जनरेटिव वीडियो प्रोपेगेशन
इस पत्र में संबोधित जनरेटिव वीडियो प्रोपेगेशन की समस्या कंप्यूटर विज़न के व्यापक क्षेत्र में निहित है, विशेष रूप से वीडियो जनरेशन और एडिटिंग के डोमेन के भीतर। ऐतिहासिक रूप से, मुख्य चुनौती एक एकल फ्रेम (या फ्रेम के एक...
पृष्ठभूमि और अकादमिक वंश
इस पत्र में संबोधित जनरेटिव वीडियो प्रोपेगेशन की समस्या कंप्यूटर विज़न के व्यापक क्षेत्र में निहित है, विशेष रूप से वीडियो जनरेशन और एडिटिंग के डोमेन के भीतर। ऐतिहासिक रूप से, मुख्य चुनौती एक एकल फ्रेम (या फ्रेम के एक विरल सेट) में किए गए परिवर्तनों को पूरे वीडियो अनुक्रम में लगातार और यथार्थवादी रूप से प्रसारित करना रही है। वीडियो प्रोपेगेशन के शुरुआती दृष्टिकोण, जो संशोधित वीडियो सामग्री में टेम्पोरल कोहेरेंस और विज़ुअल प्लाउसिबिलिटी बनाए रखने की आवश्यकता से उभरे, मुख्य रूप से पारंपरिक कंप्यूटर विज़न तकनीकों जैसे ऑप्टिकल फ्लो [9, 44], डेप्थ एस्टिमेशन [6, 55], रेडियंस फील्ड्स [33], और एटलस [20, 24] पर निर्भर थे। परिष्कृत वीडियो एडिटिंग टूल की बढ़ती मांग, जो न्यूनतम मैन्युअल प्रयास के साथ जटिल, यथार्थवादी परिदृश्यों को संभाल सके, ने इस विशिष्ट समस्या के उद्भव और विकास को प्रेरित किया है।
पिछले दृष्टिकोणों की मौलिक सीमा या "दर्द बिंदु" जिसने लेखकों को एक नया ढांचा विकसित करने के लिए प्रेरित किया, वह कई प्रमुख मुद्दों से उत्पन्न होती है। पारंपरिक तरीके अक्सर वीडियो की अवधि में त्रुटि संचय के प्रति प्रवण होते थे, जिससे बाद के फ्रेम में गुणवत्ता में गिरावट और असंगति होती थी। इसने उन्हें कम मजबूत बनाया और विविध वीडियो सामग्री में उनकी सामान्यीकरण क्षमता को सीमित कर दिया। कई पूर्व तकनीकें कार्य-विशिष्ट भी थीं, जिसका अर्थ है कि एक प्रकार के संपादन (जैसे, वस्तु निष्कासन) के लिए प्रशिक्षित मॉडल को दूसरे कार्य (जैसे, पृष्ठभूमि प्रतिस्थापन) [28, 31, 34, 61] के लिए महत्वपूर्ण पुन: प्रशिक्षण या पूरी तरह से अलग मॉडल की आवश्यकता होगी। एक एकीकृत ढांचे की यह कमी एक बड़ी बाधा थी। हाल के डिफ्यूजन-आधारित वीडियो एडिटिंग मॉडल, शक्तिशाली होने के बावजूद, उनकी अपनी बाधाएं भी थीं। कई मुख्य रूप से वस्तु के आकार में बड़े बदलाव करने या जटिल पृष्ठभूमि संशोधनों को संभालने के बजाय रूप को बदलने के लिए डिज़ाइन किए गए थे। उन्हें अक्सर प्रत्येक व्यक्तिगत फ्रेम के लिए सघन मास्क लेबलिंग की आवश्यकता होती थी, जो एक श्रम-गहन और समय लेने वाली प्रक्रिया है, जिससे वास्तविक समय या बड़े पैमाने पर अनुप्रयोग अव्यावहारिक हो जाते हैं। उदाहरण के लिए, I2VEdit [34] जैसी विधियों ने प्रत्येक वीडियो क्लिप के लिए मोशन LoRAs सीखने की आवश्यकता से कम्प्यूटेशनल जटिलता पेश की। अन्य दृष्टिकोण, जैसे ReVideo [31], ने इनपुट वीडियो के कुछ हिस्सों को काले वर्गों के साथ मास्क करना शामिल किया, जिसने अनजाने में महत्वपूर्ण जानकारी हटा दी और जटिल पृष्ठभूमि संपादन और बड़े आकार के परिवर्तनों को संभालने की उनकी क्षमता को प्रतिबंधित कर दिया। लेखकों की प्रेरणा इन सीमाओं को एक एकीकृत, जनरेटिव ढांचे का प्रस्ताव करके दूर करना था जो विविध संपादन को निर्बाध रूप से, मजबूती से, और कार्य-विशिष्ट पुन: प्रशिक्षण या सघन मास्क इनपुट की आवश्यकता के बिना प्रसारित कर सके, इस प्रकार वीडियो संपादन प्रक्रिया को काफी सरल बना सके।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष शब्द दिए गए हैं, जिन्हें शून्य-आधारित पाठक के लिए सहज, रोजमर्रा की उपमाओं में अनुवादित किया गया है:
-
जनरेटिव वीडियो प्रोपेगेशन: कल्पना करें कि आप एक क्लेमेशन फिल्म बना रहे हैं। आप पहला दृश्य बनाते हैं, फिर अपने क्ले पात्रों में से एक में एक छोटी टोपी जोड़ने का निर्णय लेते हैं। "जनरेटिव वीडियो प्रोपेगेशन" एक जादुई, सुपर-स्मार्ट सहायक की तरह है जो, संपादित पहले दृश्य को देखने के बाद, स्वचालित रूप से सभी बाद के दृश्यों को फिर से बनाता है, यह सुनिश्चित करता है कि टोपी चरित्र पर लगातार दिखाई दे, उनके साथ स्वाभाविक रूप से चले, और फिल्म में पूरी तरह से एकीकृत दिखे, बिना आपको हर फ्रेम को छूना पड़े। यह आपके प्रारंभिक संपादन को "जनरेटिव" (रचनात्मक, यथार्थवादी) तरीके से पूरे वीडियो में "प्रसारित" करता है।
-
इमेज-टू-वीडियो (I2V) जनरेशन मॉडल: इसे एक अत्यधिक कल्पनाशील कहानीकार के रूप में सोचें। आप इस कहानीकार को एक एकल तस्वीर (एक "छवि") और आगे क्या होना चाहिए इसका एक संक्षिप्त विवरण देते हैं, और वे इससे एक पूरी छोटी वीडियो अनुक्रम का आविष्कार और निर्माण कर सकते हैं। उदाहरण के लिए, आप उन्हें एक स्थिर झील की तस्वीर देते हैं और कहते हैं "पानी को धीरे-धीरे लहरें दें," और वे यथार्थवादी लहरों वाली झील का वीडियो उत्पन्न करते हैं। इस पत्र में, इस कहानीकार का उपयोग संपादित पहले फ्रेम के आधार पर वीडियो के शेष भाग को उत्पन्न करने के लिए किया जाता है।
-
चयनात्मक सामग्री एन्कोडर (SCE): एक बहुत सावधान लाइब्रेरियन की कल्पना करें। आप इस लाइब्रेरियन को एक पुस्तक के दो संस्करण देते हैं: मूल और एक जहां आपने कुछ वाक्यों को हाइलाइट किया है। इस लाइब्रेरियन का काम मूल पुस्तक के उन सभी हिस्सों को केवल याद रखना और संरक्षित करना है जिन्हें आपने हाइलाइट नहीं किया है, जबकि हाइलाइट किए गए अनुभागों को जानबूझकर अनदेखा करना है। यह मूल सामग्री को "चयनात्मक रूप से एन्कोड" करता है, जो अपरिवर्तित रहने वाली चीजों पर ध्यान केंद्रित करता है, ताकि जनरेटिव मॉडल तब पुस्तक के बाकी हिस्सों को गड़बड़ किए बिना संपादित भागों को भर सके।
-
क्षेत्र-जागरूक हानि (RA Loss): कल्पना करें कि आप एक छात्र की कला परियोजना का मूल्यांकन कर रहे हैं, जिसमें दो भाग हैं: एक ड्राइंग और एक पेंटिंग। "क्षेत्र-जागरूक हानि" एक ग्रेडिंग प्रणाली की तरह है जो यह सुनिश्चित करती है कि आप ड्राइंग (वीडियो के अपरिवर्तित भाग) और पेंटिंग (संपादित भाग) दोनों पर समान ध्यान दें, भले ही एक भाग बहुत छोटा हो या कम महत्वपूर्ण लगे। यह सुनिश्चित करता है कि मॉडल मूल सामग्री को संरक्षित करने और संपादन को सटीक रूप से प्रसारित करने दोनों पर अच्छा प्रदर्शन करना सीखे, जिससे यह दूसरे की कीमत पर एक पर बहुत अधिक ध्यान केंद्रित करने से बच सके।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएं
मुख्य समस्या सूत्रीकरण और दुविधा
यह पत्र जनरेटिव वीडियो प्रोपेगेशन की जटिल समस्या को संबोधित करता है, जिसका लक्ष्य यथार्थवाद और निरंतरता बनाए रखते हुए पहले फ्रेम के संपादन को पूरे वीडियो अनुक्रम में निर्बाध रूप से लागू करना है।
इनपुट/वर्तमान स्थिति:
शुरुआती बिंदु एक मूल वीडियो $V = \{v_1, v_2, ..., v_T\}$ है जिसमें $T$ फ्रेम शामिल हैं, और एक एकल संशोधित पहला फ्रेम $v'_1$ है। यह $v'_1$ मूल पहले फ्रेम $v_1$ पर लागू एक मनमाने संपादन का परिणाम है। मौजूदा वीडियो संपादन विधियों में आम तौर पर कई सीमाएं होती हैं: उन्हें अक्सर प्रत्येक फ्रेम के लिए सघन मास्क लेबलिंग की आवश्यकता होती है, गति मार्गदर्शन के लिए ऑप्टिकल फ्लो या डेप्थ मैप जैसे सहायक इनपुट पर निर्भर करती हैं, या प्रत्येक विशिष्ट संपादन कार्य या वीडियो क्लिप के लिए पुन: प्रशिक्षण की आवश्यकता होती है। कई विशिष्ट प्रकार के संपादन तक सीमित हैं, जैसे कि उपस्थिति परिवर्तन, और महत्वपूर्ण आकार संशोधनों या जटिल पृष्ठभूमि परिवर्तनों से जूझते हैं।
आउटपुट/लक्ष्य स्थिति:
वांछित अंतिम बिंदु एक नया, संशोधित वीडियो $V' = \{v'_1, v'_2, ..., v'_T\}$ है। प्रत्येक बाद के फ्रेम $v'_t$ (जहां $t \in \{2, ..., T\}$) के लिए, लक्ष्य यह सुनिश्चित करना है कि $v'_1$ में पेश किए गए संशोधन को पूरे वीडियो में सटीक और यथार्थवादी रूप से प्रसारित किया जाए। साथ ही, वीडियो के सभी अनएडिटेड क्षेत्रों को उपस्थिति और गति दोनों के संदर्भ में मूल सामग्री के साथ पूरी तरह से सुसंगत रहना चाहिए। ढांचे को वस्तु निष्कासन, सम्मिलन, प्रतिस्थापन, ट्रैकिंग और आउटपेंटिंग सहित वीडियो संपादन कार्यों की एक विस्तृत श्रृंखला पर सामान्य रूप से लागू किया जाना चाहिए, बिना कार्य-विशिष्ट डेटा या ऑप्टिकल फ्लो जैसे स्पष्ट गति संकेतों की आवश्यकता के।
लुप्त कड़ी या गणितीय अंतर:
सटीक लुप्त कड़ी एक एकीकृत, जनरेटिव ढांचा है जो वीडियो के संशोधित और अपरिवर्तित क्षेत्रों को प्रभावी ढंग से अलग कर सकता है और एक एकल संपादित पहले फ्रेम से पूरे अनुक्रम तक परिवर्तनों को प्रसारित कर सकता है। यह अपरिवर्तित क्षेत्रों में मूल सामग्री को संरक्षित करते हुए और विविध और जटिल संपादन परिदृश्यों में संपादित क्षेत्रों में नई, भौतिक रूप से प्रशंसनीय सामग्री उत्पन्न करते हुए प्राप्त किया जाना चाहिए। गणितीय रूप से, पत्र एक जनरेटिव फ़ंक्शन $G$ और एक चयनात्मक सामग्री एन्कोडर $E$ को परिभाषित करना चाहता है ताकि $t \in \{2, ..., T\}$ के लिए संशोधित फ्रेम $v'_t$ को $v'_t = G(E(V), v'_1, t)$ द्वारा उत्पादित किया जा सके। यहां, $E(V)$ को मूल वीडियो $V$ से केवल अपरिवर्तित जानकारी को चयनात्मक रूप से एन्कोड करना चाहिए, जिससे $G$ (एक इमेज-टू-वीडियो जनरेशन मॉडल) को $v'_1$ से बाद के फ्रेम तक संपादित सामग्री को प्रसारित करने पर ध्यान केंद्रित करने की अनुमति मिलती है। चुनौती $E$ और $G$ को इस अलगाव और सुसंगत प्रसार को स्पष्ट प्रति-फ्रेम मार्गदर्शन के बिना प्राप्त करने के लिए सहक्रियात्मक रूप से काम करने के लिए डिजाइन करने में निहित है।
दर्दनाक समझौता या दुविधा:
पिछले शोधकर्ताओं को एक मौलिक समझौते में फंसाया गया है:
1. यथार्थवाद और निरंतरता बनाम सामान्यता और लचीलापन: संपादन के अत्यधिक यथार्थवादी और लौकिक रूप से सुसंगत प्रसार (विशेष रूप से बड़े आकार के संशोधनों या पृष्ठभूमि परिवर्तनों जैसे जटिल परिवर्तनों के लिए) प्राप्त करना अक्सर सामान्यता की कीमत पर आता है। जो तरीके निरंतरता में उत्कृष्ट हैं, वे आम तौर पर स्पष्ट गति अभ्यावेदन (जैसे, ऑप्टिकल फ्लो) या प्रति-कार्य फाइन-ट्यूनिंग पर निर्भर करते हैं, जिससे वे कम लचीले होते हैं और विशिष्ट इनपुट की आवश्यकता होती है। इसके विपरीत, अधिक सामान्य जनरेटिव मॉडल अक्सर महीन-दानेदार निरंतरता बनाए रखने और समय के साथ कलाकृतियों से बचने के लिए संघर्ष करते हैं। एक पहलू में सुधार (जैसे, पर्याप्त आकार परिवर्तन की अनुमति देना) आमतौर पर दूसरे को तोड़ता है (जैसे, लौकिक सुसंगति या छाया जैसे प्रभावों का यथार्थवाद)।
2. कम्प्यूटेशनल दक्षता बनाम गुणवत्ता और दायरा: कई मौजूदा दृष्टिकोण या तो कम्प्यूटेशनल रूप से गहन प्रक्रियाओं (जैसे, सभी फ्रेम के लिए सघन मास्क लेबलिंग या प्रति-वीडियो फाइन-ट्यूनिंग) को शामिल करते हैं या सीमित गुणवत्ता और संपादन के दायरे के साथ परिणाम उत्पन्न करते हैं। दुविधा यह है कि अत्यधिक कम्प्यूटेशनल लागत या व्यापक मैन्युअल हस्तक्षेप की आवश्यकता के बिना उच्च-गुणवत्ता, विविध वीडियो संपादन कैसे प्राप्त करें।
बाधाएं और विफलता मोड
जनरेटिव वीडियो प्रोपेगेशन की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
- लौकिक निरंतरता और त्रुटि संचय: यह सुनिश्चित करना कि संपादन सैकड़ों फ्रेम में संचित त्रुटियों के बिना सुचारू रूप से और लगातार प्रसारित हों, एक बड़ी चुनौती है। यहां तक कि छोटी असंगतियां भी बाद के फ्रेम में ध्यान देने योग्य "भूतिया प्रभाव," झिलमिलाहट, या गिरावट का कारण बन सकती हैं, खासकर जटिल गति या लंबे वीडियो अनुक्रमों से निपटते समय।
- संपादित और अपरिवर्तित क्षेत्रों का अलगाव: मॉडल को संपादित क्षेत्रों के लिए नई सामग्री उत्पन्न करते हुए, अपरिवर्तित क्षेत्रों में मूल सामग्री की सटीक पहचान और संरक्षण करना चाहिए। यह अलगाव महत्वपूर्ण है; यहां विफलता से संपादित क्षेत्रों में मूल वस्तुओं का पुन: प्रकट होना या अपरिवर्तित भागों में अनपेक्षित परिवर्तन हो सकते हैं।
- विविध और जटिल संपादन को संभालना: ढांचे को वस्तु निष्कासन (संबंधित प्रभाव जैसे छाया, प्रतिबिंब), स्वतंत्र गति के साथ वस्तु सम्मिलन, और पृष्ठभूमि प्रतिस्थापन सहित संपादन कार्यों की एक विस्तृत श्रृंखला का समर्थन करने की आवश्यकता है। प्रत्येक कार्य सामग्री निर्माण और गति सुसंगति के संदर्भ में अद्वितीय चुनौतियां प्रस्तुत करता है।
- कार्य-विशिष्ट डेटा की कमी: हर संभव वीडियो संपादन कार्य के लिए बड़े पैमाने पर, युग्मित वीडियो डेटासेट बनाना अत्यधिक महंगा और समय लेने वाला है। यह डेटा विरलता सिंथेटिक डेटा जनरेशन पर निर्भरता को मजबूर करती है, जो मॉडल को वास्तविक दुनिया के वीडियो पर अच्छी तरह से सामान्यीकृत करने और सिंथेटिक कलाकृतियों को सीखने से बचने को सुनिश्चित करने की अपनी चुनौतियां पेश करती है।
- कम्प्यूटेशनल और मेमोरी सीमाएं: उच्च-रिज़ॉल्यूशन वीडियो अनुक्रमों को संसाधित करना और जटिल सामग्री के साथ नए फ्रेम उत्पन्न करने के लिए महत्वपूर्ण कम्प्यूटेशनल संसाधनों की आवश्यकता होती है। ऐसे मॉडल के लिए प्रशिक्षण और अनुमान के लिए शक्तिशाली जीपीयू और पर्याप्त मेमोरी की आवश्यकता होती है, जिससे वास्तविक समय या यहां तक कि निकट वास्तविक समय प्रदर्शन एक महत्वपूर्ण बाधा बन जाता है।
- स्पष्ट गति संकेतों की अनुपस्थिति: पारंपरिक तरीकों के विपरीत जो ऑप्टिकल फ्लो या डेप्थ मैप पर निर्भर करते हैं, यह ढांचा ऐसे स्पष्ट गति मार्गदर्शन के बिना संचालित करने का लक्ष्य रखता है। यह बाधा जनरेटिव मॉडल पर अंतर्निहित रूप से प्रशंसनीय गति को समझने और संश्लेषित करने के लिए एक उच्च बोझ डालती है, जो स्वाभाविक रूप से कठिन है।
- गैर-विभेदक वास्तविक दुनिया भौतिकी: जनरेटिव ढांचे के भीतर छाया, प्रतिबिंब और यथार्थवादी वस्तु इंटरैक्शन जैसे भौतिक प्रभावों को सटीक रूप से मॉडल करना और प्रसारित करना चुनौतीपूर्ण है, क्योंकि ये घटनाएं जटिल हैं और आसानी से विभेदक कार्यों द्वारा दर्शाई नहीं जा सकती हैं।
यह दृष्टिकोण क्यों
विकल्प की अनिवार्यता
GenProp ढांचे के लिए जनरेटिव इमेज-टू-वीडियो (I2V) मॉडल पर निर्माण करने का लेखकों का निर्णय केवल एक प्राथमिकता नहीं थी; यह मौजूदा दृष्टिकोणों की अंतर्निहित सीमाओं से प्रेरित एक रणनीतिक आवश्यकता थी। पारंपरिक वीडियो प्रोपेगेशन विधियां, जो अक्सर ऑप्टिकल फ्लो, डेप्थ मैप या एटलस पर निर्भर करती हैं, मौलिक रूप से सामान्य जनरेटिव वीडियो प्रोपेगेशन की समस्या के लिए अनुपयुक्त थीं। ये तरीके समय के साथ त्रुटियों को जमा करने के प्रवण होते हैं, सीमित मजबूती प्रदर्शित करते हैं, और महत्वपूर्ण रूप से, विभिन्न संपादन कार्यों को व्यापक पुन: प्रशिक्षण या कार्य-विशिष्ट संशोधनों के बिना संभालने की सामान्यीकरण क्षमता की कमी होती है। वे आम तौर पर एक एकल, अच्छी तरह से परिभाषित कार्य में उत्कृष्ट होते हैं लेकिन बहुमुखी प्रतिभा की आवश्यकता का सामना करने पर टूट जाते हैं।
"आह!" क्षण, हालांकि एक एकल घटना के रूप में स्पष्ट रूप से नहीं कहा गया है, राज्य-की-कला (SOTA) के पेपर के महत्वपूर्ण मूल्यांकन से अनुमान लगाया जा सकता है। यहां तक कि उन्नत डिफ्यूजन-आधारित वीडियो संपादन मॉडल, शक्तिशाली होने के बावजूद, मुख्य रूप से पाठ-निर्देशित उपस्थिति परिवर्तनों पर केंद्रित थे या बोझिल प्रति-मामला फाइन-ट्यूनिंग की आवश्यकता थी। उन्होंने महत्वपूर्ण आकार संशोधनों, जटिल पृष्ठभूमि संपादन, या डाले गए वस्तुओं की भौतिक रूप से प्रशंसनीय गति के साथ संघर्ष किया। Revideo [31] जैसी विधियों, उदाहरण के लिए, इनपुट वीडियो के कुछ हिस्सों को काले वर्गों के साथ मास्क करने पर निर्भर करती थीं, जिसने अनिवार्य रूप से महत्वपूर्ण जानकारी हटा दी और जटिल पृष्ठभूमि संपादन या बड़े आकार के परिवर्तनों को संभालने की उनकी क्षमता को प्रतिबंधित कर दिया। अन्य, जैसे I2VEdit [34], ने प्रत्येक वीडियो क्लिप के लिए मोशन LoRAs की आवश्यकता से कम्प्यूटेशनल जटिलता पेश की। अहसास यह था कि कोई भी मौजूदा विधि एक एकीकृत, सामान्य ढांचा प्रदान नहीं करती थी जो पूरे वीडियो अनुक्रम में यथार्थवाद और निरंतरता दोनों को बनाए रखते हुए, सघन मास्क एनोटेशन या सहायक गति भविष्यवाणियों की आवश्यकता के बिना, विविध पहले-फ्रेम संपादन (निष्कासन, सम्मिलन, प्रतिस्थापन, ट्रैकिंग, एकाधिक संपादन) को प्रसारित कर सके। I2V मॉडल की जनरेटिव शक्ति, जब सावधानीपूर्वक डिजाइन और संवर्धित की जाती है, इस बहुआयामी चुनौती को समग्र रूप से संबोधित करने का एकमात्र व्यवहार्य मार्ग था।
तुलनात्मक श्रेष्ठता
GenProp की गुणात्मक श्रेष्ठता इसके संरचनात्मक डिजाइन से उत्पन्न होती है, जो सीधे पिछले तरीकों की कमियों को संबोधित करती है। ऑप्टिकल फ्लो जैसे स्पष्ट गति संकेतों पर निर्भर पारंपरिक दृष्टिकोणों के विपरीत, GenProp I2V मॉडल की अंतर्निहित जनरेटिव क्षमताओं का लाभ उठाता है। यह त्रुटि संचय की समस्या को समाप्त करता है जो फ्लो-आधारित विधियों को त्रस्त करती है, जिससे लंबे वीडियो अनुक्रमों में काफी अधिक मजबूत और सुसंगत प्रसार होता है।
एक प्रमुख संरचनात्मक लाभ चयनात्मक सामग्री एन्कोडर (SCE) है। यह घटक GenProp को मूल वीडियो के अपरिवर्तित भागों से सुविधाओं को चयनात्मक रूप से एन्कोड करने की अनुमति देता है, जबकि I2V मॉडल संशोधित क्षेत्रों को प्रसारित करने पर अपनी जनरेटिव शक्ति केंद्रित करता है। यह अलगाव अपरिवर्तित क्षेत्रों में निरंतरता बनाए रखने के लिए महत्वपूर्ण है, जो अन्य तरीकों के लिए एक सामान्य विफलता बिंदु है जो अनजाने में स्थिर क्षेत्रों को बदल सकते हैं। इसके अलावा, मास्क प्रेडिक्शन डिकोडर (MPD), एक सहायक हेड के साथ प्रशिक्षित, मॉडल को संशोधन की आवश्यकता वाले क्षेत्रों को सटीक रूप से पहचानने और उन पर ध्यान केंद्रित करने के लिए निर्देशित करता है, संपादन में सटीकता बढ़ाता है और ध्यान मानचित्रों की गुणवत्ता में सुधार करता है (जैसा कि चित्र 3 में दिखाया गया है)।
शायद सबसे महत्वपूर्ण गुणात्मक छलांग GenProp की सामान्यता और लचीलापन है। यह जटिल वीडियो संपादन कार्यों की एक विस्तृत श्रृंखला का समर्थन करता है - पूर्ण वस्तु निष्कासन (छाया और प्रतिबिंब जैसे यथार्थवादी प्रभावों के साथ), पृष्ठभूमि प्रतिस्थापन, भौतिक रूप से प्रशंसनीय गति के साथ वस्तु सम्मिलन, और यहां तक कि वस्तुओं और उनके संबंधित प्रभावों को ट्रैक करना - सभी एक ही अनुमान रन के भीतर और कार्य-विशिष्ट पुन: प्रशिक्षण की आवश्यकता के बिना। यह पूर्व SOTA विधियों के विपरीत है, जो अक्सर एक कार्य के लिए विशेष होती थीं या प्रत्येक फ्रेम के लिए सघन मास्क लेबलिंग की आवश्यकता होती थी। GenProp का प्रसार-आधारित दृष्टिकोण अनुमान के दौरान किसी भी मास्क इनपुट की आवश्यकता नहीं है, संपादन प्रक्रिया को बहुत सरल बनाता है और मैन्युअल प्रयास को कम करता है। यह संरचनात्मक लाभ इसे एक एकीकृत और बहुमुखी वीडियो संपादन समाधान की पेशकश करके भारी श्रेष्ठ बनाता है।
बाधाओं के साथ संरेखण
GenProp ढांचा समस्या की कठोर आवश्यकताओं और इसकी अनूठी वास्तुशिल्प गुणों के बीच एक उल्लेखनीय "विवाह" प्राप्त करता है। आइए प्रमुख बाधाओं पर विचार करें:
- यथार्थवाद: समस्या की मांग है कि प्रसारित परिवर्तन स्वाभाविक और यथार्थवादी दिखाई दें। GenProp एक पूर्व-प्रशिक्षित I2V जनरेशन मॉडल को अपने मूल के रूप में उपयोग करके पूरी तरह से संरेखित होता है। ये मॉडल स्वाभाविक रूप से उच्च-निष्ठा, यथार्थवादी वीडियो सामग्री उत्पन्न करने के लिए डिज़ाइन किए गए हैं, यह सुनिश्चित करते हुए कि संपादित अनुक्रम विज़ुअल प्लाउसिबिलिटी बनाए रखें।
- निरंतरता: अपरिवर्तित क्षेत्र मूल वीडियो के समान रहने चाहिए, और संपादन लौकिक रूप से सुसंगत होने चाहिए। यह चयनात्मक सामग्री एन्कोडर (SCE) द्वारा संबोधित किया जाता है, जो स्पष्ट रूप से वीडियो के अपरिवर्तित भागों से जानकारी को संरक्षित करता है। क्षेत्र-जागरूक हानि (RA Loss) भी इस क्षेत्र-विशिष्ट हानि को अलग करके इसे मजबूत करती है, स्थिर क्षेत्रों में परिवर्तनों को दंडित करती है जबकि संपादित क्षेत्रों में सटीक प्रसार को प्रोत्साहित करती है। यह सुनिश्चित करता है कि मूल सामग्री को निष्ठापूर्वक संरक्षित किया जाए जहां कोई संपादन अभिप्रेत नहीं है।
- सामान्यता और बहुमुखी प्रतिभा: समाधान को पुन: प्रशिक्षण की आवश्यकता के बिना वीडियो संपादन कार्यों के एक व्यापक स्पेक्ट्रम को संभालना चाहिए। GenProp इसे अपने एकीकृत ढांचे के माध्यम से प्राप्त करता है जो पहले-फ्रेम संपादन को सामान्य वीडियो प्रसार तक विस्तारित करता है। महत्वपूर्ण रूप से, सिंथेटिक डेटा जनरेशन योजना (कॉपी-एंड-पेस्ट, मास्क-एंड-फिल, कलर फिल) प्रशिक्षण के दौरान विविध परिदृश्यों को कवर करती है, जिससे मॉडल विभिन्न अनुप्रयोगों जैसे निष्कासन, सम्मिलन, प्रतिस्थापन और ट्रैकिंग में सामान्यीकृत हो सकता है, बिना अनुमान के कार्य-विशिष्ट डेटा की आवश्यकता के।
- दक्षता और सरलता: समाधान को बोझिल मैन्युअल एनोटेशन और त्रुटि-प्रवण मध्यवर्ती अभ्यावेदन से बचना चाहिए। GenProp सभी फ्रेम के लिए सघन मास्क लेबलिंग की आवश्यकता को समाप्त करता है, जो कई पारंपरिक और यहां तक कि कुछ डिफ्यूजन-आधारित विधियों की तुलना में एक महत्वपूर्ण सरलीकरण है। यह गति भविष्यवाणी के लिए ऑप्टिकल फ्लो या डेप्थ मैप पर निर्भरता को भी बायपास करता है, इस प्रकार ऐसे मध्यवर्ती अभ्यावेदन में निहित त्रुटियों के संचय से बचता है।
- जटिल संपादन: मॉडल को महत्वपूर्ण आकार संशोधनों, स्वतंत्र वस्तु गति, और संबंधित प्रभावों के निष्कासन का समर्थन करने की आवश्यकता है। I2V मॉडल की जनरेटिव शक्ति, SCE और MPD से सटीक मार्गदर्शन के साथ मिलकर, GenProp को इन जटिल परिदृश्यों को संभालने की अनुमति देती है, जैसे कि स्वतंत्र गति वाली वस्तुएं या मुख्य वस्तु के साथ-साथ छाया और प्रतिबिंब जैसे संबंधित प्रभावों को हटाना, जो पारंपरिक तरीके अक्सर करने में विफल रहते हैं।
विकल्पों का अस्वीकरण
यह पत्र सामान्य वीडियो प्रसार समस्या के लिए उनकी मौलिक सीमाओं को उजागर करते हुए, वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए सम्मोहक कारण प्रदान करता है:
- पारंपरिक वीडियो प्रोपेगेशन विधियां (ऑप्टिकल फ्लो, डेप्थ, एटलस): ये विधियां, मौलिक होने के बावजूद, उनकी सीमित मजबूती, सामान्यीकरण क्षमता, और त्रुटि संचय के प्रति संवेदनशीलता के कारण स्पष्ट रूप से अस्वीकृत हैं। वे अक्सर एक कार्य के लिए डिज़ाइन की जाती हैं और नए अनुप्रयोगों के लिए पुन: प्रशिक्षण की आवश्यकता होती है, जिससे वे एक एकीकृत ढांचे के लिए अव्यावहारिक हो जाती हैं। स्पष्ट गति संकेतों पर उनकी निर्भरता उन्हें जटिल, गैर-कठोर विकृतियों या महत्वपूर्ण दृश्य परिवर्तनों से निपटते समय भंगुर बनाती है।
- मौजूदा डिफ्यूजन-आधारित वीडियो संपादन मॉडल (जैसे, InsV2V, Pika, AnyV2V, Revideo): जबकि डिफ्यूजन मॉडल शक्तिशाली हैं, उनके मौजूदा कार्यान्वयन वीडियो संपादन के लिए अपर्याप्त पाए गए।
- कई रूप को बदलने तक सीमित थे, न कि महत्वपूर्ण आकार परिवर्तन करने या जटिल पृष्ठभूमि संपादन को सटीकता के साथ संभालने के।
- कुछ को प्रति-मामला फाइन-ट्यूनिंग (जैसे, I2VEdit के मोशन LoRAs) की आवश्यकता थी, जिससे कम्प्यूटेशनल जटिलता बढ़ गई और प्रक्रिया धीमी हो गई।
- Revideo [31] जैसे दृष्टिकोणों ने काले वर्ग मास्क का इस्तेमाल किया, जिसने महत्वपूर्ण जानकारी हटा दी और जटिल पृष्ठभूमि संपादन और बड़े आकार के परिवर्तनों को संभालने की उनकी क्षमता को गंभीर रूप से प्रतिबंधित कर दिया, जिससे अक्सर धुंधली सीमाएं और वस्तु गति में संचित त्रुटियां होती थीं।
- AnyV2V [27] जैसे प्रशिक्षण-मुक्त ढांचे सीमित सामान्यीकरण क्षमता से ग्रस्त थे और महत्वपूर्ण आकार परिवर्तन या वस्तु सम्मिलन के साथ संघर्ष करते थे। Pika [2] ने भी महत्वपूर्ण आकार परिवर्तनों या पृष्ठभूमि संपादन के साथ खराब प्रदर्शन किया।
- पाठ संकेतों (जैसे, InsV2V) पर निर्भर विधियां अक्सर उनके प्रशिक्षण डेटा द्वारा सीमित थीं और जटिल, गैर-रूप-आधारित संपादन के साथ संघर्ष करती थीं।
- पारंपरिक इनपेंटिंग पाइपलाइन (जैसे, SAM-V2 + Propainter): वस्तु निष्कासन जैसे कार्यों के लिए, इन कैस्केडेड विधियों को मुख्य रूप से इसलिए अस्वीकृत किया गया क्योंकि उन्हें सभी फ्रेम के लिए सघन मास्क एनोटेशन की आवश्यकता होती है, एक श्रम-गहन और त्रुटि-प्रवण प्रक्रिया जिसे GenProp पूरी तरह से टालता है। इसके अलावा, Propainter को छाया और प्रतिबिंब जैसे वस्तु प्रभावों को सटीक रूप से हटाने में संघर्ष करते हुए दिखाया गया था, जिसे GenProp अपने जनरेटिव भौतिक नियमों की समझ के कारण मजबूती से संभालता है।
- ट्रैकिंग के लिए SAM-V2: जबकि SAM-V2 [39] मास्क ट्रैकिंग के लिए उत्कृष्ट है, इसे वस्तु प्रभावों (प्रतिबिंब, छाया) के साथ संघर्ष करते हुए नोट किया गया था, जो इसके प्रशिक्षण डेटा पूर्वाग्रहों के कारण था। GenProp, अपने जनरेटिव प्रीट्रेनिंग के साथ, भौतिक नियमों की बेहतर समझ प्रदर्शित करता है, जिससे यह इन संबंधित प्रभावों को लगातार ट्रैक कर सकता है।
संक्षेप में, लेखकों ने निष्कर्ष निकाला कि जबकि इन विकल्पों के घटक उपयोगी थे, किसी ने भी गुणवत्ता, दक्षता, या बहुमुखी प्रतिभा में महत्वपूर्ण समझौते के बिना निर्बाध, विविध वीडियो प्रसार के लिए आवश्यक व्यापक, मजबूत और सामान्य समाधान की पेशकश नहीं की। GenProp का एक शक्तिशाली I2V मॉडल पर एक चयनात्मक सामग्री एन्कोडर, मास्क प्रेडिक्शन डिकोडर, क्षेत्र-जागरूक हानि, और सिंथेटिक डेटा जनरेशन के उपन्यास एकीकरण इन सामूहिक सीमाओं को दूर करने का एकमात्र तरीका था।
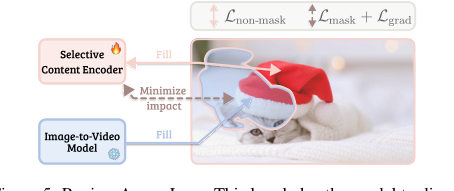 Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
गणितीय और तार्किक तंत्र
मास्टर समीकरण
GenProp के सीखने के तंत्र का मूल इसके क्षेत्र-जागरूक हानि में समाहित है, जो मॉडल को संपादन को प्रसारित करने और मूल सामग्री को संरक्षित करने के लिए निर्देशित करता है। जबकि समग्र प्रशिक्षण उद्देश्य समय के साथ हानि का योग कम करना है, एक एकल फ्रेम के लिए मौलिक हानि फ़ंक्शन, जो सभी महत्वपूर्ण घटकों को जोड़ता है, है:
$$ \mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}} $$
यह मास्टर समीकरण, समग्र प्रशिक्षण उद्देश्य के साथ जो इस हानि को समय के साथ जोड़ता है, यह निर्धारित करता है कि मॉडल जनरेटिव वीडियो प्रोपेगेशन करना कैसे सीखता है। समग्र उद्देश्य औपचारिक रूप से इस प्रकार बताया गया है:
$$ \min_{\mathcal{E}} \sum_{i=2}^{T} \mathcal{L}(G(E(V), v'_1, v_i), V_i) $$
जहां $\mathcal{E}$ मॉडल के प्रशिक्षित करने योग्य पैरामीटर का प्रतिनिधित्व करता है।
पद-दर-पद विच्छेदन
आइए मास्टर समीकरण और समग्र उद्देश्य के प्रत्येक घटक का विश्लेषण करें:
-
$\mathcal{L}$ (कुल क्षेत्र-जागरूक हानि):
- गणितीय परिभाषा: यह एक एकल वीडियो फ्रेम के लिए संयुक्त हानि मान है, जो वांछित आउटपुट और व्यवहार से विचलन के लिए कुल दंड का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह ऑप्टिमाइज़र के लिए प्राथमिक संकेत के रूप में कार्य करता है, यह दर्शाता है कि वर्तमान मॉडल का आउटपुट और आंतरिक स्थिति कितनी "खराब" है। $\mathcal{L}$ को कम करने का अर्थ है सभी उद्देश्यों में मॉडल के प्रदर्शन में सुधार करना।
- जोड़ क्यों? लेखक जोड़ का उपयोग करते हैं क्योंकि प्रत्येक पद एक अलग उद्देश्य या बाधा का प्रतिनिधित्व करता है जिसे मॉडल को संतुष्ट करना चाहिए। उन्हें जोड़कर, मॉडल को इन सभी लक्ष्यों के लिए समवर्ती रूप से अनुकूलित करने के लिए प्रोत्साहित किया जाता है। यदि एक पद उच्च है, तो कुल हानि उच्च है, जो उस विशिष्ट पहलू में समायोजन की आवश्यकता का संकेत देता है।
-
$\mathcal{L}_{\text{non-mask}}$ (गैर-मास्क क्षेत्र हानि):
- गणितीय परिभाषा: $\mathcal{L}_{\text{non-mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v^{\text{out}}_t, (1 - m_t) \cdot v_t)]$. यह डिफ्यूजन मीन स्क्वेयर्ड एरर (MSE) हानि, $\mathcal{L}_d$ है, जो उत्पन्न आउटपुट $v^{\text{out}}_t$ और ग्राउंड ट्रुथ $v_t$ के बीच गणना की जाती है, लेकिन केवल उन क्षेत्रों के लिए जो मास्क $m_t$ से ढके नहीं हैं।
- भौतिक/तार्किक भूमिका: यह पद सुनिश्चित करता है कि वीडियो के वे हिस्से जिन्हें पहले फ्रेम में संपादित नहीं किया गया था, अनुक्रम के दौरान मूल वीडियो सामग्री के साथ सुसंगत रहें। यह एक निष्ठा बाधा के रूप में कार्य करता है, अपरिवर्तित पृष्ठभूमि या वस्तुओं में अनपेक्षित परिवर्तनों को रोकता है।
- $(1 - m_t) \cdot \text{frame}$ क्यों? $(1 - m_t)$ के साथ तत्व-वार गुणन प्रभावी रूप से मास्क्ड (संपादित) क्षेत्रों को "शून्य" कर देता है, जिससे हानि गणना के लिए केवल अपरिवर्तित फ्रेम को अलग किया जा सके। यह स्थिरता उद्देश्य को विशिष्ट क्षेत्रों पर केंद्रित करने का एक सटीक तरीका है।
-
$\mathcal{L}_{\text{mask}}$ (मास्क क्षेत्र हानि):
- गणितीय परिभाषा: $\mathcal{L}_{\text{mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d(m_t \cdot v^{\text{out}}_t, m_t \cdot v_t)]$. यह डिफ्यूजन MSE हानि, $\mathcal{L}_d$ है, जो उत्पन्न आउटपुट $v^{\text{out}}_t$ और ग्राउंड ट्रुथ $v_t$ के बीच गणना की जाती है, लेकिन केवल उन क्षेत्रों के लिए जो मास्क $m_t$ से ढके हुए हैं।
- भौतिक/तार्किक भूमिका: यह पद मॉडल को संपादित सामग्री को सटीक रूप से उत्पन्न करने और पहले फ्रेम में किए गए संशोधनों को प्रसारित करने के लिए प्रेरित करता है। यह सुनिश्चित करता है कि परिवर्तन यथार्थवादी रूप से प्रस्तुत किए गए हैं और संशोधित क्षेत्र के भीतर समय के साथ सुसंगत हैं।
- $m_t \cdot \text{frame}$ क्यों? $\mathcal{L}_{\text{non-mask}}$ के समान, $m_t$ के साथ तत्व-वार गुणन मास्क्ड (संपादित) क्षेत्रों को अलग करता है, जिससे पीढ़ी उद्देश्य विशेष रूप से इन क्षेत्रों पर केंद्रित होता है।
-
$\lambda$ ($\mathcal{L}_{\text{mask}}$ के लिए भार):
- गणितीय परिभाषा: एक सकारात्मक स्केलर गुणांक (पेपर में 2.0 पर सेट)।
- भौतिक/तार्किक भूमिका: यह हाइपरपैरामीटर अन्य हानि घटकों की तुलना में मास्क्ड (संपादित) क्षेत्रों को सटीक रूप से उत्पन्न करने के महत्व को नियंत्रित करता है। उच्च $\lambda$ संपादन को सही ढंग से प्रसारित करने पर अधिक जोर देता है।
- गुणा क्यों? यह कुल हानि में $\mathcal{L}_{\text{mask}}$ के योगदान को मापता है, जिससे विभिन्न उद्देश्यों के बीच संतुलन को ठीक करने की अनुमति मिलती है।
-
$\mathcal{L}_{\text{grad}}$ (ग्रेडिएंट हानि):
- गणितीय परिभाषा: $\mathcal{L}_{\text{grad}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [m_t \cdot ||\Delta f||^2]$, जहां $\Delta f = \frac{f(E(V + \delta)) - f(E(V))}{\delta}$ इनपुट वीडियो $V$ में एक छोटे से गड़बड़ी $\delta$ के संबंध में चयनात्मक सामग्री एन्कोडर (SCE) की सुविधाओं $f(E(V))$ के ग्रेडिएंट का एक परिमित अंतर सन्निकटन है।
- भौतिक/तार्किक भूमिका: यह अलगाव के लिए एक महत्वपूर्ण पद है। यह SCE को दंडित करता है यदि इनपुट वीडियो में गड़बड़ी होने पर मास्क्ड क्षेत्र के भीतर इसकी आउटपुट विशेषताएं काफी बदल जाती हैं। लक्ष्य SCE को संपादित भागों को अनदेखा करने और केवल अपरिवर्तित सामग्री को एन्कोड करने पर ध्यान केंद्रित करने के लिए मजबूर करना है। यह SCE को I2V मॉडल के जनरेटिव कार्य में हस्तक्षेप करने या संपादित क्षेत्रों में हस्तक्षेप करने से रोकता है।
- $||\Delta f||^2$ क्यों? वर्ग L2 मानदंड सुविधाओं में परिवर्तन के परिमाण को मापता है। इस परिमाण को कम करने से SCE की सुविधाओं को मास्क्ड क्षेत्र में गड़बड़ी के प्रति स्थिर और असंवेदनशील बनने के लिए प्रोत्साहित किया जाता है।
- $m_t \cdot ||\Delta f||^2$ क्यों? मास्क $m_t$ यह सुनिश्चित करता है कि यह ग्रेडिएंट दंड केवल संपादित क्षेत्रों पर लागू हो, जहां SCE को आदर्श रूप से "अंधा" होना चाहिए।
-
$\beta$ ($\mathcal{L}_{\text{grad}}$ के लिए भार):
- गणितीय परिभाषा: एक सकारात्मक स्केलर गुणांक (पेपर में 1.0 पर सेट)।
- भौतिक/तार्किक भूमिका: यह हाइपरपैरामीटर ग्रेडिएंट दंड की ताकत को नियंत्रित करता है, यह प्रभावित करता है कि SCE को अपने एन्कोडिंग को संपादित क्षेत्रों से कितनी मजबूती से अलग करने के लिए मजबूर किया जाता है।
- गुणा क्यों? यह कुल हानि में $\mathcal{L}_{\text{grad}}$ के योगदान को मापता है।
-
$\mathcal{L}_{\text{MPD}}$ (मास्क प्रेडिक्शन डिकोडर हानि):
- गणितीय परिभाषा: यह मास्क प्रेडिक्शन डिकोडर (MPD) द्वारा अनुमानित मास्क और ग्राउंड ट्रुथ मास्क $m_t$ के बीच एक MSE हानि है।
- भौतिक/तार्किक भूमिका: यह सहायक हानि स्पष्ट रूप से MPD को संशोधित क्षेत्रों को सटीक रूप से पहचानने के लिए प्रशिक्षित करती है। ऐसा करके, यह समग्र मॉडल को कहां संपादन हैं, इसके बारे में एक स्पष्ट संकेत प्रदान करता है, जो बदले में I2V मॉडल के ध्यान और पीढ़ी प्रक्रिया को सही क्षेत्रों में निर्देशित करने में मदद करता है। यह ध्यान मानचित्रों की सटीकता में सुधार करता है।
- MSE क्यों? MSE प्रति-पिक्सेल मास्क मानों की भविष्यवाणी सहित प्रतिगमन कार्यों के लिए एक मानक और प्रभावी हानि फ़ंक्शन है।
-
$\gamma$ ($\mathcal{L}_{\text{MPD}}$ के लिए भार):
- गणितीय परिभाषा: एक सकारात्मक स्केलर गुणांक (पेपर में 1.0 पर सेट)।
- भौतिक/तार्किक भूमिका: यह हाइपरपैरामीटर स्पष्ट मास्क भविष्यवाणी कार्य के महत्व को नियंत्रित करता है।
- गुणा क्यों? यह कुल हानि में $\mathcal{L}_{\text{MPD}}$ के योगदान को मापता है।
-
$\mathbb{E}_{t \sim \mathcal{U}(1,T)}$ (समय चरणों पर अपेक्षा):
- गणितीय परिभाषा: $1$ से $T$ तक समान रूप से नमूना किए गए समय चरणों $t$ पर हानि का औसत मान।
- भौतिक/तार्किक भूमिका: यह सुनिश्चित करता है कि हानि वीडियो अनुक्रम में विभिन्न फ्रेम में गणना की जाती है, लौकिक निरंतरता और पूरे वीडियो में सामान्यीकरण को बढ़ावा देता है।
- अपेक्षा/समान नमूनाकरण क्यों? यह पूरे वीडियो में हानि का एक मजबूत अनुमान प्रदान करता है, जिससे मॉडल को विशिष्ट फ्रेम या लौकिक पदों पर ओवरफिट होने से रोका जा सके।
-
$\sum_{i=2}^{T}$ (फ्रेम पर योग):
- गणितीय परिभाषा: $2$ से $T$ तक प्रत्येक फ्रेम $i$ के लिए क्षेत्र-जागरूक हानि $\mathcal{L}$ का योग।
- भौतिक/तार्किक भूमिका: यह प्रति-फ्रेम हानियों को प्रशिक्षण के दौरान पूरे वीडियो अनुक्रम के लिए एक एकल उद्देश्य में एकत्रित करता है। पहला फ्रेम ($i=1$) संपादित इनपुट फ्रेम है, इसलिए प्रसार कार्य दूसरे फ्रेम से शुरू होता है।
- योग क्यों? प्रत्येक फ्रेम की हानि समग्र प्रशिक्षण संकेत में समान रूप से योगदान करती है, यह सुनिश्चित करती है कि मॉडल पूरे वीडियो में संपादन को लगातार प्रसारित करना सीखे।
-
$G(E(V), v'_1, v_i)$ (उत्पन्न आउटपुट फ्रेम):
- गणितीय परिभाषा: इमेज-टू-वीडियो (I2V) जनरेशन मॉडल $G$ का आउटपुट, चयनात्मक सामग्री एन्कोडर $E(V)$ से सुविधाओं, संशोधित पहले फ्रेम $v'_1$, और मूल $i$-वें फ्रेम $v_i$ (I2V मॉडल की आंतरिक प्रसंस्करण के लिए एक संदर्भ के रूप में उपयोग किया जाता है, हालांकि ग्राउंड ट्रुथ $V_i$ हानि गणना के लिए उपयोग किया जाता है) पर सशर्त।
- भौतिक/तार्किक भूमिका: यह संशोधित वीडियो के $i$-वें फ्रेम के लिए मॉडल का अनुमान है। यह पहले फ्रेम संपादन के प्रसार का प्रतिनिधित्व करता है, जबकि मूल वीडियो के अपरिवर्तित भागों के साथ निरंतरता बनाए रखता है।
-
$E(V)$ (चयनात्मक सामग्री एन्कोडर सुविधाएँ):
- गणितीय परिभाषा: मूल इनपुट वीडियो $V$ से चयनात्मक सामग्री एन्कोडर $E$ द्वारा निकाली गई अव्यक्त सुविधाएँ।
- भौतिक/तार्किक भूमिका: इस घटक को मूल वीडियो के अपरिवर्तित भागों की जानकारी को एन्कोड करने के लिए डिज़ाइन किया गया है। यह I2V मॉडल को संदर्भ प्रदान करता है, इसे उन क्षेत्रों में मूल सामग्री को संरक्षित करने के लिए निर्देशित करता है जहां कोई संपादन नहीं किया गया था।
-
$v'_1$ (संशोधित पहला फ्रेम):
- गणितीय परिभाषा: वीडियो का पहला फ्रेम, जिसे मैन्युअल रूप से या सिंथेटिक रूप से संपादित किया गया है।
- भौतिक/तार्किक भूमिका: यह प्रसार के लिए एंकर के रूप में कार्य करता है। I2V मॉडल यह समझने के लिए इसका उपयोग करता है कि क्या परिवर्तन प्रसारित करने की आवश्यकता है।
-
$v_i$ (मूल $i$-वां फ्रेम):
- गणितीय परिभाषा: मूल, अपरिवर्तित वीडियो अनुक्रम $V$ का $i$-वां फ्रेम।
- भौतिक/तार्किक भूमिका: प्रशिक्षण के दौरान I2V मॉडल के इनपुट के हिस्से के रूप में उपयोग किया जाता है, और हानि गणना में अपरिवर्तित क्षेत्रों के लिए ग्राउंड ट्रुथ के रूप में।
-
$V_i$ (ग्राउंड ट्रुथ सिंथेटिक वीडियो फ्रेम):
- गणितीय परिभाषा: सिंथेटिक वीडियो अनुक्रम $V = \{V_1, V_2, ..., V_T\}$ का $i$-वां फ्रेम, जिसे मूल वीडियो पर डेटा जनरेशन ऑपरेटर $D$ लागू करके उत्पन्न किया गया है।
- भौतिक/तार्किक भूमिका: यह प्रशिक्षण के दौरान मॉडल के लिए लक्ष्य आउटपुट है, जो प्रसार के बाद वांछित संशोधित वीडियो फ्रेम का प्रतिनिधित्व करता है।
चरण-दर-चरण प्रवाह
GenProp को एक परिष्कृत वीडियो संपादन कारखाने के रूप में कल्पना करें। यहां बताया गया है कि प्रशिक्षण के दौरान एक एकल अमूर्त डेटा बिंदु (एक वीडियो फ्रेम) अपनी असेंबली लाइन से कैसे गुजरता है:
- मूल वीडियो अंतर्ग्रहण: एक मूल वीडियो अनुक्रम, जिसे हम $V$ कहते हैं, कारखाने में प्रवेश करता है। यह $V$ फ्रेम की एक श्रृंखला है, $V_1, V_2, ..., V_T$ ।
- सिंथेटिक संपादन अनुप्रयोग (डेटा जनरेशन): एक विशेष "संपादन मशीन" (डेटा जनरेशन ऑपरेटर $D$) $V$ लेती है और इसके पहले फ्रेम पर एक सिंथेटिक संपादन लागू करती है, जिससे एक संशोधित पहला फ्रेम $v'_1$ बनता है। यह प्रत्येक फ्रेम में संपादित क्षेत्रों को सटीक रूप से सीमांकित करने वाले संबंधित ग्राउंड ट्रुथ संशोधित फ्रेम $V_2, ..., V_T$ और बाइनरी मास्क $m_1, ..., m_T$ भी उत्पन्न करता है। यह हमें एक लक्ष्य वीडियो $V' = \{v'_1, V_2, ..., V_T\}$ देता है।
- सामग्री एन्कोडिंग (चयनात्मक सामग्री एन्कोडर, SCE): पूरा मूल वीडियो $V$ "चयनात्मक सामग्री एन्कोडर" ($E$) में फीड किया जाता है। यह एन्कोडर एक स्मार्ट फ़िल्टर की तरह है; इसका काम वीडियो की अपरिवर्तित सामग्री का प्रतिनिधित्व करने वाली सुविधाओं को निकालना है, जानबूझकर उन क्षेत्रों के बारे में जानकारी को अनदेखा करने की कोशिश करना जिन्हें संपादित किया जाएगा। यह सं संशोधनों के प्रति "अंधा" होना सीख रहा है।
- प्रसार इंजन (इमेज-टू-वीडियो मॉडल): अब, प्रत्येक बाद के फ्रेम $i$ (2 से $T$ तक) के लिए:
- संशोधित पहला फ्रेम $v'_1$ (संपादन का ब्लूप्रिंट) फीड किया जाता है।
- $E(V)$ से चयनात्मक रूप से एन्कोड की गई सुविधाएँ (मूल, अपरिवर्तित दृश्य का संदर्भ) इंजेक्ट की जाती हैं।
- वर्तमान समय चरण $i$ भी प्रदान किया जाता है।
- "इमेज-टू-वीडियो जनरेशन मॉडल" ($G$) मुख्य प्रसार इंजन के रूप में कार्य करता है। यह इन इनपुट को लेता है और संशोधित वीडियो के $i$-वें फ्रेम के लिए अपना सर्वश्रेष्ठ अनुमान उत्पन्न करता है, जिसे हम $v^{\text{out}}_i$ कहते हैं। यहीं पर जादू होता है: $v'_1$ से संपादन प्रसारित किया जाता है, मूल सामग्री सुविधाओं द्वारा निर्देशित।
- मास्क भविष्यवाणी (मास्क प्रेडिक्शन डिकोडर, MPD): साथ ही, एक "मास्क प्रेडिक्शन डिकोडर" (MPD) I2V मॉडल से आंतरिक अव्यक्त अभ्यावेदन लेता है और वर्तमान फ्रेम के लिए मास्क $m_i$ की भविष्यवाणी करने का प्रयास करता है। यह एक गुणवत्ता नियंत्रण सेंसर की तरह है, जो जांचता है कि क्या मॉडल समझता है कि संपादन कहां हैं।
- हानि गणना और प्रतिक्रिया (क्षेत्र-जागरूक हानि): प्रत्येक उत्पन्न फ्रेम $v^{\text{out}}_i$ के लिए:
- निरंतरता जांच (गैर-मास्क हानि): $v^{\text{out}}_i$ के अपरिवर्तित भाग ($(1-m_i)$ द्वारा चयनित) ग्राउंड ट्रुथ $V_i$ के अपरिवर्तित भागों से तुलना की जाती है। यहां कोई भी विसंगति $\mathcal{L}_{\text{non-mask}}$ में योगदान करती है, मॉडल को मूल सामग्री को बरकरार रखने के लिए खींचती है।
- संपादन सटीकता जांच (मास्क हानि): $v^{\text{out}}_i$ के संपादित भाग ($m_i$ द्वारा चयनित) ग्राउंड ट्रुथ $V_i$ के संपादित भागों से तुलना की जाती है। यहां कोई भी त्रुटि $\mathcal{L}_{\text{mask}}$ में योगदान करती है, मॉडल को परिवर्तनों को सटीक रूप से प्रसारित करने के लिए प्रेरित करती है।
- एन्कोडर अंधापन जांच (ग्रेडिएंट हानि): एक विशेष "ग्रेडिएंट सेंसर" जांचता है कि क्या SCE की विशेषताएं बदल जाएंगी यदि इनपुट मास्क्ड क्षेत्र के भीतर थोड़ा बदल दिया गया था। यदि वे करते हैं, तो यह $\mathcal{L}_{\text{grad}}$ में जोड़ता है, जो SCE को संपादन के प्रति और भी अधिक अनभिज्ञ होने के लिए कहता है।
- मास्क भविष्यवाणी सटीकता जांच (MPD हानि): MPD के अनुमानित मास्क की तुलना ग्राउंड ट्रुथ मास्क $m_i$ से की जाती है, जो $\mathcal{L}_{\text{MPD}}$ में योगदान करती है।
- कुल हानि एकत्रीकरण: ये सभी व्यक्तिगत हानि घटक ($\mathcal{L}_{\text{non-mask}}$, $\mathcal{L}_{\text{mask}}$, $\mathcal{L}_{\text{grad}}$, $\mathcal{L}_{\text{MPD}}$) भारित ($\lambda, \beta, \gamma$) और उस फ्रेम के लिए कुल क्षेत्र-जागरूक हानि $\mathcal{L}$ बनाने के लिए जोड़े जाते हैं। यह प्रक्रिया $i=2$ से $T$ तक सभी फ्रेम के लिए दोहराई जाती है, और इन प्रति-फ्रेम हानियों को समग्र उद्देश्य प्राप्त करने के लिए जोड़ा जाता है।
- पैरामीटर समायोजन: यह कुल उद्देश्य मान फिर "ऑप्टिमाइज़र" को भेजा जाता है, जो कारखाने प्रबंधक की तरह है। यह गणना करता है कि इस कुल हानि को कम करने के लिए प्रत्येक नॉब और डायल (मॉडल पैरामीटर) को कैसे समायोजित करने की आवश्यकता है। ये समायोजन पुनरावृत्त रूप से किए जाते हैं, प्रत्येक प्रशिक्षण चरण के साथ SCE, I2V मॉडल और MPD को परिष्कृत करते हैं।
यह पूरा चक्र लाखों बार दोहराता है, धीरे-धीरे GenProp को मूल वीडियो के बाकी हिस्सों को संरक्षित करते हुए निर्बाध रूप से संपादन प्रसारित करना सिखाता है।
अनुकूलन गतिशीलता
GenProp एक सावधानीपूर्वक गढ़ी गई हानि परिदृश्य और ग्रेडिएंट डिसेंट के एक परिष्कृत अंतःक्रिया के माध्यम से सीखता है और अभिसरण करता है। अनुकूलन प्रक्रिया $i=2$ से $T$ तक सभी फ्रेम में क्षेत्र-जागरूक हानि $\mathcal{L}$ के योग के कुल उद्देश्य फ़ंक्शन को कम करके संचालित होती है।
-
ग्रेडिएंट-आधारित शिक्षण: चयनात्मक सामग्री एन्कोडर (SCE), इमेज-टू-वीडियो (I2V) जनरेशन मॉडल, और मास्क प्रेडिक्शन डिकोडर (MPD) के मॉडल पैरामीटर ($\mathcal{E}$) एक ऑप्टिमाइज़र (जैसे, एडम, जैसा कि डिफ्यूजन मॉडल के लिए आम है) का उपयोग करके पुनरावृत्त रूप से अपडेट किए जाते हैं। इसमें प्रत्येक पैरामीटर के संबंध में कुल हानि के ग्रेडिएंट की गणना शामिल है। ये ग्रेडिएंट इंगित करते हैं कि हानि को कम करने के लिए पैरामीटर को किस दिशा और परिमाण में समायोजित किया जाना चाहिए। सीखने की दर (जैसे, 5e-5 एक कोसाइन-डेके शेड्यूल और रैखिक वार्मअप के साथ) इन समायोजनों के चरण आकार को नियंत्रित करती है। मॉडल पैरामीटर का एक घातीय मूविंग एवरेज (EMA) भी बनाए रखा जाता है, जो अक्सर शोर वाले अपडेट को औसत करके अधिक स्थिर प्रशिक्षण और बेहतर अंतिम प्रदर्शन की ओर ले जाता है। प्रशिक्षण स्थिरता सुनिश्चित करने के लिए ग्रेडिएंट नॉर्म थ्रेशोल्ड (0.001) लागू किया जाता है।
-
अलगाव और निरंतरता के लिए हानि परिदृश्य को आकार देना: क्षेत्र-जागरूक हानि ($\mathcal{L}$) का अनूठा डिजाइन हानि परिदृश्य को आकार देने और मॉडल के सीखने को निर्देशित करने के लिए महत्वपूर्ण है:
- संतुलित क्षेत्र अनुकूलन: $\mathcal{L}_{\text{mask}}$ और $\mathcal{L}_{\text{non-mask}}$ पद दो प्राथमिक "घाटियों" के साथ एक हानि परिदृश्य बनाते हैं। एक घाटी संपादित क्षेत्रों के भीतर सटीक पीढ़ी को प्रोत्साहित करती है, यह सुनिश्चित करती है कि प्रसारित परिवर्तन यथार्थवादी हों। दूसरी घाटी अपरिवर्तित क्षेत्रों में मूल सामग्री के प्रति उच्च निष्ठा को बढ़ावा देती है। इन पदों को $\lambda$ के साथ भारित करके, लेखक मॉडल के फोकस को संतुलित कर सकते हैं, जिससे यह संपादन को अनदेखा करने या मूल पृष्ठभूमि को दूषित करने से बच सके। यह दोहरा उद्देश्य मॉडल को एक जटिल परिदृश्य में नेविगेट करने में मदद करता है जहां उसे मौजूदा सामग्री को संरक्षित करते हुए नई सामग्री बनानी चाहिए।
- SCE की चयनात्मकता को मजबूर करना: $\mathcal{L}_{\text{grad}}$ पद विशेष रूप से सरलतापूर्ण है। SCE को दंडित करके यदि इनपुट मास्क्ड क्षेत्र को गड़बड़ाया जाता है तो उसकी विशेषताएं बदल जाती हैं, यह SCE के आउटपुट के संबंध में हानि परिदृश्य में एक "सपाट" क्षेत्र बनाता है। यह SCE को एक प्रतिनिधित्व सीखने के लिए मजबूर करता है जो संशोधनों के प्रति अपरिवर्तनीय है, प्रभावी रूप से इसे संपादन के प्रति "अंधा" बनाता है। यह SCE की भूमिका (मूल संदर्भ को एन्कोड करना) को I2V मॉडल की भूमिका (संपादन को प्रसारित करना) से अलग करता है, भूतिया या हटाए गए वस्तुओं के पुन: प्रकट होने जैसी समस्याओं को रोकता है। इसके बिना, SCE हर जगह मूल सामग्री को पुन: बनाने का प्रयास कर सकता है, जिससे परिवर्तनों के प्रसार में बाधा उत्पन्न हो सकती है।
- ध्यान के लिए स्पष्ट मार्गदर्शन: $\mathcal{L}_{\text{MPD}}$ पद मॉडल को यह पहचानने के लिए एक स्पष्ट, पर्यवेक्षित संकेत प्रदान करता है कि संपादन कहां हैं। यह I2V मॉडल के आंतरिक ध्यान तंत्र को पीढ़ी और संशोधन के लिए सही क्षेत्रों पर ध्यान केंद्रित करने में मदद करता है। स्पष्ट रूप से मास्क सीखकर, मॉडल संपादित और अपरिवर्तित सामग्री के बीच "सीमाओं" की स्पष्ट समझ प्राप्त करता है, जिससे अधिक सटीक प्रसार और कम भ्रम होता है। यह हानि पद उन क्षेत्रों के लिए हानि परिदृश्य में एक तेज, अधिक परिभाषित सीमा बनाने में मदद करता है जिन्हें संशोधन की आवश्यकता होती है।
-
पुनरावृत्त शोधन और अभिसरण: कई पुनरावृत्तियों पर, मॉडल पुनरावृत्त रूप से अपने पैरामीटर अपडेट करता है। I2V मॉडल संपादित पहले फ्रेम और SCE के संदर्भ के आधार पर तेजी से यथार्थवादी और लौकिक रूप से सुसंगत वीडियो फ्रेम उत्पन्न करना सीखता है। SCE मूल वीडियो से मजबूत, संपादन-अज्ञेय सुविधाओं को निकालना सीखता है। MPD संशोधित क्षेत्रों की सटीक भविष्यवाणी करना सीखता है। क्षेत्र-जागरूक हानि द्वारा निर्देशित यह निरंतर प्रतिक्रिया लूप, मॉडल को एक ऐसी स्थिति की ओर ले जाता है जहां यह उच्च निष्ठा को अपरिवर्तित सामग्री के लिए बनाए रखते हुए, पूरे वीडियो अनुक्रमों में विविध पहले-फ्रेम संपादन को निर्बाध रूप से प्रसारित कर सकता है। जब ग्रेडिएंट बहुत छोटे हो जाते हैं, तो मॉडल अभिसरण करता है, यह दर्शाता है कि आगे पैरामीटर अपडेट से हानि में न्यूनतम सुधार होता है।
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
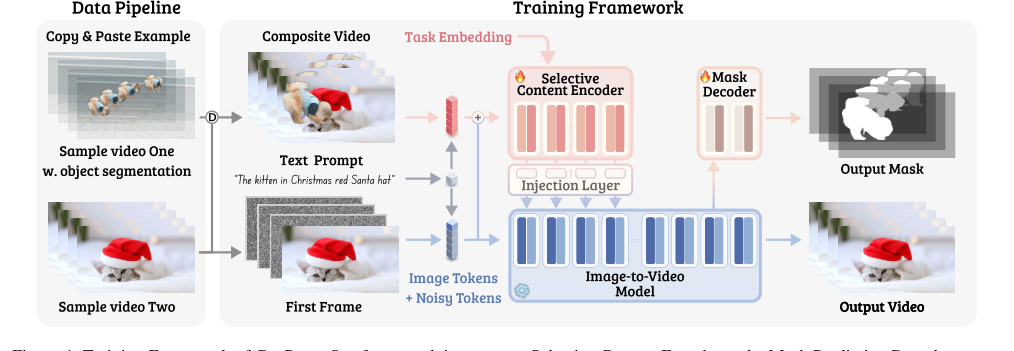 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
परिणाम, सीमाएं और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
GenProp की क्षमताओं को कठोरता से मान्य करने के लिए, लेखकों ने दो अलग-अलग बेस वीडियो जनरेशन मॉडल का लाभ उठाते हुए एक व्यापक प्रयोगात्मक सेटअप तैयार किया: Sora [32] के समान एक DiT आर्किटेक्चर और Stable Video Diffusion (SVD) [5] पर आधारित एक U-Net आर्किटेक्चर। DiT संस्करण, जिसने अंततः बेहतर वीडियो जनरेशन गुणवत्ता प्रदान की, को 32, 64, और 128 फ्रेम के लिए 12 और 24 फ्रेम प्रति सेकंड (FPS) पर, 360p के आधार रिज़ॉल्यूशन के साथ इमेज-टू-वीडियो (I2V) जनरेशन के लिए प्रशिक्षित किया गया था। चयनात्मक सामग्री एन्कोडर (SCE) और मास्क प्रेडिक्शन डिकोडर (MPD) घटकों को प्रशिक्षित किया गया था जबकि I2V मॉडल को फ्रीज रखा गया था, यह सुनिश्चित करते हुए कि GenProp का मुख्य तंत्र वीडियो जनरेशन को खरोंच से फिर से सीखने के बजाय संपादन को प्रसारित करने पर केंद्रित था।
प्रशिक्षण में कोसाइन-डेके शेड्यूलर और रैखिक वार्मअप के साथ $5 \times 10^{-5}$ की सीखने की दर शामिल थी, साथ ही स्थिरता के लिए घातीय मूविंग एवरेज भी। अस्थिरता को रोकने के लिए 0.001 का ग्रेडिएंट नॉर्म थ्रेशोल्ड लागू किया गया था। क्लासिफायर-फ्री गाइडेंस (CFG) को 20 पर सेट किया गया था। प्रशिक्षण का एक महत्वपूर्ण पहलू सिंथेटिक डेटा जनरेशन योजना थी, जिसने विभिन्न संवर्द्धन अनुपातों (0.5, 0.375, 0.125) का उपयोग कॉपी-एंड-पेस्ट, मास्क-एंड-फिल, और कलर फिल कार्यों के लिए किया। क्षेत्र-जागरूक (RA) हानि, संपादित और अपरिवर्तित क्षेत्रों को अलग करने के लिए महत्वपूर्ण, विशिष्ट भार पैरामीटर का उपयोग करती है: $\lambda = 2.0$, $\beta = 1.0$, और $\gamma = 1.0$ । सभी प्रयोग 32 या 64 NVIDIA A100 GPUs पर किए गए थे, जो आवश्यक कम्प्यूटेशनल संसाधनों की महत्वपूर्ण मात्रा को उजागर करते हैं।
GenProp को जिन "पीड़ितों" (बेसलाइन मॉडल) के साथ तुलना की गई थी, वे कार्य के अनुसार भिन्न थे। सामान्य वीडियो संपादन के लिए, इसकी तुलना InsV2V [8], AnyV2V [27], Pika [2], और ReVideo [31] से की गई थी। वस्तु निष्कासन के लिए, SAM-V2 [39] (मास्क ट्रैकिंग के लिए) और Propainter [64] (इनपेंटिंग के लिए) के एक कैस्केडेड पाइपलाइन ने बेसलाइन के रूप में काम किया। वस्तु ट्रैकिंग के लिए, SAM-V2 [39] प्रत्यक्ष प्रतियोगी था।
मात्रात्मक मूल्यांकन दो परीक्षण सेटों पर किया गया था:
1. क्लासिक टेस्ट सेट: TGVE [51] के DAVIS [36] डेटासेट को शामिल करता है, जिसमें "ऑब्जेक्ट चेंज कैप्शन" टेक्स्ट प्रॉम्प्ट होते हैं, जो वस्तु प्रतिस्थापन और उपस्थिति संपादन पर केंद्रित होते हैं।
2. चुनौतीपूर्ण टेस्ट सेट: Pexels [1] और Adobe Stock [3] से मैन्युअल रूप से क्यूरेट किए गए 30 वीडियो का एक संग्रह, जिसमें बड़े वस्तु प्रतिस्थापन, वस्तु सम्मिलन और पृष्ठभूमि प्रतिस्थापन जैसे अधिक जटिल परिदृश्य शामिल हैं। इस सेट पर संपादन वाणिज्यिक फोटो संपादन टूल या विशिष्ट बेसलाइन विधियों (जैसे, Pika के ऑनलाइन बॉक्सिंग टूल, ReVideo के मोशन पॉइंट एक्सट्रैक्शन) का उपयोग करके किए गए थे।
GenProp की सफलता के निश्चित प्रमाण कई मेट्रिक्स का उपयोग करके मापे गए थे:
- PSNRm: पीक सिग्नल-टू-नॉइज़ रेशियो, विशेष रूप से संपादित क्षेत्र के बाहर गणना की जाती है ताकि अपरिवर्तित सामग्री की निरंतरता को मापा जा सके।
- CLIP-T: संपादित फ्रेम और टेक्स्ट प्रॉम्प्ट के CLIP [38] एम्बेडिंग के बीच कोसाइन समानता, पाठ संरेखण का आकलन करती है।
- CLIP-I: फ्रेम के बीच CLIP [38] सुविधाओं के बीच की दूरी, फ्रेम-टू-फ्रेम निरंतरता को मापती है।
- उपयोगकर्ता अध्ययन: Amazon MTurk [45] पर 121 प्रतिभागियों के साथ एक मानव मूल्यांकन आयोजित किया गया, जिन्होंने GenProp के आउटपुट की तुलना बेसलाइन और मूल वीडियो से की, निर्देशों के साथ संरेखण और समग्र दृश्य गुणवत्ता का मूल्यांकन किया।
साक्ष्य क्या साबित करते हैं
साक्ष्य निर्विवाद रूप से साबित करते हैं कि GenProp का मुख्य तंत्र वास्तव में काम करता है, इसे जनरेटिव वीडियो प्रोपेगेशन के लिए एक अग्रणी ढांचा स्थापित करता है। जैसा कि तालिका 1 में दिखाया गया है, GenProp अधिकांश मेट्रिक्स पर अन्य विधियों से काफी बेहतर प्रदर्शन करता है, विशेष रूप से अधिक मांग वाले चुनौतीपूर्ण टेस्ट सेट पर। यह केवल एक वृद्धिशील सुधार नहीं है; यह एक मौलिक रूप से अधिक मजबूत और बहुमुखी दृष्टिकोण का प्रदर्शन है।
उदाहरण के लिए, वस्तु प्रतिस्थापन और पृष्ठभूमि प्रतिस्थापन (चित्र 6a, 6b) में, GenProp ने विभिन्न आकृतियों और स्वतंत्र गति वाली वस्तुओं को निर्बाध रूप से संशोधित करने, और जटिल पृष्ठभूमि संपादन करने की अपनी क्षमता का प्रदर्शन किया। यह सीधे InsV2V [8] और Pika [2] जैसे बेसलाइन की एक प्रमुख सीमा को संबोधित करता है, जो पाठ संकेतों या सीमित प्रशिक्षण डेटा पर निर्भरता के कारण महत्वपूर्ण आकार परिवर्तनों या वस्तु सम्मिलन के साथ संघर्ष करते हैं। AnyV2V [27] भी सीमित सामान्यीकरण से ग्रस्त था, और ReVideo [31] ने अक्सर अपने बिंदु ट्रैकिंग तंत्र से धुंधली सीमाएं और संचित त्रुटियां उत्पन्न कीं। GenProp की इन जटिल परिदृश्यों को प्रत्येक फ्रेम के लिए सघन मास्क लेबलिंग की आवश्यकता के बिना संभालने की क्षमता इसके प्रसार-आधारित दृष्टिकोण का एक प्रमाण है।
वस्तु और प्रभाव निष्कासन (चित्र 6c, 6d) में, GenProp ने न केवल वस्तुओं को बल्कि उनके संबंधित प्रभावों, जैसे छाया और प्रतिबिंबों को भी हटाया, और बड़े अवरुद्ध क्षेत्रों को यथार्थवादी रूप से पुनर्निर्मित करके उत्कृष्ट प्रदर्शन किया। SAM+Propainter बेसलाइन, जबकि इनपेंटिंग के लिए प्रभावी है, इन सूक्ष्म प्रभावों को हटाने में संघर्ष करती थी, जैसा कि तालिका 2 में इसके निम्न CLIP-I और उपयोगकर्ता वरीयता स्कोर द्वारा इंगित किया गया है। GenProp का एकीकृत दृष्टिकोण, जनरेटिव मॉडल का लाभ उठाते हुए, स्वाभाविक रूप से हटाए गए क्षेत्रों को प्रशंसनीय रूप से भरने के तरीके को समझता है, जिसमें पर्यावरणीय संदर्भ भी शामिल है।
उदाहरण वस्तु और प्रभाव ट्रैकिंग (चित्र 6e) के लिए, GenProp ने वस्तुओं और उनके संबंधित प्रभावों की सुसंगत ट्रैकिंग का प्रदर्शन किया, यहां तक कि ठोस रंग भराव के साथ शुरू होने पर भी। जबकि SAM-V2 [39] वास्तविक समय ट्रैकिंग के लिए तेज है और सटीक मास्क उत्पन्न कर सकता है, GenProp के वीडियो जनरेशन पर प्रीट्रेनिंग ने इसे भौतिक नियमों की एक मजबूत समझ दी है, जिससे यह उन प्रभावों को ट्रैक कर सकता है जिन्हें SAM-V2 अक्सर अपने सीमित और पक्षपाती प्रशिक्षण डेटा के कारण याद करता है। यह जनरेशन-आधारित मॉडल की क्षमता को गहरी दृश्य गतिशीलता की समझ के साथ क्लासिक विज़न कार्यों को संभालने के लिए उजागर करता है।
एब्लेशन अध्ययन ने GenProp के प्रमुख घटकों की प्रभावशीलता के निर्विवाद प्रमाण प्रदान किए:
- मास्क प्रेडिक्शन डिकोडर (MPD) ने पाठ संरेखण और निरंतरता (तालिका 3) दोनों में काफी सुधार किया। इसके बिना, आउटपुट मास्क अक्सर खराब हो जाते थे, जिससे वस्तु निष्कासन अधूरा हो जाता था और यह भ्रम होता था कि किन क्षेत्रों को प्रसारित करना है बनाम संरक्षित करना है (चित्र 7, पंक्तियाँ 1-2)। MPD का स्पष्ट पर्यवेक्षण मॉडल को परिवर्तनों को अलग करने में मदद करता है और भारी अवरोध के साथ भी पूर्ण वस्तु निष्कासन सुनिश्चित करता है।
- क्षेत्र-जागरूक हानि (RA Loss) पहले-फ्रेम संपादन के स्थिर और सुसंगत प्रसार के लिए महत्वपूर्ण थी। RA Loss के बिना, मूल वस्तु बाद के फ्रेम में धीरे-धीरे फिर से प्रकट होने लगती थी, जिससे प्रसार में बाधा आती थी (चित्र 7, पंक्तियाँ 3-5)। यह हानि सुनिश्चित करती है कि संपादित क्षेत्रों को स्थिर रूप से प्रसारित किया जाए जबकि अपरिवर्तित क्षेत्रों को सुसंगत रखा जाए।
- कलर फिल संवर्द्धन को प्रसार विफलता को संबोधित करने के लिए एक महत्वपूर्ण कारक साबित किया गया था, खासकर बड़े आकार के संशोधनों के लिए। यह मॉडल को ट्रैकिंग के लिए स्पष्ट रूप से प्रशिक्षित करता है, इसे पूरे अनुक्रम में संशोधनों को बनाए रखने के लिए निर्देशित करता है, जिससे एक लड़की को एक छोटी बिल्ली में बदलने जैसे चुनौतीपूर्ण संपादन सक्षम होते हैं (चित्र 7, पंक्तियाँ 6-8)।
संक्षेप में, GenProp की सफलता इसके सावधानीपूर्वक डिजाइन में निहित है, जो I2V मॉडल की जनरेटिव शक्ति, एक चयनात्मक सामग्री एन्कोडर, एक मास्क प्रेडिक्शन डिकोडर, और एक क्षेत्र-जागरूक हानि का लाभ उठाता है, सभी को एक बहुमुखी सिंथेटिक डेटा जनरेशन पाइपलाइन के साथ प्रशिक्षित किया गया है। यह संयोजन इसे विविध और चुनौतीपूर्ण वीडियो संपादन कार्यों में लगातार बेसलाइन से बेहतर प्रदर्शन करके अपने गणितीय दावों को बेरहमी से साबित करने की अनुमति देता है।
सीमाएं और भविष्य की दिशाएं
जबकि GenProp जनरेटिव वीडियो प्रोपेगेशन में एक महत्वपूर्ण छलांग प्रस्तुत करता है, इसकी अंतर्निहित सीमाओं को स्वीकार करना और भविष्य के विकास के लिए विचारों पर विचार करना महत्वपूर्ण है। एक अंतर्निहित सीमा कम्प्यूटेशनल लागत है; कई NVIDIA A100 GPUs पर प्रशिक्षण से पता चलता है कि उपभोक्ता-ग्रेड हार्डवेयर पर वास्तविक समय, उच्च-रिज़ॉल्यूशन वीडियो संपादन के लिए इस मॉडल को तैनात करना अभी भी एक चुनौती हो सकती है। इसके अलावा, सिंथेटिक डेटा पर निर्भरता, जबकि बहुमुखी प्रतिभा को सक्षम करती है, पूर्वाग्रहों को पेश कर सकती है या अत्यंत उपन्यास, अनक्यूरेटेड वास्तविक दुनिया के परिदृश्यों के लिए सामान्यीकरण को कम कर सकती है जो सिंथेटिक वितरण से काफी भिन्न होते हैं। पत्र यह भी नोट करता है कि पारंपरिक गुणवत्ता मेट्रिक्स कभी-कभी उत्पन्न परिणामों के यथार्थवाद को पकड़ने में विफल रहते हैं, जिसके लिए उपयोगकर्ता अध्ययन की आवश्यकता होती है, जो स्वचालित, व्यापक मूल्यांकन में एक अंतर की ओर इशारा करता है।
आगे देखते हुए, लेखक स्पष्ट रूप से मॉडल को एक से अधिक प्रमुख फ्रेम संपादन का समर्थन करने के लिए विस्तारित करने की योजना बना रहे हैं, जो जटिल, बहु-चरणीय संपादन वर्कफ़्लो के लिए इसकी लचीलापन को काफी बढ़ाएगा। वे अतिरिक्त वीडियो कार्यों को उजागर करना भी चाहते हैं जिन्हें ढांचे द्वारा समर्थित किया जा सकता है, यह सुझाव देते हुए कि GenProp की अंतर्निहित जनरेटिव शक्ति में अप्रयुक्त क्षमता है।
इन तत्काल योजनाओं से परे, इन निष्कर्षों को आगे विकसित करने और विकसित करने के लिए कई चर्चा विषय उभरते हैं:
-
उन्नत उपयोगकर्ता नियंत्रण और व्याख्यात्मकता: जबकि GenProp सघन मास्क की आवश्यकता को समाप्त करके संपादन प्रक्रिया को सरल बनाता है, अधिक सहज और दानेदार उपयोगकर्ता नियंत्रण को कैसे एकीकृत किया जा सकता है? क्या "लूप में मानव" प्रणाली, शायद इंटरैक्टिव प्रतिक्रिया तंत्र के साथ, उपयोगकर्ताओं को पारंपरिक विधियों की जटिलता को फिर से पेश किए बिना संपादन को अधिक सटीक रूप से निर्देशित करने की अनुमति दे सकती है? मॉडल के आंतरिक "तर्क" (जैसे, ध्यान मानचित्र) को उपयोगकर्ताओं के लिए अधिक व्याख्यात्मक बनाने के तरीकों की खोज भी विश्वास और नियंत्रण को बढ़ावा दे सकती है।
-
वास्तविक दुनिया की मजबूती और डेटा की कमी: वर्तमान ढांचे को सिंथेटिक डेटा से काफी लाभ होता है। हालांकि, वास्तविक दुनिया के वीडियो डेटा में अक्सर शोर, अवरोध और अप्रत्याशित गति पैटर्न होते हैं जो सिंथेटिक डेटासेट द्वारा पूरी तरह से कैप्चर नहीं किए जाते हैं। भविष्य के काम में डोमेन अनुकूलन तकनीकों या स्व-पर्यवेक्षित शिक्षण रणनीतियों का पता लगाया जा सकता है ताकि अनियंत्रित, "जंगल में" वीडियो के लिए GenProp की मजबूती में सुधार किया जा सके, संभावित रूप से सावधानीपूर्वक तैयार किए गए सिंथेटिक डेटा पर निर्भरता कम हो सके।
-
उत्पादन के लिए दक्षता और मापनीयता: व्यापक अपनाने के लिए, तेज अनुमान और कम मेमोरी फुटप्रिंट के लिए GenProp का अनुकूलन महत्वपूर्ण है। ज्ञान आसवन, मॉडल छंटाई, या अधिक कुशल वास्तुशिल्प डिजाइनों जैसी तकनीकों की जांच एज उपकरणों पर तैनाती या लंबे, उच्च-रिज़ॉल्यूशन वीडियो को वास्तविक समय में संसाधित करने में सक्षम हो सकती है। पीढ़ी की गुणवत्ता, गति और संसाधन खपत के बीच क्या व्यापार-बंद हैं, और व्यावहारिक अनुप्रयोगों के लिए उन्हें कैसे संतुलित किया जा सकता है?
-
मल्टीमॉडल एकीकरण और प्रासंगिक समझ: वीडियो स्वाभाविक रूप से मल्टीमॉडल है। अधिक सुसंगत और immersive संपादन बनाने के लिए GenProp को ऑडियो, प्रॉम्प्ट से परे पाठ विवरण, या 3D दृश्य जानकारी को कैसे शामिल किया जा सकता है? उदाहरण के लिए, किसी वस्तु की गति को संपादित करने से स्वचालित रूप से संबंधित ध्वनि प्रभाव समायोजन ट्रिगर हो सकता है, या किसी दृश्य की 3D ज्यामिति को समझने से डाली गई वस्तुओं के लिए अधिक भौतिक रूप से सटीक इंटरैक्शन और प्रकाश प्रभाव हो सकते हैं।
-
नैतिक निहितार्थ और जिम्मेदार एआई: जैसे-जैसे जनरेटिव वीडियो संपादन अधिक परिष्कृत होता जाता है, अत्यधिक यथार्थवादी लेकिन हेरफेर की गई सामग्री बनाने की क्षमता महत्वपूर्ण नैतिक चिंताएं पैदा करती है। भविष्य की चर्चाओं में ऐसे शक्तिशाली उपकरणों को जिम्मेदारी से विकसित करने और तैनात करने के तरीकों को सक्रिय रूप से संबोधित करना चाहिए, जिसमें हेरफेर की गई सामग्री का पता लगाने के लिए तंत्र, उपयोग के लिए स्पष्ट दिशानिर्देश स्थापित करना, और एआई-जनित मीडिया में पारदर्शिता सुनिश्चित करना शामिल है। यह इस तकनीक के दीर्घकालिक सामाजिक प्रभाव के लिए एक महत्वपूर्ण पहलू है।
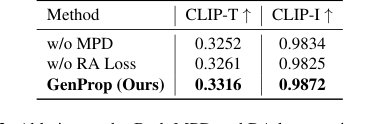 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
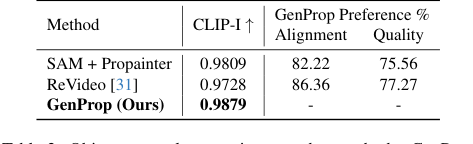 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
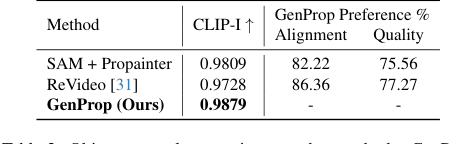 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set