Generative Video Propagation
The problem of generative video propagation, as addressed in this paper, is rooted in the broader field of computer vision, specifically within the domain of video generation and editing.
Background & Academic Lineage
The problem of generative video propagation, as addressed in this paper, is rooted in the broader field of computer vision, specifically within the domain of video generation and editing. Historically, the core challenge has been to consistently and realistically propagate changes made to a single frame (or a sparse set of frames) across an entire video sequence. Early approaches to video propagation, which emerged from the necessity to maintain temporal coherence and visual plausibility in modified video content, primarily relied on traditional computer vision techniques such as optical flow [9, 44], depth estimation [6, 55], radiance fields [33], and atlases [20, 24]. The increasing demand for sophisticated video editing tools that can handle complex, realistic scenarios with minimal manual effort has driven the emergence and evolution of this specific problem.
The fundamental limitation or "pain point" of previous approaches that motivated the authors to develop a new framework stems from several key issues. Traditional methods were often prone to error accumulation over the video's duration, leading to degraded quality and inconsistencies in later frames. This made them less robust and limited their generalization ability across diverse video content. Many prior techniques were also task-specific, meaning a model trained for one type of edit (e.g., object removal) would require significant retraining or a completely different model for another task (e.g., background replacement) [28, 31, 34, 61]. This lack of a unified framework was a major bottleneck. More recent diffusion-based video editing models, while powerful, also had their own set of constraints. Many were primarily designed for altering appearance rather than making substantial changes to object shapes or handling complex background modifications. They often required dense mask labeling for every individual frame, which is a labor-intensive and time-consuming process, making real-time or large-scale applications impractical. For instance, methods like I2VEdit [34] introduced computational complexity by necessitating learning motion LoRAs for each video clip. Other approaches, such as ReVideo [31], involved masking parts of the input video with black squares, which inadvertently removed significant information and restricted their ability to handle complex background edits and large shape alterations. The authors' motivation was to overcome these limitations by proposing a unified, generative framework that could propagate diverse edits seamlessly, robustly, and without requiring task-specific retraining or dense mask inputs, thus simplifying the video editing process significantly.
Intuitive Domain Terms
Here are a few specialized terms from the paper, translated into intuitive, everyday analogies for a zero-base reader:
-
Generative Video Propagation: Imagine you're making a claymation film. You sculpt the first scene, then decide to add a tiny hat to one of your clay characters. "Generative Video Propagation" is like having a magical, super-smart assistant who, after seeing your edited first scene, automatically resculpts all the subsequent scenes, making sure the hat appears consistently on the character, moves naturally with them, and looks perfectly integrated into the film, without you having to touch every single frame. It "propagates" your initial edit throughout the video in a "generative" (creative, realistic) way.
-
Image-to-Video (I2V) Generation Model: Think of this as a highly imaginative storyteller. You give this storyteller a single photograph (an "image") and a brief description of what should happen next, and they can invent and create an entire short video sequence from it. For example, you give them a picture of a still lake and say "make the water ripple gently," and they generate a video of the lake with realistic ripples. In this paper, this storyteller is used to generate the rest of the video based on the edited first frame.
-
Selective Content Encoder (SCE): Picture a very careful librarian. You give this librarian two versions of a book: the original and one where you've highlighted certain sentences. This librarian's job is to only remember and preserve all the parts of the original book that you didn't highlight, while deliberately ignoring the highlighted sections. It "selectively encodes" the original content, focusing on what should remain unchanged, so that the generative model can then fill in the edited parts without messing up the rest of the book.
-
Region-Aware Loss (RA Loss): Imagine you're grading a student's art project, which has two parts: a drawing and a painting. The "Region-Aware Loss" is like a grading system that makes sure you pay equal attention to both the drawing (the unchanged parts of the video) and the painting (the edited parts), even if one part is much smaller or seems less important. It ensures that the model learns to do well on both preserving the original content and accurately propagating the edits, preventing it from focusing too much on one at the expense of the other.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The paper addresses the complex problem of generative video propagation, aiming to seamlessly apply a first-frame edit to an entire video sequence while maintaining realism and consistency.
Input/Current State:
The starting point is an original video $V = \{v_1, v_2, ..., v_T\}$ consisting of $T$ frames, and a single modified first frame $v'_1$. This $v'_1$ is the result of an arbitrary edit applied to the original first frame $v_1$. Existing video editing methods typically suffer from several limitations: they often require dense mask labeling for every frame, rely on auxiliary inputs like optical flow or depth maps for motion guidance, or necessitate retraining for each specific editing task or video clip. Many are also limited to specific types of edits, such as appearance changes, and struggle with significant shape modifications or complex background alterations.
Output/Goal State:
The desired endpoint is a new, modified video $V' = \{v'_1, v'_2, ..., v'_T\}$. For each subsequent frame $v'_t$ (where $t \in \{2, ..., T\}$), the goal is to ensure that the modification introduced in $v'_1$ is accurately and realistically propagated throughout the video. Simultaneously, all unedited regions of the video must remain perfectly consistent with the original content in terms of both appearance and motion. The framework should be generaly applicable to a wide range of video editing tasks—including object removal, insertion, replacement, tracking, and outpainting—without requiring task-specific data or explicit motion cues like optical flow.
Missing Link or Mathematical Gap:
The exact missing link is a unified, generative framework that can effectively disentangle the modified and unmodified regions of a video and propagate changes from a single edited first frame to the entire sequence. This must be achieved while preserving the original content in unedited areas and generating new, physically plausible content in edited areas, across diverse and complex editing scenarios. Mathematically, the paper seeks to define a generative function $G$ and a selective content encoder $E$ such that the modified frames $v'_t$ for $t \in \{2, ..., T\}$ can be produced by $v'_t = G(E(V), v'_1, t)$. Here, $E(V)$ must selectively encode only the unchanged information from the original video $V$, allowing $G$ (an image-to-video generation model) to focus on propagating the edited content from $v'_1$ to subsequent frames. The challenge lies in designing $E$ and $G$ to work synergistically to achieve this disentanglement and consistent propagation without explicit per-frame guidance.
The Painful Trade-off or Dilemma:
Previous researchers have been trapped by a fundamental trade-off:
1. Realism and Consistency vs. Generality and Flexibility: Achieving highly realistic and temporally consistent propagation of edits (especially for complex changes like large shape modifications or background alterations) often comes at the cost of generality. Methods that excel in consistency typically rely on explicit motion representations (e.g., optical flow) or per-task fine-tuning, making them less flexible and requiring specific inputs. Conversely, more general generative models often struggle with maintaining fine-grained consistency and avoiding artifacts over time. Improving one aspect (e.g., allowing substantial shape changes) usually breaks another (e.g., temporal coherence or realism of effects like shadows).
2. Computational Efficiency vs. Quality and Scope: Many existing approaches either involve computationally intensive processes (like dense mask labeling for all frames or per-video fine-tuning) or produce results with limited quality and scope of edits. The dilemma is how to achieve high-quality, diverse video edits without incurring prohibative computational costs or requiring extensive manual intervention.
Constraints & Failure Modes
The problem of generative video propagation is insanely difficult due to several harsh, realistic constraints:
- Temporal Consistency and Error Accumulation: Ensuring that edits propagate smoothly and consistently across hundreds of frames without accumulating errors is a major challenge. Even small inconsistencies can lead to noticeable "ghosting effects," flickering, or degradation in later frames, especially when dealing with complex motions or long video sequences.
- Disentanglement of Edited and Unedited Regions: The model must accurately identify and preserve the original content in unedited regions while simultaneously generating new content for modified areas. This disentanglement is crucial; a failure here can lead to original objects reappearing in edited regions or unintended alterations in unchanged parts of the video.
- Handling Diverse and Complex Edits: The framework needs to support a wide array of editing tasks, including object removal with associated effects (shadows, reflections), object insertion with independent and physically plausible motion, and background replacement. Each task presents unique challenges in terms of content generation and motion coherence.
- Lack of Task-Specific Data: Creating large-scale, paired video datasets for every conceivable video editing task is prohibitively expensive and time-consuming. This data sparsity forces reliance on synthetic data generation, which introduces its own challenges in ensuring the model generalizes well to real-world videos and avoids learning synthetic artifacts.
- Computational and Memory Limits: Processing high-resolution video sequences and generating new frames with complex content requires significant computational resources. Training and inference for such models demand powerful GPUs and substantial memory, making real-time or even near real-time performance a significant hurdle.
- Absence of Explicit Motion Cues: Unlike traditional methods that rely on optical flow or depth maps, this framework aims to operate without such explicit motion guidance. This constraint places a higher burden on the generative model to implicitly understand and synthesize plausible motion, which is inherently difficult.
- Non-Differentiable Real-World Physics: Accurately modeling and propagating physical effects like shadows, reflections, and realistic object interactions within a generative framework is challenging, as these phenomena are complex and not easily represented by differentiable functions.
Why This Approach
The Inevitability of the Choice
The authors' decision to build upon a generative Image-to-Video (I2V) model for their GenProp framework wasn't just a preference; it was a strategic necessity driven by the inherent limitations of existing approaches. Traditional video propagation methods, often relying on optical flow, depth maps, or atlases, were fundamentally ill-suited for the problem of general generative video propagation. These methods are prone to accumulating errors over time, exhibit limited robustness, and crucially, lack the generalization ability to handle diverse editing tasks without extensive retraining or task-specific modifications. They typically excel at a single, well-defined task but fall apart when faced with the need for versatility.
The "aha!" moment, though not explicitly stated as a single event, can be inferred from the paper's critical assessment of the state-of-the-art (SOTA). Even advanced diffusion-based video editing models, while powerful, primarily focused on text-guided appearance changes or required cumbersome per-case fine-tuning. They struggled with significant shape modifications, complex background edits, or the physically plausible motion of inserted objects. Methods like Revideo [31], for instance, relied on masking parts of the input video with black squares, which inherently removed vital information and restricted their ability to handle intricate background edits or large shape alterations. Others, like I2VEdit [34], introduced computational complexity by requiring motion LoRAs for each video clip. The realization was that no existing method offered a unified, general framework capable of propagating diverse first-frame edits (removal, insertion, replacement, tracking, multiple edits) across an entire video sequence while maintaining both realism and consistency, without requiring dense mask annotations or auxiliary motion predictions. The generative power of I2V models, when carefully designed and augmented, was the only viable path to address this multifaceted challenge holistically.
Comparative Superiority
GenProp's qualitative superiority stems from its structural design, which directly addresses the shortcomings of previous methods. Unlike traditional approaches that rely on explicit motion cues like optical flow, GenProp leverages the inherent generative capabilities of I2V models. This eliminates the problem of error accumulation that plagues flow-based methods, leading to significantly more robust and consistent propagation over longer video sequences.
A key structural advantage is the Selective Content Encoder (SCE). This component allows GenProp to selectively encode features from the unchanged parts of the original video, while the I2V model focuses its generative power on propagating the modified regions. This disentanglement is crucial for maintaining consistency in unedited areas, a common failure point for other methods that might inadvertently alter stable regions. Furthermore, the Mask Prediction Decoder (MPD), trained with an auxiliary head, guides the model to accurately identify and focus on the regions requiring modification, enhancing precision in edits and improving the quality of attention maps (as shown in Figure 3).
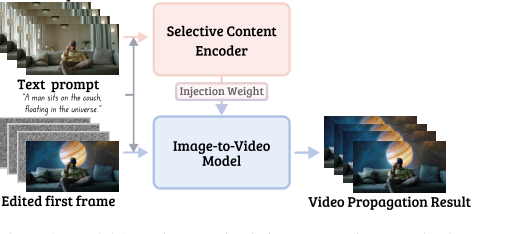 Figure 2. Model Overview. During inference, our framework takes in the original video as input through a selective content encoder (SCE) to retain content in unchanged regions. Changes applied to the first frame are propagated throughout the video using an I2V model while other regions remain intact
Figure 2. Model Overview. During inference, our framework takes in the original video as input through a selective content encoder (SCE) to retain content in unchanged regions. Changes applied to the first frame are propagated throughout the video using an I2V model while other regions remain intact
Perhaps the most significant qualitative leap is GenProp's generality and flexibility. It supports a wide range of complex video editing tasks—from complete object removal with realistic effects like shadows and reflections, to background replacement, to object insertion with physically plausible motion, and even tracking objects and their associated effects—all within a single inference run and without requiring task-specific retraining. This is a stark contrast to prior SOTA methods, which were often specialized for one task or required dense mask labeling for every frame. GenProp's propagation-based approach does not require any mask input during inference, greatly simplifying the editing process and reducing manual effort. This structural advantage makes it overwhelmingly superior by offering a truly unified and versatile solution to video editing.
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Alignment with Constraints
The GenProp framework achieves a remarkable "marriage" between the problem's harsh requirements and its unique architectural properties. Let's consider the key constraints:
- Realism: The problem demands that propagated changes appear natural and realistic. GenProp aligns perfectly by leveraging a pre-trained I2V generation model as its core. These models are inherently designed to generate high-fidelity, realistic video content, ensuring that the edited sequences maintain visual plausibility.
- Consistency: Unchanged regions must remain identical to the original video, and edits must be temporally consistent. This is addressed by the Selective Content Encoder (SCE), which explicitly preserves information from the unedited parts of the video. The Region-Aware Loss (RA Loss) further reinforces this by disentangling losses for modified and unmodified regions, penalizing changes in stable areas while encouraging accurate propagation in edited ones. This ensures that the original content is faithfully preserved where no edits are intended.
- Generality & Versatility: The solution must handle a broad spectrum of video editing tasks without requiring retraining for each. GenProp achieves this through its unified framework that extends first-frame editing to general video propagation. Crucially, the synthetic data generation scheme (Copy-and-Paste, Mask-and-Fill, Color Fill) covers diverse scenarios during training, enabling the model to generalize across various applications like removal, insertion, replacement, and tracking, without needing task-specific data at inference.
- Efficiency & Simplicity: The solution should avoid cumbersome manual annotations and error-prone intermediate representations. GenProp eliminates the need for dense mask labeling for all frames, a significant simplification over many traditional and even some diffusion-based methods. It also bypasses the reliance on optical flow or depth maps for motion prediction, thereby avoiding the accumulation of errors inherent in such intermediate representations.
- Complex Edits: The model needs to support substantial shape modifications, independent object motion, and the removal of associated effects. The generative power of the I2V model, combined with the precise guidance from the SCE and MPD, allows GenProp to handle these complex scenarios, such as objects with independent motion or the removal of shadows and reflections alongside the main object, which traditional methods often fail to do.
Rejection of Alternatives
The paper provides compelling reasons for rejecting alternative approaches, highlighting their fundamental limitations for the general video propagation problem:
- Traditional Video Propagation Methods (Optical Flow, Depth, Atlases): These methods, while foundational, are explicitly rejected due to their limited robustness, generalization ability, and susceptibility to error accumulation. They are often designed for a single task and require retraining for new applications, making them impractical for a unified framework. Their reliance on explicit motion cues makes them brittle when dealing with complex, non-rigid deformations or significant scene changes.
- Existing Diffusion-based Video Editing Models (e.g., InsV2V, Pika, AnyV2V, Revideo): While diffusion models are powerful, their existing implementations for video editing were found wanting.
- Many were limited to altering appearance rather than making significant changes to object shapes or handling complex background edits with precision.
- Some required per-case fine-tuning (e.g., I2VEdit's motion LoRAs), adding computational complexity and slowing down the process.
- Approaches like Revideo [31] used black square masks, which removed crucial information and severely restricted their ability to handle complex background edits and large shape alterations, often leading to blurry boundaries and accumulated errors in object motion.
- Training-free frameworks like AnyV2V [27] suffered from limited generalization ability and struggled with substantial shape changes or object insertion. Pika [2] similarly performed poorly with significant shape changes or background edits.
- Methods relying on text prompts (e.g., InsV2V) were often constrained by their training data and struggled with complex, non-appearance-based edits.
- Traditional Inpainting Pipelines (e.g., SAM-V2 + Propainter): For tasks like object removal, these cascaded methods were rejected primarily because they require dense mask annotations for all frames, a labor-intensive and error-prone process that GenProp completely avoids. Furthermore, Propainter was shown to struggle with accurately removing object effects like shadows and reflections, which GenProp handles robustly due to its generative understanding of physical rules.
- SAM-V2 for Tracking: While SAM-V2 [39] is excellent for mask tracking, it was noted to struggle with object effects (reflections, shadows) due to its training data biases. GenProp, with its generative pretraining, demonstrates a superior understanding of physical rules, allowing it to track these associated effects consistently.
In essence, the authors concluded that while components of these alternatives were useful, none offered the comprehensive, robust, and general solution required for seamless, diverse video propagation without significant compromises in quality, efficiency, or versatility. GenProp's novel integration of a selective content encoder, mask prediction decoder, region-aware loss, and synthetic data generation on top of a powerful I2V model was the only way to overcome these collective limitations.
Mathematical & Logical Mechanism
The Master Equation
The core of GenProp's learning mechanism is encapsulated in its Region-Aware Loss, which guides the model to simultaneously propagate edits and preserve original content. While the overall training objective is to minimize a sum of losses across frames, the fundamental loss function for a single frame, which combines all the critical components, is:
$$ \mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}} $$
This master equation, along with the overall training objective that sums this loss over time, dictates how the model learns to perform generative video propagation. The overall objective is formally stated as:
$$ \min_{\mathcal{E}} \sum_{i=2}^{T} \mathcal{L}(G(E(V), v'_1, v_i), V_i) $$
where $\mathcal{E}$ represents the model's trainable parameters.
Term-by-Term Autopsy
Let's dissect each component of the master equation and the overall objective:
-
$\mathcal{L}$ (Total Region-Aware Loss):
- Mathematical Definition: This is the combined loss value for a single video frame, representing the total penalty for deviations from the desired output and behavior.
- Physical/Logical Role: It serves as the primary signal for the optimizer, indicating how "bad" the current model's output and internal states are. Minimizing $\mathcal{L}$ means improving the model's performance across all its objectives.
- Why addition? The authors use addition because each term represents a distinct objective or constraint that the model must satisfy. By summing them, the model is encouraged to optimize for all these goals concurrently. If one term is high, the total loss is high, signaling the need for adjustment in that specific aspect.
-
$\mathcal{L}_{\text{non-mask}}$ (Non-Mask Region Loss):
- Mathematical Definition: $\mathcal{L}_{\text{non-mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v^{\text{out}}_t, (1 - m_t) \cdot v_t)]$. This is the diffusion Mean Squared Error (MSE) loss, $\mathcal{L}_d$, calculated between the generated output $v^{\text{out}}_t$ and the ground truth $v_t$, but only for the regions not covered by the mask $m_t$.
- Physical/Logical Role: This term ensures that the parts of the video that were not edited in the first frame remain consistent with the original video content throughout the sequence. It acts as a fidelity constraint, preventing unintended changes to the unedited background or objects.
- Why $(1 - m_t) \cdot \text{frame}$? Element-wise multiplication with $(1 - m_t)$ effectively "zeros out" the masked (edited) regions, isolating only the unedited parts of the frames for loss calculation. This is a precise way to focus the consistency objective on specific areas.
-
$\mathcal{L}_{\text{mask}}$ (Mask Region Loss):
- Mathematical Definition: $\mathcal{L}_{\text{mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d(m_t \cdot v^{\text{out}}_t, m_t \cdot v_t)]$. This is the diffusion MSE loss, $\mathcal{L}_d$, calculated between the generated output $v^{\text{out}}_t$ and the ground truth $v_t$, but only for the regions covered by the mask $m_t$.
- Physical/Logical Role: This term drives the model to accurately generate the edited content and propagate the modifications made to the first frame. It ensures that the changes are realistically rendered and consistent within the modified region across time.
- Why $m_t \cdot \text{frame}$? Similar to $\mathcal{L}_{\text{non-mask}}$, element-wise multiplication with $m_t$ isolates the masked (edited) regions, focusing the generation objective specifically on these areas.
-
$\lambda$ (Weight for $\mathcal{L}_{\text{mask}}$):
- Mathematical Definition: A positive scalar coefficient (set to 2.0 in the paper).
- Physical/Logical Role: This hyperparameter controls the relative importance of accurately generating the masked (edited) regions compared to other loss components. A higher $\lambda$ places more emphasis on propagating the edits correctly.
- Why multiplication? It scales the contribution of $\mathcal{L}_{\text{mask}}$ to the total loss, allowing for fine-tuning the balance between different objectives.
-
$\mathcal{L}_{\text{grad}}$ (Gradient Loss):
- Mathematical Definition: $\mathcal{L}_{\text{grad}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [m_t \cdot ||\Delta f||^2]$, where $\Delta f = \frac{f(E(V + \delta)) - f(E(V))}{\delta}$ is a finite difference approximation of the gradient of the Selective Content Encoder's (SCE) features $f(E(V))$ with respect to a small perturbation $\delta$ in the input video $V$.
- Physical/Logical Role: This is a crucial term for disentanglement. It penalizes the SCE if its output features change significantly when the input video is slightly perturbed within the masked region. The goal is to force the SCE to ignore the edited parts and focus solely on encoding the unchanged content. This prevents the SCE from inadvertently "reconstructing" removed objects or interfering with the I2V model's generative task in the edited areas.
- Why $||\Delta f||^2$? The squared L2 norm measures the magnitude of the change in features. Minimizing this magnitude encourages the SCE's features to be stable and insensitive to perturbations in the masked region.
- Why $m_t \cdot ||\Delta f||^2$? The mask $m_t$ ensures that this gradient penalty is applied only to the edited regions, which is where the SCE should ideally be "blind."
-
$\beta$ (Weight for $\mathcal{L}_{\text{grad}}$):
- Mathematical Definition: A positive scalar coefficient (set to 1.0 in the paper).
- Physical/Logical Role: This hyperparameter controls the strength of the gradient penalty, influencing how strongly the SCE is forced to disentangle its encoding from the edited regions.
- Why multiplication? It scales the contribution of $\mathcal{L}_{\text{grad}}$ to the total loss.
-
$\mathcal{L}_{\text{MPD}}$ (Mask Prediction Decoder Loss):
- Mathematical Definition: This is an MSE loss between the mask predicted by the Mask Prediction Decoder (MPD) and the ground truth mask $m_t$.
- Physical/Logical Role: This auxiliary loss explicitly trains the MPD to accurately identify the modified regions. By doing so, it provides a clear signal to the overall model about where the edits are, which in turn helps guide the I2V model's attention and generation process to the correct areas. It improves the accuracy of attention maps.
- Why MSE? MSE is a standard and effective loss function for regression tasks, including predicting pixel-wise mask values.
-
$\gamma$ (Weight for $\mathcal{L}_{\text{MPD}}$):
- Mathematical Definition: A positive scalar coefficient (set to 1.0 in the paper).
- Physical/Logical Role: This hyperparameter controls the importance of the explicit mask prediction task.
- Why multiplication? It scales the contribution of $\mathcal{L}_{\text{MPD}}$ to the total loss.
-
$\mathbb{E}_{t \sim \mathcal{U}(1,T)}$ (Expectation over time steps):
- Mathematical Definition: The average value of the loss over time steps $t$ sampled uniformly from $1$ to $T$.
- Physical/Logical Role: This ensures that the loss is computed and considered across various frames in the video sequence, promoting temporal consistency and generalization across the entire video.
- Why expectation/uniform sampling? It provides a robust estimate of the loss across the entire video, preventing the model from overfitting to specific frames or temporal positions.
-
$\sum_{i=2}^{T}$ (Summation over frames):
- Mathematical Definition: The sum of the Region-Aware Loss $\mathcal{L}$ for each frame $i$ from $2$ to $T$.
- Physical/Logical Role: This aggregates the per-frame losses into a single objective for the entire video sequence during training. The first frame ($i=1$) is the input edited frame, so the propagation task starts from the second frame.
- Why summation? Each frame's loss contributes equally to the overall training signal, ensuring that the model learns to propagate edits consistently throughout the entire video.
-
$G(E(V), v'_1, v_i)$ (Generated Output Frame):
- Mathematical Definition: The output of the Image-to-Video (I2V) generation model $G$, conditioned on the features from the Selective Content Encoder $E(V)$, the modified first frame $v'_1$, and the original $i$-th frame $v_i$ (used as a reference for the I2V model's internal processing, though the ground truth $V_i$ is used for loss calculation).
- Physical/Logical Role: This is the model's prediction for the $i$-th frame of the modified video. It represents the result of propagating the first-frame edit while maintaining consistency with the original video's unedited parts.
-
$E(V)$ (Selective Content Encoder Features):
- Mathematical Definition: The latent features extracted by the Selective Content Encoder $E$ from the original input video $V$.
- Physical/Logical Role: This component is designed to encode the information of the unchanged parts of the original video. It provides context to the I2V model, guiding it to preserve the original content where no edits were made.
-
$v'_1$ (Modified First Frame):
- Mathematical Definition: The first frame of the video, which has been manually or synthetically edited.
- Physical/Logical Role: This serves as the anchor for the propagation. The I2V model uses this as the starting point to understand what changes need to be propagated.
-
$v_i$ (Original $i$-th Frame):
- Mathematical Definition: The $i$-th frame of the original, unedited video sequence $V$.
- Physical/Logical Role: Used as part of the input to the I2V model during training, and as the ground truth for the unedited regions in the loss calculations.
-
$V_i$ (Ground Truth Synthetic Video Frame):
- Mathematical Definition: The $i$-th frame of the synthetic video sequence $V = \{V_1, V_2, ..., V_T\}$, which is generated by applying the data generation operator $D$ to an original video.
- Physical/Logical Role: This is the target output for the model during training, representing the desired modified video frame after propagation.
Step-by-Step Flow
Imagine GenProp as a sophisticated video editing factory. Here's how a single abstract data point (a video frame) moves through its assembly line during training:
- Original Video Ingestion: An original video sequence, let's call it $V$, enters the factory. This $V$ is a series of frames, $V_1, V_2, ..., V_T$.
- Synthetic Edit Application (Data Generation): A special "editing machine" (the data generation operator $D$) takes $V$ and applies a synthetic edit to its first frame, creating a modified first frame $v'_1$. It also generates corresponding ground truth modified frames $V_2, ..., V_T$ and binary masks $m_1, ..., m_T$ that precisely delineate the edited regions in each frame. This gives us a target video $V' = \{v'_1, V_2, ..., V_T\}$.
- Content Encoding (Selective Content Encoder, SCE): The entire original video $V$ is fed into the "Selective Content Encoder" ($E$). This encoder is like a smart filter; its job is to extract features that represent the unchanged content of the video, deliberately trying to ignore any information about the regions that will be edited. It's learning to be "blind" to the modifications.
- Propagation Engine (Image-to-Video Model): Now, for each subsequent frame $i$ (from $2$ to $T$):
- The modified first frame $v'_1$ (the blueprint of the edit) is fed in.
- The selectively encoded features from $E(V)$ (the context of the original, unedited scene) are injected.
- The current time step $i$ is also provided.
- The "Image-to-Video Generation Model" ($G$) acts as the main propagation engine. It takes these inputs and generates its best guess for the $i$-th frame of the modified video, which we call $v^{\text{out}}_i$. This is where the magic happens: the edit from $v'_1$ is propagated, guided by the original content features.
- Mask Prediction (Mask Prediction Decoder, MPD): Simultaneously, a "Mask Prediction Decoder" (MPD) takes internal latent representations from the I2V model and tries to predict the mask $m_i$ for the current frame. This is like a quality control sensor, checking if the model understands where the edits are.
- Loss Calculation & Feedback (Region-Aware Loss): For each generated frame $v^{\text{out}}_i$:
- Consistency Check (Non-Mask Loss): The unedited parts of $v^{\text{out}}_i$ (selected by $(1-m_i)$) are compared to the unedited parts of the ground truth $V_i$. Any discrepancy here contributes to $\mathcal{L}_{\text{non-mask}}$, pulling the model to keep original content intact.
- Edit Accuracy Check (Mask Loss): The edited parts of $v^{\text{out}}_i$ (selected by $m_i$) are compared to the edited parts of the ground truth $V_i$. Any error here contributes to $\mathcal{L}_{\text{mask}}$, pushing the model to accurately propagate the changes.
- Encoder Blindness Check (Gradient Loss): A special "gradient sensor" checks if the SCE's features would change if the input within the masked region were slightly altered. If they do, it adds to $\mathcal{L}_{\text{grad}}$, telling the SCE to be even more oblivious to edits.
- Mask Prediction Accuracy Check (MPD Loss): The MPD's predicted mask is compared to the ground truth mask $m_i$, contributing to $\mathcal{L}_{\text{MPD}}$.
- Total Loss Aggregation: All these individual loss components ($\mathcal{L}_{\text{non-mask}}$, $\mathcal{L}_{\text{mask}}$, $\mathcal{L}_{\text{grad}}$, $\mathcal{L}_{\text{MPD}}$) are weighted ($\lambda, \beta, \gamma$) and summed up to form the total Region-Aware Loss $\mathcal{L}$ for that frame. This process is repeated for all frames from $i=2$ to $T$, and all these per-frame losses are summed to get the overall objective.
- Parameter Adjustment: This total objective value is then sent to the "optimizer," which is like the factory manager. It calculates how each knob and dial (model parameter) needs to be adjusted to reduce this total loss. These adjustments are made iteratively, refining the SCE, I2V model, and MPD with each training step.
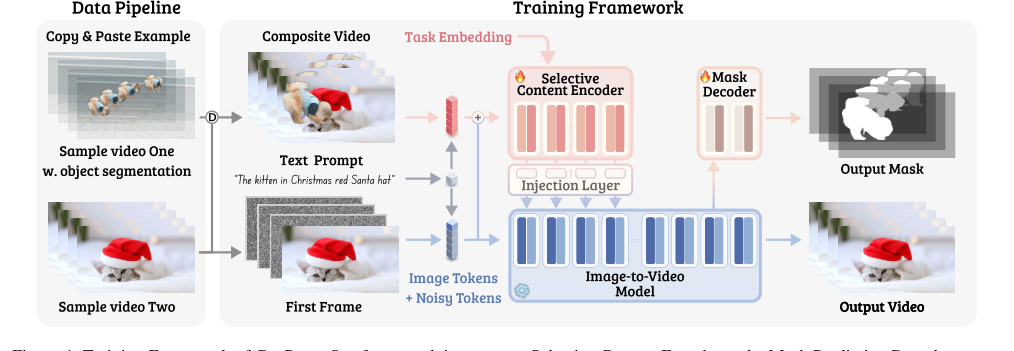 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
This entire cycle repeats millions of times, gradually teaching GenProp to seamlessly propagate edits while preserving the rest of the video.
Optimization Dynamics
GenProp learns and converges through a sophisticated interplay of gradient descent and a carefully sculpted loss landscape. The optimization process is driven by minimizing the total objective function, which is a sum of the Region-Aware Loss $\mathcal{L}$ across all frames from $i=2$ to $T$.
-
Gradient-Based Learning: The model parameters ($\mathcal{E}$) of the Selective Content Encoder (SCE), the Image-to-Video (I2V) generation model, and the Mask Prediction Decoder (MPD) are updated iteratively using an optimizer (e.g., Adam, as is common for diffusion models). This involves computing the gradients of the total loss with respect to each parameter. These gradients indicate the direction and magnitude by which parameters should be adjusted to decrease the loss. The learning rate (e.g., 5e-5 with a cosine-decay scheduler and linear warmup) controls the step size of these adjustments. An exponential moving average (EMA) of the model parameters is also maintained, which often leads to more stable training and better final performance by averaging out noisy updates. A gradient norm threshold (0.001) is applied to prevent exploding gradients and ensure training stability.
-
Loss Landscape Shaping for Disentanglement and Consistency: The unique design of the Region-Aware Loss ($\mathcal{L}$) is key to shaping the loss landscape and guiding the model's learning:
- Balanced Region Optimization: The $\mathcal{L}_{\text{mask}}$ and $\mathcal{L}_{\text{non-mask}}$ terms create a loss landscape with two primary "valleys." One valley encourages accurate generation within the edited regions, ensuring the propagated changes are realistic. The other valley promotes high fidelity to the original content in the unedited regions. By weighting these terms with $\lambda$, the authors can balance the model's focus, preventing it from either ignoring the edits or corrupting the original background. This dual objective helps the model navigate a complex landscape where it must both create new content and preserve existing content.
- Forcing SCE's Selectivity: The $\mathcal{L}_{\text{grad}}$ term is particularly ingenious. By penalizing the SCE if its features change when the input masked region is perturbed, it creates a "flat" region in the loss landscape for the SCE's output with respect to edited areas. This forces the SCE to learn a representation that is invariant to the modifications, effectively making it "blind" to the edits. This disentangles the SCE's role (encoding original context) from the I2V model's role (propagating edits), preventing issues like ghosting or the reappearance of removed objects. Without this, the SCE might try to reconstruct the original content everywhere, hindering the propagation of changes.
- Explicit Guidance for Attention: The $\mathcal{L}_{\text{MPD}}$ term provides an explicit, supervised signal for the model to identify where the edits are. This helps the I2V model's internal attention mechanisms to focus on the correct regions for generation and modification. By explicitly learning the mask, the model gains a clearer understanding of the "boundaries" between edited and unedited content, leading to more precise propagation and less confusion. This loss term helps to create a sharper, more defined boundary in the loss landscape for the regions that require modification.
-
Iterative Refinement and Convergence: Over many iterations, the model iteratively updates its parameters. The I2V model learns to generate increasingly realistic and temporally consistent video frames based on the edited first frame and the SCE's context. The SCE learns to extract robust, edit-agnostic features from the original video. The MPD learns to accurately predict the modified regions. This continuous feedback loop, guided by the region-aware loss, drives the model towards a state where it can seamlessly propagate diverse first-frame edits across entire video sequences while maintaining high fidelity to the unedited content. The model converges when the gradients become very small, indicating that further parameter updates yield minimal improvement in the loss.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate GenProp's capabilities, the authors architected a comprehensive experimental setup, leveraging two distinct base video generation models: a DiT architecture akin to Sora [32] and a U-Net architecture based on Stable Video Diffusion (SVD) [5]. The DiT variant, which ultimately yielded superior video generation quality, was trained for image-to-video (I2V) generation across 32, 64, and 128 frames at 12 and 24 frames per second (FPS), with a base resolution of 360p. The Selective Content Encoder (SCE) and Mask Prediction Decoder (MPD) components were trained while the I2V model remained frozen, ensuring that GenProp's core mechanism focused on propagating edits rather than re-learning video generation from scratch.
Training involved a learning rate of $5 \times 10^{-5}$ with a cosine-decay scheduler and linear warmup, alongside an exponential moving average for stability. A gradient norm threshold of 0.001 was applied to prevent instability. Classifier-free guidance (CFG) was set to 20. A crucial aspect of the training was the synthetic data generation scheme, which employed various augmentation ratios (0.5, 0.375, 0.125) for copy-and-paste, mask-and-fill, and color fill tasks. The Region-Aware (RA) loss, vital for disentangling edited and unedited regions, utilized specific weighting parameters: $\lambda = 2.0$, $\beta = 1.0$, and $\gamma = 1.0$. All experiments were conducted on 32 or 64 NVIDIA A100 GPUs, highlighting the significant computational resources required.
The "victims" (baseline models) GenProp was pitted against varied by task. For general video editing, it was compared to InsV2V [8], AnyV2V [27], Pika [2], and ReVideo [31]. For object removal, a cascaded pipeline of SAM-V2 [39] (for mask tracking) and Propainter [64] (for inpainting) served as the baseline. For object tracking, SAM-V2 [39] was the direct competitor.
Quantitative evaluations were performed on two test sets:
1. Classic Test Set: Comprising the TGVE [51]'s DAVIS [36] dataset, with "Object Change Caption" text prompts, focusing on object replacement and appearance editing.
2. Challenging Test Set: A collection of 30 manually curated videos from Pexels [1] and Adobe Stock [3], featuring more complex scenarios like large object replacement, object insertion, and background replacement. Edits on this set were performed using commercial photo editing tools or specific baseline methods (e.g., Pika's online boxing tool, ReVideo's motion point extraction).
The definitive evidence of GenProp's success was measured using several metrics:
- PSNRm: Peak Signal-to-Noise Ratio, specifically calculated outside the edited region to quantify consistency of unchanged content.
- CLIP-T: Cosine similarity between CLIP [38] embeddings of the edited frame and the text prompt, assessing text alignment.
- CLIP-I: Distance between CLIP [38] features across frames, measuring frame-to-frame consistency.
- User Study: A human evaluation conducted on Amazon MTurk [45] with 121 participants, who compared GenProp's outputs against baselines and original videos, judging alignment with instructions and overall visual quality.
What the Evidence Proves
The evidence unequivocally proves that GenProp's core mechanism works in reality, establishing it as a leading framework for generative video propagation. As shown in Table 1, GenProp significantly outperforms other methods across most metrics, particularly on the more demanding Challenging Test Set. This is not merely an incremental improvement; it's a demonstration of a fundamentally more robust and versatile approach.
For instance, in object replacement and background replacement (Figure 6a, 6b), GenProp showcased its ability to seamlessly modify objects with vastly different shapes and independent motion, and to perform complex background edits. This directly addresses a major limitation of baselines like InsV2V [8] and Pika [2], which struggle with significant shape changes or object insertion due to their reliance on text prompts or limited training data. AnyV2V [27] also suffered from limited generalization, and ReVideo [31] often produced blurry boundaries and accumulated errors from its point tracking mechanism. GenProp's ability to handle these complex scenarios without requiring dense mask labeling for every frame is a testament to its propagation-based approach.
In object and effect removal (Figure 6c, 6d), GenProp excelled by not only removing objects but also their associated effects, such as shadows and reflections, and realistically reconstructing large occluded areas. The SAM+Propainter baseline, while effective for inpainting, struggled to remove these subtle effects, as indicated by its lower CLIP-I and user preference scores in Table 2. GenProp's unified approach, leveraging generative models, inherently understands how to fill in removed regions plausibly, including the environmental context.
For instance object and effect tracking (Figure 6e), GenProp demonstrated consistent tracking of objects and their associated effects, even when initialized with solid color fills. While SAM-V2 [39] is faster for real-time tracking and can produce precise masks, GenProp's pretraining on video generation gives it a strong understanding of physical rules, allowing it to track effects that SAM-V2 often misses due to its limited and biased training data. This highlights the potential of generation-based models to tackle classic vision tasks with a deeper understanding of scene dynamics.
The ablation studies further provided undeniable evidence for the effectiveness of GenProp's key components:
- The Mask Prediction Decoder (MPD) significantly improved both Text Alignment and Consistency (Table 3). Without it, the output masks were often degraded, leading to incomplete object removal and confusion about which regions to propagate versus preserve (Figure 7, rows 1-2). MPD's explicit supervision helps the model disentangle changes and ensures full object removal, even with heavy occlusion.
- The Region-Aware Loss (RA Loss) was critical for stable and consistent propagation of first-frame edits. Without RA Loss, the original object tended to gradually reappear in subsequent frames, hindering the propagation (Figure 7, rows 3-5). This loss ensures that the edited areas are propagated stably while unchanged regions remain consistent.
- Color Fill Augmentation was proven to be a crucial factor for addressing propagation failure, especially for large shape modifications. It explicitly trains the model for tracking, guiding it to maintain modifications throughout the sequence, enabling challenging edits like transforming a girl into a small cat (Figure 7, rows 6-8).
In summary, GenProp's success is rooted in its careful design, leveraging the generative power of I2V models, a selective content encoder, a mask prediction decoder, and a region-aware loss, all trained with a versatile synthetic data generation pipeline. This combination allows it to ruthlessly prove its mathematical claims by consistently outperforming baselines across diverse and challenging video editing tasks.
Limitations & Future Directions
While GenProp presents a significant leap forward in generative video propagation, it's important to acknowledge its inherent limitations and consider avenues for future development. One implicit limitation is the computational cost; training on multiple NVIDIA A100 GPUs suggests that deploying this model for real-time, high-resolution video editing on consumer-grade hardware might still be a challenge. Furthermore, the reliance on synthetic data, while enabling versatility, might introduce biases or reduce generalization to extremely novel, uncurated real-world scenarios that differ significantly from the synthetic distribution. The paper also notes that traditional quality metrics sometimes fail to capture the realism of generated results, necessitating user studies, which points to a gap in automated, comprehensive evaluation.
Looking ahead, the authors explicitly plan to extend the model to support more than one key frame edits, which would significantly enhance its flexibility for complex, multi-stage editing workflows. They also aim to uncover additional video tasks that can be supported by the framework, suggesting that GenProp's underlying generative power has untapped potential.
Beyond these immediate plans, several discussion topics emerge for further developing and evolving these findings:
-
Enhanced User Control and Interpretability: While GenProp simplifies the editing process by removing the need for dense masks, how can more intuitive and granular user control be integrated for fine-tuning edits? Could a "human-in-the-loop" system, perhaps with interactive feedback mechanisms, allow users to guide the propagation process more precisely without reintroducing the complexity of traditional methods? Exploring methods to make the model's internal "reasoning" (e.g., attention maps) more interpretable to users could also foster greater trust and control.
-
Real-world Robustness and Data Scarcity: The current framework benefits greatly from synthetic data. However, real-world video data often contains noise, occlusions, and unpredictable motion patterns not fully captured by synthetic datasets. Future work could explore domain adaptation techniques or self-supervised learning strategies to improve GenProp's robustness to unconstrained, "in-the-wild" videos, potentially reducing the reliance on meticulously crafted synthetic data.
-
Efficiency and Scalability for Production: For broader adoption, optimizing GenProp for faster inference and reduced memory footprint is crucial. Investigating techniques like knowledge distillation, model pruning, or more efficient architectural designs could enable deployment on edge devices or for processing longer, higher-resolution videos in real-time. What are the trade-offs between generation quality, speed, and resource consumption, and how can these be balanced for practical applications?
-
Multimodal Integration and Contextual Understanding: Video is inherently multimodal. How could GenProp be extended to incorporate audio, text descriptions beyond prompts, or even 3D scene information to create more coherent and immersive edits? For example, editing an object's motion could automatically trigger corresponding sound effect adjustments, or understanding the 3D geometry of a scene could lead to more physically accurate interactions and lighting effects for inserted objects.
-
Ethical Implications and Responsible AI: As generative video editing becomes increasingly sophisticated, the ability to create highly realistic but manipulated content raises significant ethical concerns. Future discussions should proactively address how to develop and deploy such powerful tools responsibly, including mechanisms for detecting manipulated content, establishing clear guidelines for usage, and ensuring transparency in AI-generated media. This is a critical aspect for the long-term societal impact of this technology.
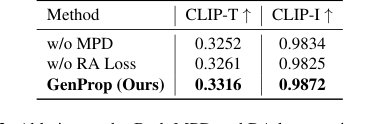 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
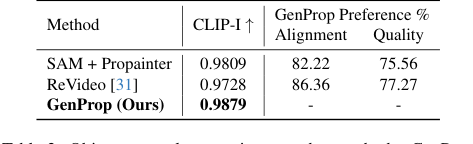 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
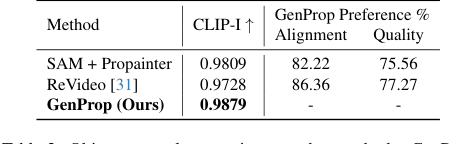 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set