Rotated Runtime Smooth: 정확한 INT4 추론을 위한 훈련 없는 활성화 스무더
Large language models have demonstrated promising capabilities upon scaling up parameters.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 문제는 대규모 언어 모델(LLM)의 규모와 복잡성이 증가함에 따라 발생합니다. 이러한 모델이 커짐에 따라 추론을 위한 서비스는 계산 자원 및 메모리 사용량 측면에서 엄청나게 비싸집니다. 이러한 비용을 완화하고 지연 시간을 개선하기 위해 양자화 방법이 널리 채택되었습니다. 양자화는 본질적으로 모델에서 사용되는 숫자(가중치 및 활성화)의 정밀도를 낮추는 것으로, 예를 들어 고정밀 부동소수점 숫자에서 INT4(4비트 정수)와 같은 저비트 정수로 줄입니다.
그러나 저비트 양자화, 특히 INT4 가중치-활성화 양자화에서 심각한 "문제점"이 나타났는데, 이는 활성화의 이상치(outliers) 존재입니다. 이러한 이상치는 활성화 텐서 내의 극단적인 값으로, 전체 값 범위를 불균형적으로 확장합니다. 전체 범위가 매우 제한된 비트 수(예: 4비트)로 압축될 때, 이러한 이상치는 사용 가능한 "정밀도 슬롯"의 대부분을 차지하여 더 일반적인 "정상" 값에는 효과적인 비트가 거의 남지 않습니다. 이는 추론 중 모델의 정확도를 심각하게 저하시킵니다.
이전 접근 방식들은 이러한 이상치를 해결하려고 시도했지만 근본적인 한계에 직면했습니다.
* 이상치 분리: 초기 방법(예: Kim et al., 2023; Dettmers et al., 2022)은 이상치를 정상 값과 분리하여 다른 행렬로 만들려고 했습니다. 여기서 주요 단점은 이러한 구현이 종종 하드웨어와 호환되지 않아 높은 지연 시간을 유발하고 추론 속도를 높이지 못한다는 것이었습니다.
* 오프라인 스무딩 및 마이그레이션 (SmoothQuant): SmoothQuant(Xiao et al., 2023)는 채널별 스무딩 스케일을 사용하여 활성화에서 가중치로 이상치를 전송하는 것을 목표로 했습니다. A8W8과 같은 더 높은 비트 양자화에는 효과적이었지만, 여러 가지 이유로 INT4 추론에는 실패했습니다.
* 스무딩 스케일은 보정 세트를 사용하여 오프라인으로 미리 계산되었기 때문에 새로운, "일치하지 않는" 온라인 활성화에 직면했을 때 비효과적이었습니다.
* 이상치는 실제로 제거되지 않고 부분적으로만 마이그레이션되어 저비트 양자화를 여전히 방해했습니다.
* SmoothQuant는 주로 "채널별" 이상치를 다루었지만 채널에 걸쳐 일관되지 않은 "스파이크" 이상치에는 어려움을 겪었으며, 이로 인해 정상 값이 "희생자"로 잘못 가지치기되었습니다.
* 회전 기반 방법 (QuaRot): QuaRot(Ashkboos et al., 2024)과 같은 최근 연구는 회전 행렬을 도입하여 이상치를 내부적으로 분산시켜 억제했습니다. A4W4 양자화에 유망했지만, 회전만으로는 완벽하게 부드러운 행렬을 보장할 수 없었고 여전히 채널별 이상치를 나타낼 수 있어 추가 개선의 여지가 있었습니다. 과제는 모든 유형의 이상치를 효과적으로 처리할 수 있는 강력하고 정확하며 훈련 없는 INT4 추론 스킴을 찾는 것이었습니다.
직관적인 도메인 용어
- 양자화 (Quantization): 수백만 가지 색조(부동소수점 숫자와 같음)를 가진 매우 상세한 색상 팔레트가 있다고 상상해 보세요. 양자화는 모든 이미지를 표현하기 위해 훨씬 더 작은 색상 세트, 예를 들어 16가지 특정 색조(4비트 정수와 같음)만 선택하는 것과 같습니다. 목표는 이미지를 훨씬 작고 빠르게 처리할 수 있도록 하면서도 가능한 한 보기 좋게 만드는 것입니다.
- 활성화의 이상치 (Outliers in Activations): 대부분의 키가 5피트에서 6피트 사이인 사람들 그룹을 생각해 보세요. 하지만 키가 20피트인 거인 몇 명과 키가 1피트인 아주 작은 사람 몇 명이 있습니다. 10개의 표시만 사용하여 모든 사람의 키 스케일을 만들려고 하면, 이러한 극단적인 거인과 작은 사람들은 스케일을 1피트에서 20피트까지 매우 넓은 범위로 확장하도록 강제합니다. 이는 일반적인 5-6피트 범위에 표시가 거의 남지 않아 5'2"인 사람과 5'4"인 사람을 구별하기 어렵게 만듭니다. "거인"과 "작은 사람"이 이상치이며, "정상" 키를 정확하게 표현하기 어렵게 만듭니다.
- INT4 추론 (INT4 Inference): 이는 매우 정확한 소수점 숫자(예: $5.123 \times 3.456$) 대신 매우 간단하고 반올림된 숫자(예: 4비트 정수가 나타낼 수 있는 -8에서 7까지의 숫자만)로 계산하는 것과 같습니다. $5 \times 3$을 계산하는 것이 $5.123 \times 3.456$을 계산하는 것보다 훨씬 빠르고 정신적 노력(또는 컴퓨터 메모리/전력)이 적게 듭니다. "INT4" 부분은 4비트 정수를 사용하는 것을 의미하며, 이는 LLM에 대한 최대 속도 및 메모리 절약을 얻기 위한 매우 공격적인 형태의 반올림입니다.
- Perplexity: 언어 모델의 맥락에서 perplexity는 모델이 시퀀스의 다음 단어에 얼마나 "놀라는지"를 측정하는 척도입니다. 문장의 다음 단어를 추측하고 있다고 상상해 보세요. 매우 확신하고 올바르게 추측하면 "놀람"이 낮습니다. 자주 틀리거나 확신이 없으면 "놀람"이 높습니다. 낮은 perplexity 점수는 언어 모델이 덜 놀란다는 것을 의미하며, 이는 텍스트를 더 잘 예측하고 언어를 더 정확하게 이해한다는 것을 나타냅니다.
표기법 테이블
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 근본적인 문제는 극도로 낮은 비트의 가중치-활성화 양자화, 특히 INT4를 사용하여 추론을 수행하려고 할 때 대규모 언어 모델(LLM)에서 발생하는 상당한 정확도 저하입니다.
입력/현재 상태는 LLM이 인상적인 기능을 가지고 있음에도 불구하고 엄청난 규모로 인해 서비스하는 데 계산 및 메모리 집약적이라는 것입니다. 모델 매개변수 및 활성화의 정밀도를 줄이는 양자화(예: FP32에서 INT4로)는 이러한 비용을 완화하고 추론 지연 시간을 개선하는 유망한 기술입니다. 그러나 INT4 가중치-활성화 양자화의 광범위한 채택에 대한 중요한 장애물은 활성화 텐서에 "이상치"가 존재한다는 것입니다. 이러한 이상치는 양자화 범위를 불균형적으로 확장하여 정상 값에 사용할 수 있는 동적 범위를 효과적으로 압축하고 상당한 정보 손실과 정확도 하락을 초래하는 극단적인 값입니다.
원하는 최종 상태(출력/목표 상태)는 정확하고 효율적인 INT4 가중치-활성화 추론을 LLM에 대해 가능하게 하는 것입니다. 이는 상당한 정확도 저하를 초래하지 않고 INT4 양자화의 계산 및 메모리 이점을 달성하는 것을 의미합니다. 본 논문은 활성화 이상치를 강력하게 처리할 수 있는 "훈련 없는 활성화 스무더"를 개발하여 정상 값이 충분한 정밀도로 양자화될 수 있도록 함으로써 다양한 LLM 제품군에 걸쳐 INT4 추론에서 최첨단 성능을 달성하는 것을 목표로 합니다.
현재 상태와 원하는 최종 상태 사이의 정확한 누락된 연결 또는 수학적 격차는 전체 활성화 텐서를 최소한의 정보 손실로 INT4로 양자화할 수 있도록 활성화 이상치를 효과적으로 "스무딩" 또는 정규화하는 방법을 찾는 것입니다. 이 모든 것은 계산 비용이 저렴하고 훈련이 필요 없어야 합니다. 수학적으로, $X$가 활성화 텐서이고 $\alpha$가 양자화를 위한 스케일링 인수(예: N비트 양자화의 경우 $\alpha = \frac{\max(|X|)}{2^{N-1}-1}$)라면, 이상치는 $\max(|X|)$를 매우 크게 만들어 $\alpha$를 크게 만듭니다. 이는 정상 값이 매우 작은 정수 값 범위에 매핑되어 심각한 정밀도 손실을 초래합니다. 누락된 연결은 $\max(|f(X)|)$가 $\max(|X|)$보다 훨씬 작은 변환 $f(X)$이며, $f(X)$는 원래 정보를 정확하게 나타내어 더 작은 $\alpha'$를 허용하고 따라서 정상 값의 더 효과적인 양자화를 가능하게 합니다. 이 변환은 또한 가중치 행렬 $W$와 호환되어 출력 $XW$를 보존해야 합니다.
이전 연구자들이 갇혀 있던 고통스러운 절충 또는 딜레마는 주로 정확도 대 효율성 대 견고성 삼각형입니다.
1. 정확도 대 효율성 (저비트 양자화): 공격적인 저비트 양자화(INT4)는 상당한 속도 향상과 메모리 절약을 제공하지만 활성화 이상치에 매우 취약하여 심각한 정확도 저하를 초래합니다. 정확도를 유지하려면 종종 더 높은 비트 폭이나 복잡한 이상치 처리가 필요하며, 이는 효율성 이점을 무효화합니다.
2. 이상치 처리 대 하드웨어 호환성/지연 시간: 이상치를 다른 행렬로 분리하거나(예: Kim et al., 2023; Dettmers et al., 2022) 가중치로 마이그레이션하는(예: SmoothQuant) 기존 방법은 종종 하드웨어 비호환성, 상당한 지연 시간 오버헤드를 도입하거나 가중치 양자화를 어렵게 만듭니다. 이는 더 빠르고 효율적인 추론이라는 핵심 목표를 훼손합니다.
3. 정적 대 동적 스무딩: 미리 계산된 스무딩 스케일(예: SmoothQuant)은 효율적이지만 온라인 활성화와 "일치하지 않게" 되어 동적 입력에 대해 비효과적이 됩니다. 런타임 스무딩은 더 강력하지만 전통적으로 용납할 수 없는 계산 오버헤드를 발생시킵니다.
4. 채널별 대 스파이크 이상치: 이상치는 "채널별"(채널 전체에 걸쳐 일관됨) 및 "스파이크"(고립된 극단적인 값)의 다른 형태로 나타납니다. 한 유형에 효과적인 방법(예: 채널별 스무딩)은 다른 유형(예: 스파이크 이상치로 인해 정상 값이 가지치기됨)에 대해 "희생자" 효과를 악화시켜 양자화 오류를 초래할 수 있습니다. 새로운 부작용 없는 통합 솔루션은 찾기 어렵습니다.
제약 조건 및 실패 모드
LLM에 대한 정확한 INT4 추론 문제는 저자가 직면한 몇 가지 가혹하고 현실적인 벽 때문에 매우 어렵습니다.
- 활성화 이상치의 극심한 희소성/크기: 활성화 이상치는 정상 값보다 수천 배 더 클 수 있습니다(예: 페이지 14에서 언급된 대로 1000배 더 큼). 이 극심한 크기는 양자화 범위를 너무 심하게 확장하여 정상 값이 효과적인 비트 거의 전부를 잃게 하여 치명적인 정확도 손실을 초래합니다.
- INT4 정밀도 제한: INT4로 양자화한다는 것은 전체 활성화 범위를 표현하기 위해 16가지 가능한 값($2^4$)만 사용할 수 있다는 것을 의미합니다. 이 극도로 제한된 정밀도는 상당한 정보 손실 없이 이상치를 수용하거나 오류의 여지를 거의 남기지 않습니다.
- 실시간 지연 시간 요구 사항: LLM 추론, 특히 사전 채우기 단계는 엄격한 실시간 지연 시간을 요구합니다. 이상치 스무딩 또는 처리 메커니즘은 실용적이려면 "무시할 수 있는 오버헤드"(페이지 2, 페이지 9)를 도입해야 합니다. 상당한 계산 시간을 추가하는 복잡한 작업은 허용되지 않습니다.
- 하드웨어 메모리 제한: LLM은 거대하며 메모리 대역폭이 종종 병목 현상입니다. 양자화는 메모리 풋프린트와 이동을 줄이는 것을 목표로 합니다. 이상치를 위해 추가적인 고정밀 데이터 또는 복잡한 데이터 구조를 저장해야 하는 솔루션은 이러한 이점을 무효화할 수 있습니다.
- 훈련 없는 요구 사항: 솔루션은 "훈련 없는" 및 "플러그 앤 플레이"(초록, 페이지 2)여야 합니다. 이는 대규모 모델의 경우 시간이 많이 걸리고 리소스 집약적인 대규모 데이터 세트에 대한 광범위한 미세 조정 또는 보정이 필요하지 않음을 의미합니다.
- 동적 입력 분포: 활성화의 분포는 LLM의 다른 입력 및 다른 계층에 따라 크게 달라질 수 있습니다. 정적 보정 세트에서 파생된 스무딩 스케일은 온라인 활성화와 "일치하지 않게" 되어(페이지 3) 비효과적인 스무딩과 정확도 저하를 초래할 수 있습니다.
- "희생자" 효과: 스무딩 스케일이 극단적인 이상치에 의해 결정될 때, 훨씬 작은 정상 값은 효과적으로 "가지치기"되거나 "희생자"(페이지 2, 그림 1c, 페이지 3)가 될 수 있습니다. 정상 값의 정밀도 손실은 미묘한 정보를 표현하는 모델의 능력에 직접적인 영향을 미치기 때문에 중요한 실패 모드입니다.
- GEMM 커널과의 비호환성: 런타임 스무딩의 단순한 구현, 특히 일관되지 않은 스무딩 스케일의 경우 고도로 최적화된 일반 행렬 곱셈(GEMM) 커널(페이지 4)에 쉽게 통합될 수 없습니다. 이는 사용자 정의 커널 또는 복잡한 블록별 계산이 필요하기 때문에 하드웨어 가속을 달성하는 것을 어렵게 만듭니다.
- 회전 후 부분적 스무딩: 회전 기반 방법(예: QuaRot)은 이상치를 분산시키는 데 도움이 되지만 완벽하게 부드러운 행렬을 보장하지 못하며 여전히 "채널별 이상치" 또는 "부분적 스무딩"(페이지 2, 그림 2c, 페이지 4)을 나타낼 수 있습니다. 이는 회전만으로는 INT4 양자화에 대한 이상치 문제를 완전히 해결하기에 불충분함을 의미합니다.
- 이상치 마이그레이션 문제: 활성화에서 가중치로 이상치를 마이그레이션하는 이전 접근 방식(예: SmoothQuant)은 특히 A4W4(페이지 1)와 같은 매우 낮은 비트 스킴의 경우 가중치를 양자화하기 어렵게 만들 수 있습니다. 이는 활성화 도메인에서 문제를 해결하는 동안 가중치 도메인에서 새로운 문제를 만듭니다.
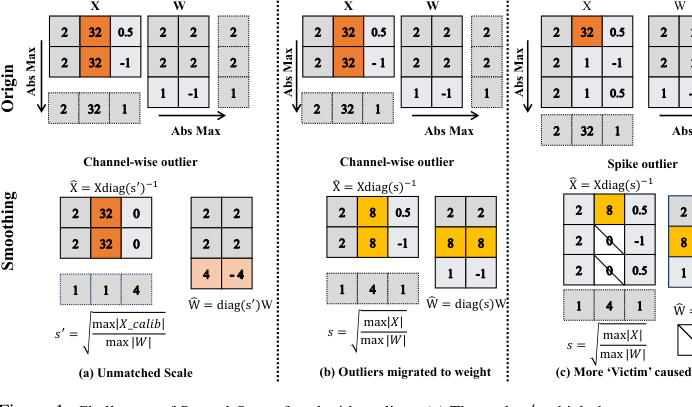 Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
Figure 1. Challenges of SmoothQuant faced with outliers. (a) The scale s′, which does not match the channel- wise maximums of activations, is ineffective for smoothing purposes. (b) The migration scheme makes it difficult to quantize the smoothed activation/weight down to 4 bits. (c) Normal values are pruned as victims after smoothing due to the spike outlier. Note that only calibration but no quantization is involved in the above process
왜 이 접근 방식인가
선택의 불가피성
저자들의 Rotated Runtime Smooth (RRS)로의 여정은 대규모 언어 모델(LLM)의 INT4 추론이라는 어려운 환경에 적용될 때 기존 최첨단(SOTA) 양자화 방법의 근본적인 한계에 의해 주도되었습니다. 기존 SOTA 방법이 불충분하다는 것을 깨달은 "정확한 순간"은 활성화 이상치의 지속적인 문제로 집약될 수 있습니다.
이상치와 정상 값을 두 개의 별도 행렬로 분리하는 것과 같은 전통적인 접근 방식(예: Kim et al., 2023; Dettmers et al., 2022)은 높은 지연 시간 또는 상당한 정확도 저하를 겪는 것으로 밝혀졌습니다. 결정적으로, 이러한 방법은 종종 하드웨어 가속과 호환되지 않아 의도한 대로 추론 속도를 높이지 못했습니다.
더 직접적인 전임자인 SmoothQuant(Xiao et al., 2023)는 채널별 스무딩 스케일을 사용하여 활성화에서 가중치로 이상치를 전송하여 이상치를 완화하려고 시도했습니다. 그러나 INT4 양자화의 경우 SmoothQuant는 세 가지 결정적인 실패에 직면했습니다.
1. 일치하지 않는 스케일: 보정 세트에서 파생된 오프라인 사전 계산 스무딩 스케일은 온라인 활성화와 자주 일치하지 않아 스무딩에 비효과적이었습니다.
2. 불완전한 이상치 제거: 이상치 채널은 완전히 제거되지 않고 부분적으로만 가중치로 마이그레이션되어 저비트 양자화(특히 INT4)를 어렵게 만들었습니다.
3. 스파이크 이상치 및 "희생자": SmoothQuant는 주로 채널별 이상치를 다루었지만 채널별로 일관되지 않은 "스파이크 이상치"를 설명하지 못했습니다. 이러한 스파이크 이상치가 존재할 때 정상 값이 스무딩 중에 의도치 않게 "희생자"로 가지치기되어 정확도 손실을 초래했습니다.
QuaRot(Ashkboos et al., 2024)과 같은 회전 기반 방법조차도 이상치를 분산시키는 데 유망했지만 이론적으로 균일하게 더 부드러운 행렬을 보장할 수는 없었습니다. 회전된 활성화, 특히 채널별 이상치가 있는 활성화는 여전히 "부분적 스무딩"(그림 2c에 설명된 대로)을 나타낼 수 있어 추가 개선의 여지가 남았습니다. 이러한 이전 방법들의 INT4 추론을 위한 훈련 없는 방식으로 채널별 및 스파이크 이상치를 모두 강력하고 정확하며 효율적으로 처리하는 데 실패한 집합은 RRS와 같은 새롭고 포괄적인 솔루션의 개발을 단순한 선택이 아닌 불가피성으로 만들었습니다.
비교 우위
Rotated Runtime Smooth (RRS)는 주로 포괄적이고 강력한 이상치 처리와 최소한의 계산 오버헤드를 통해 이전 방법에 비해 질적인 우수성을 보여줍니다.
RRS의 구조적 이점은 두 가지 접근 방식에 있습니다.
1. 런타임 스무딩 (RS): 이 구성 요소는 런타임에 동적으로 스무딩 스케일을 계산하여 채널별 이상치를 직접 처리합니다. 오프라인 보정에 의존하고 스케일을 가중치에 병합하는 SmoothQuant와 달리 RS는 일치하지 않는 스케일 문제와 마이그레이션된 이상치가 있는 가중치를 양자화하는 어려움을 피합니다. 런타임에 스무딩 스케일을 얻고 가중치에 병합하지 않음으로써 RS는 스무딩이 항상 현재 입력과 관련되도록 하여 더 적응적이고 정확하게 만듭니다.
2. 회전 연산: RRS가 스파이크 이상치를 처리하고 견고성을 향상시키는 부분입니다. 가중치와 활성화를 회전시킴으로써(QuaRot의 원칙에 따라) 스파이크 이상치는 효과적으로 토큰에 걸쳐 분산됩니다. 이 분산은 채널 간에 더 일관된 스무딩 스케일을 초래하며, 이는 채널별 스무딩 프로세스 중에 정상 값이 "희생자"가 되는 것을 방지합니다. 채널별 이상치가 있는 활성화의 경우 회전은 일관성을 유지하는 데 도움이 되며 동시에 이상치 수준을 줄일 기회를 제공합니다.
이러한 결합 전략은 이전 방법에는 없었던 구조적 이점을 제공합니다. 예를 들어 SmoothQuant는 스파이크 이상치를 효과적으로 처리할 수 없었고 보정 세트 불일치로 어려움을 겪었습니다. 순수 회전 방법은 유익했지만 자체적으로 충분한 스무딩을 보장하지 못했습니다. RRS는 둘의 최상의 측면을 통합하여 모든 유형의 이상치(채널별 및 스파이크)가 포괄적으로 처리되도록 합니다.
또한 RRS는 "플러그 앤 플레이" 구성 요소로 설계되어 INT4 행렬 곱셈에 대해 무시할 수 있는 오버헤드를 발생시킵니다. 본 논문은 융합된 GEMM 커널의 추가 런타임 스케일 곱셈이 A4W4 기준선에 비해 "무시할 수 있는 오버헤드"만 가져온다고 명시적으로 명시합니다. 이는 저비트 양자화에서 기대되는 중요한 지연 시간 이점을 희생하지 않고 우수한 정확도를 달성하므로 중요한 정성적 이점입니다. 이는 고차원 노이즈를 도입하는 것이 아니라 양자화 범위를 확장함으로써 노이즈 역할을 하는 이상치의 영향을 완화합니다.
제약 조건과의 일치
Rotated Runtime Smooth (RRS) 방법은 특히 INT4 양자화에 대해 효율적인 LLM 추론에 대한 엄격한 요구 사항과 완벽하게 일치합니다. 대규모 LLM 서비스 문제에 의해 암묵적으로 정의된 핵심 제약 조건은 다음과 같습니다.
1. INT4 추론: 주요 목표는 INT4 정밀도로 정확한 추론을 가능하게 하는 것이며, 이는 메모리 및 계산 비용을 줄이는 데 중요합니다. RRS는 "정확한 INT4 추론을 위한 훈련 없는 활성화 스무더"로 특별히 설계되었습니다. 채널별에서 스파이크 이상치까지 처리하는 모든 메커니즘은 상당한 정확도 손실 없이 LLM에 대해 INT4 양자화를 용이하게 하는 데 중점을 둡니다. LLaMA 및 Qwen 제품군에서 A4W4KV16 설정(예: LLaMA3-70B의 57.33에서 6.66으로)에서 perplexity 개선은 이 목표를 달성하는 데 효과적임을 직접적으로 검증합니다.
2. 훈련 없음: 실용적인 배포에 대한 중요한 요구 사항은 비용이 많이 드는 재훈련 또는 미세 조정을 피하는 것입니다. RRS는 명시적으로 "훈련 없음"이므로 모델 최적화에 추가 비용을 들이지 않고 사후 훈련에 적용할 수 있습니다. 이는 이미 상당한 LLM 훈련 부담에 추가되지 않는 즉시 배포 가능한 솔루션에 대한 필요성과 완벽하게 일치합니다.
3. 정확도 보존: 저비트 양자화는 종종 정확도 저하를 초래합니다. RRS의 포괄적인 이상치 완화 전략(채널별 이상치를 위한 런타임 스무딩과 스파이크 이상치를 위한 회전 결합)은 "이상치를 포괄적으로 제거"하고 "견고성을 향상"시켜 정확도를 보존하도록 설계되었습니다. 다양한 LLM 제품군에 걸쳐 perplexity 및 제로샷 QA 작업에서 SOTA 방법을 일관되게 능가하는 것은 이러한 일치를 보여줍니다.
4. 낮은 지연 시간/최소 오버헤드: 양자화는 서비스 비용과 지연 시간을 줄이는 것을 목표로 합니다. RRS는 "원래 A4W4 파이프라인에 비해 무시할 수 있는 오버헤드"를 발생시키는 런타임 스무딩 구성 요소로 효율성을 위해 설계되었습니다. 런타임 스무딩을 위한 커널 융합은 A4W4 채널별 양자화에 비해 "무시할 수 있는 오버헤드"만 추가하면서 프로세스가 GEMM 파이프라인에 효율적으로 통합되도록 합니다. 이는 높은 처리량과 낮은 지연 시간을 유지하는 제약 조건을 직접적으로 해결합니다.
5. 이상치에 대한 견고성: 문제 설명에서 이상치를 주요 장애물로 강조합니다. RRS의 채널별 및 스파이크 이상치를 모두 처리하고 일관된 스무딩 스케일을 보장하여 "희생자"를 방지하는 고유한 속성은 LLM 활성화에서 관찰되는 다양한 이상치 패턴에 본질적으로 강력합니다. 문제의 가혹한 이상치 도전과 솔루션의 고유한 이중 이상치 처리 간의 이러한 "결합"은 성공의 핵심입니다.
대안 거부
본 논문은 특히 LLM에 대한 INT4 추론의 맥락에서 단점을 강조하면서 여러 대안 접근 방식을 거부하는 명확한 이유를 제공합니다.
-
전통적인 이상치 분리 (예: LLM.int8(), Kim et al., 2023; Dettmers et al., 2022): 이상치를 고정밀 형식(혼합 INT8/FP16) 또는 별도 행렬로 분리하는 이러한 방법은 "높은 지연 시간 또는 정확도 저하"와 종종 "하드웨어와 호환되지 않아" "추론 속도를 높이지 못함"으로 인해 거부되었습니다. 특히 LLM.int8()은 "상당한 지연 시간 오버헤드를 발생시키며 FP16 추론보다 느릴 수도 있습니다."
-
SmoothQuant (Xiao et al., 2023): A8W8 양자화에 효과적이었지만, SmoothQuant는 오프라인 보정 세트에 의존하는 스무딩 스케일이 "온라인 활성화와 일치하지 않게 될 가능성이 높기" 때문에 INT4에는 불충분한 것으로 간주되었습니다. 또한 이상치를 가중치로 부분적으로만 마이그레이션하여 저비트 양자화를 어렵게 만들었고, 결정적으로 "스파이크 이상치"를 처리하지 못하여 "희생자" 가지치기를 초래했습니다.
-
순수 회전 기반 방법 (예: QuaRot, Ashkboos et al., 2024): 회전은 이상치를 분산시키는 데 도움이 되지만, 본 논문은 "단일 회전 행렬을 곱하는 것은 더 부드러운 가중치 또는 활성화를 이론적으로 보장할 수 없다"고 지적합니다. 회전 후에도 활성화는 채널별 이상치로 "부분적으로 부드러운" 상태를 유지할 수 있어(그림 2c), 회전만으로는 포괄적인 스무딩에 대한 완전한 해결책이 아님이 나타납니다. QuaRot은 또한 RRS가 단순화하려고 하는 "복잡한 온라인 하다마드 회전"을 필요로 합니다.
-
훈련 기반 양자화 (예: SpinQuant, Liu et al., 2024): 본 논문은 RRS를 SpinQuant와 명시적으로 비교하고 비용이 많이 드는 계산 비용으로 인해 훈련 기반 접근 방식을 거부합니다. SpinQuant의 훈련 프로세스는 "시간이 많이 걸리며, A100 GPU 1개에서 7B 모델에 1.5시간, 8개의 A100 GPU에서 70B 모델에 12시간이 소요됩니다." 또한 결과는 훈련 기반 방법이 "훈련 없는 방법과 비교하여 WikiText-2 perplexity를 저하시키고 여전히 개선의 여지가 있다"고 보여주어 효율성과 최종 정확도 측면에서 덜 바람직합니다.
이러한 대안을 거부하는 일관된 주제는 INT4 추론의 엄격한 요구 사항(높은 정확도, 낮은 지연 시간, 훈련 없는 강력한 솔루션 및 모든 유형의 활성화 이상치)을 동시에 충족하지 못한다는 것입니다.
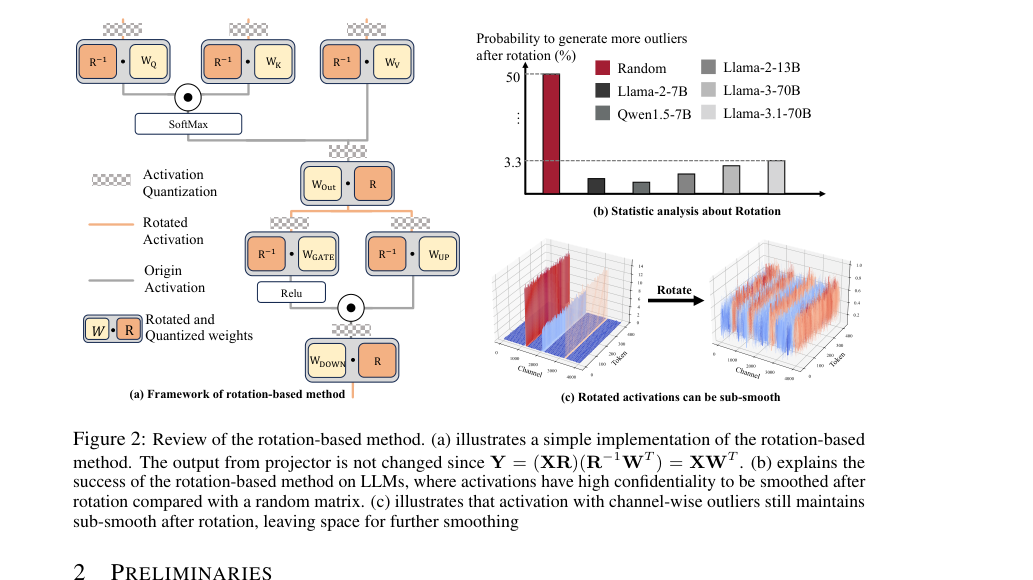 Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
Figure 2. Review of the rotation-based method. (a) illustrates a simple implementation of the rotation-based method. The output from projector is not changed since Y = (XR)(R−1WT ) = XWT . (b) explains the success of the rotation-based method on LLMs, where activations have high confidentiality to be smoothed after rotation compared with a random matrix. (c) illustrates that activation with channel-wise outliers still maintains sub-smooth after rotation, leaving space for further smoothing
수학적 및 논리적 메커니즘
마스터 방정식
Rotated Runtime Smooth (RRS) 방법의 핵심 수학적 엔진은 회전 연산과 런타임 스무딩 메커니즘을 결합합니다. 입력 활성화 행렬 $X$와 가중치 행렬 $W$가 주어졌을 때, RRS 프로세스는 다음과 같은 일련의 연산으로 요약될 수 있습니다.
$$ X_{rot} = XR \\ W_{rot} = R^{-1}W \\ s_j = \max(|(X_{rot})_j|), \quad j = 1, \dots, K \\ X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1}) \\ W'_{quant} = \text{Quantize}(W_{rot}) \\ Y = \sum_{j=1}^{K} (X'_{quant})_j (W'_{quant})_j^T s_j $$
이 방정식 세트는 활성화와 가중치가 먼저 회전되고, 활성화는 런타임에서 파생된 스케일을 사용하여 스무딩되고, 둘 다 양자화되고, 마지막으로 수정된 행렬 곱셈이 저비트 출력을 생성하는 방법을 설명합니다.
용어별 분석
마스터 방정식의 각 구성 요소를 분해하여 수학적 정의, 논리적 역할 및 설계 이유를 이해해 보겠습니다.
-
$X$: 선형 계층의 입력 활성화 텐서를 나타냅니다.
1) 수학적 정의: $N \times K$ 차원의 부동소수점 행렬로, 여기서 $N$은 일반적으로 배치 크기 곱하기 시퀀스 길이이고, $K$는 입력 채널 차원입니다.
2) 물리적/논리적 역할: 현재 선형 계층에서 처리해야 하는 이전 계층의 특징 정보를 전달합니다.
3) 이 형태인 이유: 배치 입력 특징의 표준 표현입니다. -
$W$: 선형 계층의 가중치 행렬입니다.
1) 수학적 정의: $M \times K$ 차원의 부동소수점 행렬로, 여기서 $M$은 출력 차원이고 $K$는 입력 채널 차원입니다.
2) 물리적/논리적 역할: 입력 활성화를 출력 특징으로 변환하는 학습 가능한 매개변수를 포함합니다.
3) 이 형태인 이유: 선형 계층 가중치의 표준 표현입니다. -
$R$: 회전 행렬입니다.
1) 수학적 정의: $K \times K$ 크기의 직교 행렬로, $RR^T = I$(여기서 $I$는 항등 행렬)이고 행렬식 $\det(R) = 1$입니다. 본 논문은 종종 하다마드 회전 행렬을 언급하며, 여기서 $R = \frac{1}{\sqrt{K}}[s_{i,j}]_{K \times K}$이고 요소 $s_{i,j} \in \{-1, +1\}$입니다.
2) 물리적/논리적 역할: 활성화와 가중치 모두의 벡터 공간에 선형 변환(회전)을 적용하는 주요 역할입니다. 이 회전은 양자화 범위에 대한 이상치의 영향을 덜 효과적으로 만들기 위해 활성화 내에 집중된 이상치를 "분산"시키는 데 중요합니다. $X$와 $W$를 적절하게 회전시킴으로써 원래 출력 $XW^T$는 $(XR)(R^{-1}W^T)$로 수학적으로 보존됩니다.
3) 곱셈인 이유: 행렬 곱셈은 벡터 공간에서 회전과 같은 선형 변환을 적용하는 기본 연산입니다. -
$R^{-1}$: 회전 행렬의 역행렬입니다.
1) 수학적 정의: $R$이 직교 행렬이므로 역행렬은 단순히 전치 행렬인 $R^T$입니다. 또한 $K \times K$ 행렬입니다.
2) 물리적/논리적 역할: 가중치 행렬 $W$를 $X_{rot}$과 결합될 때 전체 변환이 원래의 전체 정밀도 연산과 동일하게 유지되도록 보완적인 방식으로 회전시킵니다.
3) 곱셈인 이유: $R$과 마찬가지로 선형 변환입니다. -
$X_{rot} = XR$: 회전된 활성화 텐서입니다.
1) 수학적 정의: 입력 활성화 행렬 $X$에 회전 행렬 $R$을 곱한 결과입니다. $N \times K$ 모양을 유지합니다.
2) 물리적/논리적 역할: 특징이 회전에 의해 선형적으로 결합되고 채널에 걸쳐 재분배된 후의 활성화입니다. 이 단계는 이상치의 크기를 덜 극단적이거나 더 균일하게 분포되도록 하여 채널별 이상치를 완화하는 것을 목표로 합니다.
3) 곱셈인 이유: 회전 변환의 직접적인 적용입니다. -
$W_{rot} = R^{-1}W$: 회전된 가중치 행렬입니다.
1) 수학적 정의: 가중치 행렬 $W$에 역회전 행렬 $R^{-1}$을 곱한 결과입니다. $M \times K$ 모양을 유지합니다.
2) 물리적/논리적 역할: 회전된 후의 가중치입니다. 이 회전은 $X_{rot}$과 결합될 때 원래 행렬 곱셈의 수학적 동등성을 유지하기 위해 필요합니다.
3) 곱셈인 이유: 역회전의 직접적인 적용입니다. -
$s_j = \max(|(X_{rot})_j|)$: $j$-번째 채널의 런타임 스무딩 스케일입니다.
1) 수학적 정의: 회전된 활성화 행렬 $X_{rot}$의 각 열 $j$ (여기서 $(X_{rot})_j$는 $N \times 1$ 벡터임)에 대해, 이 연산은 해당 열의 모든 요소 중에서 최대 절대값을 계산합니다. 이는 스칼라 $s_j$를 생성합니다.
2) 물리적/논리적 역할: 이 스케일은 회전된 활성화의 각 채널에 존재하는 최대 크기를 동적으로 포착합니다. 이는 해당 채널 내의 값을 양자화에 더 적합한 범위로 가져오기 위한 정규화 계수 역할을 합니다. 최대 절대값을 사용함으로써 후속 나눗셈 중에 어떤 값도 잘리지 않도록 하여 정보를 보존합니다. 이는 "런타임 스무딩" 구성 요소의 핵심 부분으로, 채널별 이상치를 처리합니다.
3)max와 절대값인 이유:max는 필요한 스케일링 범위를 결정하는 극단적인 값을 식별합니다. 절대값은 양수 및 음수 이상치가 대칭적으로 처리되도록 합니다. -
$\text{diag}(s)^{-1}$: 스무딩 스케일의 역 대각 행렬입니다.
1) 수학적 정의: $j$-번째 대각 요소가 $1/s_j$인 $K \times K$ 대각 행렬입니다.
2) 물리적/논리적 역할: 각 열을 해당 $s_j$로 나누어 $X_{rot}$의 채널별 스케일링을 효율적으로 표현합니다.
3) 대각 행렬인 이유: 채널별 열 스케일링을 행렬 곱셈으로 표현하는 효율적인 방법입니다. -
$X_{rot}\text{diag}(s)^{-1}$: 스무딩된 회전된 활성화입니다.
1) 수학적 정의: 회전된 활성화 행렬의 각 열 $(X_{rot})_j$가 해당 스칼라 $s_j$로 요소별로 나누어진 결과입니다. 이는 $N \times K$ 행렬을 생성합니다.
2) 물리적/논리적 역할: 이는 채널별로 회전된 활성화를 정규화하는 연산입니다. 각 채널의 값을 해당 채널의 최대 크기에 따라 스케일링함으로써 이상치는 정상 값에 비해 효과적으로 "압축"되어 전체 채널의 데이터가 저비트 양자화 범위에 더 잘 맞도록 합니다.
3) 나눗셈인 이유: 최대 절대값으로 나누면 일반적으로 데이터가 $[-1, 1]$과 같은 범위로 스케일링되어 대칭 양자화 스킴에 최적입니다. -
$\text{Quantize}(\cdot)$: 양자화 함수입니다.
1) 수학적 정의: 부동소수점 숫자를 저비트 정수 표현으로 매핑하는 함수입니다. 예를 들어, INT4의 경우 float $x$를 scale 및 offset이 대상 비트 폭과 값 범위에 따라 결정되는 $q = \text{round}(x \cdot \text{scale}) + \text{offset}$과 같은 정수 $q$로 매핑할 수 있습니다.
2) 물리적/논리적 역할: 숫자의 정밀도를 줄이는 핵심 연산입니다. 고정밀 부동소수점 값을 이산적인 저비트 정수 값으로 변환하여 추론 중 메모리 풋프린트와 계산 비용을 크게 줄입니다.
3) 이 함수인 이유: 연속 값을 유한한 이산 값 집합으로 변환하는 표준 방법으로, 이는 양자화의 본질입니다. -
$X'_{quant} = \text{Quantize}(X_{rot}\text{diag}(s)^{-1})$: 양자화된 스무딩된 회전된 활성화입니다.
1) 수학적 정의: 스무딩된 회전된 활성화 행렬에 $\text{Quantize}$ 함수를 적용한 결과입니다. 저비트 정수로 구성된 $N \times K$ 행렬입니다.
2) 물리적/논리적 역할: 이는 최종 저비트, 이상치 완화 형식의 입력 활성화로, 효율적인 행렬 곱셈을 위해 준비되었습니다. -
$W'_{quant} = \text{Quantize}(W_{rot})$: 양자화된 회전된 가중치입니다.
1) 수학적 정의: 회전된 가중치 행렬에 $\text{Quantize}$ 함수를 적용한 결과입니다. 저비트 정수로 구성된 $M \times K$ 행렬입니다.
2) 물리적/논리적 역할: 이는 최종 저비트, 이상치 완화 형식의 가중치로, 효율적인 행렬 곱셈을 위해 준비되었습니다. -
$(X'_{quant})_j$: $X'_{quant}$의 $j$-번째 열입니다.
1) 수학적 정의: 저비트 정수를 포함하는 $N \times 1$ 모양의 열 벡터입니다.
2) 물리적/논리적 역할: 특정 입력 채널에 대한 양자화되고 스무딩된 활성화를 나타냅니다. -
$(W'_{quant})_j^T$: $W'_{quant}$의 $j$-번째 행(전치됨)입니다.
1) 수학적 정의: 저비트 정수를 포함하는 $1 \times M$ 모양의 행 벡터입니다. (참고: $W'_{quant}$가 $M \times K$라고 가정하면, $(W'_{quant})_j$는 $j$-번째 열, $M \times 1$입니다. 따라서 $(W'_{quant})_j^T$는 $1 \times M$입니다. 이는 $N \times M$ 외적을 위한 필요한 차원과 일치합니다.)
2) 물리적/논리적 역할: $j$-번째 입력 채널이 모든 출력 채널에 기여하는 것과 관련된 양자화된 가중치를 나타냅니다. -
$\sum_{j=1}^{K} (\cdot)$: 채널에 대한 합계입니다.
1) 수학적 정의: 이 연산자는 각각 $N \times M$ 모양의 $K$개의 개별 행렬을 합산합니다.
2) 물리적/논리적 역할: 이 합계는 각 입력 채널의 기여를 결합하여 최종 출력 행렬을 형성합니다. 각 항 $(X'_{quant})_j (W'_{quant})_j^T s_j$는 스케일링된 외적을 나타냅니다. 여기서 $s_j$로의 스케일링은 각 채널의 부분 곱의 기여도가 해당 채널의 원래 활성화 스무딩 인수로 스케일링됨을 시사하는 이 논문의 공식화의 독특한 측면입니다. 이는 스케일이 일반적으로 양자화된 값에 통합되거나 입력 또는 출력에 균일하게 적용되는 표준 양자화 행렬 곱셈에서 스케일이 처리되는 방식과는 다릅니다. 섹션 4.5, "디 양자화된 결과에 런타임 스케일 곱하기"에 대한 논문의 설명은 최종 스케일링에 대한 약간 다른 연산 순서를 시사하지만, 섹션 3.1의 방정식은 메커니즘의 가장 명시적인 수학적 진술입니다.
3) 합계인 이유: 행렬 곱셈은 본질적으로 첫 번째 행렬의 열 벡터와 두 번째 행렬의 행 벡터의 외적 합입니다. -
$Y$: 최종 출력 행렬입니다.
1) 수학적 정의: $N \times M$ 차원의 결과 행렬입니다.
2) 물리적/논리적 역할: 이는 회전, 스무딩, 양자화 및 수정된 합계 후 생성된 원래 전체 정밀도 행렬 곱셈 $XW^T$의 저비트 근사치입니다. 이는 신경망의 후속 연산을 위해 준비된 선형 계층에서 처리된 특징을 나타냅니다.
단계별 흐름
단일 추상 데이터 포인트, 예를 들어 특정 입력 토큰에 대한 특정 특징을 나타내는 $x_{token, feature\_in}$과 입력 특징을 출력 특징에 연결하는 가중치 $w_{feature\_out, feature\_in}$를 상상해 봅시다. 이들의 여정을 Rotated Runtime Smooth (RRS) 메커니즘을 통해 추적해 보겠습니다.
-
초기 진입: 우리의 추상 데이터 포인트 $x_{token, feature\_in}$은 부동소수점 활성화 행렬 $X$의 일부로 시스템에 들어갑니다. 가중치 $w_{feature\_out, feature\_in}$는 부동소수점 가중치 행렬 $W$의 일부입니다.
-
활성화 회전: 전체 활성화 행렬 $X$는 회전 행렬 $R$과 곱해지는 "회전 엔진"으로 공급됩니다. 우리의 데이터 포인트 $x_{token, feature\_in}$은 이제 변환되었습니다. 더 이상 고립되지 않고 다른 특징에 기여하고 영향을 받아, 회전된 활성화 행렬 $X_{rot}$ 내의 새로운 값 $x'_{token, feature\_k}$가 됩니다. 이 과정은 극단적인 값(이상치)을 특징 공간 전체에 균등하게 분산시키는 것을 목표로 합니다.
-
가중치 회전: 동시에 가중치 행렬 $W$는 $R^{-1}$ (역회전 행렬)과 곱해지는 "반대 회전 엔진"을 통과하여 $W_{rot}$을 생성합니다. 이는 입력 활성화가 회전된 후에도 원래 연산의 전체 수학적 무결성이 유지되도록 합니다.
-
런타임 스케일 검색: 회전된 활성화 행렬 $X_{rot}$의 각 열(특징 채널을 나타냄)에 대해 "크기 스캐너"가 최대 절대값을 식별합니다. $x'_{token, feature\_k}$를 포함하는 열의 경우 특정 스케일 $s_{feature\_k}$가 계산됩니다. 이 스케일은 동적이며 현재 입력의 특성에 적응합니다.
-
활성화 스무딩: 회전된 활성화 행렬 $X_{rot}$은 "스무딩 챔버"로 들어갑니다. 여기서 각 열의 각 값은 해당 채널의 스케일 $s_j$로 나뉩니다. 따라서 우리의 $x'_{token, feature\_k}$는 $x''_{token, feature\_k} = x'_{token, feature\_k} / s_{feature\_k}$로 스케일링됩니다. 이 연산은 각 채널 내의 값 범위를 효과적으로 "압축"하여 이상치의 영향력을 줄이고 데이터를 효율적인 저비트 양자화를 위해 준비합니다.
-
활성화 양자화: 스무딩된 회전된 활성화($X_{rot}\text{diag}(s)^{-1}$)는 "양자화 장치"로 공급됩니다. 이 장치는 각 부동소수점 값(우리의 $x''_{token, feature\_k}$ 포함)을 저비트 정수 $q_{X,token,feature\_k}$로 변환합니다. 여기서 상당한 메모리 및 계산 절감이 시작됩니다.
-
가중치 양자화: 동시에 회전된 가중치 행렬 $W_{rot}$도 자체 "양자화 장치"를 통과하여 부동소수점 값(예: $w'_{feature\_out, feature\_in}$)을 저비트 정수 $q_{W,feature\_out,feature\_in}$로 변환합니다.
-
채널별 출력 조립: 이제 시스템은 최종 출력을 조립하기 시작합니다. 각 특징 채널 $j$(1부터 $K$까지)에 대해:
- 양자화된 활성화의 $j$-번째 열 $(X'_{quant})_j$이 추출됩니다.
- 양자화된 가중치의 $j$-번째 행(전치됨) $(W'_{quant})_j^T$이 추출됩니다.
- 이 두 벡터는 곱해져(외적) 부분 출력 행렬을 형성합니다. 이 행렬은 단지 $j$-번째 채널이 최종 결과에 기여하는 것을 나타냅니다.
- 결정적으로, 이 부분 출력 행렬은 이전에 $j$-번째 활성화 채널에 대해 계산된 런타임 스무딩 인자 $s_j$로 스케일링됩니다. 이 단계는 스무딩 중에 제거된 크기 정보를 다시 도입하지만, 이제 부분 곱에 적용됩니다.
-
최종 합계: 이 스케일링된 $K$개의 부분 출력 행렬은 모두 "합계 장치"로 공급되어 요소별로 합산됩니다. 결과는 최종 출력 행렬 $Y$이며, 여기서 각 요소 $y_{token, feature\_out}$는 모든 스케일링된 채널 기여의 합입니다. 이는 전체 패스를 완료하여 저비트이지만 정확한 원래 전체 정밀도 연산의 근사치를 제공합니다.
최적화 역학
Rotated Runtime Smooth (RRS)는 훈련 없는 방법이라는 점을 명확히 하는 것이 중요합니다. 이는 메커니즘 자체에 대해 반복 학습 또는 기울기 기반 업데이트에 대한 전통적인 의미의 "최적화 역학"이 없다는 것을 의미합니다. 대신, 메커니즘은 구조적 구성 요소를 통해 직접적으로 양자화 정확도를 최적화하도록 설계되었습니다.
-
반복 학습의 부재: 모델 매개변수를 업데이트하기 위해 역전파 및 기울기 하강에 의존하는 방법과 달리, RRS는 메커니즘 작동 중에 그러한 학습 루프를 포함하지 않습니다. 회전 행렬 $R$은 고정된 사전 정의된 행렬(예: 하다마드 행렬)이거나 오프라인 보정 프로세스에서 파생되지만(관련 연구에서와 같이), 추론 중에 업데이트되지 않습니다. 스무딩 스케일 $s_j$는 각 새 입력에 대해 즉석에서 계산되므로 적응적이지만 "학습"되지는 않습니다.
-
손실 지형 탐색 없음: 훈련이 없으므로 기울기를 사용하여 "손실 지형"을 탐색하는 개념은 RRS 메커니즘 자체에 적용되지 않습니다. "최적화"는 설계 선택에 내장되어 있습니다. 즉, 양자화 오류를 최소화하고 모델 성능을 보존하기 위해 회전, 스무딩 및 양자화를 수행하는 방법입니다. 이러한 설계 선택의 효과는 직접적인 기울기 기반 최적화의 대상이 아니라 관찰된 결과인 perplexity 또는 정확도와 같은 메트릭으로 평가됩니다.
-
결정론적 상태 업데이트: RRS 메커니즘의 상태는 반복적으로 진화하지 않습니다. 각 입력에 대해 프로세스는 직접적인 결정론적 변환 시퀀스입니다.
- 활성화와 가중치는 고정된 $R$을 사용하여 회전됩니다.
- 스무딩 스케일은 현재 입력의 회전된 활성화에 따라 계산됩니다.
- 양자화는 고정된 비트 폭과 반올림 규칙을 사용하여 적용됩니다.
- 최종 행렬 곱셈(부분 곱의 특이한 채널별 스케일링 포함)이 계산됩니다.
각 단계는 직접적인 계산이며 이전 상태 또는 오류에 기반한 업데이트가 아닙니다.
-
설계 기반 "수렴": RRS의 "수렴"은 반복적인 프로세스가 아니라 본질적인 설계를 통한 상태입니다. 목표는 LLM 활성화의 "이상치"가 저비트(INT4) 양자화를 정확하게 허용할 만큼 충분히 "부드럽게" 되도록 활성화와 가중치를 변환하는 것입니다. 본 논문은 이 설계가 다양한 모델에서 perplexity 및 정확도 향상으로 이어지는 효과적인 것을 보여줍니다. 따라서 "최적화"는 반복적인 학습 프로세스가 아니라 고품질 저비트 추론을 달성하기 위한 이러한 변환의 영리한 엔지니어링에 있습니다. 메커니즘의 견고성과 성능 향상은 이러한 설계 최적화의 증거이며, 이를 매우 효율적이고 플러그 앤 플레이 솔루션으로 만듭니다. 무시할 수 있는 오버헤드는 실용적인 유용성을 더욱 강화합니다.
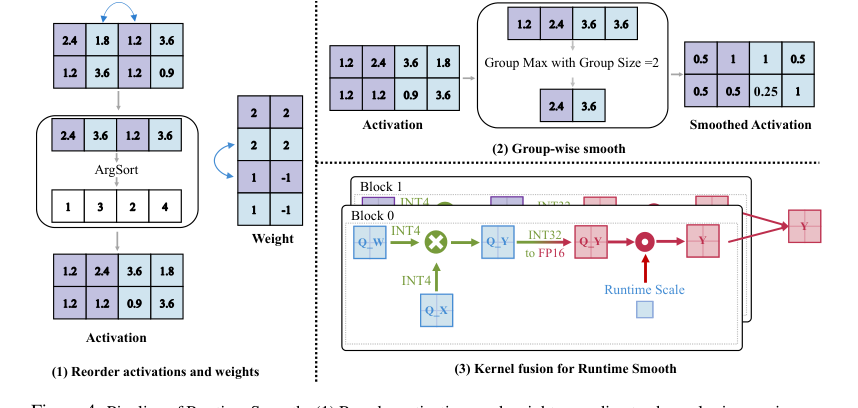 Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
Figure 4. Pipeline of Runtime Smooth. (1) Reorder activations and weight according to channel-wise maximums of activation. Note that the reordering process would not change the final result since Y = PK i=1 Xi@WT i , and Y is irrelevant with the order of i. (2) Group up activations according to block size of matrix multiplication computation. The maximums of the group are set to the runtime smoothing scale of the group. (3) In the matrix multiplication pipeline, quantized smoothed activations and weights are segmented into blocks. The block size is equivalent to the previous group size. Within a block, tiled smoothed activations are multiplied by tiled quantized weights. The runtime smoothing scales are applied to the interim result
결과, 한계 및 결론
실험 설계 및 기준선
수학적 주장을 엄격하게 검증하기 위해 저자들은 다양한 주류 대규모 언어 모델(LLM)에 걸쳐 광범위한 실험을 수행했습니다. 여기에는 LLaMA 제품군(LLaMA2-13B, LLaMA2-70B, LLaMA3-8B, LLaMA3-70B, LLaMA3.1-8B, LLaMA3.1-70B), Qwen 제품군(Qwen1.5-7B, Qwen1.5-14B), Mistral 및 Mixtral의 다양한 모델이 포함되었습니다. 평가는 특히 A4W4KV4, A4W4KV16 및 A4W16KV16과 같은 세 가지 INT4 양자화 스킴에 중점을 두었으며, 이는 각각 4비트 활성화, 4비트 가중치 및 4비트 KV 캐시 양자화를 나타내며 KV 캐시 비트 폭이 다릅니다.
활성화 양자화의 경우, 반올림(RTN) 전략을 사용하는 채널별 대칭 스킴이 사용되었습니다. KV 캐시 양자화는 128의 그룹 크기를 사용하는 서브 채널 대칭 스킴과 RTN을 사용했습니다. 가중치 양자화는 주로 기준선 'RTN' 방법을 제외하고 GPTQ(Frantar et al., 2022)를 사용하는 채널별 대칭 스킴을 사용했습니다. GPTQ의 보정 세트는 2048의 시퀀스 길이를 가진 WikiText-2의 128개 샘플로 구성되었습니다.
제안된 Rotated Runtime Smooth (RRS) 및 그 구성 요소인 Runtime Smooth (RS)가 비교된 "희생자"(기준선 모델/방법)에는 다음이 포함되었습니다.
- RTN: 기본적인 반올림 양자화입니다.
- SmoothQuant (Xiao et al., 2023): 이상치를 오프라인으로 마이그레이션하는 저명한 채널별 스무딩 방법입니다.
- GPTQ (Frantar et al., 2022): 사후 훈련 가중치 양자화 방법입니다.
- QuaRot (Ashkboos et al., 2024): 이상치 억제를 위한 회전 기반 방법입니다.
- SpinQuant (Liu et al., 2024) 및 DuQuant (Lin et al., 2024a): 훈련 기반 방법을 포함한 특정 비교를 위한 추가 기준선입니다.
핵심 메커니즘의 효능에 대한 결정적인 증거는 여러 실험 아키텍처를 통해 수집되었습니다.
1. WikiText-2의 Perplexity: 이 표준 벤치마크는 언어 모델이 텍스트 샘플을 얼마나 잘 예측하는지 측정하며, 낮은 perplexity는 더 나은 성능을 나타냅니다.
2. 제로샷 상식 QA 벤치마크: 양자화 후 모델의 추론 능력을 평가하기 위해 ARC-e, ARC-c, BoolQ 및 OBQA와 같은 작업에서 성능을 평가했습니다.
3. 축소 실험:
* 예비 축소(그림 3)는 런타임 스무딩을 SmoothQuant 및 "Origin A4W4" 기준선과 직접 비교하여 런타임 스무딩의 필요성과 가중치로 이상치를 마이그레이션하는 함정을 보여주었습니다.
* 런타임 스무딩 스케일의 그룹 크기에 대한 축소(표 4)는 정확도에 대한 이 하이퍼파라미터의 영향을 탐구했습니다.
4. 효율성 평가: RTX 4070 Ti GPU에서 NVBench를 사용하여, 저자들은 융합된 GEMM 커널의 오버헤드를 채널별 A4W4 및 서브 채널 A4W4 기준선(그림 6)과 비교하여 측정하여 접근 방식의 실용적인 실행 가능성을 입증했습니다.
5. 통계적 이상치 분석: 그림 9는 다양한 LLM 구성 요소(QKV_Projector, Output_Projector, Up_Proj 또는 Gate_Proj, Down_Projector)에 걸쳐 다양한 모델에 대한 이상치 제거의 상세한 통계적 분석을 제공하여 RRS가 다른 방법과 비교하여 활성화를 더 부드러운 범위로 효과적으로 이동시키는 것을 시각적으로 보여주었습니다.
증거가 증명하는 것
본 논문에서 제시된 증거는 LLM에 대한 훈련 없는 INT4 추론을 가능하게 하는 Rotated Runtime Smooth (RRS) 및 그 구성 요소인 Runtime Smooth (RS)의 효과에 대한 설득력 있는 증거를 제공합니다.
첫째, 채널별 이상치를 제거하도록 설계된 런타임 스무딩 (RS) 구성 요소는 상당한 개선을 보여주었습니다. 예비 축소 실험(그림 3)은 단순히 런타임 스무딩 스케일을 적용하는 것이 A4W4 양자화에 불충분했음을 명확히 보여주었습니다. 그러나 RS가 완전히 구현되었을 때 A4W4를 실현 가능하게 하여 LLaMA3-8B의 perplexity를 A4W16 설정에서 4e2에서 10.9로 극적으로 개선했습니다. 이는 이상치를 가중치로 마이그레이션하지 않고 런타임 스케일을 채택하는 핵심 아이디어를 검증하는 데 중요했으며, 이는 SmoothQuant와 같은 이전 방법의 주요 한계였습니다. 표 1에서 RS는 16-4-16 설정에서 LLaMA2-70B의 perplexity를 1e2(SmoothQuant)에서 6.95(RS)로 줄이는 등 다양한 모델 및 양자화 설정에서 SmoothQuant 및 RTN을 일관되게 능가했습니다. 또한, 활성화 전용 양자화(A4W16KV16) 하에서 RS는 LLaMA3-8B에서 40배의 개선을 달성하여 그 효과를 강조했습니다.
둘째, 회전을 런타임 스무딩과 결합하여 채널별 및 스파이크 이상치를 모두 처리하는 전체 Rotated Runtime Smooth (RRS) 방법은 우수한 성능을 제공했습니다. WikiText-2 perplexity의 주요 결과 테이블인 표 1은 RRS가 거의 모든 평가된 LLaMA, Qwen 및 Mistral 모델에서 RS, QuaRot, SmoothQuant 및 RTN을 포함한 모든 기준선을 일관되게 능가했음을 보여줍니다. 특히 주목할 만한 예는 LLaMA3-70B로, RRS는 A4W4KV16 설정에서 perplexity를 57.33에서 6.66으로, A4W4KV4 설정에서 49.76에서 6.87로 줄였습니다. 이러한 결정적인 증거는 RRS의 결합 메커니즘이 두 유형의 이상치 영향을 효과적으로 완화한다는 것을 증명합니다. 이는 동일한 모델 및 설정에 대해 각각 57.33 및 49.73을 생성한 최첨단 QuaRot보다 훨씬 뛰어난 성능입니다.
Perplexity를 넘어 RRS는 제로샷 상식 QA 작업(표 2)에서도 강점을 보여주었습니다. 다양한 LLM 및 양자화 설정에서 RRS는 평균 정확도 개선에서 약 3%로 모든 기준선(GPTQ, SmoothQuant, RS, QuaRot)을 일관되게 능가했습니다. 예를 들어, 4-4-16 양자화를 사용한 LLaMA-3-8B에서 RRS는 QuaRot의 55.0%에 비해 평균 정확도 58.0%를 달성했습니다. 이는 개선된 활성화 스무딩이 복잡한 추론 작업으로 이어진다는 것을 의미합니다.
이상치 제거의 통계 분석(그림 9)은 RRS 메커니즘이 작동하는 것을 직접적으로 시각적으로 보여줍니다. 이는 RRS가 모든 LLM 구성 요소(QKV_Projector, Output_Projector, Up_Proj 또는 Gate_Proj, Down_Projector) 및 모델에 걸쳐 'u < 4'(더 부드러운) 범주에 속하는 활성화의 비율이 원래 활성화(X), 회전된 활성화(R) 또는 런타임 스무딩 자체(RS)에 비해 훨씬 더 높다는 것을 보여줍니다. 이는 RRS가 채널별 및 스파이크 이상치를 모두 포괄적으로 제거하는 능력을 직접적으로 검증합니다.
마지막으로, 효율성 평가(그림 6 및 섹션 4.5)는 RRS 융합 커널이 A4W4 채널별 양자화 기준선에 비해 무시할 수 있는 오버헤드만 도입한다는 것을 확인합니다. 이는 RRS가 상당한 속도 저하 없이 정확도 향상을 제공하므로 INT4 추론을 위한 진정한 플러그 앤 플레이 솔루션임을 의미하는 중요한 실용적인 이점입니다. 훈련 기반 방법(표 3)과의 비교는 훈련 시간 비용을 발생시키지 않고 WikiText-2 perplexity에서 SpinQuant(훈련 기반 방법)를 능가하므로 RRS의 강점을 더욱 강조합니다.
한계 및 향후 방향
Rotated Runtime Smooth (RRS)는 훈련 없는 INT4 추론에 대한 상당한 발전을 제시하지만, 본 논문은 암묵적으로 그리고 명시적으로 여러 한계를 지적하고 미래 연구를 위한 문을 열어줍니다.
현재 한계:
1. 회전으로 인한 불완전한 스무딩 보장: 본 논문은 "회전은 더 부드러운 행렬을 보장할 수 없으며, 회전된 행렬은 여전히 채널별 이상치의 형태를 나타낼 수 있다"(섹션 1, 그림 2)고 언급합니다. 이는 회전이 도움이 되지만 그 자체로는 완벽한 해결책이 아니며 런타임 스무딩 구성 요소가 필요함을 시사합니다.
2. 스파이크 이상치로 인한 "희생자" 효과: 스파이크 이상치의 존재는 채널별 스무딩 후에도 정상 값이 "희생자"로 가지치기될 수 있습니다(섹션 1, 그림 1). RRS가 이를 완화하는 것을 목표로 하지만 근본적인 과제는 남아 있습니다.
3. 그룹 크기 민감도: 축소 실험(섹션 4.4, 표 4)은 런타임 스무딩이 A4W4와 전체 정밀도 간의 격차를 효과적으로 최소화하지만, "그룹 크기가 증가함에 따라 정확도가 저하된다"고 나타냅니다. 이는 절충을 시사하며 보편적으로 최적이 아닐 수 있는 선택된 그룹 크기에 대한 잠재적인 민감성을 나타냅니다.
4. 특정 이상치 시나리오: 저자들은 "두 개의 이상치 토큰만 있는 경우는 드물지만 잠재적으로 Rotated Runtime Smooth를 괴롭힐 수 있다"(섹션 C.1)고 언급합니다. 이는 RRS가 어려움을 겪을 수 있는 특정, 비록 드물지만, 이상치 패턴을 강조하며, 그 견고성이 절대적이지 않을 수 있음을 시사합니다.
5. 모델별 이상치 민감도: 저자들은 "모델마다 이상치에 대한 민감도가 다르다. 이상치를 추가로 억제하면 견고성을 향상시킬 수 있다"(섹션 4.2)고 관찰합니다. 이는 RRS가 일반화되었지만 추가로 최적화될 수 있는 모델별 이상치 특성이 있을 수 있음을 시사합니다.
6. 그룹 크기에 대한 하드웨어 제약 조건: Qwen1.5-7B와 같은 특정 모델의 경우 Down_projector(11008)에 대한 입력 활성화 크기는 "그룹 크기 512를 지원하지 않는다"(섹션 4.4). 이는 잠재적으로 이점을 제공할 수 있는 가장 큰 그룹 크기를 적용하는 데 실질적인 제한이 있음을 나타냅니다.
향후 방향 및 토론 주제:
- 적응형 및 동적 스무딩 전략: 그룹 크기 및 다양한 이상치 패턴에 대한 민감도를 고려할 때, 미래 연구는 적응형 스무딩 전략을 탐구할 수 있습니다. 고정된 그룹 크기 또는 보편적인 회전 대신, 실시간 활성화 통계 또는 모델 계층 특성에 따라 이러한 매개변수를 동적으로 조정할 수 있을까요? 이는 각 특정 입력 및 계층에 대한 스무딩을 최적화하기 위한 경량의 즉석 분석을 포함할 수 있으며, 잠재적으로 더 큰 정확도와 견고성을 달성할 수 있습니다.
- 이상치 억제를 위한 이론적 한계 및 보장: 본 논문은 RRS의 효과를 경험적으로 입증합니다. 회전 및 런타임 스무딩의 수학적 속성에 대한 더 깊은 이론적 조사는 이상치 억제와 양자화 오류에 미치는 영향에 대한 공식적인 한계를 설정할 수 있습니다. 이는 증명 가능한 보장을 가진 미래 양자화 방법의 보다 원칙적인 설계를 이끌 수 있습니다.
- 훈련 없는 및 훈련 기반 접근 방식의 하이브리드: RRS는 훈련이 없으며 일부 훈련 기반 방법을 능가하지만, 학습된 회전(SpinQuant에서와 같이)의 개념은 여전히 유망합니다. 미래 연구는 RRS와 같은 훈련 없는 방법의 효율성을 현재 훈련 기반 방법의 광범위한 훈련 오버헤드 없이 더 높은 정확도를 달성하기 위해 회전 또는 스무딩 스케일을 추가로 미세 조정하는 최소한의 표적 훈련 또는 미세 조정 단계를 결합하는 하이브리드 접근 방식을 조사할 수 있습니다.
- 고급 양자화를 위한 하드웨어-소프트웨어 공동 설계: RRS의 무시할 수 있는 오버헤드는 상당한 이점입니다. 이를 더욱 발전시키기 위해 RRS의 핵심인 재정렬, 그룹별 최대값 계산 및 회전 연산을 기본적으로 지원하기 위해 전용 하드웨어 가속기 또는 특수 명령어 세트를 설계할 수 있습니다. 이 공동 설계 접근 방식은 INT4 추론에 대해 전례 없는 속도 향상과 에너지 효율성을 제공할 수 있습니다.
- 다른 데이터 유형 및 모델 아키텍처로의 일반화: RRS는 LLM의 INT4 추론에 대해 검증되었습니다. 이러한 원칙이 다른 저비트 양자화 스킴(예: INT2, 이진) 또는 트랜스포머를 넘어선 다른 모델 아키텍처(예: 비전 모델 또는 다중 모달 아키텍처)로 얼마나 잘 확장될까요? 이러한 더 넓은 응용 프로그램을 조사하면 RRS를 조정하기 위한 새로운 과제와 기회가 드러날 수 있습니다.
- 적대적 공격 및 분포 변화에 대한 견고성: 양자화된 모델은 적대적 공격에 더 취약하거나 분포 외 데이터에서의 성능 저하를 겪을 수 있습니다. 미래 연구는 RRS가 활성화를 더 부드럽고 일관되게 만듦으로써 양자화된 LLM의 견고성을 이러한 문제에 대해 본질적으로 개선하는 방법, 또는 이러한 측면을 강화하기 위해 특정 수정이 필요한지 여부를 탐구할 수 있습니다.
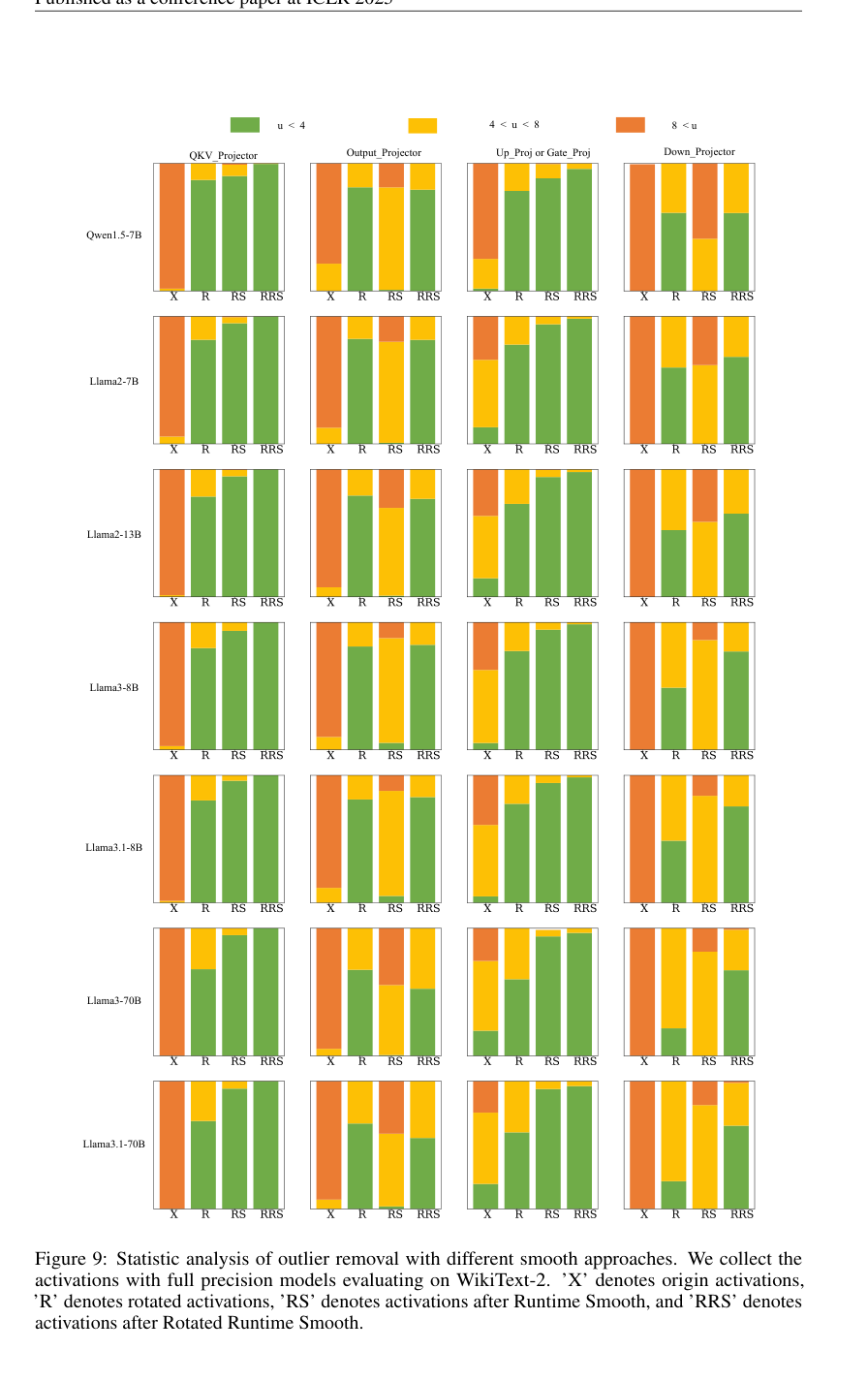 Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
Figure 9. Statistic analysis of outlier removal with different smooth approaches. We collect the activations with full precision models evaluating on WikiText-2. ’X’ denotes origin activations, ’R’ denotes rotated activations, ’RS’ denotes activations after Runtime Smooth, and ’RRS’ denotes activations after Rotated Runtime Smooth
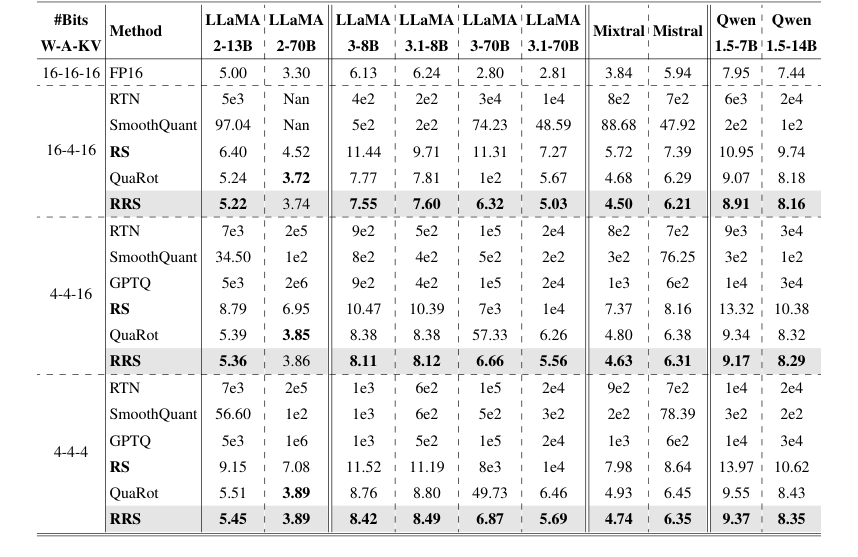 Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
Table 1. Comparison on WikiText-2 perplexity. We evaluate models and methods on three quantization schemes: A4W4KV4, A4W4KV16, and A4W16KV16. Results for SmoothQuant, GPTQ, and QuaRot were obtained by re-implementation based on their publicly released codebase
 Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
Table 3. Comparison with the training-based method, SpinQuant, where the result was obtained by re-implementation based on its publicly released codebase
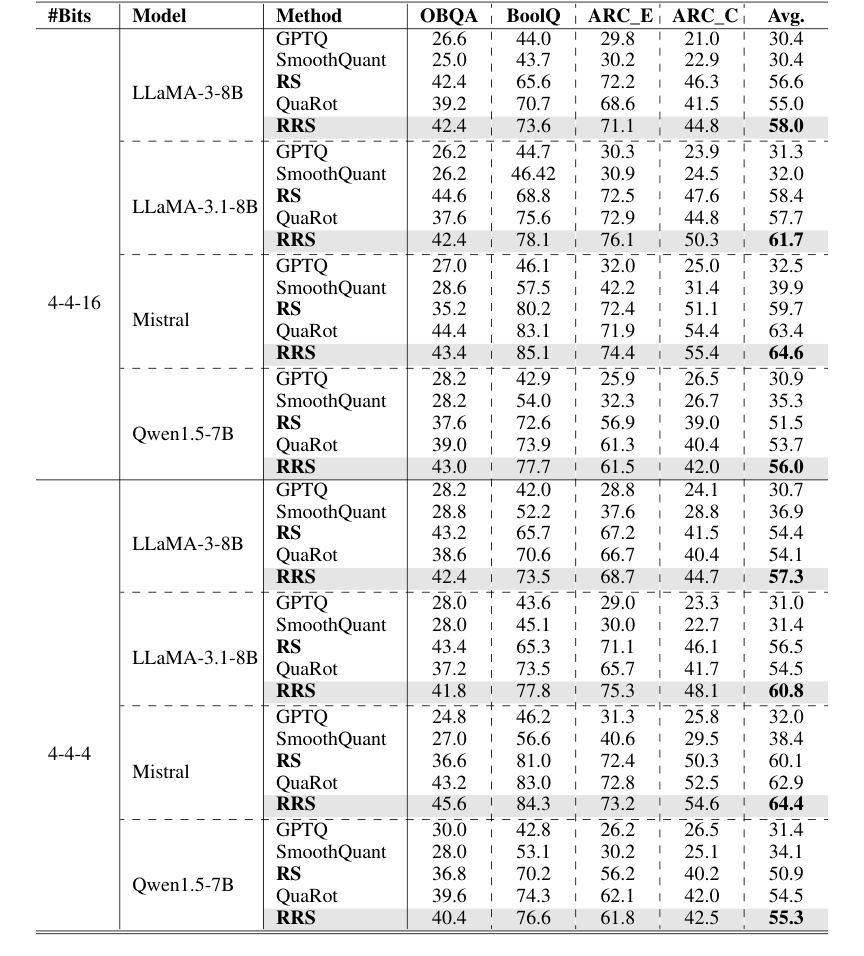 Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes
Table 2. 0-shot accuracy (%) on the Common Sense QA tasks. Each block is based on the same foundation model specified in the row. We organize all results under different quantization schemes