생성 비디오 전파 (Generative Video Propagation)
The problem of generative video propagation, as addressed in this paper, is rooted in the broader field of computer vision, specifically within the domain of video generation and editing.
배경 및 학술적 계보
본 논문에서 다루는 생성 비디오 전파 문제는 컴퓨터 비전 분야, 특히 비디오 생성 및 편집 영역에 뿌리를 두고 있다. 역사적으로 핵심 과제는 단일 프레임(또는 희소한 프레임 집합)에 가해진 변경 사항을 전체 비디오 시퀀스에 걸쳐 일관되고 사실적으로 전파하는 것이었다. 수정된 비디오 콘텐츠의 시간적 일관성과 시각적 타당성을 유지해야 하는 필요성에서 비롯된 초기 비디오 전파 접근 방식은 주로 광학 흐름(optical flow) [9, 44], 깊이 추정(depth estimation) [6, 55], 복사열 필드(radiance fields) [33], 아틀라스(atlases) [20, 24]와 같은 전통적인 컴퓨터 비전 기술에 의존했다. 최소한의 수동 노력으로 복잡하고 사실적인 시나리오를 처리할 수 있는 정교한 비디오 편집 도구에 대한 수요 증가는 이 특정 문제의 출현과 발전을 이끌었다.
저자들이 새로운 프레임워크를 개발하도록 동기를 부여한 이전 접근 방식의 근본적인 한계 또는 "고충점(pain point)"은 몇 가지 핵심 문제에서 비롯된다. 전통적인 방법은 비디오의 기간 동안 오류 누적(error accumulation)에 취약하여 후반 프레임의 품질 저하와 불일치를 초래했다. 이로 인해 견고성이 떨어지고 다양한 비디오 콘텐츠에 대한 일반화 능력(generalization ability)이 제한되었다. 또한 많은 이전 기술은 작업별(task-specific)이었는데, 이는 한 유형의 편집(예: 객체 제거)을 위해 훈련된 모델이 다른 작업(예: 배경 교체)을 위해 상당한 재훈련 또는 완전히 다른 모델을 필요로 한다는 것을 의미했다 [28, 31, 34, 61]. 통합된 프레임워크의 부족은 주요 병목 현상이었다. 최근의 확산 기반 비디오 편집 모델은 강력하지만 자체적인 제약 사항도 가지고 있었다. 많은 모델은 객체 모양에 대한 실질적인 변경을 하거나 복잡한 배경 수정을 처리하는 것보다 주로 외형 변경(altering appearance)을 위해 설계되었다. 이들은 종종 각 개별 프레임에 대해 밀집된 마스크 레이블링(dense mask labeling)을 필요로 했는데, 이는 노동 집약적이고 시간이 많이 소요되는 과정으로 실시간 또는 대규모 애플리케이션을 비현실적으로 만들었다. 예를 들어, I2VEdit [34]과 같은 방법은 각 비디오 클립에 대해 모션 LoRA를 학습해야 하는 계산 복잡성(computational complexity)을 야기했다. ReVideo [31]과 같은 다른 접근 방식은 입력 비디오의 일부를 검은색 사각형으로 마스킹하는 것을 포함했는데, 이는 의도치 않게 중요한 정보를 제거하고 복잡한 배경 편집 및 대형 모양 수정을 처리하는 능력을 제한했다. 저자들의 동기는 다양한 편집을 작업별 재훈련이나 밀집된 마스크 입력 없이 원활하고 견고하게 전파할 수 있는 통합된 생성 프레임워크를 제안함으로써 이러한 한계를 극복하고 비디오 편집 프로세스를 크게 단순화하는 것이었다.
직관적인 도메인 용어
이 논문의 몇 가지 전문 용어를 제로베이스 독자를 위한 직관적이고 일상적인 비유로 번역한 것입니다.
-
생성 비디오 전파 (Generative Video Propagation): 점토 애니메이션 영화를 만든다고 상상해 보세요. 첫 번째 장면을 조각한 다음 점토 캐릭터 중 하나에 작은 모자를 추가하기로 결정합니다. "생성 비디오 전파"는 편집된 첫 번째 장면을 본 후 마법처럼 매우 똑똑한 조수가 자동으로 후속 장면을 다시 조각하여 모자가 캐릭터에 일관되게 나타나고 자연스럽게 움직이며 영화에 완벽하게 통합되도록 하는 것과 같습니다. 이는 모든 프레임을 직접 만지지 않고도 초기 편집을 비디오 전체에 "생성적(창의적, 사실적)" 방식으로 "전파"합니다.
-
이미지-투-비디오 (I2V) 생성 모델 (Image-to-Video (I2V) Generation Model): 이것을 매우 상상력이 풍부한 이야기꾼이라고 생각하십시오. 이 이야기꾼에게 단일 사진("이미지")과 다음에 일어날 일에 대한 간략한 설명을 제공하면 그들은 그것으로부터 전체 짧은 비디오 시퀀스를 발명하고 생성할 수 있습니다. 예를 들어, 고요한 호수의 사진을 주고 "물을 부드럽게 잔물결치게 하라"고 말하면, 그들은 사실적인 잔물결이 있는 호수의 비디오를 생성합니다. 이 논문에서는 이 이야기꾼이 편집된 첫 번째 프레임을 기반으로 비디오의 나머지 부분을 생성하는 데 사용됩니다.
-
선택적 콘텐츠 인코더 (Selective Content Encoder, SCE): 매우 신중한 사서라고 상상해 보세요. 원본 책과 특정 문장에 하이라이트 표시를 한 책 두 버전을 이 사서에게 제공합니다. 이 사서의 임무는 하이라이트 표시하지 않은 원본 책의 모든 부분을 기억하고 보존하는 동시에 하이라이트 표시된 부분을 의도적으로 무시하는 것입니다. 생성 모델이 나머지 책을 망치지 않고 편집된 부분을 채울 수 있도록 원본 콘텐츠를 "선택적으로 인코딩"하여 변경되지 않은 부분에 집중합니다.
-
영역 인식 손실 (Region-Aware Loss, RA Loss): 학생의 미술 프로젝트를 채점한다고 상상해 보세요. 이 프로젝트에는 그림과 채색 두 부분이 있습니다. "영역 인식 손실"은 그림(비디오의 변경되지 않은 부분)과 채색(편집된 부분) 모두에 동등한 주의를 기울이도록 하는 채점 시스템과 같습니다. 모델이 원본 콘텐츠를 보존하고 편집을 정확하게 전파하는 두 가지 모두에서 잘 학습하도록 보장하며, 한 부분을 희생하여 다른 부분에 너무 많이 집중하는 것을 방지합니다.
표기법 테이블
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문은 생성 비디오 전파의 복잡한 문제를 다루며, 사실성과 일관성을 유지하면서 첫 프레임 편집을 전체 비디오 시퀀스에 원활하게 적용하는 것을 목표로 합니다.
입력/현재 상태:
시작점은 $T$개의 프레임으로 구성된 원본 비디오 $V = \{v_1, v_2, ..., v_T\}$와 단일 수정된 첫 번째 프레임 $v'_1$입니다. 이 $v'_1$은 원본 첫 번째 프레임 $v_1$에 임의의 편집을 적용한 결과입니다. 기존 비디오 편집 방법은 일반적으로 여러 가지 한계에 시달립니다. 각 프레임에 대한 밀집된 마스크 레이블링이 필요하거나, 모션 안내를 위해 광학 흐름 또는 깊이 맵과 같은 보조 입력에 의존하거나, 각 특정 편집 작업 또는 비디오 클립에 대해 재훈련이 필요합니다. 또한 많은 방법은 외형 변경과 같은 특정 유형의 편집으로 제한되며, 상당한 모양 수정 또는 복잡한 배경 변경에는 어려움을 겪습니다.
출력/목표 상태:
원하는 최종점은 새로운 수정된 비디오 $V' = \{v'_1, v'_2, ..., v'_T\}$입니다. 각 후속 프레임 $v'_t$ (여기서 $t \in \{2, ..., T\}$)에 대해 목표는 $v'_1$에 도입된 수정 사항이 비디오 전체에 걸쳐 정확하고 사실적으로 전파되도록 보장하는 것입니다. 동시에, 편집되지 않은 비디오 영역은 외형과 모션 모두에서 원본 콘텐츠와 완벽하게 일관성을 유지해야 합니다. 이 프레임워크는 작업별 데이터나 광학 흐름과 같은 명시적인 모션 단서 없이 객체 제거, 삽입, 교체, 추적 및 아웃페인팅을 포함한 광범위한 비디오 편집 작업에 일반적으로 적용 가능해야 합니다.
누락된 연결 또는 수학적 격차:
정확한 누락된 연결은 비디오의 수정된 영역과 수정되지 않은 영역을 효과적으로 분리하고 단일 편집된 첫 번째 프레임에서 전체 시퀀스로 변경 사항을 전파할 수 있는 통합된 생성 프레임워크입니다. 이는 수정되지 않은 영역에서 원본 콘텐츠를 보존하고 수정된 영역에서 새롭고 물리적으로 타당한 콘텐츠를 생성하는 동시에 다양하고 복잡한 편집 시나리오에 걸쳐 달성되어야 합니다. 수학적으로, 본 논문은 수정된 프레임 $v'_t$ (여기서 $t \in \{2, ..., T\}$)가 $v'_t = G(E(V), v'_1, t)$에 의해 생성될 수 있도록 생성 함수 $G$와 선택적 콘텐츠 인코더 $E$를 정의하고자 합니다. 여기서 $E(V)$는 원본 비디오 $V$에서 변경되지 않은 정보만 선택적으로 인코딩해야 하며, $G$(이미지-투-비디오 생성 모델)가 후속 프레임으로 편집된 콘텐츠를 전파하는 데 집중할 수 있도록 합니다. 과제는 명시적인 프레임별 안내 없이 이러한 분리 및 일관된 전파를 달성하기 위해 $E$와 $G$를 시너지 효과를 내도록 설계하는 것입니다.
고통스러운 절충 또는 딜레마:
이전 연구자들은 근본적인 절충에 갇혀 있었습니다.
1. 사실성과 일관성 대 일반성과 유연성: (특히 대형 모양 수정 또는 배경 변경과 같은 복잡한 변경에 대한) 편집의 매우 사실적이고 시간적으로 일관된 전파를 달성하는 것은 종종 일반성의 희생을 동반합니다. 일관성에서 뛰어난 방법은 일반적으로 명시적인 모션 표현(예: 광학 흐름) 또는 작업별 미세 조정에 의존하므로 유연성이 떨어지고 특정 입력이 필요합니다. 반대로, 더 일반적인 생성 모델은 미세한 일관성을 유지하고 시간에 따른 아티팩트를 피하는 데 어려움을 겪는 경우가 많습니다. 한 측면(예: 상당한 모양 변경 허용)을 개선하면 일반적으로 다른 측면(예: 시간적 일관성 또는 그림자 효과의 사실성)이 깨집니다.
2. 계산 효율성 대 품질 및 범위: 많은 기존 접근 방식은 계산 집약적인 프로세스(예: 모든 프레임에 대한 밀집된 마스크 레이블링 또는 비디오별 미세 조정)를 포함하거나 제한된 품질과 편집 범위를 가진 결과를 생성합니다. 딜레마는 막대한 계산 비용이나 광범위한 수동 개입 없이 고품질의 다양한 비디오 편집을 달성하는 방법입니다.
제약 조건 및 실패 모드
생성 비디오 전파 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵습니다.
- 시간적 일관성 및 오류 누적: 편집이 수백 프레임에 걸쳐 오류가 누적되지 않고 부드럽고 일관되게 전파되도록 보장하는 것은 주요 과제입니다. 사소한 불일치조차도 특히 복잡한 모션이나 긴 비디오 시퀀스를 처리할 때 눈에 띄는 "고스팅 효과", 깜박임 또는 후반 프레임의 품질 저하를 초래할 수 있습니다.
- 편집된 영역과 편집되지 않은 영역의 분리: 모델은 편집되지 않은 영역에서 원본 콘텐츠를 정확하게 식별하고 보존하는 동시에 수정된 영역에 대한 새 콘텐츠를 생성해야 합니다. 이 분리는 매우 중요합니다. 여기서 실패하면 편집된 영역에서 원본 객체가 다시 나타나거나 변경되지 않은 비디오 부분에 의도하지 않은 수정이 발생할 수 있습니다.
- 다양하고 복잡한 편집 처리: 프레임워크는 객체 제거(그림자, 반사와 같은 관련 효과 포함), 독립적이고 물리적으로 타당한 모션을 가진 객체 삽입, 배경 교체를 포함한 광범위한 편집 작업을 지원해야 합니다. 각 작업은 콘텐츠 생성 및 모션 일관성 측면에서 고유한 과제를 제시합니다.
- 작업별 데이터 부족: 상상할 수 있는 모든 비디오 편집 작업에 대해 대규모의 쌍 비디오 데이터셋을 만드는 것은 비용이 많이 들고 시간이 많이 소요됩니다. 이러한 데이터 희소성은 모델이 실제 비디오에 잘 일반화되고 합성 아티팩트를 학습하는 것을 방지하는 자체 과제를 도입하는 합성 데이터 생성에 의존하게 만듭니다.
- 계산 및 메모리 제한: 고해상도 비디오 시퀀스를 처리하고 복잡한 콘텐츠로 새 프레임을 생성하려면 상당한 계산 리소스가 필요합니다. 이러한 모델의 훈련 및 추론에는 강력한 GPU와 상당한 메모리가 필요하므로 실시간 또는 거의 실시간 성능이 중요한 장애물이 됩니다.
- 명시적인 모션 단서의 부재: 광학 흐름 또는 깊이 맵에 의존하는 전통적인 방법과 달리 이 프레임워크는 이러한 명시적인 모션 안내 없이 작동하는 것을 목표로 합니다. 이 제약은 본질적으로 어려운 타당한 모션을 암묵적으로 이해하고 합성하는 데 생성 모델에 더 큰 부담을 줍니다.
- 미분 불가능한 실제 물리: 생성 프레임워크 내에서 그림자, 반사 및 사실적인 객체 상호 작용과 같은 물리적 효과를 정확하게 모델링하고 전파하는 것은 이러한 현상이 복잡하고 미분 가능한 함수로 쉽게 표현되지 않기 때문에 어렵습니다.
왜 이 접근 방식인가
선택의 불가피성
저자들이 GenProp 프레임워크를 위해 생성 이미지-투-비디오(I2V) 모델을 기반으로 구축하기로 결정한 것은 단순한 선호가 아니라 기존 접근 방식의 내재적 한계에 의해 주도된 전략적 필요성이었습니다. 광학 흐름, 깊이 맵 또는 아틀라스에 의존하는 전통적인 비디오 전파 방법은 일반 생성 비디오 전파 문제에 근본적으로 부적합했습니다. 이러한 방법은 시간이 지남에 따라 오류가 누적되기 쉽고, 견고성이 제한적이며, 결정적으로 다양한 편집 작업을 광범위한 재훈련 또는 작업별 수정 없이 처리할 수 있는 일반화 능력이 부족합니다. 일반적으로 단일의 잘 정의된 작업에서 뛰어나지만 다재다능함이 필요한 경우 실패합니다.
"아하!" 순간은 명시적으로 단일 사건으로 명시되지는 않았지만, 최첨단(SOTA)에 대한 논문의 비판적 평가에서 추론할 수 있습니다. 강력한 확산 기반 비디오 편집 모델조차도 주로 텍스트 안내 외형 변경에 초점을 맞추거나 번거로운 사례별 미세 조정을 필요로 했습니다. 이들은 상당한 모양 수정, 복잡한 배경 편집 또는 물리적으로 타당한 객체 모션으로 어려움을 겪었습니다. 예를 들어 Revideo [31]와 같은 방법은 입력 비디오의 일부를 검은색 사각형으로 마스킹하는 데 의존했는데, 이는 본질적으로 중요한 정보를 제거하고 복잡한 배경 편집 및 대형 모양 수정을 처리하는 능력을 제한했습니다. 다른 방법(예: I2VEdit [34])은 각 비디오 클립에 대해 모션 LoRA가 필요하여 계산 복잡성을 야기했습니다. 깨달음은 단일 편집된 첫 번째 프레임에서 전체 시퀀스에 걸쳐 다양한 첫 프레임 편집(제거, 삽입, 교체, 추적, 다중 편집)을 사실성과 일관성을 유지하면서 전파할 수 있는 통합된 일반 프레임워크를 제공하는 기존 방법이 없다는 것이었습니다. I2V 모델의 생성 능력은 신중하게 설계되고 증강될 때 이러한 다면적인 문제를 전체적으로 해결할 수 있는 유일한 실행 가능한 경로였습니다.
비교 우위
GenProp의 질적 우수성은 이전 방법의 단점을 직접적으로 해결하는 구조 설계에서 비롯됩니다. 광학 흐름과 같은 명시적인 모션 단서에 의존하는 전통적인 접근 방식과 달리 GenProp은 I2V 모델의 고유한 생성 기능을 활용합니다. 이는 흐름 기반 방법의 오류 누적 문제를 제거하여 긴 비디오 시퀀스에 걸쳐 훨씬 더 견고하고 일관된 전파를 가능하게 합니다.
핵심 구조적 이점은 선택적 콘텐츠 인코더(Selective Content Encoder, SCE)입니다. 이 구성 요소를 통해 GenProp은 변경되지 않은 원본 비디오 부분의 특징을 선택적으로 인코딩할 수 있으며, I2V 모델은 수정된 영역을 전파하는 데 생성 능력을 집중합니다. 이 분리는 다른 방법에서 종종 발생하는 안정된 영역의 의도하지 않은 변경을 방지하는 데 중요한 편집되지 않은 영역의 일관성을 유지하는 데 중요합니다. 또한 보조 헤드로 훈련된 마스크 예측 디코더(Mask Prediction Decoder, MPD)는 모델이 수정이 필요한 영역을 정확하게 식별하고 집중하도록 안내하여 편집의 정확성을 높이고 주의 맵의 품질을 향상시킵니다(그림 3 참조).
아마도 가장 중요한 질적 도약은 GenProp의 일반성과 유연성일 것입니다. 객체 제거(그림자 및 반사와 같은 사실적인 효과 포함), 배경 교체, 물리적으로 타당한 모션을 가진 객체 삽입, 객체 및 관련 효과 추적과 같은 광범위한 복잡한 비디오 편집 작업을 단일 추론 실행 내에서 작업별 재훈련 없이 지원합니다. 이는 종종 단일 작업에 특화되었거나 모든 프레임에 대한 밀집된 마스크 레이블링을 필요로 했던 이전 SOTA 방법과 극명한 대조를 이룹니다. GenProp의 전파 기반 접근 방식은 추론 중에 마스크 입력이 필요하지 않아 편집 프로세스를 크게 단순화하고 수동 노력을 줄입니다. 이 구조적 이점은 진정으로 통합되고 다재다능한 비디오 편집 솔루션을 제공함으로써 압도적으로 우수합니다.
제약 조건과의 정렬
GenProp 프레임워크는 문제의 가혹한 요구 사항과 고유한 아키텍처 속성 간의 놀라운 "결합"을 달성합니다. 주요 제약 조건을 고려해 봅시다.
- 사실성: 문제는 전파된 변경 사항이 자연스럽고 사실적으로 보이도록 요구합니다. GenProp은 핵심으로 사전 훈련된 I2V 생성 모델을 활용함으로써 완벽하게 정렬됩니다. 이러한 모델은 본질적으로 고품질의 사실적인 비디오 콘텐츠를 생성하도록 설계되어 편집된 시퀀스가 시각적 타당성을 유지하도록 보장합니다.
- 일관성: 변경되지 않은 영역은 원본 비디오와 동일하게 유지되어야 하며 편집은 시간적으로 일관되어야 합니다. 이는 선택적 콘텐츠 인코더(SCE)에 의해 처리되며, 이는 비디오의 편집되지 않은 부분의 정보를 명시적으로 보존합니다. 영역 인식 손실(RA Loss)은 수정된 영역과 수정되지 않은 영역에 대한 손실을 분리하여 안정된 영역의 변경을 처벌하고 편집된 영역의 정확한 전파를 장려함으로써 이를 더욱 강화합니다. 이는 원본 콘텐츠가 의도된 편집이 없는 곳에서 충실하게 보존되도록 보장합니다.
- 일반성 및 다재다능성: 솔루션은 각 작업에 대해 재훈련할 필요 없이 광범위한 비디오 편집 작업을 처리해야 합니다. GenProp은 첫 프레임 편집을 일반 비디오 전파로 확장하는 통합 프레임워크를 통해 이를 달성합니다. 결정적으로, 합성 데이터 생성 체계(복사-붙여넣기, 마스크-채우기, 색상 채우기)는 훈련 중에 다양한 시나리오를 다루어 모델이 제거, 삽입, 교체 및 추적과 같은 다양한 응용 프로그램에 걸쳐 작업별 데이터 없이 일반화할 수 있도록 합니다.
- 효율성 및 단순성: 솔루션은 번거로운 수동 주석과 오류가 발생하기 쉬운 중간 표현을 피해야 합니다. GenProp은 많은 전통적인 방법 및 일부 확산 기반 방법보다 훨씬 간단한 모든 프레임에 대한 밀집된 마스크 레이블링의 필요성을 제거합니다. 또한 모션 예측을 위해 광학 흐름 또는 깊이 맵에 대한 의존성을 우회하여 이러한 중간 표현에 내재된 오류 누적을 피합니다.
- 복잡한 편집: 모델은 상당한 모양 수정, 독립적인 객체 모션 및 관련 효과 제거를 지원해야 합니다. I2V 모델의 생성 능력은 SCE 및 MPD의 정확한 안내와 결합되어 GenProp이 독립적인 모션을 가진 객체 또는 주요 객체와 함께 그림자 및 반사와 같은 관련 효과 제거와 같은 복잡한 시나리오를 처리할 수 있도록 합니다. 이는 전통적인 방법이 종종 실패하는 부분입니다.
대안의 거부
본 논문은 일반 비디오 전파 문제에 대한 근본적인 한계를 강조하면서 대안적인 접근 방식을 거부하는 설득력 있는 이유를 제공합니다.
- 전통적인 비디오 전파 방법 (광학 흐름, 깊이, 아틀라스): 이러한 방법은 기초적이지만 견고성, 일반화 능력 및 오류 누적에 대한 취약성 제한으로 인해 명시적으로 거부됩니다. 종종 단일 작업에 대해 설계되었으며 새로운 응용 프로그램에 대해 재훈련이 필요하여 통합 프레임워크에 비현실적입니다. 명시적인 모션 단서에 대한 의존성은 복잡한 비정형 변형 또는 상당한 장면 변경을 처리할 때 취약하게 만듭니다.
- 기존 확산 기반 비디오 편집 모델 (예: InsV2V, Pika, AnyV2V, ReVideo): 확산 모델은 강력하지만 비디오 편집을 위한 기존 구현은 부족했습니다.
- 많은 모델은 외형 변경으로 제한되었으며, 객체 모양에 대한 상당한 변경을 하거나 복잡한 배경 편집을 정밀하게 처리하는 데는 어려움을 겪었습니다.
- 일부 모델은 사례별 미세 조정(예: I2VEdit의 모션 LoRA)이 필요하여 계산 복잡성을 추가하고 프로세스를 늦췄습니다.
- Revideo [31]과 같은 접근 방식은 검은색 사각형 마스크를 사용했는데, 이는 중요한 정보를 제거하고 복잡한 배경 편집 및 대형 모양 수정을 처리하는 능력을 심각하게 제한하여 종종 흐릿한 경계와 객체 모션의 오류 누적을 초래했습니다.
- AnyV2V [27]와 같은 훈련 없는 프레임워크는 일반화 능력 제한으로 어려움을 겪었고 상당한 모양 변경 또는 객체 삽입에 어려움을 겪었습니다. Pika [2] 역시 상당한 모양 변경 또는 배경 편집에서 성능이 저하되었습니다.
- 텍스트 프롬프트(예: InsV2V)에 의존하는 방법은 종종 훈련 데이터에 의해 제한되었고 복잡한 비외형 기반 편집에 어려움을 겪었습니다.
- 전통적인 인페인팅 파이프라인 (예: SAM-V2 + Propainter): 객체 제거와 같은 작업의 경우 이러한 캐스케이드 방법은 모든 프레임에 대한 밀집된 마스크 주석을 필요로 하여 GenProp이 완전히 피하는 노동 집약적이고 오류가 발생하기 쉬운 프로세스이기 때문에 주로 거부되었습니다. 또한 Propainter는 그림자와 반사와 같은 객체 효과를 정확하게 제거하는 데 어려움을 겪는 것으로 나타났는데, 이는 GenProp이 비디오 생성에 대한 생성적 이해 덕분에 견고하게 처리합니다.
- 추적을 위한 SAM-V2: SAM-V2 [39]는 마스크 추적에 탁월하지만 훈련 데이터 편향으로 인해 객체 효과(반사, 그림자)로 어려움을 겪는 것으로 나타났습니다. 생성적 사전 훈련을 가진 GenProp은 물리 법칙에 대한 우수한 이해를 보여주어 SAM-V2가 종종 놓치는 이러한 관련 효과를 일관되게 추적할 수 있습니다.
본질적으로 저자들은 이러한 대안의 구성 요소가 유용했지만, 품질, 효율성 또는 다재다능성에서 상당한 타협 없이 원활하고 다양한 비디오 전파에 필요한 포괄적이고 견고하며 일반적인 솔루션을 제공하는 것은 없다고 결론지었습니다. 강력한 I2V 모델에 대한 선택적 콘텐츠 인코더, 마스크 예측 디코더, 영역 인식 손실 및 합성 데이터 생성의 새로운 통합은 이러한 집단적 한계를 극복하는 유일한 방법이었습니다.
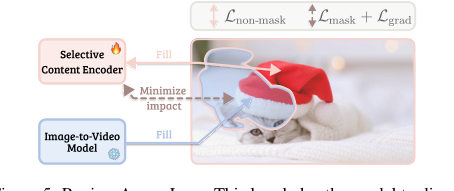 Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
수학적 및 논리적 메커니즘
마스터 방정식
GenProp의 학습 메커니즘의 핵심은 편집을 전파하고 원본 콘텐츠를 보존하도록 모델을 안내하는 영역 인식 손실에 요약되어 있습니다. 전체 훈련 목표는 프레임에 걸쳐 손실 합계를 최소화하는 것이지만, 모든 중요한 구성 요소를 결합하는 단일 프레임에 대한 기본 손실 함수는 다음과 같습니다.
$$ \mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}} $$
이 마스터 방정식과 시간 전체에 이 손실을 합산하는 전체 훈련 목표는 모델이 생성 비디오 전파를 수행하는 방법을 결정합니다. 전체 목표는 다음과 같이 공식화됩니다.
$$ \min_{\mathcal{E}} \sum_{i=2}^{T} \mathcal{L}(G(E(V), v'_1, v_i), V_i) $$
여기서 $\mathcal{E}$는 모델의 훈련 가능한 매개변수를 나타냅니다.
항별 분석
마스터 방정식과 전체 목표의 각 구성 요소를 분석해 봅시다.
-
$\mathcal{L}$ (총 영역 인식 손실):
- 수학적 정의: 이는 단일 비디오 프레임에 대한 결합된 손실 값으로, 원하는 출력 및 동작과의 편차에 대한 총 페널티를 나타냅니다.
- 물리적/논리적 역할: 최적화 프로그램에 대한 기본 신호 역할을 하여 현재 모델의 출력 및 내부 상태가 얼마나 "나쁜지"를 나타냅니다. $\mathcal{L}$을 최소화하는 것은 모든 목표에 걸쳐 모델의 성능을 개선하는 것을 의미합니다.
- 덧셈을 사용하는 이유? 저자들은 각 항이 모델이 충족해야 하는 별도의 목표 또는 제약 조건을 나타내기 때문에 덧셈을 사용합니다. 이를 합산함으로써 모델은 이러한 모든 목표를 동시에 최적화하도록 장려됩니다. 한 항이 높으면 총 손실이 높아져 해당 특정 측면의 조정 필요성을 신호합니다.
-
$\mathcal{L}_{\text{non-mask}}$ (마스크가 아닌 영역 손실):
- 수학적 정의: $\mathcal{L}_{\text{non-mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v^{\text{out}}_t, (1 - m_t) \cdot v_t)]$. 이는 생성된 출력 $v^{\text{out}}_t$와 실제 값 $v_t$ 사이의 확산 평균 제곱 오차(MSE) 손실 $\mathcal{L}_d$이지만, 마스크 $m_t$로 덮이지 않은 영역에 대해서만 계산됩니다.
- 물리적/논리적 역할: 이 항은 첫 번째 프레임에서 편집되지 않은 비디오 부분이 시퀀스 전체에 걸쳐 원본 비디오 콘텐츠와 일관성을 유지하도록 보장합니다. 이는 의도하지 않은 배경 또는 객체 변경을 방지하는 충실도 제약 역할을 합니다.
- $(1 - m_t) \cdot \text{frame}$을 사용하는 이유? $(1 - m_t)$와의 요소별 곱셈은 마스크 처리된(편집된) 영역을 효과적으로 "제로화"하여 손실 계산을 위해 편집되지 않은 프레임 부분만 격리합니다. 이는 특정 영역에 대한 일관성 목표를 집중하는 정확한 방법입니다.
-
$\mathcal{L}_{\text{mask}}$ (마스크 영역 손실):
- 수학적 정의: $\mathcal{L}_{\text{mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d(m_t \cdot v^{\text{out}}_t, m_t \cdot v_t)]$. 이는 생성된 출력 $v^{\text{out}}_t$와 실제 값 $v_t$ 사이의 확산 MSE 손실 $\mathcal{L}_d$이지만, 마스크 $m_t$로 덮인 영역에 대해서만 계산됩니다.
- 물리적/논리적 역할: 이 항은 모델이 편집된 콘텐츠를 정확하게 생성하고 첫 번째 프레임에 대한 수정을 전파하도록 유도합니다. 변경 사항이 수정된 영역 내에서 시간적으로 사실적으로 렌더링되고 일관되도록 보장합니다.
- $m_t \cdot \text{frame}$을 사용하는 이유? $\mathcal{L}_{\text{non-mask}}$와 유사하게, 요소별 곱셈은 마스크 처리된(편집된) 영역을 격리하여 생성 목표를 이러한 영역에 구체적으로 집중시킵니다.
-
$\lambda$ ($\mathcal{L}_{\text{mask}}$의 가중치):
- 수학적 정의: 양의 스칼라 계수(논문에서 2.0으로 설정됨).
- 물리적/논리적 역할: 이 하이퍼파라미터는 다른 손실 구성 요소에 비해 마스크 처리된(편집된) 영역을 정확하게 생성하는 것의 상대적 중요성을 제어합니다. 더 높은 $\lambda$는 편집 사항을 올바르게 전파하는 데 더 중점을 둡니다.
- 곱셈을 사용하는 이유? 이는 $\mathcal{L}_{\text{mask}}$의 총 손실에 대한 기여도를 조정하여 다른 목표 간의 균형을 미세 조정할 수 있습니다.
-
$\mathcal{L}_{\text{grad}}$ (그래디언트 손실):
- 수학적 정의: $\mathcal{L}_{\text{grad}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [m_t \cdot ||\Delta f||^2]$, 여기서 $\Delta f = \frac{f(E(V + \delta)) - f(E(V))}{\delta}$는 입력 비디오 $V$에 대한 작은 섭동 $\delta$에 대한 선택적 콘텐츠 인코더(SCE)의 특징 $f(E(V))$의 그래디언트의 유한 차분 근사입니다.
- 물리적/논리적 역할: 이는 분리를 위한 중요한 항입니다. 입력 비디오가 마스크 처리된 영역 내에서 약간 섭동될 때 출력 특징이 크게 변하면 SCE를 페널티를 부과합니다. 목표는 SCE가 편집된 부분을 무시하고 변경되지 않은 콘텐츠만 인코딩하는 데 집중하도록 강제하는 것입니다. 이는 SCE가 의도치 않게 제거된 객체를 "재구성"하거나 편집된 영역에서 I2V 모델의 생성 작업에 간섭하는 것을 방지합니다.
- $||\Delta f||^2$을 사용하는 이유? 제곱 L2 노름은 특징 변화의 크기를 측정합니다. 이 크기를 최소화하면 SCE의 특징이 안정적이고 마스크 처리된 영역의 섭동에 민감하지 않도록 장려됩니다.
- $m_t \cdot ||\Delta f||^2$을 사용하는 이유? 마스크 $m_t$는 이 그래디언트 페널티가 SCE가 이상적으로 "눈이 멀어야" 하는 편집된 영역에만 적용되도록 합니다.
-
$\beta$ ($\mathcal{L}_{\text{grad}}$의 가중치):
- 수학적 정의: 양의 스칼라 계수(논문에서 1.0으로 설정됨).
- 물리적/논리적 역할: 이 하이퍼파라미터는 그래디언트 페널티의 강도를 제어하여 SCE가 편집된 영역에서 분리되도록 얼마나 강하게 강제되는지에 영향을 미칩니다.
- 곱셈을 사용하는 이유? 이는 $\mathcal{L}_{\text{grad}}$의 총 손실에 대한 기여도를 조정합니다.
-
$\mathcal{L}_{\text{MPD}}$ (마스크 예측 디코더 손실):
- 수학적 정의: 이는 마스크 예측 디코더(MPD)가 예측한 마스크와 실제 마스크 $m_t$ 사이의 MSE 손실입니다.
- 물리적/논리적 역할: 이 보조 손실은 MPD가 수정된 영역을 정확하게 식별하도록 명시적으로 훈련합니다. 이를 통해 전체 모델에 편집이 어디에 있는지에 대한 명확한 신호를 제공하며, 이는 차례로 I2V 모델의 주의 및 생성 프로세스를 올바른 영역으로 안내하는 데 도움이 됩니다. 주의 맵의 정확성을 향상시킵니다.
- MSE를 사용하는 이유? MSE는 픽셀별 마스크 값 예측을 포함한 회귀 작업에 대한 표준적이고 효과적인 손실 함수입니다.
-
$\gamma$ ($\mathcal{L}_{\text{MPD}}$의 가중치):
- 수학적 정의: 양의 스칼라 계수(논문에서 1.0으로 설정됨).
- 물리적/논리적 역할: 이 하이퍼파라미터는 명시적인 마스크 예측 작업의 중요성을 제어합니다.
- 곱셈을 사용하는 이유? 이는 $\mathcal{L}_{\text{MPD}}$의 총 손실에 대한 기여도를 조정합니다.
-
$\mathbb{E}_{t \sim \mathcal{U}(1,T)}$ (시간 단계에 대한 기대값):
- 수학적 정의: $1$에서 $T$까지 균등하게 샘플링된 시간 단계 $t$에 대한 손실의 평균값입니다.
- 물리적/논리적 역할: 이는 비디오 시퀀스 전체에 걸쳐 손실이 계산되고 고려되도록 보장하여 전체 비디오에 걸쳐 시간적 일관성과 일반화를 촉진합니다.
- 기대값/균등 샘플링을 사용하는 이유? 전체 비디오에 대한 손실의 강력한 추정치를 제공하여 모델이 특정 프레임이나 시간 위치에 과적합되는 것을 방지합니다.
-
$\sum_{i=2}^{T}$ (프레임에 대한 합계):
- 수학적 정의: $2$에서 $T$까지 각 프레임 $i$에 대한 영역 인식 손실 $\mathcal{L}$의 합계입니다.
- 물리적/논리적 역할: 이는 훈련 중에 프레임별 손실을 전체 비디오 시퀀스에 대한 단일 목표로 집계합니다. 첫 번째 프레임($i=1$)은 입력 편집 프레임이므로 전파 작업은 두 번째 프레임부터 시작됩니다.
- 합계를 사용하는 이유? 각 프레임의 손실은 전체 훈련 신호에 동일하게 기여하여 모델이 전체 비디오에 걸쳐 편집을 일관되게 전파하도록 학습하도록 보장합니다.
-
$G(E(V), v'_1, v_i)$ (생성된 출력 프레임):
- 수학적 정의: 선택적 콘텐츠 인코더 $E(V)$의 특징, 수정된 첫 번째 프레임 $v'_1$, 그리고 원본 $i$-번째 프레임 $v_i$(I2V 모델의 내부 처리 참조로 사용되지만, 실제 값 $V_i$는 손실 계산에 사용됨)에 조건화된 이미지-투-비디오(I2V) 생성 모델 $G$의 출력입니다.
- 물리적/논리적 역할: 이는 수정된 비디오의 $i$-번째 프레임에 대한 모델의 추측입니다. 이는 원본 비디오의 편집되지 않은 부분과의 일관성을 유지하면서 첫 프레임 편집을 전파한 결과입니다.
-
$E(V)$ (선택적 콘텐츠 인코더 특징):
- 수학적 정의: 선택적 콘텐츠 인코더 $E$가 원본 입력 비디오 $V$에서 추출한 잠재 특징입니다.
- 물리적/논리적 역할: 이 구성 요소는 원본 비디오의 변경되지 않은 부분의 정보를 인코딩하도록 설계되었습니다. 편집이 이루어지지 않은 곳에서 원본 콘텐츠를 보존하도록 안내하는 컨텍스트를 I2V 모델에 제공합니다.
-
$v'_1$ (수정된 첫 번째 프레임):
- 수학적 정의: 수동 또는 합성적으로 편집된 비디오의 첫 번째 프레임입니다.
- 물리적/논리적 역할: 이는 전파의 앵커 역할을 합니다. I2V 모델은 이를 시작점으로 사용하여 전파해야 할 변경 사항을 이해합니다.
-
$v_i$ (원본 $i$-번째 프레임):
- 수학적 정의: 원본, 편집되지 않은 비디오 시퀀스 $V$의 $i$-번째 프레임입니다.
- 물리적/논리적 역할: 훈련 중에 I2V 모델의 입력 일부로 사용되며, 손실 계산에서 편집되지 않은 영역에 대한 실제 값으로 사용됩니다.
-
$V_i$ (실제 값 합성 비디오 프레임):
- 수학적 정의: 원본 비디오에 데이터 생성 연산자 $D$를 적용하여 생성된 합성 비디오 시퀀스 $V = \{V_1, V_2, ..., V_T\}$의 $i$-번째 프레임입니다.
- 물리적/논리적 역할: 훈련 중에 모델의 대상 출력으로, 전파 후 원하는 수정된 비디오 프레임을 나타냅니다.
단계별 흐름
GenProp을 정교한 비디오 편집 공장이라고 상상해 보세요. 훈련 중에 단일 추상 데이터 포인트(비디오 프레임)가 조립 라인을 통과하는 방법은 다음과 같습니다.
- 원본 비디오 수집: 원본 비디오 시퀀스 $V$가 공장으로 들어옵니다. 이 $V$는 프레임 $V_1, V_2, ..., V_T$의 시리즈입니다.
- 합성 편집 적용 (데이터 생성): 특수 "편집 기계"(데이터 생성 연산자 $D$)가 $V$를 가져와 첫 번째 프레임에 합성 편집을 적용하여 수정된 첫 번째 프레임 $v'_1$을 생성합니다. 또한 각 프레임의 편집된 영역을 정확하게 구분하는 해당 실제 값 수정 프레임 $V_2, ..., V_T$ 및 이진 마스크 $m_1, ..., m_T$를 생성합니다. 이를 통해 수정된 비디오 $V' = \{v'_1, V_2, ..., V_T\}$를 얻습니다.
- 콘텐츠 인코딩 (선택적 콘텐츠 인코더, SCE): 전체 원본 비디오 $V$가 "선택적 콘텐츠 인코더"($E$)에 공급됩니다. 이 인코더는 스마트 필터와 같습니다. 그 임무는 비디오의 변경되지 않은 콘텐츠를 나타내는 특징을 추출하고, 편집될 영역에 대한 정보를 의도적으로 무시하는 것입니다. 이는 수정 사항에 "눈이 멀도록" 학습하는 것입니다.
- 전파 엔진 (이미지-투-비디오 모델): 이제 각 후속 프레임 $i$(2에서 $T$까지)에 대해:
- 수정된 첫 번째 프레임 $v'_1$(편집의 청사진)이 입력됩니다.
- $E(V)$에서 선택적으로 인코딩된 특징(원본, 편집되지 않은 장면의 컨텍스트)이 주입됩니다.
- 현재 시간 단계 $i$도 제공됩니다.
- "이미지-투-비디오 생성 모델"($G$)은 주요 전파 엔진 역할을 합니다. 이 모델은 이러한 입력을 받아 수정된 비디오의 $i$-번째 프레임에 대한 최선의 추측을 생성하며, 이를 $v^{\text{out}}_i$라고 합니다. 여기서 마법이 일어납니다. $v'_1$의 편집이 원본 비디오 특징에 의해 안내되어 전파됩니다.
- 마스크 예측 (마스크 예측 디코더, MPD): 동시에 "마스크 예측 디코더"(MPD)는 I2V 모델의 내부 잠재 표현을 가져와 현재 프레임의 마스크 $m_i$를 예측하려고 시도합니다. 이것은 품질 관리 센서와 같아서 모델이 편집이 어디에 있는지 이해하는지 확인합니다.
- 손실 계산 및 피드백 (영역 인식 손실): 각 생성된 프레임 $v^{\text{out}}_i$에 대해:
- 일관성 확인 (마스크가 아닌 손실): $v^{\text{out}}_i$의 편집되지 않은 부분( $(1-m_i)$로 선택됨)은 실제 값 $V_i$의 편집되지 않은 부분과 비교됩니다. 여기서의 불일치는 $\mathcal{L}_{\text{non-mask}}$에 기여하여 모델이 원본 콘텐츠를 그대로 유지하도록 유도합니다.
- 편집 정확성 확인 (마스크 손실): $v^{\text{out}}_i$의 편집된 부분( $m_i$로 선택됨)은 실제 값 $V_i$의 편집된 부분과 비교됩니다. 여기서의 오류는 $\mathcal{L}_{\text{mask}}$에 기여하여 모델이 변경 사항을 정확하게 전파하도록 합니다.
- 인코더 눈먼 확인 (그래디언트 손실): 특수 "그래디언트 센서"는 입력 마스크 영역이 약간 변경될 때 SCE의 특징이 변하는지 확인합니다. 변하는 경우 $\mathcal{L}_{\text{grad}}$에 추가되어 SCE가 편집에 더욱 무관심하도록 지시합니다.
- 마스크 예측 정확성 확인 (MPD 손실): MPD의 예측된 마스크는 실제 마스크 $m_i$와 비교되어 $\mathcal{L}_{\text{MPD}}$에 기여합니다.
- 총 손실 집계: 이러한 개별 손실 구성 요소($\mathcal{L}_{\text{non-mask}}$, $\mathcal{L}_{\text{mask}}$, $\mathcal{L}_{\text{grad}}$, $\mathcal{L}_{\text{MPD}}$)는 가중치($\lambda, \beta, \gamma$)가 부여되고 합산되어 해당 프레임에 대한 총 영역 인식 손실 $\mathcal{L}$을 형성합니다. 이 프로세스는 $i=2$에서 $T$까지 모든 프레임에 대해 반복되며, 이러한 프레임별 손실은 전체 목표를 얻기 위해 합산됩니다.
- 매개변수 조정: 이 총 목표 값은 "최적화 프로그램"에 전송되며, 이는 공장 관리자와 같습니다. 이 관리자는 이 총 손실을 줄이기 위해 각 노브와 다이얼(모델 매개변수)을 어떻게 조정해야 하는지 계산합니다. 이러한 조정은 반복적으로 이루어져 SCE, I2V 모델 및 MPD를 각 훈련 단계마다 개선합니다.
이 전체 사이클은 수백만 번 반복되어 GenProp이 원본 비디오를 보존하면서 편집을 원활하게 전파하도록 점진적으로 가르칩니다.
최적화 역학
GenProp은 경사 하강법과 신중하게 조각된 손실 지형의 정교한 상호 작용을 통해 학습하고 수렴합니다. 최적화 프로세스는 $i=2$에서 $T$까지 모든 프레임에 걸쳐 영역 인식 손실 $\mathcal{L}$의 합계인 총 목적 함수를 최소화함으로써 주도됩니다.
-
그래디언트 기반 학습: 선택적 콘텐츠 인코더(SCE), 이미지-투-비디오(I2V) 생성 모델 및 마스크 예측 디코더(MPD)의 모델 매개변수($\mathcal{E}$)는 최적화 프로그램(예: 확산 모델에 일반적인 Adam)을 사용하여 반복적으로 업데이트됩니다. 여기에는 각 매개변수에 대한 총 손실의 그래디언트를 계산하는 것이 포함됩니다. 이러한 그래디언트는 손실을 줄이기 위해 매개변수를 조정해야 하는 방향과 크기를 나타냅니다. 학습률(예: 선형 워밍업을 갖춘 코사인 감쇠 스케줄러의 5e-5)은 이러한 조정의 단계 크기를 제어합니다. 모델 매개변수의 지수 이동 평균(EMA)도 유지되며, 이는 종종 노이즈 업데이트를 평균화하여 더 안정적인 훈련과 더 나은 최종 성능을 제공합니다. 그래디언트 노름 임계값(0.001)은 폭발적인 그래디언트를 방지하고 훈련 안정성을 보장하기 위해 적용됩니다.
-
분리 및 일관성을 위한 손실 지형 형성: 영역 인식 손실($\mathcal{L}$)의 고유한 설계는 손실 지형을 형성하고 모델의 학습을 안내하는 데 중요합니다.
- 균형 잡힌 영역 최적화: $\mathcal{L}_{\text{mask}}$ 및 $\mathcal{L}_{\text{non-mask}}$ 항은 두 개의 주요 "계곡"을 가진 손실 지형을 생성합니다. 한 계곡은 편집된 영역 내에서 정확한 생성을 장려하여 전파된 변경 사항이 사실적이도록 보장합니다. 다른 계곡은 원본 콘텐츠의 고충실도를 편집되지 않은 영역에서 촉진합니다. 이러한 항에 $\lambda$를 가중치로 부여함으로써 저자는 모델의 초점을 균형 있게 조정하여 편집 사항을 무시하거나 원본 배경을 손상시키는 것을 방지할 수 있습니다. 이 이중 목표는 모델이 새로운 콘텐츠를 생성하고 기존 콘텐츠를 보존해야 하는 복잡한 지형을 탐색하는 데 도움이 됩니다.
- SCE의 선택성 강제: $\mathcal{L}_{\text{grad}}$ 항은 특히 독창적입니다. 입력 마스크 영역이 섭동될 때 SCE의 특징이 변하면 페널티를 부과함으로써 편집된 영역에 대한 SCE 출력의 "평탄한" 영역을 생성합니다. 이는 SCE가 수정에 불변적인 표현을 학습하도록 강제하여 효과적으로 편집에 "눈이 멀게" 만듭니다. 이는 SCE의 역할(원본 컨텍스트 인코딩)과 I2V 모델의 역할(편집 전파)을 분리하여 고스팅 또는 제거된 객체의 재등장과 같은 문제를 방지합니다. 이것이 없으면 SCE는 모든 곳에서 원본 콘텐츠를 재구성하려고 시도하여 변경 사항 전파를 방해할 수 있습니다.
- 주의에 대한 명시적 안내: $\mathcal{L}_{\text{MPD}}$ 항은 모델이 편집이 어디에 있는지 식별하도록 명시적인 지도 신호를 제공합니다. 이는 I2V 모델의 내부 주의 메커니즘이 생성 및 수정에 올바른 영역에 집중하도록 돕습니다. 마스크를 명시적으로 학습함으로써 모델은 편집된 콘텐츠와 편집되지 않은 콘텐츠 간의 "경계"에 대한 명확한 이해를 얻어 더 정확한 전파와 혼란 감소로 이어집니다. 이 손실 항은 수정이 필요한 영역에 대해 더 선명하고 정의된 손실 지형을 만드는 데 도움이 됩니다.
-
반복적 개선 및 수렴: 여러 반복을 통해 모델은 매개변수를 반복적으로 업데이트합니다. I2V 모델은 SCE의 컨텍스트와 편집된 첫 번째 프레임을 기반으로 점점 더 사실적이고 시간적으로 일관된 비디오 프레임을 생성하도록 학습합니다. SCE는 원본 비디오에서 견고하고 편집에 무관한 특징을 추출하도록 학습합니다. MPD는 수정된 영역을 정확하게 예측하도록 학습합니다. 영역 인식 손실에 의해 안내되는 이 지속적인 피드백 루프는 모델을 전체 비디오 시퀀스에 걸쳐 다양한 첫 프레임 편집을 원활하게 전파하면서 편집되지 않은 콘텐츠에 대한 높은 충실도를 유지할 수 있는 상태로 이끌어갑니다. 그래디언트가 매우 작아져 매개변수 업데이트가 손실에 거의 개선을 제공하지 않는 경우 모델이 수렴합니다.
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
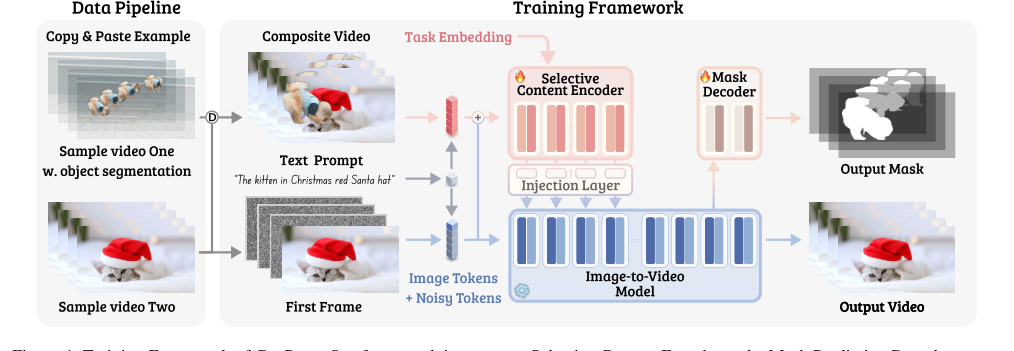 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
결과, 한계 및 결론
실험 설계 및 기준선
GenProp의 기능을 엄격하게 검증하기 위해 저자들은 DiT 아키텍처(Sora [32]와 유사)와 Stable Video Diffusion(SVD) [5] 기반 U-Net 아키텍처라는 두 가지 별도의 기본 비디오 생성 모델을 활용하는 포괄적인 실험 설계를 구성했습니다. 궁극적으로 더 우수한 비디오 생성 품질을 제공한 DiT 변형은 360p의 기본 해상도로 12 및 24 프레임/초(FPS)에서 32, 64, 128 프레임 동안 이미지-투-비디오(I2V) 생성을 위해 훈련되었습니다. 선택적 콘텐츠 인코더(SCE) 및 마스크 예측 디코더(MPD) 구성 요소는 I2V 모델이 동결된 상태로 훈련되어 GenProp의 핵심 메커니즘이 비디오 생성을 처음부터 다시 학습하는 것이 아니라 편집을 전파하는 데 집중하도록 했습니다.
훈련에는 코사인 감쇠 스케줄러와 선형 워밍업을 갖춘 $5 \times 10^{-5}$의 학습률이 사용되었으며, 안정성을 위해 지수 이동 평균이 사용되었습니다. 그래디언트 노름 임계값 0.001이 불안정성을 방지하기 위해 적용되었습니다. 분류기 없는 안내(CFG)는 20으로 설정되었습니다. 훈련의 중요한 측면은 복사-붙여넣기, 마스크-채우기 및 색상 채우기 작업에 대해 다양한 증강 비율(0.5, 0.375, 0.125)을 사용한 합성 데이터 생성 체계였습니다. 편집된 영역과 편집되지 않은 영역을 분리하는 데 중요한 영역 인식(RA) 손실은 특정 가중치 매개변수($\lambda = 2.0$, $\beta = 1.0$, $\gamma = 1.0$)를 사용했습니다. 모든 실험은 32 또는 64개의 NVIDIA A100 GPU에서 수행되었으며, 이는 필요한 상당한 계산 리소스를 강조합니다.
GenProp이 비교된 기준선 모델( "희생자")은 작업에 따라 달랐습니다. 일반 비디오 편집의 경우 InsV2V [8], AnyV2V [27], Pika [2], ReVideo [31]와 비교되었습니다. 객체 제거의 경우 SAM-V2 39와 Propainter 64의 캐스케이드 파이프라인이 기준선으로 사용되었습니다. 객체 추적의 경우 SAM-V2 [39]가 직접적인 경쟁자였습니다.
정량적 평가는 두 가지 테스트 세트에서 수행되었습니다.
1. 클래식 테스트 세트: TGVE [51]의 DAVIS [36] 데이터셋을 포함하며, 객체 교체 및 외형 편집에 초점을 맞춘 "객체 변경 캡션" 텍스트 프롬프트를 사용합니다.
2. 도전적인 테스트 세트: Pexels [1] 및 Adobe Stock [3]에서 수동으로 선별한 30개의 비디오 모음으로, 대형 객체 교체, 객체 삽입 및 배경 교체와 같은 더 복잡한 시나리오를 특징으로 합니다. 이 세트에 대한 편집은 상업용 사진 편집 도구 또는 특정 기준선 방법(예: Pika의 온라인 박싱 도구, ReVideo의 모션 포인트 추출)을 사용하여 수행되었습니다.
GenProp의 성공을 결정적으로 입증하는 것은 여러 지표를 사용하여 측정되었습니다.
- PSNRm: 편집된 영역 외부에서 계산된 피크 신호 대 잡음비로, 변경되지 않은 콘텐츠의 일관성을 정량화합니다.
- CLIP-T: 편집된 프레임과 텍스트 프롬프트의 CLIP [38] 임베딩 간의 코사인 유사도로, 텍스트 정렬을 평가합니다.
- CLIP-I: 프레임 간 CLIP [38] 특징 간의 거리로, 프레임 간 일관성을 측정합니다.
- 사용자 연구: Amazon MTurk [45]에서 121명의 참가자를 대상으로 수행된 인간 평가로, GenProp의 결과와 기준선 및 원본 비디오를 비교하고 지침과의 정렬 및 전반적인 시각적 품질을 평가했습니다.
증거가 증명하는 것
증거는 GenProp의 핵심 메커니즘이 실제로 작동함을 부인할 수 없이 입증하여 생성 비디오 전파를 위한 선도적인 프레임워크로 자리매김했습니다. 표 1에서 볼 수 있듯이 GenProp은 대부분의 지표에서 다른 방법보다 훨씬 뛰어나며, 특히 더 까다로운 도전적인 테스트 세트에서 그렇습니다. 이것은 단순한 점진적인 개선이 아니라 근본적으로 더 견고하고 다재다능한 접근 방식의 시연입니다.
예를 들어, 객체 교체 및 배경 교체(그림 6a, 6b)에서 GenProp은 모양이 크게 다르거나 독립적인 모션을 가진 객체를 원활하게 수정하고 복잡한 배경 편집을 수행하는 능력을 보여주었습니다. 이는 텍스트 프롬프트 또는 제한된 훈련 데이터에 의존하는 InsV2V [8] 및 Pika [2]와 같은 기준선의 주요 한계를 직접적으로 해결합니다. AnyV2V [27]도 일반화 능력이 제한되어 어려움을 겪었고, ReVideo [31]는 종종 흐릿한 경계와 포인트 추적 메커니즘의 누적 오류를 생성했습니다. GenProp이 모든 프레임에 대한 밀집된 마스크 레이블링 없이 이러한 복잡한 시나리오를 처리할 수 있다는 것은 전파 기반 접근 방식의 증거입니다.
객체 및 효과 제거(그림 6c, 6d)에서 GenProp은 객체뿐만 아니라 그림자와 반사와 같은 관련 효과도 제거하고 큰 가려진 영역을 사실적으로 재구성함으로써 뛰어났습니다. SAM+Propainter 기준선은 인페인팅에 효과적이었지만, 표 2에서 낮은 CLIP-I 및 사용자 선호도 점수로 표시된 것처럼 이러한 미묘한 효과를 제거하는 데 어려움을 겪었습니다. GenProp의 통합 접근 방식은 생성 모델을 활용하여 제거된 영역을 물리 법칙에 대한 생성적 이해를 통해 그럴듯하게 채우는 방법을 본질적으로 이해합니다.
인스턴스 객체 및 효과 추적(그림 6e)의 경우 GenProp은 솔리드 색상 채우기로 초기화되었음에도 불구하고 객체 및 관련 효과의 일관된 추적을 시연했습니다. SAM-V2 [39]는 실시간 추적에 더 빠르고 정확한 마스크를 생성할 수 있지만, GenProp의 비디오 생성 사전 훈련은 물리 법칙에 대한 강력한 이해를 제공하여 훈련 데이터가 제한적이고 편향된 SAM-V2가 종종 놓치는 효과를 추적할 수 있습니다. 이는 생성 기반 모델이 장면 역학에 대한 더 깊은 이해로 클래식 비전 작업을 해결할 수 있는 잠재력을 강조합니다.
결론적으로 GenProp의 성공은 I2V 모델의 생성 능력, 선택적 콘텐츠 인코더, 마스크 예측 디코더 및 영역 인식 손실을 활용하는 신중한 설계와 다재다능한 합성 데이터 생성 파이프라인으로 훈련된 조합에 기반합니다. 이 조합을 통해 다양한 도전적인 비디오 편집 작업 전반에 걸쳐 품질, 효율성 또는 다재다능성에서 상당한 타협 없이 생성 비디오 전파를 원활하게 수행할 수 있습니다.
한계 및 향후 방향
GenProp은 생성 비디오 전파 분야에서 상당한 발전을 이루었지만, 내재된 한계를 인정하고 향후 개발을 고려하는 것이 중요합니다. 하나의 암묵적인 한계는 계산 비용입니다. 여러 NVIDIA A100 GPU에서 훈련하는 것은 이 모델을 소비자 등급 하드웨어에서 실시간 고해상도 비디오 편집에 배포하는 것이 여전히 어려울 수 있음을 시사합니다. 또한 합성 데이터에 대한 의존성은 다양성을 가능하게 하지만, 합성 분포와 크게 다른 매우 새롭고 정리되지 않은 실제 시나리오에 대한 편향을 도입하거나 일반화를 줄일 수 있습니다. 이 논문은 또한 전통적인 품질 지표가 생성된 결과의 사실성을 포착하지 못하는 경우가 있다는 점을 지적하는데, 이는 사용자 연구를 필요로 하며 자동화되고 포괄적인 평가의 격차를 나타냅니다.
앞으로 저자들은 하나 이상의 키 프레임 편집을 지원하도록 모델을 확장할 계획이며, 이는 복잡한 다단계 편집 워크플로에 대한 유연성을 크게 향상시킬 것입니다. 또한 프레임워크에서 지원할 수 있는 추가 비디오 작업을 발굴하는 것을 목표로 하며, 이는 GenProp의 기본 생성 능력이 아직 활용되지 않은 잠재력을 가지고 있음을 시사합니다.
이러한 즉각적인 계획을 넘어, 이러한 발견을 더욱 발전시키고 진화시키기 위한 몇 가지 논의 주제가 있습니다.
-
향상된 사용자 제어 및 해석 가능성: GenProp은 밀집된 마스크의 필요성을 제거하여 편집 프로세스를 단순화하지만, 더 직관적이고 세분화된 사용자 제어를 통합하여 편집을 미세 조정하는 방법은 무엇입니까? 전통적인 방법의 복잡성을 다시 도입하지 않고 사용자가 전파 프로세스를 더 정확하게 안내할 수 있는 대화형 피드백 메커니즘을 갖춘 "인간 루프" 시스템을 탐색할 수 있습니까? 모델의 내부 "추론"(예: 주의 맵)을 사용자에게 더 해석 가능하게 만드는 방법을 탐구하는 것도 더 큰 신뢰와 제어를 조성할 수 있습니다.
-
실제 견고성 및 데이터 부족: 현재 프레임워크는 합성 데이터에서 크게 이점을 얻습니다. 그러나 실제 비디오 데이터에는 종종 합성 데이터셋에서 완전히 포착되지 않는 노이즈, 가려짐 및 예측 불가능한 모션 패턴이 포함됩니다. 향후 작업은 도메인 적응 기술 또는 자기 지도 학습 전략을 탐색하여 GenProp의 "야생" 비디오에 대한 견고성을 개선할 수 있으며, 세심하게 제작된 합성 데이터에 대한 의존성을 줄일 수 있습니다.
-
생산을 위한 효율성 및 확장성: 더 광범위한 채택을 위해 GenProp을 더 빠른 추론 및 감소된 메모리 풋프린트에 최적화하는 것이 중요합니다. 지식 증류, 모델 가지치기 또는 더 효율적인 아키텍처 설계와 같은 기술을 조사하면 엣지 장치에 배포하거나 실시간으로 더 길고 고해상도 비디오를 처리할 수 있습니다. 생성 품질, 속도 및 리소스 소비 간의 절충은 무엇이며, 실용적인 응용 프로그램을 위해 이러한 절충을 어떻게 균형 있게 맞출 수 있습니까?
-
다중 모달 통합 및 맥락적 이해: 비디오는 본질적으로 다중 모달입니다. GenProp을 오디오, 프롬프트 이상의 텍스트 설명 또는 3D 장면 정보를 통합하여 더 일관되고 몰입감 있는 편집을 생성하도록 확장하는 방법은 무엇입니까? 예를 들어, 객체의 모션을 편집하면 해당 사운드 효과 조정이 자동으로 트리거될 수 있으며, 장면의 3D 기하학을 이해하면 삽입된 객체에 대한 더 물리적으로 정확한 상호 작용 및 조명 효과로 이어질 수 있습니다.
-
윤리적 영향 및 책임 있는 AI: 생성 비디오 편집이 점점 더 정교해짐에 따라 매우 사실적이지만 조작된 콘텐츠를 만들 수 있는 능력은 상당한 윤리적 우려를 제기합니다. 향후 논의는 이러한 강력한 도구를 책임감 있게 개발하고 배포하는 방법을 적극적으로 해결해야 하며, 조작된 콘텐츠를 감지하기 위한 메커니즘, 사용에 대한 명확한 지침 설정 및 AI 생성 미디어의 투명성 보장을 포함합니다. 이것은 이 기술의 장기적인 사회적 영향에 대한 중요한 측면입니다.
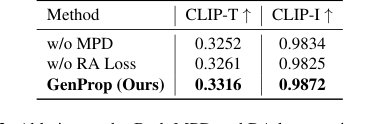 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
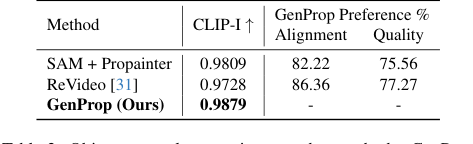 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
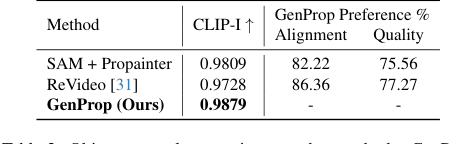 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set