 行列乗算は、ベクトル空間における回転のような線形変換を適用するための基本的な操作である。 -
$R^{-1}$: 回転行列の逆行列である。
1) 数学的定義: $R$が直交行列であるため、その逆行列は単にその転置、$R^T$である。これも$K \times K$行列である。
2) 物理的/論理的役割: $X_{rot}$と組み合わせたときの全体的な変換の数学的等価性を維持するために、重み行列$W$を補完的に回転させる。
3) 乗算である理由: $R$と同様に、線形変換である。 -
$X_{rot} = XR$: 回転された活性化テンソル。
1) 数学的定義: 入力活性化行列$X$を回転行列$R$で乗算した結果。形状は$N \times K$を維持する。
2) 物理的/論理的役割: これらの活性化は、特徴が回転によって線形に結合され、チャネル全体に再配布された後のものである。このステップは、外れ値の大きさをそれほど極端でない、またはより均一に分布させることで、チャネルごとの外れ値を軽減することを目的としている。
3) 乗算である理由: 回転変換の直接的な適用である。 -
$W_{rot} = R^{-1}W$: 回転された重み行列。
1) 数学的定義: 重み行列$W$を逆回転行列$R^{-1}$で乗算した結果。形状は$M \times K$を維持する。
2) 物理的/論理的役割: これらは回転された後の重みである。この回転は、$X_{rot}$と組み合わせたときの元の行列乗算の数学的等価性を維持するために必要である。
3) 乗算である理由: 逆回転の直接的な適用である。 -
$s_j = \max(|(X_{rot})_j|)$: $j$番目のチャネルの実行時スムージングスケール。
1) 数学的定義: 回転された活性化行列$X_{rot}$の各列$j$($(X_{rot})_j$と表記され、$N \times 1$ベクトルである)について、この操作はその列内のすべての要素の最大絶対値を計算する。これによりスカラー$s_j$が得られる。
2) 物理的/論理的役割: このスケールは、回転された活性化の各チャネルに存在する最大 magnitude を動的に捉える。これは、次の除算のために値をより管理しやすい範囲に収めるための正規化係数として機能する。最大絶対値を使用することで、後続の除算中に値がクリップされないようにし、情報が維持される。これは「Runtime Smooth」コンポーネントの重要な部分であり、チャネルごとの外れ値に対処する。
3)maxと絶対値である理由:maxは、必要なスケーリング範囲を決定する極端な値を特定する。絶対値は、正と負の外れ値の両方が対称的に扱われることを保証する。 -
$\text{diag}(s)^{-1}$: スムージングスケールの逆対角行列。
1) 数学的定義: $j$番目の対角要素が$1/s_j$である$K \times K$対角行列。
2) 物理的/論理的役割: この行列は、各列をその特定の$s_j$で除算することを可能にすることにより、$X_{rot}$のチャネルごとのスケーリングを容易にする。
3) 対角行列である理由: 要素ごとの列スケーリングを行列乗算として表現する効率的な方法である。 -
$X_{rot}\text{diag}(s)^{-1}$: スムージングされた回転活性化。
1) 数学的定義: 回転された活性化行列の各列$(X_{rot})_j$が対応するスカラー$s_j$で要素ごとに除算される。これにより、$N \times K$行列が得られる。
2) 物理的/論理的役割: この操作は、回転された活性化をチャネルごとに正規化する。各チャネルの値は、そのチャネルの最大 magnitude に基づいてスケーリングされるため、外れ値は通常の値と比較して効果的に「圧縮」され、チャネル全体のデータが低ビット量子化範囲により良く収まるようになる。
3) 除算である理由: 最大絶対値による除算は、データをスケーリングし、通常は対称量子化スキームに最適な$[-1, 1]$のような範囲にする。 -
$\text{Quantize}(\cdot)$: 量子化関数。
1) 数学的定義: 浮動小数点数を低ビット整数表現にマッピングする関数。例えば、INT4の場合、スケールとオフセットがターゲットビット幅と値の範囲によって決定されるような$q = \text{round}(x \cdot \text{scale}) + \text{offset}$として、浮動小数点数$x$を整数$q$にマッピングする可能性がある。
2) 物理的/論理的役割: 数値の精度を削減するためのコア操作である。高精度浮動小数点値を離散的な低ビット整数値に変換し、推論中のメモリフットプリントと計算コストを大幅に削減する。
3) この関数である理由: 連続値を有限個の離散値のセットに変換するための標準的な方法であり、これが量子化の本質である。 -
$X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1})$: 量子化されたスムージングされた回転活性化。
1) 数学的定義: スムージングされた回転活性化行列に$\text{Quantize}$関数を適用した結果。低ビット整数の$N \times K$行列である。
2) 物理的/論理的役割: これらは、最終的な低ビット、外れ値軽減形式の入力活性化であり、効率的な行列乗算の準備ができている。 -
$W'_{quant} = \text{Quantize}(W_{rot})$: 量子化された回転重み。
1) 数学的定義: 回転された重み行列に$\text{Quantize}$関数を適用した結果。低ビット整数の$M \times K$行列である。
2) 物理的/論理的役割: これらは、最終的な低ビット、外れ値軽減形式の重みであり、効率的な行列乗算の準備ができている。 -
$(X'_{quant})_j$: $X'_{quant}$の$j$番目の列。
1) 数学的定義: 低ビット整数を含む形状$N \times 1$の列ベクトル。
2) 物理的/論理的役割: 特定の入力チャネルの量子化およびスムージングされた活性化を表す。 -
$(W'_{quant})_j^T$: $W'_{quant}$の$j$番目の行(転置)。
1) 数学的定義: 低ビット整数を含む形状$1 \times M$の行ベクトル。(注:$W'_{quant}$が$M \times K$であると仮定すると、$(W'_{quant})_j$はその$j$番目の列、$M \times 1$である。したがって、$(W'_{quant})_j^T$は$1 \times M$である。これは、$N \times M$の外積に必要な次元と一致する)。
2) 物理的/論理的役割: $j$番目の入力チャネルがすべての出力チャネルに寄与する量子化された重みを表す。 -
$\sum_{j=1}^{K} (\cdot)$: チャネル全体での合計。
1) 数学的定義: この演算子は、$K$個の個別の行列(各形状$N \times M$)を合計する。
2) 物理的/論理的役割: この合計は、各入力チャネルからの寄与を結合して最終的な出力行列を形成する。各項$(X'_{quant})_j (W'_{quant})_j^T s_j$は、スケーリングされた外積を表す。ここでの$s_j$によるスケーリングは、本稿の定式化のユニークな側面であり、各チャネルの部分積の最終出力への寄与が、そのチャネルの活性化スムージング係数$s_j$でスケーリングされることを示唆している。これは、スケールが通常、入力または出力に均一に適用されるか、量子化値に吸収される標準的な量子化行列乗算とは異なる、部分積に適用されるチャネルごとの逆量子化または再スケーリングの一形態と解釈できる。セクション4.5「dequantized結果での実行時スケールの乗算」の説明は、最終スケーリングの操作順序がわずかに異なることを示唆しているが、セクション3.1の方程式はメカニズムの最も明確な数学的記述である。
3) 合計である理由: 行列乗算は、基本的に、最初の行列の列ベクトルと2番目の行列の行ベクトルの外積の合計である。 -
$Y$: 最終出力行列。
1) 数学的定義: 形状$N \times M$の結果行列。
2) 物理的/論理的役割: これは、回転、スムージング、量子化、および変更された合計の後で生成された、低ビット近似の完全精度行列乗算$XW^T$である。これは、ニューラルネットワーク内の後続の操作の準備ができている、線形層からの処理済み特徴を表す。
ステップバイステップフロー
単一の抽象的なデータポイント、例えばトークン$x_{token, feature\_in}$(特定の入力トークンの特定のフィーチャーを表す)と、入力フィーチャーを出力フィーチャーに接続する重み$w_{feature\_out, feature\_in}$を想像してみよう。それらのRRSメカニズムを通る旅を追ってみよう。
-
初期入力: 我々の抽象データポイント$x_{token, feature\_in}$は、浮動小数点活性化行列$X$の一部としてシステムに入る。重み$w_{feature\_out, feature\_in}$は、浮動小数点重み行列$W$の一部である。
-
活性化回転: 全体の活性化行列$X$は、「回転エンジン」に供給され、そこで回転行列$R$で乗算される。我々のデータポイント$x_{token, feature\_in}$は、もはや孤立しておらず、そのチャネル内の他のフィーチャーに寄与し、影響を受けるようになり、回転された活性化行列$X_{rot}$内の新しい値、$x'_{token, feature\_k}$となる。このプロセスは、極端な値(外れ値)をフィーチャー空間全体に均等に分散させることを目的としている。
-
重み回転: 同時に、重み行列$W$は「逆回転エンジン」を通過し、そこで$R^{-1}$(逆回転行列)で乗算され、$W_{rot}$が得られる。これにより、入力活性化が回転された後でも、元の操作の全体的な数学的整合性が維持される。
-
実行時スケール検出: 回転された活性化行列$X_{rot}$の各列(フィーチャーチャネルを表す)について、「magnitudeスキャナー」が最大絶対値を特定する。$x'_{token, feature\_k}$を含む列の場合、特定のスケール$s_{feature\_k}$が計算される。このスケールは動的であり、現在の入力の特性に適応する。
-
活性化スムージング: 回転された活性化行列$X_{rot}$は次に「スムージングチャンバー」に入る。ここでは、列内の各値は対応するチャネルごとのスケール$s_j$で除算される。したがって、$x'_{token, feature\_k}$は$x''_{token, feature\_k} = x'_{token, feature\_k} / s_{feature\_k}$にスケーリングダウンされる。この操作は、各チャネル内の値の範囲を効果的に「圧縮」し、外れ値をそれほど支配的でなくし、効率的な低ビット量子化の準備をする。
-
活性化量子化: スムージングされた回転活性化($X_{rot}\text{diag}(s)^{-1}$)は次に「量子化ユニット」に供給される。このユニットは、各浮動小数点値($x''_{token, feature\_k}$を含む)を低ビット整数$q_{X,token,feature\_k}$に変換する。ここで、大幅なメモリと計算の節約が始まる。
-
重み量子化: 並行して、回転された重み行列$W_{rot}$も独自の「量子化ユニット」を通過し、浮動小数点値($w'_{feature\_out, feature\_in}$のような)を低ビット整数$q_{W,feature\_out,feature\_in}$に変換する。
-
チャネルごとの出力組み立て: 次に、システムは最終的な出力を組み立て始める。各フィーチャーチャネル$j$($1$から$K$まで)について:
- 量子化された活性化の$j$番目の列、$(X'_{quant})_j$が抽出される。
- 量子化された重みの$j$番目の行(転置)、$(W'_{quant})_j^T$が抽出される。
- これら2つのベクトルが乗算され(外積)、部分的な出力行列が形成される。この行列は、単一のチャネル$j$の最終結果への寄与を表す。
- 重要なのは、この部分的な出力行列が、以前に計算された$j$番目の活性化チャネルの実行時スムージング係数$s_j$でスケーリングされることである。このステップは、活性化スムージング中に削除されたmagnitude情報を再導入するが、これは部分積に適用される。これは、標準的な量子化行列乗算(スケールは通常、入力または出力に均一に適用されるか、量子化値に吸収される)とは異なる。
-
最終合計: これらすべての$K$個のスケーリングされた部分出力行列が「合計ユニット」に供給され、要素ごとに合計される。結果は最終出力行列$Y$であり、各要素$y_{token, feature\_out}$は、すべてのスケーリングされたチャネル寄与の合計である。これにより、フォワードパスが完了し、元の完全精度操作の低ビット、しかし正確な近似が提供される。
最適化ダイナミクス
Rotated Runtime Smooth (RRS) がトレーニングフリーな手法であることは重要である。これは、その「最適化ダイナミクス」が、従来の意味での勾配ベースの更新や反復学習に関するものではないことを意味する。代わりに、メカニズムは、その構造コンポーネントを通じて、量子化精度を直接最適化するように設計されている。
-
反復学習の不在: 勾配降下とバックプロパゲーションに依存する手法とは異なり、RRSはメカニズムの操作中にそのような学習ループを含まない。回転行列$R$は、固定の定義済み行列(アダマール行列のような)であるか、オフラインキャリブレーションプロセスから導出される(関連研究のように)が、推論中に更新されない。スムージングスケール$s_j$は、各新しい入力に対してオンザフライで計算されるため、適応的であるが、「学習」されるわけではない。
-
損失ランドスケープトラバーサルの不在: トレーニングがないため、「損失ランドスケープ」を勾配で移動するという概念は、RRSメカニズム自体には適用されない。最適化は設計選択に埋め込まれている。つまり、低ビット(INT4)量子化を正確に可能にするために、どのように回転し、どのようにスムージングし、どのように量子化するかである。これらの設計選択の有効性は、パープレキシティや精度のようなメトリクスによって評価されるが、これらはメカニズム内の直接的な勾配ベースの最適化のターゲットではなく、観察された結果である。
-
決定論的状態更新: RRSメカニズムの状態は反復的に進化しない。各入力に対して、プロセスは直接的で決定論的な変換シーケンスである。
- 活性化と重みは、固定$R$を使用して回転される。
- スムージングスケールは、現在の入力の回転活性化に基づいて計算される。
- 量子化は、固定ビット幅と丸めルールを使用して適用される。
- 最終的な行列乗算(部分積の特異なチャネルごとのスケーリングを含む)が計算される。
各ステップは直接計算であり、前の状態またはエラーに基づく更新ではない。
-
設計駆動型「収束」: RRSの「収束」は反復プロセスではなく、その固有の設計によって達成される状態である。目標は、活性化と重みを、正確な低ビット(INT4)量子化を可能にするのに十分「スムーズ」になるように(つまり、外れ値が十分に軽減されるように)変換することである。本稿は、この設計が量子化エラーを効果的に低減し、様々なモデルでパープレキシティと精度の向上につながることを示している。したがって、「最適化」は、高品位な低ビット推論を達成するためにこれらの変換を巧妙にエンジニアリングすることにあり、反復学習プロセスではない。メカニズムの堅牢性とパフォーマンス向上は、この設計最適化の証であり、非常に効率的でプラグアンドプレイなソリューションとなっている。無視できるオーバーヘッドは、その実用的な有用性をさらに強化する。
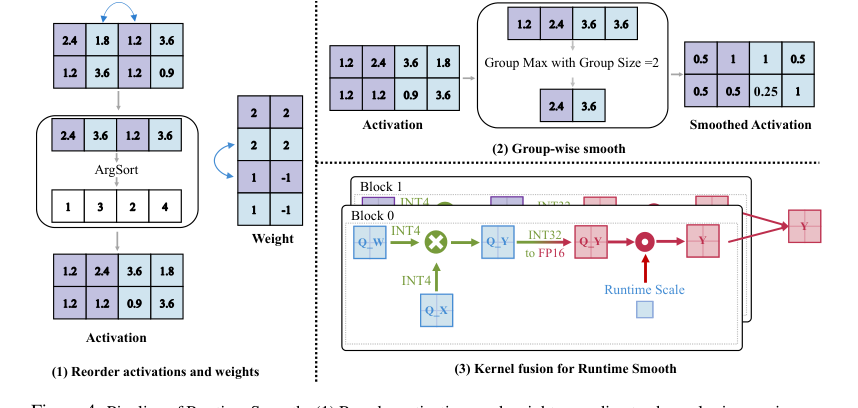 Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
結果、限界、結論
実験設計とベースライン
著者らは、数学的主張を厳密に検証するために、多様な主流大規模言語モデル(LLM)にわたる広範な実験を実施した。これらには、LLaMAファミリー(LLaMA2-13B、LLaMA2-70B、LLaMA3-8B、LLaMA3-70B、LLaMA3.1-8B、LLaMA3.1-70B)、Qwenファミリー(Qwen1.5-7B、Qwen1.5-14B)、Mistral、およびMixtralの様々なモデルが含まれていた。評価はINT4量子化に焦点を当て、特にA4W4KV4、A4W4KV16、およびA4W16KV16の3つのスキームを使用した。これらはそれぞれ4ビット活性化、4ビット重み、および4ビットKVキャッシュ量子化を表し、KVキャッシュビット幅は異なる。
活性化量子化では、チャネルごとの対称スキームと、丸め最近傍(RTN)戦略が採用された。KVキャッシュ量子化は、サブチャネルごとの対称スキームとグループサイズ128、RTNも使用した。重み量子化は主にチャネルごとの対称スキームとGPTQ(Frantar et al., 2022)を使用した。ただし、ベースラインの「RTN」手法を除く。GPTQのキャリブレーションセットは、WikiText-2から128サンプルで構成され、各シーケンス長は2048であった。
提案されたRotated Runtime Smooth (RRS) およびその構成要素であるRuntime Smooth (RS) が比較された「犠牲者」(ベースラインモデル/手法)には、以下が含まれる。
- RTN: 基本的な丸め最近傍量子化。
- SmoothQuant (Xiao et al., 2023): 外れ値をオフラインで移行する著名なチャネルごとのスムージング手法。
- GPTQ (Frantar et al., 2022): トレーニング後の重み量子化手法。
- QuaRot (Ashkboos et al., 2024): 外れ値抑制のための回転ベース手法。
- SpinQuant (Liu et al., 2024) および DuQuant (Lin et al., 2024a): 特定の比較のための追加ベースライン、トレーニングベースの手法を含む。
それらのコアメカニズムの有効性の決定的な証拠は、いくつかの実験的アーキテクチャを通じて収集された。
1. WikiText-2でのパープレキシティ: この標準ベンチマークは、言語モデルがテキストサンプルをどれだけうまく予測できるかを測定し、パープレキシティが低いほどパフォーマンスが良いことを示す。
2. ゼロショット常識QAベンチマーク: 量子化後のモデルの推論能力を評価するために、ARC-e、ARC-c、BoolQ、OBQAのようなタスクでパフォーマンスが評価された。
3. アブレーションスタディ:
* 予備的なアブレーション(図3)は、Runtime SmoothとSmoothQuant、および「Origin A4W4」ベースラインを直接比較し、実行時スムージングの必要性と、外れ値を重みに移行することの落とし穴を示した。
* 実行時スムージングのグループサイズに関するアブレーション(表4)は、このハイパーパラメータが精度に与える影響を調査した。
4. 効率評価: RTX 4070 Ti GPUでNVBenchを使用して、著者らは融合されたGEMMカーネルのオーバーヘッドを、チャネルごとA4W4およびサブチャネルA4W4ベースラインと比較して測定した(図6)。これにより、アプローチの実用的な実行可能性が証明された。
5. 統計的外れ値分析: 図9は、様々なLLMコンポーネント(QKV_Projector、Output_Projector、Up_ProjまたはGate_Proj、Down_Projector)における、様々なモデルに対する外れ値除去の詳細な統計的内訳を提供し、RRSが他の手法と比較して活性化をよりスムーズな範囲にシフトさせる方法を視覚的に実証した。
証拠が証明すること
本稿で提示された証拠は、LLMのための正確なINT4推論を可能にする上でのRotated Runtime Smooth (RRS) およびその構成要素であるRuntime Smooth (RS) の有効性を説得力のあるものとしている。
第一に、チャネルごとの外れ値を排除するように設計されたRuntime Smooth (RS)コンポーネントは、実質的な改善を示した。予備的なアブレーションスタディ(図3)は、単に実行時スムージングスケールを適用することがA4W4量子化には不十分であることを明確に示した。しかし、RSが完全に実装されると、A4W4を可能にし、A4W16設定下でのLLaMA3-8Bに対してパープレキシティを4e2から10.9に劇的に改善した。これは、外れ値を重みに移行することなく実行時スケールを採用するという中核的なアイデアを検証する上で重要であった。これは、SmoothQuantのような先行手法の重要な限界であった。表1では、RSは様々なモデルと量子化スキームで、SmoothQuantとRTNを一貫して上回っており、例えば、16-4-16スキーム下でLLaMA2-70Bのパープレキシティを1e2(SmoothQuant)から6.95(RS)に低下させた。さらに、活性化のみの量子化(A4W16KV16)下では、RSはLLaMA3-8Bで40倍の改善を達成し、その有効性を強調している。
第二に、回転と実行時スムージングを組み合わせてチャネルごとの外れ値とスパイク外れ値の両方に対処する完全なRotated Runtime Smooth (RRS)メソッドは、優れたパフォーマンスを提供した。WikiText-2パープレキシティの主要な結果表である表1は、RRSが、評価されたほぼすべてのLLaMA、Qwen、およびMistralモデルで、RS、QuaRot、SmoothQuant、およびRTNを含むすべてのベースラインを、ほぼすべてのモデルで一貫して上回っていることを示している。特に顕著な例はLLaMA3-70Bであり、RRSはA4W4KV16下でパープレキシティを57.33から6.66に、A4W4KV4下で49.76から6.87に低下させた。これらは、最先端のQuaRot(それぞれ57.33と49.73を生成した)を大幅に上回る改善である。この決定的な証拠は、RRSの組み合わせメカニズムが両方のタイプ外れ値の影響を効果的に軽減することを示している。
パープレキシティを超えて、RRSはゼロショット常識QAタスク(表2)でもその強みを示した。様々なLLMと量子化スキームで、RRSは一貫してすべてのベースライン(GPTQ、SmoothQuant、RS、QuaRot)を平均精度改善で約3%上回った。例えば、LLaMA-3-8Bで4-4-16量子化を使用した場合、RRSは平均精度58.0%を達成し、QuaRotの55.0%と比較された。これは、改善された活性化スムージングが複雑な推論タスクでのパフォーマンス向上につながることを示唆している。
外れ値除去の統計分析(図9)は、RRSのメカニズムが機能している直接的な視覚的証拠を提供する。RRSは、すべてのLLMコンポーネント(QKV_Projector、Output_Projector、Up_ProjまたはGate_Proj、Down_Projector)およびモデル全体で、元の活性化(X)、回転された活性化(R)、または実行時スムージングのみ(RS)と比較して、「u < 4」(よりスムーズ)のカテゴリに入る活性化の割合が大幅に高くなることを示している。これは、RRSがチャネルごとの外れ値とスパイク外れ値の両方を包括的に排除する能力を直接検証している。
最後に、効率評価(図6およびセクション4.5)は、RRS融合カーネルがA4W4チャネルごと量子化ベースラインと比較して無視できるオーバーヘッドしか導入しないことを確認している。これは、精度向上が大幅な減速を犠牲にすることなく達成されるため、重要な実用的な利点であり、RRSをINT4推論のための真のプラグアンドプレイソリューションとしている。トレーニングベースの手法(表3)との比較は、トレーニング時間コストを大幅にかけずに、WikiText-2パープレキシティでSpinQuant(トレーニングベースの手法)を上回るため、RRSの強みをさらに強調している。
限界と将来の方向性
Rotated Runtime Smooth (RRS) はトレーニングフリーINT4推論の大きな進歩をもたらすが、本稿は暗黙的および明示的にいくつかの限界を示しており、将来の研究の扉を開いている。
現在の限界:
1. 回転による不完全なスムージング保証: 本稿は、「回転はよりスムーズな行列を保証できず、回転された行列は依然としてチャネルごとの外れ値の形状を示す可能性がある」(セクション1、図2)と指摘している。これは、回転が役立つ一方で、それ自体では完璧な解決策ではなく、Runtime Smoothコンポーネントが必要であることを示唆している。
2. スパイク外れ値による「犠牲者」効果: スパイク外れ値の存在は、チャネルごとのスムージング後に通常の値を「犠牲者」として削除させる可能性がある(セクション1、図1)。RRSはこれを軽減することを目指しているが、根本的な課題は残っている。
3. グループサイズへの感度: アブレーションスタディ(セクション4.4、表4)は、Runtime SmoothがA4W4と完全精度の間のギャップを効果的に最小化する一方で、「グループサイズが増加すると精度が低下する」ことを示している。これはトレードオフと、普遍的に最適ではない可能性のある選択されたグループサイズへの潜在的な感度を示唆している。
4. 特定の外れ値シナリオ: 著者らは、「2つの外れ値トークンのみの場合のケースはまれであるが、Rotated Runtime Smoothを悩ませる可能性がある」(セクションC.1)と述べている。これは、RRSが苦労する可能性のある特定の、ただしまれな外れ値パターンを強調しており、その堅牢性が絶対的ではない可能性を示唆している。
5. モデル固有の外れ値感度: 著者らは、「モデルは外れ値に対する感度が異なる。外れ値をさらに抑制することで堅牢性を向上させることができる」(セクション4.2)と観察している。これは、RRSが一般化されている一方で、さらに最適化できるモデル固有の外れ値特性が存在する可能性があることを示唆している。
6. グループサイズに対するハードウェア制約: Qwen1.5-7Bのような特定のモデルでは、Down_projector(11008)の入力活性化サイズは「グループサイズ512をサポートしない」(セクション4.4)。これは、最大のグループサイズを適用する際の実際的な限界を示しており、それ以外の場合は特定の利点を提供する可能性がある。
将来の方向性と議論トピック:
- 適応的および動的なスムージング戦略: グループサイズへの感度と変化する外れ値パターンを考慮すると、将来の研究では適応的なスムージング戦略を検討できる。固定グループサイズや普遍的な回転の代わりに、リアルタイム活性化統計またはモデルレイヤー特性に基づいてこれらのパラメータを動的に調整できるか?これは、各特定の入力とレイヤーのスムージングを最適化するために、軽量なオンザフライ分析を含む可能性があり、さらに精度と堅牢性を向上させる可能性がある。
- 外れ値抑制のための理論的境界と保証: 本稿はRRSの有効性を経験的に実証している。回転と実行時スムージングの数学的特性に関するより深い理論的調査は、外れ値抑制とその量子化エラーへの影響に関する正式な境界を確立できる可能性がある。これにより、証明可能な保証を持つ将来の量子化手法のより原理的な設計につながる可能性がある。
- トレーニングフリーとトレーニングベースのアプローチのハイブリッド: RRSはトレーニングフリーであり、一部のトレーニングベースの手法を上回るが、学習された回転の概念(SpinQuantのように)は依然として有望である。将来の研究では、RRSのようなトレーニングフリー手法の効率と、回転またはスムージングスケールをさらに洗練するための最小限のターゲットを絞ったトレーニングまたはファインチューニングステップを組み合わせたハイブリッドアプローチを調査できる可能性がある。これにより、現在のトレーニングベースの手法の広範なトレーニングオーバーヘッドなしに、さらに高い精度を達成できる可能性がある。
- 高度な量子化のためのハードウェア-ソフトウェア共同設計: RRSの無視できるオーバーヘッドは大きな利点である。これをさらに推進するために、RRSの中心となる並べ替え、グループごとの最大値計算、および回転操作をネイティブにサポートするために、専用のハードウェアアクセラレータまたは特殊な命令セットを設計できる可能性がある。この共同設計アプローチは、INT4推論のための前例のない高速化とエネルギー効率を解き放つ可能性がある。
- 他のデータ型とモデルアーキテクチャへの一般化: RRSはLLMにおけるINT4推論で検証されている。これらの原則は、他の低ビット量子化スキーム(例:INT2、バイナリ)や、トランスフォーマー以外のモデルアーキテクチャ、例えばビジョンモデルやマルチモーダルアーキテクチャにどれだけうまく拡張できるか?これらのより広範なアプリケーションを調査することで、RRSを適応させるための新しい課題と機会が明らかになる可能性がある。
- 敵対的攻撃と分布シフトに対する堅牢性: 量子化モデルは、敵対的攻撃や分布外データに対するパフォーマンス低下に対して、より脆弱になる可能性がある。将来の研究では、RRSが活性化をよりスムーズで一貫性のあるものにすることで、量子化LLMの堅牢性をこれらの課題に対して本質的に向上させる可能性があるかどうか、またはこの側面を強化するために特定の変更が必要かどうかを調査できる可能性がある。
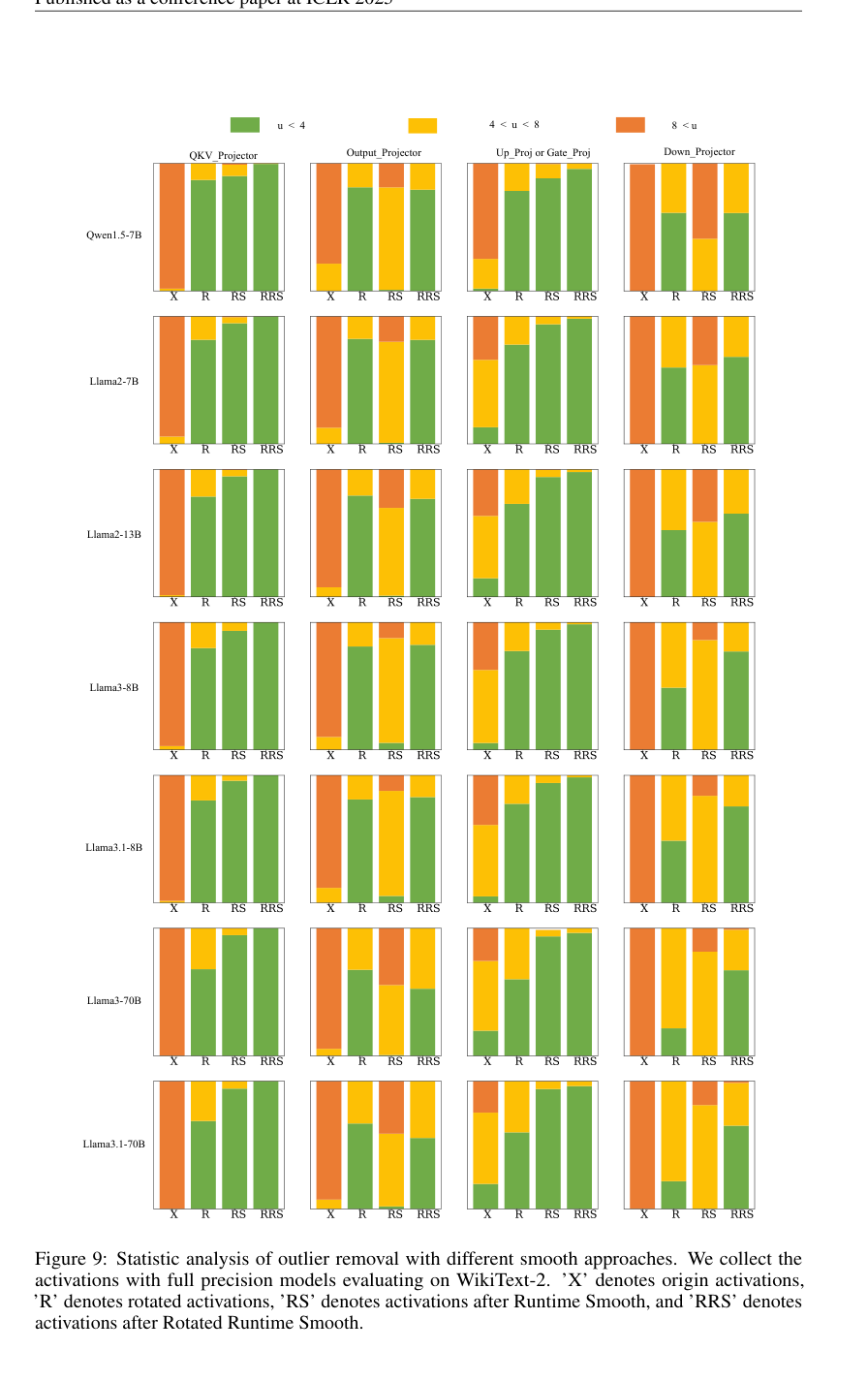 Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
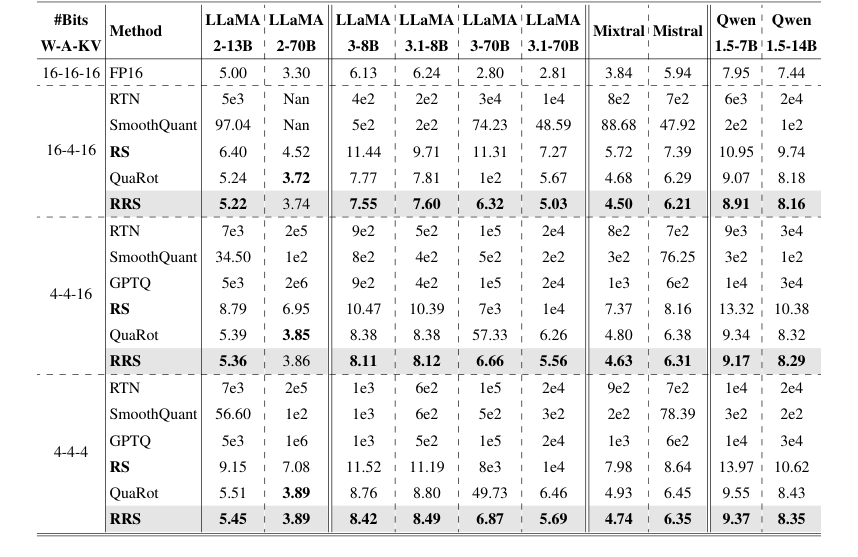 Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
 Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
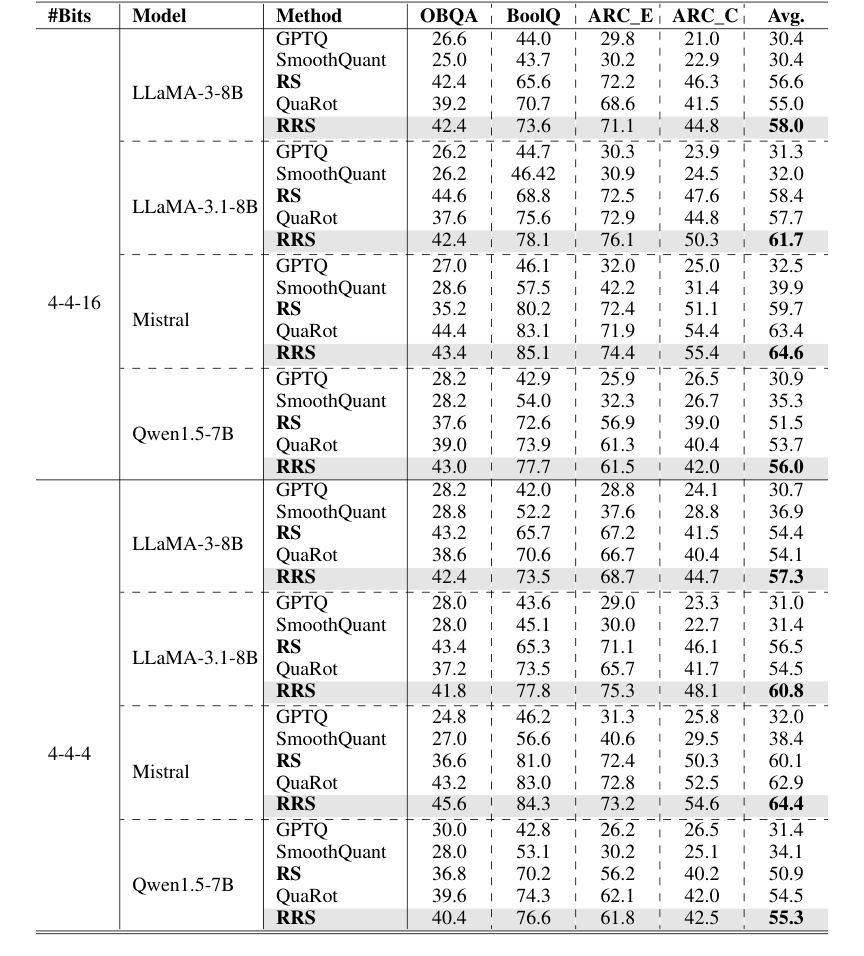 Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes