रोटेटेड रनटाइम स्मूथ: सटीक INT4 अनुमान के लिए प्रशिक्षण-मुक्त एक्टिवेशन स्मूथनर
रोटेटेड रनटाइम स्मूथ: सटीक INT4 अनुमान के लिए प्रशिक्षण-मुक्त एक्टिवेशन स्मूथनर
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या बड़े भाषा मॉडल (LLMs) के बढ़ते पैमाने और जटिलता से उत्पन्न होती है। जैसे-जैसे ये मॉडल बढ़ते हैं, अनुमान के लिए उनकी सेवा करना कम्प्यूटेशनल संसाधनों और मेमोरी उपयोग के मामले में अविश्वसनीय रूप से महंगा हो जाता है। इन लागतों को कम करने और विलंबता में सुधार करने के लिए, क्वांटाइजेशन विधियों को व्यापक रूप से अपनाया गया है। क्वांटाइजेशन अनिवार्य रूप से मॉडल में उपयोग किए जाने वाले संख्याओं (वजन और एक्टिवेशन) की सटीकता को कम करता है, उदाहरण के लिए, उच्च-सटीकता वाले फ्लोटिंग-पॉइंट नंबरों से INT4 (4-बिट पूर्णांक) जैसे निम्न-बिट पूर्णांकों तक।
हालांकि, निम्न-बिट क्वांटाइजेशन, विशेष रूप से INT4 वजन-एक्टिवेशन क्वांटाइजेशन के साथ एक महत्वपूर्ण "दर्द बिंदु" उभरा: एक्टिवेशन में आउटलायर्स की उपस्थिति। ये आउटलायर्स एक्टिवेशन टेंसर के भीतर चरम मान होते हैं जो समग्र मानों की सीमा को असमान रूप से फैलाते हैं। जब पूरी सीमा को बहुत सीमित संख्या में बिट्स (जैसे 4 बिट्स) में संपीड़ित किया जाता है, तो ये आउटलायर्स उपलब्ध "सटीकता स्लॉट" का अधिकांश हिस्सा ले लेते हैं, जिससे अधिक सामान्य, "सामान्य" मानों के लिए बहुत कम प्रभावी बिट्स बचते हैं। यह अनुमान के दौरान मॉडल की सटीकता को गंभीर रूप से खराब करता है।
पिछले दृष्टिकोणों ने इन आउटलायर्स से निपटने का प्रयास किया लेकिन मौलिक सीमाओं का सामना करना पड़ा:
* आउटलायर्स को अलग करना: शुरुआती विधियों (जैसे, किम एट अल., 2023; डेटमर्स एट अल., 2022) ने आउटलायर्स को सामान्य मानों से अलग मैट्रिक्स में अलग करने की कोशिश की। यहां प्रमुख कमी यह थी कि ये कार्यान्वयन अक्सर हार्डवेयर-संगत नहीं थे, जिससे उच्च विलंबता हुई और अनुमान में तेजी लाने में विफलता हुई।
* ऑफलाइन स्मूथिंग और माइग्रेशन (स्मूथक्वांट): स्मूथक्वांट (ज़ियाओ एट अल., 2023) का उद्देश्य चैनल-वार स्मूथिंग स्केल का उपयोग करके एक्टिवेशन से वजन तक आउटलायर्स को स्थानांतरित करना था। जबकि उच्च-बिट क्वांटाइजेशन (जैसे A8W8) के लिए प्रभावी था, यह कई कारणों से INT4 अनुमान के लिए विफल रहा:
* स्मूथिंग स्केल को एक कैलिब्रेशन सेट का उपयोग करके ऑफ़लाइन पूर्व-गणना की गई थी, जिससे वे नए, "बेमेल" ऑनलाइन एक्टिवेशन का सामना करने पर अप्रभावी हो गए।
* आउटलायर्स को वास्तव में समाप्त नहीं किया गया था, बल्कि केवल आंशिक रूप से स्थानांतरित किया गया था, फिर भी निम्न-बिट क्वांटाइजेशन में बाधा उत्पन्न हुई।
* स्मूथक्वांट ने मुख्य रूप से "चैनल-वार" आउटलायर्स को संबोधित किया लेकिन "स्पाइक" आउटलायर्स के साथ संघर्ष किया, जो चैनलों में सुसंगत नहीं होते हैं, जिससे सामान्य मानों को गलत तरीके से "पीड़ितों" के रूप में छांट दिया जाता है।
* रोटेशन-आधारित विधियाँ (क्वारोट): क्वारोट (एशकाबूस एट अल., 2024) जैसे हालिया कार्य ने आउटलायर्स को आंतरिक रूप से फैलाकर दबाने के लिए रोटेशन मैट्रिक्स पेश किए। A4W4 क्वांटाइजेशन के लिए आशाजनक होने के बावजूद, रोटेशन अकेले पूरी तरह से चिकनी मैट्रिक्स की गारंटी नहीं दे सकता है और अभी भी चैनल-वार आउटलायर्स प्रदर्शित कर सकता है, जिससे आगे सुधार की गुंजाइश बची रहती है। चुनौती एक मजबूत, सटीक और प्रशिक्षण-मुक्त योजना खोजना बनी हुई है जो INT4 अनुमान के लिए दोनों प्रकार के आउटलायर्स को प्रभावी ढंग से संभाल सके।
सहज डोमेन शब्द
- क्वांटाइजेशन: कल्पना करें कि आपके पास लाखों रंगों के साथ एक बहुत विस्तृत रंग पैलेट है (जैसे फ्लोटिंग-पॉइंट नंबर)। क्वांटाइजेशन केवल रंगों के एक बहुत छोटे सेट का उपयोग करने जैसा है, मान लीजिए कि सभी छवियों का प्रतिनिधित्व करने के लिए केवल 16 विशिष्ट रंग (जैसे 4-बिट पूर्णांक)। लक्ष्य छवियों को बहुत छोटा और संसाधित करने में तेज बनाना है, जबकि उन्हें यथासंभव अच्छा दिखाना है।
- एक्टिवेशन में आउटलायर्स: उन लोगों के समूह के बारे में सोचें जिनकी ऊंचाई ज्यादातर 5 और 6 फीट के बीच है। लेकिन फिर आपके पास कुछ विशालकाय हैं जो 20 फीट लंबे हैं और कुछ छोटे लोग हैं जो 1 फीट लंबे हैं। यदि आप केवल 10 चिह्नों का उपयोग करके सभी के लिए एक ऊंचाई पैमाना बनाने की कोशिश करते हैं, तो वे चरम विशालकाय और छोटे लोग पैमाने को एक विशाल सीमा (1 से 20 फीट) को कवर करने के लिए मजबूर करेंगे। इसका मतलब है कि सामान्य 5-6 फुट की सीमा को बहुत कम चिह्न मिलते हैं, जिससे 5'2" और 5'4" के बीच किसी व्यक्ति के बीच अंतर करना मुश्किल हो जाता है। "विशालकाय" और "छोटे लोग" आउटलायर्स हैं, जिससे "सामान्य" ऊंचाइयों का सटीक प्रतिनिधित्व करना मुश्किल हो जाता है।
- INT4 अनुमान: यह बहुत सरल, गोल संख्याओं (जैसे, केवल -8 से 7 तक की संख्याएं, जो 4-बिट पूर्णांक का प्रतिनिधित्व कर सकती हैं) के साथ गणना करने जैसा है, बजाय बहुत सटीक दशमलव के। $5.123 \times 3.456$ के बजाय $5 \times 3$ की गणना करना बहुत तेज है और कम मानसिक प्रयास (या कंप्यूटर मेमोरी/शक्ति) का उपयोग करता है। "INT4" भाग का अर्थ है 4-बिट पूर्णांक का उपयोग करना, जो LLMs के लिए अधिकतम गति और मेमोरी बचत प्राप्त करने के लिए बहुत आक्रामक गोल करने का एक रूप है।
- परप्लेक्सिटी: भाषा मॉडल के संदर्भ में, परप्लेक्सिटी एक अनुक्रम में अगले शब्द के बारे में मॉडल कितना "आश्चर्यचकित" है, इसका एक माप है। कल्पना करें कि आप एक वाक्य में अगले शब्द का अनुमान लगाने की कोशिश कर रहे हैं। यदि आप बहुत आश्वस्त हैं और सही अनुमान लगाते हैं, तो आपका "आश्चर्य" कम होता है। यदि आप अक्सर गलत या अनिश्चित होते हैं, तो आपका "आश्चर्य" अधिक होता है। एक कम परप्लेक्सिटी स्कोर का मतलब है कि भाषा मॉडल कम आश्चर्यचकित है, यह दर्शाता है कि यह टेक्स्ट की भविष्यवाणी करने में बेहतर है और भाषा को अधिक सटीकता से समझता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मौलिक समस्या अत्यंत निम्न-बिट वजन-एक्टिवेशन क्वांटाइजेशन, विशेष रूप से INT4 का उपयोग करके अनुमान करने का प्रयास करते समय बड़े भाषा मॉडल (LLMs) में महत्वपूर्ण सटीकता गिरावट है।
इनपुट/वर्तमान स्थिति यह है कि LLMs, अपनी प्रभावशाली क्षमताओं के बावजूद, अपने विशाल पैमाने के कारण सेवा करने के लिए कम्प्यूटेशनल और मेमोरी-गहन हैं। क्वांटाइजेशन, जो मॉडल मापदंडों और एक्टिवेशन की सटीकता को कम करता है (जैसे, FP32 से INT4 तक), इन लागतों को कम करने और अनुमान विलंबता में सुधार करने की एक आशाजनक तकनीक है। हालांकि, INT4 वजन-एक्टिवेशन क्वांटाइजेशन के व्यापक रूप से अपनाने में एक महत्वपूर्ण बाधा एक्टिवेशन टेंसर में "आउटलायर्स" की उपस्थिति है। ये आउटलायर्स चरम मान हैं जो असमान रूप से क्वांटाइजेशन रेंज को फैलाते हैं, प्रभावी रूप से सामान्य मानों के लिए उपलब्ध गतिशील सीमा को संपीड़ित करते हैं और महत्वपूर्ण सूचना हानि और सटीकता में गिरावट का कारण बनते हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) LLMs के लिए सटीक और कुशल INT4 वजन-एक्टिवेशन अनुमान को सक्षम करना है। इसका मतलब है कि महत्वपूर्ण सटीकता गिरावट का सामना किए बिना INT4 क्वांटाइजेशन के कम्प्यूटेशनल और मेमोरी लाभ प्राप्त करना। पत्र का उद्देश्य एक "प्रशिक्षण-मुक्त एक्टिवेशन स्मूथनर" विकसित करना है जो एक्टिवेशन आउटलायर्स को मज़बूती से संभाल सके, जिससे सामान्य मानों को पर्याप्त सटीकता के साथ क्वांटाइज किया जा सके, अंततः विभिन्न LLM परिवारों में INT4 अनुमान में अत्याधुनिक प्रदर्शन प्राप्त हो सके।
वर्तमान स्थिति और वांछित अंतिम बिंदु के बीच सटीक लुप्त कड़ी या गणितीय अंतर एक्टिवेशन आउटलायर्स को प्रभावी ढंग से "चिकना" या सामान्य करने की विधि खोजने में निहित है ताकि संपूर्ण एक्टिवेशन टेंसर को न्यूनतम सूचना हानि के साथ INT4 तक क्वांटाइज किया जा सके, साथ ही कम्प्यूटेशनल रूप से सस्ता और प्रशिक्षण-मुक्त हो। गणितीय रूप से, यदि $X$ एक एक्टिवेशन टेंसर है और $\alpha$ क्वांटाइजेशन के लिए इसका स्केलिंग कारक है (जैसे, N-बिट क्वांटाइजेशन के लिए $\alpha = \frac{\max(|X|)}{2^{N-1}-1}$), आउटलायर्स $\max(|X|)$ को बहुत बड़ा बनाते हैं, जिससे $\alpha$ बड़ा हो जाता है। इसके परिणामस्वरूप सामान्य मानों को पूर्णांक मानों की एक बहुत छोटी सीमा पर मैप किया जाता है, जिससे गंभीर सटीकता हानि होती है। लुप्त कड़ी एक परिवर्तन $f(X)$ है जैसे कि $f(X)$ में $\max(|X|)$ की तुलना में बहुत छोटा $\max(|f(X)|)$ हो, लेकिन $f(X)$ अभी भी मूल जानकारी का सटीक प्रतिनिधित्व करता है, जिससे एक छोटा $\alpha'$ और इस प्रकार सामान्य मानों का अधिक प्रभावी क्वांटाइजेशन संभव होता है। यह परिवर्तन वजन मैट्रिक्स $W$ के साथ संगत होना चाहिए ताकि आउटपुट $XW$ को संरक्षित किया जा सके।
कष्टदायक ट्रेड-ऑफ या दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह मुख्य रूप से सटीकता बनाम दक्षता बनाम मजबूती त्रिकोण है:
1. सटीकता बनाम दक्षता (निम्न-बिट क्वांटाइजेशन): आक्रामक निम्न-बिट क्वांटाइजेशन (INT4) महत्वपूर्ण गति और मेमोरी बचत प्रदान करता है लेकिन एक्टिवेशन आउटलायर्स के प्रति अत्यधिक संवेदनशील होता है, जिससे गंभीर सटीकता गिरावट होती है। सटीकता को बनाए रखने के लिए अक्सर उच्च बिट-चौड़ाई या जटिल आउटलायर हैंडलिंग की आवश्यकता होती है, जो दक्षता लाभ को नकार देती है।
2. आउटलायर हैंडलिंग बनाम हार्डवेयर संगतता/विलंबता: आउटलायर्स को संबोधित करने के मौजूदा तरीकों, जैसे कि आउटलायर्स को अलग-अलग मैट्रिक्स में अलग करना (जैसे, किम एट अल., 2023; डेटमर्स एट अल., 2022) या उन्हें वजन में स्थानांतरित करना (जैसे, स्मूथक्वांट), अक्सर हार्डवेयर असंगति, महत्वपूर्ण विलंबता ओवरहेड पेश करते हैं, या वजन क्वांटाइजेशन को कठिन बनाते हैं। यह तेज, अधिक कुशल अनुमान के मूल लक्ष्य को कमजोर करता है।
3. स्थिर बनाम गतिशील स्मूथिंग: पूर्व-गणना की गई स्मूथिंग स्केल (जैसे, स्मूथक्वांट में) कुशल हैं लेकिन ऑनलाइन एक्टिवेशन के साथ "बेमेल" हो जाते हैं, जिससे वे गतिशील इनपुट के लिए अप्रभावी हो जाते हैं। रनटाइम स्मूथिंग अधिक मजबूत है लेकिन पारंपरिक रूप से अस्वीकार्य कम्प्यूटेशनल ओवरहेड का कारण बनती है।
4. चैनल-वार बनाम स्पाइक आउटलायर्स: आउटलायर्स विभिन्न रूपों में प्रकट होते हैं: "चैनल-वार" (एक चैनल में सुसंगत) और "स्पाइक" (अलग, चरम मान)। एक प्रकार के लिए प्रभावी विधियाँ (जैसे, चैनल-वार स्मूथिंग) दूसरे के लिए "पीड़ित प्रभाव" को बढ़ा सकती हैं (जैसे, स्पाइक आउटलायर्स सामान्य मानों को छांटने का कारण बनते हैं), जिससे क्वांटाइजेशन त्रुटि होती है। नए साइड इफेक्ट्स के बिना एक एकीकृत समाधान मायावी है।
बाधाएँ और विफलता मोड
LLMs के लिए सटीक INT4 अनुमान की समस्या कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है जिनसे लेखक टकराए:
- एक्टिवेशन आउटलायर्स की अत्यधिक विरलता/परिमाण: एक्टिवेशन आउटलायर्स सामान्य मानों की तुलना में परिमाण के कई क्रम बड़े हो सकते हैं (जैसे, 1000x बड़े, जैसा कि पृष्ठ 14 पर उल्लेख किया गया है)। यह अत्यधिक परिमाण क्वांटाइजेशन रेंज को इतना गंभीर रूप से फैलाता है कि सामान्य मान लगभग अपने सभी प्रभावी बिट्स खो देते हैं, जिससे विनाशकारी सटीकता हानि होती है।
- INT4 सटीकता सीमाएँ: INT4 तक क्वांटाइज करने का मतलब है कि केवल 16 संभावित मान ($2^4$) एक्टिवेशन की पूरी श्रृंखला का प्रतिनिधित्व कर सकते हैं। यह अत्यंत सीमित सटीकता त्रुटि के लिए बहुत कम जगह छोड़ती है या महत्वपूर्ण सूचना हानि के बिना आउटलायर्स को समायोजित करने के लिए।
- वास्तविक समय विलंबता आवश्यकताएँ: LLM अनुमान, विशेष रूप से प्री-फिलिंग चरण, सख्त वास्तविक समय विलंबता की मांग करता है। किसी भी आउटलायर स्मूथिंग या हैंडलिंग तंत्र को व्यावहारिक होने के लिए "नगण्य ओवरहेड" (पृष्ठ 2, पृष्ठ 9) पेश करना चाहिए। जटिल संचालन जो महत्वपूर्ण कम्प्यूटेशनल समय जोड़ते हैं, अस्वीकार्य हैं।
- हार्डवेयर मेमोरी सीमाएँ: LLMs विशाल हैं, और मेमोरी बैंडविड्थ अक्सर एक बाधा होती है। क्वांटाइजेशन का उद्देश्य मेमोरी फुटप्रिंट और आंदोलन को कम करना है। अतिरिक्त उच्च-सटीकता डेटा या आउटलायर्स के लिए जटिल डेटा संरचनाओं को संग्रहीत करने की आवश्यकता वाले समाधान इन लाभों को नकार सकते हैं।
- प्रशिक्षण-मुक्त आवश्यकता: समाधान "प्रशिक्षण-मुक्त" और "प्लग-एंड-प्ले" (सार, पृष्ठ 2) होना चाहिए। इसका मतलब है कि यह बड़े डेटासेट पर व्यापक फाइन-ट्यूनिंग या कैलिब्रेशन पर भरोसा नहीं कर सकता है, जो बड़े मॉडल के लिए विशेष रूप से समय लेने वाला और संसाधन-गहन है।
- गतिशील इनपुट वितरण: एक्टिवेशन का वितरण एक LLM के विभिन्न इनपुट और विभिन्न परतों में काफी भिन्न हो सकता है। एक स्थिर कैलिब्रेशन सेट से प्राप्त स्मूथिंग स्केल ऑनलाइन एक्टिवेशन के साथ "बेमेल" होने की संभावना है (पृष्ठ 3), जिससे अप्रभावी स्मूथिंग और सटीकता गिरावट होती है।
- "पीड़ित" प्रभाव: जब स्मूथिंग स्केल को चरम आउटलायर्स द्वारा निर्धारित किया जाता है, तो सामान्य मान, जो बहुत छोटे होते हैं, प्रभावी रूप से "छांटे" जा सकते हैं या "पीड़ित" बन सकते हैं (पृष्ठ 2, चित्र 1c, पृष्ठ 3)। सामान्य मानों के लिए सटीकता का यह नुकसान एक महत्वपूर्ण विफलता मोड है, क्योंकि यह मॉडल की सूक्ष्म जानकारी का प्रतिनिधित्व करने की क्षमता को सीधे प्रभावित करता है।
- GEMM कर्नेल के साथ असंगति: रनटाइम स्मूथिंग के भोले कार्यान्वयन, विशेष रूप से असंगत स्मूथिंग स्केल के साथ, अत्यधिक अनुकूलित जनरल मैट्रिक्स मल्टीप्लाई (GEMM) कर्नेल (पृष्ठ 4) में आसानी से एकीकृत नहीं किए जा सकते हैं। यह हार्डवेयर त्वरण प्राप्त करना चुनौतीपूर्ण बनाता है, क्योंकि कस्टम कर्नेल या जटिल ब्लॉक-वार गणनाओं की आवश्यकता होगी।
- रोटेशन के बाद उप-स्मूथनेस: जबकि रोटेशन-आधारित विधियाँ (जैसे क्वारोट) आउटलायर्स को फैला सकती हैं, वे पूरी तरह से चिकनी मैट्रिक्स की गारंटी नहीं देती हैं और अभी भी "चैनल-वार आउटलायर्स" या "उप-स्मूथनेस" (पृष्ठ 2, चित्र 2c, पृष्ठ 4) प्रदर्शित कर सकती हैं। इसका मतलब है कि INT4 क्वांटाइजेशन के लिए आउटलायर समस्या को पूरी तरह से संबोधित करने के लिए रोटेशन अकेले अपर्याप्त है।
- आउटलायर माइग्रेशन चुनौतियाँ: एक्टिवेशन से वजन तक आउटलायर्स को माइग्रेट करने वाले पिछले दृष्टिकोण (जैसे, स्मूथक्वांट) वजन को क्वांटिफाई करना मुश्किल बना सकते हैं, खासकर A4W4 जैसे बहुत निम्न-बिट योजनाओं के लिए (पृष्ठ 1)। यह एक्टिवेशन डोमेन में एक को हल करने का प्रयास करते समय वजन डोमेन में एक नई समस्या पैदा करता है।
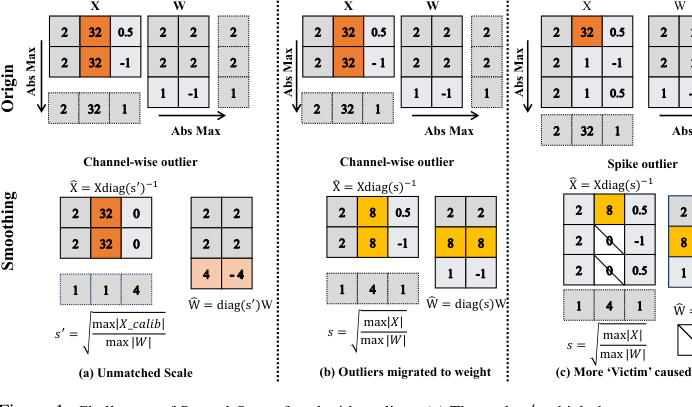 Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
लेखकों की रोटेटेड रनटाइम स्मूथ (RRS) की ओर यात्रा बड़े भाषा मॉडल (LLMs) के लिए INT4 अनुमान के चुनौतीपूर्ण परिदृश्य पर लागू होने पर मौजूदा क्वांटाइजेशन विधियों की मौलिक सीमाओं से प्रेरित थी। उस अहसास का "सटीक क्षण" कि पारंपरिक अत्याधुनिक (SOTA) विधियाँ अपर्याप्त थीं, एक्टिवेशन आउटलायर्स की लगातार समस्या पर केंद्रित थी।
पारंपरिक दृष्टिकोण, जैसे कि आउटलायर्स और सामान्य मानों को दो अलग-अलग मैट्रिक्स में अलग करने वाले (जैसे, किम एट अल., 2023; डेटमर्स एट अल., 2022), उच्च विलंबता या महत्वपूर्ण सटीकता गिरावट से पीड़ित पाए गए। महत्वपूर्ण रूप से, ये विधियाँ अक्सर हार्डवेयर त्वरण के साथ असंगत साबित हुईं, इच्छित रूप से अनुमान में तेजी लाने में विफल रहीं।
एक अधिक प्रत्यक्ष पूर्ववर्ती, स्मूथक्वांट (ज़ियाओ एट अल., 2023), ने चैनल-वार स्मूथिंग स्केल का उपयोग करके एक्टिवेशन से वजन तक उन्हें स्थानांतरित करके आउटलायर्स को कम करने का प्रयास किया। हालांकि, INT4 क्वांटाइजेशन के लिए, स्मूथक्वांट को तीन महत्वपूर्ण विफलताओं का सामना करना पड़ा:
1. बेमेल स्केल: कैलिब्रेशन सेट से प्राप्त ऑफ़लाइन पूर्व-गणना की गई स्मूथिंग स्केल अक्सर ऑनलाइन एक्टिवेशन के साथ बेमेल हो जाती थी, जिससे स्मूथिंग के लिए वे अप्रभावी हो जाती थी।
2. अपूर्ण आउटलायर उन्मूलन: आउटलायर चैनलों को पूरी तरह से समाप्त नहीं किया गया था, बल्कि केवल आंशिक रूप से वजन में स्थानांतरित किया गया था, जिससे निम्न-बिट क्वांटाइजेशन (विशेष रूप से INT4) मुश्किल हो गया।
3. स्पाइक आउटलायर्स और "पीड़ित": स्मूथक्वांट ने मुख्य रूप से चैनल-वार आउटलायर्स को संबोधित किया लेकिन "स्पाइक आउटलायर्स" को ध्यान में रखने में विफल रहा जो लगातार चैनल-वार नहीं होते हैं। जब ये स्पाइक आउटलायर्स मौजूद थे, तो सामान्य मानों को स्मूथिंग के दौरान अनजाने में "पीड़ितों" के रूप में छांट दिया गया था, जिससे सटीकता का नुकसान हुआ।
क्वारोट (एशकाबूस एट अल., 2024) जैसी रोटेशन-आधारित विधियाँ भी, आउटलायर्स को फैलाने में वादा दिखाते हुए, सैद्धांतिक रूप से एक समान रूप से चिकनी मैट्रिक्स की गारंटी नहीं दे सकीं। रोटेटेड एक्टिवेशन, विशेष रूप से चैनल-वार आउटलायर्स वाले, अभी भी "उप-स्मूथनेस" (जैसा कि चित्र 2c में दर्शाया गया है) प्रदर्शित कर सकते हैं, जिससे आगे सुधार की गुंजाइश बची रहती है। इन सभी विधियों की INT4 अनुमान के लिए प्रशिक्षण-मुक्त तरीके से दोनों चैनल-वार और स्पाइक आउटलायर्स को मज़बूती से, सटीक रूप से और कुशलता से संभालने में सामूहिक विफलता ने RRS जैसे एक नए, व्यापक समाधान के विकास को न केवल एक विकल्प, बल्कि एक अनिवार्यता बना दिया।
तुलनात्मक श्रेष्ठता
रोटेटेड रनटाइम स्मूथ (RRS) गुणात्मक रूप से पिछले तरीकों पर श्रेष्ठता प्रदर्शित करता है, मुख्य रूप से इसके व्यापक और मजबूत आउटलायर हैंडलिंग के माध्यम से, न्यूनतम कम्प्यूटेशनल ओवरहेड के साथ।
RRS का संरचनात्मक लाभ इसके दो-तरफा दृष्टिकोण में निहित है:
1. रनटाइम स्मूथ (RS): यह घटक गतिशील रूप से रनटाइम पर स्मूथिंग स्केल की गणना करके सीधे चैनल-वार आउटलायर्स को संबोधित करता है। स्मूथक्वांट के विपरीत, जो ऑफ़लाइन कैलिब्रेशन पर निर्भर करता है और स्केल को वजन में मर्ज करता है, RS बेमेल स्केल की समस्याओं से बचता है और माइग्रेटेड आउटलायर्स के साथ वजन को क्वांटाइज करने की कठिनाई से बचता है। रनटाइम पर स्मूथिंग स्केल प्राप्त करके और उन्हें वजन में मर्ज न करके, RS सुनिश्चित करता है कि स्मूथिंग हमेशा वर्तमान इनपुट के लिए प्रासंगिक हो, जिससे यह अधिक अनुकूल और सटीक हो।
2. रोटेशन ऑपरेशन: यहीं पर RRS स्पाइक आउटलायर्स से निपटता है और मजबूती को बढ़ाता है। वजन और एक्टिवेशन को घुमाकर (क्वारोट के सिद्धांत का पालन करते हुए), स्पाइक आउटलायर्स प्रभावी ढंग से टोकन में फैल जाते हैं। यह फैलाव चैनलों में अधिक सुसंगत स्मूथिंग स्केल की ओर ले जाता है, जो बदले में चैनल-वार स्मूथिंग प्रक्रिया के दौरान सामान्य मानों को "पीड़ित" बनने से रोकता है। चैनल-वार आउटलायर्स वाले एक्टिवेशन के लिए, रोटेशन स्थिरता बनाए रखने में मदद करता है जबकि आउटलायर्स के स्तर को कम करने का अवसर भी प्रदान करता है।
यह संयुक्त रणनीति एक संरचनात्मक लाभ प्रदान करती है जो पिछले तरीकों में कमी थी। उदाहरण के लिए, स्मूथक्वांट स्पाइक आउटलायर्स को प्रभावी ढंग से संभाल नहीं सका और कैलिब्रेशन सेट बेमेल से ग्रस्त था। शुद्ध रोटेशन विधियाँ, फायदेमंद होने के बावजूद, अपने आप में पर्याप्त स्मूथनेस की गारंटी नहीं देती थीं। RRS दोनों के सर्वोत्तम पहलुओं को एकीकृत करता है, यह सुनिश्चित करता है कि सभी प्रकार के आउटलायर्स (चैनल-वार और स्पाइक) को व्यापक रूप से संबोधित किया जाए।
इसके अलावा, RRS को एक "प्लग-एंड-प्ले" घटक के रूप में डिज़ाइन किया गया है, जो INT4 मैट्रिक्स गुणन के लिए नगण्य ओवरहेड का कारण बनता है। पत्र स्पष्ट रूप से बताता है कि फ्यूज्ड GEMM कर्नेल में अतिरिक्त रनटाइम स्केल गुणन A4W4 बेसलाइन की तुलना में केवल "नगण्य ओवरहेड" लाता है। यह एक महत्वपूर्ण गुणात्मक लाभ है, क्योंकि यह कम-बिट क्वांटाइजेशन से अपेक्षित महत्वपूर्ण विलंबता लाभों का त्याग किए बिना बेहतर सटीकता प्राप्त करता है। यह उच्च-आयामी शोर पेश नहीं करता है, बल्कि आउटलायर्स के प्रभाव को कम करता है जो क्वांटाइजेशन रेंज को फैलाकर शोर के रूप में कार्य करते हैं।
बाधाओं के साथ संरेखण
रोटेटेड रनटाइम स्मूथ (RRS) विधि बड़े भाषा मॉडल (LLMs) के लिए कुशल अनुमान की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, विशेष रूप से INT4 क्वांटाइजेशन के लिए। मुख्य बाधाएँ, जो बड़े LLMs की सेवा की समस्या से निहित हैं, में शामिल हैं:
1. INT4 अनुमान: प्राथमिक लक्ष्य INT4 सटीकता पर कुशल अनुमान को सक्षम करना है, जो मेमोरी और कम्प्यूटेशनल लागत को कम करने के लिए महत्वपूर्ण है। RRS को विशेष रूप से "सटीक INT4 अनुमान के लिए प्रशिक्षण-मुक्त एक्टिवेशन स्मूथनर" के रूप में डिज़ाइन किया गया है। इसकी पूरी तंत्र, चैनल-वार से स्पाइक आउटलायर्स को संभालने तक, एक्टिवेशन को महत्वपूर्ण सटीकता हानि के बिना 4-बिट क्वांटाइजेशन के लिए उपयुक्त बनाने के लिए तैयार है। LLaMA और Qwen परिवारों पर A4W4KV16 सेटिंग्स के तहत परप्लेक्सिटी सुधार (जैसे, LLaMA3-70B 57.33 से 6.66 तक) सीधे इस लक्ष्य को प्राप्त करने में इसकी प्रभावशीलता को मान्य करते हैं।
2. प्रशिक्षण-मुक्त: व्यावहारिक परिनियोजन के लिए एक महत्वपूर्ण आवश्यकता महंगी पुन: प्रशिक्षण या फाइन-ट्यूनिंग से बचना है। RRS स्पष्ट रूप से "प्रशिक्षण-मुक्त" है, जिसका अर्थ है कि इसे अतिरिक्त मॉडल अनुकूलन के बिना पोस्ट-ट्रेनिंग पर लागू किया जा सकता है। यह LLMs के पहले से ही पर्याप्त प्रशिक्षण बोझ में न जोड़ने वाले आसानी से परिनियोजित समाधान की आवश्यकता के साथ पूरी तरह से संरेखित होता है।
3. सटीकता संरक्षण: निम्न-बिट क्वांटाइजेशन अक्सर सटीकता गिरावट का कारण बनता है। RRS की व्यापक आउटलायर शमन रणनीति - चैनल-वार आउटलायर्स के लिए रनटाइम स्मूथिंग और स्पाइक आउटलायर्स के लिए रोटेशन का संयोजन - "आउटलायर्स को व्यापक रूप से समाप्त करने" और "मजबूती बढ़ाने" के लिए डिज़ाइन किया गया है, जिससे सटीकता संरक्षित होती है। परप्लेक्सिटी और जीरो-शॉट QA कार्यों में लगातार SOTA विधियों से बेहतर प्रदर्शन इसका प्रमाण है।
4. कम विलंबता/न्यूनतम ओवरहेड: क्वांटाइजेशन का उद्देश्य सेवा लागत और विलंबता को कम करना है। RRS को दक्षता के लिए इंजीनियर किया गया है, इसके रनटाइम स्मूथ घटक के साथ A4W4 मूल पाइपलाइन की तुलना में "न्यूनतम ओवरहेड" का कारण बनता है। रनटाइम स्मूथ के लिए कर्नेल फ्यूजन यह सुनिश्चित करता है कि प्रक्रिया GEMM पाइपलाइन में कुशलतापूर्वक एकीकृत हो, A4W4 प्रति-चैनल क्वांटाइजेशन की तुलना में "नगण्य ओवरहेड" जोड़ती है। यह सीधे उच्च थ्रूपुट और कम विलंबता बनाए रखने की बाधा को संबोधित करता है।
5. आउटलायर्स के प्रति मजबूती: समस्या कथन ने आउटलायर्स को मुख्य बाधा के रूप में उजागर किया है। RRS की दोनों चैनल-वार और स्पाइक आउटलायर्स को संबोधित करने की अनूठी संपत्ति, और "पीड़ितों" को सुसंगत स्मूथिंग स्केल सुनिश्चित करके रोकना, इसे LLM एक्टिवेशन में देखे जाने वाले विविध आउटलायर पैटर्न के प्रति स्वाभाविक रूप से मजबूत बनाता है। समस्या की कठोर आउटलायर चुनौती और समाधान के अद्वितीय दोहरे-आउटलायर हैंडलिंग के बीच यह "विवाह" इसकी सफलता का केंद्र है।
विकल्पों का अस्वीकरण
पत्र ने कई वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान किया है, विशेष रूप से LLMs के लिए INT4 अनुमान के संदर्भ में उनकी कमियों को उजागर किया है:
-
पारंपरिक आउटलायर पृथक्करण (जैसे, LLM.int8(), किम एट अल., 2023; डेटमर्स एट अल., 2022): इन विधियों, जो आउटलायर्स को उच्च-सटीकता प्रारूप (मिश्रित INT8/FP16) या अलग मैट्रिक्स में अलग करती हैं, को "उच्च विलंबता या सटीकता गिरावट" और अक्सर "हार्डवेयर-संगत नहीं" होने के कारण अस्वीकार कर दिया गया था, जिससे "अनुमान में तेजी लाने में विफलता" हुई। LLM.int8() विशेष रूप से "महत्वपूर्ण विलंबता ओवरहेड का परिणाम है और FP16 अनुमान से भी धीमा हो सकता है।"
-
स्मूथक्वांट (ज़ियाओ एट अल., 2023): जबकि A8W8 क्वांटाइजेशन के लिए प्रभावी था, स्मूथक्वांट को INT4 के लिए अपर्याप्त माना गया क्योंकि इसके ऑफ़लाइन, कैलिब्रेशन-सेट-निर्भर स्मूथिंग स्केल "ऑनलाइन एक्टिवेशन के साथ बेमेल होने की संभावना थी।" इसके अलावा, इसने आउटलायर्स को वजन में केवल आंशिक रूप से स्थानांतरित किया, उन्हें समाप्त करने के बजाय, जिससे निम्न-बिट क्वांटाइजेशन मुश्किल हो गया, और महत्वपूर्ण रूप से, इसने "स्पाइक आउटलायर्स" को संबोधित नहीं किया, जिससे "पीड़ित" छंटाई हुई।
-
शुद्ध रोटेशन-आधारित विधियाँ (जैसे, क्वारोट, एशकाबूस एट अल., 2024): जबकि रोटेशन आउटलायर्स को फैलाने में मदद करता है, पत्र नोट करता है कि एक एकल रोटेशन मैट्रिक्स से गुणा करना "सैद्धांतिक रूप से चिकनी वजन या एक्टिवेशन की गारंटी नहीं दे सकता है।" एक्टिवेशन, रोटेशन के बाद भी, चैनल-वार आउटलायर्स (चित्र 2c) के साथ "उप-चिकना" रह सकता है, यह दर्शाता है कि व्यापक स्मूथिंग के लिए अकेले रोटेशन एक पूर्ण समाधान नहीं था। क्वारोट के लिए "जटिल ऑनलाइन हैडामार्ड रोटेशन" की भी आवश्यकता होती है, जिसे RRS सरल बनाने का लक्ष्य रखता है।
-
प्रशिक्षण-आधारित क्वांटाइजेशन (जैसे, स्पिनक्वांट, लियू एट अल., 2024): पत्र स्पष्ट रूप से RRS की तुलना स्पिनक्वांट से करता है और उनके निषेधात्मक कम्प्यूटेशनल लागत के कारण प्रशिक्षण-आधारित दृष्टिकोणों को अस्वीकार करता है। स्पिनक्वांट की प्रशिक्षण प्रक्रिया "समय लेने वाली है, एक A100 GPU पर 7B मॉडल के लिए 1.5 घंटे और आठ A100 GPUs पर 70B मॉडल के लिए 12 घंटे लगते हैं।" इसके अलावा, परिणामों से पता चला कि प्रशिक्षण-आधारित विधियों ने "प्रशिक्षण-मुक्त विधि की तुलना में WikiText-2 परप्लेक्सिटी को खराब कर दिया और अभी भी सुधार की गुंजाइश है," जिससे वे दक्षता और अंतिम सटीकता दोनों के मामले में कम वांछनीय हो गए।
-
अन्य पुनर्व्यवस्था तकनीकें (जैसे, RPTQ, युआन एट अल., 2023; एटम, झाओ एट अल., 2024): जबकि ये विधियाँ विचरण को कम करने के लिए चैनलों को पुनर्व्यवस्थित करती हैं या मिश्रित सटीकता का उपयोग करती हैं, वे RRS द्वारा प्रदान किए जाने वाले चैनल-वार और स्पाइक आउटलायर्स दोनों के लिए व्यापक, प्रशिक्षण-मुक्त और कम-ओवरहेड समाधान प्रदान नहीं करती हैं। उदाहरण के लिए, एटम मिश्रित INT4/INT8 के साथ पुनर्व्यवस्था को एकीकृत करता है, जो शुद्ध INT4 नहीं है।
इन विकल्पों को अस्वीकार करने में लगातार विषय यह है कि वे LLMs के लिए INT4 अनुमान की सख्त मांगों को एक साथ पूरा करने में असमर्थ हैं: उच्च सटीकता, कम विलंबता, और सभी प्रकार के एक्टिवेशन आउटलायर्स के लिए एक प्रशिक्षण-मुक्त, मजबूत समाधान।
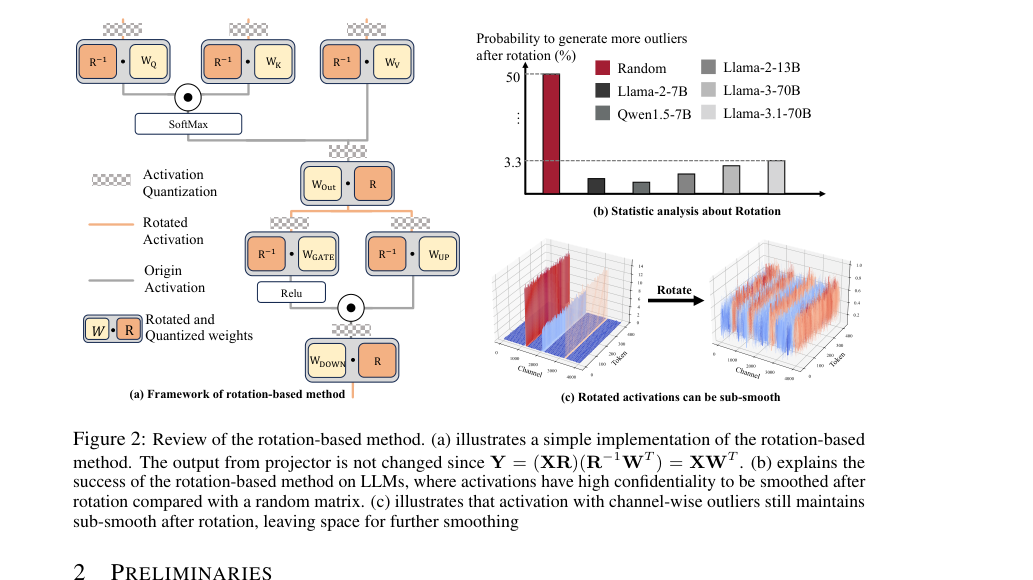 Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
गणितीय और तार्किक तंत्र
मास्टर समीकरण
रोटेटेड रनटाइम स्मूथ (RRS) विधि को शक्ति प्रदान करने वाला मुख्य गणितीय इंजन एक रोटेशन ऑपरेशन को रनटाइम स्मूथिंग तंत्र के साथ जोड़ता है। एक इनपुट एक्टिवेशन मैट्रिक्स $X$ और एक वजन मैट्रिक्स $W$ को देखते हुए, RRS प्रक्रिया को निम्नलिखित संचालन के अनुक्रम द्वारा संक्षेपित किया जा सकता है:
$$ X_{rot} = XR \\ W_{rot} = R^{-1}W \\ s_j = \max(|(X_{rot})_j|), \quad j = 1, \dots, K \\ X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1}) \\ W'_{quant} = \text{Quantize}(W_{rot}) \\ Y = \sum_{j=1}^{K} (X'_{quant})_j (W'_{quant})_j^T s_j $$
यह समीकरणों का सेट बताता है कि एक्टिवेशन और वजन को पहले कैसे घुमाया जाता है, फिर एक्टिवेशन को रनटाइम-व्युत्पन्न स्केल का उपयोग करके चिकना किया जाता है, दोनों को क्वांटाइज किया जाता है, और अंत में, एक संशोधित मैट्रिक्स गुणन निम्न-बिट आउटपुट उत्पन्न करता है।
पद-दर-पद विच्छेदन
आइए इसके गणितीय परिभाषा, तार्किक भूमिका और इसके डिजाइन के पीछे के तर्क को समझने के लिए मास्टर समीकरण के प्रत्येक घटक का विश्लेषण करें।
-
$X$: यह एक रैखिक परत के लिए इनपुट एक्टिवेशन टेंसर का प्रतिनिधित्व करता है।
1) गणितीय परिभाषा: $N \times K$ आयामों का एक फ्लोटिंग-पॉइंट मैट्रिक्स, जहां $N$ आमतौर पर बैच आकार को अनुक्रम लंबाई से गुणा किया जाता है, और $K$ इनपुट चैनल आयाम है।
2) भौतिक/तार्किक भूमिका: यह पिछली परत से फीचर जानकारी ले जाता है, जिसे वर्तमान रैखिक परत द्वारा संसाधित करने की आवश्यकता होती है।
3) यह रूप क्यों: यह इनपुट सुविधाओं के बैच के लिए मानक प्रतिनिधित्व है। -
$W$: यह रैखिक परत का वजन मैट्रिक्स है।
1) गणितीय परिभाषा: $M \times K$ आयामों का एक फ्लोटिंग-पॉइंट मैट्रिक्स, जहां $M$ आउटपुट आयाम है और $K$ इनपुट चैनल आयाम है।
2) भौतिक/तार्किक भूमिका: इसमें सीखने योग्य पैरामीटर होते हैं जो इनपुट एक्टिवेशन को आउटपुट सुविधाओं में बदलते हैं।
3) यह रूप क्यों: रैखिक परत वजन के लिए मानक प्रतिनिधित्व। -
$R$: यह रोटेशन मैट्रिक्स है।
1) गणितीय परिभाषा: $K \times K$ आकार का एक ऑर्थोगोनल मैट्रिक्स, जिसका अर्थ है $RR^T = I$ (जहां $I$ पहचान मैट्रिक्स है) और इसका निर्धारक $\det(R) = 1$ है। पत्र अक्सर एक हैडामार्ड रोटेशन मैट्रिक्स का उल्लेख करता है, जहां $R = \frac{1}{\sqrt{K}}[s_{i,j}]_{K \times K}$ तत्वों $s_{i,j} \in \{-1, +1\}$ के साथ।
2) भौतिक/तार्किक भूमिका: इसकी प्राथमिक भूमिका एक्टिवेशन और वजन दोनों के वेक्टर स्पेस को रैखिक रूप से बदलना (घुमाना) है। यह रोटेशन एक्टिवेशन के भीतर केंद्रित आउटलायर्स को "फैलाने" के लिए महत्वपूर्ण है, जिससे वे क्वांटाइजेशन रेंज पर कम प्रभावी होते हैं। दोनों $X$ और $W$ को उचित रूप से घुमाकर, मूल आउटपुट $XW^T$ को गणितीय रूप से $(XR)(R^{-1}W^T)$ के रूप में संरक्षित किया जाता है।
3) गुणा क्यों: मैट्रिक्स गुणन वेक्टर स्पेस में रोटेशन जैसे रैखिक परिवर्तनों को लागू करने के लिए मौलिक संचालन है। -
$R^{-1}$: यह रोटेशन मैट्रिक्स का व्युत्क्रम है।
1) गणितीय परिभाषा: चूंकि $R$ ऑर्थोगोनल है, इसका व्युत्क्रम बस इसका ट्रांसपोज़, $R^T$ है। यह $K \times K$ मैट्रिक्स भी है।
2) भौतिक/तार्किक भूमिका: यह वजन मैट्रिक्स $W$ को $X_{rot}$ के साथ संयुक्त होने पर मूल मैट्रिक्स गुणन की गणितीय समानता को सुनिश्चित करने के लिए एक पूरक तरीके से घुमाता है।
3) गुणा क्यों: $R$ के समान, यह एक रैखिक परिवर्तन है। -
$X_{rot} = XR$: घुमाया गया एक्टिवेशन टेंसर।
1) गणितीय परिभाषा: इनपुट एक्टिवेशन मैट्रिक्स $X$ को रोटेशन मैट्रिक्स $R$ से गुणा करने का परिणाम। यह $N \times K$ आकार को बनाए रखता है।
2) भौतिक/तार्किक भूमिका: ये एक्टिवेशन हैं जिनके फीचर्स को रोटेशन द्वारा रैखिक रूप से संयोजित और चैनलों में पुनर्वितरित किया गया है। यह कदम एक्टिवेशन में चैनल-वार आउटलायर्स को कम करने का लक्ष्य रखता है, जिससे उनके परिमाण कम चरम या अधिक समान रूप से वितरित होते हैं।
3) गुणा क्यों: यह रोटेशन परिवर्तन का प्रत्यक्ष अनुप्रयोग है। -
$W_{rot} = R^{-1}W$: घुमाया गया वजन मैट्रिक्स।
1) गणितीय परिभाषा: वजन मैट्रिक्स $W$ को व्युत्क्रम रोटेशन मैट्रिक्स $R^{-1}$ से गुणा करने का परिणाम। यह $M \times K$ आकार को बनाए रखता है।
2) भौतिक/तार्किक भूमिका: ये वजन हैं जिन्हें घुमाया गया है। यह रोटेशन $X_{rot}$ के साथ संयुक्त होने पर मूल मैट्रिक्स गुणन की गणितीय समानता को बनाए रखने के लिए आवश्यक है।
3) गुणा क्यों: व्युत्क्रम रोटेशन का प्रत्यक्ष अनुप्रयोग। -
$s_j = \max(|(X_{rot})_j|)$: $j$-वें चैनल के लिए रनटाइम स्मूथिंग स्केल।
1) गणितीय परिभाषा: घुमाए गए एक्टिवेशन मैट्रिक्स $X_{rot}$ के प्रत्येक कॉलम $j$ के लिए (जिसे $(X_{rot})_j$ के रूप में दर्शाया गया है, जो एक $N \times 1$ वेक्टर है), यह ऑपरेशन उस कॉलम में सभी तत्वों के बीच अधिकतम पूर्ण मान की गणना करता है। यह एक स्केलर $s_j$ उत्पन्न करता है।
2) भौतिक/तार्किक भूमिका: यह स्केल गतिशील रूप से घुमाए गए एक्टिवेशन के प्रत्येक चैनल में मौजूद सबसे बड़े परिमाण को कैप्चर करता है। यह मानों को क्वांटाइजेशन के लिए अधिक प्रबंधनीय सीमा में लाने के लिए एक सामान्यीकरण कारक के रूप में कार्य करता है। अधिकतम पूर्ण मान का उपयोग करके, यह सुनिश्चित करता है कि बाद के विभाजन के दौरान कोई मान क्लिप न हो, जिससे जानकारी संरक्षित हो। यह "रनटाइम स्मूथ" घटक का एक प्रमुख हिस्सा है, जो चैनल-वार आउटलायर्स को संबोधित करता है।
3)maxऔर निरपेक्ष मान क्यों:maxचरम मान की पहचान करता है जो आवश्यक स्केलिंग रेंज को निर्धारित करता है। निरपेक्ष मान सुनिश्चित करता है कि सकारात्मक और नकारात्मक दोनों आउटलायर्स को सममित रूप से माना जाता है। -
$\text{diag}(s)^{-1}$: स्मूथिंग स्केल का व्युत्क्रम विकर्ण मैट्रिक्स।
1) गणितीय परिभाषा: एक $K \times K$ विकर्ण मैट्रिक्स जहां $j$-वां विकर्ण तत्व $1/s_j$ है।
2) भौतिक/तार्किक भूमिका: यह मैट्रिक्स प्रत्येक कॉलम को उसके विशिष्ट $s_j$ से विभाजित करके $X_{rot}$ के चैनल-वार स्केलिंग को सुविधाजनक बनाता है।
3) विकर्ण मैट्रिक्स क्यों: यह एक मैट्रिक्स गुणन के रूप में तत्व-वार कॉलम स्केलिंग का प्रतिनिधित्व करने का एक कुशल तरीका है। -
$X_{rot}\text{diag}(s)^{-1}$: चिकना किए गए घुमाए गए एक्टिवेशन।
1) गणितीय परिभाषा: घुमाए गए एक्टिवेशन मैट्रिक्स के प्रत्येक कॉलम $(X_{rot})_j$ को उसके संबंधित स्केलर $s_j$ से तत्व-वार विभाजित किया जाता है। यह $N \times K$ मैट्रिक्स उत्पन्न करता है।
2) भौतिक/तार्किक भूमिका: यह ऑपरेशन घुमाए गए एक्टिवेशन को चैनल-वार सामान्य करता है। प्रत्येक चैनल के अधिकतम परिमाण के आधार पर मानों को स्केल करके, आउटलायर्स को प्रभावी ढंग से सामान्य मानों के सापेक्ष "संपीड़ित" किया जाता है, जिससे चैनल का पूरा डेटा निम्न-बिट क्वांटाइजेशन रेंज में बेहतर ढंग से फिट हो जाता है।
3) विभाजन क्यों: अधिकतम निरपेक्ष मान से विभाजन डेटा को स्केल करता है, आमतौर पर $[-1, 1]$ जैसी सीमा में, जो सममित क्वांटाइजेशन योजनाओं के लिए इष्टतम है। -
$\text{Quantize}(\cdot)$: क्वांटाइजेशन फ़ंक्शन।
1) गणितीय परिभाषा: एक फ़ंक्शन जो एक फ्लोटिंग-पॉइंट संख्या को निम्न-बिट पूर्णांक प्रतिनिधित्व में मैप करता है। उदाहरण के लिए, INT4 के लिए, यह एक फ्लोट $x$ को एक पूर्णांक $q$ पर मैप कर सकता है जैसे कि $q = \text{round}(x \cdot \text{scale}) + \text{offset}$, जहांscaleऔरoffsetलक्ष्य बिट-चौड़ाई और मानों की सीमा द्वारा निर्धारित किए जाते हैं।
2) भौतिक/तार्किक भूमिका: यह संख्याओं की सटीकता को कम करने के लिए मुख्य ऑपरेशन है। यह उच्च-सटीकता वाले फ्लोटिंग-पॉइंट मानों को असतत, निम्न-बिट पूर्णांक मानों में परिवर्तित करता है, जो अनुमान के दौरान मेमोरी फुटप्रिंट और कम्प्यूटेशनल लागत को काफी कम करता है।
3) यह फ़ंक्शन क्यों: यह निरंतर मानों को असतत मानों के एक परिमित सेट में परिवर्तित करने की मानक विधि है, जो क्वांटाइजेशन का सार है। -
$X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1})$: क्वांटाइज्ड चिकना किए गए घुमाए गए एक्टिवेशन।
1) गणितीय परिभाषा: चिकना किए गए घुमाए गए एक्टिवेशन मैट्रिक्स पर $\text{Quantize}$ फ़ंक्शन लागू करने का परिणाम। यह निम्न-बिट पूर्णांकों का $N \times K$ मैट्रिक्स है।
2) भौतिक/तार्किक भूमिका: ये इनपुट एक्टिवेशन अपने अंतिम निम्न-बिट, आउटलायर-शमन रूप में हैं, जो कुशल मैट्रिक्स गुणन के लिए तैयार हैं। -
$W'_{quant} = \text{Quantize}(W_{rot})$: क्वांटाइज्ड घुमाए गए वजन।
1) गणितीय परिभाषा: घुमाए गए वजन मैट्रिक्स पर $\text{Quantize}$ फ़ंक्शन लागू करने का परिणाम। यह निम्न-बिट पूर्णांकों का $M \times K$ मैट्रिक्स है।
2) भौतिक/तार्किक भूमिका: ये वजन अपने निम्न-बिट, आउटलायर-शमन रूप में हैं, जो कुशल मैट्रिक्स गुणन के लिए तैयार हैं। -
$(X'_{quant})_j$: $X'_{quant}$ का $j$-वां कॉलम।
1) गणितीय परिभाषा: निम्न-बिट पूर्णांकों वाले $N \times 1$ आकार का एक कॉलम वेक्टर।
2) भौतिक/तार्किक भूमिका: एक विशिष्ट इनपुट चैनल के लिए क्वांटाइज्ड और चिकना किए गए एक्टिवेशन का प्रतिनिधित्व करता है। -
$(W'_{quant})_j^T$: $W'_{quant}$ की $j$-वीं पंक्ति (ट्रांसपोज़्ड)।
1) गणितीय परिभाषा: निम्न-बिट पूर्णांकों वाले $1 \times M$ आकार का एक पंक्ति वेक्टर। (नोट: यह मानते हुए कि $W'_{quant}$ $M \times K$ है, तो $(W'_{quant})_j$ इसका $j$-वां कॉलम, $M \times 1$ है। इसलिए, $(W'_{quant})_j^T$ $1 \times M$ है। यह एक $N \times M$ बाहरी उत्पाद के लिए आवश्यक आयामों के साथ संरेखित होता है)।
2) भौतिक/तार्किक भूमिका: $j$-वें इनपुट चैनल के सभी आउटपुट चैनलों में योगदान के अनुरूप क्वांटाइज्ड वजन का प्रतिनिधित्व करता है। -
$\sum_{j=1}^{K} (\cdot)$: चैनलों पर योग।
1) गणितीय परिभाषा: यह ऑपरेटर $K$ व्यक्तिगत मैट्रिक्स का योग करता है, प्रत्येक $N \times M$ आकार का होता है।
2) भौतिक/तार्किक भूमिका: यह योग अंतिम आउटपुट मैट्रिक्स बनाने के लिए प्रत्येक इनपुट चैनल के योगदान को जोड़ता है। प्रत्येक पद $(X'_{quant})_j (W'_{quant})_j^T s_j$ एक स्केल किया गया बाहरी उत्पाद का प्रतिनिधित्व करता है। $s_j$ द्वारा स्केलिंग यहां एक अनूठा पहलू है, जो बताता है कि प्रत्येक चैनल के आंशिक उत्पाद का योगदान अंतिम आउटपुट में उस चैनल के लिए मूल एक्टिवेशन स्मूथिंग कारक द्वारा स्केल किया जाता है। इसकी व्याख्या आंशिक उत्पादों पर लागू एक प्रकार के चैनल-वार डीक्वांटाइजेशन या री-स्केलिंग के रूप में की जा सकती है, इससे पहले कि उनका योग किया जाए, जो कि मानक क्वांटाइज्ड मैट्रिक्स गुणन में स्केल को कैसे संभाला जाता है, इससे एक प्रस्थान है (जहां स्केल को अक्सर इनपुट या आउटपुट पर समान रूप से लागू किया जाता है, या क्वांटाइज्ड मानों में अवशोषित किया जाता है)। धारा 4.5, "डीक्वांटाइज्ड परिणाम पर रनटाइम स्केल को गुणा करना" में पत्र का विवरण, अंतिम स्केलिंग के लिए संचालन के एक थोड़े अलग क्रम का सुझाव देता है, लेकिन धारा 3.1 में समीकरण तंत्र का सबसे स्पष्ट गणितीय विवरण है।
3) योग क्यों: मैट्रिक्स गुणन मौलिक रूप से पहले मैट्रिक्स के कॉलम वैक्टर और दूसरे के पंक्ति वैक्टर के बाहरी उत्पादों का योग है। -
$Y$: अंतिम आउटपुट मैट्रिक्स।
1) गणितीय परिभाषा: $N \times M$ आयामों का परिणामी मैट्रिक्स।
2) भौतिक/तार्किक भूमिका: यह निम्न-बिट अनुमान है, जो रोटेशन, स्मूथिंग, क्वांटाइजेशन और संशोधित योग के बाद उत्पन्न होता है। यह न्यूरल नेटवर्क में बाद के संचालन के लिए तैयार, रैखिक परत से संसाधित सुविधाओं का प्रतिनिधित्व करता है।
चरण-दर-चरण प्रवाह
एकल अमूर्त डेटा बिंदु की कल्पना करें, जैसे $x_{token, feature\_in}$, एक टोकन के लिए एक विशिष्ट सुविधा का प्रतिनिधित्व करता है, और एक वजन $w_{feature\_out, feature\_in}$, जो एक इनपुट सुविधा को एक आउटपुट सुविधा से जोड़ता है। आइए रोटेटेड रनटाइम स्मूथ (RRS) तंत्र के माध्यम से उनकी यात्रा का पता लगाएं:
-
प्रारंभिक प्रवेश: हमारा अमूर्त डेटा बिंदु $x_{token, feature\_in}$ फ्लोटिंग-पॉइंट एक्टिवेशन मैट्रिक्स $X$ के हिस्से के रूप में सिस्टम में प्रवेश करता है। वजन $w_{feature\_out, feature\_in}$ फ्लोटिंग-पॉइंट वजन मैट्रिक्स $W$ का हिस्सा है।
-
एक्टिवेशन रोटेशन: संपूर्ण एक्टिवेशन मैट्रिक्स $X$ को एक "रोटेशन इंजन" में फीड किया जाता है जहां इसे रोटेशन मैट्रिक्स $R$ से गुणा किया जाता है। हमारा डेटा बिंदु $x_{token, feature\_in}$ अब रूपांतरित हो गया है। यह अब अलग नहीं है, बल्कि अपने चैनल में अन्य सुविधाओं में योगदान देता है और उनसे प्रभावित होता है, जो घुमाए गए एक्टिवेशन मैट्रिक्स $X_{rot}$ के भीतर एक नया मान, $x'_{token, feature\_k}$ बन जाता है। यह प्रक्रिया चरम मानों (आउटलायर्स) को फीचर स्पेस में समान रूप से वितरित करने का लक्ष्य रखती है।
-
वजन रोटेशन: एक साथ, वजन मैट्रिक्स $W$ एक "काउंटर-रोटेशन इंजन" से गुजरता है जहां इसे $R^{-1}$ (व्युत्क्रम रोटेशन मैट्रिक्स) से गुणा किया जाता है, जिससे $W_{rot}$ प्राप्त होता है। यह सुनिश्चित करता है कि इनपुट एक्टिवेशन को घुमाने के बाद भी मूल ऑपरेशन की समग्र गणितीय अखंडता बनी रहे।
-
रनटाइम स्केल खोज: घुमाए गए एक्टिवेशन मैट्रिक्स $X_{rot}$ के प्रत्येक कॉलम (एक फीचर चैनल का प्रतिनिधित्व) के लिए, एक "परिमाण स्कैनर" अधिकतम निरपेक्ष मान की पहचान करता है। $x'_{token, feature\_k}$ वाले कॉलम के लिए, एक विशिष्ट स्केल $s_{feature\_k}$ की गणना की जाती है। यह स्केल गतिशील है, जो वर्तमान इनपुट की विशेषताओं के अनुकूल है।
-
एक्टिवेशन स्मूथिंग: घुमाया गया एक्टिवेशन मैट्रिक्स $X_{rot}$ तब एक "स्मूथिंग चैंबर" में प्रवेश करता है। यहां, कॉलम में प्रत्येक मान को उसके संबंधित चैनल के स्केल $s_j$ से विभाजित किया जाता है। तो, हमारा $x'_{token, feature\_k}$ $x''_{token, feature\_k} = x'_{token, feature\_k} / s_{feature\_k}$ तक स्केल किया जाता है। यह ऑपरेशन प्रभावी रूप से प्रत्येक चैनल के भीतर मानों की सीमा को "संपीड़ित" करता है, आउटलायर्स को कम प्रभावी बनाता है और डेटा को कुशल निम्न-बिट क्वांटाइजेशन के लिए तैयार करता है।
-
एक्टिवेशन क्वांटाइजेशन: चिकना किए गए घुमाए गए एक्टिवेशन ($X_{rot}\text{diag}(s)^{-1}$) तब एक "क्वांटाइजेशन यूनिट" में फीड किए जाते हैं। यह यूनिट प्रत्येक फ्लोटिंग-पॉइंट मान, जिसमें हमारा $x''_{token, feature\_k}$ शामिल है, को निम्न-बिट पूर्णांक, $q_{X,token,feature\_k}$ में परिवर्तित करती है। यहीं से महत्वपूर्ण मेमोरी और कम्प्यूटेशनल बचत शुरू होती है।
-
वजन क्वांटाइजेशन: समानांतर में, घुमाया गया वजन मैट्रिक्स $W_{rot}$ भी अपनी स्वयं की "क्वांटाइजेशन यूनिट" से गुजरता है, जो अपने फ्लोटिंग-पॉइंट मानों (जैसे $w'_{feature\_out, feature\_in}$) को निम्न-बिट पूर्णांकों, $q_{W,feature\_out,feature\_in}$ में परिवर्तित करता है।
-
चैनल-वार आउटपुट असेंबली: अब, सिस्टम अंतिम आउटपुट को असेंबल करना शुरू करता है। प्रत्येक फीचर चैनल $j$ (1 से $K$ तक) के लिए:
- क्वांटाइज्ड एक्टिवेशन का $j$-वां कॉलम, $(X'_{quant})_j$, निकाला जाता है।
- क्वांटाइज्ड वजन की $j$-वीं पंक्ति (ट्रांसपोज़्ड), $(W'_{quant})_j^T$, निकाली जाती है।
- इन दो वैक्टरों को गुणा किया जाता है (एक बाहरी उत्पाद) एक आंशिक आउटपुट मैट्रिक्स बनाने के लिए। यह मैट्रिक्स अंतिम परिणाम में केवल $j$-वें चैनल के योगदान का प्रतिनिधित्व करता है।
- महत्वपूर्ण रूप से, इस आंशिक आउटपुट मैट्रिक्स को तब रनटाइम स्मूथिंग फैक्टर $s_j$ से स्केल किया जाता है जो पहले $j$-वें एक्टिवेशन चैनल के लिए गणना की गई थी। यह कदम उस परिमाण जानकारी को फिर से प्रस्तुत करता है जिसे एक्टिवेशन स्मूथिंग के दौरान हटा दिया गया था, लेकिन अब आंशिक उत्पाद पर लागू किया गया है।
-
अंतिम योग: ये सभी $K$ स्केल किए गए आंशिक आउटपुट मैट्रिक्स तब एक "योग यूनिट" में फीड किए जाते हैं, जो उन्हें तत्व-वार जोड़ता है। परिणाम अंतिम आउटपुट मैट्रिक्स $Y$ है, जहां प्रत्येक तत्व $y_{token, feature\_out}$ सभी स्केल किए गए चैनल योगदानों का योग है। यह फॉरवर्ड पास को पूरा करता है, मूल पूर्ण-सटीकता ऑपरेशन के निम्न-बिट, फिर भी सटीक, सन्निकटन प्रदान करता है।
अनुकूलन गतिकी
यह स्पष्ट करना महत्वपूर्ण है कि रोटेटेड रनटाइम स्मूथ (RRS) एक प्रशिक्षण-मुक्त विधि है। इसका मतलब है कि इसके "अनुकूलन गतिकी" पारंपरिक अर्थों में पुनरावृत्ति सीखने या ग्रेडिएंट-आधारित अपडेट के बारे में नहीं हैं। इसके बजाय, तंत्र को सीधे अपने संरचनात्मक घटकों के माध्यम से क्वांटाइजेशन सटीकता के लिए अनुकूलित करने के लिए डिज़ाइन किया गया है।
-
पुनरावृत्ति सीखने की अनुपस्थिति: ग्रेडिएंट डिसेंट के साथ बैकप्रॉपैगेशन पर निर्भर विधियों के विपरीत, RRS में तंत्र के संचालन के दौरान ऐसे सीखने के लूप शामिल नहीं होते हैं। रोटेशन मैट्रिक्स $R$ या तो एक निश्चित, पूर्व-निर्धारित मैट्रिक्स (जैसे हैडामार्ड मैट्रिक्स) है या ऑफ़लाइन कैलिब्रेशन प्रक्रिया से प्राप्त होता है (जैसा कि संबंधित कार्यों में है), लेकिन इसे अनुमान के दौरान अपडेट नहीं किया जाता है। स्मूथिंग स्केल $s_j$ प्रत्येक नए इनपुट के लिए ऑन-द-फ्लाई गणना की जाती है, जिससे वे अनुकूलनीय होते हैं लेकिन समय के साथ "सीखे" नहीं जाते हैं।
-
कोई हानि परिदृश्य ट्रैवर्सल नहीं: चूंकि कोई प्रशिक्षण नहीं है, इसलिए ग्रेडिएंट के साथ "हानि परिदृश्य" को नेविगेट करने की अवधारणा RRS तंत्र पर लागू नहीं होती है। "अनुकूलन" डिजाइन विकल्पों में अंतर्निहित है: क्वांटाइजेशन त्रुटि को कम करने और मॉडल प्रदर्शन को संरक्षित करने के लिए कैसे घुमाया जाए, कैसे चिकना किया जाए, और कैसे क्वांटाइज किया जाए। इन डिजाइन विकल्पों की प्रभावशीलता को परप्लेक्सिटी या सटीकता जैसे मेट्रिक्स द्वारा मूल्यांकन किया जाता है, जो प्रत्यक्ष ग्रेडिएंट-आधारित अनुकूलन के लक्ष्य होने के बजाय देखे गए परिणाम हैं।
-
नियतात्मक स्थिति अद्यतन: RRS तंत्र की स्थिति पुनरावृत्ति रूप से विकसित नहीं होती है। प्रत्येक इनपुट के लिए, प्रक्रिया परिवर्तनों का एक प्रत्यक्ष, नियतात्मक अनुक्रम है:
- एक्टिवेशन और वजन को एक निश्चित $R$ का उपयोग करके घुमाया जाता है।
- वर्तमान इनपुट के घुमाए गए एक्टिवेशन के आधार पर स्मूथिंग स्केल की गणना की जाती है।
- निश्चित बिट-चौड़ाई और राउंडिंग नियमों का उपयोग करके क्वांटाइजेशन लागू किया जाता है।
- अंतिम मैट्रिक्स गुणन (आंशिक उत्पादों के अजीब चैनल-वार स्केलिंग के साथ) की गणना की जाती है।
प्रत्येक चरण एक प्रत्यक्ष गणना है, न कि पिछले राज्यों या त्रुटियों के आधार पर एक अद्यतन।
-
डिजाइन-संचालित "अभिसरण": RRS का "अभिसरण" एक पुनरावृत्ति प्रक्रिया नहीं है, बल्कि इसके अंतर्निहित डिजाइन द्वारा प्राप्त एक स्थिति है। लक्ष्य एक्टिवेशन और वजन को इस तरह से बदलना है कि वे सटीक निम्न-बिट (INT4) क्वांटाइजेशन की अनुमति देने के लिए "चिकने" हों (अर्थात, आउटलायर्स को पर्याप्त रूप से कम किया गया हो)। पत्र प्रदर्शित करता है कि यह डिजाइन प्रभावी रूप से क्वांटाइजेशन त्रुटि को कम करता है, जिससे विभिन्न मॉडलों पर बेहतर परप्लेक्सिटी और सटीकता प्राप्त होती है। "अनुकूलन" इसलिए इन परिवर्तनों की चतुर इंजीनियरिंग में है ताकि उच्च-गुणवत्ता वाले निम्न-बिट अनुमान प्राप्त किए जा सकें, न कि पुनरावृत्ति सीखने की प्रक्रिया के बजाय। तंत्र की मजबूती और प्रदर्शन लाभ इस डिजाइन अनुकूलन का एक वसीयतनामा है, जिससे यह एक अत्यधिक कुशल और प्लग-एंड-प्ले समाधान बन जाता है। नगण्य ओवरहेड इसके व्यावहारिक उपयोगिता को और मजबूत करता है।
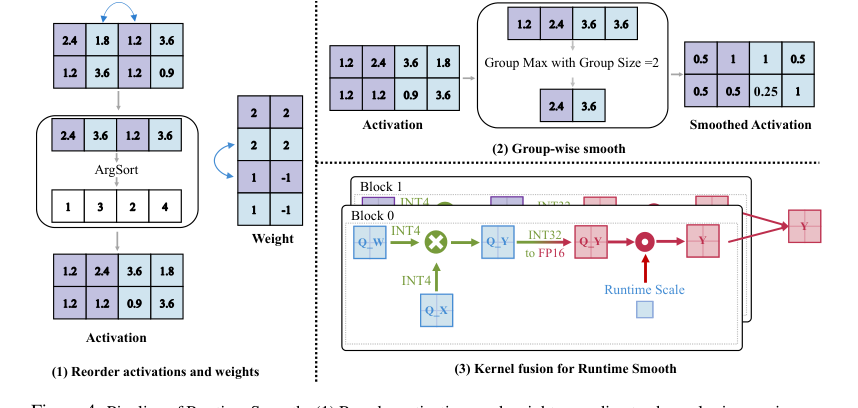 Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अपने गणितीय दावों को कठोरता से मान्य करने के लिए, लेखकों ने विभिन्न प्रकार के मुख्यधारा के बड़े भाषा मॉडल (LLMs) पर व्यापक प्रयोग किए। इनमें LLaMA परिवारों (LLaMA2-13B, LLaMA2-70B, LLaMA3-8B, LLaMA3-70B, LLaMA3.1-8B, LLaMA3.1-70B), Qwen परिवारों (Qwen1.5-7B, Qwen1.5-14B), मिस्ट्रल और मिक्सट्राल के विभिन्न मॉडल शामिल थे। मूल्यांकन INT4 क्वांटाइजेशन पर केंद्रित था, विशेष रूप से तीन योजनाओं का उपयोग करके: A4W4KV4, A4W4KV16, और A4W16KV16, जो क्रमशः 4-बिट एक्टिवेशन, 4-बिट वजन, और 4-बिट KV कैश क्वांटाइजेशन को दर्शाते हैं, जिसमें विभिन्न KV कैश बिट-चौड़ाई होती है।
एक्टिवेशन क्वांटाइजेशन के लिए, प्रति-चैनल सममित योजना का उपयोग किया गया था जिसमें राउंड-टू-नियरेस्ट (RTN) रणनीति थी। KV कैश क्वांटाइजेशन ने 128 के ग्रुपसाइज के साथ एक सब-चैनल सममित योजना का उपयोग किया, जिसमें RTN भी था। वजन क्वांटाइजेशन ने मुख्य रूप से GPTQ (फ्रंटार एट अल., 2022) के साथ एक प्रति-चैनल सममित योजना का उपयोग किया, सिवाय बेसलाइन 'RTN' विधि के। GPTQ के लिए कैलिब्रेशन सेट में 2048 की अनुक्रम लंबाई के साथ WikiText-2 के 128 नमूने शामिल थे।
उनके मुख्य तंत्र की प्रभावशीलता के निश्चित प्रमाण कई प्रयोगात्मक आर्किटेक्चर के माध्यम से एकत्र किए गए थे:
1. WikiText-2 पर परप्लेक्सिटी: यह मानक बेंचमार्क मापता है कि एक भाषा मॉडल पाठ के नमूने की कितनी अच्छी भविष्यवाणी करता है, कम परप्लेक्सिटी बेहतर प्रदर्शन का संकेत देती है।
2. जीरो-शॉट कॉमन सेंस QA बेंचमार्क: क्वांटाइजेशन के बाद मॉडल की तर्क क्षमताओं का मूल्यांकन करने के लिए ARC-e, ARC-c, BoolQ, और OBQA जैसे कार्यों पर प्रदर्शन का मूल्यांकन किया गया था।
3. एब्लेशन अध्ययन:
* एक प्रारंभिक एब्लेशन (चित्र 3) ने सीधे रनटाइम स्मूथ की तुलना स्मूथक्वांट और एक "ओरिजिन A4W4" बेसलाइन से की, जिससे रनटाइम स्मूथिंग की आवश्यकता और वजन में आउटलायर्स को माइग्रेट करने की कमियां प्रदर्शित हुईं।
* रनटाइम स्मूथिंग के ग्रुप साइज पर एक एब्लेशन (तालिका 4) ने सटीकता पर इस हाइपरपैरामीटर के प्रभाव की खोज की।
4. दक्षता मूल्यांकन: RTX 4070 Ti GPU पर NVBench का उपयोग करके, लेखकों ने प्रति-चैनल A4W4 और सब-चैनल A4W4 बेसलाइन (चित्र 6) की तुलना में उनके फ्यूज्ड GEMM कर्नेल के ओवरहेड को मापा, जिससे उनके दृष्टिकोण की व्यावहारिक व्यवहार्यता साबित हुई।
5. सांख्यिकीय आउटलायर विश्लेषण: चित्र 9 ने विभिन्न LLM घटकों (QKV_प्रोजेक्टर, आउटपुट_प्रोजेक्टर, अप_प्रोज या गेट_प्रोज, डाउन_प्रोजेक्टर) के लिए विभिन्न मॉडलों के लिए विभिन्न विधियों की तुलना में आउटलायर हटाने का एक विस्तृत सांख्यिकीय ब्रेकडाउन प्रदान किया, जो नेत्रहीन रूप से प्रदर्शित करता है कि RRS कैसे एक्टिवेशन को अन्य विधियों की तुलना में एक चिकनी सीमा में स्थानांतरित करता है।
साक्ष्य क्या साबित करते हैं
पत्र में प्रस्तुत साक्ष्य LLMs के लिए सटीक INT4 अनुमान को सक्षम करने में रोटेटेड रनटाइम स्मूथ (RRS) और इसके घटक रनटाइम स्मूथ (RS) की प्रभावशीलता का सम्मोहक प्रमाण प्रदान करते हैं।
सबसे पहले, रनटाइम स्मूथ (RS) घटक, जिसे चैनल-वार आउटलायर्स को समाप्त करने के लिए डिज़ाइन किया गया है, ने महत्वपूर्ण सुधार दिखाए। प्रारंभिक एब्लेशन अध्ययन (चित्र 3) ने स्पष्ट रूप से प्रदर्शित किया कि A4W4 क्वांटाइजेशन के लिए केवल रनटाइम स्मूथिंग स्केल लागू करना अपर्याप्त था। हालांकि, जब RS को पूरी तरह से लागू किया गया, तो इसने A4W4 को संभव बनाया, जिससे A4W16 सेटिंग के तहत LLaMA3-8B के लिए 4e2 से 10.9 तक परप्लेक्सिटी में भारी सुधार हुआ। यह वजन में आउटलायर्स को माइग्रेट किए बिना रनटाइम स्केल अपनाने के मूल विचार को मान्य करने के लिए महत्वपूर्ण था, जो स्मूथक्वांट जैसी पिछली विधियों की एक प्रमुख सीमा थी। तालिका 1 में, RS ने विभिन्न मॉडलों और क्वांटाइजेशन योजनाओं में लगातार स्मूथक्वांट और RTN से बेहतर प्रदर्शन किया, उदाहरण के लिए, 16-4-16 योजना के तहत LLaMA2-70B परप्लेक्सिटी को 1e2 (स्मूथक्वांट) से 6.95 (RS) तक कम किया। इसके अलावा, एक्टिवेशन-केवल क्वांटाइजेशन (A4W16KV16) के तहत, RS ने LLaMA3-8B पर 40x सुधार प्राप्त किया, जो इसकी प्रभावशीलता को रेखांकित करता है।
दूसरे, पूर्ण रोटेटेड रनटाइम स्मूथ (RRS) विधि, जो चैनल-वार और स्पाइक दोनों आउटलायर्स को संबोधित करने के लिए रोटेशन को रनटाइम स्मूथिंग के साथ जोड़ती है, ने बेहतर प्रदर्शन दिया। तालिका 1, WikiText-2 परप्लेक्सिटी के लिए मुख्य परिणाम तालिका, दिखाती है कि RRS ने लगभग सभी मूल्यांकित LLaMA, Qwen, और मिस्ट्रल मॉडल में बेसलाइन, जिसमें RS, क्वारोट, स्मूथक्वांट और RTN शामिल हैं, से लगातार बेहतर प्रदर्शन किया। LLaMA3-70B का एक विशेष रूप से आश्चर्यजनक उदाहरण है, जहां RRS ने A4W4KV16 के तहत परप्लेक्सिटी को 57.33 से 6.66 तक, और A4W4KV4 के तहत 49.76 से 6.87 तक कम कर दिया। ये अत्याधुनिक क्वारोट की तुलना में काफी सुधार हैं, जिसने समान मॉडल और सेटिंग्स के लिए क्रमशः 57.33 और 49.73 का परिणाम दिया। यह निश्चित प्रमाण साबित करता है कि RRS का संयुक्त तंत्र दोनों प्रकार के आउटलायर्स के प्रभाव को प्रभावी ढंग से कम करता है।
परप्लेक्सिटी से परे, RRS ने जीरो-शॉट कॉमन सेंस QA कार्यों (तालिका 2) पर भी अपनी ताकत का प्रदर्शन किया। विभिन्न LLMs और क्वांटाइजेशन योजनाओं में, RRS ने लगातार बेसलाइन (GPTQ, स्मूथक्वांट, RS, क्वारोट) को औसतन लगभग 3% सटीकता सुधार से बेहतर प्रदर्शन किया। उदाहरण के लिए, 4-4-16 क्वांटाइजेशन के साथ LLaMA-3-8B पर, RRS ने 58.0% की औसत सटीकता प्राप्त की, जबकि क्वारोट का 55.0% था। यह इंगित करता है कि बेहतर एक्टिवेशन स्मूथिंग जटिल तर्क कार्यों में बेहतर प्रदर्शन में तब्दील होती है।
आउटलायर हटाने का सांख्यिकीय विश्लेषण (चित्र 9) RRS के तंत्र के काम करने का प्रत्यक्ष दृश्य प्रमाण प्रदान करता है। यह दिखाता है कि RRS सभी LLM घटकों (QKV_प्रोजेक्टर, आउटपुट_प्रोजेक्टर, अप_प्रोज या गेट_प्रोज, डाउन_प्रोजेक्टर) और मॉडलों में मूल एक्टिवेशन (X), घुमाए गए एक्टिवेशन (R), या अकेले रनटाइम स्मूथ (RS) की तुलना में 'u < 4' (चिकना) श्रेणी में आने वाले एक्टिवेशन का काफी अधिक अनुपात होता है। यह सीधे RRS की चैनल-वार और स्पाइक दोनों आउटलायर्स को व्यापक रूप से समाप्त करने की क्षमता को मान्य करता है।
अंत में, दक्षता मूल्यांकन (चित्र 6 और धारा 4.5) पुष्टि करता है कि RRS फ्यूज्ड कर्नेल A4W4 प्रति-चैनल क्वांटाइजेशन बेसलाइन की तुलना में केवल नगण्य ओवरहेड पेश करता है। यह एक महत्वपूर्ण व्यावहारिक लाभ है, क्योंकि इसका मतलब है कि सटीकता लाभ महत्वपूर्ण मंदी की कीमत पर नहीं आते हैं, जिससे RRS INT4 अनुमान के लिए एक सच्चा प्लग-एंड-प्ले समाधान बन जाता है। प्रशिक्षण-आधारित विधियों (तालिका 3) के साथ तुलना आगे RRS की ताकत को उजागर करती है, क्योंकि यह WikiText-2 परप्लेक्सिटी में स्पिनक्वांट (एक प्रशिक्षण-आधारित विधि) से बेहतर प्रदर्शन करता है, बिना पर्याप्त प्रशिक्षण समय लागत के।
सीमाएँ और भविष्य की दिशाएँ
जबकि रोटेटेड रनटाइम स्मूथ (RRS) LLMs के लिए प्रशिक्षण-मुक्त INT4 अनुमान के लिए एक महत्वपूर्ण प्रगति प्रस्तुत करता है, पत्र में निहित और स्पष्ट रूप से कई सीमाओं को भी इंगित किया गया है और भविष्य के शोध के लिए दरवाजे खोले गए हैं।
वर्तमान सीमाएँ:
1. रोटेशन से अपूर्ण स्मूथिंग गारंटी: पत्र नोट करता है कि "रोटेशन एक चिकनी मैट्रिक्स की गारंटी नहीं दे सकता है, और एक घुमाया गया मैट्रिक्स अभी भी चैनल-वार आउटलायर्स के आकार को प्रदर्शित कर सकता है" (धारा 1, चित्र 2)। यह बताता है कि जबकि रोटेशन मदद करता है, यह अपने आप में एक पूर्ण समाधान नहीं है, जिससे रनटाइम स्मूथ घटक की आवश्यकता होती है।
2. स्पाइक आउटलायर्स से "पीड़ित" प्रभाव: स्पाइक आउटलायर्स की उपस्थिति अभी भी चैनल-वार स्मूथिंग के बाद सामान्य मानों को "पीड़ितों" के रूप में छांटने का कारण बन सकती है (धारा 1, चित्र 1)। हालांकि RRS इसे कम करने का लक्ष्य रखता है, अंतर्निहित चुनौती बनी हुई है।
3. ग्रुप साइज संवेदनशीलता: एब्लेशन अध्ययन (धारा 4.4, तालिका 4) इंगित करता है कि जबकि रनटाइम स्मूथ प्रभावी रूप से A4W4 और पूर्ण सटीकता के बीच के अंतर को कम करता है, "समूह आकार बढ़ने पर सटीकता खराब हो जाती है।" यह एक ट्रेड-ऑफ का अर्थ है और एक संभावित संवेदनशीलता है जो सार्वभौमिक रूप से इष्टतम नहीं हो सकती है।
4. विशिष्ट आउटलायर परिदृश्य: पत्र उल्लेख करता है कि "केवल दो आउटलायर टोकन वाला मामला दुर्लभ है लेकिन संभावित रूप से रोटेटेड रनटाइम स्मूथ को परेशान कर सकता है" (धारा C.1)। यह एक विशिष्ट, हालांकि असामान्य, आउटलायर पैटर्न को उजागर करता है जिसे RRS के साथ संघर्ष करना पड़ सकता है, यह सुझाव देता है कि इसकी मजबूती पूर्ण नहीं हो सकती है।
5. मॉडल-विशिष्ट आउटलायर संवेदनशीलता: लेखक अवलोकन करते हैं कि "मॉडल आउटलायर्स के प्रति अलग-अलग संवेदनशीलता रखते हैं। आउटलायर्स को और दबाने से मजबूती बढ़ सकती है" (धारा 4.2)। इसका तात्पर्य है कि जबकि RRS सामान्यीकृत है, मॉडल-विशिष्ट आउटलायर विशेषताएं हो सकती हैं जिन्हें आगे अनुकूलित किया जा सकता है।
6. ग्रुप साइज पर हार्डवेयर बाधाएँ: Qwen1.5-7B जैसे कुछ मॉडलों के लिए, डाउन_प्रोजेक्टर (11008) के लिए इनपुट एक्टिवेशन आकार "512 के ग्रुप साइज का समर्थन नहीं करता है" (धारा 4.4)। यह सबसे बड़े ग्रुप साइज को लागू करने में व्यावहारिक सीमाओं को इंगित करता है, जो अन्यथा कुछ लाभ प्रदान कर सकते हैं।
भविष्य की दिशाएँ और चर्चा विषय:
- अनुकूली और गतिशील स्मूथिंग रणनीतियाँ: ग्रुप साइज और विभिन्न आउटलायर पैटर्न के प्रति संवेदनशीलता को देखते हुए, भविष्य के काम में अनुकूली स्मूथिंग रणनीतियों का पता लगाया जा सकता है। एक निश्चित ग्रुप साइज या सार्वभौमिक रोटेशन के बजाय, क्या हम वास्तविक समय एक्टिवेशन आँकड़ों या मॉडल परत विशेषताओं के आधार पर इन मापदंडों को गतिशील रूप से समायोजित कर सकते हैं? इसमें प्रत्येक विशिष्ट इनपुट और परत के लिए स्मूथिंग को अनुकूलित करने के लिए हल्के, ऑन-द-फ्लाई विश्लेषण शामिल हो सकते हैं, जिससे और भी अधिक सटीकता और मजबूती प्राप्त हो सकती है।
- आउटलायर दमन के लिए सैद्धांतिक सीमाएँ और गारंटी: पत्र RRS की प्रभावशीलता को अनुभवजन्य रूप से प्रदर्शित करता है। रोटेशन और रनटाइम स्मूथिंग के गणितीय गुणों में एक गहरी सैद्धांतिक जांच आउटलायर दमन और क्वांटाइजेशन त्रुटि पर इसके प्रभाव की औपचारिक सीमाएँ स्थापित कर सकती है। इससे सिद्ध गारंटी के साथ भविष्य के क्वांटाइजेशन विधियों के अधिक सैद्धांतिक डिजाइन हो सकते हैं।
- हाइब्रिड प्रशिक्षण-मुक्त और प्रशिक्षण-आधारित दृष्टिकोण: जबकि RRS प्रशिक्षण-मुक्त है और कुछ प्रशिक्षण-आधारित विधियों से बेहतर प्रदर्शन करता है, सीखे गए रोटेशन की अवधारणा (जैसे स्पिनक्वांट में) अभी भी आशाजनक है। भविष्य के शोध में RRS जैसी प्रशिक्षण-मुक्त विधियों की दक्षता को और परिष्कृत रोटेशन या स्मूथिंग स्केल के साथ संयोजित करने वाले हाइब्रिड दृष्टिकोणों की जांच की जा सकती है, जिससे वर्तमान प्रशिक्षण-आधारित विधियों के व्यापक प्रशिक्षण ओवरहेड के बिना और भी उच्च सटीकता प्राप्त हो सकती है।
- उन्नत क्वांटाइजेशन के लिए हार्डवेयर-सॉफ्टवेयर सह-डिजाइन: RRS का नगण्य ओवरहेड एक महत्वपूर्ण लाभ है। इसे और आगे बढ़ाने के लिए, समर्पित हार्डवेयर त्वरक या विशेष निर्देश सेट को RRS के केंद्रीय पुनर्व्यवस्था, समूह-वार अधिकतम गणना और रोटेशन संचालन का मूल रूप से समर्थन करने के लिए डिज़ाइन किया जा सकता है। यह सह-डिजाइन दृष्टिकोण INT4 अनुमान के लिए अभूतपूर्व गति और ऊर्जा दक्षता को अनलॉक कर सकता है।
- अन्य डेटा प्रकारों और मॉडल आर्किटेक्चर में सामान्यीकरण: RRS को LLMs में INT4 अनुमान के लिए मान्य किया गया है। ये सिद्धांत अन्य निम्न-बिट क्वांटाइजेशन योजनाओं (जैसे, INT2, बाइनरी) या ट्रांसफार्मर से परे विभिन्न मॉडल आर्किटेक्चर, जैसे विजन मॉडल या मल्टी-मॉडल आर्किटेक्चर तक कितनी अच्छी तरह विस्तारित होंगे? इन व्यापक अनुप्रयोगों की जांच RRS को अनुकूलित करने के लिए नई चुनौतियों और अवसरों को प्रकट कर सकती है।
- एडवर्सेरियल हमलों और वितरण शिफ्ट के प्रति मजबूती: क्वांटाइज्ड मॉडल एडवर्सेरियल हमलों या आउट-ऑफ-डिस्ट्रीब्यूशन डेटा के तहत प्रदर्शन में गिरावट के प्रति अधिक संवेदनशील हो सकते हैं। भविष्य के काम की जांच की जा सकती है कि RRS, एक्टिवेशन को चिकना और अधिक सुसंगत बनाकर, स्वाभाविक रूप से ऐसे चुनौतियों के खिलाफ क्वांटाइज्ड LLMs की मजबूती में सुधार कैसे कर सकता है, या क्या इस पहलू को बढ़ाने के लिए विशिष्ट संशोधनों की आवश्यकता है।
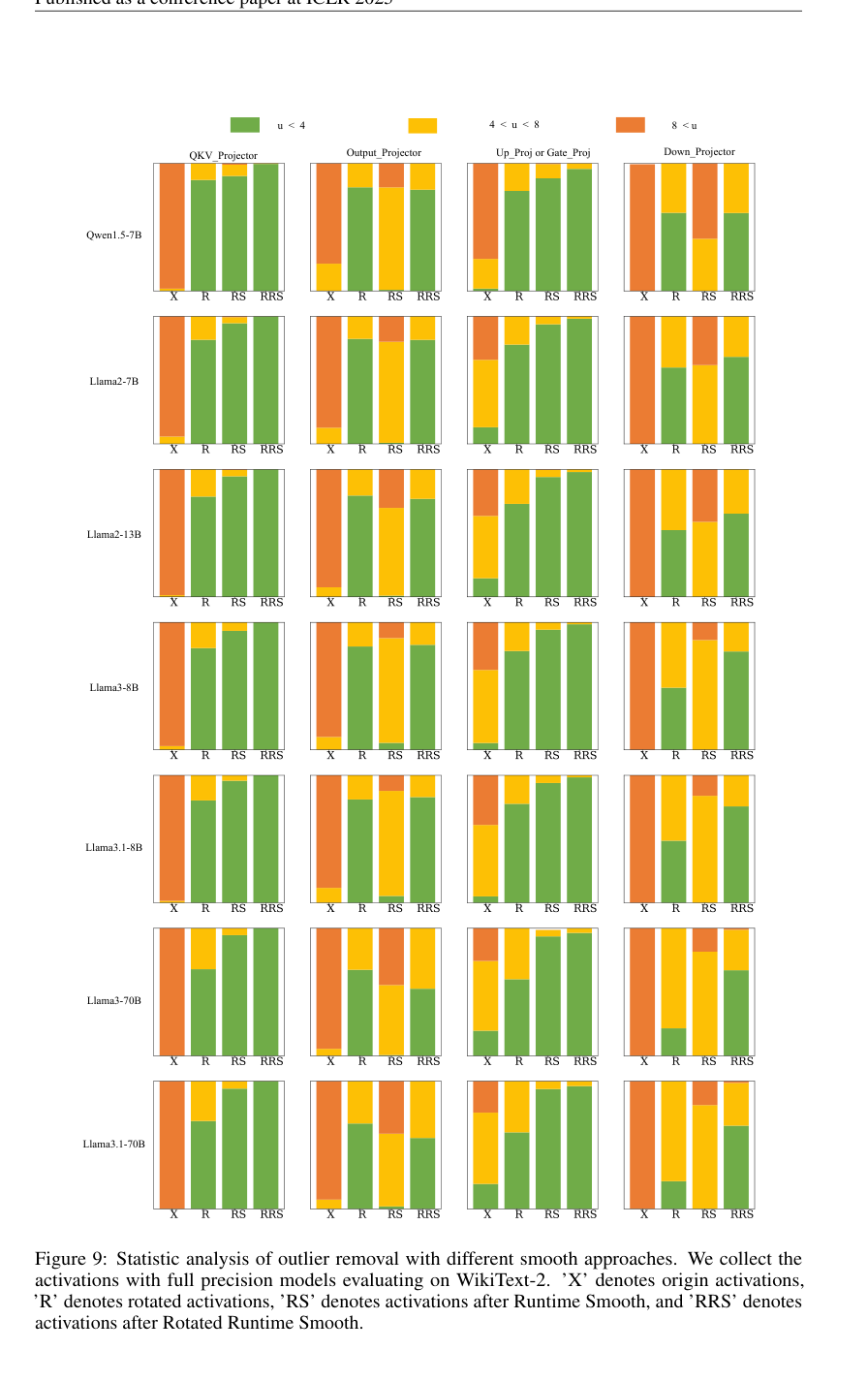 Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
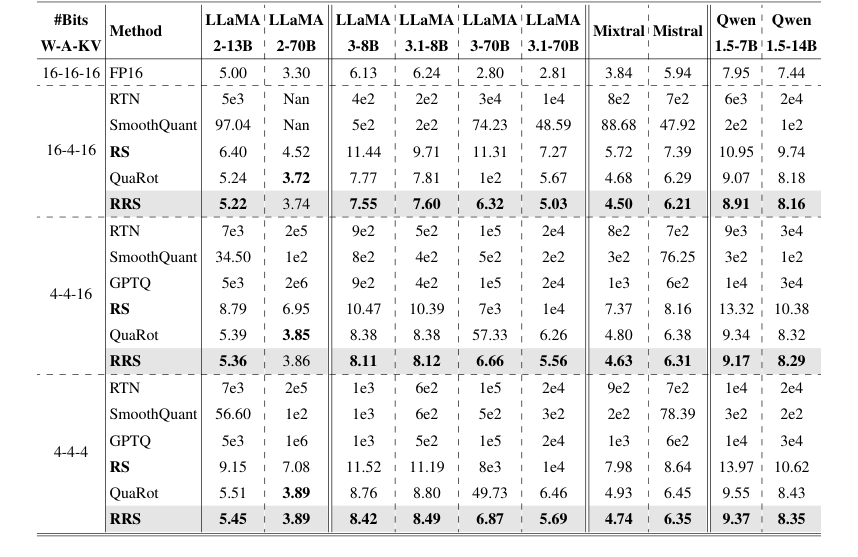 Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
 Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
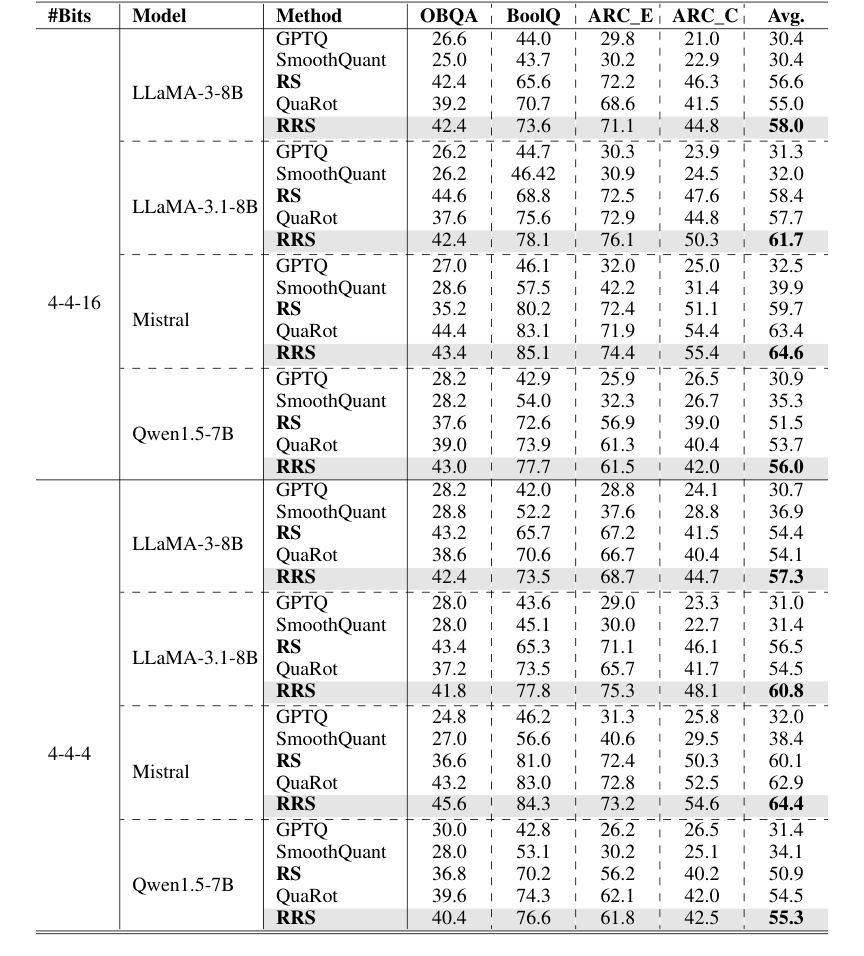 Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes